BAB II
TINJAUAN PUSTAKA
II.1 Data Mining
Data mining merupakan teknologi yang menggabungkan metoda analisis tradisional dengan algoritma yang canggih untuk memproses data dengan volume besar. Data mining adalah suatu istilah yang digunakan untuk menemukan pengetahuan yang tersembunyi di dalamdatabase.Data mining merupakan proses semi otomatik yang menggunakan teknik statistik, matematika, kecerdasanbuatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi pengetahuan potensial dan berguna yang bermanfaat yang tersimpan di dalam database besar. (Turban et al, 2005 ).
Beberapa definisi awal dari data mining meyertakan focus pada proses otomatisasi. Berry danLinoff, (2004) dalam buku Data Mining Technique for Marketing, Sales, and Customer Support mendefinisikan data mining sebagai suatu proses eksplorasi dan analisis secara otomatis maupun semi otomatis terhadap data dalam jumlah besar dengan tujuan menemukan pola atau aturan yang berarti (Larose, 2006).
Analisis yang diotomatisasi yang dilakukanoleh data mining melebihi yang dilakukan oleh sistem pendukung keputusan tradisional yang sudah banyak digunakan. Data Mining dapat menjawab pertanyaan-pertanyaan bisnis yang dengan caratradisional memerlukan banyak waktu dan cost tinggi. Data Mining mengeksplorasi basis datauntuk menemukan pola-pola yang tersembunyi, mencari informasi untuk memprediksi yangmungkin saja terlupakan oleh para pelaku bisnis karena terletak di luar ekspektasi mereka.
penyimpanan data berukuran besar. Istilah lain yang sering digunakan diantaranya knowledge discovery (mining) indatabases (KDD).
Istilah data mining dan Knowledge Discovery in Database (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lain. Dan salah satu tahapan dalam keseluruhan proses KDD adalah data mining.
II.2 Pengertian Teknik Data Mining
Ada beberapa definisi dari data mining yang dikenal diiantaranya adalah :
1. Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual.
2. Data mining adalah analisa otomatis dari data yang berjumlah besar atau kompleks dengan tujuan untuk menemukan pola atau kecenderungan yang penting yang biasanya tidak disadari keberadaannya
3. Data mining atau Knowledge Discovery in Databases (KDD) adalah pengambilan informasi
yang tersembunyi, dimana informasi tersebut sebelumnya tidak dikenal dan berpotensibermanfaat. Proses ini meliputi sejumlah pendekatan teknis yang berbeda, seperti clustering, data summarization, learning classification rules.
II.2.1 Teknik Data Mining
Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulandata berupa pengetahuan yang selama ini tidak diketahui secara manual. Perlu diingat bahwa katamining sendiri berarti usaha untuk mendapatkan sedikit data berharga dari sejumlah besar datadasar. Karena itu data mining sebenarnya memiliki akar yang panjang dari bidang ilmu sepertikecerdasan buatan (artificial intelligent), machine learning, statistik dan basisdata. Beberapa teknikyang sering disebut-sebut dalam literatur data mining antara lain yaitu association rule mining,clustering, klasifikasi, neural network, genetic algorithm dan lain-lain.
Model maupun hasil analisanya, salah satunya dengan kemampuan pembelajaran yang dimiliki beberapa teknik data mining seperti klasifikasi.Data mining adalah serangkaian proses untuk menggali nilai tambah dari suatu kumpulandata berupa pengetahuan yang selama ini tidak diketahui secara manual. Perlu diingat bahwa katamining sendiri berarti usaha untuk mendapatkan sedikit data berharga dari sejumlah besar datadasar. Karena itu data mining sebenarnya memiliki akar yang panjang dari bidang ilmu sepertikecerdasan buatan (artificial intelligent), machine learning, statistik dan basisdata. Beberapa teknikyang sering disebut-sebut dalam literatur data mining antara lain yaitu association rule mining,clustering, klasifikasi, neural network, genetic algorithm dan lain-lain.
