PENERAPAN DATA MINING DENGAN ALGORITMA NAÏVE BAYES UNTUK MENGANALISA
PELANGGAN AKTIF DALAM PENJUALAN PRODUK DI PT YOUM KWANG INDONESIA
SKRIPSI
Oleh:
WARNO WARYADI 311411007
TEKNIK INFORMATIKA
SEKOLAH TINGGI TEKNOLOGI PELITA BANGSA BEKASI
2018
i
DI PT YOUM KWANG INDONESIA
SKRIPSI
Diajukan Sebagai Salah Satu Syarat Untuk Menyelesaikan Program Strata Satu (S1) pada Program Studi Teknik Informatika
Oleh:
WARNO WARYADI 311411007
TEKNIK INFORMATIKA
SEKOLAH TINGGI TEKNOLOGI PELITA BANGSA BEKASI
2018
v
penulis dapat menyusun Skripsi yang berjudul “PENERAPAN DATA MINING DENGAN ALGORITMA NAÏVE BAYES UNTUK MENGANALISA PELANGGAN AKTIF DALAM PENJUALAN PRODUK DI PT YOUM KWANG INDONESIA”. Tidak lupa pula penulis haturkan shalawat dan salam kepada Nabi Muhammad SAW, dengan segala kerendahan hati dan kesucian iman, serta kebersihan budi, akhlak dan perilakunya, yang telah menjadi panutan bagi seluruh umat muslim di dunia.
Skripsi tersusun dalam rangka melengkapi salah satu persyaratan dalam rangka menempuh ujian akhir untuk memperoleh gelar Sarjana Komputer (S.Kom.) pada Program Studi Teknik Informatika di Sekolah Tinggi Teknologi Pelita Bangsa.
Penulis sungguh sangat menyadari, bahwa penulisan Skripsi ini tidak akan terwujud tanpa adanya dukungan dan bantuan dari berbagai pihak. Sudah selayaknya, dalam kesempatan ini penulis menghaturkan penghargaan dan ucapan terima kasih yang sebesar-besarnya kepada:
a. Bapak Dr. Ir. Suprianto, M.P selaku Ketua STT Pelita Bangsa
b. Bapak Aswan Supriyadi Sunge, S.E., M.Kom selaku Ketua Program Studi Teknik Informatika STT Pelita Bangsa.
c. Ibu Ismasari Nawangsih, M.Kom selaku Pembimbing Utama yang telah banyak memberikan arahan dan bimbingan kepada penulis dalam penyusunan Skripsi ini.
d. Bapak Basuki Edi Priyo, M.Pd selaku pembimbing yang telah meluangkan waktunya untuk memberikan pengarahan dan koreksi dalam penyusunan Skripsi ini.
e. Seluruh Dosen STT Pelita Bangsa yang telah membekali penulis dengan wawasan dan ilmu di bidang teknik informatika.
f. Seluruh staff STT Pelita Bangsa yang telah memberikan pelayanan terbaiknya kepada penulis selama perjalanan studi jenjang Strata 1.
vi
h. Ibu, Ayah dan istri serta keluarga tercinta yang senantiasa mendo’akan dan memberikan semangat dalam perjalanan studi Strata 1 maupun dalam kehidupan penulis.
i. Rekan-rekan kerja di PT Youm Kwang Indonesia yang telah banyak memberikan inspirasi dan semangat kepada penulis.
j. Semua pihak yang telah membantu baik secara langsung maupun tidak langsung hingga terselesaikannya Skripsi ini.
Akhir kata, penulis mohon maaf atas kekeliruan dan kesalahan yang terdapat dalam Skripsi ini dan berharap semoga Skripsi ini dapat memberikan manfaat bagi khasanah pengetahuan Teknologi Informasi di lingkungan STT Pelita Bangsa khususnya dan Indonesia pada umumnya.
Bekasi, Oktober 2018
Penulis
vii
kestabilan pelanggan agar tidak berpindah ke produk pesaing. Hal ini tentu diperlukan strategi pemasaran, salah satunya dengan cara menganalisa jenis pelanggan aktif atau tidak aktif dengan mengolah variabel data Customer, PO (Purchase Order), Qty, dan Jumlah Bayar. Konsep data mining akan memudahkan dalam mengklasifikasi jenis pelanggan tersebut. Oleh karena itu, penelitian ini menggunakan teknik Data Mining dengan Algoritma Naïve Bayes untuk menganalisa pelanggan aktif dalam penjualan produk di PT. Youm Kwang Indonesia. Dari 300 data pelanggan dibagi menjadi dua kelompok dengan rasio 90% atau 270 record data untuk data training dan 10% atau 30 record data untuk data testing sehingga menghasilkan nilai accuracy mencapai 70%. Dan dari 30 data testing yang diprediksi, terdapat 21 data yang diprediksi dengan tepat.
Kata Kunci : Algoritma Naïve Bayes, Data Mining dan Pelanggan.
viii
Gambar 2.2 Ilustrasi Peluang ... 24
Gambar 2.3 Rumus Naive Bayes ... 25
Gambar 2.4 Kerangka Berfikir ... 29
Gambar 3.1 Struktur Organisasi PT Youm Kwang Indonesia ... 32
Gambar 3.2 Metode Penelitian ... 34
Gambar 3.3 Potongan Packing List Penjualan ... 37
Gambar 3.4 Potongan Proses Cleaning Data ... 38
Gambar 3.5 Potongan Proses Transformasi Data ... 40
Gambar 3.6 Potongan Data Training ... 41
Gambar 3.7 Potongan Data Testing ... 41
Gambar 3.8 Langkah Pengujian Metode ... 42
Gambar 4.1 Proses Import Data ... 45
Gambar 4.2 Proses Training ... 46
Gambar 4.3 Proses Testing... 47
Gambar 4.4 Simple Distribution Model ... 48
Gambar 4.5 Potongan Distribution Table ... 49
Gambar 4.6 Potongan Hasil Klasifikasi Data ... 49
Gambar 4.7 Accuracy ... 50
Gambar 4.8 Precision ... 51
Gambar 4.9 Recall ... 51
Gambar 4.10 Kurva ROC ... 52
ix
Tabel 2.2 Soal Kasus Naive Bayes ... 27
Tabel 2.3 Hasil dari Kasus Naive Bayes ... 28
Tabel 3.1 Klasifikasi PO ... 38
Tabel 3.2 Klasifikasi Qty ... 39
Tabel 3.3 Klasifikasi Jumlah Bayar ... 39
Tabel 4.1 Data Testing ... 43
x
HALAMAN PERSETUJUAN ... ii
HALAMAN PENGESAHAN ... iii
PERNYATAAN KEASLIAN PENELITIAN ... iv
KATA PENGANTAR ... v
ABSTRAK ... vii
DAFTAR GAMBAR ... viii
DAFTAR TABEL ... ix
DAFTAR ISI ... x
BAB I PENDAHULUAN 1.1 Latar Belakang Masalah ... 1
1.2 Identifikasi Masalah ... 3
1.3 Rumusan Masalah ... 3
1.4 Batasan Masalah ... 4
1.5 Tujuan dan Manfaat ... 4
1.5.1 Tujuan ... 4
1.5.2 Manfaat ... 5
1.6 Sistematika Penulisan ... 5
BAB II TINJAUAN PUSTAKA 2.1 Tinjauan Pustaka ... 7
2.2 Dasar Teori ... 9
2.2.1 Penerapan ... 9
2.2.2 Analisa ... 9
2.2.3 Pelanggan ... 10
2.2.4 Penjualan ... 10
2.2.5 Produk ... 11
2.2.6 Data Mining ... 12
2.2.6.1 Algoritma dan Metode Data Mining ... 13
xi
2.2.6.5 Pemodelan Data Mining ... 18
2.2.6.6 Knowledge Discovery Database (KDD) ... 20
2.2.6.7 Klasifikasi ... 21
2.2.7 Algoritma Naïve Bayes ... 23
2.3 Kerangka Berfikir ... 29
BAB III METODE PENELITIAN 3.1 Objek Penelitian ... 30
3.1.1 Sejarah Perusahaan ... 30
3.1.2 Kebijakan Perusahaan ... 30
3.1.3 Struktur Organisasi ... 31
3.2 Metode Penelitian ... 34
3.3 Metode Pengumpulan Data ... 35
3.4 Pengelolaan Data Awal ... 36
3.5 Metode Yang Diusulkan ... 42
BAB IV HASIL DAN PEMBAHASAN 4.1 Implementasi Algoritma Naïve Bayes ... 43
4.2 Analisa Algoritma Naïve Bayes Dengan Rapidminer ... 45
4.2.1 Proses Import Data ... 45
4.2.2 Proses Training dan Testing ... 46
4.2.3 Hasil Klasifikasi Class ... 47
4.2.4 Evaluasi Model Confusion Matrix ... 50
4.2.5 Evaluasi Kurva ROC ... 52
4.3 Hasil Analisa Data Pelanggan Dengan Algoritma Naive Bayes ... 52
BAB V PENUTUP 5.1 Kesimpulan ... 54
5.2 Saran ... 54 DAFTAR PUSTAKA ...
LAMPIRAN ...
1 BAB I
PENDAHULUAN
1.1 Latar Belakang Masalah
Seiring berkembangnya ilmu pengetahuan dan teknologi membawa peradaban manusia ke arah teknologi informasi yang berbasis komputerisasi.
Perkembangan dunia teknologi informasi telah banyak berperan di negara maju maupun yang sedang berkembang. Teknologi informasi berperan penting dalam memperbaiki kualitas suatu instansi baik itu di pemerintahan, swasta, akademik, sekolah, kantor, maupun masyarakat luas. Pengaruh globalisasi dan kompleksitas tugas manajemen merupakan suatu alasan kuat perlunya teknologi informasi.
