ANALISIS SENTIMEN DAN ANALISIS DATA EKSPLORATIF ULASAN APLIKASI MARKETPLACE GOOGLE PLAYSTORE
Syahroni Wahyu Iriananda1*), Rangga Pahlevi Putra1), Kuncahyo Setyo Nugroho2)
1) Program Studi S1 Teknik Informatika, Universitas Widyagama Malang, Kota Malang
2) Fakultas Ilmu Komputer, Universitas Brawijaya, Kota Malang
*Email Korespondensi : [email protected] ABSTRAK
Pandemi COVID-19 dan perkembangan teknologi informasi mendorong peningkatan aktivitas belanja secara online. Aplikasi marketplace berbasis Android saat ini paling banyak diminati masyarakat karena mempunyai banyak kelebihan diantaranya dapat di akses 24 jam, banyaknya diskon, promo dan bebas ongkos kirim. Marketplace yang populer dan banyak di unduh melalui Google Playstore saat ini adalah Shopee, Tokopedia dan Lazada. Untuk mengetahui umpan balik dari pengguna, dapat dilakukan dengan menganalisa sentimen setiap tanggapan terhadap aplikasi. Dalam penelitian ini penulis menyajikan analisis sentimen (Sentiment Analysis) dan Exploratory Data Analysis (EDA).
Berdasarkan EDA, Lazada mendapat review paling baik (4-5) lebih banyak daripada aplikasi Shopee dan Tokopedia yang berarti pengguna yang menggunakan Lazada lebih senang dengan layanan mereka daripada Tokopedia dan Shopee yang masih perlu meningkatkan layanannya. Klasifikasi sentimen menggunakan metode Algoritma Decission Tree (DT) dan Random Forest (RF) memiliki nilai akurasi tertinggi dalam setiap pelatihan.
Maksimum nilai akurasi dalam pelatihan menggunakan model DT dan RF adalah 96,55%
model SVM-RBF, dan RF menghasilkan tingkat akurasi maksimum 60.08% dalam proses pengujian.
Kata kunci: analisis, sentimen, eksploratif, marketplace, playstore, apps ABSTRACT
The pandemic of COVID-19 and improvements in information technology have influenced a dramatic increase in online shopping. The Android-based marketplace application is the most popular among people due to its numerous benefits, which include 24-hour access, a broad variety of discounts, promos, and free delivery. Today, the most popular and frequently downloaded marketplaces on Google Play are Shopee, Tokopedia, and Lazada. To encourage user feedback, analyze the sentiment of each response to the application. The researchers discuss sentiment analysis (Sentiment Analysis) and exploratory data analysis in this article (EDA). According to this, Lazada obtained more positive reviews (4-5) than the Shopee and Tokopedia applications, showing that Lazada users are satisfied with their services than users on Tokopedia and Shopee, which both have room for improvement. Sentiment categorization utilizing the Decision Tree (DT) and Random Forest (RF) algorithms achieve the maximum accuracy in each training set. The greatest accuracy rate for training with the DT and RF models is 96.55 percent in the SVM-RBF model, and 60.08 percent for testing with the RF model.
Keywords: sentiment, analysis, exploratory, marketplace, playstore, apps PENDAHULUAN
Pandemi COVID-19 saat ini didukung dengan perkembangan teknologi informasi mendorong peningkatan aktivitas yang biasanya dilakukan masyarakat ini secara offline beralih menjadi online semakin meningkat. Kegiatan berbelanja, pemasaran barang dan jasa, jual-beli dapat dilakukan hanya dari rumah menggunakan telepon pintar (smartphone). Barang yang dibeli diantar oleh kurir hingga ke pintu rumah dengan cepat hanya dengan menggunakan aplikasi online marketplace. Aplikasi ini paling banyak diminati masyarakat karena mempunyai banyak kelebihan diantaranya memfasilitasi
Seminar Nasional Hasil Riset Prefix - RTR
474
proses jual beli dari berbagai macam toko, tidak harus pergi ke toko secara langsung, bisa membeli barang berbeda wilayah sesuai lokasi pengguna, dapat di akses 24 jam, banyaknya diskon, promo dan bebas ongkos kirim [1]
Salah satu marketplace yang populer dan banyak di unduh melalui Google Playstore saat ini adalah Shopee [2] Lazada, Tokopedia, JD.ID [1], Bukalapak, Blibli dan sebagainya.
Setiap pengguna memberikan ulasan atau tanggapannya terhadap aplikas, yang berupa skor penilaian (rating score), atau tanggapan berwujud teks ulasan (review). Ini sangat bermanfaat bagi pengembang aplikasi, terutama sebagai masukan saran atau kritikan, bahkan keluhan terhadap aplikasi. Sehingga dapat bermanfaat untuk pengembangan bisnis aplikasi tersebut di masa mendatang [3].
Untuk mengetahui umpan balik pengguna, dapat dilakukan analisa sentimen setiap tanggapan terhadap aplikasi. Dalam penelitian ini penulis menyajikan analisis sentimen (Sentiment Analysis) dan analisis data eksloratif (Exploratory Data Analysis) atau EDA. Hal ini memberikan gambaran statistik dan menggali wawasan tentang aplikasi berdasarkan data. EDA diperkenalkan tidak hanya untuk ahli statistik tetapi untuk non statistik juga dapat melakukan EDA karena sifat EDA adalah seek and trial [4]. Meskipun konsep EDA telah digunakan bertahun-tahun yang lalu tetapi penelitian tentang atau penelitian yang memanfaatkan konsep EDA masih terus berkembang [4].
