SENTIMENT MINING
PADA KEGIATAN PROGRAM
PENGEMBANGAN MASYARAKAT
SITI YULIYANTI
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul “Sentiment Mining pada Kegiatan Program Pengembangan Masyarakat berbasis Media Sosial” adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
RINGKASAN
SITI YULIYANTI. Sentiment Mining pada Kegiatan Program Pengembangan Masyarakat berbasis Media Sosial. Dibimbing oleh TAUFIK DJATNA dan HERU SUKOCO.
Sentiment mining merupakan bagian dari text mining yang melakukan ekstraksi dan mengolah data tekstual secara otomatis untuk mendapatkan informasi dalam suatu kalimat opini yang dianalisis untuk melihat kecenderungan opini terhadap sebuah masalah atau objek oleh seseorang, apakah cenderung beropini positif, negatif atau netral. Pengembangan masyarakat merupakan gerakan yang dirancang untuk meningkatkan taraf hidup keseluruhan masyarakat melalui partisipasi aktif dan inisiatif dari masyarakat. Permasalahan yang sering timbul yaitu pada proses implementasi dan evaluasi program pengembangan masyarakat dan penelitian yang banyak dilakukan dengan menggunakan metode kuantitatif dan kualitatif berdasarkan kuisioner dan belum memanfaatkan media sosial.
Twitter adalah media sosial yang saat ini aktif digunakan masyarakat Indonesia dalam menyampaikan opini, keluhan, saran bahkan kritik tentang permasalahan atau kegiatan yang menjadi trending topic, user yang paling banyak diantaranya adalah remaja atau anak usia sekolah berdasarkan survei Onavo Insight dan APJII. Objek penelitian ini adalah kegiatan pada program pengembangan masyarakat yang berhubungan dengan remaja yaitu kegiatan PIK-Remaja (Pusat Informasi dan Konseling Remaja) dan GenRe (Generasi Berencana) yang berada di wilayah Bogor. Berdasarkan survei kegiatan tersebut sudah didukung Twitter dalam sosialisasi samapi implementasi kegiatan sehingga menarik untuk diteliti.
Data tweet hasil crawling dari Twitter tidak terstruktur dan belum diketahui kelas sentiment. Sehingga perlu dilakukan praprosesmeliputi filter, case folding, token
dan parsing, pemeriksaan kelas sentiment dengan lexicon based serta pembobotan
term/kata dengan term frequency. Tahapan selanjutnya, mereduksi fitur dengan PCA dengan tujuan mencari nilai PC (principal component) tertinggi untuk memudahkan dan meningkatkan akurasi pada proses klasifikasi sentiment dengan tiga kelas yaitu kelas positif, negatif dan netral menggunakanSVM Sebelum klasifikasi, parameter c
dan γ yang akan digunakan pada evaluasi model di estimasi untuk menghasilkan akurasi tertinggi.
Penelitian ini menganalisis kebutuhan model sentiment mining, mengevaluasi model dan merancangan pengembangan model menggunakan diagram-diagram UML. Hasil penelitian menunjukan kegiatan yang penyebaran informasi terbaik adalah kegiatan GenRe dibandingkan kegiatan PIK-Remaja dimana persentase sentiment
positif lebih tinggi dari persentase sentiment negatif. Estimasi parameter c danγyang menghasilkan akurasi tertinggi adalah kombinasi 0.8 dan 0.8, 0.8 dan 0.9, 0.9 dan 0.8, serta 0.9 dan 0.9, dimana kombinasi parameter tersebut digunakan dalam pengujian model. Akurasi klasifikasi sentiment menunjukkan hasil yang cukup baik jika dibandingkan dengan penelitian sebelumnya yaitu sebesar 88.64% pada kegiatan GenRe dan sebesar 82.78% pada kegiatan PIK-Remaja, tingkat akurasi tidak dipengaruhi pembagian data latih dan data uji tapi dipengaruhi praproses data dan estimasi parameter (c dan γ).
SUMMARY
SITI YULIYANTI. Sentiment Mining of Activities Community Development Program based on Social Media. Supervised by TAUFIK DJATNA and HERU SUKOCO.
Sentiment mining is part of a text mining to extracting, processing textual data automatically to obtain information in a sentence opinions. The analyzed to representation the trend of opinion on an issue or an object by a person, do tend to opine positive, negative or neutral. Community development is a move designed to improve the overall living standard of the people through active participation and initiative of the people. Problems often arise is in the process of implementation and evaluation of community development programs and research is mostly done by using quantitative and qualitative methods based on the questionnaire and not take advantage of social media.
Twitter is a social media that is currently actively used the Indonesian community in delivering opinions, complaints, suggestions and even criticism of the issue or activities that a trending topic, the user most of them are teenagers or school-aged children based on surveys Onavo Insight and APJII. The object of this study is the activity on community development programs related to juvenile namely the activities of PIK-Remaja and GenRe which is in the area of Bogor. Based on a survey of these activities have been supported by Twitter in the socialization process till the implementation of activities so interesting to study.
Data tweet crawling results from Twitter unstructured and unknown class sentiment. So that needs to be done preprocessing includes filters, case folding, tokens and parsing, inspection class sentiment with lexicon based and weighting term / word with the term frequency. The next stage, reducing features with a PCA with the aim of looking for value PC (principal component), the highest to facilitate and improve the accuracy of the classification process sentiment with three classes of classes of positive, negative and neutral using SVM Before classification, the
parameters c and γ to be used in the evaluation models in the estimation to produce
the highest accuracy.
This study analyzes the representation of sentiment mining models, evaluate the model and design to development model using UML diagrams. The results showed the best information dissemination activities are the activities of the genre than PIK-Remaja activities in which the percentage of positive sentiment higher
than the percentage of negative sentiment. Estimation parameters c and γ that
© Hak Cipta Milik IPB, Tahun 2016
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
Tesis sebagai salah satu syarat untuk memperoleh gelar Magister Komputer
pada
Program Studi Ilmu Komputer
SENTIMENT MINING
PADA KEGIATAN PROGRAM
PENGEMBANGAN MASYARAKAT
SEKOLAH PASCASARJANA INSTITUT PERTANIAN BOGOR
BOGOR 2016
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga penelitian ini dapat diselesaikan. Penelitian ini
berjudul “Sentiment Mining pada Kegiatan Program Pengembangan Masyarakat
berbasis Media Sosial ”
Terima kasih penulis ucapkan kepada Bapak DrEng Ir Taufik Djatna, MSi dan Bapak DrEng Heru Sukoco, SSi MT selaku pembimbing, Dr Imas S. Sitanggang, SSi Mkom selaku penguji. Ibu Yosefa Reno, Ibu Ana dan staff BPMKB kota Bogor serta Ibu Ninuk dari FEMA IPB (Fakultas Ekologi Manusia Institut Pertanian Bogor) telah banyak memberi informasi tentang objek penelitian. Tak lupa penulis juga menyampaikan penghargaan sebesar-besarkan kepada Ibu Saryati yang tak pernah lelah mendo’akan, Bapak Amid (Alm) yang semangatnya tetap mengalir meski tak sempat mengenggam karya ini, Eteh dan Lia atas segala doa dan kasih sayangnya. Di samping itu, penulis sampaikan terima kasih kepada sahabat-sahabatku (Alm) Ela Kurniati, Teh Heti Mulyani, Puspa Citra, Novi, rekan Ilkom 2014 dan teman-teman yang telah membantu proses penelitian. Terima kasih juga penulis sampaikan kepada Direktorat Jenderal Pendidikan Tinggi (Ditjen DIKTI), STT Indonesia Tanjungpinang dan STMIK Bandung yang memberikan beasiswa dalam penyelesaian karya ilmiah ini. Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR TABEL vii
DAFTAR GAMBAR vii
DAFTAR LAMPIRAN vii
1 PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 3
Tujuan Penelitian 3
Manfaat Penelitian 3
Ruang Lingkup Penelitian 3
2 TINJAUAN PUSTAKA 4
Mining Media Sosial 4
Kegiatan Program Pengembangan Masyarakat 4
RapidMiner dengan Rscript 5
Perancangan untuk Pengembangan Model dengan UML 5
3 METODE 6
Pengumpulan data 6
Praproses 7
Reduksi Fitur dengan PCA 8
Klasifikasi Sentimen dengan SVM 9
Evaluasi Model Sentiment Mining 11
4 HASIL DAN PEMBAHASAN 12
Pengumpulan data 12
Reduksi fitur 13
Klasifikasi Sentiment 16
Pengujian Parameter (c,γ) pada Fungsi Kernel 18
Evaluasi Model 18
Pengembangan Model Sentiment Mining 21
Use Case Diagram 21
Activity Diagram 21
Sequence diagram 21
Component diagram 22
Class diagram 22
StateChart Diagram 22
5 SIMPULAN DAN SARAN 25
Simpulan 25
Saran 25
DAFTAR PUSTAKA 26
LAMPIRAN 28
DAFTAR TABEL
1 Pengurutan nilai principal component dari yang tertinggi 15 2 Presentase jumlah sentiment kegiatan GenRe dan PIK-Remaja 17 3 Grid search presentase tingkat akurasi model sentiment mining 18 4 Persentase precision dan recall pada kegiatan PIK-Remaja 19 5 Persentase precision dan recall pada kegiatan GenRe 20
6 Tingkat akurasi dengan parameter c = 0.8 dan γ = 0.8 20
7 Tingkat akurasi dengan parameter c= 0.1 dan γ = 0.6 20
DAFTAR GAMBAR
1 Tahapan analisis kebutuhan dan evaluasi pada model sentiment mining 6
2 Registrasi Twitter Apps untuk authentification key 7
3 Tampilan authentifikasi untuk key penarikan data tweet 7
4 Alur algoritme PCA (Vinondhini dan Chandrasekaran 2014) 9
5 Pemetaan data dengan fungsi hyperplane ke ruang vektor 10
6 Ilustrasi proses klasifikasi 3 kelas dengan fungsi hyperplane 10
7 Ilustrasi confusion matrix dengan tiga kelas sentimen 11
8 Ilustrasi tahapan pemeriksaan kelas sentimen 13
9 Flow knowledge proses reduksi fitur pada RapidMiner 13
10 Nilai PC terhadap proporsi varian: (a) PIK-Remaja (b) GenRe 14
11 Nilai PC null pada fitur Kegiatn PIK-Remaja 15
12 Nilai PC null pada fitur kegiatan GenRe 16
13 Flow knowledge proses proses klasifikasi sentiment 16
14 Skenario model sentiment mining: (a) PIK-Remaja (b) GenRe 17
15 Contoh ketepatan kelas pada klasifikasi sentiment 19
16 Confusion matrix Model 1 pada kegiatan GenRe 19
17 Component diagram 22
18 Statechart diagram model sentiment mining 23
19 Use case diagram 34
20 Activity diagram crawling data tweet 35
21 Activity diagram proses reduksi fitur, klasifikasi dan evaluasi model 35
22 Sequence diagram praproses data tweet 36
DAFTAR LAMPIRAN
1 Sebagian file stopword yang digunakan untuk praproses data ... 29
2 Tampilan hasil running evaluasi model pada kegiatan PIK-Remaja ... 30
3 Tampilan hasil running evaluasi model pada kegiatan GenRe ... 32
4 Use case diagram model sentiment mining ... 34
5 Activity Diagram model sentiment mining ... 35
1
PENDAHULUAN
Latar Belakang
Sentiment mining merupakan penggalian sentiment dari pengolahan data sehingga menghasilkan sebuah sentiment, dimana proses yang dilakukan sama dengan sentiment analysis dan opinion mining. Opinion mining dan sentiment analysis merupakan bagian dari text mining yang melakukan ekstraksi dan mengolah data tekstual secara otomatis untuk mendapatkan informasi sentiment dalam suatu kalimat opini yang dianalisis untuk melihat kecenderungan opini bersifat negatif atau positif (Pang dan Lee 2008).
