i PENGEMBANGAN MODEL ABSTRACT SYNTAX TREE BERBASIS
B-TREE DAN NAÏVE BAYES UNTUK PERHITUNGAN KESAMAAN
SINTAKS PADA PROGRAM KOMPUTER
SKRIPSI
I GEDE WISESA PRIYA FENTIKA NIM. 1208605081
PROGRAM STUDI TEKNIK INFORMATIKA JURUSAN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS UDAYANA BUKIT JIMBARAN
i
SURAT PERNYATAAN KEASLIAN KARYA ILMIAH
Yang bertanda tangan di bawah ini menyatakan bahwa naskah Skripsi dengan judul:……….. ……….. ………..
Nama : I Gede Wisesa Priya Fentika NIM : 1208605081
Program Studi : Teknik Informatika E-mail : [email protected] Nomor telp/HP : 087861375820
Alamat : Dusun Nyuh, Desa Lemukih, Kec. Sawan, Kab. Buleleng, Bali. Belum pernah dipublikasikan dalam dokumen skripsi, jurnal nasional maupun internasional atau dalam prosiding manapun, dan tidak sedang atau akan diajukan untuk publikasi di jurnal atau prosiding manapun. Apabila di kemudian hari terbukti terdapat pelanggaran kaidah-kaidah akademik pada karya ilmiah saya, maka saya
bersedia menanggung sanksi-sanksi yang dijatuhkan karena kesalahan tersebut, sebagaimana diatur oleh Peraturan Menteri Pendidikan Nasional Nomor 17 Tahun
2010 tentang Pencegahan dan Penanggulangan Plagiat di Perguruan Tinggi.
Demikian Surat Pernyataan ini saya buat dengan sesungguhnya untuk dapat dipergunakan bilamana diperlukan.
Bukit Jimbaran, April 2016 Yang membuat pernyataan,
ii PENGEMBANGAN MODEL ABSTRACT SYNTAX TREE BERBASIS
B-TREE DAN NAÏVE BAYES UNTUK PERHITUNGAN KESAMAAN
SINTAKS PADA PROGRAM KOMPUTER
KOMPETENSI KOMPUTASI [SKRIPSI]
Sebagai syarat untuk memperoleh gelar Sarjana Komputer pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Universitas Udayana
Tulisan ini merupakan hasil penelitian yang belum pernah dipublikasikan
I GEDE WISESA PRIYA FENTIKA
NIM. 1208605081
Pembimbing I Pembimbing II
I Made Widiartha, S.Si., M.Kom NIP. 198212202008011008
iii LEMBAR PENGESAHAN TUGAS AKHIR
Judul : Pengembangan Model Abstract Syntax Tree Berbasis B-Tree
dan Naïve Bayes Untuk Perhitungan Kesamaan Sintaks Pada Program Komputer
Kompetensi : Komputasi
Nama : I Gede Wisesa Priya Fentika NIM : 1208605081
Tanggal Seminar : 22 April 2016
Disetujui Oleh :
Pembimbing I Penguji I
(I Made Widiartha, S.Si., M.Kom) (I Komang Ari Mogi, S.Kom., M.Kom) NIP. 198212202008011008 NIP. 198409242008011007
Pembimbing II Penguji II
(I Gede Santi Astawa, S.T., M.Cs) (Ida Bagus Made Mahendra, S.Kom., M.Kom) NIP. 198006162005011001 NIP. 198006212008121002
Penguji III
(I Gede Arta Wibawa, S.T., M.Kom) NIP. 198310222008121001
Mengetahui,
Ketua Jurusan Ilmu Komputer FMIPA Universitas Udayana
iv Judul : Pengembangan Model Abstract Syntax Tree Berbasis B-Tree dan
Naïve Bayes Untuk Perhitungan Kesamaan Sintaks Pada Program
Komputer
Nama : I Gede Wisesa Priya Fentika (NIM: 1208605081) Pembimbing : 1. I Made Widiartha, S.Si., M.Kom
2. I Gede Santi Astawa, S.T., M.Cs
ABSTRAK
Pemrograman merupakan salah satu keterampilan (skill) yang harus dimiliki oleh setiap mahasiswa yang mengambil jurusan dalam ranah Teknologi Informasi (TI) pada Perguruan Tinggi. Setiap matakuliah pemrograman yang diambil, tugas membuat program merupakan suatu hal yang mutlak diperlukan untuk mengukur tingkat kepahaman akan konsep pemrograman yang diajarkan. Setiap tugas yang diberikan akan memiliki tenggat waktu (deadline) untuk dikumpulkan. Pengumpulan tugas yang bersamaan akan memunculkan permasalahan yaitu menentukan apakah dua buah program memiliki kesamaan atau tidak. Disamping itu, proses pemeriksaan tugas dilakukan secara manual sehingga membutuhkan waktu yang lama. Oleh karena itu diperlukan sebuah sistem yang dapat mempercepat dan mempermudah proses untuk pengecekan kesamaan kode program. Sistem dibuat dengan mengembangkan model Abstract Syntax Tree
(AST) berbasis B-Tree dan Naïve Bayes. Sistem ini bernama Syntax Similarity Program (SSP). Pengujian yang dilakukan pada sistem bertujuan untuk mengukur ketepatan dalam memeriksa kesamaan kode program dan kecepatan dalam proses pemeriksaan. Ketepatan diuji dengan membandingkan hasil presentase kesamaan (PK) sistem dengan hasil perhitungan manual. Sedangkan Kecepatan diuji dengan menghitung kompleksitas waktu total dari proses-proses penting pada sistem. Hasil dari pengujian ketepatan menghasilkan nilai 100 % dan hasil dari pengujian kecepatan menghasilkan nilai kompleksitas waktu O(lg n4 + n3). Dengan total 10 himpunan kode program yang diuji, hasil pengujian membuktikan bahwa pengembangan model Abstract Syntax Tree (AST) berbasis B-Tree dan Naïve Bayes dapat berjalan dengan ketepatan dan kecepatan yang baik untuk memeriksa kesamaan kode program.
