PREDIKSI CROP VARIABEL TANAMAN PADI
PADA DATA HYPERSPECTRAL MENGGUNAKAN
ALGORITME BACKPROPAGATION NEURAL NETWORK
ERICSON SIREGAR
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2010
PREDIKSI CROP VARIABEL TANAMAN PADI
PADA DATA HYPERSPECTRAL MENGGUNAKAN
ALGORITME BACKPROPAGATION NEURAL NETWORK
ERICSON SIREGAR
Skripsi
Sebagai salah satu syarat untuk memperoleh
Gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
BOGOR
2010
ABSTRACT
ERICSON SIREGAR. Prediction Of Paddy Rice Crop Variable In Hyperspectral Data Using Backpropagation Neural Network Algorithm. Under Direction of HARI AGUNG ADRIANTO AND MUHAMAD SADLY.
Hyperspectral is a new technology in remote sensing which exploits hundreds of bands. Pusat Teknologi Inventarisasi Sumber Daya Alam Badan Pengkajian dan Penerapan Teknologi (PTISDA BPPT) applies hyperspectral in agriculture for yearly yield prediction. In this research, Leaf Area Index (LAI), number of chlorophyll (SPAD), and yearly paddy yield has been predicted with hyperspectral data using backpropagation neural network (BPNN) algorithm. The regions used are Indramayu and Subang; the growth periods of paddy are vegetative, reproductive and ripening, while the heights of the spectral acquisition are 10 cm, 50 cm, and Hymap (2000 m). The data was obtained in cooperation between PTISDA BPPT and ERSDAC Japan.
In this study, three test procedures were conducted using backpropagation neural network algorithm, where the first and second procedures used Weka to predict the R2 and RMSE of LAI, SPAD, and yield. Prediction results show high accuracy for LAI but not for SPAD and yield. The third procedure used IDL for prediction yield RMSE, with a satisfactory result : an error value of 0.10153786.
Judul : Prediksi Crop Variabel Tanaman Padi Pada Data Hyperspectral Menggunakan Algoritme Backpropagation Neural Network
Nama : Ericson Siregar
NRP : G64061804
Menyetujui:
Pembimbing I,
Hari Agung Adrianto, S.Kom, M.Si NIP 197609172005011001
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc. NIP. 19601126 198601 2 001
Tanggal Lulus:
Pembimbing II,
PRAKATA
Puji syukur penulis panjatkan kepada Tuhan YME atas segala rahmat dan karunia-Nya sehingga tulisan ini berhasil diselesaikan. Tulisan ini merupakan hasil penelitian penulis sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer di FMIPA, IPB.
Tulisan ini merupakan hasil penelitian yang bekerja sama dengan Pusat Teknologi Inventarisasi Sumber Daya Alam - Badan Pengkajian dan Penerapan Teknologi (PTISDA BPPT), yang beralamat di Gedung 2 Lantai 19 jalan M.H. Thamrin no 8 Jakarta Pusat. Kegiatan penelitian tersebut dilaksanakan mulai Maret 2010 sampai dengan Juli 2010.
Pada kesempatan ini penulis ingin mengucapkan terima kasih kepada :
1. Orang tua tercinta, Bapak Nelson Siregar, SE dan Ibu Herlina Mulyani serta adik tersayang, Andreas Siregar untuk doa, kasih sayang, dan cinta kasih.
2. Bapak Hari Agung Adrianto, S.Kom, M.Si dan Bapak Dr.Ir.Muhamad Sadly, M.Eng selaku dosen pembimbing tugas akhir. Terima kasih atas kesabaran dan dukungan dalam penyelesaian tugas akhir ini.
3. Dr. Sri Nurdiati, MSc selaku Ketua Departemen Ilmu Komputer dan sebagai dosen penguji, serta seluruh staf Departemen Ilmu Komputer FMIPA IPB.
4. Bapak Dr. Anto, bapak Ir. Sidik, dan bapak Dr. M. Evri terima kasih untuk masukan, motivasi,
share dan bimbingannya.
5. Teman-teman di BPPT Yohan, Yuli, dan Agus. Terima kasih atas semangat dan kebersamaannya selama penyelesaian tugas akhir ini.
6. Sahabat-sahabatku Ilkomerz 43. Terima kasih atas motivasi dan kebersamaannya selama ini. 7. Keluargaku Naposobulung HKBP Bogor terima kasih untuk motivasi dan dukungan selama ini. 8. Seluruh pihak yang turut membantu baik secara langsung maupun tidak langsung dalam
pelaksanaan tugas akhir.