Pengembangan masyarakat (community development) adalah gerakan yang dirancang guna meningkatkan taraf hidup keseluruhan masyarakat melalui partisipasi aktif dan inisiatif dari masyarakat serta memperbesar akses masyarakat guna mencapai kondisi sosial, ekonomi, dan kualitas kehidupan yang lebih baik (Rahman 2009; Adi 2003). Permasalahan yang sering timbul pada proses implementasi dan evaluasi program pengembangan masyarakat diantaranya relationship, structure, power, shared for meaning, communication for change, motivation to decision making dan integration of disparate concerns (Phillips dan Pittman 2009).
Media sosial menjembatani celah antara dunia secara fisik dengan layanan online jejaring sosial. Terdapat beberapa hal menarik yang bisa dipelajari pada data media sosial diantaranya perilaku manusia, membantu periklanan, dan memfasilitasi gerakan masa (Gundecha dan Huan 2012). Keterkaitan media sosial dengan pengembangan masyarakat yaitu adanya peran serta atau partisipasi aktif dan inisiatif masyarakat dengan salah satu manfaat media sosial yaitu memfasilitasi gerakan masa.
Penelitian ini menggunakan media sosial yaitu Twitter karena berdasarkan demografi pengguna internet di Indonesia sekitar 49% adalah usia di bawah 25 tahun (APJII dan PUSKAKOM UI 2015) dan Indonesia merupakan negara pengguna aktif Twitter terbanyak sekitar 64% (Onavo Insight 2013). Beberapa kegiatan program pengembangan masyarakat di Indonesia sudah menggunakan partisipasi aktif dan inisiatif dari masyarakat yang melibatkan media sosial yaitu Twitter, sebagaimana Twitter sudah digunakan pada kegiatan program pengembangan masyarakat di wilayah Bogor yaitu pada kegiatan PIK-Remaja (Pusat Informasi dan Konseling Remaja) dan GenRe (Generasi Berencana), dan menjadi objek penelitian.
2
Penelitian Naradhipa dan Purwarianti (2011), melakukan klasifikasi tweet berbahasa Indonesia dengan SVM dan seleksi fitur menggunakan kamus kata (dictionary) sedangkan metode kombinasi Lexicon-Based dan SVM untuk klasifikasi sentiment netral, positif, dan negatif terhadap program televisi dengan skenario pengujian menggunakan pembagian data latih dan data uji untuk mengetahui kinerja model klasifikasi (Tiara et al. 2015). Klasifikasi sentiment positif dan negatif terhadap isu publik, menggunakan Algoritma Maximum Entropy dalam membangun model klasifikasi dengan Support Vector Machine dengan pembobotan TF-IDF pada fitur unigram, pelabelan kelas secara manual dengan POS tagger (Putranti dan Winarko 2014). Pengklasifikasian opini dengan membandingkan tipe fitur n-gram (unigram, bigram dan trigram) dan Reduksi fitur pada dataset tentang aplikasi e-commerce dengan PCA dengan metode hybrid SVM pada pengklasifikasian opini menunjukan hasil akurasi yang paling tinggi jika dibandingkan Naive Bayes dengan akurasi 77.6% dan akurasi terkecil dimiliki oleh klasifikasi tanpa reduksi fitur dengan nilai akurasi sebesar 68.8% (Vinodhini dan Chandrasekaran 2014). Pengklasifikasian SVM menggunakan polaritas 3 kategori yang diidentifikasi dengan menambahkan kategori netral membuktikan bahwa dapat meningkatkan akurasi keseluruhan klasifikasi (Koppel dan Jonathan 2006). Menurut
Jotheeswaran et al. (2012) proses reduksi fitur sebelum pengklasifikasian opini dapat meningkatkan akurasi sekitar 5%.
Sentiment mining dari Twitter untuk mengetahui respon masyarakat terhadap kegiatan pada program pengembangan masyarakat melalui tweet dari masyarakat belum pernah dilakukan, menjadi celah dalam penelitian ini berkaitan dengan permasalahan komunikasi untuk perubahan atau aksi (communication for change). Penelitian yang telah banyak dilakukan adalah mengukur respon masyarakat terhadap kegiatan melalui kuisioner dengan menghitung jumlah kelompok dalam setiap kegiatan. Hal tersebut menjadi menarik untuk diteliti, banyaknya jumlah kegiatan tidak mewakili respon positif dikarenakan masih adanya pembentukan kelompok kegiatan yang bersifat formalitas. Pemanfaataan Twitter sebagai sarana penyampaian informasi sudah banyak diimplementasikan, namun penelitian yang telah dilakukan belum memanfaatkan tweet yang berlimpah yang sangat mudah didapatkan ini.
Penelitian ini mengadopsi beberapa metode dari penelitian terdahulu yaitu menggunakan lexicond based untuk pelabelan kelas sentimen dan pembagian data untuk mengetahui tren model (Naradhipa dan Purwarianti 2011), menentukan term atau kata penting untuk membangun corpus positif dan negatif menggunakan TF-IDF untuk menjumlahkan vektor bobot pada jaringan semantik kata (Wahyudi dan Djatna 2016). Penggunaan reduksi fitur setelah praproses data untuk memudahkan proses klasifikasi dengan PCA (Vinodhini dan Chandrasekaran 2014) serta menambahkan kelas netral pada klasifikasi sentimen dengan SVM (Koppel dan Jonathan 2006 untuk mempermudah proses klasifikasi sentimen dan meningkatkan akurasi model.
3 dilakukan untuk mengukur model dari 3 parameter yaitu akurasi, precision, dan recall dengan estimasi parameter terbaik dalam algoritme klasifikasi.
Perumusan Masalah
Berdasarkan penjelasan latarbelakang, perumusan masalah penelitian ini adalah:
1. Bagaimana menganalisis kebutuhan dalam membangun model sentiment mining untuk mengetahui respon masyarakat terhadap kegiatan program pengembangan masyarakat dan mengevaluasi model sentiment mining? 2. Bagaimana melakukan perancangan untuk pengembangan model
sentiment mining?
Tujuan Penelitian
Penelitian ini bertujuan untuk mengetahui respon masyarakat terhadap kegiatan program pengembangan masyarakat berdasarkan tweet masyarakat dan mengevaluasi kinerja model serta merancang kebutuhan untuk pengembangan model sentiment mining.
Manfaat Penelitian
Manfaat dari penelitian ini adalah memperoleh model sentiment mining yang dapat melakukan praproses terhadap data tweet yang tidak terstruktur sehingga mampu mempresentasikan sebuah sentimen untuk mengetahui respon masyarakat terhadap kegiatan pada program pengembangan masyarakat, evaluasi model untuk mengetahui kinerja model serta merancang kebutuhan model untuk pengembangan model menjadi aplikasi.
Ruang Lingkup Penelitian
Ruang lingkup penelitian ini diantaranya:
1. Objek penelitian diambil dari dua kegiatan program pengembangan masyarakat yaitu kegiatan PIK-Remaja dan kegiatan GenRe di wilayah Bogor menggunakan media sosial yaitu Twitter.
