PERBANDINGAN ALGORITMA K-NEAREST NEIGHBOR DAN NAÏVE BAYES UNTUK STUDI DATA “WISCONSIN DIAGNOSIS BREAST CANCER”
Dalam mengklasifikasi data teks, terdapat beberapa algoritma klasifikasi yang dapat digunakan, antara lain algoritma Naïve Bayes dan K-Nearest Neighbor. Algoritma Naïve Bayes
dan K-Nearest Neighbor adalah dua algoritma yang memiliki tingkat akurasi yang tinggi dalam mengklasifikasikan data teks. Tingkat akurasi yang terbaik di antara kedua algoritma ini dapat diketahui dengan cara melakukan perbandingan. Perbandingan algoritma dapat dilakukan dengan cara membandingkan tingkat akurasi dari algoritma yang dibandingkan. Perbandingan algoritma bertujuan untuk mendapatkan algoritma yang dianggap paling baik pada proses klasifikasi suatu permasalahan. Maka, diharapkan dengan adanya penelitian dalam perbandingan algoritma Naïve Bayes dan K-Nearest Neighbor, dapat diketahui algoritma yang paling baik dalam pengklasifikasian data teks wisconsin diagnosis breast cancer.
DATA STUDY "WISCONSIN DIAGNOSIS BREAST CANCER"
In Classification text data, there are several classification algorithms that can be used, there are Naïve Bayes algorithm and K-Nearest Neighbor algorithm. Naïve Bayes algorithm and K-Nearest Neighbor algorithm are two algorithm that have high accuracy in classification text data. The highest accuracy between them can be discovered by comparing the both algorithm. Comparison of the algorithm can be done by comparing accuracy of the algorithm. Comparison algorithm aims to obtain an algorithm that is the best for classification process of a problems. Thus, in this research of comparison algorithm K-Nearest Neighbor and Naïve Bayes, it can be seen that a best classification algorithm for classification text wisconsin diagnosis breast cancer data.
NEIGHBORS DAN NAIVE BAYES UNTUK STUDI
DATA “WISCONSIN DIAGNOSIS BREAST CANCER”
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Disusun oleh : Paulus Dian Wicaksana
115314068
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
"
WISCONSIN DIAGNOSIS BREAST CANCER
"
A THESIS
Presented as Partial Fulfillment of the Requirements To Obtain the Sarjana Komputer Degree
In Informatics Engineering
By :
Paulus Dian Wicaksana 115314068
INFORMATICS ENGINEERING STUDY PROGRAM DEPARTEMENT OF INFORMATICS ENGINEERING
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
iii
HALAMAN PERSEMBAHAN
I don’t judge and I don’t hate
Skripsi ini saya persembahkan kepada:
vi ABSTRAK
PERBANDINGAN ALGORITMA K-NEAREST NEIGHBOR DAN NAÏVE
BAYES UNTUK STUDI DATA “WISCONSIN DIAGNOSIS BREAST CANCER”
Dalam mengklasifikasi data teks, terdapat beberapa algoritma klasifikasi yang dapat digunakan, antara lain algoritma Naïve Bayes dan K-Nearest Neighbor. Algoritma
Naïve Bayes dan K-Nearest Neighbor adalah dua algoritma yang memiliki tingkat akurasi yang tinggi dalam mengklasifikasikan data teks. Tingkat akurasi yang terbaik di antara kedua algoritma ini dapat diketahui dengan cara melakukan perbandingan. Perbandingan algoritma dapat dilakukan dengan cara membandingkan tingkat akurasi dari algoritma yang dibandingkan. Perbandingan algoritma bertujuan untuk mendapatkan algoritma yang dianggap paling baik pada proses klasifikasi suatu permasalahan. Maka, diharapkan dengan adanya penelitian dalam perbandingan algoritma Naïve Bayes dan K-Nearest Neighbor, dapat diketahui algoritma yang paling baik dalam pengklasifikasian data teks wisconsin diagnosis breast cancer.
vii
ABSTRACT
COMPARISON OF K-NEAREST NEIGHBOR AND NAIVE BAYES ALGORITHM FOR DATA STUDY "WISCONSIN DIAGNOSIS BREAST CANCER"
In Classification text data, there are several classification algorithms that can be used, there are Naïve Bayes algorithm and K-Nearest Neighbor algorithm. Naïve Bayes algorithm and K-Nearest Neighbor algorithm are two algorithm that have high accuracy in classification text data. The highest accuracy between them can be discovered by comparing the both algorithm. Comparison of the algorithm can be done by comparing accuracy of the algorithm. Comparison algorithm aims to obtain an algorithm that is the best for classification process of a problems. Thus, in this research of comparison algorithm K-Nearest Neighbor and Naïve Bayes, it can be seen that a best classification algorithm for classification text wisconsin diagnosis breast cancer data.
ix
BAB II LANDASAN TEORI ...5
2.1. Penelitian Terdahulu yang Relevan...5
2.2. Kajian Teori….. ...6
2.2.1. Penambangan Data ………...6
2.2.2. Naive Bayes Classifier...7
2.2.3. K-Nearest Neighbor…...12
2.2.4. K-Fold Cross Validation ...16
2.2.5. Pengukuran Akurasi Klasifikasi ...16
2.2.6. Kanker Payudara...17
2.2.7. Metode Hashing...21
2.2.8. WEKA (Waikato Environment for Knowledge Analysis)…………...23
x
3.1. Sumber Data ...25
3.2. Analisis Pengolahan Data...26
3.3. Perancangan Umum Sistem...28
3.4. Perancangan Umum Algoritma...29
3.5. Desain Antarmuka Sistem ...30
BAB IV IMPLEMENTASI SISTEM ...33
4.1. Implementasi Antarmuka Pemakai (User Interface)...33
4.2. Pemrosesan Input ...36
4.3. Implementasi Algoritma pada Sistem...40
BAB V ANALISIS HASIL ...52
5.1. Analisis Proses Penambangan Data ...52
5.2. Analisa Hasil……… ...71
5.3. Kelebihan dan Kekurangan Sistem ...75
BAB VI PENUTUP ...77
6.1. Kesimpulan ...77
6.2. Saran ...77
DAFTAR PUSTAKA ...78
LAMPIRAN I ...79
LAMPIRAN II ...81
LAMPIRAN III ...83
LAMPIRAN IV ...84
xi
DAFTAR TABEL
Tabel 2.1. Data buys_computer………... 8
Tabel 2.2. Tabel data teks buys_computer...9
Tabel 2.3. Tabel probabilitas yes data teks buys_computer... .10
Tabel 2.4. Tabel probabilitas no data teks buys_computer...10
Tabel 2.5. Tabel data buys_computer…... 13
Tabel 2.6. Data Numerik buys computer... 14
Tabel 2.7. Data testing KNN... 15
Tabel 3.1. Data Atribut Wisconsin Diagnosis Breast Cancer...25
Tabel 3.2. Jumlah Data Hasil Pembersihan... 27
Tabel 3.3. Deskripsi use case…..……... 28
Tabel 5.1. Tabel akurasi sistem dan weka... 70
Tabel 5.2. Tabel perhitungan jumlah operasi dasar algoritma K-Nearest Neighbor...74
xii
DAFTAR GAMBAR
Gambar 2.1. Tahapan Dalam KDD (Han & Kamber, 2006) ... 6
Gambar 2.2. Ilustrasi 3-fold Cross Validation………....16
Gambar 2.3. Confusion Matrix untuk matrix 2×2 (Tan, Steinbach, & Kumar, 2006).. 17
Gambar 2.4. Perbedaan sel normal dengan sel kanker (Weaver, 2002)……... 18
Gambar 2.5. Struktur kode hash………...…….. ... 22
Gambar 3.1. Diagram use case………….………... 28
Gambar 3.2. Desain Halaman Utama………... 30
Gambar 3.3. Gambar saat menu bar go to ditekan…………... 31
Gambar 3.4. Desain Halaman Bantuan………... 31
Gambar 3.5. Desain Halaman Klasifikasi……….. ... 31
Gambar 4.1 Tampilan Halaman Beranda... 33
Gambar 4.2. Tampilan saat menu ditekan... 34
Gambar 4.3. Tampilan Halaman Bantuan... 34
Gambar 4.4. Tampilan halaman hitung perbandingan ... 35
Gambar 4.5. Tampilan open file ... 36
Gambar 5.1. Screenshot KNN dengan 3-fold cross validation dengan menggunakan sistem... 52
Gambar 5.2. Screenshot KNN dengan 3-fold cross validation dengan menggunakan program weka. ... 53
Gambar 5.3. Screenshot KNN dengan 5-fold cross validation dengan menggunakan sistem... 54
Gambar 5.4. Screenshot KNN dengan 5-fold cross validation dengan menggunakan program weka... 55
Gambar 5.5. Screenshot KNN dengan 10-fold cross validation dengan menggunakan sistem... 56
Gambar 5.6. Screenshot KNN dengan 10-fold cross validation dengan menggunakan program weka... 57
xiii
Gambar 5.8. Screenshot KNN dengan 5-fold cross validation dengan menggunakan program weka. ... 59 Gambar 5.9. Screenshot KNN dengan 20-fold cross validation dengan menggunakan
1 BAB I PENDAHULUAN
Dalam bab pendahuluan ini, akan dikaji dalam enam hal, yaitu (1) latar belakang masalah, (2) rumusan masalah, (3) tujuan penelitian, (4) manfaat penelitian, (5) batasan masalah, dan (6) sistematika penyajian. Keenam hal tersebut akan dibahas satu per satu dalam subbab yang ada di bawah ini.