Dalam dunia bisnis, teknologi informasi merupakan bagian yang tidak dapat dipisahkan karena sebagai alat bantu dalam upaya memenangkan persaingan bisnis.
Semakin hebat tingkat persaingan antar perusahaan di era globalisasi ini, bukan hanya disebabkan pelanggan semakin cerdas, mengerti harga dan mengerti produk. Tetapi juga keterbukaan informasi dan kemajuan teknologi yang membuat pelanggan dapat mencari produk melalui berbagai media, mereka bebas mengakses informasi melalui jaringan internet untuk mencari tahu produk yang mereka inginkan. Oleh karena itu, perusahaan penyedia produk dan jasa berlomba-lomba menjadi yang terbaik memberikan pelayanan yang maksimal kepada pelanggan.
PT Youm Kwang Indonesia merupakan perusahaan manufaktur yang bergerak di bidang ekspor dan impor dengan hasil produksi benang warna yang dapat digunakan sebagai benang jahit di perusahaan garment. Adanya pelanggan yang tidak tetap kadang mereka membeli produk berpindah-pindah tempat dan perilaku pelanggan yang tidak teratur maka perusahaan perlu strategi-strategi pemasaran yang tepat guna dapat menghalangi pelanggan yang pindah ke produk pesaing tentunya dengan menggunakan etika bisnis yang berlaku. Loyalitas pelanggan merupakan salah satu tujuan aktivitas pemasaran perusahaan, di samping untuk mendapatkan keuntungan besar kepada perusahaan juga dapat memberikan efisiensi terhadap biaya operasional dan menghemat biaya promosi.
Apabila loyalitas pelanggan tetap terjaga secara otomatis pelanggan tersebut akan menjadi pelanggan yang aktif. Pelanggan yang aktif akan memberikan dampak besar kepada perusahaan dengan harapan bahwa mereka tetap percaya, melakukan pembelian produk secara terus menerus, dan dapat merekomendasikan kepada orang lain untuk membeli produk sehingga meningkatkan peluang penjualan.
Untuk menghasilkan suatu informasi mengenai pelanggan aktif dan tidak aktif maka perlu adanya pengolahan data, salah satunya dengan menggunakan teknik Data Mining yaitu teknik klasifikasi. Menurut Fayyad., et all. (dalam Suyanto, 2017:1) ‘Data Mining adalah langkah analisis terhadap proses penemuan pengetahuan di dalam basisdata atau knowledge discovery ini database yang disingkat KDD’. Dalam hal ini database pelanggan di perusahaan dapat dimanfaatkan, database dalam jumlah yang melimpah merupakan aset berharga yang dimiliki perusahaan. Dengan mengetahui pelanggan aktif/tidak, perusahaan
dapat memperoleh sebuah informasi sehingga dapat membantu mengambil keputusan-keputusan dalam menentukan strategi-strategi penjualan produk.
Berdasarkan dengan uraian masalah di atas, maka penulis melakukan penelitian ini dengan mengangkat judul “Penerapan Data Mining Dengan Algoritma Naïve Bayes Untuk Menganalisa Pelanggan Aktif Dalam Penjualan Produk di PT. Youm Kwang Indonesia”.
1.2 Identifikasi Masalah
Berdasarkan pada latar belakang serta peninjauan masalah di atas, maka penulis mengidentifikasi masalah sebagai berikut:
1. Adanya pelanggan yang tidak tetap dalam pembelian produk sehingga perusahaan tidak dapat mengetahui pendapatan tetap setiap periodenya.
2. Adanya perilaku pelanggan yang berpindah ke produk pesaing sehingga mengakibatkan penjualan produk perusahaan menurun.
1.3 Rumusan Masalah
Berdasarkan latar belakang dan identifikasi masalah yang telah disampaikan, maka dapat dirumuskan beberapa permasalahan diantaranya sebagai berikut:
1. Bagaimana mencari data pelanggan aktif dan tidak aktif di PT Youm Kwang Indonesia dalam penentuan strategi penjualan produk?
2. Bagaimana mengolah algoritma naïve bayes dalam menentukan pelanggan aktif dan tidak aktif di PT Youm Kwang Indonesia dalam upaya strategi penjualan produk?
1.4 Batasan Masalah
Dalam penelitian ini penulis perlu membuat batasan masalah, supaya pada penjelasan nanti lebih terarah, akurat dan sesuai yang diharapkan. Adapun beberapa batasan masalah yang dibuat penulis, diantaranya :
1. Algoritma yang digunakan dalam metode klasifikasi pelanggan ini adalah algoritma Naïve Bayes
2. Data training yang diambil berdasarkan dari data Customer, PO (Purchase Order), Qty, dan Jumlah Bayar.
3. Tools yang digunakan dalam implementasi penelitian ini adalah dengan menggunakan Software RapidMiner Studio.
1.5 Tujuan dan Manfaat
Adapun tujuan dan manfaat dalam penelitian ini sebagai berikut:
1.5.1 Tujuan
1. Mencari data pelanggan aktif dan tidak aktif di PT Youm Kwang Indonesia dalam penentuan strategi penjualan produk.
2. Mengolah Algoritma Naïve Bayes dengan variabel data Customer, PO (Purchase Order), Qty, dan Jumlah Bayar dalam menentukan pelanggan aktif
dan tidak aktif di PT Youm Kwang Indonesia dalam upaya strategi penjualan produk dan memanfaatkan data mining agar menjadi sebuah informasi.
1.5.2 Manfaat
Penulis berharap bahwa penelitian ini dapat berkontribusi memberikan manfaat positif kepada semua pihak, antara lain:
1. Bagi Penulis
Dari penelitian ini juga diharapkan dapat menambah wawasan dan ilmu pengetahuan bagi penulis dalam kaitannya dengan algoritma Naïve Bayes serta mengaplikasikan teori yang didapat diperkuliahan
2. Bagi Perusahaan
Memberikan kemudahan strategi kepada bagian terkait yang menangani pemasaran produk maupun pimpinan perusahaan dalam menentukan strategi- strategi penjualan produk sehingga dapat menjaga loyalitas pelanggan terhadap perusahaan dan meningkatkan keuntungan perusahaan.
3. Bagi Prodi STT Pelita Bangsa
Sebagai tambahan informasi dan sumber yang dapat dijadikan acuan oleh peneliti lain yang berkepentingan dalam permasalahan yang sama.
1.6 Sistematika Penulisan
Sistematika penulisan dibuat untuk menghasilkan suatu laporan yang lebih terarah dan tidak menyimpang dari permasalahan yang telah ditentukan. Agar maksud dan tujuan yang diharapkan dapat tercapai, penulis membagi pembahasan laporan ini dalam 4 bab, yang terdiri dari :
BAB I PENDAHULUAN
Bab ini berisi tentang uraian latar belakang masalah, identifikasi masalah, rumusan masalah, pembatasan masalah, tujuan dan manfaat penelitian dan sistematika penulisan.
BAB II LANDASAN TEORI
Bab ini menguraikan dasar – dasar teori yang digunakan dalam membangun dan mendukung penelitian ini meliputi kajian pustaka dan teori-teori tentang data mining.
BAB III HASIL DAN BAHASAN
Pada bab ini penulis akan menguraikan tentang objek penelitian meliputi struktur organisasi, sampel data, metode pengumpulan data dan alternatif pemecahan masalah.
BAB IV HASIL DAN PEMBAHASAN
Pada bab ini penulis akan menjelaskan tentang pembahasan dan pengujian dengan Algoritma Naïve Bayes untuk mencari hasil dari penelitian ini.
BAB V PENUTUP
Bab ini merupakan bab penutup yang menguraikan mengenai kesimpulan yang penulis ambil dari pembahasan pada bab-bab sebelumnya dan saran sebagai masukan terhadap permasalahan yang muncul yang diharapkan dapat bermanfaat bagi pemecahan masalah tersebut.
7 BAB II
TINJAUAN PUSTAKA
2.1 Tinjauan Pustaka
Kajian atau studi literature terkait penelitian sejenis atau metode yang sama yang digunakan untuk dapat dijadikan bahan pertimbangan dan acuan, diharapkan dapat membantu dalam penelitian yang baru akan dilakukan.
Pemanfaatan data mining dengan metode Naïve Bayes, seperti dalam penelitian Dicky Nofriansyah, dkk (2016) dalam jurnal “Penerapan Data Mining dengan Algoritma Naïve Bayes Clasifier untuk Mengetahui Minat Beli Pelanggan terhadap Kartu Internet XL(Studi Kasus di CV.Sumber Utama Telekomunikasi)”
menyimpulkan berdasarkan perhitungan akhir dengan mengalikan nilai peluang dari kasus yang diangkat bahwa nilai P(X|Keterangan=”Minat”) lebih tinggi dari P(X|Keterangan=”Tidak”) = 0.141842 banding 0.021053, sehingga kartu internet tersebut masuk dalam klasifikasi “Minat”. Hasil penelitian ini dapat memprediksi atau memperkirakan laku atau tidak kartu internet yang baru. Oleh sebab itu, algoritma Naïve Bayes sangat cocok diterapkan dalam memprediksi peluang di masa depan berdasarkan pengalaman sebelumnya.
