36 BAB IV
EVALUASI KINERJA ALGORITMA LZSS
4.1 Kompresi Maksimal Algoritma LZSS
4.1.1 Kompresi Maksimal Data Teks
Untuk mencari bentuk data yang dapat memberikan hasil kompresi LZSS yang optimal, kita harus melihat lebih jauh mengenai cara kerja algoritma LZSS.
Seperti yang telah dijelaskan pada BAB II, secara singkat cara kerja algoritma LZSS adalah mencari string yang sama pada look-ahead buffer dengan pada dictionary buffer. Ketika ada string yang sama, maka string tersebut akan dikodekan dengan menggunakan token. Karena ukurannya token lebih kecil daripada ukuran string yang sama tersebut, maka akan dihasilkan kompresi.
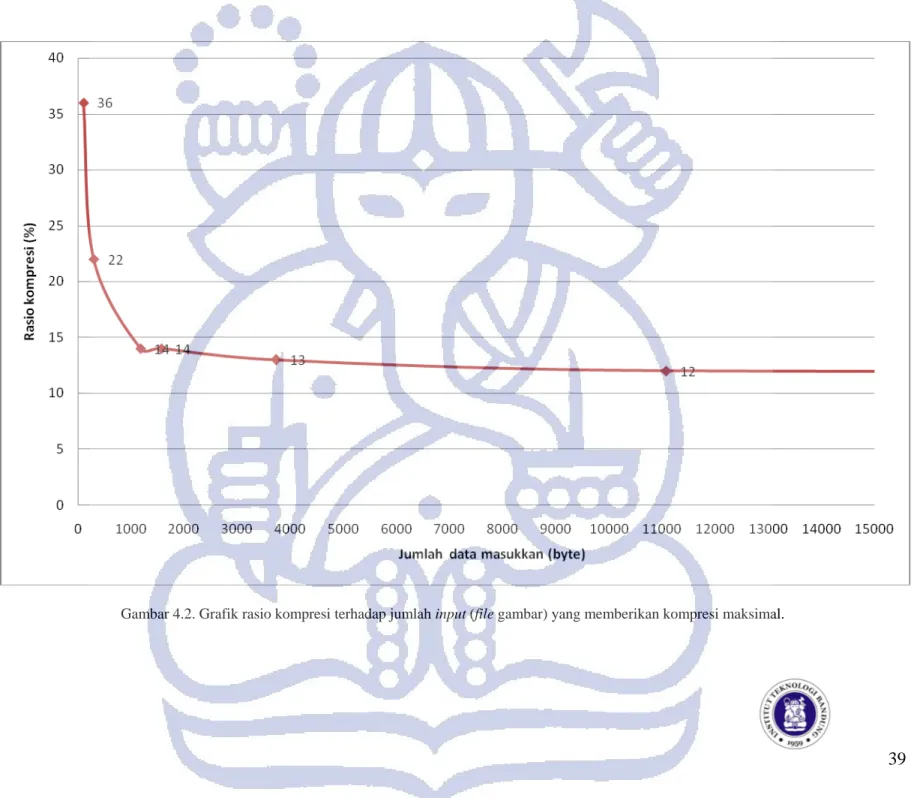
Berdasarkan pengetahuan tersebut, untuk mencari bentuk data optimal, penulis menggunakan file teks yang berisi deretan huruf yang sama sehingga tingkat terjadinya match antara look-ahead buffer dengan dictionary buffer menjadi sangat tinggi. Gambar 4-1 menunjukkan hasil tersebut. Dari gambar 4.1, terlihat bahwa tingkat kompresi maksimal dari algoritma LZSS adalah 12%. Data optimal tempat terjadinya kompresi 12% adalah ketika data tersebut memiliki 1017 karakter.
Perlu dicatat bahwa jenis file yang digunakan untuk percobaan kali ini adalah file plain text. Jenis file ini dipilih tidak banyak memiliki banyak overhead sehingga hasil yang didapatkan benar-benar menggambarkan kinerja algoritma LZSS dalam melakukan kompresi terhadap teks pada titik maksimalnya.
37
Gambar 4.1. Grafik rasio kompresi terhadap jumlah input (file teks) yang memberikan kompresi maksimal.
38 4.1.2 Kompresi Maksimal Data Gambar
Sama seperti pada data teks, penulis juga mencoba mencari bentuk data gambar seperti apa yang menghasilkan kompresi maksimal oleh algoritma LZSS.
Jenis file yang penulis gunakan pada percobaan ini adalah file gambar bitmap.
Format file bitmap penulis pilih karena merupakan format file standar yang paling mendasar untuk menyimpan file-file gambar.
