“ STATISTIK DAN KONSEP DASAR
STATISTIK SERTA PROSEDUR ANALISIS
DATANYA
“
1. PENGERTIAN STATISTIK
Kata statistik berasal dari bahasa Yunani, status yang berarti negara atau untuk menyatakan hal-hal yang berhubungan dengan ketatanegaraan.
Statistik adalah sekumpulan angka untuk menerangkan sesuatu, baik angka yang belum tersusun (masih acak) maupun angka-angka yang sudah tersusun dalam suatu daftar atau grafik.
Dalam arti yang sempit statistik diartikan sebagai keterangan ringkas berbentuk angka-angka. Contoh, jumlah kota Semarang berjumlah 20 juta jiwa.
Pengertian statistik menurut para ahli :
1. Croxton dan Cowden “statistik adalah metode untuk mengumpulkan, mengolah dan menyajikan, serta menginterpretasikan data yang berwujud angka-angka.
2. Prof. Dr. Sudjana, M.A., M.Sc. “ statistik adalah pengetahuan yang berhubungan dengan cara-cara pengumpulan data, pengolahan penganalisiannya, dan penarikan kesimpulan berdasarkan kumpulan data dan penganalisian yang dilakukan.
3. Steel dan Torrie “ statistik adalah metode yang memberikan cara-cara guna menilai ketidaktentuan dari penarikan kesimpulan yang bersifat induktif.
4. J. Supranto “ pengertian statistik dalam dua arti, yaitu :
a. Dalam arti sempit, statistik adalah data ringkasan yang berbentuk angka (kuantitatif). b. Dalam arti luas, statistik adalah ilmu ang mempelajari cara pengumpulan, penyajian, dan analisis data, serta cara pengambilan kesimpulan secara umum berdasarkan hasil penelitian yang menyeluruh.
6. Ir. M. Iqbal Hasan, M.M. “statistik adalah ilmu yang mempelajari tentang seluk beluk data, yaitu tentang pengumpulan, pengolahan, penganalisian, penafsiran, dan penarikan kesimpulan dari data yang berbentuk angka-angka.
2. PERANAN STATISTIK
a. Dalam kehidupan sehari-hari; statistik memiliki peranan sebagai penyedia bahan-bahan atau keterangan-keterangan berbagai hal untuk diolah dan ditafsirkan.
b. Dalam penelitian ilmiah; statistik memiliki peranan sebagai penyedia alat untuk mengemukakan atau menemukan kembali keterangan-keterangan seolah-olah tersembunyi angka-angka statistik.
c. Dalam ilmu pengetahuan; statistik memiliki peranan sebagai peralatan analisis dan interpretasi dari data kuantitatif ilmu pengetahuan, sehingga didapatkan suatu kesimpulan dari data-data tersebut.
3. PERLUNYA STATISTIK
Perlunya mengetahui atau mempelajari statistik adalah karena statistik berperan sebagai alat bantu dalam hal-hal berikut :
a. Menjelaskan hubungan antara variabel-variabel; variabel merupakan sesuatu yang nilainya tidak tetap, seperti harga, produksi, hasil penjualan, umr, dan tinggi. Dengan statistik, variabel-variabel tersebut dapat dijelaskan. Misalnya, hubungan antara permintaan produk dengan tingkat pendapatan, dengan jumlah penduduk atau dengan jenis penganut agama. Analisis korelasi dan regresi yang dapat menjawabnya
b. Membuat rencana dan ramalan; dengan statistik dapat membuat rencana dan meramalkan misalnya, rencana pembuatan perumahan untuk lima tahun mendatang dari suatu pemerintahan kota, yang dipengaruhi oleh banyak faktor, seperti jumlah penduduk dan tingkat pendapatan masyarakat. Analisis data berkala yang dapat menjawabnya. c. Mengatasi berbagai perubahan; dengan statistik dapat mengatasi berbagai jenis
seluruh harga barang untuk periode saat itu dari periode sebelumnya. Perhitungan angka indeks dapat memberikan jawabannya.
d. Membuat keputusan yang lebih baik; dengan menggunakan statistik dapat membuat keputusan yang lebih baik dan rasional. Misalnya, seorang kepala bagian pemasaran sebuah perusahaan dihadapkan pada kondisi yang tidak menentu dari produk perusahaannya dimasa datang, apakah pemasaran produk itu akan tinggi, rendah, atau sedang. Kepala bagian pemasaran harus dapat mengambil sikap atau tindakan tertentu, misalnya melakukan perluasan dengan membangun sendiri dan memepertahankan kapasitas produk yang ada. Teori keputusan dan uji hipotesis dapat membantu pelaksanaannya.
4. FUNGSI STATISTIK
a. Bank data, menyediakan data untuk diolah dan dinterpretasikan agar dapat dipakai untuk menerangkan keadaan yang perlu diketahui atau diungkap.
b. Alat quality control, sebagai alat pembantu standarisasi dan sekaligus sebagai alat pengawasan.
c. Alat analisis, merupakan suatu metode penganalisisan data.
d. Pemecahan masalah dan pembuatan keputusan, sebagai dasar penetapan kebijakan dan langkah lebih lanjut untuk mempertahankan, mengembangkan perusahaan dalam perolehan keuntungan.
5. BEBERAPA KONSEP DASAR STATISTIK
1. Populasi adalah keseluruhan nilai yang mungkin, hasil pengukuran ataupun perhitungan, kualitatif maupun kuantitatif mengenai karakteristik tertentu dari semua anggota kumpulan yang lengkap dan jelas yang ingin dipelajari sifat-sifatnya.
Contohnya, keseluruhan mahasiswa sebuah perguruan tinggi, jika mahasiswa perguruan tinggi tersebut dijadikan sebagai objek penelitian.
2. Sampel adalah bagian dari sebuah populasi yang dianggap dapat mewakili populasi tersebut.
3. Variabel diskrit adalah variabel yang selalu memiliki nilai bulat dalam bilangan asli, tidak berbentuk pecahan atau variabel yang tidak mengambil seluruh nilai dalam sebuah interval (selang).
Contohnya:
1) Jumlah anak yang terdapat dalam sebuah keluarga, dapat berjumlah 0,1,2,3,4,… ., tidak mungkin berjumlah 0,5; 1,43; 2,452; … .
2) S = {5,6,7,8}
Data yang dinyatakan dalam bentuk variabel dsikrit (s) adalah data diskrit.
4. Variabel kontinu adalah variabel yang memiliki nilai sembarang, baik berupa nilai bulat maupun pecahan, diantara dua nilai tertentu atau variabel yang mengambil seluruh nilai dalam suatu interval.
Contohnya:
1) Tinggi badan seseorang 150 cm, 163,54 cm 2) S = {X : 1 ≤ X ≤ 3}
Data yang dinyatakan dalam bentuk variabel kontinu (s) disebut variable kontinu. 5. Pembulatan Data; pembulatan itu biasanya dilakukan kea rah bilangan terdekat.
Pembulatan ke bawah dapat dilakukan kearah bilangan terdekat. Pembulatan ke baewah dapat dilakukan pada bilangan sampai dengan 5, selebihnya dibulatkan ke atas.
Contohnya:
1) 56,47 dibulatkan menjadi 56,5 2) 453,500 dibulatkan menjadi 453
Pembulatan data itu berguna untuk membuat notasi yang digunakan untuk menyatakan penjumlahan.
