Theophilus Wellem, Yu-Kuen Lai, and Wen-Yaw Chung
Chung Yuan Christian UniversityChung Li, Taiwan, R.O.C
E-mail: {g9776070, ylai, eldanny}@cycu.edu.tw
Abstract— Sketch-based methods are widely used in high-speed network monitoring applications. In this paper, we present a parallel implementation of sketch computations using Open Computing Language (OpenCL) on Graphics Processing Unit (GPU) for network traffic change detection. The parallel nature of the computation on sketch data structure makes it suitable for implementation on GPU. Comparing to the implementation on CPU, the experiment results show the speed up of 2.8 times and 4 times in average for sketch table size of 1024 up to 32768 using two different forecasting methods.
Keywords- Traffic monitoring; Sketch; GPU; OpenCL; Moving Average; Exponentially Weighted Moving Average
I. INTRODUCTION
Anomalies in network traffic are common in today’s network due to flash crowds, worm, and denial of service (DoS) attack. These anomalies often result in abrupt changes on traffic volume. Therefore, traffic monitoring and measurements for detecting these changes is important for anomaly detection. The problem of finding flows with significant changes in traffic volume has been addressed in several works. There are several methods for detecting changes in network traffic such as, sliding window based on nonparametric cumulative sum (CUSUM) [1], sketch-based [2, 3], and Combinatorial Group Testing approaches [4]. Sketch-based methods are interesting due to its small memory requirement and proven to have high accuracy for detecting changes in network traffic.
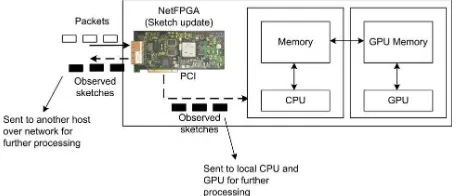
We have implemented a sketch-based scheme for change detection on NetFPGA platform [5] in our previous work [6], and we developed a prototype of distributed NetFPGA-based network monitoring framework for network-wide traffic anomaly detection based on this system, as shown in Figure 1. In this scheme, a collection of NetFPGA traffic monitoring system acts as monitors in the network. These monitors collect the traffic from parts of the network using sketch. The sketches can be either processed locally or sent to a remote server at network operation center for further processing. We observed that the number of observed sketch increases in proportion with the inverse of the observing time interval. Therefore, the CPU workload increases because of intensive sketch computation due to shorter observing time interval. Beside the computation of forecast sketch and forecast error sketch, the estimate operation to get estimated
total traffic volume for a given flow, needs to compute several hash values. The number of hash values to be computed depends on the number of sketch table, H. The hash computations on estimate operation should be done for each flow and can become a bottleneck of the system.
Recently, Graphics Processing Unit (GPU) is increasingly being used for general purpose computation, including packet processing applications, because of its parallel processing capability and computational power. Some packet processing applications often applied same task to each packet, which is suitable to the Single Instruction Multiple Data (SIMD) processing on GPU. The other advantage is that GPUs are available at low cost together with the commodity CPUs compared to another accelerator, such as FPGAs or dedicated hardware. In this paper, we explore the implementation of the statistical computation of a sketch-based scheme for network traffic change detection using OpenCL [7] on GPU to accelerate the computation. The parallel nature of the computation on sketch data structure makes it suitable for implementation on GPU. Our experiment results show about 2.8 times and 4 times speed up in average for sketch table size of 1024 up to 32768 using two different forecasting methods. The remainder of this paper is organized as follows. In Section II, we provide the general background on data stream and sketch data structure. Section III introduces OpenCL and GPU as an OpenCL compute device, Section IV explains the system architecture and implementation, Section V describes the experimental setup, and Section VI presents the experiment results and evaluation. Section VII discusses related work, and Section VIII concludes the paper and gives some future works.
