KUALITAS UDARA BERDASARKAN INDEKS STANDAR
PENCEMAR UDARA (ISPU)
Diajukan untuk memenuhui salah satu syarat memperoleh gelar Sarjana Komputer
Disusun oleh:
Nama : Dani Purwanto
NIM
: 311510045
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK
UNIVERSITAS PELITA BANGSA
KABUPATEN BEKASI
i
KUALITAS UDARA BERDASARKAN INDEKS STANDAR
PENCEMAR UDARA (ISPU)
Diajukan untuk memenuhi salah satu syarat memperoleh gelar Sarjana Komputer
Disusun oleh:
Nama : Dani Purwanto
NIM
: 311510045
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK
UNIVERSITAS PELITA BANGSA
KABUPATEN BEKASI
ii
HALAMAN PERSETUJUAN
Nama : Dani Purwanto
NIM : 311510045
Program Studi : Teknik Informatika-S1
Judul Tugas Akhir : Klasifikasi Naive Bayes Untuk Memprediksi Kualitas Udara Berdasarkan Indeks Standar Pencemar Udara (ISPU)
Tugas Akhir ini telah diperiksa dan disetujui, Bekasi, 20 Desember 2019
Menyetujui:
Dosen Pembimbing I Dosen Pembimbing II
Asep Muhidin, S.Kom, M.Kom NIDN: 0403057601
Agus Suwarno, S.Kom, M.T. NIDN: 0408058302
Mengetahui:
Ka. Prodi Teknik Informatika Dekan Fakultas Teknik Universitas Pelita Bangsa
Aswan S. Sunge, SE., M.Kom NIDN: 0426018003
Putri Anggun Sari, S.Pt., M.Si. NIDN: 0424088403
iii Program Studi : Teknik Informatika-S1
Judul Tugas Akhir : Klasifikasi Naive Bayes Untuk Memprediksi Kualitas Udara Berdasarkan Indeks Standar Pencemar Udara (ISPU)
Tugas Akhir ini telah diujikan dan dipertahankan dihadapan dewan penguji pada sidang tugas akhir tanggal 11 Januari 2020. Menurut pandangan kami, tugas akhir ini
memadai dari segi kualitas maupun kuantitas untuk tujuan penganugrahan gelar Sarjana Komputer (S.Kom)
Bekasi, 11 Januari 2020 Dewan Penguji:
Dosen Penguji I
Drs. Muhtajuddin Danny, M.Kom NIDN. 0401056703
Dosen Penguji II
M. Makmun Effendi, M.Kom NIDN. 0430087804
Ka. Prodi Teknik Informatika
Aswan S. Sunge, SE., M.Kom NIDN. 0426018003
iv Nama : Dani Purwanto
NIM : 311510045
Menyatakan bahwa karya ilmiah saya yang berjudul :
Klasifikasi Naive Bayes Untuk Memprediksi Kualitas Udara Berdasarkan Indeks Standar Pencemar Udara (ISPU)
Merupakan karya asli saya (kecuali cuplikan dan ringkasan yang masing-masing telah saya jelaskan sumbernya dan perangkat pendukung seperti laptop dll). Apabila dikemudian hari, karya saya disinyalir bukan karya asli saya, yang disertai dengan bukti-bukti yang cukup, maka saya bersedia untuk dibatalkan gelar saya beserta hak dan kewajiban yang melekat pada gelar tersebut. Demikian Surat pernyataan ini saya buat dengan sebenarnya.
Dibuat di: Bekasi
Tanggal : 20 Desember 2019 Yang menyatakan
v Nama : Dani Purwanto
NIM : 311510045
Demi mengembangkan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Pelita Bangsa Hak Bebas Royalti Non-eksklusif (Non-Exclusive Royalty-Free Right) atas karya ilmiah saya yang berjudul:
Klasifikasi Naive Bayes Untuk Memprediksi Kualitas Udara Berdasarkan Indeks Standar Pencemar Udara (ISPU)
Beserta perangkat yang diperlukan (bila ada). Dengan Hak Bebas Royalti Non-Eksklusif ini, Universitas Pelita Bangsa berhak untuk menyimpan data, mengcopy ulang, menggunakan dan mengelola dalam bentuk database, serta mendistribusikan dan menampilkan/mempublikasikan karya ilmiah ini di internet atau media lain untuk kepentingan akademis tanpa ijin dari saya selama tetap mencantumkan saya sebagai penulis dan pemilik hak cipta. Segala bentuk tuntutan hukum yang timbul atas pelanggaran Hak Cipta karya ilmiah ini menjadi tanggungjawab saya pribadi
Dibuat di: Bekasi
Tanggal : 20 Desember 2019 Yang menyatakan
vi
Laporan Tugas Akhir ini. Penulisan Laporan Tugas Akhir dengan judul
“KLASIFIKASI NAIVE BAYES UNTUK MEMPREDIKSI KUALITAS UDARA
BERDASARKAN INDEKS STANDAR PENCEMAR UDARA (ISPU)”
dimaksudkan untuk mencapai gelar Sarjana Komputer Strata Satu pada Program Studi Teknik Informatika, Universitas Pelita Bangsa.
Penulis menyadari bahwa dalam penyusunan Laporan Tugas Akhir ini bukanlah dari jerih payah sendiri, melainkan dari bimbingan berbagai pihak. Oleh sebab itu penulis mengucapkan banyak terimakasih kepada semua pihak yang turut membantu dalam proses penulisan Laporan Tugas Akhir ini, yaitu kepada:
1. Hamzah Muhammad M, S.K.M., M.M., selaku Rektor Universitas Pelita Bangsa. 2. Putri Anggun Sari, S.Pt., M.Si., selaku Dekan Fakultas Teknik Universitas Pelita
Bangsa.
3. Aswan S. Sunge, SE., M.Kom, selaku Ketua Program Studi Teknik Informatika 4. Asep Muhidin, S.Kom, M.Kom, selaku Dosen Pembimbing I yang telah
memberikan bimbingan dan masukan kepada penulis.
5. Agus Suwarno, S.Kom, M.T., selaku Dosen Pembimbing II yang telah memberikan bimbingan dan masukan kepada penulis.
6. Seluruh Dosen pengajar Strata satu (S1) Teknik Informatika Universitas Pelita Bangsa, yang telah mendidik dan memberikan pengetahuan yang tak ternilai kepada penulis selama mengikuti perkuliahan.
7. Orang tua, istri, serta keluarga tercinta yang telah memberikan dukungan moril, doa dan kasih saying.
8. Teman-teman mahasiswa Strata satu (S1) Teknik Informatika Universitas Pelita Bangsa yang selalu membantu dalam setiap kesempatan.
vii
9. Semua pihak yang namanya tidak dapat disebutkan satu per satu.
Penulis menyadari bahwa mungkin masih terdapat kekurangan dalam Laporan Tugas Akhir ini. Oleh karena itu, kritik dan saran dari pembaca sangat bermanfaat bagi penulis. Semoga laporan ini dapat bermanfaat bagi semua pihak yang membacanya.
Bekasi, 20 Desember 2019
viii
estetika dan kenyamanan, atau merusak properti. Secara internasional penilaian kualitas udara menggunakan Air Quality Index (AQI). Di Indonesia dikenal dengan Indeks Standar Pencemar Udara (ISPU) yang mengacu Keputusan Menteri Negara Lingkungan Hidup Nomor: KEP 45 / MENLH / 1997 mengenai Indeks Standar Pencemar Udara. Indeks Standar Pencemar Udara (ISPU) merupakan angka atau nilai yang tidak mempunyai satuan untuk menggambarkan kondisi kualitas udara ambien di lokasi dan waktu tertentu. Parameter utama pada ISPU adalah Karbon Monoksida (CO), Nitrogen (NO2), Ozon (O3), Sulfur Dioksida (SO2), dan Partikulat Matter (PM10). Penelitian ini bertujuan untuk mendapatkan klasifikasi kualitas udara berdasarkan Indeks Standar Pencemar Udara (ISPU). Dari data yang ditetapkan membutuhkan teknik data mining dengan algoritma yang bisa melakukan perhitungan lebih akurat. Algoritma Naive Bayes merupakan metode untuk klasifikasi dengan menggunakan teori probabilitas yang memiliki tingkat akurasi tinggi. Dari data Indeks Standar Pencemar Udara (ISPU) daerah DKI Jakarta yang diklasifikasikan menggunakan algoritma Naive Bayes dan diujikan menggunakan tools WEKA 3.8 menghasilkan akurasi hingga 93%. Hal ini menunjukkan bahwa model algoritma klasifikasi Naive Bayes mencapai klasifikasi hampir sempurna dan algoritma Naive Bayes Classifier bisa memberikan pemecahan dalam mengetahui kualitas pencemaran udara.