Muhammad Husni Rifqo dan Ardi Wijaya (2017) dalam penelitiannya dengan judul “Implementasi Algoritma Naïve Bayes dalam Menentukan Pemberian Kredit”, penelitian ini untuk memprediksi dan mengklasifikasi nasabah mana saja yang bermasalah atau tidak bermasalah dan diharapkan mampu meningkatkan akurasi dalam menganalisa kelayakan kredit. Adapun data yang
digunakan adalah data Agiing kredit dan untuk perbandingan akurasi model penelitian ini juga menggunakan public data set yang ada di UCI data set yaitu data persetujuan kredit (credit approval) negara Japan dan Australia. Dari hasil penelitian ini terbukti bahwa model naïve bayes mempunyai akurasi yang baik, hal ini terbukti dari hasil evaluasi penelitian bahwa model Naïve Bayes mampu menganalisa pelanggan yang baik dan pelanggan yang buruk baik menggunakan data Agiing Leasing ACC maupun menggunakan data credit approval negara Australia dan Japan dari UCI data set dengan tingkat akurasi yang baik. Dan banyaknya record dan atribut pada sebuah data set mempengaruhi tingkat akurasi dari model Naïve Bayes ini.
Pada penelitian sebelumnya Algoritma Naïve Bayes juga digunakan oleh Alfa Saleh (2015) dalam jurnal “Implementasi Metode Klasifikasi Naïve Bayes dalam Memprediksi Besarnya Penggunaan Listrik Rumah Tangga”, menyimpulkan bahwa metode Naïve Bayes memanfaatkan data training untuk menghasilkan probabilitas setiap kriteria untuk class yang berbeda, sehingga nilai- nilai probabilitas dari kriteria tersebut dapat dioptimalkan untuk memprediksi penggunaan listrik berdasarkan proses klasifikasi yang dilakukan oleh metode Naïve Bayes itu sendiri. Dan berdasarkan data rumah tangga yang dijadikan data training, metode Naïve Bayes berhasil mengklasifikasikan 47 data dari 60 data yang diuji. Sehingga metode Naïve Bayes berhasil memprediksi besarnya penggunaan listrik rumah tangga dengan persentase keakuratan sebesar 78.3333%.
2.2 Dasar Teori 2.2.1 Penerapan
Menurut Mella Sri Rahayu Nursrilfa (2013:194) penerapan adalah suatu perbuatan mempraktekkan suatu teori, metode, dan hal lain untuk mencapai tujuan tertentu dan untuk suatu kepentingan yang diinginkan oleh suatu kelompok atau golongan yang telah terencana dan tersusun sebelumnya.
Jadi, penerapan dapat diartikan sebagai suatu tindakan untuk mengaplikasikan suatu cara dengan maksud untuk mencapai tujuan tertentu.
2.2.2 Analisa
Menurut Hidayat (dalam Riska, dkk., 2017:45) analisis adalah kemampuan pemecahan masalah subjek ke dalam elemen-elemen konstituen, mencari hubungan-hubungan internal dan diantara elemen-elemen, serta mengatur format- format pemecahan masalah secara keseluruhan yang ada pada akhirnya menjadi sebuah nilai-nilai ekspektasi. Daya analisis juga merupakan gambaran dari abilitas dalam fungsi-fungsi mencirikhaskan fakta-fakta yang berbasis pada hipotesis yang dibangun. Serta abilitas dalam fungsi-fungsi evaluasi material-material yang bersifat ekstrak dan kompleks. Daya analisis dapat mempertegas asumsi-asumsi pemecahan masalah-masalah yang ada. Identifikasi pemecahan masalah tersebut akan diakhiri dengan kesimpulan yang dibangun ke dalam susunan pernyataan- pernyataan yang jauh lebih tegas dan pasti.
Menurut Makinuddin & Tri Hidayat (dalam Riska, dkk., 2017:45) Analisis adalah aktivitas yang memuat sejumlah kegiatan seperti mengurai, membedakan,
memilah sesuatu untuk digolongkan dan dikelompokkan kembali menurut kriteria tertentu kemudian dicari kaitannya dan ditafsir maknanya.
2.2.3 Pelanggan
Menurut Fakhri Hadi, dkk (2017:71) Pelanggan merupakan bagian penting dari perusahaan karena dapat memberikan keuntungan bagi perusahaan dan meningkatkan faktor pertumbuhan pada suatu perusahaan. Perusahaan akan melakukan segala cara untuk mempertahankan pelanggan yang memberikan keuntungan besar bagi perusahaan tetapi, perusahaan sulit untuk mendapatkan pelanggan yang memberikan keuntungan besar bagi perusahaan. Sifat pelanggan yang selalu pilih-pilih membuat perusahaan sulit untuk membedakan mana pelanggan yang memberikan keuntungan besar bagi perusahaan atau pelanggan yang kurang menguntungkan bagi perusahaan.
Pelanggan Aktif adalah pelanggan dari perusahaan jika dia melakukan pembelian berulang dari produk perusahaan tersebut dan diharapkan untuk membeli setidaknya sekali dalam setiap 12 bulan durasi. Mereka adalah orang- orang yang memaksimalkan pendapatan perusahaan dan dengan demikian perusahaan bekerja untuk mempertahankan pelanggan dengan meningkatkan pengalaman mereka dan memberikan diskon.
2.2.4 Penjualan
Penjualan merupakan salah satu fungsi pemasaran yang sangat penting dan pemasaran bagi para pengusaha dalam mencapai tujuaanya yaitu memperoleh laba untuk menjaga kelangsungan hidup bisnisnya. Sebenarnya pengertian penjualan sangat luas, beberapa ahli mengemukakan tentang definisi penjualan antara lain:
Menurut Bunafit Nugroho (2013:189) transaksi penjualan yaitu transaksi menjual barang atau distribusi barang dari gudang atau toko kita kepada pelanggan (customer).
Menjual adalah proses interaksi antara calon pembeli dan calon penjual dalam menjajaki sebuah transaksi barang atau jasa yang saling dibutuhkan kedua pidak. Adapun 4 syarat utama menjual adalah:
1. Ada calon pembeli dan penjual,
2. Proses interaksi komunikasi dan persepsi,
3. Menjajaki sebuah transaksi/pertukaran kepentingan, 4. Barang, jasa, ide, gagasan, rencana, keyakinan dan prinsip.
Transaksi penjualan menurut Tata Sutabri (2014:152) adalah persetujuan jual beli antara dua pihak. Dan menurut I Putu Agus Eka Pratama (2015:3) transaksi penjualan dilakukan secara langsung melalui tatap muka antara penyedia barang dan jasa dengan para konsumen.
2.2.5 Produk
Menurut Sarini Kodu (2013:1251) Produk adalah segala sesuatu yang dapat ditawarkan kepasar untuk mendapatkan perhatian, dibeli, digunakan, atau dikonsumsi yang dapat memuaskan keinginan atau kebutuhan.
Produk menurut Kotler & Keller (dalam Resty Avita Haryanto, 2013:1466) adalah is anything that can be offered to a market to satisfy a want or need. Produk adalah apa saja yang dapat ditawarkan kepada pasar untuk memuaskan keinginan atau kebutuhan.
2.2.6 Data Mining
Menurut Clifton (dalam Suyanto, 2017:1) ‘Data Mining didefinisikan sebagai proses penemuan pola-pola baru dari kumpulan-kumpulan data sangat besar, meliputi metode-metode yang yang merupakan irisan artificial intelligence, machine learnin, statistics, dan database systems’.
Menurut Taruna R., S., Hiranwal, S., (dalam Alfa Saleh, 2015:208) ‘Data Mining merupakan proses pengekstrasian infromasi dari sekumpulan data yang sangat besar melalui penggunaan algoritma dan teknik penarikan dalam bidang statistik, pembelajaran mesin dan sistem manajemen basis data’.
Menurut Larose (dalam M. Husni Rifqo dan Ardi Wijaya, 2017:121)
‘Data Mining adalah proses menelusuri pengetahuan baru, pola dan tren yang dipilih dari jumlah data yang besar yang disimpan dalam repositori atau tempat penyimpanan dengan menggunakan teknik pengenalan pola serta statistik dan teknik matematika’.
Menurut David Hand, dkk (dalam Prabowo Pudjo Widodo, dkk., 2013:2)
‘Data mining adalah analisa terhadap data (biasanya data yang berukuran besar) untuk menemukan hubungan yang jelas serta menyimpulkan yang belum diketahui sebelumnya dengan cara terkini dipahami dan berguna bagi pemilik data tersebut’.
Data mining sudah ada sejak lama dan teori-teorinya pun sudah banyak dibahas dalam berbagai literatur. Teori-teori tersebut antara lain: Naïve Bayes dan Nearest Neighbour, Pohon Keputusan, Aturan Asosiasi, K-Means Clustering dan Text Mining, Bramer (dalam Prabowo Pudjo Widodo, dkk., 2013:2). Sedangkan
perkembangan terkini menghadirkan algoritma-algoritma yang baru dikembangkan antara lain: Jaringan Syaraf Tiruan (JST), Algoritma Genetik, Fuzzy C-Means, Support Vector Machine (SVM) dan lain-lain, Larose (dalam Prabowo Pudjo Widodo, dkk., 2013:2)
2.2.6.1 Algoritma dan Metode Data Mining
Menurut Dicky Nofriansyah dan Gunadi Widi Nurcahyo (2015:7) pada proses pemecahan masalah dan pencarian pengetahuan baru terdapat beberapa klasifikasi secara umum yaitu:
1. Estimasi
Digunakan untuk melakukan estimasi terhadap sebuah data baru yang tidak memiliki keputusan berdasarkan histori data yang telah ada. Contohnya ketika melakukan estimasi pembiayaan pada saat pembangunan sebuah hotel baru pada kota yang berbeda.
2. Asosiasi
Digunakan untuk mengenali kelakuan dari kejadian-kejadian khusus atau proses dimana hubungan asosiasi muncul pada saat kejadian. Adapun metode pemecahan masalah yang sering digunakan seperti algoritma Apriori.
