DATA MINING LANJUT
Klasifikasi Data Otomotif
Menggunakan SVM Light
Proyek
Disusun
Oleh:
FITRA RIYANDA
1208107010079
JURUSAN INFORMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SYIAH KUALA
DARUSSALAM, BANDA ACEH
JUNI, 2013
ABSTRAK
Klasifikasi data secara otomatis merupakan salah satu sarana yang sangat penting dalam informasi dan memudahkan segalanya untuk mendapatkan informasi. Dalam laporan ini menyajikan klasifikasi data baru dengan menggunakan perbandingan antara model positif yang memiliki label. Dalam kasus ini melakukan penelitian masalah klasifikasi data dokumen otomotif. Pemberian data training set dilakukan dengan melakukan perbandingan antara data training set positif dan kamus yang sudah dinormalisasi dengan threshold sebanyak 45% dan 50% masing-masing dibandingkan dan data training set dibangun menjadi sebuah fitur untuk masing-masing threshold dan dilakukan pengujian dengan membangun model dari data
testing set untuk masing-masing threshold yang sudah dibangun menjadi sebuah fitur
menggunakan svm classify.
DAFTAR ISI
Halaman
ABSTRAK ... i
DAFTAR ISI ... ii
DAFTAR GAMBAR ... iii
BAB I PENDAHULUAN 1.1. Latar Belakang ... 1
1.2. Rumusan Masalah ... 2
1.3. Tujuan Penelitian ... 2
1.4. Manfaat Penelitian ... 2
BAB II TINJAUAN KEPUSTAKAAN 2.1. Data Mining ... 3
2.2. Data Warehouse ... 4
2.2.1. Kegunaan Data Warehouse ... 5
2.2.2. Konsep Dasar Data Warehouse ... 5
2.3. Metode KNN (K-Nearest Neighbor) ... 6
2.3.1. Algoritma KNN ... 7
2.3.2. Metode SMART ... 9
BAB III METODE KERJA 3.1. Pengambilan Data Sampel ... 13
3.2. Membersihkan Data Dokumen ... 13
3.3. Membagi Dataset Menjadi Data Training dan Testing ... 13
3.4. Membangun Kamus dan Threshold ... 14
3.5. Membangun Fitur, Model dan Pengujian ... 15
BAB IV HASIL DAN PEMBAHASAN 4.1. Data Hasil Pengamatan ... 16
4.2. Pembahasan ... 19
BAB V PENUTUP 5.1. Kesimpulan ... 21
5.2. Saran ... 21
DAFTAR GAMBAR
Halaman
Gambar 2.1. Flowchart Metode KNN... 8
Gambar 2.2. Flowchart Metode SMART ... 11
Gambar 3.1. Flowchart Tahapan Kerja ... 12
Gambar 4.1. Training Set Kamus 45% ... 16
Gambar 4.2. Testing Set Kamus 45% ... 17
Gambar 4.3. Training Set Kamus 50% ... 18
BAB I
PENDAHULUAN
1.1 Latar Belakang
Klasifikasi teks merupakan proses untuk membangun atau menempatkan label kategori yang telah ditetapkan untuk dokumen baru berdasarkan klasifikasi pembelajaran dari data traning set. Klasifikasi teks secara mudah dapat dilakukan dengan melakukan pembelajaran secara manual, tetapi itu hanya dapat dilakukan dalam jumlah yang terbatas atau relatif sedikit dan membutuhkan waktu yang lama. Dengan pesatnya pertumbuhan informasi dari berbagai penjuru pada dunia internet dengan jumlah yang sangat banyak dan bertambah setiap detiknya. Tentunya salah satu mengenali suatu teks dokumen tergolong dalam suatu kategori, salah satu cara pengorganisasian jumlah teks dokumen dalam jumlah besar dengan mengelompokkan mereka kedalam taksonomi deskriptif atau topikal dari teks dokumen itu sendiri.
Minat membaca pengguna sehari-hari dalam kebutuhannya guna mendapatkan informasi semakin banyak. Buku menjadi salah satu faktor utama minat pembaca semakin berkurang sehingga sulit untuk mendapatkan informasi dikarenakan beberapa faktor seperti kurang praktis, susah untuk mendapatkannya dan membutuhkan biaya yang mahal untuk mendapatkannya tetapi dalam buku tersebut tidak mendapatkan informasi yang cukup sesuai keinginan pengguna. Oleh sebab itu semakin berkembang teks dokumen yang memuat informasi sesuai kebutuhan pengguna dan lebih menarik minat membaca karena lebih praktis dan murah. Sering kali, dalam suatu teks dokumen tidak terdapat informasi mengenai topik utama dari teks dokumen tersebut, sehingga pengguna tidak melakukan kajian tentang informasi yang dimuat dalam teks dokumen tersebut, padahal dalam teks dokumen tersebut mungkin merupakan kebutuhan yang di inginkan pengguna. Oleh karena itu perlu dilakukan pengkajian teks web dokumen secara otomatis guna mempermudah dalam menentukan topik yang dibahas dalam suatu teks dokumen tersebut. Salah satu contoh yang telah dilakukan sebelumnya dengan menggunakan SVM berbasis metode pembelajaran adaptif untuk klasifikasi teks ( Tao Peng, 2007).
