DAFTAR PUSTAKA
Achsan, H. T. Y. & Wibowo, W. C., 2013 . A Fast Distributed Focused-Web Crawling.
24th DAAAM International Symposium on Intelligent Manufacturing and Automation,
p. 492 – 499.
Apache Ignite, 2016. Apache Ignite. [Online] Available at: https://ignite.apache.org
[Diakses 16 September 2016].
APJII, 2015. Profil Pengguna Internet Indonesia 2014. Jakarta: Asosiasi Penyelenggara Jasa Internet Indonesia.
Avraam, I. & Anagnostopoulos, I., 2011. A Comparison over Focused Web Crawling Strategies. 15th Panhellenic Conference On Informatics (PCI), p. 245 – 249.
Baeza-Yates, R., Marin, M., Castillo, C. & Rodriguez, A., 2005. Crawling a Country: Better Strategies than Breadth-First for Web Page Ordering.
Chakrabarti, S., Berg, M. v. d. & Dom, B., 1999. Focused Crawling: A New Approach to Topic-Specific Web Resource Discovery. Computer Networks, pp. 1623-1640. Coulouris, G. F., Dollimore, J. & Kindberg, T., 2012. Distributed Systems: Concepts and Design. 5 penyunt. Boston: Addison Wesley.
Ikatan Dokter Anak Indonesia, 2015. IDAI - Public Articles. [Online] Available at: http://www.idai.or.id/artikel
[Diakses 11 Juli 2016].
Janbandhu, R., Dahiwale, P. & Raghuwanshi, . M., 2014. Analysis of Web Crawling Algorithms. International Journal on Recent and Innovation Trends in Computing and Communication, p. 488 – 492 .
Kateglo, 2016. Kateglo ~ Kamus, tesaurus, dan glosarium bahasa Indonesia. [Online] Available at: http://www.kateglo.com/
[Diakses 1 Agustus 2016].
Kementerian Kesehatan Republik Indonesia, 2013. Kementerian Kesehatan Republik Indonesia - Kamus. [Online]
Available at: http://www.depkes.go.id/folder/view/full-content/structure-kamus.html [Diakses 21 Juli 2016].
Khodra, L. M. & Wibisono, Y., 2005. Clustering Berita Berbahasa Indonesia. Jurnal FPMIPA UPI dan KK Informatika ITB.
Kohlschütter, C., Fankhauser, P. & Nejdl, W., 2010. Boilerplate Detection using Shallow Text Features. The third ACM international conference on Web search and data mining, pp. 441-450.
Kritikopoulos, A., Sideri, M. & Stroggilos, K., 2004. CrawlWave: A Distributed Crawler. 3rd Hellenic Conference on Artificial Intelligence.
Loo, B. T., Cooper, O. & Krishnamurthy, S., 2001. Distributed Web Crawling over DHTs.
McCallum, A. & Nigam, K., 1998. A Comparison of Event Models for Naive Bayes Text Classification. AAAI/ICML-98 Workshop on Learning for Text Categorization, pp. 41-48.
Nasri, M., Shariati, S. & Sharifi, M., 2008. Availability and Accuracy of Distributed Web Crawlers: A Model-Based Evaluation. Second UKSIM European Symposium on Computer Modeling and Simulation, pp. 453-458.
Rajaraman, A. & Ullman, J. D., 2011. Mining of Massive Datasets. United Kingdom: Cambridge University Press.
Salton, M., 1983. Introduction to Modern Information Retrieval. New York: McGraw Hill.
Seeger, M., 2010. Building Blocks of A Scalable Web Crawler. Tesis. Stuttgart Media University.
Sharma, S. & Gupta, P., 2015. The Anatomy of Web Crawlers. International Conference on Computing, Communication and Automation (ICCCA2015), pp. 849-853.
Tala, F. Z., 2003. A Study of Stemming Effects on Information Retrieval in Bahasa Indonesia. Skripsi. Universiteit van Amsterdam.
Treselle System, 2014. Boilerpipe – Web Content Extraction without Boilerplates.
[Online]
Available at: http://www.treselle.com/blog/boilerpipe-web-content-extraction-without-boiler-plates/
[Diakses 6 Agustus 2016].
Triawati, C., 2009. Metode Pembobotan Statistical Concept Based untuk Klastering dan Kategorisasi Dokumen Berbahasa Indonesia. s.l.:s.n.
Tsai, C. H., Ku, T., Yang, P. Y. & Chen, M. J., 2014. A Distributed Multi-Tasking Job Scheduling Mechanism for Web Crawlers. International Conference of Soft Computing and Pattern Recognition, pp. 243-248.
Weiss, S., Indurkhya, N., Zhang, T. & Damerau, F., 2005. Text Mining: Predictive Methods fo Analyzing Unstructered Information. New York: Springer.
Wikipedia, 2010. Multithreading (computer architecture). [Online] Available at: https://en.wikipedia.org/wiki/Multithreading_(computer_architecture) [Diakses 15 September 2016].
Wikipedia, 2016. Web crawler. [Online]
Available at: https://en.wikipedia.org/wiki/Web_crawler [Diakses 15 September 2016].
BAB 3
ANALISIS DAN PERANCANGAN SISTEM
Bab ini menjelaskan tentang analisis dan perancangan sistem yang bangun untuk
focused crawler dengan sistem terdistribusi. Adapun dua tahapan yang dibahas pada bab ini yaitu tahap analisis dan tahap perancangan sistem. Pada analisis sistem meliputi kebutuhan perangkat lunak dan perangkat keras dan pada perancangan sistem meliputi tahapan untuk perancangan sistem terdistribusi dan juga tahapan percobaan yang dilakukan.
3.1. Analisis Sistem
Focused crawler dengan sistem terdistribusi dalam penelitian kali ini dirancang dengan syarat sebagai berikut:
Sistem yang terdistribusi yang dibangun menggunakan 1 buah PC (Personal Computer) master dan 4 buah PC slaves.
PC master bertugas untuk mengkoordinasikan tugas kepada komputer slaves
dan juga memberikan daftar seeds URL yang akan di-crawl pada masing-masing slaves
PC slaves bertugas untuk crawling dan juga klasifikasi konten PC master yang digunakan dengan spesifikasi:
1) Processor Intel Core i5-3450 3.10 GHz 2) RAM 4 GB
3) Windows 7 Ultimate 64 bit 4) HDD 250 GB
5) Java 1.8.0_74
PC slaves sebanyak 4 buah komputer PC yang memiliki spesifikasi hardware
yang sama yaitu:
1) Processor Inter Core i3-4150 3.50 GHz 2) RAM 2 GB
3) Windows 7 Enterprise 64 bit 4) HDD 250 GB
5) Java 1.8.0_74
Komunikasi data antara master dan slaves menggunakan jaringan LAN (Local Area Network)
3.2. Perancangan Sistem
Perancangan sistem dilakukan berdasarkan arsitektur berikut ini :
3.2.1. Tahapan Perancangan Sistem
Perancangan sistem meliputi perancangan crawler master dan crawler slaves. Kedua jenis crawler ini memiliki perbedaan tugas sehingga memiliki tahapan perancangan yang berbeda.
3.2.1.1. Perancangan Crawler Master
Berikut ini adalah beberapa tugas dari crawler master sebagai berikut: 1) Memanajemen seeds URL
Pada penelitian ini seeds URL yang digunakan dapat dilihat pada tabel 3.1.
Tabel 3.1 Daftar seeds URL
29 https://www.ibudanbalita.com/ 30 https://www.klikdokter.com/
31 https://www.progoldparentingclub.co.id/ 32 https://www.tanyadok.com/
URL ini dipilih karena menurut penulis berisi konten-konten artikel yang berhubungan dengan topik yang dipilih (dalam hal ini ‘kesehatan’) 2) Membagikan seeds URL untuk setiap crawler slaves
Crawler master membagikan seeds URL yang ada ke semua crawler slaves yang ada, pseudocode yang diimplimentasikan dalam penelitan.
Gambar 3.2. Pseudocode pembagian seeds URL
Setiap job memiliki tugas untuk meng-crawl seeds URL yang telah ditetapkan. Setiap pembuatan job, apache ignite dalam fitur computer grid akan otomatis membagikan job pada setiap node yang ada, dimana ilustrasinya dapat dilihat pada gambar 3.3.
Gambar 3.3. Ilustrasi pembagian job pada Apache Ignite
3) Site ordering
Pada penelitian ini penulis membuat dua model site ordering yaitu dengan algoritma Larger Sites First dan tanpa Larger Sites First.
Inisialisasi seeds URL yang tersedia FOR setiap URL yang tersedia
Buat job
Perancangan untuk algoritma ini adalah user dapat memilih apakah akan menggunakan Larger Site First atau tidak.
Algoritma ini mengurutkan dari website terbesar sampai yang terkecil, yang dapat diketahui dengan menghitung jumlah link yang dimilikinya. Semakin banyak link yang dimiliki maka semakin besar website tersebut.
4) Training
Hal pertama yang dilakukan pada tahap ini adalah mengumpulkan
dataset mengenai topik (dataset kesehatan). Dalam penelitian ini terdapat 2 dataset yaitu dataset kesehatan dan bukan kesehatan. Penulis menjadikan kata-kata kunci bidang kesehatan menjadi dataset kesehatan yang akan diinginkan untuk proses training. Penulis memperoleh kata kunci kesehatan dari http://www.idai.or.id/, http://www.depkes.go.id/ dan http://www.kateglo.com/.
Untuk dari situs http://www.idai.or.id/ penulis mengambil 284 artikel yang terdapat pada situs tersebut dan menghitung nilai TF-IDF dari artikel-artikel tersebut dan mengambil 1000 nilai TF-IDF paling besar lalu menyaring kembali secara manual dan akhirnya didapatkan sebanyak 367 kata.