Penelitian ini perlu dilakukan untuk memberikan kontribusi dan referensi terkait komparasi analisis sentimen dan analisis data eksploratif (EDA) terhadap aplikasi marketplace terbaik di Indonesia yang digunakan pada perangkat Android sehingga diharapkan juga dapat memperkaya referensi dan dapat berkontribusi pada penelitian berikutnya.
Penelitian ini bertujuan untuk menyelidiki bagaimana analisis sentimen dapat digunakan sebagai solusi alternatif untuk mengukur umpan balik positif, negatif, dan netral dari review pengguna marketplace dengan tren peringkat teratas di Google Playstore menurut data dari Appanie.com selama kurun waktu tertentu. Ini adalah suatu cara yang lebih komprehensif untuk membantu pengguna membuat keputusan yang tepat untuk produk dan layanan marketplace yang ingin mereka gunakan berdasarkan totalitas review [5].
Diharapkan bahwa penelitian ini akan bermanfaat bagi pengguna dalam membuat keputusan yang lebih baik ketika melakukan belanja online dan dapat bertindak sebagai mekanisme umpan balik bagi pengembang dan manajemen untuk menyediakan layanan yang lebih baik.
Penelitian Terkait
Analisa sentimen (Sentiment Analysis) merupakan salah satu bagian bidang ilmu dengan pendekatan Penambangan Teks (Text Mining) yang dapat mengekstraksi teks untuk mendapatkan sentimen bahkan emosi seseorang [6]. Rhohmawati, dkk. [7] melakukan analisa sentimen dengan menerapkan metode Maximum Entropy dengan akurasi sebesar 97,3%. Ahmadi dkk. [1] menggunakan Support Vector Machine (SVM) dengan cross- validation 10x lipat untuk menganalisa aplikasi marketplace Tokopedia dengan akurasi 90,67%, JD.ID 75,3%, Blibli 74%, Shopee 70%, dan tingkat akurasi terendah pada marketplace Lazada 69%. Sementara itu Azhar dkk. [8] menganalisa sentimen aplikasi Klikindomaret menggunakan SVM kemudian dikomparasi dengan metode Naïve Bayes (NB), kemudian dilakukan optimasi terhadap Feature Selection (FS) pada kedua metode tersebut menggunakan Particle Swarm Optimization (PSO). Cross-validation pada NB dengan FS menghasilkan akurasi 75,21%, dan cross-validation pada SVM dengan FS menghasilkan 81,84%, ini menunjukkan bahwa optimasi pada SVM lebih baik dibandingkan NB. Fransika dan Gufroni [9] menganalisa sentiment pengguna aplikasi provider By.U menggunakan SVM dengan 5-Fold Validation menghasilkan tingkat akurasi 84,7%. Ranjan dan Mishra [10] membandingkan SVM dengan beberapa algoritma yaitu NB, Logistic
Regression (LR), KNN, Random Forest (RF). Pada artikel ini juga menyajikan korelasi antara review mahasiswa dengan review Google Playstore melalui analisis eksploratif (EDA) dan visualisasi polaritas sentiment. Subyektivitas dibandingkan dengan harga, jumlah instalasi, tipe, ukuran, kategori dan peringkat (rating). Dari pelatihan (training) yang dilakukan menghasilkan akurasi untuk SVM maksimal 93,37%, LR sebesar 87,8% dan NB 85,5%.
Rahman [11] melakukan analisis sentimen terhadap aplikasi Shopee, Ruangguru, Tokopedia, dan Gojek menggunakan metode NB dan Algoritma Genetika. Menghasilkan nilai akurasi terbesar pada aplikasi Tokopedia 96,87%, Gojek 96,54%, selisih hanya 0,01%
dengan aplikasi Shopee yaitu 96,53% dan nilai akurasi terendah adalah Ruangguru 95,54%.
Sementara itu analisis sentimen terhadap 1000 review pengguna aplikasi Grab dilakukan Wahyudi dan Kusumawardhana [2] menggunakan metode SVM dengan hasil akurasi sebesar 85,54%.
Dalam penelitian ini metode yang digunakan dalam pelatihan adalah SVM dengan type kernel yang berbeda, Decission Tree, Random Forest dan Logistics Regression. Akurasi setiap metode tersebut kemudian dikomparasi sehingga peneliti dapat memberikan kesimpulan metode mana yang paling sesuai untuk tugas klasifikasi sentimen.
METODE PENELITIAN
Penelitian ini menganalisis ulasan pengguna aplikasi marketplace Shopee, Tokopedia dan Lazada di Google Playstore menggunakan pendekatan Text Mining. Menggunakan algoritma machine learning dalam tugas klasifikasi seperti SVM, dan Random Forest dengan tahapan penelitan yang dapat dilihat pada gambar 1 berikut.
