IMPLEMENTASI DEEP LEARNING MENGGUNAKAN CONVOLUTIONAL NEURAL NETWORK UNTUK KLASIFIKASI CITRA MIKROSKOPIS
STOMATA TANAMAN HERBAL CURCUMA
SKRIPSI
ANDES PAHALA S 121402048
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN
2019
IMPLEMENTASI DEEP LEARNING MENGGUNAKAN CONVOLUTIONAL NEURAL NETWORK UNTUK KLASIFIKASI CITRA MIKROSKOPIS
STOMATA TANAMAN HERBAL CURCUMA
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat memperoleh ijazah Sarjana Teknologi Informasi
ANDES PAHALA S 121402048
PROGRAM STUDI S1 TEKNOLOGI INFORMASI
FAKULTAS ILMU KOMPUTER DAN TEKNOLOGI INFORMASI UNIVERSITAS SUMATERA UTARA
MEDAN 2019
ii
PERNYATAAN
IMPLEMENTASI DEEP LEARNING MENGGUNAKAN CONVOLUTIONAL NEURAL NETWORK UNTUK KLASIFIKASI CITRA MIKROSKOPIS
STOMATA TANAMAN HERBAL CURCUMA
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya saya sendiri, kecuali beberapa kutipan dan ringkasan yang masing-masing telah disebutkan sumbernya.
Medan, 20 Desember 2019
Andes Pahala S 121402048
UCAPAN TERIMA KASIH
Puji dan syukur kepada Tuhan Yesus Kristus yang telah memberikan berkat dan kasih-Nya sehingga penulis dapat menyelesaikan skripsi ini, sebagai syarat untuk memperoleh gelar Sarjana Komputer di Universitas Sumatera Utara.
Ucapan terima kasih penulis sampaikan kepada :
1. Kedua orangtua, adik-adik, dan juga seluruh anggota keluarga penulis yang senantiasa memberikan kasih sayang, doa dan dukungan kepada penulis.
2. Ibu Ulfi Andayani, S.Kom., M.Kom., selaku dosen pembimbing I dan bapak Imam Bagus Sumantri, S.Farm., M.Si,Apt., selaku dosen pembimbing II yang telah memberikan waktu, ide dan tenaganya untuk membimbing penulis dalam penyelesaian skripsi.
3. Bapak Dedy Arisandi, S.T., M.Kom., selaku dosen pembanding I dan bapak Niskarto Zendrato, S.Kom., M.Kom., selaku dosen pembanding II yang telah memberikan kritik dan saran kepada penulis dalam penyempurnaan skripsi.
4. Dekan dan Wakil Dekan Fakultas Ilmu Komputer dan Teknologi Informasi, Ketua Program Studi Teknologi Informasi beserta para dosen dan pegawai di lingkungan Fakultas yang telah membimbing dan membantu penulis selama masa perkuliahan dan proses pengerjaan skripsi.
5. Kepala Laboratorium Farmasi Universitas Sumatera Utara, pegawai dan asisten laboratorium yang telah membantu penulis dalam proses pengambilan data skripsi.
6. Abang, adik dan teman seangkatan program studi Teknologi Informasi USU yang telah menemani dan memberikan dukungan, waktu, kritik dan saran kepada penulis selama proses perkuliahan sampai penyelesaian skripsi.
7. Semua pihak yang terlibat secara langsung ataupun tidak langsung yang tidak dapat penulis ucapkan satu persatu dalam proses penyelesaian skripsi.
Semoga Tuhan memberkati.
iv
ABSTRAK
Banyak sekali jenis tanaman herbal yang berasal dari genus yang sama. Kemiripan ciri yang ada pada tanaman herbal menjadikannya sulit untuk dibedakan. Apalagi dalam bidang farmasi, yang sangat riskan untuk membuat kesalahan. Bagian tanaman yang sering menjadi bahan pembuatan obat herbal adalah daun, sehingga penelitiaan tentang daun dan organel penyusunnya sangat penting bagi dunia farmasi. Oleh karena itu diperlukan adanya suatu pendekatan untuk mengidentifikasi jenis organel yang ada pada daun, dimana organel yang paling sering diteliti adalah bagian stomata. Jadi, pendekatan neural network dibutuhkan untuk membedakan ciri tanaman pada genus yang sama. Pada penelitian ini ada 2 spesies tanaman pada genus Curcuma, yaitu kunyit dan temulawak. Penelitian ini dilakukan dengan mengimplementasikan Deep Learning menggunakan Convolutional Neural Network (CNN) dengan bantuan proses filter gabor dan ekstraksi fitur menggunakan Gray Level Cooccurance Matrix (GLCM). Penelitian dilakukan dengan menggunakan 160 citra mikroskopis tanaman herbal Curcuma sebagai data latih dengan akurasi pelatihan 93.1% dan data uji sebanyak 40 citra dengan akurasi sebesar 92.5%. Dari proses pengujian sistem dapat disimpulkan bahwa besarnya tingkat akurasi dipengaruhi oleh beberapa faktor seperti bentuk citra awal, parameter CNN, dan jumlah dataset.
Kata Kunci: Convolutional Neural Network, Genus Curcuma, Klasifikasi Stomata
THE IMPLEMENTATION OF DEEP LEARNING USING CONVOLUTIONAL NEURAL NETWORK BASED ON STOMATA
MICROSCOPIC IMAGE OF CURCUMA HERBAL PLANTS
ABSTRACT
There are so many types of herbal plants that come from the same genus. The similarity of features in herbal plants makes it difficult to distinguish. Especially in the pharmaceutical field, which is very risky for making mistakes. The part of plants that is often used as ingredients for herbal medicines is the leaves, so research on leaves and their constituent organelles is very important for the pharmaceutical world.
Therefore an approach is needed to identify the types of organelles present in the leaves, where the organelles most frequently studied are the stomata. So, a neural network approach is needed to distinguish plant characteristics in the same genus. In this research there are 2 species of plants in the Curcuma genus, namely turmeric and ginger. This research was conducted by implementing Deep Learning using Convolutional Neural Network (CNN) with the help of the gabor filter process and feature extraction using the Gray Level Cooccurance Matrix (GLCM). The study was conducted using 160 microscopic images of Curcuma herbal plants as training data with training accuracy of 93.1% and test data of 40 images with an accuracy of 92.5%.
From the system testing process it can be concluded that the level of accuracy is influenced by several factors such as the initial image shape, CNN parameters, and the number of datasets.
Keywords: Convolutional Neural Network, Curcuma Genus, Stomata Classification
vi
DAFTAR ISI
Halaman
PERSETUJUAN i
PERNYATAAN ii
UCAPAN TERIMA KASIH iii
ABSTRAK iv
ABSTRACT v
DAFTAR ISI vi
DAFTAR TABEL ix
DAFTAR GAMBAR x
BAB 1 PENDAHULUAN
1.1. Latar Belakang 1
1.2. Rumusan Masalah 4
1.3. Batasan Masalah 4
1.4. Tujuan Penelitian 4
1.5. Manfaat Penelitian 4
1.6. Metodologi Penelitian 4
1.7. Sistematika Penulisan 5
BAB 2 LANDASAN TEORI
2.1. Tanaman Herbal 7
2.1.1 Morfologi Tumbuhan 7
2.1.2 Stomata Daun 8
2.1.3 Genus Curcuma 9
2.2. Pengenalan Citra 11
2.3. Pengolahan Citra 11
2.3.1 Akuisisi Citra 12
2.3.2 Resizing 12
2.3.3 Grayscaling 13
2.4. Filter Gabor 13
2.5. Fitur Ekstraksi 14
2.5.1 Gray Level Co-Occurrence Matrix (GLCM) 14
2.6. Convolutional Neural Network (CNN) 16
2.6.1 Operasi Konvolusi 17
2.6.2 Stride 20
2.6.3 Zero Padding 20
2.6.4 Dropout Regularization 20
2.6.5 Softmax Classifier 20
2.7. Penelitian Terdahulu 21
BAB 3 ANALISIS DAN PERANCANGAN
3.1. Dataset 23
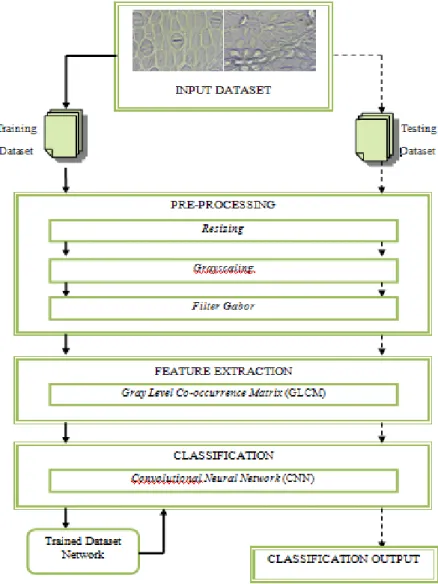
3.2. Arsitektur Umum 25
3.2.1 Pre-Trained Neural Network 26
3.2.2 Testing Neural Network 26
3.2.3 Pre-Processing 26
3.2.4 Feature Extraction 28
3.2.5 Convolutional Neural Network 34
3.2.6 Output 41
3.3. Perancangan Antarmuka Sistem 41
3.3.1 Halaman Depan 41
3.3.2 Halaman Pelatihan 42
3.3.3 Halaman Pengujian 43
BAB 4 IMPLEMENTASI DAN PENGUJIAN
4.1. Implementasi Sistem 44
4.1.1 Spesifikasi Perangkat Keras dan Lunak 44 4.1.2 Implementasi Perancangan Antarmuka 44 4.1.2.1 Tampilan Halaman Utama 45 4.1.2.2 Tampilan Halaman Pelatihan 45
viii
4.2. Pengujian Sistem 47
BAB 5 KESIMPULAN DAN SARAN
5.1. Kesimpulan 54
5.2. Saran 54
DAFTAR PUSTAKA 55
DAFTAR TABEL
Halaman
Tabel 2.1 Penelitian Terdahulu 22
Tabel 3.1 Pembagian Dataset 23
Tabel 3.2 Nilai Matriks GLCM 30
