Fakultas Ilmu Komputer
Optimasi Metode Extreme Learning Machine Dalam Penentuan Kualitas
Air Sungai Menggunakan Algoritme Genetika
Regina Anky Chandra1, Edy Santoso2, Sigit Adinugroho3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Seiring dengan meningkatnya jumlah populasi manusia, sumber air bersih yang ada di bumi terus berkurang. Dampak yang diberikan akibat tercemarnya sumber air juga tidak dapat diremehkan. Beberapa diantaranya adalah menurunnya kadar oksigen yang ada di bumi dikarenakan tumbuhan tidak dapat berfotosintesis dengan baik, mengganggu kesuburan tanah, mematikan hewan-hewan yang hidup di dalam air dan masih banyak dampak lainnya. Salah satu sumber air di muka bumi ini berasal dari sungai. Untuk menjaga kualitas air agar tetap pada kondisi alamiahnya, perlu dilakukan pengukuran dan analisis terhadap air sungai tentang status mutu airnya. Pada penelitian ini digunakan 7 parameter pengukuran kualitas air sungai yang kemudian akan diklasifikasikan menjadi 3 kelas berbeda. Kelas klasifikasi dibagi menjadi tercemar ringan, tercemar sedang dan tercemar berat. Sedangkan metode yang digunakan untuk pengukuran dan analisis pada penelitian ini adalah metode Extreme Learning Machine
(ELM) dan Algoritme Genetika. Dalam penelitian ini, bobot awal yang digunakan pada proses training
dan testing ELM akan dioptimasi menggunakan Algoritma Genetika. Data training dan data testing yang digunakan, ditentukan oleh 5 fold yang telah dibentuk dari data awal yang berjumlah 150 data. Data tiap
fold akan diuji menjadi data testing secara bergantian. Berdasarkan hasil pengujian dari penelitian yang telah dilakukan, penelitian ini mampu meraih tingkat akurasi sebesar 88.0002%.
Kata kunci: kualitas air sungai, klasifikasi, prediksi, extreme learning machine (elm), algoritma genetika
Abstract
Along with the increasing number of human population, the source of clean water on earth continues to decrease. The impact given due to contamination of water sources is also not light. Some of them are the decrease in oxygen levels in the earth because plants can not photosynthesize well, disrupt soil fertility, kill animals that live in water and many other impacts. One of the water sources on earth is from the river. To maintain water quality in order to stay in its natural condition, it is necessary to measure and analyze the water quality status of river water. In this research used 7 parameters of river water quality measurement which will be classified into 3 different classes. Classification class is divided into lightly polluted, moderately polluted and heavily polluted. While the method used for the measurement and analysis in this study is the method of Extreme Learning Machine (ELM) and Genetic Algorithm. In this study, the input weight used in the ELM training and testing process will be optimized using Genetic Algorithm. Training and testing data used, determined by 5 fold that has been formed from the initial data which amounts to 150 data. The data of each fold will be tested into data testing alternately. Based on the results of testing of research that has been done, this research is able to achieve an accuracy of 88.0002%.
Keywords: river water quality, classification, prediction, extreme learning machine (elm), genetic algorithm
1. PENDAHULUAN
Air merupakan satu dari sekian banyak sumber daya alam yang banyak digunakan oleh makhluk hidup dan sudah menjadi kebutuhan pokok untuk bertahan hidup. Tidak ada bidang
bersih yang ada di bumi terus berkurang. Hal ini dikarenakan hilangnya sumber air akibat alih lahan pertanian dan pemukiman penduduk serta pencemaran air yang semakin buruk dan memprihatinkan dari hari ke hari. Akibatnya, banyak air yang tercemar dan susah sekali mencari sumber air bersih. Dampak yang diberikan akibat tercemarnya sumber air juga tidak ringan. Beberapa diantaranya adalah menurunnya kadar oksigen yang ada di bumi karena tumbuhan tidak bisa berfotosintesis dengan baik, mengganggu kesuburan tanah, mematikan hewan-hewan yang hidup di dalam air (Budiarta et al., 2016).
Penurunan kualitas air akan menurunkan dayaguna, hasil guna, produktivitas, daya dukung dan daya tampung dari sumberdaya air yang pada akhirnya akan menurunkan kekayaan sumber daya air. Salah satu sumber air di muka bumi ini berasal dari sungai. Tidak sedikit juga air sungai yang mengalami penurunan kualitas air. Untuk menjaga kualitas air agar tetap pada kondisi alamiahnya, perlu dilakukan pengelolaan dan pengendalian pencemaran air secara bijaksana. Hal ini dibutuhkan upaya pemantauan dan pengendalian pencemaran terhadap air sungai. Upaya yang dilakukan yaitu melakukan pengukuran dan analisis terhadap air sungai tentang status mutu air sebagaimana yang ditetapkan dalam Peraturan Pemerintah no 82 tahun 2001 (Azizah, 2016).