1.1 Latar Belakang Masalah
Penambangan Data adalah proses pengumpulan informasi penting dari sejumlah data besar yang tersimpan di basis data, gudang data, atau tempat penyimpanan lainnya (Han & Kamber, 2006).Perkembangan penambangan data tidak terlepas dari kemajuan teknologi informasi yang memungkinkan data dalam jumlah yang besar terakumulasi. Seiring dengan semakin dibutuhkannya penambangan data muncul beberapa algoritma klasifikasi untuk memproses data dalam jumlah besar.
Klasifikasi adalah proses pembelajaran secara terbimbing (supervised learning). Klasifikasi digunakan untuk memprediksi kelas dari objek yang kelasnya belum diketahui (Raviya & Gajjar, 2013). Metode klasifikasi yang umum digunakan antara lainDecision Tree, K-Nearest Neighbor, Naïve Bayes, neural network dan support vector machines (Sahu dkk, 2011).Maka dari itu penulis tertarik untuk membandingkan beberapa metode klasifikasi. Perbandingan metode klasifikasi dilakukan untuk menentukan jenis klasifikasi yang paling cocok digunakan dengan data yang berbentuk informasi teks.
Sebagai tahap awal dalam penelitian, penulis melakukan pengamatan awal terhadap beberapa jurnal ilmiah diantaranya berupa penelitian oleh Adel Aloraini (2012)
akan membandingkan dua algoritma lain yaitu (1) Naive Bayes dan (2) K-Nearest Neighbor.
Perbandingan algoritma adalah membandingkan dua algoritma yang bertujuan untuk mengetahui algoritma mana yang paling baik diantara kedua algoritma yang dibandingkan.
Adapun dipilihnya algoritma Naïve Bayes dan K-Nearest Neighbors sebagai algoritma pengklasifikasian teks yang dibandingkan karena tingkat akurasi dari kedua algoritma ini dalam pengklasifikasian dokumen teks relatif tinggi. Hal ini dibuktikan melalui jurnal penelitian yang dilakukan oleh Dedy Santoso, Dian Eka Ratnawati, dan Indriati (2015) berjudul „Perbandingan Kinerja Metode Naive Bayes, K-Nearest Neighbor, dan Metode Gabungan K-Means dan LVQ dalam Pengkategorian Buku
Komputer Berbahasa Indonesia Berdasarkan Judul dan Sinopsis‟. Pada hasil penelitian tersebut menunjukkan bahwa rata-rata akurasi metode KNN mencapai 96% dan metode
Naive Bayes mencapai 98%.
Klasifikasi Naive Bayes Adalah metode classifier yang berdasarkan probabilitas dan Teorema Bayesian dengan asumsi bahwa setiap variabel X bersifat bebas (independence). Klasifikasi KNN merupakan metode klasifikasi yang menentukan label (class) dari suatu objek baru berdasarkan class yang mayoritas dari kneighbor dalam
training set.
Algoritma K-Nearest Neighbor dan Naïve Bayes Classifier masing – masing memiliki kelebihan dan kekurangan. Oleh karena itu, pada penelitian ini penulis akan melakukan perbandingan antara kedua algoritma tersebut untuk memperoleh algoritma yang paling maksimal dalam klasifikasi terhadap data wisconsin breast cancer. Adapun parameter pembanding kedua algoritma adalah tingkat akurasi system, dan waktu proses kedua algoritma.
Oleh karena itu penulis mengembangkan sebuah penelitian dengan judul
„Perbandingan Algoritma K-Nearest Neighbors dan Naive Bayes untuk Studi Data
Wisconsin Breast Cancer Data‟.
merasa data ini memadai dan sesuai dengan penelitian karena mempunyai jumlah data yang cukup banyak sehingga bisa mendapatkan hasil klasifikasi yang baik.
1.2 Rumusan Masalah
Rumusan masalah dibuat agar penelitian menjadi lebih terarah. Berdasarkan uraian latar belakang diatas, peneliti merumuskan rumusan masalah ”Sejauh mana perbedaan akurasi algoritma naive bayes dan KNN dalam mengklasifikasikan data
wisconsin breast cancer?”. 1.3 Tujuan Penelitian
Tujuan penelitian ini adalah mendapatkan hasil perbandingan dari kedua algoritma berupa tingkat akurasi, dan waktu proses, serta menentukan algoritma mana yang memiliki algoritma yang lebih baik dan lebih baik.
1.4 Manfaat Penelitian
Penelitian ini diharapkan dapat memberikan manfaat bagi mahasiswa dan penelitian lain.
(1) Bagi Mahasiswa
Penelitian dapat membantu menambah wawasan dan memperluas pengetahuan tentang algoritma, khususnya ketiga algoritma yang dipakai di tugas akhir ini. (2) Bagi Penelitian Lain
Penelitian ini sebagai bentuk sumbangan terhadap penelitian lainnya agar dapat mengembangkan penelitian lebih lanjut berkaitan dengan masalah perbandingan algoritma.
1.5 Batasan Masalah
1.6 Sistematika Penyajian
Penelitian ini terdiri dari lima bab: BAB I PENDAHULUAN
Bab ini berisi tentang latar belakang masalah, rumusan masalah, tujuan masalah, tujuan penelitian, manfaat penelitian, batasan masalah, dan sistematika penyajian.
BAB II LANDASAN TEORI
Bab ini berisi tentang penelitian terdahulu yang relevan dan kajian teori yang dipakai untuk menunjang penelitian.
BAB III PERANCANGAN SISTEM
Bab ini berisi tentang perancangan sistem yang akan dibangun. Bab ini membahas tentang sumber data, analisis pengolahan data, dan desain antarmuka sistem.
BAB IV IMPLEMENTASI SISTEM
Bab ini membahas hasil tentang implementasi sistem yang telah dirancang pada bab iii.
BAB V ANALISIS HASIL
Bab ini berisi tentang analisis sistem yang telah dibangun pada bab iv. BAB VI PENUTUP
BAB II
LANDASAN TEORI
Dalam bab landasan teori ini akan dikaji dua hal, yaitu (1) penelitian terdahulu yang relevan dan (2) kajian teori. Kedua hal tersebut akan dibahas satu per satu dalam subbab yang ada di bawah ini.
2.1 Penelitian Terdahulu yang Relevan
Penelitian tentang perbandingan algoritma memang beberapa kali telah dilakukan. Kajian terhadap penelitian-penelitian tersebut sangat beragam sesuai dengan permasalahan yang diamati oleh peneliti lain. Hal yang menjadi keberagaman penelitian mengenai perbandingan algoritma adalah mengenai algoritma yang digunakan dan sumber data yang dianalisis.
Penelitian mengenai perbandingan algoritma pernah dilakukan oleh Adel
Aloraini (2012) dalam jurnal berjudul „Different Machine Learning Algorithms for
Breast Cancer Diagnosis‟. Adapun yang menjadi objek penelitian adalah data wisconsin
breast cancer. Penelitian tersebut mencoba membandingkan kelima algoritma yaitu, (1)
Bayesian Network, (2) Naive Bayes, (3) J48, (4) ADTree, dan (5) Multilayer Neural Network. Berikut ini adalah hasil penelitian yang dilakukan oleh Adel Aloraini.
(1) Membuktikan bahwa kecerdasan buatan dapat membantu pakar dalam mendeteksi penyakit kanker payudara.
(2) Bayesian Network dan Naive Bayes adalah algoritma yang berbeda.
(3) Bayesian Network adalah algoritma yang terbaik dibandingkan keempat algoritma lainnya.
Renaldo Malau (2015) dalam skripsinya yang berjudul Perbandingan Akurasi Algoritma Naive Bayes Classifier dan Algoritma Bayesian Belief Network dalam
mengklasifikasikan mahasiswa Universitas Sanata Dharma Program Studi Teknik
Informatika menemukan bahwa akurasi kedua algoritma itu setelah diuji menggunakan metode 5-fold cross validation, Naive Bayes Classifier sebanyak 49,0909%, dan
Bayesian Belief Network sebanyak 52,7273%, dan membuktikan bahwa metode
Cahyo Darujati (2010) dalam jurnalnya berjudul Perbandingan Klasifikasi Dokumen Teks menggunakan Metode Naïve Bayes dengan K-Nearest Neigtbor
menemukan bahwa Naïve Bayes kinerjanya lebih baik dari K-Nearest Neighbordalam pengklasifikasian dokumen teks.
