BAB 2
LANDASAN TEORI
2.1.Citra
Citra (image) sebagai salah satu komponen multimedia memegang peranan sangat
penting sebagai bentuk informasi visual. Citra mempunyai karakteristik yang tidak
dimiliki oleh data teks, yaitu citra kaya dengan informasi. Sebuah gambar dapat
memberikan informasi yang lebih banyak daripada informasi tersebut disajikan dalam
bentuk kata-kata (tekstual) (Munir, R. 2004).
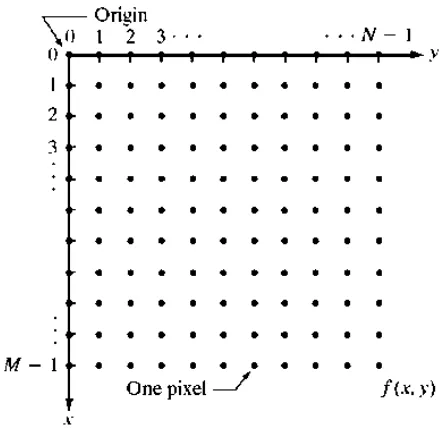
Satuan atau bagian terkecil dari suatu citra disebut piksel (pixel atau picture
element) yang berarti elemen citra. Sebuah citra adalah kumpulan piksel-piksel yang
disusun dalam larik dua-dimensi. Indeks baris dan kolom (x, y) dari sebuah piksel
dinyatakan dalam bilangan bulat. Untuk menunjukkan lokasi suatu piksel, koordinat (0,
0) digunakan untuk posisi kiri atas dalam bidang citra, dan koordinat (m-1, n-1)
digunakan untuk posisi kanan bawah dalam citra berukuran mxn piksel seperti pada
Gambar 2.1. Untuk menunjukkan tingkat pencahayaan suatu piksel, seringkali
digunakan bilangan bulat yang besarnya 8-bit, dengan lebar selang nilai 0 – 255, dimana
0 untuk warna hitam, 255 untuk warna putih dan tingkat abu-abu berada di antara
Gambar 2.1 Koordinat bidang citra
2.1.1. Pengolahan citra
Pengolahan citra adalah pemrosesan citra, menjadi citra yang kualitasnya lebih baik
(Munir, R. 2004). Menurut Hermawati, F.A. (2013), tujuan pengolahan citra adalah:
1. Untuk memperbaiki kualitas citra (gambar) dilihat dari aspek radiometrik
(peningkatan kontras, transformasi warna, restorasi citra) atau dari aspek
geometrik (rotasi, translasi, skala, transformasi geometrik).
2. Melakukan proses penarikan informasi, deskripsi objek atau pengenalan objek
terhadap pola yang terkandung di dalam citra.
3. Melakukan kompresi atau reduksi data untuk penyimpanan data, transmisi data,
dan waktu proses data.
2.1.2. Segmentasi citra
Segmentasi merupakan proses membagi suatu citra ke dalam komponen-komponen
region atau objek (Hermawati, F.A. 2013). Menurut Zhou, et al. (2010), segmentasi
citra secara umum dilakukan berdasarkan diferensiasi warna, sehingga citra tersebut
akan melalui proses pengelompokan yang memungkinkan piksel-piksel dipisahkan
sesuai dengan intensitas warna. Salah satu skema segmentasi adalah thresholding (atau
binerisasi) dimana ambang batas ditentukan secara manual atau empiris. Sebagai
histogram. Namun, segmentasi ini terkadang dapat mengarah kepada hasil
pengelompokan yang keliru jika piksel citra tersebar secara berantakan.
2.1.3. Citra biner
Citra biner (binary image) adalah citra yang hanya mempunyai dua nilai derajat
keabuan: hitam dan putih. Piksel-piksel objek bernilai 1 dan piksel-piksel latar belakang
bernilai 0. Pada waktu menampilkan gambar, 0 adalah putih dan 1 adalah hitam. Jadi,
pada citra biner, latar belakang berwarna putih sedangkan objek berwarna hitam (Munir,
R. 2004). Berikut contoh citra biner pada Gambar 2.2.
Gambar 2.2 Contoh citra teks biner (Kasar, T. 2007)
Menurut Ahmad, U. (2005), citra biner hanya membutuhkan memori 1 bit untuk
menyimpan data satu piksel sehingga algoritma untuk citra biner dapat berjalan lebih
cepat dan prosesnya lebih murah dibandingkan dengan proses pada citra abu-abu.