II. BACKGROUND
of items. Each item, at = (kt, ut) consists of a key, kt and an update, ut. Network traffic can be regarded as a data stream since the packets arrive rapidly as a series of items. The key,
kt represent the traffic flow (i.e., kt is chosen from one or more fields of the packet header, such as source IP address, destination IP address, etc.) and the update utis the packet count. In general, for monitoring and measurement purpose, sampling is used to collect this massive network traffic. Sampling also reduces the requirement for large storage space. Another approach is to use synopsis data structure to summarize the network traffic. Sketch [8, 9] is a space-efficient data structure used for building compact summary (synopsis) of network traffic. The sketch size is small, so it can be stored in router’s SRAM. If the sketch needs to be sent over the network, it consumes insignificant amount of bandwidth. Due to its linearity, sketch can be combined using arithmetic operations. Using sketch, the collection and analysis of network traffic can be done online and in a distributed way. Thus, make it possible to build a distributed network monitoring framework.
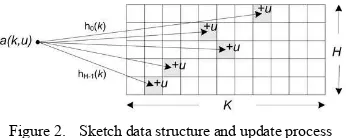
Sketch data structure utilizes a set of counters to summarize the values from items in data stream and universal hash functions [10] to determine the position of the counters to be updated. In general, sketch has two main operations: update and query. The update operation updates the sketch for each item in the data stream. Initially, all counters are set to zero. When an item a1 = (kt, ut) arrives, the key kt is hashed and the counters are then updated (incremented) using the update value ut. The query operation is used to get the estimated value for a key kt. The algorithms used by the query operation to derive the estimated value are different among variant of sketches. The k-ary sketch designed in [1] is a two-dimensional array of counters C[i][j], where 0 ≤ i ≤ H – 1, 0 ≤ j ≤ K – 1. Each row H is associated with a universal hash function, hi, so the parameter H represents the number of hash functions used (i.e., sketch depth) and the hash result from hashing a key, kt is j. Parameter K represents the sketch table size (sketch width). The update operation is defined as
H i u k h i C k h i
C[][ i( t)]= [][ i( t)]+ t,∀ ∈ (1)
This is illustrated in Figure 2. In our previous work [6], we used the source IP address as the key and the total packet length as the update. There is one observed sketch updated for each time interval Δt. Thus, at the end of an observing the counters in the sketch contain the total bytes for incoming
keys in the corresponding interval. The query operation (or estimate operation) returns the estimated total bytes for a particular source IP address in this interval.
III. OPENCL
Open Computing Language (OpenCL) is an open industry standard parallel programming framework that allows developers to program heterogeneous collection of CPUs, GPUs and other computing devices or accelerators (e.g. IBM Cell B.E). It supports data-parallel and task-parallel programming model. Further, it consists of a language, Application Programming Interface (API), libraries and runtime system to support software development [7]. OpenCL platform model consists of a host and one or more OpenCL devices. An OpenCL device is comprised of one or more compute units, and a compute unit is divided into one or more processing elements. OpenCL application consists of two parts: the host program, which is executed on the host, and kernels, which are executed on the device. The execution model is as follow. When a kernel is to be executed, the host sends the kernel to the device for execution. Kernel instances (called work-items) are mapped into an N-dimensional space called NDRange. The work-items are organized into work-groups, and work-work-items in the work-group run in parallel. In OpenCL model, work-groups are mapped to compute units and work-items are mapped to processing elements. During execution, kernel can access its own memory (device memory), which is divided into four distinct regions: global memory, constant memory, local memory, and private memory. The movement of data between host memory and device memory is done using buffer objects. The host copy input data to the buffer objects in device memory, the device does the computation using the input data, and the host read the buffer objects back to get the computation result. To hide the memory latency, OpenCL employs techniques, such as asynchronous memory transfer, switching between work-items when a work-item is waiting for memory access, and global memory cache (if exist). Details of OpenCL can be found in [7].
In OpenCL platform, GPU is treated as a device consisting of compute units. A compute unit contains several stream cores, and a stream core consists of several processing elements. For example, ATI Radeon HD 5870 GPU has 20 compute units, each compute unit has 16 stream cores, and each stream core contains 5 processing elements, so the total number of processing elements is 1600 [11].