Untuk dari situs http://www.depkes.go.id/ penulis mengambil kata kunci
kesehatan dari halaman kamus
(http://www.depkes.go.id/folder/view/full-content/structure-kamus.html) dan hanya mengambil kata yang bukan merupakan singkatan dan hanya memiliki satu katadan didapatkan sebanyak 697 kata.
Untuk dari situs http://www.kateglo.com/ penulis mengambil kata-kata
dari halaman glosarium
Penulis juga mengambil kata-kata untuk bidang selain kesehatan dari situs http://www.kateglo.com/ yaitu bidang ekonomi, keuangan, olahraga, otomotif, politik dan teknologi informasi. Untuk lebih lengkapnya dapat dilihat pada tabel 3.2 dan 3.3.
Tabel 3.2 Kata kunci bidang kesehatan
Sumber Jumlah Kata
Tabel 3.3 Kata kunci bidang bukan kesehatan
Sumber Jumlah Kata
Setelah mendapatkan daftar seeds URL yang akan di-crawl dari master, slaves
akan melakukan tugasnya sebagai berikut:
1) Crawling
a. Fetch
Mengambil konten dari halaman web dari URL yang sedang
b. Parse
Mem-parse HTML untuk mendapatkan tag maupun atribute
HTML untuk mendapatkan konten yang diinginkan dari halaman tersebut dan mengambil link yang ada di halaman tersebut yang akan dimasukkan kedalam URL Queue untuk di-crawl
selanjutnya.
c. Filter
Menyaring konten halaman agar mendapatkan konten artikel dengan cara menghilangkan konten-konten seperti boilerpate
ataupun template yang dipakai pada halaman tersebut dan mengambil konten utamanya.
2) Content Extraction
a. Tokenizing
Tokenizing atau tokenisasi adalah proses awal dimana artikel tersebut akan dihapus beberapa tanda baca yang tidak perlu seperti tanda seru (!), koma (,) dan lain – lain dan dijadikan berupa token.
b. Case Folding
Proses ini adalah proses penyamaan case dalam sebuah dokumen. Hal ini disebabkan karena tidak semua dokumen teks konsisten dalam penggunaan huruf kapital. Oleh karena itu dilakukan case folding untuk mengkonversi semua teks kedalam suatu bentuk standar (lowercase).
c. Filtering
Proses ini merupakan proses pembuangan kata-kata umum pada artikel tersebut sehingga hanya akan tersisa kata-kata yang khusus. Daftar kata-kata yang dibuang adalah menggunakan
Stop-Word list bahasa Indonesia (Tala, 2003).
3) Classification
antara topik kesehatan atau tidak. Jika hasil yang didapatkan lebih condong ke topik kesehatan maka artikel tersebut akan disimpan. 3.2.2. Tahapan Percobaan Sistem
Tahapan ini bertujuan untuk menghitung tingkat akurasi algoritma Naive Bayes Classifier dengan menggunakan dataset yang telah didapatkan, mencari jumlah
thread yang optimal dan pengaruh penggunaan algoritma larger sites first pada
page ordering.
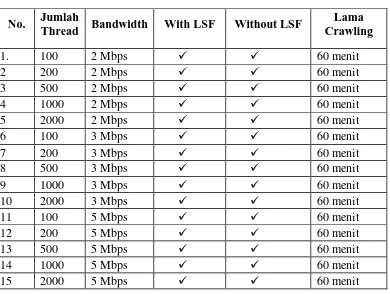
Untuk jumlah thread yang optimal percobaan dilakukan dengan mengobservasi penggunaan memory dan cpu setiap thread nya. Percobaan dilakukan dengan metode page ordering Larger Sites First dan tanpa Larger Sites First. Percobaan juga dilakukan untuk jumlah bandwidth yang berbeda. Tabel 3.4 menunjukkan percobaan yang dilakukan.
Tabel 3.4 Rancangan percobaaan thread dan bandwith
No. Jumlah
Thread Bandwidth With LSF Without LSF
Lama
3.2.3. Perancangan Sistem Bagian Depan (Front End)
1) Crawler Master
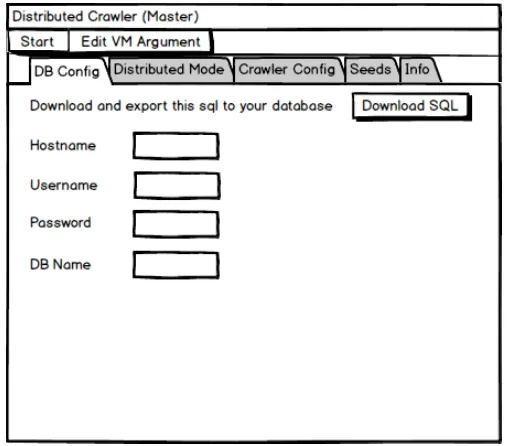
Crawler master dapat mengkonfigurasi database yang akan dipakai, mulai dari nama host, username, password, nama database dan dapat meng-export SQL (Structured Query Language) yang telah disediakan kedalam database pengguna. Gambaran rancangan tampilan konfigurasi
database dapat dilihat pada gambar 3.4.
Gambar 3.4. Konfigurasi database (Crawler master)
Crawler master juga dapat mengkonfigurasi distributed mode seperti menambahkan ip address crawler slaves yang rancangannya dapat dilihat pada gambar 3.5.
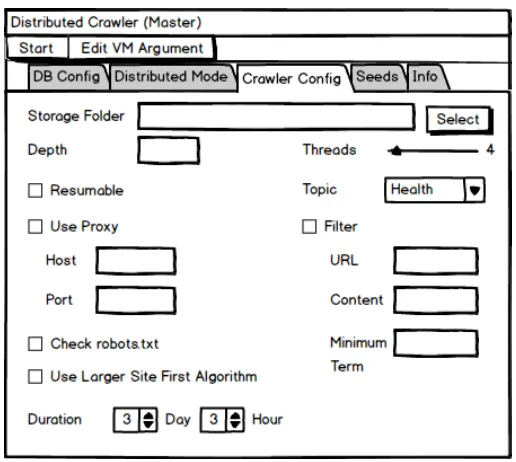
Crawler master dapat mengkonfigurasi crawler yang akan digunakan seperti direktori penyimpanan (storage folder), kedalaman URL (depth) yang dihitung dari URL root yang ilustrasinya dapat dilihat pada gambar 3.6, crawler dapat di resume (URL yang telah dikunjungi akan disimpan dan dapat dilanjutkan dilain waktu), menggunakan proxy, mengecek robots.txt pada setiap website, menggunakan algoritma larger site first, jumlah thread yang akan digunakan, menentukan topik focused crawler, mem-filter URL, konten dan minimum term(kata) yang dikunjungi dan menentukan lama durasi crawler yang dapat dilihat pada gambar 3.7.
Gambar 3.6. Ilustrasi crawler depth
Crawler master dapat meng-edit seeds URL yang akan di-crawl pada tab seeds yang rancangannya dapat dilihat pada gambar 3.8.
Gambar 3.8. Konfigurasi Seeds (Crawler master)
Selain itu pengguna juga dapat menyunting VM argument yang akan dipakai pada tombol “Edit VM Argument” dan melihat info dari aplikasi
crawler pada tab ‘Info’.
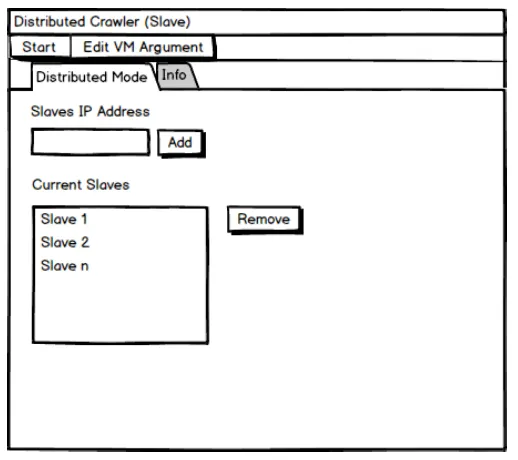
2) Crawler Slaves
Pada mode terdistribusi crawler slaves dapat mengkonfigurasi setiap ip address yang ingin dipakai serta melihat info aplikasi. Gambaran rancangan tampilan crawler slaves dapat dilihat pada gambar 3.9.
BAB 4
IMPLEMENTASI DAN PENGUJIAN
Pada bab ini membahas tentang hasil site ordering mengunakan Larger Site First Algorithm, hasil dari proses crawling dan hasil dari proses content extraction yang diperoleh dari implementasi Larger Site First Algorithm dan Naive Bayes Classifier
dalam Focused Crawler terdistribusi yang sesuai dengan analisis dan perancangan yang telah dibahas pada Bab 3.
4.1. Hasil Site Ordering
Bagian ini dijabarkan hasil yang diperoleh dari site ordering menggunakan algoritma larger site first dilakukan crawler master dengan menghitung jumlah link yang ada pada halaman tersebut dan mengurutkannya mulai dari yang terbesar sampai yang terkecil, jika terdapat URL yang tidak dapat dikunjungi atau URL yang melebihi batas waktu (request timeout) maka URL tersebut dinyatakan tidak memiliki link (link=0) yang mengakibatkan URL tersebut berada di urutan terbawah. Pseudocode dapat dilihat pada gambar 4.1. Untuk hasil pengurutannya dapat dilihat pada tabel 4.1
Tabel 4.1 Hasil Site Ordering menggunakan Larger Site First Algorithm
Sebelum Sesudah
http://anakkitasehat.com/ http://health.detik.com/
http://artikelkesehatananak.com/ http://www.vemale.com/tags/kesehata n-anak/
http://artikeltentangkesehatan.com/ http://bidanku.com/ http://bebeclub.co.id/article/ http://www.depkes.go.id/ http://bidanku.com/ https://www.klikdokter.com/ http://dechacare.com/ http://dechacare.com/
http://dikes.badungkab.go.id/index.php/ars
ip-artikel http://www.posyandu.org/
http://duniaanak.org/ http://www.informasikesehatan.my.id/
Gambar 4.1. Pseudocode site ordering Inisialisasi seeds URL yang tersedia
FOR setiap URL
IF tidak ada respon Link = 0 ELSE
4.2. Hasil Crawling
Pada bagian ini dijabarkan hasil pada proses crawling yaitu berupa hasil pada proses
filter konten untuk mendapatkan konten artikel menggunakan boilerpipe, dengan cara menghilangkan template, boilerplate, header, sidebar maupun footer. Misalkan artikel pada link
http://health.detik.com/read/2016/09/25/170008/3306373/763/kata-dokter-soal-pantangan-makan-jeruk-bali-bagi-pasien-cml?l992203755
akan menghasilkan artikel seperti pada gambar 4.2.
