Nama Lengkap : Citrawati Isra Salekhah Tempat, Tanggal Lahir : Bandung, 24 Desember 1993
Jenis Kelamin : Perempuan
Agama : Islam
Kewarganegaraan : Indonesia
Alamat : Jl. Raya Jepara Kudus Km. 7 01/02 Ngabul
Tahunan Jepara
No. Telepon : 08112255922
Email : [email protected]
B. Pendidikan Formal
1998 – 1999 : TK Pertiwi, Jepara
1999 – 2005 : SD Negeri Panggang 2, Jepara
2005 – 2008 : SMP Negeri 2, Jepara
2008 – 2011 : SMA Negeri 1, Jepara
Jurusan Ilmu Pengetahuan Alam
2011 – 2016 : Universitas Komputer Indonesia, Bandung
Jurusan S1 – Teknik Informatika
C. Riwayat Pekerjaan
Kerja praktik di PT. MediaWave Interaktif Tahun 2014.
Bandung, 25 Agustus 2016
Citrawati Isra Salekhah
IMPLEMENTASI METODE MULTI CLASS SUPPORT
VECTOR MACHINE UNTUK KLASIFIKASI EMOSI PADA
LIRIK LAGU BAHASA INDONESIA
SKRIPSI
Diajukan untuk Menempuh Ujian Akhir Sarjana
CITRAWATI ISRA SALEKHAH
10111473
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
iii
KATA PENGANTAR
Assalamu’alaikum Warahmatullahi Wabarakatuh.
Alhamdulillahi Rabbil ‘Alamin, segala puji dan syukur Penulis panjatkan kehadirat Allah SWT yang atas rahmat dan karunia-Nya, tidak lupa shalawat serta salam tercurah limpahkan kepada Baginda Rasulullah SAW, sehingga Penulis dapat
menyelesaikan skripsi yang berjudul “IMPLEMENTASI METODE MULTI
CLASS SUPPORT VECTOR MACHINE UNTUK KLASIFIKASI EMOSI PADA
LIRIK LAGU BAHASA INDONESIA” untuk memenuhi salah satu syarat dalam
menyelesaikan studi jenjang strata satu (S1) di Program Studi Teknik Informatika, Fakultas Teknik dan Ilmu Komputer, Universitas Komputer Indonesia.
Dikarenakan keterbatasan yang dimiliki Penulis, penyusunan skripsi ini tidak akan terwujud tanpa mendapat banyak dukungan, bantuan dan masukan dari berbagai pihak. Untuk itu melalui kata pengantar ini, Penulis ingin menyampaikan rasa terimakasih yang sebesar-besarnya kepada:
1. Allah SWT atas segala nikmat yang telah diberikan, beserta izin-Nya lah sehingga Penulis dapat menyelesaikan skripsi ini.
2. Kedua orang tua, ibu (Erni Suryani) dan ayah (Soelchan Saleh) yang telah memberikan kasih sayang, doa dan dukungan baik moril maupun materi, sehingga Penulis dapat menyelesaikan skripsi ini.
3. Ibu Ednawati Rainarli, S. Si., M. Si., selaku dosen wali Penulis di kelas IF-11/2011 dan dosen pembimbing Penulis. Terimakasih karena telah banyak meluangkan waktu untuk memberikan bimbingan, saran, ilmu dan nasehatnya selama proses penyusunan skripsi ini.
4. Bapak Alif Finandhita, S. Kom., M. T., selaku reviewer, karena telah memberikan saran, ilmu dan masukannya kepada Penulis.
iv
6. Bapak dan Ibu dosen serta seluruh staf pegawai Program Studi Teknik Informatika Universitas Komputer Indonesia yang telah membantu Penulis selama proses perkuliahan.
7. Terima kasih kepada Bang Ali yang telah membagi ilmunya serta bertukar pikiran tentang metode Multi Class Support Vector Machine.
8. Teman-teman seperjuangan skripsi semester genap 2015/2016, anak-anak bimbingan ibu Ednawati Rainarli S. Si., M. Si., serta angkatan 2011 terutama kelas IF-11 yang selalu memberi dukungan dan semangat kepada Penulis selama penyusunan skripsi.
9. Terima kasih kepada 3J (Ismi Muwakhidah, Sri Jayanti) yang selalu memberikan dukungan, motivasi, serta meluangkan waktunya untuk bermain bersama.
10. Teman-teman Secret Admirer (Rismayanti, Dewi Raida, Shandhi Shinta, Sesky Oktaliva, Mutiara Fitryana, Luthfia Sarafina Nuryadin, Rifan Muhammad Furqon, Abudin) yang selalu memberikan dukungan, motivasi, serta telah meluangkan waktunya untuk bermain bersama.
11. Serta seluruh pihak yang tidak dapat Penulis sebutkan satu persatu, terimakasih atas segala bentuk dukungannya untuk menyelesaikan skripsi ini.
Penulis menyadari bahwa penulisan skripsi ini masih jauh dari kata sempurna. Oleh karena itu, Penulis mengharapkan saran dan masukan yang bersifat membangun untuk perbaikan dan pengembangan skripsi ini selanjutnya. Akhir kata, semoga penulisan skripsi ini dapat bermanfaat bagi penulis khususnya dan bagi pembaca pada umumnya.
Wassalamu’alaikum Warahmatullahi Wabarakatuh.
Bandung, 25 Agustus 2016
v
DAFTAR ISI
ABSTRAK ... i
ABSTRACT ... ii
KATA PENGANTAR ... iii
DAFTAR ISI ... v
DAFTAR GAMBAR ... ix
DAFTAR TABEL ... xi
DAFTAR SIMBOL ... xiii
DAFTAR LAMPIRAN ... xvii
BAB 1 PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 2
1.3 Maksud dan Tujuan ... 2
1.4 Batasan Masalah ... 2
1.5 Metodologi Penelitian ... 3
1.5.1 Metode Pengumpulan Data ... 3
1.5.2 Metode Pembangunan Perangkat Lunak ... 4
1.5.3 Metode Klasifikasi ... 5
1.6 Sistematika Penulisan ... 6
BAB 2 LANDASAN TEORI ... 9
2.1 Emosi ... 9
2.2 International Survey On Emotion Antecedents And Reaction (ISEAR) .... 9
vi
2.3.1 Case Folding ... 10
2.3.2 Convert Negation ... 10
2.3.3 Tokenizing ... 11
2.3.4 Stopwords Removal ... 11
2.3.5 Stemming ... 12
2.4 Pembobotan TF-IDF ... 18
2.5 Metode Support Vector Machine ... 18
2.6 Pengukuran Kinerja Klasifikasi ... 23
2.7 Pemrograman Berorientasi Objek ... 24
2.8 Unified Modeling Language ... 25
2.8.1 Use Case Diagram ... 26
2.8.2 Activity Diagram ... 26
2.8.3 Class Diagram ... 26
2.8.4 Sequence Diagram ... 27
BAB 3 ANALISIS DAN PERANCANGAN ... 29
3.1 Analisis Masalah ... 29
3.2 Analisis Proses ... 29
3.3 Analisis Data Masukan ... 31
3.4 Analisis Preprocessing ... 32
3.4.1 Case Folding ... 33
3.4.2 Convert Negation ... 34
3.4.3 Tokenizing ... 36
3.4.4 Stopword Removal ... 37
3.4.5 Stemming ... 39
vii
3.6 Analisis Metode Multi Class Support Vector Machine ... 45
3.6.1 Analisis Pelatihan Multi Class Support Vector Machine ... 45
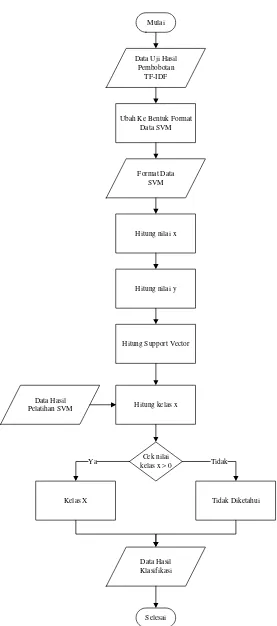
3.6.2 Analisis Pengujian Multi Class Support Vector Machine ... 51
3.7 Analisis Kebutuhan Non Fungsional ... 53
3.7.1 Analisis Kebutuhan Perangkat Keras ... 54
3.7.2 Analisis Kebutuhan Perangkat Lunak ... 54
3.7.3 Analisis Pengguna ... 54
3.8 Analisis Kebutuhan Fungsional ... 54
3.8.1 Use Case Diagram ... 55
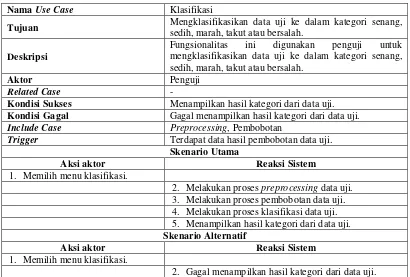
3.8.2 Use Case Skenario ... 56
3.8.3 Activity Diagram ... 59
3.8.4 Class Diagram ... 62
3.8.5 Sequence Diagram ... 63
3.9 Perancangan Sistem ... 67
3.9.1 Perancangan Struktur Menu ... 67
3.9.2 Perancangan Antarmuka ... 67
3.9.3 Perancangan Pesan ... 69
3.9.4 Jaringan Semantik ... 69
BAB 4 IMPLEMENTASI DAN PENGUJIAN ... 71
4.1 Implementasi ... 71
4.1.1 Implementasi Perangkat Keras ... 71
4.1.2 Implementasi Perangkat Lunak ... 71
4.1.3 Implementasi Antarmuka ... 72
4.2 Pengujian ... 72
viii
4.2.2 Skenario Pengujian ... 72
4.2.3 Hasil Pengujian ... 74
4.2.4 Evaluasi Pengujian ... 78
BAB 5 KESIMPULAN DAN SARAN ... 79
5.1 Kesimpulan ... 79
5.2 Saran ... 79
81 no. 1, pp. 180-187, 2015.