Meskipun penelitian tentang perbandingan algoritma pernah dilakukan, penelitian tersebut masih layak dilakukan. Masih banyak algoritma yang perlu dibandingkan untuk mengetahui algoritma mana yang paling akurat.
Oleh karena itu, penulis akan membandingkan algoritma yang berbeda dari penelitian-penelitian sebelumnya yaitu (1) Naive Bayes dan (2) K-nearest Neighbor.
2.2 Kajian Teori
2.2.1 Penambangan Data
Penambangan Data adalah proses pengumpulan informasi penting dari sejumlah data besar yang tersimpan di basis data, gudang data, atau tempat penyimpanan lainnya (Han & Kamber, 2006). Penambangan data merupakan proses yang tidak dapat dipisahkan dengan Knowledge Discovery in Database (KDD), karena penambangan data adalah salah satu tahap dalam proses KDD seperti yang ditunjukkan oleh gambar 2.1.
Menurut Han dan Kamber (2006), tahapan-tahapan dalam proses KDD adalah sebagai berikut:
1. Pembersihan data (Data Cleaning)
Pembersihan data merupakan proses untuk menghilangkan data yang mengandung noise, atau data yang tidak konsisten.
2. Integritas data (Data Integration)
Pada tahap ini akan dilakukan penggabungan data yang berasal dari berbagai sumber.
3. Seleksi data (Data Selection)
Pada tahap ini akan dilakukan pemilihan data yang relevan dari database. 4. Transformasi data (Data Transformation)
Pada tahap ini data akan ditransformasikan kedalam format yang sesuai untuk diproses dalam penambangan data.
5. Penambangan data (Data Mining)
Penambangan data merupakan proses penting dimana metode akan disistemkan untuk mengekstrak pola data.
6. Evaluasi pola (Pattern Evaluation)
Pada tahap ini, pola/model yang dihasilkan dari teknik data mining akan mengidentifikasi pola-pola yang menarik berdasarkan ukuran tertentu
7. Presentasi pengetahuan (Knowledge Presentation)
Pada tahap ini akan dilakukan teknik visualisasi yang digunakan untuk menampilkan pengetahuan hasil proses mining kepada pengguna.
2.2.2 Naive Bayes Classifier
Untuk menghitung nilai kelas yang akan dibandingkan (ya atau tidak), dilakukan perhitungan probabilitas P(Vj):
P(Vj)= |docj| |Contoh|
Dimana docj adalah banyaknya dokumen yang memiliki kategori j dalam pelatihan, sedangkan Contoh banyaknya dokumen dalam contoh yang digunakan untuk pelatihan. Untuk nilai P(Wk|Vj) , yaitu probabilitas kata wk dalam kategori j ditentukan dengan :
P(Wk|Vj)= Nk+1 N+|vocabulary|
Dimana nk adalah frekuensi munculnya kata wk dalam dokumen yang ber kategori vj ditambah 1, hal ini berfungsi untuk menghindari angka 0 dalam data atau biasa disebut Laplace Smoothing, sedangkan nilai n adalah banyaknya seluruh kata dalam dokumen berkategori vj, dan vocabulary adalah banyaknya kata dalam contoh pelatihan.
Contoh Naïve Bayesian
Berikut contoh kasus yang akan diselesaikan dengan metode Naïve Bayes Classifier:
Tabel 2.1 Data buys computer
10. 41 Medium Yes Fair Yes
11. 29 Medium Yes Excelent Yes
12. 31..40 Medium No Excelent Yes
13. 31..40 High Yes Fair Yes
14. 41 Medium No Excelent No
Berdasarkan data pada tabel 2.1., model Naïve Bayes Classifier adalah sebagai berikut:
1. Tentukan P(yes) sebagai probabilitas orang yang membeli komputer dan P(no) sebagai probabilitas orang yang tidak membeli komputer dengan rumus sebagai berikut:
P(yes/no) = |doc j| |Contoh|
Dimana doc j adalah banyaknya dokumen yang memiliki kategori j dalam pelatihan, sedangkan Contoh banyaknya dokumen dalam contoh yang digunakan untuk pelatihan.
Berikut perhitungannya : a. Tabel data
Tabel 2.2 Tabel data teks buys_computer
10. 0 0 1 0 1 0 1 0 1 0 Yes
Tabel 2.3 Tabel probabilitas yes data teks buys_computer
No Age<
Tabel 2.4 Tabel probabilitas no data teks buys_computer
1. Kemudian tentukan P(Wk|Yes) dan P(Wk|No) yaitu probabilitas kata wk dalam kategori yes atau no ditentukan dengan :
P(Wk|Yes)=Nk+1
N+|Vocabulary|
Dimana nk adalah frekuensi munculnya kata wk dalam dokumen yang ber kategori yes atau no, sedangkan nilai n adalah banyaknya seluruh kata dalam dokumen berkategori yes atau no, dan vocabulary adalah banyaknya kata dalam contoh pelatihan.
1. Terakhir mencari nilai probabilitas data test.
Misalkan diketahui umur 29 tahun, berpenghasilan tinggi (high), Bukan pelajar, dan peringkat rating (credit_rating) fair, maka perhitungan probabilitas untuk menentukan apakah dia membeli komputer atau tidak adalah:
P(X|Y=yes) =
P(Yes)*(E1=<30|Yes)*P(E2=high|Yes)*P(E3=No|Yes)*P(E4=fair|Yes) = 0.64*0.06*0.06*0.08*0.15 = 3.61 * 10-5
P(X|Y=no) = P(E1=<30|No)*P(E2=high|No)*P(E3=No|No)*P(E4=fair|No) = 0.36*0.13*0.1*0.16*0.1 = 7.93 * 10-5
Setelah didapatkan hasil likelihood maka hasil tersebut dibagi dengan total hasil likelihood supaya mendapatkan nilai probabilitas, maka:
P(X|Y=yes) = 3.61 * 10-5/(3.61 * 10-5+7.93 * 10-5)=0.31 P(X|Y=no)=7.93 * 10-5/(3.61 * 10-5+7.93 * 10-5)=0.69
Berdasarkan hasil perhitungan tersebut, probabilitastidak (0,69) lebih besar jika dibandingkan dengan probabilitas ya (0,31), sehingga dapat disimpulkan bahwa untuk kasus ini orang yang berumur 29 tahun, berpenghasilan tinggi, bukan pelajar, dan memiliki credit rating fair masuk dalam kelas orang yang tidak membeli computer.
2.2.3 K-Nearest Neighbor
K-Nearest Neighbor (KNN) termasuk kelompok instance-based learning.
...(1)
Dengan D adalah jarak antara titik pada data training x dan titik data testing y
yangakan diklasifikasi, dimana x=x1,x2,…,xi dan y=y1,y2,…,yi dan I
merepresentasikan nilai atribut serta n merupakan dimensi atribut.
Pada fase training, algoritma ini hanya melakukan penyimpanan vektor-vektor fitur dan klasifikasi data training sample. Pada fase klasifikasi, fitur-fitur yang sama dihitung untuk testing data (yang klasifikasinya tidak diketahui). Jarak dari vektor baru yang ini terhadap seluruh vektor training sample dihitung dan sejumlah k buah yang paling dekat diambil.
Langkah-langkah untuk menghitung metode Algoritma K-Nearest Neighbor: a. Menentukan Parameter K (Jumlah tetangga paling dekat).
b. Menghitung kuadrat jarak Euclid (queri instance) masing-masing objek terhadap datasampel yang diberikan.
c. Kemudian mengurutkan objek-objek tersebut ke dalam kelompok yang mempunyai jarak Euclid terkecil.
d. Mengumpulkan kategori Y (Klasifikasi Nearest Neighbor).
e. Dengan menggunakan kategori Nearest Neighbor yang paling mayoritas maka dapatdiprediksi nilai queri instance yang telah dihitung. Contoh K-Nearest Neighbor
Berikut contoh kasus yang akan diselesaikan dengan metode K-Nearest Neighbor:
Tabel 2.5 Tabel data buys_computer
8. 29 Medium No Fair No
Tabel 2.6 Data Numerik buys computer
Age Income Student Credit_Rating Class
1 3 2 1 No
1. Menghitung Euclidean Distance
Misalkan kita memiliki dua buah titik, titik A dan titik B yang masing masing dapat dipresentasikan dalam bentuk vektor sebagai berikut:
B = [b1 b2 b3 …. bn] T
Maka jarak Euclid antara kedua titik tersebut dapat dicari dengan rumus: D2 = (a1-b1)2 + (a2-b2)2 + (a3-b3)2+ ….. + (an-bn)2
atau
D= √ (a1-b1)2 + (a2-b2)2 + (a3-b3)2+ ….. + (an-bn)2
Misalkan diketahui umur 29 tahun, berpenghasilan tinggi (high), Bukan pelajar, dan peringkat rating (credit_rating) fair, maka perhitungan probabilitas untuk menentukan apakah dia membeli komputer atau tidak jika ditentukan memiliki 1 jarak terdekat (k) adalah:
Vektor data testing:
Tabel 2.7 Data testing KNN Age Income Student Credit_Rating
1 3 2 1
Membandingkan dengan rumus Euclidean Distance: D1(x,y)=√(1-1) 2 +(3-3) 2 +(2-2) 2 +(1-1) 2 =0
orang yang berumur 29 tahun, berpenghasilan tinggi, bukan pelajar, dan memiliki credit rating fair masuk dalam kelas orang yang tidak membeli computer.