Tabel 3.3 Hasil Perhitungan Nilai Ekstraksi Ciri Matriks GLCM 34
Tabel 3.4 Tabel Proses dengan Metode CNN 40
Tabel 4.1 Skenario Penulisan Nilai Parameter Max Epoch 47
Tabel 4.2 Skenario Pengujian Nilai Mini Batch 47
Tabel 4.3 Skenario Pengujian Jumlah Data Latih 48
Tabel 4.4 Hasil Data Pengujian Sistem 49
x
DAFTAR GAMBAR
Halaman
Gambar 2.1 Struktur Anatomi Daun 8
Gambar 2.2 Taksonomi Genus Curcuma 9
Gambar 2.3 Stomata Curcuma longa (kunyit) 10
Gambar 2.4 Stomata Curcuma zanthorrhiza (temulawak) 11
Gambar 2.5 Contoh Penentuan Awal Matrix GLCM 15
Gambar 2.6 Matriks framework menjadi Matriks Simetris 15
Gambar 2.7 Normalisasi Matriks GLCM 16
Gambar 2.8 Proses Konvolusi pada CNN 17
Gambar 2.9 Operasi Max Pooling 19
Gambar 3.1 Citra Mikroskopis Tanaman Kunyit 24
Gambar 3.2 Citra Mikroskopis Tanaman Temulawak 24
Gambar 3.3 Arsitektur Umum Penelitian 25
Gambar 3.4 Tampilan Hasil Grayscale 27
Gambar 3.5 Tampilan Hasil Filter Gabor 28
Gambar 3.6 Matriks Input Awal 30
Gambar 3.7 Matriks GLCM 4x4 30
Gambar 3.8 Convolutional Layer 1 37
Gambar 3.9 Convolutional Layer 2 38
Gambar 3.10 Operasi Max Pooling 1 38
Gambar 3.11 Convolutional Layer 3 39
Gambar 3.12 Convolutional Layer 4 39
Gambar 3.13 Operasi Max Pooling 2 40
Gambar 3.14 Rancangan Tampilan Home 42
Gambar 3.15 Rancangan Tampilan Halaman Pelatihan 42
Gambar 3.16 Rancangan Tampilan Halaman Pengujian 43
Gambar 4.1 Tampilan Halaman Utama 45
Gambar 4.2 Tampilan Halaman Pelatihan 46
Gambar 4.3 Tampilan Halaman Pengujian 46
Gambar 4.4 Tampilan Hasil Klasifikasi Akhir 48
BAB 1 PENDAHULUAN
1.1. Latar Belakang
World Health Organization (WHO) memberikan defenisi tanaman herbal sebagai tanaman yang digunakan untuk tujuan pengobatan, dan merupakan bahan asli dalam pembuatan obat herbal (WHO, 1998). Tanaman herbal memiliki ribuan jenis spesies dengan total sekitar 40.000 jenis tanaman herbal yang telah dikenal di dunia, dimana sekitar 30.000 jenisnya disinyalir berada di wilayah Indonesia. Jumlah tersebut mewakili 90% dari tanaman obat yang ada di benua Asia. Dari jumlah tersebut, 25%
diantaranya atau sekitar 7.500 jenis sudah diketahui memiliki khasiat herbal atau sering disebut tanaman obat, namun hanya 1.200 jenis tanaman yang sudah dimanfaatkan untuk bahan baku obat-obatan herbal (PT. Sido Muncul, 2015).
Berdasarkan Keputusan Kepala BPOM Nomor HK.00.05.4.2411 Tahun 2004 Tentang Ketentuan Pokok Pengelompokan dan Penandaan Obat Bahan Alam Indonesia, obat herbal Indonesia dapat dikelompokkan menjadi jamu, Obat Herbal Terstandar (OHT) dan Fitofarmaka. Jamu hanya memiliki klaim pembuktian tradisional, sedangkan OHT adalah obat herbal yang telah dibuktikan mutu, manfaat, dan keamanannya secara ilmiah dan menggunakan bahan baku yang sudah memenuhi standar dan biasanya telah diuji pra klinik. Sementara fitofarmaka adalah obat herbal terstandar yang telah dilakukan pembuktian lebih lanjut secara ilmiah, karena telah dilakukan uji klinik. (Buletin Infarkes, 2015).
Dari berbagai jenis tanaman herbal yang ada, lebih banyak dimanfaatkan untuk bahan baku jamu, padahal jamu tidak bersifat kuratif atau menyembuhkan, tetapi hanya pencegahan. Hanya sekitar 5% jenis yang dimanfaatkan sebagai bahan fitofarmaka, dimana sudah diuji klinis pada manusia dapat meningkatkan level kuratif atau bisa menyembuhkan (Harian Jurnalasia, 2017). Hal ini diakibatkan salah satunya oleh kurangnya riset lanjutan yang dilakukan dan basis teknologi.
Jenis tanaman herbal yang paling sering digunakan salah satunya berasal dari genus Curcuma, dengan contoh spesiesnya yaitu kunyit (Curcuma longa) dan temulawak (Curcuma zanthorrhiza). Kedua spesies ini termasuk dalam 10 spesies tanaman herbal yang paling banyak dipergunakan, terkhusus kunyit menempati posisi kedua setelah jahe dari genus Zingiber. Istilah genus dan spesies dipelajari dalam taksonomi. Taksonomi itu sendiri merupakan suatu pengelompokan suatu individu menjadi spesies, menyusun spesies menjadi kelompok yang lebih besar, dan memberi nama kelompok tersebut, sehingga menghasilkan klasifikasi (Judd, et al, 2007).
Tingkatan klasifikasi dari yang terunik hingga ke tingkat kemiripan yang lebih besar, yaitu spesies, genus, famili, ordo, kelas, divisi, dan kingdom. Kemiripan tanaman juga menjadi salah satu faktor yang menghambat pemanfaatan tanaman herbal, dimana akan sangat beresiko apabila terjadi kesalahan pemilihan jenis tanaman yang menjadi bahan obat. Perbedaan tersebut dapat dilihat dari segi morfologi ataupun anatomi tumbuhan.
Tumbuhan secara morfologi atau tampilan eksternalnya memiliki 3 bagian pokok, yaitu akar, batang dan daun. Daun merupakan organ terpenting bagi tumbuhan dalam melangsungkan hidupnya karena tumbuhan adalah organisme autotrof obligat yang harus memasok kebutuhan energinya sendiri melalui konversi energi cahaya menjadi energi kimia. Daun merupakan bagian tumbuhan yang paling sering diteliti dalam bidang biologi maupun farmasi, terutama bagian-bagian penyusunnya yang bersifat mikroskopis.
Secara anatomi, daun memiliki 3 jaringan, yaitu jaringan epidermis (lapisan luar), jaringan mesofil (lapisan dalam) dan jaringan pengangkut. Pada jaringan epidermis daun inilah terdapat stomata. Stomata lebih mudah untuk diteliti karena terdapat pada lapisan epidermis daun yang merupakan lapisan luar daun, sehingga memungkinkan untuk dilihat langsung dari mikroskop tanpa perlakuan khusus seperti pengamatan pada jaringan mesofil.
Stomata merupakan organel mikroskopis yang terdapat pada daun yang berperan dalam respirasi tanaman, fotosintesis, jalur masuk pathogen, prediksi produktivitas tanaman, dan prediksi perubahan lingkungan seperti konsentrasi karbondioksida, tingkat cahaya dan temperatur udara. Peran tersebut merupakan alasan mengapa stomata sangat penting untuk diteliti. Hubungan stomata antara
3
untuk bagian herbarium, pembelajaran tipe stomata, ataupun pengenalan cirri stomata tanaman. Ciri stomata tanaman ini beragam antartanaman, tetapi akan menjadi sulit dibedakan jika sudah mencapai tingkatan genus. Peran teknologi informasi dalam pengenalan ciri stomata yang cepat dan baik sangat diperlukan dalam laporan herbarium ataupun dalam penelitian lanjutan lainnya di bidang farmasi.
Beberapa penelitian sebelumnya pada daun tanaman telah dilakukan untuk menyelesaikan permasalahan identifikasi diantaranya yaitu dilakukan oleh V. A.
Gulhane, et al (2011) adalah melakukan pengidentifikasian dan mendiagnosis penyakit pada daun kapas dengan menggunakan metode fuzzy, Artificial Neural Network (ANN), dan Support Vector (SVM). Peneliti juga menggunakan ekstraksi warna dan tekstur pada penelitian ini. Peneliti menggunakan 20 citra daun berpenyakit dan 25 citra daun normal. Menggunakan segmentasi warna dan kualitas gambar yang baik akan meningkat hasil diagnosis. Pada penelitian ini didapatkan akurasi sebesar 85%.
Selanjutnya, Permata E, et al (2014) melakukan penelitian untuk mengklasifikasikan daun tanaman kakao yang sehat atau terkena penyakit menggunakan Backpropagation. Pada penelitian ini didapatkan akurasi sebesar 86%
dari total 90 data citra.
Penelitian selanjutnya oleh Aniket Gharat, et al (2017) melakukan penelitian menggunakan Convolutional Neural Network (CNN) untuk mendeteksi penyakit pada daun tanaman melalui pendektan jaringan saraf tiruan. Selain itu juga peneliti menggunakan invariant moment sebagai esktraksi fitur. Pada penelitian ini didapatkan akurasi sebesar 88%.