Gambar 1. Diagram Alur Penelitian Observasi Data
Penelitian ini diawali dengan kegiatan observasi data pada website Appannie.com. Kriteria observasi data adalah aplikasi Google Playstore yang dapat diunduh secara gratis dan digunakan pada perangkat Android, dengan judul kategori “Belanja” atau Shopping.
Beberapa aplikasi marketlace gratis yang digunakan di Indonesia selama bulan September sampai dengan Desember 2021.
Gambar 2. Tren Peringkat Aplikasi Gratis Terbaik di Indonesia Selama 90 Hari, (Appanie.com)
Merujuk pada Gambar 2, dalam kurun waktu tertentu aplikasi marketplace Shopee memiliki tren No.1 secara konsisten untuk aplikasi kategori belanja Shopping. Berikutnya diikuti posisi ke-2 yaitu aplikasi marketplace Lazada yang sebagian besar berada diposisi tersebut, meski beberapa saat Lazada mengalami penurunan tingkat hingga menjadi nomor ke-3, namun dapat naik kembali ke posisi no.2. Berikutnya marketplace Tokopedia disajikan secara dinamis berada di peringkat maksimal nomor ke-2, dan paling rendah
Seminar Nasional Hasil Riset Prefix - RTR
476
berada pada peringkat ke-5. Ini memberikan gambaran kepada peneliti untuk melakukan analisa data ekploratif untuk mendukung kinerja analisa sentimen terhadap review pengguna. Berdasarkan hasil observasi yang telah dilakukan peneliti menentukan 3 (tiga) aplikasi marketplace yang secara stabil berada pada peringkat pertama yaitu Shopee, kedua adalah Tokopedia dan ketiga adalah Lazada.
Pengumpulan Data
Dalam penelitian ini, data utama diperoleh langsung dari sumber aslinya oleh peneliti untuk memecahkan topik penelitian [12]. Data yang gunakan terkait ulasan/tanggapan (review) dari setiap aplikasi yang diteliti. Data tersebut didapatkan dari Google Playstore, sebanyak 3599 ulasan pengguna aplikasi Shopee 1200 data, Tokopedia 1199 data dan Lazada 1200 data yang disusun menurut kategori ulasan yang paling relevan, karena kategori yang paling relevan menampilkan data ulasan yang paling erat hubungannya dengan program dan berisi tentang review dan evaluasi dari pengguna. Proses pengumpulan data menggunakan pendekatan Data Scraping dengan menggunakan Bahasa Python yang merupakan Bahasa pemrograman yang paling umum digunakan dalam penelitian Data Science untuk melakukan EDA [13]. Data ulasan tersebut kemudian disimpan dalam file CSV agar dapat terbaca dengan baik dan bisa di proses kembali.
Text Preprocessing
Pra-pemrosesan (text preprocessing) data merupakan langkah pertama dari penambangan teks (text mining). Hal Ini berarti mengkonversi data menjadi format yang sesuai sehingga dapat diproses lebih lanjut. Dalam penelitian ini akan dilakukan banyak proses pre- processing pada data teks, antara lain tokenisasi untuk memecah setiap kata, case folding merubah semua karakter menjadi huruf kecil, number filter menghilangkan seluruh karakter angka, filter URL menghapus seluruh alamat web, filter email menghapus kata yang mengandung unsur email seperti “@” (at) dan “.” (dot), filter punctuation menghapus seluruh tanda baca, filter n-karakter menghapus seluruh kata yang memiliki jumlah karakter tertentu, data cleaning membersihkan data hasil preprocessing teks yang pada akhirnya bernilai kosong (null), normalisasi bahasa mengembalikan suku kata bahasa gaul, alay, atau slang menjadi Bahasa baku atau bentuk normal, stop word removal menghapus kata yang tidak mengandung suatu arti jika berdiri sendiri, dan stemming mengembalikan suku kata yang memiliki awalan/akhiran menjadi bentuk baku atau aslinya.
Feature Extraction
Ekstraksi Fitur (Feature Extraction) merupakan tahapan dalam tugas klasifikasi untuk dapat memberikan suatu ciri khusus suatu obyek, salah satunya dengan pembobotan Term Frequency Inverse Document Frequency (TFIDF) dilakukan untuk mengubah dokumen teks menjadi bentuk vektor yang dapat digunakan untuk proses klasifikasi dengan SVM, Random Forest dan model algoritma Machine Learning lainnya. TFIDF ini memiliki pengaruh yang cukup signifikan dalam tugas klasifikasi [14]. Proses pembobotan TFIDF menggunakan bahasa pemrograman python dengan memanfaatkan library Tfidfvectorizor dengan parameter min_df = 5 dan default lainnya. TFIDF adalah skema pembobotan dengan rumus berikut[15]:
TFIDFj = TF x IDF (1)
Term Frequency (TF). TF merupakan frekuensi kemunculan, kata atau kelompok kata dalam dokumen. Ini juga disebut model Bag of Words (BoW). Dalam model ini, setiap dokumen direpresentasikan sebagai vektor 0 (nol) dan 1 (satu). Jika sebuah kata ada dalam dokumen, sesuai dengan vektor dikodekan sebagai "1" dan jika tidak, itu dikodekan sebagai 0. Karena jumlah frekuensi suku kata mungkin sangat besar, rumus berikut juga sering digunakan untuk menghitung nilai TF:
(2)
dimana tfi menunjukkan frekuensi kata i dalam dokumen j.
