Fakultas Ilmu Komputer
Universitas Brawijaya
3616
Sentimen Analisis Layanan Produk Indihome menggunakan Information
Gain dan Metode K-Nearest Neighbor
Atika Anggraeni1, Imam Cholissodin2, Marji3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Perkembangan zaman pada waktu ke waktu semakin mempengaruhi era digital di berbagai belahan dunia, oleh karena perkembangan zaman tersebut dibutuhkan jaringan internet. Pengguna yang membutuhkan jaringan internet adalah dari berbagai kalangan yaitu mulai dari pelajar hingga pekerja. Meningkatnya kebutuhan jaringan internet pada setiap tahunnya sehingga dapat menghasilkan keuntungan untuk jasa penyedia jasa internet, salah satunya adalah PT. Telekomunikasi Indonesia, Tbk (Telkom). Pengguna pada jaringan internet yang disediakan oleh perusahaan ini adalah masyarakat di seluruh Indonesia. Oleh karena hal tersebut, tidak menutup kemungkinan terdapat saran mendorong maupun keluhan dari pelanggan. Pada penelitian ini menggunakan tanggapan dari masyarakat berupa komentar positif dan komentar negatif. Untuk melihat komentar tersebut termasuk positif atau negatif harus melakukan beberapa tahapan analisis untuk mendapatkan hasil akhir. Tahapan yang dilakukan yaitu pre-processing, seleksi fitur Information Gain, pembobotan term dan klasifikasi algoritma K-Nearest Neighbor (KNN). Pada penelitian ini menggunakan 480 data latih dan 120 data uji. Penelitian ini mendapatkan nilai akurasi tertinggi sebesar 86,67%, precision sebesar 94,44%, recall sebesar 81,73%, dan f-measure sebesar 87,63%.
Kata kunci: analisis sentimen, klasifikasi, layanan produk indihome, information gain, k-nearest neighbor
Abstract
The development of the times from time to time increasingly influences the digital era in various parts of the world, because the development of this era requires an internet network. Users who need an internet network come from various groups, from students to workers. The increasing of internet network labor every year so that it can generate profits for internet service providers, one of which is PT. Telekomunikasi Indonesia, Tbk (Telkom). Users on the internet network provided by this company are people throughout Indonesia. Because of this, it is possible that there are encouraging suggestions or complaints from customers. In this study using responses from the public in the form of positive comments and negative comments. To find out whether these comments are positive or negative, you must carry out several stages of analysis to get the final result. The steps taken are pre-processing, Information Gain feature selection, term weighting and classification of the K-Nearest Neighbor (KNN) algorithm. This study uses 480 training data and 120 test data. This study obtained the highest accuracy value of 86.67%, with a precision of 94.44%, a recall of 81.73%, and f-measure of 91,30%.
Keywords: sentiment analysis, classification, Indihome product service, information gain, k-nearest neighbor
1. PENDAHULUAN
Semakin berkembangnya zaman maka semakin majunya era digital di berbagai belahan dunia. Jaringan internet sangat dibutuhkan oleh berbagai kalangan dari pelajar hingga pekerja. Hampir semua menggunakan jaringan internet untuk aktifitas sehari-hari, disamping hal tersebut banyak sekali manfaat. Pengguna Indihome sendiri adalah masyarakat di seluruh
Indonesia. Karena banyaknya pelanggan Indihome, tidak menutup kemungkinan untuk adanya keluhan pelanggan dan saran mendorong untuk pihak Indihome. Keluhan pelanggan dari Indihome sendiri berbagai macam mulai dari rusaknya jaringan ketika hujan, koneksi down waktu tidak menentu, teknisi yang tidak handal saat membenahi jaringan, pembatasan fair usage dan keluhan lainnya. Tidak hanya keluhan dari
meningkatkan kepuasan dan memaksimalkan pengalaman yang menyenangkan dari setiap konsumen. Sehingga hal tersebut dapat meminimumkan hal kurang menyenangkan, yang berdampak kepada pelanggan hingga berpindah ke penyedia jasa lain.