2. Kelas sentimen pada Model sentiment mining meliputi positif, negatif dan netral.
4
2 TINJAUAN PUSTAKA
Mining Media Sosial
Media sosial sebagai sebuah kelompok aplikasi berbasis internet yang dibangun atas dasar ideologi dan teknologi Web 2.0, dan memungkinkan penciptaan dan pertukaran user-generated content (Kaplan dan Haenlein 2010). Sedangkan menurut Brogan pada tahun 2010 dalam bukunya yang berjudul “Social Media 101 Tactic and Tips to Develop Your Business Online”, sosial media adalah satu set baru komunikasi dan alat kolaborasi yang memungkinkan banyak jenis interaksi yang sebelumnya tidak tersedia untuk orang biasa. Terdapat beberapa hal menarik yang bisa dipelajari pada data sosial media (Gundecha dan Huan 2012):
1. Banyak pertanyaan menarik yang berhubungan dengan perilaku manusia yang dapat dipelajari pada data media sosial.
2. Membantu pengiklan untuk menemukan orang-orang yang bisa dipengaruhi untuk memaksimalkan jangkauan produk mereka dalam anggaran periklanan 3. Membantu sosiolog untuk mengungkap perilaku manusia
4. Memfasilitasi gerakan massa
Twitter adalah salah satu media sosial yang tepat untuk berbagi ide, bank gagasan, tempat untuk mengumpulkan informasi, untuk menginspirasi pikiran, atau untuk melihat apa yang teman anda lakukan. Twitter merupakan mikroblog paling populer di Indonesia dan memungkinkan pengguna untuk mengirim dan membaca pesan yang disebut kicauan (tweet), berupa teks maksimal 140 karakter yang ditampilkan pada halaman profil pengguna. Penelitian ini menggunakan media sosial yaitu Twitter karena berdasarkan penelitian Gundecha dan Huan (2012), Twitter dapat memfasilitasi gerakan masa yang dalam penelitian dapat dianalisis untuk mengetahui respon masyarakat terhadap suatu kegiatan.
Kegiatan Program Pengembangan Masyarakat
Pemberdayaan masyarakat merupakan bagian dari pengembangan masayrakat (community development). Pengembangan masyarakat adalah proses penguatan masyarakat secara aktif dan berkelanjutan berdasarkan prinsip keadilan sosial, partisipasi dan kerja sasma yang setara. Pengembangan masyarakat mengekspresikan nilai-nilai keadilan, kesetaraan, akuntabilitas, kesempatan, pilihan, partisipasi, kerjasama, dan proses belajar keberlanjutan. Menurut Windy (2011), ruang lingkup evaluasi untuk mengetahui keberhasilan program antara lain pencapaian hasil, evaluasi program dan pengawasan mutu, seleksi lokasi dan sasaran kemiskinan, organisasi masyarakat, efektivitas biaya, pengembangan kualitas sumber daya manusia, kepuasan terhadap program serta keberlanjutan program.
5 esehatan reproduksi Remaja (KRR) adalah tiga risiko yang dihadapi oleh remaja, yaitu risiko yang berkaitan dengan seksualitas, NAPZA, HIV dan AIDS (BkkbN 2012).
RapidMiner dengan Rscript
RapidMiner adalah aplikasi data mining berbasis sistem open-source dunia yang ternama dan merupakan platform untuk merancang proses analisis data secara plug-and-play (Ristoski et al. 2015). Keunggulan yang kompetitif dengan solusi yang meliputi integrasi data, analitis ETL, data analisis, pelaporan dalam satu suite tunggal dan mampu memvisualisasikan kriteria kinerja seperti kurva ROC rata-rata atau plot 3D dari matriks. Antarmuka pengguna grafis dari RapidMiner lebih mudah dan lebih efisien untuk digunakan dibandingkan dengan WEKA yang Explorer ketika bekerja dengan blok dapat digunakan kembali dan mencoba untuk membuat koneksi ke database. Semua sumber RapidMiner menggunakan GNU Affero Umum Public License (AGPL) dan bahasa Java (Kosorus et al. 2011). Rapidminer ditulis dalam bahasa pemrograman Java dengan mengintegrasikan proyek data mining Weka dan statistika R.
Rscript adalah bahasa pemrograman R yang berada dalam Rapidminer. R memiliki menjadi standar de facto antara statistik untuk pengembangan perangkat lunak statistik, dan secara luas digunakan untuk pengembangan perangkat lunak statistik dan analisis data. R merupakan bahasa pemrograman sebelum S yang diciptakan oleh John Chambers. R diciptakan oleh Ross Ihaka dan Robert Pria di University of Auckland, Selandia Baru, dan dikembangkan oleh Tim R Pembangunan Core. R menyediakan berbagai macam teknik statistik dan grafis dengan pemodelan linear dan non-linear, klasik uji statistik, analisis time-series, klasifikasi, clustering, dan lain-lain.
R memungkinkan pengguna untuk menambahkan fungsi tambahan dengan mendefinisikan fungsi baru. R memiliki banyak fitur yang sama dengan baik fungsional dan pemrograman berorientasi objek bahasa. Kemampuan R diperluas melalui package yang memungkinkan teknik statistik khusus, perangkat grafis, serta kemampuan ekspor dan import ke banyak format data eksternal dengan kompilasi dan berjalan pada berbagai UNIX platform, Windows dan Mac OS (Kosorus et al.2011). Penelitian ini membangunan model sentiment mining
menggunakan Rscript pada Rapidminer dengan bahasa pemrograman R.
Perancangan untuk Pengembangan Model dengan UML
6
3 METODE
Metode penelitian meliputi analisis kebutuhan model sentimet mining dengan evaluasi model dan perancangan untuk pengembangan model. Tahapan analisis model dengan evaluasi model meliputi pengumpulan data, crawling, praproses, reduksi fitur, klasifikasi sentiment dan evaluasi yang direpresentasikan pada Gambar 1 dan objek menggunakan diagram-diagram UML.
Data
Tweet
Stopword Filter, Case Folding,
Token & Parsing
Hapus Stopword
Pemeriksaan Kelas
Lexicon Based
Matriks tweet
Corpus Negatif dan Positif
Pembobotan TF
Pembobotan Sentiment
Reduksi Fitur dengan PCA
Varian = 80% PC = tinggi
CM ≤ 1 Reduksi fitur
tidak
Klasifikasi dengan SVM
Estimasi parameter (c, y) ya
Evaluasi Model
Model 1 [60% data latih, 40% data uji] Model 2 [70% data latih, 30% data uji] Model 3 [80% data latih, 20% data uji] Model 4 [90% data latih, 10% data uji] Twitter Authentifikasi key Indikator penarikan tweets Mengirim tweets Permintaan tweets Pengumpulan data Praproses
Simpan file
Presentase sentiment Hasil klasifikasi sentiment Hasil evaluasi
Matriks tweet TF
Gambar 1 Tahapan analisis kebutuhan dan evaluasi pada model sentiment mining
Pengumpulan data
7 program pengembangan masyarakat, kemudian melakukan crawling (pengambilan data tweet) menggunakan library Twitter API (Application Programming Interface) dengan kata kunci PIK-Remaja Bogor dan GenRe Bogor.
Gambar 2 Registrasi Twitter Apps untuk authentificationkey
Sebelum crawling data tweet, analis melakukan membuat akun App baru untuk registrasi melalui Twitter Management, seperti pada Gambar 2 sehingga diperoleh key untuk authentifikasi pada Twitter sebagaimana diilustrasikan pada Gambar 3.
Gambar 3 Tampilan authentifikasi untuk key penarikan data tweet
Praproses
Praproses dilakukan dengan tujuan memperbaiki data yang kurang terstruktur, data yang tidak konsisten dan mengurangi noise (gangguan) pada proses klasifikasi (Hemalatha et al. 2012). Praproses pada penelitian ini terdiri dari filter, case folding, token dan parsing, hapus stopword, pelabelan kelas dan pembobotan kata.
a. Filter
Proses menyaring tweet dengan menghapus username atau @, link html, “RT” (tanda retweet), angka, dan data redudan (Tiara et al. 2015).
b. Case Folding
8
c. Token dan parsing
Pengechekan tweet dari karakter pertama sampai karakter terakhir, jika bukan tanda pemisah kata seperti titik (.), koma (,), spasi, atau tanda pemisah lain (-, +, /, &, !, ?), maka digabungkan dengan karakter selanjutnya. Sedangkan parsing tweet memisahkan tweet menjadi kumpulan kata (Putranti dan Winarko 2014). d. Penghapusan Stopword
Menghapus kata sambung, kata depan atau kata penghubung menggunakan file stopword tala.txt yang dimodifikas, misalnya penambahan huruf a, b, sampai dengan z (Tiara et al. 2015).
e. Pembobotan term pada tweet
Perhitungan TF (Term Frequency) yaitu perhitungan frekuensi kemunculan sebuah kata terhadap tweet untuk menunjukkan seberapa penting sebuah kata terhadap sebuah tweet yang ada pada sebuah koleksi tweet (Wu et al. 2008; Wahyudin dan Djatna 2016). Hasil tahapan d dan e dijadikan suatu vektor W. Dimana W ={w1, w2, ... wi} dan i ϵ s berisi kandidat kata sentimen dan W ϵ V
denganV merupakan corpus yang berisi fitur dan kata sentimen. f. Pemeriksaan Kelas
Tahapan ini memberi label kelas dengan lexicon based pada setiap tweet berdasarkan kelas positif dan negatif yang ada pada corpus lexicon dengan Bahasa Indonesia. Selanjutnya dihitung nilai kedekatan kata dengan corpus lexicon menggunakan Persamaan 1. Jika nilai atau score akhir adalah positif maka diasumsikan fitur dalam tweet ber-sentiment positif. Jika nilai atau score akhir adalah negatif maka diasumsikan fitur dalam tweet bersentimen negatif, dan jika bukan keduanya maka tweet termasuk kelas netral (Tiara et al. 2015; Ding et al. 2008).