1.2 Rumusan Masalah
Dalam kasus penelitian ini membahas tentang pengkajian atau klasifikasi teks dokumen dalam kategori otomotif.
1.3 Tujuan Penelitian
Mengklasifikasikan sebuah teks dokumen untuk menentukan apakah sebuah teks dokumen tersebut membahas tentang otomotif ataupun bukan.
1.4 Manfaat Penelitian
Mengetahui topik yang dimuat dalam suatu teks dokumen guna memberikan informasi kepada pengguna dan memberikan pemahaman lebih lanjut kepada penulis dalam tahapan ataupun proses pembangunan fitur dan model dalam klasifikasi.
BAB II
TINJAUAN PUSTAKA
2.1 Data Mining
Secara sederhana data mining adalah suatu proses untuk menemukan
interesting knowledge dari sejumlah data yang disimpan dalam basis data atau media
penyimpanan data lainnya. Dengan melakukan data mining terhadap sekumpulan data, akan didapatkan suatu interesting pattern yang dapat disimpan sebagai
knowledge baru. Pattern yang didapat akan digunakan untuk melakukan evaluasi
terhadap data-data tersebut untuk selanjutnya akan didapatkan informasi.
Tehnik dalam Data Mining datang dari Basis Data, Machine Learning, dan Statistik. Elemen-elemen kunci untuk Data Mining ini telah dibuat dalam beberapa tahun terakhir. Secara umum tugas dari Data Mining dapat dibagi ke dalam dua tipe, yaitu Predictive Data Mining dan Knowledge Discovery / Description Data Mining.
Predictive Data Mining adalah tipe data mining untuk memprediksi nilai
suatu variabel di masa yang akan datang atau nilai variabel lain berdasarkan beberapa variabel yang saat ini telah diketahui nilainya. Yang termasuk dalam tipe ini antara lain: klasifikasi, regresi, dan deteksi deviasi.
Knowledge Discovery / Description Data Mining yang juga sering disebut
sebagai pencarian pola (pattern discovery) adalah tipe data mining yang digunakan untuk mendapatkan pola yang tersembunyi dalam data dan bisa dipahami oleh manusia, biasanya ditampilkan dalam bentuk kalimat yang mudah dimengerti, misalnya “Jika seseorang membeli produk A maka juga membeli produk B”. Meskipun pola ini bisa ditemukan oleh manusia tanpa bantuan komputer – khususnya jika jumlah variabel dan datanya kecil – namun jika jumlah variabel puluhan bahkan ratusan dan jumlah data ribuan bahkan jutaan maka diperlukan waktu bertahun-tahun untuk mendapatkan pola-pola tersebut. Disinilah peran teknologi informasi dengan dukungan sistem data mining membantu dalam penyelesaian permasalahan ini. Yang termasuk tipe ini adalah: klusterisasi, aturan asosiasi, dan penemuan pola sekuensial.
Dengan data mining perusahaan bisa mendapatkan informasi penting dan
profitable tentang klien atau pelanggan yang pada akhirnya bisa meningkatkan
keuntungan perusahaan atau mengurangi kerugian. Kegunaan informasi pada data
mining seperti diatas sering disebut sebagai Market Basket Analysis. Dalam jangka
panjang, data mining dapat membuat sebuah perusahaan lebih kompetitif.
Ada beberapa model data mining berdasarkan tugas atau tujuan yang harus dihasilkan. Model-model tersebut antara lain: klasifikasi, klusterisasi, assosiasi, pencarian sequence, regresi, dan deteksi deviasi.
2.2 Data Warehouse
Pengertian Data Warehouse dapat bermacam-macam namun mempunyai inti yang sama, seperti pendapat beberapa ahli berikut ini :
Menurut W.H. Inmon dan Richard D.H., data warehouse adalah koleksi data yang mempunyai sifat berorientasi subjek,terintegrasi,time-variant, dan bersifat tetap dari koleksi data dalam mendukung proses pengambilan keputusan
management.
Menurut Vidette Poe, data warehouse merupakan database yang bersifat analisis dan read only yang digunakan sebagai fondasi dari sistem penunjang keputusan.
Menurut Paul Lane, data warehouse merupakan database relasional yang didesain lebih kepada query dan analisa dari pada proses transaksi, biasanya mengandung history data dari proses transaksi dan bisa juga data dari sumber lainnya.
