Skripsi
Diajukan Sebagai Salah Satu Syarat Kelulusan Pada Program Studi Sistem Informasi Jenjang Strata-1 Fakultas Teknik dan Ilmu Komputer
ANDRI KURNAEDI 1.05.07.454
PROGRAM STUDI SISTEM INFORMASI
FAKULTAS TEKNIK DAN ILMU KOMPUTER
UNIVERSITAS KOMPUTER INDONESIA
B A N D U N G
i
bekerja dengan melakukan parsing kode sumber, lalu menerapkan aturan penerjemahan, dan menampilkan hasil terjemahan ke keluaran. Translator Pascal ke C dapat mengoptimalisasikan waktu yang butuhkan pengguna untuk melakukan alih bahasa Pascal ke C.
Fungsi pengenalan dan penerjemahan dapat dibuat dengan kakas. Untuk mendapatkan aturan penerjemahan yang dimaksud, perlu dilakukan perbandingan sintaksis dari C dan Pascal. Elemen grammar yang harus dieksplorasi adalah struktur program, deklarasi (variabel, tipe, konstanta, dll), ekspresi, statement, aturan penamaan obyek program, dll. Dengan menggunakan algoritma pencocokan string, algoritma Boyer-Moore menjadi pilihan penting dalam proses penerjemahan. Kemiripan antara Pascal dan C memungkinkan keduanya untuk saling diterjemahkan secara penuh.
Selain itu, diketahui pula bahwa Pascal dan C merupakan bahasa pengenalan bagi programmer pemula. Nilai awal sangat mempengaruhi akhir, apabila di awal sudah mengalami kesulitan, dikhawatirkan untuk kedepannya akan menimbulkan banyak isu-isu seputar penguasaan ilmu pemrograman terhadap programmer pemula. Dengan menggabungkan nilai kegunaan translator yang dikaitkan terhadap peningkatan penguasaan ilmu pemrograman dasar, maka diharapkan dapat tercipta suatu aplikasi translator dengan kelebihan-kelebihan dari sudut pandang akademis.
ii
Translator Pascal to C runs to do parsing source code, then it applies the rule of translating. In addition, it presents the result of the target translation. Translator Pascal to C is able to optimize the time needed for users to carry out translation of Pascal to C.
The intoducing and translating function can be created accurately. To gain the rule of translating needs to be compared the syntactic rule from C and Pascal. The grammmar elements that must be explored are the structure of programme, the customs declarations(variable, type, constancy, etc), an expression, a statement, the regulation of the object naming of programme, etc. Using algorithm with fitting string, Boyer-Moore algorithm becomes an important option in translating process. The similarities between Pascal and C enables both of them to be translated each other completely.
Moreover, Pascal and C are an introduction language for the beginner programmers. The first value can influence the end one very much. If in the beginning there have been the difficulties, they will cause many issues around the programming knowledge to the beginner ones next time. Compounding the value of translator that is connected to the mastery improvement of the base programming knowledge, Hopefully it can be created a translator application with the superiority of academic point of view.
iii
Assalamu’alaikum Wr. Wb.
Segala puji dan syukur penulis ucapkan kehadirat Allah swt. atas segala
rahmat, hidayah dan Karunia-Nya, dan tidak lupa juga sholawat serta salam
penulis limpahkan kepada Nabi Muhammad SAW, sehingga penulis dapat
menyelesaikan Laporan Skripsi yang berjudul “PENERAPAN STRING MATCHING MENGGUNAKAN ALGORITMA BOYER-MOORE PADA TRANSLATOR BAHASA PASCAL KE C”. Laporan ini diajukan untuk memenuhi salah satu syarat kelulusan Program Strata-1 pada Jurusan Manajemen
Informatika di Universitas Komputer Indonesia.
Penulis dengan segala kerendahan hati mengharapkan saran dan koreksi
yang membangun dari pembaca sehingga dalam penulisan selanjutnya dapat lebih
baik. Penulis banyak mendapatkan bantuan material maupun spiritual dari
berbagai pihak. Dalam kesempatan ini, penulis ingin menyampaikan rasa terima
kasih yang sebesar-besarnya dan setulus-tulusnya kepada :
1. Bapak Dr. Ir. Eddy Suryanto Soegoto, M.Sc., selaku Rektor Universitas
Komputer Indonesia.
2. Bapak Dr. Arry Akhmad Arman, selaku Dekan Fakultas Teknik Universitas
Komputer Indonesia.
3. Bapak Dadang Munandar SE, MSi selaku Ketua Jurusan Program Studi
Sistem Informasi Universitas Komputer Indonesia.
4. Ibu Wartika, S.Kom., M.T, selaku Dosen Wali MI-10 yang telah banyak
iv yang telah beliau berikan kepada penulis.
6. Para penguji yang telah memberikan masukan-masukan demi kelancaran
dalam proses kelulusan penulis.
7. Semua dosen, staff, dan karyawan Program Studi Sistem Informasi
Universitas Komputer Indonesia.
8. Kedua orang tua dan keluarga yang dengan tulus mendoakan, memberikan
dorongan moril dan materil, masukan, perhatian, dukungan sepenuhnya, dan
kasih sayang yang tidak ternilai.
9. Kepada sahabat terbaik, Helmi Nopiansyah, terima kasih atas semua bantuan
dan dukungannya. Maaf sudah sangat merepotkan. Penulis bangga telah
mengenalnya.
10. Kepada Acep BL dan Dodi Permana sebagai team kuesioner. Semoga suatu
hari nanti penulis dapat membalas semua kebaikan yang telah diberikan.
11. Kepada seluruh Mahasiswa IF angkatan 2008 dan 2010 serta Mahasiswa MI
angkatan 2007 yang telah meluangkan waktu untuk mengisi kuesioner
penelitian skripsi penulis.
12. Kepada Reza William, terima kasih atas kehadiran dan bantuannya disaat
penulis sangat membutuhkan uluran tenaga.
13. Kepada teman-teman kos, terima kasih atas pengertian dan dukungannya
v
ladang amal dan ibadah yang tidak hanya di dunia tetapi juga di akhirat.
Akhir kata, penulis berharap semoga laporan ini berguna dan bermanfaat
bagi penulis dan pembaca. Semoga segala bantuan yang telah diberikan kepada
penulis mendapat balasan dari Allah swt. Amin.
Wassalamu’alaikaum Wr. Wb.
Bandung, Agustus 2011
BAB I PENDAHULUAN
1.1. Latar Belakang
Seperti diketahui, proses alih kode perangkat lunak dari satu bahasa ke
bahasa lain seringkali menjadi kendala dikalangan programmer. Ada berbagai
alasan yang melatarbelakangi hal ini, contohnya ketidakcukupan penguasaan
terhadap bahasa target, waktu, referensi, dan lain-lain. Keperluan alih kode bahasa
pun dapat terjadi dengan alasan perubahan proses bisnis, integrasi, regulasi
perusahaan, adaptasi dengan teknologi baru, hardware, maupun hal lainnya.
Proses alih kode tidaklah mudah, terlebih jika kode sumber aplikasi yang
diterjemahkan kompleks dan memiliki ukuran yang besar. Proses alih kode akan
membutuhkan banyak waktu dan tenaga, serta rentan terhadap kesalahan. Maka
diperlukan suatu solusi untuk melakukan proses alih kode secara otomatis dengan
bantuan sebuah alat. Alat yang dimaksud adalah program yang dapat
menterjemahkan kode sumber ke bahasa lain yang dikehendaki. Alat tersebut di
kenal sebagai Translator. Translator adalah program yang menterjemahkan suatu
huruf dengan himpunan terkecil hingga terbesar dari bahasa asal ke bahasa target.
Saat ini, banyak kegiatan akademik di bidang ilmu kajian pemrograman
menggunakan Pascal sebagai pengenalan ilmu pemrograman. Pascal dipilih
karena keluwesan sintaks dan lebih banyak menggunakan bahasa manusia dalam
penggunaannya. Bahasa lain yang juga biasa digunakan adalah C. C lebih banyak
dibandingkan Pascal. C lebih mendorong penggunanya untuk berfikir lebih kreatif
dalam menyusun logika pemrograman, karena C memiliki kompleksitas dan
variasi sintaks yang lebih rumit dibandingkan Pascal.
Pascal dan C memiliki banyak kesamaan, diantaranya sama-sama
berparadigma prosedural, penerus seri bahasa ALGOL, waktu pertama kali
muncul yang hampir bersamaan, dan lain-lain. C bersifat robust, fleskibel, efisien,
ekspresif dan permisif. Pascal memiliki sintaks yang jelas dan mudah dimengerti,
sehingga banyak dipakai di lingkungan akademik. C banyak dipakai di
lingkungan industri dan sering digunakan sebagai antarmuka dengan software
sistem.