6. Notasi sigma; merupakan notasi yang digunakan untuk menyatakan penjumlahan. Notasi sigma dilambangkan dengan ∑.
Contoh:
Dua variable X dan Y masing-masing memiliki nilai-nilai: X1 = 3, X2 = -4, X3= 6, X4= -1
Y1 = -2, Y2 = 8, Y3 = -6, Y4= 7
Penyelesaian:
(a) ∑X = 3 + (-4) + 6 + (-1) = 4
(b) ∑XY = (3) (-2) + (-4) (8) + (6) (-5) + (-1) (7) = -75 (c) ∑Y2 = (-2)2 + 82 + (-5)2 + 72 = 142
(d) ∑X2Y = 32 (-2) + (-4)2 (8) + 62 (-5) + (-1)2 (7) = - 63
6. PENGERTIAN DATA
a. Data adalah informasi atau fakta yang tertuang dalam angka atau bukan angka.
b. Data adalah sesuatu yang diketahui. Jadi data memberikan gambaran tentang sesuatu
keadaan atau persoalan.
c. Kata “data” merupakan bentuk jamak sedangkan bentuk tunggalnya adalah datum. Jadi data sama dengan datum-datum. Data statistik data yang berwujud angka, namun tidak semua angka disebut data statistik. Suatu angka atau bilangan disebut data statistik bila angka tersebut menunjukkan suatu ciri dari suatu penelitian yang bersifat agregatif yaitu pencatatan yang dilakukan lebih dari satu kali pada satu individu serta mencerminkan suatu kegiatan dalam bidang tertentu.
7. PEMBAGIAN DATA
1. Data menurut sifatnya dapat dibagi menjadi :
1. Data kualitatif adalah data yang tidak berbentuk angka.
Misalnya jenis pekerjaan seseorang ( petani, pedagang PNS, ABRI, wiraswasta , dll), tingkat pendidikan( SD, SMP,SMA ,PT).
Agar dapat diolah dan dianalisis dengan statistik harus diubah menjadi data kuantitatif.
2. Data kuantitatif adalah data yang berbentuk angka.
Misalnya berat badan, tinggi badan, kecepatan, indek prestasi mahasiswa, dan lain-lain.
Adapun berdasarkan cara memperoleh data, data kuantitatif dibagi menjadi dua yaitu:
2. Data menurut sumbernya dapat dibagi menjadi :
1. Data internal adalah data yang menggambarkan keadaan didalam suatu perusahaan. 2. Data eksternal adalah data yang menggambarkan keadaan luar perusahaan
3. Data menurut cara memperolehnya dibagi menjadi :
1. Data Primer : data yang dikumpulkan sendiri langsung dari obyekya.
2. Data Sekunder : data yang sudah dikumpulkan dan diolah sendiri oleh pihak lain. 4. Data menurut waktu pengumpulannya, dibagi menjadi:
1. Data cross section : data yang dikumpulkan pada suatu waktu tertentu.
2. Data time series/runtut waktu : data yang dikumpulkan dari waktu ke waktu untuk memberikan gambaran tentang perkembangan suatu keadaan dari waktu ke waktu.
8. CARA PENGUMPULAN DATA
a) Cara pengumpulan data menurut Ir. M. Iqbal Hasan, M.M., yaitu : Didalam statistika terdapat dua cara pengumpulan data :
1. Sensus, yaitu cara pengumpulan data, jika seluruh elemen (anggota) populasi diselidiki satu persatu.
2. Sampling adalah cara pengumpulan data, jika yang diselidiki hanya sebagian dari anggota populasi (sampel).
Sedangkan cara pengambilan sampel (sampling) ada dua cara, yaitu :
1. Cara random : adalah cara pemilihan sejumlah anggota populasi untuk menjadi anggota/ elemen sampel yang pemilihannya dilakukan sedemikian rupa sehingga setiap anggota populasi mendapat kesempatan yang sama untuk dipilih menjadi anggota sampel.
2. Cara non random : ialah suatu cara pemilihan sampel/anggota populasi untuk
menjadi anggota sampel, jika setiap anggota populasi tidak mendapat kesempatan
yang sama untuk dipilih menjadi anggota sampel (non probabilistic sample).
b) Menurut Suharyadi, adapun teknik pengumpulan data dapat dilakukan dengan berbagai macam cara, antara lain menggunakan: tes, wawancara , angket , observasi , dokumentasi dan lain-lain.
9. SKALA PENGUKURAN
ditetapkan. Misalnya orang dapat digambarkan dalam beberapa karakteristik seperti umur, pendapatan, pendidikan, jenis kelamin dan preferensi terhadap merek barang tertentu. Skala pengukuran yang sesuai dapat digunakan untuk menunjukan karakteristik tersebut. Menurut Stevens (1946) skala pengukuran dapat dikelompokan menjadi empat jenis yaitu, skala nominal, ordinal, interval dan rasio.
a. Skala Nominal
Skala nominal adalah pengukuran yang paling rendah tingkatannya ini terjadi apabila bilangan atau lambing-lambang lain digunakan untuk mengklasifikasikan obyek, orang, hewan atau benda lain. Apabila bilangan atau lambang-lambang lain digunakan untuk mengidentifikasikan kelompok dimana beberapa obyek dapat dimasukkan kedalamnya maka bilangan atau lambang itu membentuk suatu skala nominal (klasifikasi).
Sebagai contoh misalnya kita menggolongkan ternak dalam himpunan ternak besar, ternak kecil, ternak unggas dan aneka ternak. Dalam hal ini skala untuk mengukur variable ternak terdiri dari empat titik. Titik skala dinamakan kelas atau kategori. Demikian pula pengelompokan suatu kejadian menjadi dua kelompok yang dikenal
dengan skala nominal dikotonik dan biasanya diberi lambang himpunan {0,1}.
Misalnya kejadian mati dan hidup sembuh dan sakit, tidak berhasil, berhasil, tidak ditemukan dan ditemukan.
b. Skala Ordinal (Ranking)
Skala ordinal terjadi bila obyek yang ada dalam satu katagori suatu skala tidak hanya berbeda dengan obyek-obyek itu, tetapi juga mempunyai hubungan satu dengan yang lain. Huubungan yang ada biasa kita jumpai diantara kelas-kelas adalah : lebih tinggi, lebih disenangi, lebih sering, lebih sulit, lebih dewasa dan sebagainya.
Pengukuran yang dilakukan dalam skala ordinal adalah obyek dibedakan menurut persamaanya dan menurut urutannya. Jadi dapat dibuat urutan atau rangking yang lengkap dan teratur diantar kelas-kelas. Sebagai contoh kejadian suatu penyakit pada ternak babi dibagi menjadi sering sekali, sering, kadang-kadang, dan tidak pernah. Kejadian ini bisa dikuantitatifkan dengan memberikan lambang himpunan
angka-angka {4,3,2,1}.
Pengukuran dalam skala interval lebih kuat dari skala ordinal, sebab pengukuran dicapai selain dengan persamaan dan urutannya juga mengetahui jarak (interval) antara dua kelas.
Skala interval mepunyai cirri unit pengukuran yang dan konstan yang memberikan suatu bilangan (nyata) untuk setiap pasangan obyek-obyek dalam himpunan berurutan itu. Dalam pengukuran semacam ini perbandingan antar ainterval sembarang adalah independent denagn unit pengukuran dan skala interval mempunyai titik nol sembarang.
Sebagai contoh skala interval adalah skala untuk mengkur suhu misalnya skala Celcius dan Fahrenheit. Kedua alat ini mempunyai titik nol dan unit pengukuran yang berbeda. Namun kedua alat ini memberikan informasi yang sama, karena ada hubungan linear antara kedua skala tersebut yaitu temperatur dalam skala yang satu
dapat ditransformasikan ke skala yang lain dengan rumus transformasi F=9/5 C +
32, F adalah derajat temperatur dalam Fahrenheit dan C adalah derajat temperatur
dalam Celcius, contoh lain adalah semua skala ordinal yang mempunyai titik nol dan
unit pengukuran sembarang.
d. Skala Rasional
Skala rasional disamping mempunyai sifat seperti skala interval masih juga mempunyai sifat lain yaitu titik nolnya tertentu. Dalam skala rasional perbandingan dua titik skala sembarang adalah independen dengan unit pengukuran.
Contoh skala rasio adalah skala untuk pengukuran panjang, berat, luas isi (volume) dan sebagainya, termasuk pula banyak orang banyak ternak dan sebagainya.