Cntohnya pemanfaatan algoritma asosiasi yaitu pada bidang marketing ketika sebuah minimarket melakukan tata letak produk yang dijual berdasarkan produk-produk mana yang paling sering dibeli konsumen, selain itu seperti tata letak buku yang dilakukan pustakawan di perpustakaan.
3. Klasifikasi
Suatu teknik dengan melihat pada kelakuan dan atribut dari kelompok yang telah didefinisikan. Teknik ini dapat memberikan klasifikasi pada data baru dengan memanipulasi data yang ada yang telah diklasifikasi dan dengan menggunakan hasilnya untuk memberikan sejumlah aturan. Salah satu contoh yang mudah dan populer adalah dengan Decision Tree yaitu salah satu metode klasifikasi yang paling populer karena mudah untuk interpretasi seperti algoritma C4.5, ID3 dan lain-lain. Contoh pemanfaatannya adalah pada bidang akademik yaitu klasifikasi siswa yang layak masuk ke dalam kelas unggulan atau akselerasi di sekolah tertentu.
4. Klastering
Digunakan untuk menganalisis pengelompokan berbeda terhadap data, mirip dengan klasifikasi, namun pengelompokan belum didefinisikan sebelum dijalankannya tool data mining. Biasanya menggunakan metode neural network atau statistik, analitikal hierarki cluster. Clustering membagi item menjadi kelompok-kelompok berdasarkan yang ditemukan tool data mining.
5. Prediksi
Algoritma prediksi biasanya digunakan untuk memperkirakan atau forecasting suatu kejadian sebelum kejadian atau peristiwa tertentu terjadi.
Contohnya pada bidang Klimatologi dan Geofisika, yaitu bagaimana Badan Meterologi dan Geofisika (BMKG) memperkirakan tanggal tertentu bagaimana cuacanya, apakah hujan, panas, dan lain sebagainya. Ada beberapa metode yang sering digunakan salah satunya adalah Metode Rough Set.
2.2.6.2 Jenis Permasalahan Data Mining
Aplikasi yang menggunakan Data Mining bermaksud menyelesaikan permasalahan dengan membangun model berdasarkan data yang sudah digali untuk diterapkan terhadap data yang lain. Secara umum ada dua jenis tipologi aplikasi Data Mining (Prabowo Pudjo Widodo, dkk., 2013:5):
1. Metode Prediksi, yang bermaksud memprediksi nilai yang akan datang berdasarkan data-data yang telah ada variabelnya seperti klasifikasi, regresi, detikasi anomali dan lain-lain.
2. Metode Deskriptif, yang bermaksud membantu user agar mudah melihat pola-pola yang berasal dari data yang ada.
2.2.6.3 Kegunaan Data Mining
Secara umum kegunaan data mining dapat dibagi menjadi dua: deskriptif dan prediktif. Deskriptif berarti data mining digunakan untuk mencari pola-pola yang dapat dipahami manusia yang menjelaskan karakteristik data. Sedangkan prediktif berarti data mining digunakan untuk membentuk sebuah model pengetahuan yang akan digunakan untuk melakukan prediksi. Menurut Fayyad et all (dalam Suyanto, 2017:3) Berdasarkan fungsionalitasnya, tugas-tugas data mining bisa dikelompokan ke dalam enam kelompok berikut ini :
1. Klasifikasi (classification): men-generalisasi struktur yang diketahui untuk diaplikasikan pada data-data baru. Misalkan, klasifikasi penyakit ke dalam sebuah jenis, klasifikasi email ke dalam spam atau bukan.
2. Klasterisasi (clustering): Mengelompokan data, yang tidak diketahui label kelasnya, ke dalam sejumlah kelompok tertentu sesuai dengan ukuran kemiripannya.
3. Regresi (regression): menemukan suatu fungsi yang memodelkan data dengan galat (kesalahan prediksi) seminimal mungkin.
4. Deteksi anomali (anomaly detection): mengidentifikasi data yang tidak umum, bisa berupa outlier (pencilan), perubahan atau deviasi yang mungkin sangat penting dan perlu investigasi lebih lanjut.
5. Pembelajaran aturan asosiasi (association rule learning) atau pemodelan kebergantungan (dependency modeling): mencari relasi antar variabel.
6. Perangkuman (summarization): menyediakan representasi data yang lebih sederhana, meliputi visualisasi dan pembuatan laporan.
2.2.6.4 Aplikasi-Aplikasi Data Mining
Kemampuan perangkat keras dalam mengelola data yang berukuran besar baik prosesor dan harddisk, berkembangnya perangkat lunak pembuat aplikasi data mining, mengakibatkan tingginya permintaan terhadap aplikasi berbasis data mining dalam berbagai bidang. Selain itu, riset-riset yang dikembangkan oleh ilmuwan di seluruh dunia tentang teknik-teknik dan algoritma-algoritmanya banyak membantu kualitas dari sistem berbasis data mining seperti (Prabowo Pudjo Widodo, dkk., 2013:16) :
1. Perbankan dan Finansial
Bidang ini sangat membutuhkan aplikasi berbasis data mining dan telah lama menggunakan aplikasi-aplikasi tersebut. Dipergunakan dalam: Pemodelan
dan Deteksi Pelanggaran (Fraud), Analisis Resiko, Analisis Trend, Analisis Keuntungan, dan Sistem Pendukung Pemasaran.
2. Keuangan
Dalam bidang keuangan, aplikasi data mining biasa digunakan dalam:
Peramalan harga saham, pemilihan jenis usaha dagang, manajemen portofolio, peramalan harga barang, merger dan akuisisi perusahaan, peramalan bencana keuangan.
3. Kebijakan Penjualan
Pada bidang ritel dan supermarket (hypermarket) strategi penjualan telah banyak yang menggunakan teknik data mining, antara lain: data warehouse, segmentasi pelanggan, identifikasi profil nasabah, evaluasi harga produk tertentu (barang antik, mobil bekas, seni, dan lain-lain)
4. Kesehatan
Kesehatan juga merupakan salah satu bidang penting pertama yang mendorong pengembangan metode data mining, dari teknik visualisasi, memprediksi biaya perawatan kesehatan, hingga sistem diagnosis berbasis komputer.
5. Telekomunikasi
Dalam beberapa tahun terakhir, telekomunikasi telah mengambil manfaat dari penggunaan teknologi data mining. Terutama karena persaingan yang ketat antar operator telekomunikasi saat ini. Diperlukan sistem yang mampu mengidentifikasi profil pelanggan, memelihara loyalitas pelanggan, hingga strategi untuk menjual produk baru. Beberapa masalah yang dapat
diselesaikan dengan teknik data mining dalam bidang ini antara lain: deteksi penipuan dalam penggunaan telepon seluler, identifikasi profil pelanggan yang menguntungkan, identifikasi faktor yang mempengaruhi perilaku pelanggan terhadap beragam penggilan telepon, identifikasi resiko terhadap investasi baru (misalnya serat optik, nano-teknologi, semikonduktor, dan lain- lain), identifikasi perbedaan dalam produk dan jasa antar pesaing.
2.2.6.5 Pemodelan Data Mining
Menurut Prabowo Pudjo Widodo, dkk (2013:12) pemodelan adalah penggunaan prinsip atau teknik-teknik tertentu dalam suatu rancangan sistem.
Misalnya penerapan data mining untuk penjualan, perancang perlu memahami hal-hal yang berkaitan dengan penjualan mulai dari aspek internal hingga perekonomian global yang mungkin saja berpengaruh terhadap pengolahan data yang terjadi. Sebagai bahan pertimbangan, menurut Gounescu (dalam Prabowo Pudjo Widodo, dkk., 2013:13):
1. Identifikasi
Ini merupakan tahapan pertama dalam pemodelan data mining dari suatu permasalahan yang ada di lapangan. Dalam mengidentifikasi suatu masalah, dijumpai dua pendekatan yang saling bertolak belakang. Pendekatan yang pertama adalah pendekatan yang mengutamakan pengetahuan terdahulu dari suatu kasus. Dalam hal ini pengetahuan apriori menjadi andalan utama para pendukung teori ini. Pendekatan kedua adalah pengidentifikasian yang murni berdasarkan data yang ada. Sejauh mungkin dihindari dugaan awal terhadap suatu kondisi. Tidak ada pendekatan yang lebih baik antara satu dengan
lainnya. Sebaiknya para perancang sistem yang berbasis data mining mengombinasikan kedua pendekatan itu. Dugaan awal pada pendekatan pertama bisa membuat sistem menjadi bias sedangkan hanya mendasarkan pada data saja akan menemui kesulitan karena data yang akan diolah harus data yang terstruktur dengan benar (fine).
2. Estimasi dan Pencocokan
Setelah tahap identifikasi selesai, tahap berikutnya adalah membuat formulasi numerik terhadap suatu model. Tahapan ini dikenal dengan nama tahapan pencocokan model dengan data. edangkan konversi dari model menjadi angka numerik disebut dengan istilah estimasi.
3. Pengujian
Pengujian merupakan tahap terakhir sebelum sistem diimplementasikan.
Sistem yang telah dibuat diuji terhadap data lain yang belum pernah dimiliki dan bukan data yang dipakai untuk membentuk model itu. Keberhasilan dari pengujian bergantung dari output yang dihasilkan oleh suatu sistem yang diuji, apakah sesuai dengan kenyataan yang ada atau tidak.
4. Penerapan praktis
Tiap perancang sistem berbasis data mining harus menyadari bahwa sistem yang dirancang adalah ditunjukan untuk menyelasaikan permalahan- permasalahan yang ada di lapangan. Oleh karena itu baik atau buruknya suatu sistem tergantung dari kemanfaatan yang diperoleh terhadap penggunaannya.
Pengguna di lapangan tidak terlalu memperhatikan proses yang kita lalui
dalam pemodelan data mining, mereka hanya tahu manfaat apa yang diberikan oleh sistem yang dibuat tersebut.
