Yoshiharu Ishikawa
Jianliang Xu (Eds.)
123
LNCS 10988
Second International Joint Conference, APWeb-WAIM 2018
Macau, China, July 23–25, 2018
Proceedings, Part II
Commenced Publication in 1973 Founding and Former Series Editors:
Gerhard Goos, Juris Hartmanis, and Jan van Leeuwen
Editorial Board
David HutchisonLancaster University, Lancaster, UK Takeo Kanade
Carnegie Mellon University, Pittsburgh, PA, USA Josef Kittler
University of Surrey, Guildford, UK Jon M. Kleinberg
Cornell University, Ithaca, NY, USA Friedemann Mattern
ETH Zurich, Zurich, Switzerland John C. Mitchell
Stanford University, Stanford, CA, USA Moni Naor
Weizmann Institute of Science, Rehovot, Israel C. Pandu Rangan
Indian Institute of Technology Madras, Chennai, India Bernhard Steffen
TU Dortmund University, Dortmund, Germany Demetri Terzopoulos
University of California, Los Angeles, CA, USA Doug Tygar
University of California, Berkeley, CA, USA Gerhard Weikum
Jianliang Xu (Eds.)
Web and Big Data
Second International Joint Conference, APWeb-WAIM 2018
Macau, China, July 23
–
25, 2018
Proceedings, Part II
South China University of Technology Guangzhou
China
Yoshiharu Ishikawa Nagoya University Nagoya
Japan
Hong Kong Baptist University Kowloon Tong, Hong Kong China
ISSN 0302-9743 ISSN 1611-3349 (electronic) Lecture Notes in Computer Science
ISBN 978-3-319-96892-6 ISBN 978-3-319-96893-3 (eBook) https://doi.org/10.1007/978-3-319-96893-3
Library of Congress Control Number: 2018948814
LNCS Sublibrary: SL3–Information Systems and Applications, incl. Internet/Web, and HCI ©Springer International Publishing AG, part of Springer Nature 2018
This work is subject to copyright. All rights are reserved by the Publisher, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilms or in any other physical way, and transmission or information storage and retrieval, electronic adaptation, computer software, or by similar or dissimilar methodology now known or hereafter developed.
The use of general descriptive names, registered names, trademarks, service marks, etc. in this publication does not imply, even in the absence of a specific statement, that such names are exempt from the relevant protective laws and regulations and therefore free for general use.
The publisher, the authors and the editors are safe to assume that the advice and information in this book are believed to be true and accurate at the date of publication. Neither the publisher nor the authors or the editors give a warranty, express or implied, with respect to the material contained herein or for any errors or omissions that may have been made. The publisher remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Thanks also go to the workshop co-chairs (Leong Hou U and Haoran Xie), demo co-chairs (Zhixu Li, Zhifeng Bao, and Lisi Chen), industry co-chair (Wenyin Liu), tutorial co-chair (Jian Yang), panel chair (Kamal Karlapalem), local arrangements chair (Derek Fai Wong), and publicity co-chairs (An Liu, Feifei Li, Wen-Chih Peng, and Ladjel Bellatreche). Their efforts were essential to the success of the conference. Last but not least, we wish to express our gratitude to the treasurer (Andrew Shibo Jiang), the Webmaster (William Sio) for all the hard work, and to our sponsors who generously supported the smooth running of the conference. We hope you enjoy the exciting program of APWeb-WAIM 2018 as documented in these proceedings.
June 2018 Yi Cai
Organizing Committee
Honorary Chair
Lionel Ni University of Macau, SAR China General Co-chairs
Zhiguo Gong University of Macau, SAR China
Qing Li City University of Hong Kong, SAR China Kam-fai Wong Chinese University of Hong Kong, SAR China Program Co-chairs
Yi Cai South China University of Technology, China Yoshiharu Ishikawa Nagoya University, Japan
Jianliang Xu Hong Kong Baptist University, SAR China Workshop Chairs
Leong Hou U University of Macau, SAR China
Haoran Xie Education University of Hong Kong, SAR China Demo Co-chairs
Zhixu Li Soochow University, China
Zhifeng Bao RMIT, Australia
Lisi Chen Wollongong University, Australia Tutorial Chair
Jian Yang Macquarie University, Australia Industry Chair
Wenyin Liu Guangdong University of Technology, China Panel Chair
Kamal Karlapalem IIIT, Hyderabad, India Publicity Co-chairs
An Liu Soochow University, China
Wen-Chih Peng National Taiwan University, China Ladjel Bellatreche ISAE-ENSMA, Poitiers, France Treasurers
Leong Hou U University of Macau, SAR China
Andrew Shibo Jiang Macau Convention and Exhibition Association, SAR China
Local Arrangements Chair
Derek Fai Wong University of Macau, SAR China Webmaster
William Sio University of Macau, SAR China
Senior Program Committee
Bin Cui Peking University, China
Byron Choi Hong Kong Baptist University, SAR China Christian Jensen Aalborg University, Denmark
Demetrios
Zeinalipour-Yazti
University of Cyprus, Cyprus Feifei Li University of Utah, USA Guoliang Li Tsinghua University, China K. Selçuk Candan Arizona State University, USA
Kyuseok Shim Seoul National University, South Korea Makoto Onizuka Osaka University, Japan
Reynold Cheng The University of Hong Kong, SAR China Toshiyuki Amagasa University of Tsukuba, Japan
Walid Aref Purdue University, USA
Wang-Chien Lee Pennsylvania State University, USA Wen-Chih Peng National Chiao Tung University, Taiwan
Wook-Shin Han Pohang University of Science and Technology, South Korea Xiaokui Xiao National University of Singapore, Singapore Ying Zhang University of Technology Sydney, Australia
Program Committee
Alex Thomo University of Victoria, Canada
An Liu Soochow University, China
Baoning Niu Taiyuan University of Technology, China Bin Yang Aalborg University, Denmark
Bo Tang Southern University of Science and Technology, China Zouhaier Brahmia University of Sfax, Tunisia
Chih-Chien Hung Tamkang University, China Chih-Hua Tai National Taipei University, China Cuiping Li Renmin University of China, China Daniele Riboni University of Cagliari, Italy
Defu Lian Big Data Research Center, University of Electronic Science and Technology of China, China Dejing Dou University of Oregon, USA
Dimitris Sacharidis Technische Universität Wien, Austria Ganzhao Yuan Sun Yat-sen University, China Giovanna Guerrini Universitàdi Genova, Italy
Guanfeng Liu The University of Queensland, Australia
Guoqiong Liao Jiangxi University of Finance and Economics, China Guanling Lee National Dong Hwa University, China
Haibo Hu Hong Kong Polytechnic University, SAR China Hailong Sun Beihang University, China
Han Su University of Southern California, USA
Haoran Xie The Education University of Hong Kong, SAR China Hiroaki Ohshima University of Hyogo, Japan
Hong Chen Renmin University of China, China Hongyan Liu Tsinghua University, China
Hongzhi Wang Harbin Institute of Technology, China Hongzhi Yin The University of Queensland, Australia Hua Wang Victoria University, Australia
Ilaria Bartolini University of Bologna, Italy
James Cheng Chinese University of Hong Kong, SAR China Jeffrey Xu Yu Chinese University of Hong Kong, SAR China Jiajun Liu Renmin University of China, China
Jialong Han Nanyang Technological University, Singapore Jianbin Huang Xidian University, China
Jian Yin Sun Yat-sen University, China Jiannan Wang Simon Fraser University, Canada Jianting Zhang City College of New York, USA Jianxin Li Beihang University, China
Jianzhong Qi University of Melbourne, Australia Jinchuan Chen Renmin University of China, China Ju Fan Renmin University of China, China
Jun Gao Peking University, China
Junhu Wang Griffith University, Australia
Kai Zeng Microsoft, USA
Kai Zheng University of Electronic Science and Technology of China, China
Karine Zeitouni Universitéde Versailles Saint-Quentin, France
Lei Zou Peking University, China
Leong Hou U University of Macau, SAR China Liang Hong Wuhan University, China
Lisi Chen Wollongong University, Australia