v Title : Development of B-Tree based Abstract Syntax Tree and Naïve Bayes for Syntax Similarity Computation on Computer Programs
Name : I Gede Wisesa Priya Fentika (NIM: 1208605081) Supervisor : 1. I Made Widiartha, S.Si., M.Kom
2. I Gede Santi Astawa, S.T., M.Cs
ABSTRACT
Programming is one of the skills prossessed by any student who majored in the realm of Information Technology (IT) in Higher Education. In each programming course taken, the task of creating a program is something that is necessary to measure the level of understanding of the concept of programming taught. Any given task will have a deadline to submit. The submission of tasks simultaneously will bring up problems that may determine whether the two programs have similarities or not. In addition, the evaluation process of a task is done manually so it takes a long time. Therefore, a system is needed that can speed up and simplify the process for checking the similarity of the program code. The system is created by developing the Abstract Syntax Tree (AST) based on B-Tree
and Naive Bayes. This system is called Syntax Similarity Program (SSP). Tests conducted on the system aims to measure the accuracy in checking the program code and the speed in the examination process. Accuracy is tested by comparing the system of similarity percentage results (PK) with the results of manual computations while speed is tested by computing the total time complexity of important processes on the system. The results of testing the accuracy yielded the value of 100% and the results of testing the speed yielded value time complexity O(lgn4 + n3). With a total of 10 sets of program codes tested, the test results proved that the development model of Abstract Syntax Tree (AST) based on B-Tree and
Naive Bayes could run with good accuracy and speed for examining the program codes.
vi KATA PENGANTAR
Penelitian dengan judul “Pengembangan Model Abstract Syntax Tree
Berbasis B-Tree dan Naïve Bayes Untuk Perhitungan Kesamaan Sintaks Pada Program Komputer” ini disusun dalam rangkaian kegiatan pelaksanaan Tugas Akhir di Jurusan Ilmu Komputer FMIPA UNUD. Penelitian ini dilaksanakan pada periode Juli 2015 hingga April 2016 di Universitas Udayana.
Sehubungan dengan telah terselesaikannya penelitian ini, maka diucapkan terima kasih dan penghargaan kepada berbagai pihak yang telah membantu penyusun, antara lain:
1. Bapak I Made Widiartha, S.Si., M.Kom sebagai Pembimbing I yang telah banyak meluangkan waktu untuk membantu pelaksanaan penelitian ini; 2. Bapak I Gede Santi Astawa, S.T., M.Cs sebagai Pembimbing II yang telah
bersedia mengkritisi, memeriksa dan menyempurnakan penulisan ini;
3. Bapak Agus Muliantara, S.Kom., M.Kom selaku Ketua Jurusan Ilmu Komputer Universitas Udayana yang telah banyak memberikan masukan dan motivasi sehingga memperlancar dalam proses pengerjaan penelitian ini; 4. Bapak-bapak dan ibu-ibu dosen di Jurusan Ilmu Komputer yang telah
meluangkan waktu turut memberikan saran dan masukan dalam pelaksanaan penelitian;
5. Kawan-kawan di Jurusan Ilmu Komputer yang telah memberikan dukungan moral dalam penyelesaian penelitian ini.
Disadari pula bahwa sudah tentu hasil-hasil dari penelitian ini masih mengandung kelemahan dan kekurangan. Memperhatikan hal ini, maka masukan dan saran-saran penyempurnaan sangat diharapkan.