Penulis menyadari bahwa pelaksanaan penelitian ini masih jauh dari kesempurnaan, namun besar harapan penulis bahwa apa yang telah dikerjakan dapat memberikan manfaat bagi semua pihak.
Bogor, Oktober 2010
v
RIWAYAT HIDUP
Penulis dilahirkan di Bogor pada tanggal 4 September 1988 yang merupakan anak pertama dari dua bersaudara dengan ayah bernama Nelson Siregar dan Ibu bernama Herlina Mulyani. Pada tahun 2006 lulus dari Sekolah Menengah Atas Negeri 5 Bogor dan diterima di Institut Pertanian Bogor melalui jalur USMI atau Undangan Seleksi Masuk IPB pada tahun yang sama. Setelah mengikuti kuliah matrikulasi selama satu tahun, penulis diterima di Departemen Ilmu Komputer.
vi
DAFTAR ISI
Halaman
DAFTAR GAMBAR ... vii
DAFTAR TABEL ... vii
DAFTAR LAMPIRAN ... vii
PENDAHULUAN Latar Belakang ... 1 Tujuan ... 1 Ruang Lingkup ... 1 Manfaat ... 2 TINJAUAN PUSTAKA Crop Variabel Tanaman Padi ... 2
Hyperspectral ... 2
Jaringan Syaraf Tiruan ... 2
Multilayer Perceptron ... 3
Backpropagation ... 3
Supervised Learning ... 5
Root Mean Square Error (RMSE) ... 5
Koefisien Determinasi (R2) ... 5
Cross Validation ... 5
Supplied Test Set ... 5
METODE PENELITIAN Studi Pustaka ... 5
Pengenalan Data ... 6
Praproses ... 6
Pembuatan Prosedur Uji Data ... 8
Pembagian dan Penyesuaian Data ... 8
Data Latih... 8
Data Uji ... 8
Rancangan Eksperimen ... 8
Lingkungan Pengembangan ... 8
HASIL DAN PEMBAHASAN Cross Validation 5 Fold Data Indramayu dan Subang ... 9
Supplied Test Set Data Indramayu dan Subang ... 11
8-Fold Cross Validation ... 12
Evaluasi dan Analisis Hasil ... 12
KESIMPULAN DAN SARAN Kesimpulan ... 12
Saran ... 13
DAFTAR PUSTAKA... 13
vii
DAFTAR GAMBAR
Halaman
1 Hubungan perubahan panjang gelombang spektrum gandumdengan LAI ... 1
2 Hubungan perubahan panjang gelombang spektrum gandum dengan kandungan klorofil ... 1
3 Grafik perbandingan reflectance ... 2
4 Model backpropagation neural network ... 4
5 Tahapan metode penelitian ... 6
6 Diagram alur proses data. ... 7
7 Contoh file reflectance pada Data 0.0 ... 7
8 Desain model backpropagation. ... 8
9 Grafik R2 LAI. ... 9
10 Grafik RMSE LAI. ... 9
11 Grafik R2 SPAD ... ..10
12 Grafik RMSE SPAD ... 10
13 Grafik R2 Yield ... 10
14 Grafik RMSE Yield ... 11
15 Grafik batang perbandingan R2 Hymap. ... 11
16 Grafik batang perbandingan RMSE Hymap. ... 11
DAFTAR TABEL
Halaman 1 Nama data dan tahap praproses ... 62 Jumlah data untuk prosedur uji ... 8
3 Prediksi nilai R2 LAI dengan Cross Validation 5 fold ... 9
4 Prediksi nilai RMSE LAI dengan Cross Validation 5 fold ... 9
5 Prediksi nilai R2 SPAD dengan Cross Validation 5 fold ... 9