[2] S. M. Mohamad and S. Kiritchenko, "Using Hastags to Capture Fine Emotion Categories from Tweets," Computational Intelligence, vol. 31, no. 2, pp. 301-326, 2015.
[3] F. Kleedorfer, P. Knees and T. Pohle, "Oh Oh Oh Whoah! Towards Automatic Topic Detection in Song Lyrics," in Studio Smart Agent Technologies, Austria, 2008.
[4] L. Sofiyani, Z. Abidin and H. Nurhayati, "Klasifikasi Emosi untuk Teks Berbahasa Indonesia dengan Menggunakan K-Nearest Neighbor," pp. 294-299, 2012.
[5] F. Wulandini and A. S. Nugroho, "Text Clasification Using Support Vector Machine for Webmining Based Spatio Temporal Anlysis of the Spread of Tropical Diseases," International Conference on Rural Information and
Communication Technology, pp. 189-192, 2009.
[6] E. Prasetyo, DATA MINING - Mengolah Data menjadi Informasi Menggunakan Matlab, Yogyakarta: ANDI, 2014.
[7] "aaac emotion-research.net," The Association for the Advancement of Affective Computing (AAAC), [Online]. Available: http://emotion-research.net/toolbox/toolboxdatabase.2006-10-13.2581092615. [Accessed 11 March 2016].
[8] "KapanLagi.com," KLN KapanLagi Network, [Online]. Available: http://lirik.kapanlagi.com. [Accessed 11 March 2016].
[9] "wow keren," MEDIA INFO, 2016. [Online]. Available: http://www.wowkeren.com. [Accessed 11 March 2016].
[10] C. D. Manning, P. Raghavan and H. Schutze, An Introduction to Information Retrieval, Cambridge: Cambridge University Press, 2009.
[11] W. A. Gani, "Klasifikasi Emosi pada Teks Bahasa Indonesia Menggunakan Metode K-Nearest Neighbor dengan Pembobotan WIDF," Jurnal Ilmiah
82
[12] L. Agusta, "Perbandingan Algoritma Stemming Porter dengan Algoritma Nazief & Andriani untuk Stemming Dokumen Teks Bahasa Indonesia," Konferensi Nasional Sistem dan Informatika, pp. 196-201, 2009.
[13] M. Nazir, Metode Penelitian, Bogor: Ghalia Indonesia, 2011.
[14] Direktorat Tenaga Kependidikan, Direktorat Jenderal Peningkatan Mutu Pendidik dan Tenaga Kependidikan, Pendekatan, Jenis, dan Metode Penelitian Pendidikan, Jakarta: Departemen Pendidikan Nasional, 2008.
[15] K. Oatley and J. M. Jenkins, Understanding Emotions, Blackwell, 1996.
[16] M. J. Power and T. Dalgleish, Cognition and Emotion, LEA Press, 1997.
[17] F. Z. Tala, "A Study of Stemming Efects on Information Retrieval in Bahasa Indonesia," Institute for Logic, Language, and Computation Univesite itvan Amsterdam The Netherlands, Amsterdam, 2003.
[18] I. Destuardi and S. Sumpeno, "Klasifikasi Emosi untuk Teks Bahasa Indonesia Menggunakan Metode Naive Bayes," Seminar Nasional Pascasarjana, 2009.
[19] S. Chakrabarti, Mining the Web: Discovering Knowledge from Hypertext Data, San Francisco: Morgan Kaufman, 2003.
[20] J. Han, M. Kamber and J. Pei, Data Mining : Concepts and Techniques, Morgan Kaufmann, 2011.
[21] G. S. Budhi, I. Gunawan and F. Yuwono, "Algoritma Porter Stemmer for Bahasa Indonesia untuk Pre-processing Text Mining Berbasis Metode Market Basket Analysis," PAKAR Jurnal Teknologi Informasi dan Bisnis, vol. 7, 2006.
[22] D. Grossman and F. Ophir, Information Retrieval: Algorithm and Heuristics, Kluwer Academic Publisher, 1998.
[23] N. Christianini and J. S. Taylor, "An Introduction to Support Vector Machines and Other Kernels-based Learning Methods," Cambridge University Press, 2000.
83
[25] M. H, "Support Vector Machines-Kernels and The Kernel Trick," An elaboration for the Hauptseminar Reading Club: Support Vector Machines, 2006.
[26] P. A. Octaviani, "Penerapan Metode Klasifikasi Support Vector Machine (SVM) pada Data Akreditasi Sekolah Dasar (SD) di Kabupaten Magelang," Universitas Diponegoro, S1 Statistika, Semarang, 2014.
[27] R. A. Mauludiya, "Simulasi dan Analisis Klasifikasi Genre Musik Berbasis FFT dan Support Vector Machine," Universitas Telkom, S1 Teknik Telekomunikasi, Bandung, 2015.
[28] R. A. S and S. M., Modul Pembelajaran Rekayasa Perangkat Lunak (Terstruktur dan Berorientasi Objek), Bandung: Modula, 2013.
1
1
BAB 1
PENDAHULUAN
1.1 Latar Belakang Masalah
Teks merupakan salah satu media yang digunakan untuk berkomunikasi dan menyampaikan informasi [1]. Tidak hanya memuat informasi, teks juga dapat mengekspresikan emosi [2]. Lirik lagu merupakan salah satu bentuk teks yang dapat digunakan sebagai objek dalam penelitian klasifikasi emosi. Dalam penentuan emosi, lirik lagu merupakan elemen yang memiliki makna paling kuat dalam menggambarkan emosi [3].
Penelitian terhadap klasifikasi emosi pada lirik lagu Bahasa Indonesia pernah dilakukan sebelumnya oleh Lailatus Sofiyana menggunakan metode K-Nearest Neighbor (K-NN) dengan nilai akurasi mencapai 60% [4]. Penelitian tersebut belum menghasilkan tingkat akurasi yang maksimal karena performansi metode klasifikasi yang digunakan kurang baik dalam mengklasifikasikan teks. Hal ini ditunjukkan pada penelitian klasifikasi teks Bahasa Indonesia yang dilakukan oleh Fatimah Wulandini bahwa metode K-NN memberikan hasil akurasi paling rendah dibandingkan metode klasifikasi Support Vector Machine, Naïve Bayes Classifier, dan C4.5 Decision Tree dengan akurasi sebesar 49,17% [5].
Support Vector Machine (SVM) merupakan metode klasifikasi yang berakar
dari teori pembelajaran statistik yang hasilnya sangat menjanjikan untuk memberikan hasil yang lebih baik dari metode yang lain. Selain itu, SVM juga bekerja dengan baik pada set data dengan dimensi yang tinggi [6], seperti teks. Hal
ini dibuktikan dengan penelitian Fatimah Wulandini yang berjudul “Text Classification Using Support Vector Machine for Webmining Based Spatio
benar sesuai dengan kelas asli ke dalam 6 kelas kategori, yaitu economy, defense & security, education, health, sports, dan politics [5]. Berdasarkan hasil dari penelitian tersebut membuktikan bahwa metode SVM dapat memecahkan masalah klasifikasi multi class dengan baik.
Berdasarkan uraian diatas, maka pada penelitian ini digunakan metode Multi Class Support Vector Machine untuk mengklasifikasikan emosi pada lirik lagu Bahasa Indonesia.
1.2 Rumusan Masalah
Berdasarkan latar belakang yang telah dijelaskan, maka rumusan masalah dalam penelitian ini adalah bagaimana cara mengimplementasikan metode Multi Class Support Vector Machine untuk klasifikasi emosi pada lirik lagu Bahasa Indonesia.
1.3 Maksud dan Tujuan
Maksud dari penelitian ini adalah mengimplementasikan metode Multi Class Support Vector Machine untuk klasifikasi emosi pada lirik lagu Bahasa Indonesia. Sedangkan tujuan yang ingin dicapai dari penelitian ini adalah mengetahui besar akurasi yang didapatkan dengan mengimplementasikan metode Multi Class Support Vector Machine untuk klasifikasi emosi pada lirik lagu Bahasa Indonesia.
1.4 Batasan Masalah
Agar penelitian yang dilakukan lebih terarah dan mencapai sasaran yang ditentukan, maka diperlukan sebuah pembatasan masalah atau ruang lingkup kajian, yaitu sebagai berikut:
1. Data latih yang digunakan adalah data dari International Survey On Emotion Antecedents And Reaction (ISEAR) berjumlah 1000 data pernyataan dengan format (.txt) [7].
2. Data uji yang digunakan adalah lirik lagu Bahasa Indonesia berjumlah 30 data dengan format (.txt) [4] [8] [9].
3
4. Tahapan preprocessing meliputi case folding, convert negation, tokenizing, stopword removal, dan stemming [10][11].
5. Algoritma stemming yang digunakan adalah algoritma Nazief & Adriani [12]. 6. Metode pembobotan yang digunakan adalah TF-IDF [10].
