BAB 2
TINJAUAN PUSTAKA
2.1 Karakter ASCII
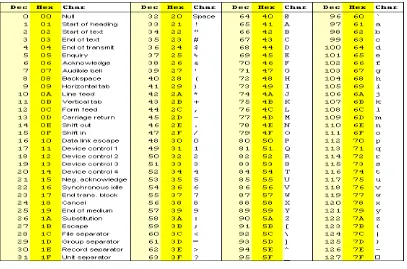
ASCII (American Standard Code for Information Interchange) merupakan suatu standar internasional dalam kode huruf dan simbol seperti Hex dan Unicode. Kode ASCII sebenarnya memiliki komposisi bilangan biner sebanyak 8 bit. Dimulai dari 0000 0000 hingga 1111 1111. Total kombinasi yang dihasilkan sebanyak 256, dimulai dari kode 0 hingga 255 dalam sistem bilangan desimal. Adapun kombinasi kode ASCII yang dikenali komputer seperti ditunjukkan pada Gambar 2.1 (Mukodim, 1994).
Gambar 2.1 Kombinasi Kode ASCII (Mukodim, 1994)
Aplikasi komputer menggunakan kode ASCII untuk mengenali dan menampilkan pola huruf, angka atau karakter khusus lainnya pada layar monitor. Untuk data yang berbentuk huruf dan angka saja, tidak termasuk karakter khusus seperti koma (,), titik (.), tanda tanya (?), data ini disebut dengan data alfanumerik (Mukodim, 1994).
2.2 Pencarian (Searching)
Pencarian (searching) merupakan suatu proses mencari solusi dari suatu permasalahan melalui sekumpulan kemungkinan ruang keadaan (state space). Ruang keadaan merupakan suatu ruang yang berisi semua keadaan yang mungkin. Teknik pencarian dapat dibagi menjadi 2 bagian, yaitu pencarian buta (blind search) dan pencarian heuristic (heuristic search). Pencarian buta merupakan pencarian yang penelusurannya dimulai dengan tidak ada informasi awal yang digunakan dalam proses pencarian, sedangkan Pencarian heuristik merupakan pencarian yang penelusurannya dimulai dengan adanya informasi awal yang digunakan dalam proses pencarian (Kusumadewi & Purnomo, 2005).
Algoritma pencarian adalah algoritma untuk mencari nilai dalam struktur data. Pencocokan string merupakan bagian penting dari sebuah proses pencarian string (string searching) dalam sebuah dokumen. Hasil dari pencarian sebuah string dalam dokumen tergantung dari teknik atau cara pencocokan string yang digunakan. Untuk mengukur performansi metode pencarian, terdapat empat kriteria yang dapat digunakan, yaitu (Coppin, 2004):
1. Completeness
Apakah metode tersebut menjamin penemuan solusi jika solusinya memang ada.
2. Time complexity
Berapa lama waktu yang diperlukan. 3. Space complexity
4. Optimality
Apakah metode tersebut menjamin menemukan solusi yang terbaik jika terdapat beberapa solusi berbeda.
2.3 Algoritma Pencarian Data
Dalam ilmu komputer, sebuah algoritma pencarian dijelaskan secara luas adalah sebuah algoritma yang menerima masukan berupa sebuah masalah dan menghasilkan sebuah solusi untuk masalah tersebut, yang biasanya didapat dari evaluasi beberapa kemungkinan solusi. Sebagian besar algoritma yang dipelajari oleh ilmuwan komputer adalah algoritma pencarian (Nievergelt, 2000).
Pencarian data (table look-up atau storage and retrieval information) adalah suatu proses untuk mengumpulkan sejumlah informasi di dalam pengingat komputer dan kemudian mencari kembali informasi yang diperlukan secepat mungkin. Metode pencarian data dapat dilakukan dengan dua cara yaitu pencarian internal (internal searching) dan pencarian eksternal (external searching). Pada pencarian internal, semua rekaman yang diketahui berada dalam pengingat komputer sedangkan pada pencarian eksternal, tidak semua rekaman yang diketahui berada dalam pengingat komputer, tetapi ada sejumlah rekaman yang tersimpan dalam penyimpan luar misalnya pita atau cakram magnetis (Nievergelt, 2000).