Sebagai perbandingan, citra abu-abu dengan intensitas 256 tingkat membutuhkan
memori delapan kali lebih besar dibandingkan dengan memori yang dibutuhkan oleh
citra biner untuk tingkat resolusi citra yang sama.
2.1.4. Pengenalan pola citra
Pengenalan pola mengelompokkan data numerik dan simbolik (termasuk citra) secara
otomatis oleh mesin (dalam hal ini komputer). Tujuan pengelompokan adalah untuk
mengenali suatu objek di dalam citra. Manusia bisa mengenali objek yang dilihatnya
karena otak manusia telah belajar mengklasifikasi objek-objek di alam sehingga mampu
membedakan suatu objek dengan objek lainnya. Kemampuan sistem visual manusia
inilah yang dicoba ditiru oleh mesin. Komputer menerima masukan berupa citra objek
deskripsi objek
deskripsi objek di dalam citra (Munir, R. 2004). Ilustrasi pengenalan pola pada citra
dapat dilihat pada Gambar 2.3.
Gambar 2.3 Ilustrasi pengenalan pola
Contoh pengenalan pola misalnya pada Gambar 2.4 adalah salah satu huruf kemasan
makanan yang digunakan sebagai data masukan untuk mengenali karakter ‘S’. Dengan
menggunakan algoritma pengenalan pola, diharapkan komputer dapat mengenali bahwa karakter tersebut adalah ‘S’.
Gambar 2.4 Citra karakter ‘S’ untuk pengenalan huruf
2.2.Binerisasi Otomatis
Operasi binerisasi secara manual akan merepotkan dan menyebabkan penundaan, tidak
dapat diterapkan untuk operasi real-time, di mana pengambilan citra melalui kamera
dan operasi binerisasi serta operasi-operasi lainnya dilakukan secara
berkesinambungan. Alternatif lainnya adalah dengan memberikan suatu nilai yang tetap
dalam algoritma program. Untuk dapat memilih nilai batas atau nilai threshold yang
tepat secara otomatis, pengetahuan tentang objek dalam pemandangan, pengetahuan
tentang aplikasi dan pengetahuan tentang lingkungan harus digunakan di dalam
algoritma program komputer yang dikembangkan. Pengenalan
Binerisasi otomatis menganalisis distribusi nilai abu-abu di dalam citra untuk
memilih nilai threshold yang paling mendekati. Kebanyakan metoda binerisasi otomatis
menggunakan ukuran dan probabilitas distribusi intensitas dengan menghitung
histogram intensitas dari citra (Ahmad, U. 2005).
2.2.1. Dasar-dasar thresholding citra
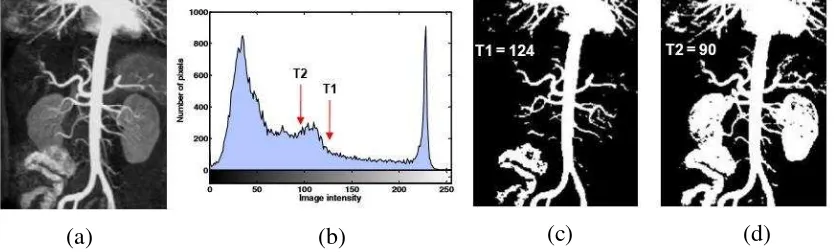
Thresholding dengan histogram adalah salah satu teknik yang populer untuk segmentasi
citra monokrom (Gambar 2.5). Salah satu cara yang jelas untuk mengekstraksi objek
dari latar belakang adalah untuk memilih ambang batas (threshold) yang memisahkan
histogram. Setiap titik , dengan ketentuan , (misal = ) disebut
sebagai titik objek. Selain dari itu, titik ini disebut titik background. Dengan kata lain,
citra yang telah melalui tahap pengambangan , didefinisikan sebagai:
, = { if if ,, < (Zhou, et al. 2010) (2.1)
Keterangan :
, = Matriks nilai biner citra , = Matriks nilai grayscale citra = Nilai ambang batas (threshold)
Gambar 2.5 Thresholding citra berdasarkan histogram (Zhou, et al. 2010) 2.2.2. Global optimal thresholding
Global thresholding hanya menggunakan satu nilai ambang pada atribut citra global
yang dapat diestimasi berdasarkan statistik ataupun heuristik, kemudian
mengklasifikasikan bagian piksel-piksel citra apakah termasuk ke dalam foreground
atau background. Kelemahan utama dari metode global thresholding adalah metode
tersebut tidak dapat membedakan piksel-piksel yang memiliki tingkat keabuan yang
sama namun termasuk ke dalam kelompok yang berbeda. Metode global optimal
thresholding melibatkan iterasi melalui semua kemungkinan nilai ambang dan memilih
nilai yang optimal untuk keseluruhan citra (Som, et al. 2011).