Gambar 4.2. Contoh hasil filter menggunakan boilerpipe
4.3. Hasil Content Extraction
Pada bagian ini dijabarkan hasil dari proses content extraction sebelum artikel diklasifikasikan. Tahap pertama adalah proses tokenizing yang hasilnya dapat dilihat pada gambar 4.3 yang merupakan proses dari artikel pada gambar 4.2. Setelah itu artikel
Kata Dokter Soal Pantangan Makan Jeruk Bali bagi Pasien CML Radian Nyi Sukmasari - detikHealth
Ilustrasi pasien dan dokter (Foto: Thinkstock) Berita Lainnya
Puluhan Calon Profesional Kesehatan dari Indonesia dan Luar Negeri Ikuti Pelatihan di Kulonprogo
Jakarta, Pada pasien Chronic Myeloid Leukemia (CML) atau yang dalam bahasa Indonesia disebut dengan Leukemia Granulositik Kronik (LGK), ada satu asupan yang mesti dihindari yakni jeruk bali. Mengapa begitu?
Diungkapkan dr Nadia Ayu Mulansari SpPD, KHOM dari RS Cipto Mangunkusumo, asupan yang memiliki interaksi dengan imatinib mesylate yang dikonsumsi pasien CML yaitu grapefruit atau grapefruit juice. Nah, jeruk bali dikatakan dr Nadia termasuk kelompok grapefruit.
"Beberapa ada yang bilang delima juga (termasuk kelompok grapefruit), tapi nggak sih. Dari penelitian, disebutkan ada komponennya di situ (grapefruit) yang berinteraksi dengan obatnya," kata dr Nadia dalam diskusi bersama Himpunan Masyarakat Peduli Elgeka di Bakmi GM, Jl Sunda, Jakarta Pusat, Sabtu (24/9/2016).
Ia menambahkan, grapefruit memang bisa berinteraksi dengan beberapa jenis obat kanker, dan obat CML termasuk salah satunya. Beberapa waktu lalu ahli hematologi onkologi medik RS Kanker Dharmais, dr Hilman Tadjoedin SpPD, KHOM mengatakan selain jeruk bali, tidak ada pantangan makanan atau minuman bagi pasien CML.
Justru, kata dr Hilman dalam pengobatan kemoterapi konsumsi makanan tidak dibatasi namun tetap, bukan berarti pasien bisa makan sesukanya atau tidak terkontrol.
Baca juga: Benarkah Lemon Lebih Hebat dari Kemoterapi dalam Membunuh Sel Kanker?
"Saat dikemo, kan perut bisa mual, badan nggak enak. Jadinya malah nggak nafsu makan. Tapi tetap harus makan kan. Mau makan daging merah boleh tapi konsumsi makanan yang lain juga, konsumsi makanan bergizi, termasuk buah dan sayur," tutur dr Hilman.
tersebut akan melakukan proses case folding yang bisa dilihat pada gambar 4.4. Dan tahap yang terakhir adalah proses filtering yang bisa dilihat pada gambar 4.5.
Gambar 4.3. Contoh hasil Tokenizing
Gambar 4.4. Contoh hasil Case Folding
Gambar 4.5. Contoh hasil Filtering
Kata Dokter Soal Pantangan Makan Jeruk Bali bagi Pasien CML Radian Nyi Sukmasari detikHealth Ilustrasi pasien dan dokter Foto Thinkstock Berita Lainnya Puluhan Calon Profesional Kesehatan dari Indonesia dan Luar Negeri Ikuti Pelatihan di Kulonprogo Jakarta Pada pasien Chronic Myeloid Leukemia CML atau yang dalam bahasa Indonesia disebut dengan Leukemia Granulositik Kronik LGK ada satu asupan yang mesti dihindari yakni jeruk bali Mengapa begitu Diungkapkan dr Nadia Ayu Mulansari SpPD KHOM dari RS Cipto Mangunkusumo asupan yang memiliki interaksi dengan imatinib mesylate yang dikonsumsi pasien CML yaitu grapefruit atau grapefruit juice Nah jeruk bali dikatakan dr Nadia termasuk kelompok grapefruit Beberapa ada yang bilang delima juga termasuk kelompok grapefruit tapi nggak sih Dari penelitian disebutkan ada komponennya di situ grapefruit yang berinteraksi dengan obatnya kata dr Nadia dalam diskusi bersama Himpunan Masyarakat Peduli Elgeka di Bakmi GM Jl Sunda Jakarta Pusat Sabtu Ia menambahkan grapefruit memang bisa berinteraksi dengan beberapa jenis obat kanker dan obat CML termasuk salah satunya Beberapa waktu lalu ahli hematologi onkologi medik RS Kanker Dharmais dr Hilman Tadjoedin SpPD KHOM mengatakan selain jeruk bali tidak ada pantangan makanan atau minuman bagi pasien CML Justru kata dr Hilman dalam pengobatan kemoterapi konsumsi makanan tidak dibatasi namun tetap bukan berarti pasien bisa makan sesukanya atau tidak terkontrol Baca juga Benarkah Lemon Lebih Hebat dari Kemoterapi dalam Membunuh Sel Kanker Saat dikemo kan perut bisa mual badan nggak enak Jadinya malah nggak nafsu makan Tapi tetap harus makan kan Mau makan daging merah boleh tapi konsumsi makanan yang lain juga konsumsi makanan bergizi termasuk buah dan sayur tutur dr Hilman Dikutip dari leukaemia org au pasien CML tidak dibolehkan mengonsumsi grapefruit atau minum grapefruit juice Pasalnya grapefruit termasuk buah yang dapat menghambat kerja tyrosine kinase inhibitor TKI dalam hal ini imatinib yang menghambat proses terbentuknya protein abnormal Bcr Abl pada pasien CML Pada dasarnya grapefruit dapat menginduksi lapisan lambung untuk menghasilkan sitokrom yang dapat memetabolisme obat sebelum mencapai sistem darah
kata dokter soal pantangan makan jeruk bali bagi pasien cmlradian nyi sukmasari detikhealth ilustrasi pasien dan dokter foto thinkstock berita lainnya puluhan calon profesional kesehatan dari indonesia dan luar negeri ikuti pelatihan di kulonprogo jakarta pada pasien chronic myeloid leukemia cml atau yang dalam bahasa indonesia disebut dengan leukemia granulositik kronik lgk ada satu asupan yang mesti dihindari yakni jeruk bali mengapa begitu diungkapkan dr nadia ayu mulansari sppd khom dari rs cipto mangunkusumo asupan yang memiliki interaksi dengan imatinib mesylate yang dikonsumsi pasien cml yaitu grapefruit atau grapefruit juice nah jeruk bali dikatakan dr nadia termasuk kelompok grapefruit beberapa ada yang bilang delima juga termasuk kelompok grapefruit tapi nggak sih dari penelitian disebutkan ada komponennya di situ grapefruit yang berinteraksi dengan obatnya kata dr nadia dalam diskusi bersama himpunan masyarakat peduli elgeka di bakmi gm jl sunda jakarta pusat sabtu ia menambahkan grapefruit memang bisa berinteraksi dengan beberapa jenis obat kanker dan obat cml termasuk salah satunya beberapa waktu lalu ahli hematologi onkologi medik rs kanker dharmais dr hilman tadjoedin sppd khom mengatakan selain jeruk bali tidak ada pantangan makanan atau minuman bagi pasien cml justru kata dr hilman dalam pengobatan kemoterapi konsumsi makanan tidak dibatasi namun tetap bukan berarti pasien bisa makan sesukanya atau tidak terkontrol baca juga benarkah lemon lebih hebat dari kemoterapi dalam membunuh sel kanker saat dikemo kan perut bisa mual badan nggak enak jadinya malah nggak nafsu makan tapi tetap harus makan kan mau makan daging merah boleh tapi konsumsi makanan yang lain juga konsumsi makanan bergizi termasuk buah dan sayur tutur dr hilman dikutip dari leukaemia org au pasien cml tidak dibolehkan mengonsumsi grapefruit atau minum grapefruit juice pasalnya grapefruit termasuk buah yang dapat menghambat kerja tyrosine kinase inhibitor tki dalam hal ini imatinib yang menghambat proses terbentuknya protein abnormal bcr abl pada pasien cml pada dasarnya grapefruit dapat menginduksi lapisan lambung untuk menghasilkan sitokrom yang dapat memetabolisme obat sebelum mencapai sistem darah
4.4. Hasil Pengujian
Pada bagian ini dijabarkan hasil percobaan akurasi algoritma Naive Bayes Classifier
dengan menggunakan dataset yang telah didapatkan dengan cara mencoba dengan 50 artikel yang bertopik kesehatan, 50 artikel yang tidak bertopik kesehatan dan 50 artikel yang memiliki kata kesehatan tetapi isi dari artikel tersebut bukan merupakan topik kesehatan (semi kesehatan). Maka dari itu didapatkan hasil yang tertera pada tabel 4.2.