6 Prediksi nilai RMSE SPAD dengan Cross Validation 5 fold ... 10
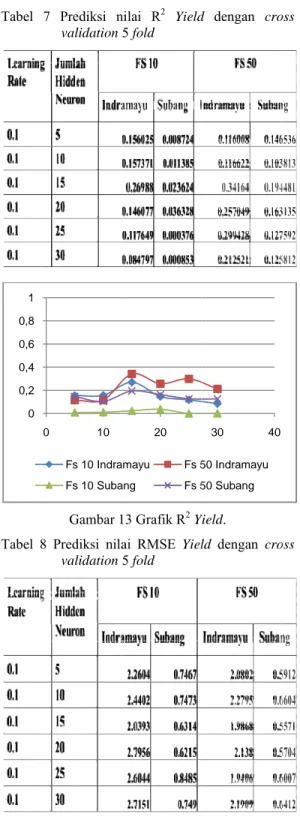
7 Prediksi nilai R2 Yield dengan Cross Validation 5 fold ... 10
8 Prediksi nilai RMSE Yield dengan Cross Validation 5 fold ... 10
9 Prediksi nilai R2 LAI, SPAD, dan Yield dengan Supplied Test set data Hymap ... 11
10 Prediksi nilai RMSE LAI, SPAD, dan Yield dengan Supplied Test set data Hymap ... 11
DAFTAR LAMPIRAN
Halaman 1 Contoh reflectance data 0.1 ... 152 Contoh reflectance data 0.2 ... 15
3 Contoh reflectance data 1.0 ... 15
4 Contoh tampilan source code backpropagation neural network pada IDL ... 16
5 Grafik pola sebaran LAI ... 16
6 Grafik pola sebaran SPAD ... 17
7 Grafik pola sebaran Yield ... 17
8 Hasil 8-fold cross validation data hymap terhadap data Yield ... 18
1
PENDAHULUAN
Latar Belakang
Teknologi hyperspectral merupakan teknologi baru di dunia penginderaan jarak jauh (remote
sensing) yang menarik perhatian Pusat Teknologi
Inventarisasi Sumber Daya Alam (PTISDA) Badan Pengkajian dan Penerapan Teknologi (BPPT) untuk melakukan pengkajian, penerapan, dan pengembangan teknologi untuk mendukung program ketahanan pangan nasional.
Hyperspectral merupakan lanjutan dari
teknologi konvensional yaitu multispectral remote
sensing. Teknologi tersebut secara signifikan
menambah kekuatan remote sensing, dimulai dari determinasi dan identifikasi orientasi pemecahan suatu permasalahan. Sekarang PTISDA BPPT bekerjasama dengan Earth Remote Sensing Data
Analysis Center (ERSDAC) Jepang membuat
program aplikasi teknologi hyperspectral remote
sensing untuk pertanian yang disebut proyek
Hypersri. Tujuan proyek tersebut yaitu untuk membangun model prediksi produktifitas padi berbasis teknologi hyperspectral. Data yang dimiliki BPPT terdiri atas data laboratorium variabel-variabel pertanian yaitu indeks luas permukaan daun (leaf area index/LAI), jumlah kandungan klorofil (SPAD), dan hasil panen (Yield).
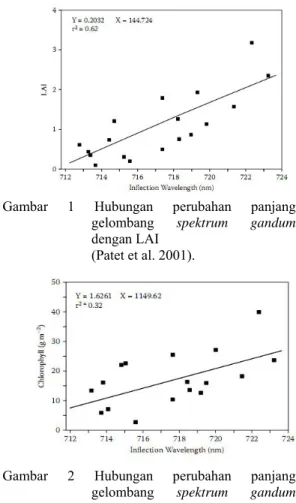
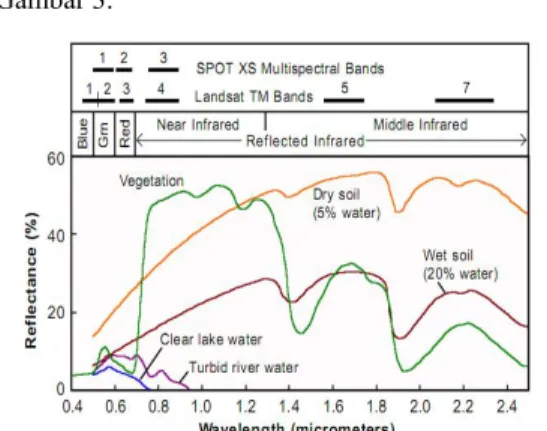
Patet et al. (2001) dalam Smith (2006) melakukan penelitian untuk menemukan hubungan antara perubahan panjang gelombang spektrum gandum dan leaf area index (LAI) atau indeks luas permukaan daun dan juga hubungan antara perubahan panjang gelombang spektrum gandum dengan kandungan klorofil. Hubungan linear dari perubahan panjang gelombang dengan LAI dan kandungan klorofil gandum mengindikasikan bahwa resolusi tinggi data spektral dapat digunakan untuk memperkirakan kondisi pertumbuhan hasil panen dan mengidentifikasi tekanan hasil panen.