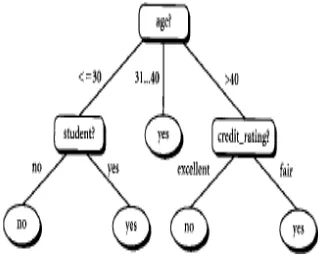
A. Classification
prediksi menggunakan struktur pohon atau strukturberhirarki.Decision tree adalah struktur flowchart yang menyerupai tree (pohon), dimana setiapsimpul internal menandakan suatu tes pada atribut, setiap cabang merepresentasikan hasil tes, dansimpul daun merepresentasikan kelas atau distribusi kelas. Alur pada decision tree di telusuri darisimpul akar ke simpul daun yang memegang prediksikelas untuk contoh tersebut. Decision tree mudah untuk dikonversi ke aturan klasifikasi(classification rules)
Gambar 2.1 Contoh decision tree
B. Association
untukkombinasi barang tertentu.Penting tidaknya suatu aturan assosiatif dapat diketahui dengan dua parameter, supportyaitu prosentasi kombinasi atribut tersebut dalam basisdata dan confidence yaitu kuatnya hubunganantar atribut dalam aturan asosiatif.Motivasi awal pencarian association rule berasal dari keinginanuntuk menganalisa data transaksi supermarket, ditinjau dari perilaku customer dalam membeliproduk. Association rule ini menjelaskan seberapa sering suatu produk dibeli secara bersamaan.Sebagai contoh, association rule “beer =>diaper (80%)” menunjukkan bahwa empat dari limacustomer yang membeli beer juga membeli diaper. Dalam suatu association rule X =>Y, X disebutdengan antecedent dan Y disebut dengan consequent.Rule.
C. Clustering
Digunakan untuk menganalisis pengelompokkan berbeda terhadap data, mirip denganklasifikasi, namun pengelompokkan belum didefinisikan sebelum dijalankannya tool data mining. Biasanya menggunkan metode neural network atau statistik. Clustering membagi item menjadi kelompok-kelompok berdasarkan yang ditemukan tool data mining.Prinsip dari clustering adalah memaksimalkan kesamaan antar anggota satu kelas danmeminimumkan kesamaan antar cluster. Clustering dapat dilakukan pada data yang memilikibeberapa atribut yang dipetakan sebagai ruang multidimensi.
Ilustrasi dari clustering dapat dilihatdi Gambar 3 dimana lokasi, dinyatakan dengan bidang dua dimensi, dari pelanggan suatu tokodapat dikelompokkan menjadi beberapa cluster dengan pusat cluster ditunjukkan oleh tanda positif(+).
Banyak algoritma clustering memerlukan fungsi jarak untuk mengukur kemiripan antar data,diperlukan juga metoda untuk normalisasi bermacam atribut yang dimiliki data.
II.3 Definisi Data Mining
Kemajuan dalam pengumpulan data dan teknologi penyimpanan yang cepatmemungkinkan organisasi menghimpun jumlah data yang sangat luas. Alat dan teknik analisis datayang tradisional tidak dapat digunakan untuk mengektrak informasi dari data yang sangat besar.Untuk itu diperlukan suatu metoda baru yang dapat menjawab kebutuhan tersebut. Data miningmerupakan teknologi yang menggabungkan metoda analisis tradisional dengan algoritma yangcanggih untuk memproses data dengan volume besar.
II.4 Tahapan Data Mining
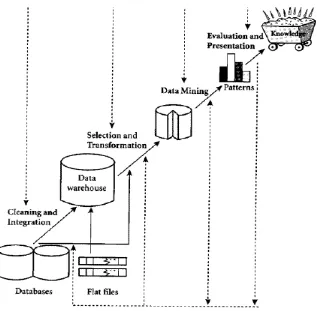
Gambar 2.3. Tahap-Tahap Data Mining
Sebagai suatu rangkaian proses, data mining dapat dibagi menjadi beberapa tahap yangdiilustrasikan di Gambar 1. Tahap-tahap tersebut. bersifat interaktif di mana pemakai terlibatlangsung atau dengan perantaraan knowledge base.