Bukit Jimbaran, April 2016 Penyusun
viii
4.2 Implementasi Melakukan Ekstraksi Data ... 34
4.3 Implementasi Perhitungan Naïve Bayes ... 39
4.4 Implementasi Pembuatan Abstract Syntax Tree (AST) ... 41
4.5 Implementasi Proses Tree Pattern Matching (TPM) ... 44
4.6 Implementasi Proses Inisialisasi Hasil Statistik ... 46
4.7 Tampilan Antarmuka Sistem ... 49
4.7.1 Tampilan Input Data ... 49
4.7.2 Tampilan Lihat Kode Program ... 50
4.7.3 Tampilan Data Kategori ... 50
4.7.4 Tampilan Status Proses ... 51
4.7.5 Tampilan Tabel Probabilitas ... 51
ix
4.8 Hasil dan Pengujian Sistem ... 52
4.8.1 Hasil Uji Coba Sistem ... 52
4.8.2 Analisa Hasil ... 55
BAB V KESIMPULAN DAN SARAN ... 58
5.1 Kesimpulan ... 58
5.2 Saran ... 58
x DAFTAR TABEL
Tabel 2.1 Program “hello world!” Programmer A ... 5
Tabel 2.2 Program “hello world!” pada Programmer B ... 5
Tabel 2.3 Format Penulisan Elemen Kode Program pada Java ... 6
Tabel 2.4 Kata Kunci pada Java ... 9
Tabel 2.5 Daftar Separator di dalam Java ... 10
Tabel 2.6 Daftar Metacharacter ... 12
Tabel 2.7 Contoh Source Code pada Java ... 14
Tabel 3.1 Data Penting pada Format Penulisan Elemen Pemrograman ... 22
Tabel 3.2 Data Kategori untuk Kode Program ... 24
Tabel 4.1 Pseudocode untuk Mencari File Input ... 33
Tabel 4.2 Pseudocode untuk Melihat Isi File Input ... 33
Tabel 4.3 Pseudocode Menghitung Jumlah Baris Kode Program ... 34
Tabel 4.4 Daftar Regex untuk Ekstraksi Data ... 35
Tabel 4.5 Pseudocode Melakukan Ekstraksi Data dengan Regex ... 36
Tabel 4.6 Pseudocode Ekstraksi Struktur dari Kode Program ... 37
Tabel 4.7 Pseudocode Ekstraksi Konten dari Kode Program ... 37
Tabel 4.8 Contoh Kode Program Java untuk Menghitung Probabilitas .... 39
Tabel 4.9 Pseudocode Menghitung Probabilitas dengan Naïve Bayes ... 40
Tabel 4.10 Pseudocode Membuat Kelas Node untuk B-Tree ... 41
Tabel 4.11 Pseudocode Pembuatan Node Root pada B-Tree ... 43
Tabel 4.12 Pseudocode Pembuatan Node Child pada B-Tree ... 43
Tabel 4.13 Pseudocode Proses Tree Pattern Matching Antara 2 Kode Program ... 45
Tabel 4.14 Pseudocode Menampilkan Nilai Probabilitas pada Tabel ... 47
Tabel 4.15 Pseudocode Menampilkan Tabel Detail Pemeriksaan Kode Program ... 48
xi DAFTAR GAMBAR
Gambar 1.1 Rancangan Sistem ... 4
Gambar 2.1 Model AST untuk Source Code pada Tabel 2.6 ... 14
Gambar 2.2 Contoh Struktur B-Tree dengan Nilai Orde 5 ... 15
Gambar 2.3 Sebuah Proses Mapping dengan TPM ... 18
Gambar 3.1 Flowchart Proses Pemeriksaan Kode Program ... 19
Gambar 3.2 Tampilan Antarmuka SSP versi 2.0 ... 25
Gambar 3.3 Tampilan Antarmuka Header pada SSP ... 26
Gambar 3.4 Tampilan Antarmuka Input Data Program pada SSP ... 26
Gambar 3.5 Tampilan Antarmuka Hasil Ekstraksi Kode Program pada SSP 27 Gambar 3.6 Tampilan Antarmuka Proses Perhitungan pada SSP ... 27
Gambar 3.7 Tampilan Antarmuka Hasil Statistik pada SSP ... 28
Gambar 3.8 Flowchart Ekstraksi Data ... 28
Gambar 3.9 Flowchart Preprocessing ... 29
Gambar 3.10 Flowchart Pembentukan Pohon ... 29
Gambar 3.11 Flowchart Perhitungan Naïve Bayes ... 29
Gambar 3.12 Flowchart Tree Pattern Matching ... 30
Gambar 3.13 Skema Pemeriksaan Kesamaan untuk 2-5 Kode Program .... 31
Gambar 4.1 Contoh B-Tree dari Sebuah Kode Program ... 43
Gambar 4.2 Tampilan Hasil Input Data ... 50
Gambar 4.3 Hasil Data Kategori dengan Input sama dengan 5 ... 50
Gambar 4.4 Tampilan Informasi Status Proses ... 51
Gambar 4.5 Tampilan Tabel Probabilitas ... 51
Gambar 4.6 Tampilan Tabel Detail Pemeriksaan ... 51
Gambar 4.7 Tabel Hasil Pemeriksaan ... 52
Gambar 4.8 Grafik Pengujian Ketepatan Pemeriksaan Kode Program Secara Manual dan Otomatis dengan SSP... 55
xii Gambar 4.10 Grafik Laju Pertumbuhan Fungsi Pemeriksaan Kode dengan
xiii DAFTAR LAMPIRAN
1
BAB I PENDAHULUAN
1.1 Latar Belakang
Pemrograman merupakan suatu subjek keterampilan (skill) yang harus dimiliki oleh mahasiswa yang mengambil jurusan dibidang teknologi informasi seperti ilmu komputer, teknik informatika, sistem informasi, manajemen informatika, dan lainnya (Suarga, 2006). Ada banyak bahasa pemrograman yang dapat dipelajari oleh mahasiswa mulai dari bahasa pemrograman prosedural seperti C dan Pascal sampai bahasa pemrograman berorientasi objek seperti Java, .NET, dan C++.