2.2.4 K-Fold Cross Validation
Pada penelitian ini metode yang digunakan untuk menguji pola klasifikasi adalah metode k-fold cross validation. Dalam k-fold cross validation, data dibagi menjadi k bagian, D1, D2,..Dk, dan masing-masing D memiliki jumlah data yang sama. Kemudian lakukan proses perulangan sebanyak k, dimana dalam setiap perulangan ke-i, Di akan dijadikan data testing, dan sisanya akan digunakan sebagai data training. Sebagai contoh, misalkan akan dilakukan metode cross validation dengan menggunakan 3 fold. Pertama pilih salah satu fold menjadi data testing, kemudian gunakan fold sisanya sebagai data training. Hal ini dilakukan berulang untuk semua kombinasi data training-testing.Untuk mengilustrasikan metode ini, perhatikan Gambar 2.9.
Gambar 2.2 Ilustrasi 3-fold Cross Validation
2.2.5 Pengukuran Akurasi Klasifikasi
Keakuratan hasil klasifikasi dapat diukur dengan menggunakan confusion matrix. Confusion matrix adalah media yang berguna untuk menganalisis seberapa baik
tupel negatif. True positive mengacu pada tupel positif yang diberi label dengan tepat oleh classifier, sementara true negatif adalah tupel negatif yang diberi label dengan tepat oleh classifier.False positive adalah tupel negatif yang diberi label dengan tidak tepat. Demikian pula, false negative adalah tupel positif yang diberi label dengan tidak tepat.Istilah-istilah ini berguna ketika menganalisis kemampuan classifier dan diringkas dalam Gambar 2.10.
Gambar 2.3 Confusion Matrix untuk matrix 2×2 (Tan, Steinbach, & Kumar, 2006)
Misalkan terdapat confusion matrix 2×2 seperti pada Gambar 2.10, maka rumus yang akan digunakan untuk menghitung akurasi adalah sebagai berikut:
Rumus 2.6 diatas dapat juga didefinisikan seperti pada rumus berikut:
2.2.6 Kanker Payudara
2.2.6.1 Definisi Kanker Payudara
Gambar 2.4 Perbedaan sel normal dengan sel kanker (Weaver, 2002) 2.2.6.2 Epidemiologi
Di Indonesia setiap tahunnya diperkirakan terdapat 100 penderita kanker baru setiap 100.000 penduduk seiring peningkatan angka harapan hidup, sosial ekonomi serta perubahan pola penyakit (Tjindarbumi, 2000). Kasus baru kanker payudara pada wanita di Amerika Serikat tahun 2005 adalah 211.240 dengan kematian 40.410, di Indonesia terdapat 114.649 penderita (National CancerInstitute, 2005). Di RSUP. Dr. Sardjito Yogyakarta pasien kanker payudara yang dirawat ada 252 orang pada tahun 2005. Pada tahun 2006 di Amerika Serikat, kasus kanker payudara (wanita saja) menempati urutan pertama (32%) dan penyebab kematian kedua setelah kanker paru (Anonim, 2007). 2.2.6.3 Etiologi
Penyebab kanker payudara belum diketahui secara pasti. Faktor risiko yang sangat berpengaruh terhadap timbulnya kanker payudara antara lain genetik, faktor endokrin, dan faktor lingkungan.
a. Faktor Endokrin
Faktor endokrin akan mempengaruhi insidensi pada kanker payudara, diantaranya adalah total durasi lamanya menstruasi, early menarche (menstruasi di umur dini), nulliparity (wanita yang tidak memiliki anak) dan melahirkan anak pertama di umur >30 tahun akan meningkatkan risiko lama hidup pada perkembangan kanker payudara (Dipiro, 2003).
b. Faktor Genetik
dengan mutasi gen BRCA-1 atau BRCA-2 akan terkena kanker payudara (Anonim, 2003b).
c. Faktor Lingkungan
Makanan, nutrisi, dan terpapar senyawa radioaktif dapat memicutimbulnya kanker payudara (Anonim, 2003b).
2.6.3.4. Patofisiologi
Identifikasi subtipe histopatologi kanker payudara penting karena ada hubungannya dengan aspek klinik yaitu prediksi metastasis, terapi dan prognosis.
a. Dasar klasifikasi subtipe histopatologi kanker payudara yang sering digunakanadalah WHO tahun 1981. Menurut WHO subtipe histopatologi kankerpayudara ada 2 macam yaitu :
1). carcinoma noninvasive
Carcinoma noninvasive artinya sel yang membahayakan mengikatkelenjar lain pada lobus, dengan tidak ada bukti penetrasi pada sel tumormenyambung dengan dasar membran di sekitar 2 tipe pada struktur yangdikelilingi jaringan fibrous. Umumnya kanker payudara adalahadenocarcinoma yang berasal dari sel epitel pada pembuluh atau kelenjar.Ada dua bentuk pada carcinoma noninvasive yaitu ductal carcinoma insitudan
lobular carcinoma insitu. 2). carcinoma invasif
Carcinoma invasif adalah sel yang rusaknya melewati dasar membrandi sekeliling struktur payudara, dimana sel tersebut muncul dan menyebar disekeliling jaringan. Ukuran carcinoma bermacam-macam, kurang dari10mm dan kedalaman lebih dari 80mm, namun yang sering dijumpai yaknikedalaman 20-30mm. Secara klinis akan terlihat kuat dan jelas serta kulitnampak bersisik dengan punting susu tertarik ke dalam (Underwood, 2001).
b. Anatomi payudara
Payudara manusia berbentuk kerucut tetapi sering kali berukuran tidaksama. Payudara memanjang dari tulang rusuk kedua atau ketiga sampai tulang rusuk keenam
atau ketujuh, dari tepi sentral ke garis aksilaris anterior. “Ekor”payudara memanjang
Payudara normal mengandung jaringan kelenjar, duktus,jaringan otot penyokong, lemak, pembuluh darah, saraf, dan pembuluh limfe(Guiliano, 2001).
2.6.3.5. Tanda dan Gejala Klinis
Berupa benjolan pada payudara, eksema punting susu atau pendarahan pada punting susu, tetapi umumnya berupa benjolan yang tidak nyeri. Benjolan itumula-mula kecil, makin lama makin besar lalu melekat pada kulit dan menimbulkan perubahan kulit payudara atau punting susu.Kulit atau punting susu akan tertarik ke dalam (retraksi), berwarna merah kecoklatan sampai menjadi udema hingga kulit kelihatan seperti kulit jeruk,mengkerut dan timbul ulkus. Ulkus tersebut makin lama akan semakin membesardan akhirnya akan menghancurkan seluruh payudara dengan bau yang busuk danmenjadi mudah berdarah (Anonim, 2000a).
2.6.3.6. Diagnosis
Secara umum diagnosis kanker payudara dibedakan menjadi 2 yaitu skrining dan diagnostik. Yang termasuk skrining antara lain :
a. pemeriksaan payudara sendiri (SADARI) yang dilakukan setahun sekalisetelah umur 20 tahun,
b. pemeriksaan payudara oleh dokter yang dimulai pada umur 20 tahun, setiap 3tahun sekali pada umur 20-39 tahun dan setiap tahun sekali setelah umur 40tahun,
c. mammografi skrining yang dilakukan pada pasien tanpa gejala untukmendeteksi adanya kanker payudara yang samar (Ramli, 2000).
Yang termasuk diagnostik (Ramli, 2000) :
a. anamnesa meliputi tanda, gejala dan faktor risiko,
b. pemeriksaan fisik meliputi keadaan umum, dan tanda metastasis
2.2.7 Metode Hashing atau Hashmap
Map adalah salah satu bentuk struktur data. Hashmap adalah struktur data map yang di berikan kemampuan hashing. hashing adalah salah satu metode pemberian nilai pada string, yang biasanya di pakai untuk pembandingan kesamaan atau kedekatan dari satu string ke string yang lain. Pada proses pencarian pada hashmap yaitu pertama membuat nilai hash pada string yang di cari kemudian membandingkan nilai hash
tersebut dengan nilai hash pada semua string yang ada di hashmap atau di struktur data.
Hashing/Hashmap merupakan metode untuk menyimpan dan mengambil catatan dari database. Hal ini memungkinkan kita untuk melakukan penyisipan, menghapus, dan mencari catatan berdasarkan nilai kunci pencarian.Hashing/Hashmap adalah metode pencari pilihan karena sangat efisien ketika diterapkan dengan benar. Bahkan,
system hash yang diprogram dengan benar biasanya melihat hanya satu atau dua catatan untuk setiap pencarian, insert, atau menghapus operasi. Waktu pencarian data melalui
hashing jauh lebih effisien dari pada pencarian data biner pada array yang diurutkan dari n catatan dengan waktu O (log n), atau pencarian data dengan binary tree yang mana memiliki waktu O(log n). Namun pada kenyataannya hashing sulit untuk diterapkan dengan benar (Nurhaerty,2008).