Lu Chen Aalborg University, Denmark
Maria Damiani University of Milan, Italy
Markus Endres University of Augsburg, Germany Mihai Lupu Vienna University of Technology, Austria Mirco Nanni ISTI-CNR Pisa, Italy
Mizuho Iwaihara Waseda University, Japan
Peiquan Jin University of Science and Technology of China, China Peng Wang Fudan University, China
Qin Lu University of Technology Sydney, Australia Ralf Hartmut Güting Fernuniversität in Hagen, Germany
Raymond Chi-Wing Wong Hong Kong University of Science and Technology, SAR China
Ronghua Li Shenzhen University, China Rui Zhang University of Melbourne, Australia Sanghyun Park Yonsei University, South Korea
Sanjay Madria Missouri University of Science and Technology, USA Shaoxu Song Tsinghua University, China
Shengli Wu Jiangsu University, China
Shimin Chen Chinese Academy of Sciences, China Shuai Ma Beihang University, China
Shuo Shang King Abdullah University of Science and Technology, Saudi Arabia
Takahiro Hara Osaka University, Japan Tieyun Qian Wuhan University, China
Tingjian Ge University of Massachusetts, Lowell, USA Tom Z. J. Fu Advanced Digital Sciences Center, Singapore
Tru Cao Ho Chi Minh City University of Technology, Vietnam Vincent Oria New Jersey Institute of Technology, USA
Wee Ng Institute for Infocomm Research, Singapore Wei Wang University of New South wales, Australia Weining Qian East China Normal University, China Weiwei Sun Fudan University, China
Wen Zhang Wuhan University, China
Wolf-Tilo Balke Technische Universität Braunschweig, Germany Wookey Lee Inha University, South Korea
Xiang Zhao National University of Defence Technology, China Xiang Lian Kent State University, USA
Xiangliang Zhang King Abdullah University of Science and Technology, Saudi Arabia
Xiangmin Zhou RMIT University, Australia Xiaochun Yang Northeast University, China
Xiaofeng He East China Normal University, China
Xiaohui (Daniel) Tao The University of Southern Queensland, Australia Xiaoyong Du Renmin University of China, China
Xin Cao The University of New South Wales, Australia Xin Huang Hong Kong Baptist University, SAR China Xin Wang Tianjin University, China
Xingquan Zhu Florida Atlantic University, USA Xuan Zhou Renmin University of China, China Yafei Li Zhengzhou University, China Yanghua Xiao Fudan University, China Yanghui Rao Sun Yat-sen University, China
Yang-Sae Moon Kangwon National University, South Korea Yaokai Feng Kyushu University, Japan
Yi Cai South China University of Technology, China Yijie Wang National University of Defense Technology, China Yingxia Shao Peking University, China
Yongxin Tong Beihang University, China
Yu Gu Northeastern University, China
Yuan Fang Institute for Infocomm Research, Singapore Yunjun Gao Zhejiang University, China
and Advances
Xuemin Lin
School of Computer Science and Engineering, University of New South Wales, Sydney
Ninghui Li
Department of Computer Sciences, Purdue University [email protected]
Lei Chen
Department of Computer Science and Engineering, Hong Kong University of Science and Technology
Database and Web Applications
Fuzzy Searching Encryption with Complex Wild-Cards Queries
on Encrypted Database . . . 3 He Chen, Xiuxia Tian, and Cheqing Jin
Towards Privacy-Preserving Travel-Time-First Task Assignment
in Spatial Crowdsourcing . . . 19 Jian Li, An Liu, Weiqi Wang, Zhixu Li, Guanfeng Liu, Lei Zhao,
and Kai Zheng
Plover: Parallel In-Memory Database Logging on Scalable Storage Devices . . . 35 Huan Zhou, Jinwei Guo, Ouya Pei, Weining Qian, Xuan Zhou,
and Aoying Zhou
Inferring Regular Expressions with Interleaving from XML Data . . . 44 Xiaolan Zhang, Yeting Li, Fei Tian, Fanlin Cui, Chunmei Dong,
and Haiming Chen
Efficient Query Reverse Engineering for Joins
and OLAP-Style Aggregations . . . 53 Wei Chit Tan
DCA: The Advanced Privacy-Enhancing Schemes
for Location-Based Services . . . 63 Jiaxun Hua, Yu Liu, Yibin Shen, Xiuxia Tian, and Cheqing Jin
Data Streams
Discussion on Fast and Accurate Sketches for Skewed Data Streams:
A Case Study . . . 75 Shuhao Sun and Dagang Li
Matching Consecutive Subpatterns over Streaming Time Series . . . 90 Rong Kang, Chen Wang, Peng Wang, Yuting Ding, and Jianmin Wang
A Data Services Composition Approach for Continuous Query
on Data Streams . . . 106 Guiling Wang, Xiaojiang Zuo, Marc Hesenius, Yao Xu, Yanbo Han,
Discovering Multiple Time Lags of Temporal Dependencies from
Fluctuating Events. . . 121 Wentao Wang, Chunqiu Zeng, and Tao Li
A Combined Model for Time Series Prediction in Financial Markets . . . 138 Hongbo Sun, Chenkai Guo, Jing Xu, Jingwen Zhu, and Chao Zhang
Data Mining and Application
Location Prediction in Social Networks . . . 151 Rong Liu, Guanglin Cong, Bolong Zheng, Kai Zheng, and Han Su
Efficient Longest Streak Discovery in Multidimensional Sequence Data . . . 166 Wentao Wang, Bo Tang, and Min Zhu
Map Matching Algorithms: An Experimental Evaluation . . . 182 Na Ta, Jiuqi Wang, and Guoliang Li
Predicting Passenger’s Public Transportation Travel Route Using Smart
Card Data . . . 199 Chen Yang, Wei Chen, Bolong Zheng, Tieke He, Kai Zheng, and Han Su
Detecting Taxi Speeding from Sparse and Low-Sampled Trajectory Data . . . . 214 Xibo Zhou, Qiong Luo, Dian Zhang, and Lionel M. Ni
Cloned Vehicle Behavior Analysis Framework . . . 223 Minxi Li, Jiali Mao, Xiaodong Qi, Peisen Yuan, and Cheqing Jin
An Event Correlation Based Approach to Predictive Maintenance . . . 232 Meiling Zhu, Chen Liu, and Yanbo Han
Using Crowdsourcing for Fine-Grained Entity Type Completion in
Knowledge Bases . . . 248 Zhaoan Dong, Ju Fan, Jiaheng Lu, Xiaoyong Du, and Tok Wang Ling
Improving Clinical Named Entity Recognition with Global
Neural Attention . . . 264 Guohai Xu, Chengyu Wang, and Xiaofeng He
Exploiting Implicit Social Relationship for Point-of-Interest
Recommendation . . . 280 Haifeng Zhu, Pengpeng Zhao, Zhixu Li, Jiajie Xu, Lei Zhao,
and Victor S. Sheng
Spatial Co-location Pattern Mining Based on Density Peaks Clustering
A Tensor-Based Method for Geosensor Data Forecasting . . . 306 Lihua Zhou, Guowang Du, Qing Xiao, and Lizhen Wang
Query Processing
AggregatekNearest Neighbor Queries in Metric Spaces . . . 317 Xin Ding, Yuanliang Zhang, Lu Chen, Keyu Yang, and Yunjun Gao
Finding the K Nearest Objects over Time Dependent Road Networks . . . 334 Muxi Leng, Yajun Yang, Junhu Wang, Qinghua Hu, and Xin Wang
Reverse Top-k Query on Uncertain Preference . . . 350 Guohui Li, Qi Chen, Bolong Zheng, and Xiaosong Zhao
Keyphrase Extraction Based on Optimized Random Walks
on Multiple Word Relations . . . 359 Wenyan Chen, Zheng Liu, Wei Shi, and Jeffrey Xu Yu
Answering Range-Based ReversekNN Queries . . . 368 Zhefan Zhong, Xin Lin, Liang He, and Yan Yang
Big Data and Blockchain
EarnCache: Self-adaptive Incremental Caching for Big Data Applications . . . 379 Yifeng Luo, Junshi Guo, and Shuigeng Zhou
Storage and Recreation Trade-Off for Multi-version Data Management . . . 394 Yin Zhang, Huiping Liu, Cheqing Jin, and Ye Guo
Decentralized Data Integrity Verification Model in Untrusted Environment. . . 410 Kun Hao, Junchang Xin, Zhiqiong Wang, Zhuochen Jiang,
and Guoren Wang
Enabling Concurrency on Smart Contracts Using Multiversion Ordering . . . . 425 An Zhang and Kunlong Zhang
ElasticChain: Support Very Large Blockchain by Reducing
Data Redundancy . . . 440 Dayu Jia, Junchang Xin, Zhiqiong Wang, Wei Guo, and Guoren Wang
A MapReduce-Based Approach for Mining Embedded Patterns
from Large Tree Data . . . 455 Wen Zhao and Xiaoying Wu
Text Analysis
Abstractive Summarization with the Aid of Extractive Summarization . . . 3 Yangbin Chen, Yun Ma, Xudong Mao, and Qing Li
Rank-Integrated Topic Modeling: A General Framework . . . 16 Zhen Zhang, Ruixuan Li, Yuhua Li, and Xiwu Gu
Multi-label Classification via Label-Topic Pairs . . . 32 Gang Chen, Yue Peng, and Chongjun Wang
Similarity Calculations of Academic Articles Using Topic Events