Berdasarkan penelitian yang disebutkan sebelumnya, belum ada penelitian tentang pengolahan citra dari organel stomata daun itu sendiri yang sangat dibutuhkan dalam bidang farmasi, dimana ini masih dilakukan secara manual oleh ahli farmasi untuk pengklasifikasiannya. Oleh karena itu penulis mengajukan penelitian yang diimplementasikan untuk kebutuhan laboratorium farmasi dalam pengenalan stomata tanaman herbal yang berjudul “Implementasi Deep Learning Menggunakan Convolutional Neural Network Untuk Klasifikasi Citra Mikroskopis Stomata Tanaman Herbal Curcuma”.
1.2. Rumusan Masalah
Secara umum, ahli farmasi mengenali jenis stomata tanaman masih secara manual.
Untuk itu, diperlukan suatu pendekatan teknologi yang dapat membantu para ahli farmasi dalam mengenali jenis stomata tanaman herbal yang diteliti seperti pada genus Curcuma.
1.3. Batasan Masalah
Penelitian ini memiliki batasan-batasan atau ruang lingkup permasalahan yang akan diteliti. Batasan-batasan yang dimaksud adalah:
a. Input yang digunakan adalah citra mikrokospis stomata dalam file gambar berekstensi .png
b. Jumlah dataset yang digunakan dalam penelitian ini sebanyak 200 citra stomata.
c. Citra mikrokopis stomata yang digunakan memiliki ukuran 100 x 100 piksel.
d. Terdapat dua spesies tanaman herbal dari genus Curcuma dalam penelitian ini, yaitu kunyit (Curcuma longa) dan temulawak (Curcuma zanthorrhiza).
e. Menggunakan foto mikroskopis stomata dengan perbesaran 400 kali.
1.4. Tujuan Penelitian
Tujuan dari penelitian ini adalah merancang sebuah sistem untuk mengklasifikasikan jenis tanaman herbal pada genus Curcuma dengan menggunakan metode Convolutional Neural Network berdasarkan citra mikroskopis stomatanya.
1.5. Manfaat Penelitian
Manfaat dari penelitian ini adalah :
a. Mempermudah pengguna di bidang farmasi dan herbarium dalam pengenalan ciri stomata antartanaman pada genus Curcuma.
b. Dapat menjadi laporan herbarium dalam pendataan stomata tanaman untuk penelitian lanjutan di bidang farmasi.
c. Sebagai bahan pembelajaran dan referensi untuk penelitian lain dibidang image processing dan Convolutional Neural Network.
5
1.6. Metodologi Penelitian
Adapun tahapan – tahapan yang akan dilakukan pada penelitian ini adalah : a. Studi Literatur
Pada tahap ini dilakukan pengumpulan bahan referensi tentang taksonomi tumbuhan, genus Curcuma, stomata daun, Neural Network, Filter Gabor, Gray Level Co-occurrence Matrix, dan Convolutional Neural Network yang diperoleh melalui buku, jurnal, artikel dan sumber referensi lainnya.
b. Analisis Permasalahan
Pada tahap ini dilakukan analisis terhadap informasi yang sudah dikumpulkan pada tahap sebelumnya, sehingga didapatkan pemahaman mengenai metode Convolutional Neural Network untuk pengklasifikasian stomata tanaman Curcuma.
c. Perancangan
Pada tahap ini dilakukan perancangan berdasarkan analisis permasalahan yang dilakukan pada tahap sebelumnya.
d. Implementasi
Pada tahap ini dilakukan implementasi pembangunan sistem sesuai dengan analisis dan perancangan yang telah dilakukan.
e. Pengujian
Pada tahap ini dilakukan pengujian terhadap sistem yang dibangun menggunakan metode Convolutional Neural Network (CNN) dalam pengklasifikasian stomata tanaman Curcuma untuk memastikan hasil yang diperoleh sesuai dengan yang diharapkan.
f. Dokumentasi dan Penyusunan Laporan
Pada tahap akhir dilakukan dokumentasi dan penyusunan laporan dari keseluruhan penelitian yang telah dilakukan.
1.7. Sistematika Penulisan
Sistematika penulisan dari skripsi ini terdiri dari lima bagian bab, yaitu sebagai berikut :
Bab 1: Pendahuluan
Bab ini membahas tentang latar belakang, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metodologi penelitian, dan sistematika penelitian.
Bab 2: Landasan Teori
Bab ini berisi tentang teori-teori pemahaman yang digunakan untuk dapat memahami permasalahan dalam penelitian ini. Teori yang dibahas berhubungan dengan neural network, filter gabor, Gray Level Co-occurrence Matrix, dan Convolutional Neural Network serta penelitian terdahulu sebagai referensi teori dalam penelitian ini.
Bab 3: Analisis dan Perancangan
Bab ini menjabarkan tentang arsitektur umum dalam membangun sistem pengklasifikasian citra mikroskopis stomata tanaman herbal curcuma menggunakan metode Convolutional Neural Network (CNN).
Bab 4: Implementasi dan Pengujian
Bab ini berisi pembahasan tentang implementasi dari yang telah dibahas dari bab 3. Bab ini juga berisi tentang hasil pengujian dari sistem yang telah dibangun.
Bab 5: Kesimpulan dan Saran
Bab ini berisi kesimpulan dari penelitian yang telah dilakukan dan memuat saran-saran yang diajukan untuk pengembangan penelitian selanjutnya.
BAB 2
LANDASAN TEORI
Bab ini membahas tentang teori-teori yang digunakan sebagai landasan dalam memahami dan menyelesaikan permahasalahan yang ada dalam penelitian ini.
2.1. Tanaman Herbal
Tanaman herbal atau medical plant adalah tanaman yang digunakan dengan tujuan pengobatan dan menjadi bahan asli dalam pembuatan obat herbal (WHO, 1998).
Tanaman herbal itu sendiri sangatlah banyak, bahkan sampai memiliki ribuan jenis spesies dengan total 40.000 jenis tanaman herbal yang telah dikenal di dunia, dimana sekitar 30.000 jenisnya disinyalir berada di Indonesia. Jumlah tersebut sudah mewakili 90% dari tanaman obat yang ada di Asia. Dari jumlah tersebut, 25% diantaranya atau sekitar 7.500 jenis sudah diketahui memiliki khasiat herbal, namun hanya 1.200 jenis tanaman yang sudah dimanfaatkan untuk bahan baku obat-obatan herbal (PT. Sido Muncul, 2015).
2.1.1. Morfologi Tumbuhan
Morfologi tumbuhan merupakan suatu bidang ilmu yang mempelajari tentang bentuk fisik dan struktur tubuh dari tumbuhan. Morfologi tumbuhan berguna untuk mengidentifikasi tumbuhan secara visual agar keragaman tumbuhan yang sangat besar bisa dikenali dan diklasifikasikan, serta diberi nama yang tepat untuk setiap kelompok yang terbentuk. Bagian tumbuhan yang secara nyata dapat menunjukkan perbedaan ciri utama dinamakan kormus, yang merupakan bagian pokok tumbuhan yang terdiri dari tiga bagian, yaitu akar, batang dan daun.
Daun merupakan salah satu organ tumbuhan yang paling banyak diteliti oleh para ahli karena memiliki banyak peran penting. Beberapa manfaat daun yaitu:
1) Tempat terjadinya fotosintesis atau proses pembuatan makanan pada tumbuhan hijau.
2) Sebagai organ pernapasan atau respirasi tanaman.
3) Tempat terjadinya transpirasi (oleh stomata yang ada di daun).
4) Tempat terjadinya gutasi atau proses pelepasan air dalam bentuk cair dari jaringan daun.
5) Alat perkembangbiakkan vegetatif. Misalnya pada tanaman cocor bebek (tunas daun).
2.1.2. Stomata Daun
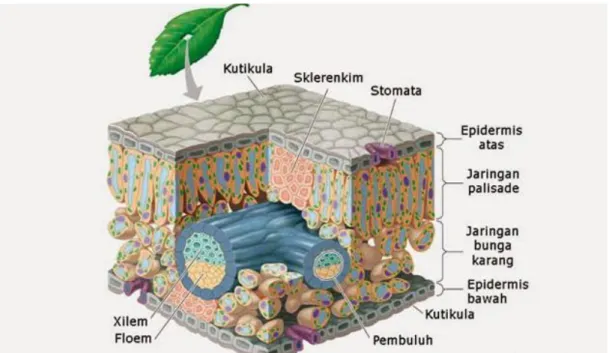
Gambar 2.1 Struktur Anatomi Daun (Permata et al, 2014)
Daun memiliki 3 jaringan, yaitu jaringan epidermis (lapisan epidermis atas dan bawah), jaringan mesofil (lapisan jaringan palisade dan jaringan bunga karang), dan jaringan pengangkut (pembuluh xilem, dan floem).
Pada jaringan epidermis daun inilah terdapat stomata. Stomata lebih mudah untuk diteliti karena terdapat pada lapisan epidermis daun yang merupakan lapisan luar daun, sehingga memungkinkan untuk diteliti lebih mudah tanpa perlakuan khusus seperti pengamatan pada jaringan mesofil yang lebih sulit.
Adapun peranan penting yang menjadi alasan akan pentingnya penelitian stomata adalah:
9
1) Berperan dalam proses fotosintesis sebagai jalur masuknya gas karbondioksida yang dibutuhkan daun sebagai bahan pembuatan makanan pada tumbuhan
2) Berperan dalam proses respirasi atau pernapasan tanaman.
3) Mendeteksi produktifitas tanaman dengan meneliti kemampuan stomata beradaptasi dengan kondisi lingkungan seperti pola hujan, perubahan iklim, ataupun temperature.