IV. SYSTEM ARCHITECTURE AND IMPLEMENTATION
The architecture of our system is shown in Figure 3. The sketch is stored in SRAM on NetFPGA board. After the sketch is updated in hardware, it is read by our software (via
Figure 2. Sketch data structure and update process
the PCI), and put into the host memory for further processing on the local host. The other way is the NetFPGA send the sketch data over network to the another host. The CPU then read the packets and extracts the sketch data for processing by GPU. This way makes it possible to read sketch data from different locations in the network. In this work, we are focusing on the implementation of statistical computation from the sketches. Several forecast methods were proposed in [2] to compute the forecast sketch: Moving Average (MA), S-shaped Moving Average (SMA), Exponentially Weighted Moving Average (EMWA), and Non-Seasonal Holt-Winters (NSHW). These four models are simple smoothing models. The other models are AutoRegressive Integrated Moving Average (ARIMA) models: ARIMA0 and ARIMA1. We use the MA as in our previous work and the EWMA here..
A. Forecast Sketch and Error Sketch Computations
The forecast sketch Sf(t) is computed using the observed sketches (observed sketch is denoted by So(t)) in the past interval and the forecast error sketch, Se(t).
Moving Average - The forecast sketch for each time interval is computed using moving average of observed sketches of past W intervals. Parameter W is called the window size. This is shown in (2).
Exponentially Weighted Moving Average - Using EWMA, the computation of forecast sketch is shown in (4)
⎩
The software has been implemented on CPU and GPU to compare their performance and to observe the benefit of using GPU to accelerate the computation. We implemented two main kernels to compute the forecast sketch and forecast error sketch. The host application reads the sketch data, writes it into the buffers allocated in the GPU memory, and executes the kernels to compute the forecast sketch and forecast error sketch. For the MA case, the first kernel took the sketch data of the first W observing time intervals, t1, t2, …, tW from the buffer and computes the moving average value. For the subsequent time interval, the kernel computes the forecast sketch according to (3). The kernel instances (or work-items) are mapped to 2-dimensional NDRange, where each thread operates on a single element of the sketches in parallel. The second kernel took the result of the first kernel and the observed sketch (from a buffer) to compute the error sketch according to (5). These computations are similar to arithmetic operations on matrices and vectors.
The EWMA case is almost similar to MA. The differences are on the number of sketch data it needs to compute the forecast sketch for each time interval and the multiplication operation. For example, according to (4), computation of forecast sketch at time t = 3 (for example with α= 0.5) is Sf(3) = 0.5 So(2) + 0.5 Sf(2). Therefore, it needs less number of buffers compared to the MA case at t = 3. In both case of H values, the size of global work-items and local work-items are adjusted according to the sketch size used, the maximum kernel work group size and maximum work-item size supported by the devices, to maximize device utilization. The maximum work group size and maximum work item size supported by ATI Radeon HD 4670 is 128.
V. EXPERIMENTAL SETUP AND DATASET
The specification of CPU and GPU used in the experiment is shown in Table I. Intel CPUs each has two cores and the GPU has eight compute units, with total of 320 processing elements. The OpenCL implementation used is ATI Stream Technology SDK v2.2 [12]. The GPU is plugged into the Intel Pentium Dual Core E6300 PC. The sketch data for the experiment is obtained from our previous work, which uses network traces from MAWI Working Group Traffic Archive [13]. We used the first 15-minute trace consists of 51,778 flows of distinct source IP addresses. This data is used as the input to the software developed in this work. The observing time interval Δt is 60 seconds and
CPU Intel Pentium Dual Core E6300, 2.8 GHz, 2 GB Memory CPU Intel Core 2 Duo T5500, 1.66 GHz, 1 GB Memory GPU ATI Radeon HD 4670, 750 MHz, 256 MB Memory
the MA window size W = 3. For the sketch parameters, we choose H = 3 and H = 5, and K = 1024, 2048 up to 32768.