Selain itu metode pencarian data juga dapat dikelompokkan menjadi pencarian statis (static searching) dan pencarian dinamis (dynamic searching). Pada pencarian statis, banyaknya rekaman yang diketahui dianggap tetap, pada pencarian dinamis, banyaknya rekaman yang diketahui bisa berubah-ubah yang disebabkan oleh penambahan atau penghapusan suatu rekaman (Nievergelt, 2000).
2.3.1 Pencarian Berurutan (Sequential Searching)
Pencarian berurutan sering disebut pencarian linear merupakan metode pencarian yang paling sederhana. Pencarian berurutan menggunakan prinsip bahwa data yang ada dibandingkan satu per satu secara berurutan dengan yang dicari sampai data tersebut ditemukan atau tidak ditemukan (Boyer & Moore, 1977).
Pada dasarnya, pencarian ini hanya melakukan pengulangan dari 1 sampai dengan jumlah data. Pada setiap pengulangan, dibandingkan data ke-i dengan yang dicari. Apabila sama, berarti data telah ditemukan. Sebaliknya apabila sampai akhir pengulangan tidak ada data yang sama, berarti data tidak ada. Pada kasus yang paling buruk, untuk N elemen data harus dilakukan pencarian sebanyak N kali pula (Boyer & Moore, 1977).
Secara umum, algoritma pencarian berurutan mengikuti prosedur sebagai berikut (Boyer & Moore, 1977):
1. i ← 0
2. Ketemu ← false
3. Selama Ketemu = false dan (i <= N) kerjakan baris 4 4. Jika (Data[i] = x) maka Ketemu ← true, jika tidak i ← i + 1
5. Jika Ketemu = true maka i adalah indeks dari data yang dicari, jika tidak data tidak ditemukan.
Atau, dapat juga dituliskan sebagai berikut (Boyer & Moore, 1977):
int SequentialSearch(int x) {
int i = 0;
bool ketemu = false;
Fungsi diatas akan mengembalikan indeks dari data yang dicari. Apabila data tidak ditemukan maka fungsi diatas akan mengembalikan nilai –1 (Boyer & Moore, 1977).
2.3.2 Pencarian Biner (Binary Search)
Salah satu syarat agar pencarian biner dapat dilakukan adalah data sudah dalam keadaan urut. Dengan kata lain, apabila data belum dalam keadaan urut, pencarian biner tidak dapat dilakukan. Dalam kehidupan sehari-hari, sebenarnya kita juga sering menggunakan pencarian biner. Misalnya saat ingin mencari suatu kata dalam kamus (Boyer & Moore, 1977).
Prinsip dari pencarian biner dapat dijelaskan sebagai berikut : mula-mula diambil posisi awal 0 dan posisi akhir = N - 1, kemudian dicari posisi data tengah dengan rumus (posisi awal + posisi akhir) / 2. Kemudian data yang dicari dibandingkan dengan data tengah. Jika lebih kecil, proses dilakukan kembali tetapi posisi akhir dianggap sama dengan posisi tengah –1. Jika lebih besar, porses dilakukan kembali tetapi posisi awal dianggap sama dengan posisi tengah + 1. Demikian seterusnya sampai data tengah sama dengan yang dicari (Boyer & Moore, 1977).
Secara umum, algoritma pencarian biner mengikuti prosedur sebagai berikut (Boyer & Moore, 1977):
1. L ← 0
2. R ← N - 1
3. Ketemu ← false
4. Selama (L <= R) dan Ketemu = false kerjakan baris 5 sampai dengan 8
5. m ← (L + R) / 2
6. Jika (Data[m] = x) maka Ketemu ← true 7. Jika (x < Data[m]) maka R ← m – 1 8. Jika (x > Data[m]) maka L ← m + 1
Atau, dapat juga dituliskan sebagai berikut (Boyer & Moore, 1977): ditemukan maka fungsi diatas akan mengembalikan nilai –1 (Boyer & Moore, 1977).