:
.
( )
( , )
i i ii
w w s w V i
w so
score f
dis w f
(1) wi = katasentimen
V = ruang sample terdiri dari tweet yang berisi fitur dan katasentimen s = seluruh kata sentimen
so= label atau kelas sentimen (+, -, 0)
dis (wi, f) = Jarak antara fitur (f) dan kata sentimen (wi)
Reduksi Fitur dengan PCA
Principal Component Analysis (PCA) adalah teknik reduksi dimensi dan mengekstrak fitur untuk menemukan dimensi fitur yang lebih rendah. Istilah varians terbesar ini disebut pengurangan dimensi, sebagai vektor yang berisi data asli dan n -dimensi diturunkan ke vektor terkompresi (Subramanian dan Venkatachalam 2015) sedangkan menurutVinondhini dan Chandrasekaran (2014), PCA merupakan metode pengidentifikasian pola data dan mereduksi atribut tanpa mengurangi nilai informasi sebagaimana diilustrasikan pada Gambar 4. Konsep PCA menggunakan metode statistika untuk mereduksi dimensi pada kumpulan fitur atau atribut. Penelitian ini mengasumsikan T adalah matriks (n . m) sebagai vektor data tweet sejumlah n dan m
9
Tahapan pertama PCA adalah standarisasi atau normalisasi data dengan mengurangkan masing-masing data dengan mean. Selanjutnya menentukan matriks kovarian menggunakan Persamaan 2 , dimana xi yaitu tweet ke i, yi adalah fitur
yang dimiliki tweet ke i,
x
meanadalah rataan tweet sedangkany
meanadalah rataan fitur.Algoritme PCA
i Hitung matriks kovarian
ii Hitung eigen value dan eigen vektor iii Mereduksi dimensi pada data
iv Hitung standar tranformasi matriks T v Hitung domain fitur (p) untuk di review
Gambar 4 Alur algoritme PCA (Vinondhini dan Chandrasekaran 2014)
Cov (x,y) merupakan jumlah dari perkalian zero mean x dan zero mean y yang dibagi dengan jumlah seluruh tweet dikurangi 1. Zero mean adalah selisih antara nilai dengan rataan dari kumpulan nilai berada.
1
(
)(
)
( , )
1
N
i mean i mean
n
x
x
y
y
Cov x y
n
(2)Eigen value merupakan nilai karakteristik suatu matrik yang didapatkan dari matrik kovarian dan digunakan dalam menghitung eigen vector untuk mendapatkan nilai PC pada setiap fitur, nilai PC1 merupakan nilai PC tertinggi yang akan digunakan pada proses selanjutnya yaitu klasifikasi sentimen. Proses reduksi fitur melibatkan perhitungan varian, eigen value dan eigen vector untuk menghasilkan nilai PC (principal component) yang digunakan dalam mereduksi fitur. Jika nilai
cummulative variance sudah ≤ 1 maka, fitur dikatakan sudah tidak varian akan direduksi, sehingga mempermudah dan mempercepat proses klasifikasi dengan data yang memiliki banyak fitur menggunakan RapidMiner dengan Rsciprt (Rapid-I 2015).
Klasifikasi Sentimen dengan SVM
10
Gambar 5 Pemetaan data dengan fungsi hyperplane ke ruang vektor
Proses klasifikasi menggunakan konsep mencari fungsi hyperplane terbaik yang akan menjadi support vector dan digunakan dalam klasifikasi terlihat pada Gambar 5 dan Gambar 6 yang diadopsi dari Nugroho et al. (2003). Penggunaan fungsi kernel RBF (Radial Basis Function) sebagaimana penelitian yang telah dilakukan menghasil akurasi lebih tinggi pada klasifikasi sentimen dibandingkan kernel Polynomial dan Sigmoid dan pengklasifikasian SVM dengan fungsi kernel RBF memberikan akurasi yang paling baik dibandingkan dengan fungsi kernel linier maupun polinomial (Muis dan Affandes 2015), maka penelitian ini menggunakan fungsi kernel RBF sehingga model hyperplane menggunakan Persamaan 3.
2
1
(
)
exp(
(||
||) )
d Nsv
d i i i
i
f x
y
x x
b
(3)dimana :
Nsv (Number of support vector) : jumlah support vector
i : 1,2,3,..., Nsv b : bias
y : Label/kelas dari data tweet α : Alpha pengali lagrange
exp(-γ(||xi-xd||)2) : Fungsi kernel RBF
Pembelajaran dengan SVM bertujuan untuk membentuk hyperplane dengan mencari support vector pada data latih dengan output alpha (α), dimana α positif disebut support vector. C1= kelas positif, C2 = kelas negatif, C3= kelas netral, sedangkan H1 = Hyperplane 1, H2 = Hyperplane 2, H3 = Hyperplane 3.
(a) (b)
11 Berdasarkan Gambar 7(a) pembentukan hyperplane paling positif yaitu kombinasi antara hyperplane yang memisahkan tiga kelas sentiment yaitu H12, H23, H13 seperti ditunjukan pada Gambar 7(b). Hyperplane tersebut menghasilkan support vector akan digunakan untuk mengkasifikasi kelas.
Penelitian ini melakukan estimasi parameter terbaik dengan mengunakan grid search. Grid search bertujuan membuat grid parameter dari setiap pasangan (c, γ). Parameter nilai (c, γ) ditentukan terlebih dahulu dengan rentang nilai 0.1 sampai 0.9, kemudian memasangkan setiap nilai paramter (c, γ) sehingga pasangan parameter yang menghasilkan akurasi tertinggi digunakan dalam skenario pengujian 4 model berdasarkan persentase data latih dan data uji.
Evaluasi Model Sentiment Mining
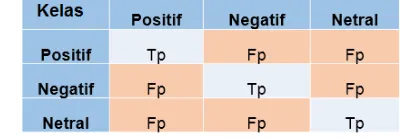
Evaluasi kinerja model klasifikasi dapat dilihat berdasarkan tiga parameter yaitu akurasi, precision dan recall sebagaimana juga telah dilakukan pada penelitian Tiara et al. pada tahun 2015 dengan Persamaan 2, dimana tweetklasifikasi
merupakan jumlah tweet yang diklasifikasikan secara benar dan total data tweet yang diujikan tweetuji terhadap tweetklasifikasi.
latih uji tweet Akurasi tweet
(2)Tp p
Tp Fp
(3)
Precision (p) pada kelas positif merupakan Tp yaitu jumlah tweet dengan kelas sentimen positif diklasifikasi secara benar dibagi dengan TpFp yaitu jumlah total tweet yang diklasifikasi sebagai kelas positif.
Tp r
Tp Fn
(4)
Recall (r) adalah jumlah tweet diklasifikasi positif dibagi dengan TpFn
yaitu jumlah total tweet dalam data uji dengan kelas positif. Evaluasi kinerja model direpresentasikan dalam confusion matrix sebagaimana ditunjukan pada Gambar 7 yang diadopsi dari Kumar dan Abirami (2015).
12
4 HASIL DAN PEMBAHASAN
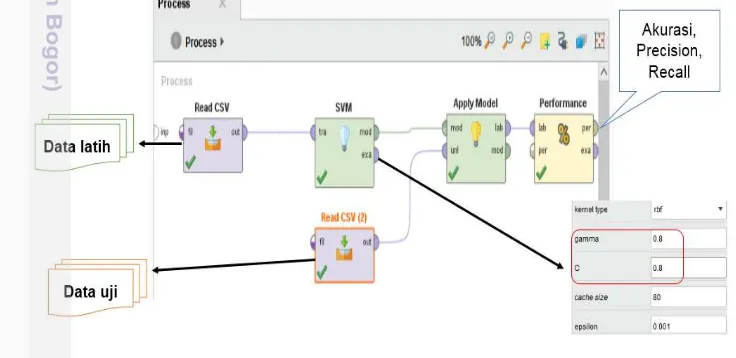
Tahapan ini menjelaskan hasil dan pembahasan penelitian yang meliputi pengumpulan data dan praproses, analisis tweet hasil reduksi fitur, analisis proses klasifikasi evaluasi model menggunakan interface RapidMiner Studio 7.1 dengan Rscript. Perancangan untuk pengembangan model sentiment mining menggunakan diagram-diagram UML.
Pengumpulan data
Tahapan pertama pada proses crawling yaitu koneksi API dengan cara registrasi melalui Twitter Application Management untuk mendapatkan API Key, API Secret, Access Token, Access Token Secret kemudian melakukan autentifikasi. Selanjutnya melakukan pengambilan data berdasarkan kata kunci dengan parameter yang diinginkan, misalnya pada penelitian ini kata kunci yang digunakan adalah tentang kegiatan PIK-Remaja dan GenRe yang berada diwilayah Bogor dengan jumlah 1000 tweet untuk masing-masing kegiatan pada tanggal 1 Januari 2015 sampai 1 Januari 2016.
Tahapan selanjut yaitu menyimpan file dengan format .csv (comma delimited). Setelah dilakukan praproses terhadap dataset yang meliputi filter, case folding, hapus stopword, token dan parsing, pembobotan dan pemeriksaan kelas diperoleh 1219 fitur dari 1000 tweet pada kegiatan PIK-Remaja dan 1302 fitur dari 1000 tweet kegiatan GenRe.