4) Berperan sebagai jalur phatogen, dimana proses membuka dan menutupnya stomata dapat menjadi kesempatan bagi phatogen untuk masuk ke dalam daun.
5) Menjadi faktor yang mempengaruhi perubahan lingkungan dari kadar karbondioksida yang diproduksinya terhadap hubungannya dengan banyak atau sedikitnya jumlah stomata tanaman.
2.1.3. Genus Curcuma
Curcuma adalah salah satu genus dari famili Zingiberaceae yang memiliki sekitar 100 spesies yang tersebar di wilayah Asia Tenggara, India, China, Selandia Baru, dan Australia bagian utara. Beberapa spesies juga dilaporkan terdapat diwilayah tropis lain seperti Afrika tropis, Florida, Amerika Tengah, dan Kepulauan Pasifik (Raju et al, 2006).
Gambar 2.2 Taksonomi Genus Curcuma (Raju, V.C, 2006)
Beberapa spesies tanaman pada genus Curcuma yang tidak asing dalam kehidupan sehari-hari di Indonesia adalah kunyit (Curcuma longa), temulawak (Curcuma zanthorrhiza) dan temugiring (Curcuma heyneana).
Tanaman genus Curcuma menjadi penting bagi perkembangan dunia pengobatan global karena terdapat potensi penghambatan terhadap berbagai macam gejala penyakit, seperti anti peradangan, anti kanker, kolera, anti virus, anti diabetes, hypoclorestaemik, anti biotik, dan anti rematik. Tanaman genus Curcuma telah digunakan sebagai bahan obat untuk mengatasi penyakit Alzheimer’s serta penggunaan lain sebagai aroma terapi, anti serangga, dan industri parfum.
Gambar 2.3 Stomata Curcuma longa (kunyit)
Pengambilan gambar stomata kunyit dilakukan menggunakan mikroskop elektrik di laboratorium farmasi Universitas Sumatera Utara (USU) dengan perbesaran 10x40 dengan format gambar .png.
11
Gambar 2.4 Stomata Curcuma zanthorrhiza (temulawak)
Sama halnya dengan kunyit, gambar stomata tanaman temulawak diambil dengan mikroskop elektrik di laboratorium farmasi USU dengan perbesaran 10x40 dan berformat .png.
2.2. Pengenalan Citra
Citra adalah suatu representasi (gambaran), imitasi atau kemiripan dari suatu objek.
Citra terbagi 2 yaitu ada citra yang bersifat analog dan ada pula citra yang bersifat digital. Citra analog adalah citra yang sifatnya kontinu seperti gambar pada monitor televisi, hasil CT Scan, foto sinar X, dll. Sedangkan pada citra digital adalah citra yang dapat diolah oleh komputer (T,Sutoyo et al. 2009: 9).
2.3. Pengolahan Citra
Pengolahan citra digital adalah teknologi yang menerapkan sejumlah algoritma komputer untuk memproses citra digital. Hasil keluaran dari proses tersebut dapat berupa gambar ataupun karakteristik yang merepresentasikan citra. (Zhou, et al.
2010). Menurut (Efford, 2000), pengolahan citra adalah istilah umum untuk teknik yang dilakukan dalam memodifikasi atau memanipulasi citra dengan berbagai cara.
Umumnya gambar dua dimensi yang dapat diolah dengan mudah adalah foto. Setiap foto dalam bentuk citra digital bisa diolah dengan menggunakan perangkat lunak tertentu. Pengolahan citra ini berguna untuk memperbaiki kualitas gambar atau citra digital untuk menghasilkan gambar atau citra yang sesuai dengan keinginan dari pengguna atau menghasilkan citra dengan kualitas yang lebih baik. Pengolahan citra juga dilakukan agar informasi yang terdapat di dalam citra tersebut dapat tersampaikan dengan baik kepada pengguna (user). Sebuah citra bisa saja berisi banyak informasi, namun seringkali citra yang diliki mengalami penurunan kualitas ataupun penurunan mutu (degradasi), misalnya mengandung cacat (noise), warna yang terlalu kontras, kurang tajam, ataupun kabur (blur). Hasil seperti itu dapat membuat citra akan sulit untuk diinterpretasikan karena informasi yang telah disampaikan oleh citra sudah berkurang (Efford, 2000).
2.3.1 Akuisisi Citra
Akuisisi citra merupakan tahapan awal dari proses pengolahan citra untuk mendapatkan suatu citra digital. Tujuan dari akuisisi citra adalah untuk menentukan data mana yang diperlukan dan metode perekaman citra digital apa yang dipilih. Citra digital bukan sebuah data digital seperti biasanya, namun sebuah representasi dari citra asal yang bersifat analog. Analog yang dimaksud adalah bersifat kontinyu, dihasilkan dari sistem optic. Citra digital ditampilkan komputer dengan berbagai macam susunan warna dan 17 tingkat kecerahan yang berbeda, susunan warna inilah yang menyebabkan citra bersifat analog.
2.3.2 Resizing
Resizing merupakan salah satu operasi yang paling banyak digunakan dalam pengolahan citra. Proses perubahan ukuran citra dilakukan dengan proses resizing, baik memperbesar ataupun memperkecil resolusi citra. Resizing juga dapat digunakan untuk menormalisasi ukuran semua citra agar memiliki ukuran yang sama. Proses ini dilakukan untuk mengukur ulang citra dengan mengecilkan pixel dari citra tersebut, sehingga dihasilkan citra baru yang merupakan bagian dari citra asli dimana memiliki ukuran lebih kecil dari citra awal setelah melalui tahap smoothing dan interpolasi untuk menghasilkan citra yang lebih baik (Rahmat, R. F et al, 2016).
13
2.3.3 Grayscale (Tingkat Keabuan)
Grayscale adalah proses pengubahan warna citra menjadi format warna yang hanya berdasarkan tingkat keabuan. Pada proses ini, informasi hue dan saturation dihilangkan dari piksel dan hanya meninggalkan nilai brightness. Setiap piksel dari citra grayscale memiliki nilai brightness antara 0 (hitam) sampai 255 (putih). Foto hitam putih merupakan contoh umum dari model warna grayscale. Walaupun disebut hitam putih, sesungguhnya foto tersebut terbentuk dari banyak warna abu-abu yang berbeda (Kadir & Susanto, 2012). Tujuan dari perhitungan grayscale ini adalah untuk memudahkan dalam proses segmentasi. Menurut (Kadir & Susanto, 2012) algoritma perhitungan tingkat keabuan, piksel dari suatu citra yang mengandung warna-warna RGB (Red, Green, dan Blue) dengan menjumlahkan nilai warna merah, hijau, dan biru kemudian dibagi tiga sehingga didapatkan nilai rata-rata dari ketiga warna. Dalam rangka mendapatkan nilai rata-rata tersebut, persamaan yang digunakan seperti pada persamaan 2.1.
(2.1)
Dimana:
I = nilai intensitas keabuan sebuah piksel citra hasil grayscale R = nilai komponen merah pada sebuah piksel
G = nilai komponen hijau pada sebuah piksel B = nilai komponen biru pada sebuah piksel
2.4. Filter Gabor
Filter gabor merupakan salah satu filter yang mampu mensimulasikan karakteristik sistem visual manusia dalam mengisolasi frekuensi dan orientasi dari citra. Fungsi Gabor diperkenalkan oleh seorang fisikawan yang bernama Denis Gabor pada tahun 1946 sebagai alat untuk deteksi sinyal dalam noise / derau. Pada tahun 1980 seseorang bernama Dougman menggunakan filter gabor ini ke citra 2 Dimensi. Jadilah filter gabor yang digunakan untuk menganalisis tekstur dan deteksi tepi pada sebuah citra.
Langkah-langkah penggunaan gabor filter yaitu dengan melakukan inisialisasi parameter yang berdasarkan skala, orientasi, jumlah kolom dan baris matriks. Tahapan
selanjutnya adalah menentukan downsampling dari baris dan kolom matriks.
downsampling adalah proses untuk mengecilkan ukuran matriks dengan hanya mengambil poin-poin penting dari matriks tersebut. Semakin besar nilai downsampling, maka semakin kecil pula ukuran matriks yang dihasilkan, sehingga perhitungan dapat dilakukan lebih cepat, tetapi tingkat kecocokannya akan semakin lemah, demikian pula sebaliknya.
2.5. Fitur Ekstraksi
Ekstraksi fitur merupakan bagian fundamental dari analisis citra. Fitur adalah karakteristik atau ciri unik dari suatu objek (Sutoyo, 2009). Karakteristik fitur yang baik sebaiknya memenuhi persyaratan seperti berikut ini:
1. Dapat membedakan suatu objek dengan yang lainnya (discrimination).
2. Memperhatikan kompleksitas komputasi.
3. Independence (tidak terikat) yang berarti bersifat invarian terhadap berbagai transformasi (rotasi, penyekalaan, pergeseran, dan lain sebagainya).
4. Jumlahnya sedikit, karena fitur yang jumlahnya sedikit akan dapat menghemat waktu komputasi dan ruang penyimpanan untuk proses selanjutnya (proses pemanfaatan fitur).
2.5.1. Gray Level Co-occurrence Matrix (GLCM)
Gray Level Co-occurrence Matrix (GLCM) diusulkan pertama kali oleh Haralick pada tahun 1973 dan memiliki 28 fitur untuk menjelaskan pola spasial (Kadir & Susanto 2013). GLCM menggunakan perhitungan tekstur pada orde kedua. Misalkan, f(x,y) adalah citra dengan ukuran Nx dan Ny yang memiliki piksel dengan kemungkinan hingga L level dan vektor r adalah vektor arah ofset spasial. GLCM→(i,j) didefinisikan sebagai 𝑟 jumlah piksel dengan j1, ..., L yang terjadi pada ofset vektor r terhadap piksel dengan nilai i1, ..., L, yang dapat dinyatakan dalam rumus (Newsam &
Kammath 2005):
(2.2)
15
Sebagai ilustrasi, ketetanggaan piksel dapat dipilih ke arah timur (kanan).