1. Pembersihan data, Digunakan untuk membuang data yang tidakkonsisten dan noise
3. Transformasi data,Transformasi dan pemilihan data ini untuk menentukan kualitas dari hasil data mining, sehinggadata diubah menjadi bentuk sesuai untuk di-Mining.
4. Aplikasi Teknik Data Mining,Aplikasi teknik data mining sendiri hanya merupakan salah satu bagian dari proses data mining Ada beberapa teknik data mining yang sudah umum dipakai.
5. Evaluasi pola yang ditemukan,Dalam tahap ini hasil dari teknik data mining berupa pola-pola yang khas maupun model prediksidievaluasi untuk menilai apakah hipotesa yang ada memang tercapai.
6. Presentasi Pengetahuan,Presentasi pola yang ditemukan untuk menghasilkan aksi tahap terakhir dari proses data miningadalah bagaimana memformulasikan keputusan atau aksi dari hasil analisa yang didapat.
Sesuai yang tercantum dalam buku “Advances in Knowledge Discovery danData mining” terdapat definisi sebagai berikut: Knowledge discovery (data mining) in databases (KDD) adalah keseluruhan proses non-trivial untuk mencari dan mengidentifikasi pola (pattern) dalam data, dimana pola yang ditemukan bersifat sah (valid), baru (novel), dapat bermanfaat (potentially usefull), dapat dimengerti (ultimately understandable)[2].
1. Data Selection
Istilah data mining dan knowledge discovery in databases (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbedaakan tetapi berkaitan satu sama lain. Dan salah satu tahapan dalam keseluruhan proses KDD adalah data mining. Proses KDD secara garis besar dapat dijelaskan sebagai berikut[2]:
2. Pre-processing/ Cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses cleaningpada data yang menjadi focus KDD. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal. 3. Transformation
Codinga dalah proses transformasipada data yang telah dipilih, sehingga data tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data
4. Data mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode atau algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation/ Evaluation
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut dengan interpretation.
contoh, pada saat coding atau data mining, analis menyadari proses cleaning belum dilakukan dengan sempurna, atau mungkin saja analis menemukan data atau informasi baru untuk “memperkaya” data yang sudah ada.
II.5 Arsitektur Sistem Data mining
Data mining merupakan proses pencarian pengetahuan yang menarik dari data berukuran besar yang disimpan dalam basis data, data warehouse atau tempat penyimpanan informasi lainnya. Dengan demikian arsitektur sistem data mining memiliki komponen-komponen utama yaitu:
1. Basis data, data warehouse atau tempat penyimpanan informasi lainnya.
2. Basis data dan data warehouse server. Komponen ini bertanggung jawab dalam pengambilan relevant data, berdasarkan permintaan pengguna.
3. Basis pengetahuan. Komponen ini merupakan domain knowledge yang digunakan untuk memandu pencarian atau mengevaluasi pola-pola yang dihasilkan. Pengetahuan tersebut meliputi hirarki konsep yang digunakan untuk mengorganisasikan atribut atau nilai atribut ke dalam level abstraksi yang berbeda. Pengetahuan tersebut juga dapat berupa kepercayaan pengguna (user belief), yang dapat digunakan untuk menentukan kemenarikan pola yang diperoleh. Contoh lain dari domain knowledge adalah threshold dan metadata yang menjelaskan data dari berbagai sumber yang heterogen.
4. Data mining engine. Bagian ini merupakan komponen penting dalam arsitektur sistem data mining. Komponen ini terdiri modul-modul fungsional data mining seperti karakterisasi, asosiasi, klasifikasi, dan analisis cluster.