Untuk mendapatkan aturan penerjemahan dari Pascal ke C, penulis perlu
memadankan sintaksis Pascal dan C. Alih kode pada beberapa aspek bahasa
Pascal ke C tidak bisa dilakukan secara straight-forward (kata per kata), namun
memerlukan proses pencocokan sintaksis untuk menyesuaikan lingkungan Pascal
maupun C yang menghasilkan nilai kebenaran maksimal, sehingga
masing-masing lingkungan dapat terdefinisi dengan baik. Untuk itu, dibutuhkannya suatu
algoritma pencocokan sintaksis dengan efisiensi proses terhadap waktu. Dengan
menggunakan Algoritma Boyer Moore sebagai metode pencocokan kata,
diharapkan aplikasi ini dapat menghasilkan keluaran dengan kebenaran mutlak.
1.2. Identifikasi dan Rumusan Masalah 1.2.1. Identifikasi Masalah
ini, dapat diidentifikasikan beberapa masalah berdasarkan latar belakang di atas,
yaitu :
1. Dibutuhkannya banyak waktu dan tenaga dalam proses alih kode Pascal ke
C, serta rentan terhadap kesalahan.
2. Alih kode pada beberapa aspek bahasa Pascal ke C tidak bisa dilakukan
secara straight-forward.
3. Diperlukannya suatu solusi algoritma untuk melakukan proses alih kode
Pascal secara otomatis ke bahasa C.
1.2.2. Rumusan Masalah
Berdasarkan identifikasi masalah yang mengacu pada permasalahan di
atas, maka dirumuskanlah beberapa masalah sehubungan pembangunan
Translator, yaitu :
1. Bagaimana alur algoritma translator dapat mengalihkan Pascal ke C secara
otomatis.
2. Bagaimana metode penerjemahan kode yang digunakan dapat
mengalihkan Pascal ke C dengan benar.
3. Bagaimana translator dapat melakukan pencocokan lingkungan kode
Pascal ke C dengan waktu yang relatif singkat.
1.3. Maksud dan Tujuan Penelitian
Berdasarkan pemaparan di atas, berikut maksud dan tujuan
1.3.1. Maksud Penelitian
Alasan utama pembangunan translator ini adalah untuk menciptakan
sebuah aplikasi pendukung yang dapat mengalihkan suatu kode bahasa program
ke bahasa program yang lain, yaitu Pascal ke C. Sehingga dapat menjadi solusi
ketika dibutuhkannya perubahan kode secara besar dari kode Pascal ke C.
1.3.2. Tujuan Penelitian
Berikut merupakan tujuan dari pembangunan translator Pascal ke C :
1. Menemukan alur algoritma translator yang dapat mengalihkan Pascal ke C
secara otomatis.
2. Menemukan metode penerjemahan kode yang digunakan dapat
mengalihkan Pascal ke C dengan benar.
3. Mengembangkan metode pencocokan lingkungan Pascal ke C dengan
pertimbangan lama waktu proses.
1.4. Manfaat Penelitian
Berikut akan dijelaskan manfaat penelitian ini berdasarkan manfaat
akademis dan manfaat taktis.
1.4.1. Manfaat Akademis
Penelitian pembangunan translator memiliki manfaat besar terhadap
kegiatan akademik penulis yaitu sebagai pemenuhan syarat kelulusan Strata 1.
1.4.2. Manfaat Taktis
Dari sudut pandang pengguna, translator Pascal ke C memiliki manfaat
sebagai translator otomatis yaitu merubah Pascal ke C secara cepat dan akurat.
Selain itu, translator juga dapat digunakan sebagai pembanding penggunaan
sintaksis kode Pascal terhadap C, sehingga membantu pengguna untuk
menyimpulkan penggunaan suatu sintaksis Pascal pada C.
1.5. Batasan Masalah
Dalam penelitian ini, Translator hanya dapat menterjemahkan kode
sumber Pascal ke C, dengan spesifikasi kode sumber sebagai berikut :
1. Pernyataan
a. Sederhana
i. Pernyataan Assignment, ditandai dengan penggunaan operator
assignment (:=).
ii. Pemanggilan procedure input-keyboard dan output-monitor serta
pernyataan goto
b. Terstruktur
i. Pernyataan Conditional, pernyataan seleksi kondisi.
ii. Pernyataan Repetitive, pernyataan perulangan.
c. Pernyataan Compound, gabungan antara pernyataan sederhana dan
terstruktur. Ditandai dengan penggunaan “begin” dan “end”.
2. Tipe Data Sederhana
b. Real
c. Karakter dan string
d. Boolean
3. Ekspresi
a. Numerik / aritmatika
b. String
c. Boolean / logika
Dari spesifikasi di atas, kode sumber yang dimaksud adalah kode sumber
sub-program tanpa keikutsertaan bagian deklarasi dan lainnya, dengan begin –
end, if – else, while – do, repeat – until, for – do, goto, Input (read/readln ke scanf,
masukan dari keyboard), Output (write/writeln ke printf, keluaran ke layar)
sebagai pernyataan yang dapat dialihkan. Selain itu, tranlator hanya dapat
dijalankan pada Sistem Operasi Windows XP dan setelahnya.
1.6. Lokasi dan Waktu Penelitian
Berikut jadwal lokasi dan waktu penelitian pembangunan translator :
Tabel 1.1 Jadwal Penelitian
Tabel 1.1 Jadwal Penelitian (lanjut)
4 Pembuatan Perangkat Lunak
BAB II
LANDASAN TEORI
2.1. Konsep Dasar Algoritma 2.1.1. Sejarah Algoritma
Ditinjau dari asal-usul katanya, kata Algoritma mempunyai sejarah yang
unik. Orang hanya menemukan kata algorism yang berarti proses menghitung
dengan angka arab. Seseorang dikatakan algorist jika orang tersebut menghitung
menggunakan angka arab. Para ahli bahasa berusaha menemukan asal kata ini,
namun hasilnya kurang memuaskan.
Akhirnya para ahli sejarah matematika menemukan asal kata tersebut yang
berasal dari nama penulis buku arab yang terkenal yaitu Abu Ja’far Muhammad
Ibnu Musa Al-Khuwarizmi. Al-Khuwarizmi dibaca orang barat menjadi
Algorism. Al-Khuwarizmi menulis buku yang berjudul Kitab Al Jabar
WalMuqabala yang artinya “Buku pemugaran dan pengurangan” (The book of
restoration and reduction). Dari judul buku tersebut diperoleh akar kata “Aljabar”
(Algebra).
Perubahan kata dari algorism menjadi algorithm muncul karena kata
algorism sering dikelirukan dengan arithmetic, sehingga akhiran –sm berubah
menjadi –thm. Karena perhitungan dengan angka Arab sudah menjadi hal yang
biasa, maka lambat laun kata algorithm berangsur-angsur dipakai sebagai metode
perhitungan (komputasi) secara umum, sehingga kehilangan makna kata aslinya.
2.1.2. Definisi Algoritma
Algoritma adalah urutan langkah-langkah logis penyelesaian masalah yang
disusun secara sistematis dan logis. Kata logis merupakan kata kunci dalam
algoritma. Langkah-langkah dalam algoritma harus logis dan harus dapat
ditentukan bernilai salah atau benar. Dalam beberapa konteks, algoritma adalah
spesifikasi urutan langkah untuk melakukan pekerjaan tertentu.
Pertimbangan dalam pemilihan algoritma adalah algoritma haruslah benar.
Artinya algoritma akan memberikan keluaran yang dikehendaki dari sejumlah
masukan yang diberikan. Tidak peduli serumit apapun algoritma, jika
memberikan keluaran yang salah, pastilah algoritma tersebut bukanlah algoritma
yang baik.
Pertimbangan lain yang harus diperhatikan adalah seberapa baik hasil
yang dicapai oleh algoritma tersebut. Hal ini penting terutama pada algoritma
untuk menyelesaikan masalah yang memerlukan aproksimasi hasil. Algoritma
yang baik harus mampu memberikan hasil yang sedekat mungkin dengan nilai
yang sebenarnya.
Selanjutnya adalah efisiensi algoritma. Efisiensi algoritma dapat ditinjau
dari 2 hal yaitu efisiensi waktu dan memori. Meskipun algoritma memberikan
keluaran yang benar, tetapi jika harus menunggu lama untuk mendapatkan
keluarannya, algoritma tersebut bukanlah algoritma yang baik, setiap orang
Dalam kenyataannya, setiap orang bisa membuat algoritma yang berbeda
untuk menyelesaikan suatu permasalahan, walaupun terjadi perbedaan dalam
menyusun algoritma, tentunya diharapkan keluaran yang sama.
2.2. Pengantar Pascal 2.2.1. Sejarah Pascal
Pascal merupakan pengembangan dari bahasa Algol 60, bahasa
pemrograman untuk sains komputasi. Tahun 1960, beberapa ahli komputer
bekerja untuk mengembangkan bahasa Algol, salah satunya adalah Dr. Niklaus
Wirth dari Swiss Federal Institute of Technology (ETH-Zurich), yang merupakan
anggota grup yang membuat Algol.
Tahun 1971, diterbitkan suatu spesifikasi untuk highly-structured
language (bahasa tinggi yang terstruktur) yang menyerupai Algol yaitu Pascal.
Pascal bersifat data oriented, yaitu programmer diberi keleluasaan untuk
mendefinisikan data sendiri. Pascal juga merupakan teaching language (banyak
dipakai untuk pengajaran tentang konsep pemrograman). Kelebihan yang lain
adalah penulisan kode Pascal yang luwes.