Disamping itu juga, dilihat dari segi bobot pengukuran data yang dikumpulkan maka skala data dapat dibagi menjadi dua jenis, yaitu :
a. Data kualitatif, yaitu data yang dilihat menurut persamaannya dan menurut
urutannya serta jaraknya (interval). Data ini sangat berhubungan dengan nominal ordinal. Misalnya, tingkat kecepatan pada suatu wi-fi dapat dibedakan menjadi sangat cepat (excellent), cepat (very good), cukup cepat (good), lambat (low), dan sangat lambat (poor). Tingkat kecepatan ini dapat dikuantitatifkan dengan
memberikan lambang himpunan angka-angka {5,4,3,2,1}.
b. Data kuantitatif adalah data yang sangat erat berhubungan dengan interval rasio.
Skema pengukuran dalam mengolah data.
10. PROSEDUR PENGOLAHAN DATA
Dalam prosedur pengolahannya, data harus memiliki kriteria-kriteria penilaian atau parameter sebagai titik acuan dalam mengolah data. Berdasarkan proses kronologis pengolahan data, statistik dapat berupa statistic parametrik dan statistik non-parametrik. Statistika parametrik adalah suatu uji yang modelnya menetapkan adanya syarat-syarat tertentu (asumsi-asumsi) tentang variabel random atau populasi yang merupakan sumber sampel penelitian. Sedangkan uji statistik yang tidak memerlukan adanya syarat-syarat tersebut disebut statistika non-parametrik. Statistika parametik lebih banyak digunakan untuk menganalisis data yang berskala interval dan rasio dengan dilandasi asumsi tertentu seperti normalitas. Statistika non-parametik dapat digunakan untuk menganalisis data yang berskala nominal dan ordinal.
Selain itu, statistika parametrik juga merupakan metode penafsiran yang menetapkan asumsi yang sangat ketat dari karakteristik populasi yang anggotanya diambil sebagai sampel, dan diharapkan statistik dari sampel, betul-betul bisa mencerminkan parameter dari populasi. Asumsi-asumsi ini mencakup:
a. Sampel harus diambil dari suatu populasi yang berdistribusi normal.
b. Jika sampel diambil dari dua atau lebih populasi yang berbeda, maka populasi tersebut harus memiliki varians (d2) yang sama.
c. Hanya untuk data berskala interval dan rasio (memiliki nilai dalam bentuk numerik atau angka nyata).
dalam asumsi statistika parametrik, secara metodologis sulit dipenuhi oleh penelitian bidang ilmu sosial. Sebab dalam kajian ilmu sosial:
a. Sulit untuk memenuhi asumsi distribusi normal b. Kesamaan varians (d2),
c. Banyak data yang tidak berbentuk numerik, hanya berupa skor rangking atau hanya bersifat nilai kategori.
Skema pedoman penggunaan parameter pada statistik inferensial
11.HIPOTESIS
maka peneliti akan mengatakan “... berhasil menolak hipotesis (H0) yang mengatakan...”. Jika pengujian ini gagal, maka peneliti akan mengatakan “... gagal menolak hipotesis (H0) yang mengatakan...”
Secara umum ada tiga bentuk hipotesis:
1. Hipotesis dua pihak (two tailed) H0 : Φ = Φ0
H1 : Φ ≠ Φ0 Contoh:
Ho : Rata-rata nilai UAN siswa SLTA negeri se-DIY sama dengan swasta H1 : Rata-rata nilai UAN siswa SLTA negeri se-DIY berbeda dengan swasta 2. Hipotesis sepihak (kanan)
H0 : Φ ≤ Φ0 H1 : Φ > Φ0 Contoh:
Ho : Rata-rata nilai UAN siswa SLTA negeri se-DIY kurang dari sama dengan 8,0 H1 : Rata-rata nilai UAN siswa SLTA negeri se-DIY lebih dari 8,0
3. Hipotesis sepihak (kiri) H0 : Φ ≥ Φ0
H1 : Φ < Φ0 Contoh:
Ho : Rata-rata nilai UAN siswa SLTA swasta se-DIY lebih dari sama dengan 8,0
H1 : Rata-rata nilai UAN siswa SLTA swasta se-DIY kurang dari 8,0 Beberapa catatan:
1. Perumusan hipotesis harus didukung oleh landasan teoritis yang tepat sehingga
kebenaran hipotesis dapat dipertanggung jawabkan. Contoh korelasi antara pendapatan dan pengeluaran harus ditentukan berdasarkan teori/substansi.
2. Dianjurkan peneliti berusaha memilih hipotesis sepihak karena menunjukkan
kedalaman pengetahuan peneliti terhadap permasalahan yang akan diselesaikan.
3. Hipotesis dua pihak hanyalah dipakai jika peneliti kurang yakin tentang nilai
4. Benar atau salahnya hipotesis tidak akan pernah diketahui dengan pasti kecuali bila kita memeriksa seluruh populasi. Oleh karena itu kita mengambil sampel random dari populasi tersebut dan menggunakan informasi yang dikandung sampel itu untuk memutuskan apakah hipotesis tersebut kemungkinan besar benar atau salah. Bukti data dari sampel yang tidak konsisten dengan hipotesis membawa kita pada penolakan hipotesis tersebut, demikian juga sebaliknya. Perlu ditegaskan bahwa penerimaan suatu hipotesis statistik adalah merupakan akibat dari ketidakcukupan bukti untuk menolaknya, dan tidak berimplikasi bahwa hipotesis itu benar.
5. Secara umum, pengujian hipotesis dibedakan 2, pengujian hipotesis komparatif dan
asosiasi. Pengujian hipotesis komparasi berkaitan dengan pengujian perbedaan (difference) mean antara dua kelompok atau lebih. Pengujian hipotesis asosiasi berkaitan dengan menguji antara dua variabel.
12. PENYAJIAN DATA HASIL DISTRIBUSI FREKUENSI
Distribusi frekuensi dapat juga disajikan dalam bentuk sebagai berikut:
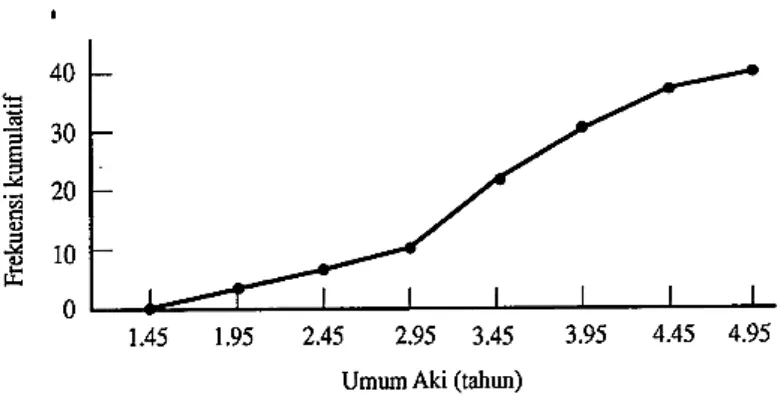
1. Penyajian data dengan menggunakan grafik data numerik yang sangat luas yaitu diagram balok seperti gambar dibawah ini.
Contoh penyajian data dengan Diagram Balok pada distribusi frekuensi umur Aki
2. Penyajian data dalam bentuk Histogram. Histogram berbeda dengan Diagram Balok dalam hal sebagai lebar baloknya digunakan batas kelas bukan limit kelas. Untuk beberapa masalah tertentu akan lebih baik bila sumbu tegaknya menyatakan frekuensi
Histogram Persentase, bentuknya persis dengan histogram frekuensi, hanya skala tegaknya berbeda.
Histogram Frekuensi
Biasanya ada kecenderungan bahwa yang menjadi patokan adalah luas dari persegi panjang tersebut bukan tingginya. Tetapi untuk lebar kelas yang berbeda, tinggi persegi panjang itu harus dibagi dengan perbandingan lebar yang lebih besar dengan gaya yang lebih kecil. Hal ini dapat dilihat dalam gambar dibawah ini, karena lebar kelas yang dipakai ada dua lebar kelas, maka lebar kelas dari 2.5-3.4, lebar kelasnya harus kita bagi dengan lebar kelas lainnya, yaitu didapat ternyata lebar selang 2.5-3.4 dua kali lebih panjang dari lebar kelas lainnya. Sehingga tinggi dari kelas 2.5-3.4, harus dibagi 2.
