PENERAPAN ALGORITMA NEAREST
FEATURE MIDPOINT PADA APLIKASI
FACE RECOGNITION
Hasna Fairuz Lutfiyah1, Ikma Fitri Yenia2, Indah Siti Sarah3, Esa Firmansyah, S.T., M.Kom.4 1 DesaMaja Selatan, Maja, Majalengka
2Jl. Kopo Gg. Wiradisastra No. 14 Kota Bandung 3Jl. Ir. H. Juanda, Cianjur
1[email protected], 2[email protected], 3[email protected], 4[email protected]
Abstrak
Sistem Pengenalan Wajah dapat mengidentifikasi atau memverifikasi seorang individu dari citra digital. Sistem pengenalan wajah yang baik itu system dapat mengenali semua variasi wajah yang timbul. Variasi ini dapat berupa ekspresi wajah, tingkat pencahayaan wajah dan aksesoris-aksesoris wajah. Proses identifikasi wajah akan dilakukan denngan mencari jalur terpendek antara wajah yang dikenali dengan semua variasi hasil ekstrapolasi dan interpolasi prototype pada tiap kelas. Variasi tersebut akan ditangkap oleh garis-garis maya yang dibuat dari 2 prototype dalam sebuah kelas. Implementasi dari metode ini bisa mencapai tingkat akurasi lebih dari 90% dengan waktu eksekusi 0.5 detik pada kondisi optimal. Pengenalan wajah dapat dilakukan menggunakan metode Nearest Feature Line yang diperbaiki menjadi Nearest Feature midpoint Perbaikan yang diberikan oleh NFM adalah peningkatan kecepatan eksekusi 43.93% dari penggunaan NFL dengan tingkat akurasi hampir sama. Kedua metode masih sangat bergantung pada citra masukan. Variasi yang berlebih pada latar belakang dan besar ukuran citra akan mempengaruhi hasil akurasi. Kekurangan ini dapat diminimalkan dengan melakukan proses cropping dan reisizing.
Kata Kunci: pengenalan wajah, principal component analysis, nearest feature line, nearest feature midpoint
Abstract
The Face Recognition System can identify or verify an individual from a digital image. Good facial recognition system that the system can recognize all the variations of faces that arise. These variations can include facial expressions, facial lighting levels and facial accessories. The process of identifying the face will be done by looking for the shortest path between the recognizable face with all variations of extrapolation and prototype interpolation in each class. The variation will be captured by virtual lines created from 2 prototypes in a class. Implementation of this method can achieve an accuracy of more than 90% with a 0.5 second execution time under optimal conditions. Facial recognition can be done using the Nearest Feature Line method that is fixed to Nearest Feature midpoint The improvement provided by NFM is
an increase in execution speed of 43.93% of the use of NFL with almost the same accuracy. Both methods still depend heavily on the input image. Excessive variations in the background and size of the image will affect the accuracy of the results. This shortage can be minimized by doing the process of cropping and reisizing.
Keywords: face recognition, principal component analysis, nearest feature line, nearest feature midpoint
1. PENDAHULUAN 1.1. Latang Belakang
Berdasarkan data Asosiasi Penyelenggara Jasa Internet Indonesia (APJII), pengguna internet di Indonesia terus mengalami peningkatan. Tahun 1998 hanya 500 ribu orang yang menggunakan internet, namun dimulai pada tahun 2012 pengguna internet meroket menjadi 63 juta orang. Angka itu bahkan diprediksi akan terus meningkat menjadi 139 juta orang pada tahun 2016. Begitu juga yang terjadi terhadap penggunaan telepon
genggam atau smartphone. Bila dibandingkan
dengan pengguna internet yang 'hanya' 83 juta, di Indonesia saat ini pengguna aktif ponsel telah mencapai 281,9 juta orang. Jumlah tersebut menggambarkan bahwa setiap orang di Indonesia memegang ponsel sebanyak 1,13 unit. Teknologi dikembangkan untuk memenuhi kebutuhan masyarakat. Berbagai macam kebutuhan masyarakat seiring dengan berkembangnya teknologi dapat terpenuhi dengan baik.
Media sosial merupakan salah satu hal yang dibutuhkan oleh masyarakat saat ini. Bahkan anak usia dini pun sudah mahir bermain sosial media. Dengan meningkatnya pengguna sosial media menjadikan para developer meningkatkan bahkan menambah fiture aplikasi sosial media masing-masing. Salah satunya adalah pengembangan fitur pengenalan wajah dalam aplikasi sosial media seperti facebook.
