ASOSIASI DATA MINING PENJUALAN DENGAN MENGGUNAKAN ALGORITMA FP-GROWTH
( STUDI KASUS : MARKET BASKET ANALYSIS (MBA) ) Final Project Data Mining
Oleh
Rizal M Noor
117006214
JURUSAN TEKNIK INFORMATIKA
FAKULTAS TEKNIK UNIVERSITAS SILIWANGI TASIKMALAYA
1. PENDAHULUAN
Bidang ilmu pengetahuan, bisnis dan pemerintahan telah melahirkan
tumpukan data yang sangat melimpah. Tumpukan data ini yang akhirnya
dikumpulkan dan diolah oleh kemampuan teknologi informasi menjadi beberapa “pengetahuan” baru yang dapat dimanfaatkan. Namun metoda analisis dan pengolahan data yang ada, masih kesulitan dalam menangani data dalam jumlah
besar. Sementara, kebutuhan akan informasi dari gudang data ini memaksa untuk
lahirnya sebuah teknologi baru yang dapat mengolah data dalam jumlah besar.
Maka lahirlah data mining, sebuah teknologi baru yang menjawab kebutuhan ini.
Sebuah perusahaan pemasaran dapat mengumpulkan data transaksi
dengan cepat sehingga menghasilkan data yang sangat besar. Pertumbuhan data
yang pesat itukadang dibiarkanbegitu saja dan tidak digunakan. Dengan data
mining atau lebih tepatnya Market Basket Analysis (MBA), data yang banyak itu
dapat diolah sehingga didapatkan informasi tersembunyi yang akan menghasilkan
knowledge yang berguna untuk pengambilan keputusan para decision maker
perusahaan pemasaran tersebut.
MBA merupakan salah satu contoh dari data mining yang digunakan
untuk menganalisa kebiasaan konsumen dalam berbelanja. MBA bisa menjadi
tidak berguna ketika dihadapkan pada data yang kecil, namun akan menghasilkan
informasi yang berharga ketika diperlakukan pada data yang besar seperti misalnya
data transaksi sebuah supermarket besar.
Salah satu teknik dalam data mining yang terkenal dan cocok untuk
MBA adalah association rule mining. Association rule mining memiliki beberapa
algoritma yang sudah sering digunakan diantaranya algoritma Apriori, FP-Growth,
dan CT-PRO yang dimana ketiga algoritma tersebut memiliki kelebihan dan
kekurangan masing-masing. Dalam dokumen penelitian ini penulis akan
menggunakan algoritma FP-Growth.
2. LANDASAN TEORI 2.1 Data
Data merupakan sekumpulan fakta yang nantinya akan menjadi
Informasi yang didapatkan harus sesuai dengan kebutuhan dan harus
dipastikan bahwa informasi tersebut memiliki kualitas yang baik. Ada
beberapa faktor yang mempengaruhi kualitas dari sebuah informasi, yaitu
keakuratan, kerelevanan, tepat waktu dan penyajiannya. Informasi yang nanti
didapatkan atau sering disebut dengan knowledge, harus memiliki nilai yang
baik. Informasi ini akan digunakan untuk penentuan keputusan dan kebijakan
serta langkah apa yang akan sebaiknya dilakukan selanjutnya, jadi proses
dalam mendapatkan informasi ini haruslah menggunakan proses dan teknologi
yang dapat dipercaya kebenarannya.
2.2 Data Mining
Data Mining adalah sebuah teknologi baru yang memiliki potensi
sangat besar dalam penggalian informasi yang tersembunyi. Data mining juga
sering didefinisikan sebagai proses ekstraksi informasi prediktif tersembunyi
dari database yang sangat besar. Teknologi ini memungkinkan sebuah
perusahaan untuk lebih proaktif dalam penyusunan strategi yang efektif dan
juga dalam pengambilan keputusan berdasarkan perilaku dan tren masa depan
yang dapat diprediksi oleh proses data mining.
Secara umum, data mining memiliki istilah populer yaitu
Knowledge Discovery from Databases atau disingkat KDD.
2.3 Jenis-jenis Data Mining Menurut Fungsinya
Data mining dibagi menjadi beberapa jenis menurut dari
fungsinya (Atje Setiawan, 2009), yaitu:
a. Konsep atau kelas description
b. Association Analysis
c. Klasifikasi dan Prediksi
d. Cluster Analysis
e. Outlier Analysis
f. Evaluation Analysis
2.4 Association Rule
Assosiation Rule merupakan suatu proses untuk menemukan
(minsup) dan syarat minimum untuk confidence (minconf) pada sebuah
database.