Histogram Frekuensi yang benar dengan lebar kelas yang tidak sama
3. Cara Penyajian data lainnya adalah dalam bentuk poligon frekuensi. Poligon frekuensi dibentuk dengan memplotkan frekuensi kelas terhadap titik tengah kelas dan kemudian menghubungkan titik-titik yang berurutan dengan garis lurus. Dengan kata lain poligon merupakan bangun bersisi banyak yang tertutup. Jika frekuensi yang ada dalam bentuk frekuensi relatif, maka disebut poligon frekuensi relatif atau poligon persentase.
Ogif atau Poligon Frekuensi Kumulatif
Grafik garis lainnya disebut Poligon Frekuensi Kumulatif atau Ogif, didapat dengan memplotkan frekuensi kumulatif yang lebih kecil daripada batas atas kelas terhadap batas atas kelasnya.
13. PENGERTIAN DISTRIBUSI FREKUENSI
Semakin banyak data yang diambil atau didapatkan maka semakin mencerminkan populasinya namun data yang terlalu banyak sulit menyajikan dan sulit menginterprestasikan. hal ini dapat dipermudah apabila data itu kita ringkas menjadi distribusi frekuensi atau table frekuensi.
Distribusi frekuensi adalah susunan angka menurut besarnya (kuantitas) yang disebut frekuensi distribusi kuantitatif atau menurut katagorinya (kualitasnya) yang disebut distribusi frekuensi kualitatif (katagori).
14. PENYUSUNAN DISTRIBUSI FREKUENSI
Distribusi frekuensi dapat dibuat dengan mengikuti pedoman berikut. 1) Mengurutkan data dari yang terkecil ke yang terbesar.
2) Menentukan jangkauan (range) dari data. Jangkauan = data terbesar – data terkecil. 3) Menentukan banyaknya kelas (k).
keterangan :
k = banyaknya kelas. n = banyaknya data.
Hasilnya dibulatkan, biasanya ke atas. 4) Menentukan panjang interval kelas.
Panjang interval kelas (i) = Jangkauan (R)Banyaknya kelas (k)
5) Menentukan batas bawah kelas pertama.
Batas bawah kelas pertama biasanya dipilih dari data terkecil atau data terkecil yang berasal dari pelebaran jangkauan (data yang lebih kecil dari data terkecil) dan selisihnya harus kurang dari panjang interval kelasnya.
6) Menuliskan frekuensi kelas secara melidi dalam kolom turus atau tally (system turus) sesuai banyaknya data.
Beberapa catatan tentang penyusunan distribusi frekuensi
1) Pada pembuatan distribusi frekuensi, perlu dijaga jangan sampai ada adat yang tidak dimasukkan ke dalam kelas atau ada data yang masuk ke dalam dua kelas yang berbeda. 2) Titik tengah kelas diusahakan bilangan bulat/tidak pecahan.
3) Nilai frekuensi diusahakan tidak ada yang nol. 4) Dalam menentukan banyaknya kelas (k), diusahakan:
a) Tidak terlalu sedikit, sehingga pola kelompok kabur; b) Banyaknya kelas berkisar 5 sampai 15 buah;
c) Jika jangkauan terlalu besar maka banyaknya kelas antara 10 sampai 20. 5) Cara lain dalam menetapkan banyaknya kelas ialah :
a) Memilih atau menetapkannya sesuai dengan kebutuhan yang diinginkan;
b) Menggunakan rumus
k = R + 1
i Keterangan : R = jangkauan
i = panjang interval kelas
cara tersebut dipakai dengan mencoba menetapkan terlebih dahulu panjang interval kelasnya (i).
1. Dari hasil pengukuran diameter pipa-pipa yang dibuat oleh sebuah mesin ( dalam mm terdekat ), diperoleh data sebagai berikut.
78 72 74 79 74 71 75 74 72 68 72 73 72 74 75 74 73 74 65 72 66 75 80 69 82 73 74 72 79 71 70 75 71 70 70 70 75 76 77 67 Buatlah distribusi frekuensi dari data tersebut!
Penyelesaian:
c. Banyaknya kelas (k) adalah K = 1 + 3,3 log 40
= 1 + 5,3 = 6,3 ≈ 6
d. Panjang interval kelas (i) adalah; i = 17/6 = 2,8 ≈ 3 e. Batas kelas pertama adalah 65 (data terkecil) f. Tabelnya :
g. Berdasarkan tabel di atas maka distribusi frekuensi nilai statistiknya adalah :
74 – 76 77 – 79 80 – 82
13 4 2
Jumlah 40
h. Penyajian Data Hasil Distribusi Frekuensi di atas dapat dilihat sebagai berikut:
1. Penyajian data dengan menggunakan diagram balok
2. Penyajian data dengan menggunakan bentuk polygon frekuensi
4. Penyajian data dengan menggunakan bentuk Pie Chart
15. UKURAN PEMUSATAN DATA
a. Rata- Rata Hitung (Mean)
Harga rata-rata hitung atau arithmetric mean (disingkat mean) merupakan ukuran pemusatan yang sudah sangat dikenal dan banyak digunakan dalam kehidupan sehari. Harga rata-rata hitung didefinisikan sebagai jumlah semua data yang ada dibagi dengan
banyaknya data, biasanya diberi lambing Y.
Apabila data dalam distribusi frekuensi maka rumus untuk menghitung rata-rata hitung adalah :
Disini i=1,2, k (k adalah banyaknya interval kelas) fi adalah frekuensi kelas ke-I dan Xi
adalah nilai tengah kelas ke- i. Sebagai contoh kita hitung rata-rata hitung dari table distribusi frekuensi kuantitatif (Tabel 1).
Y = 4(32,5) + 6(37,5) +……+6(62,5) = 4.850 = 48,50 gram/ekor/hari
100 100
b. Median (Me)
Median sekumpulan data adalah nilai data yang terletak di tengah-tengah apabila data disusun menurut besarnya. Jika sekumpulan data banyaknya genap maka median adalah rata-rata dua harga yang ditengah-tengah.
banyaknya data genap maka kita ambil dua harga yang ditenagh dan selanjutnya hitung rata-rata dengan demikian diperoleh harga median.
Sebagai contoh misalnya median 7 data yang diurut dari kecil ke besar sebagai berikut ;
No. Urut : 1 2 3 4 5 6 7
Nilai ; 6 7 11 12 16 17 18
Jadi nilai mediannya (Me) = 12
Untuk mencari nomor lokasi data dirumuskan
nt = n+1
2
Untuk contoh diatas nomor urutan data yang ditengah-tengah.
nt = 7+1 = 4
2
Apabila data berbentuk distribusi frekuensi mak aunuk mencari median (Me) dapat dilakukan sebagai berikut :
1. cari nomor lokasi tengah dengan rumus
nt = n+1
2 2. tentukan batas bawah interval kelas lokasi median ( Lm).
3. tentukan frekuensi komulatif kurang dari batas bawah interval kelas tersebut kita singkat tbb.
4. cari tambahan frekuensi (d) dengan rumus d = nt – tbb
5. Median (Me) = [ Lm = ( d/fm) (I)1, disini fm adalah frekuensi pada interval kelas lokasi median dan I adalah interval kelas.
Sebagai contoh kita hitung median distribusi frekuensi kuantitatif (table 1) sebagai berikut :
1.
nt = 100+1 = 50,5
2
2. lokasi median berada pada nomor kelas ke – 4 dengan batas bawah 45 3. Frekuensi komulatif kurang dari batas bawah (<45) yaitu tbb adalah 30 4. d = 50,5 – 30 = 20,5
c. Kuartil, Desil dan Persentil
jika median adalah harga yang membagi distribusi data menjadi dua bagian yang sama, maka kuarti (K) adalah harga yang membagi distribusi data menjadi 4 bagian yang sama, sehingga terdapat tiga harga kuartil I,II, dan III. Kuartil II berimpit/ sama dengan menghitung median, kuartil I dan III adalah mediab dari bsgian data pertama dan kedua setelah median seluruh ditentukan.