Data warehouse memisahkan beban kerja analisis dari beban kerja transaksi
dan memungkinkan organisasi menggabung/konsolidasi data dari berbagai macam sumber.
Jadi, data warehouse merupakan metode dalam perancangan database, yang menunjang DSS (Decission Support System) dan EIS (Executive Information System). Secara fisik data warehouse adalah database, tapi perancangan data warehouse dan
database sangat berbeda. Dalam perancangan database tradisional menggunakan
normalisasi, sedangkan pada data warehouse normalisasi bukanlah cara yang terbaik. Dari definisi-definisi yang dijelaskan tadi, dapat disimpulkan data warehouse adalah database yang saling bereaksi yang dapat digunakan untuk query dan analisisis, bersifat orientasi subjek, terintegrasi, time-variant,tidak berubah yang digunakan untuk membantu para pengambil keputusan.
2.2.1 Kegunaan Data Warehouse
Berdasarkan pengertian data warehouse diatas, data warehouse diperlukan bagi para pengambil keputusan manajemen dari suatu organisasi/perusahaan. Dengan adanya data warehouse, akan mempermudah pembuatan aplikasi-aplikasi DSS (Decision Support System) dan EIS (Executive
Information System) karena kegunaan dari data warehouse adalah khusus untuk
membuat suatu database yang dapat digunakan untuk mendukung proses analisa (OLAP), mengambil keputusan, pembuatan laporan, penggalian informasi baru (Data Mining) dari banyak data dan proses executive informasi.
2.2.2 Konsep Dasar Data Warehouse
Data warehouse adalah kumpulan macam-macam data yang subject oriented, integrated, time variant, dan nonvolatile dalam mendukung proses
pembuatan keputusan (Inmon and Hackathorn, 1994).
Data warehouse sering diintegrasikan dengan berbagai sistem aplikasi
untuk mendukung proses laporan dan analisis data dengan menyediakan data histori, yang menyediakan infrastruktur bagi EIS dan DSS.
a. Subject Oriented
Data warehouse diorganisasikan pada subjek-subjek utama, seperti
pelanggan, barang/ produk, dan penjualan. Berfokus pada model dan analisis pada data untuk membuat keputusan, jadi bukan pada setiap proses transaksi atau
bukan pada OLTP. Menghindari data yang tidak berguna dalam mengambil suatu keputusan.
b. Integrated
Dibangun dengan menggabungkan/menyatukan data yang berbeda.
relational database, flat file, dan on-line transaction record. Menjamin
konsistensi dalam penamaan, struktur pengkodean, dan struktur atribut diantara data satu sama lain.
c. Data warehouse time variant
Data disimpan untuk menyediakan informasi dari perspektif historical, data yang tahun-tahun lalu/ 4-5 thn. Waktu adalah elemen kunci dari suatu data
warehouse/ pada saat pengcapture-an.
d. Non Volatile
Setiap kali proses perubahan, data akan di tampung dalam tiap-tiap waktu. Jadi tidak di perbaharui terus menerus. Data warehouse tidak memerlukan pemrosesan transaksi dan recovery. Hanya ada dua operasi initial
loading of data dan access of data.
Data warehouse bukan hanya tempat penyimpanan data, Data warehouse
adalah Business Intelligence tools, tools to extract, merubah (transform) dan menerima data (load) ke penyimpanan (repository) serta mengelola dan menerima
metadata.
2.3 Metode KNN (K-Nearest Neighbor)
Prinsip kerja K-Nearest Neighbor (KNN) adalah mencari jarak terdekat antara data yang akan dievaluasi dengan K tetangga (neighbor) terdekatnya dalam data pelatihan.
Teknik ini termasuk dalam kelompok klasifikasi nonparametric. Di sini kita tidak memperhatikan distribusi dari data yang ingin kita kelompokkan. Teknik ini
sangat sederhana dan mudah diimplementasikan. Mirip dengan teknik klastering, kita mengelompokkan suatu data baru berdasarkan jarak data baru itu ke beberapa data/tetangga (neighbor) terdekat.
Tujuan algoritma KNN adalah mengklasifikasikan obyek baru berdasarkan atribut dan training sample. Clasifier tidak menggunakan model apapun untuk dicocokkan dan hanya berdasarkan pada memori. Diberikan titik query, akan ditemukan sejumlah k obyek atau (titik training) yang paling dekat dengan titik query. Klasifikasi menggunakan voting terbanyak diantara klasifikasi dari k obyek. Algoritma KNN menggunakan klasifikasi ketetanggaan sebagai nilai prediksi dari
query instance yang baru. Algoritma metode KNN sangatlah sederhana, bekerja
berdasarkan jarak terpendek dari query instance ke training sample untuk menentukan KNN-nya.
