Informasi Dokumen
- Penulis:
- Jim Bird
- Pengajar:
- Courtney Allen, Editor
- Sekolah: O’Reilly Media
- Mata Pelajaran: Software Security
- Topik: DevOpsSec: Delivering Secure Software Through Continuous Delivery
- Tipe: Book
- Tahun: 2016
- Kota: Sebastopol
Ringkasan Dokumen
I. DevOpsSec: Delivering Secure Software through Continuous Delivery
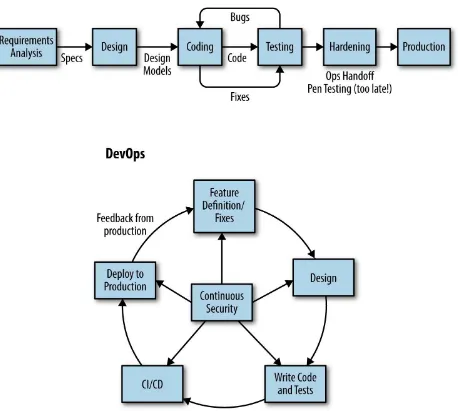
This section introduces the concept of DevOpsSec, emphasizing its role in integrating security into the DevOps process. It discusses how traditional practices in software development, such as ITIL and Waterfall, are being replaced by more agile methodologies that prioritize speed and efficiency. The section highlights the importance of continuous experimentation and automation in modern IT service delivery, and how these practices can enhance security without compromising on speed. By breaking down silos between development and operations, organizations can deliver value more effectively while maintaining a focus on security.
II. Security and Compliance Challenges and Constraints in DevOps
This section outlines the major security and compliance challenges that arise in a DevOps environment. The rapid pace of change in IT, exemplified by organizations like Amazon and Etsy, poses significant challenges for security teams that must keep up with frequent deployments. Additionally, the section discusses how the Agile emphasis on minimal upfront design complicates traditional security practices, as security teams often struggle to integrate their processes into a fast-moving development cycle. The influence of Lean principles in DevOps further exacerbates the tension between security and speed, requiring innovative approaches to maintain compliance without hindering delivery.
2.1 Speed: The Velocity of Delivery
The section emphasizes the unprecedented speed at which DevOps teams deploy changes, often exceeding 50 deployments a day. This rapid pace creates challenges for security teams, who must find ways to assess risks and implement controls without the luxury of time for traditional testing and auditing processes. The challenge lies in adapting security measures to fit within this fast-moving environment while still ensuring adequate protection against vulnerabilities.
2.2 Where’s the Design?
This subsection discusses the Agile principle of prioritizing working software over comprehensive documentation, which often leads to insufficient design time. In a DevOps context, this can make it difficult for security teams to engage effectively, as they may lack the necessary design documents to conduct thorough threat modeling. The constant evolution of design and code complicates the security review process, necessitating new strategies for integrating security considerations early in development.
2.3 Eliminating Waste and Delays
This subsection highlights the Lean influence on DevOps, where the focus is on maximizing efficiency and minimizing delays. While this approach can speed up delivery, it can also create friction with security requirements, as teams may question the value of investing time in security for features that might be discarded shortly after development. This tension necessitates a careful balance between delivering value quickly and ensuring that security measures are adequately addressed.
III. Keys to Injecting Security into DevOps
This section provides a roadmap for integrating security into the DevOps lifecycle. It emphasizes the need for security to shift left, meaning that security considerations should be integrated earlier in the development process rather than tacked on at the end. The section also underscores the importance of fostering a culture of security within development teams, where security engineers work alongside developers to identify and mitigate risks proactively. By adopting practices such as threat modeling and automated security testing, organizations can create a more resilient security posture while maintaining the agility that DevOps offers.
3.1 Building Security into DevOps: Etsy’s Story
This subsection presents Etsy as a case study in successfully integrating security into a high-velocity development environment. Etsy’s approach emphasizes trust, verification, and collaboration between security and engineering teams. By fostering a culture of shared responsibility and providing developers with the tools and knowledge to address security issues, Etsy has managed to maintain a robust security posture while continuously deploying changes. This model serves as an example for other organizations looking to balance speed and security.
3.2 Shift Security Left
The subsection elaborates on the concept of shifting security left, which involves embedding security practices early in the development cycle. This proactive approach allows teams to identify vulnerabilities during the design and coding phases, thus reducing the likelihood of security issues arising later. Training developers in security principles and providing them with the necessary tools can empower them to take ownership of security, making it an integral part of the development process.
IV. Security as Code: Security Tools and Practices in Continuous Delivery
This section discusses the integration of security into the Continuous Delivery pipeline, emphasizing the concept of 'Security as Code.' By mapping out the processes involved in code and infrastructure changes, organizations can identify key points to implement security checks without introducing delays. The section highlights the importance of automation in maintaining security compliance and ensuring that security practices are consistently applied across all deployments. By treating security as an integral part of the development process, organizations can enhance their overall security posture while leveraging the benefits of Continuous Delivery.
4.1 Continuous Delivery
This subsection defines Continuous Delivery and its significance in the DevOps framework. Continuous Delivery automates the process of building, testing, and deploying applications, ensuring that changes can be reliably and efficiently delivered to production. By integrating security checks into this automated pipeline, organizations can maintain compliance and address vulnerabilities quickly, thus enhancing their security posture while adhering to the rapid pace of DevOps.
Referensi Dokumen
- Continuous Delivery ( Dave Farley )
- Interview ( Dave Farley )
- About the Author ( Jim Bird )