ABSTRAK
Data minning adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data minning berisi pencarian trend atau pola yang diinginkan dalam database besar untuk membantu pengambilan keputusan. Dalam penulisan tugas akhir ini menggunakan implementasi dari algoritma ID3. Dengan menggunakan algoritma ID3 dapat digunakan untuk menambang data query pada situs website. Situs www.inkuiri.com adalah sebuah situs yang digunakan untuk pencarian barang yang terdiri dari beberapa kategori, diantaranya adalah fashion, smartphone, motorbike dan talisman. Data yang digunakan terdiri dari 5 atribut yaitu : interest (main), type, city, waktu dan bulan. Hasil akhir yang akan didapat adalah pola interest user yang melakukan query.
▸ Baca selengkapnya: koleksi data pada situs web dikenal juga dengan
(2)ABSTRACT
Data Minning is a term used to describe the knowledge discovery in databases .
Data Minning unbiased search trend or a desired pattern in a large database to
help make decisions . In this thesis using an implementation of the algorithm ID3 .
By using ID3 algorithm can be used for data mining queries on the web site .
Www.inkuiri.com sites is a site used for the search item consists of several
categories , including fashion , smartphone , motorbike and talisman . The data
used consists of five attributes , namely : interest ( main) , type, city, time and
month . The final results will be obtained is user interest patterns that do queries .
Tests carried out using 500 new data . Average yield - average value of
Decision Tree
Studi Kasus : www.inkuiri.com
Skripsi
Diajukan Untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Oleh :
Yustina Dyah Utami
115314094
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
ii
Data Mining Query on a Site Website Using Decision Tree Algorithm
Studi Kasus : www.inkuiri.com
A Thesis
Presented As Partial Fullfillment of the Requirements To Obtain the Sarjana Komputer Degree
By :
Yustina Dyah Utami
Student Number 115314094
INFORMATICS ENGINEERING STUDY PROGRAM
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
iv
v
HALAMAN PERSEMBAHAN
“7Mintalah, maka akan diberikan kepadamu; carilah, maka kamu akan
mendapat; ketoklah, maka pintu akan dibukakan bagimu. 8Karena setiap
orang yang meminta, menerima dan setiap orang yang mencari, mendapat
dan setiap orang yang mengetok, baginya pintu dibukakan.”
(Matius 7 : 7 – 8)
Tugas akhir ini saya persembahkan kepada :
Tuhan Yesus Kristus
Terimakasih atas berkatNya yang sungguh luar biasa sehingga tugas akhir ini dapat terselesaikan.
Bapak (alm) dan Ibu
Terimakasih atas dukungan dan doa yang diberikan kepada penulis.
Kakak tercinta
vi
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini tidak memuat karya atau bagian karya orang lain, kecuali yang telah disebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, 19 Februari 2016
Penulis,
vii
ABSTRAK
Data minning adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database. Data minning berisi pencarian trend atau pola yang diinginkan dalam database besar untuk membantu pengambilan keputusan. Dalam penulisan tugas akhir ini menggunakan implementasi dari algoritma ID3. Dengan menggunakan algoritma ID3 dapat digunakan untuk menambang data query pada situs website. Situs www.inkuiri.com adalah sebuah situs yang digunakan untuk pencarian barang yang terdiri dari beberapa kategori, diantaranya adalah fashion, smartphone, motorbike dan talisman. Data yang digunakan terdiri dari 5 atribut yaitu : interest (main), type, city, waktu dan bulan. Hasil akhir yang akan didapat adalah pola interest user yang melakukan query.
viii
ABSTRACT
Data Minning is a term used to describe the knowledge discovery in databases . Data
Minning unbiased search trend or a desired pattern in a large database to help make
decisions . In this thesis using an implementation of the algorithm ID3 . By using ID3
algorithm can be used for data mining queries on the web site . Www.inkuiri.com sites
is a site used for the search item consists of several categories , including fashion ,
smartphone , motorbike and talisman . The data used consists of five attributes , namely
: interest ( main) , type, city, time and month . The final results will be obtained is user
interest patterns that do queries .
Tests carried out using 500 new data . Average yield - average value of
ix
LEMBAR PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma :
Nama : Yustina Dyah Utami
Nomor Mahasiswa : 115314094
Demi pengembangan ilmu pengetahuan, saya memberikan kepada Perpustakaan Universitas Sanata Dharma karya ilmiah saya yang berjudul :
Penambangan Data Query pada Situs Web dengan Menggunakan Algoritma
Decision Tree
(Studi Kasus : www.inkuiri.com)
beserta perangkat yang diperlukan. Dengan demikian saya memberikan kepada Perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data, mendistribusikan secara terbatas, dan mempublikasikannya di Internet atau media lain untuk kepentingan akademis tanpa perlu meminta ijin dari saya maupun memberikan royalty kepada saya selama tetap mencantumkan nama saya sebagai penuulis.
Demikian pernyataan ini saya buat dengan sebenarnya. Dibuat di Yogyakarta
Pada tanggal : 19 Februari 2016 Yang menyatakan,
x
KATA PENGANTAR
Puji syukur penulis panjatkan kehadirat Tuhan Yang Maha Esa, yang telah melimpahkan berkat dan rahmatNya sehingga penulis dapat menyelesaikan tugas akhir yang berjudul “Penambangan Data Query pada Situs Web dengan Menggunakan
Algoritma Decision Tree”. Tugas akhir ini ditulis sebagai salah satu syarat
memperoleh gelar sarjana program studi Teknik Informatika, Fakultas Sains dan Teknologi Universitas Sanata Dharma.
Dalam kesempatan ini, penulis mengucapkan terimakasih banyak kepada :
1. Tuhan Yesus Kristus yang telah menuntun dan memberikan berkat yang melimpah dan solusi terbaik sehingga tugas akhir ini dapat terselesaikan.
2. Ibu Sri Hartati Wijono, S.Si M.Kom, selaku Dosen Pembimbing atas segala waktu, kesabaran, serta memberi kritik dan saran yang membangun dalam membantu penyelesaian tugas akhir ini.
3. Mas Audris yang telah memberikan solusi dalam penyelesaian tugas akhir ini.
4. Kedua orangtua, Bapak (Alm.) T. Marto Atmodjo dan Ibu Martina Rumiyati yang selalu bersabar membimbing penulis dan mendoakan penulis.
xi
memberikan solusi dan berbagi keluh kesah.
7. Sahabat terkasih, Agnes Alfani Restu Putri yang selalu setia menemani untuk saling berbagi berbagai hal.
8. Bulan Mahadewi dan Monica Susi Diatmasari yang sudah banyak saling berbagi hal mengenai kuliah dan berjuang bersama.
9. Teman – teman Teknik Informatika 2011, terkhusus untuk anggota C++ yang telah sama – sama berjuang dan saling menyemangati dan memberi inspirasi.
10.Seluruh staff pengajar Prodi Teknik Informatika yang telah memberikan ilmu pengetahuan yang sangat berguna bagi penulis.
11.Semua pihak yang telah membantu, yang tidak dapat disebutkan satu per satu.
Penulis menyadari masih banyak kekurangan dalam penyusunan tugas akhir ini. Namun penulis berharap tugas ini bermanfaat bagi pengembangan ilmu pengetahuan.