and Domain Knowledge. . . 45 Ming Liu, Bo Lang, and Zepeng Gu
Sentiment Classification via Supplementary Information Modeling . . . 54 Zenan Xu, Yetao Fu, Xingming Chen, Yanghui Rao, Haoran Xie,
Fu Lee Wang, and Yang Peng
Training Set Similarity Based Parameter Selection for Statistical
Machine Translation . . . 63 Xuewen Shi, Heyan Huang, Ping Jian, and Yi-Kun Tang
Social Networks
Identifying Scholarly Communities from Unstructured Texts . . . 75 Ming Liu, Yang Chen, Bo Lang, Li Zhang, and Hongting Niu
A Hybrid Spectral Method for Network Community Detection . . . 90 Jianjun Cheng, Longjie Li, Haijuan Yang, Qi Li, and Xiaoyun Chen
Personalized Top-n Influential Community Search over Large
Social Networks . . . 105 Jian Xu, Xiaoyi Fu, Liming Tu, Ming Luo, Ming Xu, and Ning Zheng
Matrix Factorization Meets Social Network Embedding for Rating
Prediction. . . 121 Menghao Zhang, Binbin Hu, Chuan Shi, Bin Wu, and Bai Wang
An Estimation Framework of Node Contribution Based
Multivariate Time Series Clustering via Multi-relational Community
Detection in Networks . . . 138 Guowang Du, Lihua Zhou, Lizhen Wang, and Hongmei Chen
Recommender Systems
NSPD: An N-stage Purchase Decision Model
for E-commerce Recommendation . . . 149 Cairong Yan, Yan Huang, Qinglong Zhang, and Yan Wan
Social Image Recommendation Based on Path Relevance. . . 165 Zhang Chuanyan, Hong Xiaoguang, and Peng Zhaohui
Representation Learning with Depth and Breadth for Recommendation
Using Multi-view Data . . . 181 Xiaotian Han, Chuan Shi, Lei Zheng, Philip S. Yu, Jianxin Li,
and Yuanfu Lu
Attentive and Collaborative Deep Learning for Recommendation . . . 189 Feifei Li, Hongyan Liu, Jun He, and Xiaoyong Du
Collaborative Probability Metric Learning . . . 198 Hongzhi Liu, Yingpeng Du, and Zhonghai Wu
UIContextListRank: A Listwise Recommendation Model
with Social Contextual Information . . . 207 Zhenhua Huang, Chang Yu, Jiujun Cheng, and Zhixiao Wang
Information Retrieval
Diversified Keyword Expansion on Multi-labeled Graphs. . . 219 Mohammad Hossein Namaki, Yinghui Wu, and Xin Zhang
Distributedk-Nearest Neighbor Queries in Metric Spaces . . . 236 Xin Ding, Yuanliang Zhang, Lu Chen, Yunjun Gao, and Baihua Zheng
Efficient Grammar Generation for Inverted Indexes . . . 253 Yan Fan, Xinyu Liu, Shuni Gao, Zhaohua Zhang, Xiaoguang Liu,
and Gang Wang
LIDH: An Efficient Filtering Method for ApproximatekNearest
Neighbor Queries Based on Local Intrinsic Dimension. . . 268 Yang Song, Yu Gu, and Ge Yu
Query Performance Prediction and Classification for Information
Aggregate Query Processing on Incomplete Data . . . 286 Anzhen Zhang, Jinbao Wang, Jianzhong Li, and Hong Gao
Machine Learning
Travel Time Forecasting with Combination of Spatial-Temporal
and Time Shifting Correlation in CNN-LSTM Neural Network . . . 297 Wenjing Wei, Xiaoyi Jia, Yang Liu, and Xiaohui Yu
DMDP2: A Dynamic Multi-source Based Default Probability
Prediction Framework . . . 312 Yi Zhao, Yong Huang, and Yanyan Shen
Brain Disease Diagnosis Using Deep Learning Features from Longitudinal
MR Images . . . 327 Linlin Gao, Haiwei Pan, Fujun Liu, Xiaoqin Xie, Zhiqiang Zhang,
Jinming Han, and the Alzheimer’s Disease Neuroimaging Initiative
Attention-Based Recurrent Neural Network for Sequence Labeling . . . 340 Bofang Li, Tao Liu, Zhe Zhao, and Xiaoyong Du
Haze Forecasting via Deep LSTM. . . 349 Fan Feng, Jikai Wu, Wei Sun, Yushuang Wu, HuaKang Li,
and Xingguo Chen
Importance-Weighted Distance Aware Stocks Trend Prediction . . . 357 Zherong Zhang, Wenge Rong, Yuanxin Ouyang, and Zhang Xiong
Knowledge Graph
Jointly Modeling Structural and Textual Representation for Knowledge
Graph Completion in Zero-Shot Scenario . . . 369 Jianhui Ding, Shiheng Ma, Weijia Jia, and Minyi Guo
Neural Typing Entities in Chinese-Pedia . . . 385 Yongjian You, Shaohua Zhang, Jiong Lou, Xinsong Zhang,
and Weijia Jia
Knowledge Graph Embedding by Learning to Connect Entity with Relation . . . 400 Zichao Huang, Bo Li, and Jian Yin
StarMR: An Efficient Star-Decomposition Based Query Processor for
SPARQL Basic Graph Patterns Using MapReduce . . . 415 Qiang Xu, Xin Wang, Jianxin Li, Ying Gan, Lele Chai, and Junhu Wang
PRSPR: An Adaptive Framework for Massive RDF Stream Reasoning . . . 440 Guozheng Rao, Bo Zhao, Xiaowang Zhang, Zhiyong Feng,
and Guohui Xiao Demo Papers
TSRS: Trip Service Recommended System Based on Summarized
Co-location Patterns . . . 451 Peizhong Yang, Tao Zhang, and Lizhen Wang
DFCPM: A Dominant Feature Co-location Pattern Miner . . . 456 Yuan Fang, Lizhen Wang, Teng Hu, and Xiaoxuan Wang
CUTE: Querying Knowledge Graphs by Tabular Examples. . . 461 Zichen Wang, Tian Li, Yingxia Shao, and Bin Cui
ALTAS: An Intelligent Text Analysis System Based on Knowledge Graphs . . . 466 Xiaoli Wang, Chuchu Gao, Jiangjiang Cao, Kunhui Lin, Wenyuan Du,
and Zixiang Yang
SPARQLVis: An Interactive Visualization Tool for Knowledge Graphs . . . 471 Chaozhou Yang, Xin Wang, Qiang Xu, and Weixi Li
PBR: A Personalized Book Resource Recommendation System . . . 475 Yajie Zhu, Feng Xiong, Qing Xie, Lin Li, and Yongjian Liu
with Complex Wild-Cards Queries
on Encrypted Database
He Chen1, Xiuxia Tian2(B), and Cheqing Jin1 1
School of Data Science and Engineering, East China Normal University, Shanghai, China
watch [email protected],[email protected] 2
College of Computer Science and Technology, Shanghai University of Electric Power, Shanghai, China
Abstract. Achieving fuzzy searching encryption (FSE) can greatly enrich the basic function over cipher-texts, especially on encrypted database (like CryptDB). However, most proposed schemes base on cen-tralized inverted indexes which cannot handle complicated queries with wild-cards. In this paper, we present a well-designed FSE schema through Locality-Sensitive-Hashing and Bloom-Filter algorithms to generate two types of auxiliary columns respectively. Furthermore, an adaptive rewrit-ing method is described to satisfy queries with wild-cards, such as percent and underscore. Besides, security enhanced improvements are provided to avoid extra messages leakage. The extensive experiments show effec-tiveness and feasibility of our work.
Keywords: Fuzzy searching encryption
·
Wild-cards searching CryptDB1
Introduction
Cloud database is a prevalent paradigm for data outsourcing. In considera-tion of data security and commercial privacy, both individuals and enterprises prefer outsourcing them in encrypted form. CryptDB [21] is a typical out-sourced encrypted database (OEDB) which supports executing SQL statements on cipher-texts. Its transparency essentially relies on the design of splitting attri-butions and rewriting queries on proxy middle-ware. Under this proxy-based encrypted framework, several auxiliary columns are extended with different encryptions and query semantics are preserved through modifying or appending SQL statements.
Supported by the National Key Research and Development Program of China (No. 2016YFB1000905), NSFC (Nos. 61772327, 61532021, U1501252, U1401256 and 61402180), Project of Shanghai Science and Technology Committee Grant (No. 15110500700).
c
To enrich basic functions on cipher-texts, searchable symmetric encryp-tion (SSE) is proposed for keyword searching with encrypted inverted indexes [4,13,22,24], and then dynamic SSE (DSSE) achieves alterations on various cen-tralized indexes to enhance applicability [2,11,12,14]. Besides, the studies about exact searching with boolean expressions are extended in this field to increase accuracy [3,10]. Furthermore, the researches of similar searching among docu-ments or words are widely discussed through introducing locality sensitive hash-ing algorithms [1,7–9,15,18,19,23,25–27]. However, these proposed schemes are not applicable to OEDB scenario because of the centralized index design and cannot handle complex fuzzy searching with wild-cards.