Kata kunci: Data Mining, Naive bayes, Klasifikasi, Kualitas Pencemaran Udara, ISPU.
ix
Internationally the air quality assessment uses the Air Quality Index (AQI). In Indonesia, it is known as the Air Pollution Standards Index (ISPU) which refers to the Decree of the State Minister for the Environment Number: KEP 45 / MENLH / 1997 concerning the Air Pollution Standards Index. The Air Pollution Standard Index (ISPU) is a number or value that does not have a unit to describe the condition of ambient air quality at a particular location and time. The main parameters at ISPU are Carbon Monoxide (CO), Nitrogen (NO2), Ozone (O3), Sulfur Dioxide (SO2), and Particulate Matter (PM10). This study aims to obtain an air quality classification based on the Air Pollution Standards Index (ISPU). From the data set requires data mining techniques with algorithms that can do calculations more accurately. Naive Bayes algorithm is a method for classification using probability theory which has a high degree of accuracy. From the data of the Air Pollution Standards Index (ISPU) of DKI Jakarta which is classified using the Naive Bayes algorithm and tested using WEKA 3.8 tools produces an accuracy of up to 93%. This shows that the Naive Bayes classification algorithm model reaches an almost perfect classification and the Naive Bayes Classifier algorithm can provide a solution in knowing the quality of air pollution.
x
HALAMAN PENGESAHAN... iii
PERNYATAAN KEASLIAN SKRIPSI ... iv
PERNYATAAN PERSETUJUAN PUBLIKASI ... v
UCAPAN TERIMAKASIH ... vi
ABSTRAK ... viii
ABSTRACT ... ix
DAFTAR ISI ... x
DAFTAR TABEL ... xiii
DAFTAR GAMBAR ... xiv
DAFTAR LAMPIRAN ... xv BAB I PENDAHULUAN ... 1 1.1 Latar Belakang... 1 1.2 Identifikasi Masalah ... 3 1.3 Batasan Masalah ... 3 1.4 Rumusan Masalah ... 3 1.5 Tujuan Penelitian ... 4 1.6 Manfaat Penelitian ... 4 1.7 Sistematika Penulisan ... 4
BAB II TINJAUAN PUSTAKA DAN LANDASAN TEORI ... 6
2.1 Tinjauan Pustaka ... 6
2.1.1 Kajian Jurnal Pertama ... 6
2.1.2 Kajian Jurnal ke-Dua... 7
2.1.3 Kajian Jurnal ke-Tiga ... 7
2.1.4 Kajian Jurnal ke-Lima ... 8
xi
2.2 Landasan Teori ... 9
2.2.1 Udara ... 9
2.2.2 Pencemaran Udara... 10
2.2.3 Kualitas Udara ISPU (Indeks Standar Pencemar Udara) ... 11
2.2.4 Data Mining... 14
2.2.5 Knowledge Discovery in Database (KDD) ... 18
2.2.6 Klasifikasi... 19
2.2.7 Algoritma Naive Bayes ... 20
2.2.8 Persamaan Metode Naive Bayes ... 21
BAB III METODE PENELITIAN... 25
3.1 Objek Penelitian ... 25 3.2 Jenis Data... 25 3.3 Kerangka Pemikiran ... 27 3.4 Metode Penelitian ... 28 3.5 Pengumpulan Data... 28 3.5.1 Sumber Data ... 28 3.5.2 Variabel Data... 30
3.5.3 Metode Pengumpulan Data ... 31
3.6 Analisa Pengolahan Data... 31
3.6.1 Pembersihan Data (Cleaning Data) ... 31
3.6.2 Data Integration and Transformation ... 32
3.6.3 Selection Data ... 32
3.6.4 Proses Data Mining ... 33
3.6.5 Evaluation and Presentation ... 35
3.6.6 Data Training dan Data Testing ... 36
3.7 Dokumentasi Penelitian ... 36
3.8 Instrumen Penelitian ... 36
3.8.1 Kebutuhan Perangkat Keras (Hardware) ... 37
3.8.2 Kebutuhan Perangkat Lunak (Software) ... 37
xii
4.1 Pemahaman Bisnis... 38
4.2 Pemahaman Data ... 38
4.3 Persiapan Data (Data Preparation) ... 39
4.4 Modelling... 39
4.4.1 Menghitung Class Probabilitas ... 40
4.4.2 Menghitung Conditional Probabilitas ... 40
4.4.3 Perhitungan Manual Data Testing: ... 45
4.5 Evaluation... 49
4.5.1 Pengujian Algoritma Naive Bayes dengan Tools Weka 3.8 ... 49
4.5.2 Evaluation Confusion Matrix ... 54
4.5.3 Kurva ROC... 56
BAB V PENUTUP... 60
5.1 Kesimpulan ... 60
5.2 Saran ... 60
xiii
Tabel 3. 1 Kerangka Pemikiran ... 27
Tabel 3. 2 Data Pencemar Udara ISPU ... 29
Tabel 3. 3 Atribut Data Selection ... 33
Tabel 3. 4 Confusion Matrix... 35
Tabel 4. 1 Probabilitas Atribut Critical ... 41
Tabel 4. 2 Mean dan Std Deviasi Atribut PM10 ... 44
Tabel 4. 3 Mean dan Std Deviasi Atribut SO2... 44
Tabel 4. 4 Mean dan Std Deviasi Atribut CO... 44
Tabel 4. 5 Mean dan Std Deviasi Atribut O3 ... 45
Tabel 4. 6 Mean dan Std Deviasi Atribut NO2 ... 45
Tabel 4. 7 Sampel Uji Data Testing... 46
Tabel 4. 8 Confusion Matrix... 54
xiv
Gambar 2. 3 Alur Pengklasifikasian ... 20
Gambar 3. 1 Alur Klasifikasi Naive Bayes ... 34
Gambar 4. 1 Tampilan Awal Tools Weka 3.8 ... 50
Gambar 4. 2 Diagram Data Training ISPU ... 51
Gambar 4. 3 Prior Tiap Kelas Target Data Training ... 52
Gambar 4. 4 Hasil Klasifikasi Data Testing ... 53
Gambar 4. 5 Kurva ROC Klasifikasi Kelas BAIK ... 56
Gambar 4. 6 Kurva ROC Klasifikasi Kelas SEDANG... 57
Gambar 4. 7 Kurva Klasifikasi Kelas TIDAK SEHAT... 58
xv
1 1.1 Latar Belakang
Udara merupakan komponen alam yang sangat dibutuhkan oleh makhluk hidup. Tanpa udara, tidak mungkin ada makhluk hidup yang bisa bertahan hidup. Udara merupakan substansi yang berada di sekeliling kita, seluruh kehidupan, dan substansial yang berada di bumi. Udara sering dikaitkan dengan istilah tidak dapat dilihat namun dapat dirasakan. Istilah ini memang benar adanya, karena udara sendiri tidak memiliki warna dan tidak dapat dilihat secara kasat mata. Udara hanya dapat dirasakan, terutama ketika terjadi pergerakan udara, seperti angin, kepulan asap, dan sebagainya.
Sementara itu, kondisi lingkungan khususnya kondisi udara sangat dipengaruhi oleh faktor-faktor, diantaranya faktor transportasi, faktor industri, dan faktor pembangunan insfrastruktur kota. Polusi udara merupakan salah satu masalah yang sering dialami oleh kota-kota besar di negara maju dan berkembang. Pencemaran udara ini diakibatkan oleh perkembangan transpotasi dan industri yang begitu pesat. Kualitas udara dapat diukur berdasarkan Indeks Standar Pencemar Udara (ISPU). Terdapat lima komponen pencemaran udara sebagai pengamatan berdasarkan ISPU, yaitu Tingkat Partikular (PM10), Sulfur Dioksida (SO2), Karbon Monoksida (CO), Ozon Permukaan (O3), dan Nitrogen Dioksida (NO2).
Menghirup udara berpolusi memberikan dampak yang lebih buruk ketimbang menghirup asap rokok. Bila dihirup secara rutin dan stagnan, menghirup udara yang tidak bersih bisa memicu berbagai macam penyakit. Penyakit yang kerap datang akibat udara di lingkungan yang tidak bersih adalah Infeksi Saluran Pernapasan Akut (ISPA). Berdasarkan laporan rutin dari fasilitas pelayanan kesehatan DKI Jakarta menyatakan tren penyakit ISPA meningkat sepanjang tahun 2016 - 2018.
Dengan level AQI, menurut level AirVisual tersebut, DKI Jakarta menempati peringkat ke-21 kota paling berpolusi di dunia. AQI merupakan indeks yang digunakan AirVisual untuk mengukur tingkat keparahan polusi udara di sebuah kota. Rentang nilai AQI adalah 0-500, makin tinggi nilai AQI, makin parah pula tingkat polusi udara di kota tersebut.
Dalam penerapan Data Mining, terdapat beberapa metode untuk menganalisa, memantau atau memperkirakan data hasil ukur selanjutnya ataupun dampaknya. Peneletian terdahulu yang membahas tentang polutan udara yaitu yang dilakukan oleh Warsito, Ispriyanti, dan Widayanti pada tahun 2008 dengan judul Clustering Data Pencemaran Udara Sektor Industri Di Jawa Tengah Dengan Kohonen Neural Netwok di mana mereka mendapatkan hasil serta kesimpulan bahwa beban pencemaran udara pada sektor industri di Jawa Tengah pada tahun 2006 dengan jaringan kohonen dapat dikelompokkan cluster 1 merupakan industri tekstil, cluster 2 terdiri dari industri makanan, industri minuman, industri kimia dasar, industri non logam, industri semen, industri kapur dan gips, industri logam dasar, ind ustri hasil-hasil olahan logam, industri rumah sakit, dan industri perhotelan, sedangkan pada cluster 3 terdapat industri kayu, industri olahan kayu, dan industri kertas [1]. Penelitian berjudul Deteksi Non-RTH (Ruang Terbuka Hijau) Kota Malang Berbasis Citra Google Earth Dengan Menggunakan Naive Bayes Classifier oleh Santoso pada tahun 2016, diperoleh kesimpulan dari hasil uji coba dengan menggunakan 100 sampel image objek Non-RTH yang terdiri dari 20 sampel image objek Non-RTH rumah tinggal, 20 image objek gedung/kantor, 20 image objek lapangan, 20 image objek sawah, dan 20 image objek jalan secara umum menunjukan bahwa sistem dapat mendeteksi dengan akurasi hingga 81% [2].
Algoritma klasifikasi Naive Bayes akan digunakan untuk menemukan aturan kondisi lingkungan terhadap udara dengan beberapa polutan. Naive Bayes merupakan salah satu algoritma untuk melakukan klasifikasi menggunakan metode probabilitas dan statistik yang dikemukakan oleh ilmuwan Inggris yaitu Thomas Bayes. Algoritma
Naive Bayes memprediksi peluang di masa depan berdasarkan pengalaman di masa sebelumnya sehingga dikenal sebagai Teorama Bayes. Ciri utama dari Naive Bayes Classifier ini adalah asumsi yang sangat kuat akan independensi dari masing-masing kondisi atau kejadian. Metode ini hanya membutuhkan jumlah data pelatihan (training data) yang kecil untuk menentukan estimasi parameter yang diperlukan dalam proses
pengklasifikasian. Oleh karena itu, penulis mengusulkan judul ”Klasifikasi Naive Bayes Untuk Memprediksi Kualitas Udara Berdasarkan Indeks Standar Pencemar Udara (ISPU)”.