Sebuah sistem pengenalan wajah yang handal harus tetap bisa bekerja dan mampu menangani masukan citra wajah dengan berbagai variasi terutama dalam sudut pengambilan, ekspresi, pencahayaan dari citra yang dijadikan masukan. Dari ketiga variasi tersebut, variasi wajah yang sama dalam pencahayaan dan sudut pan-dang pada saat pengambilan citra biasanya jauh lebih besar dari pada ekspresi wajah yang sama.[1]
Salah satu teknik biometric yang sangat menarik adalah aplikasi yang mampu mendeteksi dan mengidentifikasi wajah. Saat ini, pengenalan wajah melalui aplikasi komputer dibutuhkan untuk mengatasi berbagai masalah, antara lain dalam identifikasi pelaku kejahatan, pengembangan sistem keamanan, pemrosesan citra maupun film, dan interaksi manusia komputer.[2]
Sistem pengenalan wajah telah banyak di kembangkan menggunakan berbagai metode seperti metode PCA, LDA, kernel, Bayesian Framework, dan masih banyak lagi.
Dari beberapa metode yang telah disebutkan tadi disini akan dicoba implementasi pengenalan wajah menggunakan algoritma nearest feature midpoint (NFM). NFM merupakan metode pengenalan wajah yang di definisikan sebagai metode perbaikan dari metode sebelumya yaitu nearest feature line (NFL).
2. TINJAUAN PUSTAKA 2.1. Pengolahan Citra Digital
Pengolahan citra digital (Digital Image Processing) adalah sebuah disiplin ilmu yang mempelajari tentang teknik-teknik mengolah citra. Pada aplikasi pengolahan citra digital pada umumnya, citra digital dapat dibagi menjadi 3, color image, balck and white image dan binary image.[3]
Gambar 1. Citra Digital
Citra digital adalah suatu citra f(x,y) yang memiliki koordinat spatial, dan tingkat kecerahan yang diskrit. Citra yang terlihat merupakan Pengenalan ini dapat dibagi menjadi dua bagian yaitu : Dikenali atau tidak dikenali, setelah
dilakukan perbandingan dengan pola yang sebelumnya disimpan di dalam database. Metoda ini juga harus mampu mengenali objek bukan wajah. Perhitungan model pengenalan wajah memiliki beberapa masalah. Kesulitan muncul ketika wajah direpresentasikan dalam suatu pola yang berisi informasi unik yang membedakan dengan wajah yang lain.[2]
2.3. Principal Component Analysis dan Eigenface Proyeksi ruang eigen (eigenspace) juga dikenal sebagai Karhunen-Loeve (KL) atau juga dinamakan dengan Principal Component Analysis
(PCA). Algoritma eigenface memanfaatkan Principal Component Analysis (PCA) untuk himpunan bobot-bobot yang mendeskripsikan kontribusi dari tiap vector dalam ruang wajah.[4] Langkah-langkah yang digunakan dalam Principal Component Analysis dalam penelitian data dengan dimensi sejumlah elemen pada sebuah vektor. Pada pembentukan eigenface, data ini berupa citra wajah dengan jumlah dimensi sama dengan jumlah pixel dalam didapat dengan mencari nilai kovarian untuk tiap dimensi terhadap semua dimensi dalam him- punan data pada persamaan (2). Cmxn = (ci,j=cov(Dimi, Dimj)) (2)[1]
d. Mencari eigenvector dan eigenvalue
e. Memilih komponen utama data
antar dimensinya. Dari sini, tentukan P eigenvector terbesar yang mewakili data.[1]
f. Membentuk himpunan data baru
2.4. Nearest Feature Line (NFL)
Dasar pemikiran NFL didasarkan pada pertimbangan berikut: Sebuah suara sesuai dengan titik (vektor) di ruang fitur. Ketika satu suara berubah secara terus-menerus ke yang lain dalam beberapa cara, ia menarik lintasan yang menghubungkan titik-titik fitur yang terkait dalam ruang fitur. Lintasan karena perubahan antara suara prototipe dari kelas yang sama merupakan subruang yang mewakili kelas itu. Suara audio kelas ini harus dekat dengan ruang bagian meskipun mungkin belum tentu prototipe asli.[5]
Oleh karena itu terdapat dua anggota yang ber- beda dalam tiap kelas. Selanjutnya prototype akan dise- but sebagai point. Metode NFL menggunakan sebuah model linier untuk menginterpolasi dan mengekstrapo- lasi tiap pasang point dari sebuah kelas yang sama. Dari kedua point ini, ditarik sebuah garis yang mengenerali- sasi kapasitas representasi kedua point tersebut. Garis yang menghubungkan dua point dalam satu kelas yang sama ini disebut dengan Feature Line garis fitur.[1]
Secara virtual garis fitur akan menyediakan point-point fitur yang tak terbatas dari kelas point tersebut se- hingga kapasitas himpunan prototype dalam sebuah ke- las akan bertambah. Untuk sebuah kelas c dengan jum- lah anggota Nc >1 akan terbentuk Kc =Nc (Nc - 1) /2 buah garis yang bisa digunakan sebagai representasi dari kelas tersebut. Misalkan untuk lima protoype dalam sebuah kelas, maka representasi kelas tersebut bisa diperbanyak menjadi 10 jumlah garis fitur yang bisa dibangun.[1]
2.5. Nearest Feature Midpoint (NFM)
NFM adalah metode klasifikasi yang merupakan perbaikan dari NFL. NFM mengasumsikan setidaknya akan terdapat dua prototype berbeda pada sebuah kelas. Didalam NFM sebuah sub ruang fitur dibentuk untuk ti- ap kelas yang terdiri dari titik tengah fitur (feature mid- point) antara tiap dua prototype pada kelas yang sama, x1 dan x2, dan dinotasikan sebagai mx1x2. Prototype pada kelas yang sama akan digeneralisasi oleh titik tengah fitur untuk merepresentasikan variasi dari kelas sehing-ga kemampuan pengklasifikasi melakukan generalisasi juga akan meningkat. Jarak NFM adalah jarak eucli-dean terkecil antara objek yang diuji dengan semua titik tengah yang mungkin dibangun.[1]
Gambar 2. Grafik hubungan penggunaan jumlah eigenface dengan rata-rata error rate.