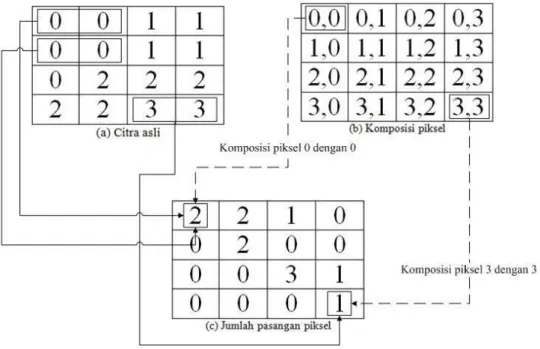
Salah satu cara untuk merepresentasikan hubungan ini yaitu berupa (1,0), yang menyatakan hubungan dua piksel yang sejajar secara horizontal dengan piksel bernilai 1 diikuti dengan piksel bernilai 0, sehingga jumlah kelompok piksel yang memenuhi hubungan tersebut dihitung. Hal ini dapat dilihat pada Gambar 2.5.
Gambar 2.5. Contoh penentuan awal matriks GLCM (Kadir & Susanto 2013).
Matriks pada Gambar 2.5 dinamakan matrix framework. Matriks ini kemudian diolah menjadi matriks simetris dengan cara menambahkan dengan hasil transposnya, seperti yang terlihat pada Gambar 2.6.
. Gambar 2.6 Matriks framework menjadi matriks simetris (Kadir & Susanto
2013)
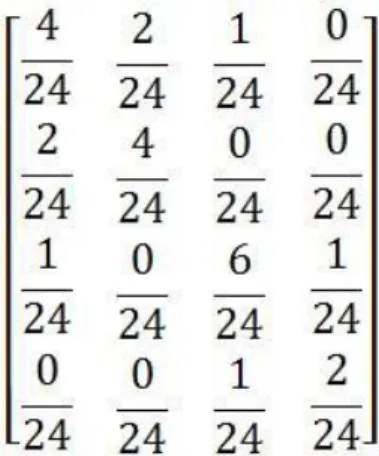
Untuk menghilangkan ketergantungan pada ukuran citra, nilai-nilai elemen GLCM perlu dinormalisasikan, sehingga jumlahnya bernilai 1. Dengan demikian, hasil normalisasi dari matriks GLCM pada Gambar 2.7.
Gambar 2.7. Normalisasi matriks GLCM (Kadir & Susanto 2013)
Untuk mendapatkan fitur tekstur GLCM, hanya 4 besaran yang diusulkan oleh Haralick (1973) untuk dipakai. Beberapa fitur yang akan dipakai nantinya adalah contrast, correlation, energy, dan homogeneity.
1) Contrast
Merupakan ukuran keberadaan variasi aras keabuan antarpiksel citra dengan lokasi relatif. Kontras memiliki memiliki batas nilai dari 0 hingga pangkat 2 dari panjang matriks GLCM simetris.
2) Correlation
Merupakan ukuran ketergantungan linear antar nilai aras keabuan dalam citra.
3) Energy
Merupakan nilai dari jumlah kuadrat pada elemen-elemen matriks GLCM.
4) Homogeneity
Digunakan untuk mengukur homogenitas yaitu ukuran kedekatan distribusi masing-masing elemen pada matriks GLCM ke matriks GLCM diagonal.
2.6. Convolutional Neural Network (CNN)
Convolutional Neural Network (CNN) merupakan pengembangan dari Multilayer
17
jaringan yang tinggi dan banyak diaplikasikan pada data citra. Pada klasifikasi citra, MLP kurang sesuai untuk digunakan karena tidak menyimpan informasi spasial dari data citra dan menganggap setiap piksel adalah fitur yang independen sehingga menghasilkan hasil yang kurang baik.
CNN memiliki cara kerja yang mirip dengan MLP, namun dalam CNN setiap neuron dipresentasikan dalam bentuk dua dimensi, tidak seperti MLP yang setiap neuron hanya berukuran satu dimensi. Karena sifat proses konvolusi, maka CNN hanya bisa digunakan pada data yang memiliki struktur dua dimensi seperti citra dan suara.
2.6.1. Operasi Konvolusi
Operasi konvolusi merupakan operasi pada dua fungsi argumen bernilai nyata.
Operasi ini menerapkan fungsi output sebagai feature map dari input citra. Penentuan volume output juga dapat ditentukan dari masing-masing lapisan dengan hyperparameters. Hyperparameter yang digunakan pada persamaan di bawah ini digunakan untuk menghitung banyaknya neuron aktivasi dalam sekali output.
(2.3)
Berdasarkan persamaan di atas, dapat dihitung ukuran spasial dari volume output dimana hyperparameter yang dipakai adalah ukuran volume (W), filter/kernel (F), Stride yang diterapkan (S) dan jumlah padding nol yang digunakan (P). Stride merupakan nilai yang digunakan untuk menggeser filter melalui input citra dan Zero Padding adalah nilai untuk mendapatkan angka nol di sekitar border citra.
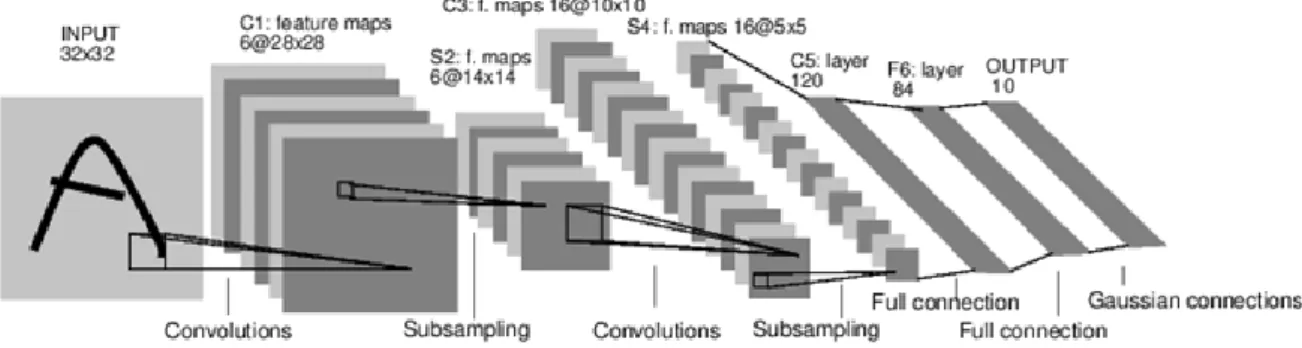
Gambar 2.8 Proses Konvolusi pada CNN (LeCun et al., 1998) (W – F + 2P) / S +1
Convolutional Neural Network memiliki 4 layer utama, yaitu : 1) Convolutional Layer
Convolutional Layer melakukan operasi konvolusi terhadap input ataupun output dari layer sebelumnya. Konvolusi adalah suatu istilah matematis yang berarti mengaplikasikan sebuah fungsi pada output fungsi lain secara berulang.
Konvolusi 2 buah fungsi f(x) dan g(x) didefinisikan sebagai berikut :
∫ (2.4)
Tujuan dilakukannya konvolusi pada data citra adalah untuk mendapatkan ciri dari citra input. Konvolusi akan menghasilkan transformasi linear dari data input sesuai informasi spasial pada data. Bobot pada layer tersebut menspesifisikasikan kernel konvolusi yang digunakan, sehingga kernel konvolusi dapat dilatih berdasarkan input pada CNN (Suartika et al, 2016).
2) Max Pooling (Subsampling)
Max Pooling adalah proses untuk meningkatkan invariansi posisi dari fitur menggunakan operasi Max. Max Pooling membagi output dari Convolutional Layer menjadi beberapa grid kecil lalu mengambil nilai maksimal dari setiap grid untuk menyusun matriks citra yang telah direduksi seperti pada gambar 2.9. Grid yang berwarna merah, hijau, kuning dan biru merupakan kelompok grid yang akan dipilih nilai maksimumnya. Sehingga hasil proses tersebut dapat dilihat pada kumpulan grid disebelah kanannya. Proses tersebut memastikan fitur yang didapatkan akan sama meskipun objek citra mengalami translasi (pergeseran).
19
Gambar 2.9. Operasi Max Polling (Li et al., 2017)
3) ReLu (Rectified Linear Units)
Layer ini mengaplikasikan fungsi aktivasi tak jenuh pada node ( ) = + = 𝑚 (0, ). Layer ini meningkatkan sifat non-linier dari fungsi pengambil keputusan dan semua jaringan tanpa mempengaruhi bidang reseptif dari Convolutional Layer. ReLu juga banyak digunakan karena dapat melatih neural network lebih cepat.
4) Fully Connected Layer
Neuron pada Fully Connected Layer memiliki hubungan yang lengkap pada semua aktivasi dalam layer sebelumnya. Aktivasi tersebut kemudian di komputasi dengan sebuah perkalian matriks diikuti oleh bias offset. Hasil dari proses konvolusi menjadi input pada fully-connected layer. Fully-connected layer adalah lapisan dimana semua neuron aktivasi dari lapisan sebelumnya terhubung semua dengan neuron di lapisan selanjutnya seperti halnya jaringan saraf tiruan biasa. Setiap aktivasi dari lapisan sebelumnya perlu diubah menjadi data satu dimensi sebelum dapat dihubungkan ke semua neuron di fully-connected layer. Lapisan ini biasanya digunakan pada metode Multi- Layer Perceptron (MLP) dan bertujuan untuk mengolah data sehingga bisa diklasifikasikan. Perbedaan antara fully-connected layer dengan lapisan konvolusi biasa adalah neuron di lapisan konvolusi terhubung hanya ke daerah tertentu pada input, sementara pada fully-connected layer memiliki neuron yang secara keseluruhan terhubung. Namun, kedua lapisan tersebut masih mengoperasikan produk dot, sehingga fungsinya tidak begitu berbeda.