Yogyakarta, 05 Februari 2016
xii
DAFTAR ISI
HALAMAN PERSEMBAHAN ... v
PERNYATAAN KEASLIAN KARYA ... vi
ABSTRAK ... vii
ABSTRACT ... viii
LEMBAR PERNYATAAN PERSETUJUAN ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR GAMBAR ... xv
DAFTAR TABEL ... xvi
BAB I ... 1
PENDAHULUAN ... 1
1.1 Latar belakang ... 1
1.2 Rumusan Masalah ... 3
1.3 Tujuan Penelitian ... 4
1.4 Manfaat ... 4
1.5 Batasan Masalah ... 4
1.6 Luaran ... 4
1.7 Sistematika Penulisan ... 5
BAB II ... 6
LANDASAN TEORI ... 6
2.1 Penambangan Data (Data Mining) ... 6
xiii
2.4 Decision Tree (Pohon Keputusan) ... 9
2.5 Kegunaan Pohon Keputusan... 11
2.6 Kelebihan dan kekurangan dari Decision Tree (Pohon Keputusan) ... 11
2.6.1 Kelebihan Decision Tree (Pohon Keputusan) ... 11
2.6.2 Kekurangan Decision Tree (Pohon Keputusan) ... 12
2.7 Algoritma Decision Tree (Pohon Keputusan) ... 12
2.8 Perhitungan Akurasi ... 13
BAB III ... 14
Identifikasi Perhitungan dengan Decision Tree ... 14
3.1 Pengenalan Data ... 14
3.2 Pemrosesan data... 17
3.3 Proses Perhitungan Algoritma ID3 ... 22
3.4 Output Sistem ... 23
3.5 Diagram Use Case ... 24
3.5.1 Narasi Use Case ... 24
3.6 Contoh Proses Perhitungan Data ... 28
3.7 Perancangan Umum Sistem ... 48
3.7.1 Masukkan Sistem ... 48
3.7.2 Perancangan antar muka dengan user ... 49
3.8 Diagram Kelas ... 52
3.8.1 Diagram Kelas Use case Login ... 52
3.8.2 Diagram Kelas Use case Masukkan Data ... 54
xiv
4.1 Spesifikasi Perangkat Keras dan Perangkat Lunak... 56
4.2 Implementasi Pemrosesan Data ... 56
4.2.1 Pembersihan Data ... 56
4.3 Implementasi Use Case ... 65
4.4 Implementasi Diagram Kelas ... 74
BAB V ... 75
PENGUJIAN DATA ... 75
5.1 Pengujian Data ... 75
5.3 Menghitung akurasi ... 76
5.4 Kelebihan dan Kekurangan Program ... 84
BAB VI ... 85
KESIMPULAN dan SARAN ... 85
6.1 Kesimpulan ... 85
6.2 Saran... 85
Daftar Pustaka ... 86
LAMPIRAN 1 ... 87
LAMPIRAN 2 ... 111
xv
DAFTAR GAMBAR
Gambar 2. 1 Bidang Ilmu Data Minning... 7
Gambar 2. 2 Blok Diagram Model Klasifikasi ... 8
Gambar 3. 1 Flowchart Decision Tree ... 23
Gambar 3. 2 Diagram Use Case ... 24
Gambar 3. 3 Bentuk awal pohon dengan gain tertinggi waktu ... 33
Gambar 3. 4 Pembentukkan pohon untuk cabang malam ... 34
Gambar 3. 5 Pembentukan pohon untuk cabang pagi ... 36
Gambar 3. 6 Pembentukan pohon untuk cabang pagi dan city Jakarta... 37
Gambar 3. 7 Pembentukan pohon untuk atribut bulan ... 39
Gambar 3. 8 Pembentukan pohon untuk cabang awal ... 41
Gambar 3. 9 Pembentukan pohon untuk bulan awal dan type Smartphone ... 42
Gambar 3. 10 Pembentukan pohon untuk cabang tengah ... 44
Gambar 3. 11 Pembentukkan pohon untuk cabang akhir ... 45
Gambar 3. 12 Diagram Kelas Use Case Login ... 53
Gambar 3. 13 Diagram Kelas Use Case Masukkan Data ... 54
Gambar 3. 14 Diagram Kelas Pengujian ... 55
Gambar 4. 1 Halaman FormLogin ... 66
Gambar 4. 2 Pemberitahuan berhasil login ... 66
Gambar 4. 3 Form Halaman Utama ... 67
Gambar 4. 4 Halaman tab menu data ... 68
Gambar 4. 5 Halaman File Chooser untuk mengambil data ... 68
Gambar 4. 6 Data yang sudah berhasil ditampilkan ... 69
Gambar 4. 7 Hasil pohon keputusan ... 71
Gambar 4. 8 Halaman Prediksi ... 72
xvi
DAFTAR TABEL
Tabel 3. 1 Tabel atribut data mentah... 14
Tabel 3. 2 Aturan Transformasi Data _source_created ... 19
Tabel 3. 3 Tabel Variabel Input ... 20
Tabel 3. 4 Tabel data yang akan diolah ... 28
Tabel 3. 5 Tabel pengelompokkan data dari setiap atribut... 30
Tabel 3. 6 Tabel perhitungan nilai entropy semua atribut ... 31
Tabel 3. 7 Perhitungan data pada cabang malam ... 33
Tabel 3. 8 Perhitungan data pada cabang pagi ... 35
Tabel 3. 9 Perhitungan data pada cabang Jakarta ... 36
Tabel 3. 10 Perhitungan data pada cabang siang ... 38
Tabel 3. 11 Perhitungan data pada cabang awal ... 40
Tabel 3. 12 Perhitungan data pada cabang Smartphone ... 41
Tabel 3. 13 Perhitungan data pada cabang tengah ... 43
Tabel 3. 14 Perhitungan data pada cabang akhir ... 44
Tabel 3. 15 Penjelasan atribut masukkan sistem ... 48
Tabel 4. 1 Contoh data yang sudah dilakukan pembersihan ... 57
Tabel 4. 2 Contoh file dari kategori fashion ... 57
Tabel 4. 3 Contoh file dari kategori smartphone ... 58
Tabel 4. 4 Contoh file dari kategori motorbike ... 58
Tabel 4. 5 Contoh file dari kategori talisman ... 59
Tabel 4. 6 Contoh file yang telah digabungkan ... 59
Tabel 4. 7 Nama – nama atribut yang belum diseleksi ... 60
Tabel 4. 8 Hasil nama atribut yang telah diseleksi ... 61
xvii
Tabel 5. 1 Hasil Pengujian ke - 1 ... 77
Tabel 5. 2 Hasil Pengujian ke - 2 ... 77
Tabel 5. 3 Hasil Pengujian ke - 3 ... 78
Tabel 5. 4 Hasil Pengujian ke - 4 ... 79
Tabel 5. 5 Hasil Pengujian ke - 5 ... 79
Tabel 5. 6 Hasil Pengujian ke - 6 ... 80
Tabel 5. 7 Hasil Pengujian ke - 7 ... 81
Tabel 5. 8 Hasil Pengujian ke - 8 ... 81
Tabel 5. 9 Hasil Pengujian ke - 9 ... 82
Tabel 5. 10 Hasil Pengujian ke - 10 ... 83
BAB I
PENDAHULUAN
1.1 Latar belakang
Saat ini, dunia teknologi berkembang dengan sangat pesat. Manusia, semakin dimudahkan untuk melakukan pekerjaan dengan menggunkan teknologi yang berkembang saat ini. Dari sisi komunikasi perkembangan teknologi paling mudah kita dapat, kita lihat, dan kita rasakan. Saat ini, banyak sekali smartphone yang dijual dipasaran. Setiap perusahaan smartphone bersaing untuk memasarkan produk – produk yang mereka miliki. Perusahaan pun, semakin melengkapi produknya dengan berbagai macam aplikasi yang semakin memudahkan manusia untuk berkomunikasi.
Di jaman yang serba instant ini, manusia semakin ingin mendapatkan barang atau pun jasa dengan mudah. Hal ini yang memotivasi dunia pasar untuk ikut berkembang. Oleh sebab itu, kegiatan jual beli kini banyak dilakukan secara online, seiring dengan berkembangnya teknologi. Saat ini, jual beli online banyak kita temui, dan dengan mudah kita bisa membeli barang yang kita inginkan.
mengetahui hilangnya pelanggan karena pesaing? Bagaimana mengetahui item produk atau konsumen yang memiliki kesamaan karakteristik? Bagaimana mengidentifikasi produk-produk yang terjual bersamaan dengan produk lain. Bagaimana memprediksi tingkat penjualan? Bagaimana menilai tingkat resiko dalam menentukan jumlah produksi suatu item. Bagaimana memprediksi perilaku bisnis di masa yang akan datang?
Dari banyaknya pengunjung yang mengakses website inkuiri.com, maka ada informasi yang menyimpan data yang dapat ditambang. Berdasarkan data yang ada tersebut, data yang dapat ditambang adalah query dari pencarian yang telah dimasukkan oleh pengguna. Query tersebut berupa data barang seperti; “jam tangan endogawa”, “lipstick”, hp android, batu bacan, velg motor dan
sebagainya. Hasil dari query tersebut kemudian dikelompokkan menjadi 4 kategori yaitu fashion, smartphone, motorbike, dan talisman. Selain hasil dari query, data lain yang dapat ditambang adalah nama kota dimana sedang dilakukan pencarian, type (perangkat) yang sedang digunakan untuk melakukan pencarian, waktu (pagi, siang atau malam) melakukan pencarian, dan bulan (awal, pertengahan, atau akhir) melakukan pencarian.
Dalam penelitian ini, penulis akan mengolah data dengan menggunakan algoritma Decision Tree. Pertama, dipilih data yang relevan yang dapat digunakan untuk penelitian ini. Kedua, data yang sudah jadi diolah ke dalam sistem yang akan melakukan perhitungan sesuai dengan algoritma ID3. Ketiga, setelah tree (pohon) terbentuk maka akan dilakukan pengujian data untuk mengetahui keakuratan (akurasi) data.