Desil (D) adalah harga-harga yang membagi data menjadi 10 bagian maka ada 9 harga desil. Letak/harga desil yang ke 5 sama dengan median prinsip cara harga desil yang lain menghitungnya sama dengan menghitung median. Persentil (P) adalah harga-harga yang
membagi distribusi data menjadi 100 bagian maka ada 99 harga persentil. Nilai D2
berimpit/sama dengan P20 nilai tersebut menunjukkan bahwa data yang lebih kecil dari
D2 atau P20 sebanyak 2/10 atau 20/100 yaitu 20 % Nilai tengah kisaran (NTK) dapat
dihitung denagn rumus
NTK = P25 + P75 = KI + KIII
2 2
d. Modus (Mo)
Modus adalah data yang paling sering muncul atau data yang frekuensinya tertinggi. Sebagai contoh misalnya data berat 10 orang bayi yang baru lahir pada suatu rumah sakit adalah sebagai berikut
No. bayi 1 2 3 4 5 6 7 8 9 10
Berat (kg) 4,0 3,5 4,0 5,5 3,5 4,0 4,5 3,5 4,5 4,0
Modusnya = 4 kg
Modus pada tabel distribusi frekuensi (table 1) adalah 47,5
e. Nilai tengah Geometrik
Dalam keadaan data seperti ini rata-rata hitung kurang cocok atau memberikan informasi kurang berguna maka untuk memperoleh informasi yang lebih cocok atau berguna digunakan rata-rata geometrik denagn rumus sebagai berikut
Contoh jumlah bakteri pada daging ayam per gram selama 4 hari penyimpanan adalah sebagai berikut
Maka nilai rata-rata geometrik jumlah bakteri daging ayam selama 4 hari penyimpanan adalah :
Cara lain untuk menghitung rata-rata geometric adalah denagn melakukan transformasi data denagn logaritma )log)
5
Hasil ini dapat memberikan informasi yang lebih berguna, karena rata-rata geometrik menunjukkan bahwa rata-rata jumlah bakteri pada hari ke 2 dan juga merupakan median dari data tersebut.
f. Nilai tengah Harmonik
H = n = n 1 + 1 +……….. 1 n
Σ 1
Y1 Y2 Yn i=1 Yi
Contoh seorang petni membelanjakan uangnya Rp. 5.000,- untuk membeli 10 ekor ayam (@ Rp 5.00,-perekor) dan uangnya yang Rp 5.000 lagi untuk
membeli 5 ekor ayam yang lebih besar ukuran tubuhnya (@ rp 1000,-perekor) maka harga rata-rata seekor ayam adalah ;
H= 2 = 2/3 = 666,67 Rp/ekor 1 + 1 3
500 1000 1000
Jadi harga perekor ayam untuk Rp 10.000,- uang yang dibelanjakan untuk mebeli 15 ekor ayam adalah Rp 666,67.
Perhitungan diatas dapat juga dikerjakan denagn cara sebagai berikut
Data yang mempunyai nilai tengah harmonic sebenarnya merupakan data yang kurang serasi atau harmonis dari seluk beluk satuan data ini dapat diharmoniskan denagn
melakukan kebalikkan ( 1/ Yi) karena satuannya yang lebih cocok digunakan dalam
perhitungan adalah ekor/Rp
Uang yang dibelanjakan petani :
Rp/ekor (Yi) 50000/10 = 5000 5000/5 =1000
Ekor/Rp (1/Yi) 10/5000=0,002 5/5000=0,001
2 Σ X
i
Y = i= 1 = 0,002 + 0,001 =0,003 =0,0015 ekor/Rp
2 2 2 Jadi H = (1/ Y) = 1/ 0,0015 = 666,67 Rp/ekor
16. UKURAN PENYEBARAN DATA
Ukuran pemusatan data atau nilai tengah data kurang dapat dipercaya apabila kita ingin membandingkan dua buah data atau lebih demikian juga jika kita ingin melakukan estimasi terhadap suatu populasi yang sedang kita pelajari karena nilai tengah sebagai indicator tunggal tidak dapat mengambarkan keadan datanya. Untuk itu kita pelajari ukuran penyebaran (dispersi) data sebagai berikut :
a. Rentang (range )
rentang (range) atau kisaran data adalah deviasi yang paling sederhana didefinisinkan sebagai perbedaan harga yang tertinggi denagn yang terendah dari sekumpulan data. Jadi rentang adalah data terbesar dikurangi data terkecil. Rentang memberikan gambaran seberapa jauh data itu memencar (merentang) tetapi tidak menunjukkan tentang keragaman datanya. Dua kumpulan data yang mempunyai rentang yang sama belum tentu keadaannya sama.
Contoh;
Data kelompok I : 45, 50,50,55,60,70, dan 80 Range = 80-45 =35
Data kelompok II : 45,60,72,70,75,76 dan 80 Range = 80-45 =35
b. Rata-rata Simpangan Absolut
jarak setiap data (nilai pengamatan )denagn rata-ratanya (mean) disebut simpangan yang dirumuskan dengan :
bila data lebih besar dari rata-rata maka simpangan nya bersifat positif. Bila data lebih kecil dari rata-ratanya maka simpangannya lebih kecil dari rata-ratanya maka simpanganya bernilai negative dan bila sama dengan rata-ratanya maka simpangannya sama dengan nol. Jumlah semua simpangan sama dengsn nol,jadi dapat dirumuskan
jumlah simpangan =
n
i 1
(Yi – Y) = nΣ di = 0
jadi karena jumlah simpanagn selalu sama dengan nol maka tidak memberikan informasi apa-apa,untuk itu diperbaiki denagn mencari nilai absolutnya sehingga dirumuskan :
│d│=
c. Simpangan baku dan Ragam
Simpangan baku (standar deviasi) dan bentuk kuadratnya disebut ragam (varian) juga merukana deviasi yang juga memperhitungkan tiap data terhadap meanya. Ragam didefinisikan sebagai jumlah kuadrat simpanagn setiap data terhadap rata-ratanya dibagi denagn n-1 disini n adalh banyaknya data sedangkan
simpangan baku (standar deviasi) didefinisikan sebagai akar positif dari ragam (variasi) dirumuskan sebagai :
S2 =
jumlah kuadrat (JK) jadi standar deviasinya dirumuskan menjadi S =SD=√S2
Untuk lebih praktis dalam perhitungan dapat diturunkan rumus definisinya sebagai
untuk data yang tersusun dalam distribusi frekuensi maka digunakan rumus
k
k (Σ f iYi)2
S2 = Σ f iYi 2 -- i=1
i=1 n_____
n - 1
Disini f I adalah frekuensi interval ke I Yi adalah nilai tengah interval ke I k adalah banyaknya interval dan n adalah banyaknya data ( n = Σ fi)
i=1
contoh berat badan (kg) 5 ekor sapi bali jantan yang dipotong di suatu RPH seperti
No Berat (Yi) (Yi - Y.) │Yi - Y│ (Yi - Y)2
total 1064 0,0 31,2 266,80 226686
rataan 212,8 0,0 6,24 13,36 45337,2
Rentang =220 -200 = 20
Untuk data yang berbentuk distribusi frekuensi table 1 maka
koefisien keragaman (koefisien variasi ) adalah merupakan ukuran penyebaran nisbi
(relative) dari suatu data dan dirumuskan :
KK = (S/Y.) x 100%
disini S adalah simpangan baku dan Y adalah rata-rata
koefisien keragaman merupakan ukuran penyebaran data yang dapat menggambarkan ketelitian hasil penelitian yaitu semakinkecil nilainya maka penelitian itu semakin teliti koefisien keragaman biasanya dianggap baik jika ≤ 30%.
17. ANALISIS KORELASI DAN REGRESI
Analisis korelasi bertujuan untuk mengetahui apakah ada hubungan antara dua variabel atau lebih. Sedangkan tujuan analisis regresi adalah untuk memprediksi seberapa jauh pengaruh yang ada tersebut (yang telah dianalisis melalui analisis korelasi).