1.2 Identifikasi Masalah
1. Polusi udara mengakibatkan penyakit Insfeksi Saluran Pernapasa Akut (ISPA). 2. Tidak stabilnya kualitas udara sehari-hari yang terkadang baik, sedang, tidak
sehat, sangat tidak sehat, hingga berbahaya.
3. Susahnya mengetahui kualitas udara mendatang dengan data ISPU yang sudah ada sebelumnya.
4. Berkembangnya atau semakin banyaknya faktor-faktor yang dapat memicu meningkatnya zat pencemar udara.
1.3 Batasan Masalah
1. Menggunakan data Indeks Standar Pencemar Udara (ISPU) wilayah DKI Jakarta tahun 2018 yang diunduh dari bank data Portal Satu Data Indonesia,
www.data.go.id.
2. Algoritma yang digunakan adalah Naive Bayes Classifier.
1.4 Rumusan Masalah
Bagaimana proses klasifikasi guna mengetahui kualitas udara dengan menggunkan data ISPU daerah DKI Jakarta tahun 2018 dengan algoritma Naive Bayes?
1.5 Tujuan Penelitian
Penelitian ini bertujuan untuk mendapatkan klasifikasi kualitas udara berdasarkan Indeks Standar Pencemar Udara (ISPU) menggunakan algoritma Naive Bayes Classifier.
1.6 Manfaat Penelitian
Dari laporan penelitian ini diharapkan mampu memberikan manfaat, diantaranya yaitu:
1. Bagi Penulis
a. Membantu penulis untuk bisa memahami proses klasifikasi Naive Bayes. b. Untuk menerapkan ilmu yang diperoleh selama berada di bangku kuliah. 2. Bagi Institusi
a. Diharapkan dapat menjadi pembelajaran untuk penelitian selanjutnya dengan topik pembahasan yang berhubungan dengan judul penelitian ini.
3. Bagi Organisasi
a. Membantu masyarakat mengetahui kondisi kualitas udara dengan parameter pencemar dari data ISPU.
1.7 Sistematika Penulisan
BAB I merupakan pendahuluan yang berisikan latar belakang, identifikasi masalah, batasan masalah, rumusan masalah, tujuan penelitian, manfaat penelitian, dan sistematika penulisan. Bab pendahuluan ini berisikan hahl-hal yang mendasari dilakukannya penelitian mengenai kualitas udara.
BAB II berisikan landasan teori yang dipakai untuk pembuatan dan penyusunan tugas akhir, merupakan tinjauan pustaka dari jurnal atau penelitian terdahulu mengenai metode algoritma yang digunakan dan kualitas pencemaran udara.
BAB III merupakan metodologi penelitian yang berisikan tentang data dan alur proses training dan testing data. Pada bab ini dijabarkan tentang proses yang dilakukan serta tahapan pada metode algoritma yang digunakan.
BAB IV merupakan hasil dari pembahasan dan pengujian terhadap klasifikasi algoritma Naive Bayes.
BAB V merupakan penutup yang berisikan kesimpulan dan saran dari rumusan masalah pada penelitian ini.
6 2.1 Tinjauan Pustaka
Berdasarkan dengan judul penelitian mengenai “Klasifikasi Kualitas Udara yang
Sehat Menggunakan Algoritma Naive Bayes Classifier”, maka perlu mempelajari jurnal mengenai penelitian sebelumnya oleh peneliti yang lebih dahulu melakukan penelitian yang menggunakan algoritma Naive Bayes sebagai pengklasifikasi.
2.1.1 Kajian Jurnal Pertama
Nama Peneliti : Irwan Budi Santoso
Judul Jurnal : Deteksi Non-RTH (Ruang Terbuka Hijau) Kota Malang Berbasis Citra Google Earth Menggunakan Naive Bayes Classifier
Depublish : Jurnal Ilmu Komputer dan Teknologi Informasi
Tahun : 2016
Volume & No : vol. 7, no. 2
Halaman : 59-64
Penelitian yang dilakukan oleh Santoso pada tahun 2016 yang berjudul Deteksi Non-RTH (Ruang Terbuka Hijau) Kota Malang Berbasis Citra Google Earth Menggunakan Naive Bayes Classifier. Salah satu upaya yang bisa dilakukan untuk membantu menyelesaikan persoalan banjir, polusi udara, dan temperatur udara di perkotaan dengan memanfaatkan foto satelit seperti yang disediakan oleh Google Earth guna memantau kondisi lingkungan secara riil berupa non-Ruang Terbuka Hijau (non-RTH). Dengan metode Naive Bayes Classifier (NBC), hasil uji coba dengan menggunakan sampel pengujian menunjukan tingkat akurasi metode tersebut dalam mendeteksi objek non-RTH kota Malang sebesar 81% dengan menggunakan 100
sampel image objek Non-RTH yang terdiri dari 20 sampel image objek RTH rumah tinggal, 20 image objek gedung/kantor, 20 image objek lapangan, 20 image objek sawah, dan 20 image objek [2].
2.1.2 Kajian Jurnal ke-Dua
Nama Peneliti : Sandi Fajar Rodiyansyah
Judul Jurnal : K-Means dan Fuzzy C-Means Pada Analisis Data Polusi Udara Di Kota X
Depublish : Seminar Nasional Teknologi Informasi dan Multimedia
Tahun : 2017
Volume & No : vol. 5, no. 1
Halaman : 25-30
Penelitian yang dilakukan oleh Rodiyansyah pada tahun 2017 yang bejudul K-Means dan Fuzzy C-K-Means Pada Analisis Data Polusi Udara Di Kota X. Berikut dalam upaya analisa data polusi udara harian di suatu kota dengan membandingan algoritma K-Means dengan algoritma Fuzzy C-Means, didapat hasil pengujian dengan clustering dari kedua algoritma bahwa rata-rata standar deviasi pada hasil clustering algoritma Fuzzy C-Means lebih kecil daripada rata-rata standar deviasi pada hasil clustering algoritma K-Means. Selain itu pada kesimpulan penelitian ini diketahui bahwa parameter Natrium Dioksida (NO2), Non Metal Hydro Carbon (NMHC), dan Natrium Oksida (NOx) memliki pengaruh yang signifikan terhadap proses clustering [3].
2.1.3 Kajian Jurnal ke-Tiga
Nama Peneliti : Aang Alim Murtopo
Judul Jurnal : Prediksi Kelulusan Tepat Waktu Mahasiswa STMIK YMI Tegal Menggunakan Algoritma Naive Bayes
Depublish : Jurnal CSRID
Tahun : 2015
Halaman : 145-154
Penelitian yang dilakukan oleh Murtopo pada tahun 2015 dengan judul Prediksi Kelulusan Tepat Waktu Mahasiswa STMIK YMI Tegal Menggunakan Algoritma Naive Bayes. Pada penelitian ini peneliti menggunaan algoritma Naive Bayes sebagai penghitung probabilitas untuk melakukan prediksi kemungkinana tepat waktu atau tidak tepat waktu dalam menentukan kelulusan mahasiswa dengan confusion matrix dengan menggunakan 10-fold cross falidation dengan melibatkan faktor internal dan faktor eksternal yang menghasilkan akurasi klasifikasi mahasiswa lulus tepat waktu sebesar 91.37%, sedangkan evaluasi pengujian menggunakan 10-fold cross falidation menghasilkan nilai tertinggi dengan akurasi 94.34% dengan rata-rata akurasi sebesar 91.92 sedangkan evaluasi dengan kurva ROC dengan metode AUC sebesar 0.898 dan ini berarti termasuk dalam Good Classifacation [4].
2.1.4 Kajian Jurnal ke-Lima
Nama Peneliti : Sandi Fajar Rodiyansyah dan Edi Winarko
Judul Jurnal : Klasifikasi Posting Twitter Kemacetan Lalulintas Kota Bandung Menggunakan Naive Bayesian Classification
Depublish : IJCCS
Tahun : 2012
Volume & No : vol. 6, no. 1
Halaman : 91-100
Penelitian yang dilakukan oleh Rodiyansyah dan Winarko pada tahun 2012 dengan judul Klasifikasi Posting Twitter Kemacetan Lalulintas Kota Bandung Menggunakan Naive Bayesian Classification. Pada penelitian ini peneliti mengunakan algoritma Naive Bayes guna melakukan pengklasifikasian data tweet yang mengandung tentang informasi lalu-lintas kota Bandung. Dengan memanfaatkan data yang didapat dari memanfaatkan API search twitter dan agar data dapat dilakukan pengklasifikasian, peneliti melakukan pelabelan pada data sesuai kelas-kelas yang ditentukan kemudian menentukan data training dan data testing. Dari data yang
diujikan didapat keakurasian sebesar 72% dengan 100 data dan keakurasian sebesar 99,11% dengan 13106 data [5].
2.1.5 Kajian Jurnal ke-Enam Nama Peneliti : Evy Priyanti
Judul Jurnal : Penerapan Algoritma Naive Bayes Untuk Klasifikasi Bakteri Gram-Negatif
Depublish : Jurnal teknik Komputer
Tahun : 2017
Volume & No : vol. 3, no. 2
Halaman : 68-76
Penelitian yang dilakukan oleh Priyanti pada tahun 2017 dengan judul Penerapan Algoritma Naive Bayes Untuk Klasifikasi Bakteri Gram-Negatif. Teknik klasifikasi bakteri Gram-negatif dari cara lokalisasi protein menjadi bagian-bagian berdasarkan urutan asam amino mereka. Lokalisasi protein digunakan untuk memeriksa metode yang cocok untuk sebuah penelitian dengan algoritma yang sesuai. Klasifikasi ini menggunakan dataset ecoli dari uci dataset yang terdiri dari 8 kelas. Penelitian ini dilakukan untuk mengetahui jenis bakteri Gram-negatif berupa bakteri ecoli yang dibedakan dengan skema fenotip berdasarkan algoritma Naive Bayes yang memiliki tingkat akurasi dan kecepatan maksimal. Pada penelitian ini secara umum mendapatkan nilai akurasi yang baik yaitu 80.93% [6].