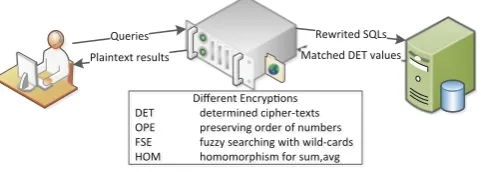
Matched DET values
Fig. 1.The client-proxy-database framework synthesizes various encryptions together, such as the determined encryption (DET) preserves symmetric character for en/decryption, the order-preserving encryption (OPE) persists order among numeric values, the fuzzy searching encryption (FSE) handles queries on text, and the homo-morphic encryption (HOM) achieves aggregation computing.
Therefore, it is meaningful and necessary to achieve fuzzy searching encryp-tion over outsourced encrypted database. As shown in Fig.1, the specific frame-work accomplishes transparency and homomorphism by rewriting SQL state-ments on auxiliary columns. In this paper, we focus on resolving the functionality of ‘like’ queries with wild-cards (‘%’ and ‘ ’). Our contributions are summarized as follows:
– We propose a fuzzy searching encryption with complex wild-cards queries on encrypted database which extends extra functionality for the client-proxy-database framework like CryptDB.
– We present an adaptive rewriting method to handle different query cases on two types of auxiliary columns. The formal column works for similar search-ing by locality sensitive hashsearch-ing and the latter multiple columns work for maximum substring matching by designed bloom-filter vectors.
– We evaluate the efficiency, correctness rate and space overhead by adjusting the parameters in auxiliary columns. Besides, security enhanced improve-ments are provided to avoid extra messages leakage. The extensive experi-ments also indicate the effectiveness and feasibility of our work.
2
Related Work
In recent years, many proposed schemes have been attempting to achieve fuzzy searching encryption with helps of similarity [1,8,9,15,23,25–27]. The most of them introduce locality sensitive hashing (LSH) to map similar items together and bloom-filter to change the method of measuring. Wang et al.’s work [23] was one of the first works to present fuzzy searching. They encode every words in each file into same large bloom-filter space as a vector and evaluate similarity of target queries by computing the inner product for top-k results among vectors. Kuzu et al.’s work [15] generates similar feature vectors by embedding keyword strings into the Euclidean space which approximately preserves the relative edit distance. Fu et al.’s work [8] proposes an efficient multi-keyword fuzzy ranked search schema which is suitable for common spelling mistakes. It benefits from counting uni-gram among keywords and transvection sorting to obtain ranked candidates. Wang et al.’s work [26] generates a high-dimensional feature vector by LSH to support large-scale similarity search over encrypted feature-rich mul-timedia data. It stores encrypted inverted file identifier vectors as indexes while mapping similar objects into same or neighbor keyword-buckets by LSH based on Euclidean distance. In contrast to sparse vectors from bi-gram mapping, their work eliminates the sparsity and promotes the correctness as well. However, there are many problems in existing schemes including the insufficient metric conversion, the coarse-grained similarity comparison, the extreme dependency of assistant programs and the neglect about wild-card queries.
Meanwhile, the proposal of CryptDB [21] has attracted world-wide attention because they provide a practical way to combine various attribution-preserving encryptions over encrypted database. Then many analogous researches [5,16,17, 20] study its security definitions, feasible frameworks, extensible functions and optimizations. Chen et al. [5] consider these encrypted database as a client-proxy-database framework and presents symmetric column for en/decryption and aux-iliary columns for supporting executions. This framework helps execute SQL statements directly over cipher-texts through appending auxiliary columns with different encryptions. It also benefits from the transparency of en/decryption processes and combines various functional encryptions together. Therefore, it is meaningful to achieve efficient fuzzy searching with complex wild-cards queries on proxy-based encrypted database.
3
Preliminaries
3.1 Basic Concepts
Table 1.Various n-gram forms in our scheme
N-gram methods Value Description
String secure The original keyword
Counting uni-gram [8] s1, e1, c1, u1, r1, e2 Preserve repetitions Bi-gram #s, se, ec, cu, ur, re, e# Preserve adjacent letters Tri-gram sec, ecu, cur, ure Preserve triple adjacent letters Prefix and suffix @s, e@ Beginning and ending of sentence
In general, bi-gram is the most common converting method which maintains the connotative information between adjacent letters. However, each change of single letter will double influence bi-gram results and cause reduction of matching probability. The counting uni-gram preserves repetitions and benefits on letter-confused comparison cases, such as misspelling of a letter, missing or adding a letter and reversing the order of two letters. However, it reduces the degree of constraint along with increasing false positives. The tri-gram is a more strict method which only suits the specific scene like existing judgment. The prefix and suffix preserve the beginning and ending of data to meet edge-searching.
B. Bloom-Filter. The Bloom-filter is a compact structure reflecting whether specific elements exist in prepared union. In our schema, we introduce this algo-rithm to judge existence about maximized substring fragments and represent the sparse vector through decimal numbers in separated columns. Given words fragments setS ={e1, . . . , e#e}, a bloom-filter maps each elementeiinto a same l-bit sparse array bykindependent hash functions. Positive answer is provided only if all bits of matched positions are true.
C. Locality Sensitive Hashing. The locality sensitive hashing (LSH) algo-rithm helps reduce the dimension of high-dimensional data. In our schema, we introduce this algorithm to map similar items together with high probability. Besides, the specific manifestation of the algorithm is different under different measurement standards. However, there is no available method for levenshtein distance among text. So that a common practice is converting texts to fragment sets with n-gram methods.
Definition 1 (Locality sensitive hashing). Given a distance metric function D, a hash function family H = {hi : {0,1}d → {0,1}t|i = 1, . . . , M} is (r1, r2, p1, p2)-sensitive if for anys, t∈ {0,1}d and any
h∈ Hsatisfies: ifD(s, t)≤r1 thenP r[hi(p) =hi(q)]≥p1;
ifD(s, t)≥r2 thenP r[hi(p) =hi(q)]≤p2.
3.2 Functional Model
Let D = (d1, . . . , d#D) be sensitive row data (each line contains some words respectively, as di = |di|j=1wj) andi C = {cdet, clsh, cbf} be the corresponding cipher-texts. Two types of indexing methods are enforced: the first one achieves similar searching among words through dimension reductions with locality sensi-tive hashing (letmbe the dimension of LSH,nbe the tolerance andLrepresents its conversion); the last one achieves maximum substring matching through bit operation with bloom-filter (letlbe the length of vector space,kbe the amount of hashing functions andB represents its conversion). We consider LSH tokens set Ti = Lnm(|di|
j=1Gss(w i
j)) be the elementary ciphers for clsh, and BF vector Vi =Bk
l( |di|
j=1Gmsm(wji)) be the ciphers of whole continuous sequence forcbf. Besides, G represents n-gram methods for similar searching or maximum sub-string matching.
Definition 2 (Fuzzy searching encryption). A proxy-based encrypted database implements fully fuzzy searching with rewriting SQL statements through the fol-lowing polynomial-time algorithms:
(Kdet, Ln
m, Blk) ← KeyGen(λ, m, n, l, k): Given security parameter λ, dimensionmof LSH and tolerancen,vector lengthlof BF and hash amountk, it outputs a primary key Kdet for determining encryption, Ln
m for LSH,Bkl for BF. The security parameter λ helps initialize the hash functions and random-ization processes.
l,the plain-textdi is encrypted to determined cipher-texts cdet, ciphersTi for similar searching and ciphersVi for maximum substring matching respectively.
(cdet||Ti||Vi)←Trapdoor(expression): Given the query expression analyzed from ‘like’ clause, the adaptive rewriting method help generate representing ele-ments out of different considerations with wild-cards condition. The determined cipher-texts would return in next step over encrypted database and Kdet helps decryption.
As shown in definition of fuzzy searching encryption, we mainly emphasize transformation processes like building, indexing and executing. There exist other functional methods such as updating, deleting to achieve dynamically of our schema. It is applicable for outsourced encrypted database through rewriting SQL statements including ‘create’, ‘insert’, ‘select’ and so on.
3.3 Security Notions
4
Proposed Fuzzy Searching Encryption
4.1 Two Types of Functional Auxiliary Columns
The multiple-attributions-splitting design in cloud database synthesizes various encryptions to preserve query semantics. As shown in Table2, two types of aux-iliary columns (c-LSH and c-BF) are appended on cloud database along with a symmetrical determined column (DET).
Table 2.Storage pattern of multiple functional columns in database cdet clsh(m = 4, wid = 2) cbf(1) . . . cbf( 0x1234 (“I love apple”) 19030024, 01000409, 00020412 1077036627 . . . 1957741388 0x3456 (“lave banana”) 01000409, 00020303 1079642851 . . . 625017556 0x5678 (“I love coconut”) 19030024, 01000409, 06000700 1626500087 . . . 1687169793
This schema aims at handling queries with wild-cards on cipher-texts. So that several appended columns could store different functional ciphers with various encryptions, such as determination (DET) of data for equality, locality sensitive hashing (LSH) of words fragments for similar searching, bloom-filter (BF) among lines for maximum substring matching.
