60
Penderita Diabetes Melitus Tipe II Di Rumah Sakit Abdul Wahab
Syahranie Samarinda Tahun 2015
Yazid Fathullah
1,*, Desi Yuniarti
2, Rito Goejantoro
21Laboratorium Statistika Terapan, Jurusan Matematika, FMIPA, Universitas Mulawarman 2Program Studi Statistika, Jurusan Matematika, FMIPA, Universitas Mulawarman
Email korespondensi: [email protected]
Abstracts DM type II is one of the most common diseases suffered by Indonesian society. To
anticipate the exposure of this disease, an action is needed to reduce the risk by knowing the factors. Some of the risk factors are Hereditary, Age, Sex, Obesity, Dietary habit, Sports Activities. Research of the classification of DM type II has been done by using classification methods. Such as CART, CHAID, ANN and others. The level of accuracy of a classification method such as CART can be increased to provide better classification results using the boosting method. Boosting is an ensemble method used to improve the accuracy of a classification method. One of the variations of boosting is adaboost. Several studies have also shown that adaboost is able to improve the accuracy of a classification method. This research was conducted to examine the implementation of boosting on CART method. The results showed that the accuracy of CART after boosting has increased. From the research results, 300 patients with Diabetes Mellitus were 277 patients suffering from type II DM and it is obtained that CART method showed a significant variable effect of DM type II with an accuracy of 94% is a hereditary same as boosting CHART method, with higher accuracy than CART method that is equal to 98.67%.
Keywords: boosting, CART, diabetes melitus tipe II, classification. Pendahuluan
Klasifikasi adalah salah satu metode statistik untuk mengelompokkan atau mengklasifikasikan suatu data yang disusun secara sistematis. Masalah klasifikasi sering dijumpai dalam kehidupan sehari-hari, baik klasifikasi data pada bidang akademik, kesehatan, keuangan, maupun pada bidang lainnya. Masalah klasifikasi ini muncul ketika terdapat sebuah pengamatan yang heterogen. Secara garis besar, klasifikasi dapat diartikan sebagai metode pengelompokkan atau pengalokasian suatu objek atau observasi dalam satu grup tertentu. [1]
CART yang diperkenalkan oleh Breiman et al (1984) merupakan sebuah metodologi untuk
analisis data yang besar melalui prosedur pemilihan biner yang digunakan untuk menggambarkan hubungan antara variabel respon dengan variabel prediktor. Model yang dihasilkan oleh CART berupa model pohon. Model pohon tersebut akan menjadi pohon klasifikasi jika variabel respon merupakan dua kategori.[2]
Tingkat akurasi dari suatu metode klasifikasi dapat ditingkatkan dengan tujuan memberikan hasil klasifikasi yang lebih baik. Salah satu cara yang dapat digunakan adalah dengan menggunakan metode ensemble. Metode ensemble adalah suatu metode yang menggabungkan beberapa model klasifikasi untuk memberikan hasil yang lebih baik [2]. Metode ensemble yang digunakan dalam
penelitian ini adalah boosting. Boosting diperkenalkan oleh Freund dan Schapire pada tahun 1995.[3]
Machine Learning (ML) merupakan bagian
dari ilmu Artificial Intellegence (AI) adalah suatu disiplin ilmu yang berkonsentrasi dengan desain dan pengembangan algoritma yang didasarkan pada data input atau informasi yang didapatkan [3]. Dengan proses
learning, akan didapatkan suatu pola (pattern)
dari suatu informasi yang dapat digunakan untuk menyelesaikan masalah prediksi dan klasifikasi.[4]
Diabetes mellitus adalah penyakit yang
ditandai dengan kadar gula darah yang tinggi yang disebabkan oleh gangguan pada sekresi insulin atau gangguan kerja insulin atau keduanya. Diabetes mellitus (DM) dibagi menjadi beberapa tipe. DM tipe I biasanya menimbulkan gejala sebelum usia pasien 30 tahun, walaupun gejala dapat muncul kapan saja. Pasien DM tipe I memerlukan insulin dari luar tubuhnya untuk kelangsungan hidupnya. DM tipe II biasanya dialami saat pasien berusia 30 tahun atau lebih, dan pasien tidak tergantung dengan insulin dari luar tubuh, kecuali pada keadaan-keadaan tertentu. Tipe DM lainnya adalah DM gestasional, yakni DM yang terjadi pada ibu hamil, yang disebabkan oleh gangguan toleransi glukosa pada pasien tersebut. Saat ini jumlah pasien DM tipe II semakin meningkat, dikarenakan pola hidup yang
61 semakin tidak sehat, misalnya kurang aktivitas fisik serta pola makan yang tidak sehat. Faktor risiko untuk DM tipe II antara lain: genetik, lingkungan, usia tua, obesitas, kurangnya aktivitas fisik, riwayat DM gestasional, serta ras atau etnis tertentu. Penderita Diabetes Melitus (DM) tipe II memiliki resiko untuk menderita penyakit yang berhubungan dengan lemak seperti penyakit jantung dan pembuluh darah atau terjadinya komplikasi dengan penyakit lain. Untuk mengantisipasi terkena penyakit DM tipe II, diperlukan suatu tindakan untuk mengurangi resiko terkena penyakit ini. Salah satu cara yang dapat dilakukan adalah dengan mengetahui faktor-faktor resiko yang menyebabkan DM tipe II.