Nilai k yang terbaik untuk algoritma ini tergantung pada data. Secara umum, nilai k yang tinggi akan mengurangi efek noise pada klsifikasi, tetapi membuat batasan antara setiap klasifikasi menjadi semakin kabur. Nilai k yang bagus dapat dipilih dengan optimasi parameter, misalnya dengan menggunakan cross-validation. Kasus khusus dimana klasifikasi diprekdisikan berdasarkan training data yang paling dekat (dengan kata lain, k=1) disebut algoritma Nearest Neighbor.
Kelebihan KNN (K-Nearest Neighbor):
1. Tangguh terhadap training data yang memiliki banyak noise. 2. Efektif apabila training datanya besar.
Kelemahan KNN (K-Nearest Neighbor):
1. KNN perlu menentukan nilai dari parameter k (jumlah dari tetangga terdekat). 2. Training berdasarkan jarak tidak jelas mengenai jenis jarak apa yang harus
digunakan.
3. Atribut mana yang harus digunakan untuk mendapatkan hasil terbaik.
4. Biaya komputasi cukup tinggi karena diperlukan perhitungan jarak dari tiap
2.3.1 Algoritma KNN
1. Tentukan parameter K
2. Hitung jarak antara data yang akan dievaluasi dengan semua pelatihan 3. Urutkan jarak yang terbentuk (urut naik)
4. Tentukan jarak terdekat sampai urutan K 5. Pasangkan kelas yang bersesuaian
6. Cari jumlah kelas dari tetangga yang terdekat dan tetapkan kelas tersebut sebagai kelas data yang akan dievaluasi
Rumus KNN:
(
)
∑
= − = p i i i i x x d 1 2 1 2 …(1) Keterangan: 1 x = Sampel Data 2x = Data Uji / Testing i = Variabel Data d = Jarak
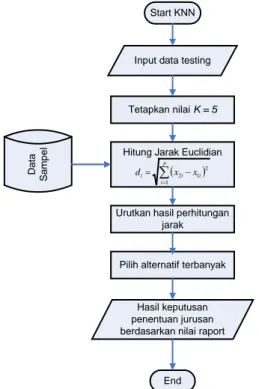
Di bawah ini merupakan flowchart dari metode KNN:
Start KNN
Input data testing
Tetapkan nilai K = 5
Hitung Jarak Euclidian
( ) ∑ = − = p i i i i x x d 1 2 1 2
Urutkan hasil perhitungan jarak
Pilih alternatif terbanyak
Hasil keputusan penentuan jurusan berdasarkan nilai raport
D a ta S a m p e l End
Gambar 2.1 Flowchart dari Metode KNN
2.3.2 Metode SMART (Simple Multi Attribute Rating Technique)
SMART merupakan metode pengambilan keputusan yang multiatribut. Teknik pembuatan keputusan multiatribut ini digunakan untuk membantu stakeholder dalam memilih antara beberapa alternatif. Setiap alternatif terdiri dari sekumpulan atribut dan setiap atribut mempunyai nilai-nilai, nilai ini dirata-rata dengan skala tertentu. Setiap atribut mempunyai bobot yang menggambarkan seberapa penting ia dibandingkan dengan atribut lain.
Dengan SMART pembobotan atribut dilakukan dengan dua langkah yaitu:
1. Mengurutkan kepentingan suatu atribut dari level terburuk ke level terbaik. 2. Membuat perbandingan rasio kepentingan setiap atribut dengan atribut lain
dibawahnya.
SMART lebih banyak digunakan karena kesederhanaanya dalam merespon kebutuhan pembuat keputusan dan caranya menganalisa respon. Analisa yang terlibat adalah transparan sehingga metode ini memberikan pemahaman masalah yang tinggi dan dapat diterima oleh pembuat keputusan. Pembobotan pada SMART menggunakan skala antara 0 sampai 1, sehingga mempermudah perhitungan dan perbandingan nilai pada masing-masing alternatif.
Model yang digunakan dalam SMART:
…(2) Keterangan:
wj = nilai pembobotan kriteria ke-j dan k kriteria u(ai) = nilai utility kriteria ke-i untuk kriteria ke-i
Pemilihan keputusan adalah mengidentifikasi mana dari n alternatif yang mempunyai nilai fungsi terbesar.
2.3.2.1 Teknik SMART
1. Langkah 1: menentukan jumlah kriteria
2. Langkah 2: sistem secara default memberikan skala 0-100 berdasarkan prioritas yang telah diinputkan kemudian dilakukan normalisasi.
Normalisasi =
∑
j j w w …(3)∑
= = m J i i j i wu a a u 1 ), ( ) ( i =1,2,...mKeterangan : wj : bobot suatu kriteria
∑
w : total bobot semua kriteria j3. Langkah 3: memberikan nilai kriteria untuk setiap alternatif. 4. Langkah 4: hitung nilai utility untuk setiap kriteria masing-masing.