Inverse Document Frequency (IDF). Rumus ini awal diberikan oleh [16] dan kemudian dikembangkan oleh [17] sehingga nilai dari perhitungan berikut,
(3)
Dimana di mana N adalah jumlah total dokumen dalam koleksi dan nj adalah jumlah dokumen yang mengandung setidaknya satu terjadinya istilah i.
Data Splitting
Setelah dilakukan proses pre-processing dan berlanjut proses ektraksi fitur dengan TFIDF, perlu dilakukan proses pemilihan dan pembagian data yang digunakan untuk proses Training dan Testing algoritma machine learning. Pada penelitian ini terdapat beberapa skenario pembagian data (data splitting) yang antara lain adalah 60:40, 70:30 dan 80:20.
Artinya dari setiap dataset akan dibagi menjadi 60% untuk set data latih, dan 40% set data uji. Berlaku pula untuk skrenario data splitting yang lain. Ini bertujuan untuk mengetahui jumlah data latih dan data uji yang ideal untuk setiap algoritma machine learning.
Support Vector Machine (SVM)
SVM merupakan algoritma machine learning yang memisahkan data kelas dengan mencari hyperplane yang paling optimal [9]. Klasifikasi dengan metode SVM dilakukan dengan bahasa pemrograman python dengan menggunakan library sklearn.svm untuk proses klasifikasi dengan metode SVM, selain itu menggunakan library sklearn.metrics untuk mengukur performansi model klasifikasi atau mengetahui akurasi pembelajaran dengan SVM. Distribusi data latih dan data uji dilakukan menggunakan Validasi 5 kali lipat dengan pustaka KFold di sklearn.modelselection. Pada penelitian ini digunakan SVM dengan berbagai kernel Linear, RBF dan Polynomial kemudian dibandingkan dengan Decission Tree, Random Forest, dan Logistics Regression.
Metode Klasifikasi Ensemble (Random Forest)
Metode klasifikasi ensemble adalah algoritma pembelajaran yang membangun satu set pengklasifikasi alih-alih satu pengklasifikasi, dan kemudian mengklasifikasikan titik data baru dengan mengambil suara dari prediksi mereka. Ensemble classifier yang paling umum digunakan adalah Bagging, Boosting dan Random Forest (RF) [18] [19]. Peneliti menggunakan library python sklearn.ensemble untuk klasifikasi dengan Random Forest.
HASIL DAN PEMBAHASAN Exploratory Data Analysis (EDA)
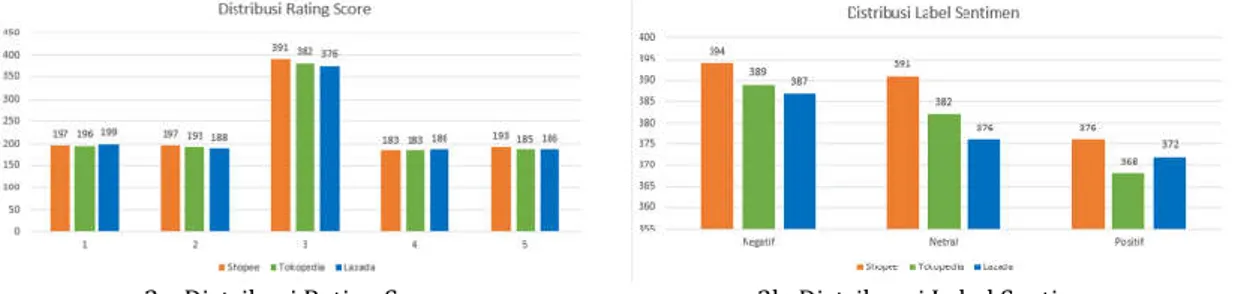
Distribusi Rating Score merupakan gambaran dari sebaran pengguna aplikasi marketplace yang memberikan nilai (score) berupa angka. Data distribusi rating score ini didapatkan setelah tahapan pre-processing dan data cleaning terhadap kolom data
“clean_content” yang bernilai kosong (null). Penilaian pengguna terdiri dari angka 1 (satu), dengan persepsi nilai terendah (paling negatif), angka 2 (dua) untuk persepsi “Negatif”, angka 3 (tiga) untuk persepsi nilai tengah atau “Netral”, angka 4 (empat) untuk persepsi
“Positif” dan nilai 5 (lima) dengan persepsi nilai tertinggi atau “Sangat Positif”. Distribusi penilaian terhadap aplikasi marketplace Shopee, Tokopedia, dan Lazada dipresentasikan pada Gambar 3a dibawah ini.
Penilaian pengguna terhadap tiga aplikasi marketplace dapat dilihat cukup merata.
Perbedaan yang paling signifikan terjadi pada penilaian dengan rating score 3 (tiga) dengan persepsi “Netral”, dimana pengguna terdapat 391 pengguna memberikan rating aplikasi Shopee lebih besar daripada pengguna aplikasi Tokopedia sebanyak 382 orang, sedangkan aplikasi Lazada terdapat 376 pengguna yang memberikan rating 3 (tiga). Aplikasi Lazada ini justru lebih unggul pada persepsi “Baik” atau rating score 4 (empat) dengan selisih 3 (tiga) yaitu 186, lebih banyak daripada Shopee dan Lazada dinilai “Positif” oleh 183 orang.