1.2 Rumusan Masalah
Berdasarkan latar belakang di atas, maka permasalahan yang akan diselesaikan dalam penelitian ini, adalah :
2. Apakah algoritma ID3 mempunyai keakuratan yang baik dalam mengelompokkan query dalam sebuah situs data pencarian?
1.3 Tujuan Penelitian
Tujuan dari penelitian yang akan dibuat adalah :
Membantu perusahaan untuk mengetahui pola user yang melakukan query untuk interest tertentu.
1.4 Manfaat
Manfaat yang akan diperoleh adalah :
Perusahaan dapat mengetahui pola interestuser yang melakukan query.
1.5 Batasan Masalah
Berikut adalah batasan masalah dalam penelitian Tugas Akhir :
1. User harus lebih spesifik lagi dalam menuliskan kata kunci pencarian barang agar barang yang dicari dapat ditemukan dengan tepat.
2. Dalam penelitian yang dibuat ini hanya 4 kategori yang digunakan yaitu, fashion, smartphone, motorbike dan talisman.
1.6 Luaran
1.7 Sistematika Penulisan
Bab I Pendahuluan
Bab ini berisi mengenai hal yang mendasari dilakukannya penelitian ini. Dalam bab ini juga terdapat beberapa hal yang meliputi; perumusan masalah, tujuan, batasan masalah, manfaat penelitian dan sistematika penulisan.
Bab II Landasan Teori
Bab ini berisi mengenai penjelasan dasar teori – teori yang dipakai dalam penelitian ini. Algoritma decision tree akan lebih banyak dijelaskan pada bab ini.
Bab III Identifikasi Perhitungan dengan Decision Tree
Bab ini berisi mengenai pemrosesan data awal dan desain user interface.
Bab IV Implementasi
Bab ini berisi implementasi program yang merupakan penerapan langsung dari algoritma yang dipakai dalam penelitian ini, yaitu algoritma decision tree.
Bab V Pengujian Data
Bab ini berisi mengenai pengujian data dan mendapatkan hasil akurasi
Bab VI Kesimpulan dan Saran
BAB II
LANDASAN TEORI
2.1Penambangan Data (Data Mining)
Data minning adalah suatu istilah yang digunakan untuk menguraikan penemuan pengetahuan di dalam database.Data minning adalah proses yang menggunakan teknik statistic, matematika, kecerdasan buatan, dan machine learning untuk mengekstraksi dan mengidentifikasi informasi yang bermanfaat dan pengetahuan yang terkait dari berbagai database besar (Turban, dkk. 2005).
Gambar 2. 1 Bidang Ilmu Data Minning
2.2Tahap – tahap pada Penambangan Data
Secara sistematis, ada tiga langkah utama dalam data mining (Gonunseca, 2011) :
1. Eksplorasi/pemrosesan awal data
Eksplorasi /pemrosesan awal data terdiri dari pembersihan data, normalisasi data, transformasi data, penanganan data yang salah, reduksi dimensi,pemilihan subset fitur, dan sebagainya.
2.3Teknik Klasifikasi
Klasifikasi merupakan proses pembelajaran suatu fungsi tujuan (target) f yang memetakan tiap himpunan atribut x ke satu dari label kelas y. Fungsi target disebut juga model klasifikasi. Blok diagram model klasifikasi dapat dilihat seperti pada Gambar 2.2.
Input Output
Atribute set (x) Class
Tabel (y)
Gambar 2. 2 Blok Diagram Model Klasifikasi
Ada 2 jenis model Klasifikasi, yaitu :
Pemodelan Deskriptif (descriptive modelling)
Model klasifikasi yang dapat berfungsi sebgai suatu alat penjelasan untuk membedakan objek – objek dalam kelas – kelas yang berbeda. Pemodelan Prediktif (predictive modeling)
Model klasifikasi yang dapat digunakan untuk memprediksi label kelas recod yang tidak diketahui.
Teknik klasifikasi (classifier) merupakan suatu pendekatan sistematis untuk membangun model klasifikasi dari suatu himpunan data masukan. Tiap
teknik menggunakan suatu algoritma pembelajaran (learning algorithm) untuk mendapatkan suatu model yang paling memenuhi hubungan antara himpunan atribut dan label kelas dalam data masukan. Masukan dari model klasifikasi merupakan sekumpulan record (training set). Tiap record meliputi himpunan attributes, yang salah satu atributnya merupakan class. Model untuk atribut kelas merupakan suatu fungsi dari nilai – nilai atribut lainnya. Suatu test set digunakan untuk menentukan keakuratan model tersebut. Biasanya data – set yang diberikan dibagi menjadi training dan test sets, dimana training set digunakan untuk membangun model dan test set digunakan untuk memvalidasi.
2.4Decision Tree (Pohon Keputusan)
Pohon (tree) adalah sebuah struktur data yang terdiri dari simpul (node) dan rusuk (edge). Simpul pada sebuah pohon dibedakan menjadi tiga, yaitu simpul akar (root node), simpul percabangan/internal (branch/internal node) dan simpul daun (leaf node). Pohon keputusan merupakan representasi sederhana dari teknik klasifikasi untuk sejumlah kelas berhingga, dimana simpul internal maupun simpul akar ditandai dengan nama atribut, rusuk – rusuknya diberi label nilai atribut yang mungkin dan simpul daun ditandai dengan kelas – kelas yang berbeda.
masing rangkaian pembagian,anggota himpunan hasil menjadi mirip satu dengan yang lain (Berry& Linoff, 2004).
Untuk memilih atribut sebagai akar, didasarkan pada nilai gain tertinggi dari atribut – atribut yang ada. Untuk menhitung gain digunakan rumus seperti tertera dalam persamaan :
(2.1)
Keterangan :
S : himpunan kasus n : jumlah partisi S
pi : proporsi dari Si terhadap S
Sementara itu, perhitungan nilai entropi dapat dilihat pada persamaan berikut :
(2.2)
Keterangan :
S : himpunan kasus A : atribut
2.5Kegunaan Pohon Keputusan
Prosedur diagram pohon dapat digunakan untuk :
1. Segmentasi
Mengidentifikasi orang – orang yang dapat dimasukkan ke dalam kelompok tertentu.
2. Stratifikasi
Mengenakan kasus – kasus (data) ke dalam satu dari beberapa kategori, seperti kelompok – kelompok yang berisiko rendah, menengah dan tinggi.
3. Prediksi
Membuat aturan dan menggunakan aturan tersebut untuk memprediksi kejadian – kejadian di masa yang akan datang.
4. Pengurangan data dan penyaringan variabel
Memilih prediktor – prediktor yang bermanfaat dari seperangkat variabel untuk digunakan dalam membuat model parametric baku.
5. Penggabungan kategori dan diskretisasi variabel – variabel kontinu
Mengode ulang kategori – kategori prediktor dalam kelompok dan variabel kontinu dengan meminimisasi hilangnya informasi dikarenakan proses diskretisasi.
2.6Kelebihan dan kekurangan dari Decision Tree (Pohon Keputusan)
2.6.1 Kelebihan Decision Tree (Pohon Keputusan)
2. Untuk mem-break down proses pengambilan keputusan yang kompleks menjadi lebih simple sehingga pengambil keputusan akan lebih menginterpretasikan solusi dari permasalahan.
3. Bisa dijadikan sebagai tool pengambilan keputusan terakhir.
4. Mengubah keputusan yang kompleks menjadi lebih simple, spesifik dan mudah.
2.6.2 Kekurangan Decision Tree (Pohon Keputusan)
1. Kesulitan dalam mendesain pohon keputusan yang optimal.
2. Hasil kualitas keputusan yang didapatkan dari metode pohon keputusan sangat tergantung pada bagaimana pohon tersebut didesain.
3. Terjadi overlap terutama ketika kelas – kelas dan kriteria yang digunakan jumlahnya sangat banyak.
4. Pengakumulasian jumlah error dari setiap tingkat dalam sebuah pohon keputusan yang besar.
2.7Algoritma Decision Tree (Pohon Keputusan)
Algoritma ID3
1. Dimulai dari node akar.
2. Untuk semua fitur, hitung nilai entropy untuk semua sampel (data latih) pada node.
4. Lakukan secara rekursif pada setiap cabang yang dibuat dengan mengulangi langkah 2 sampai 4 hingga semua data dalam setiap node hanya memberikan satu label kelas. Node yang tidak dapat dipecah lagi merupakan daun yang berisi keputusan (label kelas).
2.8Perhitungan Akurasi
Untuk menghitung nilai akurasi, maka digunakan rumus sebagai berikut :
� � �= � ℎ_� _� �_
BAB III
Identifikasi Perhitungan dengan Decision Tree
3.1Pengenalan Data
Www.inkuiri.com adalah sebuah situs pencarian yang digunakan untuk mencari beberapa barang yang diinginkan oleh pengguna. Dari query – query yang dimasukkan oleh pengguna maka data tersebut tersimpan dalam database. Ada 43 atribut yang dapat dilihat dari setiap query yang dimasukkan oleh pengguna. Dari 43 atribut tersebut akan dipilih beberapa yang dapat digunakan untuk penelitian tugas akhir ini. Data yang diperoleh dari perusahaan www.inkuiri.com berupa file spreadsheet. Kemudian data tersebut diolah dengan beberapa tahapan yang akan menghasilkan aturan – aturan untuk klasifikasi.