Langkah untuk mengetahui opini dari masyarakat dengan melakukan analisis sentimen. Analisis sentimen merupakan tahapan untuk mengetahui isi dan mengolah sebuah data yang berupa teks, guna mendapatkan informasi suatu opini. Analisis sentimen untuk mengetahui sudut pandangan dari suatu opini, apakah dari opini tersebut mengarah positif atau negatif (Rozi, 2012). Analisis pada sentimen ini dilakukan bertujuan mengetahui opini mengenai layanan produk Indihome, karena hal ini banyak sekali menimbulkan tanggapan dari pelanggan seperti suka atau tidaknya pelanggan terhadap produk. Hasil dari sentimen yang diperoleh mengenai Indihome menjadi pengaruh terhadap produk dan layanan sebuah perusahaan, karena dapat dijadikan acuan untuk masyarakat dalam mengambilan keputusan (Onantya, et al., 2019)
Penelitian yang dilakukan yaitu mengenai layanan produk Indihome metode K-Nearest Neighbor. Dari klasifikasi ini melakukan pengelompokkan opini tersebut termasuk ke dalam opini positif atau negatif. Metode K-Nearest Neighbor ini menghasilkan nilai akurasi yang baik, seperti pada penelitian “Sentimen Analisis Kepuasan Pengguna Data Servis Menggunakan Algoritma K-Nearest Neighbor” (Wibawa, et al., 2018). Pada penelitian memberi kesimpulan bahwa semakin sedikit tetangga, makin nilai akurasi semakin besar. Hal ini terlihat pada nilai k = 20 dengan akurasi sebesar 97,65%. Kemudian dilakukan pengujian performansi sistem diperoleh nilai akurasi sebesar 98,94%, f-measure sebesar 92,90%, recall sebesar 93,74%, precision sebesar 92,21%. Berdasarkan hasil pengujian pada data yang menghasilkan lebih unggul karena memiliki nilai negatif yang relatif sedikit dan memiliki nilai positif yang lebih banyak.
Seleksi fitur pada penelitian ini berfungsi untuk mengurangi dimensi atribut. Tujuan dari seleksi fitur sendiri ini untuk mendapatkan memiliki sama pentingnya di dalam kumpulan data. Seleksi fitur juga memiliki tujuan untuk mempercepat proses penggunaan klasifikasi yang digunakan dan lebih efektif (Arifin, 2015). Hasil akurasi dengan Information Gain (IG)
didapatkan lebih baik akurasi dibandingkan dengan tanpa menggunakan IG. Penggunaan Information Gain pada penelitian penyakit
jantung menunjukkan hasil akurasi
menggunakan Information Gain yaitu 84,62% hingga 88,46%. Sedangkan, penelitian tanpa menggunakan seleksi fitur IG sebesar 61,54% pada kelas sebaran seimbang dan 73,08% pada kelas sebaran tidak seimbang (Aini, et al., 2018). Selain itu, penelitian “Network Intrusion Detection using Feature Selection and Decision tree classifier” (Sheen & Rajesh, 2008) memberi kesimpulan dari algoritma Chi Square, Information Gain, ReliefF, KDDcup 99 didapatkan kinerja yang lebih dengan menggunakan seleksi fitur Information Gain. 2. TINJAUAN PUSTAKA
2.1 Analisis Sentimen
Analisis sentimen merupakan tahapan untuk mengetahui isi dan mengolah sebuah data yang berupa teks, guna mendapatkan informasi dari opini yang ada. Analisis sentimen dilakukan untuk melihat pandangan dari suatu opini, apakah dari opini tersebut mengarah positif atau negatif (Rozi, 2012). Tujuan dari analisis sentimen adalah memberikan sebuah ulasan dari sesuatu hal atau produk, kemudian dianalisis ke dalam bentuk nyata.
Menurut Liu (2012) pada analisis sentimen bertujuan untuk megetahui opini dan penilaian dari seseorang terhadap peristiwa, layanan maupun produk. Dari hasil sentimen analisis didapatkan apakah masyarakat suka atau tidaknya terhadap produk atau jasa layanan tersebut. Hasil dari sentimen tersebut akan dijadikan acuan bagi masyarakat untuk mengambil sebuah keputusan (Onantya, et al., 2019). Analisis sentimen yang digunakan pada penelitian ini yaitu level dokumen yang bersifat objektif.
2.2 Text Preprocessing
Proses pre-processing teks pada penelitian ini dilakukan agar data siap dianalisis. Tahapan ini terdapat antara lain data cleaning, case folding, stopword removal, stemming dan tokenization. Pada pre-processing untuk memudahkan penelitian, dikarenakan pada teks bersifat tidak terstruktur dan tidak mudah untuk diolah. Jadi oleh hal tersebut dilakukan proses pre-processing untuk menjadikan data siap diolah. Proses ini sangat diperlukan pada analisis
sentimen karena pada tiap kata ataupun kalimat dapat berisi kata tidak terstruktur dan noise yang tinggi (Mujilahwati, 2016).