2.6.2. Stride
Salah satu parameter yang juga penting dalam operasi CNN adalah Stride. Stride merupakan parameter yang menentukan berapa jumlah pergeseran filter. Jika nilai stride adalah satu, maka filter akan bergeser sebanyak satu piksel secara horizontal lalu vertikal. Semakin kecil stride yang digunakan, maka semakin detail informasi yang didapatkan dari sebuah input, namun membutuhkan komputasi lebih jika dibandingkan dengan stride yang besar.
2.6.3. Zero Padding
Zero padding merupakan parameter yang menentukan jumlah piksel (berisi nilai nol) yang akan ditambahkan di setiap sisi dari input. Hal ini digunakan untuk memanipulasi dimensi output dari convolutional layer (faeture map). Penggunaan zero padding memungkinkan untuk mengatur dimensi output agar tetap sama dengan dimensi input, atau setidaknya tidak berkurang secara drastis. Sehingga selanjutnya bisa dilakukan ekstraksi feature yang lebih mendalam. Selain itu, penggunaan zero padding bisa menjadikan performa dari model menjadi meningkat, karena filter akan fokus pada informasi yang sebenarnya yaitu yang berada di antara zero padding tersebut.
2.6.4. Dropout Regularization
Dropout adalah teknik regularisasi jaringan syaraf dimana beberapa neuron akan dipilih secara acak dan tidak dipakai selama pelatihan. Neuron-neuron ini dapat dibilang dibuang secara acak. Hal ini berarti bahwa kontribusi neuron yang dibuang akan diberhentikan, sementara jaringan dan bobot baru juga tidak diterapkan pada neuron pada saat melakukan backpropagation.
2.6.5. Softmax Classifier
Softmax Classifier merupakan bentuk lain dari algoritma Logistic Regression yang dapat kita gunakan untuk pengklasifikasian. Standar klasifikasi yang biasa dilakukan oleh algoritma Logistic Regression adalah tugas untuk klasifikasi kelas biner.
21
` Notasi fj menunjukkan hasil fungsi untuk setiap elemen ke-j pada vektor keluaran kelas. Argumen z adalah hipotesis yang diberikan oleh model pelatihan agar dapat diklasifikasi oleh fungsi Softmax. Softmax juga memberikan hasil yang lebih intuitif dan juga memiliki interpretasi probabilistik yang lebih baik dibanding algoritma klasifikasi lainya. Softmax memungkinkan kita untuk menghitung probabilitas untuk semua label. Dari label yang ada akan diambil sebuah vektor nilai bernilai riil dan merubahnya menjadi vektor dengan nilai antara nol dan satu yang bila semua dijumlah akan bernilai satu.
2.7. Penelitian Terdahulu
Beberapa penelitian sebelumnya telah dilakukan untuk menyelesaikan permasalahan identifikasi diantaranya yaitu dilakukan oleh V. A. Gulhane, et al (2011) adalah melakukan pengidentifikasian dan mendiagnosis penyakit pada daun kapas dengan menggunakan metode fuzzy, Artificial Neural Network (ANN), dan Support Vector (SVM). Peneliti juga menggunakan ekstraksi warna dan tekstur pada penelitian ini.
Peneliti menggunakan 20 citra daun berpenyakit dan 25 citra daun normal.
Menggunakan segmentasi warna dan kualitas gambar yang baik akan meningkat hasil diagnosis. Pada penelitian ini didapatkan akurasi sebesar 85%.
Selanjutnya, Permata E, et al (2014) melakukan penelitian untuk mengklasifikasikan daun tanaman kakao yang sehat atau terkena penyakit menggunakan Backpropagation. Pada penelitian ini didapatkan akurasi sebesar 86%
dari total 90 data citra.
Pada sebuah penelitian Amos et al.(2016) didapatkan hasil bahwa pengenalan wajah menggunakan neural network memiliki akurasi yang tinggi dibanding metode lama seperti Principal Component Analysis atau Eigenfaces. Pada penelitian ini didapatkan akurasi sebesar 93%.
Penelitian selanjutnya oleh Aniket Gharat, et al (2017) melakukan penelitian menggunakan Convolutional Neural Network (CNN) untuk mendeteksi penyakit pada daun tanaman melalui pendektan jaringan saraf tiruan. Selain itu juga peneliti menggunakan invariant moment sebagai esktraksi fitur. Pada penelitian ini didapatkan akurasi sebesar 88%.
Penelitian selanjutnya oleh Triano Nurhikmat (2018) yang menggunakan metode Convolutional Neural Network untuk mengklasifikasikan karakter yang
terdapat dalam kesenian wayang golek. Dari penelitian tersebut didapat akurasi sebesar 93%.
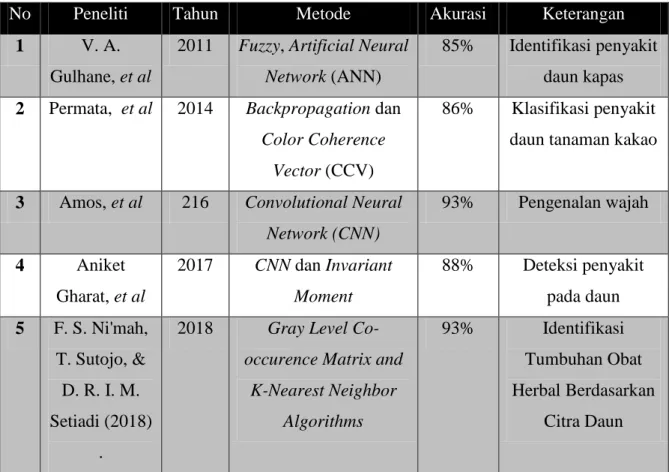
Tabel 2.1 Penelitian Terdahulu
No Peneliti Tahun Metode Akurasi Keterangan
1 V. A.
Gulhane, et al
2011 Fuzzy, Artificial Neural Network (ANN)
85% Identifikasi penyakit daun kapas 2 Permata, et al 2014 Backpropagation dan
Color Coherence Vector (CCV)
86% Klasifikasi penyakit daun tanaman kakao
3 Amos, et al 216 Convolutional Neural Network (CNN)
93% Pengenalan wajah
4 Aniket Gharat, et al
2017 CNN dan Invariant Moment
88% Deteksi penyakit pada daun 5 F. S. Ni'mah,
T. Sutojo, &
D. R. I. M.
Setiadi (2018) .
2018 Gray Level Co- occurence Matrix and
K-Nearest Neighbor Algorithms
93% Identifikasi Tumbuhan Obat Herbal Berdasarkan
Citra Daun
BAB 3
ANALISIS DAN PERANCANGAN
Bab ini berisi tentang analisis dan perancangan sistem menggunakan metode Convolutional Neural Network umtuk mengkasifikasikan stomata tanaman herbal pada genus Curcuma. Tahap analisis berisi tentang analisis data yang digunakan dalam penelitian ini, sedangkan tahap perancangan berisi perancangan sistem dan antarmuka sistem.
3.1. Dataset
Data yang digunakan dalam penelitian ini adalah citra mikroskopis stomata tanaman kunyit (Curcuma longa) dan temulawak (Curcuma zanthorrhiza). Data mikroskopis pada penelitian ini didapat dari laboratorium penelitian di fakultas Farmasi USU.
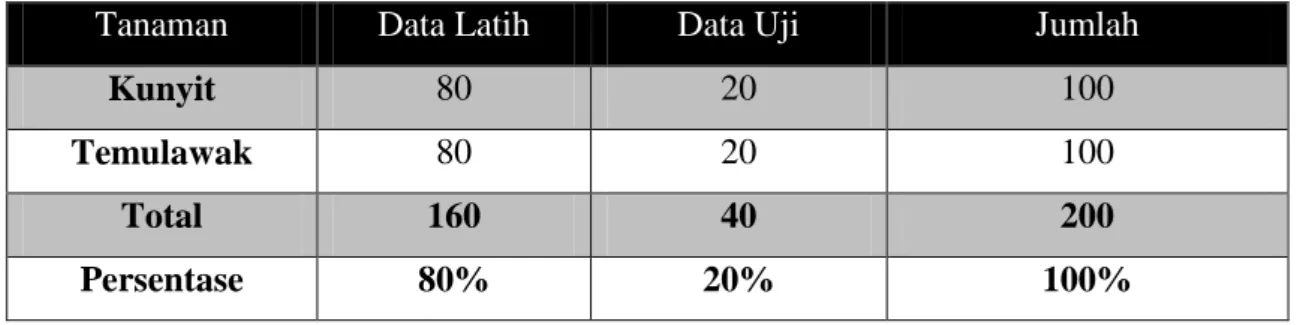
Pengambilan citra dilakukan menggunakan mikroskop elektrik dengan perbesaran 10x40 skala perbesaran. Adapun data pelatihannya menggunakan 80 citra mikroskopis untuk masing-masing tanaman, sehingga total data pelatihan ada 160 citra. Sedangkan untuk data pengujian menggunakan 20 citra mikroskopis untuk masing-masing tanaman, sehingga total data latihnya ada 40 citra. Pembagian data citra selengkapnya dapat dilihat pada table 3.1.