Pada penelitian yang dilakukan ini menggunakan data yang di dapat dari www.inkuiri.com. Data yang digunakan adalah data query hasil dari pencarian kata yang dimasukkan oleh user. Atribut data mentah yang diperoleh dari perusahaan www.inkuiri.com seperti pada Tabel 3.1.
Tabel 3. 1 Tabel atribut data mentah
No Nama atribut Keterangan Nilai
1 took
2 timed_out
3 |
5 successful
Fashion, Smartphone, Motorbike, Talisman 19 _source__device__type Atribut ini
menyimpan data 21 _source__filter__location Atribut ini
menyimpan data 23 _source__filter__price Atribut ini
menyimpan data 24 _source__filter__site Atribut ini
menyimpan data
website yang Europe, China, Anonymous Proxy, Singapore, Bangladesh,
United Kingdom, Macau, dll 28 _source__location__region Atribut ini
menyimpan data region negara
2, 4, 8, CA, 30, OR, 81, 10, 14, 32, 7, 11, 40, 26, 38, 22, 37, VA, dll
29 _source__location__city Atribut ini menyimpan data hp android, batu bacan, dll
34 _source__profile_id Atribut ini menyimpan data profile_id
54ae4a4c2c3ee4.74521373 ,
dll 35 _source__session_id 36 _source__created Atribut ini
menyimpan data waktu
1420709262000, dll
37 _source__os__family Atribut ini menyimpan data os_family
Windows, Ios, Android
38 _source__os__name Atribut ini menyimpan data os_name
Browser, Mobile browser
39 _source__user_agent__famil Firefox, Opera mini, dll
40 _source__user_agent__type
Sebelum data diolah dengan menggunakan sistem, terlebih dahulu dilakukan beberapa tahap sebagai pemrosesan data awal yaitu sebagai berikut :
1. Pembersihan Data
2. Integrasi Data
Pada tahap integrasi data ini dilakukan penggabungan data dari beberapa file menjadi satu tabel yang utuh. Data yang dikumpulkan berasal dari beberapa file yang berbeda sehingga harus digabungkan agar sesuai untuk ditambang.
3. Penyeleksian Data
tersebut dihapus atau dilakukan pembuangan karena dianggap tidak dapat dijadikan sebagai variable untuk menentukan pencarian pola.
Data yang diperoleh setelah dilakukan tahap penyeleksian data adalah _source_audience_interest, _source_device_type, _source_location_city, dan _source_created.
4. Transformasi Data
Pada tahap ini dilakukan peringkasan data, dari data mentah menjadi data yang mudah dikelola. Pada penelitian ini tranformasi data yang dilakukan adalah atribut _source_created. Atribut tersebut berupa angka yang kemudian diolah menjadi waktu dan bulan. Waktu berupa : pagi, siang dan malam, sedangkan bulan berupa : awal, tengah dan akhir. Aturan transformasi data seperti pada Tabel 3.2.
Tabel 3. 2 Aturan Transformasi Data _source_created
_source_created aturan
waktu 00:00 am - 08:00 am pagi
08:01 am - 16:00 pm siang 16:00 pm - 23:59 pm malam
bulan 1-10 awal
11-20 tengah
5. Penambangan data
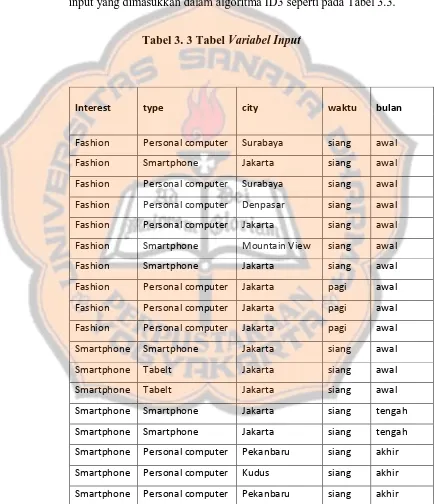
Setelah dilakukan beberapa tahapan tersebut di atas, selanjutnya data yang sudah jadi diolah menggunakan algoritma ID3. Contoh variabel input yang dimasukkan dalam algoritma ID3 seperti pada Tabel 3.3.
Tabel 3. 3 Tabel Variabel Input
Interest type city waktu bulan
V klasifikasi pencarian situs website.
6. Evaluasi Pola
Pada tahap perbaikan ini dilakukan pengujian pola dengan persamaan 2.3.
7. Presentasi Pengetahuan
Akhir dari penelitian yang akan dilakukan adalah membuat aplikasi dengan tampilan antarmuka yang mudah dimengerti oleh pengguna.
3.3Proses Perhitungan Algoritma ID3
Data yang telah dimasukkan pada sistem selanjutnya akan diproses oleh sistem dengan menggunakan algoritma ID3. Proses yang dilakukan oleh sistem adalah sebagai berikut :
1. Memasukkan username dan password untuk masuk ke sistem. 2. Memasukkan data berupa spread sheet.
3. Pembentukan pohon berawal dari menghitung nilai entropy untuk node akar (semua data) terhadap komposisi kelas. Selanjutnya menghitung nilai entropy untuk setiap nilai atribut terhadap kelas.
4. Setelah perhitunganentropy selesai selanjutnya menghitung nilai gain untuk setiap atribut.
5. Dari perhitungangain maka akan mendapatkan nilai paling besar diantara atribut – atribut tersebut dan dijadikan sebagai node akar.
7. Setelah sistem selesai menghitung maka akan ditampilkan hasil pohon yang terbentuk.
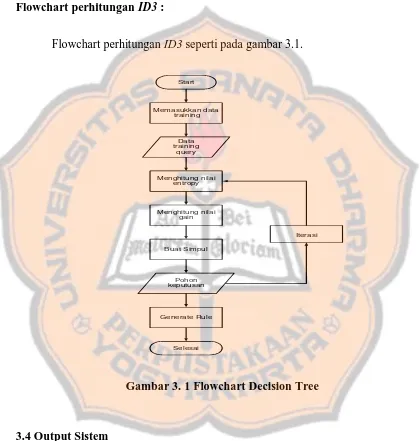
Flowchart perhitungan ID3 :
Flowchart perhitungan ID3 seperti pada gambar 3.1.
Start
Memasukkan data training
Data training
query
Menghitung nilai entropy
Menghitung nilai gain
Buat Simpul
Pohon keputusan
Generate Rule
Selesai
Iterasi
Gambar 3. 1 Flowchart Decision Tree
3.4Output Sistem
Hasil keluaran sistem :
3.5Diagram Use Case
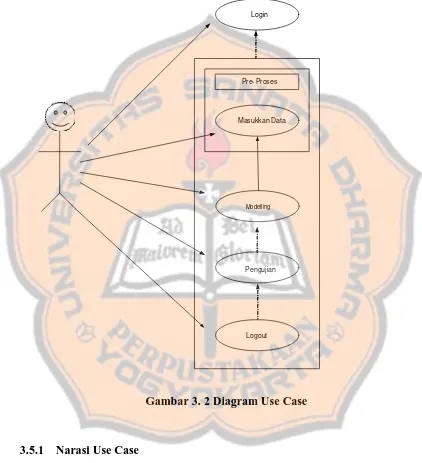
Diagram use case untuk sistem yang dibuat seperti pada Gambar 3.2.
Login
Masukkan Data
Pengujian
Logout Pre- Proses
Modelling
Gambar 3. 2 Diagram Use Case
3.5.1 Narasi Use Case
Deskripsi : Use case ini berfungsi untuk meningkatkan keamanan sistem dengan membandingkan username dan password yang dimasukkan pengguna.
Skenario :
Nama use case : Masukkan data
Aktor : Pengguna
Deskripsi : Use case ini berfungsi untuk memasukkan dan menampilkan data yang akan diolah oleh sistem.
Aksi Aktor Reaksi Sistem
1. User mengetikkan username dan password di form login lalu klik tombol login.
2. Sistem membandingkan username dan password yang dimasukkan user dengan username dan password di tabel user.
Skenario :
Nama use case : Modelling Aktor : Sistem
Deskripsi : Use case ini berfungsi untuk melakukan perhitungan data dan membangun tree.
Aksi Aktor Reaksi Sistem
1. Pengguna memasukkan data dengan menekan tombol browser.
2. Pengguna memilih file data yang akan digunakan.
3. Pengguna menekan tombol tampilkan.
4. Sistem menampilkan data.
Skenario :
Nama use case: Pengujian Aktor : Pengguna
Deskripsi : Use case ini berfungsi untuk melakukan pengujian data.