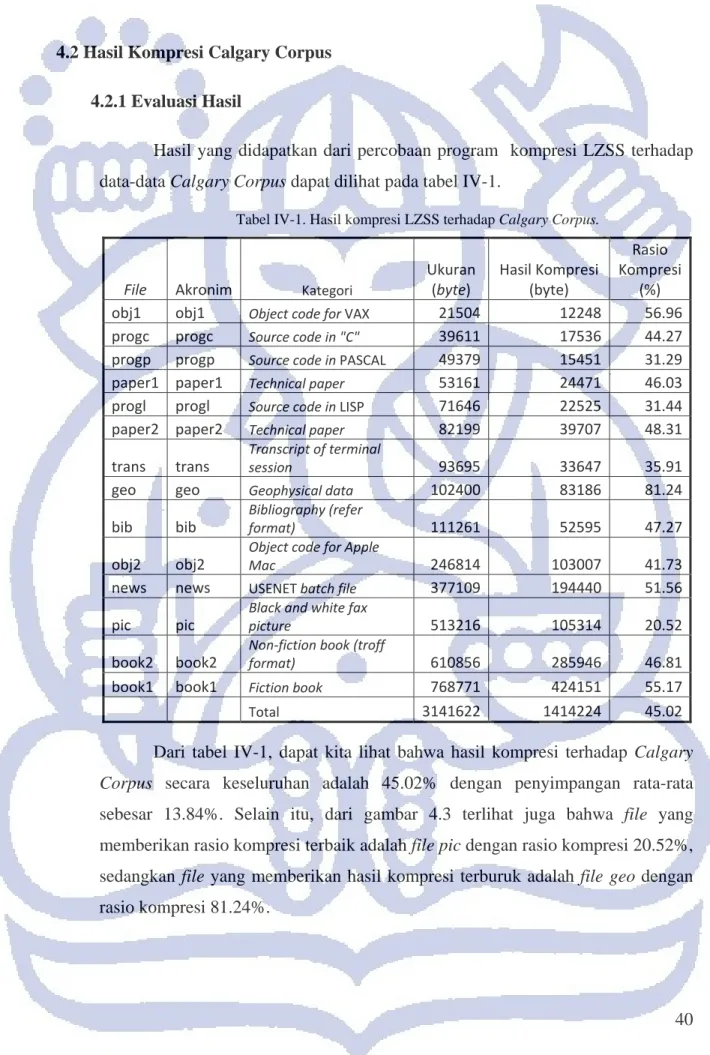
Hasil yang didapatkan ditunjukkan oleh gambar 4.2. Hasil tersebut menunjukkan bahwa kompresi maksimum yang dapat dicapai oleh algoritma LZSS terhadap file gambar sama dengan kompresi maksimum terhadap file teks, yaitu sebesar 12%. Hasil ini dicapai ketika file input memiliki besar minimal 4500 byte, sedangkan bentuk file yang memberikan hasil kompresi maksimal ini adalah file gambar monotone dengan warna apapun.
Hasil percobaan ini sesuai dengan prinsip kerja dari algoritma LZSS yaitu mengkodekan deretan string yang sama dengan token sehingga lebih efisien.
Semakin banyak piksel yang memiliki warna yang sama, maka semakin banyak pula token yang digunakan untuk mewakili piksel tersebut. Dengan demikian, maka kompresi algoritma LZSS terhadap file tersebut akan semakin meningkat.
39
Gambar 4.2. Grafik rasio kompresi terhadap jumlah input (file gambar) yang memberikan kompresi maksimal.
40 4.2 Hasil Kompresi Calgary Corpus
4.2.1 Evaluasi Hasil
Hasil yang didapatkan dari percobaan program kompresi LZSS terhadap data-data Calgary Corpus dapat dilihat pada tabel IV-1.
Tabel IV-1. Hasil kompresi LZSS terhadap Calgary Corpus.
File Akronim Kategori
Ukuran (byte)
Hasil Kompresi (byte)
Rasio Kompresi
(%)
obj1 obj1 Object code for VAX 21504 12248 56.96
progc progc Source code in "C" 39611 17536 44.27 progp progp Source code in PASCAL 49379 15451 31.29 paper1 paper1 Technical paper 53161 24471 46.03 progl progl Source code in LISP 71646 22525 31.44 paper2 paper2 Technical paper 82199 39707 48.31 trans trans
Transcript of terminal
session 93695 33647 35.91
geo geo Geophysical data 102400 83186 81.24
bib bib
Bibliography (refer
format) 111261 52595 47.27
obj2 obj2
Object code for Apple
Mac 246814 103007 41.73
news news USENET batch file 377109 194440 51.56
pic pic
Black and white fax
picture 513216 105314 20.52
book2 book2
Non‐fiction book (troff
format) 610856 285946 46.81
book1 book1 Fiction book 768771 424151 55.17
Total 3141622 1414224 45.02
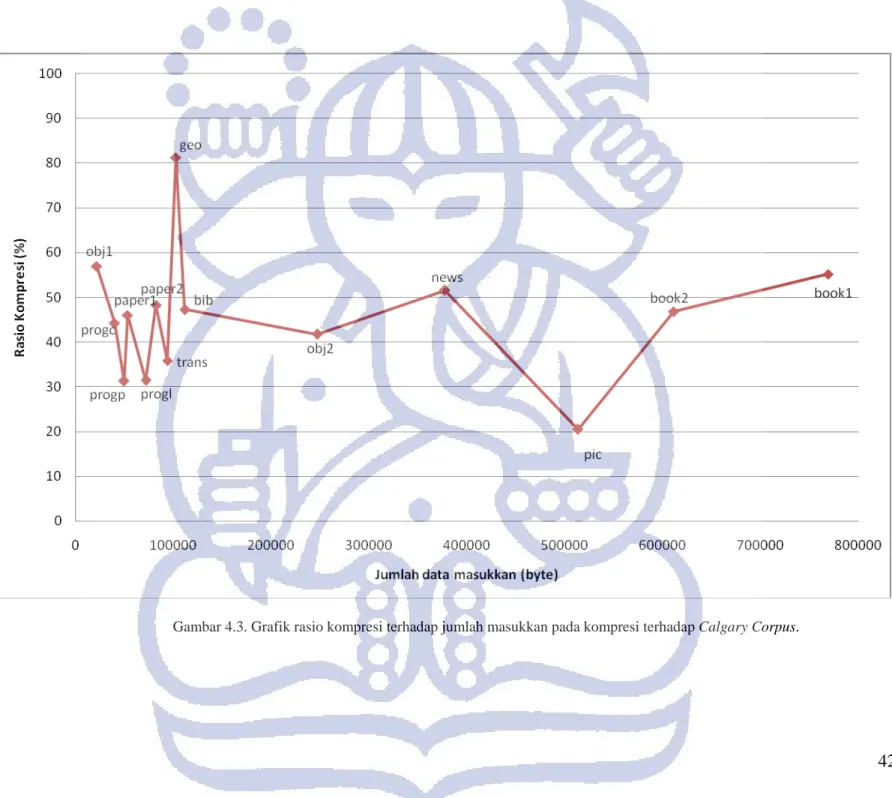
Dari tabel IV-1, dapat kita lihat bahwa hasil kompresi terhadap Calgary Corpus secara keseluruhan adalah 45.02% dengan penyimpangan rata-rata sebesar 13.84%. Selain itu, dari gambar 4.3 terlihat juga bahwa file yang memberikan rasio kompresi terbaik adalah file pic dengan rasio kompresi 20.52%, sedangkan file yang memberikan hasil kompresi terburuk adalah file geo dengan rasio kompresi 81.24%.