Penelitian ini dibatasi pada metode
machine learning yang digunakan adalah Boosting CART. Faktor-faktor resiko DM tipe II
yang digunakan adalah riwayat keluarga, umur, jenis kelamin, status obesitas, pola makan, dan aktifitas olah raga berdasarkan ketersedian sumber data dari RS AW Syahranie Samarinda.
Metodologi
Penelitian dilakukan bulan Desember 2016 sampai dengan Maret 2017 bertempat di Laboratorium Statistika Terapan Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Mulawarman (FMIPA UNMUL) dengan tempat pengambilan data di Rumah Sakit Abdul Wahab Syahranie Samarinda. Metode penelitian ini adalah Boosting CART (Classification and Regression Tree), yaitu metode klasifikasi untuk memprediksi dan melihat factor apa saja yang sangat berpengaruh pada penderita diabete mellitus tipe 2. Tahapan penelitian meliputi; pengambilan sampling (purposive sampling), penentuan sampel dengan pertimbangan tertentu.
Hasil dan Pembahasan Statistika Deskriptif
Berikut adalah jumlah penderita dan status penderita
Tabel 1. Tabulasi Status Penderita Diabetes Melitus
Status Penderita DM tipe II Frekuensi
Tidak Menderita 23
Menderita 277
Total 300
Berdasarkan Tabel 1 dapat diketahui bahwa pasien yang menderita DM tipe II sebanyak 277 pasien. Pasien yang tidak menderita DM tipe II sebanyak 23 pasien dari
total sebanyak 300 penderita Diabetes Melitus di RS AW Syahranie pada tahun 2015.
Tabel 2. Tabulasi Status DM Tipe II terhadap Riwayat Keluarga Status DM Tipe II Riwayat Keluarga (X1) Jumlah Tidak Ada Ada Tidak Menderita 23 0 23 Menderita 23 254 277 Jumlah 46 254 300
Berdasarkan Tabel 2 dapat diketahui bahwa pasien yang menderita DM tipe II dan memiliki riwayat penyakit DM tipe II sebanyak 254 pasien.
Tabel 3. Tabulasi Status DM Tipe II terhadap Jenis Kelamin
Status DM Tipe II
Jenis Kelamin (X3) Jumlah Laki-Laki Peremp uan Tidak Menderita 15 8 23 Menderita 122 155 277 Jumlah 137 163 300
Berdasarkan Tabel 3 di atas dapat diketahui bahwa pasien yang menderita DM tipe II paling banyak berjenis kelamin perempuan sebanyak 155 pasien. Untuk pasien yang tidak menderita DM tipe II paling banyak adalah laki-laki dengan 15 pasien. Tabel 4. Tabulasi Status DM Tipe II terhadap
Obesitas Status DM Tipe II Obesitas (X4) Jumlah Tidak Menderita Menderita Tidak Menderita 14 9 23 Menderita 22 255 277 Jumlah 36 264 300
Berdasarkan Tabel 4 dapat diketahui bahwa pasien yang menderita DM tipe II dan menderita obesitas sebanyak 255 pasien.
62 Tabel 5. Tabulasi Status DM Tipe II terhadap
Pola Makan Status DM Tipe II Pola Makan (X5) Jumlah Memenuhi Tidak Memenuhi Tidak Menderita 9 14 23 Menderita 255 22 277 Jumlah 264 36 300
Berdasarkan Tabel 5 di atas dapat diketahui bahwa pasien yang menderita DM tipe II dan memenuhi kriteria sehat sebanyak 255 pasien.