Misalnya, dengan analisis korelasi ingin diketahui apakah ada hubungan antara terjadinya perang antarnegara dengan kegiatan perlombaan senjata (arm races). Bila melalui analisis korelasi terbukti bahwa ada hubungan diantara kedua variabel tersebut, maka analisis regresi akan memperkirakan jika jumlah senjata dinaikan sekian ribu jumlahnya maka kondisi konflik antarnegara akan seperti apa terjadinya.
Selain itu juga kita mengenal alat analisis statistika lainnya, yaitu uji-t dan uji-f (anova). Apa bedanya antara uji-t dan anova dengan analisis korelasi/regresi. Perbedaannya adalah, bila uji-t dan anova menguji ada-tidaknya perbedaan dua sampel atau lebih, maka analisis regresi menguji ada-tidaknya hubungan dua variabel atau lebih.
1. ANALISIS KORELASI
Tujuan dari analisis korelasi adalah untuk mengetahui apakah diantara dua variabel terdapat hubungan atau tidak, dan jika ada hubungan bagaimanakah arah hubungan dan seberapa besar hubungan tersebut. Data pada analisis korelasi dapat berupa data kualitatif maupun kuantitatif, yang masing-masing mempunyai ukuran korelasi sendiri-sendiri.
Contoh Analisis Korelasi dengan SPSS:
Contoh1:
Untuk data yang berskala interval dan atau rasio (bersifat kuantitatif/parametrik) tipe
analisis korelasi yang digunakan adalah Pearson Correlation atau istilah lainnya adalah
Product Moment Correlation. Sedangkan untuk yang berskala ordinal kita gunakan
Spearman Correlation (Statistik Non-Parametrik).
Kembali ke contoh kasus tersebut di atas, kedua variabel yang ada yaitu pengetahuan kewarganegaraan dan tingkat partisipasi politik umumnya belum memiliki standar yang baku dalam skala nilainya. Biasanya untuk mendapatkan nilai-nilai bagi variabel-variabel tersebut kita terlebih dahulu melakukan pengukuran kepada sejumlah responden mengenai tingkat pengetahuannya tentang kewarganegaraan dan tingkat partisipasi politiknya, biasanya kita akan menyebarkan angket yang berisi sejumlah daftar pertanyaan atau pernyataan yang akan mengukur sejauh mana level pengetahuan kewarganegaraannya dan tingkat partisipasi politiknya, baik level pengetahuan kewarganegaraan dan tingkat partisipasi politik keduanya merupakan konsep yang berkaitan dengan perilaku seorang manusia. Seperti telah diulas dalam modul sebelumnya, para peneliti ilmu sosial umumnya menggunakan Skala Likert guna
mengukur persepsi atau perilaku sosial. Maka biasanya data yang akan didapatkan
dari hasil survey/penyebaran angket yang mengukur tingkat pengetahuan kewarganegaraan seseorang dan tingkat partisipasi politiknya akan berskala ordinal. Misalkan untuk mengukur pengetahuan seseorang dibuatkan instrumen yang terdiri atas 6 butir pertanyaan guna mengukur pengetahuannya tentang kewarganegaraan yang diberikan kepada 5 orang responden (A,B,C,D dan E). Dari lima orang responden akan memiliki jawaban atas angket yang diberikan sebagai berikut.
No Resp Jawaban atas pertanyaan nomor
ke-1 2 3 4 5 6
A 3 2 3 1 2 3
B 4 4 4 2 3 4
C 5 5 5 3 4 5
D 5 5 5 5 5 7
E 7 7 7 7 7 7
Maka nilai-nilai jawaban tersebut terlebih dahulu harus di transformasikan ke dalam
data interval. Misalkan hasilnya (Succesive Interval-nya) diperoleh sebagai berikut:
No Resp Jawaban atas pertanyaan nomor
ke-1 2 3 4 5 6
A 3 2 3 1 2 3
C 2.271106 2.271106 2.271106 1.946443 1.946443 1.946443 D 2.271106 2.271106 2.271106 2.595769 2.595769 3.068991 E 3.542213 3.542213 3.542213 3.542213 3.542213 3.068991
Lalu untuk mendapatkan skor tiap-tiap responden untuk menentukkan tingkat pengetahuan kewarganegaraan yang dimilikinya digunakan rumus tertentu (caranya dibahas pada topik berikutnya). Skor tingkat pengetahuan kewarganegaraan dari kelima responden tersebut akhirnya, misalnya diperoleh sebagai berikut.
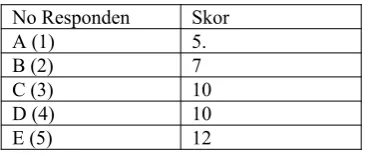
Tabel Skor Reponden untuk Tingkat Pengetahuan Kewarganegaraan
Selanjutnya hal yang sama dilakukan pula untuk mendapatkan skor mengenai tingkat partisipasi politiknya, sehingga misalnya akhirnya diperoleh data sebagai berikut.
Tabel Data Lengkap
No Responden Skor Tingkat
Pengetahuan Kewarganegaraan Partisipasi PolitikSkor Tingkat
1 5 1
2 7 3
3 10 5
4 10 7
5 12 9
Selanjutnya kita olah dengan SPSS, dengan langkah-langkah sebagai berikut:
1. Buat file dengan nama korelasi1.sav dalam folder pribadi Anda, berkenaan dengan data
lengkap di atas. Misalkan variabel Skor Tingkat Pengetahuan Kewarganegaraan kita namai Citizenship dan Skor Tingkat Partisipasi Politik kita namai Participation, hasilnya seperti berikut.
No Responden Skor
A (1) 5.
B (2) 7
C (3) 10
D (4) 10
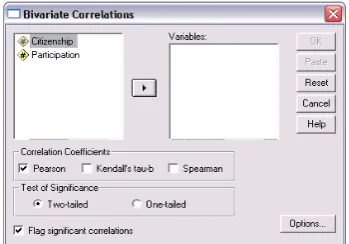
2. Jika sudah nampak, dari menu utama SPSS, pilih menu Analyze. Kemudian pilih submenu Correlate, dan pilih bivariate. Maka akan tampak di layar tampilan seperti gambar berikut:
3. Selanjutnya adalah mengisi menu-menu yang ada sebagai berikut:
a. Variable yang akan dikorelasikan, pilih Citizenship dan Participation
b. Correlation Coeffitients atau alat hitung koefisien korelasi. Pilih Pearson.
c. Test of Significance yang akan digunakan, pilih Two-tailed untuk uji dua sisi.
d. Flag significant correlations pilih untuk diaktifkan, dengan cara mengkliknya.
e. Kemudian tekan tombol Options, hingga tampak di layar tampilan seperti ini.
f. Lalu pada pilihan statistics abaikan saja.
g. Pada menu missing values, pilih Exclude case pairwise untuk aktif. Selanjutnya
h. Tekan OK untuk mengakhiri pengisisian prosedur analisis. Selanjutnya SPSS melakukan pekerjaan analisis yang hasilnya dapat terlihat pada bagian output berikut ini.
Correlation is significant at the 0.01 level (2-tailed). **.
Analisis Output
1. Arti Angka Korelasi (Lihat Pearson Correlation)
Ada dua hal dalam penafsiran korelasi, yaitu tanda ‘+” atau ‘-“ yang berhubungan dengan arah korelasi, serta kuat tidaknya korelasi.
Korelasi antara Citizenship dengan Participation, didapat angka +0,969 (tanda “+” disertakan karena tidak ada tanda “-“ pada output, jadi otomatis positif). Hal ini berarti :
Arah korelasi positif, artinya semakin tinggi tingkat pengetahuan
kewarganegaraan seseorang maka partisipasi politiknya cenderung semakin besar. Demikian pula sebaliknya.
Besaran korelasi (0,969) yang > 0,5, berarti tingkat pengetahuan
kewarganegaraan seseorang berkorelasi KUAT dengan partisipasi politiknya.
