ANALISA PERBANDINGAN TEKNIK-TEKNIK DATA MINING UNTUK
PREDIKSI PRESTASI AKADEMIK SISWA
Imam Syaifuddin(1), Reddy Alexandro Harianto(2)
Sekolah Tinggi Teknik Surabaya
e-mail: drimamskom@hotmail.com(1), reddy@stts.edu(2)
ABSTRAK
Kemampuan untuk memprediksi kinerja akademik siswa sangat penting dalam sistem pendidikan. Banyak penelitian yang dilakukan untuk memprediksi prestasi akademik, penelitian ini menelaah beberapa kajian tentang pemanfaatan data mining untuk memprediksi prestasi akademik siswa. Berbagai metode dan algoritma data mining digunakan dalam memprediksi prestasi akademik, pada penelitian ini dilakukan perbandingan dua model prediksi prestasi akademik siswa yaitu penggunaan Algoritma Decision Tree dan Bayesian Network. Hasil dari metode yang di teliti mempunyai akurasi yang hampir sama, Algoritma Decision Tree rata-rata akurasi mencapai 97,5669% sedangkan Bayesian Network rata-rata akurasinya 94,8199%. Hasil dari penelitian ini sangat membantu bagi lembaga pendidikan untuk memantau secara dini prestasi akademik siswa, sehingga bisa dilakukan pendampingan proses belajar agar dapat tercapai prestasi yang diharapkan.
Kata kunci: Data Mining, Decison Tree, Multi Layer Perceptron, Prestasi akademik
ABSTRACT
The ability to predict the academic aptitude of students is very important in an education system. Many researches have been done to predict academic achievement, this research involves a few prior studies in the usage of data mining to predict students' academic achievements. There are many methods and algorithms in data mining that can be used to predict academic achievement, in this research a comparison will be done between two student academic achievement prediction models, the Decision Tree Algorithm and Bayesian Network. Results from the chosen methods have similar accuracy rates, with the Decision Tree Algorithm achieving an average of 97.5669% accuracy, whereas the Bayesian Network reaches an average accuracy of 94.8199%. The result of this research is useful for educational institutes to observe students' academic achievement from early on, so assistance in the learning process can be given in order to reach the expected achievement.
Keywords: Data Mining, Decison Tree, Multi Layer Perceptron, Academic Performance.
PENDAHULUAN
Pendidikan adalah pembelajaran pengetahuan, keterampilan, dan kebiasaan sekelompok orang yang diturunkan dari satu generasi ke generasi berikutnya melalui pengajaran, pelatihan, atau penelitian [1]. Dalam sebuah proses pendidikan terdapat suatu sistem yang menunjang terhadap siklus pendidikan, sistem tersebut saling menunjang sehingga menghasilkan output yang diharapkan. Kegagalan salah satu sistem akan mengakibatkan output yang tidak diharapkan. Banyak upaya preventif yang dilakukan oleh lembaga pendidikan agar sistem berfungsi sebagaimana mestinya agar menghasilkan output yang maksimal.
Salah satu yang dapat digunakan untuk memantau proses kegiatan pembelajaran adalah dengan data mining. Data Mining adalah suatu istilah yang digunakan untuk menemukan pengetahuan yang tersembunyi di dalam database. Data mining merupakan proses semi otomatik yang menggunakan teknik statistik, matematika, kecerdasan buatan dan mechine learning untuk mengekstraksi dan mengidentifikasi informasi pengetahuan potensial dan berguna yang bermanfaat yang tersimpan di dalam database besar. Berbagai metode data mining dalam melakukan analisa dan prediksi prestasi akademik, baik
menggunakan algoritma tunggal maupun penggabungan beberapa algoritma dengan tujuan mendapatkan hasil yang lebih baik. Diantaranya adalah:
Kajian yang dilakukan Behrouz Minaei Bidgoli dkk terhadap sistem pendidikan berbasis web untuk memprediksi prestasi akademik, yang mana semua siswa berinteraksi dengan sistem tersebut, mereka merancang, mengimplementasikan dan mengevaluasi serangkaian pola lalu membandingkan kinerja siswa. Selanjutnya dengan belajar suatu bobot yang sesuai dengan fitur yang digunakan pada algoritma genetika proses prediksi selanjutnya dilakukan.