Tabel 4.2. Hasil percobaan akurasi klasifikasi Jenis
Lalu dilakukan pengujian dengan menggunakan jumlah thread yang berbeda dan menggunakan bandwith yang berbeda seperti pada tabel 3.4. dimana untuk setiap percobaannya dihitung jumlah file/artikel yang ter-download, total ukuran file, penggunaan heap memory dan penggunaan cpu untuk setiap penggunaannya untuk setiap penggunaan Larger Site First (LSF) dan tidak menggunakan LSF yang dilihat hasilnya per menit. Untuk perhitungan heap memory dan penggunaan cpu dengan perumpamaan A = Komputer 1, B = Komputer 2, C = Komputer 3 dan D = Komputer 4. Yang dapat dilihat pada tabel 4.3 sampai tabel 4.22
Tabel 4.3. Hasil Crawling dengan LSF pada bandwith 2 Mbps (jumlah file)
Tabel 4.4. Hasil Crawling tidak dengan LSF pada bandwith 2 Mbps (jumlah file)
Tabel 4.5. Hasil Crawling dengan LSF pada bandwith 2 Mbps (ukuran file (KB))
Thread Kom Total
A B C D
100 69577725 28904271 21708161 17909664 138099821 200 28240542 69363015 16990193 22133799 136727549 500 21737395 21052132 27264842 67375033 137429402 1000 11419831 21140539 11169824 70258637 113988831 2000 57665947 8669302 10601608 9494330 86431187
Tabel 4.6. Hasil Crawling tidak dengan LSF pada bandwith 2 Mbps (ukuran file (KB))
Thread Kom Total
A B C D
100 14718288 89496311 24427857 7904326 136546782 200 25044483 91823031 11781590 9574337 138223441 500 67823083 350922098 81962878 32384743 533092802 1000 5941639 85488993 21988304 9288824 122707760 2000 6547383 17507643 10360783 7500809 41916618
Tabel 4.7. Hasil Crawling dengan LSF pada bandwith 3 Mbps (jumlah file)
Tabel 4.8. Hasil Crawling tidak dengan LSF pada bandwith 3 Mbps (jumlah file)
Tabel 4.9. Hasil Crawling dengan LSF pada bandwith 3 Mbps (ukuran file (KB))
Thread Kom Total
A B C D
100 14930791 24675201 26849071 77356101 143811164 200 79393592 13159151 28111764 22526793 143191300 500 15507508 20164305 19650188 91818267 147140268 1000 20570748 11616420 81307259 18364192 131858619 2000 9066175 9715376 8560876 26880628 54223055
Tabel 4.10. Hasil Crawling tidak dengan LSF pada bandwith 3 Mbps (ukuran file (KB))
Thread Kom Total
A B C D
100 5499864 11544501 31959601 88003350 137007316 200 12658901 33030603 90312660 6564870 142567034 500 27654417 9868587 12234356 91667497 141424857 1000 12394699 28218157 78866222 8396623 127875701 2000 16237303 8748434 8110208 4158332 37254277
Tabel 4.11. Hasil Crawling dengan LSF pada bandwith 5 Mbps (jumlah file)
Tabel 4.12. Hasil Crawling tidak dengan LSF pada bandwith 5 Mbps (jumlah file)
Tabel 4.13. Hasil Crawling dengan LSF pada bandwith 5 Mbps (ukuran file (KB))
Thread Kom Total
A B C D
100 11786681 26607674 91382004 12488697 142265056 200 13581048 29354225 92855846 12495532 148286651 500 29452814 18572552 79056376 20216666 147298408 1000 6440600 87225347 23189401 11615549 128470897 2000 5389701 8673330 9265317 7543570 30871918
Tabel 4.14. Hasil Crawling tidak dengan LSF pada bandwith 5 Mbps (ukuran file (KB))
Thread Kom Total
A B C D
100 12196295 89421099 32282044 6115772 140015210 200 93513614 6261529 32133699 13097025 145005867 500 31295701 13099098 6484052 92576902 143455753 1000 7303126 85691176 12004445 8088835 113087582 2000 1406993 8412054 2384958 23342528 35546533
Gambar 4.6. Grafik perbandingan hasil jumlah crawling menggunakan LSF dan tidak (2 Mbps)
Gambar 4.7. Grafik perbandingan hasil jumlah crawling menggunakan LSF dan tidak (3 Mbps)
100 200 500 1000 2000
LSF 26749 26771 27198 22008 13575
No LSF 25192 26886 27288 22735 13420
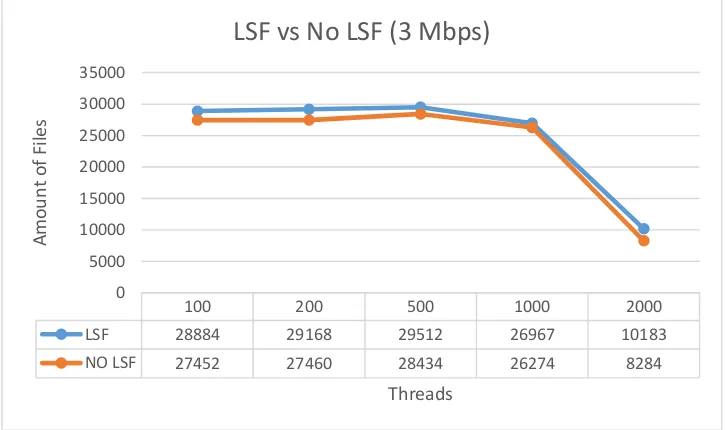
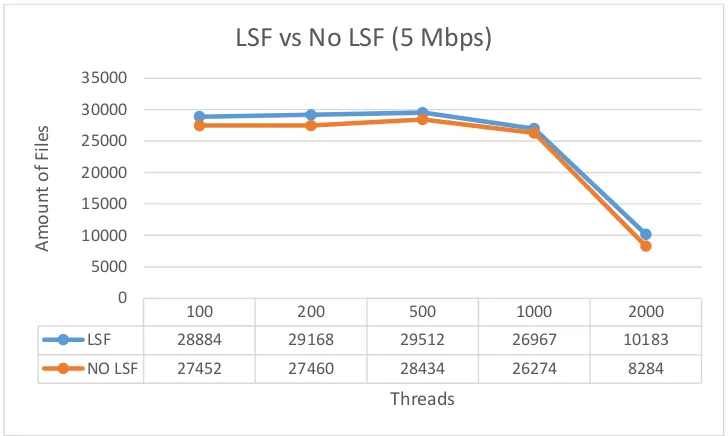
0
LSF 28884 29168 29512 26967 10183
NO LSF 27452 27460 28434 26274 8284
Gambar 4.8. Grafik perbandingan hasil jumlah crawling menggunakan LSF dan tidak (5 Mbps)
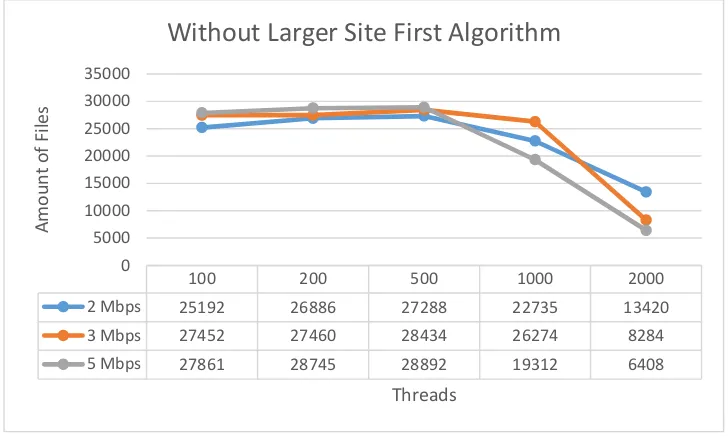
Sedangkan untuk perbandingan hasil menggunakan bandwith yang berbeda maka sebagian data menunjukkan kenaikan performa ketika bandwith semakin besar, akan tetapi jika melihat perbedaan antara jumlah hasil pada bandwith 3 Mbps dan 5 Mbps maka sebagian mengalami kenaikan dan sebagian lagi tidak dengan perbandingan 5:5 jika dibandingan dengan bandwith 3 Mbps dan 2 Mbps sebagian mengalami kenaikan dengan perbandingan 8:2. Yang dapat dilihat pada gambar 4.9 dan 4.10.
Gambar 4.9. Grafik perbandingan jumlah hasil dengan bandwith yang berbeda menggunakan LSF
100 200 500 1000 2000
LSF 28884 29168 29512 26967 10183
NO LSF 27452 27460 28434 26274 8284
0
2 Mbps 26749 26771 27198 22008 13575
3 Mbps 28884 29168 29512 26967 10183
5 Mbps 28414 29448 29955 24663 8553
Gambar 4.10. Grafik perbandingan jumlah hasil dengan bandwith yang berbeda tidak menggunakan LSF
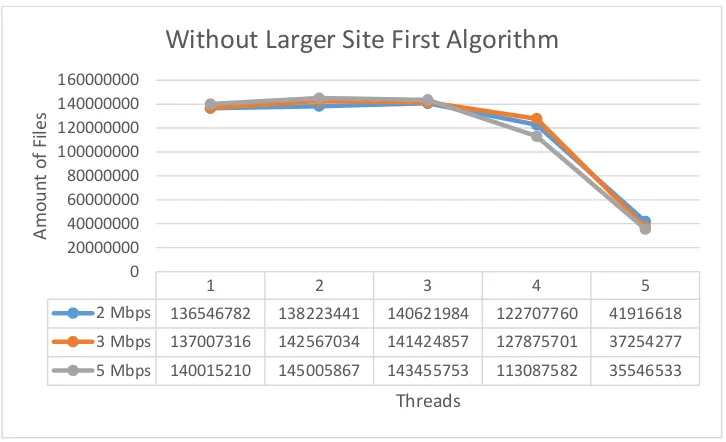
Sedangkan untuk ukuran file dengan jumlah file tidak selalu berbanding lurus yang artinya jika semakin banyak file maka jumlah ukuran file tidak selalu bertambah besar yang dapat dilihat pada gambar 4.11, 4.12
Gambar 4.11. Grafik perbandingan jumlah hasil (ukuran file) dengan bandwith yang berbeda menggunakan LSF
100 200 500 1000 2000
2 Mbps 25192 26886 27288 22735 13420
3 Mbps 27452 27460 28434 26274 8284
5 Mbps 27861 28745 28892 19312 6408
0
2 Mbps 138099821 136727549 137429402 113988831 86431187
3 Mbps 143811164 143191300 147140268 131858619 54223055
Gambar 4.12. Grafik perbandingan jumlah hasil (ukuran file) dengan bandwith yang berbeda tidak menggunakan LSF
Ketika percobaan dilakukan terjadi error pada saat pengujian menggunakan 2000
thread dimana terdapat masalah pada heap memory seperti pada gambar 4.13.