7. Metode Multi Class Support Vector Machine yang digunakan adalah one against all [6].
8. Fungsi kernel yang digunakan adalah linear [6].
1.5 Metodologi Penelitian
Metodologi penelitian merupakan cara utama yang digunakan peneliti untuk mencapai tujuan dan menentukan jawaban atas masalah yang diajukan [13]. Metode penelitian yang digunakan dalam penelitian ini adalah metode eksperimen. Metode eksperimen didefinisikan sebagai metode sistematis guna membangun hubungan yang mengandung fenomena sebab akibat. Metode eksperimen merupakan metode inti dari model penelitian yang menggunakan pendekatan kuantitatif [14]. Variabel bebas yang diteliti adalah metode klasifikasi Multi ClassSupport Vector Machine yang digunakan untuk klasifikasi emosi pada lirik lagu Bahasa Indonesia, sedangkan variabel terikatnya adalah nilai akurasi.
Penelitian ini memiliki 3 metode dalam pelaksanaannya, yaitu metode pengumpulan data, metode pembangunan perangkat lunak, dan metode klasifikasi. Berikut ini merupakan penjelasan dari masing-masing metode:
1.5.1 Metode Pengumpulan Data
Metode pengumpulan data yang digunakan dalam penelitian ini adalah sebagai berikut:
a. Studi Literatur
b. Observasi
Observasi yang dilakukan adalah pengumpulan data dari International Survey
On Emotion Antecedents And Reaction (ISEAR) yang digunakan sebagai data latih
dan lirik lagu Bahasa Indonesia sebagai data uji.
1.5.2 Metode Pembangunan Perangkat Lunak
Metode pembangunan perangkat lunak merupakan langkah-langkah yang akan dilakukan dalam membangun simulasi untuk mengklasifikasikan emosi pada lirik lagu Bahasa Indonesia. Berikut ini adalah tahapan metode pembangunan perangkat lunak yang akan dilakukan dalam penelitian ini, dapat dilihat pada Gambar 1.1
Perancangan Analisis
Implementasi
Pengujian
Gambar 1.1 Metode Pembangunan Perangkat Lunak
Berikut merupakan penjelasan masing-masing tahapan dari Gambar 1.1:
1. Analisis
Dalam tahapan ini dilakukan untuk mempelajari konsep dan analisis mengenai klasifikasi emosi menggunakan metode Multi Class Support Vector Machine.
2. Perancangan
5
3. Implementasi
Pada tahap ini akan dilakukan proses implementasi metode Multi Class Support Vector Machine ke dalam simulasi yang akan dibangun sesuai dengan perancangan yang dibuat pada tahap sebelumnya.
4. Pengujian
Pada tahap ini akan dilakukan pengujian terhadap simulasi yang telah dibangun, apakah simulasi yang dibangun sudah sesuai dengan tujuan dari penelitian.
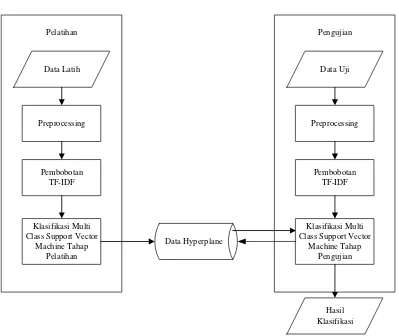
1.5.3 Metode Klasifikasi
Berikut adalah gambaran metode klasifikasi yang dilakukan dalam penelitian ini dapat dilihat pada Gambar 1.2
Pelatihan
Data Latih
Preprocessing
Pembobotan
Pengujian
Data Uji
Preprocessing
Pembobotan
Model Klasifikasi
Berikut penjelasan dari masing-masing tahapan Gambar 1.2:
1. Preprocessing
Data latih dan data uji yang akan digunakan dilakukan proses preprocessing untuk mengubah bentuk data yang belum terstruktur menjadi data yang terstruktur. Proses preprocessing ini terdiri dari 5 tahap yaitu case folding, convert negation, tokenizing, stopword removal dan stemming.
2. Pembobotan
Data latih dan data uji yang telah dipreprocessing akan dilakukan pembobotan menggunakan metode pembobotan TF-IDF.
3. Model
Data latih yang telah melalui proses preprocessing dan pembobotan akan dijadikan model untuk acuan dalam memprediksikan kelas teks.
4. Klasifikasi
Data uji yang telah melalui proses preprocessing dan pembobotan akan dilakukan klasifikasi menggunakan model yang dihasilkan pada tahap pelatihan. Metode klasifikasi yang digunakan pada penelitian ini adalah Multi Class Support Vector Machine.
1.6 Sistematika Penulisan
Sistematika penulisan penelitian ini disusun untuk memberikan gambaran umum mengenai penelitian yang dikerjakan. Sistematika penulisan penelitian adalah sebagai berikut:
BAB 1 PENDAHULUAN
Bab ini menjelaskan tentang gambaran umum mengenai isi laporan skripsi yang berisi penjelasan meliputi latar belakang masalah, rumusan masalah, maksud dan tujuan, batasan masalah, metodologi penelitian, serta sistematika penulisan dalam penelitian tentang implementasi metode Multi ClassSupport Vector Machine untuk klasifikasi emosi pada lirik lagu Bahasa Indonesia.
BAB 2 LANDASAN TEORI
7
BAB 3 ANALISIS DAN PERANCANGAN
Bab ini berisi penjelasan mengenai analisis masalah dari objek penelitian yang dilakukan untuk mengetahui masalah apa yang timbul dan mencoba memecahkan masalah tersebut, analisis proses, analisis kebutuhan data masukan, analisis proses prepocessing, analisis pembobotan TF-IDF, analisis klasifikasi emosi dengan metode Multi Class Support Vector Machine, dan pengukuran kinerja klasifikasi dari penggunaan metode Multi Class Support Vector Machine untuk klasifikasi emosi pada lirik lagu Bahasa Indonesia. Selain itu dijelaskan juga analisis kebutuhan non fungsional, analisis kebutuhan fungsional, dan perancangan struktur menu, perancangan antarmuka, perancangan pesan, dan jaringan semantik dari perangkat lunak yang akan dibangun.
BAB 4 IMPLEMENTASI DAN PENGUJIAN
Bab ini berisi tentang implementasi dari analisis dan perancangan yang telah dilakukan pada bab sebelumnya. Implementasi yang dilakukan terdiri dari implementasi sistem berupa implementasi perangkat keras, implementasi perangkat lunak, dan implementasi antarmuka. Selain itu dilakukan pengujian terhadap perangkat lunak yang dibangun melalui rencana pengujian, skenario pengujian, serta mengukur kinerja klasifikasi emosi yang dihasilkan. Informasi yang ditampilkan dari implementasi dan pengujian yang dilakukan berupa sebuah kategori emosi dari lirik lagu.
BAB 5 KESIMPULAN DAN SARAN
9
2
BAB 2
LANDASAN TEORI
2.1 Emosi
Emosi dapat digambarkan sebagai keadaan yang pada umumnya disebabkan oleh suatu kejadian penting sebuah subyek yang meliputi (a) keadaan mental sadar yang dinyatakan dengan kemampuan mengenali, kualitas perasaan dan diarah untuk beberapa subyek, (b) gangguan jasmani pada beberapa organ tubuh, (c) pengenalan ekspresi pada wajah, suara dan isyarat tubuh, (d) kesiapan untuk melakukan tindakan tertentu. Karenanya emosi dalam sosiobiologi adalah kecenderungan mental (conative dan kognitif), keadaan, proses dan model komputasi harus spesifikasi semirip mungkin [15].
Sejumlah penelitian tentang emosi manusia telah dilakukan sehingga ada kesepakatan tentang emosi dasar [16]:
1. Takut sebagai ancaman fisik atau sosial untuk diri sendiri.
2. Marah sebagai ganjalan atau frustasi dari peran atau tujuan yang dirasakan orang lain.
3. Jijik menggambarkan penghapusan atau jarak dari seseorang, obyek, atau menolak ide untuk diri sendiri dan menghargai peran dan tujuan.
4. Sedih digambarkan sebagai kegagalan atau kerugian tentang peran dan tujuan. 5. Senang digambarkan sebagai berhasil atau bergerak menuju selesainya peran
yang bernilai atau tujuan.
2.2 International Survey On Emotion Antecedents And Reaction (ISEAR)
mereka bereaksi. Data akhir ini memuat laporan tentang tujuh emosi masing-masing sekitar 3.000 responden di 37 negara di lima benua [7].
Dalam penelitian ini data latih yang digunakan diperoleh dari dataset ISEAR yang berbahasa Inggris kemudian diterjemahkan ke dalam bahasa Indonesia tanpa mengurangi maksud dari kalimat-kalimat dalam ISEAR. Data yang diambil sebanyak 1000 data dengan banyak masing-masing emosi adalah 200 data karena terdapat lima kategori emosi yang akan diklasifikasikan. Lima kategori emosi tersebut adalah senang, sedih, marah, takut dan bersalah.