Selanjutnya kajian dengan topik yang sama juga dilakukan V. Ramesh, dkk dalam memprediksi prestasi akademik siswa pada lembaga pendidikan yang mana faktor personal, sosial-ekonomi, psikologi dan variabel lingkungan dikaji, mereka menggunakan klasifikasi, pohon keputusan dan Naive Bayes dengan metode multi layer perception. Penelitian ini dilakukan pada sekolah yang menerapkan sistem pendidikan berbasis teknologi informasi yang memanfaatkan berbagai sarana pendidikan berbasis sistem yang terdiri atas sistem kehadiran yang mewajibkan semua siswa melaksanakan absensi fingerprint, sistem penilaian dan sistem konseling yang terintegrasi untuk memprediksi prestasi akademik. Semua siswa berinteraksi dengan sistem tersebut, sehingga data yang dihasilkan oleh sistem yang digunakan dapat digunakan untuk diteliti dan dievaluasi untuk membentuk serangkaian pola sehingga dapat memprediksi kinerja siswa. Selanjutnya dengan belajar suatu bobot yang sesuai dengan fitur yang digunakan pada algoritma genetika proses prediksi selanjutnya dilakukan.
Penelitian ini sangat berguna untuk mengidentifikasi prestasi siswa lebih dini, sehingga dapat di pantau untuk segera diberikan tindakan pada siswa agar mendapatkan prestasi yang optimal. Tujuan utama dari penelitian ini adalah:
Mengidentifikasi variabel sekunder yang dapat mempengaruhi prestasi akademik siswa
Memprediksi nilai akademik siswa berdasarkan aktivitas melakukan absensi melalui fingerprint Memprediksi perilaku dan akhlak siswa agar
dilakukan penganan lebih dini
Mengidentifikasi kelompok siswa terhadap variabel yang di berikan sebagai tolak ukur penelitian.
Mengelompokkan problem yang dihadapi siswa sehingga dapat diberikan prioritas penanganan Mencari algoritma terbaik yang bisa digunakan
untuk melakukan Identifikasi terhadap prestasi akademik siswa.
Pada bagian berikut kita akan menggambarkan metodologi keseluruhan penelitian, platform data-mining, model dan akan membandingkan tiap algoritma yang digunakan serta hasil akhir dari algoritma dalam memprediksi prestasi akademik siswa.
METODOLOGI
Pada bagian ini membahas proses yang dilakukan dalam melakukan penelitian terhadap prediksi prestasi akademik siswa, bagaimana tahapan masing-masing peneliti dalam mengumpulkan data dan menganalisanya.
Dalam literatur data mining, berbagai kerangka umum telah dikenalkan bagaimana tata laksana pengumpulan data, menganalisa data, menyebarluaskan hasil, menerapkan hasil dan pemantauan perbaikan.
Salah satu model adalah CRISP-DM (Proses Cross-Industry Standard untuk data mining) diusulkan pada pertengahan 1990-an oleh konsorsium Eropa Metodologi CRISP-DM terutama terdiri dari enam langkah: memahami tujuan, mengumpulkan data, menyiapkan data, membangun model, mengevaluasi model menggunakan salah satu metode evaluasi, dan akhirnya penyebaran yang menggunakan model untuk prediksi masa depan dari kinerja siswa.