Gambar 4.13. Error yang didapatkan pada percobaan menggunakan 2000 thread
Maka dari itu penguji mengubah initial java heap size dan maximum java heap size
yang semula adalah 512 MB menjadi 768 MB. Dan semenjak dilakukan perubahan tersebut tidak dijumpai lagi error seperti pada gambar 4.13.
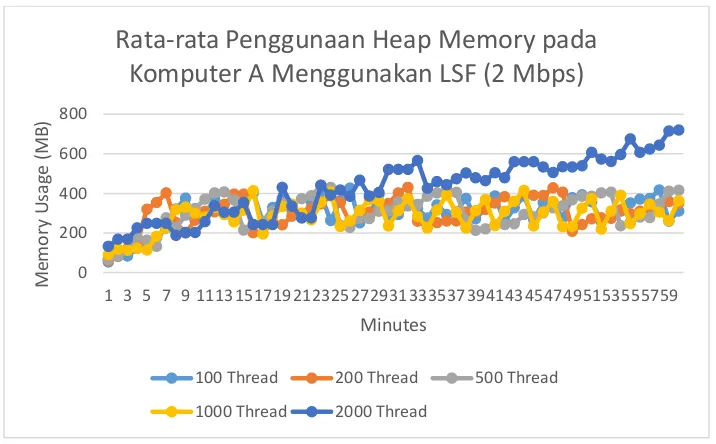
Maka untuk hasil penggunaan heap memory tidak terlalu berpengaruh dengan perubahan jumlah thread, pemakaian LSF, ataupun bandwith yang dipakai melainkan dipengaruhi berapa banyak jumlah heap memory yang pengguna definisikan untuk menjalankan program tersebut seperti contoh pada gambar 4.14 dan 4.15.
1 2 3 4 5
2 Mbps 136546782 138223441 140621984 122707760 41916618
3 Mbps 137007316 142567034 141424857 127875701 37254277
Gambar 4.14. Grafik penggunaan heap memory di komputer A menggunakan LSF
Gambar 4.15. Grafik penggunaan heap memory di komputer B tidak menggunakan LSF
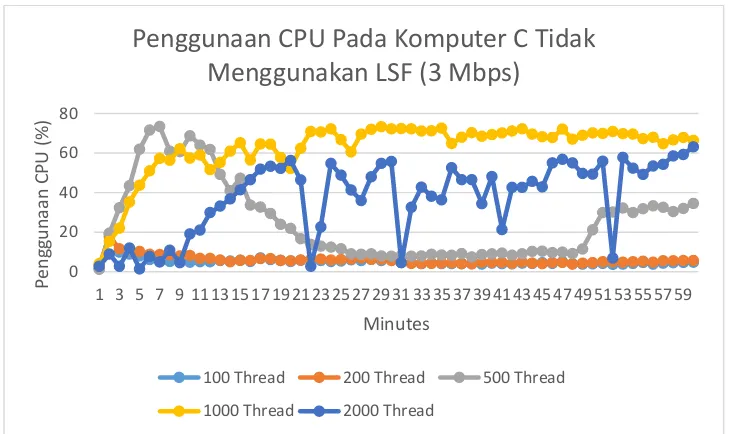
Sedangkan untuk penggunaan cpu akan semakin besar jika thread semakin besar, pada percobaan ini terkecuali pada pemakaian thread 2000 dikarenakan heap memory yang dinaikkan sehingga beban program sebagian dialihkan ke penggunaan heap memory. Untuk lebih jelasnya dapat dilihat pada gambar 4.16. dan 4.17.
0 200 400 600 800
1 3 5 7 9 11131517192123252729313335373941434547495153555759
Me
Rata-rata Penggunaan Heap Memory pada
Komputer A Menggunakan LSF (2 Mbps)
100 Thread 200 Thread 500 Thread
1000 Thread 2000 Thread
1 3 5 7 9 11131517192123252729313335373941434547495153555759
Me
Rata-rata Penggunaan Heap Memory pada
Komputer A Tidak Menggunakan LSF (3 Mbps)
100 Thread 200 Thread 500 Thread
Gambar 4.16. Grafik penggunaan CPU di komputer C menggunakan LSF
Gambar 4.17. Grafik penggunaan CPU di komputer C tidak menggunakan LSF
Dari hasil pengujian yang didapatkan bahwa pada penggunaan 1000 dan 2000 thread
terjadi penurunan performa dikarenakan CPU mempunyai batas dalam memproses
thread, jadi tidak serta merta semakin banyak thread maka semakin tinggi performa yang didapatkan. Justru apabila terlalu banyak thread yang akan diproses maka terdapat thread yang sedang menunggu untuk diproses dan mengakibatkan terganggunya kinerja thread yang sedang dijalankan dan pada akhirnya menurunkan kinerja secara keseluruhan.
Penggunaan CPU Pada Komputer C
Menggunakan LSF (2 Mbps)
100 Thread 200 Thread 500 Thread
1000 Thread 2000 Thread
Penggunaan CPU Pada Komputer C Tidak
Menggunakan LSF (3 Mbps)
100 Thread 200 Thread 500 Thread
Secara umum klasifikasi menggunakan naive bayes classifier pada focused crawler
mempunyai tingkat akurasi sebesar 90%, yang keakuratannya dapat berkurang apabila terdapat kata kunci kesehatan pada artikel bukan kesehatan dikarenakan pada naive
bayes classifier menghitung frekuensi kemunculan kata dan tidak melihat
keterkaitannya dengan kata yang lain. Untuk performa crawling menggunakan algoritma larger site first lebih besar dibandingkan dengan yang tidak menggunakannya. Apabila semakin banyak thread maka semakin banyak pula hasil
crawling yang didapatkan yang dibatasi oleh kemampuan komputer. Jika melebihi batas kemampuan maka justru akan menurunkan performa. Dan dapat disimpulkan bahwa penggunaan jumlah thread yang efektif pada penelitian kali ini adalah menggunakan 500 thread. Pada pemakaian bandwith apabila semakin besar bandwith maka semakin tinggi hasil yang didapatkan. Untuk jumlah ukuran file tidak selalu berbanding lurus dengan jumlah file yang didapatkan. Apabila semakin banyak thread yang dipakai maka tidak mempengaruhi penggunaan heap memory, melainkan dipengaruhi oleh inisialisasi oleh pengguna. Dan apabila semakin banyak thread yang dipakai maka semakin banyak
cpu usage yang dibutuhkan, yang dapat diminimalisir oleh penambahan jumlah heap memory yang dipakai.
4.5. Implementasi Sistem Bagian Depan (Front-End)
Pada bagian ini dijabarkan tampilan serta prosedur operasional dari antarmuka front end
yang telah dibangun yang hanya bisa diakses untuk OS Windows dan Linux yang berbasis GUI.
4.5.1. Tampilan Antarmuka
Antarmuka front-end dalam penelitian ini dibangun atas dua macam yaitu untuk
Crawler Master dan Crawler Slaves.
4.5.1.1.Tampilan Crawler Master
Antarmuka front-end crawler master dalam penelitian ini dibangun berdasarkan rancangan yang telah dijabarkan pada Bab 3 yaitu:
1) Konfigurasi Database
digunakan pada saat crawling. Tampilannya dapat dilihat pada gambar 4.18.
Gambar 4.18. Tampilan ‘DB Config’ pada crawler master
2) Konfigurasi penggunaan mode terdistribusi
Pada bagian ini pengguna dapat memilih dapat menggunakan mode terdistribusi apa tidak dan mengkonfigurasi IP Address yang digunakan slaves node. Tampilannya dapat dilihat pada gambar 4.19.
Gambar 4.19. Tampilan ‘Distributed Mode’ pada crawler master 3) Konfigurasi Crawler
tersebut tidak dapat digunakan pada mode terdistribusi. Tampilannya dapat dilihat pada gambar 4.20.
Gambar 4.20. Tampilan ‘Crawler Config’ pada crawler master
4) Daftar seeds URL
Pada bagian ini pengguna dapat menynting seeds URL yang akan digunakan. Tampilannya dapat dilihat pada gambar 4.21.
Gambar 4.21. Tampilan ‘Seeds’ URL pada crawler master
4.5.1.2.Tampilan Crawler Slaves
Gambar 4.22. Tampilan ‘Crawler Config’ pada crawler master 4.5.2. Prosedur Operasional
4.5.2.1.Single Mode (Non Distributed)
Pengguna hanya perlu menjalankan crawler master mengkonfigurasi pada tab DB Config, Crawler Config, Seeds dan pada tab “Distributed Mode” uncheck “Use Distributed Mode”. Lalu pengguna dapat menyunting VM Argument pada tombol “Edit VM Argument” yang
tampilannya seperti pada gambar 4.23.
4.5.2.2.Distributed Mode
Pertama sekali yang dilakukan adalah menjalankan slaves node pada setiap komputer yang ingin dijadikan slaves node dengan cara menjalankan crawler slaves dan mengkonfigurasi setiap IP address yang akan digunakan lalu tekan tombol “START” seperti pada gambar 4.24. Apabila pengguna menggunakan OS non GUI maka dapat menjalankan file run.bat/run.sh dan mengedit file ip.cfg didalam direktori “resources”.
Gambar 4.24. Contoh tampilan menjalankan node pada crawler slaves
Apabila berhasil maka akan muncul informasi jumlah node yang aktif seperti pada gambar 4.25.