Menurut Ding et al. (2008), pemeriksaan kelas memiliki empat langkah dalam menentukan orientasi sentimen berdasarkan pendekatan lexicon yaitu : 1. Tandai kata yang mengandung sentimen : untuk setiap kalimat yang berisi satu
atau lebih kata sentimen, langkah ini menandai semua kata dan frasa dalam sentimen kalimat. Setiap kata positif diberikan skor sentimen +1 dan setiap kata negatif diberikan skor sentimen -1. Berdasarkan Gambar 4, fitur ke-5 (w5) dan
fitur ke-6 (w6) mengandung kata yang terdapat pada corpus positif maka diberi
skor [+1].
2. Terapkan sentimen shifter yaitu kata-kata dan frase yang dapat mengubah orientasi sentimen dengan kata negasi seperti tidak, tidak pernah, tidak ada, ngga, nggak dan tidak bosen adalah jenis yang paling umum. Maka tweet menjadi
“launching pik remaja nggak lama : ) semangat tapi seru” karena terdapat kata
negasi “nggak” maka bernilai [-1].
3. Menangani klausa tapi- : penggunaan klausa tapi juga dapat merubah orientasi sentimen. Sebuah kalimat mengandung klausa tapi- dan setelahnya mengandung kata sentimen akan bertentangan dengan kata sebelum klausa tapi-. Sehingga tweet yang dicontohkan menjadi sebagai berikut “launching pik remaja nggak lama [+1] , tapi seru [+1].
13
w1 w2 w3 w4 w5 w6 w7 w8 w9
fitur (wi) launching pik remaja nggak lama :) semangat tapi seru
tandai kata
sentimen -1 -1 +1 +1 +1
kata
negasi +1 +1 +1 +1
klausa
tapi- +1 +1 +1 +1
Gambar 8 Ilustrasi tahapan pemeriksaan kelas sentimen
Berdasarkan Gambar 4, fitur w1, w2, w3 tidak diberi skor atau diabaikan karena tidak mengandung kata yang ada di dalam corpus sentimen. Sehingga dapat disimpulkan tweet “launching pik remaja nggak lama : ) semangat tapi seru” merupakan kelas positif dengan bobot sentimen [+4].
Reduksi fitur
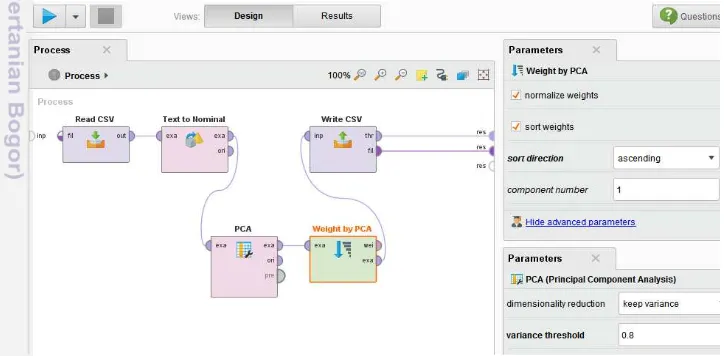
Proses reduksi fitur melibatkan perhitungan varian, eigen value dan eigen vector untuk menghasilkan nilai PC (principal component) yang digunakan dalam mereduksi fitur sehingga mempermudah proses klasifikasi, yang direpresentasikan pada Gambar 9 menggunakan bahasa R yang disediakan RapidMiner Studio yaitu Rscript (Rapid-I 2015).
Gambar 9 Flow knowledge proses reduksi fitur pada RapidMiner
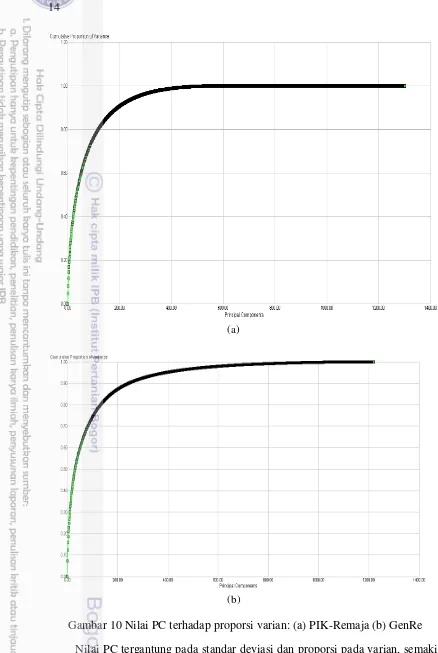
Menurut Vinodhini dan Chandrasekaran (2014), nilai PC yang tinggi bergantung pada standar deviasi dan proporsi varian dan fitur dikatakan tidak varian jika nilai eigen value atau cumulative varian ≤ 1 sebagaimana direpresentasikan pada Gambar 10 (a) dan 10 (b). Gambar 10 (a), merepresentasikan nilai PC terhadap cummulative variance untuk kegiatan PIK-Remaja yang menunjukkan bahwa pada fitur 1200 dan seterusnya nilai cummulative variance sudah sama yaitu 1.
14
(a)
(b)
15 Tabel 1 Pengurutan nilai principal component dari yang tertinggi
Component (PC)
Standar Deviasi (SD)
Proporsi Varian (PV)
Kumulatif Varian (CV)
PC1 0.561 0.075 0.075
PC2 0.452 0.049 0.123
PC3 0.393 0.037 0.160
PC4 0.331 0.024 0.186
PC5 0.268 0.019 0.210
PC6 0.276 0.018 0.230
PC7 0.274 0.018 0.248
. . . .
. . . .
. . . .
PCn SDn PVn CVn
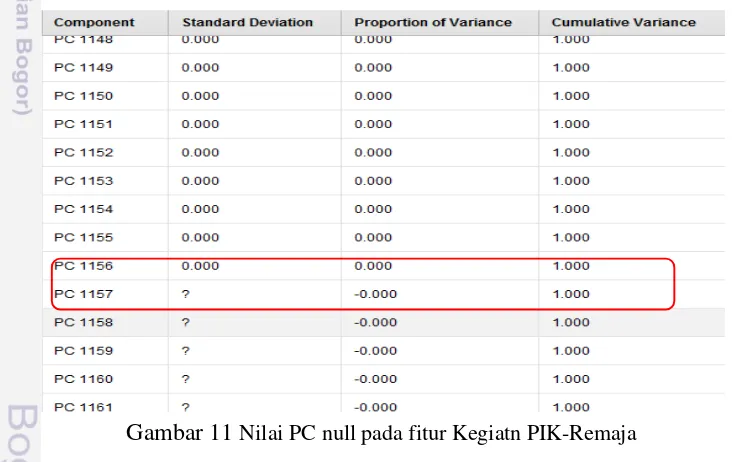
Pada Tabel 1, ditampilkan sebagian dataset dengan nilai PC tertinggi berbanding lurus nilai standar deviasi dan proporsi varian sedangkan Gambar 11 menunjukan nilai PC1 sampai PCn untuk setiap fitur kemudian diurutkan fitur dengan nilai PC1 tertinggi. Penggunaan fitur yang direduksi dengan PCA untuk proses klasifikasi mempertimbangkan kriteria untuk mereduksi fitur yaitu nilai PC tinggi dan nilai cummulative variance ≤ 1. Jika fitur memenuhi kriteria maka akan digunakan untuk proses klasifikasi sedangkan fitur yang tidak memenuhi kriteria akan direduksi atau tidak digunakan dalam proses klasifikasi.
Gambar 11 Nilai PC null pada fitur Kegiatn PIK-Remaja
16
Gambar 12 Nilai PC null pada fitur kegiatan GenRe
Berdasarkan hasil reduksi fitur pada masing-masing dataset kegiatan diperoleh 1156 fitur dari 1219 fitur pada kegiatan PIK-Remaja dan 951 fitur dari 1302 fitur pada kegiatan GenRe yang akan digunakan pada proses klasifikasi.
Klasifikasi Sentiment
Penerapan algoritme SVM dengan penambahan kelas netral diharapkan mampu menghasilkan model yang baik dengan tingkat akurasi yang tinggi, ilustrasi proses klasifikasi direpresentasikan pada Gambar 13. Parameter SVM yang digunakan merupakan kombinasi nilai c dan γ dari hasil estimasi.
Gambar 13 Flow knowledge proses proses klasifikasi sentiment
17 PIK-Remaja sebesar 37.90%, hal tersebut menjawab tujuan penelitian yang kedua yaitu kegiatan dengan tingkat persentase positif tertinggi adalah GenRe yang berarti memiliki respon yang baik dalam penyebaran informasi tentang sosialisasi, penyuluhan serta implementasi kegiatan. Jumlah persentase diperoleh dari pembobotan sentiment yaitu nilai +1 untuk positif, nilai -1 untuk negatif dan 0 untuk netral.
Tabel 2 Presentase jumlah sentiment kegiatan GenRe dan PIK-Remaja
Kelas sentiment
PIK Remaja GenRe
Jumlah Persentase (%) Jumlah tweet Persentase (%)
Positif 379 37.90 392 39.20
Negatif 196 19.60 200 20.00
Netral 425 42.50 408 40.80
Total 1000 100 1000 100
Penggunaan estimasi parameter dan pembagian data dalam pembangunan model bertujuan untuk mengetahui bagaimana pengaruhnya terhadap tingkat akurasi pada proses klasifikasi sentiment.