Grafik hubungan antara panjang gelombang spektrum gandum dengan LAI dapat dilihat pada Gambar 1 dan hubungan antara panjang gelombang spektrum gandum dengan kandungan klorofil dapat dilihat pada Gambar 2.
Dasar data mengenai penelitian hyperspectral yang diperoleh dalam penelitian ini akan diterapkan metode Backpropagation Neural Network untuk memprediksi indeks luas permukaan daun (LAI), SPAD, dan Yield menggunakan nilai spektral tanaman padi.
Gambar 1 Hubungan perubahan panjang gelombang spektrum gandum
dengan LAI (Patet et al. 2001).
Gambar 2 Hubungan perubahan panjang gelombang spektrum gandum
dengan kandungan klorofil (Patet et al. 2001).
Tujuan
Tujuan dari penelitian ini yaitu memprediksi nilai leaf area index (LAI), jumlah klorofil daun (SPAD), dan hasil panen (Yield) tanaman padi berbasiskan data hyperspectral dengan menggunakan algoritme Backpropagation Neural
Network (BPNN).
Ruang Lingkup
Data yang digunakan yaitu data hyperspectral dan data crop variabel milik PTISDA BPPT yang bekerja sama dengan ERSDAC Jepang. Data
hyperspectral yang digunakan terdiri atas nilai-nilai reflectance dan panjang gelombang padi. Pada data
yang akan digunakan, penentuan kelas telah ditentukan berdasarkan wilayah, jenis padi, masa pertumbuhan, dan ketinggian pengambilan data. Wilayah yang digunakan yaitu Indramayu dan Subang, masa pertumbuhan tanaman padi yaitu vegetatif, reproduktif, dan ripening, sedangkan ketinggian pengambilan data spektral yaitu 10 cm, 50 cm, dan Hymap (2000 m). Data untuk ketinggian 10 dan 50 cm disebut data Field_Spect 10 dan Field_Spect 50. Hasil prediksi dievaluasi
2 menggunakan nilai koefisien determinasi (R2) dan
sebagai pembanding kebaikan hasil prediksi juga digunakan Root Mean Square Error (RMSE).
Manfaat
Manfaat dari penelitian ini yaitu membantu penelitian hyperspectral untuk mendapatkan hasil akurasi dari algoritme Backpropagation Neural
Network (BPNN).
TINJAUAN PUSTAKA
Crop Variabel Tanaman Padi
LAI (Leaf Area Index), merupakan pengukuran luas indeks daun tanaman padi. Pengukuran rasio total vegetasi permukaan daun padi dibagi dengan vegetasi atas permukaan tanah. SPAD (Special
Products Analysis Division), adalah transmisi
klorofil yang tinggi dengan jangkauan inframerah pendek cahaya berwarna merah, karena tumbuhan hijau menyerap radiasi yang terlihat untuk fotosintesis. Yield (hasil panen), data hasil panen yang diambil saat masa panen oleh mantri tani setempat. Hasil panen akan digunakan sebagai pengujian data.
Hyperspectral
Hyperspectral remote sensing merupakan suatu
teknologi pencitraan jarak jauh yang merupakan adaptasi dari multispectral remote sensing.
Multispectral menghasilkan gambar dengan
beberapa band panjang gelombang yang relatif luas sedangkan hyperspectral mengumpulkan data gambar secara bersamaan dalam puluhan atau ratusan band spektral yang berdekatan.
Data citra hyperspectral dihasilkan oleh alat yang disebut imaging spectrometer yang melibatkan konvergensi dua teknologi yaitu spektroskopi dan pencitraan jauh (Smith 2006). Smith (2006) menyatakan bahwa spektrum gambar hasil penyesuaian sensor, atmosfer, dan efek medan dibandingkan dengan spektrum reflectance lapangan atau laboratorium untuk memetakan material permukaan objek yang terkait.
Pada umumnya, sensor mengumpulkan data secara pasif atau aktif. Sensor pasif mengumpulkan dan merekam energi elektromagnetik yang dipantulkan atau dipancarkan oleh permukaan suatu fitur tertentu, khususnya terusan dari sebuah lensa optik. Sensor aktif menghasilkan energi pemiliknya dan kemudian mengumpulkan sinyal yang dipantulkan dari permukaan bumi.