2.3 Information Gain
Information Gain merupakan metode pemeringkatan yang digunakan untuk menganalisis kategori teks, microarray dan data citra. Fitur yang digunakan untuk menyeleksi data agar data yang terpilih adalah data yang relevan (Chormunge & Jena, 2016). Fitur Information Gain dapat mempresentasikan aspek penting pada kategori sentimen, sehingga pada fitur yang tidak berpengaruh akan terhapus. Fitur ini mengurangi noise dari data yang tidak relevan. Perhitungan menggunakan fitur ini akan menghapus nilai yang lebih rendah apabila nilai tersebut lebih kecil dibandingkan threshold yang sudah ditentukan (Wang, et al., 2006). Seleksi fitur ini juga termasuk ke dalam perhitungan yang populer. Untuk rumus perhitungan Information Gain ditunjukkan pada Persamaan (1) (Uguz, 2011). 𝐼𝐺(𝑡) = − ∑ 𝑃(𝑐𝑖) log 𝑃(𝑐𝑖) |𝑐| 𝑖=1 + P(𝑡) ∑ 𝑃(𝑐𝑖|t) log 𝑃(𝑐𝑖|t) |𝑐| 𝑖=1 + P(𝑡̅) ∑ 𝑃(𝑐𝑖|𝑡̅) log 𝑃(𝑐𝑖|𝑡̅) |𝑐| 𝑖=1 (1) Keterangan:
• 𝑐 adalah kategori kelas pada dokumen • 𝑖 adalah index pada dokumen
• 𝑃(𝑐𝑖) adalah probabilitas untuk kategori i
• 𝑃(𝑡) adalah probabilitas term muncul • 𝑃(𝑡̅) adalah probabilitas term tidak
muncul
• 𝑃(𝑐𝑖|t) adalah kondisi probabilitas
bersyarat munculnya term
• 𝑃(𝑐𝑖|𝑡̅) adalah kondisi probabilitas bersyarat tidak munculnya term
2.4 K-Nearest Neighbor
Klasifikasi K-Nearest Neighbor adalah metode pengelompokkan sesuai dengan jarak data baru ke tetangga terdekat. K-Nearest Neighbor dilakukan implementasi dengan cara mengatur satu parameter k. Data latih pada klasifikasi ini disimpan untuk dijadikan data baru, sehingga akan mendapatkan perbandingan banyak tingkat kemiripan pada data latih tersebut. Metode K-NN memberikan kemudahan
untuk menulusuri keputusan kelas yang dibentuk, sehingga mudah untuk menganalisis dan mengubah model. Namun, K-NN sendiri memiliki kelemahan yaitu sangat mempengaruhi fitur-fitur yang relevan (Arifin, 2015).
Penelitian ini menggunakan cosine similarity untuk menghitung kedekatan nilai tetangga (k). Cosine similarity yaitu perhitungan yang didasarkan dengan miripnya dua buah vektor. Hasil dari data latih dan data uji semakin mirip maka akan semakin sesuai. K-Nearest Neighbor ditunjukkan pada Persamaan (2) (Suguna & Thanushkodi, 2010).
𝑆𝐼𝑀(𝑋, 𝑑𝑖) = ∑𝑚𝑗=1𝑋𝑗∗𝑑𝑖𝑗 √(∑𝑚 𝑋𝑗)2 𝑖=1 ∗√(∑𝑚𝑖=1𝑑𝑖𝑗)2 (2) Keterangan:
• X adalah data uji • di adalah data latih
• xj dan dij adalah bobot pada tiap term
pada sebuah dokumen
Pada metode K-Nearest Neighbor ini memiliki tahapan-tahapan yang perlu dilakukan, yaitu:
1. Menentukan k tetangga untuk
ditentukannya kelas data uji
2. Perhitungan nilai k paling dekat dengan jarak antar data uji dan data latih
3. Mengurutkan jarak yang terbesar hingga terkecil
4. Pengambilan data sebanyak nilai k terdekat 5. Menentukan hasil klasifikasi dari kelas
mayoritas 2.5 Pengujian
2.6.1 K-Fold Cross Validation
K-Fold Cross Validation adalah metode yang paling umum digunakan untuk melakukan evaluasi kinerja prediktif model. Pengujian ini memiliki tujuan untuk memprediksi kinerja model dan data yang tersedia menggunakan suatu algoritma, kemudian membandingkan keakuratan dari kinerja yang digunakan (Yadav & Shukla, 2016).
Data latih yang digunakan berfungsi untuk pembentukan model, kemudian pada data uji berfungsi untuk validasi. Tahapan untuk melakukan validasi menggunakan K-Fold Cross
yaitu membagi data secara acak berjumlah beberapa bagian (k). Pada tiap fold tidak boleh memiliki data yang sama dengan fold lainnya. Data latih yang digunakan pada fold adalah sisa dari data yang tidak terpakai oleh data uji (Supartini, et al., 2017). Nilai k pada validasi ini digunakan secara acak agar dapat mengetahui tingkat terjadi kesalahan. Pada K-Fold Cross Validation didapatkan hasil akhir evaluasi dengan melakukan perhitungan rata-rata keseluruhan evaluasi tiap grup (Neale, et al., 2019).
2.6.1 Confusion Matrix
Confusion Matrix atau evaluasi berfungsi untuk mengukur kinerja hasil dari penelitian atau klasifikasi sentimen. Penelitian menggunakan evaluasi untuk mengetahui akurasi dari penelitian. Perhitungan evaluasi untuk membandingkan hasil dari klasifikasi dari pakar dengan hasil prediksi pada program.
Tabel 1. Confusion Matrix
True
(Prediksi)
False
(Prediksi)
True (Aktual) True Positive
(TP)
False Positive
(FP)
False (Aktual) False Negative
(FN)
True Negative
(TN)
• True Positive (TP) adalah jumlah dari data benar pada kelas milik sendiri. • False Positive (FP) adalah jumlah data
salah pada kelas milik sendiri.