(a)
(b)
Gambar 14 Skenario model sentiment mining: (a) PIK-Remaja (b) GenRe 226 166 269 123 311 81 350 42 129 71 142 58 157 43 179 21 245 163 289 119 332 76 371 37 0 50 100 150 200 250 300 350 400 60% data latih
40% data uji 70% data latih
30% data uji 80% data latih
20% data uji 90% data latih
10% data uji
Model 1 Model 2 Model 3 Model 4
Jum la h se nt ime nt
Positif Negatif Netral
127 69 140 56 155 41 177 19 251 167 295 123 338 80 377 41 600 400 700 300 800 200 900 100 0 100 200 300 400 500 600 700 800 900 1000
222 164 265 121 307 79 346 40
60% data latih
40% ata uji 70% data latih
30% data uji 80% data latih
20% data uji 90% data latih
10% data uji
Jum la h se nt ime nt
18
Pada Gambar 14 direpresentasikan jumlah setiap kelas sentiment berdasarkan skenario model. Gambar 14 (a) menunjukan bahwa jumlah terbanyak sentiment positif kegiatan PIK-Remaja sebanyak 350 tweet sedangkan pada Gambar 14 (b) jumlah terbanyak sentiment positif kegiatan GenRe sebanyak 346 tweet yang keduanya berada dalam data latih pada Model 4.
Pengujian Parameter (c,γ) pada Fungsi Kernel
Pengujian parameter c dan γ dilakukan dengan menggunakan data yang terdiri dari 50% data latih dan 50% data uji dan Persamaan 2. Berdasarkan Tabel 3 menunjukkan beberapa pasangan nilai parameter yang memberikan akurasi paling baik pada klasifikasi kelas sentiment sebesar 97.44% yaitu (c=0.8, γ=0.8), (c=0.8,
γ=0.9), (c=0.9, γ=0.8) dan (c=0.9, γ=0.9). Pasangan nilai parameter tersebut akan digunakan pada tahap selanjutnya untuk menguji tingkat akurasi klasifikasi SVM pada model.
Tabel 3 Grid search presentase tingkat akurasi model sentiment mining
c y 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9
0,1 43,96 38,83 38,83 38,83 38,83 38,83 38,83 38,83 38,83
0,2 73,63 66,67 54,41 50,55 38,83 38,83 38,83 38,83 38,83
0,3 78,39 78,75 78,39 79,12 75,82 65,2 58,97 58,61 56,04
0,4 80,95 82,05 82,78 82,78 80,59 84,62 83,88 83,88 83,52
0,5 82,42 83,88 86,45 89,38 88,28 87,55 84,25 83,35 84,98
0,6 82,78 84,62 86,45 88,28 91,21 91,21 92,67 96,34 96,34
0,7 83,15 84,62 86,45 87,91 91,58 91,58 93,41 96,7 96,7
0,8 83,52 86,81 87,55 88,28 90,11 91,58 93,41 97,44 97,44
0,9 83,52 86,81 87,55 88,28 89,01 91,94 93,77 97,44 97,44
Tabel 3 menunjukan bahwa pasangan parameter c dan γ yang menghasilkan akurasi tertinggi adalah 0.8 dan 0.8, 0.8 dan 0.9, 0.9 dan 0.8, 0.9 dan 0.9. Karena parameter tersebut memiliki persentase akurasi yang sama, maka pasangan
parameter c dan γ yang digunakan pada pengujian model adalah c= 0.8 dan γ =0.8.
Evaluasi Model
Penggunaan parameter dari hasil estimasi parameter pada pengujian model sentiment mining, bertujuan untuk meningkatkan nilai akurasi, precision dan recall antar model sebagaimana juga telah dilakukan pada penelitian Tiara et al. (2015) dengan Persamaan 2, Persamaan 3 dan Persamaan 4.
19
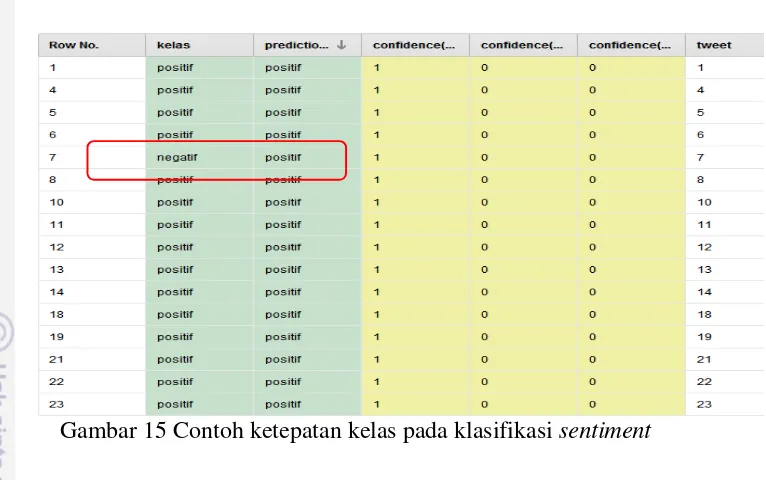
Gambar 15 Contoh ketepatan kelas pada klasifikasi sentiment
Gambar 16 merupakan salah satu confusion matrix model yang dihasilkan dari penelitian dan merupakan model dengan akurasi tertinggi.
Gambar 16 Confusion matrix Model 1 pada kegiatan GenRe
[image:31.595.134.517.73.313.2]Berdasarkan Tabel 4, presentase recall pada kegiatan PIK-Remaja tertinggi dimiliki Model 3 pada kelas sentimen negatif sebesar 84.26% dan terendah pada Model 1 sebesar 65.09% sedangkan precision tertinggi diperoleh dari Model 3 sebesar 80% dan terendah dimiliki Model 1 pada kelas sentimen positif sebesar 66.20%.
Tabel 4 Persentase precision dan recall pada kegiatan PIK-Remaja Kelas
Sentiment
Model 1 Model 2 Model 3 Model 4
precision recall precision recall precision recall precision recall
Positif 74.19 65.09 70.37 75.53 75.53 75.53 75.53 73,96 Negatif 66.20 74.60 77.78 84.26 79.82 84.26 78.90 79.63 Netral 71.56 75.00 79.41 73.24 80,00 73.24 71.43 72.46
[image:31.595.111.514.594.828.2]20
Tabel 5 menunjukan presentase precision dan recall pada kegiatan GenRe, precision tertinggi dimiliki Model 3 pada kelas sentimen netral sebesar 91.80%.
Tabel 5 Persentase precision dan recall pada kegiatan GenRe Kelas
Sentiment
Model 1 Model 2 Model 3 Model 4
precision recall precision recall precision recall precision recall
Positif 86,73 87,63 87,25 82,41 82,65 86,17 82,29 82,29 Negatif 87,50 87,50 85,94 87,30 85,09 89,81 83,33 87,96 Netral 90,99 90,18 83,18 87,25 91,80 78,87 84,13 76,81
Rataan 88,41 88,44 85,46 85,65 86,51 84,95 83,25 82,35
Berdasarkan Tabel 4 dan Tabel 5, banyaknya jumlah kelas sentimen tidak berbanding lurus dengan tingkat precision ataupun recall karena seperti digambarkan pada Gambar 15 (a) dan 15 (b), jumlah tweet dengan sentimen positif selalu lebih banyak dibandingkan tweet dengan sentimen negatif.
Tabel 6 Tingkat akurasi dengan parameter c = 0.8 dan γ = 0.8
Model PIK-Remaja GenRe
Model 1 (60% data latih dan 40% data uji) 82.78 88.64
Model 2 (70% data latih dan 30% data uji) 79.49 85.35
Model 3 (80% data latih dan 20% data uji) 78.75 85.71
Model 4 (90% data latih dan 10% data uji) 78.39 83.15
Rataan 79.85 85.71
Berdasarakan Tabel 6 dan Tabel 7 menunjukan presentase tingkat akurasi pada setiap model dengan akurasi tertinggi diperoleh dengan melakukan estimasi terlebih dahulu sehingga dapat diketahui bahwa klasifikasi sentiment dengan parameter hasil estimasi lebih tinggi dibandingkan langsung memilih nilai parameter. Penjelasan tersebut dipertegas dengan direpresentasikannya tingkat akurasi antara klasifikasi dengan menggunakan parameter c= 0.1 dan γ = 0.6 pada Tabel 5 dan menggunakan parameter yang memiliki akursi tertinggi pada proses
[image:32.595.90.466.623.741.2]pelatihan data yaitu dengan parameter c= 0.8 dan γ = 0.8.
Tabel 7 Tingkat akurasi dengan parameter c= 0.1 dan γ = 0.6
Model
PIK-Remaja
(%) GenRe(%)
Model 1 (60% data latih dan 40% data uji) 71.06 81.32
Model 2 (70% data latih dan 30% data uji) 75.46 76.92
Model 3 (80% data latih dan 20% data uji) 78.39 83.88
Model 4 (90% data latih dan 10% data uji) 75.82 81.68
21 Berdasarkan hasil pengujian model, tingkat akurasi baik untuk masing-masing kegiatan nilai akurasi lebih dari 70%. Kegiatan dengan akurasi tertinggi adalah model 1 sebesar 88.68 % yang dihasilkan dari data kegiatan GenRe sedangkan pada kegiatan PIK-Remaja sebesar 82.78%.
Pengembangan Model Sentiment Mining
Pengembangan model dilakukan dengan merancangan model menggunakan diagram-diagram UML yang meliputi use case diagram, state diagram, activity diagram, sequence diagram, component diagram dan class diagram dengan tujuan memudahkan dalam memahami tahapan pemodelan yang dilakukan untuk pengembangan menjadi aplikasi pada penelitian selanjutnya.