A. c-LSH. The c-LSH column, which stores the locality sensitive hashing values of each sentence, represents a message digest after dimensionality reduction. It
IPA: inverted position array(lave)={1,2,4,7,10,11,12,14,17,20}
helps map similar items together with probability which equals to the jaccard distance between their inverted position arrays (IPA for short).
During transforming process, n-gram methods are utilized (such as bi-gram and counting uni-gram) for dividing texts into fragments and finally to sparse vec-tors (IPA for short). As shown in Fig.2, the transforming process maps every rows to separate signature collections by steps. This process changes measurement from levenshtein distance on texts to jaccard similarity on IPAs. So that the particular minhash algorithm could reduce the dimensions of numeric features for each sub-ject (words). Finally, each word is converted to a linked sequence as a token and the c-LSH stores tokens set with comma to represent data of whole line.
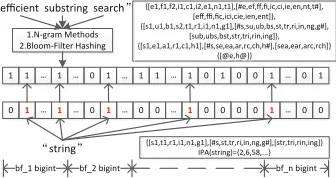
B. c-BF. The multiple auxiliary c-BF columns, which represents macroscopic bloom-filter spaces for each row, are implemented on several ‘bigint’ (32-bit) columns. The database will return the DET ciphers where all c-BF columns cover the target sequences through native bit arithmetic operation ‘&’. Briefly, these columns are proposed for maximum substring matching which is a supplement to the c-LSH column above.
bf_1 bigint bf_2 bigint bf_n bigint {[e1,f1,f2,i1,c1,i2,e1,n1,t1],[#e,ef,ff,fi,ic,ci,ie,en,nt,t#],
efficient substring search
{[s1,t1,r1,i1,n1,g1],[#s,st,tr,ri,in,ng,g#],[str,tri,rin,ing]} IPA(string)={2,6,58,...}
Fig. 3.The maximum substring matching over c-BF vectors which are stored in multi-ple ‘bigint’ auxiliary columns separately. After mapping fragments from whole sentence to vectors, queries execute with bit matching.
During mapping process, we respectively generate vectors for each row through bloom-filter hashing with following n-gram methods: bi-gram, tri-gram, prefix and suffix. These auxiliary columns are designed for substring matching so that the implicit information need be maximally persisted from origin strings. Through matching fragments between target bit vector and stored separated ‘bigint’ numbers, we could obtain all matched rows as shown in Fig.3.
4.2 Adaptive Rewriting Method over Queries with Wild-Cards
In SQL, wild-card characters are used in ‘like’ expression: the percent sign ‘%’ matches zero or more characters and the underscore ‘ ’ matches a single charac-ter. Usually the former symbol is a coarse-grained comparable delimiter and the latter could be tolerated by locality sensitive hashing in slightly different cases. So we construct an adaptive rewriting method over queries with wild-cards as shown in Fig.4.
We consider three basic cases according to the number of percent signs to meet indivisible string fragments. Furthermore in every basic case, we also divide three sub-cases according to the number of underscore to benefit from different auxiliary columns. Besides, each query text is considered as whole word and substring while experiment exhibits the optimal selection.
Fig. 4.Adaptive rewriting method over queries with wild-cards. We consider percent sign as a coarse-grained separator and few underscore could be tolerated according to similarity.
Firstly, the double percent signs case means that user attempts finding rows which contains the given string. Because the LSH function could tolerate small differences naturally, the sub-case with no underscore could accomplish similar searching among whole words. We achieve the one underscore sub-case with part matching method. This clever trick helps adjust fineness of similar searching as shown in Fig.5. The multiple underscores sub-case is achieved by maximum substring matching on c-BF columns with bloom-filter.
Thirdly, in the last no percent sign case, the user might already obtain most of target information and attempt to match specific patterns with underscore. Besides no underscore sub-case could be treated as determining equality oper-ation, the maximum substring matching on c-BF column could meet the rest sub-cases’ requirements.
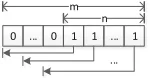
Additionally, the tolerance parameter n is proposed as a flexible handler under the dimension m of locality sensitive hashing auxiliary column. Briefly, every features of word are set as fixed-length numbers which is filled by zero in basic scheme. As a linked string with all m features, the token could be con-verted to different variants where some feature parts replacing with underscores. We joint every possible cases together for database searching with keyword ‘or’ through a called bubble function as shown in Fig.5.
... 0 ... 0 1 1 ... 1
m n
Fig. 5. The part matching method represents the adjustable fineness in c-LSH col-umn with the tolerance parameter n and the LSH dimension m. For instance, let m = 4, n = 3 and the target feature set be{1,2,3,4}, therefore the candidate set is {234,1 34,12 4,123}by this method.
The adaptive rewriting method helps generate trapdoor queries to meet the wild-cards fuzzy searching encryption in database through similar searching on c-LSH column and maximum substring matching on c-BF columns.
4.3 LSH-Based Security Improvements
The security of our schema relies on three parts. The symmetric cryptogra-phy algorithm guarantees the security on determining column and the divided bloom-filter vectors are presented by unidentifiable hashing ciphers. However, the content in c-LSH column might leak some extra information such as sizes and sequences of plain-texts. We present three improvements to enhance security and an integrated algorithm as followed.
A. Linking Features Without Padding
In basic scheme, we pad each feature with zero by the upper limit wid which benefits selecting process. To enhance security, we cancel the zero padding before linking features to a token. Meanwhile, the part matching method is also changed to an analogous bi-gram form. For instance, a secure enhanced part matching method isselect m det where m lsh like ‘%ab%’ or m lsh like ‘%bc%’ wherea,b,c are multiple features of a word. We discuss the validity with experiments. B. Modifying Sequences of Tokens
to malicious attacker. To overcome this leakage, we modify the sequences ran-domly by hashing permutations. Additionally, we implement the permutation function with P : y = a∗x+b modc where a is relatively-prime to c. This improvement protects the relation between invisible words and specific tokens. Since the matching only demands on existing rather than order, so this sequence modification helps for security protection.
C. Appending Confusing Tokens
The tokens sets in row leak the size of words. Appending tokens is a practical way for security, but what kind of token content should be added is the target of our discussion. The first way is appending repeated tokens from itself. It is simple and effective, but it only improves limited security. The second way is appending a little random tokens. Because of sparsity and randomization, few random tokens might not change the matching results. The third way is append-ing tokens combined from separated features among this tokens set. This way also influences the matching precision and increases proportion of false positive. Actually, these ways help greatly enhance security despite of disturbances. D. Integrated Security Enhanced Algorithm
We present an integrated algorithm for security enhancement which combines all above implementations. As shown in Algorithm1, this algorithm transforms the tokens set in each row to an security enhanced one. It helps prevent information leakage from c-LSH column.
Algorithm 1. Security Enhanced Improvements
Input:tokenm[#wordi] which represents them-dimensional tokens set of line i,widbe width of feature with zero padding,amountbe the lower bound for appending tokens
Output: an optimal security enhanced set e token[amount]
1 Lett represent token and eachtcan be split intomfeatures bywid; 2 Generate a permutation function withF :y=a∗x+b modc where
c=amountand (a, c) = 1;
3 Letc= 0 be the count for permutation; 4 foreacht intokenm[#wordi] do 5 Generate a temporary stringet; 6 forint j=0; j<m; j++do
7 Remove the zero prefix oft.substr(j∗wid,(j+ 1)∗wid); 8 Link it toet;
9 e token[F(c+ +)]=et; 10 whilec < amountdo
11 Generate a temporary stringet;forint k=0; k<m; k++do 12 Get a featuretokenm[random()].substr(k∗wid,(k+ 1)∗wid); 13 Remove the zero prefix and link it toet;
5
Performance Evaluation
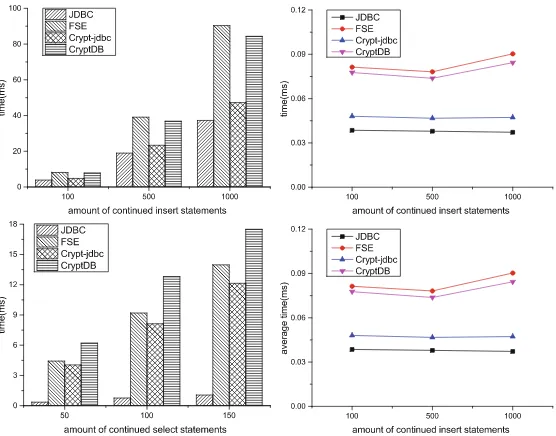
In this section, we evaluate the performance of our work. Firstly, we discuss the effect of different n-gram methods about matching accuracy in c-LSH col-umn. Secondly, we discuss the effect of bloom-filter length on collision degree and space usage of maximum substring matching. Thirdly, we discuss perfor-mance of adaptive rewriting method. Finally, we compare execution efficiency and space occupancy among efficient proposed schemes. The proposed scheme is implemented in Core i5-4460 3.20 GHz PC with 16 GB memory, and the used datasets include 2000 TOEFL words, the leaked user data of CSDN and the reuters news.