2.2 Landasan Teori
Pada Bagian ini berisi dasar teori yang mendukung serta berkaitan dengan tugas akhir. Dasar teori yang digunakan berasal dari buku, jurnal ilmiah, atau artikel ilmiah.
2.2.1 Udara
Udara merupakan campuran gas yang terdapat di permukaan bumi serta mengelilingi bumi. Udara tersebut tersusun dari campuran gas dalam jumlah yang
banyak, seperti nitrogen 78%, oksigen 20%, argon 0,93%, dan karbon dioksida 0,30% kemudian sisanya adalah dalam bentuk gas yang lain. Sementara uap air yang ada dalam udara bersumber dari pergaulan air laut, sungai, dan lainnya. Berd asarkan fungsi, gas yang sangat dibutuhkan dalam kehidupan makhluk hidup salah satunya yakni oksigen (Ilham, 2019) [7].
Udara dibedakan menjadi udara emisi dan udara ambien. Udara emisi yaitu udara yang dikeluarkan oleh sumber emisi seperti knalpot kendaraan bermotor dan cerobong gas buang industri. Sedangkan udara ambien adalah udara bebas di permukaan bumi pada lapisan troposfer yang berada di wilayah yurisdiksi Republik Indonesia yang dibutuhkan dan mempegaruhi kesehatan manusia, makhluk hidup, dan unsur lingkungan hidup lainnya. Unsur-unsur berbahaya yang masuk ke dalam atmosfer dapat berupa Karbon Monoksida (CO), Nitrogen Dioksida (NO2), Sulfur Dioksida (SO2), Hidro Carbon (HC), dan lain-lain ((Kurniawati, Rahmawati, & Wilandari, 2015) [8].
2.2.2 Pencemaran Udara
Udara dikatakan telah tercemar apabila telah terjadi perubahan terhadap komposisi udara, terutama terjadi penambahan gas lain yang menimbulkan gangguan. Hal ini sesuai dengan definisi undang-undang no. 14 tahun 1982 tentang pokok-pokok pengelolaan lingkungan hidup, yaitu pencemaran udara adalah adanya atau masuknya salah satu atau lebih zat pencemar di udara dalam jumlah dan waktu tertentu yang dapat menimbulkan gangguan pada manusia, hewan, tumbuhan, dan benda-benda lainnya (Prayudi & Susanto, 2001) [9].
Berlebihnya tingkat konsentrasi zat pencemar di udara hingga melampaui ambang batas toleransi yang diperkenankan akan akan mempunyai dampak negatif yang berbahaya terhadap lingkungan, baik manusia, tumbuh-tumbuhan, hewan, dan rusaknya benda-benda (material) serta berpengaruh pada kualitas air hujan (hujan
asam), yang berakibat pada mata rantai berikutnya yaitu pada ekosistem flora-fauna (Budiyono, 2001) [10].
2.2.3 Kualitas Udara ISPU (Indeks Standar Pencemar Udara)
Indeks standar pencemar udara (ISPU) adalah laporan kualitas udara kepada masyarakat untuk menerangkan seberapa bersih atau tercemarnya kualitas udara dan bagaimana dampaknya terhadap kesehatan setelah menghirup udara tersebut selama beberapa jam atau hari. Penetapan ISPU ini mempertimbangkan tingkat mutu udara terhadap kesehatan manusia, hewan, tumbuhan, bangunan, dan nilai estetika. ISPU ditetapkan berdasarkan 5 pencemar utama yaitu: Karbon Monoksida (CO), Sulfur Dioksida (SO2), Nitrogen Dioksida (NO2), Ozon Permukaan (O3), dan Partikel Debu (PM10). Di Indonesia ISPU diatur berdasarkan keputusan Badan Pengendali Dampak Lingkungan (Bapedal) Nomor KEP-107/Kabapedal/11/1997 (Wikipedia, 2019) [11].
Berikut tabel skala kategori Indeks Standar Pencemar Udara yang dapat dilihat pada Tabel 2. 1:
Tabel 2. 1 Kualitas Udara (ISPU) ISPU Pencemar Udara Level Dampak Kesehatan
0 – 50 Baik Tidak memberikan dampak bagi kesehatan manusia dan hewan.
51 – 100 Sedang Tidak berpengaruh pada kesehatan manusia ataupun hewan tetapi berpengaruh pada tumbuhan yang peka.
101 – 199 Tidak Sehat Bersifat merugikan pada manusia ataupun kelompok hewan yang peka atau dapat menimbulkan kerusakan pada tumbuhan ataupun nilai estetika.
Tabel 2. 1 Kualitas Udara (ISPU) (Lanjutan)
200 – 299 Sangat Tidak Sehat Kualitas udara yang dapat merugikan kesehatan pada sejumlah segmen populasi yang terpapar.
300 – 500 Berbahaya Kualitas udara berbahaya yang secara umum dapat merugikan kesehatan yang serius pada populasi (misalnya iritasi mata, batuk, dahak, dan sakit tenggorokan). Sumber: Indeks Standar Pencemaran Udara (Wikipedia, 2019) [11].
Kualitas udara pencemar ISPU ditetapkan berdasarkan 5 pencemar utama, yaitu CO, SO2, NO2, Ozon Permukaan (O3), dan Partikulat Debu (PM10) (Rimantho, 2007) [12]:
1. CO
CO merupakan rumus kimia untuk gas karbon monoksida. Gas ini dihasilkan dari pembakaran bahan bakar yang tidak sempurna. Pembakaran tidak sempurna, salah satu sebabnya adalah kurangnya jumlah oksigen. Bila karena saring udara yang tersumbat, bisa juga karena karburator kotor dan setelannya tidak tepat. Asap kendaraan merupakan sumber utama bagi karbon monoksida di berbagai perkotaan. Data mengungkapkan bahwa 60% pencemaran udara di kota-kota besar disumbang oleh transportasi umum. Karbon monoksida bersifat racun, mengakibatkan turunnya berat janin, meningkatkan jumlah kematian bayi, serta menimbulkan kerusakan otak. Standar baku mutu yang diperbolehkan adalah 10.000 µg/Nm3.
2. SO2
SO2 merupakan rumus kimia untuk gas sulfur dioksida. Gas ini berasal dari hasil pembakaran bahan bakar yang mengandung sufur. Selain dari bahan bakar, sulfur juga terkandung dalam pelumas. Gas sulfur dioksida sukar dideteksi karena merupakan gas tidak berwarna. Sulfur dioksida dapat menyebabkan gangguan pernapasan, pencernaan, sakit kepala, sakit dada, d an saraf. Pada kadar di bawah batas ambang,
dapat menyebabkan kematian. Korban sulfur dioksida bukan hanya manusia, tetapi juga bangunan dan tumbuhan. Keberadaan gas ini di udara dapat menimbulkan hujan asam yang merusakkan bahan bngunan dan menghambat pertumbuhan tanaman. Standar baku mutu yang diperbolehkan adalah 365 µg/Nm3.
3. NO2
NO2 singkatan dari nitrogen dioksida. Zat nitrogen dioksida sangat beracun sehingga dapat menyebabkan iritasi pada mata, hidung, dan saluran pernapasan serta menimbulkan kerusakan paru-paru. Gas ini terbentuk dari pembakaran tidak sempurna. Setelah bereaksi di atmosfer, zat ini membentuk partikel-partikel nitrat sangat halus sehingga dapat menembus bagian terdalam paru-paru. Partikel-partikel nitrat ini pula, jika bergabung dengan air baik air di paru-paru atau uap air di awan akan membentuk asam. Asam ini dapat merusak tembok bangunan dan menghambat pertumbuhan tanaman. Jika bereaksi dengan sisa hidro karbon yang tidak terbakar, akan membentuk smog atau kabut berwarna cokelat kemerahan. Standar baku mutu yang diperbolehkan adalah 150 µg/Nm3.
4. O3
O3 merupakan lambang dari ozon. Senyawa kimia ini tersusun atas tiga atom oksigen. Ozon merupakan gas yang sangat beracun dan berbau sangit. Ozon terbentuk ketika percikan listrik melintas dalam oksigen. Adanya ozon dapat dideteksi melalui bau (aroma) yang timbul oleh mesin-mesin bertenaga listrik. Secara kimiawi. Ozon lebih aktif ketimbang oksigen biasa dan juga merupakan zat pengoksidasi yang lebih baik.
Biasanya, ozon digunakan dalam proses pemurnian (purifikasi) air, sterilisasi udara, dan pemutihan jenis makanan tertentu. Di atmosfer, terjadinya ozon berasal dari nitrogen oksida dan gas organik yang dihasilkan oleh emisi kendaraan maupun industri. Di samping dapat menimbulkan kerusakan serius pada tanaman, ozon berbahaya bagi
kesehatan, terutama penyakit pernafasan seperti bronkitis maupun asma. Standar baku mutu yang diperbolehkan adalah 235 µg/Nm3 pada pengukuran selama 1 jam.
5. PM10
PM10 merupakan kependekan dari particulat matter atau partikulat. Partikulat merupakan zat pencemar padat maupun cair yang terdispersi di udara. Partikulat ini dapat berupa debu, abu, jelaga, asap, uap, kabut, atau aerosol. Jenis-jenis partikulat dibedakan berdasarkan ukurannya. Partikel yang sangat kecil dapat bergabung satu sama lain membentuk partikel yang lebih besar.
Partikulat dalam emisi gas buang dapat terdiri atas bermacam-macam komponen. Beberapa unsur kandungan partikulat adalah karbon (dari pembakaran tidak sempurna) dan logam timbel (dari pembakaran bensin bertimbel). Sebagian partikulat keluar dari cerobong pabrik sebagai asap hitam tebal. Tetapi, yang paling berbahaya adalah butiran-butiran halus sehingga dapat menembus bagian terdalam paru-paru. Jika ini yang terjadi, organ pernapasan akan terganggu. Standar baku mutu yang diperbolehkan adalah 150 µg/Nm3.