Tabel 6. Tabulasi Status DM Tipe II terhadap Aktifitas Olahraga Status DM Tipe II Aktifitas Olahraga (X6) Jumlah Aktif Kurang Tidak Menderita 9 14 23 Menderita 255 22 277 Jumlah 264 36 300
Berdasarkan Tabel 6 di atas dapat diketahui bahwa pasien yang menderita DM tipe II dan aktif berolahraga sebanyak 255 pasien.
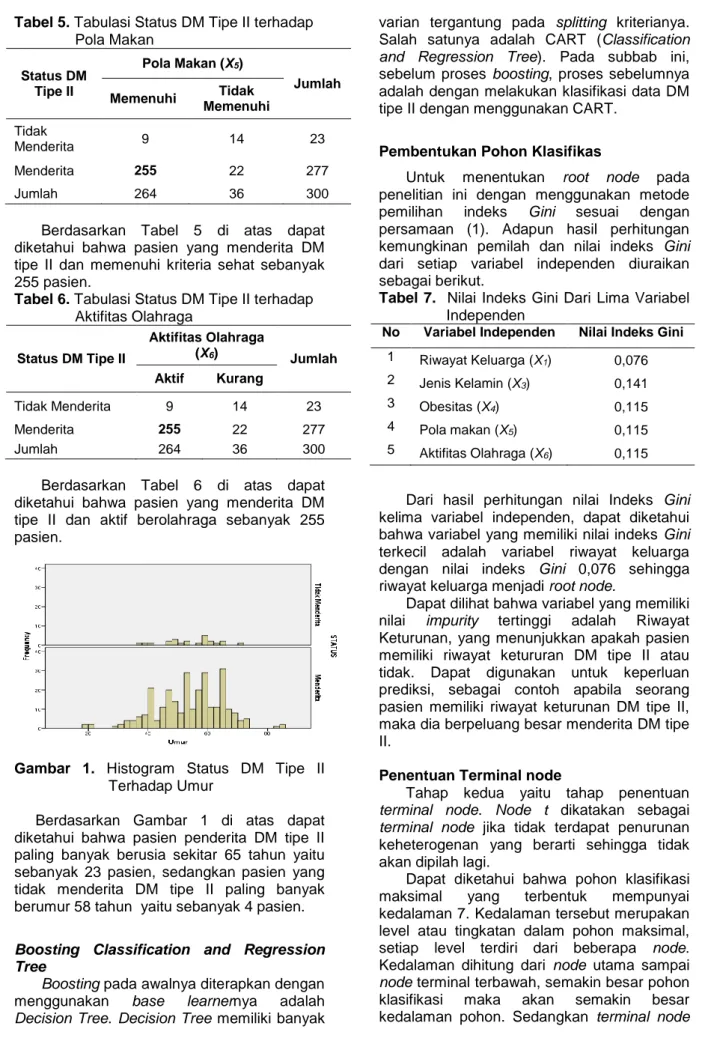
Gambar 1. Histogram Status DM Tipe II Terhadap Umur
Berdasarkan Gambar 1 di atas dapat diketahui bahwa pasien penderita DM tipe II paling banyak berusia sekitar 65 tahun yaitu sebanyak 23 pasien, sedangkan pasien yang tidak menderita DM tipe II paling banyak berumur 58 tahun yaitu sebanyak 4 pasien. Boosting Classification and Regression Tree
Boosting pada awalnya diterapkan dengan
menggunakan base learnernya adalah
Decision Tree. Decision Tree memiliki banyak
varian tergantung pada splitting kriterianya. Salah satunya adalah CART (Classification
and Regression Tree). Pada subbab ini,
sebelum proses boosting, proses sebelumnya adalah dengan melakukan klasifikasi data DM tipe II dengan menggunakan CART.
Pembentukan Pohon Klasifikas
Untuk menentukan root node pada penelitian ini dengan menggunakan metode pemilihan indeks Gini sesuai dengan persamaan (1). Adapun hasil perhitungan kemungkinan pemilah dan nilai indeks Gini dari setiap variabel independen diuraikan sebagai berikut.