Hasing/Hashmap adalah teknik untuk melakukan penambahan, penghapusan, dan pencarian dengan rata – rata waktu konstan.Selain itu hashing juga dikenal dengan sebutan hash table. Hash tables adalah array dengan sel-sel yang ukurannya telah ditentukan dan dapat berisi data atau key yang berkesesuaian dengan data. Selain itu
Hash tables merupakan struktur data yang sering digunakan untuk mengimplementasikan ADT (Abstract Data Type) pada sebuah Dictionary, yaitu ADT (Abstract Data Type) yang hanya mengizinkan pencarian, penyisipan, dan penghapusan elemen-elemen yang ada di dalamnya. (Ruli dkk, 2008.).
Hash Table merupakan solusi elegan untuk menyelesaikan masalah pencarian.
dikarenakan table hash seperti halnya hashmap menyimpan setiap pasangan kunci atau nilai dari setiap data. Jika diketahui sebuah kuncinya maka bukan hal yang mustahil lagi untuk mencari atau mengetahui nilai dari data tersebut. Namun lain halnya jika hash table diimplementasikan pada system set data maka untuk mencari sebuah nilai kita harus mencari kunci di dalam table hash padahal semua nilai yang berada dalam tabel berisi null (Anonim. 2012).
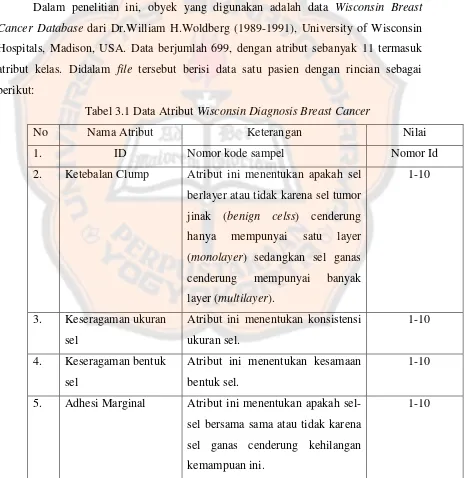
Dalam tabel hash yang digunakan pada Java, setiap lokasi array sebetulnya adalah suatu list berantai yang berisi pasangan kunci/nilai (atau mungkin juga list
kosong). Jika dua item memiliki kode hash yang sama, maka kedua item tersebut akan ada pada list yang sama. Strukturnya bisa digambarkan sebagai berikut:
Gambar 2.5 Struktur kode hash
Pada gambar 2.5., hanya ada satu item dengan kode hash 0, tidak ada item
dengan kode hash 1, dua item dengan kode hash 2, dan seterusnya. Pada tabel hash
yang dirancang dengan benar, hampir semua list berantai berisi nol atau satu elemen saja, dengan rata-rata panjang list kurang dari 1. Meskipun kode hash dari suatu kunci mungkin tidak membawa kita langsung pada kunci yang kita mau, akan tetapi tidak akan lebih dari satu atau dua item yang harus kita cari sebelum kita sampai pada item
2.2.8 WEKA (Waikato Environment for Knowledge Analysis)
WEKA (Waikato Environment for Knowledge Analysis) adalah suatu perangkat lunak pembelajaran mesin yang populer ditulis dengan Java, yang dikembangkan di Universitas Waikato di Selandia Baru. WEKA adalah perangkat lunak gratis yang tersedia di bawah GNU General Public License. WEKA menyediakan penggunaan teknik klasifikasi menggunakan pohon keputusan dengan algoritma J48. Teknik klasifikasi dan algoritma yang digunakan di WEKA disebut classifier.
2.2.8.1 Cara menggunakan WEKA
Cara termudah untuk menggunakan WEKA adalah melalui interface pengguna grafis yang disebut Explorer. Hal ini memberikan akses ke semua fasilitas dengan menggunakan pilihan menu dan pengisian formulir. Sebagai contoh, dataset dapat dibaca dengan cepat dari file ARFF (atau spreadsheet) menggunakan Interface Explorer. Kelemahan mendasar dari Interface Explorer adalah bahwa Explorer
memegang semuanya dalam memori utama. Ketika dataset dibuka, maka semua data set tersebut masuk ke dalam memori utama. Ini berarti bahwa Explorer hanya dapat diterapkan untuk masalah kecil sampai menengah. Namun, WEKA berisi beberapa algoritma tambahan yang dapat digunakan untuk memproses dataset yang sangat besar.
Interface Knowledge Flow memungkinkan merancang konfigurasi untuk pengolahan data secara streaming. Interface Knowledge Flow memungkinkan untuk menarik kotak yang mewakili algoritma pembelajaran dan sumber data di sekitar layar dan bergabung bersama-sama ke dalam konfigurasi yang diinginkan oleh user. Hal ini memungkinkan untuk menentukan aliran data dengan menghubungkan komponen yang mewakili sumber data, alat preprocessing, algoritma pembelajaran (learning algorithms), metode evaluasi, dan modul visualisasi. Jika filter dan algoritma pembelajaran (learning algorithms) mampu, maka data akan dimuat dan diproses secara bertahap.
Interface yang ketiga adalah Experimenter, dirancang untuk membantu menjawab pertanyaan praktis dasar ketika menerapkan teknik klasifikasi dan regresi
interface eksperimenter memungkinkan untuk mengotomatisasi proses dengan membuatnya mudah untuk menjalankan pengklasifikasi dan filter dengan pengaturan parameter yang berbeda pada korpus dataset, untuk mengumpulkan statistik kinerja, dan melakukan tes signifikansi. Pengguna advanced dapat menggunakan eksperimenter untuk mendistribusikan beban komputasi di beberapa mesin menggunakan Java Remote Method Invocation (RMI).
BAB III
PERANCANGAN SISTEM
Dalam bab metodologi penelitian ini akan dikaji tiga hal, yaitu (1) sumber data, (2) analisis pengolahan data, (3) desain antarmuka sistem. Ketiga hal tersebut akan dibahas satu per satu dalam subbab yang ada di bawah ini.
3.1 Sumber Data
Dalam penelitian ini, obyek yang digunakan adalah data Wisconsin Breast Cancer Database dari Dr.William H.Woldberg (1989-1991), University of Wisconsin Hospitals, Madison, USA. Data berjumlah 699, dengan atribut sebanyak 11 termasuk atribut kelas. Didalam file tersebut berisi data satu pasien dengan rincian sebagai berikut:
Tabel 3.1 Data Atribut Wisconsin Diagnosis Breast Cancer
No Nama Atribut Keterangan Nilai
1. ID Nomor kode sampel Nomor Id
2. Ketebalan Clump Atribut ini menentukan apakah sel berlayer atau tidak karena sel tumor jinak (benign celss) cenderung hanya mempunyai satu layer (monolayer) sedangkan sel ganas cenderung mempunyai banyak layer (multilayer).
1-10
3. Keseragaman ukuran sel
Atribut ini menentukan konsistensi ukuran sel.
1-10
4. Keseragaman bentuk sel
Atribut ini menentukan kesamaan bentuk sel.
1-10
5. Adhesi Marginal Atribut ini menentukan apakah sel-sel bersama sama atau tidak karena sel ganas cenderung kehilangan kemampuan ini.
6. Ukuran sel tunggal epitel
Atribut ini menentukan apakah
ephitelial cell cenderung membesar atau tidak.
1-10
7. Bare Nuclei Atribut ini menentukan apakah sel dikelilingi sitoplasma (sisa sel) atau tidak.
1-10
8. Bland Kromatin Atribut ini menentukan tingkat tekstur dari sel kromatin.
1-10
9. Nukleous Normal Atribut ini menentukan bentuk dari nucleoli.
1-10
10. Mitosis Atribut ini menentukan seberapa banyak sel kanker membagi, membelah atau memperbanyak dirinya.
1-10
11. Kelas Atribut ini menentukan
kelas apakah tumor yang diderita jinak atau parah.
2 untuk Benign
dan 4 untuk
Malignant.
3.2 Analisis Pengolahan Data
Sebelum data diolah menggunakan sistem, dilakukan pemrosesan data awal terlebih dahulu sesuai dengan proses KDD. Ada empat langkah pemrosesan data yaitu (1) pembersihan data, (2) seleksi data, (3) transformasi data, dan (4) penambangan data. 3.2.1 Pembersihan Data
Pada tahap ini, dilakukan pembersihan terhadap data-data yang tidak lengkap, kosong atau null, data yang mengandung noise, dan data tidak konsisten. Pada tahap ini data yang bernilai null atau kosong, akan dibersihkan dengan cara dihapus secara
Tabel 3.2 Jumlah Data Hasil Pembersihan
Jumlah data kanker payudara
Data awal 699
Data tidak lengkap 16
Jumlah data bersih 683
3.2.2 Seleksi Data
Pada tahap ini akan dilakukan penyeleksian data untuk mengurangi data yang tidak relevan dan redundant. Menurut Tan, Steinbach, dan Kumar (2006), atribut yang tidak relevan adalah atribut yang berisi informasi yang tidak berguna untuk melakukan penambangan data, sedangkan atribut yang berlebihan (redundant) adalah atribut yang menduplikasi banyak atau semua informasi yang terdapat didalam satu atau lebih atribut lain.