2.2.2. Ciri – Ciri Pascal
Susunan dari kode-kode dalam teks Pascal harus ditulis secara terurut,
pernyataan-pernyataan yang ditulis lebih awal akan dieksekusi lebih dahulu. Oleh
maka variable itu harus terdefinisi dahulu sebelumnya. Hal ini terutama
menyangkut pada pemanggilan sub-program oleh sub-program yang lain.
Blok dengan batas-batas yang jelas.Pascal memberikan pembatas yang
jelas pada tiap-tiap blok, seperti pada blok program utama, sub-program, struktur
kontrol (pengulangan/ pemilihan), dll. Pemakaian kata kunci “begin” untuk
mengawali operasi pada blok dan “end” untuk menutupnya memudahkan
programmer menyusun programnya dengan mudah.
2.3. Pengantar C 2.3.1. Sejarah C
Berasal dari bahasa BCPL (Basic Combined Programming Language)
oleh Martin Richard, Cambridge tahun 1967, Ken Thompson membuat bahasa B
untuk dipakai pada komputer DEC PDP-7 dibawah sistem operasi UNIX pada
Bell laboratory, Murray Hill, New Jersey tahun 1970.
Bahasa B merupakan suatu bahasa pemrograman yang tidak memiliki
jenis suatu data seperti halnya PL/M. Berdasarkan gambaran bahasa B, Dennis
Ritchie menulis bahasa C. Nama C diambil berdasarkan urutan sesudah B dari
bahasa BCPL. Tujuan bahasa C pada mulanya untuk membentuk suatu sistem
operasi yang akan digunakan pada mesin komputer DEC PDP-11 yang baru.
Pada tahun 1975, sistem operasi UNIX versi 6 dan bahasa C mulai
diberikan kepada Universitas maupun Akademi. Dan pada tahun 1979, sistem
operasi UNIX versi 7 dikeluarkan dengan bahasa C. Sistem operasi ini (versi 7)
Pada 1978 Dennis Ritchie dan Brian Kernighan kemudian
mempublikasikan buku The C Programming Language yang semakin memperluas
pemakaiannya dan dijadikan standar oleh ANSI (American National Standard
Institute) pada tahun 1989. C kemudian dikembangkan lagi oleh Bjarne Stroustrup
menjadi C++ (1986). C dan/atau C++ banyak digunakan sebagai bahasa
pemrograman untuk membuat sistem operasi.
2.3.2. Ciri-ciri C
Program C pada hakekatnya tersusun atas sejumlah blok fungsi. Sebuah
program minimal mengandung sebuah fungsi. Fungsi pertama yang harus ada
dalam program C dan sudah ditentukan namanya adalah main(). Setiap fungsi
terdiri atas satu atau beberapa pernyataan, yang secara keseluruhan dimaksudkan
untuk melaksanakan tugas khusus. Bagian pernyataan fungsi (sering disebut tubuh
fungsi) diawali dengan tanda kurung kurawal buka ({) dan diakhiri dengan tanda
kurung kurawal tutup (}). Di antara kurung kurawal itu dapat dituliskan
statemen-statemen program C.
Namun pada kenyataannya, suatu fungsi bisa saja tidak mengandung
pernyataan sama sekali. Walaupun fungsi tidak memiliki pernyataan, kurung
kurawal haruslah tetap ada. Sebab kurung kurawal mengisyaratkan awal dan akhir
definisi fungsi. Bahasa C dikatakan sebagai bahasa pemrograman terstruktur
karena strukturnya menggunakan fungsi-fungsi sebagai program-program
bagiannya (subroutine). Fungsi-fungsi yang ada selain fungsi utama (main())
utama atau diletakkan di file pustaka (library). Jika fungsi-fungsi diletakkan di file
pustaka dan akan dipakai di suatu program, maka nama file judulnya (header file)
harus dilibatkan dalam program yang menggunakannya dengan preprocessor
directive berupa #include.
2.4. Konsep Dasar String Matching 2.4.1. String Matching
String matching adalah pencarian sebuah pattern pada sebuah teks. Prinsip
kerja algoritma string matching adalah sebagai berikut:
1. Memindai teks dengan bantuan sebuah window yang ukurannya sama
dengan panjang pattern.
2. Menempatkan window pada awal teks.
3. Membandingkan karakter pada window dengan karakter dari pattern.
Setelah pencocokan (baik hasilnya cocok atau tidak cocok), dilakukan shft
ke kanan pada window. Prosedur ini dilakukan berulang-ulang sampai
window berada pada akhir teks. Mekanisme ini disebut mekanisme
sliding-window.
Algoritma string matching mempunyai tiga komponen utama, yaitu:
1. Pattern, yaitu deretan karakter yang akan dicocokkan dengan teks,
dinyatakan dengan x[0..m-1], panjang pattern dinyatakan dengan m.
2. Teks, yaitu tempat pencocokan pattern dilakukan, dinyatakan dengan
3. Alfabet, yang berisi semua simbol yang digunakan oleh bahasa pada teks
dan pattern, dinyatakan dengan ∑ dengan ukuran dinyatakan dengan
ASIZE.
2.4.2. Algoritma Boyer-Moore
Algoritma Boyer-Moore termasuk algoritma string matching yang paling
efisien dibandingkan algoritma-algoritma string matching lainnya. Karena
sifatnya yang efisien, banyak dikembangkan algoritma string matching dengan
bertumpu pada konsep algoritma Boyer-Moore, beberapa di antaranya adalah
algoritma Turbo BM dan algoritma Quick Search.
Algoritma Boyer-Moore menggunakan metode pencocokan string dari
kanan ke kiri yaitu memindai karakter pattern dari kanan ke kiri dimulai dari
karakter paling kanan. Algoritma Boyer-Moore menggunakan dua fungsi shift
yaitu good-suffix shift dan bad-character shift untuk mengambil langkah
berikutnya setelah terjadi ketidakcocokan antara karakter pattern dan karakter teks
yang dicocokkan.
2.5. Konsep Dasar Stack
Stack adalah suatu bentuk khusus dari linear list (suatu struktur data yang
merupakan himpunan terurut yang dapat berkurang atau bertambah setiap saat) di
mana operasi penyisipan dan penghapusan atas elemen-elemennya hanya dapat
dilakukan pada satu sisi saja yang disebut sebagai “TOP”. Ada empat operasi
1. Create, operator ini berfungsi untuk membuat sebuah stack kosong.
2. IsEmpty, operator ini berfungsi untuk menentukan apakah suatu stack
adalah stack kosong.
3. Push, operator ini berfungsi untuk menambahkan satu elemen ke dalam
stack.
4. Pop, operator ini berfungsi untuk mengeluarkan satu elemen dari dalam
stack.
Dalam penggunaannya, untuk menempatkan stack biasanya digunakan
sebuah array. Tetapi perlu diingat di sini bahwa stack dan array adalah dua hal
yang berbeda. Selain itu penggunaan stack dengan array dirasakan kurang tepat.
Penggunaan stack pada pembangunan Translator ini menggunakan record sebagai
implementasi stack.
2.6. Konsep Dasar Pohon Biner
Tree/pohon merupakan struktur data yang tidak linear/non linear yang
digunakan terutama untuk merepresentasikan hubungan data yang bersifat
hierarkis antara elemen-elemennya. Kumpulan elemen yang salah satu elemennya
disebut dengan root (akar) dan sisa elemen yang lain disebut sebagai simpul
(node/vertex) yang terpecah menjadi sejumlah himpunan yang tidak saling
berhubungan satu sama lain, yang disebut subtree/cabang.
Sebuah pohon biner T dapat didefinisikan sebagai sekumpulan terbatas
a. T dikatakan kosong (disebut null tree/pohon null atau empty tree/pohon
kosong)
b. T terdiri dari sebuah node khusus yang dipanggil R, disebut root dari T
dan node-node T lainnya membentuk sebuah pasangan terurut dari binary
tree T1 dan T2 yang tidak berhubungan yang kemudian dipanggil subtree
kiri dan subtree kanan.
Jika T1 tidak kosong maka rootnya disebut successor kiri dari R dan jika
T2 tidak kosong, maka rootnya disebut successor dari R.
Jenis-jenis binary tree :
1. Complete Binary Tree
Suatu binary tree T akan disebut complete/lengkap jika semua levelnya
memiliki child 2 buah kecuali untuk level paling akhir. Tetapi pada akhir
level setiap leaf/daun muncul terurut dari sebelah kiri.
2. Extended Binary Tree : 2-Tree
Sebuah binary tree dikatakan 2-tree atau extended binary tree jika tiap
simpul N memiliki 0 atau 2 anak. Simpul dengan 2 anak disebut dengan
simpul internal (internal node), dan simpul dengan 0 anak disebut dengan
external node. Kadang-kadang dalam diagram node-node tersebut
dibedakan dengan menggunakan tanda lingkaran untuk internal node dan
2.7. Konsep Dasar Flowchart
Flowchart adalah representasi grafis peta atau dari suatu proses.