Manifestations of Different N-gram Methods on c-LSH Column. Uti-lizing bi-gram and counting uni-gram, we achieve similar searching on c-LSH column by introducing minhash algorithm based on the jaccard distance of frag-ments set. Intuitively, every change of character would greatly influence the cor-responding fragments union over bi-gram method. So we introduce the counting uni-gram method to balance this excessiveness relativity. In this experiment, we evaluate the performance of these two n-gram methods and the combined one respectively.
The dataset we used is a 2000 TOEFL words set and we construct three variants of them to reveal the efficiency about LSH-based similar searching under different N-gram methods. The ways getting variants include append-ing a letter in the middle or in one side for every words, such as ‘word’ into ‘words’,‘wosrd’,‘sword’. We calculate the average matched rows to reflect the searching results.
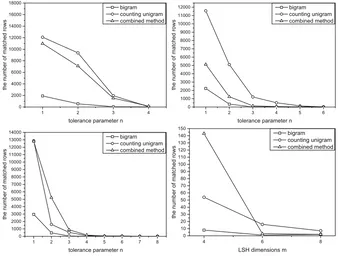
As shown in Fig.6, we choosem= 4,6,8 to reveal matched numbers through part matching method withn. And the accuracy rate has a big promotion when n is larger than half of m. Besides, the combined method performs well when m≥6. It is reflected about the variation trend of accuracy that the amount of false positive reduces while the correct items remain unchanged.
The Bloom-Filter Length on c-BF Columns. In second experiment, we valuate collision accuracy and space occupancy under impacts of bloom-filter length and hashing function amount on c-BF columns when executing maximum substring matching. In detail, we attempt to find out an appropriate setting about the number of hashing function and the vector length of our bloom-filter structures.
Fig. 6. The matching size under the tolerance parameter n and the LSH dimension m over variants of TOEFL words set. The first three graphs show the performance of different n-gram methods about part-matching respectively. The last graph shows the LSH dimension only complete-matching whenm=n.
Fig. 7. The experiments show performance of maximum substring searching under different bloom-filter lengthland different hashing amountk. We utilize fifty thousand rows of leaked CSDN account data and set several degrees of sparsity about bloom-filter vector while each row contains 50 characters. The left graph shows matching sizes of substring ‘163.com’ onl
32
Fig. 8. The experiment shows the performance of adaptive rewriting method under different combinations, and reveals the most qualified modes for each fuzzy searching cases. Some expressions are used, such as ‘%america%’, ‘%am rica%’, ‘%am ri a%’.
Because the bloom-filter lengthlcorresponds to the amount of c-BF columns, this experiment discuss relations between matching accuracy and space occu-pancy under different amount of bloom-filter hashing functions. As shown in Fig.7, the amount of matching size drops rapidly in the first place and then gets stable when sparsity is close to one-sixth.
The Performance of Adaptive Rewriting Method. This experiment aims at verifying effectiveness of the adaptive rewriting method. After auxiliary columns storing values as indexes, the ‘like’ clauses with wild-cards are analyzed by an adaptive rewriting method and rewritten to trapdoors. In this experiment, we consider the content of expression as a word or substring for comparison, and execute different types of queries with basic and security enhanced schemes respectively.
The dataset we used is Reuters-21578 news of 1987 [28]. In this experiment, we mainly discuss the double ‘%’ cases because the other single ‘%’ and no ‘%’ cases carry out analogous steps. The only difference is that these cases addition-ally consider the prefix and suffix.
As shown in Fig.8, we compare the matched size under different combi-nations. We also execute the origin SQL statements on extra stored plain-text column for contrast. It helps find the best combination modes under various wild-cards cases. We accomplish this experiment with the sparsity of c-BF columns being one-sixth and the dimension of c-LSH column being six. The graph shows that ‘W and S’ is fit for double ‘%’ no ‘ ’ and double ‘%’ one ‘ ’ cases while ‘S’ is fit for double ‘%’ few ‘ ’ case. Besides, we discuss the performance of LSH-based security enhanced method and the graph confirms its feasibility.
Fig. 9.This experiment show the execution efficiency among proposed schemes.
As shown in Fig.9, our schema verifies this point and performs well comparing to normal JDBC, Crypt-jdbc and CryptDB.
6
Conclusion
This paper investigates the problem about fuzzy searching encryption with com-plex wild-cards queries on proxy-based encrypted database, then gives a practi-cal schema with two types of auxiliary columns and rewriting SQL statements. Besides, security enhanced implementations and extensive experiments show the effectiveness. In future, the serialization and compression of functional cipher-texts would be studied to reduce space overhead.
References
1. Boldyreva, A., Chenette, N.: Efficient fuzzy search on encrypted data. In: Cid, C., Rechberger, C. (eds.) FSE 2014. LNCS, vol. 8540, pp. 613–633. Springer, Heidel-berg (2015).https://doi.org/10.1007/978-3-662-46706-0 31
4. Chase, M., Kamara, S.: Structured encryption and controlled disclosure. In: Abe, M. (ed.) ASIACRYPT 2010. LNCS, vol. 6477, pp. 577–594. Springer, Heidelberg (2010).https://doi.org/10.1007/978-3-642-17373-8 33
5. Chen, H., Tian, X., Yuan, P., Jin, C.: Crypt-JDBC model: optimization of onion encryption algorithm. J. Front. Comput. Sci. Technol.11(8), 1246–1257 (2017) 6. Curtmola, R., Garay, J., Kamara, S., Ostrovsky, R.: Searchable symmetric
encryp-tion: improved definitions and efficient constructions. In: ACM Conference on Com-puter and Communications Security, pp. 79–88 (2006)
7. Fan, K., Yin, J., Wang, J., Li, H., Yang, Y.: Multi-keyword fuzzy and sortable ciphertext retrieval scheme for big data. In: 2017 IEEE Global Communications Conference, GLOBECOM 2017, pp. 1–6. IEEE (2017)
8. Fu, Z., Wu, X., Guan, C., Sun, X., Ren, K.: Toward efficient multi-keyword fuzzy search over encrypted outsourced data with accuracy improvement. IEEE Trans. Inf. Forensics Secur.11(12), 2706–2716 (2017)
9. Hahn, F., Kerschbaum, F.: Searchable encryption with secure and efficient updates. In: ACM SIGSAC Conference on Computer and Communications Security, pp. 310–320 (2014)
10. Jho, N.S., Chang, K.Y., Hong, D., Seo, C.: Symmetric searchable encryption with efficient range query using multi-layered linked chains. J. Supercomput. 72(11), 1–14 (2016)
11. Kamara, S., Papamanthou, C.: Parallel and dynamic searchable symmetric encryp-tion. In: Sadeghi, A.-R. (ed.) FC 2013. LNCS, vol. 7859, pp. 258–274. Springer, Heidelberg (2013).https://doi.org/10.1007/978-3-642-39884-1 22
12. Kamara, S., Papamanthou, C., Roeder, T.: Dynamic searchable symmetric encryp-tion. In: ACM Conference on Computer and Communications Security, pp. 965–976 (2012)
13. Kurosawa, K., Ohtaki, Y.: UC-secure searchable symmetric encryption. In: Keromytis, A.D. (ed.) FC 2012. LNCS, vol. 7397, pp. 285–298. Springer, Heidelberg (2012).https://doi.org/10.1007/978-3-642-32946-3 21
14. Kurosawa, K., Sasaki, K., Ohta, K., Yoneyama, K.: UC-secure dynamic searchable symmetric encryption scheme. In: Ogawa, K., Yoshioka, K. (eds.) IWSEC 2016. LNCS, vol. 9836, pp. 73–90. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-44524-3 5
15. Kuzu, M., Islam, M.S., Kantarcioglu, M.: Efficient similarity search over encrypted data. In: IEEE International Conference on Data Engineering, pp. 1156–1167 (2012)
16. Lesani, M.: MrCrypt: static analysis for secure cloud computations. ACM SIG-PLAN Not.48(10), 271–286 (2013)
17. Li, J., Liu, Z., Chen, X., Xhafa, F., Tan, X., Wong, D.S.: L-EncDB: a lightweight framework for privacy-preserving data queries in cloud computing. Knowl.-Based Syst.79, 18–26 (2015)
18. Liu, Z., Li, J., Li, J., Jia, C., Yang, J., Yuan, K.: SQL-based fuzzy query mechanism over encrypted database. Int. J. Data Wareh. Min. (IJDWM)10(4), 71–87 (2014) 19. Liu, Z., Ma, H., Li, J., Jia, C., Li, J., Yuan, K.: Secure storage and fuzzy query over encrypted databases. In: Lopez, J., Huang, X., Sandhu, R. (eds.) NSS 2013. LNCS, vol. 7873, pp. 439–450. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-38631-2 32
21. Popa, R.A., Redfield, C.M.S., Zeldovich, N., Balakrishnan, H.: CryptDB: pro-tecting confidentiality with encrypted query processing. In: ACM Symposium on Operating Systems Principles, SOSP 2011, Cascais, Portugal, October, pp. 85–100 (2011)
22. Song, D.X., Wagner, D., Perrig, A.: Practical techniques for searches on encrypted data. In: IEEE Symposium on Security and Privacy, p. 44 (2000)
23. Wang, B., Yu, S., Lou, W., Hou, Y.T.: Privacy-preserving multi-keyword fuzzy search over encrypted data in the cloud. In: 2014 Proceedings of IEEE INFOCOM, pp. 2112–2120 (2014)