Pada data wisconsin diagnosis breast cancer berisi 11 atribut, dan tidak semua dipakai untuk mengklasifikasi kanker. Maka dari itu dilakukan penghapusan atribut yang tidak dipakai, atribut yang tidak terpakai adalah atribut id, sehingga atribut id dihapus.
3.2.3 Transformasi Data
Pada tahap ini akan dilakukan transformasi data kedalam format yang dapat dikelola oleh sistem. Data nilai kelas memiliki format 2 dan 4, format ini diubah yaitu 2 menjadi benign, dan 4 untuk menjadi malignant.
3.2.4 Penambangan Data
Pada tahap ini data teks akan ditambang dengan menggunakan sistem. Langkah awal dari pemrosesan input adalah membaca data teks ke dalam sistem. Setelah data dibaca data berupa data string dan data tercampur didalam satu baris data, sehingga data perlu dipisah kemudian diubah ke tipe data double, kecuali data kelas yaitu benign dan
3.3 Perancangan Umum Sistem
Pada subbab ini akan dijelaskan gambaran yang dibangun, berupa diagram Use Case, Skenario Use Case, diagram aktifitas, dan desain antarmuka sistem.
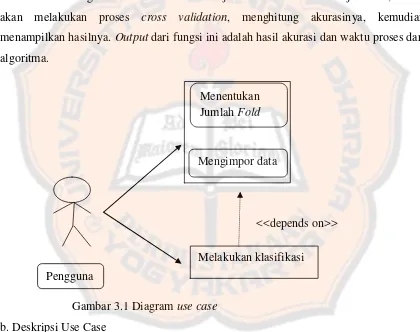
a. Diagram use case
Aktor dari sistem ini hanya satu, yaitu peneliti, namun seterusnya akan disebut pengguna. Fungsi utama yang dapat dilakukan pengguna adalah melakukan klasifikasi. Selain itu pengguna dapat menentukan fold dan mengimpor data.
Ketika fungsi melakukan klasifikasi dijalankan sistem akan menjalankan, sistem akan melakukan proses cross validation, menghitung akurasinya, kemudian menampilkan hasilnya. Output dari fungsi ini adalah hasil akurasi dan waktu proses dari algoritma.
Gambar 3.1 Diagram use case b. Deskripsi Use Case
Fungsi yang dapat dilakukan oleh Pengguna terhadap sistem digambarkan dengan diagram use case seperti pada Gambar 3.2. Berikut ini deskripsi atau penjelasan dari diagram tersebut:
Tabel 3.3 Deskripsi use case
digunakan dalam proses cross validation.
2. Mengimpor data Use casi ini digunakan untuk
memasukkan data kedalam sistem menggunakan file berekstensi .data. Data yang dimasukkan akan ditambang dengan menggunakan algoritma NB dan KNN. 3. Melakukan klasifikasi Use case ini digunakan untuk
melakukan proses klasifikasi dan menghitung akurasi. Pengguna dapat melihat hasil akurasi yang dihasilkan. c. Skenario Use Case
Skenario use case merupakan penjabaran masing-masing use case yang terdapat pada diagram use case. Skenario use case dapat dilihat pada lampiran 2.
d. Diagram Aktivitas
Diagram aktifitas digunakan untuk menunjukkan kegiatan yang dilakukan oleh pengguna dan sistem dalam setiap use case. Rincian diagram aktifitas sistem ini dapat dilihat pada lampiran 3.
3.4 Perancangan Algoritma
3.4.1. Perancangan Algoritma KNN
Berikut adalah proses jalannya algoritma KNN. 1. Pertama masukkan data kanker payudara
2. Untuk proses sebanyak data kanker payudara, lakukan langkah 3-5
3. Hitung jarak antara data testing dengan data training dengan menggunakan rumus Euclidean Distance.
4. Bandingkan jarak untuk mendapatkan jarak terdekat yaitu jarak yang mempunyai nilai terkecil.
5. Setelah mendapatkan jarak terdekat ambil nilai jarak terdekat untuk mendapatkan nilai klasifikasi.
3.4.2. Perancangan Algoritma Naïve Bayes
Berikut adalah proses jalannya algoritma Naïve Bayes. 1. Pertama masukkan data kanker payudara.
2. Untuk proses sebanyak data kanker payudara, lakukan langkah 3-6 3. Hitung probabilitas nilai kelas yang ingin dibandingkan.
4. Hitung probabilitas Ketebalan Clump, Keseragaman ukuran sel, Keseragaman bentuk sel, Adhesi Marginal, Ukuran sel tunggal epitel, Bare Nuclei, Bland Kromatin, Nukleous Normal, Mitosis.
5. Hitung probabilitas data test dengan mengkalikan seluruh probabilitas kelas data test, kemudian hasil dari perhitungan probabilitas dibagi jumlah nilai total probabilitas untuk mendapatkan nilai probabilitas.
6. Bandingkan probabilitas yes dan no, pilih probabilitas yang paling tinggi. 7. Selesai
3.5 Desain Antarmuka Sistem 3.5.1 Halaman Utama
Gambar 3.2 Desain Halaman Utama
Halaman utama merupakan halaman yang muncul pertama kali saat sistem dijalankan. Halaman ini memiliki menu bar menu dan keluar. Saat menu bar menu ditekan maka sistem akan menampilkan Gambar 3.4. Saat menu bar keluar ditekan, maka sistem akan keluar dari program.
Gambar 3.3 Gambar saat menu bar go to ditekan 3.5.2 Halaman Bantuan
Gambar 3.4. Desain Halaman Bantuan
Halaman bantuan merupakan halaman yang membantu pengguna untuk mengenal sistem dan beberapa informasi tentang menu – menu pada sistem. Sama seperti halaman utama di halaman bantuan juga terdapat menu bar menu dan keluar.
Saat menu bar menuditekan maka sistem akan menampilkan Gambar 3.4. Saat menu bar keluar ditekan, maka sistem akan keluar dari program.
3.5.3 Halaman Klasifikasi
Gambar 3.5 Desain Halaman Klasifikasi
Menu Keluar
Tempat pengguna dapat membaca manual – manual atau bantuan sistem ini.
Menu Keluar
KNN Naive Bayes
Proses
Akurasi
Menu
Halaman Beranda Hitung Perbandingan Bantuan
Halaman klasifikasi merupakan halaman yang pengguna gunakan untuk mengklasifikasi data dan melihat akurasi dan waktu prosesnya. Pada halaman ini ada dua menu bar, tiga radio button, dan satu tombol proses. Saat menu bar menu ditekan maka sistem akan menampilkan Gambar 3.4. Saat menu bar keluar ditekan, maka sistem akan keluar dari program. Jika pengguna menekan radio button KNN dan mengklik tombol proses maka program akan menampilkan akurasi, dan waktu proses dari algoritma KNN.Jika pengguna menekan radio button Naive Bayes dan mengklik tombol
proses maka program akan menampilkan akurasi, dan waktu proses dari algoritma
BAB IV
IMPLEMENTASI SISTEM
Bab ini berisi tentang hasil penelitian berupa sistem yang dibangun berdasarkan analisis dan perancangan yang telah dibahas pada bab sebelumnya dan pembahasan mengenai hasil yang didapatkan. Adapun sistem dibangun dengan software Netbeans IDE 7.0.1 pada komputer dengan spesifikasi memory 2 GB dan hardisk 465 GB.
4.1 Implementasi Antarmuka Pemakai (User Interface)
Pada subbab ini akan dibahas mengenai implementasi dari sistem yang telah direncanakan pada bab sebelumnya. Sistem akan mempunyai tiga halaman yaitu (1) halaman beranda, (2) halaman bantuan, dan (3) halaman hitung perbandingan
4.1.1. Halaman Beranda
Halaman utama merupakan halaman yang muncul pertama kali saat sistem dijalankan. Halaman ini memiliki menu barmenu dan keluar. Saat menu bar menuditekan maka sistem akan menampilkan Gambar 4.2. Saat menu bar keluar ditekan, maka sistem akan keluar dari program.
Gambar 4.2 Tampilan saat menu ditekan
Ketika submenu bar form help ditekan maka akan menampilkan halaman bantuan seperti Gambar 4.3
4.1.2 Halaman Bantuan
Gambar 4.3 Tampilan Halaman Bantuan
menu bar menu ditekan maka sistem akan menampilkan Gambar 4.2. Saat menu bar keluar ditekan, maka sistem akan keluar dari program. Saat pengguna menekan submenu bar pada Gambar 4.2 dan memilih form hitung perbandingan maka akan menampilkan seperti Gambar 4.4.