5. Iterasi
Seperti pembuatan suatu produk dalam industri, terjadi proses berulang antarsatu tahap dengan tahap lainnya guna memperoleh produk yang dapat bersaing. Iterasi mengharuskan perancang untuk selalu berfikir kembali terhadap model yang dibuatnya. Dengan adanya perulang-ulangan diharapkan diperoleh model yang tangguh dan cocok dengan situasi dan kondisi yang yang terjadi saat implementasi.
2.2.6.6 Knowledge Discovery Database (KDD)
Menurut Dicky Nofriansyah dan Gunadi Widi Nurcahyo (2015:4) pada proses Data Mining yang biasa disebut Knowledge Discovery Database (KDD) terdapat beberapa proses yaitu sebagai berikut:
1. Seleksi Data (Selection)
Selection (seleksi/ pemilihan) data dari merupakan sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam Knowledge Discovery Database (KDD) dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Pemilihan Data (Preprocessing/Cleaning)
Proses Preprocessing mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak(tipografi). Juga dilakukan proses Enrichment, yaitu
proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformasi (Transformation)
Pada fase ini yang dilakukan adalah mentransformasi bentuk data yang belum memiliki entitas yang jelas ke dalam bentuk data yang valid atau siap untuk dilakukan proses Data Mining.
4. Data Mining
Pada fase ini yang dilakukan adalah menerapkan algoritma atau metode pencarian pengetahuan.
5. Interpretasi / Evaluasi (Interpratation/Evaluation)
Pada fase terakhir ini yang dilakukan adalah proses pembentukan keluaran yang mudah dimengerti yang bersumber pada proses Data Mining pola informasi.
2.2.6.7 Klasifikasi
Bagian sangat penting dalam data mining adalah teknik klasifikasi, yaitu bagaimana mempelajari sekumpulan data sehingga dihasilkan aturan yang bisa mengklasifikasikan atau mengenali data-data baru yang belum pernah dipelajari.
Klasifikasi dapat didefinisikan sebagai proses untuk menyatakan suatu objek data sebagai salah satu kategori (kelas) yang telah didefinisikan sebelumnya, menurut Zaki et all (dalam Suyanto, 2017:115). Klasifikasi banyak digunakan dalam berbagai aplikasi, diantaranya adalah deteksi kecurangan (fraud detection), pengelolaan pelanggan, diagnosis medis, prediksi penjualan, dan sebagainya.
Bagaimana cara membangun sebuah model klasifikasi (classifier)? Model klasifikasi dapat dibangun berdasarkan pengetahuan seorang pakar(ahli). Namun, mengingat himpunan data yang sangat besar, model klasifikasi lebih sering dibangun menggunakan teknik pembelajaran dalam bidang machie learning.
Proses pembelajaran secara otomatis terhadap suatu himpunan data mampu menghasilkan model klasifikasi (fungsi target) yang memetakan objek data x (input) ke salah satu kelas y yang telah didefinisikan sebelumnya. Jadi, proses pembelajaran memerlukan masukan (input) berupa himpunan data latih (traning set) yang berlabel (memiliki atribut kelas) dan mengeluarkan output yang berupa sebuah model klasifikasi.
Menurut Dicky Nofriansyah dan Gunadi Widi Nurcahyo (2015:17) Klasifikasi merupakan sebuah proses training (pembelajaran) suatu fungsi tujuan (target) yang digunakan untuk memetakan tiap himpunan atribut suatu objek ke satu dari label kelas tertentu yang didefinisikan sebelumnya. Teknik klasifikasi ini cocok digunakan dalam mendeskripsikan data set dengan tipe data dari suatu himpunan data yaitu biner atau nominal. Adapun kekurangan dari teknik ini yaitu tidak tepat untuk himpunan data ordinal karena pendekatan-pendekatan yang digunakan secara implisit dalam kategori data.
Ada beberapa teknik klasifikasi yang digunakan sebagai solusi pemecahan kasus diantaranya yaitu:
1. Algoritma C4.5
2. Algoritma K-Nearest Neighbor 3. ID3
4. Naïve Bayes Clasification
5. CART (Clasification And Regression Tree)
2.2.7 Algoritma Naïve Bayes
Menurut Rini Artika (2013:124) Algoritma adalah merupakan kumpulan perintah untuk menyelesaikan suatu masalah. Perintah – perintah ini dapat diterjemahkan secara bertahap dari awal hingga akhir. Masalah tersebut dapat berupa apa saja, dengan catatan untuk setiap masalah, ada kriteria kondisi awal yang harus dipenuhi sebelum menjalankan algoritma.
Naïve Bayes ini menggunakan teorema Bayes, yang ditemukan oleh Thomas Bayes di abad 18. Menurut Dicky Nofriansyah dan Gunadi Widi Nurcahyo (2015:35) Naïve Bayesian Classifier merupakan salah satu algoritma pemecahan masalah yang termasuk dalam metode klasifikasi pada Data Mining.
Naïve Bayesian Classifier mengadopsi ilmu statistika yaitu dengan menggunakan teori kemungkinan (probabilitas) untuk menyelesaikan sebuah kasus Supervised Learning, artinya dalam himpunan data terdapat label, class, atau target sebagai acuan atau gurunya.
Naïve Bayesian Classifier dalam konsep penyelesaiannya tidak jauh beda dengan konsep Nearest Neighbor. Seperti kita ketahui bahwasanya dalam metode klasifikasi terdapat beberapa fase penyelesaian yaitu dimulai dari training dan diakhiri dengan proses testing sehingga dihasilkan sebuah keputusan yang akurat.
Berikut ini adalah gambar alur pemecahan metode klasifikasi:
Gambar 2.1 Fase Penyelesaian Metode Klasifikasi Sumber : Dicky Nofriansyah dan Gunadi Widi Nurcahyo
Pada Naïve Bayes Clasifier yang dimaksud Learning yaitu proses pembelajaran dengan cara menghitung nilai probabilistik dari suatu kasus. Sedang testing yaitu proses pengujian menggunakan model yang mengadopsi data testing.
Adapun contoh teori peluang sehingga kita mudah memahami Naïve Bayes Clasifier dapat terlihat pada gambar dan penjelasan di bawah ini:
Gambar 2.2 Ilustrasi Peluang
Sumber : Dicky Nofriansyah dan Gunadi Widi Nurcahyo
Dari gambar di atas dapat kita mengetahui secara sederhana bahwasanya peluang untuk mendapatkan no.1 yaitu : 1/6. Dengan asumsi jumlah yang bernilai dadu no.1 ada 1 sedangkan total keseluruhan dadu ada 6.
Naïve Bayes adalah pengklasifikasian statistic yang dapat digunakan untuk memprediksi probabilitas keanggotaan suatu class. Naïve bayes didasarkan pada teorema bayes yang memiliki kemampuan klasifikasi serupa dengan decision tree dan neural network. Naïve bayes terbukti memiliki akurasi dan kecepatan yang tinggi saat diaplikasikan ke dalam database dengan data yang besar.
Traning
Data Learning Model Test Data Accuracy
Algorithm
Peluang untuk mendapatkan No
“1” pada saat di lemparkan ke atas
P(H|X) = P(X|H) P(H) P(X)
Berikut ini adalah rumus untuk mencari nilai peluang dari Hipotesa benar(valid) untuk data sampel X yaitu:
Gambar 2.3 Rumus Naïve Bayes Sumber : Suyanto
Dari gambar 2.3, sebagai dasar teori bayesian sebagai pemecahan masalah, kita harus mengetahui terlebih dahulu beberapa hal diantaranya yaitu:
X = Data dengan class yang belum diketahui
H = Hipotesis data X merupakan suatu class spesifik
P(H|X) = Probabilitas hipotesis H berdasar kondisi X (posteriori probability) P(H) = Probabilitas hipotesis H (prior probability)
P(X|H) = Probabilitas X berdasar kondisi pada hipotesis H P(X) = Probabilitas dari X
Di mana X adalah bukti, H adalah hipotesis, P(H|X) adalah probabilitas bahwa hipotesis H benar untuk bukti X atau dengan kata lain P(H|X) merupakan probabilitas posterior H dengan syarat X, P(X|H) adalah probabilitas bahwa bukti X benar untuk hipotesis H atau probabilitas posterior X dengan syarat H, P(H) adalah probabilitas prior hipotesis H, dan P(X) adalah probabilitas prior bukti X.
Dalam data mining, X adalah sebuah tuple atau objek data, H adalah hipotesis atau dugaan bahwa tuple X adalah kelas C. Secara spesifik, dalam masalah klasifikasi dapat menghitung P(H|X) sebagai probabilitas bahwa hipotesis H benar untuk tuple X atau dengan kata lain P(H|X) adalah probabilitas bahwa tuple X berada dalam kelas C. Sementara itu, P(H) adalah probabilitas
prior bahwa hipotesis H benar untuk setiap tuple tidak peduli nilai-nilai atributnya sedangkan P(X) adalah probabilitas prior dari tuple X.
Sehingga Naïve Bayes Clasifier dapat didefinisikan juga sebagai metode klasifikasi yang berdasarkan teori probabilitas dan teorema bayesian dengan asumsi bahwa setiap variabel atau parameter penentu keputusan bersifat bebas (independence) sehingga keberadaan setiap variabel tidak ada kaitannya dengan keberadaan atribut lain.