2. Signifikansi Hasil Korelasi (lihat Sig. (2-tailed))
Bila kita hendak merumuskan hipotesis bahwa antara dua variabel, yaitu tingkat pengetahuan kewarganegaraan seseorang dengan partisipasi politiknya memiliki hubungan (korelasi), maka secara statistik dapat dinyatakan seperti berikut:
H0:Tidak ada hubungan (korelasi) antara dua variabel Hi: Ada hubungan (korelasi) antara dua variabel
Maka bila kita ingin menguji hipotesis ini, kita misalnya dapat menguji dengan melakukan uji dua sisi. Dasar pengambilan keputusannya adalah dengan dasar probabilitas sebagai berikut:
Jika probabilitas < 0,05 (atau 0,01) maka Ho ditolak
Catatan: 0,05 atau 0,01 adalah tergantung pilihan kita.
Keputusan pada contoh kasus yang kita miliki pada keterangan Sig. (2-tailed) diperoleh angka probailitasnya 0,007 maka kedua variabel tersebut memang SECARA NYATA berkorelasi. Hal ini bisa dilihat juga dari adanya tanda ** pada angka korelasi.
3. Jumlah Data yang Berkorelasi
Dapat dilihat dari dari nilai N, karena tidak ada data yang hilang, maka data yang diproses adalah 5.
2. KORELASI PARSIAL
Kadang-kadang dalam suatu penelitian kita perlu menambahkan lagi satu variabel yang berfungsi sebagai pengontrol dari dua variabel yang telah berkorelasi terlebih dahulu. Misalnya seperti pada contoh di atas, bila kita ingin menghitung korelasi parsial antara tingkat pengetahuan kewarganegaraan seseorang dengan perilaku demokratisnya dimana partisipasi politik menjadi variabel kontrol. Karena ketiga variabel bersifat kuantitatif, maka tipe analisis korelasi yang digunakan adalah Pearson.
Langkah-langkah yang ditempuh:
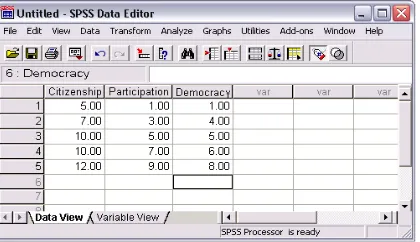
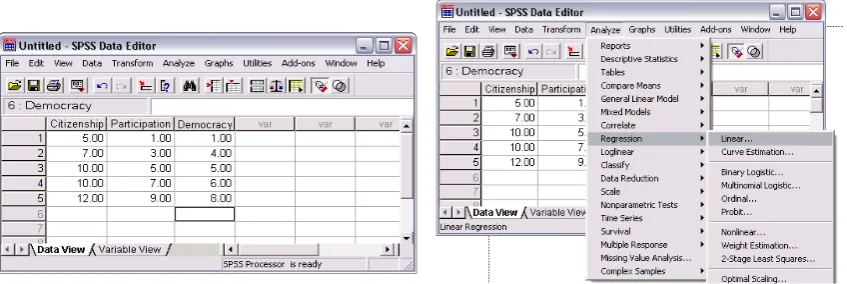
1. Buka lagi file korelasi1.sav, lalu kita tambahkan 1 lagi variabel dengan nama
Democracy yang mewakili variabel tingkat perilalu demokrasi seseorang. Sehingga diperoleh tampilan sebagai berikut:
2. Jika sudah nampak, dari menu utama SPSS, pilih menu Analyze. Kemudian pilih
submenu Correlate, dan pilih Partial. Maka akan tampak di layar tampilan seperti
3. Pengisian:
a. Variable yang akan dikorelasikan, pilih Citizenship dan Democracy b. Controlling for (variabel pengontrol), pilih participation
c. Test of Significance yang akan digunakan, pilih Two-tailed untuk uji dua sisi. d. Display actual signifance level pilih untuk diaktifkan, dengan cara mengkliknya.
e. Abaikan yang lainnya, kemudian tekan tombol OK untuk prosessing data.
Outputnya sebagai berikut:
Correlations
Correlations
1 .969** .968**
.007 .007
5 5 5
.969** 1 .977**
.007 .004
5 5 5
.968** .977** 1
.007 .004
5 5 5
Pearson Correlation Sig. (2-tailed) N
Pearson Correlation Sig. (2-tailed) N
Pearson Correlation Sig. (2-tailed) N
Citizenship
Participation
Democracy
Citizenship Participation Democracy
Correlation is significant at the 0.01 level (2-tailed). **.
Correlations
Analisis Hasil Pengolahan oleh SPSS:
Analisis Output
1. Arti Angka Korelasi (Lihat Correlation)
Pada hasil output ada dua bagian, yang pertama adalah Analsis Korelasi Pearson (Bivariat) antara 3 variabel, yaitu Citizenship, Participation dan Democracy. Sedangkan bagian yang kedua analisis korelasi antara Citizenship dengan Democracy dimana Participation menjadi variabel pengontrolnya.
Bila dibandingkan terlihat bahwa angka korelasi antara Citizenship dengan Democracy dengan menggunakan variabel pengontrol nilainya menjadi turun, yaitu dari 0,968 menjadi 0,397. Sedangkan tandanya masih “positif’. Hal ini berarti bahwa dengan memperhitungkan besarnya tingkat partisipasi politik seseorang, masih ada korelasi positif antara tingkat pengetahuan kewarganegaraan dengan perilaku demokratisnya. Sehingga, semakin tinggi tingkat partisipasi politik seseorang, dan jika perilaku demokrasinya pun meningkat, maka ada kecenderungan partisipasi politik orang tersebut akan semakin meningkat. Demikian pula sebaliknya.
3. KORELASI UNTUK DATA ORDINAL
Untuk data yang bersifat ordinal, seperti hasil dari penyebaran kuisioner yang berisi variabel berjenjang seperti: Sangat baik, Baik, Tidak Baik dan seterusnya, maka harus menggunakan korelasi Spearman dan Kendall. Jadi datanya bisa kualitatif maupun kuantitatif.
Mari kita lihat contoh kasus analisis untuk data ordinal dengan membuka file nilai karyawan.
Selanjutnya kita akan menghitung korelasi antara Prestasi Kerja, IQ yang dimiliki dan Loyalitas karyawan. Karena ketiga variabel tersebut kualitatif maka korelasi yang digunakan adalah korelasi Spearman dan Kendall.
Langkah-langkahnya sebagai berikut: 1. Buka file nilai_karyawan
2. Dari menu utama SPSS, pilih menu Analyze. Kemudian pilih submenu Correlate,
dan pilih Bivariate. Maka akan tampak di layar tampilan seperti gambar berikut:
3. Pengisian: Bila pada analsis data kuantitatif yang dicentang pada Correlation
Coefficients adalah Pearson, maka sekarang yang harus dicentang adalah Kendall’s tau-b dan Spearman (jangan lupa nonaktifkan yang Pearson-nya).
4. Untuk variabel, isikan prestasi, IQ dan Loyalitas dengan cara mengkliknya untuk menyorotnya, lalu klik tanda panah.
NonParametric Correlation
Correlation is significant at the 0.01 level (2-tailed). **.
Analisis: Penafsirannya sama dengan penafsiran pada analisis Pearson.
1. Arti Angka Korelasi (Lihat Pearson Correlation)
Korelasi antara Prestasi dan Loyalitas adalah positif, atau semakin loyal seorang
karyawan, maka prestasinya cenderung semakin bagus. Demikian pula sebaliknya. Akan tetapi angka korelasi sebesar 0,299 < 0,5 menunjukkan lemahnya hubungan kedua variabel tersebut.
Korelasi antara IQ dengan Loyalitas positif dan nilainya 0,072 0,5 menunjukan
hubungan keduanaya lemah.
Korelasi antara Prestasi dengan IQ adalah negatif, atau semakin tinggi IQ
karyawan maka prestasinya cenderung makin jelek, demikian pula sebaliknya. Namun angka korelasi 0,015 < 0,5 menunjukkan lemahnya hubungan ekedua variabel tersebut. Catatan: angka korelasi yang dipakai adalah korelasi Kendall. Namun bila diukur dengan Spearman, hasilnya tidak jauh berbeda.