Dalam matakuliah pemrograman yang diambil oleh mahasiswa setiap semesternya, tugas untuk membuat program adalah hal mutlak yang harus diberikan untuk mengetahui tingkat kepahaman mahasiswa akan konsep pemrograman pada matakuliah tersebut. Umumnya tugas yang diberikan akan memiliki tenggat waktu (deadline) untuk diselesaikan. Pengumpulan tugas yang bersamaan akan memunculkan permasalahan yaitu menentukan apakah dua buah program memiliki kesamaan atau tidak. Disamping itu, proses pemeriksaan tugas dilakukan secara manual sehingga membutuhkan waktu yang lama. Oleh karena itu diperlukan sebuah sistem yang dapat mempercepat
dan mempermudah proses untuk pengecekan kesamaan kode program.
Berdasarkan penelitian yang sudah pernah dipublikasikan, berbagai solusi telah ditawarkan untuk mengecek kesamaan pada kode program komputer. Diantaranya yaitu membandingkan aplikasi dari beberapa metode yang digunakan dalam mengecek kesamaan tekstual dari sebuah source code, metode yang dibandingkan adalah Abstract Syntax Tree (AST), Control Flow Graph
2
penggandaan kode berbasis pohon, dengan metode yang digunakan adalah
parse tree (Lingxiao Jiang, et al, 2012). Memecahkan masalah Tree Pattern Query dan mengembangkan algoritma yang lebih efisien menggunakan Tree Pattern Matching (Fei Ma, 2006).
Pada penelitian yang relevan diatas, umumnya metode berbasis tree
merupakan metode yang baik untuk digunakan dalam mendeteksi kesamaan kode program dengan berbagai tujuan. Salah satu metode yang berbasiskan tree
adalah Abstract Syntax Tree (AST), karena AST dapat memetakan struktur dan konten tekstual dari sebuah kode program komputer. Namun pada penelitian sebelumnya, model AST langsung dibentuk untuk keseluruhan kode program. Jika model AST dibentuk untuk keseluruhan program kemudian dihitung kesamaannya, maka proses pencocokan akan berlangsung lama sedangkan belum tentu kesamaan kode berlaku di seluruh bagian program. Hal ini juga dibuktikan kompleksitas kasus terbaik yang dihasilkan oleh proses pemeriksaan yaitu O(n3) dengan n adalah jumlah node (Baxter, et al, 1998). Berdasarkan kelemahan tersebut, maka diperlukan suatu pengembangan metode untuk melakukan seleksi pada bagian kode program tertentu yang berpotensi terjadinya kesamaan struktur dan konten tekstual pada program. Metode yang diusulkan pada penelitian ini adalah dengan menggunakan struktur data B-Tree
untuk pengaturan AST dan Naïve Bayes untuk melakukan perhitungan
probabilitas pada AST. Harapannya, proses pemeriksaan kode program dilakukan jika hasil probabilitas yang dihasilkan sama antar dua kode program.
1.2 Rumusan Masalah
Berdasarkan latar belakang di atas, maka permasalahan yang dapat dirumuskan adalah
1. Bagaimana pengaruh Naïve Bayes dalam memeriksa kesamaan kode program ?
3
1.3 Batasan Masalah
Adapun beberapa batasan masalah pada penelitian ini, diantaranya :
1. Kode program komputer yang dipakai sebagai bahan penelitian dibatasi hanya pada kode program dengan bahasa Java.
2. Kode pada program diasumsikan telah dapat berjalan dengan benar, dimana setiap kode program memiliki 1 buah kelas, dan setiap baris pada kode program mewakili sebuah statement pemrograman.
3. Tipe ekstensi dari setiap kode program yang akan diinputkan adalah dalam bentuk .txt.
4. Berdasarkan tipe plagiarisme (Omuta, 2007), sistem hanya dapat mengenali kemiripan tekstual tipe I (penambahan komentar dan baris kosong) dan tipe II (modifikasi nama variabel atau nama fungsi).
1.4 Tujuan Penelitian
Adapun tujuan dari penelitian ini adalah
1. Tujuan dari penelitian ini adalah membuat sistem yang dapat mempercepat proses pemeriksaan kesamaan kode program komputer dengan pengembangan model Abstract Syntax Tree (AST) berbasis B-Tree dan Naïve Bayes dibandingkan dengan model AST tanpa B-Tree
dan Naïve Bayes.
1.5 Manfaat Penelitian
Adapun manfaat dari penelitian ini adalah dapat menghasilkan sebuah sistem yang dapat digunakan oleh kalangan masyarakat khususnya kalangan akademik untuk mendeteksi kesamaan kode pada pembuatan program komputer khususnya dalam bahasa Java.