41 Penulis sebenarnya tertarik untuk melihat isi file pic untuk dapat mengetahui lebih lanjut bentuk file seperti apa yang memberikan hasil kompresi yang baik menggunakan algoritma LZSS. Namun, ternyata file pic tersebut memiliki extension yang tidak dapat dibuka pada lingkungan Microsoft Windows sehingga penelusuran terhadap file tersebut tidak mungkin untuk dilakukan.
Tetapi, menurut informasi dari [4], file ini merupakan file gambar hitam putih yang digunakan untuk fax.
Menurut penulis, gambar yang hanya terdiri dari warna hitam dan putih akan memberikan rasio kompresi yang baik ketika dikompresi menggunakan algoritma LZSS, karena gambar hitam putih hanya memiliki dua jenis simbol masukan. File gambar hitam putih dapat dianalogikan dengan file teks yang hanya terdiri dari dua huruf. Dengan demikian, match akan lebih sering terjadi sehingga rasio kompresi yang dihasilkan akan baik.
42
Gambar 4.3. Grafik rasio kompresi terhadap jumlah masukkan pada kompresi terhadap Calgary Corpus.
43 4.2.2 Perbandingan Dengan Metode Existing
Perbandingan hasil kompresi algoritma LZSS dengan algoritma kompresi lainnya dapat dilihat pada tabel IV-2.
Tabel IV-2. Perbandingan hasil kompresi LZSS terhadap program kompresi lainnya.
Program Kompresi Rasio Kompresi (%)
WinRAR 24.25
Gzip 32.75
WinZip 33.12
PPMC 35.87
Compress 42.50
LZSS 45.00
Pack 55.37
Hasil yang didapatkan menunjukkan bahwa algoritma LZSS menempati urutan ke-6 dalam kompresi terhadap Calgary Corpus. WinRAR sebagai pembanding tambahan menempati peringkat pertama dengan rasio kompresi sebesar 24.25%, sedangkan peringkat terakhir ditempati oleh program Pack dengan rasio kompresi sebesar 55.37%. Seperti yang telah dijelaskan sebelumnya, program yang digunakan sebagai pembanding utama adalah program Pack dan Compress karena kedua program ini memiliki sifat yang sama dengan program implementasi algoritma LZSS, yaitu hanya menggunakan sebuah algoritma tunggal dalam melakukan proses kompresi.
Percobaan kompresi terhadap Calgary Corpus ini menujukkan salah satu kelemahan LZSS, yaitu buruknya kinerja ketika digunakan untuk melakukan kompresi terhadap file-file kecil. Hal ini sangat sejalan dengan apa yang telah dijelaskan pada BAB II, yaitu bahwa algoritma kompresi yang berbasis dictionary coding kurang cocok untuk digunakan pada file kecil karena frekuensi terjadinya match pada file kecil belum dapat mengimbangi jumlah bit-bit redundan yang digunakan ketika mengeluarkan token. Kelemahan ini diatasi dengan sangat baik oleh program kompresi WinRAR, yaitu dengan cara melakukan kompresi lebih lanjut menggunakan Huffman Coding. Dengan digunakannya solusi tersebut,
44 maka simbol-simbol bagian dari token yang sering muncul dapat dikodekan menggunakan kode yang paling pendek.