Pada citra hyperspectral sumber data memasukkan 10 atau lebih data band. Lebar band data memiliki range 1 sampai 15 nanometer, sedangkan pada multispectral lebar band berkisar antara 50 sampai 120 nanometer. Data
multispectral bisa memiliki celah/renggang antara spectral band yang dikumpulkan, sedangkan data hyperspectral memiliki kumpulan band yang
kontinyu (Borengasser et al. 2008).
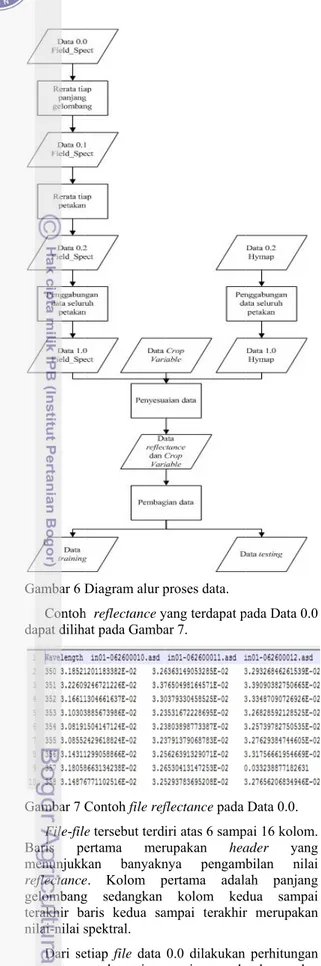
Reflectance adalah persentase cahaya yg di
pantulkan oleh suatu material (Borengasser et al. 2008). Nilai reflectance bervariasi untuk setiap benda dengan bahan yang berbeda. Grafik perbandingan nilai reflectance dapat dilihat pada Gambar 3.
Gambar 3 Grafik perbandingan reflectance (Smith 2006).
Jaringan Syaraf Tiruan (Artificial Neural
Network)
Neural Network (NN) adalah suatu prosesor
yang melakukan pendistribusian secara besar-besaran, yang memiliki kecenderungan alami untuk menyimpan suatu pengenalan yang pernah dialaminya. Dengan kata lain NN memiliki kemampuan untuk melakukan pembelajaran dan pendeteksian terhadap suatu objek. Secara mendasar, sistem pembelajaran adalah proses penambahan pengetahuan pada NN yang bersifat kontinuitas, sehingga pada saat digunakan pengetahuan tersebut dieksploitasikan secara maksimal dalam mengenali suatu objek.
Menurut Kusumadewi (2006), jaringan syaraf tiruan merupakan salah satu representasi buatan dari otak manusia yang selalu mencoba untuk mensimulasikan proses pembelajaran pada otak manusia tersebut. Jaringan syaraf tiruan dikembangkan sebagai model matematis dari syaraf biologis dengan asumsi bahwa :
1. Pemrosesan terjadi pada elemen-elemen sederhana yang disebut neuron.
2. Sinyal dilewatkan antar neuron melalui penghubung.
3. Setiap penghubung memiliki bobot yang mengalikan sinyal yang lewat.
4. Setiap neuron memiliki fungsi aktivasi yang menentukan nilai sinyal output.
3 Jaringan syaraf dapat digolongkan menjadi
berbagai jenis berdasarkan pada arsitekturnya, yaitu pola hubungan antara neuron-neuron, dan algoritme
trainingnya, yaitu cara penentuan nilai bobot pada
penghubung.
Multilayer Perceptron
Multilayer Perceptron adalah jaringan syaraf
tiruan feedforward yang terdiri atas sejumlah neuron yang dihubungkan oleh weight penghubung. Neuron-neuron tersebut disusun dalam lapisan-lapisan yang terdiri atas satu lapisan-lapisan input (input
layer), satu atau lebih lapisan tersembunyi (hidden layer), dan satu lapisan output (output layer).