6. Antarmuka pengguna grafis. Modul ini berkomunikasi dengan pengguna dan sistem data mining. Melalui modul ini, pengguna berinteraksi dengan sistem mengan menentukan kueri atau task data mining. Antarmuka juga menyediakan informasi untuk memfokuskan pencarian dan melakukan eksplorasi data mining berdasarkan hasil data mining antara. Komponen ini juga memungkinkan pengguna untuk mencari (browse) basis data dan skema data warehouse atau struktur data, evaluasi pola yang diperoleh dan visualisasi pola dalam berbagai bentuk.
Data mining dapat diaplikasikan pada berbagai jenis penyimpanan data seperti basis data relational, data warehouse, transactional database, object-oriented and object-relational databases, spatial databases, time-series data and temporal data, text databases and multimedia databases, heterogeneous and legacy databases dan WWW.
1. Basis data Relasional Basis data relasional merupakan koleksi dari table. Setiap table berisi atribut (field) dan biasanya menyimpan sejumlah besar tuple (record). Setiap tuple dalam table relasional merepesentasikan sebuah objek yang diidentifikasikan oleh kunci unik dan dideskripsikan oleh sekumpulan nilai atribut. Data relasional dapat diakses oleh kueri basis data yang ditulis dalam bahasa kueri relasional seperti SQL atau dengan bantuan antarmuka pengguna grafis.
2. Data warehouse Data warehouse merupakan tempat penyimpanan informasi yang dikumpulkan dari berbagai sumber, disimpan dalam skema yang dipersatukan (unified schema) dan biasanya bertempat pada tempat penyimpanan tunggal. Data warehouse dikonstruksi melalui sebuah proses data cleaning, data transformation, data integration, data loading dan periodic data refreshing.
supplier atau aktivitas. Data disimpan untuk menyediakan informasi dari perspektif sejarah (seperti 5-10 tahun yang lalu) dan biasanya data tersebut diringkas (summarized). Sebagai contoh, daripada menyimpan data rinci dari transaksi penjualan, data warehouse dapat menyimpan ringkasan dari transaksi per tipe item untuk setiap toko atau diringkas dalam level yang lebih tinggi seperti daerah pemasaran.
Data warehouse biasanya dimodelkan oleh struktur basis data multidimensional, dimana setiap dimensi berkaitan dengan sebuah atribut atau sekumpulan atribut dalam skema, dan setiap sel menyimpan nilai dari ukuran agregasi seperti count dan sales_amount. Struktur fisik dari data warehouse dapat berupa penyimpanan basis data relasional atau sebuah kubus data multidimensional.
Selain data warehouse, terdapat istilah penyimpanan data yang lain yaitu data mart. Sebuah data warehouse mengumpulkan informasi mengenai subjek-subjek yang menjangkau seluruh organisasi, dengan demikian cakupannya enterprise-wide. Sedangkan data mart merupakan sub bagian dari data warehouse. Fokus data mart adalah pada subjek yang dipilih dan dengan demikian cakupannya adalah department-wide.
II.6 Tugas-tugas dalam Data mining
Tugas-tugas dalam data mining secara umum dibagi ke dalam dua kategori utama:
1. Prediktif. Tujuan dari tugas prediktif adalah untuk memprediksi nilai dari atribut tertentu berdasarkan pada nilai dari atribut-atribut lain. Atribut yang diprediksi umumnya dikenal sebagai target atau variabel tak bebas, sedangkan atribut-atribut yang digunakan untuk membuat prediksi dikenal sebagai explanatory atau variabel bebas.
2. Deskriptif. Tujuan dari tugas deskriptif adalah untuk menurunkan pola-pola (korelasi, trend, cluster, trayektori, dan anomali) yang meringkas hubungan yang pokok dalam data. Tugas data mining deskriptif sering merupakan penyelidikan dan seringkali memerlukan teknik postprocessing untuk validasi dan penjelasan hasil.
Berikut adalah tugas-tugas dalam data mining:
1. Analisis Asosiasi (Korelasi dan kausalitas)
Analisis asosiasi adalah pencarian aturan-aturan asosiasi yang menunjukkan kondisi-kondisi nilai atribut yang sering terjadi bersama-sama dalam sekumpulan data. Analisis asosiasi sering digunakan untuk menganalisa market basket dan data transaksi.