1.6 Metodologi Penelitian
4 Naïve Bayes. Adapun sub bahasan langkah-langkah yang akan dijadikan pedoman dalam penelitian ini adalah desain penelitian, pengumpulan data,
pengolahan data awal, dan metode yang digunakan. 1.6.1 Desain Penelitian
Desain penelitian yang dipakai adalah penelitian eksperimental. Penelitian ini akan mengembangkan salah satu cara yang biasa digunakan dalam mendeteksi plagiarisme pada kode program komputer yaitu dengan membuat model Abstract Syntax Tree (AST). Proses penelitian ini dapat ditunjukkan dalam bentuk bagan pada gambar 1.1.
Gambar 1.1. Rancangan sistem
Mengingat banyaknya bahasa pemrograman yang ada, rancangan sistem pada gambar 1.1 diatas tidak hanya dibuat mengkhusus untuk suatu bahasa pemrograman, melainkan menekankan konsep generalisasi untuk setiap
5
BAB II
TINJAUAN PUSTAKA
2.1 Sintaks Program Komputer
Kruse (1987) Mendefinisikan sintaks pada program komputer merupakan representasi dari struktur logika penulis program untuk mencapai tujuan atau output yang dikehendaki. Sintaks dapat ditulis dalam berbagai bahasa pemrograman seperti bahasa C, Java, C++, dsb. Penulisan sintaks untuk suatu program dengan suatu tujuan bisa dituliskan dengan sintaks yang berbeda. Misalnya terdapat 2 orang programmer A dan B yang bertujuan untuk mencetak tulisan “hello world !” sebanyak 3 kali dengan bahasa Java, maka programmer A dapat menulis kode program dengan sintaks berikut
Tabel 2.1. Program “hello world !” programmer A import javax.io;
class mainProgram{
public static void main(String[] args){ System.out.println(“hello world !”); System.out.println(“hello world !”); System.out.println(“hello world !”); }
}
Sedangkan programmer B menulisnya dengan sintaks berikut
Tabel 2.2. Program “hello world !” pada programmer B import javax.io;
class mainProgram{
public static void main(String[] args){ for(int i = 1; i <= 3; i++){
System.Out.print(“hello world !”); }
} }
6
pemeriksaan kode program. Sehingga tetap memperhitungkan kesamaan kode program untuk bahasa pemrograman yang sama. Pemeriksaan dilakukan
dengan memperhatikan struktur dan konten pada kode program tersebut. 2.1.1 Elemen Dasar Bahasa Java
Untuk memeriksa kesamaan kode program dalam bahasa Java, sistem harus mengetahui beberapa elemen dasar dari Java yaitu tata cara atau format penulisan kode program, kata kunci (keyword) pada Java, dan separator. Untuk tata cara atau format penulisan kode program, Rahardjo, dkk (2007) menjelaskan elemen yang dimaksud diantaranya seperti komentar, variabel, kontrol program, input/output, kelas dan objek, dsb. Berikut merupakan tabel yang menjelaskan format penulisan elemen-elemen pada program Java beserta penjelasannya
Tabel 2.3. Format penulisan elemen kode program pada java
NO FORMAT PENULISAN PENJELASAN
1 //ini komentar Komentar untuk satu baris.
2 /*ini komentar
beberapa baris*/
Komentar untuk beberapa baris.
3 /**
*Program “HelloWorld”
*@author Wisesa
*/
Komentar untuk keperluan dokumentasi suatu program.
4 tipe namaVariabel; Deklarasi satu variabel dengan
tipe data tertentu.
5 tipe variabel1,variabel2; Deklarasi beberapa variabel dengan tipe data yang sama.
6 tipe variabel = nilai; Inisialisasi nilai pada sebuah variabel.
7 tipe variabel1 = nilai1,
variabel2 = nilai2;
Inisialisasi beberapa nilai pada beberapa variabel.
8 tipe variabel1
=(tipeTarget) nilai;
Proses typecasting (konversi nilai ke tipe data yang berbeda).
7
10 variabelArray = new
tipe[jumlahElemen];
Inisialisasi array satu dimensi.
11 tipe[][] namaArray; Deklarasi array dua dimensi.
12 variabelArray = new
tipe[jumElemen][jumElemen]
Prosedur kontrol if-else untuk pemilihan 2 kondisi.
Prosedur kontrol if-elseif-else untuk pemilihan 3 atau lebih
Prosedur kontrol switch-case untuk pemilihan kondisi.
sebuah perulangan dengan beberapa inisialisasi dan iterasi.
8
Prosedur kontrol do-while untuk sebuah perulangan.
21 class NamaKelas{
..
}
Deklarasi sebuah kelas.
22 NamaKelas variabel = new
NamaKelas();
Instansiasi kelas dan memasukkan referensi ke sebuah variabel.
23 tipe
namaMethod(daftar-parameter){
..
}
Deklarasi sebuah method pada sebuah kelas.
Deklarasi sebuah method pada sebuah kelas dengan suatu nilai balik.
25
namaKonstruktor(daftar-parameter){
..
}
Deklarasi konstruktor pada sebuah kelas.
26 tingkat-akses tipe
namaVariabel;
Deklarasi variabel dengan tingkat akses.