Jumlah pembandingan minimum pada pencarian biner adalah 1 kali, yaitu apabila data yang dicari tepat berada di tengah-tengah. Jumlah pembandingan maksimum yang dilakukan dengan pencarian biner dapat dicari menggunakan rumus logaritma, yaitu (Boyer & Moore, 1977):
C = 2log(N) ... (2.1)
2.4 Algoritma Boyer-Moore
Misalnya ada sebuah usaha pencocokan yang terjadi pada teks [i..i + n − 1], dan anggap ketidakcocokan pertama terjadi diantara teks[i + j] dan pattern[j], dengan 0 < j < n. Berarti, teks[i + j + 1..i + n − 1] = pattern[j + 1..n − 1] dan a = teks[i + j] tidak sama dengan b = pattern[j]. Jika u adalah akhiran dari pattern sebelum b dan v adalah sebuah awalan dari pattern, maka penggeseran-penggeseran yang mungkin adalah (Soleh et. al, 2010):
1. Penggeseran good-suffix yang terdiri dari mensejajarkan potongan teks [i + j + 1..i + n − 1] = pattern [j + 1..n − 1] dengan kemunculannya paling kanan di pattern yang didahului oleh karakter yang berbeda dengan pattern[j]. Jika tidak ada potongan seperti itu, maka algoritma akan mensejajarkan akhiran v dari teks [i + j + 1..i + n − 1] dengan awalan dari pattern yang sama.
2. Penggeseran bad-character yang terdiri dari mensejajarkan teks[i + j] dengan kemunculan paling kanan karakter tersebut di pattern. Bila karakter tersebut tidak ada di pattern, maka pattern akan disejajarkan dengan teks [i + n + 1].
Secara sistematis, langkah-langkah yang dilakukan algoritma Boyer-Moore pada saat mencocokkan string adalah (Soleh et. al, 2010):
1. Algoritma Boyer-Moore mulai mencocokkan pattern pada awal teks.
2. Dari kanan ke kiri, algoritma ini akan mencocokkan karakter per karakter pattern dengan karakter di teks yang bersesuaian, sampai salah satu kondisi berikut dipenuhi :
a. Karakter di pattern dan di teks yang dibandingkan tidak cocok (mismatch). b. Semua karakter di pattern cocok. Kemudian algoritma akan memberitahukan
penemuan di posisi ini.
2.5 Algoritma ApostolicoGiancarlo
Algoritma apostolico giancarlo merupakan algoritma pengembangan dari algoritma boyer-moore. Perbedaan algoritma apostolico giancarlo dari algoritma boyer-moore terletak pada proses pencariannya yang menggunakan sebuah variabel bantu sebagai pengingat dalam proses pencarian. Variabel bantu pada algororitma apostolico giancarlo ini berfungsi untuk menyimpan informasi pasangan yang sudah cocok pada shift sebelumnya. Hal ini yang menjadi kelebihan dari algoritma apostolico giancarlo, jika dibandingkan dengan algoritma booyer-moore (Crochemore et. al, 2004).
Pada dasarnya, Apostolico giancarlo menyimpan pattern dari hasil setiap perbandingan yang sama, agar perbandingan tersebut tidak terjadi lagi. Pertama-tama akan disamakan posisi pattern dengan 8 karakter pertama pada teks, seperti terlihat pada Tabel 2.1 (Mirabella, 2012).
Tabel 2.1 Menyamakan Posisi Pattern
Teks G C A T C G C A G A G A G T A T A C A T T A C G Pattern - - - G
Setelah itu, akan dilakukan pergeseran dengan karakter-buruk seperti pada algoritma Boyer-Moore, dan akan ditemukan perbandingan selanjutnya sampai ditemukan perbandingan karakter buruk lagi, seperti terlihat pada Tabel 2.2.
Tabel 2.2 Pergeseran Dengan Karakter Buruk
Teks G C A T C G C A G A G A G T A T A C A T T A C G Pattern - - - G A G
Tabel 2.3 Perbandingan Setelah Karakter Yang Sama
Teks G C A T C G C A G A G A G T A T A C A T T A C G
Pattern G C - - A G A G
Ditemukan bahwa karakte G dan A sama seperti pada perbandingan sebelumnya, lalu ditemukan satu karakter berikutnya lagi yang sama yaitu G. Karena sampai saat ini terdapat pattern baru di tabel Skip yaitu AGAG, maka selanjutnya akan dilakukan perbandingan selanjutnya untuk karakter yang tidak sama. Ditemukan karakter G dan C yang sama dengan teks. Oleh karena itu, akan langsung dilakukan lompatan tujuh karakter seperti pada lompatan akhiran-baik pada Boyer-Moore, yang hasilnya seperti terlihat pada Tabel 2.4 (Mirabella, 2012).