Tabel 7. Nilai Indeks Gini Dari Lima Variabel Independen
No Variabel Independen Nilai Indeks Gini
1 Riwayat Keluarga (X1) 0,076
2 Jenis Kelamin (X3) 0,141
3 Obesitas (X4) 0,115
4 Pola makan (X5) 0,115
5 Aktifitas Olahraga (X6) 0,115
Dari hasil perhitungan nilai Indeks Gini kelima variabel independen, dapat diketahui bahwa variabel yang memiliki nilai indeks Gini terkecil adalah variabel riwayat keluarga dengan nilai indeks Gini 0,076 sehingga riwayat keluarga menjadi root node.
Dapat dilihat bahwa variabel yang memiliki nilai impurity tertinggi adalah Riwayat Keturunan, yang menunjukkan apakah pasien memiliki riwayat ketururan DM tipe II atau tidak. Dapat digunakan untuk keperluan prediksi, sebagai contoh apabila seorang pasien memiliki riwayat keturunan DM tipe II, maka dia berpeluang besar menderita DM tipe II.
Penentuan Terminal node
Tahap kedua yaitu tahap penentuan
terminal node. Node t dikatakan sebagai terminal node jika tidak terdapat penurunan
keheterogenan yang berarti sehingga tidak akan dipilah lagi.
Dapat diketahui bahwa pohon klasifikasi maksimal yang terbentuk mempunyai kedalaman 7. Kedalaman tersebut merupakan level atau tingkatan dalam pohon maksimal, setiap level terdiri dari beberapa node. Kedalaman dihitung dari node utama sampai
node terminal terbawah, semakin besar pohon
klasifikasi maka akan semakin besar kedalaman pohon. Sedangkan terminal node
63 yang dihasilkan oleh pohon klasifikasi maksimal adalah 7 terminal node.
Penandaan Label Kelas
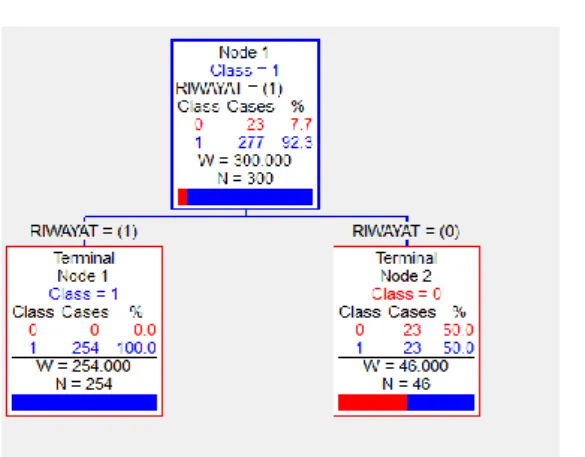
Tahap ketiga adalah penamaan label kelas, dimana pemberian label kelas untuk setiap node. Sebagai contoh untuk node 1.
Sehingga node induk diberi label kelas memiliki riwayat, karena peluang kelas tersebut lebih besar dari pada peluang kelas tidak memiliki riwayat. Proses penandaan label kelas ini berlaku pada semua node terutama node terminal, karena terminal node adalah node yang sangat penting dalam memprediksi suatu objek pada kelas tertentu jika objek berada pada terminal node tersebut. Pemangkasan Pohon Klasifikasi Untuk Mendapatkan Pohon Optimal
Gambar 2. Plot Relative Cost
Nilai relative cost yang dimiliki pohon maksimal (0,185) lebih besar dibandingkan nilai relative cost yang dimiliki pohon optimal (0,083). Oleh karena itu perlu dilakukan pemangkasan pohon maksimal agar didapatkan nilai relative cost yang paling kecil. Berdasarkan Gambar 2 menunjukkan nilai
relative cost minimum pada pohon optimal
sebesar 0,083 dan nilai parameter complexity sebesar 0,072 yang menunjukkan bahwa nilai
relative cost minimum lebih besar dari parameter complexity maka tidak perlu lagi
ada pemangkasan karena sudah terbentuk pohon klasifikasi yang optimal, sehingga terbentuk pohon klasifikasi optimum seperti pada Gambar 3.
Gambar 3. Pohon Optimal setelah dilakukan proses pruning
Pohon optimal yang sudah dipangkas dan telah terpilih setelah dilakukan proses pemangkasan pohon atau pruning dapat dilihat pada Gambar 3.