Use Case Diagram
Tahap konseptualisasi dalam UML dilakukan dengan pembuatan use case diagram yang merupakan deskripsi peringkat tertinggi bagaimana perangkat lunak (sistem atau aplikasi) berinteraksi dengan pengguna dan use case diagram tidak hanya sangat penting pada tahap analisis tetapi juga untuk tahap perancangan, untuk mencari kelas yang terlibat dalam melakukan pengujian (Nugroho 2009). Pengguna pada use case merupakan analis atau bukan end user dikarenakan use case diagram ini untuk menggambarkan keterhubungan pembangun model dengan model. Use case diagram pada Gambar use case, menunjukan interaksi analis dengan pemodelan sentiment mining. Fungsi utama use case terdapat pada use case crawling tweet, praproses, reduksi fitur, klasifikasi dan evaluasi model. Berdasarkan gambar use case pada Lampiran 4 setiap use case memiliki kriteria yang berbeda yaitu use case yang bergantung pada proses lain (extends) dan use case yang tidak bergantung pada proses lain (include). Fungsi dari setiap use case dijelaskan pada Tabel 1 dalam Lampiran 4.
Activity Diagram
Diagram ini berhubungan dengan diagram Statechart dan pada dasarnya activity diagram sering digunakan oleh flowchart. Statechart diagram, berfokus pada obyek yang dalam suatu proses (atau proses menjadi suatu obyek), activity diagram berfokus pada aktifitas yang terjadi dalam suatu proses tunggal atau menunjukkan bagaimana aktifitas-aktifitas yang bergantung satu sama lain. Gambar activity diagram pada Lampiran 5 menunjukan bahwa aktifitas crawling data tweet sangat bergantung pada ketersediaan tweet di server Twitter dan koneksi jaringan internet untuk authentifikasi key yang sudah diregistrasi.
Gambar activity diagram klasifikasi pada Lampiran 5 menunjukan bahwa proses klasifikasi tidak akan dapat diproses jika fitur terbaik belum diperoleh melalui pengechekan nilai PC (principal component) dan CM (cummulative variance), dan proses reduksi fitur tidak dapat dilakukan juga sebelum praproses dilakukan. Perhitungan akurasi, precision, dan recall merupakan proses akhir untuk mengetahui kinerja model yang telah dibangun.
Sequence diagram
22
dikirimkan dan diterima antar objek, perancangan sequence diagram praproses digambarkan pada Lampiran 6. Time line praproses data tweet dimulai dengan pembacaan data tweet berupa file.csv setelah data terbaca dan dapat ditampilkan kemudian data diolah mulai dari praproses 2.a yaitu filter data tweet sampai dengan 2.f yaitu pelabelan kelas sentiment berdasarkan pembentukan corpus positif dan negatif yang telah dilakukan pada pembobotan kata.
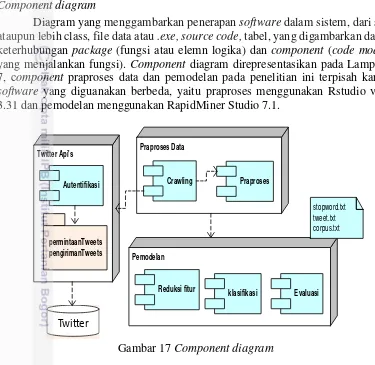
Component diagram
Diagram yang menggambarkan penerapan software dalam sistem, dari satu ataupun lebih class, file data atau .exe, source code, tabel, yang digambarkan dalam keterhubungan package (fungsi atau elemn logika) dan component (code module yang menjalankan fungsi). Component diagram direpresentasikan pada Lampiran 7, component praproses data dan pemodelan pada penelitian ini terpisah karena software yang diguanakan berbeda, yaitu praproses menggunakan Rstudio versi 3.31 dan pemodelan menggunakan RapidMiner Studio 7.1.
Pemodelan Praproses Data
Praproses Crawling
Twitter Api's
Autentifikasi
Reduksi fitur
Twitter permintaanTweets pengirimanTweets
stopword.txt tweet.txt corpus.txt
[image:34.595.88.463.183.548.2]klasifikasi Evaluasi
Gambar 17 Component diagram
Keterlibatan komponen pada perancangan model klasifikasi sentimen, diantaranya komponen Twitter dan sentiment mining. Model sentiment mining tidak dapat melakukan pengolahan data tweet jika belum ada data tweet dari komponen Twitter, sehingga model sangat bergantung pada crawling yang berasal dari Twitter. Class diagram
Class diagram bersifat statis, menggambarkan hubungan apa yang terjadi bukan apa yang terjadi jika kelas berhubungan, dengan merepresentasikan relasi antar kelas untuk mempermudah pengembangan model dalam tranformasi model menjadi sebuah aplikasi, sebagaimana ditunjukan pada gambar di Lampiran 6. StateChart Diagram
23 menyebabkan perubahan pada keadaannya. Gambar 18 menunjukan state Crawling_Tweets memiliki precondition “data tweet belum ada” dan postcondition
dikatakan “data tweet dikirim” jika autentifikasi key berhasil dan tweet dengan kata
[image:35.595.122.507.148.609.2]kunci yang diinginkan tersedia, kemudian dataset tweet dapat disimpan dalam file dengan format .csv.
Gambar 18 Statechart diagram model sentiment mining
Model sentiment mining yang dibangun mampu mengolah data tweet yang tidak terstruktur sehingga dapat diperoleh informasi tentang kelas sentimen, mereduksi fitur pada data tweet dan diperoleh 1156 fitur dari 1219 fitur pada kegiatan PIK-Remaja dan 951 fitur dari 1302 fitur pada kegiatan GenRe yang akan digunakan pada proses klasifikasi. Model juga mampu mengkasifikasikan kelas sentimen dengan akurasi yang cukup baik. Berdasarkan hasil pengujian model nilai akurasi lebih dari 70%. Kegiatan dengan akurasi tertinggi adalah model 1 sebesar
Crawling tweets
Praproses tweets
Reduksi fitur
Hasil
evaluasi model Data Training Data Testing
Simpan «precondition»
{data tweets belum ada}
«postcondition» {data tweets dikirim} Input indikator crawling
permintaanTweets Koneksi TwitterAPI autentifikasi key «requirement» kata kunci jumlah tweet range waktu «invariant» {Filter case folding hapus stopword tokenizing & parsing pelabelan kelas pembobotan kata}
«postcondition» {data telah dipraproses}
kelas sentiment c dan y niali akurasi Pemodelan «postcondition» {hasil klasifikasi} pengirimanTweets «postcondition» {data telah direduksi}
Pembagian data
Model 1 : data latih 60% & data uji 40% Model 2 : data latih 70% & data uji 30% Model 3 : data latih 80% & data uji 20% Model 4 : data latih 90% & data uji 10% Presentase akurasi, precision, dan recall «precondition»
{kirim indikator}
«postcondition» {kirim tweet}
«precondition» {konfirmasi isi indikator}
<postcondition>> {cek ketersediaan tweet}
<precondition>> {tweet belum dipraproses}
«precondition» {pembangunan model}
24
25
5
SIMPULAN DAN SARAN
Simpulan
Model sentiment mining yang dibangun dan dirancang mampu mengektraksi data tekstual menjadi terstruktur sehingga dapat menghasilkan sentimen dan diklasifikasikan untuk mengetahui respon masyarakat terhadap kegiatan pada program pengembangan masyarakat. Berdasarkan data tweet yang di-crawling sebanyak 1000 tweet dari masing-masing kegiatan, setelah dilakukan praproses diperoleh 1219 ditur dan 1302 fitur dan setelah direduksi fitur menjadi 1156 fitur dan 951 fitur. Hasil penelitian menunjukkan jumlah presentase sentimen positif kegiatan GenRe sebesar 39.20% dan PIK-Remaja sebesar 37.90% yang berarti bahwa kegiatan GenRe memiliki respon masyarakat yang lebih baik dari kegiatan PIK-Remaja. Tingkat akurasi yang dihasilkan data tweet dengan reduksi fitur yang tertinggi dimiliki Model 1 dengan 60% data latih dan 40% data uji pada kegiatan GenRe yaitu akurasi sebesar 88.64%, precision sebesar 91.80%, dan recall sebesar 90.18% sedangkan untuk kegiatan PIK-Remaja akurasi terbesar 82.78% diperoleh dari Model 1, precision sebesar 86.81%, dan recall sebesar 85.09% Tingkat akurasi dipengaruhi praproses dan estimasi parameter pada algoritme klasifikasi tetapi tidak dipengaruhi pembagian data latih dan data uji.
Saran
26
DAFTAR PUSTAKA
Adi IR. 2003. Pemberdayaan, Pengembangan Masyarakat, dan Intervensi Komunitas: Seri Pemberdayaan Masyarakat 03. Lembaga Penerbit Fakultas Ekonomi Universitas Indonesia. ISBN: 979-9242-44-5.
[APJII, PUSKAKOM UI]. 2015. Hasil Survei Pengguna Internet di Indonesia. Cable News Network Indonesia.
[BKKBN]. 2012. Petunjuk Teknis Monitoring dan Evaluasi Penerapan dan Pencapaian Standar Pelayanan Minimal (SPM) Bidang Keluarga Berencana dan Keluarga Sejahtera di kabupaten dan kota. BKKBN Nasional.
Ding X, Liu B, Yu PS. 2008. A Holistic Lexicon-Based Approach to Opinion Mining. ACM 978-1-59593-927-9/08/0002. Information Storage and Retrieval]: Information Search and Retrieval: Information filtering. [Natural Language Processing] – Text analysis.
Gundecha P, Huan L. 2012. Mining Social Media: A Bref Intorduction. Informs. ISBN: 978-0-9843378-3-5. http://dx.doi.org/10.1287/educ.1120.0105
Hemalatha I, Varma PG, Govardhan A. 2012. Preprocessing the Informal Text for Efficient Sentiment Analysis. IJETTCS. Vol.1 [Juli–Agustus]. ISSN: 2278-6856. Kumar JA, Abirami S. 2015. An Experimental Study of Feature Extraction Techniques
in Opinion Mining. IJSCAI. Vol.4 No.1 DOI:105.5121/IJSCAI.2015.4102. Koppel M, Schler J. 2006. The Importance of Neutral Example for Learning Sentiment.