2.3 Preprocessing
Preprocessing adalah tahapan untuk mempersiapkan teks menjadi data yang
akan diolah di tahapan berikutnya. Masukan awal pada proses ini adalah berupa dokumen teks. Teks yang akan dilakukan proses pada umumnya memiliki beberapa karakteristik, diantaranya adalah memiliki dimensi yang tinggi, terdapat noise pada data, dan terdapat struktur teks yang tidak baik. Agar dapat dihasilkan fitur yang baik dan mewakili data dengan baik, perlu dilakukan tahapan preprocessing [17].
Adapun tahapan preprocessing yang akan dilakukan pada penelitian ini yaitu case folding, convert negation, tokenizing, stopword removal dan stemming. Berikut adalah gambaran tahap preprocessing yang dapat dilihat pada Gambar 2.1:
Case Folding Convert
Negation Tokenizing
Stopword
Removal Stemming
Gambar 2.1 Tahap Preprocessing
2.3.1 Case Folding
Case folding merupakan tahapan proses mengubah semua huruf dalam teks
dokumen menjadi huruf kecil, serta menghilangkan karakter selain a-z, kecuali karakter pemecah kalimat, seperti spasi, tab, dan newline (lompat baris) [17].
2.3.2 Convert Negation
11
cinta” dan “tidak senang” dapat menempatkan dokumen dalam kelas yang berbeda.
Kata-kata negasi tersebut meliputi kata “bukan”, “tidak” dan “tanpa”. Jika terdapat kata negasi maka akan digabungkan dengan kata setelahnya.
Langkah-langkah pada tahap convert negation adalah sebagai berikut: a. Kata yang digunakan adalah hasil dari case folding.
b. Jika ditemukan data yang mengandung kata-kata negasi maka kata negasi tersebut akan digabungkan dengan kata setelah kata negasi tersebut.
2.3.3 Tokenizing
Tokenizing adalah proses pemotongan string input berdasarkan tiap kata yang menyusunnya. Pemecahan kalimat menjadi kata-kata tunggal dilakukan dengan melihat pemisah seperti spasi, tab, dan newline (lompat baris) [17].
2.3.4 Stopwords Removal
Kebanyakan bahasa resmi di berbagai negara memiliki kata fungsi dan kata sambung seperti artikel dan preposisi yang hampir selalu muncul pada dokumen teks. Biasanya kata-kata ini tidak memiliki arti yang lebih di dalam memenuhi kebutuhan seorang searcher di dalam mencari informasi. Kata-kata tersebut (misalnya a, an, the on pada bahasa Inggris) disebut sebagai stopwords [19]. Sebuah sistem text retrieval biasanya disertai dengan sebuah stoplist. Stoplist berisi sekumpulan kata yang 'tidak relevan', namun sering sekali muncul dalam sebuah dokumen. Dengan kata lain stoplist berisi sekumpulan stopwords [20].
Stopwords removal adalah sebuah proses untuk menghilangkan kata yang
'tidak relevan' pada hasil parsing sebuah dokumen teks dengan cara membandingkannya dengan stoplist yang ada [21]. Tahapan ini bertujuan untuk menghilangkan kata yang dianggap tidak dapat memberikan pengaruh dalam menentukan suatu kategori tertentu dalam suatu dokumen. Proses ini dilakukan karena kata tersebut sering muncul hampir di setiap dokumen sehingga dianggap tidak dapat menjadi pembeda yang baik dalam membedakan kategori yang satu dengan kategori yang lain.
lanjut dan kata tersebut akan dihilangkan. Sebaliknya apabila sebuah kata tidak termasuk ke dalam stoplist maka kata tersebut akan masuk ke proses berikutnya.
Stoplist yang digunakan diambil dari penelitian Fadillah Z. Tala dengan judul A study of Stemming Effects on Information Retrieval in Bahasa Indonesia. Jumlah stopword yang terdapat pada penelitian tersebut adalah sebanyak 756 kata [17]. Kata-kata yang termasuk stopword tersebut biasanya berupa kata ganti orang, kata penghubung, pronominal penunjuk, dan lain sebagainya.
2.3.5 Stemming
Stemming merupakan suatu proses yang terdapat dalam sistem information
retrieval yang mentransformasi kata-kata yang terdapat dalam suatu dokumen ke
kata-kata akarnya (root word) dengan menggunakan aturan-aturan tertentu. Sebagai contoh, kata bersama, kebersamaan, menyamai, akan di-stem ke root word-nya
yaitu “sama”. Kata dasar yang digunakan diambil dari situs http://bahtera.org. Bahtera adalah kamus Bahasa Indonesia yang menjadi rujukan sesuai Kamus Besar Bahasa Indonesia, kata dasar yang terdapat di bahtera ini sebanyak 28.526 kata. Proses stemming pada teks berbahasa Indonesia berbeda dengan stemming pada teks berbahasa Inggris. Pada teks berbahasa Inggris, proses yang diperlukan hanya proses menghilangkan sufiks. Sedangkan pada teks berbahasa Indonesia, selain sufiks, prefiks, dan konfiks juga dihilangkan.
Algoritma yang digunakan pada proses ini adalah algoritma Nazief & Adriani. Berdasarkan hasil penelitian [12] menyimpulkan bahwa proses stemming dokumen teks berbahasa Indonesia menggunakan algoritma Porter memiliki prosentase keakuratan (presisi) lebih kecil dibandingkan dengan stemming menggunakan algoritma Nazief & Adriani. Oleh karena itu, pada penelitian ini algoritma stemming yang digunakan adalah algoritma Nazief & Adriani.
Algoritma yang dibuat oleh Bobby Nazief dan Mirna Adriani ini memiliki tahap-tahap sebagai berikut:
1. Cari kata yang akan distem dalam kamus. Jika ditemukan maka diasumsikan bahwa kata tersebut adalah root word. Maka algoritma berhenti.
13
lagi untuk menghapus Possesive Pronouns (“-ku”, “-mu”, atau “-nya”), jika ada.
3. Hapus Derivation Suffixes (“-i”, “-an” atau “-kan”). Jika kata ditemukan di kamus, maka algoritma berhenti. Jika tidak maka ke langkah 3a.
a. Jika “-an” telah dihapus dan huruf terakhir dari kata tersebut adalah “-k”,
maka “-k” juga ikut dihapus. Jika kata tersebut ditemukan dalam kamus maka algoritma berhenti. Jika tidak ditemukan maka lakukan langkah 3b. b. Akhiran yang dihapus (“-i”, “-an” atau “-kan”) dikembalikan, lanjut ke
langkah 4.
4. Hapus Derivation Prefix. Jika pada langkah 3 ada sufiks yang dihapus maka pergi ke langkah 4a, jika tidak pergi ke langkah 4b.
a. Periksa tabel kombinasi awalan-akhiran yang tidak diijinkan. Jika ditemukan maka algoritma berhenti, jika tidak pergi ke langkah 4b. b. For i = 1 to 3, tentukan tipe awalan kemudian hapus awalan. Jika root word
belum juga ditemukan lakukan langkah 5, jika sudah maka algoritma berhenti. Catatan: jika awalan kedua sama dengan awalan pertama algoritma berhenti.
5. Melakukan Recoding.
6. Jika semua langkah telah selesai tetapi tidak juga berhasil maka kata awal diasumsikan sebagai root word. Proses selesai.
Tipe awalan ditentukan melalui langkah-langkah berikut:
1. Jika awalannya adalah: “di-”, “ke-”, atau “se-” maka tipe awalannya secara berturut-turut adalah “di-”, “ke-”, atau “se-”.
2. Jika awalannya adalah “te-”, “me-”, “be-”, atau “pe-” maka dibutuhkan sebuah proses tambahan untuk menentukan tipe awalannya.
3. Jika dua karakter pertama bukan “di-”, “ke-”, “se-”, “te-”, “be-”, “me-”, atau
“pe-” maka berhenti.
4. Jika tipe awalan adalah “none” maka berhenti. Jika tipe awalan adalah bukan
Tabel 2.1 Kombinasi Awalan Akhiran yang Tidak Diijinkan Awalan Akhiran yang tidak diijinkan
be- -i
di- -an
ke- -i, -kan
me- -an
se- -i, -kan
Tabel 2.2 Cara Menentukan Tipe Awalan Kata yang Diawali dengan “te-” Following Characters
Tabel 2.3 Jenis Awalan Berdasarkan Tipe Awalannya Tipe Awalan Awalan yang harus dihapus
di- di-
Untuk mengatasi keterbatasan pada algoritma di atas, maka ditambahkan aturan-aturan dibawah ini:
1. Aturan untuk reduplikasi.
- Jika kedua kata yang dihubungkan oleh kata penghubung adalah kata yang sama maka root word adalah bentuk tunggalnya, contoh: “buku-buku” root word-nya adalah “buku”.
- Kata lain, misalnya “bolak-balik”, “berbalas-balasan”, dan “seolah-olah”. Untuk mendapatkan root word-nya, kedua kata diartikan secara terpisah. Jika keduanya memiliki root word yang sama maka diubah menjadi bentuk
tunggal, contoh: kata “berbalas-balasan”, “berbalas” dan “balasan” memiliki root word yang sama yaitu “balas”, maka root word “berb
15
“balik” memiliki root word yang berbeda, maka root word-nya adalah
“bolak-balik”
2. Tambahan bentuk awalan dan akhiran serta aturannya.
- Untuk tipe awalan “mem-“, kata yang diawali dengan awalan “memp-”
memiliki tipe awalan “mem-”.
- Tipe awalan “meng-“, kata yang diawali dengan awalan “mengk-” memiliki
tipe awalan “meng-”.