…(4) Keterangan :
ui(ai) : nilai utility kriteria ke-1 untuk kriteria ke-i Cmax : nilai kriteria maksimal
Cmin : nilai kriteria minimal Cout i : nilai kriteria ke-i
5. Langkah 5: hitung nilai akhir masing-masing.
∑
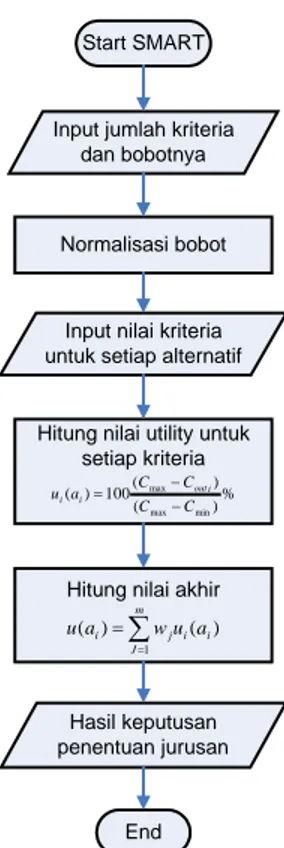
= = m J i i j i wu a a u 1 ), ( ) ( % ) ( ) ( 100 ) ( min max max C C C C a u outi i i − − =Di bawah ini merupakan flowchart dari metode SMART
Start SMART
Input jumlah kriteria dan bobotnya
Normalisasi bobot
Input nilai kriteria untuk setiap alternatif
Hitung nilai utility untuk setiap kriteria % ) ( ) ( 100 ) ( min max max C C C C a u outi i i − − =
Hitung nilai akhir
∑ = =m J i i j i wu a a u 1 ) ( ) ( Hasil keputusan penentuan jurusan End
BAB III
METODE KERJA
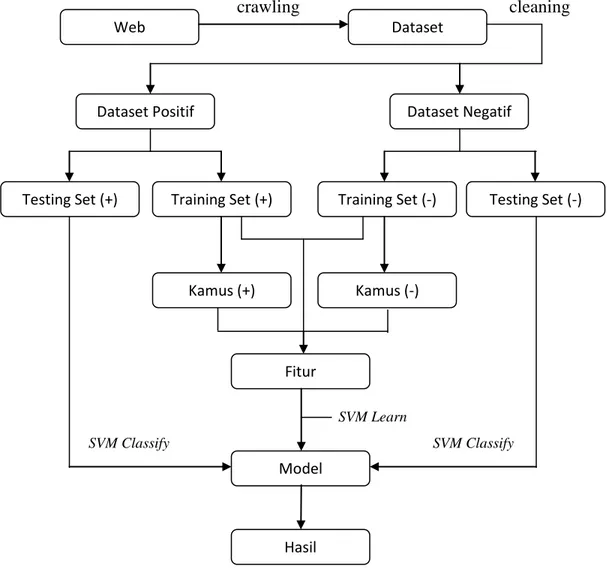
Dalam prosedur penelitian dari tahapan melakukan klasifkasi dataset menggunakan SMV Light tampak pada chart berikut:
crawling cleaning
SVM Learn
SVM Classify SVM Classify
Gambar 3.1 Flowchart Tahapan Kerja
Dataset Web
Dataset Positif Dataset Negatif
Testing Set (+) Training Set (+) Training Set (-) Testing Set (-)
Kamus (+)
Fitur
Model
Hasil
3.1 Pengambilan Data Sample
Pengambilan data sample masing-masing data untuk melakukan fitur baik dataset positif maupun dataset negatif dilakukan dengan mengcrawling data teks dokumen menggunakan Swish-E. Dari metode crawling data menggunakan Swish-e perlu dilakukan beberapa tahapan seperti melakukan installasi pada linux dan kemudian membangun beberapa program untuk melakukan eksekusi perintah, didalam program ini dapat diberikan berupa alamat url yang dituju juga memfilter jenis data yang ingin di crawled. Proses crawling dengan menggunakan metode ini membutuhkan waktu yang sangat lama tergantung banyaknya permintaan crawling data maupun kecepatan koneksi. Setelah dilakukan crawling data dari berbagai situs yang membahas topik untuk data positif dan data negatif masing-masing sebanyak 12 ribu untuk data teks dokumen positif dan 10 ribu untuk data teks dokumen kemudian dipisahkan masing-masing direktori positif dan direktori negatif.