Jaringan Saraf Tiruan (JST) merupakan upaya untuk memodelkan pemrosesan informasi berdasarkan kemampuan sistem saraf manusia. Salah satu metode dalam JST adalah Extreme Learning Machine (ELM). ELM merupakan
salah satu metode di dalam jaringan saraf tiruan
feedforward dengan satu hiddenlayer atau lebih
dikenal dengan istilah Single Hidden Layer Feedforward Neural Network (SLFNs). Metode
ELM lebih unggul dalam proses learning speed,
serta mempunyai tingkat akurasi yang lebih baik dibandingkan dengan metode konvensional seperti Moving Average dan Exponential Smoothing, sehingga hasil prediksi yang
dihasilkan lebih optimal dan akurat (Agustina et al., 2010).
Algoritme Genetika (Genetic Algorithms), merupakan tipe Algoritme Evolusi yang paling populer dan banyak diterapkan pada masalah-masalah kompleks. Seiring berkembang pesatnya teknologi informasi, Algoritme Genetika juga semakin berkembang dengan diterapkannya berbagai macam modifikasi ke
dalam Algoritme Genetika. Karena
kemampuannya untuk menyelesaikan berbagai masalah kompleks, algoritme ini banyak digunakan di dalam berbagai bidang yang sering menghadapi masalah optimasi, serta permasalahan yang memiliki model matematika yang cukup rumit. Algoritme Genetika menghasilkan himpunan solusi optimal yang sangat berguna pada peyelesaian masalah dengan banyak obyektif (Mahmudy, 2015).
Untuk mengatasi kelemahan pada penelitiannya, Alencar et al. (2016) mengusulkan sebuah metode baru untuk memangkas neuron hidden layer menggunakan Algoritme Genetika. Pendekatan yang diusulkan, disebut GAP-ELM, memilih subset dari hidden neuron untuk mengoptimalkan
fungsi fitness multiobjective yang didapat dari
penggabungan antara akurasi dan jumlah neuron
yang dipangkas. Kinerja GAP-ELM lebih efisien ketika diterapkan pada beberapa dataset di dunia
nyata dibandingkan dengan metode SLFN lain dan metode pemangkasan terkenal yang disebut
Optimally Pruned ELM (OP-ELM). Pada
percobaan penelitiannya, mereka menyatakan bahwa GAP-ELM adalah alternatif yang valid
untuk permasalahan klasifikasi.
Berdasarkan uraian tersebut, penulis
mengajukan penelitian yang berjudul “Optimasi
Metode Extreme Learning Machine dalam
Penentuan Kualitas Air Sungai Menggunakan
Algoritme Genetika”. Penelitian ini
menggunakan Algoritme Genetika dikarenakan algoritme ini cukup fleksibel untuk dihibridisasikan dengan algoritme lainnya (Gen & Cheng, 1997 disitasi dalam Mahmudy, 2015). Beberapa penelitian membuktikan bahwa Algoritme Genetika yang dimodifikasi atau
di-hybrid sangat efektif untuk menghasilkan solusi
yang lebih baik (Mahmudy, Marian & Luong 2013e, 2013f, 2014 disitasi dalam Mahmudy 2015). Penelitian ini bertujuan untuk mengoptimalkan kinerja atau meningkatkan akurasi dari penelitian yang sebelumnya (Azizah, 2016) yang memiliki nilai akurasi sebesar 87.89%, agar prediksi yang dihasilkan lebih akurat.
2. AIR SUNGAI
untuk kesejahteraan manusia serta kehidupan yang ada di dalam sungai itu sendiri. Karena itu sungai merupakan salah satu ekosistem yang penting bagi manusia (Siahaan et al., 2011 disitasi dalam Budiarta et al., 2016, p2).
Pemanfaatan air harus dilakukan secara bijak dengan mempertimbangkan kepentingan generasi sekarang dan yang akan datang. Akan tetapi, seiring meningkatnya proses pembangunan di berbagai bidang dan laju pertumbuhan penduduk yang semakin pesat menyebabkan pemanfaatan air tidak lagi dilakukan dengan baik. Hal ini memberikan dampak buruk yang mempengaruhi sifat fisik dan sifat kimia air sehingga menurunkan kualitas air. Pengelolaan sumber daya air bertujuan menyediakan air dalam jumlah yang cukup dengan kualitas yang sesuai dengan tujuannya (Azizah, 2016).
Kualitas air merupakan istilah yang menggambarkan kesesuaian atau tingkat kecocokan air untuk penggunaan tertentu, misalnya: air minum, rumah tangga, perikanan, pengairan/irigasi, peternakan, industri, rekreasi dan sebagainya. Kualitas air dapat diketahui dengan melakukan pengujian tertentu terhadap air tersebut. Pengujian yang umumnya dilakukan adalah uji kimia, fisik, biologi, atau uji wujud air (bau dan warna). Pada penelitian ini, akan digunakan parameter fisika yaitu TSS, parameter kimia organik yang meliputi BOD, COD, DO, pH dan parameter kimia anorganik yang meliputi fenol, minyak dan lemak.