• True Negative (TN) adalah jumlah data salah selain milik sendiri.
• False Negative (FN) adalah jumlah data salah di kelas selain milik sendiri. Perhitungan menggunakan confusion matrix antara lain:
Precision adalah mengetahui ketepatan informasi yang diinginkan oleh pengguna dengan hasil yang didapatkan. Rumus precision ditunjukkan pada Persamaan (3).
𝑃𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = 𝑇𝑃
𝑇𝑃+𝐹𝑃 (3)
Recall adalah jumlah kesesuaian yang terklasifikasi secara benar dari sistem. Pada precision dan recall termasuk ke dalam pendukung yang penting, sehingga dengan
adanya nilai dari precision dan recall dapat memperbaiki algoritma. Rumus recall ditunjukkan pada Persamaan (4).
𝑅𝑒𝑐𝑎𝑙𝑙 = 𝑇𝑃
𝑇𝑃+𝐹𝑁 (4)
F-measure adalah hasil pengukuran yang didapatkan rata-rata bobot harmonik precision dan recall. Bobot harmonk yaitu rata-rata yang didapatkan dari precision dan recall. Kelas negatif pada f-measure tidak dianggap sebagai kelas utama. Rumus f-measure ditunjukkan pada Persamaan (5).
𝑓 𝑚𝑒𝑎𝑠𝑢𝑟𝑒 =2∗𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛∗𝑟𝑒𝑐𝑎𝑙𝑙
𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛+𝑟𝑒𝑐𝑎𝑙𝑙
(5)
Akurasi adalah menunjukkan ketepatan sistem memberikan hasil klasifikasi yang benar dibanding seluruh hasil klasifikasi. Rumus akurasi ditunjukkan pada Persamaan (6).
Akurasi = TP+TN
TP+TN+FP+FN (6) Acuan dalam pengukuran ketepatan penelitian ini menggunakan akurasi, karena pada nilai akurasi lebih lengkap dan lebih menyeluruh dalam mengevaluasi algoritma. Hasil pada akurasi tidak kemungkinan untuk mendapatkan hasil undefined. Sedangkan, apabila menggunakan f-measure sebagai acuan ketepatan penelitian dapat menghasilkan nilai undefined, karena didalamnya mengandung nilai sensitifity atau disebut dengan recall dan nilai specificity yaitu precision (Cholissodin, et al., 2020).
3. METODOLOGI PENELITIAN 3.1 Teknik Pengumpulan Data
Pengumpulan data pada penelitian ini dengan menggunakan data primer, yang diambil dengan dipilah secara manual dari media sosial yaitu Twitter. Data tersebut merupakan kumpulan cuitan masyarakat berbahasa Indonesia. Teknik dari pengumpulan data yaitu memperhatikan secara langsung masyarakat mengenai layanan produk Indihome. Kata kunci yang digunakan dari tweet pada studi kasus penelitian ini adalah “Indihome”. Pencarian data dilakukan mulai pada tanggal 7 Juli 2020 hingga 25 Februari 2021 yang didapatkan melalui Twitter. Validasi penelitian ini didapatkan dari pemungutan suara sebanyak 30 responden dengan menggunakan media google form. Apabila hasil pemungutan suara didapatkan netral yaitu 15 positif dan 15 negatif, maka akan
menambahkan 1 responden. Data yang dijadikan pakar adalah data yang memiliki suara paling banyak. Kemudian, data yang telah dikumpulkan akan dilakukan proses pelatihan dan pengujian secara bervariasi dengan memberikan kelas positif serta kelas negatif.
3.2 Implementasi Algoritma
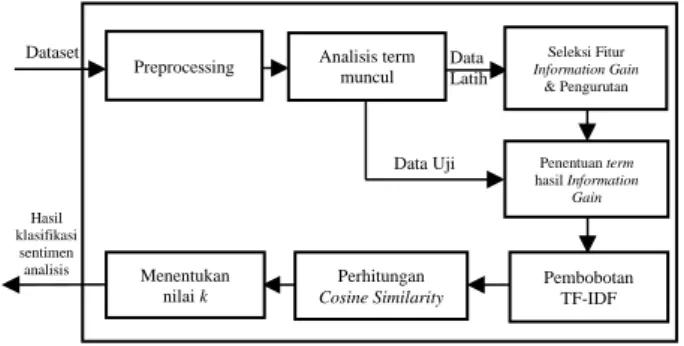
Sistem pada penelitian ini yaitu membangun sebuah program mengenai sentimen analisis layanan produk Indihome. Pada implementasi algoritma diawali dengan melakukan pengumpulan data yang digunakan. Kemudian, memisahkan 2 bagian data yaitu latih dan uji. Hal pertama yang dilakukan yaitu pre-processing kata yakni data cleaning, case folding, stopword removal, stemming dan tokenization. Kemudian, dilakukan pembobotan kata dengan TF-IDF. Kemudian, melakukan penentuan threshold untuk proses seleksi fitur. Hasil term yang terpilih sesuai dengan nilai threshold akan disimpan untuk melanjutkan ke proses selanjutnya, sedangkan term tidak terpilih akan dihapus. Pada proses seleksi fitur ini threshold pada Information Gain berfungsi untuk mencari data yang relevan dan menghapus data yang tidak terlalu penting. Setelah melakukan seleksi fitur, melakukan perhitungan menggunakan metode K-Nearest Neighbor. Untuk mendapatkan hasil akhir yaitu dilakukan confusion matrix yang meliputi precision, recall, f-measure, akurasi kemudian dilakukan validasi menggunakan k-fold cross yang terbagi menjadi beberapa fold. Gambaran implementasi algoritma pada penelitian ditampilkan pada Gambar 1.