Berikut contoh-contoh aturan yang terdapat pada awalan sebagai pembentuk kata dasar.
1. Awalan SE-
Se + semua konsonan dan vokal tetap tidak berubah. Contoh:
- Se + bungkus = sebungkus - Se + nasib = senasib - Se + arah = searah - Se + ekor = seekor
2. Awalan ME-
a. Me + vokal (a, i, u, e, o) menjadi sengau “meng”. Contoh:
- Me + inap = menginap - Me + asuh = mengasuh
- Me + ubah = mengubah
- Me + ekor = mengekor - Me + oplos = mengoplos b. Me + konsonan b menjadi “mem”
Contoh:
- Me + beri = memberi
- Me + besuk = membesuk
c. Me + konsonan (c, d, j) menjadi “men” Contoh:
- Me + cuci = mencuci - Me + didik = mendidik - Me + dengkur = mendengkur - Me + jepit = menjepit
- Me + jemput = menjemput
d. Me + konsonan g dan h menjadi “meng” Contoh:
- Me + gosok = menggosok
- Me + hokum = menghukum
e. Me + konsonan k menjadi “meng” (luluh) Contoh:
- Me + kukus = mengukus
- Me + kupas = mengupas
f. Me + konsonan p menjadi “mem” (luluh) Contoh:
- Me + pesona = mempesona
- Me + pukul = memukul
g. Me + konsonan s menjadi “meny” (luluh) Contoh:
- Me + sapu = menyapu
- Me + satu = menyatu
h. Me + konsonan t menjadi “men” (luluh) Contoh:
- Me + tanama = menanam
- Me + tukar = menukar
i. Me + konsonan (l, m, n, r, w) menjadi tetap “me” Contoh:
- Me + lempar = melempar
- Me + masak = memasak
17
- Me + warna = mewarna
3. Awalan KE-
Ke + semua konsonan dan vokal tetap tidak berubah. Contoh:
- Ke + bawa = kebawa
- Ke + atas = keatas
4. Awalan PE-
a. Pe + konsonan (g, h, k) dan vokal menjadi “per” Contoh:
- Pe + gelar + an = pergelaran - Pe + hitung + an = perhitungan - Pe + kantor + an = perkantoran b. Pe + konsonan “t” menjadi “pen” (luluh)
Contoh:
- Pe + tukar = penukar - Pe + tikam = penikam
c. Pe + konsonan c, d, j, z) menjadi “pen” Contoh:
- Pe + cuci = pencuci - Pe + didik = pendidik - Pe + jahit = penjahit - Pe + zina = penzina
d. Pe + konsonan (b, f, v) menjadi “pem” Contoh:
- Pe + beri = pemberi
- Pe + bunuh = pembunuh
e. Pe + konsonan “p” menjadi “pem” (luluh) Contoh:
f. Pe + konsonan “s” menjadi “peny” (luluh) Contoh:
- Pe + siram = penyiram - Pe + sabar = penyabar
g. Pe + konsonan (l, m, n, r, w, y) tetap tidak berubah. Contoh:
- Pe + lamar = pelamar
- Pe + makan = pemakan
- Pe + nanti = penanti - Pe + wangi = pewangi
Hasil proses stemming tersebut digunakan dalam melakukan pembobotan TF-IDF.
2.4 Pembobotan TF-IDF
Pembobotan dapat diperoleh berdasarkan jumlah kemunculan suatu term (kata) dalam sebuah dokumen term frequency (tf) dan jumlah kemunculan term dalam koleksi dokumen inverse document frequency (idf). Nilai idf sebuah term dapat dihitung menggunakan persamaan sebagai berikut [22]:
��� = ��� (2.1)
D adalah jumlah dokumen dan dfi adalah jumlah kemunculan (frekuensi) term terhadap D.
Adapun persamaan yang digunakan untuk menghitung bobot (W) masing-masing dokumen terhadap kata kunci (query), yaitu:
��,�= � �,�∗ ���� (2.2)
dengan keterangan sebagai berikut: d = dokumen ke–d
t = term ke–t dari kata kunci tf = term frekuensi/frekuensi kata
��,� = bobot dokumen ke–d terhadap term ke–t.
2.5 Metode Support Vector Machine
Support Vector Machine (SVM) adalah sistem pembelajaran yang
19
(feature space) berdimensi tinggi, dilatih dengan algoritma pembelajaran yang didasarkan pada teori opimasi dengan mengimplementasikan learning bias yang berasal dari teori pembelajaran statistik [23]. SVM adalah salah satu teknik yang relatif baru dibandingkan dengan teknik lain, tetapi memiliki performansi yang lebih baik di berbagai bidang aplikasi seperti bioinformatics, pengenalan tulisan tangan, klasifikasi teks dan lain sebagainya [24]. Proses pembelajaran pada SVM bertujuan untuk mendapatkan hipotesis berupa bidang pemisah (hyperplane) terbaik. Hyperplane terbaik tidak hanya dapat memisahkan data tetapi juga memiliki margin (jarak) yang paling besar. Data yang berada pada hyperplane disebut support vector.
Data pada ruang input (input space) berdimensi d dinotasikan dengan =
∈ ℜ� sedangkan label kelas dinotasikan dengan ∈ {− , + }untuk i = 1, 2, …n.
Dimana n adalah banyaknya data. Diasumsikan kedua kelas -1 dan +1 dapat terpisah secara linear bidang pembatas [25], maka persamaan bidang pembatasnya didefinisikan pada persamaan (2.3) berikut:
. + = (2.3)
Data yang terbagi ke dalam dua kelas, yang termasuk kelas -1 (sampel negatif) didefinisikan sebagai vektor yang memenuhi pertidaksamaan (2.4) berikut:
. + < untuk = − (2.4)
Sedangkan yang termasuk kelas +1 (sampel positif) memenuhi pertidaksamaan (2.5) berikut:
. + > untuk = + (2.5)
Dimana: = data input
= label yang diberikan w = nilai dari bidang normal
Parameter w dan b adalah parameter yang akan dicari nilainya. Bila label data = -1, maka pembatas menjadi persamaan (2.6) berikut:
. + − (2.6)
Bila label data = +1, maka pembatas menjadi persamaan (2.7) berikut:
. + + (2.7)
Margin terbesar dapat dicari dengan cara memaksimalkan jarak antar bidang pembatas kedua kelas dan titik terdekatnya, yaitu 2/|w|. Hal ini dirumuskan sebagai permasalahan quadratic programming (QP) problem yaitu mencari titik minimal persamaan (2.8) dengan memperhatikan persamaan (2.9) berikut:
� = || || (2.8)
∗ + − , = , . . , (2.9)
Permasalahan ini ini dapat dipecahkan dengan berbagi teknik komputasi. Lebih mudah diselesaikan dengan mengubah persamaan (2.8) ke dalam fungsi
Lagrangian pada persamaan (2.10), dan menyederhanakannya menjadi persamaan
(2.11) berikut:
, , = || || − ∑� ( � + − )
= (2.10)
, , = || || − ∑� � +
= + ∑�= (2.11)
Dimana adalah lagrange multiplier yang bernilai nol atau positif ( ≥ 0). Nilai optimal dari persamaan (2.11) dapat dihitung dengan meminimalkan L terhadap , dan . Dapat dilihat pada persamaan (2.12) sampai (2.14) berikut:
��
�� = − ∑�= = (2.12)
��
� = ∑�= = (2.13)
��
� = ∑�= � + − ∑�= = (2.14)
21
, , = || || − ∑� � +
= − ∑�= (2.15)
Dengan memperhatikan persamaan (2.16) dan (2.17) berikut:
− ∑�
= = (2.16)
∑�= = (2.17)
Model persamaan (2.15) diatas merupakan model primal Lagrange.
Sedangkan dengan memaksimalkan L terhadap , persamannya menjadi
persamaan (2.18) berikut:
∑ − ∑�
= , = �
= (2.18)
Dengan memperhatikan persamaan (2.19) berikut:
∑� =
= , , = , . . , (2.19)
Untuk mendapatkan nilai , langkah pertama adalah mengubah setiap
kalimat menjadi nilai vektor (support vector) = . Kemudian nilai vektor dari
setiap kalimat dimasukkan ke persamaan (2.20) berikut:
� = � = {√ + > → (4 − +
−
4 − + − )
√ + →
(2.20)
Nilai x didapatkan dari persamaan (2.21) kernel linear untuk x berikut:
∑� �
= , = , , = , . . , (2.21)
Nilai y didapatkan dari persamaan (2.22) kernel linear untuk y berikut:
∑� �
= , = , , = , . . , (2.22)
Untuk mendapatkan jarak tegak lurus yang optimal dengan
∑� ���
= , = (2.23)
∑�= , = ��� = (2.24)
Setelah parameter didapatkan, kemudian masukkan ke persamaan (2.25) berikut:
�̃ = ∑� �
= (2.25)
Selanjutnya digunakan persamaan (2.26) untuk mendapatkan nilai w dan b:
= + (2.26)
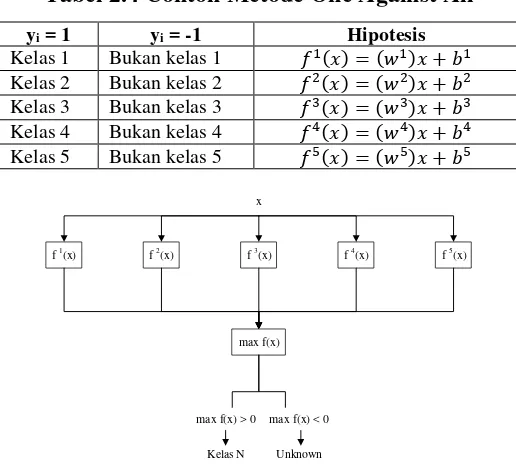
Pada awalnya SVM dikembangkan untuk persoalan klasifikasi dua kelas, kemudian dikembangkan kembali untuk klasifikasi multikelas. Dalam klasifikasi kasus multikelas, hyperplane yang terbentuk adalah lebih dari satu. Salah satu metode pendekatan yang digunakan adalah One Against All (OAA). Metode OAA untuk kasus klasifikasi k-kelas, menemukan khyperplane dimana k adalah banyak kelas dan ρ adalah hyperplane. Dalam metode ini ρ(ℓ) diujikan dengan semua data dari kelas ℓ dengan label +1, dan semua data dari kelas lain dengan label -1 [26]. Berikut ini merupakan ilustrasi untuk persoalan klasifikasi dengan lima buah jumlah kelas, digunakan lima buah SVM biner pada Tabel 2.4 Dan penggunaannya pada pengklasifikasian data baru pada Gambar 2.2 [27].