Langkah-langkah dalam suatu proses yang ditampilkan dengan bentuk simbolik, dan aliran
proses ini ditunjukkan dengan panah menghubungkan simbol. Pemrograman
komputer flowchart dipopulerkan pada 1960-an yang digunakan untuk
memetakan logika program. Dalam pekerjaan peningkatan kualitas, flowchart
sangat berguna untuk menampilkan bagaimana proses saat ini berfungsi atau bisa
idealnya fungsi.
Flowchart dapat membantu melihat apakah langkah-langkah proses telah
logis, mengungkap masalah atau miskomunikasi, menentukan batas-batas proses,
dan mengembangkan dasar umum pengetahuan tentang proses. Flowcharting
proses seringkali membawa kepada redudansi cahaya, penundaan, buntu, dan jalur
tidak langsung yang dinyatakan akan tetap diperhatikan atau diabaikan. Tapi
BAB III
METODOLOGI PENELITIAN
3.1. Analisis Masalah
Pada analisis masalah ini, penulis akan menjabarkan mengenai aturan
terjemahan yang diberlakukan pada suatu Teks yang dikenali sebagai Pascal.
Idealnya, suatu teks akan dikenali sebagai pernyataan Pascal jika teks
tersebut telah sukses melalui proses compile pada Turbo Pascal 7.0. Pernyataan
Pascal tidak bisa secara langsung diterjemahkan ke bentuk C. Proses
penerjemahan pun harus memiliki kualifikasi yang baik dari sudut lama waktu
proses yang dibutuhkan. Maka harus diterapkannya beberapa fungsi pengenalan,
diantaranya:
1. Penyesuaian algoritma Boyer-Moore pada setiap kasus pencocokan.
2. Proses pencocokan string terhadap teks, dimaksudkan agar setiap kata
dapat dikenali oleh translator dan dapat diterjemahkan.
3. Aturan terjemahan, dimaksudkan sebagai aturan yang diterapkan jika
ditemukannya sebuah bentuk pernyataan di dalam teks.
4. Mengenali jenis ekspresi yang dioperasikan dan menemukan bentuk hasil
operasi dari Pascal ke C.
5. Proses handling untuk setiap bentuk penyataan yang tidak memiliki
aturan penerjemahan.
3.2. Analisis Translator
Berikut pemaparan kebutuhan primer/utama translator sebagai alat alih
bahasa Pascal ke C.
3.2.1. Algoritma Boyer-Moore
Algoritma Boyer-Moore adalah salah satu algoritma pencarian string,
dipublikasikan oleh Robert S. Boyer, dan J. Strother Moore pada tahun 1977.
Algoritma ini dianggap sebagai algoritma yang paling efisien pada aplikasi
umum.
Tidak seperti algoritma pencarian string yang ditemukan sebelumnya,
algoritma Boyer-Moore mulai mencocokkan karakter dari sebelah kanan pattern.
Ide dibalik algoritma ini adalah bahwa dengan memulai pencocokkan karakter
dari kanan, dan bukan dari kiri, maka akan lebih banyak informasi yang didapat.
3.2.1.1. Cara Kerja Algoritma Boyer-Moore
Dimisalkan ada sebuah usaha pencocokan yang terjadi pada teks[i..i + n −
1], dan anggap ketidakcocokan pertama terjadi di antara teks[i + j] dan pattern[j],
dengan 0 < j < n. Berarti, teks[i + j + 1..i + n − 1] = pattern[j + 1..n − 1] dan a =
teks[i + j] tidak sama dengan b = pattern[j].
Jika u adalah akhiran dari pattern sebelum b dan v adalah sebuah awalan
dari pattern, maka penggeseran-penggeseran yang mungkin adalah :
1. Penggeseran good-suffix yang terdiri dari mensejajarkan potongan teks[i +
j + 1..i + n − 1] = pattern[j + 1..n − 1] dengan kemunculannya paling
kanan di pattern yang didahului oleh karakter yang berbeda dengan
mensejajarkan akhiran v dari teks[i + j + 1..i + n − 1] dengan awalan dari
pattern yang sama.
2. Penggeseran bad-character yang terdiri dari mensejajarkan teks[i + j]
dengan kemunculan paling kanan karakter tersebut di pattern. Bila
karakter tersebut tidak ada di pattern, maka pattern akan disejajarkan
dengan teks[i + n + 1].
Secara sistematis, langkah-langkah yang dilakukan algoritma
Boyer-Moore pada saat mencocokkan string adalah :
1. Algoritma Boyer-Moore mulai mencocokkan pattern pada awal teks.
2. Dari kanan ke kiri, algoritma ini akan mencocokkan karakter per karakter
pattern dengan karakter di teks yang bersesuaian, sampai salah satu
kondisi berikut dipenuhi :
a. Karakter di pattern dan di teks yang dibandingkan tidak cocok
(mismatch).
b. Semua karakter di pattern cocok. Kemudian algoritma akan
memberitahukan penemuan di posisi ini.
3. Algoritma kemudian menggeser pattern dengan memaksimalkan nilai
penggeseran good-suffix dan penggeseran bad-character, lalu mengulangi
3.2.1.2. Pseudocode Algoritma Boyer-Moore
Berikut representasi dari algorima Boyer-Mooyer dengan menggunakan
pseudocode :
Gambar 3.3 Pseudocodealgoritma Boyer-Moore preBmBc Tabel untuk penggeseran bad-character dan good-suffix dapat dihitung
dengan kompleksitas waktu dan ruang sebesar O(n + σ) dengan σ adalah besar
Gambar 3.4 Pseudocode algoritma Boyer-Moore Search
Pada fase pencarian, algoritma Boyer-Moore membutuhkan waktu sebesar
O(mn), pada kasus terburuk, algoritma ini akan melakukan 3n pencocokkan
karakter, namun pada performa terbaiknya algoritma ini hanya akan melakukan
O(m/n) pencocokkan.
3.2.2. Analisis Aturan Penerjemahan
Aturan penerjemahan adalah hasil hubungan sintaksis pernyataan Pascal
terhadap C. Aturan penerjemahan digunakan untuk mengenali dan memecah
C. Aturan ini diperoleh dari hasil analisis kedua sintaksis. Berikut penjabaran dari
kedua sintaksis.
3.2.2.1. Analisis Sintaksis Pernyataan Pascal
Analisis dikaji berdasarkan sintaksis Pascal yang telah ditetapkan.
Sedangkan pengaplikasian pernyataan, dikaji berdasarkan aturan di Turbo Pascal
7.0. Pengkajian pertama yaitu Pascal tidak case sensitif.
3.2.2.1.1. Pernyataan / Statement
Pernyataan Adalah instruksi atau gabungan instruksi, yang menyebabkan
komputer melakukan aksi. Ragam pernyataan dalam Pascal terdiri atas :
1. Pernyataan sederhana, setiap jenis pernyataan ini harus diakhiri oleh “;”.
a. Menandai sebuah item data ke sebuah variabel (assignment statement).
Analisis bentukan pernyataan, contoh :
X := Y * 4.135 ;
Variabel Operator Ekspresi Tutup
Variabel diasumsikan sebagai sebuah pengenal / identifier khusus.
Pernyataan ini dikenali jika ditemukannya operator “:=” setelah pengenal
dan hanya jika pengenal telah terdaftar sebagai variabel. Setelah itu,
operator harus diikuti oleh sebuah ekspresi. Nilai keharusan adalah
mutlak, artinya jika tidak diikuti oleh sebuah ekspresi, maka penyataan ini
dinyatakan salah. Selain itu, ekspresi harus memiliki hasil operasi dengan
tipe data yang sama terhadap variabel.
Analisis bentukan pernyataan, contoh :
Write (Y * 4.135, „andrik‟) ;
Pengenal Ekspresi Tutup
Pengenal write tidak harus selalu diikuti oleh sebuah ekspresi.
Ekspresi yang dimiliki write harus diapit oleh “(“ dan “)” serta ekpresi
tidak diperkenankan berupa karakter kosong. Jumlah ekspresi tidak
dibatasi, hanya saja masing-masing ekspresi harus dipisahkan oleh “,”.
Nilai keharusan adalah mutlak. Aturan ini diterapkan pula pada
penggunaan pengenal WRITELN.
Read (Y, Z) ;
Pengenal Variabel Tutup
Aturan penggunaan pengenal read dapat menggunakan aturan
penggunaan pengenal write, hanya saja penggunaan ekspresi pada read
tidak diizinkan. Pernyataan ini hanya mengenal variabel. Variabel bernilai
benar hanya jika variabel tersebut telah terdaftar. Aturan ini diterapkan
pula pada pernyataan READLN.
Readkey ;
Readkey dikenali sebagai pernyataan benar jika setelah pengenal
diikuti “;”. Selain itu readkey dinyatakan salah. Karakter newline, tab, dan
space diabaikan.
Gotoxy (y, z) ;
Pengenal Ekspresi Tutup
Penggunaan pengenal gotoxy dapat diterapkan penggunaan
pengenal write. Hanya saja, gotoxy harus diikuti sebuah ekspresi dan
ekspresi harus selalu diapit oleh “(“ dan “)”. Sedangkan ekspresi harus
berjumlah 2 dan hasil operasi ekspresi harus bertipe bilangan bulat.