Sebelum pengumpulan data, pertama-tama tentukan perangkat yang digunakan dalam memproses dan menganalisa data mining, banyak sekali perangkat yang ditawarkan dalam pengelolaan data-mining, baik yang berbayar maupun yang open source, dari 30 daftar perangkat data-mining, kita menyeleksi 10 perangkat yang dapat digunakan untuk menganalisa dan memproses data dengan kapasitas yang besar, kemudian dari 10 perangkat kita seleksi menjadi 3 tool yaitu: weka, orange dan yale, dari 3 perangkat, weka sangat baik dalam proses data mining dengan data yang sangat besar.
1. Persiapan Data
Data adalah salah satu bagian penting dari penelitian, ada beberapa langkah yang perlu diperhatikan dalam pengumpulan data, antara lain: Mengidentifikasi variabel-variabel yang diteliti Menjabarkan variabel-variabel dalam beberapa
dimensi
Mencari indikator-indikator setiap dimensi Mendeskripsikan kisi-kisi instrumen
Merumuskan item-item pertanyaan atau pernyataan instrumen.
Selama pengumpulan data, data yang relevan dikumpulkan dan kualitas data harus diverifikasi. Biasanya, data yang dikumpulkan tidak lengkap, mengandung kesalahan dan tidak konsisten. Oleh karena itu data harus dibersihkan agar hasil yang didapatkan dalam proses data mining lebih akurat. Pembersihan data melibatkan beberapa proses seperti mengisi nilai-nilai yang hilang; smoothing data, mengidentifikasi atau menghapus outlier, dan menyelesaikan inkonsistensi. Kemudian, data dibersihkan diubah menjadi bentuk tabel yang cocok untuk model data mining. Data yang dibersihkan akan dibagi menjadi dua; pelatihan atau data pembelajaran (60%) dan sisanya adalah untuk memvalidasi data. Pelatihan data ini diterapkan untuk mengembangkan model sedangkan data divalidasi digunakan untuk memverifikasi model yang dipilih.
Pengumpulan data yang berpengaruh pada prestasi akademik siswa diidentifikasi, sejumlah faktor yang dianggap memiliki pengaruh dikategorikan sebagai variabel input sedangkan Variabel output pada sisi lain mewakili beberapa nilai, Data primer dikumpulkan dari siswa dan data sekunder dikumpulkan dari sekolah.
Data primer dikumpulkan melalui kuesioner yang dibagikan kepada siswa secara acak, pertanyaan yang dihimpun melalui kuesioner berisi tentang aspek personal, sosial-ekonomi dan psikologi responden yang berhubungan erat dengan aspek-aspek untuk prestasi akademik siswa.
Persiapan data akademik dilakukan dengan menganalisis dan menyiapkan data historis penilaian tiap mata pelajaran dari catatan akademis pada sekolah yang dikumpulkan pada periode semester ganjil 2015/2016, berdasarkan model penilaian kurikulum 2013 yang diklasifikasikan dalam 10 kelompok, rentang nilai yang diberikan tiap mata pelajaran seperti pada Tabel 1.
Tabel 1: Tabel Skala Penilaian berdasarkan Kurikulum 2013
No. SKOR NILAI 1 0.00 skor 1,00 D 2 1,00 skor ≤ 1,33 D + 3 1,33 skor ≤ 1,66 C - 4 1,66 skor ≤ 2,00 C 5 2,00 skor ≤ 2,33 C + 6 2,33 skor ≤ 2,66 B - 7 2,66 skor ≤ 3,00 B 8 3,00 skor ≤ 3,33 B + 9 3,33 skor ≤ 3,66 A - 10 3,66 skor ≤ 4,00 A
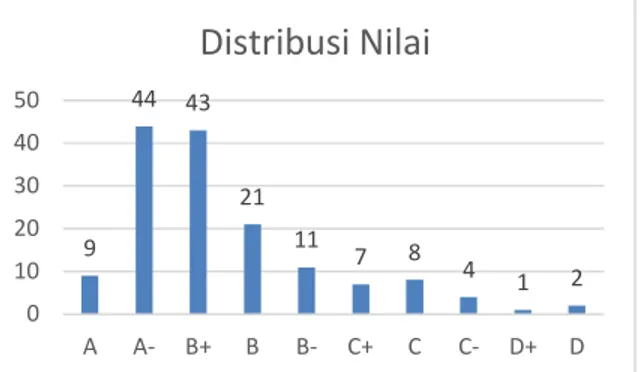
Hasil pengelompokan untuk persiapan data seperti pada Gambar 1, data yang diperoleh pada grafik adalah hasil distribusi nilai pada persiapan data, yang proses pengelompokan nilai berdasarkan Tabel 1.