3.2 Membersihkan Data Teks Dokumen
Setelah seluruh file yang diinginkan selesai di crawling, tahap selajutnya yaitu melakukan cleaning data. Data yang telah di-clean dalam program tersebut dimasukkan dalam sebuah folder yang berisikan semua file yang telah dibersihkan untuk masing-masing data cleaned dari dataset positif dan negatif. Dari seluruh data yang terdapat dalam file tersebut hanya mengambil title dan isi dari content saja.
3.3 Membagi Dataset Menjadi Data Training dan Testing
Dari hasil cleaned untuk masing-masing dataset positif dan negatif tersebut, barulah dipisahkan menjadi data trainingset sebanyak 75% ( ± 10 ribu file) dan selebihnya dimasukkan ke data testingset sebanyak 25% dari ± 12 ribu file dataset positif dan juga untuk dataset negatif sebanyak ± 10 ribu file dipisahkan menjadi
data trainingset sebanyak 75% ( ± 7500 file) dan selebihnya dimasukkan ke data testingset sebanyak 25%.
3.4 Membangun Kamus Bigrams dan Threshold
Setelah seluruh data selesai di bersihkan dan dipisahkan menjadi data
trainingset dan data testingset untuk masing-masing dataset positif dan negatif,
barulah dilakukan proses penggabungan seluruh file data trainingset untuk masing-masing dataset positif dan negatif menjadi kedalam satu file. Setelah dilakukan penggabungan masing-masing dataset, barulah dilakukan proses pembangunan kamus untuk data trainingset positif dan negatif. Dalam proses ini dibangun kamus yang sering muncul dengan frekuensi tertentu dan tidak termasuk stopword yang merupakan kata-kata pendukung yang tidak dapat dipakai untuk membangun kamus. Stopword ini berfungsi memfilter kata-kata yang sering muncul dalam conten dan tidak ikut dimasukkan kedalam kamus menggunakan program perl one-grams.pl, two-grams.pl dan tree-grams.pl.
Setelah pembangunan kamus yang memiliki jumlah banyak kata yang muncul dari masing-masing kelompok kamus bigrams, kemudian dilakukan perhitungan nilai frekuensi tiap-tiap kamus dimana frekuensi didapatkan dari jumlah kata dibagi dengan jumlah kata yang paling banyak muncul. Dari ini dapat diperoleh data dengan nilai antara 0 sampai 1 untuk tiap frekuensinya. Dari nilai frekkuensi masing-masing kamus bigrams positif dan negatif dilakukan normalisasi dengan membandingkan dan melakukan eliminasi observasi untuk rasio. Banyaknya rasio dengan threshold dilakukan dengan dua jenis sebagai perbandingan yaitu sebesar 45% dan 50%. Untuk melakukan hal tersebut, data trainingset kamus negatif dibutuhkan sebagai pembanding untuk data trainingset pada kamus positif.
Untuk melakukan normalisasi, tahapan untuk diteliti menggunakan dua metode yaitu melakukan eliminasi observasi langsung dari kelompok bigrams (satu kata, dua kata dan tiga kata) untuk masing-masing kamus positif dan kamus negatif. Metode kedua yaitu dengan melakukan penggabungan kamus masing-masing kelompok bigrams (satu kata, dua kata dan tiga kata) sehingga terbentuk masing-masing kamus positif dan negatif yang sudah digabungkan untuk masing-masing-masing-masing rasio 45% dan 50%.
3.5 Membangun Fitur, Model dan Pengujian
Untuk tahapan pembangunan fitur, diperlukan kamus akhir positif dan negatif dari masing-masing kamus yang telah dinormalisasi dan diperlukan juga data
trainingset positif juga data trainingset negatif. Bagian yang diambil dalam proses
pembangunan fitur yaitu bagian judul, bagian atas dari isi konten, bagian tengah dari isi konten dan bagian akhir dari isi konten. Sehingga proses pembangunan fitur dapat dirumuskan dengan formula berikut:
,
Dari formula tersebut, jumlah fitur atribut berjumlah 4 bagian, 3 jenis gram dan 2 kategori, sehingga total dari jumlah atribut adalah 24 jenis fitur. Fitur untuk bagian judul dari kategori p (Cp), disimbol Ftitle,p, adalah jumlah kata pada bagian
judul yang ditemukan dalam kamus kategori p atau Dic(Cp), dibagi dengan jumlah
kata pada bagian judul (tidak termasuk stopword). Dimana n adalah jumlah kata dalam bagian yang dipertimbangkan (tidak termasuk stopword), misalnya bagian judul, bagian atas, tengah dan bawah konten, dan k adalah jumlah halaman web berkategori Cp. Setiap bagian diberi bobot yang berbeda dengan asumsi bagian atas
konten web lebih penting dari bagian tengah, dan bagian tengah konten lebih penting dari pada bagian bawah web.