Tabel 3.1. Pembagian Dataset
Tanaman Data Latih Data Uji Jumlah
Kunyit 80 20 100
Temulawak 80 20 100
Total 160 40 200
Persentase 80% 20% 100%
Contoh data citra mikroskopis stomata yang digunakan dapat dilihat pada gambar 3.1:
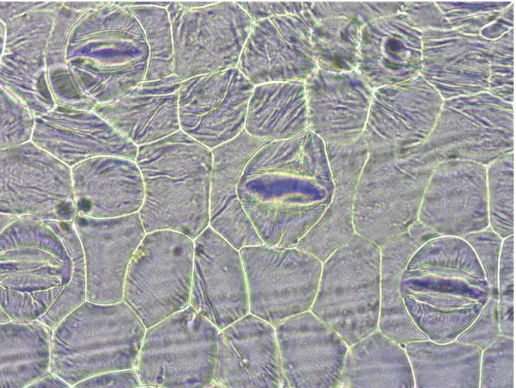
Gambar 3.1. Citra mikroskopis stomata tanaman kunyit (Curcuma longa)
Gambar 3.1 menunjukkan bahwa stomata kunyit memiliki tekstur yang sedikit lebih teratur, begitupun susunan organel-organel tetangganya.
Gambar 3.2. Citra mikroskopis stomata tanaman temulawak (Curcuma zanthorrizha)
Gambar 3.2 menunjukkan bahwa stomata temulawak memiliki tekstur yang sedikit agak kasar dari stomata kunyit dan organel-organel tetangganya posisinya sedikit acak.
25
3.2. Arsitektur Umum
Metode Convolutional Neural Network (CNN) yang digunakan dalam penelitian ini memiliki tahapan dalam pengklasifikasian data tanaman. Tahapan yang pertama adalah proses pengumpulan data pelatihan yang digunakan dalam pembelajaran neural network. Metode CNN memiliki pre-trained neural network yang menggunakan data latih untuk melatih neural network. Proses pelatihan ini dilakukan untuk mendeteksi nilai yang ada pada gambar untuk menghasilkan ciri setiap gambar tanaman. Nilai inilah yang akan disimpan dan digunakan sebagai pengenal (classifier). Classifier ini digukanan pada tahap pengujian untuk proses klasifikasi tanaman.
Untuk lebih jelasnya mengenai gambaran metode penelitian dapat dilihat pada gambar 3.3 yang menunjukkan arsitektur umum yang digunakan dalam penelitian ini.
Gambar 3.3. Arsitektur Umum Penelitian
3.2.1. Pre-Trained Neural Network
Pada tahapan ini, neural network dilatih menggunakan total 160 data citra tanaman dengan format .png. Adapun proses dari pre-trained neural network ini dapat bekerja dengan beberapa data pelatihan, seperti:
1) Citra mikroskopis tanaman yang dikenal (kunyit dan temulawak), 2) Citra mikroskopis tanaman yang sama atau mirip, dan
3) Citra mikroskopis tanaman yang berbeda.
Kondisi di atas kemudian diproses untuk mendapatkan suatu nilai ciri untuk tiap citra menggunakan Convolutional Neural Network (CNN). Nilai ciri tersebut selanjutnya akan dilatih kembali untuk memastikan agar nilai ciri citra dari tanaman yang sama akan identik, dan sebaliknya mempunyai nilai yang berbeda untuk tanaman yang berbeda. Proses ini diulang terus-menerus sampai didapatkan kondisi neural network yang ideal.
Hasil dari proses inilah yang akan digunakan sebagai Trained Neural Network dan akan berguna untuk proses klasifikasi tanaman selanjutnya.
3.2.2. Testing Neural Network
Pada proses ini data uji yang digunakan sebanyak 20 citra untuk tiap jenis tanaman, jadi totalnya adalah 40 citra berformat .png.
3.2.3. Pre-Processing
Tahap pre-processing memungkinkan untuk menghasilkan citra yang lebih baik, sehingga akan lebih mudah diproses dan menghasilkan output yang lebih optimal pada tahap berikutnya.
1) Resizing
Citra yang diinput akan mengalami perubahan ukuran (resizing) menjadi 100x100. Proses ini bertujuan untuk mempercepat proses klasifikasi dan menyamaratakan ukuran citra setiap data.
2) Grayscaling
Pada tahap ini, citra yang sudah diubah ukurannya akan diproses grayscale menjadi citra keabuan. Berhubung pada penelitian tentang stomata ini
27
memerlukan data tekstur citra dan bukan citra warna, maka dapat dilakukan grayscale.
Citra yang telah diproses pada tahap grayscaling akan menghasilkan piksel-piksel warna gelap dan terang atau disebut dengan gradasi citra. Gradasi citra ini yang akan menghasilkan pola tertentu yang dapat digunakan pada tahapan selanjutnya.
Gambar 3.4 Tampilan Hasil Grayscale
3) Filter Gabor
Tahapan ini dilakukan dengan menginisialiasi variabel berikut:
Tentukan parameter u, v, m, n untuk digunakan dalam perhitungan gabor filter bank.
Variabel u adalah jumlah skala (kecil ke besar), dengan nilai default adalah 5, variabel v adalah jumlah orientasi (horizontal, vertikal, diagonal), dengan nilai default adalah 8. Variabel m adalah jumlah baris dalam matriks gabor filter 2 dimensi, nilainya harus integer bulat ganjil, dengan nilai default adalah 39, dan n adalah jumlah kolom dalam matriks gabor filter 2 dimensi, nilainya harus integer bulat ganjil, dengan nilai default adalah 39. Dengan demikian penulis menetapkan nilai sebagai berikut dalam kode program:
gaborFB.u = 6;
gaborFB.v = 9;
gaborFB.m = 39;
gaborFB.n = 39;
Tentukan parameter d1, d2 untuk digunakan dalam perhitungan gabor features
Parameter d1 dan d2 merupakan downsampling dari baris dan kolom matriks. Fungsinya untuk mengecilkan ukuran matriks dengan cara mengambil poin-poin penting dari matriks tersebut. Semakin besar nilai downsampling, maka semakin kecil pula ukuran matriks yang dihasilkan, sehingga perhitungan dapat dilakukan lebih cepat, tetapi tingkat kecocokannya akan semakin lemah, demikian pula sebaliknya.
Berikut adalah nilai yang ditetapkan penulis untuk parameter downsampling:
gaborFE.d1 = 3;
gaborFE.d2 = 3;
Gambar 3.5 Tampilan Hasil Proses Filter Gabor
3.2.4. Feature Extraction
Ekstraksi fitur yang dipakai dalam penelitian ini adalah Gray Level Co-Occurrence Matrix (GLCM). Metode ekstraksi fitur GLCM adalah salah satu ekstraksi order kedua pada fitur statistic tekstur. Ekstraksi order kedua menunjukkan hubungan statistik antara 2 piksel. GLCM adalah sebuah matriks dengan jumlah baris dan kolom sebanding dengan jumlah gray level (G) dalam suatu citra.
Metode GLCM dapat menghasilkan setidaknya 4 ekstraksi cirri dari suatu citra digital tiap sudut ketetanggan pikselnya. Besaran tersebut antara lain contrast, correlation, energy, dan homogeneity.
29
1) Contrast
Merupakan ukuran keberadaan variasi aras keabuan antarpiksel citra dengan lokasi relatif. Contrast memiliki memiliki batas nilai dari 0 hingga pangkat 2 dari panjang matriks GLCM simetris. Pada citra dengan elemen piksel yang bernilai sama secara keseluruhan, contrast bernilai 0. Untuk mencari ekstraksi fitur contrast dapat digunakan rumus sebagai berikut:
𝑟 ∑ ∑
(3.1) 2) Correlation
Merupakan ukuran ketergantungan linear antarnilai tingkat keabuan dalam citra. Correlation dalam GLCM berfungsi untuk mengatur ketergantungan linier dari tingkat keabuan dalam ketetanggan piksel citra. Untuk mencari ekstraksi fiturnya dapat digunakan rumus sebagai berikut:
𝑟𝑟 ∑ ∑
(3.2) 3) Energy
Merupakan nilai dari jumlah kuadrat pada elemen-elemen matriks GLCM.
Energy memiliki nilai yang tinggi ketika citra memiliki homogenitas yang baik atau nilai piksel yang hampir sama. Untuk mencari nilai ekstraksi fiturnya dapat digunakan rumus berikut:
𝑟 ∑ ∑
(3.3) 4) Homogeneity
Digunakan untuk mengukur homogenitas yaitu ukuran kedekatan distribusi masing-masing elemen pada matriks GLCM ke matriks GLCM diagonal.
Untuk mencari ekstraksi fiturnya dapat digunakan rumus berikut:
𝑚 ∑ ∑
(3.4)
Tahapan awal untuk melalukan perhitungan besaran pada GLCM adalah menentukan matriks inputan terlebih dahulu.
0 1 0 1
2 3 1 1
0 2 3 2
2 1 3 1
Gambar 3.6 Matriks input awal
Dengan perhitungan GLCM, maka akan didapat nilai GLCM dari matriks 4x4 tersebut seperti gambar berikut ini:
0 0.125 0.042 0 0.125 0.083 0.042 0.125 0.042 0.042 0 0.125
0 0.125 0.125 0 Gambar 3.7 Matriks GLCM 4x4 sudut 0o
Selanjutnya kita masukkan nilai matriks yang sudah didapat ke dalam table untuk mempermudah perhitungan. Untuk piksel 0 tidak perlu dicantumkan karena jika dimasukkan dalam rumus hasilnya juga akan tetap bernulai 0 atau tidak mempengaruhi perhitungan yang ada.