Keharusan ini bersifat mutlak.
2. Terstruktur:
a. Pernyataan perulangan (Repetitive statement)
Analisis bentukan pernyataan, contoh:
While Y > 100 Do Readkey;
Pengenal Ekspresi Pengenal Pernyataan
Pengenal while harus selalu diikuti oleh ekspresi yang jika
dioperasikan akan menghasilkan tipe boolean, dan harus selalu diikuti oleh
pengenal do. Tidak ada aturan khusus mengenai penggunaan pernyataan
pada while. Aturan penggunaan pernyataan mengikuti kesesuaian jenis
Repeat Readkey; Until Y > 100;
Pengenal Pernyataan Pengenal Ekspresi
Pengenal repeat harus selalu diikuti oleh pengenal until setelah
pernyataan. Sedangkan penggunaan pernyataan tidak menjadi sebuah
keharusan. Aturan khusus pada pengenal until adalah, satu pernyataan
sebelum until dapat menggunakan “;” sebagai penutup maupun tidak.
For Y:=1+Y To Y +
100
Do Readkey;
Pengenal P_Assignment Pengenal Ekspresi Pengenal Pernyataan
Pernyataan di atas harus selalu terdiri dari 3 buah pengenal seperti
yang terlihat pada contoh. Pengenal to dapat diganti dengan menggunakan
downto. Hal terpenting dalam operasi ekspresi pada P_Assignment adalah
hasil operasi ekspresi harus bertipe bilangan bulat. Penggunaan pernyataan
setelah pengenal do merupakan suatu ketidakharusan.
b. Pernyataan kondisi (Conditional statement)
Analisis bentukan pernyataan, contoh :
If Y > 100 Then Readkey Else Read;
Pengenal Ekspresi Pengenal Pernyataan Pengenal Pernyataan
Pada penggunaan pernyataan di atas, aturan pertama yaitu
pengenal then hanya dianggap benar jika sebelum pengenal tersebut
ditemukan pengenal if, dan else hanya dianggap benar jika di sebelum
dianggap benar jika setelahnya ditemukan pernyataan then. Kondisi
khusus untuk else, pernyataan sebelum else harus tidak diikuti oleh “;”,
keharusan bersifat mutlak. Sedangkan aturan untuk penggunaan
pernyataan, mengikuti aturan pernyataan yang berkesesuaian. Untuk
ekspresi, hasil operasi ekspresi harus bertipe boolean, keharusan bernilai
mutlak.
c. Pernyataan campuran (Compound statement), jenis pernyataan ini dapat
terbentuk dari berbagai jenis pernyataan. Perbedaan yang mencolok dari
jenis pernyataan ini adalah pada penggunaan blok pernyataan. Pernyataan
campuran selalu diapit oleh pernyataan BEGIN dan END.
Analisis bentukan pernyataan, contoh :
Begin ← Awalan
Bentuk awalan pada pernyataan ini harus selalu dituliskan sebagai
begin dengan tanpa penyatuan terhadap karakter lain selain newline, tab,
dan space, baik di awal maupun di akhir. Selain itu, pernyataan ini harus
menggunakan end sebagai penutup blok. End harus selalu diikuti oleh “;”.
Sedangkan penggunaan begin dan end dapat disetarakan dengan
penggunaan pernyataan readkey. Terdapat suatu aturan khusus di
pernyataan ini, yaitu satu pernyataan sebelum end diizinkan untuk tidak
3.2.2.1.2. Tipe Data
Jenis – jenis tipe data sederhana yang dikenal dalam bahasa Pascal antara
lain yaitu :
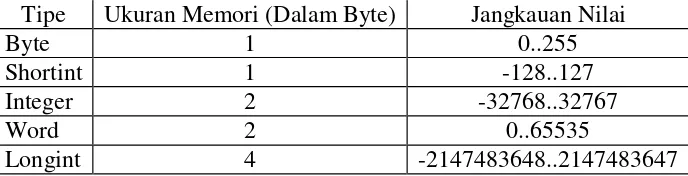
1. Integer. Tipe data ini terdiri atas integer positif, integer negatif dan nol yang
merupakan nilai bilangan bulat. Pada Turbo Pascal 7.0 jenis tipe data ini di
bagi atas beberapa bagian, yaitu :
Tabel 3.1 Tipe data integer Pascal
Tipe Ukuran Memori (Dalam Byte) Jangkauan Nilai
Byte 1 0..255
Shortint 1 -128..127
Integer 2 -32768..32767
Word 2 0..65535
Longint 4 -2147483648..2147483647
Operator Integer terdiri atas : + , - , * , / , DIV dan MOD.
2. Real. Penulisan untuk jenis data ini selalu menggunakan titik desimal. Nilai
konstanta numerik real berkisar dari 1E-38 sampai dengan 1E+38. E
menunjukkan nilai 10 pangkat. Contoh :
123.45 | 12E5 | 12E+5 | -12.34 penulisan benar.
12345. salah, titik desimal tidak boleh di belakang
.1234 salah, titik desimal tidak boleh di muka
Pada Turbo Pascal, jenis data ini dibedakan atas :
Tabel 3.2 Tipe data real Pascal
Tipe Ukuran Memori (Dalam Byte) Jangkauan Nilai
Single 4 1.5x10E-45..3.4x10E38
Double 8 5.0x10E-324..1.7x10E308
Extended 10 1.9x10E-4951..1.1x10E4932
Operator untuk tipe data ini terdiri atas : + , - , * dan /
3. Karakter dan string. Tipe data karakter adalah karakter tunggal atau sebuah
karakter yang ditulis diantara tanda petik tunggal, seperti misalnya
„A‟,‟a‟,‟!‟,‟5‟ dsb. Dasarnya adalah ASCII Character Set. Sedangkan tipe data
string merupakan urut-urutan dari karakter yang terletak di antara tanda petik
tunggal. Nilai data string akan menempati memori sebesar banyaknya
karakter stringnya ditambah dengan 1 byte. Bila panjang dari suatu string di
dalam deklarasi variabel tidak disebutkan, maka dianggap panjangnya adalah
255 karakter.
4. Boolean. Jenis data ini mempunyai nilai TRUE atau FALSE. Operator untuk
tipe data ini adalah :
a.Logical Operator, yaitu : NOT, AND dan OR
b.Relational Operator, yaitu : >, <, >=, <=, <> dan =
3.2.2.1.3. Ekspresi
Sebuah ekspresi dapat dikenali dengan penggunaan tanda “(“ dan “)”
maupun tidak. Penggunaan variabel di dalam sebuah pernyataan, dapat
dikategorikan sebagai ekspresi.
1. Numerik / aritmatika dan string. Ekspresi aritmatika adalah semua jenis
ekspresi yang jika dioperasikan akan menghasilkan nilai dengan tipe data
numerik (integer / real). Begitupun sebaliknya dengan ekspresi string.
2. Boolean / logika. Jenis ekspresi yang jika dioperasikan akan menghasilkan
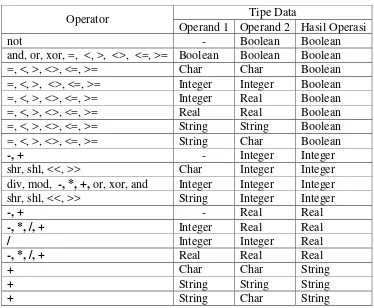
Tabel 3.3 Tipe data hasil operasi ekspresi Pascal
Operator Tipe Data
Operand 1 Operand 2 Hasil Operasi
not - Boolean Boolean shr, shl, <<, >> String Integer Integer
-, + - Real Real
3.2.2.2. Analisis Sintaksis Pernyataan C
Di dalam penggunaannya, terdapat beberapa perbedaan yang cukup
mendasar mengenai bentukan sebuah pernyataan, ekspresi, maupun tipe data C
terhadapa Pascal. Pengkajian penggunaan pernyataan C dilandasi dengan sintaksis
C yang ditelah dipatenkan, sedangkan penulisan pernyataan dikaji melalui Turbo
C 3.0. Pengkajian pertama yaitu C case sensitif. Pada penerapannya, sintataksis
pernyataan C hanya digunakan sebagai aturan penggabungan hasil translasi. Oleh
karena itu pengkajian dibatasi terhadap pernyataan yang memiliki hubungan
terhadap sintaksis pernyataan Pascal yang digunakan sebagai kode sumber.
1. Tipe data integer dan boolean. Pada C, tidak terdapat tipe boolean. C
menggunakan bilangan 0 sebagai false dan selain 0 sebagai true.
2. String kontrol (%SC). Diartikan sebagai penentu format dari sebuah tipe
data hasil operasi ekspresi yang digunakan untuk membaca ataupun
menampilkan sebuah ekspresi.
Tabel 3.4 Daftar string kontrol C String
Kontrol Keterangan
%c Sebuah karakter
%s Sebuah string
%u Data bilangan tak bertanda (unsigned) dalam bentuk desimal %d, %i Bilangan integer bertanda (signed) dalam bentuk desimal %o Bilangan bulat tak bertanda dalam bentuk oktal
%x, %X Bilangan bulat tak bertanda dalam bentuk heksadesimal
%f Bilangan real
%e, %E Bilangan real dalam notasi eksponensial
%g, %G Bilangan real dengan kesesuaian terhadap format %f atau %E l Merupakan awalan yang digunakan untuk %d, %u, %x, %X,
%o untuk menyatakan long int. Jika diterapkan bersama %e %E, %f, %F, %g atau %G akan memiliki nilai double.