3. EXTREME LEARNING MACHINE
Extreme Learning Machine (ELM)
merupakan metode pembelajaran baru dari JST. Metode ini diperkenalkan oleh Huang (2004). ELM adalah jaringan syaraf tiruan feedforward
sederhana dengan satu hidden layer yang lebih
dikenal dengan istilah Single Hidden Layer Feedforward Neural Networks (SLFNs).
Metode ELM ini dibuat untuk mengurangi
kelemahan-kelemahan JST feedforward
terutama mengenai learning speed. JST feedforward memiliki learning speed rendah,
dikarenakan JST feedforward menggunakan
slow gradient based learning algorithm untuk
melakukan training dan semua parameter pada jaringan ditentukan secara iteratif dengan menggunakan metode pembelajaran tersebut.
Pada ELM parameter-parameter seperti
input weight dan hidden bias dipilih secara
random dari nilai tertentu, sehingga ELM
memiliki learning speed yang cepat dan mampu
menghasilkan good generalization performance.
Dengan random pada range tertentu, bisa
menghindari hasil prediksi yg tidak stabil (Huang et al., 2005).
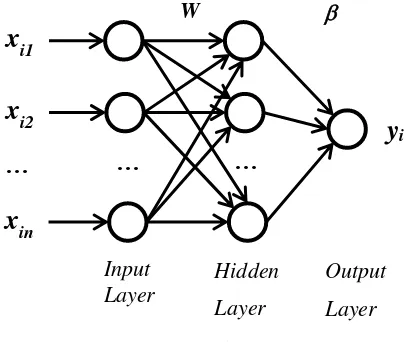
Secara umum model jaringan syaraf tiruan yang menggunakan ELM sebagai metode pembelajarannya menurut Huang, et al.. dapat dilihat pada Gambar 1.
Gambar 1 Struktur ELM
Metode ELM mempunyai model matematis yang berbeda dari jaringan syaraf tiruan
feedforward. Model matematis dari ELM lebih
sederhana dan efektif. Struktur dari metode ELM bisa dilihat pada Gambar 1.
Langkah-langkah perhitungan dengan metode ELM ini dibedakan menjadi 2 proses, yaitu proses training dan proses testing.
3.1 Proses Training
Sebelum digunakan untuk proses prediksi, ELM harus melalui proses training terlebih
dahulu. Tujuan dari proses ini adalah mendapatkan output weight dengan tingkat kesalahan yang rendah. Langkah-langkah proses
training metode ELM yaitu sebagai berikut: 1. Inisialisasi input weight dan bias dengan
bilangan acak yang kecil.
2. Menghitung semua keluaran di hidden layer
dengan menggunakan fungsi aktivasi. Perhitungan keluaran hidden layer
ditunjukkan pada Persamaan 1.
𝐻𝑖𝑗 = (∑ 𝑥𝑖𝑘. 𝑤𝑗𝑘 𝑇 𝑛
𝑘=1
) + 𝑏𝑗 (1)
Keterangan:
𝐻𝑖𝑗 = Matriks keluaran hidden
layer. W
Input Layer
Hidden
Layer
Output
Layer
y
i…
…
x
i1x
i2𝑖 = [1, 2, ..., N], dimana N adalah jumlah data.
𝑗 = [1, 2, ..., Ñ], dimana Ñ adalah jumlah hidden neuron.
𝑘 = Jumlah input neuron.
𝑤 = Bobot input dengan ukuran
ordo matriks, hidden neuron x input neuron.
𝑤𝑇 = Bobot input yang
di-transpose. 𝑥 = Data input.
𝑏 = Bias.
3. Setelah keluaran hidden layer (𝐻)
didapatkan, kemudian (𝐻) dihitung dengan
menggunakan fungsi aktivasi sigmoid biner yang ditunjukkan pada Persamaan 2.
𝑓(𝑥) =1 + 𝑒1 −𝑥 (2)
Keterangan:
𝑓(𝑥) = Fungsi aktivasi sigmoid
biner 2.71828183
𝑒 = Eksponensial
𝑥 = Data ke x.
4. Menghitung Matriks Moore-Penrose Generalized Inverse/ Moore-Penrose Pseudo Inverse (𝐻+) dari hasil keluaran hidden layer dengan fungsi aktivasi dengan
Persamaan 3.
𝐻+= (𝐻𝑇𝐻)−1𝐻𝑇 (3)
Keterangan:
𝐻+ = Matriks Moore-Penrose
Generalized Inverse.
𝐻𝑇 = Matriks H yang telah di
-transpose.