Seminar Nasional Hasil Riset Prefix - RTR
478
Penilaian dengan persepsi “Paling Positif” dengan nilai angka 5 (lima) paling banyak diberikan untuk Shopee yaitu 193 orang, selisih 7 orang lebih banyak daripada penilaian terhadap Lazada yaitu 186 orang, sedangkan jumlah pengguna yang menilai Tokopedia dengan angka ini adalah 185 orang pengguna.
3a. Distribusi Rating Score 3b. Distribuasi Label Sentimen Gambar 3. Distribusi Rating Score dan Label Sentimen
Pada tahapan training dan testing dengan metode berbagai metode machine learning, membutuhkan label pelatihan, maka data setiap review pengguna perlu disematkan label sentiment “Negatif”, “Netral”, dan “Positif”. Distribusi Label Sentimen dipresentasikan pada Gambar 3b tersebut memberikan gambaran kepada peneliti, melakukan pemberian label dengan cara yang sederhana, yaitu dengan mengubah rating score 1-2 menjadi label
“Negatif”, rating score 3 (tiga) menjadi label “Netral” dan score 4-5 menjadi label “Positif”.
Berdasarkan konversi ini distribusi rating score dapat dikembangkan menjadi Distribusi Label Sentimen yang merupakan hasil dari akumulasi penilaian pengguna.
Gambar 4. Jumlah Review Per Bulan
Menurut hasil analisis data, Bulan bijaksana adalah di bulan November untuk Tokopedia memiliki jumlah umpan balik maksimum disusul kemudian aplikasi Lazada, sedangkan pada bulan Desember jumlah umpan balik maksimum adalah aplikasi Shopee kemudian Lazada dan Tokopedia lebih minim seperti yang disajikan pada Gambar 4. Dalam kurun waktu September sampai dengan bulan Desember tahun 2021,
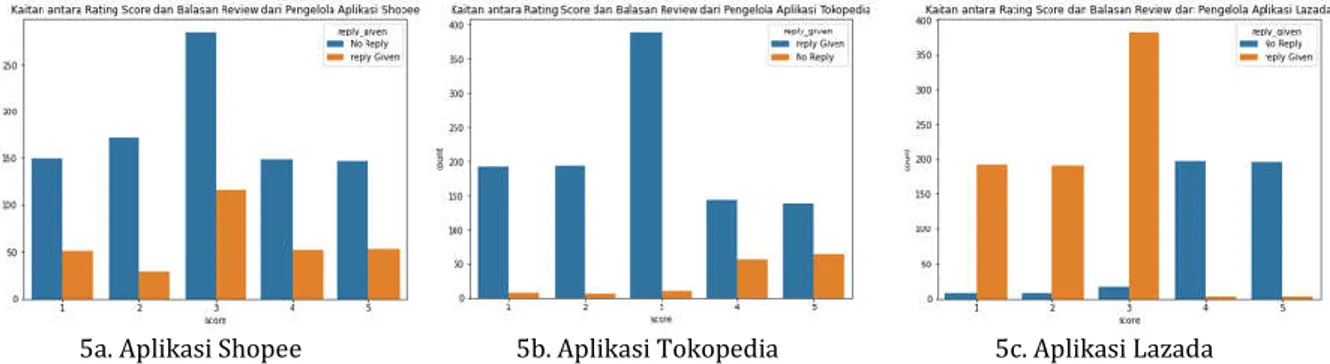
Hasil EDA untuk Aplikasi Shopee menunjukkan bahwa manajemen telah menjawab konten/umpan balik yang memiliki skor sentimen netral yang ditunjukkan dengan angka 3 (tiga) lebih banyak daripada membalas yang memiliki skor sentiment negatif (angka 1-2) dan skor sentimen positif (angka 4- 5). Hal ini merupakan indikator yang baik bahwa Shopee lebih responsif terhadap pengguna Aplikasi Shopee yang memiliki pengalaman cukup baik. Menurut data, review yang memiliki rating negatif telah mendapat jumlah suara yang lebih sedikit dari review positif, yang mengatakan bahwa mungkin saja pengguna yang memberikan review juga dalam beberapa periode waktu menghadapi masalah yang sama.
Hasil yang sedikit berbeda untuk aplikasi marketplace Tokopedia. Menurut analisis data untuk Tokopedia, manajemen menjawab rasio konten/umpan maksimal pada pengguna
yang memiliki pengalaman cukup baik terhadap aplikasi Tokopedia. Jumlah review yang dijawab lebih banyak daripada review yang tidak terjawab oleh manajemen. Ini berarti bahwa manajemen serius memperhatikan review penggunanya, lebih responsive dibandingkan aplikasi Shopee. Manajemen telah memberikan jawaban umpan balik peringkat rendah dan peringkat tengah daripada menjawab feedback peringkat tinggi.