L Merupakan awalan yang digunakan untuk %f, %e, %E, %g dan %G untuk menyatakan long double
h Merupakan awalan yang digunakan untuk %d, %i, %o, %u, %x, atau %X untuk menyatakan short int
3.2.2.3. Analisis Hubungan Sintaksis Pascal dan C
Pada tahapan analisis ini, hubungan antara Pascal dan C akan dikaji
berdasarkan hubungan bentukan per pernyataan, ekspresi, maupun tipe data yang
apabila dieksekusi memiliki nilai operasi yang sama. Dengan batasan pengkajian
bahwa nilai kebenaran masukan kode sumber pernyataan hanya dinilai
berdasarkan sintaksis pernyataan Pascal, sedangkan sintaksis pernyataan C hanya
3.2.2.3.1. Hubungan Pernyataan Assignment
Pascal variable := ekspresi ;
C variable = ekspresi ;
Dari kedua bentukan ditemukan hubungan bahwa pernyataan assignment
dibedakan oleh bentuk operator.
Dari kedua bentukan ditemukan hubungan bahwa pernyataan output write
pada Pascal memiliki nilai eksekusi yang sama terhadap printf pada C, hanya saja
perbedaan muncul pada penyusunan ekspresi Pascal terhadap C. C
memungkinkan sebuah string tidak dikategorikan sebagai bagian dari ekspresi.
Sedangkan bagian %SC, mewakili setiap ekspresi yang ada secara terurut. Contoh
lain untuk pernyataan ini yaitu :
Pascal writeln(ekspresi, „andrik‟);
C printf(“%sc andrik\n”, ekspresi);
Pada contoh di atas terlihat bahwa pengenal Pascal mengalami perubahan,
tetapi tidak pada C. Perubahan C hanya terjadi pada bagian %SC, dimana di akhir
penggunaan %SC terjadi penambahan “\n” yang mewakili fungsi “ln” pada
3.2.2.3.3. Hubungan Pernyataan Input
Pascal read(var1, var2);
C scanf(“%sc1 %sc2”, &var1, &var2);
Dari contoh di atas terlihat bahwa read-scanf mempunyai karakteristik
yang hampir sama dengan write-printf. Terlihat pula bahwa read-scanf hanya
menerima variabel sebagai ekspresi dan penambahan operator alamat “&” sebagai
awalan pada bagian variabel. Sedangkan penerapan readln pada C, disimpulkan
sama.
Pascal readkey;
C getch();
Readkey mempunyai persamaan fungsi terhadap getch, sedangkan getch
harus diikuti oleh ekspresi kosong yaitu “()”. Dapat diartikan bahwa readkey
selalu di akhiri oleh “;” sedangkan getch di akhiri oleh “();”.
3.2.2.3.4. Hubungan Pernyataan Gotoxy
aturan Pascal dapat diterapkan langsung ke C tanpa perubahan sedikitpun kecuali
3.2.2.3.5. Hubungan Pernyataan Perulangan
Pascal while ekspresi_logika do penyataan;
C while (ekspresi_logika) pernyataan;
Pada contoh di atas, terlihat bahwa ekspresi while C harus selalu diapit
oleh “(“ dan “)” dan ekspresi harus menghasilkan tipe integer. Selain itu, while C
hanya mengenal satu pengenal yaitu while, sedangkan while-do Pascal harus
terdapat dua pengenal yaitu while dan do.
Pascal repeat pernyataan until ekspresi_logika;
C do pernyataan while(not (ekspresi_logika));
Pada contoh telihat bahwa ekspresi do-while pada C menggunakan
operator not, operator not difungsikan sebagai penyesesuaian sintaksis Pascal dan
C. Diketahui bahwa repeat-until pada Pascal akan terus melakukan perulangan
jika bernilai false, dan sebaliknya pada do-while C.
Pascal for p_assignment to ekspresi do pernyataan;
C for (p_assignment; var >= ekspresi; var++)
pernyataan;
Pascal for p_assignment downto ekspresi do
pernyataan;
C for (p_assignment; var <= ekspresi; var--)
pernyataan;
Dari dua contoh di atas, disimpulkan bahwa pengenal to/downto pada for
pascal mempunyai nilai yang sama terhadap increment/decrement variabel yang
3.2.2.3.6. Hubungan Pernyataan Kondisi (Conditional)
Pascal if e_logika then pernyataan;
C if (e_logika) pernyataan;
Pascal if e_logika then pernyataan else pernyataan;
C if (e_logika) pernyataan; else pernyataan;
Dari kedua contoh di atas, terlihat dua perbedaan sintaksis yaitu pada
penggunaan “;” di sebelum pengenal else dan penggunaan ekspresi logika.
3.2.2.3.7. Hubungan Pernyataan Campuran
Pascal begin pernyataan; end;
C { pernyataan; }
Dari contoh di atas terlihat bahwa begin-end memiliki nilai kesamaan
terhadap {-}. Sedangkan aturan pernyataan, mengikuti aturan hubungan
pernyataan yang berkesesuaian.
3.2.2.3.8. Hubungan Tipe Data
Berikut merupakan tipe data C yang mempunyai nilai tipe yang sama atau
mendekati terhadap tipe data Pascal.
Tabel 3.5 Persamaan Tipe Data Pascal ke C
Tabel 3.5 Persamaan Tipe Data Pascal ke C (lanjut)
Pada dasarnya, sebuah ekspresi tersusun oleh operand dan operator.
Berikut representasi hubungan ekspresi Pascal ke C melalui keterkaitan operan
dan operator.
Tabel 3.6 Persamaan Operator Pascal ke C
Hirarki Operator Hirarki Operator
Pascal C Pascal C
operator pada Pascal dan C. Ketika operator dioperasikan terhadap operand. Hasil
operasi dapat menghasilkan tipe data yang sama maupun berbeda terhadap
3.3. Analisis Perangkat Lunak dan Perangkat Keras
Perangkat yang dibutuhkan dalam pembuatan Translator ini terdiri dari 2
bentuk perngkat, yaitu perangkat keras dan perangkat lunak.
1. Perangkat keras yang dibutuhkan yaitu:
1 Unit komputer lengkap (netbook), prosessor Intel Atom CPU N280, RAM 2
Gb, VGA 256 Mb, tersedia Mouse
2. Perangkat lunak yang dibutuhkan sebagai sistem operasi yang ada pada
komputer dan sebagai media pengembangan Translator antara lain:
a.Sistem Operasi Windows 7
b.Program Visual Basic 6.0
BAB IV PERANCANGAN
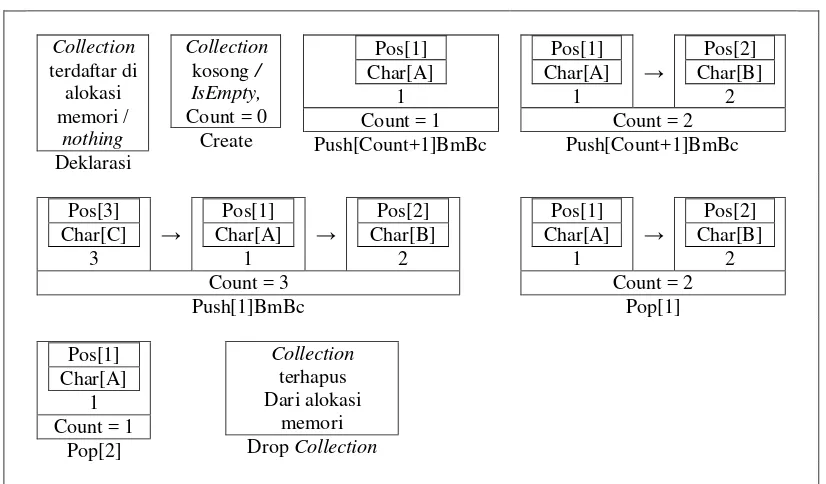
4.1. Implementasi Stack dengan Single Linked List Sebagai Collection Control Pada Translator
Pengggunaan stack dengan single link list dimaksudkan sebagai
manajemen memori pada runtime Translator. Single link list difungsikan sebagai
media penyimpanan data sementara hasil proses algoritma Boyer-Moore. Dimana
stack memiliki nilai batas penyimpanan yang dinamis. Sehingga dapat
memaksimalkan alokasi memori terhadap kebutuhan Translator yang sedang
berjalan. Di Visual Basic 6.0, stack dengan single link list dapat
diimplementasikan sebagai collection control. Operasi-operasi yang diterapkan
pada collection antara lain :
1. Deklarasi yaitu proses pendaftaran collection control pada alokasi memori.
2. Push, yaitu operasi menambahkan elemen pada urutan terakhir, di awal
ataupun di akhir tumpukan dengan class module sebagai implementasi
record pada elemen.