Bar-Ilan University. Computational Intelligence 22(2), pp. 100-109.
Kosorus H, Honigl J, Kung J. 2011. Using R, WEKA and RapidMiner in Time Series Analysis of Sensor Data for Structural Health Monitoring. International Workshop on Database and Expert Systems Applications. IEEE. 529-4188/11 DOI 10.1109/DEXA.2011.88
Muis IA, Affandes M. 2015. Penerapan Metode SVM menggunakan Kernel RBF pada Klasifikasi Tweet. Jurnal Sains, Teknologi dan Industri. Vol. 12(2): 189–197. ISSN:1693-2390 print / ISSN:2407-0939 online.
Naradhipa AR, Purwarianti P. 2011. Sentiment Classification for Indonesian Message in Sosial Media. International Conference on Electrical Engineering and Informatics.
Nugroho A. 2009. Rekayasa Perangkat Lunak menggunakan UML dan Java. ANDI Yogyakarta. Ed.I. ISBN:978-979-29-0989-0
Nugroho AS, Witarto AB, Handoko D. 2003. Teori dan Aplikasi Support Vector Machine. Kuliah Umum Ilmu Komputer.com. http://asnugroho.net.
[Onavo Insight]. 2013. Pengguna Penetrasi Twitter di Dunia. Data Aggregated reach of the Twitter mobile App. http://www.jagatreview.com/2013/09/indonesia-negara-dengan-tingkat-penetrasi-twitter-tertinggi-di-dunia/[29/08/2016:10.10]. Pang B, Lee L. 2008. Opinion Mining and Sentimen Analysis. Foundations and Trends
R in Information Retrieval. Vol. 2. Nos. 1–2 (2008) 1–135.
Philips R, Pittman RH. 2009. An Introduction to Community Development. ISBN: 0-203-88693-3. First published by Routledge. USA dan Canada.
Putranti ND, Winarko E. 2014. Analisis Sentiment Twitter untuk Teks Berbahasa Indonesia dengan Maximum Entropy dan Support Vector Machine. IJCCS. Vol.8 No.1: 91-100. ISSN: 1978-1520.
27 [Rapid-I]. 2001. The RapidMiner (free) Basic Edition is available under the AGPL license using RapidMiner Studio. Unit Artificial Intelligence dari Technical University of Dortmund. https://rapidminer.com/
Ristoski P, Bizer C, Paulheim H. 2015. Accepted Manuscript Mining the Web of Linked Data with RapidMiner. PII: S1570-8268(15)00050-5 DOI: http://dx.doi.org/10.1016/j.websem. Reference: WEBSEM 378.
Subramanian KM, Venkatachalam K. 2015. Framework for Evaluating Camera Opinions. Journal of Applied Sciences, Engineering, and Technology Vol.7: 519-525. ISSN: 2040-7459; e-ISSN: 2040-7467.
Tiara, Sabariah MK, Effendy M. 2015. Sentiment Analysis on Twitter Using the Combination of Lexicon-Based and Support Vector Machine for Assessing the Performance of a Television Program. ICoICT.
Vinodhini G, Chandrasekaran RM. 2014. Opinion Mining using Pricnciple Component Analysis Based Ensemble Model for E-Commerce Application. CSIT. Vol. 2 No.3:169-179. DOI 10.1007/s40012-014-0055-3. Spinger.
Wahyudin I, Djatna T. 2016. Cluster Analysis for SME Risk Analysis Documents Based on Pillar K-Means. TELKOMNIKA. Vol.14 No.2 pp. 674~683 ISSN: 1693-6930.
28
29 Lampiran 1 Sebagian file stopword yang digunakan untuk praproses data
ada begitukah benarlah bisakah
adalah begitulah berada boleh
adanya begitupun berakhir bolehkah
adapun bekerja berakhirlah bolehlah
agak belakang berakhirnya buat
agaknya belakangan berapa bukan
agar Benar berapakah bukankah
akan Benarkah berapalah bukanlah
akankah bagaimanapun berapapun bukannya
akhir Bagi berarti bulan
akhiri Bagian berkehendak bung
akhirnya Bahkan berkeinginan cara
aku Bahwa berkenaan caranya
akulah bahwasanya berlainan cukup
amat Baik berlalu cukupkah
amatlah Bakal berlangsung cukuplah
anda bakalan berlebihan cuma
andalah Balik bermacam dahulu
antar Bapa
bermacam-macam dalam
antara Bapak bermaksud dan
antaranya Baru bermula dapat
apa bawah bersama dari
apaan beberapa bersama-sama daripada
apabila begini bersiap datang
apakah beginian bersiap-siap dekat
apalagi beginikah bertanya demi
apatah beginilah bertanya-tanya demikian
artinya begitu berturut demikianlah
asal berawal berturut-turut dengan
asalkan berbagai bertutur depan
atas berdatangan berujar di
atau Beri berupa dia
ataukah berikan besar diakhiri
ataupun berikut betul diakhirinya
awal berikutnya betulkah dialah
awalnya berjumlah biasa diantara
bagai berkali-kali biasanya diantaranya
30
Lampiran 2 Tampilan hasil running evaluasi model pada kegiatan PIK-Remaja
1. Model 1 dengan 60% data latih dan 40% data uji Penggunaan parameter c= 0.1 dan γ = 0.6
Penggunaan parameter c= 0.8 dan γ = 0.8
2. Model 2 dengan 70% data latih dan 30% data uji Penggunaan parameter c= 0.1 dan γ = 0.6
31 Lanjutan Lampiran 2
3. Model 3 dengan 80% data latih dan 20% data uji Penggunaan parameter c= 0.1 dan γ = 0.6
Penggunaan parameter c= 0.8 dan γ = 0.8
4. Model 4 dengan 90% data latih dan 10% data uji Penggunaan parameter c= 0.1 dan γ = 0.6
32
Lampiran 3 Tampilan hasil running evaluasi model pada kegiatan GenRe
1. Model 1 dengan 60% data latih dan 40% data uji Penggunaan parameter c= 0.1 dan γ = 0.6
Penggunaan parameter c= 0.8 dan γ = 0.8
2. Model 2 dengan 70% data latih dan 30% data uji Penggunaan parameter c= 0.1 dan γ = 0.6
33 Lanjutan Lampiran 3
3. Model 3 dengan 80% data latih dan 20% data uji Penggunaan parameter c= 0.1 dan γ = 0.6
Penggunaan parameter c= 0.8 dan γ = 0.8
Model 4 dengan 90% data latih dan 10% data uji
Penggunaan parameter c= 0.1 dan γ = 0.6
34
Lampiran 4 Use case diagram model sentiment mining
Model sentiment mining
Twitter API's input indikator crawling Permintaan tweet crawling tweets Pengguna Praproses
Case Folding Filter
Tokenizing
Hapus Stopword
[image:46.595.70.466.74.791.2]Reduksi fitur Klasifikasi sentiment <<extends >> Evaluasi model <<include>> <<include>> <<include>> <<include>> <<extends>> <<extends>> «extends» Pelabelan kelas <<iexten ds>> <<extends>> <<extends>> Autentifikasi Pengiriman tweets <<include>> << incl ude>> Pembobotan kata
Gambar 19 Use case diagram
Tabel 1 Keterangan proses pada use case diagram model sentiment mining
No Use Case Deskripsi
1 Crawling tweet Proses menarik tweet dengan memasukan keyword
2 Permintaan tweet Untuk autentifikasi key dan permintaan tweet
3 Case Folding Untuk mengubah seluruh kata ke dalam huruf kecil
4 Filter tweet
Untuk menghapus alamat URL, username, Retweet
5 Token & parsing
Proses untuk memecah tweet menjadi potongan kata dengan menambahkan index.
6 Hapus Stopword
Proses menghapus setiap kata penghubung (dan, karena, jika dan lain-lain)
7
8
Pelabelan
sentiment
Pembobotan
Proses pemberian label sentiment pada setiap tweet,
dimana kelas sentiment terdiri dari positif, negatif dan netral
Pembobotan dilakukan terhadap kata dan sentiment.
9 10
Reduksi fitur Klasifikasi
Mereduksi fitur dan merepresentasikan penyebaran Proses yang digunakan untuk mengklasifikasikan
sentiment
11 Evaluasi
35
Lampiran 5 Activity Diagram model sentiment mining
Pengguna Twitter API
registrasi key Authentifikasi key
Input oindikator Permintaan tweet
Pengiriman tweet Check ketersediaan tweet
ada Tidak ada
[image:47.595.86.475.58.813.2]notifikasi simpan
Gambar 20 Activity diagram crawling data tweet
Pengguna PCA
baca data tweet Praproses
Check fitur
PC =tinggi CM < = 1
Reduksi fitur
tidak
Simpan
ya
pemodelan
Pembagian data SVM
Klasifikasi
Hitung akurasi, Precision, recall
x-validation
X= 4
36
Lampiran 6 Sequence dan class diagram model sentiment mining
Pengguna BacaTweet
1. Input data tweet()
Praproses
3. Simpan() 2.a.Filter()
2.b.CaseFolding() 2.c.Token&Parsing() 2.d.HapusStopword() 2.e.Pembobotan kata()
[image:48.595.46.445.30.821.2]2.f.Pelabelan kelas() Tampil data tweet
Gambar 22 Sequence diagram praproses data tweet
37