Gambar 1: Distribusi Nilai yang dikumpulkan dari sekolah
Selain data nilai akademik data yang digunakan dalam penelitian ini adalah data absensi siswa. Data absensi siswa digunakan sebagai variabel pendukung yang berhubungan dengan prestasi akademik siswa. Sistem kehadiran pada sekolah ini menggunakan fingerprint yang direkam setiap hari oleh sekolah, pre processing data dilakukan untuk menghasilkan data prosentase kehadiran tiap bulan, berdasarkan Persamaan 1.
= ∑ (1)
Selanjutnya data prosentase tiap bulan jumlah kan berdasarkan Persamaan 2.
=∑ (2)
Kemudian data prosentase tiap semester dikonversi menjadi {A, B, C, D, E}, dengan rentang data prosentase untuk A: 85-100, B: 75-84, C:55-74, D: 35-54 dan E:0-34. 9 44 43 21 11 7 8 4 1 2 0 10 20 30 40 50 A A- B+ B B- C+ C C- D+ D
Distribusi Nilai
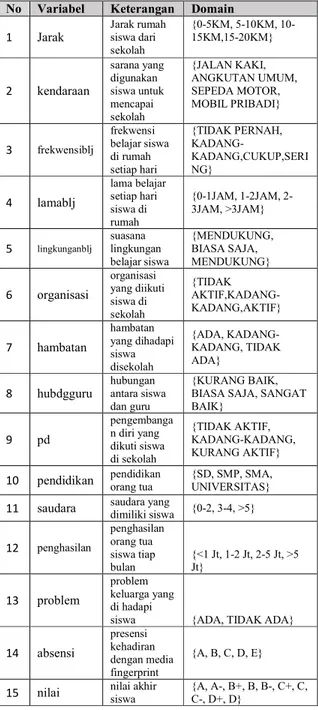
Data Primer yang diperoleh dari siswa melalui kuesioner, digunakan sebagai variabel prediksi disajikan dalam Tabel 2.
Tabel 2: Variabel dan Domain yang digunakan No Variabel Keterangan Domain
1 Jarak Jarak rumah siswa dari sekolah {0-5KM, 5-10KM, 10-15KM,15-20KM} 2 kendaraan sarana yang digunakan siswa untuk mencapai sekolah {JALAN KAKI, ANGKUTAN UMUM, SEPEDA MOTOR, MOBIL PRIBADI} 3 frekwensiblj frekwensi belajar siswa di rumah setiap hari {TIDAK PERNAH, KADANG-KADANG,CUKUP,SERI NG} 4 lamablj lama belajar setiap hari siswa di rumah {0-1JAM, 1-2JAM, 2-3JAM, >3JAM} 5 lingkunganblj suasana lingkungan belajar siswa {MENDUKUNG, BIASA SAJA, MENDUKUNG} 6 organisasi organisasi yang diikuti siswa di sekolah {TIDAK AKTIF,KADANG-KADANG,AKTIF} 7 hambatan hambatan yang dihadapi siswa disekolah {ADA, KADANG-KADANG, TIDAK ADA} 8 hubdgguru hubungan antara siswa dan guru {KURANG BAIK, BIASA SAJA, SANGAT BAIK} 9 pd pengembanga n diri yang dikuti siswa di sekolah {TIDAK AKTIF, KADANG-KADANG, KURANG AKTIF}
10 pendidikan pendidikan orang tua {SD, SMP, SMA, UNIVERSITAS} 11 saudara saudara yang dimiliki siswa {0-2, 3-4, >5}
12 penghasilan penghasilan orang tua siswa tiap bulan {<1 Jt, 1-2 Jt, 2-5 Jt, >5 Jt} 13 problem problem keluarga yang di hadapi
siswa {ADA, TIDAK ADA}
14 absensi presensi kehadiran dengan media fingerprint {A, B, C, D, E}
15 nilai nilai akhir siswa {A, A-, B+, B, B-, C+, C, C-, D+, D}