Untuk aplikasi Lazada, manajemen menjawab rasio konten/umpan balik yang mirip dengan perilaku balasan pada Tokopedia, yaitu lebih banyak memberikan jawaban atas umpan balik pengguna yang memiliki pengalaman cukup baik dan pengalaman negatif.
5a. Aplikasi Shopee 5b. Aplikasi Tokopedia 5c. Aplikasi Lazada Gambar 5. Relasi antara Rating Score dan Balasan Review dari Pengguna Aplikasi Marketplace
Tinjauan keseluruhan dari ketiga perusahaan berdasarkan EDA, Lazada mendapat review paling baik (4-5) lebih banyak daripada aplikasi Shopee dan Tokopedia yang berarti pengguna yang menggunakan Lazada lebih senang dengan layanan mereka daripada Tokopedia dan Shopee. Berikutnya Tokopedia yang juga tidak terlalu ketinggalan dan setidaknya datang Shopee yang perlu meningkatkan Layanannya mengingat hanya sekitar 150 – 300 pengguna yang memberikan nilai Positif(4-5). Menurut analisis data, peringkat Negatif (skor 1-2) adalah Shopee karena peneliti mengatakan Shopee harus meningkatkan layanannya untuk bersaing dengan perusahaan lain, dan peringkat paling Positif adalah aplikasi Lazada yang merupakan pertanda baik. Namun dalam penelitian ini kami tidak dapat benar-benar menggunakan matriks ini karena kami tidak memiliki lebih banyak data untuk mengklarifikasinya.
Analisis Sentimen Aplikasi Marketplace
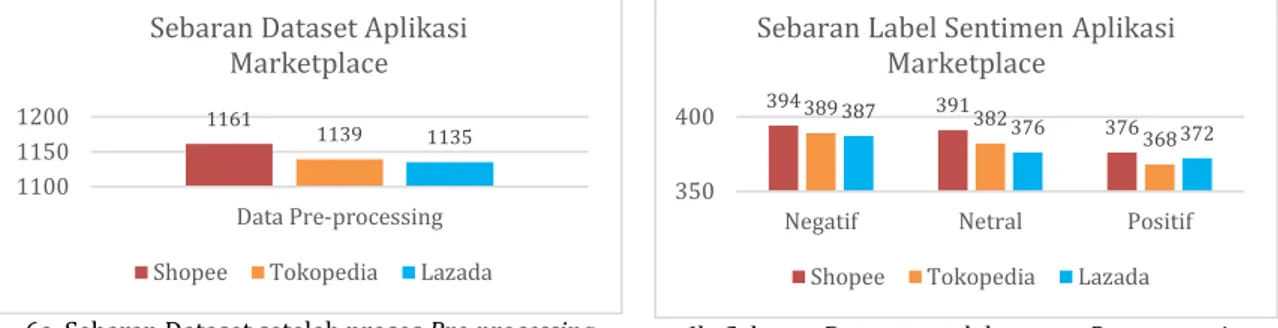
Tahapan akhir dari penelitian ini adalah klasifikasi sentiment. Sebaran dataset aplikasi marketplace tertera pada Tabel 1. Sebanyak total 3599 data review pengguna didapatkan dari data scrapping dengan menggunakan Bahasa pemrograman Python pada Google Colab. Terbagi menjadi 3 dataset yang dikategorikan menurut aplikasi marketplace, yaitu 1200 baris data Shopee, 1199 data Tokopedia, dan 1200 item data untuk aplikasi Lazada. Jumlah total sebanyak 3599 tersebut merupakan data yang sebelum dilakukan proses pre-processing teks.
Tabel 1. Sebaran Dataset Shopee, Tokopedia dan Lazada
Jumlah tersebut berkurang setelah dilakukan proses pre-processing. Tergambar pada Gambar 6a, pada dataset Shopee yang awalnya terdapat 1200 menjadi 1161 baris data.
Demikian pula yang terjadi pada dataset Tokopedia dan Lazada yang masing berkurang menjadi 1139 untuk Tokopedia dan Lazada adalah yang paling minimum yaitu 1135 baris
Seminar Nasional Hasil Riset Prefix - RTR
480
data. Hal ini terjadi karena dalam proses pre-processing terdapat sub proses penghapusan data kosong (null). Sebaran label sentiment yang digunakan untuk melakukan pelatihan dan pengujian menggunakan algoritma machine learning tertera pada gambar 6b. Aplikasi Shopee memiliki sebaran label sentiment paling maksimum diantara ketiganya. Dari 1161 total jumlah data, sebanyak 394 label sentiment “Negatif”, 391 label sentiment “Netral” dan 376 data berlabel “Positif”. Sementara itu label “Positif” paling minimum adalah aplikasi Tokopedia berjumlah 368 dari total 1139 data review penggunanya.
6a. Sebaran Dataset setelah proses Pre-processing 6b. Sebaran Dataset setelah proses Pre-processing
Gambar 6. Sebaran Dataset Awal dan Label Sentimen setelah proses Pre-processing Proses ektraksi fitur dengan TFIDF menghasilkan matriks data Word Dictionary dari setiap review pengguna. Jumlah ini merupakan akumulasi dari setiap kata (word) yang muncul pada teks review setiap aplikasi marketplace. Seperti yang tertera pada Tabel 1.
terdapat 2278 jumlah kata yang dihasilkan dari dataset Shopee, 2160 kata terkumpul dari dataset Tokopedia, dan dataset Lazada menghasilkan sebanyak 2228 kata.