2.2.4 Data Mining
Data mining adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data mining adalah proses yang menggunakan teknik statistic, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar. Data mining adalah suatu proses menemukan hubungan yang berarti, pola, dan kecenderungan dengan memeriksa sekumpulan besar data yang tersimpan dalam penyimpanan dengan menggunakan teknik pengenalan pola seperti teknik stastik dan matematika (Nofriansyah, 2014) [13].
Data mining adalah proses menemukan hubungan baru yang mempunyai arti, pola, dan kebiasaan dengan memilah-milah sebagian besar data yang disimpan dalam
media penyimpanan dengan menggunakan teknologi pengenalan pola seperti teknik statistik dan matematik. Data mining merupakan gabungan dari beberapa disiplin ilmu yang menyatukan teknik dari pembelajaran mesin, pengenalan pola, statistik, database, dan visualisasi untuk penanganan permasalahan pengambilan informasi dari database yang besar (Mardi, 2016) [14].
Istilah data mining memiliki hakikat sebagai disiplin ilmu yang tujuan utamanya adalah untuk menemukan, menggali, atau menambang pengetahuan dari data atau informasi yang kita miliki. Data mining sering disebut juga sebagai Knowledge Discovery in Database (KDD) (Ridwan , Suyono , & Sarosa , 2013) [15].
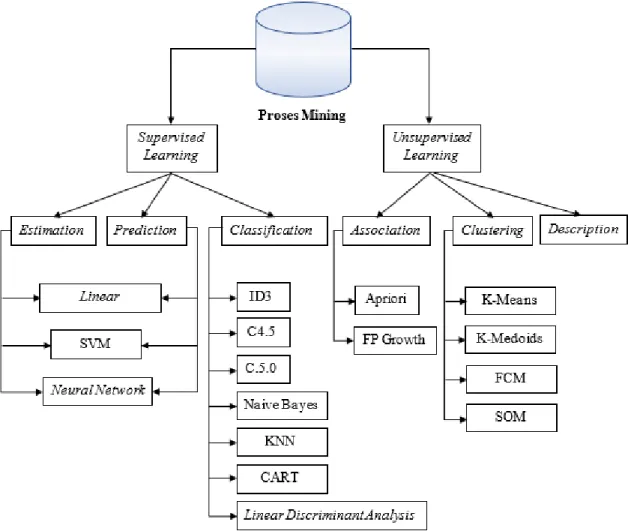
Beberapa metode yang dapat digunakan berdasarkan pengelompokan data mining dapat dilihat pada gambar 2. 1
Gambar 2. 1Tahap-tahap Data Mining
Sumber: Tahap-tahap Data Mining (Ridwan , Suyono , & Sarosa , 2013) [15]. 1. Metode Pelatihan
Secara garis besar metode pelatihan yang digunakan dalam teknik-teknik data mining dibedakan ke dalam dua pendekatan, yaitu:
• Unsupervised learning, metode ini diterapkan tanpa adanya latihan (training) dan tanpa ada guru (teacher). Guru di sini adalah label data.
• Supervised learning, yaitu metode belajar dengan adanya latihan dan pelatih. Dalam pendekatan ini, untuk untuk menemukan fungsi keputusan, fungsi pemisah, atau fungsi regresi, digunakan beberapa contoh data yang mempunyai output atau label selama proses training.
2. Pengelompokan Data Mining
Ada beberapa teknik yang dimiliki data mining berdasarkan tugas yang bisa dilakukan, yaitu:
• Deskripsi
Para peneliti biasanya mencoba menemukan cara untuk mendeskripsikan pola dan trend yang tersembunyi dalam data.
• Estimasi
Estimasi mirip dengan klasifikasi, kecuali variabel tujuan yang lebih kearah numerik dari pada kategori.
• Prediksi
Prediksi mempunyai kemiripan dengan estimasi dan klasifikasi. Hanya saja, prediksi hasilnya menunjukkan suatu yang belum terjadi (mungkin terjadi di masa depan).
• Klasifikasi
Dalam klasifikasi variabel, tujuan bersifat kategorik. Misalnya, kita akan mengklasifikasikan pendapat dalam tiga kelas, yaitu pendapat tinggi, pendapat sedang, dan pendapat rendah.
• Clustering
Clustering lebih ke arah pengelompokan record, pengamatan, atau kasus dalam kelas yang memiliki kemiripan.
• Assosiasi
Mengidentifikasi hubungan antara berbagai peristiwa yang terjadi pada satu waktu.
2.2.5 Knowledge Discovery in Database (KDD)
Knowledge Discovery in Database adalah Keseluruhan proses non-trival untuk mencari dan mengidentifikasi pola (pattern) dalam data, di mana pola yang ditemukan bersifat sah, baru, dapat bermanfaat dan dapat dimengerti (Priyanti, 2017) [6].
Gambar 2. 2Tahap-Tahap Data Mining Dalam Proses KDD Sumber: Tahap-tahap Data Mining dalam proses KDD (Jananto, 2013) [16].
Tahapan dari proses Knowledge Discovey in Database (KDD) adalah: 1. Pembersihan Data (Cleaning Data)
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten atau data tidak relevan.
Cleaning and Integration Selection and Transformation Data Mining Evaluation and Presentation Databases Data Warehouse Pattern Knowledge
2. Integrasi (Integration)
Integrasi data merupakan penggabungan data dari berbagai database ke dalam satu database baru.
3. Seleksi (Selection)
Data yang ada pada database sering kali tidak semuanya dipakai, oleh karena itu hanya data yang sesuai untuk dianalisis yang akan diambil dari database. 4. Transformasi (Transformation)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam data mining.
5. Proses Mining
Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data. Beberapa metode yang dapat digunakan berdasarkan pengelompokan data mining.
6. Evaluasi Pola (Pattern evaluation)
Untuk mengidentifikasi pola-pola menarik ke dalam knowledge based yang ditemukan.
7. Presentasi Pengetahuan (Knowledge Presentation)
Merupakan visualisasi dan penyajian pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna.
2.2.6 Klasifikasi
Klasifikasi merupakan suatu proses menemukan kumpulan pola atau fungsi yang mendeskripsikan serta memisahkan kelas data yang satu dengan yang lainnya untuk menyatakan objek tersebut masuk pada kategori tertentu yang sudah dikategorikan. Klasifikasi adalah bentuk analisis data yang mengekstrak model yang menggambarkan kelas data (Novandya & Oktaria, 2017) [17].
Metode klasifikasi adalah proses untuk menemukan model atau fungsi yang menjelaskan atau membedakan konsep atau kelas data, dengan tujuan untuk dapat
memperkirakan kelas suatu objek yang labelnya tidak diketahui. Dalam mencapai tujuan tersebut, proses klasifikasi membentuk suatu model yang mampu membedakan data ke dalam kelas-kelas yang berbeda berdasarkan aturan atau fungsi tertentu. Model
itu sendiri bisa berupa aturan “jika-maka”, berupa pohon keputusan, atau formula matematis (Bustami, 2013) [18].
Gambar 2. 3 Alur Pengklasifikasian Sumber: Alur Pengklasifikasian (Bustami, 2013) [18].
2.2.7 Algoritma Naive Bayes
Naive bayes merupakan salah satu algoritma yang terdapat pada teknik klasifikasi. Naive bayes merupakan pengklasifikasian dengan metode probabilitas dan stastistik yang dikemukakan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi peluang di masa depan berdasarkan pengalaman di masa sebelumnya sehingga dikenal sebagai teorama bayes. Teorama tersebut dikombinasikan dengan Naive di mana diasumsikan kondisi antar atribut saling bebas. Klasifikasi Naive Bayes diasumsikan bahwa ada atau tidak, ciri tertentu dari sebuah kelas tidak ada hubungannya dengan ciri dari kelas lainya (Bustami, 2013) [18].
Algoritma Naive Bayes adalah metode klasifikasi berbasis probabilitas dengan mengasumsikan diantara atribut atau fitur objek bersifat independen. Naive bayes saat ini masih menjadi topik yang hangat, khususnya terkait dengan perbaikan metode tersebut untuk meningkatkan performansi dalam klasifikasi. Dalam banyak aplikasi seringkali diasumsikan fungsi peluang (probability density function) setiap atribut atau fiturnya berdistribusi normal (gaussian) maka asumsi tersebut sangat berpengaruh dalam pembentukan Naive Bayes Classifier (Santoso, 2016) [2].
Atribut Set (x) Classification
Model Class Label (y)
Naive bayes adalah algoritma yang sering digunakan dalam pengkategorian teks. Ide dasarnya adalah menggabungkan probabilitas kata-kata dan kategori untuk memperkirakan probabilitas dari kategori sebuah dokumen. Naive bayes merupakan algoritma paling sederhana dari pengklasifikasian probabilistik (Wati, 2016) [19].
Bayesian classification adalah pengklasifikasian statistik yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu class. Bayesian classification didasarkan pada teorama Bayes yang memiliki kemampuan klasifikasi serupa dengan decesion tree dan neural network. Bayesian classification terbukti memiliki akurasi dan kecepatan yang tinggi saat diaplikasikan ke dalam database dengan data yang besar (Jananto, 2013) [16].