Selanjutnya dari pengelompokan data tersebut dipilihlah atribut utama yang relevan sebagai variabel yang merepresentasikan dan mempengaruhi prestasi akademik siswa. Tabel 3 menunjukkan ringkasan dari atribut utama, pengelompokan data dan “Information Gain” setiap atribut untuk prediksi prestasi akademik siswa. Nilai “Information Gain” didapatkan dari nilai
entropy yang dihasilkan dari sampel yang telah di splitting menggunakan nilai pada atribut kelompok sampel tersebut. Langkah ini menggunakan induksi Decision Tree dan berguna untuk mengidentifikasi atribut-atribut yang memiliki pengaruh terbesar pada klasifikasi.
Tabel 3: Rangking Atribut yang bisa digunakan berdasarkan Information Gain
Rangking Variabel Information Gain 1 frekwensiblj 0.6655 2 jarak 0.1965 3 penghasilan 0.1654 4 lamablj 0.1593 5 pendidikan 0.1187 6 lingkunganblj 0.0907 7 saudara 0.0777 8 organisasi 0.071 9 absensi 0.0693 10 problem 0.0608 11 hubdgguru 0.0583 12 hambatan 0.0555 13 kendaraan 0.0399 14 Pd 0.0373
Proses pengelompokan untuk menentukan “Information Gain” menggunakan “atribute
evaluator”, untuk memulai pemilihan atribut maka
dua objek harus di set up, yaitu: “atribute
evaluator” dan “metode pencarian”. Evaluator
digunakan untuk menentukan atribut apa yang layak digunakan. Metode pencarian digunakan untuk menentukan teknik pencarian yang terbaik, dari 15 atribut 14 atribut yang dapat digunakan pada penelitian ini.
2. Pemodelan Prediksi Prestasi Akademik Seperti disebutkan sebelumnya, banyak sekali teknik yang digunakan para peneliti dalam memprediksi prestasi akademik siswa, pada bagian ini akan dijelaskan lebih detail teknik yang digunakan setelah persiapan data dilakukan. Teknik yang digunakan pada penelitian ini adalah menggunakan beberapa model kemudian membandingkan tiap-tiap teknik dan model yang mempunyai akurasi terbaik.
Bayesian Network merupakan salah satu teknik yang populer yang digunakan untuk prediksi suatu permasalahan karena dibangun berdasarkan teori
probabilistik dan teori graf, teori probabilistik berhubungan langsung dengan data sedangkan teori graf berhubungan langsung dengan bentuk representasi yang ingin didapatkan dalam melakukan prediksi (Heckerman, 1995).
Selain Bayesian Network, Teknik Decision Tree digunakan dalam penelitian ini, Decision Tree adalah pemetaan mengenai alternatif-alternatif pemecahan masalah yang dapat diambil dari masalah tersebut. Decision tree memperlihatkan faktor-faktor probabilitas yang akan mempengaruhi alternatif-alternatif keputusan tersebut.