VI. RESULTS AND EVALUATION
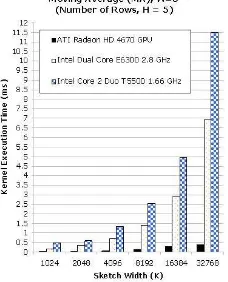
The baseline to evaluate the performance is the CPU implementation. For the GPU implementation, we measure the kernel execution time to derive the speedup achieved. Based on our experiments, the kernel execution time for computing the forecast error sketch is smaller than the forecast kernel, since it is only involve a subtraction operation. Here, we present the result of the forecast kernel execution time obtained using ATI Stream Profiler. Figure 4 and Figure 5 show the MA forecast kernel execution time for
H = 3 and H = 5, respectively. The kernel execution time does not include the time needed to launch the kernel, read, and write the buffer. We can observe that for each value of K, the GPU performs better than CPU. The kernel execution time is increasing with if the value of H or K is increasing. Comparing the H values, the kernel execution time for H = 5 is slightly slower than for H = 3 because more data need to be processed by the kernel. Figure 6 and 7 show the EWMA forecast kernel execution time. It shows the same trend compared to the MA case for H = 3 and H = 5, but the kernel execution time is faster than the MA kernel. Based on the profiler results, the EMWA forecast kernel have less ALU and fetch instructions in the execution compared to the MA
forecast kernel.
In Figure 8, we compared the EWMA forecast kernel execution time on GPU, including the time to write and read the buffer. We can observe that the time to write and read the buffer have significant contributions to the total execution time. For K = 1024, the values are 0.009 ms and 0.139 ms (include the time to write/read buffer), the difference is 0.13 ms. The difference is increasing with the sketch width and the trend is similar for H = 5 and in the MA case. In average, the time to write and read the buffer dominates 86% and 87% of execution time for EWMA and MA, respectively.
We also compared the kernel execution time on GPU (include the time to write and read the buffer) to the CPU implementation as shown in Figure 9. As we can observe, for small sketch width, the execution time on Intel Dual Core E6300 CPU is slightly faster than the GPU, but for larger sketch width, the GPU performs better than CPU. For MA with H = 3 and H = 5, it achieves about 2.8 times speed up in average for all sketch width, and for EWMA, it achieves about 4 times speed up. Overall, the implementation on GPU shows better performance compared to the CPU implementation. At this time, our kernel code does not include some optimization such as NDRange and memory optimization. We leave the optimization for future work.
VII. RELATED WORK
The work in [2] is a sequential implementation using C on 400 MHz SGI R12k processor and 900 MHz UltraSPARC-III processor. The work in [14] implemented sketch-based change detection on 500 MHz Imagine stream processor and 1.4 GHz Intel IXP2800 network processor. Several works also proposed of using GPU for network packet processing tasks, such as IP routing lookup (software router) [15], pattern matching algorithm [16], regular expression matching using deterministic finite automata (DFA) [17] or nondeterministic finite automata (NFA) [18]. Most of these works utilize NVIDIA CUDA or directly map their algorithm to follow the traditional graphics processing (i.e., using the pixel shader or vertex shader and OpenGL).
Figure 6. Kernel execution time of forecast kernel for EWMA, H=3
Figure 4. Kernel execution time of forecast kernel for MA, W=3, H=3
VIII. CONCLUSION AND FUTURE WORK
In this paper, we implemented the statistical computation of a sketch-based change detection scheme on GPU using OpenCL. The implementation on GPU using OpenCL shows significant performance improvement compared to that on CPU, with 2.8 times and 4 times speed up in average for sketch width of 1024 up to 32768 using two different forecast methods. For future work, we expect more performance improvement with code optimizations and memory latency hiding techniques in OpenCL.
ACKNOWLEDGMENT
This work was funded in part by the National Science Council, Taiwan, under the Grants No. NSC 98-3114-E-009-008-CC2 and NSC 99-2221-E-033-011.
[2] B. Krishnamurthy, S. Sen, Y. Zhang, and Y. Chen, “Sketch-based change detection: Methods, evaluation, and applications,” in
Proceedings of the 3rd ACM SIGCOMM Conference on Internet
Measurement, IMC ’03. ACM, October 2003, pp. 234–247.