𝐻 = Matriks H hasil keluaran
hidden layer yang telah
diaktivasi.
(𝐻𝑇𝐻)−1 = Inverse dari perkalian matriks 𝐻𝑇dengan 𝐻.
5. Menghitung output weight dari hidden layer
ke output layer yang ditunjukkan pada
Persamaan 4.
𝛽 = 𝐻+𝑇 (4)
Keterangan:
𝛽 = Matriks output weight dari hidden layer ke output layer.
𝐻+ = Matriks Moore-Penrose
Generalized Inverse.
𝑇 = Matriks Target.
3.2 Proses Testing
Proses testing dilakukan berdasarkan input weight, bias, dan output weight yang sesuai dari
perhitungan training. Proses training bertujuan
untuk mengembangkan model ELM, sedangkan proses testing bertujuan untuk mengevaluasi
kemampuan ELM sebagai metode untuk memprediksi. Langkah-langkah proses testing
yaitu sebagai berikut:
1. Inisialisasi input weight dan bias yang
didapatkan pada perhitungan training.
2. Menghitung semua keluaran di hidden layer
dengan menggunakan fungsi aktivasi menggunakan Persamaan 1 dan 2.
3. Menggunakan hasil output weight dari hidden layer ke output layer dari proses training. Menghitung keluaran pada output layer yang merupakan hasil prediksi yang ditunjukkan pada Persamaan 5.
𝑦 = 𝐻𝛽 (5)
Keterangan:
𝑦 = Output hasil prediksi.
𝐻 = Keluaran hidden layer
dengan fungsi aktivasi.
𝛽 = Output weight.
4. ALGORITME GENETIKA
Algoritme genetika merupakan algoritme yang populer dan telah digunakan untuk menyelesaikan masalah-masalah optimasi yang bersifat kompleks di bidang fisika, biologi, ekonomi, sosiologi dan lain-lain. (Mahmudy, 2015). Algoritme genetika merupakan suatu metode yang menggunakan seleksi alam yang merupakan bagian utama dari prinsip evolusi sebagai dasar pemikiran untuk menyelesaikan suatu permasalahan. Prinsip ini dikemukakan oleh Charles Darwin, dimana tanpa menghiraukan prinsip dasar penurunan sifat, Darwin mengemukakan penggabungan kualitas induk pada generasi berikutnya, disamping itu bahwa individu yang mampu beradaptasi dengan lingkunganya akan mempunyai kesempatan hidup yang lebih besar.
paper yang berjudul “Adaption in Natural and Artificial System” mengunakan konsep dasar
algoritme genetika. Algoritme genetika bekerja dengan suatu populasi string dan melakukan proses pencarian nilai optimal secara parallel, dengan mengunakan operator genetika.
Algoritme genetika akan melakukan
rekombinasi antar individu. Algoritme genetika memiliki elemen dasar berupa string yang tersusun dari rangkaian substring (gen), yang masing-masing merupakan kode dari parameter dalam ruang solusi dimana suatu string
(kromosom) menyatakan kandidat solusi. Kumpulan string dalam populasi berkembang dari generasi ke generasi melalui operator genetika. Pada setiap iterasi, individu-individu (kromosom) dalam populasi itu akan dievolusi dan diseleksi untuk menentukan populasi pada generasi berikutnya. Populasi ini akan terus berulang sampai menemukan suatu parameter dengan nilai yang paling optimal sesuai dengan yang diinginkan
4.1 Representasi Kromosom
Gen adalah suatu sel dari suatu kromosom atau nilai yang terdapat dalam Algoritme Genetika ini dapat dibentuk oleh sebuah byte
bahkan tidak menutup kemungkinan suatu
string. Gen ini mewakili sebagian kecil dari
solusi permasalahan.
Individu dalam populasi disebut string, genotype atau kromosom-kromosom terdiri dari
unit-unit yang dinamakan gen, karakter,
decoder. Kromosom ini dapat mewakili suatu
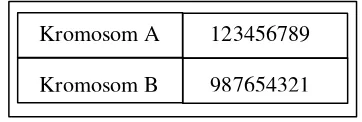
solusi, dimana dapat diilustrasikan dalam Gambar 2 dibawah ini:
Gambar 2 Representasi kromosom
4.2 Inisialisasi
Tahap inisialisasi ini bertujuan untuk membangkitkan himpunan solusi baru secara acak yang terdiri dari sejumlah string kromosom dan ditempatkan pada penampungan yang disebut dengan populasi. Pada tahap ini miu (µ)
yang menyatakan ukuran populasi atau popsize
harus ditentukan. Panjang string kromosom (stringLen) dihitung berdasarkan presisi variabel
dan solusi yang dicari (Mahmudy, 2015).