Gambar 3. Grafik hubungan jumlah citra latih yang digunakan dengan error rate.
3. PEMBAHASAN DAN HASIL
Uji coba dilakukan untuk mendapatkan konfigurasi optimal dari sistem pengenalan wajah. Basis data yang digunakan dalam pengujian adalah: basis data Bern.
Gambar 4. Grafik hubungan penggunaan jumlah citra latih dan waktu eksekusi pada proses training.[1]
Skenario 1
Proses pengenalan wajah dilakukan untuk mencoba semua kemungkinan konfigurasi. Dilakukan perulangan untuk mendapatkan hasil yang representatif sebanyak 10 kali. Konfigurasi yang dimaksudkan adalah: [1]
Tabel 1. Tingkat akurasi pengujian dari skenario 2.
Pengamatan Basis Data Rata –rata(%
)
(s) NFLNFM 0.3050.129 0.7850.349 0.173 0.4212
3 0.078 0.1855
Perbai
kan 42.318 44.495 45.002 43.938
(1) Titik proyeksi yang diuji µ = -1.0, µ = -0.5, µ = 0, µ = 0.25, µ = 0.5 (NFM), µ = 0.75, µ = 1.0, µ =1.5, µ = 2.0, dan menggunakan metode NFL (menghitung para- meter µ).
(2) Jumlah citra latih dimulai dari dua (syarat pemben-tukan FL) sampai jumlah citra per kelas – 2 (sebagai ci-tra uji).
(3) Jumlah eigenface yang diuji = 3, 5, 8, 10, 15, 20, 30, 40, 60 dan 70.
Untuk pengamatan atas titik proyeksi di Gambar 1[1] terlihat penggunaan FP6 (pada titik 0.75*FL), FP5 (NFM), FP4 (pada titik 0.25*FL) dan NFL (hasil penca-rian parameter proyeksi citra uji pada FL) diperoleh tingkat kesalahan kurang dari 20%. Sebagai catatan, FL adalah feature point atau garis fitur.[1]
Tampak dari grafik pada Gambar 2 bahwa untuk semua basis data dan proyeksi titik citra uji ke FL rata-rata errornya akan semakin kecil dengan bertambahnya eigenface yang digunakan. Tampak juga bahwa pertam-bahan akurasi pada penggunaan setidaknya lima belas eigenface tidak signifikan.[1]
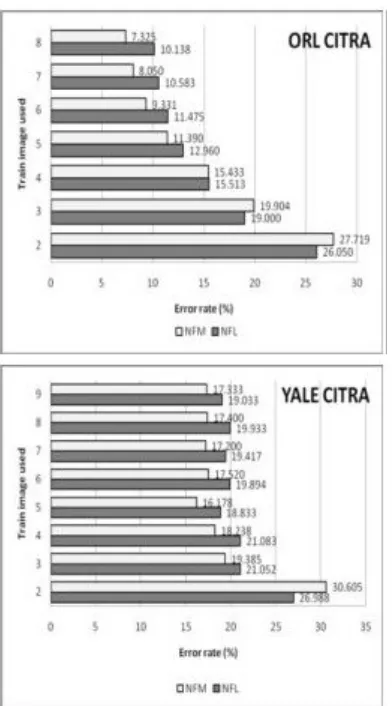
Pada Gambar 3 tampak bahwa pemakaian citra latih berpengaruh pada tingkat akurasi. Berkurangnya nilai error paralel dengan bertambahnya citra latih yang digunakan. Namun pengaruh ini kurang signifikan se-telah penggunaan setidaknya lima citra latih. Sedang-kan Gambar 3 menunjukkan bahwa waktu eksekusi un-tuk pelatihan akan bertambah seiring dengan bertam-bahnya citra latih yang digunakan. Fenomena itu juga terjadi untuk waktu eksekusi pengujian.[1]
Skenario 2
Pengujian pada skenario dua dilakukan hanya menggunakan konfigurasi optimal dan perulangan sebanyak 50 kali. Dari pengujian diperoleh prosentase ting- kat akurasi yang ditunjukkan pada Tabel 1.[1]
Untuk memastikan perbedaan tingkat akurasi dan waktu eksekusi metode NFL dan NFM, maka hasil aku-rasi dan waktu eksekusi kedua metode tersebut akan diuji dengan Uji-t. Diasumsikan ukuran sampel kurang dari 30, populasi berdistribusi normal dan terdiri dari dua sampel yang saling bebas dan berpasangan. Peng-ujian dilakukan pada taraf keberartian 0.05 atau confi-dence interval 95% dengan aplikasi bantu SPSS v.10.[1]