Gambar 4.25. Contoh tampilan informasi node yang aktif Selanjutnya pengguna menjalankan program crawler master dan mengkonfigurasi pada tab “DB Config”, “Crawler Config”, “Seeds” dan pada tab “Distributed Mode: pastikan check “Use Distributed Mode” dan isi IP addressslaves yang digunakan lalu tekan tombol “START” seperti
Gambar 4.26. Contoh tampilan menjalankan crawler master pada ‘Distributed Mode’
Lalu apabila sukses maka slaves node akan mulai meng-crawling
halaman web seperti pada gambar 4.27.
BAB 5
KESIMPULAN DAN SARAN
Bab ini membahas tentang kesimpulan dari penerapan metode yang diajukan untuk perancangan Focused Web Crawler dengan sistem terdistribusi dan saran untuk pengembangan yang dapat dilakukan pada penelitian selanjutnya
5.1. Kesimpulan
Berdasarkan penerapan metode dari arsitektur umum yang dirancang Focused Web Crawler dengan sistem terdistribusi, didapatkan beberapa kesimpulan yakni:
1. Klasifikasi pada focused crawler menggunakan naive bayes yang mempunyai tingkat akurasi sebesar 90%.
2. Keakuratan klasifikasi dapat berkurang apabila terdapat kata kunci kesehatan pada artikel bukan kesehatan dikarenakan pada naive bayes classifier
menghitung frekuensi kemunculan kata dan tidak melihat keterkaitannya dengan kata yang lain.
3. Kecepatan pengambilan data dari web crawler dapat ditingkatkan dengan menggunakan sistem terdistribusi.
4. Kecepatan web crawler yang menggunakan algoritma larger site first lebih tinggi dibandingkan dengan yang tidak menggunakannya.
5. Semakin banyak thread maka semakin banyak pula hasil crawling yang didapatkan, yang dibatasi oleh kemampuan komputer. Jika melebihi batas kemampuan maka justru akan menurunkan kecepatannya.
6. Penggunaan jumlah thread yang efektif pada penelitian kali ini adalah menggunakan 500 thread.
7. Semakin banyak thread yang dipakai maka tidak mempengaruhi penggunaan
8. Semakin banyak thread yang dipakai maka semakin banyak cpu usage yang dibutuhkan, yang dapat diminimalisir oleh penambahan jumlah heap memory
yang dipakai 5.2. Saran
Saran yang dapat penulis berikan untuk pengembangan selanjutnya adalah sebagai berikut:
1. Menggunakan algoritma site ordering yang mempunyai performa yang lebih tinggi.
2. Menggunakan algoritma klasifikasi yang mempunyai keakuratan yang lebih tinggi sehingga dapat mengakuratkan hasil pada artikel semi kesehatan.
BAB 2
LANDASAN TEORI
2.1. Web Crawler
Web Crawler adalah meng-crawl (merayapi) seluruh informasi suatu website yang biasanya digunakan untuk meng-index suatu website, pemeliharaan website, atau digunakan untuk memperoleh data khusus contohnya email. Dan hal ini juga dapat digunakan untuk memvalidasi hyperlink dan kode HTML.
Web Crawler dimulai dengan me-list daftar URL yang akan dikunjungi, yang disebut dengan seed. Web crawler akan mengunjungi URL yang ada di daftar dan mengidentifikasi semua hyperlink di halaman tersebut serta menambahkannya kedalam daftar URL yang akan dikunjungi yang disebut crawl frontier. URL yang telah ada dikunjungi dan diambil informasi yang ada sesuai yang dibutuhkan.
Dengan banyaknya jumlah URL yang mungkin di-crawl oleh crawler server yang membuatnya sulit untuk menghindari pengambilan konten yang sama. Misalkan protokol HTTP GET membuat kombinasi URL yang sangat banyakdan sedikit dari URL tersebut menghasilkan konten yang berbeda dan selebihnya menghasilkan konten yang sama untuk URL yang berbeda, inilah yang menimbulkan masalah bagi crawler
Gambar 2.1 Arsitektur Web Crawler(Wikipedia, 2016)
Salah satu jenis dari web crawler adalah focused crawler yang merupakan web crawler
yang mengambil data dengan spesifikasi tertentu, misalkan dengan topik ‘kesehatan’, maka crawler hanya akan mengambil halaman web yang hanya berhubungan dengan topik kesehatan. Algoritma ini mencari kesamaan dari halaman yang sedang di-crawl
dengan query yang diberikan. Pada pendekatan ini, web crawler akan men-download
halaman web yang mirip dengan halaman yang lainnya, yang dapat dibantu dengan menggunakan Naive Bayes Classifier untuk mengklasifikasikan apakah halaman yang sedang dikunjungi mempunyai kemiripan dengan query yang diberikan. (Janbandhu, et al., 2014)
2.2. Multithreading
Multithreading adalah kemampuan CPU single-core ataupun multi-core dalam menjalankan beberapa proses secara bersamaan. Berbeda dengan multiprocessing, dimana thread membagi sumber daya seperti unit komputer, CPU caches, maupun
Translation Lookaside Buffer (TLB).
Jika thread melewatkan cache. Thread yang lain dapat memakai sumber daya yang tidak terpakai, yang dapat mempercepat eksekusi secara keseluruhan. Jika sebuah
thread tidak dapat memakai semua sumber daya yang ada, dengan menjalankan thread
2.3. Boilerpipe
Boilerpipe merupakan salah satu algoritma ekstraksi konten pada halawan HTML yang menyediakan algoritma untuk mendeteksi dan menghapus konten-konten selain main content seperti boilerplate ataupun template. Boilerplate merupakan web template yang sering digunakan untuk membangun proyek web baru. Dimana hal ini dapat mempermudah web developer untuk membangun website. Salah satu cara yang digunakan adalah dengan menghitung jumlah kata pada setiap blok halaman web. Apabila blok tersebut mempunyai jumlah kata terbanyak, maka dapat dikatakan blok tersebut merupakan konten utama. Sedangkan blok yang mempunyai sedikit kata, maka dapat dikatakan bahawa blok tersebut merupakan boilerplate (Kohlschütter, et al., 2010).
Terdapat beberapa teknik extraction yang dapat digunakan sesuai dengan jenis halaman yang akan di-extract yaitu:
Tabel 2.1 Jenis Boilerpipe Extraction
Teknik Extraction Deskripsi
ArticleExtractor Meng-extract konten artikel berita.
DefaultExtractor Meng-extract konten web biasa.
LargestContentExtractor
Mirip dengan DefaultExtractor, tetapi tetap mengambil konten yang paling besar. Cocok
digunakan untuk web yang bukan artikel.
KeepEverythingExtractor Mengambil semua dalam web sebagai konten.
Format output yang dapat digunakan adalah html, htmlFragment, text, json dan debug. (Kohlschütter, 2016)
Gambar 2.2 Ilustrasi Boilerpipe (Treselle System, 2014) Header
Content Side Bar
Footer
Pada penelitian ini jenis ekstraksi yang dipakai adalah ArticleExtractor, dikarenakan sumber data yang diambil bersumber dari artikel.
2.4. Text Prepocessing
Text Preprocessing merupakan tahapan awal dari text mining yang bertujuan mempersiapkan teks menjadi data yang akan mengalami pengolahan pada tahap selanjutnya. Pada text mining, data mentah yang berisi informasi memiliki struktur yang sembarang, sehingga diperlukan proses pengubahan bentuk menjadi data yang terstruktur sesuai kebutuhan, yaitu biasanya akan mejadi nilai-nilai numerik. Proses ini disebut Text Preprocessing (Triawati, 2009).
Pada tahap ini, tindakan yang dilakukan adalah tokenizing yaitu proses penguraian deskripsi yang semula berupa kalimat mejadi kata-kata kemudian menghilangkan
delimiter-delimiter seperti tanda koma (,), tanda titik (.), spasi dan karakter angka yang terdapat pada kata tersebut, Case Folding yaitu penyamaan case dalam sebuah dokumen dan filtering yaitu proses pembuangan kata-kata umum sehingga hanya akan tersisa kata-kata yang khusus (Weiss, et al., 2005).
2.5. Naïve Bayes Classifier
Klasifikasi Bayes adalah klasifikasi statistik yang dapat memprediksi kelas suatu anggota probabilitas. Untuk klasifikasi Bayes sederhana yang lebih dikenal sebagai Naïve Bayesian Classifier dapat diasumsikan bahwa efek dari suatu nilai atribut sebuah kelas yang diberikan adalah bebas dari atribut-atribut lain. Asumsi ini disebut class conditional independence yang dibuat untuk memudahkan perhitungan-perhitungan
pengertian ini dianggap “naive”, dalam bahasa lebih sederhana naïve itu
mengasumsikan bahwa kemunculan suatu term kata dalam suatu kalimat tidak dipengaruhi kemungkinan kata-kata yang lain dalam kalimat padahal dalam kenyataanya bahwa kemungkinan kata dalam kalimat sangat dipengaruhi kemungkinan keberadaan kata-kata yang dalam kalimat. Dalam Naïve Bayes di asumsikan prediksi atribut adalah tidak tergantung pada kelas atau tidak dipengaruhi atribut laten
C adalah anggota kelas dan X adalah variabel acak sebuah vektor sebagai atribut nilai yang diamati. c mewakili nilai label kelas dan x mewakili nilai atribut vector yang diamati. Jika diberikan sejumlah x tes untuk klasifikasi maka probablitas tiap kelas untuk atribut prediksi vektor yang diamati adalah
� � = |� = =� � = � � = |� =� � =
Model multinomial mengambil jumlah kata yang muncul pada sebuah dokumen, dalam model multinomial sebuah dokumen terdiri dari beberapa kejadian kata dan di asumsikan panjang dokumen tidak bergantung pada kelasnya. Dengan menggunakan asumsi Bayes yang sama bahwa kemungkinan tiap kejadian kata dalam sebuah dokumen adalah bebas tidak terpengaruh dengan konteks kata dan posisi kata dalam dokumen. Tiap dokumen di di gambarkan sebagai distribusi multinomial kata, Nit
dihitung dari jumlah kemunculan kata wt yang terjadi dalam dokumen di . Maka kemungkinan sebuah dokumen diberikan sebuah kelas adalah (McCallum & Nigam, 1998)
Disini perkiraan untuk kemungkinan untuk kata wt dalam kelas cj adalah
kebanyakan sistem besar masih menggunakan sistem sentral yang berjalan pada satu
mainframe dengan terminal-terminal yang terhubung kepadanya. Sistem tersebut bayak kelemahannya dimana terminal-terminal hanya sedikit kemampuan pemrosesannya dan semua tergantung pada komputer sentral.