4.3 Reproduksi
Reproduksi merupakan sebuah proses yang dilakukan untuk menghasilkan keturunan (offspring) yang berasal dari induk kromosom
yang dipilih secara random. Terdapat dua operator genetika dalam reproduksi yaitu
crossover dan mutasi.
• Crossover
Persilangan pada algoritme genetika melibatkan dua buah individu yang dipilih secara acak menjadi parent yang akan membentuk kromosom baru. Proses ini diawali dengan penentuan tingkat crossover (crossover rate / cr). Nilai ini menentukan rasio dari keturunan (offspring) yang dihasilkan dari proses crossover. Hasil offspring dari proses
crossover diperoleh dengan mengalikan cr dengan ukuran populasi (popsize). Pada Extended Intermediate Crossover, dipilih 2 parents untuk melakukan perhitungan crossover menggunakan Persamaan 6.
𝐶(1) = 𝑃(1) + 𝛼(P(2) − P(1))
𝐶(2) = 𝑃(2) + 𝛼(P(1) − P(2)) (6)
Keterangan:
𝐶 = Hasil/Offspring crossover. 𝑃 = Parent.
𝛼 = alpha, nilai dibangkitkan secara random.
• Mutasi
Pada proses mutasi digunakan 1 kromosom parent sebagai inputannya yang
diambil secara random dan memperhitungkan
inputan mutation rate-nya. Sistem melakukan
perulangan untuk menghasilkan offspring dari
hasil mutasi sejumlah mutation rate dikalikan
dengan jumlah populasi awal (popsize). Proses
mutasi menggunakan metode random mutation
dilakukan dengan memilih satu posisi atau titik dari suatu kromosom pada parent terpilih.
Kemudian nilai dari posisi kromosom terpilih akan dimutasi menggunakan Persamaan 7. Setelah proses selesai maka akan tampil individu dari hasil mutasi kromosom yang dipilih secara
random.
𝑥′(𝑖) = 𝑥′(𝑖) + 𝑟(𝑚𝑎𝑥
𝑖− 𝑚𝑖𝑛𝑗) (7)
Keterangan:
𝑥′(𝑖) = Hasil/Offspring mutasi.
𝑟 = Nilai yang dibangkitkan secara random.
𝑚𝑎𝑥𝑖 = Nilai maksimal dari 1 kolom seluruh individu (kolom kromosom terpilih).
𝑚𝑖𝑛𝑗 = Nilai minimal dari 1 kolom seluruh individu (kolom kromosom terpilih). 123456789
987654321 Kromosom A
4.4 Evaluasi
Melakukan evaluasi pada data kromosom terhadap nilai fitness yang digunakan. Nilai fitness merupakan suatu ukuran baik tidaknya
suatu solusi yang dinyatakan sebagai satu individu, atau dengan kata lain nilai fitness
menyatakan nilai dari fungsi tujuan. Algoritme
genetika mempunyai tujuan untuk
memaksimalkan nilai fitness atau mencari nilai
fitness maksimal.
Pada Algoritme Genetika, suatu individu dievaluasi berdasarkan suatu nilai tertentu berdasarkan suatu fungsi tertentu sebagai ukuran nilai fitness-nya. Pada masalah
optimasi, jika solusi yang dicari adalah memaksimalkan fungsi h, maka nilai fitness
yang digunakan adalah nilai dari fungsi h
tersebut, yakni f = h. Sedangkan jika masalahnya
adalah meminimalkan fungsi h, maka fungsi h
tidak bisa digunakan secara langsung. Sehingga nilai fitness untuk masalah minimasi adalah f = 1/h, yang artinya semakin kecil nilai h, maka
semakin besar nilai f. Namun fungsi ini akan
bermasalah jika h bernilai 0, yang akan
mengakibatkan f bernilai tak hingga. Maka, h
perlu ditambah dengan sebuah bilangan. Sehingga rumus fitness bisa menghasilkan solusi
yang optimal. Fitness yang digunakan pada
penelitian ini ditunjukkan pada Persamaan 8.
𝒇(𝒙) = 𝐴𝑘𝑢𝑟𝑎𝑠𝑖𝑃𝑟𝑒𝑑𝑖𝑘𝑠𝑖𝐸𝐿𝑀 (8)
Di mana :
- 𝑥 adalah individu yang akan dihitung nilai
fitness-nya
4.5 Seleksi
Seleksi merupakan tahapan terakhir pada sekali proses evolusi yang dilakukan untuk memilih individu dari himpunan populasi dan
offspring yang akan dipertahankan hidup pada generasi berikutnya. Semakin besar nilai fitness
kromosom, maka semakin besar peluang kromosom tersebut terpilih. Hal ini dilakukan agar terbentuk generasi berikutnya yang lebih baik dari generasi sekarang (Mahmudy, 2015).
Metode seleksi yang digunakan dalam penelitian ini adalah metode seleksi elitism.