Dari hasil pada tabel IV-2 juga dapat dilihat bahwa algoritma LZSS menempati posisi yang lebih baik ketimbang program Pack yang menggunakan algoritma tunggal Huffman Coding. Menurut penulis, hal ini mencerminkan bagaimana baiknya kinerja algoritma LZSS yang menjadi suatu entropy encoder ketika file masukan besar. Ketika file masukan besar, maka kemungkinan terjadinya match akan lebih besar sehingga memungkinkan algoritma LZSS melakukan fungsi kompresi yang sangat baik bahkan lebih baik daripada Huffman Coding. Berbeda halnya dengan algoritma LZSS, kinerja Huffman Coding sangat bergantung pada seberapa besar akurasi permodelan probabilitas simbol terhadap probabilitas simbol sebenarnya pada suatu file. Ketika model yang digunakan untuk menentukan codeword sesuai dengan kenyataan pada suatu file yang akan dikompresi, maka rasio kompresi yang didapatkan akan baik. Namun, apabila model yang digunakan kurang sesuai untuk memprediksi kemungkinan munculnya suatu simbol, maka rasio kompresi yang dihasilkan akan buruk.
Menurut penulis, algoritma LZSS lebih cocok digunakan untuk kompresi file teks dengan ukuran besar dibandingkan dengan Huffman Coding. Hal ini terkait dengan rasio kompresi terbaik yang dapat dicapai oleh suatu algoritma kompresi (rasio kompresi ketika algoritma tersebut menjadi entropy encoder).
Berdasarkan percobaan pencarian rasio kompresi maksimum, untuk tipe file teks, sario kompresi algoritma LZSS dapat mencapai 11.82 %. Untuk Huffman Coding rasio kompresi maksimumnya dapat dicari dengan menggunakan permisalan penggunaan model yang paling efisien. Sebagai contoh, penggunaan codeword satu bit untuk huruf a akan menghasilkan kompresi maksimal sebesar 12.5 % ketika digunakan untuk melakukan kompresi terhadap file yang sama dengan file yang digunakan ketika mencari rasio kompresi maksimal algoritma LZSS (file plain text yang berisi huruf a sebanyak 1017 karakter). Dari hasil demikian, terlihat bahwa algoritma LZSS memiliki peluang untuk bekerja lebih baik
45 dibandingkan dengan Huffman Coding ketika digunakan untuk kompresi file teks dengan ukuran besar.
Jika ditinjau berdasarkan hasil kompresi terhadap Calgary Corpus, maka program WinRAR dari algoritma LZSS memiliki perbedaan efisiensi sebesar 21.25%.
4.3 Hasil Kompresi Canterbury Corpus
4.3.1 Evaluasi Hasil
Hasil kompresi algoritma LZSS terhadap Canterbury Corpus dapat dilihat pada tabel IV-3.
Tabel IV-3. Hasil kompresi LZSS terhadap Canterbury Corpus.
File Akronim Kategori
Ukuran (byte)
Hasil Kompresi (byte)
Rasio kompresi (%) grammar.lsp list LISP source 3721 1541 41.41 xargs.1 man GNU manual page 4227 2128 50.34
fields.c csrc C source 11150 3846 34.49
cp.html html HTML source 24603 10945 44.49
sum sprc SPARC Executable 38240 17803 46.56 asyoulik.txt play Shakespeare 125179 65555 52.37 alice29.txt text English text 152089 73122 48.08 lcet10.txt tech Technical writing 426754 199727 46.80 plrabn12.txt poem Poetry 481861 262948 54.57 ptt5 fax CCITT test set 513216 105314 20.52 kennedy.xls excl Excel Spreadsheet 1029744 288121 27.98
Total 2810784 1031050 36.68
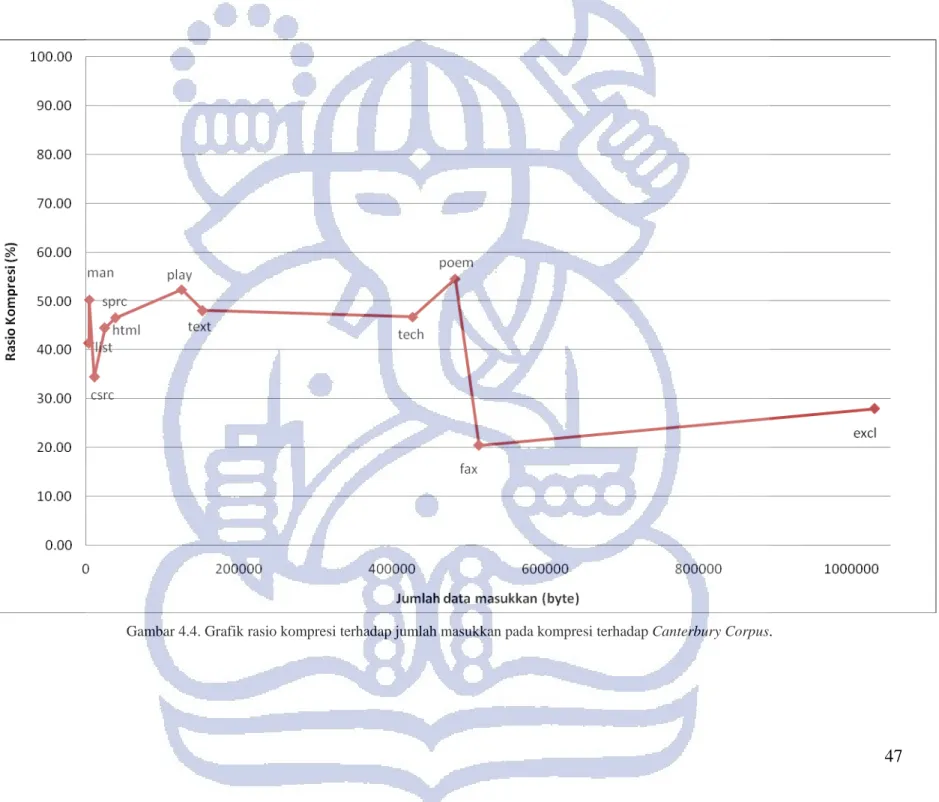
Dari tabel IV-3 terlihat bahwa rasio kompresi terbaik terjadi pada file ptt5 yaitu sebesar 20.52 %, sedangkan kompresi terburuk terjadi pada file plrabn12.txt yaitu sebesar 54.57 %. Menurut deskripsi, file ptt5 merupakan suatu file standar yang digunakan untuk melakukan tes pada mesin fax. File tersebut tidak dapat penulis lihat isinya karena memiliki ekstensi yang tidak jelas. File plrabn.txt merupakan sebuah file plain text yang isinya berupa kumpulan puisi-puisi.