Menurut Ahmad, U. (2005), langkah-langkah dalam menentukan nilai batas
threshold secara global dengan metode iterasi adalah sebagai berikut:
1. Pilih nilai awal untuk operasi threshold, dengan merupakan nilai rata-rata
dari intensitas citra keseluruhan.
2. Bagi citra menjadi dua daerah, � dan � , menggunakan nilai awal.
3. Hitung nilai rata-rata intensitas � dan � masing-masing daerah � dan � .
4. Hitung nilai threshold yang baru dengan rumus =µ +µ .
5. Ulangi langkah (2) sampai (4) hingga nilai-nilai � dan � tidak berubah lagi.
2.2.3. Adaptive local thresholding
Dalam thresholding secara lokal, nilai-nilai ambang batas secara spasial bervariasi dan
ditentukan berdasarkan konten lokal dari citra yang digunakan. Perbedaannya dengan
metode global adalah thresholding lokal memiliki kinerja yang lebih baik terhadap
noise ataupun kesalahan yang muncul akibat suatu informasi penting yang berdekatan
dengan bagian citra teks atau objek citra (Som, et al. 2011).
Pendekatan langsung dalam metode adaptif adalah dengan membagi citra
menjadi beberapa bidang berukuran × lalu memilih threshold untuk bagian
citra berdasarkan histogram dari bagian ke- ( , ). Hasil akhir dari proses ini
adalah gabungan dari daerah pada bagian-bagian citra tadi, yang sebenarnya berasal
dari satu citra yang lebih besar (Ahmad, U. 2005). Gambar 2.6 menunjukkan perbedaan
(a) (b)
Gambar 2.6 Perbedaan global dengan adaptif thresholding (Zhou, et al. 2010)
Menurut Hermawati, F.A. (2013), langkah-langkah dalam melakukan proses
thresholding secara adaptif adalah sebagai berikut:
1. Ambil subcitra pertama berukuran × .
2. Hitung variance dari subcitra tersebut setelah melakukan perhitungan mean.
Rumus Mean Subcitra :
= ̅ = ∑=
Rumus Varians Subcitra :
=∑= −− ̅
3. Jika > , maka = x � − i �, kemudian gunakan nilai T
untuk melakukan global thresholding.
4. Jika , maka = x � − i � , kemudian gunakan langsung
nilai T untuk menentukan output citra biner.
5. Ulangi langkah (1) dengan subcitra selanjutnya sampai semua subcitra selesai
diproses.
2.3.Optical Character Recognition (OCR)
OCR adalah sebuah pendekatan yang menyediakan pengenalan karakter alfanumerik
baik yang berupa tulisan tangan maupun computer text hanya dengan memindai citra (2.2)
tersebut secara digital dan mengubahnya menjadi bentuk yang dapat di-scan melalui
scanner, kemudian sistem OCR menafsirkan citra tadi dan mengubahnya menjadi data
ASCII. Pengenalan karakter seperti ini juga populer disebut sebagai Optical Character
Recognition (OCR). OCR merupakan salah satu bidang penelitian yang memiliki
potensi besar di masa depan dimana kita ingin melacak dan mencari setiap informasi
yang dipertukarkan. Masalah yang sering timbul terdapat pada tulisan tangan, hal ini
dikarenakan ketidakpastian seperti variasi dalam model kaligrafi, kesamaan dalam teks
tulisan dan variasi dalam gaya penulisan (Patel, U. 2013).