Deklarasi method dengan tingkat akses dan parameter.
28 class nama-subclass
extends nama-superclass{
..
}
Melakukan proses penurunan terhadap suatu kelas.
Deklarasi try-catch untuk
9
Deklarasi try-catch untuk pencegahan eksepsi dengan beberapa tipe eksepsi.
Format penulisan kode program pada tabel 2.3 nantinya akan menjadi acuan pada sistem untuk memeriksa konten dari kode program ataupun mengenali struktur dari kode program.
Selain format penulisan, sistem juga harus mengenali kata kunci (keyword) pada Java. Menurut Rahardjo, dkk (2007), kata kunci adalah kata-kata yang telah didefinisikan oleh compiler dan memiliki arti dan tujuan spesifik. Java melarang pembuatan sebuah pengenal (nama variabel, konstanta, kelas, maupun method) dengan menggunakan kata kunci. Tabel 2.4 berikut ini menunjukkan kata kunci yang terdapat di dalam Java.
Tabel 2.4. Kata kunci pada Java
abstract double int strictfp
boolean else interface super
break extends long switch
byte final native synchronized
case finally new this
catch float package throw
char for private throws
class goto protected transient
const if public try
continue implements return void
default import short volatile
do instanceof static while
10
dari kode, melainkan hanya membutuhkan tata cara penulisan kode program, maka makna penulisan kata kunci dapat diabaikan.
Elemen dasar yang juga penting dari sebuah bahasa pemrograman, khususnya java adalah adanya separator. Separator digunakan untuk memisahkan salah satu bagian program dengan bagian lainnya. Salah satu contoh dari separator yang paling sering digunakan pada setiap kode program adalah semicolon (tanda titik koma (;)), yang digunakan untuk memisahkan statement yang satu dengan yang lainnya. Tabel 2.5 menunjukkan daftar separator di dalam Java.
Tabel 2.5. Daftar separator di dalam Java
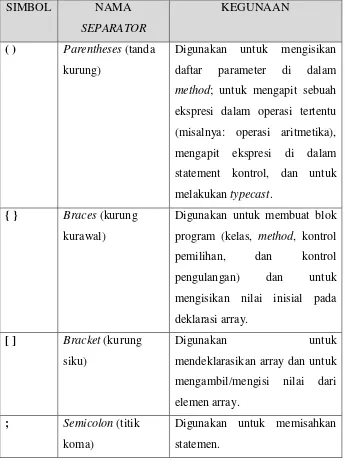
SIMBOL NAMA
SEPARATOR
KEGUNAAN
( ) Parentheses (tanda kurung)
Digunakan untuk mengisikan daftar parameter di dalam
method; untuk mengapit sebuah ekspresi dalam operasi tertentu (misalnya: operasi aritmetika), mengapit ekspresi di dalam statement kontrol, dan untuk melakukan typecast.
{ } Braces (kurung kurawal)
Digunakan untuk membuat blok program (kelas, method, kontrol pemilihan, dan kontrol pengulangan) dan untuk mengisikan nilai inisial pada deklarasi array.
[ ] Bracket (kurung siku)
Digunakan untuk
mendeklarasikan array dan untuk mengambil/mengisi nilai dari elemen array.
; Semicolon (titik koma)
11
, Comma (koma) Digunakan untuk memisahkan variabel pada saat proses deklarasi. Juga dapat digunakan pada saat menggunakan statemen
for.
. Period (titik) Digunakan untuk memisahkan nama paket, subpaket, dan kelas.
Juga digunakan untuk memisahkan data/method dari sebuah referensi objek.
2.2 Ekspresi Reguler
Menurut Aho, dkk (1994), ekspresi reguler atau yang biasa dikenal dengan
regex merupakan sebuah ekspresi yang menjadi notasi penjelasan mengenai suatu bahasa. Regex dapat mendefinisikan secara tepat bahasa yang sama dan berperan sebagai bahasa input untuk banyak sistem yang memproses untaian
string, seperti perintah search pada UNIX yaitu grep atau perintah-perintah sejenis untuk menemukan untai yang dilihat seseorang pada web browser atau sistem pemformatan teks.