Setelah proses pembangunan selesai, maka dengan menggunakan SVM
Learning dan dengan fitur yang telah dibangun, dapat dilakukan pembangunan model
dari fitur tersebut. Setelah model telah dibangun, tahapan selanjutnya dengan mengklasifikasi data testingset dari dataset positif dan dataset negatif dengan menggunakan SVM Classify sehingga menghasilkan output dugaan dari model yang telah dibangun.
BAB IV
HASIL DAN PEMBAHASAN
4.1 Data Hasil Pengamatan
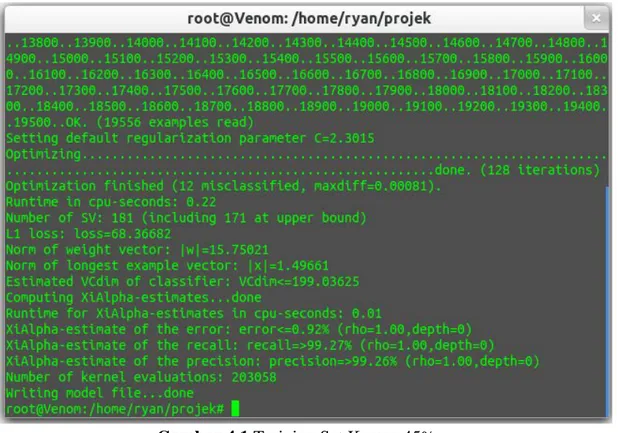
Dari hasil yang telah diperoleh dari pembangunan fitur dataset positif dan negatif menggunakan kamus dengan threshold sebanyak 45% terdapat pada gambar berikut:
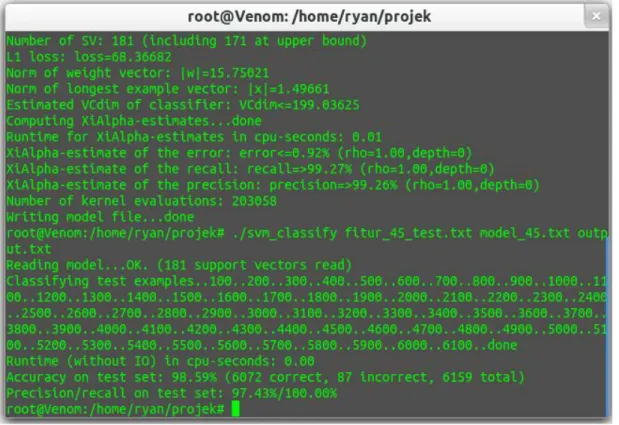
Gambar 4.1 Training Set Kamus 45%
Gambar tersebut menunjukkan dari proses pembangunan model dengan menggunakan kamus yang dinormalisasikan dengan rasio 45% menghasilkan error prediction 0.92%, dengan nilai recall 99,27% dan precision dengan nilai 99,26%.
Setelah model dibangun, selanjutnya melakukan pengujian dataset dari model tersebut dengan data testingset positif dan negatif yang menghasilkan output seperti pada gambar berikut:
Gambar 4.2 Testing Set Kamus 45%
Dari hasil pengujian menggunakan model yang telah dibangun dengan menggunakan SVM Classify dan mengklasifikasi dari data testing menghasilkan akurasi sebesar 98,59% dengan 6072 dugaan yang benar dan 87 dugaan yang salah dari 6159 dataset keseluruhan. Nilai dari precision dan recall dari hasil pengujian yaitu 97,43%.
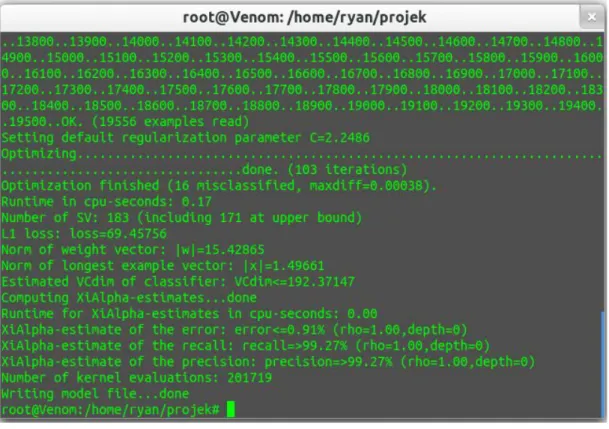
Begitu juga dari hasil yang telah diperoleh dari pembangunan fitur dataset positif dan negatif menggunakan kamus dengan threshold sebanyak 50% terdapat pada gambar berikut:
Gambar 4.3 Training Set Kamus 50%
Gambar tersebut menunjukkan dari proses pembangunan model dengan menggunakan kamus yang dinormalisasikan dengan rasio 50% menghasilkan error prediction 0.91%, dengan nilai recall 99,27% dan precision dengan nilai 99,27%.