Dalam menentukan suatu Association Rule umumnya terdapat
dua ukuran kepercayaan (interestingness measure), yaitu support dan
confidence. Kedua ukuran ini akan digunakan untuk interesting association
rules dengan dibandingkan dengan batasan yang telah ditentukan. Batasan
inilah yang terdiri dari minsup dan minconf.
Assosiation Rule Mining adalah suatu prosedur untuk mencari
hubungan antar item dalam suatu dataset. Dimulai dengan mencari frequent
itemset, yaitu kombinasi yang paling sering terjadi dalam suatu itemset dan
harus memenuhi minimum support.
Dalam tahap ini akan dicari kombinasi item yang memnuhi
syarat minimum dari nilai support dalam database. Untuk mendapatkan nilai
support untuk sebuah item A dapat diperoleh dari rumus berikut :
Support (A) = (2.1)
Sementara itu, untuk mencari nilai support dari 2-item dapat diperoleh dari
rumus berikut :
Support (A,B) = P (A∩ B) = (2.2)
Setelah semua frequent item dan Large itemset ditemukan, dapat dicari semua
Association Rules yang memenuhi syarat minimum untuk confidence
(minconf) dengan menggunakan rumus berikut ini :
Confidence (AB) = P (B|A) =
(2.3)
2.5 Market Basket Analysis
Market Basket Analysis adalah salah satu teknik pemodelan
dalam data mining berdasarkan teori yang mana jika anda membeli suatu grup Jumlah transaksi yang mengandung item A
Total transaksi
Jumlah transaksi yang mengandung A dan B
Total transaksi
Jumlah transaksi yang mengandung A dan B
item, anda akan memiliki kemungkinan membeli itemset yang lain (data
mining concept and technique, Jiawei Han).
Market Basket berdasarkan kumpulan item yang dibeli oleh
konsumen dalam sebuah transaksi. Dalam hal ini, kuantitas dari sebuah item
yang dibeli konsumen tidak mempengaruhi proses analisis ini. Market Basket
Analysis hanya berdasarkan tipe-tipe item yang berbeda, tidak peduli seberapa
banyak kuantitasnya. Dalam Market Basket Analysis akan dianalisis
akumulasi kumpulan transaksi dari sejumlah besar konsumen dalam periode
waktu yang telah berlangsung.
Proses ini menganalisis buying habits dari para konsumen
dengan menemukan hubungan assosiasi antar item-item yang berbeda yang
seringkali dibeli oleh konsumen. Hasil dari proses analisis ini nantinya akan
sangat berguna bagi perusahaan retail khususnya seperti toko swalayan dan
supermarket untuk mengembangkan strategi pemasaran dan proses
pengambilan keputusan dengan melihat item-item berbeda yang sering dibeli
secara bersamaan oleh konsumen dalam satu waktu.
Beberapa kombinasi item yang sering dibeli konsumen memang
terkadang sangat mudah untuk ditebak, contohnya seringkali konsumen
membeli susu bayi dan popok secara bersamaan. Pola ini sangat biasa terjadi
dan mudah ditebak karena susu bayi dan popok memiliki hubungan yang
sangat dekat. Namun terkadang pola seperti deterjen dan telur jarang
terfikirkan karena deterjen dan telur tidak mempunyai hubungan sama sekali.
Melalui Market Basket Analysis, pola- pola yang terkadang tidak terfikirkan
ini dapat ditemukan dengan mudah sehingga akan membantu pengambilan
keputusan dan proses pengembangan strategi bagi perusahaan retail. Masalah-
masalah seperti kehabisan stok akan diminimalisir dengan diketahuinya pola
pembelian konsumen melalui Market Basket Analysis sehingga dapat
meningkatkan penjualan perusahaan tersebut.