Metode seleksi elitism bekerja dengan cara mengumpulkan semua individu dalam populasi (parent) dan offspring dalam satu penampungan.
Kemudian melakukan sorting secara descending
(dari terbesar ke terkecil) pada nilai fitness nya.
Individu terbaik/tertinggi akan di ambil sesuai dengan jumlah populasi awal/popsize/miu (µ).
Individu terbaik dalam penampungan akan lolos untuk masuk dalam generasi berikutnya. Metode seleksi elitism menjamin individu yang terbaik
akan selalu lolos (Mahmudy, 2015).
5. METODE
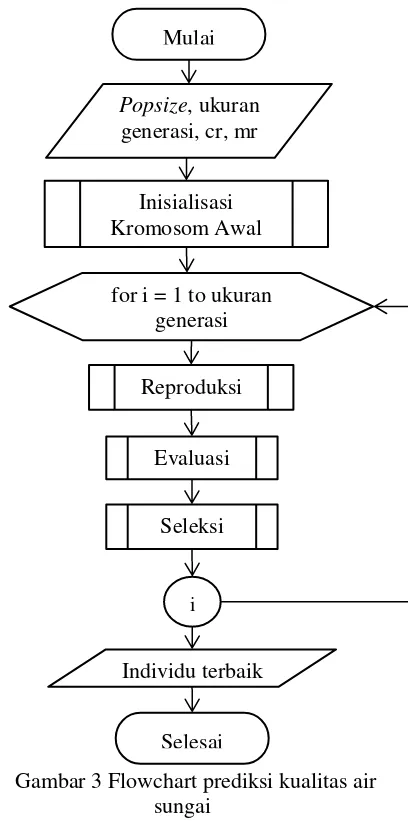
Langkah-langkah komputasi pada penelitian ini dapat dilihat pada flowchart Gambar 3.
Gambar 3 Flowchart prediksi kualitas air sungai
Komputasi ELM akan terjadi di dalam proses evaluasi untuk menghasilkan nilai
fitness.
Popsize, ukuran
generasi, cr, mr
Seleksi Inisialisasi Kromosom Awal
Evaluasi Reproduksi for i = 1 to ukuran
generasi Mulai
Individu terbaik i
Gambar 4 Flowchart prediksi kualitas air sungai
6. HASIL DAN PEMBAHASAN
6.1 Pengujian Popsize
Pengujian popsize bertujuan untuk mengetahui ukuran populasi yang menghasilkan tingkat akurasi terbaik. Pengujian popsize pada penelitian ini akan dilakukan dengan 5 variasi
popsize yang berbeda. Variasi popsize yang digunakan adalah kelipatan 10, dimulai dari 10 hingga 50. Pada masing-masing variasi popsize akan dilakukan percobaan
sebanyak 7 kali percobaan. Karena pada perhitungan Algoritme Genetika dan Extreme Learning Machine banyak melibatkan variabel
yang dibangkitkan secara random,
mengakibatkan nilai yang dihasilkan setiap kali
running program akan berbeda, sehingga
dilakukan beberapa kali percobaan untuk diambil nilai rata-rata akurasi terbaiknya.
Parameter lain yang digunakan untuk mendukung pengujian ini, diantaranya adalah ukuran generasi dan kombinasi cr mr. Selama pengujian sebanyak 7 kali percobaan, pengujian
popsize dengan ukuran yang sama, nilai dari
kedua parameter tersebut tidak boleh berubah/diganti. Nilai parameter yang digunakan pada pengujian ini yaitu ukuran generasi = 100, cr = 0.4 dan mr = 0.2. Hasil
pengujian variasi popsize dapat dilihat pada
Gambar 5.
Gambar 5 Hasil pengujian popsize
Berdasarkan grafik hasil pengujian popsize
di atas, popsize 20 menghasilkan rata-rata
akurasi tertinggi, yaitu 86.6666. Pada grafik diatas ditunjukkan ketidakstabilan rata-rata akurasi, akan tetapi pada ukuran generasi 20-50 mulai ditunjukkan kestabilan rata-rata akurasinya. Pada penelitian ini dapat disimpulkan bahwa semakin besar popsize-nya,
akan semakin rendah rata-rata akurasi yang dihasilkan. Menurut Mahmudy (2015), semakin besar nilai dari popsize, akan memengaruhi
waktu komputasi dan menyebabkan kinerja Algoritme Genetika meningkat bahkan melakukan eksplorasi lebih luas lagi. Oleh karena itu, Algoritme Genetika memiliki kemungkinan untuk mengeksplorasi area yang tidak optimum.
6.2 Pengujian Ukuran Generasi
Pengujian ukuran generasi bertujuan untuk mengetahui ukuran generasi yang menghasilkan tingkat akurasi terbaik. Pengujian ukuran generasi pada penelitian ini akan dilakukan dengan 5 variasiukuran generasi yang berbeda. Variasi ukuran generasi yang digunakan adalah kelipatan 10, dimulai dari 10 hingga 50. Pada masing-masing variasi ukuran generasi akan dilakukan percobaan sebanyak 7 kali percobaan.