4.1.3 Halaman Hitung Perbandingan
Gambar 4.5 Tampilan open file
Halaman hitung perbandingan adalah halaman yang digunakan pengguna untuk mengklasifikasi dan melihat tingkat akurasi dari algoritma. Pada halaman ini pertama-tama pengguna membuka file yang hendak diklasifikasikan yaitu wisconsin breast cancer dataset dengan menekan tombol open file kemudian akan tampil kotak dialog seperti gambar 4.5 kemudian cari file tekan tombol open, selanjutnya isikan jumlah fold pada edit text jumlah fold ,selanjutnya pilih algoritma yang hendak dipakai dengan memilih salah satu radio button, kemudian setelah memilih algoritma tekan tombol proses dan akurasi,dan waktu proses akan ditampilkan.
4.2 Pemrosesan Input
Pada subbab ini akan dibahas beberapa langkah dalam preprocessing dari data
wisconsin breast cancer yang akan dilakukan oleh sistem agar data dapat dimasukkan ke dalam proses perhitungan klasifikasi. Data yang digunakan adalah data yang berbentuk teks, agar data teks ini dapat di proses dengan klasifikasi, maka langkah pertama adalah membaca data teks kemudian menulis ulang data teks ini menjadi data yang dapat diproses ke dalam sistem klasifikasi.
4.2.1 Membaca Data Teks ke dalam Sistem
membaca teks dari baris awal sampai dengan baris akhir. Berikut adalah kode programnya:
public class LineIterator implements Iterable<String>, Iterator<String>, Closeable {
private BufferedReader in = null; private String next = null;
Pada kode program diatas dilakukan pengimplementasian untuk melakukan perulangan sampai baris terakhir. Kemudian setelah itu dilakukan pembacaan teks perbaris.
private static InputStream stream(File f) { try {
4.2.2 Menulis Ulang Teks di dalam Sistem
Pada tahap ini akan dilakukan penulisan ulang teks yang telah dibaca ke dalam sistem agar dapat diproses ke dalam klasifikasi KNN dan NB. Langkah – langkah yang dilakukan yaitu (1) memecah nilai berdasarkan separator, (2) mengubah nilai menjadi bertipe double untuk kelas pembanding dan string untuk kelas yang dibandingkan, hal ini dilakukan agar nilai dapat dimasukkan ke dalam proses perhitungan klasifikasi, dan (3) menyimpan ke dalam kelas dataset.
Langkah pertama adalah memecah nilai berdasarkan pemisahnya (separator). Berikut adalah kode programnya:
Dataset out = new DefaultDataset(); //simpan ke out
Pada kode program ini langkah pertama yang dilakukan adalah membuat tempat penyimpanan untuk data yang telah ditulis ulang yaitu pada out. Kemudian dilakukan perulangan sebanyak baris pada data, dan dilakukan pemisahan berdasarkan separator
dengan perintah split dan menyimpannya pada string array yaitu arr, kemudian membuat media penyimpanan untuk nilai kelas pembanding yang akan diubah menjadi bertipe double ke dalam double array yaitu values.
Langkah kedua adalah mengubah nilai menjadi bertipe double untuk kelas pembanding dan string untuk kelas yang dibandingkan untuk melakukan hal ini yang pertama dilakukan adalah melakukan perulangan sebanyak baris yang dipisah (split). Selama melakukan perulangan masukkan nilai sesuai indexnya dengan ketentuan index ke-0 adalah nilai kelas yang dibandingkan dan index selanjutnya adalah nilai yang dibandingkan kemudian menggabungkan kembali menjadi sebuah array yang berisi nilai kelas yang dibandingkan dan kelas pembanding.
String classValue = null;
for (int i = 0; i < arr.length; i++) {
Pada kode program diatas dilakukan perulangan sebanyak baris yang dipisah – pisah kemudian untuk kelas index yang ke-0 disimpan ke dalam string yaitu kelas value dan kelas index sisanya dikonversi menjadi double, kemudian disimpan di array double
4.3 Implementasi Algoritma pada Sistem
Pada subbab ini akan dibahas beberapa pengimplementasian dari algoritma ke dalam sistem. Pengimplementasian yang dibahas, yaitu (1) algoritma K-Nearest Neighbor, (2) algoritma Naïve Bayes, dan (3) teknik Cross Validation.
4.3.1 Algoritma K-Nearest Neighbor
Pada bagian ini akan dijelaskan beberapa langkah untuk melakukan klasifikasi dengan KNN menggunakan data yang telah di preprocessing. Beberapa langkahnya yaitu, (1) menghitung jarak kemiripan (similarity) antara data training dengan data test
dengan menggunakan rumus euclidean distance, (2) membandingkan jarak kemiripan (similarity) untuk mendapatkan tetangga terdekat (nearest neighbor), dan (3) Mengambil nilai kelas dari tetangga terdekat (nearest neighbor) untuk dijadikan sebagai nilai hasil klasifikasi.
4.3.1.1 Menghitung Euclidean Distance
Hal pertama yang dilakukan klasifikasi KNN adalah menghitung jarak kemiripan (similarity), untuk menghitung jarak kemiripan (similarity) sistem menggunakan perhitungan euclidean distance. Langkah pertama adalah memastikan bahwa data testing dan training adalah data angka, kemudian barulah sistem akan menghitung jarak kemiripan (similarity) data testing dan training dengan menggunakan rumus euclidean distance, berikut adalah cuplikan kodingnya:
if (!Double.isNaN(y.value(i)) && !Double.isNaN(x.value(i))) // isNan adalah Not a Number
sum += (y.value(i) - x.value(i)) * (y.value(i) - x.value(i)); }
return Math.sqrt(sum);
// kembalikan nilai akar dari sum }
4.3.1.2 Membandingkan Jarak Terdekat (Nearest Neighbor)
Langkah kedua adalah membandingkan jarak kemiripan (similarity) dari semua data yang telah dihitung menggunakan rumus euclidean distance untuk mendapatkan jarak terdekat (nearest neighbor). Langkah pertama adalah dengan membuat suatu tempat untuk menyimpan nilai jarak terdekat ke dalam sebuah map, berikut adalah
source code-nya:
Map<Instance, Double> closest = new HashMap<Instance, Double>(); // untuk menyimpan instance dan nilai jarak terdekat
double max = dm.getMaxValue();
Selanjutnya untuk setiap data kanker lakukan perhitungan jarak euclidean distance antara data yang dites dengan data yang di-training dengan memanggil method
euclidean distance yang telah dibuat sebelumnya. for (Instance tmp : this) {
// perulangan dilakukan sebanyak dataset double d = dm.UkurdgnEuclid(inst, tmp); // hitung dengan euclidean distance
Kemudian lakukan perbandingan antar jarak terdekat untuk mendapatkan jarak yang paling dekat. Untuk mendapatkan jarak yang paling dekat (nearest neighbor) ada beberapa langkah yaitu (1) menyimpan semua hasil perhitungan euclidean distance ke sebuah hashmap, (2) mengurutkan jarak dari terdekat ke terjauh, dan (3) menghapus jarak terjauh dan mengambil jarak terdekat sesuai k yang telah ditentukan.
if (dm.compare(d, max) && !inst.equals(tmp)) { // Cek jika sudah dicompare
closest.put(tmp, d);
max = removeFarthest(closest,dm); }} // hapus jarak terjauh
return closest.keySet();}
Pada kode program diatas jika jumlah jarak terdekat melebihi k maka sistem akan menghapus jarak terjauh sehingga sistem akan mengambil jarak terdekat sesuai dengan k yang telah ditentukan. Dan kode program di bawah ini adalah untuk menghapus jarak terjauh.
private double removeFarthest(Map<Instance, Double> vector,DistanceMeasure dm) {
Pada kode program di atas sistem akan mengurutkan jarak terdekat dan akan menghapus jarak yang paling jauh.
Setelah jarak terdekat didapatkan maka langkah selanjutnya adalah menentukan nilai hasil klasifikasi dengan mengambil nilai dari data yang merupakan data yang memiliki jarak terdekat.
4.3.1.3 Mengambil Nilai Jarak Terdekat
menambah satu (+1) pada nilai yang dimiliki oleh jarak terdekat. Penambahan nilai satu pada value yang dimiliki jarak terdekat bertujuan agar pada saat perbandingan probabilitas sistem akan memilih atau mengambil nilai yang dimiliki oleh jarak terdekat sebagai nilai hasil dari klasifikasi. Berikut adalah kode programnya:
Set<Instance> neighbors = training.kNearest(k, instance, dm); // menyimpan hasil jarak terdekat
/* Membangun kelas distribusi */
HashMap<Object, Double> out = new HashMap<Object, Double>(); // menyimpan hasil klasifikasi
for (Object o : training.classes()){ // Selama o bagian dari data training
out.put(o, 0.0);
// set nilai kelasnya menjadi 0 for (Instance i : neighbors) { // selama I bagian dari jarak terdekat
out.put(i.classValue(), out.get(i.classValue()) + 1); //set nilai kelas menjadi 1
}
return out; // kembalikan nilai out
Setelah didapatkan nilai satu untuk nilai kelas yang dibandingkan maka sistem akan membandingkan nilai tersebut untuk menentukan hasil akhir klasifikasi. Berikut adalah kode program untuk membandingkan nilai.
public Object classify(Instance instance) {
Map<Object, Double> distribution = KelasDistribusi(instance); double max = 0;
Object out = null;
for (Object key : distribution.keySet()) { if (distribution.get(key) > max) { max = distribution.get(key);
} }
return out; }
Pada method ini sistem akan membandingkan nilai kelas yang telah diberi bobot pada method KelasDistribusi(), misalnya: nilai jarak terdekat adalah yes maka yes akan diberi nilai 1 dan no akan diberi nilai 0 maka method ini akan mengeluarkan yes sebagai hasil dari klasifikasi.