Penelitian ini akan memodelkan prediksi prestasi akademik siswa dengan tiga model, model pertama berdasarkan data sebenarnya pada variabel nilai yaitu konversi nilai berupa {A, A-, B+, B, B-, C+, C, C-, D+, D}, model kedua dengan prediksi nilai berdasarkan {BAIK, GAGAL} dan model ketiga berdasarkan {BAIK, PERINGATAN,GAGAL}.
Dengan menggunakan model tersebut atribut input di perbaiki dengan mengelompokkan rentang nilai pada klasifikasi baru untuk mengevaluasi akurasi perubahan prediksi. Hasil tuning terhadap rentang nilai dengan model algoritma Decision Tree dan Bayesian Network didapatkan perbedaan hasil prediksi, seperti yang terpapar pada Tabel 4
ANALISA DAN HASIL
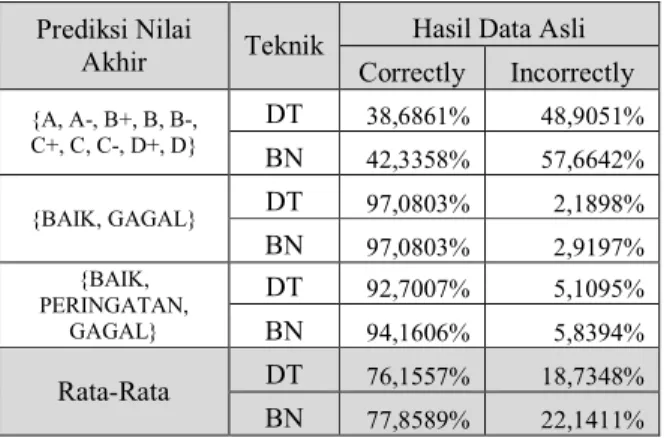
Ringkasan hasil prediksi menggunakan algoritma Decision Tree dan Bayesian Network terlihat pada Tabel 4. Hasil penelitian juga menunjukkan algoritma Bayesian Network rata-rata hasil prediksi dengan tepat mengungguli algoritma Decision Tree.
Hasil training pada teknik Decision Tree terdapat UnClassified Instances pada tiap-tiap model. Model pertama sebanyak 12,4088 % data yang tidak dapat diprediksi, sedangkan model kedua 0,7299% dan model ketiga 2,1898%, sedangkan untuk teknik yang menggunakan Bayesian Network mampu memprediksi semua data training yang di berikan. Perbandingan hasil data training pada masing-masing model berbeda akurasinya, model pertama akurasinya sangat rendah dibandingkan dengan model kedua dan ketiga. Akurasi model pertama {A, A-, B+, B, B-, C+, C, C-, D+, D}, hanya mampu memprediksi benar 38,6861% dengan teknik Decision Tree dan 42,3358% dengan menggunakan Bayesian Network dibandingkan dengan model
kedua {BAIK, GAGAL} dan model ketiga {BAIK, PERINGATAN, GAGAL} yang mencapai 90%
Tabel 4: Perbandingan Hasil TrainingDecision Tree dan Bayesian Network dengan Data Asli
Prediksi Nilai
Akhir Teknik
Hasil Data Asli Correctly Incorrectly {A, A-, B+, B, B-, C+, C, C-, D+, D} DT 38,6861% 48,9051% BN 42,3358% 57,6642% {BAIK, GAGAL} DT 97,0803% 2,1898% BN 97,0803% 2,9197% {BAIK, PERINGATAN, GAGAL} DT 92,7007% 5,1095% BN 94,1606% 5,8394% Rata-Rata DT 76,1557% 18,7348% BN 77,8589% 22,1411%
Setelah pemeriksaan hasil lebih detail menggunakan confusion matrix di temukan ada ketidakseimbangan yang besar dalam distribusi output tiap kelompok dan akurasi kelompok yang lebih kecil jauh lebih rendah dibandingkan akurasi kelompok yang lebih besar, terutama pada model pertama.