Dari hasil analisis terlihat bahwa untuk hipotesa H0: rata-rata akurasi kedua metode identik, thitung=0.028 <
t(11,0.025)=1.80 dengan df (degree of freedom) n-1 = 11 dan
0.025 adalah setengah dari α(0.05)=0.025.[1]
Dikarenakan thitung(0.028)<ttabel(1.80) maka H0
diterima sehingga pernyataan rataan akurasi kedua metode sama adalah benar. Keputusan juga bisa diambil dengan melihat nilai significant Sig.(2-tailed) = 0.978 > setengah α = 0.025 maka H0 diterima.[1]
Analisis uji H1: rata-rata waktu kedua metode identik menghasilkan nilai thitung=2.617 > t(11,0.025)=1.80.
Karena thitung(2.617) > ttabel(1.80) maka H1 ditolak
se-hingga pernyataan rataan waktu eksekusi kedua metode sama adalah salah. Dikarenakan juga nilai Sig.(2-tailed) = 0.016 < setengah α = 0.025 maka H1 ditolak.[1]
Berdasarkan analisa H0 dan H1 terbukti bahwa NFM memperbaiki waktu eksekusi dari algoritma NFL. [1]
4. PENUTUP
Dari penelitian dan pembahasan yang dilakukan menunjukkan bahwa pengenalan wajah dapat dilakukan menggunakan metode Nearest Feature Line yang diperbaiki dengan metode Nearest Feature Midpoint. Perbaikan yang di berikan oleh metode Nearest Feature Midpoint (NFM) adalah peningkatan yang kecepatan eksekusinya 43.93% dari penggunaan NFL dengan tingkat akurasi yang hampir sama.
Uji coba dalam proses pengenalan wajah ini dilakukan untuk mendapat konfigurasi yang optimal. Basis data yang digunakan yaitu basis data Bern.
Proses pengenalan wajah dilakukan untuk mencoba semua kemungkinan konfigurasi. Kedua metode masih sangat bergantung pada citra masukan. Variasi yang berlebih pada latar belakang dan besar ukuran citra akan mempengaruhi hasil akurasi. Kekurangan ini bisa diminimalkan dengan melakukan proses pendahuluan pada citra yang akan digunakan meliputi cropping dan resizing [1]
DAFTAR PUSTAKA
[1] D. Purwitasari, R. Soelaiman, and F. T. Informasi,
“Implementasi Pengenalan Wajah Berbasis Algoritma Nearest Feature Midpoint,” no. July, 2015.
[2] Sepritahara, “Sistem Pengenalan Wajah (Face
Recognition) Menggunakan Metode Hidden
Markov Model (Hmm),” Uma ética para
quantos?, vol. XXXIII, no. 2, pp. 81–87, 2012.
[3] W. S. Pambudi and A. N. Tompunu, “Aplikasi
Sensor Vision untuk Deteksi MultiFace dan Menghitung Jumlah Orang,” vol. 2012, no. Semantik, pp. 26–33, 2012.
[4] M. Murinto, “Pengenalan Wajah Manusia Dengan
Metode Principle Component Analysis (Pca),”
TELKOMNIKA (Telecommunication Comput. Electron. Control., vol. 5, no. 3, p. 177, 2007.
[5] S. Z. Li, “Content-based audio classification and
retrieval using the nearest feature line method,”

![Gambar 4. Grafik hubungan penggunaan jumlah citralatih dan waktu eksekusi pada proses training.[1]](https://thumb-ap.123doks.com/thumbv2/123dok/3892273.1853303/5.595.57.276.69.362/gambar-grafik-hubungan-penggunaan-jumlah-citralatih-eksekusi-training.webp)