46 Meskipun file ini tidak memiliki gambar, tetapi file ini menggunakan gaya bahasa yang sangat khusus dimana jarang terjadi pengulangan. Hal inilah yang membuat kinerja algoritma LZSS terhadap file tersebut menjadi buruk.
Gambar 4.4 menunjukkan grafik jumlah masukkan Canterbury Corpus terhadap rasio kompresi algoritma LZSS. Dari grafik tersebut dapat kita lihat bahwa untuk jumlah input rendah, rasio kompresi algoritma LZSS sangat berariasi tergantung pada isi dari file yang dikompresikan. Namun, seiring dengan pertambahan jumlah input, rasio kompresi algoritma LZSS menjadi semakin membaik.
47
Gambar 4.4. Grafik rasio kompresi terhadap jumlah masukkan pada kompresi terhadap Canterbury Corpus.
48 4.3.2 Perbandingan Dengan Metode Existing
Perbandingan hasil kompresi algoritma LZSS dengan algoritma kompresi lainnya dapat dilihat pada tabel IV-4.
Tabel IV-4. Perbandingan kompresi LZSS dengan program lainnya.
Program Kompresi Rasio kompresi (%)
WinRAR 14.87
WinZip 26.37
PPMC 27.37
Gzip 31.75
LZSS 36.62
Compress 41.37
Pack 56.50
Hasil yang didapatkan kembali menunjukkan bahwa program kompresi WinRAR memiliki rasio kompresi yang paling tinggi dibandingkan dengan program lainnya. Program WinRAR menempati urutan pertama dengan rasio kompresi sebesar 14.87%. Sedangkan posisi terakhir ditempati oleh program Pack dengan rasio kompresi kurang lebih empat kali rasio kompresi milik WinRAR, yaitu sebesar 56.5%.
Algoritma LZSS berada pada posisi ke 5 dengan rasio kompresi sebesar 36.625. Posisi ini lebih baik daripada hasil terhadap Calgary Corpus. Selain itu, rasio kompresi algoritma LZSS pun mengalami kenaikkan kurang lebih sebesar 20%. Kedua hal ini menunjukkan bahwa algoritma LZSS lebih cocok untuk digunakan pada data-data yang ada pada masa sekarang (yang diwakili oleh Canterbury Corpus).
Dari hasil pada tabel IV-4, terlihat bahwa LZSS menempati posisi yang lebih baik ketimbang kedua program pembanding utama, yaitu Pack dan Compress. Penjelasan mengapa LZSS bekerja lebih baik dibandingkan dengan program kompresi Pack telah penulis jelaskan sebelumnya pada subbab 4.2.2.
Selanjutnya, penulis akan menjelaskan mengapa algoritma LZSS bekerja lebih baik ketimbang program Compress yang menggunakan algoritma LZW.
49 Menurut penulis, file teks yang sangat besar akan terbentuk banyak string berurutan yang berbeda. Bila dikaitkan dengan cara kerja LZW yang selalu menambahkan string baru apabila string tersebut tidak muncul, maka dengan banyaknya string berbeda tersebut ukuran dictionary dari algoritma LZW akan menjadi sangat besar. Dengan demikian, maka token yang digunakan untuk mewakili posisi suatu string pada dictionary juga akan semakin besar sehingga jumlah bit yang dibutuhkan untuk token tersebut akan menjadi besar pula. Selain itu, sifat algoritma LZW yang selalu menambahkan entry baru pada dictionary juga akan membuat implementasinya menjadi sebuah program sulit jika besarnya dictionary tidak dibatasi. Kesulitan tersebut terjadi dalam proses decoding file hasil kompresi karena besarnya token yang digunakan tidak konstan. Menurut penulis, salah satu alternatif yang mungkin digunakan untuk masalah ini adalah dengan membatasi ukuran dari dictionary yang digunakan sehingga ukuran token yang dikeluarkan dapat diprediksi berapa besarnya. Apabila solusi ini digunakan untuk implementasi, maka hal ini juga akan turut memperburuk kinerja algoritma LZW itu sendiri. Apabila solusi ini digunakan pada program implementasi, maka akan ikut memperburuk kinerja algoritma LZW. Alasannya adalah karena ketika ukuran token dibuat konstan, maka string-string pada posisi awal yang sebelumnya bisa diwakilkan menggunakan token dengan ukuran yang lebih kecil (misal string pada posisi 10 dapat diwakilkan cukup dengan token berukuran 4 bit) sekarang harus diwakilkan dengan ukuran token yang sama dengan ukuran token yang telah ditetapkan. Dengan demikian, maka akan dihasilkan rasio kompresi yang kurang baik bahkan lebih buruk dari algoritma LZSS.