2.2.8 Persamaan Metode Naive Bayes
Persamaan dari metode Naive Bayes adalah (Delpiah & Patima, 2018) [20] :
𝑃(𝐻|𝑋) =𝑃(𝑋|𝐻)
𝑃(𝑋) . 𝑃(𝐻)
Keterangan:
X : Data dengan class yang belum diketahui
H : Hipotesis data X merupakan suatu class spesifik
P(H|X) : Probabilitas hipotesis H berdasarkan kondisi X (posterior probability) P(H) : Probabilitas hipotesis H (prior probability)
P(X|H) : Probabilitas X berdasarkan kondisi pada hipotesis H P(X) : Probabilitas X
Untuk menjelaskan teorama Naive Bayes, perlu diketahui bahwa proses klasifikasi memerlukan sejumlah petunjuk untuk menentukan kelas apa yang cocok bagi sampel yang dianalisis tersebut. Karena itu, teorama bayes di atas disesuaikan sebagai contoh sebagai berikut:
𝑃(𝐶|𝐹1 … 𝐹𝑛) =𝑃(𝐶)𝑃(𝐹1 … 𝐹𝑛|𝐶) 𝑃(𝐹1 … 𝐹𝑛)
Di mana Variabel C merepresentasikan kelas, sementara variabel F1 ... Fn merepresentasikan karakteristik petunjuk yang dibutuhkan untuk melakukan klasifikasi atau kriteria. Maka rumus tersebut menjelaskan bahwa peluang masuknya sampel karakteristik tertentu dalam kelas C (posterior) adalah peluang munculnya kelas C (sebelum masuknya sampel tersebut, seringkali disebut prior), dikali dengan peluang kemunculan karakteristik-karakteristik sampel pada kelas C (disebut juga likehood), dibagi dengan peluang kemunculan karakteristik-karakteristik sampel secara global ( disebut juga evidence). Karena itu, rumus di atas dapat pula ditulis secara sederhana sebagai berikut:
𝑃𝑜𝑠𝑡𝑒𝑟𝑖𝑜𝑟 = 𝑃𝑟𝑖𝑜𝑟 × 𝑙𝑖𝑘𝑒ℎ𝑜𝑜𝑑
𝑒𝑣𝑖𝑑𝑒𝑛𝑐𝑒
Nilai Evidence selalu tetap untuk setiap kelas pada satu sampel. Nilai dari posterior tersebut nantinya akan dibandingkan dengan nilai nilai posterior kelas lainnya untuk menentukan ke kelas apa suatu sampel akan diklasifikasikan. Penjabaran lebih lanjut rumus Bayes tersebut dilakukan dengan menjabarkan (C|F1,…,Fn) menggunakan aturan perkalian sebagai berikut :
𝑃𝐶|𝐹1, … , 𝐹𝑛) = 𝑃(𝐶) 𝑃(𝐹1, … , 𝐹𝑛|𝐶) = 𝑃(𝐶)𝑃(𝐹1|𝐶)𝑃(𝐹2, … , 𝐹𝑛|𝐶, 𝐹1)
= 𝑃(𝐶)𝑃(𝐹1|𝐶)𝑃(𝐹2|𝐶, 𝐹1)𝑃(𝐹3, … , 𝐹𝑛|𝐶, 𝐹1, 𝐹2)
= 𝑃(𝐶)𝑃(𝐹1|𝐶)𝑃(𝐹2|𝐶, 𝐹1)𝑃(𝐹3|𝐶, 𝐹1, 𝐹2), 𝑃(𝐹4, … , 𝐹𝑛|𝐶, 𝐹1, 𝐹2, 𝐹3) = 𝑃(𝐶)𝑃(𝐹1|𝐶)𝑃(𝐹2|𝐶, 𝐹1)𝑃(𝐹3|𝐶, 𝐹1, 𝐹2) … 𝑃(𝐹𝑛|𝐶, 𝐹1, 𝐹2, 𝐹3, … , 𝐹𝑛 − 1)
Dapat dilihat bahwa hasil penjabaran tersebut menyebabkan semakin banyak dan semakin kompleksnya faktor-faktor syarat yang mempengaruhi nilai probabilitas, yang hampir mustahil untuk dianalisa satu persatu. Akibatnya, perhitungan tersebut menjadi sulit untuk dilakukan. Di sini digunakan asumsi independensi yang sangat tinggi (naif), bahwa masing-masing petunjuk (F1,F2,…,Fn) saling bebas (independen) satu sama lain. Dengan asumsi tersebut, maka berlaku suatu kesamaan sebagai berikut:
𝑃(𝑃𝑖|𝐹𝑗 =𝑃𝐹𝑖 ∩ 𝐹𝑗 𝑃(𝐹𝑗) = 𝑃(𝐹𝑖)𝑃(𝐹𝑗) 𝑃(𝐹𝑗) = 𝑃(𝐹𝑖) Untuk i ≠ j, sehingga 𝑃(𝐹𝑖|𝐶, 𝐹𝑗) = 𝑃(𝐹𝑖|𝐶)
Dari persamaan ini dapat disimpulkan bahwa asumsi independensi naif tersebut membuat syarat peluang menjadi sederhana, sehingga perhitungan menjadi mungkin untuk dilakukan. Selanjutnya penjabaran P(C|F1,…,Fn) dapat disederhanakan menjadi persamaan:
𝑃(𝑋2|𝐶)𝑃(𝑋3|𝐶) … 𝑃(𝐶|𝑋1, … , 𝑋𝑛) = 𝑃(𝑋1|𝐶) = ∏ 𝑃
𝑛
𝑖 =1
(𝑋𝑖|𝐶)
Persamaan di atas merupakan model dari teorama Naive Bayes yang selanjutnya akan digunakan dalam proses klasifikasi. Untuk klasifikasi dengan data kontinyu digunakan rumus Densitas Gauss:
𝑃(𝑋
𝑖= 𝑥
𝑖|𝑌 = 𝑦
𝑖) =
1
√2𝜋𝜎
𝑖𝑗𝑒
−(𝑋𝑖−𝜇𝑖𝑗) 2 2𝜎𝑖𝑗2 Keterangan : P : Peluang Xi : Atribut ke-i xi : Nilai atribut ke-i Y : Kelas yang dicari yi : Sub kelas yang dicariµ : Mean, menyatakan rata-rata dari seluruh atribut
σ : Standar Deviasi, menyatakan varian dari seluruh atribut
π : 3.14
25 3.1 Objek Penelitian
Objek penelitian merupakan topik permasalahan yang dikaji dalam penelitian. Adapun objek penelitian ini menggunakan data pencemar udara ISPU daerah DKI Jakarta, yang mana kita ketahui DKI Jakarta menjadi pusat perbincangan mengenai kondisi udara yang tercemar. Jakarta menyandang gelar kota dengan pencemaran udara terburuk di Asia Tenggara. Ibu Kota Indonesia ini berada di daftar puncak kota paling berpolusi pada tahun 2018. Hasil tersebut didapat dari studi yang dilakukan oleh Greenpeace dan IQ AirVisual. Sementara itu, untuk kategori dunia, jakarta berada diperingkat ke-161.
Mengenai pengelompokan status kualitas udara dengan menerapkan algoritma Naive Bayes Classifier dapat diketahui prediksi kualitas udara yang sehat, kualitas udara sedang, kualitas udara tidak sehat, dan kualitas udara sangat tidak sehat. Dari objek penelitian yang ditentukan, peneliti melakukan identifikasi terhadap masalah yang akan diteliti. Kemudian peneliti menetapkan penyelesaian untuk masalah yang ditemukan.
3.2 Jenis Data
Data yang digunakan pada penelitian ini merupakan data sekunder, d ata sekunder adalah data yang didapat tidak secara langsung dari objek atau subjek penelitian. Data ini didapat dari bank data Portal Satu Data Indonesia, data Indeks Standar Pencemar Udara (ISPU) wilayah DKI Jakarta tahun 2018 yang terhitung antara tanggal 1 Januari 2018 hingga 31 Desember 2018. Dari dataset ini didapatkan jumlah record atau data sebanyak 1861 data, dengan 10 atribut termasuk atribut kelas, yaitu:
1. Tanggal
Tanggal pengukuran kualitas udara 2. Wilayah
Merupakan wilayah pengukuran 3. Tingkat Partikulat (PM10)
Partikulat salah satu parameter yang diukur 4. Sulfur Dioksida (SO2)
Sulfida (dalam bentuk SO2) salah satu parameter yang diukur 5. Karbon Monoksida (CO)
Karbon Monoksida salah satu parameter yang diukur 6. Nitrogen Dioksida (NO2)
Nitrogen Dioksida salah satu parameter yang diukur 7. Ozon Permukaan (O3)
Ozon salah satu parameter yang diukur
8. Maximal
Nilai ukur paling tinggi dari seluruh parameter yang diukur dalam waktu yang sama
9. Critical
Parameter yang hasil pengukurannya paling tinggi 10. Categori
Categori hasil perhitungan ISPU dan merupakan class yang menjadi target klasifikasi
3.3 Kerangka Pemikiran
Dalam kerangka pemikiran ini terdapat beberapa tahap-tahapan selama penelitian dari mulai persiapan penelitian hingga pembuatan dokumentasi penelitian.
Berikut ini adalah tabel kerangka pemikiran dalam proses penelitian:
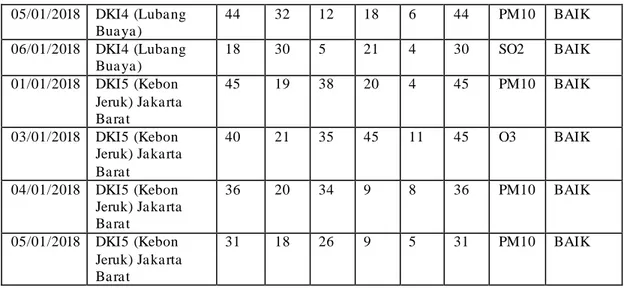
Tabel 3. 1Kerangka Pemikiran Kerangka Pemikiran
Tahapan Kegiatan Hasil
Mula i Ta ha p 1 Penda hulua n 1. Menentuka n objek penelitia n 2. Identifika si Ma sa la h Ma sa la h Ta ha p 2 Pengumpula n Da ta 1. Menca ri da ta
2. Studi Litera tur
Da ta Penelitia n
Ta ha p 3 Pengola ha n Da ta
1. Ana lisa Algoritma NBC denga n proses KDD 2. Metode Na ive Ba yes
Da ta Training da n Da ta Testing
Ta ha p 4 lida si da n Ha sil
1. Menentuka n Ha sil Prediksi 2. Pengujia n Weka 3.8 da n
Perhitunga n Akura si
Ha sil Prediksi
Ta ha p 5 Dokumenta si
Membua t dokumen ha sil penelitia n Tuga s Akhir
Dokumenta si La pora n Tuga s
Akhir
3.4 Metode Penelitian
Pada tahap ini, data yang digunakan adalah data Indeks Standar Pencemar Udara (ISPU) daerah DKI Jakarta. Data tersebut akan diolah dengan menggunakan metode CRISP-DM.