Parameter lain yang digunakan untuk mendukung pengujian ini, diantaranya adalah
popsize dan kombinasi cr mr. Selama pengujian sebanyak 7 kali percobaan, pengujian ukuran generasi dengan ukuran yang sama, nilai dari kedua parameter tersebut tidak boleh berubah/diganti. Nilai parameter yang digunakan pada pengujian ini yaitu popsize = 50,
83,3334 86,6666 86 85,3334
82,6666
77.523480.3809 79.2381 77,714477.1429
70 75 80 85 90
10 20 30 40 50
Pengujian
Popsize
Rata-rata Akurasi Terbaik Rata-rata Akurasi Total Extreme
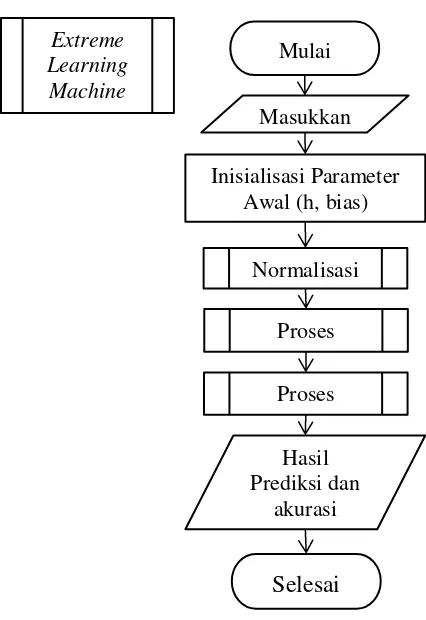
Learning Machine
Mulai
Masukkan
Inisialisasi Parameter Awal (h, bias)
Proses
Training
Normalisasi
Selesai
Hasil Prediksi danakurasi Proses
cr = 0.4 dan mr = 0.2. Hasil pengujian variasi
popsize dapat dilihat pada Gambar 6.
Gambar 6 Hasil pengujian ukuran generasi
Berdasarkan grafik hasil pengujian ukuran generasi di atas, ukuran generasi 20 menghasilkan rata-rata akurasi tertinggi, yaitu 86.6668. Grafik diatas menunjukkan ketidakstabilan rata-rata akurasi. Pada ukuran generasi 10 hingga 40, rata-rata akurasi mengalami penurunan, sedangkan pada ukuran generasi 50 mulai ditunjukkan peningkatan rata-rata akurasinya. Semakin banyak ukuran generasinya bukan berarti solusi yang dihasilkan akan optimal. Pada jumlah tertentu (saat mulai stabil), ukuran generasi memiliki kemungkinan lebih tinggi dalam menghasilkan solusi yang optimal. Menurut Mahmudy (2015), semakin besar nilai dari ukuran generasi, akan
memengaruhi waktu komputasi dan
menyebabkan kinerja Algoritme Genetika meningkat bahkan melakukan eksplorasi lebih luas lagi. Oleh karena itu, Algoritme Genetika memiliki kemungkinan untuk mengeksplorasi area yang tidak optimum.
6.3 Pengujian Kombinasi cr dan mr
Pengujian kombinasi cr (crossover rate) dan
mr (mutation rate) bertujuan untuk mengetahui
ukuran kombinasi cr dan mr yang menghasilkan tingkat akurasi terbaik. Pengujian kombinasi cr dan mr pada penelitian ini akan dilakukan dengan 11 variasi kombinasi cr dan mr yang berbeda. Pada masing-masing variasikombinasi cr dan mr akan dilakukan percobaan sebanyak 7 kali percobaan.
Parameter lain yang digunakan untuk mendukung pengujian ini, diantaranya adalah
popsize dan ukuran generasi. Selama pengujian sebanyak 7 kali percobaan, pengujiankombinasi
cr dan mr dengan kombinasi yang sama, nilai dari kedua parameter tersebut tidak boleh berubah/diganti. Nilai parameter yang digunakan pada pengujian ini yaitu popsize = 20,
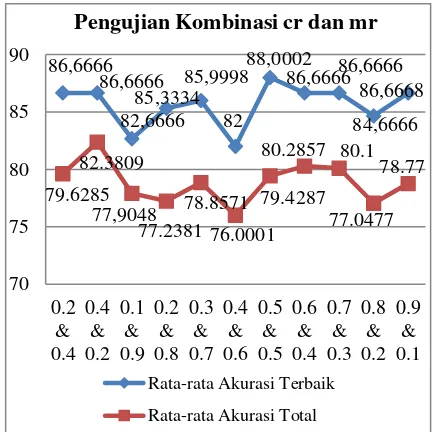
dan ukuran generasi = 20. Hasil pengujian variasi popsize dapat dilihat pada Gambar 7.