Skenario :
Aksi Aktor Reaksi Sistem
1. Sistem mengolah data untuk mendapatkan informasi nilai entropy dan nilai gain tertinggi yang dicari. 2. Sistem menampilkan hasil perhitungan
data.
3. Sistem menampilkan hasil pembentukan pola.
Aksi Aktor Reaksi Sistem
1. Sistem menampilkan halaman utama. 2. Pengguna memilih tab menu
prediksi.
3.6Contoh Proses Perhitungan Data
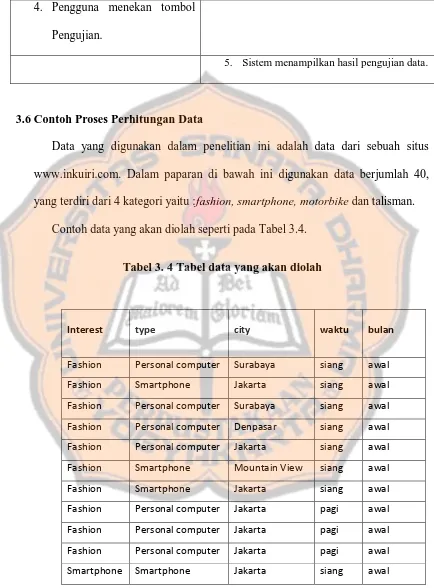
Data yang digunakan dalam penelitian ini adalah data dari sebuah situs www.inkuiri.com. Dalam paparan di bawah ini digunakan data berjumlah 40, yang terdiri dari 4 kategori yaitu :fashion, smartphone, motorbike dan talisman.
Contoh data yang akan diolah seperti pada Tabel 3.4.
Tabel 3. 4 Tabel data yang akan diolah
Interest type city waktu bulan
Fashion Personal computer Surabaya siang awal Fashion Smartphone Jakarta siang awal Fashion Personal computer Surabaya siang awal Fashion Personal computer Denpasar siang awal Fashion Personal computer Jakarta siang awal Fashion Smartphone Mountain View siang awal Fashion Smartphone Jakarta siang awal Fashion Personal computer Jakarta pagi awal Fashion Personal computer Jakarta pagi awal Fashion Personal computer Jakarta pagi awal Smartphone Smartphone Jakarta siang awal
4. Pengguna menekan tombol Pengujian.
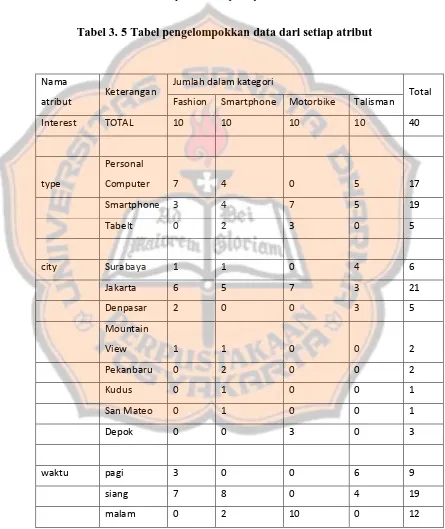
Setelah memperoleh data seperti di atas, selanjutnya data dikelompokkan berdasarkan nilai dalam setiap atribut seperti pada Tabel 3.5.
Tabel 3. 5 Tabel pengelompokkan data dari setiap atribut
Nama
atribut Keterangan
Jumlah dalam kategori
Total Fashion Smartphone Motorbike Talisman
bulan awal 10 3 4 5 22
tengah 0 2 3 3 8
akhir 0 5 3 2 10
Setelah data dikelompokan, untuk mengetahui node pertama terlebih dulu hitung nilai entropy dari setiap atribut berdasarkan data yang telah dikelompokan dengan menggunakan Persamaan 2.2.
Entropy(semua) = - (( p (fashion|semua) x log2 p (fashion|semua)) + ( p (smartphone|semua) xlog2 p (smarthphone|semua)) + ( p (motorbike|semua) x log2 p (motorbike|semua)) + ( p (talisman|semua) x log2 p (talisman|semua)))
= - (((10/40) x log2 (10/40)) + ((10/40) x log2 (10/40)) + ((10/40) x log2 (10/40)) + (10/40) x log2 (10/40)))= 2
Setelah mendapatkan nilai entropy dan nilaigain dari semua data maka selanjutnya dihitung nilai entopry untuk setiap atribut yang ada. Hasil nilai gain yang paling besar akan dijadikan sebagai node akar. Hasil perhitungan nilai entropy dari semua atribut dapat dilihat pada Tabel 3.6.
Tabel 3. 6 Tabel perhitungan nilai entropy semua atribut
Node Jumlah F S M T Entropy Gain 1 Total 40 10 10 10 10 2
computer
waktu
? ?
?
pagi
siang malam
Gambar 3. 3 Bentuk awal pohon dengan gain tertinggi waktu
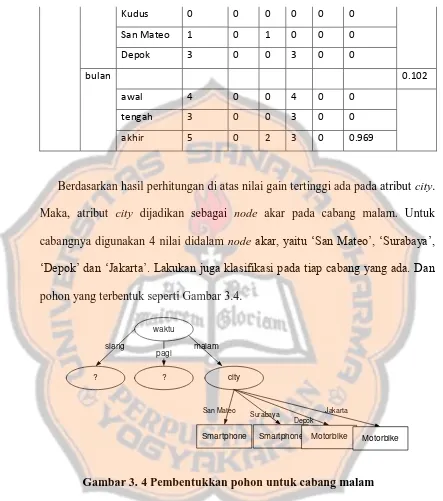
Dalam perhitungan entropy dan gain berikutnya, atribut waktu tidak dilibatkan. Lakukan pengelompokkan kembali untuk node internal di cabang malam, sehingga di dapat hasil seperti Tabel 3.7.
Tabel 3. 7 Perhitungan data pada cabang malam
Node Jumlah F S M T Entropy Gain 2 Total 12 0 2 10 0 0.64
type 0.278 Personal
computer 1 0 1 0 0 0
Smartphone 8 0 1 7 0 0.543 Tabelt 3 0 0 3 0 0
city 0.64 Surabaya 1 0 1 0 0 0
Jakarta 7 0 0 7 0 0
Denpasar 0 0 0 0 0 0 Mountain
Kudus 0 0 0 0 0 0 San Mateo 1 0 1 0 0 0 Depok 3 0 0 3 0 0
bulan 0.102 awal 4 0 0 4 0 0
tengah 3 0 0 3 0 0
akhir 5 0 2 3 0 0.969
Berdasarkan hasil perhitungan di atas nilai gain tertinggi ada pada atribut city. Maka, atribut city dijadikan sebagai node akar pada cabang malam. Untuk cabangnya digunakan 4 nilai didalam node akar, yaitu „San Mateo‟, „Surabaya‟, „Depok‟ dan „Jakarta‟. Lakukan juga klasifikasi pada tiap cabang yang ada. Dan
pohon yang terbentuk seperti Gambar 3.4.
waktu
? city
?
pagi
siang malam
San Mateo
Surabaya
Depok
Jakarta
Smartphone Smartphone Motorbike Motorbike
Gambar 3. 4 Pembentukkan pohon untuk cabang malam
Tabel 3. 8 Perhitungan data pada cabang pagi
Node Jumlah F S M T Entropy Gain 3 Total 9 3 0 0 6 0.918
type 0.074 Personal
computer 8 3 0 0 5 0.951
Smartphone 1 0 0 0 1 0
Tabelt 0 0 0 0 0 0
city 0.38 Surabaya 2 0 0 0 2 0
Jakarta 5 3 0 0 2 0.97 Denpasar 2 0 0 0 2 0 Mountain
View 0 0 0 0 0 0 Pekanbaru 0 0 0 0 0 0 Kudus 0 0 0 0 0 0 San Mateo 0 0 0 0 0 0 Depok 0 0 0 0 0 0
bulan 0.074 awal 8 3 0 0 5 0.951
tengah 1 0 0 0 1 0
akhir 0 0 0 0 0 0
cabangnya digunakan 3 nilai didalam node akar, yaitu „Jakarta‟, „Denpasar‟, dan
„Surabaya‟.Dan pohon yang terbentuk seperti Gambar 3.5.
waktu
city city
?
pagi
siang malam
San Mateo
Surabaya
Depok
Jakarta
? Surabaya
Jakarta Denpasar
Talisman Talisman
Smartphone Smartphone Motorbike Motorbike
Gambar 3. 5 Pembentukan pohon untuk cabang pagi
Untuk node city dengan cabang Jakarta harus dilakukan perhitungan kembali karena masih belum terklasifikasi kedalam satu kelas keputusan, sehingga masih harus dilakukan proses pencarian node selanjutnya. Hasil perhitungan nilai untuk cabang Jakarta dapat dilihat pada Tabel 3.9.