Enam fase CRISP-DM (Cross Industry Standard Process for Data Mining) sebagai berikut ((Novandya & Oktaria, 2017) [17]:
a. Fase Pemahaman Bisnis (Business Understanding Phase) b. Fase Pemahaman Data (Data Understanding Phase) c. Fase Pengolahan Data (Data Preparation Phase) d. Fase Pemodelan (Modelling Phase)
e. Fase Evaluasi (Evaluation Phase) f. Fase Penyebaran (Deployment Phase)
“Isi dan hasil dari metode CRISP-DM terdapat pada bab IV”.
3.5 Pengumpulan Data 3.5.1 Sumber Data
Data yang digunakan dalam penelitian ini adalah data pencemar udara ISPU daerah DKI Jakarta yang didapat dari bank data Portal Satu Data Indonesia
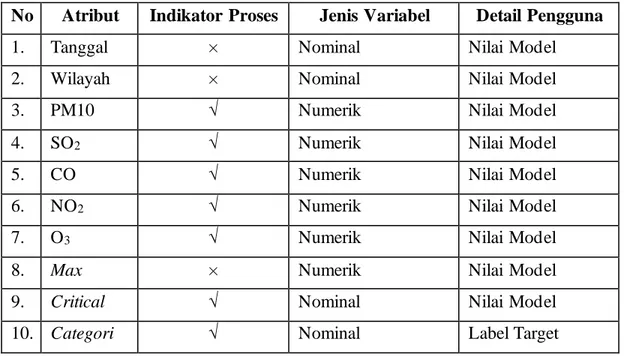
Tabel 3. 2Data Pencemar Udara ISPU Tanggal Stasiun PM1 0 SO2 CO O3 NO 2 MA X Critica l Categori 01/01/201 8 DKI1 (Bundera n HI) 35 20 22 27 2 35 PM10 BAIK 02/01/201 8 DKI1 (Bundera n HI) 14 18 12 17 1 18 SO2 BAIK 04/01/201 8 DKI1 (Bundera n HI) 24 21 20 19 2 24 PM10 BAIK 05/01/201 8 DKI1 (Bundera n HI) 23 19 17 21 2 23 PM10 BAIK 06/01/201 8 DKI1 (Bundera n HI) 18 19 14 24 2 24 O3 BAIK 07/01/201 8 DKI1 (Bundera n HI) 21 20 14 27 2 27 O3 BAIK 01/01/201 8 DKI2 (Kela pa Ga ding) 59 29 36 33 9 59 PM10 SEDAN G 02/01/201 8 DKI2 (Kela pa Ga ding) 18 28 5 33 14 33 O3 BAIK 03/01/201 8 DKI2 (Kela pa Ga ding) 52 33 15 73 23 73 O3 SEDAN G 04/01/201 8 DKI2 (Kela pa Ga ding) 53 49 12 47 15 53 PM10 SEDAN G 05/01/201 8 DKI2 (Kela pa Ga ding) 35 32 11 19 10 35 PM10 BAIK 06/01/201 8 DKI2 (Kela pa Ga ding) 20 28 6 24 5 28 SO2 BAIK 01/01/201 8
DKI3 (Ja ga ka rsa) 14 17 22 35 5 35 O3 BAIK
02/01/201 8
DKI3 (Ja ga ka rsa) 17 16 7 39 3 39 O3 BAIK
03/01/201 8
DKI3 (Ja ga ka rsa) 15 16 15 101 8 101 O3 TIDAK
SEHAT 04/01/201
8
DKI3 (Ja ga ka rsa) 11 16 14 57 5 57 O3 SEDAN
G 05/01/201
8
DKI3 (Ja ga ka rsa) 21 16 17 28 6 28 O3 BAIK
06/01/201 8
DKI3 (Ja ga ka rsa) 16 16 7 30 4 30 O3 BAIK
01/01/201 8 DKI4 (Luba ng Bua ya ) 76 31 31 33 6 76 PM10 SEDAN G 02/01/201 8 DKI4 (Luba ng Bua ya ) 23 31 7 36 3 36 O3 BAIK 03/01/201 8 DKI4 (Luba ng Bua ya ) 53 35 16 96 10 96 O3 SEDAN G 04/01/201 8 DKI4 (Luba ng Bua ya ) 53 33 12 49 9 53 PM10 SEDAN G
Tabel 3. 2 Data Pencemar Udara ISPU (Lanjutan) 05/01/2018 DKI4 (Luba ng Bua ya ) 44 32 12 18 6 44 PM10 BAIK 06/01/2018 DKI4 (Luba ng Bua ya ) 18 30 5 21 4 30 SO2 BAIK 01/01/2018 DKI5 (Kebon Jeruk) Ja ka rta Ba ra t 45 19 38 20 4 45 PM10 BAIK 03/01/2018 DKI5 (Kebon Jeruk) Ja ka rta Ba ra t 40 21 35 45 11 45 O3 BAIK 04/01/2018 DKI5 (Kebon Jeruk) Ja ka rta Ba ra t 36 20 34 9 8 36 PM10 BAIK 05/01/2018 DKI5 (Kebon Jeruk) Ja ka rta Ba ra t 31 18 26 9 5 31 PM10 BAIK 3.5.2 Variabel Data
Variabel data yang terdapat pada penelitian ini meliputi variabel input dan variabel output atau target.
1. Variabel Input
Variabel input dinyatakan sebagai data sempel pencemar udara serta tingkat angka kandungan zat pencemar di udara. Berikut ini adalah variabel input yang terdapat pada data uji pencemar udara ISPU yang akan digunakan untuk mengklasifikasi yaitu Tanggal, Stasiun, Tingkat Partikulat PM10, Sulfur Dioksida (SO2), Karbon Monoksida (CO), Ozon Permukaan (O3), Nitrogen Dioksida (NO2), Maximal, Critical, dan Categori.
2. Variabel Target
Variabel target dinyatakan sebagai hasil dari penelitian yang dilakukan terhadap variabel input. Sedangkan variabel target dari penelitian ini adalah atribut
“Categori” yang berisikan label “Baik, Sedang, Tidak Sehat, dan Sangat Tidak
3.5.3 Metode Pengumpulan Data
Dalam pengumpulan data-data yang dibutuhkan dalam penelitian ini menggunakan studi literatur. Pengumpulan data dilakukan untuk memperoleh informasi yang dibutuhkan dalam rangka mencapai tujuan penelitian. Agar data yang diperoleh valid dan tidak diragukan kebenarannya proses pengumpulan data dilakukan dengan cara mencari berbagai macam referensi dan informasi yang berkaitan dengan penelitian yang didapatkan dari jurnal, buku-buku, maupun artikel.
Studi literatur atau bisa disebut dengan studi pustaka adalah mencari referensi dan informasi yang berhubungan dengan polutan udara dan dampaknya bagi lingkungan di sekitarnya maupun metode klasifikasi dalam algoritma naive bayes yang digunakan dalam penelitian ini. Dalam melakukan penelitian yang menjadi literature atau tinjauan pustaka yaitu dengan kajian pustaka atau studi literatur. Suatu penelitian tidak lepas dari kajian pustaka atau studi literatur. Penelitian didukung oleh teori-teori yang mendasari masalah, informasi, dan pemikiran-pemikiran yang relevan, serta bersumber dari buku, jurnal, maupun prosiding.
3.6 Analisa Pengolahan Data
Sebelum dilakukan proses pengklasifikasian data, dilakukan metode pemrosesan data awal terlebih dahulu sesuai dengan proses metode Knowledge Discovery in Database (KDD). Data pencemar udara ISPU daerah DKI Jakarta yang didapatkan tidak semua data atau record dan atribut digunakan, data atau record dan atribut harus melalui beberapa tahap pengolahan awal data sehingga mendapatkan data yang berkualitas. Terdapat beberapa langkah pemrosesan data sebelum data diklasifikasi, berikut langkah-langkah dalam proses Knowledge Discovery in Database (KDD):
3.6.1 Pembersihan Data (Cleaning Data)
Pada tahap ini akan dilakukan pembersihan data yang tidak lengkap, kosong (null), noise, data yang terduplikat, dan data yang tidak konsisten. Dalam langkah ini,
data yang bernilai kosong (null), akan dibersihkan dengan cara dihapus secara manual, dan akan dilakukan penghapusan atribut atau mengganti data tersebut. Pembersihan data dilakukan kemudian dilanjutkan proses integrasi, transformasi, dan seleksi data.
3.6.2 Data Integration and Transformation
Pada tahap ini, akan dilakukan penggabungan data dari berbagai database yang berbeda. Teknik integration yang digunakan untuk menganalisis data korelasi, atribut yang redudant dan duplikat data, dan transformation digunakan untuk meningkatkan akurasi dan efisiensi algoritma. Kelebihan algoritma Naive Bayes adalah mampu melakukan proses data yang bernilai nominal, ordinal, atau kontinyu. Sehingga nilai dari tiap-tiap atribut yang terdapat pada dataset tidak perlu ditransfomasikan.
1. Mengintegrasikan berbagai database atau file-file. 2. Transformasi data (data transformation).
3. Normalisasi dan agregasi.
3.6.3 Selection Data
Pada proses ini akan diambil data yang relevan dengan data yang dianalis yaitu dengan mengurangi jumlah atribut dan record yang ada sehingga didapat data yang tetap informatif.
Tabel 3. 3Atribut Data Selection
No Atribut Indikator Proses Jenis Variabel Detail Pengguna
1. Tanggal × Nominal Nilai Model
2. Wilayah × Nominal Nilai Model
3. PM10 √ Numerik Nilai Model
4. SO2 √ Numerik Nilai Model
5. CO √ Numerik Nilai Model
6. NO2 √ Numerik Nilai Model
7. O3 √ Numerik Nilai Model
8. Max × Numerik Nilai Model
9. Critical √ Nominal Nilai Model
10. Categori √ Nominal Label Target
Tabel di atas merupakan atribut yang akan dipakai dalam penelitian ini. Dengan
indikator “√” menandakan atribut akan digunakan dan indikator “×” menandakan
atribut tidak akan digunakan.