4.3.2 Algoritma Naive Bayes
Dalam implementasi algoritma ini akan dijelaskan beberapa proses dalam perhitungan Naive Bayes dalam klasifikasi teks. Langkah – langkah yang dilakukan dalam proses klasifikasi teks dengan Naïve Bayes adalah (1) menghitung frekuensi kelas, baik kelas yang dibandingkan maupun kelas pembanding, (2) menghitung probabilitas kelas, baik kelas yang dibandingkan maupun kelas pembanding, (3) menghitung nilai likelihood dengan mengkalikan semua probabilitas kelas, (4) menormalisasikan nilai likehood ke dalam bentuk probabilitas, dan (5) membandingkan nilai probabilitas likehood dan nilai yang tertinggi dijadikan hasil akhir dari klasifikasi. 4.3.2.1 Menghitung Frekuensi Kelas
Langkah pertama adalah menghitung frekuensi kelas. Frekuensi disini adalah banyaknya sebuah data dalam kategori tertentu, penulis mengambil contoh untuk data buys_computer yang telah dibahas di bab sebelumnya adalah banyaknya pembeli berusia 30 tahun yang membeli komputer atau banyaknya pembeli yang masih pelajar yang membeli komputer dan seterusnya.
Langkah pertama adalah menyimpan nilai dari frekuensi kelas kedalam sebuah
array double.
double[] FrekuensiKelas = new double[numClasses]; // menyimpan jumlah frekuensi kelas
Kemudian pada bagian selanjutnya dilakukan perulangan sebanyak jumlah kelas yang dimiliki oleh data kanker, kemudian setting nilai frekuensi kelas menjadi 0.
FrekuensiKelas[i] = 0;
// setting frekuensi kelas menjadi 0 }
Selanjutnya dilakukan perulangan untuk setiap data yang muncul sesuai dengan kategori tertentu yang dipanggil maka frekuensi kelas akan otomatis bertambah 1.
for (Instance inst : Instances2Train) {
FrekuensiKelas[Classname2IndexCCountermap.get(inst.classValue())]++;
Classname2IndexCCountermap bisa mendeteksi kepemilikan kelas pada nilai kelas pembanding sehingga ketika nilai keluar maka pada kelas pemilik sistem akan menambahkan nilai satu.
for (Object o : trainingData.classes()) { String classname = o.toString(); pembanding pada setiap data training, sehingga ketika dipanggil sistem akan menambah nilai frekuensi kelas data tersebut.
Kemudian langkah selanjutnya adalah menghitung probabilitas masing-masing kelas.
4.3.2.2 Menghitung Probabilitas Kelas
Langkah kedua adalah menghitung probabilitas kelas dari masing – masing kelas. Dalam proses klasifikasi naive bayes perhitungan probabilitas kelas dihitung dengan menggunakan rumus sebagai berikut:
Rumus tersebut yang akan diimplementasikan dalam kode program ini. Langkah pertama adalah membuat sebuah array untuk menyimpan nilai frekuensi dan probabilitas, kemudian lakukan iterasi sebanyak jumlah kelas lakukan perhitungan probabilitas. Berikut adalah kode programnya:
private double[] HitungProbsKelas() {
double[] probs = trainResult.getClassFreqs().clone(); // menyimpan probabilitas kelas
double[] freq = trainResult.getClassFreqs().clone(); for (int k = 0; k < numClasses; k++) {
probs[k] = (freq[k] + 1) / (numInstances + numClasses);
} return probs; }
4.3.2.3 Menghitung Kelas Distribusi Naïve Bayes
Langkah ketiga adalah menghitung probabilitas likehood dari naive bayes
dengan mengkalikan semua probabilitas kelas, kemudian menormalisasi hasil likehood ke dalam bentuk probabilitas, dan kemudian membandingkan probabilitas kelas yang dibandingkan untuk mendapatkan hasil akhir dari klasifikasi. Yang pertama dilakukan adalah membuat suatu tempat penyimpanan atau map untuk menyimpan nilai frekuensi, fitur tabel dan menyimpan hasil klasifikasi.
HashMap<Object, Double> out = new HashMap<Object, Double>(numClasses);
// menyimpan hasil klasifikasi
Hashtable<Integer, Hashtable<Double, ClassCounter>> featureName_HT = trainResult.getFeatureTable();
// menyimpan fitur tabel
double[] freq = trainResult.getClassFreqs().clone(); double total = 0;
P(yes/no) = |doc j| |Contoh|
for (int k = 0; k < numClasses; k++) { double denominator = freq[k];
double classScore2 = freq[k]/numInstances;
Pada bagian kode program diatas adalah implementasi dari hitung probabilitas nilai kelas yang akan dibandingkan dan akan diulang sebanyak jumlah kelas dalam kasus ini diulang dua kali karena kelas yang dibandingkan adalah dua (yes dan no). Kemudian setelah menghitung probabilitas nilai kelas selanjutnya sistem akan menghitung nilai dari kelas pembanding lainnya dengan menggunakan rumus:
P(Wk|Vj)= Nk+1 N+|vocabulary|
Kemudian mengkalikan seluruh probabilitas kelas pembanding untuk kategori yes dan no untuk mendapatkan likelihood yang nantinya akan dibandingkan.
for (Object key : featureName_HT.keySet()) {
Pada bagian ini sistem menghitung probabilitas kelas pembanding yang muncul dan mengkalikan seluruhnya untuk mendapatkan nilai likelihood, kemudian sistem menormalisasi nilai likelihoss agar berbentuk probabilitas dengan cara likelihood yes ataupun no dibagi hasil total dari penjumlahan hasil perkalian likelihood yes dan no.
for (int l = 0; l < classes.length; l++) {
Kemudian setelah mendapat nilai probabilitas barulah dibandingkan, kemudian sistem akan mengembalikan nilai probabilitas tertinggi sebagai hasil akhir klasifikasi.
public Object classify(Instance instance) {
Map<Object, Double> distribution = KelasDistribusi(instance); double max = 0;
Object out = null;
for (Object key : distribution.keySet()) { if (distribution.get(key) > max) {
max = distribution.get(key);
Teknik cross validation digunakan untuk memvalidasi keakuratan dari suatu klasifikasi. Pada bagian ini akan dijelaskan beberapa proses dalam melakukan evaluasi dengan cross validation.
4.3.3.1 Menghitung Evaluasi Cross Validation
Langkah pertama yang dilakukan adalah membuat suatu tempat penyimpanan data untuk validasi dan data untuk training.
for (int i = 0; i < numFolds; i++) { Dataset validation = folds[i];
// untuk menyimpan data validasi Dataset training = new DefaultDataset();
// untuk menyimpan data training
Pada kode program diatas perulangan dilakukan untuk mengambil data untuk dijadikan data validasi untuk setiap perulangan, dan perulangan dilakukan sebanyak jumlah fold yang diinginkan, kemudian setelah pengambilan data validasi sisa data nya dijadikan sebagai data training.
for (int j = 0; j < numFolds; j++) { if (j != i)
training.addAll(folds[j]); } classifier.buildClassifier(training);
Pada kode program diatas perulangan digunakan untuk mengambil semua data kecuali data yang dijadikan sebagai data validasi. Kemudian melatihnya dengan klasifikasi yang diinginkan. Selanjutnya menentukan jumlah benar yang positif (true positif), jumlah benar yang negatif (true negative), jumlah salah yang positif (false positif) dan jumlah salah yang negatif (false negative).
Pada bagian ini dilakukan pengecekan pada data yang dijadikan validasi dan dicocokan dengan data yang telah di-training. Langkah pertama adalah menjalankan proses klasifikasi
for (Instance instance : validation) {
// Selama instance bagian dari validation Object prediction = classifier.classify(instance);
Kemudian setelah proses dijalankan maka pengecekan dimulai dari klasifikasi yang bernilai benar terlebih dahulu.
// Selama o bagian dari out.keySet() Kemudian sistem akan mengecek hasil klasifikasi yang salah.
} else {// jika prediksi tidak sama dengan kelas for (Object o : out.keySet()) {
// Selama o bagian dari out.keyset if (prediction.equals(o)) {
out.get(o).fp++; }
/* instance is positive class */
else if (o.equals(instance.classValue())) {
return out; //kembalikan nilai out/hasil }