Sampai saai ini ada tipe sistem yang utama yaitu:
Sistem Personal yang tidak terditribusi dan dirancang untuk satu workstation
saja.
Sistem Embedded yang bejalan pada satu processor atau pada kelompok prosessor yang terintegrasi.
Sistem Terdistribusi dimana perangkat lunak sistem berjalan pada kelompok
processor yang bekerja sama dan terintegrasi secara longgar, dengan dihubungkan oleh jaringan. Contohnya sistem ATM bank, sistem groupware, dll
Menurut (Coulouris, et al., 2012) mengidentifikasi enam karakteristik yang penting untuk sistem terdistribusi yaitu:
Pemakain bersama sumber daya
Keterbukaan. Keterbukaan sistem adalah terbuka untuk banyak sistem operasi dan banyak vendor
Konkurensi. Sitem terdistribusi memungkinkan beberapa proses dapat beroperasi pada saat yang sama pada berbagai computer di jaringan. Proses ini dapat (tapi tidak perlu) berkomunikasi satu dengan lainnya pada saat operasi normalnya.
Skalabilitas. Sitem terdistribusi dapat diskala dengan meng-upgrade atau menambahkan sumber daya baru untuk memenuhi kebutuhan sistem.
Toleransi kesalahan. Sitem terdistribusi bersifat toleran terhadap beberapa kegagalan perangkat keras dan lunak dan layanan terdegradasi dapat diberikan ketika terjadi kegagalan.
Kompleksitas. Sistem terdistribusi bersigat lebih kompleks daripada sistem sentral.
Keamanan. Sistem terdistribusi dapat diakses dari beberapa komputer dan jalur jaringan mudah disadap, sehingga keamanan jarinagan sistem terdistribusi menjadi masalah yang besar.
Kemampuan untuk dikendalikan. Komputer yang terdapat di sistem terdistribusi bis aterdiri dari berbagai tipe yang berbeda dan mungkin dijalankan pada sistem operasi yang berbeda pula. Kesalahan pada satu mesin bisa berakibat pada yang lainnya. Sehingga harus banyak usaha untuk mengendalikannya.
Tidak dapat diramalkan. Sistem terdistribusi tidak dpat diramalkan tanggapannya. Tanggapan tergantung beban total sistem, pengorganisasiandan beban jaringannya.
2.7. Apache Ignite
Apache Ignite In-Memory Data Fabric merupakan platform yang memungkinkan untuk melakukan komputasi dan transaksi dengan dataset yang besar secara real-time, terintegrasi dan terdistribusi yang memungkinkan memiliki kecepatan yang lebih besar dibandingkan dengan sistem penyimpanan tradisional maupun teknologi flash.
Apache Ignite In-Memory Data Fabric dirancang untuk melakukan in-memory
computing untuk mendapatkan performa komputasi yang tinggi, advance data-grid,
service grid, maupun streaming.
Gambar 2.4 Fitur Apache Ignite (Apache Ignite, 2016) 2.8.1. In-Memory Compute Grid
Distributed parallel processing memiliki kemampuan untuk mengeksekusi komputasi didalam cluster dan menngembalikan hasilnya kembali.
Gambar 2.5 In-Memory Compute Grid (Apache Ignite, 2016) 2.8.2. In-Memory Data Grid
In-Memory Data Grid merupakan key-value in-memory store yang memungkinkan caching data in-memory didalam cluster terdistribusi. Ignite data grid merupakan salah satu pengimplementasian transaksional atau atomic
data dalam cluster terdistribusi.
Gambar 2.6 In-Memory Data Grid (Apache Ignite, 2016) 2.8. Penelitian Terdahulu
membandingkan beberapa algoritma dalam mesin crawler seperti Breadth First Search Algorithm, Depth First Search Algorithm, Page Rank Algorithm. Penelitian ini menunjukkan bahwa Focused Crawling Algorithm mempunyai kelebihan daripada algoritma yang lainnya, dimana algoritma ini mempunyai response time yang paling kecil daripada yang lain.
Penelitian yang dilakukan Ricardo Baeza-Yates, Mauricio Marin, Carlos Castillo, Andrea Rodriguez pada tahun 2005 mereka meneliti algoritma apa yang efektif untuk dipakai dalam Page Ordering dalam web crawler. Algoritma Breadth-First
mempunyai performa yang buruk dibandingkan dengan algoritma yang lain.
Larger-Sites-First mempunyai kelebihan daripada OPIC, yaitu membutuhkan waktu
perhitungan yang sedikit dan juga tidak membutuhkan bobot yang terdapat pada link
pada halaman yang dilakukan oleh OPIC. Dengan begitu Larger-Sites-First yang mempunyai performa yang lebih baik daripada algoritma yang lainnya. Algoritma ini mengurutkan website yang akan di-crawl berdasarkan halaman yang dimiliki dari terbanyak sampai yang terkecil.
Pada tahun 2013, Harry T Yani Achsan, Wahyu Catur Wibowo mereka meneliti penggunaan multi thread web crawler pada satu komputer yang akan didistribusikan ke
public proxy server. Karena jika tidak memakai proxy server, web crawler dapat di anggap sebagai ‘cyber-attack’ dan akan di ‘ban’ oleh web server. Mereka juga meneliti bahwa multi thread web crawler harus memakai jumlah thread yang optimal untuk memaksimalkan waktu men-download, karena jika terlalu banyak thread akan mengurangi kenerja komputer, tetapi jika terlalu banyak thread akan mengurangi kecepatan dalam mengumpulkan data. Mereka menyimpulkan bahwa menggunakan multi thread web crawler yang didistribusikan ke public proxy server merupakan cara yang lebih mudah dan murah daripada menggunakan web crawler terdistribusi yang menggunakan beberapa komputer.
BAB 1 PENDAHULUAN
1.1. Latar Belakang
Perkembangan internet yang semakin pesat membuat masyarakat dapat memperoleh informasi dengan cepat. Informasi yang disajikan pun beragam jenis, seperti kesehatan, keuangan, teknologi dan lain sebagainya. Pemanfaatan informasi dari internet sangat tepat di terapkan di Indonesia, karena masyarakat indonesia yang sudah terbiasa dengan internet. Dimana menurut siaran pers yang dikemukakan oleh Asosiasi Penyelenggara Jasa Internet Indonesia (APJII), di Tahun 2014 pengguna internet di Indonesia mencapai 88,1 juta atau setara dengan 34,9% dari jumlah penduduk Indonesia (APJII, 2015).
Salah satu pemanfaatan informasi dari internet yang dapat diterapkan di Indonesia adalah sebagai salah satu sumber informasi kesehatan. Dengan jumlah artikel kesehatan di internet yang terus meningkat, maka internet dapat menjadi sumber informasi kesehatan yang cost effective atau berbiaya murah.
Mengingat beragamnya jenis informasi yang terdapat di situs-situs di internet, maka dibutuhkan suatu mekanisme mengumpulkan informasi kesehatan yang akurat dan efisien.
kecil daripada yang lain. Focused Crawling algorithm adalah algoritma Crawler yang akan mengambil data dengan spesifikasi tertentu, misalkan dengan topik ‘kesehatan’, maka crawler hanya akan mengambil halaman web yang hanya berhubungan dengan topik kesehatan. Algoritma ini akan mencari kesamaan dari halaman yang sedang
di-crawl dengan query yang diberikan (Chakrabarti, et al., 1999). Pemilihan urutan alamat situs atau page ordering juga mempengaruhi performa dari suatu web crawler. Dimana pada penelitian yang dilakukan oleh Ricardo Baeza-Yates, Mauricio Marin, Carlos Castillo, Andrea Rodriguez pada tahun 2005 mengungkapkan metode Larger-Sites-First terbukti mempunyai performa yang lebih baik dari algoritma lainnya. Algoritma ini mengurutkan website yang akan di-crawl berdasarkan halaman yang dimiliki dari terbanyak sampai yang terkecil.
Berdasarkan hal ini, penerapan algoritma focused crawling dengan metode Larger Sites First untuk page ordering dapat diterapkan untuk pengumpulan artikel kesehatan dari internet dengan response time lebih baik. Tahapan pengumpulan artikel kesehatan dengan algoritma focused crawler juga meliputi algoritma ekstraksi dan pengklasifikasian artikel. Ekstraksi artikel dilakukan untuk dapat mengetahui isi kandungan artikel sehingga artikel dapat di klasifikasikan apakah termasuk artikel kesehatan atau bukan. Algoritma klasifikasi yang digunakan yaitu algoritma Naive Bayes Classifier.
Peningkatan performa mesin crawler juga dapat dilakukan dengan cara perancangan mesin crawler terdistribusi dan juga memanfaatkan penggunaan
multithread. Beberapa penelitian terdahulu telah membuktikan bahwa sistem terdistribusi dapat meningkatkan performa dari suatu mesin crawler dan penggunaan
1.2. Rumusan Masalah
Adapun rumusan masalah pada penelitian ini adalah:
Bagaimana cara mesin crawler mengumpulkan artikel khusus di bidang kesehatan? Bagaimana cara meningkatkan kecepatan pengambilan data dari web crawler
dengan sistem terdistribusi?