Tabel 2.4 Contoh Metode One Against All yi = 1 yi = -1 Hipotesis
23
Konsep pada OAA yaitu dimisalkan pada kasus lima kelas, kelas 1, 2, 3, 4 dan 5. Bila akan diujikan ρ(1), semua data dalam kelas 1 diberi label +1 dan data dari kelas 2, 3, 4 dan 5 diberi label -1. Pada ρ(2), semua data dalam kelas 2 diberi label +1 dan data dari kelas 1, 3, 4 dan 5 diberi label -1. Pada ρ(3), semua data dalam kelas 3 diberi label +1 dan data dari kelas 1, 2, 3 dan 4 diberi label -1. Pada ρ(4),
semua data dalam kelas 4 diberi label +1 dan data dari kelas 1, 2, 3, 4 diberi label -1. Begitu juga untuk ρ(5), semua data dalam kelas 5 diberi label +1 dan data dari
kelas 1, 2, 3 dan 4 diberi label -1. Kemudian dicari hyperplane dengan algoritma SVM dua kelas. Maka akan didapat hyperplane untuk masing-masing kelas di atas. Kemudian kelas dari suatu data baru x ditentukan berdasarkan nilai terbesar dari hyperplane [26]:
kelas x = arg maxℓ= …k (w ℓ)T. ϕ x + b ℓ (2.27)
2.6 Pengukuran Kinerja Klasifikasi
Pengukuran kinerja klasifikasi pada data asli dan data hasil dari model klasifikasi dilakukan dengan menggunakan tabulasi silang (matriks konfusi) yang berisi informasi tentang kelas data asli yang direpresentasikan pada baris matriks dan kelas data hasil prediksi suatu algoritma direpresentasikan pada kolom klasifikasi [6]. Berikut merupakan contoh matriks konfusi:
Tabel 2.5 Matriks Konfusi Lima Kelas
Fij Kelas Prediksi (j)
Menurut [6] ketepatan klasifikasi dapat dilihat dari akurasi klasifikasi. Akurasi klasifikasi menunjukkan performasi model klasifikasi secara keseluruhan, dimana semakin tinggi akurasi klasifikasi hal ini semakin baik performansi model klasifikasi.
Akurasi =jumlah data yang diprediksi secara benar
=� +� +� +� +� +� +� +� +� +� +� +� +� +� +� +� +� +� +� +� +� +� +� +� +� +�� +� +� +� +� (2.28)
2.7 Pemrograman Berorientasi Objek
Pemrograman berorientasi objek adalah suatu strategi pembangunan perangkat lunak yang mengorganisasikan perangkat lunak sebagai kumpulan objek yang berisi data dan operasi yang diberlakukan terhadapnya. Suatu cara bagaimana sistem perangkat lunak dibangun melalui pendekatan objek secara sistematis, serta didasarkan pada penerapan prinsip-prinsip pengelolaan kompleksitas yang meliputi, rangkaian aktivitas analisis berorientasi objek, perancangan berorientasi objek, pemrograman berorientasi objek, dan pengujian berorientasi objek. Konsep dasar berorientasi objek diantaranya [28]:
1. Kelas (Class) adalah kumpulan objek-objek dengan karakteristik yang sama. Kelas merupakan definisi statik dan himpunan objek yang sama yang mungkin lahir atau diciptakan dari kelas tersebut. Sebuah kelas akan mempunyai sifat (atribut), kelakuan (operasi/metode), hubungan (relationship) dan arti. Suatu kelas dapat diturunkan dan kelas semula dapat diwariskan ke kelas yang baru. 2. Objek (Object)adalah abstraksi dan sesuatu yang mewakili dunia nyata seperti benda, manusia, satuan organisasi, tempat, kejadian, strutur, status, atau hal-hal lain yang bersifat abstrak. Objek merupakan suatu entitas yang mampu menyimpan informasi (status) dan mempunyai operasi (kelakuan) yang dapat diterapkan atau dapat berpengaruh pada status objeknya. Objek mempunyai siklus hidup yaitu diciptakan, dimanipulasi, dan dihancurkan.
3. Metode (Method) adalah operasi atau metode pada sebuah kelas hampir sama dengan fungsi atau prosedur pada terstruktur. Sebuah kelas boleh memiliki lebih dari satu metode atau operasi. Metode atau operasi yang berfungsi untuk memanipulasi objek itu sendiri.
25
5. Abstraksi (Abstraction) merupakan prinsip untuk merepresentasikan dunia nyata yang kompleks menjadi satu bentuk model yang sederhana dengan mengabaikan aspek-aspek lain yang tidak sesuai dengan permasalahan.
6. Enkapsulasi (Encapsulation) adalah pembungkusan atribut data dan layanan (operasi-operasi) yang dipunyai objek untuk menyembunyikan implementasi dan objek sehingga objek lain tidak mengetahui cara kerja.
7. Pewarisan (Inheritance) adalah mekanisme yang memungkinkan satu objek mewarisi sebagian atau seluruh definisi dan objek lain sebagai bagian dari dirinya.
8. Antarmuka (Interface) sangat mirip dengan kelas, tetapi tanpa atribut kelas dan tanpa memiliki metode yang dideklarasikan. Antarmuka biasanya digunakan agar kelas lain tidak langsung mengakses ke suatu kelas.
9. Reusability merupakan pemanfaatan kembali objek yang sudah didefinisikan
untuk suatu permasalahan pada permasalahan lainnya yang melibatkan objek tersebut.
10. Generalisasi dan Spesialisasi menunjukkan hubungan antara kelas dan objek yang umum dengan kelas dan objek yang khusus. Misalnya kelas yang lebih umum (generalisasi) adalah kendaraan darat dan kelas khususnya (spesialisasi) adalah mobil dan motor.
11. Komunikasi antar objek dilakukan lewat pesan (message) yang dikirim dan satu objek ke objek lainnya.
12. Polimorfisme (Polymorphism) adalah kemampuan suatu objek untuk digunakan dibanyak tujuan yang berbeda dengan nama yang sama sehingga menghemat baris program.
13. Package adalah sebuah kontainer atau kemasan yang daoat digunakan untuk
mengelompokkan kelas-kelas sehingga memungkinkan beberapa kelas yang bernama sama disimpan dalam package yang berbeda.
2.8 Unified Modeling Language
diagram yang digunakan proses pembuatan perangkat lunak berorientasi objek diantaranya, use case diagram, activity diagram, class diagram dan sequence diagram [28].
2.8.1 Use Case Diagram
Use case diagram merupakan pemodelan untuk tingkah laku (behavior) pada sistem yang akan dibuat. Use case mendeskripsikan sebuah interaksi antara satu atau lebih aktor dengan sistem yang akan dibuat. Use case diagram digunakan untuk mengetahui fungsi apa saja yang terdapat pada sistem. Terdapat dua hal utama yang diperlukan dalam pembentukan suatu use case diagram yaitu aktor dan use case.
1. Aktor merupakan orang, benda maupun sistem lain yang berinteraksi dengan sistem yang akan dibangun.
2. Use Case merupakan fungsionalitas atau layanan yang disediakan oleh sistem
sebagai unit-unit yang saling bertukar pesan antar unit atau aktor.
2.8.2 Activity Diagram
Activity diagram menggambarkan workflow (aliran kerja) atau aktivitas dari sebuah sistem, proses bisnis atau menu yang ada pada perangkat lunak. Setiap use case yang telah dibentuk digambarkan aktivitasnya dalam activity diagram, mulai dari peran aktor, peran sistem, dan decision. Activity diagram juga banyak digunakan untuk mendefinisikan hal-hal berikut:
1. Rancangan proses bisnis dimana setiap urutan aktivitas yang digambarkan merupakan proses bisnis sistem.
2. Urutan atau pengelompokan tampilan dari sistem / user interface dimana setiap aktivitas dianggap memiliki sebuah rancangan tampilan antarmuka.
3. Rancangan pengujian dimana setiap aktivitas dianggap memerlukan sebuah pengujian yang perlu didefinisikan kasus ujinya.