2. Signifikansi Hasil Korelasi (lihat Sig. (2-tailed))
Korelasi antara Prestasi dengan Loyalitas adalah signifikan (Probabilitas 0,005
jauh lebih kecil daripada 0,05), yang berarti adanya hubungan yang benar-benar signifikan antara Prestasi dan Loyalitas seorang karyawan.
Korelasi anatara IQ dengan Loyalitas hampir signifikan (Probabilitas adalah
Korelasi antara Prestasi dengan IQ adalah tidak signifikan (Probabilitas 0,893 jauh lebih besar daripada 0,05), yang berarti antara Prestasi dan IQ seorang karyawan tidak ada hubungan.
3. Jumlah Data yang Berkorelasi
Dapat dilihat dari dari nilai N, karena tidak ada data yang hilang, maka data yang diproses adalah 75. (Simpan hasil output dengan nama korelasi3).
4. ANALISIS REGRESI
Kita telah menggunakan analisis korelasi dengan SPSS, selanjutnya kita akan menggunakan analisis regresi. Tujuan dari analisis regresi adalah untuk memprediksi besar Variabel Terikat (Dependent Variable) dengan menggunakan data Variabel Bebas (Independent Variable) yang sudah diketahui besarnya.
Pada dasarnya tahapan penyusunan model analisis regresi adalah sebagai berikut: 1. Menentukan yang mana variabel bebas dan variabel terikatnya
2. Menentukan metode pembuatan model regresi, dalam SPSS ada beberapa pilihan, yaitu: Enter, Stepwise, Forward dan Backward (perbedaanya akan dibahas pada bagian lain). Default SPSS adalah metode Enter. Jika kita memilih metode Stepwise, maka uji signifikansi justru mendahului uji asumsi seperti normalitas dan sebagainya, oleh karena itu dalam latihan kita akan menggunakan default SPSS yaitu metode Enter.
3. Melihat ada tidaknya data yang outlier (ekstrem)
4. Menguji asumsi-asumsi pada regresi berganda, seperti normalitas, Linieritas, Heteroskedastisitas dan lain-lainnya.
5. Menguji signifikansi model (uji-t, uji-F dan sebagainya) 6. Intepretasi model Regresi Berganda
Persamaan model regresi dinyataakan dalam rumusan sebagai berikut:
Y = a + bX1 + cX2
Keterangan:
Y = Variabel dependen
a, b, c = konstanta-konstanta regresi
Contoh:
Kembali kita buka lagi file sebelumnya yang menggambarkan antara tingkat partisipasi politik seseorang dengan tingkat pengetahuan kewarganegaraannya dan tingkat perilaku demokrasinya. Dalam analisis regresi kita ingin meprediksi, bagaimana tingkat partisipasi politik seseorang bila tingkat pengetahuan kewarganegaraannya dan tingkat perilaku demokrasinya berubah-ubah nilainya. Untuk itu kita lihat lagi contoh data yang kita punya sebelumnya.
Tabel Data Analisis Regresi
Responden Participation Citizenship Democracy
1 1 5 1
2 3 7 4
3 5 10 5
4 7 10 6
5 9 12 8
Langkah-langkah:
1. Buat atau jika sudah ada buka lagi file SPSS yang memuat data ini.
3. Untuk pengisian, sebagai berikut:
a. Untuk pilihan Dependent (variabel terikat). Pilih variabel Participation b. Untuk Independent(s) pilih Citizenship dan Democracy
c. Method, pilih Enter d. Abaikan bagian lain
e. Tekan OK untuk prosessing data maka outputnya diperoleh sebagai berikut.
Output dan Analisisnya
Model Summary
.982a .963 .927 .85442
Model 1
R R Square
Adjusted R Square
Std. Error of the Estimate
Predictors: (Constant), Democracy, Citizenship a.
Bagian ini menggambarkan derajat keeratan hubungan antarvariabel.
Angka R sebesar 0.982(a) menunjukkan bahwa korelasi/hubungan antara Participation
dengan kedua variabel independen-nya adalah kuat (karena besarnya > 0,5).
Angka R Square atau Koefisien Determinasi adalah 0.963 (berasal dari 0,982 x 0,982).
Ini artinya bahwa 0,963 atau 96,3% variasi dari Participation dapat dijelaskan oleh variasi dari kedua variabel independen, yaitu Democracy dan Citizenship. Sedangkan sisanya (100-96,3 = 0,7) atau 7% dijelaskan oleh sebab-sebab yang lain. Untuk variabel independen lebih dari dua sebaiknya gunakan Adjusted R Square yang pada latihan kita nilainya 0,927.
Std. Error of the Estimate yang nilainya 0.85442 menggambarkan tingkat ketepatan
ANOVAb
38.540 2 19.270 26.396 .037a
1.460 2 .730
Squares df Mean Square F Sig.
Predictors: (Constant), Democracy, Citizenship a.
Dependent Variable: Participation b.
Bagian ini menggambarkan tingkat signifikansi. Dari uji ANOVA atau test, didapat F-hitung 26.396 dengan tingkat signifikansi sebesar 0,037. Karena probabilitas (tingkat signifikansi) ini lebih kecil daripada 0,05 maka model regresi ini bisa dipakai untuk memprediksi tingkat partisipasi politik seseorang. Dengan kata lain, tingkat pengetahuan kewarganegaraan seseorang dan tingkat perilaku demokratisnya secara bersama-sama berpengaruh terhadap tingkat partisipasi politiknya.
Coefficientsa
-2.300 2.491 -.924 .453
.411 .610 .360 .673 .570
.768 .654 .629 1.175 .361
(Constant)
Sedangkan bagian ini menggambarkan seberapa besar koefisien regresinya.
Persamaan regresi yang diperoleh adalah sebagai berikut:
Participation = -2.300 + 0,411 Citizenship + 0,768 Democracy
Konstanta sebesar -2,30 menyatakan bahwa jika seseorang tidak memiliki pengetahuan
kewarganegaraan dan perilaku demokratis maka partisipasi politiknya -2,30. Secara kualitatif tentu tidak ada perilaku “minus”, mungkin dapat diintepretasikan dalam konteks budaya politik gal itu adalah budaya “apatis”. Jangan lupa juga, bahwa secara nyata ketiga variabel itu berskala ordinal, tidak memiliki angka “nol” seperti dalam batasan skala interval.
Koefisien regresi 0,411 menunjukkan bahwa setiap pengetahuan kewarganegaraan
seseorang bertambah +1 poin, maka partisipasi politiknya akan bertambah 0,411 poin.
Koefisien regresi 0,768 menunjukkan bahwa setiap tingkat perilaku demokratis
Sedangkan uji-t digunakan untuk menguji signifikansi konstanta dan setiap variabel independen.
Hipotesis yang dibangun adalah sebagai berikut: Ho = Koefisien Regresi Tidak Signifikan
Hi = Koefisien Regresi Signifikan
Pengambilan keputusan (berdasarkan probabilitas, lihat kolom Sig.) adalah sebagai berikut:
Jika Sig. > 0,05 maka Ho diterima
Jika Sig. < 0,05 maka Ho ditolak , Hi diterima
Terlihat bahwa pada kolom Sig. untuk ketiga variabel tersebut, yaitu konstanta = 0,453, Citizenship = 0,57 dan Democracy = 0,361 mempunyai angka signifikansi > 0,05, dengan demikian Ho diterima atau dengan kata lain kedua variabel tersebut tidak cukup signifikan mempengaruhi tingkat partisipasi politik seseorang.
Kejadian di atas mungkin disebabkan karena data-data yang ada memang menunjukkan
hal tersebut.
SUMBER REFERENSI
Prasetyo, Ary. (2008). Statistik Deskeiotif. Bandung: Materi 2 Bahan Ajar Statistik.
Sumirin. (2012). Matematika Terapan, Statistik. Semarang: Bahan Ajar Statistik Magister Teknik Sipil.
Wahyudi, Imam. (2012). Statistik. Semarang: Bahan Ajar Statistik Magister Teknik Sipil. Munir, Sahibul. (2008). Statistik I ( Deskriptif ) “Ruang Lingkup Statistik Deskriptif“. _______ : Universitas Mercu Buana.