Gambar 1. Diagram Blok Implementasi Algoritma
4. PENGUJIAN DAN ANALISIS
4.1 Pengujian Pengaruh Pada K-Fold Cross
Validation
Pengujian k-Fold Cross Validation yaitu dengan penggunaan 5-fold. Untuk data 1-fold akan digunakan menjadi data uji dan fold lainnya
sebagai data latih. Pada pengujian tiap fold menggunakan nilai k yang bertujuan memperoleh hasil evaluasi yakni akurasi, precision, recall, dan f-measure. Berikut hasil pengujian pada fold ke-1 ditunjukkan pada Tabel 2.
Tabel 2. Pengujian Fold ke-1
k Akurasi F-Measure Recall Precision
1 78,33 86,02 83,33 88,89 2 78,33 84,71 90 80 3 80,83 87,83 83,84 92,22 4 81,67 87,78 87,78 87,78 5 80,83 87,70 84,54 91,11 6 80 86,81 85,87 87,78 7 86,67 91,40 88,54 94,44 8 87,5 91,80 90,32 93,33 9 86,67 91,40 88,54 94,44 10 85 90,22 88,30 92,22
Pengujian yang ditunjukkan pada Tabel 2 didapatkan nilai evaluasi yakni akurasi sebesar 86,67%, f-measure sebesar 91,40%, recall sebesar 88,54% dan f-measure sebesar 94,44%. Pada penelitian ini dilakukan dengan 10 nilai k yang berbeda. Setelah dilakukan pengujian didapatkan rata-rata pada setiap fold, untuk menghasilkan fold yang terbaik. Berikut ditunjukkan rata-rata pengujian tiap fold pada Tabel 3.
Tabel 3. Hasil Rata-rata Fold Terbaik
Fold Akurasi F-Measure Recall Precision
1 82,58 88,57 87,11 90,22 2 77,08 85,38 81,76 89,78 3 79,42 86,27 86,23 86,89 4 76,67 83,57 86,58 81 5 80,92 87,73 84,49 91,67
Pengujian yang ditunjukkan pada Tabel 3 hasil rata-rata fold terbaik yaitu dihasilkan oleh fold 1. Pada fold 1 ini menghasilkan akurasi, recall, f-measure terbaik yaitu akurasi sebesar 82,58%, f-measure sebesar 88,57%, recall sebear 87,11%. Fold yang mendapatkan akurasi terbaik akan dilanjutkan pada pengujian seleksi fitur Information Gain. Setelah dilakukan perhitungan rata-rata fold terbaik, kemudian dilakukan penentuan nilai k terbaik yang didapatkan dari 5-fold. Berikut ditunjukkan hasil rata-rata kinerja seluruh nilai k terbaik dari 5-fold pada Tabel 4. Hasil klasifikasi sentimen analisis Dataset Data Latih Preprocessing Analisis term
muncul Seleksi Fitur Information Gain & Pengurutan Penentuan term hasil Information Gain Menentukan nilai k Perhitungan Cosine Similarity Pembobotan TF-IDF Data Uji
Tabel 4. Rata-rata Kinerja Seluruh Nilai K Terbaik dari 5-fold
k Akurasi F-Measure Recall Precision
1 77,33 84,48 86,82 82,67 2 74,50 81,51 88,87 75,56 3 78,17 85,86 83,51 88,44 4 76,33 83,83 86,23 82,00 5 78,17 85,85 83,27 88,89 6 78,50 84,71 86,44 82,89 7 81,67 88,39 84,43 92,89 8 82,67 88,99 85,09 93,33 9 82 88,74 83,76 94,44 10 82,17 88,3 86,38 90,89
Tabel 4 merupakan hasil rata-rata dari seluruh nilai k dengan pengujian akurasi, precision, recall, f-measure. Pengujian di atas menunjukkan bahwa nilai rata-rata hasil evaluasi tertinggi yang didapatkan adalah saat k = 8 untuk akurasi sebesar 82,67%, f-measure sebesar 88,99%, recall sebesar 85,09%, dan precision sebesar 93,33%.