3. Pop, yaitu operasi mengambil sebuah elemen data pada urutan terujung
dan menghapus elemen tersebut dari collection.
4. IsEmpty, yaitu proses pemeriksaan apakah collection dalam keadaan
kosong.
5. Create, yaitu proses pembuatan collection kosong, dengan pemberian nilai
6. Drop, yaitu operasi penghapusan collection dari alokasi memori, dengan
pemberian nilai nothing.
Berikut representasi metode pemanfaatan collection untuk mendukung
kinerja Translator dengan diasumsikan BmBc sebagai class module, Pos dan Char
sebagai elemen class module.
Collection
Gambar 4.1 Operasi standar pada collection Visual Basic 6.0.
4.2. Implementasi Binary Tree Sebagai Class Modules Control Pada Translator
Sama halnya dengan implementasi stack, binary tree difungsikan sebagai
solusi pemecahan hirarki operator pada sebuah ekspresi.
A
Gambar 4.3 Representasi binary tree
Pada implementasinya, binary tree hanya digunakan sebagai tempat
penyimpanan sementara dari potongan-potongan teks yang dikenali sebagai
sebuah ekpresi. Berikut algoritma penerapan binary tree pada translator:
1. Lakukan pencarian posisi dengan menggunakan prosedur BM untuk 2 kata
kunci pada teks. Kata kunci-1 merupakan kata kunci dengan arti buka
(tanda yang menyebutkan sebuah awalan) dan Kata kunci-2 merupakan
kata kunci dengan arti tutup (tanda yang menyebutkan sebuah akhiran).
Contoh, kata kunci-1 : “(“ dan kata kunci-2 : “)”
2. Jika jumlah posisi kedua kata kunci yang ditemukan tidak sama (tidak
sepasang) maka berikan pesan kesalahan.
3. Jika jumlah posisi kedua karakter sama, maka bandingkan antara posisi
paling pertama dari kata kunci-1 terhadap posisi paling pertama dari kata
4. Jika kata kunci-1 memiliki nilai perbandingan terbesar, maka proses ulang
(rekursif) teks dengan menambahkan kata kunci awalan dan akhiran pada
kedua ujung teks.
5. Tambahkan setiap nilai posisi yang ditemukan ke dalam binary tree.
Binary tree pada posisi ini merupakan binary tree yang tersusun dengan 1
subtree kanan, 0 subtree kiri. Difungsikan untuk memudahkan dalam
pengurutan node.
6. Urutkan setiap posisi yang berkesesuaian (pasangan) antara posisi kata
kunci-1 dan 2 dengan menggunakan metode pengurutan Order.
Pre-Order dimaksudkan agar pengolahan operasi terjadi dari posisi buka-tutup
terluar (hirarki terkecil). Langkah Pre-Order dilakukan dengan
mengunjungi root Bineary Tree, mengunjungi subtree kiri, lalu subtree
kanan secara rekursif.
7. Pada setiap proses pengunjungan, dilakukan perubahan bentuk pada binary
tree hingga menjadi sebuah binary tree transversal dengan Pre-Order
sebagai tolok ukur struktur tree.
8. Setelah posisi-posisi kata kunci-1 dan 2 telah tersusun sebagaimana
semestinya, terjemahkan bagian teks yang berada pada posisi yang
berkesesuaian terhadap masing-masing posisi pada binary tree. Proses
pengunjungan subtree dilakukan dengan metode Post-Order secara
rekursif, dengan tujuan agar teks dapat terpecah dari bagian paling dalam
4.3. Implementasi Algoritma Boyer-Moore pada Translator
Fungsi utama pada Translator terhadap teks yang dibentuk menjadi
pernyataan atau serangkaian pernyataan Pascal adalah pencocokan suatu pattern
tertentu yang diasumsikan sebagai pemisah rangkaian pembentuk pernyataan
Pascal. Pencocokan ini dilakukan untuk memenggal teks berdasarkan posisi
pattern terhadap teks, sehingga teks dapat dikenali sebagai pernyataan Pascal dan
diterjemahkan ke pernyataan C.
Kaidah pertama dari algoritma Boyer-Moore ini adalah masing-masing
karakter dari pattern pencocokan harus mempunyai kode ASCII yang sama
terhadap target karakter yang ada pada teks serta karakter-karakter antara pattern
dan target harus terurut sama persis.
Kaidah yang kedua adalah hasil penerjemahan teks berdasarkan
pencocokan pattern akan bernilai benar secara utuh jika teks telah sukses melalui
proses compile pada compiler Turbo Pascal 7.0. Walaupun demikian, Translator
menerapkan fungsi-fungsi yang dapat memastikan kebenaran sintaksis pernyataan
berdasarkan perolehan posisi pattern terhadap teks dan mengabaikan beberapa
kesalahan sederhana pada sintaksis sehingga dapat diterjemahkan ke bentuk C.
Dengan kata lain, suatu teks memungkinkan diterjemahkan secara utuh, sebagian,
atau tidak sama sekali. Untuk itu, dibutuhkan suatu basis pengetahuan dalam
pencocokan posisi dan pemenggelan pattern terhadap teks.
4.3.1. Pengembangan Cara Kerja Umum Algoritma Boyer-Moore
Secara Umum, langkah-langkah dari teknik penerapan Boyer-Moore pada
1. Menjalankan prosedur preBmBc dan preBmGs untuk mendapatkan nilai
perbandingan pergeseran.
a. Menjalankan prosedur preBmBc. Fungsi dari prosedur ini adalah untuk
menentukan berapa besar pergeseran yang dibutuhkan untuk mencapai
karakter tertentu pada pattern dari karakter pattern terakhir/terkanan.
Hasil dari prosedur preBmBc disimpan pada stack bmBc.
b. Menjalankan prosedur preBmGs. Sebelum menjalankan isi prosedur ini,
prosedur suffix dijalankan terlebih dulu pada pattern. Fungsi dari
prosedur suffix adalah memenggal sejumlah karakter yang dimulai dari
karakter terakhir/terkanan dengan sejumlah karakter yang dimulai dari
setiap karakter yang lebih kiri. Hasil dari prosedur suffix disimpan pada
stack suff. Dengan demikian suff[i] mencatat panjang dari suffix yang
cocok dengan segmen dari pattern yang di akhiri karakter ke-i.
c. Dengan prosedur preBmGs, dapat diketahui berapa banyak langkah pada
pattern dari sebuah segmen ke segmen lain yang sama, dimana letaknya
lebih kiri dengan karakter di sebelah kiri segmen yang berbeda. Prosedur
preBmGs menggunakan stack suff untuk mengetahui semua pasangan
segmen yang sama.
2. Menjalankan prosedur BM, proses pencocokan pattern dengan menggunakan
hasil dari prosedur preBmBc dan preBmGs yaitu stack bmBc dan bmGs
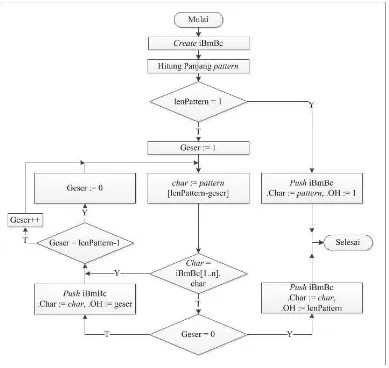
4.3.1.1. Prosedur preBmBc
Prosedur preBmBc memiliki tiga nilai penting, diantaranya :
1. Pattern, sebagai subjek pencocokan terhadap teks.
2. Karakter, sebagai karakter-karakter yang terdapat pada pattern.
3. Occurence Heuristic (OH), sebagai nilai pergeseran yang diperoleh ketika
menemukan ketidakcocokan karakter.
4. Pergeseran, sebagai nilai yang dicapai ketika melakukan pergeseran dari
kanan ke kiri pattern.
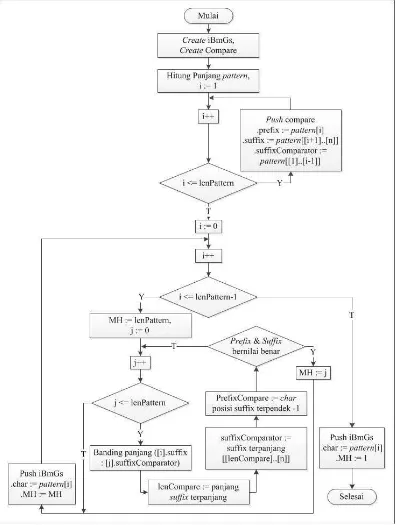
Langkah-langkah pelaksanaan prosedur :
1. Create atau berikan nilai kosong ke stack iBmBc.
2. Lakukan perhitungan terhadap panjang pattern. Jika panjang tidak lebih dari
satu, maka hentikan proses dengan menambahkan langsung nilai OH dan
karakter ke dalam stack iBmBc. Jika tidak, maka lanjutkan ke proses
selanjutnya.
3. Cacahan karakter pattern mulai dari karakter ke-2 paling kanan.
4. Bandingkan setiap karakter yang dicacah terhadap stack iBmBc, jika karakter
yang dicacah tidak ditemukan di dalam stack, maka tambahkan karakter
tersebut ke dalam stack dimana OH sama dengan jumlah pergeseran karakter
yang telah dilakukan.