[3] R. Schweller, A. Gupta, E. Parsons, and Y. Chen, “Reverse hashing for sketch-based change detection on high-speed networks,” in
Proceedings of the ACM/USENIX Internet Measurement Conference,
IMC’04. ACM, October 2004.
[4] G. Cormode and S. Muthukrishnan, “What’s new: Finding significant differences in network data streams,” Proceedings of 23rd Annual Joint Conference of the IEEE Computer and Communications
Societies, (INFOCOM 2004), vol. 3, pp. 1534–1545, 2004.
[5] J. Naous, G. Gibb, S. Bolouki, and N. McKeown, “NetFPGA: Reusable router architecture for experimental research,” in
Proceedings of the ACM Workshop on Programmable Routers for
Extensible Services of Tomorrow. ACM, 2008, pp. 1–7.
[6] Y.-K. Lai, N.-C.Wang, T.-Y. Chou, C.-C. Lee, T. Wellem, and H. Nugroho, “Implementing on-line sketch-based change detection on a NetFPGA platform,” in Proceedings of the 1st Asia NetFPGA
Developers Workshop, Daejeon, South Korea, 2010.
[7] The OpenCL Specification, Version 1.0 Rev. 48, Khronos OpenCL
Working Group, 2009. [Online]. Available: http://www.khronos.org/registry/cl/specs/opencl-1.0.pdf.
[8] A. Gilbert, Y. Kotidis, S. Muthukrishnan, and M. Strauss, “QuickSAND: Quick summary and analysis of network data,” DIMACS, Center for Discrete Mathematics and Theoretical Computer Science, Tech. Rep. 2001-43, November 2001.
[9] G. Cormode and S. Muthukrishnan, “An improved data stream summary: The count-min sketch and its applications,” Journal of
Algorithms, vol. 55, no. 1, pp. 58–75, April 2005.
[10] J. Carter and M. Wegman, “Universal classes of hash functions,” Journal
oof Computer and System Sciences, vol. 18, no. 2, pp. 143–154, 1979.
[11] ATI Stream SDK OpenCL Programming Guide, Advanced Micro Devices,
Inc., 2010. [Online]. Available: http://developer.amd.com/gpu/ATI StreamSDK/assets/ATIStreamSDK OpenCL Programming Guide.pdf [12] ATI Stream SDK v2.2. Advanced Micro Devices, Inc. [Online].
Available: http://developer.amd.com/gpu/ATIStreamSDK/Pages/default.aspx [13] MAWI Working Group Traffic Archive. MAWI Working Group.
[Online]. Available: http://mawi.wide.ad.jp/mawi/samplepoint-B/20030227/. [14] Y.-K. Lai and G. Byrd, “High-throughput sketch update on a
low-power stream processor,” in Proceedings of the 2006 ACM/IEEE Symposium on Architecture for Networking and Communications
Systems, ANCS ’06. ACM, December 2006, pp. 123–132.
[15] S. Mu, X. Zhang, N. Zhang, J. Lu, Y. Deng, and S. Zhang, “IP routing processing with graphic processors,” in Design, Automation & Test in
Europe Conference & Exhibition (DATE), 2010, 2010, pp. 93–98.
[16] J. Peng, H. Chen, and S. Shi, “The GPU-based string matching system in advanced AC algorithm,” in International Conference on
Computer and Information Technology. IEEE Computer Society,
2010, pp. 1158–1163.
[17] R. Smith, N. Goyal, J. Ormont, K. Sankaralingam, and C. Estan, “Evaluating GPUs for network packet signature matching,” in IEEE International Symposium on Performance Analysis of Systems and
Software (ISPASS), 2009, pp. 175–184.
[18] N. Cascarano, P. Rolando, F. Risso, and R. Sisto, “iNFAnt: NFA pattern matching on GPGPU devices,” ACM SIGCOMM Computer
Communication Review, vol. 40, no. 5, pp. 21–26, 2010.