Tabel 2. Hasil Training Dataset Marketplace
Tabel 2 mempresentasikan hasil pelatihan setiap algoritma machine learning dengan variasi jumlah data sesuai scenario yang telah ditentukan. Berdasarkan pelatihan model yang dilakukan oleh peneliti, didapatkan bahwa Algoritma Decission Tree (DT) dan Random Forest (RF) memiliki nilai akurasi tertinggi dalam setiap pelatihan.
Tabel 3. Hasil Pengujian Dataset Marketplace
Nilai akurasi maksimum menggunakan dataset Shopee, dengan skenario data splitting 70% data latih, dan 30% data uji. Menghasilkan tingkat akurasi sebesar 96,55%
dengan menggunakan algoritma DT dan RF, namun hasil pengujian pada Tabel 3 memperlihatkan hasil yang tidak selaras. Tingkat akurasi yang jauh lebih rendah yaitu
1161 1139 1135
1100 1150 1200
Data Pre-processing Sebaran Dataset Aplikasi
Marketplace
Shopee Tokopedia Lazada
394 391
376
389 382
368
387 376 372
350 400
Negatif Netral Positif
Sebaran Label Sentimen Aplikasi Marketplace
Shopee Tokopedia Lazada
41,54% menggunakan DT dan 44,69% untuk metode RF. Secara keseluruhan hasil pengujian yang dilakukan penelitian ini dipresentasikan pada Tabel 3.
Dalam proses pengujian model, peneliti melakukan validasi menggunakan cross- validation 5-Fold. Dari berbagai pengujian yang telah dilakukan, variabel 5-Fold memiliki hasil yang maksimum. Pada tabel 3 menunjukkan bahwa model SVM dengan kernel Radial Basis Function (RBF) dan Random Forest (RF) memiliki tingkat akurasi maksimum 60,08%
pada skenario data splitting 80% data latih berbanding 20% data uji untuk dataset Tokopedia. Namun hasil ini belum sesuai dengan harapan peneliti, sehingga diperlukan kajian dan penelitian selanjutnya salah satunya analisis sentiment berbasis Leksikon.
KESIMPULAN
Berdasarkan hasil kajian tentang EDA, Shopee dan Lazada telah mendapatkan jumlah Umpan Balik terbesar dibandingkan dengan Tokopedia, namun dalam penelitian ini kami tidak dapat benar-benar menggunakan matriks ini sebagai patokan pengguna dalam menilai aplikasi mengingat kami tidak memiliki lebih banyak data untuk mengklarifikasinya.
Berdasarkan pelatihan dan pengujian yang telah dilakukan, didapatkan disimpulkan bahwa bahwa Algoritma Decission Tree (DT) dan Random Forest (RF) memiliki nilai akurasi tertinggi dalam setiap pelatihan. Maksimum nilai akurasi dalam pelatihan menggunakan model DT dan RF adalah 96,55%, dengan skenario data latih 70%, data uji 30% pada dataset Shopee. Sedangkan nilai akurasi maksimum dalam pengujian menggunakan metode SVM-RBF dan RF adalah 60.08% dengan skenario 80% data latih dan 20% data uji pada dataset Tokopedia. Dengan demikian berdasarkan penelitian yang telah dilakukan, Algoritma Random Forest merupakan metode terbaik untuk kajian analisis sentimen review aplikasi marketplace di Google Playstore ini.
Menurut penelitian ini, untuk lebih memperkuat hasil Analisa sentiment, perlu dilakukan penelitian lebih lanjut yaitu analisis sentiment yang berbasis Leksikon sehingga benar-benar dapat memberikan gambaran secara utuh terhadap sentimen setiap review penggunanya. Namun penelitian analisis sentimen berbasis leksikon memiliki banyak tantangan, terlebih lagi analisis sentimen dalam Bahasa Indonesia yang memiliki beragam Bahasa campuran, slang word, dan Bahasa daerah yang seringkali terdapat dalam review pengguna aplikasi Google Playstore, hal ini tentunya memberikan peluang bagi penelitian selanjutnya untuk memberikan kontribusi lebih baik pada penelitian analisis sentimen berbahasa Indonesia.
UCAPAN TERIMA KASIH
Terima kasih kepada Lembaga Penelitian dan Pengabdian Masyarakat (LPPM) Universitas Widyagama Malang yang telah mendukung penelitian ini melalui program Hibah Penelitian Internal (PERINTIS).
REFERENSI
[1] M. I. Ahmadi, F. Apriani, M. Kurniasari, S. Handayani, and D. Gustian, “SENTIMENT ANALYSIS ONLINE SHOP ON THE PLAY STORE USING METHOD SUPPORT VECTOR MACHINE (SVM),” p. 8, 2020.
[2] R. Wahyudi and G. Kusumawardhana, “Analisis Sentimen pada review Aplikasi Grab di Google Play Store Menggunakan Support Vector Machine,” J. Inform., vol. 8, no. 2, p.
8, 2021.