5. Lakukan langkah-4 kembali, dengan melakukan perpindahan 1 karakter ke
kiri hingga mencapai karakter paling kiri secara terus menerus.
6. Jika telah mencapai karakter paling kiri, cacah karakter paling kanan lalu
Berikut representasi prosedur preBmBc dengan menggunakan flowchart :
Gambar 4.4 Flowchart pengembangan prosedur preBmBc Contoh kasus,
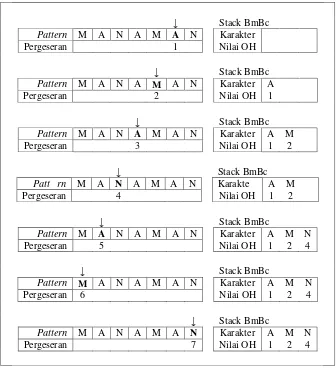
Pattern : MANAMAN
Stack BmBc
Gambar 4.5 Penyelesaian contoh kasus Prosedur preBmBc
Pada gambar di atas, terlihat bahwa karakter yang ditunjuk akan
ditambahkan ke dalam stack BmBc jika tidak ditemukan pada stack BmBc dengan
nilai OH yang berkesesuaian dengan nilai pergeseran.
4.3.1.2. Prosedur preBmGs
Prosedur preBmGs memiliki enam nilai penting, diantaranya:
1. Pattern, sebagai subjek pencocokan terhadap teks.
2. Match Heuristic (MH), sebagai nilai pergeseran yang diperoleh ketika
3. Compare, sebagai akhiran atau sejumlah karakter sebelah kanan dari sebuah
karakter pattern yang diperoleh dari pergeseran kanan ke kiri.
4. Prefix, sebagai awalan atau karakter pattern yang diperoleh dari pergeseran
dari kiri ke kanan.
5. Suffix, sebagai akhiran sebelah kanan prefix.
6. Pergeseran, sebagai nilai yang dicapai ketika melakukan pergeseran dari
compare.
Langkah-langkah pelaksanaan prosedur :
1. Create atau berikan nilai kosong ke stack iBmGs dan Compare.
2. Lakukan aksi yang sama dengan preBmBc jika panjang pattern tidak lebih
dari satu.
3. Cacah compare terhadap pattern. Lalu simpan hasil pencacah dengan
menambahkan ke dalam stack compare.
4. Cacah prefix dan suffix terhadap pattern. Lalu simpan hasil pencacahan prefix
ke dalam stack BmGs, dan bandingkan suffix terhadap compare dengan
melihat kecocokan antara masing-masing prefix.
5. Jika panjang kedua suffix tidak sama besar, cacah salah satu suffix yang
memiliki panjang terbesar kearah kanan sepanjang suffix dengan panjang
terkecil. Jika ditemukan kecocokan antar suffix, bandingkan prefix kedua
suffix. Jika prefix yang diperbandingkan adalah sama, maka kecocokan tidak
dapat diterima.
6. Untuk compare, prefix didapat ketika terjadi pencacahan pada compare, prefix
terhadap compare sebelum terjadinya pencacahan. Jika tidak terjadi
pemotongan, maka prefix-compare bernilai null.
7. Untuk indeks prefix paling kanan, nilai MH harus selalu bernilai 1.
Sedangkan nilai MH pada prefix lainnya, diberikan ketika ditemukan
ketidakcocokan antara prefix-suffix terhadap prefix-compare dan
ditemukannya kecocokan di antara kedua suffix sebesar nilai pergeseran
terbentuknya compare.
8. Ulangi langkah 5 hingga compare yang terakhir.
Berikut representasi prosedur preBmGs dengan menggunakan flowchart :
Gambar 4.6 Flowchart pengembangan prosedur preBmGs
Pattern : MANAMAN
Penyelesaian :
Tabel 4.1 Daftar pencacahan prefix dan suffix dari pattern Suffix (kanan-kiri) Prefix Suffix (kiri-kanan)
Null M ANAMAN
M A NAMAN
MA N AMAN
MAN A MAN
MANA M AN
MANAM A N
MANAMA N Null
Dari tabel di atas, diasumsikan bahwa telah terjadi pemotongan pada
kedua sisi suffix terhadap prefix pada pattern. Terlihat bahwa masing-masing
suffix dipersatukan oleh prefix hingga menjadi satu kesatuan pattern utuh.
Sedangkan null diartikan kosong, yakni semua kondisi pencocokan akan bernilai
Gambar 4.7 Penyelesaian contoh kasus Prosedur preBmGs
Pada gambar di atas terlihat bahwa pergeseran pada compare memiliki
peran utama dalam penentuan nilai MH. Berbeda dengan nilai OH, nilai MH
selalu diberikan pada karakter-karakter yang ada pada pattern. Penyusunan stack
BmGs pun berdasarkan urutan indeks posisi karakter pada pattern.
4.3.1.3. Prosedur BM
Prosedur BM memiliki empat nilai penting, diantaranya :
2. Teks, sebagai objek pencocokan.
3. Stack BmBc, sebagai pembanding ketika ditemukan ketidak cocokan.
4. Stack BmGs, sebagai pembanding ketika ditemukan kecocokan.
Langkah-langkah pelaksanaan prosedur :
1. Pencocokan dimulai dari indeks teks terkecil atau dari karakter paling kiri.
2. Pencocokan per karakter dimulai dari karakter paling kanan pattern.
3. Setiap kali ditemukan ketidakcocokan karakter, maka ambil nilai OH pada
stack BmBc dengan karakter yang berkesesuaian terhadap teks, lalu nilai OH
dikurangi dengan jumlah kecocokan yang telah terjadi. Ambil nilai MH pada
stack BmGs dengan indeks karakter yang ditemukan ketidakcocokan, lalu
bandingkan dengan nilai OH yang telah dioperasikan. Dengan nilai terbesar,
geser pattern kearah kiri teks dan ulangi pencocokan.
4. Jika nilai kecocokan sama dengan panjang pattern maka pattern telah
ditemukan pada teks, geser pattern sepanjang jumlah karakter pattern ke arah
kiri teks untuk melanjutkan pencocokan selanjutnya.
Contoh kasus,
Pattern : MANAMAN
Teks : NAMANANAMMANAMAN
Gambar 4.8 Penyelesaian contoh kasus Prosedur BM
Pada gambar di atas terlihat bahwa pergeseran pada pattern selalu
mengikuti keputusan dari hasil perbandingan OH dan MH. Pada umumnya,
pencocokan standar akan mencocokan karakter per karakter, ketika ditemukan
ketidakcocokan maka pattern akan digeser satu langkah ke arah selanjutnya.
Namun tidak demikian pada algoritma Boyer-Moore. Inilah yang menjadi alasan
utama penulis menerapkan algoritma ini sebagai pusat pemecahan pernyataan
Pascal sebagai awal proses penerjemahan dan ketika dibutuhkannya sebuah proses
pencocokan string.
Berikut detail pengembangan prosedur BM sebagai pencapaian proses
pencocokan dan validasi string masukan agar menjadi lebih efisien terhadap
Gambar 4.9 Flowchart pengembangan algoritma Boyer-moore
Terlihat pada gambar bahwa terdapat penambahan proses pada algoritma
Boyer-Moore, yaitu cek kualifikasi pattern dan database, serta terdapat proses
kualifikasi pencocokan. Berikut detail pengembangan proses algoritma
Proses pengambilan nilai BmBc dan BmGs pada database dimaksudkan
agar proses perhitungan nilai keputusan pergeseran oleh prosedur BmBc dan
BmGs dapat menjadi lebih optimal, karena nilai keputusan telah tersimpan untuk
beberapa pattern dengan nilai ketetapan. Namun proses filter pada database
(recordset) membutuhkan estimasi waktu tertentu. Maka jika dibandingkan proses
pencocokan nilai keputusan oleh prosedur preBmBc dan preBmGs untuk pattern
yang lebih pendek, proses cek database akan menjadi lebih lama. Untuk itu,
keputusan pengecekan database ditentukan dari parameter prosedur BM pada saat
pemanggilan.
Terdapat pula parameter plusPos yang berfungsi sebagai nilai tambah
untuk setiap posisi yang ditemukan. plusPos digunakan pada saat pencocokan
string yang membutuhkan posisi akhir, tengah, maupun posisi tertentu dari sebuah
karakter yang terdapat pada pattern terhadap teks.
Terdapat pula kriteria jumlah pencocokan, kriteria ini difungsikan sebagai
parameter jumlah pencocokan yang dibutuhkan. Sebagai contoh, jika terdapat 10
kecocokan, maka pencocokan akan dihentikan ketika mencapai kecocokan ke-5,
dimana 5 adalah kriteria jumlah pencocokan. Sehingga menjadikan algoritma
Boyer-Moore berjalan lebih optimal dan sesuai kebutuhan Translator.
4.3.2. Basis Pengetahuan Algoritma Translator
Basis pengetahuan algoritma Translator Pascal ke C dibangun oleh 2 dasar
sintaksis seperti yang telah dijelaskan sebelumnya. Berikut representasi sintaksis