4. Rancangan menu yang ditampilkan pada perangkat lunak.
2.8.3 Class Diagram
Class diagram menggambarkan interaksi dan relasi antar kelas yang ada di
27
dimiliki oleh suatu kelas. Atribut dan metode dapat memiliki salah satu sifat sebagai berikut:
1. Private, tidak dapat dipanggil dari luar kelas yang bersangkutan.
2. Protected, hanya dapat dipanggil oleh kelas yang bersangkutan dan anak-anak
yang mewarisinya.
3. Public, dapat dipanggil oleh siapa saja.
Class diagram menggambarkan relasi atau hubungan antar kelas dari sebuah sistem. Berikut ini beberapa gambaran relasi yang ada dalam class diagram:
1. Association
Hubungan antar class yang statis. Class yang mempunyai relasi asosiasi menggunakan class lain sebagai atribut pada dirinya.
2. Aggregation
Relasi yang membuat class yang saling terikat satu sama lain namun tidak terlalu berkegantungan.
3. Composition
Relasi agregasi dengan mengikat satu sama lain dengan ikatan yang sangat kuat dan saling berkegantungan.
4. Dependency
Hubungan antar class dimana class yang memiliki relasi dependency menggunakan class lain sebagai atribut pada method.
5. Realization
Hubungan antar class dimana sebuah class memiliki keharusan untuk mengikuti aturan yang ditetapkan class lainnya.
2.8.4 Sequence Diagram
Sequence diagram menggambarkan kelakuan objek pada use case dengan
mendeskripsikan waktu hidup objek dan message yang dikirimkan dan diterima antar objek. Oleh karena itu untuk menggambarkan sequence diagram maka harus diketahui objek-objek yang terlibat dalam sebuah use case beserta metode-metode yang dimiliki kelas yang diinstansiasi menjadi objek itu.
29
3
BAB 3
ANALISIS DAN PERANCANGAN
3.1 Analisis Masalah
Berdasarkan dari perumusan masalah yang sudah didapat, maka dapat dijabarkan secara lebih terperinci tentang masalah yang ditemukan dalam penelitian ini. Masalah yang ditemukan adalah pada penelitian [4] belum menghasilkan tingkat akurasi yang maksimal karena performansi metode klasifikasi yang digunakan kurang baik dalam mengklasifikasikan teks. Solusi yang diberikan adalah mengganti metode tersebut dengan metode Multi Class Support Vector
Machine karena metode tersebut berhasil mengklasifikasikan 111 dari 120 artikel
teks Bahasa Indonesia secara benar sesuai dengan kelas asli ke dalam 6 kelas kategori, yaitu economy, defense & security, education, health, sports, dan politics. Oleh karena itu, diimplementasikanlah metode Multi Class Support Vector
Machine untuk mengklasifikasikan emosi pada lirik lagu Bahasa Indonesia.
3.2 Analisis Proses
Pelatihan
Gambar 3.1 Tahapan Proses Yang Akan Dilakukan
Berikut adalah penjelasan dari Gambar 3.1:
1. Tahap pertama yang dilakukan adalah proses pelatihan. Dalam proses pelatihan data latih akan melalui tiga proses utama yaitu proses preprocessing, pembobotan tf-idfdan klasifikasi Multi Class Support Vector Machine tahap pelatihan. Proses preprocessing itu sendiri terdiri dari lima proses yaitu case folding, convert negation, tokenizing, stopword removal dan stemming.
a. Case folding adalah tahapan untuk mengubah semua huruf dalam dokumen
menjadi lowercase (huruf kecil) semua.
b. Convert negation adalah tahapan untuk mengkoversi kata-kata negasi yang
terdapat pada suatu kalimat.
c. Tokenizing adalah tahapan untuk memotong string input berdasarkan tiap
31
d. Stopword removal adalah tahapan untuk menghilangkan kata yang tidak relevan pada hasil parsing sebuah dokumen teks dengan cara membandingkannya dengan stoplist yang ada.
e. Stemming adalah tahapan untuk mentransformasi kata-kata yang terdapat
dalam suatu dokumen ke kata-kata akarnya dengan menggunakan aturan-aturan tertentu.
Setelah proses preprocessing, dilakukan proses pembobotan kata menggunakan pembobotan TF-IDF. Proses selanjutnya adalah proses klasifikasi Multi Class Support Vector Machine tahap pelatihan. Proses ini dilakukan untuk mendapatkan data hyperplane dari data latih yang telah dimasukkan kemudian data hyperplane tersebut dimasukkan ke dalam database.
2. Tahap kedua yang dilakukan adalah tahap pengujian. Data uji yang dimasukkan melalui proses yang sama seperti data latih yaitu proses preprocessing dan pembobotan. Setelah proses pembobotan, data uji akan melalui proses klasifikasi Multi Class Support Vector Machine tahap pengujian. Proses ini dilakukan untuk mengklasifikasikan data uji menggunakan data hyperplane yang diperoleh pada tahap pelatihan. Hasil dari tahap pengujian ini adalah hasil klasifikasi berupa kategori emosi dari data uji yang telah dimasukkan.
3.3 Analisis Data Masukan
Data yang digunakan dalam penelitian ini terdiri dari dua jenis yaitu data latih dan data uji. Berikut data masukan yang akan digunakan:
1. Data latih yang digunakan berasal dari data International Survey On Emotion
Antecedents and Reaction (ISEAR) yang berbahasa Inggris kemudian
diterjemahkan ke dalam bahasa Indonesia tanpa mengurangi maksud dari kalimat-kalimat dalam ISEAR.
2. Data uji yang akan digunakan adalah data lirik lagu berbahasa Indonesia dengan format (.txt).
Tabel 3.1 Sampel Data Latih
Data Latih Kategori Pernyataan
P1 Senang Ketika saya bertemu dengan seorang gadis dan memintanya untuk kencan dan dia setuju, (saya pikir gadis ini tidak menyukai saya), ini adalah emosi senang.
P2 Sedih Saya merasa sedih ketika ayah saya sakit.
P3 Marah Saya merasa sangat marah ketika saya diperlakukan tidak adil P4 Takut Ketakutan saya muncul dalam bentuk kecemburuan. Saya takut
bahwa pacar saya jatuh cinta dengan pria lain, aku takut kehilangan dia.
P5 Bersalah Saya merasa bersalah ketika saya mengkhianati orang yang saya cintai
Tabel 3.2 Sampel Data Uji
Data Uji Kategori Lirik Lagu
L1 ? Aku juga ingin jatuh cinta seperti yang lainnya
Kini saatnya untuk jatuh cinta karna dia tlah nyatakan cinta Tapi Ku takut-takut jatuh cinta
Takut-takut patah hatinya
Namun kini bimbang yang ku rasa Akankah dia trus setia
Atau hanya untuk sementara Membuat aku kecewa
Tapi Ku takut-takut jatuh cinta Takut-takut patah hatinya
33
Case Folding Convert
Negation Tokenizing
Stopword
Removal Stemming
Gambar 3.2 Tahap Preprocessing
Preprocessing ini dilakukan pada data latih dan uji yang menjadi data masukan, berikut penjelasan dari tahapan preprocessing yang akan dilakukan:
3.4.1 Case Folding
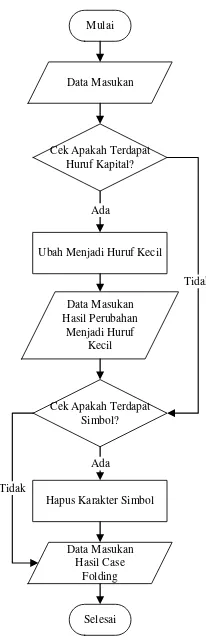
Pada tahap ini dilakukan perubahan pada semua huruf dalam dokumen menjadi huruf kecil dan menghilangkan karakter selain a-z, dengan tujuan untuk menyeragamkan karakter dalam dokumen tersebut. Adapun flowchart dari tahap case folding dapat dilihat pada Gambar 3.3 berikut:
Mulai
Gambar 3.3 Flowchart Case Folding
Tabel 3.3 Tahap Case Folding
Pernyataan
Tahap Case Folding Ubah Menjadi Huruf Kecil Hapus Karakter
Simbol memintanya untuk kencan dan dia setuju, (saya pikir gadis ini tidak menyukai saya), ini adalah emosi senang.
ketika saya bertemu dengan seorang gadis dan memintanya untuk kencan dan dia setuju, (saya pikir gadis ini tidak menyukai saya), ini
Berikut ini adalah penjelasan dari Tabel 3.3 di atas: a. Cek huruf kapital
Data masukan P1 dilakukan pengecekan apakah terdapat huruf kapital atau tidak. Pada P1 terdapat huruf kapital yaitu huruf K pada kata pertama.
b. Ubah menjadi huruf kecil
Huruf K pada kata pertama diubah menjadi huruf kecil menjadi huruf k. c. Cek karakter simbol
Data hasil dari perubahan menjadi huruf kecil dilakukan pengecekan apakah terdapat karakter simbol atau tidak. Pada P1 terdapat simbol koma (,), kurung buka tutup (()) dan titik (.).
d. Hapus karakter simbol
Karakter simbol koma (,), kurung buka tutup (()) dan titik (.) dihapus dari P1. Data hasil penghapusan karakter simbol disimpan sebagai data hasil case folding yang nantinya akan digunakan pada tahap convert negation.