Aturan-aturan asosiasi memiliki bentuk X ⇒ Y, bahwa A1 ∧ A2 ∧ … ∧ Am
→ B1 ∧ B2 ∧ … ∧ Bn, dimana Ai (untuk i = 1, 2, …, m) dan Bj (untuk j = 1,
2, …,
n) adalah pasangan-pasangan nilai atribut. Aturan asosiasi X ⇒ Y diinterpretasikan sebagai tuple-tuple basis data yang memenuhi kondisi-kondisi dalam X juga mungkin memenuhi kondisi-kondisi dalam Y.
Contoh dari aturan asosiasi adalah age(X, “20..29”) ^ income(X, “20..29K”) ⇒ buys(X, “PC”) [support = 2%, confidence = 60%]
Klasifikasi dan Prediksi Klasifikasi adalah proses menemukan model (fungsi) yang menjelaskan dan membedakan kelas-kelas atau konsep, dengan tujuan agar model yang diperoleh dapat digunakan untuk memprediksikan kelas atau objek yang memiliki label kelas tidak diketahui. Model yang turunkan didasarkan pada analisis dari training data (yaitu objek data yang memiliki label kelas yang diketahui). Model yang diturunkan dapat direpresentasikan dalam berbagai bentuk seperti aturan IF-THEN klasifikasi, pohon keputusan, formula matematika atau jaringan syarf tiruan.
Dalam banyak kasus, pengguna ingin memprediksikan nilai-nilai data yang tidak tersedia atau hilang (bukan label dari kelas). Dalam kasus ini biasanya nilai data yang akan diprediksi merupakan data numeric. Kasus ini seringkali dirujuk sebagai prediksi. Di samping itu, prediksi lebih menekankan pada identifikasi trend dari distribusi berdasarkan pada data yang tersedia.
1. Analisis Cluster Tidak seperti klasifikasi dan prediksi, yang menganalisis objek data yang diberi label kelas, clustering menganalisis objek data dimana label kelas tidak diketahui. Clustering dapat digunakan untuk menentukan label kelas tidak diketahui dengan cara mengelompokkan data untuk membentuk kelas baru. Sebabai contoh clustering rumah untuk menemukan pola distribusinya. Prinsip dalam clustering adalah memaksimumkan kemiripan intra-class dan meminimumkan kemiripan interclass.
2. Analisis Outlier Outlier merupakan objek data yang tidak mengikuti perilaku umum dari data. Outlier dapat dianggap sebagai noise atau pengecualian. Analisis data outlier dinamakan outlier mining. Teknik ini berguna dalam fraud detection dan rare events analysis.
waktu. Teknik ini dapat meliputi karakterisasi, diskriminasi, asosiasi, klasifikasi, atau clustering dari data yang berkaitan dengan waktu.
Data mining merupakan bidang interdisplin. Disiplin ilmu ini banyak dipengaruhi oleh disiplin sistem basis data, statistika, ilmu informasi, mesinpembelajaran, dan visualisasi. Sistem data mining dapat diklasifsikasikan berdasarkan beberapa kategori, yaitu :
1. Klasifikasi berdasarkan data yang akan di-mine seperti relational, transactional, object-oriented, object-relational, spatial, time-series, text, multi-media dan www.
2. Klasifikasi berdasarkan pengetahuan yang akan di-mine, yaitu berdasarkan fungsionalitas data mining seperti karakterisasi, diskriminasi, asosiasi, klasifikasi, clustering, analisis outlier dan analisis evolusi. Sistem data mining yang komprehensif biasanya menyediakan beberapa fungsi-fungsi data mining.
3. Klasifikasi berdasarkan teknik yang akan digunakan seperti database-oriented, data warehouse (OLAP), machine learning, Statistics, Visualization dan neural network.
4. Klasifikasi berdasarkan aplikasi yang diadaptasi, sebagai contoh system data mining untuk keuangan, telekomunikasi, DNA, dan e-mail.