24. Wang, C., Cao, N., Li, J., Ren, K.: Secure ranked keyword search over encrypted cloud data. In: IEEE International Conference on Distributed Computing Systems, pp. 253–262 (2010)
25. Wang, J., Ma, H., Tang, Q., Li, J., Zhu, H., Ma, S., Chen, X.: Efficient verifiable fuzzy keyword search over encrypted data in cloud computing. Comput. Sci. Inf. Syst.10(2), 667–684 (2013)
26. Wang, Q., He, M., Du, M., Chow, S.S.M., Lai, R.W.F., Zou, Q.: Searchable encryp-tion over feature-rich data. IEEE Trans. Dependable Secur. Comput. PP(99), 1 (2016)
27. Wei, X., Zhang, H.: Verifiable multi-keyword fuzzy search over encrypted data in the cloud. In: International Conference on Advanced Materials and Information Technology Processing (2016)
Travel-Time-First Task Assignment
in Spatial Crowdsourcing
Jian Li1, An Liu1(B), Weiqi Wang1, Zhixu Li1, Guanfeng Liu1, Lei Zhao1,
and Kai Zheng2
1 School of Computer Science and Technology, Soochow University, Suzhou, China [email protected]
2 University of Electronic Science and Technology of China, Chengdu, China
Abstract. With the ubiquity of mobile devices and wireless networks, spatial crowdsourcing (SC) has gained considerable popularity and importance as a new tool of problem-solving. It enables complex tasks at specific locations to be performed by a crowd of nearby workers. In this paper, we study the privacy-preserving travel-time-first task assign-ment problem where tasks are assigned to workers who can arrive at the required locations first and no private information are revealed to unau-thorized parties. Compared with existing work on privacy-preserving task assignment, this problem is novel as tasks are allocated accord-ing to travel time rather than travel distance. Moreover, it is challengaccord-ing as secure computation of travel time requires secure division which is still an open problem nowadays. Observing that current solutions for secure division do not scale well, we propose an efficient algorithm to securely calculate the least common multiple (LCM) of every workers speed, based on which expensive division operation on ciphertexts can be avoided. We formally prove that our protocol is secure against semi-honest adversaries. Through extensive experiments over real datasets, we demonstrate the efficiency and effectiveness of our proposed protocol.
Keywords: Spatial crowdsourcing
·
Privacy-preserving Task assignment1
Introduction
Thanks to the ubiquitous wireless networks and powerful mobile devices, spatial crowdsourcing has gained considerable popularity and importance as a new tool of problem-solving. It can be applied to simple tasks such as photo-taking where people act as sensors, or to complex tasks such as handyman service where people work as intelligent processing units. As an emerging crowdsourcing mode, spatial crowdsourcing differs from other crowdsourcing modes in that people in spatial crowdsourcing, also known as workers, must physically move to certain places to perform those spatial tasks. Recently years have witnessed an upsurge of interest
c
in spatial crowdsourcing applications in daily life, ranging from local search-and-discovery (e.g., Foursquare) to home repair and refresh (e.g., TaskRabbit).
A typical workflow of spatial crowdsourcing consists of four steps: task/worker registration, task assignment, answer aggregation, and quality con-trol [1]. Among them, task assignment focuses on allocating a set of tasks to a set of workers according to a set of constraints such as location, time, and budget. Typically finding an optimal assignment subject to multiple constraints is NP-hard, which calls for efficient yet effective algorithms. Based on specific optimization goals, a variety of approaches have been proposed, for example, to maximize the total number of completed tasks [2], to maximize the number of tasks performed by a single worker [3] and to maximize the reliability-and-diversity score of assignments [4].
The problem of task assignment becomes even tougher when privacy issues are taken into account. It is not hard to see that the data used for decision making in task assignment is usually private and thus need to be kept secret due to the lack of trust among workers, task requesters, and the spatial crowd-sourcing server. To achieve privacy, these private data should be protected by for example encryption using mature cryptographical algorithms or perturbation using emerging privacy-preserving techniques. However, the noise introduced by these mechanisms will decrease significantly the utility of the data and sometimes even will make the data useless. It is therefore more challenging to deal with task assignment with the extra privacy constraint.
Fig. 1.Spatial crowdsourcing where travel time is more important than travel distance
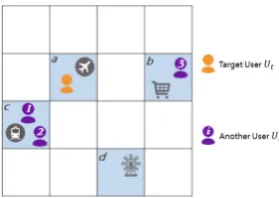
named Alice and Bob are available when the task is issued, and their distances to the user are 500 m and 1,000 m, respectively. Using the aforementioned strat-egy, the spatial crowdsourcing server will assign this task to Alice as she is nearer to the user. As shown in the figure, however, Alice is in a traffic jam. On the other hand, Bob is in a smooth traffic and he can arrive at the users location before Alice. This simple example motivates us to consider, travel-time-first, a more effective strategy when allocating tasks to workers in practice.
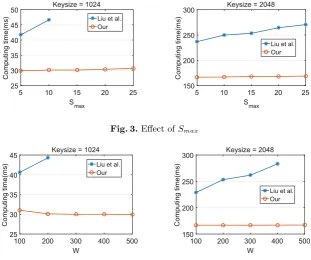
In this paper, we propose a privacy-preserving task assignment protocol for spatial crowdsourcing platforms taking travel-time-first strategy, that is, workers who can first arrive at the location of a given task have priority over others. While it is more effective than travel-distance-first in practice, travel-time-first makes privacy-preserving task assignment more challenging due to the required division operation involved in the computation of travel time. For every user, his/her location and speed are both private and should be protected. How to perform division efficiently and accurately on encrypted or perturbed data is still an open problem. In [9], the authors propose a protocol for secure division based on ElGamal cryptosystem. However, this protocol does not scale well and cannot be applied to large spatial crowdsourcing system for the key length should be set large enough to avoid computation overflow and this will introduce prohibitive computation cost. To overcome this weakness, we transform the secure division problem into a secure least common multiple (LCM) problem. We propose an efficient way to calculate the LCM securely. Through extensive experiments, we demonstrate the feasibility and efficiency of our solution.
The remainder of this paper is organized as follows: Sect.2 discusses related work. Problem definition and background knowledge are presented in Sect.3. Section4introduces our approach in details. Section5analyzes the security and complexity of our approach theoretically. Section6 evaluates our approach on real datasets. Section7concludes the paper.
2
Related Work
in reality. Our work focuses on privacy-preserving during an execution of task assignment.
In recent years, the public concern over privacy has stimulated lots of research efforts in privacy-preserving. A location based query solution is proposed by Paulet et al. [15] that employs two protocols that enables a user to privately determine and acquire location data. In [16], Liu et al. propose an efficient app-roach to protecting mutual privacy in location-based queries by performing two rounds of oblivious transfer (OT) extension on two small key sets. A solution built on the Paillier public-key cryptosystem is presented by Yi et al. [17] for mutual privacy-preserving kNN query with fixed k and is extended in [18] where k is dynamic. Unfortunately, these solutions where workers location are private data of the SC platform are not suitable for our framework for workers loca-tion should be known to the SC platform in a secret way. Also, in [19], Sun et al. focus on the privacy-preserving task assignment in SC by presenting an approach where location privacy of workers can be protected in a k-annoymity manner. In [5], To et al. propose a framework for protecting location privacy of workers participating in SC tasks without protecting task location. Liu et al. [20] propose an efficient solution to securely compute the similarity between two encrypted trajectories without revealing nothing about the trajectories. How-ever, their protocols also cannot be applied to our framework for they have too heavy computation cost to solve large task assignment problems.
3
Problem and Preliminary
In this section, we first present some definitions used in our work and then briefly introduce some cryptosystems based on which our protocol is built.
3.1 Problem Definitions
Definition 1 (Spatial Task).A spatial task, denoted as T, is a task to be per-formed lT.