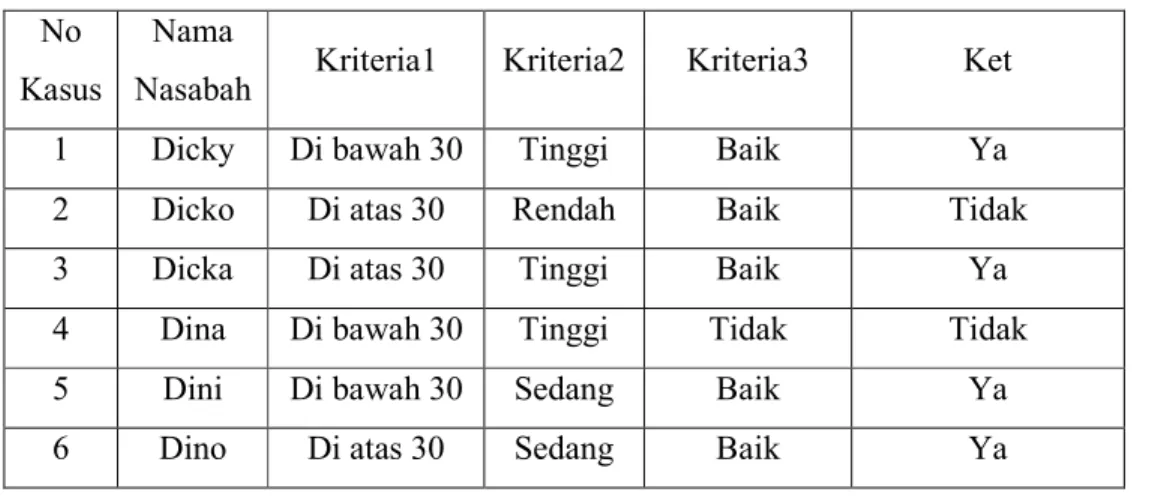
Sebagai contoh kasus Naïve Bayes seperti pada tabel 2.1. Pada sebuah Bank Swasta di Indonesia, terdapat seorang calon nasabah yang ingin mengajukan Kredit Perumahan Rakyat (KPR). Dalam hal ini terdapat beberapa nasabah yang telah mengajukan KPR ke Bank tersebut. Berikut ini adalah data-data nasabah yang pernah mengajukan KPR di Bank Swasta tersebut.
Tabel 2.1 Sampel Kasus Naïve Bayes No
Kasus
Nama
Nasabah Kriteria1 Kriteria2 Kriteria3 Ket
1 Dicky Di bawah 30 Tinggi Baik Ya
2 Dicko Di atas 30 Rendah Baik Tidak
3 Dicka Di atas 30 Tinggi Baik Ya
4 Dina Di bawah 30 Tinggi Tidak Tidak
5 Dini Di bawah 30 Sedang Baik Ya
6 Dino Di atas 30 Sedang Baik Ya
Keterangan:
Kriteria 1 = Menjelaskan tentang kriteria “Umur”
Kriteria 2 = Menjelaskan tentang kriteria “Penghasilan”
Kriteria 3 = Menjelaskan tentang kriteria “BI Checking”
Soal : Misalkan terdapat seorang nasabah baru yang ingin mengajukan Kredit Perumahan Rakyat (KPR) dengan keterangan di bawah ini:
Tabel 2.2 Soal Kasus Naïve Bayes
Nama Nasabah Kriteria 1 Kriteria 2 Kriteria 3
Dian Di atas 30 Sedang Baik
Penyelesaian:
1. Hitung nilai P(X|Ci) untuk setiap class i
a. P(Kriteria 1 = ”Di atas 30” | Keterangan = “Ya”) P(Kriteria 1 = 2/4 = 0.5)
b. P(Kriteria 1 = ”Di atas 30” | Keterangan = “Tidak”) P(Kriteria 1 = 1/2 = 0.5)
c. P(Kriteria 2 = ”Sedang” | Keterangan = “Ya”) P(Kriteria 2 = 2/4 = 0.5)
d. P(Kriteria 2 = ”Sedang” | Keterangan = “Tidak”) P(Kriteria 2 = 0/2 = 0)
e. P(Kriteria 3 = ”Baik” | Keterangan = “Ya”) P(Kriteria 3 = 4/4 = 1)
f. P(Kriteria 3 = ”Baik” | Keterangan = “Tidak”) P(Kriteria 3 = 1/2 = 0.5)
2. Hitung nilai P(X|Ci) untuk setiap kelas (label) a. P(X|Keterangan = “Ya”)
= 0.5 x 0.5 x 1 = 1.25
b. P(X|Keterangan = “Tidak”)
= 0.5 x 0 x 0.5 = 0 3. Hitung nilai P(X|Ci) * P(Ci)
a. P(X|Keterangan = “Ya”) x P(Keterangan = “Ya”)
= 1.25 x 4/6 = 0.8333
b. P(X|Keterangan = “Tidak”) x P(Keterangan = “Tidak”)
= 0 x 2/6 = 0
4. Menentukan kelas dari kasus tersebut
Berdasarkan perhitungan akhir dengan mengalikan nilai peluang dari kasus yang di angkat, kita melihat bahwa nilai P(X|Keterangan = “Ya”) lebih tinggi dari P(X|Keterangan = “Tidak”) = 0.8333 banding 0, maka
Tabel 2.3 Hasil dari Kasus Naïve Bayes Nama
Nasabah Kriteria 1 Kriteria 2 Kriteria 3 Keterangan
Dian Di atas 30 Sedang Baik Ya
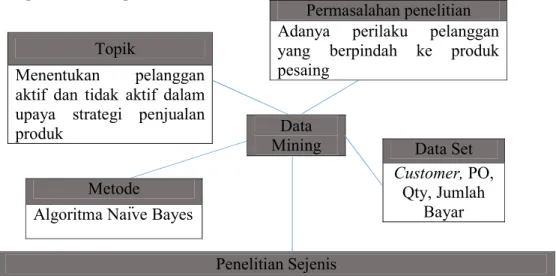
2.3 Kerangka Berfikir
Dari permasalahan dan tinjauan pustaka yang telah dikemukakan pada bab sebelumnya, selanjutnya dapat disusun kerangka pemikiran terhadap penelitian yang diajukan, dimana kerangka pemikiran merepresentasikan suatu konsep dan pola pikir yang dilakukan untuk mengatasi permasalahan penelitian. Berikut merupakan bagan alur kerangka pemikiran dari hasil pendekatan landasan teori dan permasalahan penelitian di atas :
Gambar 2.4 Kerangka Berfikir Sumber : Penulis
Permasalahan penelitian Adanya perilaku pelanggan yang berpindah ke produk pesaing
Topik
Menentukan pelanggan aktif dan tidak aktif dalam upaya strategi penjualan
produk Data
Mining Data Set
Customer, PO, Qty, Jumlah
Bayar Metode
Algoritma Naïve Bayes
Penelitian Sejenis
“ Penerapan Data Mining dengan Algoritma Naïve Bayes Clasifier untuk Mengetahui Minat Beli Pelanggan terhadap Kartu Internet XL(Studi Kasus di
CV.Sumber Utama Telekomunikasi) ( Dicky Nofriansyah, dkk, 2016)”
“Implementasi Algoritma Naïve Bayes dalam Menentukan Pemberian Kredit ( Muhammad Husni Rifqo dan Ardi Wijaya, 2017)”
“Implementasi Metode Klasifikasi Naïve Bayes dalam Memprediksi Besarnya Penggunaan Listrik Rumah Tangga ( Alfa Saleh, 2015)”
30 BAB III
METODE PENELITIAN
3.1 Objek Penelitian 3.1.1 Sejarah Perusahaan
PT. Youm Kwang Indonesia merupakan perusahaan yang bergerak di bidang manufacture, yang mana hasil produksinya dikirim ke perusahaan lain baik lokal maupun ekspor. Kantor pusat dan tempat produksi PT. Youm Kwang Indonesia bertempat di Delta Silicon V Blok G 03 B Nomor 03 Kawasan Lippo Cikarang Desa Cicau Kecamatan Cikarang Pusat Kabupaten Bekasi 17530 Jawa Barat Indonesia, dengan nomor telepon (021)-29472022/25 dan nomor faksimile (021)-29472026/27.
PT. Youm Kwang Indonesia berdiri pada tahun 2009 dengan IUI yang terbaru Nomor 245/1/IU/III/PMA/INDUSTRI/2012 yang dikeluarkan oleh BKPM dan terdaftar sebagai Kawasan Berikat nomor Skep 2331/KM.4/2012 yang diterbitkan oleh Direktorat Jenderal Bea Cukai di bawah Kementrian Keuangan pada tanggal 24 Juli 2012. PT. Youm Kwang Indonesia bergerak dalam bidang penyempurnaan benang (benang warna) dengan berbagai tipe produk benang jahit dengan produksi utamanya adalah benang nylon, poly textured, poly core dan polyester.
3.1.2 Kebijakan Perusahaan
PT Youm Kwang Indonesia selalu berusaha melakukan perbaikan berkesinambungan untuk menjadi supplier terbaik dengan cara memenuhi
kepuasan pelanggan dan menciptakan nilai-nilai baru yang selaras dengan komitmen untuk menjaga keselamatan dan kesehatan kerja serta menjaga kelestarian lingkungan.
Sebagai perusahaan besar pasti memiliki visi dan misi untuk dijadikan sebagai tujuan kerja dan pencapaian. Berikut adalah visi serta misi dari PT Youm Kwang Indonesia :
1. Visi
Menjadikan Perusahaan produsen pencelupan benang yang berkualitas kelas dunia dengan pengiriman tepat waktu dan memberikan kepuasan pelanggan 2. Misi
a. Menyediakan produk dengan kualitas terbaik
b. Meningkatkan pelayanan jasa untuk memenuhi kepuasan pelanggan.
c. Kami ingin memberikan kontribusi lebih terhadap pertumbuhan ekonomi nasional.
d. Menjaga pelaksanaan “pengaruh tidak semestinya” dengan laboratorium pihak ke tiga dan staff pengujian internal yang tepat, terlatih dan disiplin.
e. Meningkatkan penerapan sistem manajemen keselamatan dan kesehatan kerja.