4.2 Pengujian Pengaruh Fitur Information
Gain
Pengujian seleksi fitur Information Gain menggunakan hasil fold terbaik dari 5-fold untuk mendapatkan nilai akurasi, precision, recall, dan juga f-measure. Pada fold terbaik yang didapatkan sebelumnya adalah fold ke-1, untuk penelitian ini threshold menggunakan sebesar 30%, 60%, 70%, 90% dan 100%. Untuk melakukan pengujian seleksi fitur Information Gain ditunjukkan pada Tabel 5.
Tabel 5. Rata-rata Pengujian Seluruh Nilai K
Threshold Akurasi Precision Recall F-Measure
30% 75,83 100 75,63 86,14 50% 76,33 99,11 76,67 86,32 60% 76,33 99,11 76,67 86,32 90% 76,36 96,59 77,95 86,55 100% 78,67 95,45 79,91 86,46
Berdasarkan hasil pengujian seleksi fitur ini dapat dibandingkan hasil evaluasi program menggunakan Information Gain (IG) dan tanpa menggunakan IG. Rata-rata nilai IG tertinggi yaitu saat threshold = 90% dengan nilai akurasi sebesar 77,42% dan f-measure sebesar 86,18%, sedangkan saat program tidak menggunakan seleksi fitur IG menghasilkan akurasi sebesar 82,58% dan f-measure sebesar 88,57%.
4.3 Analisis Pengujian Pengaruh pada k-Fold
Cross Validation
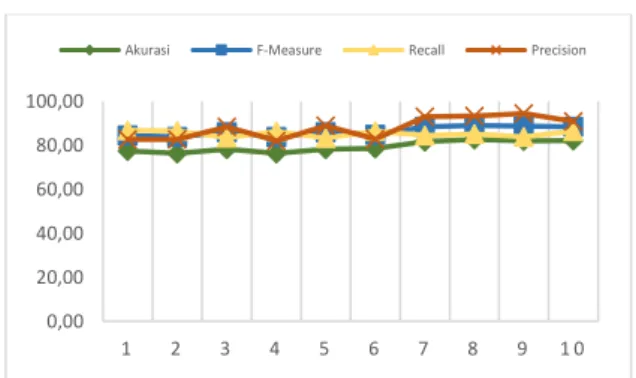
Analisis hasil pengujian ini yaitu melakukan 5-fold yang bertujuan untuk mencari nilai dari k yang terbaik. Skenario pengujian ini terbagi menjadi 5 buah fold, yang tiap fold terdiri dari 120 data. Berikut ditunjukkan Gambar 1 hasil nilai k pada setiap fold.
Gambar 2. Grafik Hasil Nilai K Pada Setiap Fold Pada Gambar 2 menunjukkan nilai dari akurasi tertinggi terdapat pada nilai k = 10, nilai dari precision tertinggi dimulai dari k = 9, untuk recall tertinggi didapatkan pada k = 2, dan hasil f-measure tertinggi didapatkan k = 9. Analisis hasil diketahui dari rata-rata akurasi yang diperoleh adalah 82,17%.
Pada pengujian ini tidak didapatkan hasil yang berubah secara signifikan pada setiap nilai k. Hal tersebut dikarenakan pada penyebaran data yang tidak sama rata dan sebaran data tidak seimbang, yang menyebabkan program bergantung pada satu kelas yaitu kelas positif. Pengujian pada penelitian ini menggunakan dataset yang digunakan yaitu berjumlah 600 data terdiri dari 450 kelas positif dan 150 kelas negatif. Penelitian ini menunjukkan bahwa nilai dari akurasi, precision, recall, f-measure didapatkan stabil.
4.4 Analisis Pengujian Pengaruh Information
Gain
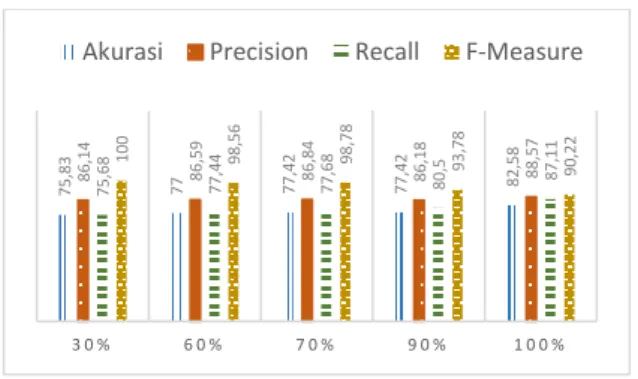
Skenario pengujian analisis ini melakukan pengujian pada seleksi fitur dari Information Gain (IG) yang menggunakan threshold yaitu 30%, 60%, 70%, 90% dan 100%. Pada threshold ini dilakukan pengujian dari hasil fold yang terbaik. Berikut ditunjukkan hasil grafik dari pengujian seleksi fitur pada Gambar 3.