50 4.4 Hasil Kompresi Data Archieve Comparison Test
4.4.1 Kompresi Teks
4.4.1.1 Evaluasi Hasil
Hasil kompresi algoritma LZSS terhadap data teks yang digunakan pada ACT ditunjukkan pada tabel IV-5.
Tabel IV-5. Hasil kompresi LZSS terhadap file teks dari ACT.
D
Dari tabel IV-5, dapat kita lihat bahwa file yang mengasilkan rasio kompresi terbaik adalah file 1musk10.txt yaitu sebesar 49.93%, sedangkan file yang menghasilkan kompresi terburuk adalah file world95.txt dengan rasio kompresi 53.06%. Nilai rata-rata rasio kompresi dari ketiga file tersebut adalah sebesar 52.06%. Nilai rata-rata ini lebih buruk jika dibandingkan dengan nilai rata-rata rasio kompresi algoritma LZSS terhadap kedua jenis Corpus.
Dari gambar 4.5, dapat kita lihat juga bahwa rasio kompresi algoritma LZSS terhadap file teks dari ACT tidak terlalu bervariasi seperti hasil kompresi terhadap kedua Corpus. Menurut penulis, hal ini terjadi karena ketiga file teks tersebut memiliki karakteristik yang hampir sama (yaitu merupakan sebuah karya tulis non-ilmiah, sehingga seluruh isi file merupakan tulisan) dan memiliki ukuran file yang tidak terlalu jauh berbeda pula. Kedua karakteristik inilah yang menyebabkan kompresi yang dihasilkan oleh algoritma LZSS terhadap ketiga file tersebut tidak jauh berbeda.
File Akronim Kategori
Ukuran (byte)
Hasil Kompresi
(byte)
Rasio kompresi
(%) anne11.txt anne Anne of Gables 586390 303797 51.81 1musk10.txt musk The 3 Musketeers 1344739 671444 49.93 world95.txt world CIA Book 2988578 1586203 53.08
Total 4919707 2561444 52.06
51
Gambar 4.5. Grafik rasio kompresi terhadap jumlah masukkan pada kompresi terhadap file teks dari ACT.
52 4.4.1.2 Perbandingan Dengan Metode Existing
Perbandingan hasil kompresi algoritma LZSS dengan program lainnya ketika melakukan kompresi terhadap file teks yang digunakan pada ACT dapat dilihat pada tabel IV-6.
Tabel IV-6. Perbandingan hasil kompresi LZSS dengan program lain terhadap file teks ACT.
Dari tabel IV-6, dapat kita lihat bahwa hasil kompresi tertinggi tetap ditempati oleh program WinRAR dengan rasio kompresi sebesar 25.5%, sedangkan kompresi terburuk juga tetap ditempati oleh program kompresi Pack dengan rasio kompresi sebesar 64.62%. Kompresi dengan algoritma LZSS menempati urutan kelima dengan rasio kompresi sebesar 52%.
Perubahan peringkat terjadi pada program WinZip, PPMC, dan Gzip.
Program WinZip, yang tadinya menempati urutan kedua pada kompresi terhadap Canterbury Corpus, hanya menempati urutan keempat pada percobaan kali ini. Sedangkan peringkat PPMC dan peringkat Gzip masing- masing naik satu peringkat menjadi peringkat dua dan tiga secara berurutan.
Program Kompresi Rasio Kompresi (%)
WinRAR 25.50
PPMC 30.12
Gzip 32.25
WinZip 32.87
LZSS 52.00
Compress 59.50
Pack 64.62
53 4.4.2 Pengompresian File TIFF
4.4.2.1 Evaluasi Hasil
Hasil kompresi algoritma LZSS terhadap file-file gambar yang digunakan oleh ACT dapat kita lihat pada tabel IV-7. Hasil yang didapatkan menunjukkan bahwa kompresi tertinggi terjadi pada file frymire.TIFF, dengan rasio kompresi sebesar 15.28%. Sedangkan hasil terburuk adalah kompresi terhadap file clegg.TIFF yaitu sebesar 112.2%.
Tabel IV-7. Hasil kompresi file TIFF.
File
Ukuran
(byte) Hasil Kompresi (byte)
Rasio kompresi (%)
Clegg 1749650 1963137 112.2017
Frymire 3706306 566383 15.2816
Lena 786568 852639 108.3999
Monarch 1179784 1022627 86.67917
Peppers 786568 798470 101.5132
Sail 1179784 1149924 97.46903
Serrano 1498414 233356 15.57353
Tulips 1179784 1177853 99.83633
Total 12066858 7764389 64.34474
Jika dilakukan perbandingan secara sekilas, berdasarkan pada prinsip kerja algoritma LZSS, seharusnya file peppers-lah yang memiliki hasil kompresi paling baik. Hal ini dikarenakan file tersebut sebagian besar hanya terdiri dari warna merah, hijau, dan hitam. Tetapi pada kenyataannya, file tersebut malah termasuk file yang tidak terkompresi, dan bahkan menjadi tereskpansi oleh algoritma LZSS. Menurut pendapat penulis, hal ini terjadi karena adanya penggunaan gradien warna pada gambar tersebut.