Tabel 3. 9 Perhitungan data pada cabang Jakarta
Node Jumlah F S M T Entropy Gain 4 Total 5 3 0 0 2 0.97 type 0
Personal
Smartphone 0 0 0 0 0
Untuk hasil perhitungan dari cabang Jakarta ternyata didapat nilai yang sama antara atribut type dan atribut bulan. Maka, untuk berikutnya diambil atribut yang terletak lebih awal, yaitu atribut type. Setelah atribut type menjadi node maka
Lakukan pengelompokkan kembali untuk node internal di cabang siang, sehingga di dapat hasil seperti pada Tabel 3.10.
Tabel 3. 10 Perhitungan data pada cabang siang
Node Jumlah F S M T Entropy Gain 5 Total 19 7 8 0 4 1.517
type 0.332 Personal
computer 7 4 3 0 0 0.982
Smartphone 10 3 3 0 4 1.566 Tabelt 2 0 2 0 0 0
city 0.563 Surabaya 4 2 0 0 2 1
Jakarta 9 3 5 0 1 1.35 Denpasar 2 1 0 0 1 1 Mountain
View 1 1 0 0 0 0 Pekanbaru 2 0 2 0 0 0 Kudus 1 0 1 0 0 0 San Mateo 0 0 0 0 0 0 Depok 0 0 0 0 0 0
bulan 0.591 awal 10 7 3 0 0 0.876
tengah 4 0 2 0 2 1
Berdasarkan hasil perhitungan di atas nilai gain tertinggi ada pada atribut bulan. Maka, atribut bulan dijadikan sebagai node akar pada cabang siang. Untuk cabangnya digunakan 3 nilai didalam node akar, yaitu „awal‟, „tengah‟, dan
„akhir‟. Lakukan juga klasifikasi pada tiap cabang yang ada. Dan pohon yang
terbentuk seperti Gambar 3.7.
waktu
Gambar 3. 7 Pembentukan pohon untuk atribut bulan
Tabel 3. 11 Perhitungan data pada cabang awal
Node Jumlah F S M T Entropy Gain 6 Total 10 7 3 0 0 0.876
type 0.548 Personal
computer 4 4 0 0 0 0
Smartphone 4 3 1 0 0 0.821 Tabelt 2 0 2 0 0 0
city 0.279 Surabaya 2 2 0 0 0 0
Jakarta 6 3 3 0 0 1
Denpasar 1 1 0 0 0 0 Mountain
View 1 1 0 0 0 0 Pekanbaru 0 0 0 0 0 0 Kudus 0 0 0 0 0 0 San Mateo 0 0 0 0 0 0 Depok 0 0 0 0 0 0
waktu
Gambar 3. 8 Pembentukan pohon untuk cabang awal
Untuk node type dengan cabang Smartphone harus dilakukan perhitungan kembali karena masih belum terklasifikasi kedalam satu kelas keputusan, sehinnga masih harus dilakukan proses pencarian node selanjutnya. Perhitungan untuk cabang Smartphoneseperti pada Tabel 3.12
Tabel 3. 12 Perhitungan data pada cabang Smartphone
Jakarta 3 2 1 0 0 0.14
Untuk perhitungan dari cabang Smartphone, hanya ada satu atribut, yaitu city. Maka atribut city dijadikan node berikutnya dan terdapat satu cabang yang mempunyai nilai tertinggi, yaitu „Jakarta‟. Dan pohon yang terbentuk seperti
Gambar 3.9.
Selanjutnya lakukan perhitungan untuk cabang tengah dan didapat hasil seperti pada Tabel 3.13.
Tabel 3. 13 Perhitungan data pada cabang tengah
Node Jumlah F S M T Entropy Gain
waktu
Gambar 3. 10 Pembentukan pohon untuk cabang tengah
Selanjutnya untuk perhitungan yang terakhir adalah perhitungan untuk cabang akhir. Dan didapat hasil seperti pada Tabel 3.14.
Tabel 3. 14 Perhitungan data pada cabang akhir
Jakarta 1 0 0 0 1 0 antara atribut type dan atribut city. Maka, untuk berikutnya diambil atribut yang terletak lebih awal, yaitu atribut type. Dan pohon yang terbentuk seperti Gambar 3.11.
waktu
city city
bulan
siang malam
San Mateo Surabaya Depok Jakarta
type
Dengan memperhatikan pohon keputusan pada Gambar 3.11 di atas diketahui bahwa pohon keputusan telah terbentuk. Dan setelah didapatkan tree, tahap selanjutnya adalah mengubahmenjadi rule. Berikut ini adalah bentuk tree yang diubah menjadi rule:
R1 : if waktu = siang ^ bulan = awal ^ type = Personal Computer THEN interest = Fashion
R2 : if waktu = siang ^ bulan = awal ^ type = Smartphone ^ city = Jakarta THEN interest = Fashion
R3 : if waktu = siang ^ bulan = awal ^ type = Tabelt THEN interest = Fashion R4 : if waktu = siang ^ bulan = tengah ^ city = Surabaya THEN interest = Smartphone
R5 : if waktu = siang ^ bulan = tengah ^ city = Jakarta THEN interest = Smartphone
R6 : if waktu = siang ^ bulan = tengah ^ city = Denpasar THEN interest = Talisman
R7 : if waktu = siang ^ bulan = akhir ^ type = Personal Computer THEN interest = Smartphone
R8 : if waktu = siang ^ bulan = akhir ^ type = Smartphone THEN interest = Talisman
R9 : if waktu = pagi ^ city = Surabaya THEN interest = Talisman
R11 : if waktu = pagi ^ city = DenpasarTHEN interest = Talisman
R12 : if waktu = malam ^ city = San Mateo THEN interest = Smartphone R13 : if waktu = malam ^ city = Surabaya THEN interest = Smartphone R14 : if waktu = malam ^ city = Depok THEN interest = Motorbike R15 : if waktu = malam ^ city = Jakarta THEN interest = Motorbike
R16 : if waktu = siang ^ bulan = tengah ^ city = SurabayaTHEN interest = Talisman
Berikut ini adalah pola yang terbentuk berdasarkan rule yang telah disederhanakan:
Pola 1 : if waktu = siang OR pagi^ bulan = awal ^ city = Jakarta ^type =
Personal Computer OR Smartphone OR Tabelt THEN interest = Fashion
Pola 2 : if waktu = siang OR malam ^ bulan = tengah OR akhir ^ city = Surabaya
OR Jakarta OR San Mateo OR Surabaya ^ type = Personal ComputerTHEN interest = Smartphone
Pola 3 : if waktu = malam ^ city = Depok OR Jakarta THEN interest =
Motorbike
Pola 4 : if waktu = siang OR pagi ^ bulan = tengah OR akhir ^ city = Denpasar
3.7Perancangan Umum Sistem
3.7.1 Masukkan Sistem
Data yang menjadi masukkan sistem terdiri dari 5 atribut yaitu : interest, type, city, waktu dan bulan. Penjelasan mengenai atribut – atribut yang digunakan sebagai masukkan sistem seperti pada Tabel 3.15.