Seperti yang dijelaskan oleh Aho, dkk (1994), terdapat tiga operator pada regex. Ketiga operasi tersebut adalah
1. Gabungan (union) dua bahasa L dan M (disimbolkan dengan L M), yaitu himpunan untaian string yang berada baik pada L atau M atau pada keduanya. Sebagai contoh, jika L = {001, 10, 111} dan M = {∈, 001}, maka L M = {∈, 10,001, 111}
2. Rentengan (concantenation) bahasa L dan M (disimbolkan dengan L.M) adalah himpunan untaian string yang dapat dibentuk dengan mengambil sembarang untai pada L dan merentengnya dengan sembarang untai pada M. Sebagai contoh, jika L = {001, 10, 111} dan M = {∈, 001}, maka L.M atau disingkat LM saja, adalah {001,
12
identitas rentengan, untai yang dihasilkan sama dengan untai pada L. Akan tetapi, tiga untai yang terakhir pada LM dibentuk dengan
mengambil setiap untai pada L dan merentengnya dengan untai dengan untai kedua pada M yaitu 001. Sebagai contoh, 10 dari L direnteng dengan 001 dari M akan menghasilkan 10001 pada LM. 3. Tutupan (closure) bahasa L dilambangkan dengan L* dan mewakili
himpunan yang untaianya dapat dibentuk dengan mengambil sembarang nomor untai dari L, mungkin dengan pengulangan (untai yang sama mungkin dipilih lebih dari satu kali) dan merenteng semuanya. Contohnya, jika L = {0, 1}, maka L* adalah seluruh untai angka yang terdiri dari 0 dan 1 sedemikian hingga angka-angka selalu berpasangan (misalnya 011, 11110) dan ∈, tetapi tidak
pernah 01011 atau 101. Lebih formal lagi, L* adalah gabungan tak
berhingga ⋃ ��≥ �, dimana L0 = {∈}, L1 = L dan Li dengan i > 1 adalah LL…L (rentengan salinan L sebanyak i).
Pada sistem operasi UNIX, terdapat aturan baku yang disebut standar IEEE
POSIX Basic Regular Expression atau BRE, seperti yang dijelaskan oleh Ken (1968). Pada sintaks BRE, hampir semua karakter diberlakukan secara harfiah. Tabel 2.7 dibawah merupakan daftar Metacharacter dan deskripsinya.
Tabel 2.6. Daftar Metacharacter
Metacharacter Deskripsi
. Sesuai dengan satu karakter apa saja. Dalam
kurung siku, karakter titik sesuai dengan titik secara harfiah. Misal, a.c cocok pada “abc”,dll. Tapi [a.c] hanya cocok pada “a”, “.”, atau “c”.
[] Ekspresi kurung siku. Sesuai dengan satu
13
misalkan [abcx-z] sesuai dengan “a”, “b”, “c”, “x”, “y”, “z”. Karakter diberlakukan secara harfiah jika berada diawal atau diakhir tanda kurung siku, atau jika diawali dengan karakter
escape seperti: [abc-], [-abc], atau [a\-bc].
[^] Sesuai dengan satu karakter apa saja yang tidak
ada dalam kurung.
^ Sesuai dengan awal string. Pada toolline-based,
notasi ini sesuai dengan awal baris di mana saja.
$ Sesuai dengan akhir string. Pada toolline-based,
notasi ini sesuai dengan akhir baris di mana saja.
BRE: \ (\)
ERE: ()
Mendefinisikan subexpression yang dapat dipanggil kemudian.
\n Sesuai dengan subexpression ke-n dimana n
bernilai 1 sampai 9.
* Sesuai dengan elemen sebelumnya sebanyak 0
atau beberapa kali.
BRE: \{m,n\}
ERE: {m,n}
Sesuai dengan elemen sebelumnya minimal sebanyak m kali namun tidak lebih dari n kali.
ERE :? Sesuai dengan elemen sebelumnya sebanyak 0
atau 1 kali.
ERE: + Sesuai dengan elemen sebelumnya minimal
sebanyak 1 kali.
ERE: | Operator alternasi yang sesuai dengan expression
14
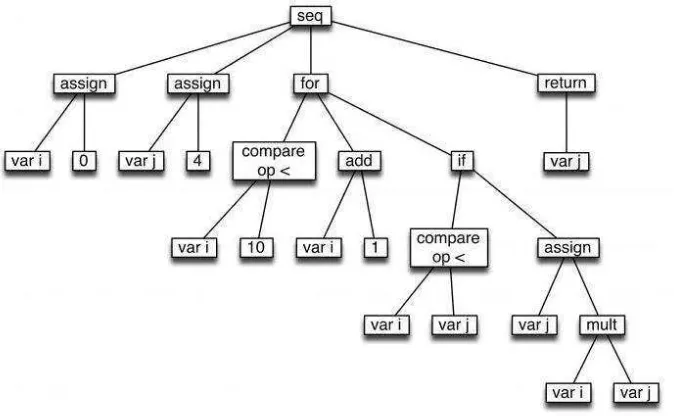
2.3 Abstract Syntax Tree (AST)
Fei (2006) menyatakan, dalam ilmu komputer, Abstract Syntax Tree (AST)
merupakan pohon yang merepresentasikan struktur abstrak sintaks dari source code yang ditulis dalam suatu bahasa pemrograman komputer. Setiap node
dikonstruksi berdasarkan parameter penting yang ada pada source code. Pada AST, sebuah informasi bisa ditambahkan dalam konteks menjelaskan data dari node yang dibuat. Misalnya untuk keperluan penjelasan informasi dalam pemrosesan variabel.
Misalnya diberikan sebuah source code dari program Java seperti pada tabel 2.6 berikut
Tabel 2.7. Contoh source code pada Java
int i=0;
int j=4;
for (; i<10; i++){
if (i<j) j=i*j;
}
return j;
Maka AST yang dihasilkan dari source code diatas ditunjukkan oleh gambar 2.1 berikut
15
Namun isi dari setiap node pada AST dapat disesuaikan dengan konteks permasalahan atau dalam konteks ini sesuai hasi ekstraksi dari data input kode
program. Jika data yang diekstraksi berupa konten dari program, maka node dari AST akan diisi oleh konten tersebut.