Penggunaan gradien menghasilkan suatu ilusi bahwa warna yang digunakan adalah sama. Padahal, jika dilihat dari komposisi RGB, warna-warna yang digunakan pada file peppers sebagian besar berbeda, hanya saja kurang bisa dibedakan oleh mata manusia.
54 4.4.2.2 Perbandingan Dengan Metode Existing
Perbandingan hasil kompresi algoritma LZSS dengan program kompresi lainnya terhadap file gambar pada ACT dapat dilihat pada tabel IV-8.
Tabel IV-8. Perbandingan hasil kompresi terhadap file gambar ACT.
Program Kompresi Rasio kompresi (%)
WinRAR 30.62
Gzip 40.00
WinZip 41.25
PPMC 52.62
Compress 56.25
Pack 60.62
LZSS 64.25
Dari tabel IV-8, dapat kita lihat bahwa hasil kompresi terbaik kembali ditempati oleh program kompresi WinRAR dengan rasio kompresi sebesar 30.62%. Algoritma LZSS menempati peringkat paling bawah dengan rasio kompresi sebesar 64.25%. Dari hasil tersebut, terlihat bahwa rasio kompresi yang dihasilkan oleh algoritma LZSS paling tidak dua kali lebih buruk dibandingkan dengan rasio kompresi program WinRAR.
Dari hasil ini, dapat disimpulkan bahwa sebenarnya algoritma LZSS tidak cocok untuk kompresi file gambar. Hal ini dikarenakan kurangnya fleksibilitas LZSS dalam melakukan kompresi terhadap suatu file yang isinya kurang banyak pengulangan seperti kebanyakan file gambar.
Meskipun pada suatu file gambar biasanya terlihat memiki warna yang sama (terlihat homogen), tetapi sebenarnya warna-warna tersebut memiliki perbedaan (dalam level RGB-nya). Contoh yang dapat kita ambil adalah hasil kompresi algoritma LZSS terhadap file frymire dibandingkan dengan hasil kompresi terhadap file peppers. Meskipun file frymire terlihat tidak
55 homogen, tetapi rasio kompresinya lebih tinggi ketimbang file peppers yang terlihat jauh lebih homogen.
4.5 Hasil Kompresi Data Milik Penulis
4.5.1 Teks
4.5.1.1 Evaluasi Hasil
Seperti yang telah dijelaskan pada BAB II, penggunaan data milik penulis sebagai data training set bertujuan untuk mencari suatu bentuk data yang apabila dikompresi oleh algoritma LZSS akan memberikan hasil yang maksimal. Hasil kompresi algoritma LZSS terhadap data teks milik penulis dapat dilihat pada gambar 4.6-4.8.
Gambar 4.6. Rasio kompresi LZSS terhadap jumlah masukkan pada kelompok file teks buku teknik.
Grafik pada gambar 4.6 memiliki rata-rata rasio kompresi sebesar 64.35% dan simpangan baku sebesar 24.81%. Kedua nilai ini merupakan nilai rata-rata tertinggi dan nilai simpangan baku tertinggi bila dibandingkan
56 dengan kelompok file teks yang lainnya. Menurut penulis, nilai rata-rata rasio kompresi kelompok file buku teknik ini tinggi karena banyaknya gambar yang terdapat pada file-file tertentu pada kelompok teks buku teknik. Sedangkan tingginya nilai simpangan baku disebabkan karena adanya beberapa file pada kelompok file teks buku teknik yang memiliki sedikit gambar sehingga akan memberikan tingkat kompresi yang baik diantara hasil-hasil kompresi lainnya yang buruk, atau dapat dikatakan bahwa file-file buku teknik memiliki tingkat kehomogenan yang buruk.
Dengan demikian, nilai simpangan baku akan menjadi besar.
Gambar 4.7. Rasio kompresi LZSS terhadap jumlah masukkan pada kelompok file teks buku non-teknik.
Grafik pada gambar 4.7 memiliki rasio kompresi rata-rata sebesar 45.52% dengan nilai simpangan baku sebesar 17.28%. Hasil ini sesuai seperti yang telah diprediksikan, yaitu bahwa nilai rata-rata kelompok file teks buku non-teknik akan lebih kecil dari kelompok file teks buku teknik.
Menurut penulis, hal ini disebabkan karena pada buku non-teknik jarang ditemukan gambar-gambar. Bila ditemukan gambar, biasanya kebanyakan gambar tersebut adalah gambar hitam putih yang dapat dikompresi dengan
57 menggunakan algoritma LZSS. Bila melihat dari besarnya nilai deviasi standar yang lebih rendah, maka dapat dikatakan bahwa kelompok file buku non-teknik memiliki tingkat kehomogenan yang lebih tinggi dibandingkan dengan kelompok file buku teknik.
Gambar 4.8. Rasio kompresi LZSS terhadap jumlah masukkan pada kelompok file teks artikel bahasa Indonesia.