Definition 2 (Workers). Let W ={w1,· · ·, wn} be a set of n workers. Each
worker w has an ID idw, a locationlw, a constant speedsw, and an acceptance rateARwwhich is the probability that he/she accepts a task assigned to him/her.
As mentioned in the introduction, we mainly consider travel-time-first, a new task assignment strategy in privacy-preserving spatial crowdsourcing. Ideally, we only need to find a workerw∈W who can first arrive atlT and then assignT to w. This works if the worker is certain to accept the assigned task, but sometimes it is not. Therefore we consider a more general case where every worker w has an acceptance ratio denoted as ARw for an assignment, and we need to ensure the probability that a task T is accepted by at least one worker is larger than a given thresholdαT. In this case, we need to find a set of workersU ⊂W rather than a single worker. It is easy to see that the probability thatT is accepted by at least one worker inU isαU = 1−
Definition 3 (Travel-time-first Task Assignment Problem). Given a set of workers W, a task T and its acceptance thresholdαT, the travel-time-first task assignment assigns task T to a set of workersU ⊂W such that:
d(li, lT) si ≤
d(lj, lT)
sj and αT ≤αU (1)
for∀i∈U and∀j ∈W\U.
Privacy-preserving means all the private data should be hidden from unau-thorized parties in the procedure of task assignment. To accurately define the ability of unauthorized parties, we adopt a typical adversary model, i.e., the semi-honest model [21]. Specifically, all parties in this model are assumed to be semi-honest, that is, they follow a given protocol exactly as specified, but may try to learn as much as possible about other parties private input from what they see during the protocols execution. This can be formally defined by the real-ideal paradigm as follows: for all adversaries, there exists a probabilistic polynomial-time simulator, so that the view of the adversary in the real world and the view of the simulator in the ideal world are computationally indistinguishable. Specifically, the security of a protocol Π is defined as follows:
Definition 4. Let pi(1 ≤ i ≤ n) be n parties involved in a protocol Π. For pi(1 ≤ i ≤n), its view, private input and extra knowledge it can infer during an execution ofPi are defined asVi,Xi andKi respectively. A protocolP ihas a strong privacy guarantee, that is, pi cannot learn any knowledge except the final output of pi, if these exists a probabilistic polynomial-time simulator Pi such that:
Pi(Xi,Π(X1,· · ·, Xn), Ki)X1,···,Xn≡Vi(X1· · ·, Xn)X1···,Xn (2)
and Ki =∅, where ≡ means computational indistinguishability. However, this strong guarantee cannot be achieved sometimes forKi=∅. IfKi=∅, Π is said to be privacy-preserving withKidisclosure againstpiin the sense that it reveals no more knowledge than Ki and the final output to pi.
Now we are ready to define the problem of privacy-preserving travel-time-first task assignment as follows:
Definition 5 (Privacy-preserving Travel-time-first Task Assignment Problem). Given a set of workers W, a taskT and its acceptance threshold αT, the travel-time-first task assignment assigns task T to a set of workersU ⊂W such that Eqs. (1) and (2) hold.
3.2 Cryptosystems
PRG can be implemented by using a one-way hash function denoted asGk. For Paillier, its encryption and decryption are denoted as Ep and Dp, respec-tively. For ElGamal, its encryption and decryption are denoted as Ee and De, respectively. The important properties of Paillier and ElGamal are listed as fol-lows:
Homomorphic Properties of Paillier:Given m1 andm2 are two messages,
we have:
Ep(m1)Ep(m2) =Ep(m1+m2). (3)
Ep(m)k=Ep(km). (4)
Commutative-Like Property of ElGamal:Given a messagem, we have:
Eha
e (Eehb(m)) =Eehb(Eeha(m)). (5)
4
Proposed Privacy-Preserving Framework
In this section, we will introduce our privacy-preserving framework in details and explain how to get LCM in a safe and secret way byAP encryption strategy.
4.1 Framework Overview
As Fig.2shows, our proposed framework consists of six stages, namely Initializa-tion, Distance, LCM, Time, Comparison and Verification respectively. Different colors mean different stages.
4.2 Detailed Framework
Next, every stage in details is described in this subsection.
Initialization Stage.Firstly, the KP generates a pair of keys for Paillier. Then the KP keeps the encryption key public and the decryption key private respec-tively because the computations of the SC platform and workers are based on encrypted data while the KP has to decrypt data to find the chosen worker. Besides, the KP generates a cyclic groupGfor ElGamal based on which the KP and all workers generate their own pair of keys and keep them secret.
Distance Stage.Given a spatial taskT, the SC platform encrypts task location lT(xT, yT) with the encryption key of Paillier by calculatingEp(x2T+y2T),Ep(xT) andEp(yT). Then these three ciphertexts are sent to all workers. Without hold-ing the decryption key of Paillier, every worker wi can calculate the encrypted square of the distance based on the Euclidean distance and the homomorphic properties shown in Eqs.3 and4as follows:
Ep(d2(lT, li)) =Ep(x2T+y2T)Ep(xT)−2xiEp(yT)−2yiEp(x2i +y2i) (6)
It should be noted that it also works when every worker encrypts location and the SC platform calculatesEp(d2(lT, li)). However, it will cost much more computing
resources for every worker can calculate in parallel. That is to say, our proposed method is good for reducing the computation cost of the SC platform.
LCM Stage. At first, we explain why we need to get the LCM of all worker’s speed. As defined in Definition3, our framework prefers the worker who has the shortest travel time. To this end, we have to face division operation on ciphertexts which is still an open problem nowadays during the computation of travel time. Though we cannot solve the problem of division operation, a transformation can be employed to avoid the division operation based on the following lemma:
Lemma 1. Let W ={w1,· · ·, wn} be a set ofn workers,D={d1,· · ·, dn} be
the distance between task location and the worker wi,Slcm be the LCM of every worker’s speed si and s′
i =Slcm/si where 1 ≤i ≤n. So for any two different workers wi, wj∈W, if dis′
i< djs′j holds then we must infer di/si< dj/sj.
Proof. dis′
i< djs′j⇐⇒dis′i/Slcm< djs′j/Slcm⇐⇒di/si< dj/sj.
Deforming the formula of travel time can help us avoid the division operation over ciphertexts, which is the reason why we need to get the LCM. Note that the product of all speeds is not suitable here for it may cause the overflow of the multiplication of all speeds [9]. The process of calculating the LCM byAP encryption strategy in a safe and secret way will be introduced in the next subsection. In the end, the SC platform will inform the KP and all workers of the LCM.
Time Stage.Upon receiving the LCMSlcm, every workerwi can calculate an equivalent encrypted travel timet′
on the Lemma 1 wheret′
i=d(li, lT)s′i andti=d(li, lT)/si. For no worker holds the decryption key of Paillier, homomorphic properties of Paillier are used again as follows:
is calculated by Eq.6andsiis the speed of workerwi. Then the worker sends the encrypted equivalent travel time with his own ID to the SC platform for comparison in the form of (i, Ep(t′2
i )).
Comparison Stage. When receiving the list of (i, Ep(t′2
i )), the SC platform adopts a PRG Gk to encrypt the ID of workers as (Gk(i), Ep(t′Gk2 (i))) for the protection of workers especially the chosen worker. Then the SC platform sends the list (Gk(i), Ep(t′2
Gk(i))) to the KP and sends everyGk(i) to the corresponding
workerwi. With the decryption key of Paillier, the KP can decrypt Ep(t′Gk2 (i))
to obtain thet′2 whereSlcmis achieved in the LCM. And then the KP can easily find the chosen worker who has the shortest tGk(i). Then, the ID of the chosen workerGk(i∗)
is encrypted by ElGamal, whose output isEKP
e (Gk(i∗)). At last, the KP sends EKP
e (Gk(i∗)) to the SC platform. This encrypting operation is essential because the SC platform can infer that who is the chosen worker fromGk(i∗). However, whenARis not always 100%, we will return a set of chosen workers instead of a chosen worker.
Verification Stage. To ensure only the chosen worker can learn the true task location, the SC platform hides the true task location by encrypting EKP
where function his a length-match hash function which is used shorten a long bit-string and it is proved to be semantically secure. We perform exclusive-OR on thelT and the output of functionhbecause an important property of exclusive-OR isa⊕b⊕a=b. Based on this property, only the chosen workerw∗
i can infer the true task location byls=E(ls)⊕h(EKP
e (Gk(i∗))). The detailed procedure is as follows:
With their own ElGamal, every worker encrypts their own encrypted IDGk(i) received in the comparison stage as Ewi
e (Gk(i)) and sends it to the KP. For all ElGamals are based on the same cyclic group G, commutative-like encryption can be implemented by EKP
e (Eewi(Gk(i))) =Eewi(EeKP(Gk(i))) with the same random number for the consistence ofEKP
e and the result is sent back to workers. Every workerwi can decrypt it by the decryption key of his own ElGamal and getEKP