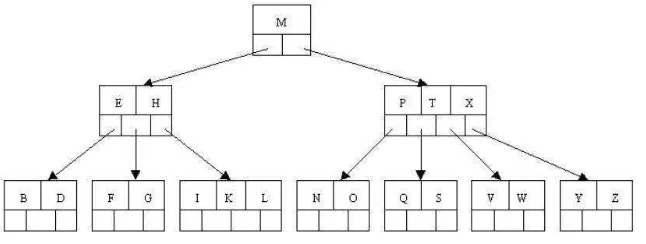
2.4 Struktur Data B-Tree
Menurut Cormen, dkk (2001), B-Tree adalah sebuah m-ary balanced search tree khusus yang digunakan dalam basis data karena strukturnya memungkinkan data yang disimpan untuk disisipi, dihapus, dan diambil dengan jaminan proses dengan waktu terburuk adalah O(log n), dimana setiap simpulnya terdiri dari (m/2) sampai m buah simpul anak, di mana m > 1 merupakan bilangan bulat . m adalah orde. Akar pohon B-tree paling sedikit memiliki 2 simpul anak. B-tree adalah struktur yang baik jika pohon digunakan pada memori yang lambat, karena ketinggian dan jumlah akses dapat diperkecil dengan mengambil bilangan m yang besar. Berikut merupakan contoh dari B-Tree dengan nilai orde sama dengan 5.
Gambar 2.2. Contoh struktur b-tree dengan nilai orde 5.
Didalam B-Tree, terdapat sejumlah operasi dasar yang sering digunakan, beberapa diantaranya akan diterapkan untuk membuat dan mengakses struktur b-tree dari kode program. Operasi dasar tersebut adalah
Searching. Sama halnya dengan Binary Search Tree (BST), jalan yang dipakai dalam proses pencarian adalah dengan cara Breath First Search
16
mengembangkan pohon pencarian secara horizontal sedangkan DFS secara vertikal.
Inserting. Proses penyisipan dilakukan untuk menambahkan sebuah data pada B-Tree tanpa harus menghapus node yang berada diataranya.
2.5 Probabilitas Naïve Bayes
Probabilitas Bayesian adalah suatu interpretasi dari kalkulus yang memuat konsep probabilitas sebagai derajat dimana suatu pernyataan dipercaya benar. Teori Bayesian juga dapat digunakan sebagai alat pengambilan keputusan untuk memperbaharui tingkat kepercayaan dari suatu informasi.
Umumnya, Naïve Bayes memiliki kelebihan mudah untuk dipahami, hanya memerlukan pengkodean yang sederhana, serta lebih cepat dalam perhitungan. Sedangkan kekurangan dari teori probabilitas bayesian yang banyak dikritisi oleh para ilmuwan adalah karena pada teori ini, satu probabilitas saja tidak bisa mengukur seberapa dalam tingkat keakuratannya. Dengan kata lain, kurang bukti untuk membuktikan kebenaran jawaban yang dihasilkan dari teori ini.
Teorema Bayes menerangkan hubungan antara probabilitas terjadinya peristiwa A dengan syarat peristiwa B telah terjadi dan probabilitas terjadinya peristiwa B dengan syarat peristiwa A telah terjadi.
� | = ��
Keterangan:
� | = peluang A dengan syarat B � = peluang A irisan B
� = peluang B.
17
= � = … �
= … �
Karena A1, A2, …, AN saling bebas maka
� = � + � + ⋯ + � �
Dari pers(1), jika posisi A dan B ditukar, maka dapat dirubah menjadi
� = � | �
Sehingga pers(4) dapat disubstitusi ke pers(3) menjadi
� = � | � + � | � + ⋯ + � | � � �
Jadi didapatkan probabilitas kejadian marginal dari B adalah
� = ∑ � | � � �
�
�=
Untuk peluang bersyarat, diperoleh peluang total yaitu
� | � =� � � =∑ �� | �
� � � �
�=
Keterangan:
� | � = peluang kejadian bebas B dengan syarat kejadian Ai
� = peluang kejadian marginal dari A
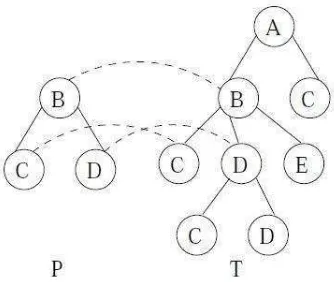
2.6 Tree Pattern Matching (TPM)
18
kesamaan terhadap node yang ada didalamnya. Proses pencocokan juga disebut sebagai mapping, karena proses ini akan melihat kesesuaian data antar
pattern dan pohon atau hutan. P akan dikatakan match dengan T atau F jika T
atau F juga mengandung data pada P dengan kesesuaian yang sama. Berikut merupakan contoh dari proses mapping menggunakan TPM dengan pola P dan pohon T.