3.1.3 Struktur Organisasi
Para pelaku yang menjalankan sistem dalam perusahaan memiliki kewenangan yang berbeda–beda sesuai dengan job deskripsi yang telah didapatkan berdasarkan proporsi serta kompetensi dan kemampuan yang dimiliki oleh para pelaku yang terdapat dalam perusahaan ataupun suatu organisasi.
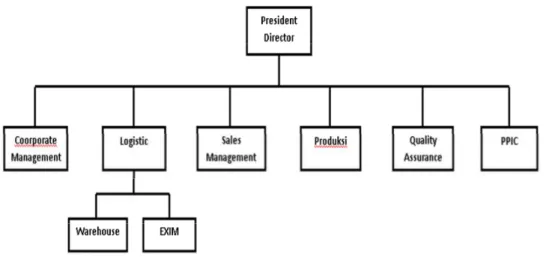
Sebagai perusahaan dengan sistem yang modern PT Youm Kwang Indonesia juga memiliki struktur organisasi yang kompleks. Keseluruhan struktur organisasi PT Youm Kwang Indonesia digambarkan sebagai berikut:
Gambar 3.1 Struktur Organisasi PT. Youm Kwang Indonesia Sumber : Penulis
Berdasarkan struktur organisasi pada Gambar 3.1, tugas dari masing- masing bagian yang terkait dengan bidangnya sebagaimana tercantum dalam struktur organisasi perusahaan antara lain:
1. President Director
a. Memimpin, mengkoordinasi dan mengawasi seluruh kegiatan perusahaan.
b. Memimpin rapat perusahaan dalam rangka meningkatkan dan mengembangkan perusahaan.
c. Pengambil keputusan tertinggi di perusahaan.
2. Coorporate Management
a. Menangani HRD, Recruitment, menangani pelatihan dan kehadiran karyawan.
b. Mengatur masalah keuangan perusahaan, melakukan pembayaran, penagihan kepada customer
c. Membuat laporan keuangan dan pajak perusahaan
3. Logistic
a. Warehouse (WH)
Menangani pemasukan dan pengeluaran barang.
Menyediakan barang yang dibutuhkan oleh bagian produksi.
Memastikan barang-barang untuk pengiriman sudah tersedia.
Mengecek on time delivery.
Membuat laporan stok gudang
Membuat surat jalan pengiriman b. EXIM (Ekspor Impor)
Membuat dokumen Bea Cukai (pengiriman domestic/export dan pemasukan barang).
Menangani ekspor/impor dan dokumen-dokumen perijinan lainnya.
Membuat laporan bulanan dan 4 bulanan pemasukan dan pengeluaran barang per dokumen pabean Kawasan Berikat.
4. Sales Management
a. Memperluas jaringan bisnis dan mempromosikan produk b. Berhubungan langsung dengan pelanggan.
c. Memenuhi pencapaian target sales penjualan.
5. Produksi
a. Menyediakan barang sesuai dengan order.
b. Menjamin bahwa stok untuk pengiriman selalu tersedia.
c. Menangani mesin dan memperbaiki mesin.
d. Membuat sample untuk produk baru.
e. Memproduksi barang sesuai pesanan pelanggan.
6. Quality Assurance
a. Menangani complain dari pelanggan.
b. Mengontrol kualitas dan pengecekan barang.
c. Memastikan kualitas barang yang masuk dan keluar.
7. PPIC (Planning, Production and Inventory Control) / Purchasing
a. Melakukan pembelian (import dan local) dan memastikan barang datang tepat waktu.
b. Menangani impor dan dokumen-dokumennya.
c. Pengecekan PO ke supplier.
3.2 Metode Penelitian
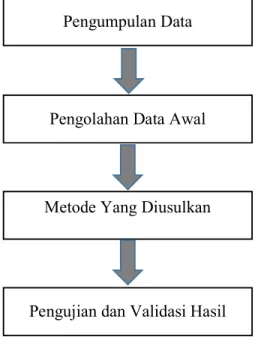
Penelitian merupakan kegiatan pengumpulan, pengolahan, análisis, dan penyajian data yang dilakukan secara sistematis dan obyektif untuk memecahkan suatu persoalan. Metode penelitian diharapkan dapat memberikan arah dan pedoman dalam melakukan penelitian agar dapat memperoleh hasil penelitian yang akurat, cermat, dan berkualitas sesuai dengan permasalahan yang dihadapi dan selalu konsisten. Metode yang digunakan dalam penelitian ini adalah metode penelitian deskriptif kuantitatif. Berikut ini adalah tahapan-tahapan dalam melakukan penelitian data mining:
Gambar 3.2 Metode Penelitian Sumber : Penulis Pengumpulan Data
Pengolahan Data Awal
Metode Yang Diusulkan
Pengujian dan Validasi Hasil
1. Pengumpulan Data
Tahapan ini menjelaskan mengenai dari mana sumber data didapatkan untuk keperluan penelitian ini.
2. Pengolahan Data Awal
Tahapan ini menjelaskan tahap awal dalam data mining. Data yang didapat akan diolah ke format yang dibutuhkan, pengelompokan dan penentuan atribut dari data awal.
3. Metode Yang Diusulkan
Pada bagian ini menjelaskan tentang metode yang diusulkan untuk digunakan dalam penelitian ini, yaitu dengan menggunakan Algoritma Naïve Bayes.
4. Pengujian dan Validasi Hasil
Pada bagian ini menjelaskan tentang pengujian, hasil prediksi dari penerapan Data Mining menggunakan Algoritma Naïve Bayes.
3.3 Metode Pengumpulan Data
Penelitian ini diselenggarakan di PT. Youm Kwang Indonesia. Sebagai dasar dalam penyusunan penelitian ini, penulis mengumpulkan data melalui : 1. Penelitian lapangan
Metode pengumpulan data dilakukan melalui beberapa pendekatan dan cara dengan tujuan untuk memperoleh data primer yang aktual antara lain :
a. Pengamatan langsung untuk mengumpulkan data yang berhubungan dengan obyek penelitian.
b. Melakukan wawancara langsung (tatap muka) kepada beberapa pegawai / bagian terkait di PT Youm Kwang Indonesia
2. Penelitian kepustakaan
Dengan penelitian kepustakaan, penulis memperoleh data sekunder melalui beberapa buku literatur, jurnal ilmiah, majalah ilmiah, panduan akademik dan sebagainya.
3.4 Pengelolaan Data Awal
Pengelolaan data awal pada penelitian ini mencakup semua kegiatan yang berhubungan dengan persiapan data sebelum melanjutkan ke dalam proses pemodelan data mining. Dalam pengelolaan data awal akan dilakukan beberapa tahapan, tahapan tersebut adalah : Seleksi Data (Selection), Pemilihan Data (Preprocessing/Cleaning) dan Transformasi (Transformation).
1. Seleksi Data (Selection)
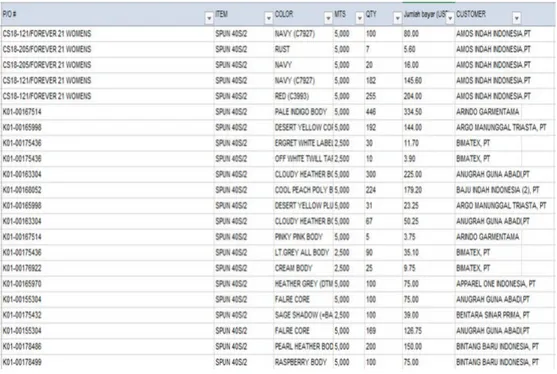
Selection (seleksi/ pemilihan) data merupakan sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam Data Mining. Data hasil seleksi ini yang akan digunakan untuk proses Data Mining. Dan dalam penelitian ini data yang digunakan untuk menentukan pelanggan aktif dan tidak aktif adalah data “Packing List Penjualan” di PT Youm Kwang Indonesia. Berikut ini adalah data “Packing List Penjualan” di PT Youm Kwang Indonesia:
Gambar 3.3 Potongan Packing List Penjualan Sumber : PT. Youm Kwang Indonesia
2. Pemilihan Data (Preprocessing/Cleaning)
Sebelum proses Data Mining dapat dilaksanakan, perlu dilakukan proses cleaning pada data yang menjadi fokus Data Mining. Proses cleaning mencakup antara lain membuang duplikasi data, memeriksa data yang inkonsisten, menghapus data yang tidak diperlukan dan memperbaiki kesalahan pada data, seperti kesalahan cetak(tipografi). Juga dilakukan proses Enrichment, yaitu proses “memperkaya”
data yang sudah ada dengan data atau informasi lain yang relevan, layak dan diperlukan untuk proses Data Mining. Setelah dilakukan proses membuang duplikasi data dan menghapus data yaitu Item, Color dan MTS sehingga menghasilkan 300 record data pelanggan sebagai berikut:
Gambar 3.4 Potongan Proses Cleaning Data Sumber : Penulis
3. Transformasi (Transformation)
Pada fase ini yang dilakukan adalah mentransformasi bentuk data yang belum memiliki entitas yang jelas ke dalam bentuk data yang valid atau siap untuk dilakukan proses Data Mining.