3.6.4 Proses Data Mining
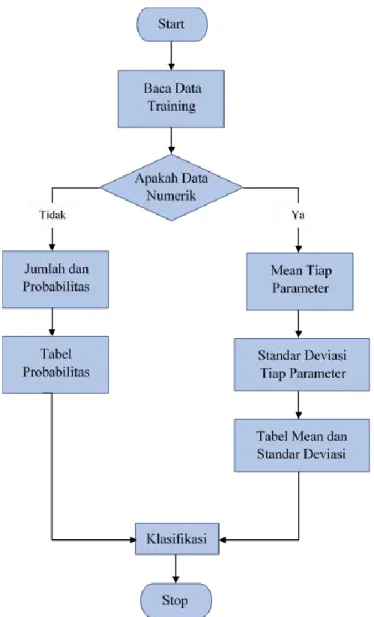
Data yang telah diproses pada tahap sebelumnya kemudian akan diuji menggunakan algoritma Naive Bayes. Langkah ini melakukan perhitungan manual dengan menggunakan rumus Naive Bayes dari data yang telah didapat dari proses sebelumnya. Berikut adalah alur dari metode klasifikasi Naive Bayes.
Gambar 3. 1Alur Klasifikasi Naive Bayes
1. Baca data training.
2. Hitung jumlah dan probabilitas, namun apabila data numerik maka cari nilai mean dan standar deviasi dari masing-masing parameter yang merupakan data numerik.
3. Mendapatkan nilai dalam tabel mean, standar deviasi dan probabilitas. 4. Solusi kemudian dihasilkan.
3.6.5 Evaluation and Presentation
Pada tahapan ini akan dijelaskan mengenai prosedur kerja atau langkah-langkah dalam penggunaan aplikasi Weka 3.8, dari proses input data yang akan digunakan hingga proses klasifikasi data dengan menggunakan algoritma dari metode Naive Bayes Classifier.
Langkah evaluation dilakukan untuk menentukan hasil klasifikasi yang didapatkan, apakah merupakan sebuah klasifikasi yang baik atau belum menurut hasil dari pengujian data testing terhadap data training yang telah diproses pada aplikasi weka 3.8. Dalam tahap ini akan dilakukan validasi dan pengukuruan keakuratan hasil yang akan dicapai dengan menggunakan metode confusion matrix. Confusion matrix yaitu mempresentasikan hasil evaluasi model dengan menggunakan tabel matriks. Jika dataset terdiri dari dua kelas, maka kelas pertama dianggap positif dan kelas kedua dianggap negatif. Evaluasi dari confusion matrix tersebut menghasilkan nilai akurasi, precision, dan recall.
Tabel 3. 4 Confusion Matrix Correct
Classification
Classified
+ -
+ True Positives False Negatives
- False Positive True Negatives
Perhitungan nilai akurasi didefinisikan dengan persamaan sebagai berikut: Akurasi = 𝑇𝑃+𝑇𝑁 𝑇𝑃+𝑇𝑁+𝐹𝑃+𝐹𝑁 Recall = 𝑇𝑃 𝑇𝑃+𝐹𝑁 Presisi = 𝑇𝑃 𝑇𝑃+𝐹𝑃 Dalam hal ini dijelaskan bahwa :
TN = Jumlah dari data yang terklasifikasi di kelas sebaliknya yang benar.
FP = Jumlah data yang dianggap berada di kelas yang benar oleh sistem padahal seharusnya data tersebut berada di kelas sebaliknya.
FN = Jumlah data yang dianggap berada di kelas yang sebaliknya oleh sistem padahal seharusnya data tersebut berada di kelas yang benar.
3.6.6 Data Training dan Data Testing
Dari data yang sudah melalui proses seleksi data, maka data akan dibagi menjadi dua bagian yaitu data training dan data testing. Dalam penelitian ini penulis menggunakan 800 data sebagai data training dan 200 data sebagai data testing.
“Untuk melihat data training dan data testing dapat dilihat di halaman lampiran”.
3.7 Dokumentasi Penelitian
Tahap dokumentasi penelitian adalah tahap akhir dalam penelitian ini yaitu tahap penulisan laporan penelitian. Adapun dalam tahap ini penulis melakukan konsultasi terhadap dosen pembimbing untuk mendapatkan masukan, kritik, dan saran dari dosen pembimbing untuk keberhasilan dalam penulisan laporan penelitian. Seluruh data yang diperoleh dari serangkaian proses penelitian yang telah dilakukan akan menghasilkan sebuah laporan yang nantinya akan diujikan kembali kepada pembimbing dan penguji penelitian.
3.8 Instrumen Penelitian
Instrumen penelitian berfungsi sebagai alat bantu dalam mengumpulkan data-data yang dibutuhkan dalam sebuah penelitian. Penyusunan instrumen seperti halnya mengevaluasi, karena dengan mengevaluasi peneliti dapat memperoleh data dari objek yang diteliti dan hasil yang didapatkan bisa diukur memakai standar yang sebelumnya telah ditentukan oleh peneliti. Di dalam penulisan dan penelitian ini penulis
membutuhkan beberapa instrumen antara lain adalah perangkat keras maupun perangkat lunak untuk menunjang penyelesaian penelitian.
Berikut ini adalah spesifikasi perangkat keras dan perangkat lunak yang dibutuhkan, diantaranya:
3.8.1 Kebutuhan Perangkat Keras (Hardware)
Di dalam penelitian ini penulis memerlukan sebuah penunjang perangkat keras komputer/ laptop dengan spesifikasi sebagai berikut:
1. Processor AMD A8-7410 with AMD Radeon R5 Graphics 2.20 GHz
2. Harddisk 500 GB
3. RAM 4.00 GB
4. Layar Monitor 11 inch
3.8.2 Kebutuhan Perangkat Lunak (Software)
Di dalam penelitian ini penulis memerlukan penujang perangkat lunak yang terdapat pada komputer, demi kelancaran dalam penelitian berikut ini perangkat lunak yang dibutuhkan oleh penulis:
1. Sistem Operasi
Pada penelitian ini penulis menggunakan sistem operasi yang digunakan adalah Microsoft Windows 10 64 bit.
2. Microsoft Office Word 2010
Software ini digunakan untuk mengolah laporan hasil penelitian. 3. Microsoft Office Excel 2010
Software ini digunakan sebagai media penulisan dan pengulahan dataset, data training, serta data testing.
4. Tools Weka 3.8
Framework yang digunakan untuk melihat hasil akurasi dari algoritma yang digunakan terhadap dataset yang sedang diteliti.
38 4.1 Pemahaman Bisnis
Pemahaman tujuan terhadap sudut pandang bisnis, kemudian diterjemahkan ke dalam pendefinisian masalah dalam data mining. Selanjutnya menentukan rencana dan strategi untuk mencapai tujuan tersebut.
1. Data diambil dari situs web www.data.go.id.
2. Dari data ISPU yang diunduh dapat disimpulkan bahwa kualitas udara menjadi topik utamanya.
3. Terdapat empat kualitas udara yang menjadi persoalan diantaranya ada kualitas baik, sedang, tidak sehat, dan sangat tidak sehat.
4. Penelitian ini menggunakan algoritma Naive Bayes untuk menentukan klasifikasi kualitas udara.
4.2 Pemahaman Data
Data yang digunakan adalah data Indeks Standar Pencemar Udara (ISPU) daerah DKI Jakarta yang telah dikumpulkan, pada proses ini telah dilakukan pemahaman mendalam tentang data yang telah dilakukan pada proses sebelumnya, yaitu mengidentifikasi masalah kualitas data.
1. Terdapat sepuluh atribut pada data Indeks Standar Pencemar Udara (ISPU) daerah DKI Jakarta, diantaranya ada tanggal, stasiun, PM10, SO2, CO, O3, NO2, MAX, critical, dan categori.
“untuk keterangan dapat dilihat di sub bab 3. 2”
2. Dari data tersebut dicari pokok permasalahan yang dapat dilihat pada identifikasi masalah.
4.3 Persiapan Data (Data Preparation)
Tahap ini meliputi semua kegiatan untuk membangun dataset akhir (data yang akan diproses).
1. Pertama, penentuan data yang akan diolah.
2. Ke-dua, penanganan data missing value, kosong (null), noise, data yang terduplikat, dan data yang tidak konsisten. Dalam langkah ini, data yang bernilai kosong (null), akan dibersihkan dengan cara dihapus secara manual, dan akan dilakukan penghapusan atribut atau mengganti data tersebut.
3. Ke-tiga, menentukan atribut yang digunakan.
“data atribut yang digunakan dapat dilihat pada tabel 3. 3”
4. Ke-empat, melakukan konversi data. Dengan atribut yang telah dipilih kemudian dikonversikan menggunakn tools bantu data mining.
“data training dan data testing dapat dilihat pada halaman lampiran”.
4.4 Modelling
Berikut adalah persamaan dari algoritma Naive Bayes [20]:
𝑃(𝐻|𝑋) =𝑃(𝑋|𝐻)
𝑃(𝑋) . 𝑃(𝐻)
Keterangan:
X : Data dengan class yang belum diketahui
H : Hipotesis data X merupakan suatu class spesifik
P(H|X) : Probabilitas hipotesis H berdasarkan kondisi X (posterior probability) P(H) : Probabilitas hipotesis H (prior probability)
P(X|H) : Probabilitas X berdasarkan kondisi pada hipotesis H P(X) : Probabilitas X


![Gambar 2. 2 Tahap-Tahap Data Mining Dalam Proses KDD Sumber: Tahap-tahap Data Mining dalam proses KDD (Jananto, 2013) [16]](https://thumb-ap.123doks.com/thumbv2/123dok/3220106.2351125/34.918.195.761.310.777/gambar-tahap-mining-proses-sumber-mining-proses-jananto.webp)
![Gambar 2. 3 Alur Pengklasifikasian Sumber: Alur Pengklasifikasian (Bustami, 2013) [18]](https://thumb-ap.123doks.com/thumbv2/123dok/3220106.2351125/36.918.169.777.336.448/gambar-alur-pengklasifikasian-sumber-alur-pengklasifikasian-bustami.webp)