3.4.2 Convert Negation
35
Gambar 3.4 Flowchart Convert Negation
Adapun contoh tahap convert negation diterapkan pada data latih pernyataan pertama (P1) dapat dilihat pada Tabel 3.4 berikut:
Tabel 3.4 Tahap Convert Negation
Tahap Convert Negation Hasil Case
Folding
Gabung Kata Negasi dengan Kata Setelahnya Hasil Convert Negation
ketika saya bertemu dengan seorang gadis dan memintanya untuk kencan dan dia setujusaya pikir gadis ini tidakmenyukai sayaini adalah emosi senang
Berikut ini adalah penjelasan dari Tabel 3.4 di atas:
a. Cek kata negasi
b. Gabung kata negasi dengan kata setelahnya
Kata negasi tidak digabungkan dengan kata setelahnya yaitu kata menyukai sehingga menjadi kata tidakmenyukai. Data hasil penggabungan kata negasi dengan kata setelahnya tersebut disimpan sebagai data hasil convert negation yang nantinya akan digunakan pada tahap tokenizing.
3.4.3 Tokenizing
Pada tahap ini dilakukan pemotongan kalimat berdasarkan tiap kata yang menyusunnya. Proses ini melakukan penguraian deskripsi yang semula berupa kalimat-kalimat (delimeter kata) menjadi kata-kata. Adapun flowchart dari tahap tokenizing dapat dilihat pada Gambar 3.5 berikut:
Mulai
Data Masukan Hasil Convert
Negation
Pecah Data Menjadi Kata (Token)
Data Masukan Hasil Tokenizing
Selesai Cek Apakah Data Masukan Bertemu
Spasi?
Ya Tidak
Gambar 3.5 Flowchart Tokenizing
37
Tabel 3.5 Tahap Tokenizing
Tahap Tokenizing
Hasil Convert Negation Pecah Data Menjadi Kata Hasil Tokenizing ketika saya bertemu dengan
seorang gadis dan memintanya untuk kencan dan dia setuju saya pikir gadis ini
tidakmenyukai sayaini adalah emosi senang
Berikut ini adalah penjelasan dari Tabel 3.5 di atas:
a. Cek spasi
Data latih P1 hasil convert negation dilakukan pengecekan apakah data bertemu spasi atau tidak. Setiap kata pada P1 bertemu spasi.
b. Pecah data menjadi kata
Pecah data menjadi kata setiap bertemu spasi. Data hasil pemecahan data menjadi kata tersebut disimpan sebagai data hasil tokenizing yang nantinya akan digunakan pada tahap stopword removal.
3.4.4 Stopword Removal
Pada tahapan ini dilakukan penghapusan sebuah kata yang dianggap tidak dapat memberikan pengaruh dalam menentukan suatu kategori tertentu dalam suatu dokumen, biasanya berupa kata ganti orang, kata penghubung, penunjuk, dan sebagainya.
ke, di, sebuah, dalam, belum, bagaimana, agar, bahwa, masihkah dan lain sebagainya. Adapun flowchart dari tahap stopword removal dapat dilihat pada Gambar 3.6 berikut:
Mulai
Data Masukan Hasil Tokenizing
Cek Apakah Terdapat Stopword?
Hapus Stopword Pada Data Masukan
Data Masukan Hasil Stopword
Removal
Selesai Ya
Tidak
Gambar 3.6 Flowchart Stopword Removal
39
Tabel 3.6 Tahap Stopword Removal
Tahap Stopword Removal
Hasil Tokenizing Hapus Stopword Hasil Stopword Removal ketika
Berikut adalah penjelasan dari Tabel 3.6 di atas:
a. Cek stopword
Data latih P1 hasil tokenizing dilakukan pengecekan apakah terdapat stopword atau tidak. Pada P1 terdapat stopword yaitu ketika, saya, dengan, seorang, dan, untuk, dia, ini dan adalah.
b. Hapus stopword
Pada proses ini dilakukan pengolahan kata hasil dari stopword removal menjadi kata dasar yaitu dengan menghilangkan imbuhan awalan atau akhiran.
Mulai
Gambar 3.7 Flowchart Stemming
41
Tabel 3.7 Tahap Stemming
Tahap Stemming
Hasil Stopword Removal Hasil Stemming bertemu
Berikut merupakan penjelasan dari setiap urutan proses yang dilalui kata bertemu pada tahap stemming hingga ditemukan kata dasarnya:
a. Cari kata dalam kamus kata dasar.
Kata bertemu tidak terdapat dalam kamus kata dasar sehingga kata bertemu akan menuju proses selanjutnya yaitu pengecekan inflection suffixes.
b. Cek inflection suffixes
Pada kata bertemu tidak memiliki akhiran -kah, -lah, -ku, -mu atau -nya maka kata bertemu akan langsung menuju proses selanjutnya yaitu pengecekan derivation suffixes.
c. Cek derivation suffixes
Pada kata bertemu tidak memiliki akhiran -i, -an atau -kan, maka kata bertemu akan langsung menuju proses penghapusan derivation prefix.
d. Cek derivation prefix
Kata bertemu memiliki tipe awalan ber- sehingga awalan ber- tersebut dihapus sehingga menjadi kata temu. Kata temu tersebut dicek apakah terdapat di dalam kamus atau tidak, ternyata kata temu ada di dalam kamus sehingga kata temu tersebut menjadi kata dasar dari kata temu dan disimpan sebagai hasil dari proses stemming.
dijadikan sebagai data hasil preprocessing yang nantinya akan digunakan pada tahap pembobotan TF-IDF.
3.5 Analisis Pembobotan TF-IDF
Dalam pengenalan emosi pada teks, pembobotan kata digunakan untuk mendapatkan suatu topik atau keyword dari kumpulan teks. Salah satu metode pembobotan adalah Term Frequency-Inverse Document Frequency (TF-IDF). Nilai bobot suatu kata (term) menyatakan kepentingan bobot tersebut dalam merepresentasikan emosi. Pada penelitian ini pembobotan diperoleh dari jumlah kemunculan term dalam satu dokumen term frequency (tf) dan sebuah kata di dalam kumpulan dokumen atau jumlah kemunculan term dalam koleksi dokumen inverse document frequency (idf). Nilai idf sebuah term (kata) dapat dihitung menggunakan persamaan (2.1). Untuk menghitung bobot (W) masing-masing dokumen terhadap setiap term (kata) dapat menggunakan persamaan (2.2). Adapun flowchart dari proses pembobotan tf-idf dapat dilihat pada Gambar 3.8 berikut:
Mulai
Data Hasil Preprocessing
Hitung Term Frekuensi (tf) Pada Tiap Kalimat
Hitung Dokumen Frekuensi (df)
Hitung idf
Hitung w
Data Hasil Pembobotan
TF-IDF
Selesai
43
Berikut adalah data latih yang sudah melewati tahapan preprocessing dapat dilihat pada Tabel 3.8:
Tabel 3.8 Data Latih Setelah Preprocessing
Pernyataan Kata
P1 temu gadis minta kencan setuju pikir gadis tidakmenyukai emosi senang P2 sedih ayah sakit
P3 marah laku tidakadil
P4 takut muncul bentuk cemburu takut pacar jatuh cinta pria takut hilang P5 salah khianat cinta
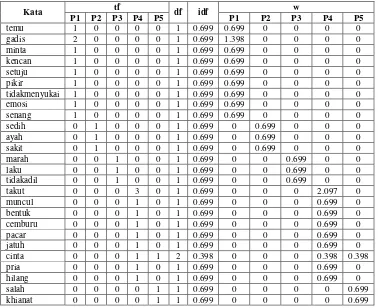
Contoh perhitungan pembobotan TF-IDF akan diterapkan pada kata temu dalam pernyataan pertama (P1).
a. Menghitung Term Frequency (tf)
Data hasil preprocessing dilakukan perhitungan kemunculan kata temu (term
frequency (tf)) pada setiap dokumen. Dokumen pada contoh kasus ini adalah P1,
P2, P3, P4, dan P5.
Tabel 3.9 Term Frequency Kata Cinta
Kata Term Frequency (tf)
P1 P2 P3 P4 P5
temu 1 0 0 0 0
Dari Tabel 3.9 dijelaskan bahwa kata takterduga pada pernyataan pertama (P1) muncul sebanyak satu kali, sedangkan pada P2, P3, P4, dan P5 kata temu tidak muncul sama sekali (0).
b. Menghitung Document Frequency (df)
Nilai document frequency (df) didapatkan dari jumlah dokumen yang mengandung kata temu yaitu 1 pada dokumen P1 saja.
c. Menghitung Inverse Document Frequency (idf)
Nilai inverse document frequency (idf) kata temu didapatkan dengan cara dihitung menggunakan persamaan (2.1):
IDF = log (df) = log ( ) = logD = .
d. Menghitung W
Menghitung bobot (w) kata temu pada setiap pernyataan dapat dihitung menggunakan persamaan (2.2). Berikut perhitungan w untuk setiap dokumen pernyataan:
Dari perhitungan w yang telah dilakukan di atas, diperoleh nilai w untuk P1 adalah 0.699 serta w untuk P2, P3, P4, dan P5 adalah 0.
Berikut hasil perhitungan pembobotan TF-IDF keseluruhan kata data latih hasil preprocessing dapat dilihat pada Tabel 3.10:
Tabel 3.10 Hasil Perhitungan Pembobotan TF-IDF Data Latih