1.3. Tujuan Penelitian
Tujuan utama yang ingin dicapai pada penelitian ini adalah menghasilkan focusedweb crawler terdistribusi untuk mengumpulkan artikel kesehatan.
1.4. Batasan Masalah
Dalam melakukan penelitian ini, peneliti membatasi ruang masalah yang akan diteliti. Batasan-batasan masalah yang digunakan adalah :
1. Seeds awal yang digunakan sebanyak 32 URL yang merupakan situs berbahasa Indonesia
2. Topik yang digunakan adalah kesehatan. 3. Konten yang diambil merupakan artikel.
4. Dataset kesehatan untuk klasifikasi diacu dari www.idai.or.id, www.depkes.go.id dan www.kateglo.com.
5. Crawler tidak akan meng-crawl external link dari URL seeds.
6. Jumlah node yang digunakan untuk sistem terdistribusi adalah satu master dan 4
slaves.
1.5. Manfaat Penelitian
Manfaat yang diperoleh dari penelitian ini adalah:
1. Menghasilkan suatu metode untuk pengumpulan artikel kesehatan berbahasa indonesia.
2. Mampu mengintegrasikan hasil penelitian peneliti lain untuk membangun sebuah
1.6. Metodologi Penelitian
Tahapan-tahapan yang akan dilakukan dalam pelaksanaan penelitian ini adalah sebagai berikut :
1. Studi Literatur
Tahap ini dilaksanakan untuk mengumpulkan dan mempelajari informasi-informasi yang diperoleh dari buku, jurnal dan berbagai sumber referensi lain yang berkaitan dengan penelitian seperti focused web crawler, Naive Bayyes Classifier, Sistem Terditribusi, Multi Thread, Larger Sites First.
2. Analisis Permasalahan
Pada tahap ini dilakukan analisis terhadap berbagai informasi yang telah diperoleh dari berbagai sumber yang terkait dengan penelitian agar didapatkan metode yang tepat untuk menyelesaikan masalah dalam penelitian ini.
3. Perancangan Sistem
Tahap ini dilakukan perancangan sistem untuk menyelesaikan permasalahan yang terdapat di dalam tahap analisis. Kemudian dilanjutkan dengan mengimplementasikan hasil analisis dan perancangan ke dalam sistem.
4. Implementasi dan Pengujian
Pada tahap ini dilakukan implementasi ke dalam kode sesuai dengan analisis dan perancangan yang telah dilakukan pada tahap sebelumnya. Dan dilakukan pengujian terhadap hasil yang didapatkan melalui implementasi algoritma Larger Sites First dan
Naive Bayes Classifier dalam Focused Crawler terdistribusi.
5. Analisis dan Pengambilan Kesimpulan
Pada tahap ini dilakukan analisis data yang didapatkan dari implementasi algoritma
Larger Sites First dan Naive Bayes Classifier dalam Focused Crawler terdistribusi dan menyipulkan hasil analisis tersebut.
1.7. Sistematika Penulisan
Bab ini berisi latar belakang dari penelitian yang dilaksanakan, rumusan masalah, tujuan penelitian, batasan masalah, manfaat penelitian, metodologi penelitian, serta sistematika penulisan.
Bab 2: Landasan Teori
Bab ini berisi teori-teori yang diperlukan untuk memahami permasalahan yang dibahas pada penelitian ini. Teori-teori yang berhubungan dengan Web Crawler, Focused Crawling Algorithm, Larger Site-First, Multithreading, Naive Bayes Classifierdan sistem terdistribusi akan dibahas pada bab ini.
Bab 3: Analisis dan Perancangan
Bab ini menjelaskan tentang analisis dan perancangan sistem yang bangun untuk
focused crawler dengan sistem terdistribusi. Adapun dua tahapan yang dibahas pada bab ini yaitu tahap analisis dan tahap perancangan sistem. Pada analisis sistem meliputi kebutuhan perangkat lunak dan perangkat kerasdan pada perancangan sistem meliputi tahapan untuk perancangan sistem terdistribusi dan juga tahapan percobaan yang dilakukan.
Bab 4: Implementasi dan Pengujian
Bab ini berisi pembahasan tentang implementasi dari perancangan yang telah dijabarkan pada bab 3. Selain itu, hasil yang didapatkan selama proses yang terjadi pada penelitian juga dijabarkan pada bab ini.
Bab 5: Kesimpulan dan Saran
ABSTRAK
Salah satu teknik untuk mengumpulkan informasi berupa artikel dari Internet adalah dengan menggunakan mesin crawler. Salah satu algoritma untuk mengumpulkan artikel hanya untuk topik tertentu pada sebuah mesin crawler dapat menggunakan Focused Crawling Algorithm dengan metode pengklasifikasian seperti naive bayes. Tahapan pengumpulan artikel meliputi algoritma ekstraksi dan pengklasifikasian artikel. Ekstraksi artikel dilakukan untuk dapat mengetahui isi kandungan artikel sehingga artikel dapat di klasifikasikan apakah termasuk artikel dengan topik tertentu atau bukan. Untuk mempercepat waktu yang dibutuhkan dalam pengumpulan informasi maka dapat dirancang dengan sistem terdistribusi dan dikombinasikan dengan metode
multithreading dan pemakaian algoritma larger site first dalam pengurutan situs yang akan di-crawl pertama kali. Penelitian dilakukan dengan menggunakan thread dan
bandwith yang berbeda. Selain menghitung hasil dari crawling, peneliti juga menghitung penggunaan heap memory dan cpu pada saat proses crawling. Hasil yang didapat adalah hasil crawling menggunakan algoritma larger site first lebih tinggi dibandingkan dengan tidak menggunakannya. Begitu juga dengan penggunaan thread
dan bandwith, semakin besar maka semakin besar juga hasilnya. Akan tetapi ada berapa faktor yang menyebabkan menurunnya performa walaupun thread yang digunakan banyak. Untuk itu thread yang efektif digunakan pada penelitian kali ini adalah dengan 500 thread.
FOCUSED WEB CRAWLER WITH DISTRIBUTED SYSTEM
ABSTRACT
One technique for collecting information in the form of articles on the Internet is to use web crawler. One of algorithm to collect articles only for particular topics on web crawler can be use Focused Crawling Algorithm with classification method such as Naive Bayes. The stages collection of articles covering the extraction content and classification. Article extraction is to determine the contents of the articles, so that the article can be classified if the articles is on a specific topic or not. To speed up the time of collecting information, then can be designed with distributed systems and combined with multithreading method and larger site first algorithm in the sequencing of the site will be crawled first. The research was conducted by using a different thread and internet bandwidth. In addition to calculating the results of the crawling, the researchers also calculated the use of heap memory and cpu while crawling process. The results obtained are the result of usage larger site algorithm is higher compared to not using it. Likewise with the use of thread and bandwidth higher then the higher the results. But many factors can be decreased performance although the thread used a lot. Therefore the effective thread used in this research is the 500 threads.
SISTEM TERDISTRIBUSI
SKRIPSI
ATRAS NAJWAN
121402060
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI
UNIVERSITAS SUMATERA UTARA
MEDAN
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Teknologi Informasi
ATRAS NAJWAN 121402060
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : FOCUSED WEB CRAWLER DENGAN SISTEM
TERDISTRIBUSI
Kategori : SKRIPSI
Nama : ATRAS NAJWAN
Nomor Induk Mahasiswa : 121402060
Program Studi : S1 TEKNOLOGI INFORMASI
Departemen : TEKNOLOGI INFORMASI
Fakultas : FAKULTAS ILMU KOMPUTER DAN EKNOLOGI
INFORMASI Komisi Pembimbing :
Pembimbing 2 Pembimbing 1
Dani Gunawan, ST., M.T Amalia, ST., M.T
NIP. 19820915 201212 1 002 NIP. 19791221 201404 2 001
Diketahui/disetujui oleh
Program Studi S1 Teknologi Informasi Ketua,
PERNYATAAN
FOCUSED WEB CRAWLER DENGAN
SISTEM TERDISTRIBUSI
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 27 Agustus 2016
UCAPAN TERIMA KASIH
Puji dan syukur penulis sampaikan ke hadirat Allah SWT yang telah memberikan rahmat serta restu-Nya sehingga penulis dapat menyelesaikan skripsi ini sebagai syarat untuk memperoleh gelar Sarjana Teknologi Informasi.
Pertama, penulis ingin mengucapkan terima kasih kepada Ibu Amalia S.T., M.T. selaku pembimbing pertama dan Bapak Dani Gunawan, S.T., M.T. selaku pembimbing kedua yang telah meluangkan waktu dan tenaganya untuk membimbing penulis dalam penelitian serta penulisan skripsi ini. Tanpa inspirasi serta motivasi yang diberikan dari kedua pembimbing, tentunya penulis tidak akan dapat menyelesaikan skripsi ini. Penulis juga mengucapkan terima kasih kepada Bapak Prof. Dr. Opim Salim Sitompul, M.Sc. sebagai dosen pembanding pertama dan Ibu Dr. Elviawaty Muisa Zamzami, S.T., M.T., M.M. sebagai dosen pembanding kedua yang telah memberikan masukan serta kritik yang bermanfaat dalam penulisan skripsi ini. Ucapan terima kasih juga ditujukan kepada semua dosen serta pegawai di lingkungan program studi Teknologi Informasi, yang telah membantu serta membimbing penulis selama proses perkuliahan.
Penulis tentunya tidak lupa berterima kasih kepada orang tua penulis, yaitu Bapak Dr. Jamaludin, M.A., Ibu Tansa Trisna SHB, S.Pd.I. dan Ibu Almh. Khairani yang telah membesarkan penulis dengan sabar dan penuh kasih sayang, serta doa dari mereka yang selalu menyertai selama ini. Terima kasih juga penulis ucapkan kepada kakak penulis Rizka Zulhaini, S.S. dan adik penulis Nabilah Alwani yang selalu memberikan dukungan kepada penulis.