Berdasarkan Gambar 3 dapat diketahui bahwa variabel independen yang menjadi pemilah utama pada pohon klasifikasi optimal adalah variabel riwayar keturunan (X1). Pengamatan node utama (node 1) dipilah menjadi dua node anak berdasarkan variabel meliliki riwayat keturunan atau tidak memiliki riwayat keturunan. Dari 300 pengamatan pada node 1, sebanyak 46 pengamatan dipilah ke
node kanan (node 2 ). Sedangkan sebanyak
254 pengamatan dipilah ke node kiri (node 1). Adapun interpretasi hasil untuk masing-masing node terminal adalah sebagai berikut: 1. Terminal node 1 terdiri dari 254
pengamatan yang diprediksi sebagai kelompok penderita diabetes melitus tipe II yang memiliki riwayat keturunan.
2. Terminal node 2 terdiri dari 46 pengamatan yang diprediksi sebagai kelompok penderita diabetes melitus tipe II yang tidak memiliki riwayat keturunan. Hasil Klasifikasi dan Akurasi dari Metode CART
Pohon klasifikasi optimal yang telah terpilih tadi kemudian dilihat hasil klasifikas dan diuji tingkat keakuratannya dalam mengelompokkan data. Dari hasil output
software SPSS Modeler dapat dilihat hasil
dan ketepatan metode CART pada Tabel 4.8 berikut.
64 Tabel 8. Predictor Importance menggunakan
CART Variabel Persentase CART Riwayat 0,47% Obesitas 0,19% Jenis Kelamin 0,11% Akfitas Olahraga 0,11% Pola Makan 0,11% Umur 0,01%
Pada Tabel 8 dapat dilihat bahwa riwayat keluarga memiliki predictor importance yang paling besar sebesar 0,47%, lalu obesitas sebesar 0,19%, sedangkan jenis kelamin, aktifitas olahraga, dan pola makan memiliki
predictor importance yang sama besarnya
yaitu 0,11%, dan yang paling kecil yaitu umur sebesar 0,01%. Dari Tabel 8 juga dapat dilihat riwayat keluarga merupakan variabel yang paling berpengaruh untuk terjadinya DM tipe II yaitu sebesar 0,47% sedangkan umur menjadi variabel yang pengaruhnya paling kecil untuk terjadinya DM tipe II dengan menggunakan CART ini yaitu hanya sebesar 0,01% atau hampir tidak berpengaruh.
Berikut adalah tabel hasil dan ketepatan klasifikasi CART.
Tabel 9. Confusion matrix dengan metode CART Model CART Prediksi Jumlah Tidak Menderita Menderita Aktual Tidak Menderita 20 3 23 Menderita 15 262 277
Pada Tabel 9 diberikan objek yang tepat diklasifikasikan dan yang salah untuk masing-masing kelompok. Angka yang diblok menyatakan jumlah obyek kelompok tertentu yang salah klasifikasi atau misclassification oleh metode ini.
Dari 23 pengamatan yang diklasifikasikan ke dalam kategori tidak menderita DM tipe II, diperoleh 20 pasien tepat diklasifikasikan ke dalam kategori tidak menderita DM tipe II dan 3 pasien tidak tepat diklasifikasikan ke dalam kategori tidak menderita DM tipe II.
Dari 277 pengamatan yang diklasifikasikan ke dalam kategori menderita DM tipe II, diperoleh 262 pasien tepat diklasifikasikan ke dalam kategori menderita DM tipe II dan 15 pasien tidak tepat
diklasifikasikan ke dalam kategori menderita DM tipe II.
Berdasarkan Tabel 9 dapat dilihat bahwa untuk pasien yang menderita DM tipe II salah terklasifikasi menjadi tidak menderita ada sebanyak 15 pengamatan. Sedangkan yang tidak menderita yang salah terklasifikasi menderita DM tipe II ada sebanyak 3 pasien.
Total pengamatan yang misklasifikasi dengan menggunakan metode CART ada sebanyak 18 pengamatan, angka BP (Benar Positif) dan TN (Benar Negatif) sehingga didapatkan tingkat akurasi ketepatan klasifikasi CART sebagai berikut :
Akurasi =
Sehingga akurasi dari model CART ini adalah sebesar 94,0%.