Tabel 2.4 Melakukan Lompatan Karakter
Teks G C A T C G C A G A G A G T A T A C A T T A C G
Pattern - - - G
Proses ini akan dilakukan berulang kali hingga setiap karakter pada pattern memiliki karakter yang sama pada teks (Mirabella, 2012).
Berdasarkan penjelasan di atas, secara singkat, cara kerja algoritma giancarlo apostolico dapat disimpulkan sebagai berikut:
1. Input lokasi file yang akan dicari. 2. Input kata kunci pencarian.
3. Untuk setiap file yang diperiksa, urutkan nama file sesuai abjad tanpa ada karakter yang mengalami perulangan.
5. Untuk setiap file yang diperiksa, lakukan pencocokan nama file terhadap kata kunci. Jika tidak terjadi kecocokan, lakukan shift berdasarkan kriteria karakter nama file, apakah termasuk bad-suffix shift atau good-suffix shift.
6. Good-suffix shift dilakukan jika karakter nama file bukan termasuk karakter buruk (memiliki kode lebih kecil dari n+1). Pergeseran dilakukan hingga ditemukan karakter yang cocok dengan karakter nama file pada kata kunci. 7. Bad-suffix shift dilakukan jika karakter nama file termasuk dalam karakter
buruk (memiliki kode n+1). Pergeseran dilakukan sebanyak n+1.
8. Proses pencarian dihentikan jika seluruh karakter nama file yang diperiksa telah cocok dengan karakter pada kata kunci.
9. Hitung jumlah pergerseran (shift) untuk masing-masing pencarian nama file.
2.6 Penelitian Terdahulu
Dalam masalah pencarian file menggunakan algoritma apostolico giancarlo ini, ada beberapa Penelitian terdahulu yang digunakan sebagain referensi sebagai berikut.
Lecroq T. (1992) dengan menggunakan teknik Apostolico Giancarlo dengan fungsi untuk menghitung prefix terpanjang dalam string pencarian. Apostolico giancarlo hanya membutuhkan maksimal tiga kali pencarian untuk suffix yang sama.
Pada penelitian yang diterapkan oleh Crochemore et al. (1997) Apostolico Giancarlo Apostolico giancarlo memiliki efisiensi yang baik dalam kecepatan pencarian string yang sama. Dengan menggunakan teknik Apostolico Giancarlo dengan fungsi pengingat string yang sudah pernah cocok pada pencarian sebelumnya.
Juga pada penelitian yang lakukan oleh Crochemore et al. (2002) Apostolico giancarlo mampu mengatasi masalah pencarian dengan kecepatan setengah dari kecepatan algoritma Boyer-Moore dengan menggunakan variasi fungsi shift.
Mirabella F M. (2013) dengan menerapkan metode Turbo-BM, Apostolico Giancaro dan Horspool maka hasil yang dicapai untuk Algoritma Turbo-BM dan Apostolico Giancarlo lebih cepat dalam penyelesaian solusi dibandingkan dengan Boyer-Moore.
Horspool, Raita, Quicksearch, Maximal Shift, Liu-Du-Ishi, The Smith, Zhu-Takaoka, Baeza-Yates.
Al-Khamaiseh et al. (2014) dengan Survey mengenai algoritma Exact string matching dan Approximate String Matching dalam masalah Intrusion Detection System menggunakan metode Exact String Matching dan Approximate String Matching .
Adapun penelitian terdahulu yang digunakan sebagai referensi dalam penelitian ini sebagaimana terlihat pada Tabel 2.5.
Tabel 2.5 Penelitan Terdahulu
Koloud Al-Khamaiseh & Shadi Al-Shagarin (2014)
Exact String Matching dan Approximate String
Matching