Tabel 3.2 Nilai Matriks GLCM
GLCM Nilai
(1,2) 0.125
(1,3) 0.042
(2,1) 0.125
(2,2) 0.083
(2,3) 0.042
(2,4) 0.125
31
(3,2) 0.042
(3,4) 0.125
(4,2) 0.125
(4,3) 0.125
Tahapan selanjutnya kita masukkan nilai matriks GLCM ke dalam rumus besaran contrast, correlation, energy, dan homogeneity.
1) Contrast
∑ ∑
{
}
{ }
Contrast = 0.192
2) Correlation
∑ ∑
{
}
33
{
}
Correlation = 0.1047
3) Energy
∑ ∑
{
}
{ }
Energy = 0.1076
4) Homogeneity
∑ ∑
{
}
{
}
Homogeneity = 0.441
Berdasarkan perhitungan yang dilakukan, maka dihasilkan nilai ekstraksi ciri dari matriks GCLM 4x4 seperti pada table 3.3.
Tabel 3.3 Hasil Perhitungan Nilai Ektraksi Ciri dari Matriks GLCM
Contrast 0.192
Correlation 0.104
Energy 0.107
Homogeneity 0.441
3.2.5. Convolutional Neural Network (CNN)
Pada tahapan ini data citra akan diklasifikasikan ke dalam 2 jenis output, yaitu citra stomata kunyit atau temulawak. Total data yang digunakan adalah 200 citra yang akan dibagi menjadi data latih dan data uji dengan perbandingan 160 : 40, dimana 160 data latih memuat 80 data dari tiap kategori, sedangkan 40 data uji memuat 20 data dari tiap kategori.
35
Tahapan awal dari pengolahan citra ini adalah dengan mengubah ukuran citra yang awalnya berukuran 100x100 piksel menjadi 32x32 piksel. Dianjurkan untuk menggunakan citra dengan ukuran nilai pangkat 2, seperti 16, 32, 64, 128 dan seterusnya. Untuk ukuran 16x16 ke bawah akan membuat informasi piksel banyak yang hilang, sedangkan untuk ukuran 128x128 atau lebih besar akan membuat tingkat pemrosesan menjadi lebih lambat. Ukuran yang ideal adalah 32x32 piksel dan 64x64 piksel. Dengan pertimbangan tersebut, penulis membuat nilai ukuran yang digunakan adalah 32x32.
Pada bab sebelumnya sudah dijelaskan bahwa proses umum pada CNN terdiri dari proses konvolusi, fungsi aktivasi, dan pooling. Banyaknya proses dalam tahapan ini disesuaikan dengan kebutuhan penelitian.
Proses konvolusi dilakukan sebanyak 4 kali, atau terdapat 4 convolution layers yang digunakan. Pada umumnya sudah cukup 2 layer saja yang digunakan untuk model klasifikasi, tetapi pada penelitian ini digunakan jaringan yang lebih deep sebagai implementasi deep learning untuk melatih model yang ada dan melihat bagaimana kinerja dari model prosesnya.
Adapun fungsi aktivasi yang digunakan adalah ReLu untuk menjadikan proses training menjadi lebih cepat. Ukuran kernel/filter yang digunakan untuk setiap layer konvolusi yaitu sebesar 3x3. Sedangkan ukuran pooling yang digunakan yaitu sebesar 2x2. Pooling dilakukan dua kali, yaitu setelah dua proses konvolusi pertama dan setelah dua proses konvolusi selanjutnya. Hal ini dilakukan agar ukuran input tidak berkurang secara drastis di setiap proses yang dilakukan, sehingga informasi citra input yang dimiliki masih berguna dan bisa digunakan dalam proses klasifikasi.
Sedangkan jumlah filter/kernel yang digunakan juga variatif, yaitu sebanyak 32 filter untuk layer konvolusi 1 dan 2 serta 64 filter untuk layer konvolusi 3 dan 4.
Penggunaan jumlah filter lebih banyak pada dua layer konvolusi terakhir dikarenakan ukuran input pada kedua lapisan tersebut lebih kecil, sehingga dibutuhkan lebih banyak filter untuk mengesktrak informasi citra. Pada proses akhir yaitu klasifikasi, softmax classifier digunakan untuk memberikan hasil yang lebih intuitif, sehingga memudahkan dalam melakukan klasifikasi dari interpretasi probabilistik untuk semua label yang dihasilkan.
Proses yang terjadi yaitu dimulai dengan melakukan “encoding” dari sebuah citra menjadi features yang berupa angka yang merepresentasikan citra tersebut. Pada
proses konvolusi pertama, citra sebagai input berukuran 32x32 piksel sebenarnya adalah multidimensional array dengan ukuran 32x32x3 (3 adalah jumlah channel RGB). Citra inilah yang akan dilakukan beberapa proses seperti yang disebutkan pada model. Filter akan digerakkan dengan stride 1 ke seluruh bagian dari input citra, mulai dari sudut kiri atas sampai kanan bawah. Setiap pergeseran filter pada input citra dilakukan operasi “dot” atau perhitungan matematis. Pada penelitian ini tidak ditambahkan zero padding, sehingga ukuran input yang digunakan sama dengan 32x32 piksel. Dengan kata lain, output yang dihasilkan dari proses konvolusi memiliki ukuran yang lebih kecil.
Besarnya ukuran citra yang dihasilkan dari proses konvolusi pertama ini menjadi 30x30 piksel. Hasil ukuran ini juga bisa didapatkan menggunakan perhitungan dibawah ini.
(W-F+2P)/S+1 = 32-3+2(0)/1 + 1 = 30
Begitu juga seterusnya untuk melakukan perhitungan ukuran citra yang terbentuk. Hasil operasi ini kemudian dikenakan dengan fungsi aktivasi yairu ReLu dan pooling. Masukan untuk fungsi aktivasi tersebut adalah nilai real dan keluaran dari fungsi tersebut adalah nilai antara 0 dan 1. Jika masukannya sangat negatif, maka keluaran yang didapatkan adalah 0, sedangkan jika masukan sangat positif maka nilai keluaran yang didapatkan adalah 1. Pada prinsipnya, pooling layer terdiri dari sebuah filter dengan ukuran dan stride tertentu akan bergeser ke seluruh area feature map.
Pooling yang digunakan yaitu Max Pooling. Tujuan dari penggunaan pooling layer yaitu untuk mengurangi dimensi dari feature map (downsampling).
Dengan menggunakan filter ukuran 2x2 dan stride 2 pada operasi max pooling, didapatkan ukuran citra yang terbentuk setelah dilakukan proses konvolusi pertama, dikenakan fungsi aktivasi, kemudian operasi max pooling adalah sebesar 14x14 pixel.
Hasil dari proses konvolusi berupa feature map yang digunakan kembali sebagai input untuk proses konvolusi berikutnya. Proses tersebut berjalan hingga berakhirnya proses konvolusi. Selain itu, metode regularisasi yang digunakan dropout, dimana beberapa neuron akan dipilih secara acak dan tidak dipakai selama pelatihan. Neuron-neuron ini dapat dibilang dibuang secara acak. Hal ini berarti bahwa kontribusi neuron yang
37
dibuang akan diberhentikan sementara jaringan dan bobot baru juga tidak diterapkan pada neuron pada saat melakukan backpropagation.
Adapun alur dari proses konvolusinya dapat dijelaskan dengan gambar berikut:
Gambar 3.8 Convolutional Layer 1
Penggunaan filter 3x3 dan stride 1 pada proses konvulasi dilakukan agar tidak terlalu banyak data informasi yang hilang.
Gambar 3.9 Convolutional Layer 2
Pada tahap kedua disarankan juga untuk menetapkan filter 3x3 dan stride 1 karena ukuran piksel tidak terlalu tinggi, sehingga masih bisa dilakukan mengambilan informasi citra lebih dalam.
Gambar 3.10 Operasi Max Pooling 1
Setelah melakukan 2 kali proses konvolusi, yang mana sudah terbilang cukup untuk pengambilan informasi citra awal, ditetapkan operasi max pooling dengan filter 2x2 dan stride 2 untuk memperkecil ukuran piksel lebih signifikan.
39
Gambar 3.11 Convolutional Layer 3
Pada tingkat proses konvolusi ketiga diberikan filter yang lebih besar untuk mereduksi lagi ukuran piksel hasil, tetapi tetap dengan stride 1 agar tidak terjadi kehilangan informasi piksel yang terlalu besar, serta ditetapkan juga perubahan kernel menjadi 64.
Gambar 3.12 Convolutional Layer 4
Pada tingkat layer konvolusi keempat, atau yang terakhir terjadi proses yang sama seperti pada layer yang ketiga.
Gambar 3.13 Operasi Max Pooling 2
Operasi max pooling kedua sama dengan operasi max pooling yang pertama, baik itu filter 2x2 dan stride 1, hanya saja terjadi pada kernel 64.
Hasil dari proses konvolusi berupa feature map masih berbentuk multidimensional array, sehingga dilakukan reshape atau flatten feature map menjadi sebuah vektor agar bisa digunakan sebagai input dari fully-connected layer, hingga pada akhirnya dilakukan klasifikasi citra. Pada fully-connected layer digunakan neuron sebanyak 256, hingga pada akhirnya model terbentuk dan berhasil melakukan klasifikasi antara citra kunyit dan temulawak. Hasil dari model ditunjukkan pada table berikut:
Tabel 3.4 Tabel Proses dengan metode CNN
Layer Output Jumlah Neuron
Input citra 32 x 32 x 3 0
Convolution layer 1 30 x 30 x 32 28.800 Convolution layer 2 28 x 28 x 32 25.088
Max pooling 1 14 x 14 x 32 0
Dropout 1 14 x 14 x 32 0
Convolution layer 3 12 x 12 x 64 9.216 Convolution layer 4 10 x 10 x 64 6.400
Max pooling 2 5 x 5 x 64 1.600