2.3.1. Tahapan proses OCR
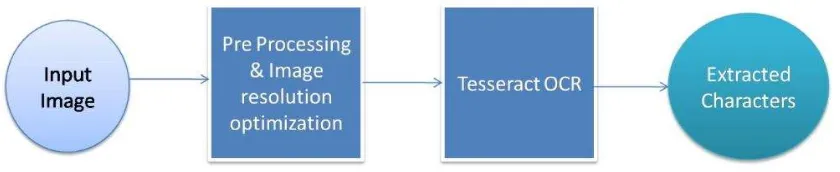
Menurut Patel, U. (2013), tahapan-tahapan proses yang terjadi pada saat pengenalan
suatu karakter teks adalah input data citra, pre-processing, segmentasi teks, normalisasi,
ekstraksi fitur, klasifikasi dan post-processing seperti pada Gambar 2.7.
Gambar 2.7 Tahapan OCR (Patel, U. 2013) 2.3.2. Tesseract OCR
Tesseract menduduki peringkat salah satu dari tiga engine pada tahun 1995 yang
akurasinya diuji oleh Universitas Nevada, Las Vegas. Tesseract mengalami kemajuan
yang signifikan setelah kemudian diambil alih oleh Google. Tesseract merupakan salah
satu OCR engine open source yang paling akurat dalam hal pendeteksian. Tesseract
dapat diterapkan pada Linux, Windows dan Mac OSX. Selain itu, Tesseract juga dapat
sekitar 149 bahasa yang didukung Tesseract yang berasal dari paket-paket. Tesseract
adalah sistem deteksi berbasis teks dengan berbagai bahasa yang dapat kita manipulasi
dan dapat juga dikembangkan engine tersebut dengan data pelatihan sendiri (Badla, S.
2014).
2.3.3. Cara kerja Tesseract OCR
Menurut Badla, S. (2014), hal yang penting dilakukan agar mendapatkan akurasi deteksi
teks yang tepat adalah pada saat pre-processing.
Gambar 2.8 Proses utama Tesseract OCR (Badla, S. 2014)
Gambar 2.8 menunjukkan bahwa ada dua subsistem utama yang dikerjakan.
Pertama adalah tahap pre-processing dan yang kedua adalah tahap Tesseract OCR.
Tahap yang menjadi fokus adalah tahap pre-processing dimana sebelum melalui proses
pengenalan, citra harus disederhanakan agar memudahkan pada saat tahap Tesseract.
Proses waktu yang digunakan juga harus ditinjau pada saat tahap pre-processing agar
tidak menambah running-time.
Proses pengenalan karakter menggunakan data latih berupa kamus data karakter
yang tersedia pada Tesseract. Setelah proses pre-processing, tahap selanjutnya akan
dilakukan tahapan pengenalan karakter yang terdiri dari proses feature extraction,
segmentasi, dan word recognition. Proses feature extraction dilakukan untuk
mendapatkan outline karakter, sedangkan proses segmentasi melakukan pemotongan
karakter pada teks. Pada proses word recognition, hasil segmentasi akan dicocokkan
dengan data latih berdasarkan bahasa yang sesuai. Library Tesseract akan ditanamkan
pada sistem aplikasi berbasis Android sehingga citra yang menjadi masukan akan
2.4.Penelitian yang Relevan
Berikut beberapa penelitian yang relevan dengan algoritma Thresholding Adaptif dan
Tesseract OCR:
1. Nugroho Meganofa (2015) dalam skripsi yang berjudul Aplikasi Pencari Info
Obat dengan Masukan Citra Teks Kemasan Obat Berbasis Android
Menggunakan Tesseract OCR Engine. Dapat disimpulkan bahwa aplikasi info
obat mampu mengenali citra teks kemasan obat dengan tingkat akurasi terbaik
mencapai 96.80% dari 70 citra teks kemasan obat yang diuji dengan jenis font
Serif dan Sans Serif. Nilai usability aplikasi terhadap responden mendapat hasil
sebesar 86.93%.
2. Eka Mala Sari Rochman (2011) dalam jurnal yang berjudul Algoritma
Thresholding Adaptif untuk Binerisasi Citra Dokumen Berwarna. Dapat
disimpulkan bahwa penelitian dilakukan dengan thresholding secara adaptif
pada citra dokumen berwarna dengan mengekstraksi foreground dan melakukan
binerisasi pada masing-masing foreground dengan ambang yang berbeda. Uji
coba dilakukan terhadap 8 citra dokumen dan rata-rata tingkat pengenalan