Untuk mengatasi masalah ini, maka dilakukan re-sample data menggunakan fasilitas yang ada pada weka, untuk membuat data lebih seimbang distribusinya. Prediksi menggunakan data re-sample jauh lebih akurat hasil nya yang ditunjukkan pada Tabel 5.
Tabel 5: Perbandingan Hasil TrainingDecision Tree dan Bayesian Network dengan Data Re-Sample
Prediksi Nilai
Akhir Teknik
Hasil Data Re-Sample Correctly Incorrectly {A, A-, B+, B, B-, C+, C, C-, D+, D} DT 98,5401% 1,4599% BN 91,7591 % 8,7591% {BAIK, GAGAL} DT 99,2701% 0,7299% BN 99,2701% 0,7299% {BAIK, PERINGATAN, GAGAL} DT 94,8905% 5,1095% BN 93,4307% 6,5693% Rata-Rata DT 97,5669% 2,4331% BN 94,8199% 5,3527%
Hasil menggunakan data re-sample menunjukkan teknik Decision Tree lebih unggul dengan rata-rata 97,5669% dari pada Bayesian Network yang hanya mencapai akurasi 94,8199%, juga tidak ada UnClassified Instances pada tiap-tiap model pada Teknik Decision Tree, sehingga semua instance
dapat diprediksi dengan baik. Rata-rata kemampuan prediksi yang dihasilkan pada masing-masing teknik meningkat lebih akurat dan merata pada tiap-tiap model yang diteliti.
Re-sample yang dilakukan pada data asli memberikan dampak yang signifikan terhadap pola distribusi data, sehingga membuat algoritma prediksi yang digunakan bekerja dengan optimal dengan data dan variabel yang di buat pada masing-masing metode yang diteliti.
KESIMPULAN
1. Secara umum akurasi hasil prediksi yang dilakukan menggunakan teknik Algoritma Decision tree dan Bayesian Network tidak berbeda nyata untuk ketiga model yang diteliti, kedua teknik mencapai akurasi rata-rata mencapai 90%, tetapi bila ditinjau lebih detail maka Algoritma Decision Tree lebih unggul dibandingkan Algoritma Bayesian Network. Sehingga kedua teknik Algoritma bisa direkomendasikan untuk digunakan pada kasus-kasus prediksi.
2. Hasil pengujian dari variabel input dengan menggunakan information gain, didapatkan bahwa frekuensi belajar mempunyai peranan yang sangat penting dalam memprediksi prestasi belajar siswa, dibandingkan dengan variabel-variabel lain.
3. Dari penelitian ini dapat disimpulkan bahwa data mining untuk prediksi akademik siswa dapat berguna dalam banyak konteks, untuk penerimaan siswa, dapat mengidentifikasi siswa yang layak mendapat beasiswa dan memprediksi siswa akan lulus atau tidak pada akhir studi sehingga dapat dipantau lebih dini untuk dilakukan perhatian yang lebih maksimal agar tidak terjadi kegagalan.
DAFTAR PUSTAKA
1. Muslihah Wook. 2009. Predicting NDUM Student’s Academic Performance Using Data Mining Techniques. International Conference on Computer and Electrical Engineering.
2. Nguyen Thai-Nghe, Paul Janecek, and Peter Haddawy. 2007. A Comparative Analysis of Techniques for Predicting Academic Performance. IEEE.
3. Behrouz Minaei-Bidgoli, Deborah A. Kashy, Gerd Kortemeyer'. 2003. Predicting Student Performance: an Application of Data Mining Methods With an Educational Web-Based
System, International Journal on Computer Science and Engineering November.
4. V.Ramesh, P.Parkav and K.Ramar. 2013. Predicting Student Performance: A Statistical and Data Mining Approach, International Journal of Computer Applications, Volume 63– No.8.
5. Prabowo Pudjo Widodo, dkk. 2013. Penerapan Data Mining dengan MATLAB, Rekayasa Sains, Cetakan Pertama.