a. Mengklasifikasikan PO (Purchase Order), Klasifikasi PO (Purchase Order) ini berdasarkan banyak pelanggan yang menerbitkan PO. Sehingga PO diklasifikasikan menjadi seperti pada tabel di bawah ini:
Tabel 3.1 Klasifikasi PO
PO Klasifikasi
0 – 10 Sedikit
>10 – 25 Sedang
> 25 Banyak
b. Mengklasifikasikan Qty, Klasifikasi Qty (Quantity) ini berdasarkan jumlah pembelian produk yang dilakukan pelanggan. Sehingga Qty diklasifikasikan menjadi seperti pada tabel di bawah ini:
Tabel 3.2 Klasifikasi Qty
Qty Klasifikasi
0 – 10.000 Kecil
>10.000 – 25.000 Standar
> 25.000 Besar
c. Mengklasifikasikan Jumlah bayar, Klasifikasi Jumlah bayar ini berdasarkan jumlah pembayaran atas pembelian yang dilakukan pelanggan. Sehingga Jumlah bayar diklasifikasikan menjadi seperti pada tabel di bawah ini:
Tabel 3.3 Klasifikasi Jumlah Bayar Qty Klasifikasi 0 – $ 10.000 Kecil
>$ 10.000 – $ 25.000 Standar
> $ 25.000 Besar
Setelah melakukan tranformasi bentuk data dan memiliki entitas yang jelas, maka format data akhir ini yang akan dijadikan sebagai data yang siap untuk dilakukan proses Data Mining adalah sebagai berikut:
Gambar 3.5 Potongan Proses Transformasi Data Sumber : Penulis
Dari gambar 3.5 di atas terlihat bahwa data yang digunakan dan diolah berjumlah 300 record data, kemudian data tersebut dibagi menjadi dua kelompok yaitu data training dan data testing. Pembagian data menjadi data training dan data testing pada penelitian ini menggunakan rasio 90% atau 270 record data untuk data training dan 10% atau 30 record data untuk data testing yang disimpan dalam format file excel.
Data training merupakan data yang digunakan dalam melakukan pembelajaran sedangkan data testing adalah data yang tidak pernah dipakai sebagai pembelajaran dan akan berfungsi sebagai data pengujian kebenaran atau keakurasian hasil pembelajaran, Written, etc. (dalam Ni Luh Ratniasih, dkk.,
2017:14). Berikut ini adalah data training dan data testing yang akan digunakan dalam pengolahan data mining:
Gambar 3.6 Potongan Data Training Sumber : Penulis
Gambar 3.7 Potongan Data Testing Sumber : Penulis
3.5 Metode Yang Diusulkan
Pada penelitian ini akan dilakukan analisa menggunakan metode klasifikasi dengan Algoritma Naïve Bayes. Pemilihan Algoritma Naïve Bayes ini dikarenakan dapat memprediksi peluang di masa depan berdasarkan pengalaman dimasa sebelumnya sehingga dikenal sebagai Teorema Bayes (Dicky Nofriansyah, dkk., 2016:82).
Data packing list penjualan akan diolah menggunakan metode klasifikasi dengan Algoritma Naïve Bayes kemudian dicari hasil akurasinya. Dalam tahapan ini akan dilakukan beberapa langkah yaitu sebagai berikut:
Gambar 3.8 Langkah Pengujian Metode Sumber : Penulis
Pengolahan data dengan Naïve Bayes
Pengujian dengan tools Rapidminer
Evaluasi hasil: Confussion matrix dan Kurva ROC Data Set packing list penjualan
43 BAB IV
HASIL DAN PEMBAHASAN
4.1 Implementasi Algortima Naïve Bayes
Setelah mendapatkan jumlah record data training dan data testing, selanjutnya akan dilakukan pengolahan data mining berdasarkan dari data yang sudah disiapkan sebelumnya yaitu 90% atau 270 data training dan 10% atau 30 data testing. Berikut ini adalah sebagai sample data testing yang akan diuji:
Tabel 4.1 Data Testing
Customer PO Qty Jumlah Bayar
(USD)
Jenis Pelanggan ZIBEN
INDONESIA PT
SEDIKIT BESAR SEDANG ?
Tahapan penyelesaian data mining dengan menggunakan Algoritma Naïve Bayes perhitungan secara manual adalah sebagai berikut:
1. Hitung nilai P(X|Ci) untuk setiap class i
a. P(PO = “Sedikit” | Jenis Pelanggan = “Aktif ”) P(PO = 68/103 = 0.6601941748 )
b. P(PO = “Sedikit” | Jenis Pelanggan = “Tidak Aktif ”) P(PO = 150/167 = 0.8982035928 )
c. P(Qty = “Besar” | Jenis Pelanggan = “Aktif”) P(Qty = 21/103 = 0.2038834951 )
d. P(Qty = “Besar” | Jenis Pelanggan = “Tidak Aktif”)
P(Qty = 7/167 = 0.0419161677 )
e. P(Jumlah bayar = “Sedang” | Jenis Pelanggan = “Aktif”) P(Jumlah bayar = 10/103 = 0.0970873786 )
f. P(Jumlah bayar = “Sedang” | Jenis Pelanggan = “Tidak Aktif”) P(Jumlah bayar = 9/167 = 0.0538922156 )
2. Hitung nilai P(X|Ci) untuk setiap kelas (label) a. P(X | Jenis Pelanggan = “Aktif”)
= 0.6601941748 x 0.2038834951 x 0.0970873786 = 0.0130682229 b. P(X | Jenis Pelanggan = “Tidak Aktif”)
= 0.8982035928 x 0.0419161677 x 0.0538922156 = 0.0020290016 3. Hitung nilai P(X|Ci) * P(Ci)
a. P(X | Jenis Pelanggan = “Aktif”) x P(Pelanggan = “Aktif”)
= 0.0130682229 x 103/270 = 0.004985285
b. P(X | Jenis Pelanggan = “Tidak Aktif”) x P(Pelanggan = “Tidak Aktif”)
= 0.0020290016 x 167/270 = 0.0012549751 4. Menentukan kelas dari kasus tersebut
Berdasarkan perhitungan akhir dengan mengalikan nilai peluang dari kasus yang diangkat, kita melihat bahwa nilai P(X | Jenis Pelanggan = “Aktif”) lebih tinggi dari P(X | Jenis Pelanggan = “Tidak Aktif”) = 0.004985285 banding 0.0012549751. Sehingga dapat disimpulkan bahwa pelanggan tersebut masuk dalam klasifikasi “Pelanggan Aktif”.
4.2 Analisa Algortima Naïve Bayes Dengan Rapidminer
Dalam penelitian ini juga kemudian akan dilakukan pengujian untuk mendapatkan hasil akurasi Algoritma Naïve Bayes yang benar, maka diperlukan alat ukur yang tepat yaitu dibantu dengan menggunakan tools Rapidminer Studio versi 9.0.
4.2.1 Proses Import Data
Data awal yang sudah dilakukan beberapa tahapan seperti selection, cleaning dan transformation diimport ke dalam tools Rapidminer Studio 9.0
Gambar 4.1 Proses Import Data Sumber : Penulis
4.2.2 Proses Training dan Testing
Proses training yaitu suatu proses melakukan pelatihan data pada model (Naïve Bayes). Sedangkan proses testing yaitu melakukan pengujian data yang menghasilkan grafik atau pola.
Gambar 4.2 Proses Training Sumber : Penulis
Pada gambar 4.2 dijelaskan bahwa proses training menggunakan 270 record data training yang dihubungkan dengan blok model Naïve Bayes untuk mengetahui distribusi data.
Gambar 4.3 Proses Testing Sumber : Penulis
Pada gambar 4.3 dijelaskan bahwa proses testing menggunakan 270 record data training dengan blok model Naïve Bayes dan 30 record data testing kemudian dihubungkan dengan garis penghubung pada blok apply model dan performance sebagai penampil informasi hasil pengujian data.
4.2.3 Hasil Klasifikasi Class 1. Simple Distribution Model
Gambar di bawah ini adalah Distribution Model pengujian dengan Algoritma Naïve Bayes. Mengahasilkan dua kelas dengan perincian kelas yang aktif = 0.381 dan 4 distribusi, sedangkan untuk kelas tidak aktif mendapatkan hasil = 0.619 dan 4 distribusi.
Gambar 4.4 Simple Distribution Model Sumber : Penulis
2. Distribution Table
Tabel distribusi hasil analisa dengan Algoritma Naïve Bayes terhadap tabel data packing list penjualan dalam mengklasifikasikan jenis pelanggan dapat dilihat pada gambar di bawah ini:
Gambar 4.5 Potongan Distribution Table Sumber : Penulis
3. Hasil Klasifikasi
Pada ExampleSet(Apply Model) merupakan hasil prediksi pengujian data testing terhadap data training dengan menggunakan Algoritma Naïve Bayes.
Gambar 4.6 Potongan Hasil Klasifikasi Sumber : Penulis
4.2.4 Evaluasi Model Confusion Matrix
Percobaan proses klasifikasi yang telah dilakukan dengan tools Rapidminer Studio 9.0 menggunakan Algoritma Naïve Bayes mendapatkan hasil sebagai berikut:
1. Accuracy
Dengan mengetahui jumlah data yang diklasifikasikan secara benar maka dapat diketahui hasil akurasi adalah 70.00% dari hasil data testing.
Gambar 4.7 Accuracy Sumber : Penulis 2. Precision
Precision adalah jumlah data yang true positive (jumlah data yang dikenali secara benar sebagai positif) dibagi dengan jumlah data yang dikenali sebagai positif.
Dari hasil pengujian ini menghasilkan nilai precision sebesar 63.64% untuk kelas tidak aktif dan 87.50% untuk kelas aktif.
Gambar 4.8 Precision Sumber : Penulis 3. Recall
Recall adalah jumlah data yang true positive dibagi dengan jumlah data yang sebenarnya positif (true positive + true negative). Dari hasil pengujian ini menghasilkan nilai recall sebesar 46.67% untuk kelas aktif dan 93.33% untuk kelas tidak aktif.
Gambar 4.9 Recall Sumber : Penulis