Proses Boosting CART
Proses selanjutnya adalah melakukan
boosting pada metode CART. Boosting di
dalam penelitian ini berfungsi untuk meningkatkan tingkat akurasi dari hasil klasifikasi pada percobaan metode sebelumnya yaitu metode CART, proses
boosting pada penelitian ini tentu saja
merubah hasil klasifikasi dari metode CART dan mendapatkan hasil klasifikasi yang tingkat akurasinya lebih tinggi dari CART.
Dari hasil output software SPSS Modeler dapat dilihat hasil dan ketepatan metode
boosting CART seperti pada Tabel 4.10.
Tabel 10. Predictor Importance menggunakan
Boosting CART Variabel Persentase Boosting CART Riwayat 0,48% Obesitas 0,17% Jenis Kelamin 0% Akfitas Olahraga 0,17% Pola Makan 0,17% Umur 0,01%
Pada Tabel 10 dapat dilihat bahwa riwayat keluarga memiliki predictor importance yang paling besar sebesar 0,48%, lalu obesitas, aktifitas olahraga, dan pola makan sebesar 0,17 %, umur sebesar 0,01% dan Jenis kelamin yang paling kecil yaitu sebesar 0%. Dari Tabel 4.10 di atas juga dapat dilihat riwayat keluarga merupakan variabel yang paling berpengaruh untuk terjadinya DM tipe II yaitu sebesar 0,48% sedangkan jenis kelamin
65 menjadi variabel yang pengaruhnya paling kecil untuk terjadinya DM tipe II dengan menggunakan Boosting CART ini yaitu hanya sebesar 0% atau tidak berpengaruh. Tabel yang memperlihatkan perbandingan antara data aktual dan hasil prediksi dengan menggunakan metode CART.
Berikut adalah tabel hasil dan ketepatan klasifikasi Boosting CART.
Tabel 11. Confusion matrix dengan metode
Boosting CART Model Boosting CART Prediksi Jum lah Tidak Menderita Menderita Aktual Tidak Menderita 19 4 23 Menderita 0 277 277
Pada Tabel 11 diberikan objek yang tepat diklasifikasikan dan yang salah untuk masing-masing kelompok. Angka yang diblok menyatakan jumlah obyek kelompok tertentu yang salah klasifikasi atau misclassification oleh metode ini.
Dari 23 pengamatan yang diklasifikasikan menjadi kategori tidak menderita DM tipe II, diperoleh 19 pasien tepat diklasifikasikan ke dalam kategori tidak menderita DM tipe II dan 4 pasien tidak tepat diklasifikasikan ke dalam kategori tidak menderita DM tipe II.
Dari 277 pengamatan yang diklasifikasikan ke dalam kategori menderita DM tipe II, diperoleh 277 pasien tepat diklasifikasikan ke dalam kategori menderita DM tipe II dan tidak ada pasien tidak tepat diklasifikasikan ke dalam kategori menderita DM tipe II.
Berdasarkan Tabel 9 dapat dilihat bahwa untuk pasien yang menderita DM tipe II salah terklasifikasi menjadi tidak menderita ada sebanyak 4 pengamatan. Sedangkan yang tidak menderita yang salah terklasifikasi menderita DM tipe II ada sebanyak 0 pasien. Total pengamatan yang misklasifikasi dengan menggunakan metode Boosting CART ada sebanyak 4 pengamatan, angka BP (Benar Positif) dan BN (Benar Negatif) sehingga didapatkan tingkat akurasi ketepatan klasifikasi CART sebagai berikut :
Akurasi =
Sehingga akurasi dari model Boosting CART ini adalah sebesar 98,67%.
Kesimpulan
Berdasarkan analisis maka kesimpulan dari penelitian ini adalah sebagai berikut.
1. Faktor-faktor yang paling signifikan mempengaruhi terjadi Klasifikasi DM tipe II di RS Abdul Wahab Syahranie tahun 2015 dengan penerapan CART ialah riwayat keluarga.
2. Faktor-faktor yang paling signifikan mempengaruhi terjadi Klasifikasi DM tipe II di RS Abdul Wahab Syahranie tahun 2015 dengan penerapan Boosting CART ialah riwayat keluarga.
3. Hasil Klasifikasi dan akurasi DM tipe II di RS Abdul Wahab Syahranie tahun 2015 dengan penerapan CART didapatkan sebesar 282 data yang dapat terklasifikasikan dengan tepat dan akurasi sebesar 94,0%.