Gambar 7 Hasil pengujian kombinasi cr dan
mr
Berdasarkan grafik hasil pengujian kombinasi cr dan mr di atas, kombinasi cr = 0.5 dan mr = 0.5 menghasilkan rata-rata akurasi tertinggi, yaitu 88.0002. Pada grafik diatas ditunjukkan ketidakstabilan rata-rata akurasi. Semakin banyak ukuran generasinya bukan berarti solusi yang dihasilkan akan optimal. Pada jumlah tertentu (saat mulai stabil), kombinasi cr mr memiliki kemungkinan lebih tinggi dalam menghasilkan solusi yang optimal. Menurut Mahmudy, 2015, setiap permasalahan akan memiliki kombinasi nilai cr dan mr yang berbeda-beda. Nilai cr yang terlalu rendah akan mengakibatkan tidak ditemukannya solusi optimal dari permasalahan, sedangkan nilai mr yang terlalu rendah akan mengakibatkan konvergensi dini.
7. KESIMPULAN DAN SARAN
Metode ELM-GA dapat digunakan untuk menentukan kualitas air sungai. Pada penelitian ini, input weight/bobot awal dioptimasi
menggunakan Algoritme Genetika. Proses optimasi dilakukan dengan melakukan perhitungan menggunakan Algoritme Genetika. Pada tahap evaluasi, nilai fitness dihitung Pengujian Kombinasi cr dan mr
Rata-rata Akurasi Terbaik
menggunakan metode Extreme Learning Machine, dengan individu gabungan sebagai
bobot awal atau input weight-nya secara
bergantian.
Berdasarkan pengujian yang telah dilakukan pada bab sebelumnya, ketiga pengujian tersebut mempengaruhi waktu eksekusi dan nilai akurasi yang dihasilkan. Semakin besar popsize dan ukuran generasinya akan membutuhkan waktu eksekusi yang cukup lama. Banyaknya popsize dan generasi tidak selalu menghasilkan solusi yang optimal. Solusi optimal yang didapatkan oleh penelitian ini berdasarkan pengujian yang telah dilakukan, diantaranya parameter popsize dengan ukuran 20 dan nilai akurasi 86.6666%, parameter ukuran generasi sejumlah 20 dan nilai akurasi 86.6668% serta parameter kombinasi cr dan mr mendapatkan nilai akurasi 88.0002% dengan kombinasi cr = 0.5 dan mr = 0.5.
Akurasi pada penelitian ini mencapai 88.0002%, meningkat 0.1102% dari penelitian sebelumnya (Azizah, 2016) yang dapat menyentuh angka 87.89%.
Pada penelitian yang akan datang diharapkan akan dilakukan pengembangan atau penggabungan metode lain dengan ELM seperti
Optimally Pruned Extreme Learning Machine
(OPELM), Parallel Layer Extreme Learning Machine (PL-ELM), Radial Basis Function Extreme Learning Machine (RBF-ELM), dan
metode modifikasi ELM lain dapat digunakan pada penelitian selanjutnya untuk meningkatkan hasil klasifikasi.
Pada penelitian selanjutnya juga diharapkan peneliti dapat melakukan seleksi fitur untuk meningkatkan tingkat akurasi prediksi dalam penentuan kualitas air sungai. Seleksi fitur dapat
dilakukan untuk mengurangi jumlah
fitur/parameter yang tidak mempengaruhi tingkat akurasi atau menghapus beberapa data yang kurang atau tidak relevan.
DAFTARPUSTAKA
Agustina, Irwin Dwi, Wiwik Anggraeni, S.Si, M.Kom, dan Ahmad Mukhlason, S.Kom, M.Sc. 2010. Penerapan Metode Extreme Learning Machine untuk Peramalan Permintaan. Institut Teknologi Sepuluh Nopember. Surabaya.
Azizah, Alvia Nur. 2016. Penentuan Kualitas Air Sungai Menggunakan Metode Extreme Learning Machine. Fakultas Ilmu Komputer Universitas Brawijaya. Malang.
Budiarta, Aprilyan David, Rizqy Ajie Setiawan, Siska Putri Nuralisa dan Umi Hidayati. 2016. Kajian Kualitas Air Dengan Menggunakan Analisis Parameter Fisik Dan Kimia Pada Sungai Desa Wiyurejo Kecamatan Pujon Kabupaten Malang. Fakultas Ilmu Sosial Universitas Negeri Malang. Malang.
Huang, G.B., Zhu, Q.Y., dan Siew, C.K. 2004. Extreme Learning Machine : A New Learning Scheme of Feedforward neural Networks. Proceedings of International Joint Conference on Neural Networks. Budapest, Hungary, 25-29 Juli 2004. Singapura: Nanyang Avenue.