[3] S. Moghaddam, “Beyond Sentiment Analysis: Mining Defects and Improvements from Customer Feedback,” in Advances in Information Retrieval, vol. 9022, A. Hanbury, G.
Kazai, A. Rauber, and N. Fuhr, Eds. Cham: Springer International Publishing, 2015, pp.
400–410. doi: 10.1007/978-3-319-16354-3_44.
Seminar Nasional Hasil Riset Prefix - RTR
482
[4] A. Bezerra, I. Silva, L. A. Guedes, D. Silva, G. Leitão, and K. Saito, “Extracting Value from Industrial Alarms and Events: A Data-Driven Approach Based on Exploratory Data Analysis,” Sensors, vol. 19, no. 12, p. 2772, Jun. 2019, doi: 10.3390/s19122772.
[5] N. Kamaruddin, S. A. Abas, and A. Wahab, “Comparative Study on Sentiment Analysis Approach for Online Shopping Review,” Turk. J. Comput. Math. Educ. TURCOMAT, vol.
12, no. 3, pp. 1358–1370, Apr. 2021, doi: 10.17762/turcomat.v12i3.907.
[6] V. A. and S. S. Sonawane, “Sentiment Analysis of Twitter Data: A Survey of Techniques,”
Int. J. Comput. Appl., vol. 139, no. 11, pp. 5–15, Apr. 2016, doi:
10.5120/ijca2016908625.
[7] U. Rhohmawati, I. Slamet, and H. Pratiwi, “Sentiment Analysis Using Maximum Entropy on Application Reviews (Study Case: Shopee on Google Play),” J. Ilm. Tek.
Elektro Komput. Dan Inform., vol. 5, no. 1, Jul. 2019, doi: 10.26555/jiteki.v5i1.13087.
[8] M. Azhar, N. Hafidz, B. Rudianto, and W. Gata, “Marketplace Sentiment Analysis Using Naive Bayes And Support Vector Machine,” PIKSEL Penelit. Ilmu Komput. Sist. Embed.
Log., vol. 8, no. 2, pp. 91–100, Sep. 2020, doi: 10.33558/piksel.v8i2.2272.
[9] S. Fransiska and A. I. Gufroni, “Sentiment Analysis Provider by.U on Google Play Store Reviews with TF-IDF and Support Vector Machine (SVM) Method,” Sci. J. Inform., vol.
7, no. 2, p. 10, 2020.
[10] S. Ranjan and S. Mishra, “Comparative Sentiment Analysis of App Reviews,”
ArXiv200609739 Cs Stat, Jun. 2020, Accessed: Dec. 12, 2021. [Online]. Available:
http://arxiv.org/abs/2006.09739
[11] A. Rahman, E. Utami, and S. Sudarmawan, “Sentimen Analisis Terhadap Aplikasi pada Google Playstore Menggunakan Algoritma Naïve Bayes dan Algoritma Genetika,” J.
Komtika Komputasi Dan Inform., vol. 5, no. 1, pp. 60–71, Jul. 2021, doi:
10.31603/komtika.v5i1.5188.
[12] B. Gupta, M. Negi, K. Vishwakarma, G. Rawat, and P. Badhani, “Study of Twitter Sentiment Analysis using Machine Learning Algorithms on Python,” Int. J. Comput.
Appl., vol. 165, no. 9, pp. 29–34, May 2017, doi: 10.5120/ijca2017914022.
[13] M. Rahmany, A. M. Zin, and E. A. Sundararajan, “COMPARING TOOLS PROVIDED BY PYTHON AND R FOR EXPLORATORY DATA ANALYSIS,” IJISCS Int. J. Inf. Syst. Comput.
Sci., vol. 4, no. 3, Art. no. 3, Nov. 2020.
[14] S. W. Iriananda, M. A. Muslim, and H. S. Dachlan, “Identifikasi Kemiripan Teks Menggunakan Class Indexing Based dan Cosine Similarity Untuk Klasifikasi Dokumen Pengaduan,” MATICS, vol. 10, no. 2, p. 30, Mar. 2019, doi: 10.18860/mat.v10i2.5327.
[15] H. Nguyen, A. Veluchamy, M. Diop, and R. Iqbal, “Comparative Study of Sentiment Analysis with Product Reviews Using Machine Learning and Lexicon-Based Approaches,” vol. 1, no. 4, p. 23, 2018.
[16] S. Robertson, “Understanding inverse document frequency: on theoretical arguments for IDF,” J. Doc., vol. 60, no. 5, pp. 503–520, Oct. 2004, doi:
10.1108/00220410410560582.
[17] K. Spärck Jones, “IDF term weighting and IR research lessons,” J. Doc., vol. 60, no. 5, pp. 521–523, Oct. 2004, doi: 10.1108/00220410410560591.
[18] Ö. Akar and O. Güngör, “Classification of multispectral images using Random Forest algorithm,” J. Geod. Geoinformation, vol. 1, no. 2, pp. 105–112, 2012, doi:
10.9733/jgg.241212.1.
[19] G. Khanvilkar and Prof. Deepali Vora, “Sentiment Analysis for Product Recommendation Using Random Forest,” Int. J. Eng. Technol., vol. 7, no. 3.3, p. 87, Jun.
2018, doi: 10.14419/ijet.v7i3.3.14492.