2.6 Algoritma FP-Growth
Algoritma FP-Growth merupakan salah satu alternatif algoritma
yang cukup efektif untuk mencari himpunan data yang paling sering muncul
(frequent itemset) dalam sebuah kumpulan data yang besar. Algoritma
Algoritma FP-Growth ini dikembangkan dari algoritma apriori. Algoritma
apriori menghasilkan kombinasi yang sangat banyak sehingga sangat tidak
efisien. Algoritma FP-Growth ini merupakan salah satu solusi dari algoritma
apriori yang memakan waktu yang sangat lama karena harus melakukan
pattern matching yang secara berulang-ulang. Sedangkan dalam proses
Algoritma FP-Growth terdapat banyak kelebihan yang terbukti sangat efisien
karena hanya dilakukan pemetaan data atau scan database sebanyak 2 kali untuk membangun struktur ”tree”. Maka dari itu, Algoritma FP-Growth dikenal juga dengan sebutan algoritma FP-Tree. Dengan menggunakan
struktur FP-Tree, algoritma FP-Growth dapat langsung mengekstrak frequent
itemset dari susunan FP-Tree yang telah terbentuk.
3. METODE PENELITIAN 3.1 Data
Dalam penelitian ini akan digunakan data mentah yaitu sebuah
data transaksi penjualan sebuah supermarket dalam suatu periode waktu. Data
sekunder ini terdiri dari 4627 jumlah transaksi penjualan dengan 216 jenis
item.
Tabel 1 Sampel Data
Bread Spices Biscuits Deodorant Canned fruit Cheese Break
True ? ? ? ? True True ? ?
yang dijual, sementara baris- baris selanjutnya menunjukkan transaksi
pembelian konsumen, setiap baris mewakili satu kali transaksi. Sementara
dalam kolom transaksi, kode (true) memiliki arti konsumen membeli item
tersebut, sementara kode (?) berarti konsumen tidak membeli item tersebut.
3.2 Metodologi Penelitian
Penelitian ini akan dilakukan dengan tahap-tahap yang mengikuti
proses Knowledge Discovery from Databases (KDD) sebagai berikut:
1. Data Cleaning
3.3 Pencarian Aturan Asosiasi Menggunakan Algoritma FP-Growth
Proses pencarian frequent itemset dengan menggunakan
algoritma FP-Growth akan dilakukan dengan cara membangkitkan struktur
data tree atau disebut dengan FP-Tree. Metode FP-Growth untuk
menghasilkan frequent item melalui pembangunan struktur pohon keputusan
dibagi menjadi tiga tahapan utama, yaitu :
1. Tahap pembangkitan conditional pattern base
3. Tahap pencarian frequent itemset.
4. HASIL DAN PEMBAHASAN 4.1 Implementasi Software
Data transaksi penjualan ini diolah menggunakan software
WEKA versi 3.6.4. Untuk bisa menggunakan software ini, data yang
digunakan sebagai masukan harus dalam format *.arff atau *.csv. Untuk
mengganti format data dapat digunakan pengolah data Microsoft Excel untuk
mengganti menjadi format *.csv dan dengan menggunakan software WEKA
itu sendiri untuk mengganti menjadi format *.arff.
Gambar 1. Tampilan Utama WEKA 3.6.4
4.2 Preprocessing
Sebelum melakukan proses mining terlebih dahulu dilakukan
tahap preprocessing, yaitu merubah format data agar dapat digunakan dalam
software.