Tabel 3. 15 Penjelasan atribut masukkan sistem
No Atribut Penjelasan Nilai
1 interest Atribut interest menyimpan hasil kategori dari pencarian yaitu; Fashion, Smartphone, Motorbike dan Talisman
Fashion, Smartphone, Motorbike, Talisman
2 type Atribut type menyimpan data type yang digunakan sebagai alat pencarian
Personal computer, Smartphone, Tablet
3 city Atribut city menyimpan data nama kota dimana sedang dilakukan pencarian
Surabaya, Jakarta, Denpasar, Mountain View, Pekanbaru, Kudus, San Mateo, Depok
4 waktu Atribut waktu menyimpan data waktu yang sedang melakukan pencarian
3.7.2 Perancangan antar muka dengan user
3.7.2.1Halaman Login
Login
Username : Password :
Login 5 bulan Atribut bulan menyimpan
data bulan masuk dalam urutan ; awal, tengah, akhir
3.7.2.2Halaman Utama
judul
Fakultas Sains & Teknologi Universitas Sanata Dharma Yogyakarta
2016
3.7.2.3Halaman Data
Hasil
Home Data Prediksi Bantuan
Logo USD
Home Data Prediksi Bantuan
3.7.2.4Halaman Prediksi (Pengujian)
Hasil
Home Data Prediksi Bantuan
3.8Diagram Kelas
3.8.1 Diagram Kelas Use case Login
FormLogin
FormLogin ( ) : <<kostruktor>> TombolLoginActionPerformed : void
HalamanUtama
- fashionField : Object - st : Statement
- rs : Resultset - koneksi : Koneksi - file : File
- dt : String [ ] [ ]
- tabelModel : DefaultTabelModel
CekLogin
+ cekLogin (String, String) : boolean
+ HalamanUtama ( ) : <<konstruktur>> +
Browse1ActionPerformed(java.awt.event.Actio nEvent evt) : void
+
Tampilkan1ActionPerformed(java.awt.event.Ac tionEvent evt) : void
+
ProsesActionPerformed(java.awt.event.ActionE vent evt) : void
+
Browse2ActionPerformed(java.awt.event.Actio nEvent evt) : void
+
Tampilkan2ActionPerformed(java.awt.event.Ac tionEvent evt) : void
+
PengujianActionPerformed(java.awt.event.Acti onEvent evt) : void
+ TestingFold() : void
+ transformData(String[][] data, int idx) : String + joinData(String[][] data1, String[][] data2) : String
+ getDataByFold(String[][] data,int fold, int foldID) : String
+ getData() : String + transfromData() : int
3.8.2 Diagram Kelas Use case Masukkan Data
HalamanUtama
- fashionField : Object - st : Statement
- rs : Resultset - koneksi : Koneksi - file : File
- dt : String [ ] [ ]
- tabelModel : DefaultTabelModel + HalamanUtama ( ) : <<konstruktur>>
+ Browse1ActionPerformed(java.awt.event.ActionEvent
+ TestingFold() : void
+ transformData(String[][] data, int idx) : String + joinData(String[][] data1, String[][] data2) : String + getDataByFold(String[][] data,int fold, int foldID) : String
+ getData() : String + transfromData() : int
Gambar 3. 13 Diagram Kelas Use Case Masukkan Data
Data + setInterest (String) : void + getInterest() : String + setType (String) : void + getType ( ) :String + setCity (String) : void + getCity ( ) : String + setWaktu (String) : void + getWaktu ( ) : String + setBulan (String) :void + getBulan ( ) : String
BacaFile
3.8.3 Diagram Kelas Use Case Pengujian
HalamanUtama
- fashionField : Object - st : Statement
- rs : Resultset - koneksi : Koneksi - file : File
- dt : String [ ] [ ]
- tabelModel : DefaultTabelModel + HalamanUtama ( ) : <<konstruktur>> +
+ TestingFold() : void
+ transformData(String[][] data, int idx) : String + joinData(String[][] data1, String[][] data2) : String + getDataByFold(String[][] data,int fold, int foldID) : String
+ getData() : String + transfromData() : int
Gambar 3. 14 Diagram Kelas Pengujian
Tree
- root : Node
+ buildTree(String tabel) : void + printTree() : void
+ testing(String data) : void + removeAtt(String, int) : String + saveTree ( ) : void
BAB IV
IMPLEMENTASI SISTEM
4.1Spesifikasi Perangkat Keras dan Perangkat Lunak
Spesifikasi perangkat lunak yang digunakan dalam implementasi sistem adalah :
1. Sistem Operasi : Microsoft Windows 7 Ultimate 2. Bahasa pemrograman : Java Netbeans IDE 7.3
Spesifikasi perangkat keras yang digunakan dalam implementasi sistem adalah :
1. Processor : Intel Atom N570, 1.66 GHz 2. Memory : 2 GB DDR3
3. Harddisk : 320 GB
4.2Implementasi Pemrosesan Data
4.2.1 Pembersihan Data
Tabel 4. 1 Contoh data yang sudah dilakukan pembersihan Fashion Personal computer Surabaya 1.42071E+12 Fashion Smartphone Jakarta 1.42071E+12 Fashion Personal computer Surabaya 1.42071E+12 Motorbike Tabelt Depok 1.42074E+12 Motorbike Smartphone Jakarta 1.42074E+12 Motorbike Smartphone Jakarta 1.42074E+12 Smartphone Smartphone Jakarta 1.42071E+12 Smartphone Tabelt Jakarta 1.42071E+12 Smartphone Tabelt Jakarta 1.42071E+12 Talisman Smartphone Surabaya 1.4207E+12 Talisman Smartphone Jakarta 1.42071E+12 Talisman Personal computer Jakarta 1.42071E+12
4.2.2 Integrasi Data
Contoh file yang belum digabungkan dari file kategori fashionseperti pada Tabel 4.2.
Tabel 4. 2 Contoh file dari kategori fashion
_source__audience _source_device _source _source _interest _type _location _created
_city
Fashion Personal
computer Surabaya 1.42E+12 Fashion Smartphone Jakarta 1.42E+12 Fashion Personal
Contoh file yang belum digabungkan dari file kategori smartphone seperti pada Tabel 4.3.
Tabel 4. 3 Contoh file dari kategori smartphone
_source__audience _source_device _source _source _interest _type _location _created
_city
Smartphone Smartphone Jakarta 1.42E+12 Smartphone Tabelt Jakarta 1.42E+12 Smartphone Tabelt Jakarta 1.42E+12
Contoh file yang belum digabungkan dari file kategori motorbike seperti pada Tabel 4.4.
Tabel 4. 4 Contoh file dari kategori motorbike
_source__audience _source_device _source _source _interest _type _location _created
_city
Motorbike Tabelt Depok 1.42E+12 Motorbike Smartphone Jakarta 1.42E+12 Motorbike Smartphone Jakarta 1.42E+12
Tabel 4. 5 Contoh file dari kategori talisman
_source__audience _source_device _source _source _interest _type _location _created
_city
Talisman Smartphone Surabaya 1.42E+12 Talisman Smartphone Jakarta 1.42E+12 Talisman Personal
computer Jakarta 1.42E+12
Contoh file yang telah digabungkan dari 4 kategori seperti pada Tabel 4.6.
Tabel 4. 6 Contoh file yang telah digabungkan
4.2.3 Penyeleksian Data
Dari 43 atribut yang didapat kemudian dilakukan penyeleksian atribut yang bisa digunakan untuk penelitian ini. Atribut – atribut asli yang belum dilakukan seleksi seperti pada Tabel 4.7.
Tabel 4. 7 Nama – nama atribut yang belum diseleksi
27 _source__location__country_name 28 _source__location__region
29 _source__location__city 30 _source__location__latlong001 31 _source__location__latlong002 32 _source__page
33 _source__query 34 _source__profile_id 35 _source__session_id 36 _source__created 37 _source__os__family 38 _source__os__name
39 _source__user_agent__family 40 _source__user_agent__type 41 _source__user_agent__user_agent 42 _source__filter__location-
43 _source__filter__category-
Atribut yang sudah dilakukan seleksi seperti pada Tabel 4.8.
Tabel 4. 8 Hasil nama atribut yang telah diseleksi
_source__audience _source_device _source _source _interest _type _location _created
_city
4.2.4 Transformasi Data
Pada tahap ini data yang ditransformasi adalah data dari atribut _source_created. Pertama, data asli dibagi dengan 1000, berikut adalah contoh transformasinya, seperti pada Tabel 4.9.
Tabel 4. 9 Contoh perhitungan waktu yang pertama
_source__created Hasil1 1.42071E+12 1420709258 1.42071E+12 1420709262 1.42071E+12 1420709283 1.42071E+12 1420709488 1.42071E+12 1420709579
Kedua, hasil yang telah dibagi dengan 1000 selanjutnya dihitung lagi dan didapat hasil seperti pada Tabel 4.10.
Hasil2 = 1420709258/86400+25569
Tabel 4. 10 Contoh perhitungan waktu yang kedua
Setelah di dapat hasil seperti di atas maka hasil2 dipecah menjadi waktu dan bulan dengan aturan yang ada pada tabel 3.2.
4.2.5 Penambangan Data
Penambangan Data pada tahap ini adalah melakukan perhitungan data sebagai berikut :
_source__created Hasil1 Hasil 2
a. Menghitung nilai entropy
public double[] entropy(int[][] data) {//menghitung nilai
entropy
double[] hasil = new double[data.length];
for (int i = 0; i < data.length; i++) {
int[] tempData = data[i];
int tot = 0;
for (int j = 0; j < tempData.length; j++) {
tot += tempData[j]; // mencari jumlah mmasing2
interest
}
hasil[i] = 0;
for (int j = 0; j < tempData.length; j++) { // loop untuk
setiap partisi atribut
double temp = ((double) tempData[j] / tot) *
log2(((double) tempData[j] / tot)); // menghitung peluang
partisi dalam interest
hasil[i] += Double.isInfinite(temp) ||
Double.isNaN(temp) ? 0 : temp; // menghindari nilai tidak
terdefinisi.