Grafik pada gambar 4.8 memiliki nilai rata-rata sebesar 35.8% dan nilai simpangan baku sebesar 10%. Nilai ini merupakan dua nilai terkecil yang didapatkan pada percobaan bagian ini. Menurut penulis, rendahnya nilai rata-rata disebabkan oleh dua faktor, yaitu bentuk dari file yang sebagian besar berupa teks dan jenis bahasa yang digunakan pada teks tersebut. Bentuk file yang sebagian besar berupa teks jelas akan memberikan tingkat kompresi algoritma LZSS yang tinggi, sedangkan penggunaan bahasa Indonesia akan lebih meningkatkan kinerja algoritma terhadap file tersebut. Hasil-Hasil yang berada di atas 50% menunjukkan adanya bentuk-bentuk file yang menyimpang dari karakteristik kelompok file artikel berbahasa indonesia.
58 Bahasa Indonesia memberikan hasil kompresi yang lebih baik karena struktur kata pada bahasa indonesia yang biasanya selalu berselang- seling antara vokal dengan konsonan. Karakteristik ini sangat berbeda dengan karakteristik bahasa Inggris yang lebih sering menempatkan lebih dari satu konsonan secara berurutan. Dengan sifat karakteristik dari bahasa Indonesia yang demikian, maka jumlah match antara dictionary buffer dengan look-ahead buffer akan menjadi lebih tinggi.
4.5.2 Pengompresian File Gambar
4.5.2.1 Evaluasi Hasil
Seperti yang dijelaskan pada BAB II, percobaan ini bertujuan untuk mencari bentuk file gambar yang akan memberikan hasil kompresi yang baik ketika dikompresi dengan menggunakan algoritma LZSS. Hasil tersebut dapat kita lihat pada tabel IV-9.
59
Tabel IV-9. Hasil kompresi terhadap file gambar milik penulis.
Input Bitmap
Output LZSS no Ukuran (Kb) Karakter Karakter % com
white 251 256026 30258 11.82
black 251 256026 30257 11.82
1 5626 5760054 5566321 96.64 2 3601 3686454 2741681 74.37 3 2305 2359350 647153 27.43 4 1407 1440054 742315 51.55 5 1407 1440054 520630 36.15
6 9 8278 4684 56.58
7 1407 1440054 729773 50.68 8 2305 2359359 1758529 74.53 9 2881 2949174 638908 21.66 10 2572 2632758 2736140 103.93 11 5626 5760054 1024245 17.78 12 5626 5760054 4173068 72.45 13 2305 2359350 1852756 78.53 14 5626 5760054 5019784 87.15 15 701 717654 622667 86.76 16 701 717654 678329 94.52 17 3841 3932214 2617607 66.57 18 3841 3932214 3186689 81.04 19 3001 3072054 2650951 86.29 20 1046 1071054 610644 57.01
Seperti yang terlihat pada tabel IV-9, hasil percobaan memberikan rasio kompresi tertinggi sebesar 11.82 % dan hasil kompresi terendah sebesar 97.12 %. Hasil kompresi tertinggi didapatkan dengan bentuk file optimal (seperti yang dijelaskan pada subbab 4.1.2) yaitu berisi file gambar polos berwarna putih. File lainnya yang juga memiliki hasil kompresi yang baik adalah file nomor 9 dan file nomor 11. Isi kedua file tersebut dapat kita lihat pada gambar 4.9 - 4.10.
60
Gambar 4.9. File gambar nomor 9.
Gambar 4.10. File gambar nomor 11.
Dari gambar 4.9, dapat kita lihat bahwa pada file gambar nomor 9 terdapat banyak piksel dengan warna yang sama (berwarna biru) dan pada jarak yang berurutan (berdekatan). Dengan banyaknya piksel dengan warna yang sama secara berurutan, maka ketika dilakukan pengompresian oleh algoritma LZSS, maka akan banyak terjadi match antara dictionary buffer dengan look-ahead buffer. Dengan demikian, maka rasio kompresi yang didapatkan terhadap file tersebut akan tinggi. Hal yang sama juga terjadi pada file gambar 11. Piksel-Piksel pada file gambar tersebut sebagian besar memiliki warna yang sama, yaitu warna putih. Hal inilah yang membuat rasio kompresi terhadap file tersebut menjadi baik.
Dari tabel 3, didapatkan hasil bahwa kompresi terburuk terjadi pada file gambar 10 dengan rasio kompresi sebesar 103.93%. Rasio tersebut bahkan menunjukkan bahwa algoritma LZSS bukan hanya tidak mampu
61 untuk melakukan kompresi terhadap file tersebut bahkan malah melakukan expansi sebesar 3.93%. Isi dari file nomor 10 dapat kita lihat pada gambar 4.11.
Gambar 4.11. File gambar nomor 10.
Dari gambar 4.11, dapat kita lihat bahwa file nomor 10 secara sekilas terdiri dari banyak piksel yang berwarna kuning. Secara logika, maka seharusnya file tersebut memiliki tingkat kompresi sebaik file-file lainnya. Tetapi, hasil yang didapatkan dari percobaan tidaklah mendukung hipotesis tersebut. Menurut penulis, beberapa sebabnya adalah:
Piksel-Piksel dengan warna yang sama (warna kuning) tersebut tidak terletak secara berurutan. Hal ini dapat dibuktikan ketika piksel gambar tersebut dianalisis dengan menggunakan software untuk image processing.
Piksel-Piksel yang terlihat memiliki warna sama sebenarnya tidak memiliki colour palette RGB yang sama persis. Hal ini menyebabkan algoritma LZSS tidak menganggap ada match, karena nilai RGB-nya berbeda.