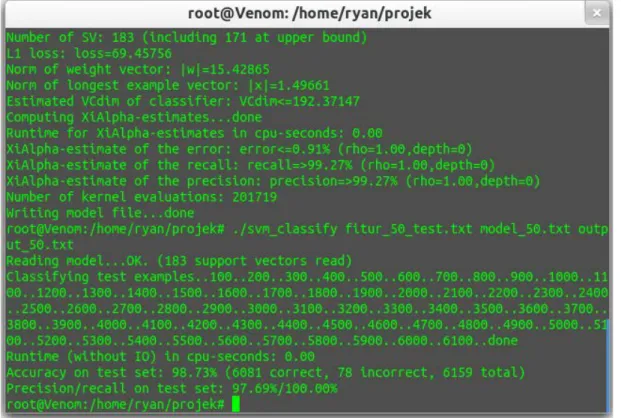
Sama seperti tahapan sebelumnya, setelah model dibangun, selanjutnya melakukan pengujian dataset dari model tersebut dengan data testingset positif dan negatif yang menghasilkan output seperti pada gambar berikut:
Gambar 4.4 Testing Set Kamus 50%
Dari hasil pengujian menggunakan model yang telah dibangun dengan menggunakan SVM Classify dan mengklasifikasi dari data testing menghasilkan akurasi sebesar 98,73% dengan 6081 dugaan yang benar dan 78 dugaan yang salah dari 6159 dataset keseluruhan. Nilai dari precision dan recall dari hasil pengujian yaitu 97,69%.
4.2 Pembahasan
Setelah melakukan pengujian sampel menggunakan SVM Light Classify dari model yang telah dibangun untuk tiap masing-masing kamus menghasilkan perbedaan akurasi. Tahap pengujian dengan kamus rasio 45% memiliki nilai akurasi lebih sedikit dibandingkan pengujian dengan menggunakan kamus berasio 50% sebagai dugaan dari sample yang memiliki tingkat akurasi sedikit lebih baik dengan nilai 98,73% berbanding dengan 98,59%.
Dari perhitungan tersebut dapat dihitung dengan nilai precision dan recall semua class maka yang diduga sehingga mendapatkan nilai F-Measure dan nilai rata-rata F-Measure dari setiap class yang ada. Begitu juga dengan Precision dan
Recall untuk masing-masing class.
Cara perhitungan dari hasil dari tiap-tiap class tersebut dapat dilakukan dengan menggunakan rumus sebagai berikut:
Precision = TP Recall = TP F-Measure = 2 (P x R)
TP + FP TP + FN P + R Dimana, P : Precision
R : Recall
TP : True Positif, merupakan nilai yang diduga benar (akurat) FP : False Positif, merupakan nilai yang diduga salah tetapi positif FN : False Negatife, merupakan benar nilai tersebut diduga salah (akurat)
BAB V
PENUTUP
5.1 Kesimpulan
Dari hasil pengujian dataset menggunakan kamus dengan rasio 45% dalam normalisasinya menghasilkan akurasi sebesar 98,59% dimana 6072 dugaan yang benar dan 87 dugaan yang salah dari 6159 dataset keseluruhan. Sedangkan hasil pengujian dataset menggunakan kamus dengan rasio 50% dalam normalisasinya menghasilkan akurasi sebesar 98,73% dimana 6081 dugaan yang benar dan 78 dugaan yang salah dari 6159 dataset keseluruhan.
Dari perbandingan terhadap dua pengujian tersebut, pembangunan model dengan menggunakan kamus dengan rasio 50% dalam proses normalisasinya sedikit lebih baik dibandingkan dengan menggunakan model dari kamus dengan rasio 45%.
5.2 Saran
Dari proses yang telah dilakukan untuk pembangunan kamus hingga model, terdapat sedikit error dalam prosesnya, itu terjadi karena kamus yang dibangun terdapat karakter yang tidak dikenali dari kamus yang dibangun. Oleh karena itu disarankan agar membangun kamus yang terbebas dari karakter-karakter yang tidak diketahui dengan memprosesnya lebih bersih, sehingga dapat menjadikan proses pembangunan model dengan baik.
DAFTAR PUSTAKA
Berry, M.W., & Kogan, J. (2010).Text Mining: Application and Theory. Chichester: JohnWiley & Sons, Ltd.Feldman, R., & Sanger, J.
(2007).The Text Mining Handbook: Advanced Approaches
in Analyzing Unstructured Data. New York: Cambridge University
Press.Gresnews.
Tao Peng, Wanli Zuo, Fengling He.2007. SVM based adaptive learning method for text classification from positive and unlabeled documents. China, Springer-Verlag London.
Xiangju Qin, Yang Zhang, Chen Li, Xue Li.2013. Learning from data streams with only positive and unlabeled data. New York, Springer