}
hasil[i] = -hasil[i];
}
return hasil;
b. Menghitung nilai gain
public double gain(double[] entropy, int[][] data)
{//menghitung nilai gain
if (entropy == null) { // entropynya harus ada
entropy = this.entropy(data);
}
int jum = 0;
int tot[] = new int[data.length];
for (int i = 0; i < data.length; i++) { // menghitung jumlah
setiap partisi atribut
int[] tempData = data[i];
tot[i] = 0;
for (int j = 0; j < tempData.length; j++) {
tot[i] += tempData[j];
}
jum += tot[i];
}
double gain = 0;
for (int i = 0; i < tot.length; i++) { // menghitung semua
(peluang * entropy) masing2 atribute
gain += (double) tot[i] / jum * entropy[i];
}
int[][] interest = new int[1][data[0].length];
for (int i = 0; i < data.length; i++) { // menghitung jumlah
4.3Implementasi Use Case
Login dilakukan dengan cara mengisikan username dan password pada Halaman FormLogin seperti pada Gambar 4.1. Selanjutnya sistem akan mencocokkan username dan password yang telah dimasukkan, jika sesuai maka sistem akan muncul pemberitahuan seperti pada Gambar 4.2
for (int j = 0; j < data[i].length; j++) {
interest[0][j] += data[i][j];
}
}
double entropySemua = this.entropy(interest)[0]; //
menghitung entrpy semua
Helper.textAreaActive.setText(
Helper.textAreaActive.getText() + "Entropy semua " +
entropySemua + "\n");
// System.out.println("Entropy semua " + entropySemua);
gain = entropySemua - gain; // rumus gain = entropysemua -
jumlah (peluang * entropy)
return gain;
Gambar 4. 1 Halaman FormLogin
Gambar 4. 2 Pemberitahuan berhasil login
Gambar 4. 3 Form Halaman Utama
Gambar 4. 4 Halaman tab menu data
Gambar 4. 5 Halaman File Chooser untuk mengambil data
Gambar 4. 6 Data yang sudah berhasil ditampilkan
Selanjutnya untuk dapat melihat hasil pohon keputusan dari data yang telah diambil pengguna cukup menekan tombol Proses maka akan keluar hasil contoh sebagian treeseperti pada Gambar 4.7
Depok-Motorbike
Denpasar-Talisman Jakarta-Smartphone Personal computer, Smartphone, Tabelt, 0-awal =
Tabelt-Smartphone Jakarta,
Mountain View, 0-Smartphone = Mountain View-Fashion Jakarta-Fashion
Personal computer-Fashion
Gambar 4. 7Contoh Hasil pohon keputusan
Gambar 4. 8 Halaman Prediksi
Gambar 4. 9 Halaman Prediksi dengan data yang sudah ditampilkan
4.4Implementasi Diagram Kelas
BAB V
PENGUJIAN DATA
5.1Pengujian Data
Data yang digunakan untuk membuat tree (pohon keputusan) adalah data sebanyak 375 data. Dari data tersebut hanya akan dibentuk menjadi satu tree. Untuk pengujian menggunakan data sebanyak 500 data yang berbeda. Data sebanyak 500 tersebut akan dicoba dimasukkan ke dalam tree. Dari hasil tersebut akan didapat jumlah data yang benar dan data yang salah. Data yang benar akan digunakan untuk menghitung nilai akurasi. Hasil dari pencarian pola klasifikasi pencarian situs website dengan menggunakan 375terdapat pada lampiran 2.
5.2Hasil Pola Klasifikasi
Hasil rule seperti pada lampiran 3 dapat disederhanakan seperti berikut :
Pola 1 : Interest Fashion = if waktu = pagi OR siang^bulan = tengah OR akhir
OR awal^type = Personal Computer OR Smartphone^city = Boardman OR Surabaya OR Bogor OR Denpasar OR Jakarta OR London OR Mountain View OR Palembang OR Samarinda OR San Mateo OR Singapore OR Sleman OR Tejgaon OR Yogyakarta.
Pola 2 : Interest Smartphone = if waktu = malam OR pagi OR siang^city =
Singapore OR Surabaya OR Beijing OR Bogor OR Jakarta OR Madiun OR Palembang OR Tangerang OR Yogyakarta OR Surakarta OR Depok OR Kudus OR Makasar OR Pekanbaru^bulan = awal OR akhir OR tengah^type = Personal Computer OR Smartphone OR Tabelt.
Pola 3 : Interest Motorbike = if waktu = malam OR pagi^city = Jakarta OR
Batam OR Boardman OR Depok OR Kudus OR Medan OR Mountain View OR Pontianak OR San Mateo OR Surabaya OR Tangerang OR Bekasi OR Mojokerto OR Saragota OR Tokyo^bulan = tengah OR akhir OR awal^type = Personal Computer OR Smartphone.
Pola 4 : Interest Talisman = if waktu = pagi OR siang^bulan = tengah OR awal
OR akhir^type = Personal Computer OR Tabelt OR Smartphone^city = Providence OR Pontianak OR Jakarta OR Bandung OR Dki Jakarta OR Kudus OR Medan OR Mega OR Palembang OR Sidoarjo OR Surabaya.
5.3Menghitung akurasi
5. 1 Hasil Pengujian ke - 1
Untuk menghitung akurasi digunakan persamaan 2.3
Akurasi = (12/50) * 100 =24%
Hasil pengujian 2 dapat dilihat pada Tabel 5.2.
pred.
Talisman 2 0 0 1 9 1 11
jumlah 9 41
Untuk menghitung akurasi digunakan persamaan 2.3
Akurasi = (9/50) * 100 = 18%
Hasil pengujian 3 dapat dilihat pada Tabel 5.3.
Tabel 5. 3 Hasil Pengujian ke - 3
Untuk menghitung akurasi digunakan persamaan 2.3
Hasil pengujian 4 dapat dilihat pada Tabel 5.4.
Untuk menghitung akurasi digunakan persamaan 2.3
Akurasi = (10/50) * 100 = 20%
Hasil pengujian 5 dapat dilihat pada Tabel 5.5.
pred.
Untuk menghitung akurasi digunakan persamaan 2.3
Akurasi = (12/50) * 100 = 24%
Hasil pengujian 6 dapat dilihat pada Tabel 5.6.
Tabel 5. 6 Hasil Pengujian ke - 6
Untuk menghitung akurasi digunakan persamaan 2.3
Hasil pengujian 7 dapat dilihat pada Tabel 5.7.
Untuk menghitung akurasi digunakan persamaan 2.3
Akurasi = (8/50) * 100 = 16%
Hasil pengujian 8 dapat dilihat pada Tabel 5.8.
pred.
Untuk menghitung akurasi digunakan persamaan 2.3
Akurasi = (8/50) * 100 = 16%
Hasil pengujian 9 dapat dilihat pada Tabel 5.9.
Tabel 5. 9 Hasil Pengujian ke - 9
Untuk menghitung akurasi digunakan persamaan 2.3
Hasil pengujian 10 dapat dilihat pada Tabel 5.10.
Untuk menghitung akurasi digunakan persamaan 2.3
Akurasi = (8/50) * 100 = 16%
Dari sepuluh kali pengujian di dapat hasil seperti pada Tabel 5.11.
Pengujian 10 16% Rata - rata 190/10 = 19%
Rata – rata hasil yang didapat dari sepuluh kali pengujian adalah 19 % dengan nilai maksimum : 24 % dan nilai minimum : 16 %.
5.4Kelebihan dan Kekurangan Program
1. Kelebihan Program :
a. Program ini dapat digunakan untuk klasifikasi pada data yang berbeda.
b. Program bisa dicoba dengan atribut lebih dari sama dengan 5. 2. Kekurangan Program :
BAB VI
KESIMPULAN dan SARAN
6.1Kesimpulan
Kesimpulan dari tugas akhir ini adalah :
1. Algoritma ID3 berhasil diimplementasikan dengan 375 dataquery pencarian situs website dengan menggunakan 4 kategori yang ada.
2. Dari hasil 10 kali pengujian dengan 500 data didapat hasil akurasi yang paling tinggi yaitu sebesar 24%. Nilai maksimum didapat niliai sebesar 24% dan nilai minimum didapat nilai sebesar 16%. Rata – rata nilai akurasi yang didapat adalah sebesar 19%.
6.2Saran
Saran yang diperlukan untuk perbaikan dan pengembangan program lebih lanjut adalah :
1. Program dapat menerima masukan file berupa csv tidak hanya yang bertipe .xls.
2. Data untuk pengujian diperbesar agar didapat nilai akurasi yang lebih tinggi.
Daftar Pustaka
Hermawati Fajar Astuti, 2003, Data Mining, Yogyakarta,
Iko Pramudiono, 2003, Pengantar Data Mining, Kuliah Umum IlmuKomputer.Com
Sarwono Jonathan, 2013, 12 Jurus Ampuh SPSS untuk Riset Skripsi, Jakarta,
Taufiq Luthfi, Emha, Kusrini, 2009, Algoritma Data Mining, Yogyakarta,