0,00 20,00 40,00 60,00 80,00 100,00 1 2 3 4 5 6 7 8 9 1 0
Gambar 3. Grafik Pengujian Nilai Threshold Seleksi Fitur
Pada grafik di atas menunjukkan hasil dari variasi pada pengujian menggunakan hasil fold terbaik dari hasil klasifikasi. Pada pengujian tersebut terdapat beberapa variasi nilai dari threshold, jika pada hasil dari threshold semakin tinggi akan menghasilkan nilai f-measure dan akurasi semakin tinggi. Pengujian menggunakan Information Gain menghasilkan rata-rata f-measure dan akurasi tertinggi dari threshold = 90% yaitu akurasi sebesar 77,42 % dan f-measure sebesar 86,18%. Sedangkan, hasil akurasi dan f-measure terendah ditunjukkan ketika threshold = 30% yaitu akurasi sebesar 75,83% dan f-measure sebesar 86,14%. Untuk hasil tanpa menggunakan Information Gain mendapatkan hasil evaluasi yaitu akurasi yang didapatkan sebesar 82,58 %, dan f-measure yaitu sebesar 88,57%.
Hasil pengujian ini menghasilkan bahwa data layanan produk Indihome banyak menghasilkan term yang relevan. Sehingga, menunjukkan bahwa semakin besar nilai threshold, maka semakin banyak term yang akan diambil untuk melakukan proses berikutnya. Sedangkan, untuk nilai threshold lebih kecil akan mendapatkan term yang lebih sedikit untuk melakukan proses selanjutnya. Semakin besar nilai threshold, maka semakin besar pengaruh terhadap pengklasifikasian. Term yang menghasilkan nilai lebih tinggi menunjukkan bahwa term tersebut berisi informasi yang berguna untuk klasifikasi
5. PENUTUP 5.1 Kesimpulan
1. Pada pengujian seleksi fitur Information Gain semakin besar nilai dari threshold yang digunakan, maka semakin tinggi hasil evaluasi. Term yang memiliki nilai gain lebih tinggi yaitu menunjukkan bahwa term tersebut mempunyai informasi lebih tinggi,
sehingga menunjukkan diskriminasi lebih tinggi dibandingkan term lainnya dan berarti term tersebut berisi informasi yang berguna untuk klasifikasi. Hasil kombinasi antara klasifikasi dan seleksi fitur menghasilkan nilai akurasi yang rendah, jika dibandingkan dengan klasifikasi K-Nearest Neighbor tanpa menggunakan seleksi fitur Information Gain. Karena, data pada layanan produk Indihome memiliki noise yang hampir tidak ada dan term pada data banyak yang relevan. Sehingga, semakin besar nilai threshold, maka semakin besar pengaruhnya pula terhadap pengklasifikasian.
2. Dalam penelitian untuk menentukan kelas sentimen produk layanan Indihome menggunakan seleksi fitur Information Gain dan metode klasifikasi K-Nearest Neighbor menghasilkan nilai tertinggi f-measure sebesar 91,30%, akurasi sebesar 86,67%, precision sebesar 93,33%, recall 89,36%. Nilai tertinggi saat menggunakan dataset pada fold ke-1 dengan k = 2, dan threshold tertinggi didapatkan saat threshold sebesar 70%. Sedangkan hasil rata-rata tanpa penggunaan seleksi fitur Information Gain mendapatkan hasil evaluasi yaitu akurasi didapatkan sebesar 82,58%, dan f-measure yaitu sebesar 88,57%. Dari pengujian dilakukan kesimpulan bahwa nilai threshold dan data yang digunakan dalam proses pelatihan berpengaruh pada penelitian ini.
5.2 Saran
1. Pada tanggapan Indihome terdapat kata-kata yang baku dan singkatan. Untuk penelitian selanjutnya, dapat melakukan proses perbaikan kata untuk kata baku dan kata singkat, sehingga dapat mengurangi kata dengan penulisan berbeda namun bermakna sama.
2. Mengembangkan penelitian dengan seleksi fitur lainnya untuk mengetahui nilai-nilai evaluasi dengan penggunaan seleksi fitur lainnya mendapatkan nilai-nilai evaluasi lebih baik atau tidak dan penggunaan teknik optimasi untuk seleksi fitur dan juga untuk seleksi data, baik dalam kondisi seimbang maupun tidak seimbang.
3. Melakukan identifikasi sebaran pada data, kemudian melakukan pengecekan data tersebut termasuk linier atau non-linier dan membutuhkan teknik Kernel sebagai teknik
7 5 ,8 3 77 77,4 2 7 7 ,4 2 82 ,5 8 8 6 ,1 4 8 6 ,5 9 8 6 ,8 4 8 6 ,1 8 8 8 ,5 7 7 5 ,6 8 7 7 ,4 4 7 7 ,6 8 8 0 ,5 87,1 1 100 98,5 6 9 8 ,7 8 9 3 ,7 8 9 0 ,2 2 3 0 % 6 0 % 7 0 % 9 0 % 1 0 0 %
pemetaan data ke dimensi tinggi seperti pada penelitian oleh (Kusumadewi, et al., 2020). 6. DAFTAR PUSTAKA
Aini, S. H. A., Sari, Y. A. & Arwan, A., 2018. Seleksi Fitur Information Gain untuk
Klasifikasi Penyakit Jantung
Menggunakan Kombinasi Metode K-Nearest Neighbor dan Naïve Bayes. Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, Volume 2, pp. 2546-2554.