Gambar 2. Data dengan format *.csv
Gambar 4. Preprocessing
4.3 Hasil Algoritma FP-Growth
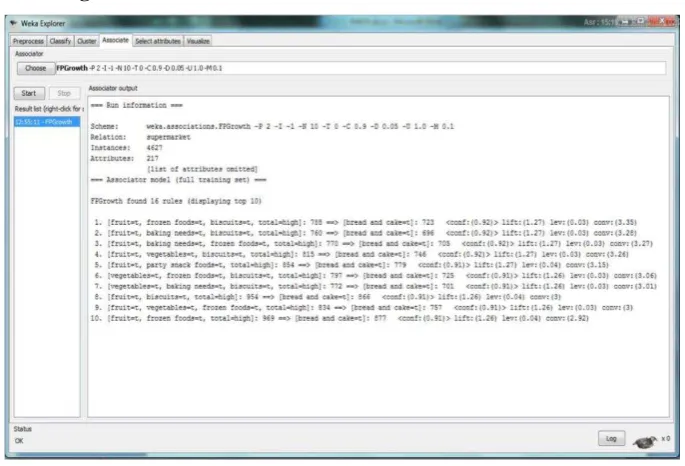
Gambar 5. Hasil
Dari hasil yang didapat menggunakan software WEKA 3.6.4
dihasilkan 16 rules dan ditampilkan 10 rules yang paling strong. Berikut rules
yang ditemukan :
1. [fruit, frozen foods, biscuits]: 788 ==> [bread and cake]: 723
2. [fruit, baking needs, biscuits]: 760 ==> [bread and cake]: 696
<conf:(0.92)> lift:(1.27) lev:(0.03) conv:(3.28)
3. [fruit, baking needs, frozen foods]: 770 ==> [bread and
cake]: 705 <conf:(0.92)> lift:(1.27) lev:(0.03) conv:(3.27)
4. [fruit, vegetables, biscuits]: 815 ==> [bread and cake]: 746
<conf:(0.92)> lift:(1.27) lev:(0.03) conv:(3.26)
5. [fruit, party snack foods]: 854 ==> [bread and cake]: 779
<conf:(0.91)> lift:(1.27) lev:(0.04) conv:(3.15)
6. [vegetables, frozen foods, biscuits]: 797 ==> [bread and
cake]: 725 <conf:(0.91)> lift:(1.26) lev:(0.03) conv:(3.06)
7. [vegetables, baking needs, biscuits]: 772 ==> [bread and
cake]: 701 <conf:(0.91)> lift:(1.26) lev:(0.03) conv:(3.01)
8. [fruit, biscuits]: 954 ==> [bread and cake]: 866
<conf:(0.91)> lift:(1.26) lev:(0.04) conv:(3)
9. [fruit, vegetables, frozen foods]: 834 ==> [bread and cake]:
757 <conf:(0.91)> lift:(1.26) lev:(0.03) conv:(3)
10. [fruit, frozen foods]: 969 ==> [bread and cake]: 877
<conf:(0.91)> lift:(1.26) lev:(0.04) conv:(2.92)
4.4 Kegunaan Hasil
Dari rules yang didapatkan, maka strategi yang dapat digunakan oleh
perusahaan pemasaran (swalayan) yaitu :
1. Mengatur penempatan posisi item-item yang saling frequent dengan jarak
berdekatan sehingga konsumen dapat lebih mudah berbelanja.
2. Atau dapat pula dengan mengatur penempatan posisi item-item yang
saling frequent dengan jarak yang berjauhan dan menempatkan frequent
itemset lain diantaranya, sehingga peluang konsumen membeli item lain
5. KESIMPULAN DAN SARAN
Berdasarkan penelitian yang telah dilakukan sebelumnya, maka dapat
ditarik beberapa kesimpulan sebagai berikut:
1. Dengan menggunakan algoritma FP-Growth dengan bantuan
software WEKA 3.6.4 didapatkan hasil berupa aturan (rules) yang
merupakan kumpulan frequent itemset dengan nilai confidence
yang tinggi.
2. Dengan didapatkannya rules ini maka perusahaan pemasaran dapat
menggunakan rules tersebut dalam membuat strategi-strategi untuk
meningkatkan penjualan.
3. Hasil implementasi telah dilakukan dengan menghasilkan nilai
strong confidence paling tinggi 92 %
Saran dari hasil penelitian ini adalah :
1. Penelitian selanjutnya dapat menggunakan data yang lebih
besar lagi sehingga rules yang dihasilkan lebih beragam dan
lebih berguna untuk pengambilan keputusan. Semakin besar
data semakin berguna informasi yang dihasilkan.
2. Penelitian selanjutnya juga bisa mencoba menggunakan
algoritma data mining lain sehingga dapat dicari algoritma
DAFTAR PUSTAKA
Borgelt, Christian. 2005. An Implementation of the FP-Growth Algorithm,
(Online), http://fuzzy.cs.uni-magdeburg.de/~borgelt/ (diakses 28 Juni 2011).
Bouckaert, Remco., dkk. 2010. WEKA Manual for Version 3-6-2, (Online),
http://kent.dl.sourceforge.net/project/weka/dokumentation/3.6.x/(diakses 5
Agustus 2011).
Coenen, F. 2003. The LUCS-KDD FP-Growth Association Rule Mining
Algorithm, (Online), http://www.cxc.liv.ac.uk/~frans/ (diakses 28 Juni 2011).
Erwin. 2009. Analisis Market Basket Dengan Algoritma Apriori dan FP-Growth,