II.7 Pengertian SSVM (Smooth Support Vektor Machine).
teori dasar SVM dan aplikasinya dalam bioinformatika, khususnya pada analisaekspresi gen yang diperoleh dari analisa microarray.Konsep SVM dapat dijelaskan secara sederhanasebagai usaha mencari hyperplaneterbaik yangberfungsi
sebagai pemisah dua buah class padainput space.
Konsep dasar SVMsebenarnya merupakan kombinasi harmonis dariteori-teori
komputasi yang telah ada puluhantahun sebelumnya, seperti margin hyperplane(Duda &
Hart tahun 1973, Cover tahun 1965,Vapnik 1964, dsb.), kernel diperkenalkan
olehAronszajn tahun 1950, dan demikian jugadengan konsep-konsep pendukung yang
lain.
Akan tetapi hingga tahun 1992, belum pernahada upaya merangkaikan
komponen-komponentersebut.
II.7.1 KARAKTERISTIK SVM
Karakteristik SVM sebagaimana telah dijelaskanpada bagian sebelumnya, dirangkumkan
sebagaiberikut:
1. Secara prinsip SVM adalah linear classifier
2. Pattern recognition dilakukan denganmentransformasikan data pada input
spaceke ruang yang berdimensi lebih tinggi, danoptimisasi dilakukan pada ruang
vector yangbaru tersebut. Hal ini membedakan SVMdari solusi pattern
recognition padaumumnya, yang melakukan optimisasiparameter pada ruang
hasil transformasiyang berdimensi lebih rendah daripadadimensi input space.
3. Menerapkan strategi Structural RiskMinimization (SRM)
4. Prinsip kerja SVM pada dasarnya hanyamampu menangani klasifikasi dua class.
II.7. 2 KELEBIHAN DAN KEKURANGAN SVM
Dalam memilih solusi untuk menyelesaikansuatu masalah, kelebihan dan
kelemahanmasing-masing metode harus diperhatikan.Selanjutnya metode yang tepat
dipilih denganmemperhatikan karakteristik data yang diolah.Dalam hal SVM, walaupun
berbagai studi telahmenunjukkan kelebihan metode SVMdibandingkan metode
konvensional lain, SVMjuga memiliki berbagai kelemahan. KelebihanSVM antara lain
1. Generalisasi
Generalisasi didefinisikan sebagaikemampuan suatu metode (SVM, neuralnetwork, dsb.) untuk mengklasifikasikansuatu pattern, yang tidak termasuk data yangdipakai dalam fase pembelajaran metode itu.Vapnik menjelaskan bahwa generalizationerror dipengaruhi oleh dua faktor: errorterhadap training set, dan satu faktor lagiyang dipengaruhi oleh dimensi VC(Vapnik-Chervokinensis). Strategipembelajaran pada neural network danumumnya metode learning machinedifokuskan pada usaha untukmeminimimalkan error pada training-set.Strategi ini disebut Empirical RiskMinimization (ERM). Adapun SVM selainmeminimalkan error pada training-set, jugameminimalkan faktor kedua. Strategi inidisebut Structural Risk Minimization (SRM),dan dalam SVM diwujudkan denganmemilih hyperplane dengan margin terbesar.Berbagai studi empiris menunjukkan bahwapendekatan SRM pada SVM memberikanerror generalisasi yang lebih kecil daripadayang diperoleh dari strategi ERM padaneural network maupun metode yang lain.
2. Curse of dimensionality.
bidang biomedicalengineering, karena biasanya data biologi yang tersedia sangat terbatas, dan penyediaannya memerlukan biaya tinggi.Vapnik membuktikan bahwa tingkat generalisasi yang diperoleh oleh SVM tidak dipengaruhi oleh dimensi dari input vector. Hal ini merupakan alasan mengapa SVM merupakan salah satu metode yang tepat dipakai untuk memecahkan masalah berdimensi tinggi, dalam keterbatasan sampel data yang ada.