Arifin, M., 2015. IG-KNN Untuk Prediksi Customer Churn Telekomunikasi. SIMETRIS, Volume 6, pp. 1-10.
Cholissodin, I. et al., 2020. AI, Machine Learning & Deep Learning. s.l.:Researchgate.
Chormunge, S. & Jena, S., 2016. Efficient Feature Subset Selection Algorithm for High Dimensional Data. International Journal of Electrical and Computer Engineering (IJECE), August.pp. 1880-1888.
Dixit, M., Sharma, R., Shaikh, S. & Muley, K., 2020. Internet Traffic Detection using Naïve Bayes andK-Nearest Neighbors (KNN) algorithm. Madurai, India, India , IEEE.
Kachavimath, A. V., Nazare, S. V. & Akki, S. S., 2020. Distributed Denial of Service Attack Detection using Naïve Bayes and K-Nearest Neighbor for Network Forensics. Bangalore, India, India, IEEE.
Kusumadewi, V. A., Cholissodin, I. & Adikara, P. P., 2020. Klasifikasi Jurusan Siswa menggunakan K-Nearest Neighbor dan Optimasi. Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, 4(4), pp. 1315-1323.
Mujilahwati, S., 2016. Pre-Processing Text Mining Pada Data Twitter. Seminar Nasional Teknologi Informasi dan Komunikasi, pp. 2089-9815.
Nair, A. J. et al., 2019. An Ensemble-Based Feature Selection and Classification of Gene Expression using Support Vector Machine, K-Nearest Neighbor, Decision Tree. Coimbatore, India, India , IEEE. Neale, C., Workman, D. & Dommalapati, A.,
2019. Cross Validation: A Beginner’s
Guide. [Online]
Available at:
https://towardsdatascience.com/cross-
validation-a-beginners-guide-5b8ca04962cd
Onantya, I. D., Indriati, I. & Adikara, P. P., 2019. Analisis Sentimen Pada Ulasan Aplikasi BCA Mobile Menggunakan BM25 Dan Improved K-Nearest Neighbor. Jurnal Pengembangan Teknologi Informasi dan Ilmu Komputer, 3(3), pp. 2575-2580. Putri, F. O., Indriati, I. & Wihandika, R. C.,
2020. Analisis Sentimen Pada Ulasan Pengguna MRT Jakarta Menggunakan Metode Neighbor-Weighted K-Nearest Neighbor Dengan Seleksi Fitur Information Gain. Jurnal Pengembangan Teknologi Informasi dan Ilmu Komput, 4(7), pp. 2195-2203.
Rozi, I. F., 2012. Implementasi Opinion Mining (Analisis Sentimen) untuk Ekstraksi Data Opini Publik pada Perguruan Tinggi. Jurnal EECCIS, Volume 6, pp. 37-43. Sheen, S. & Rajesh, R., 2008. Network intrusion
detection using feature selection and Decision tree classifier. Hyderabad, India, IEEE.
Sidani, A. A., Cherry, A., Hajj-Hassan, H. & Hajj-Hassan, M., 2019. Comparison between K-Nearest Neighbor and Support Vector Machine Algorithms for PPG Biometric Identification. IEEE.
Suguna, N. & Thanushkodi, D. K., 2010. An
Improved k-Nearest Neighbor
Classification Using Genetic Algorithm. IJCSI International Journal of Computer Science Issues, 7(4), pp. 18-21.
Supartini, I. A. M., Sukarsa, I. K. G. & Srinadi, I. G. A. M., 2017. Analisis Diskriminan Pada Klasifikasi Desa Kabupaten Tabanan Menggunakan Metode K-Fold Cross Validation. E-Jurnal Matematika, 6(2), pp. 106-115.
Uguz, H., 2011. A Two-Stage Feature Selection Method For Text Categorization By Using Information Gain, Principal Component Analysis And Genetic Algorithm. Science Direct, pp. 1024-1032.
Wang, i., Guan, Y., Wang, X. & Xu, Z., 2006. A Novel Feature Selection Method Based on
Category Information Analysis for Class Prejudging in Text Classification. IJCSNS International Journal of Computer Science and Network Security, 6(1A), pp. 113-119.
Wibawa, D. W., Nasrun, M. & Setianingsih, C., 2018. Sentimen Analysis On User Satisfaction Level Of Celullar Data Service Using The K-Nearest Neighbor (K-NN) Algorithm. Bandung, Indonesia, IEEE.
Windasari, I. P., Uzzi, F. N. & Satoto, K. I., 2017. Sentiment Analysis on Twitter Posts: An Analysis of Positive or Negative Opinion On GoJek. Semarang, Indonesia, IEEE.
Yadav, S. & Shukla, S., 2016. Analysis Of k-Fold Cross-Validation Over Hold-Out Vadilation On Colossal Datasets For Quality Classification. 6th International Advanced Computing Conference, pp. 78-83.