4. Hasil Klasifikasi dan akurasi DM tipe II di RS Abdul Wahab Syahranie tahun 2015 dengan penerapan Boosting CART didapatkan sebesar 296 data yang dapat terklasifikasikan dengan tepat dan akurasi sebesar 98,67%.
Daftar Pustaka
[1] Johnson, R. and Wichern D. (2007). Applied Multivariate Statistical Analysis Sixth Edition. New Jersey: Pearson Prentice Hall.
[2] Breiman, L., Friedman, J.H., Olsen, R.A., and Stone, C.J. (1984). Classification and Regression Trees. New York: Chapman & Hall.
[3] Rokach, Lior. (2010). Pattern Classification using Ensembles Methods. World Scientific Publishing Co. Pte. Ltd. [4] Zhang, Y. (2010). New Advance in
Machine Learning. In-Tech. Croatia
[5] Adiningsih, R.U. (2011). Faktor-Faktor Yang Berhubungan Dengan Kejadian Diabetes Militus Tipe 2 Pada Orang Dewasa di Kota Padang Panjang. Skripsi S-1 Ilmu Kesehatan Masyaakat Universitas Andalas Padang
[6] Bagus, Sartono, Utami Dyah Syafitri (2010) Metode Pohon Gabungan: Solusi Pilihan Untuk Mengatasi Kelemahan Pohon Regresi Dan Klasifikasi Tunggal (Ensemble Tree : An Alternative toward Simple Classification and Regression Tree) Forum Statistika dan Komputasi, April 2010 p : 1-7 Vol 15 No.1 ISSN : 0853-8115
[7] Fernanda, Jerhi Wahyu (2012) Boosting Neural Network dan Boosting Cart Pada Klasifikasi Diabetes Militus Tipe II Jurnal
66 Matematika Vol. 2 No. 2, Desember 2012. ISSN : 1693-1394
[8] Freund Y, Schapire R E. (1997). A decisi theoretic generalization of on-line learning and an application to boosting. Journal of Computer and System Sciences, 55:119-139.
[9] Furqon. (1997). Statistik Terapan Untuk Penelitian. Bandung: Alphabeta.
[10] Giudici, Paolo. (2003). Applied Data Mining, Statistical Method for Business and industry. Italy: Faculty of Economics Unversity of Pavia.
[11] Handayani, S.A. (2003). Faktor-Faktor Risiko Diabetes Melitus Tipe II di Semarang dan Sekitarnya. Thesis S-2 Magister Ilmu Kesehatan Masyarakat Universitas Diponegoro Semarang
[12] Jonathan, S. et. al. (1999). The Epidemiology of Diabetes : a World-Wide Problem. University of Sydney.
[13] Khardori, R. (2011). Type 2 Diabetes Melitus.
http://emedicine.medscape.com/article/11 7853-overview#a0104. Diakses pada tanggal 25 Oktober 2016 pukul 20.00. [14] Lewis, R.J. (2000). An Introduction to
Classification and Regression Tree (CART) Analysis. Annual Meeting of the Society for Academic Emergency Medicine in San Franscisco. California: Departement of Emergency Medicine.
[15] Nathan, D.M., Delahanty, L.M. (2009). Menaklukkan Diabetes. Gramedia:Jakarta [16] Okun, O.(2011). Feature Selection and
Ensemble Methods for
Bioinformatics:Algorithmic Classification and Implementations. United States of America:IGI Global
[17] Schaefer, R.L. (1986). Alternative Estimators in logistic Reggresion When the Data are Collinear. Stat Comput Simul, 25, 75-91.
[18] Siegel, S. (1985). Statistika Nonparametrik Untuk Ilmu-Ilmu Sosial, Jakarta: Gramedia.
[19] Statsoft, (2003). Classification and Regression Trees (C&RT) Theory and Application.
http://www.statsoft.com/textbook/stCART. html. Diakses pada tanggal 15 September 2016.
[20] Sugiyono. (2010). Statistik Nonparametrik untuk Penelitian. CV. Bandung: Alfabeta [21] Timofeev, Roman. (2004). Classification
and Regression Trees (C&RT) Theory and Application. A Master Thesis. CASE- Center of Applied Statistics and Economics. Berlin: Humboldt University. [22] Yohannes, Y dan Hoddinott, J. (1999).
Classification and Regression Trees: An Introduction. Washington, D.C: International Food Policy Research Institute.