Menurut Riedmiller (1994, p50), lapisan input menerima sinyal dari luar, kemudian melewatkannya ke lapisan tersembunyi pertama, yang diteruskan sehingga akhirnya mencapai lapisan output. Proses yang terjadi pada multilayer
perceptron neural network, adalah sebagai berikut: Input, proses ini merupakan bagian dari sistem
kerja secara keseluruhan, karena proses masukan digunakan untuk menunjang pada proses pembelajaran serta proses pengujian. Pada proses ini, masukan diklasifikasikan berdasarkan keinginan pengguna, dimana bentuk masukan dapat berupa nilai logic atau bilangan biner ( 1 atau 0 ), atau juga bisa berupa nilai angka atau bilangan real (12.5 atau 100) dapat juga melakukan proses dengan menggunakan bilangan negatif.
Proses pembelajaran, pada bagian ini merupakan sisi kelebihan dari metode neural
network, dimana setiap permasalahan yang akan
dihadapi dapat dipecahkan dengan melalui tahapan pembelajaran, seperti halnya otak manusia yang secara sifat biologis, memiliki kemampuan untuk mempelajari hal-hal yang baru. Memang pada dasarnya, neural network ini dibuat untuk dapat mempelajari sesuatu hal yang baru sehingga mampu melakukan penganalisisan tanpa menggunakan suatu rumusan yang baku. Proses pembelajaran ini sangat mempengaruhi sensitifitas kemampuan dalam melakukan penganalisisan, semakin banyak bahan atau masukan sebagai pembelajaran maka semakin mudah dan sensitif dalam melakukan analisis. Umumnya untuk membahas hal-hal yang cukup kompleks,
multilayer perceptron neural network memiliki hidden neuron yang digunakan untuk mengimbangi
setiap permasalahan yang dihadapi, umumnya untuk melakukan penganalisisn pada hal-hal yang rumit, rancangan neural network yang dibuat minimal memiliki tiga layer, namun hal ini tergantung pada tingkat kompleksitas yang dihadapi.
Proses perhitungan, saat pembelajaran Proses ini melibatkan dua faktor penting, yaitu masukan dan keluaran yang ditentukan. Keluaran tersebut merupakan bagian dari sistem atau metode pembelajaran yang dinamakan supervised learning, dengan demikian setiap masukan memiliki keluaran yang nantinya dijadikan sebagai acuan pembelajaran. Hal inilah yang membuat neural
network melakukan penganalisisan, selain
banyaknya masukan yang diberikan, proses pembelajaran yang dilakukan secara berulang pun menunjang kemampuan neural network saat menganalisis.
Output, bagian ini merupakan proses yang
digunakan untuk mengetahui seberapa besar pengaruh pembelajaran terhadap keluaran yang diinginkan.
Backpropagation
Backpropagation adalah istilah dalam
penggunaan metode multilayer perceptron untuk melakukan proses update pada nilai vektor weight dan bias. Dalam penelitian ini pendekatan yang digunakan untuk update adalah Gradient Descent
Backpropagation. Adapun bentuk metode weight
ini memiliki beberapa macam, antara lain adalah sebagai berikut :
Gradient Descent Backpropagation (GD)
Metode steepest descent, juga dikenal sebagai
gradient descent method, merupakan salah satu dari
teknik lama untuk meminimalkan fungsi yang didefinisikan pada ruang input multidimensi. Metode ini membentuk dasar bagi banyak metode langsung yang digunakan dalam mengoptimalkan masalah yang terbatas maupun yang tidak terbatas. Walaupun metode ini konvergensinya lambat, tetapi metode ini paling sering digunakan dalam teknik optimasi nonlinear karena kesederhanaanya. Metode ini merupakan proses update untuk nilai
weight dan bias dengan arah propagasi fungsinya
selalu menurunkan nilai weight sebelumnya. Bentuk vektor weight tersebut berlaku seperti metode berikut :
Wk+1 = wk – α . gk ,
dengan α merupakan learning rate dan g merupakan gradient yang berhubungan dengan nilai error yangdiakibatkan oleh weight tersebut.
Gradient Descent Backpropagation dengan Momentum (GDM)
Penggunaan Momentum pada metode ini
memberikan nilai tambah dimana hasil update diharapkan tidak berhenti pada kondisi yang dinamakan Local Minimum. Update dilakukan sehingga proses penelusuran mencapai nilai minimum yang paling puncak dalam pengertian nilai error yang paling kecil dapat tercapai.
4
Variable Learning Rate Backpropagation dengan Momentum (GDX)
Penggunaan metode ini bertujuan untuk mempercepat waktu penyelesaian sehingga proses mendapatkan nilai error yang paling kecil dapat tercapai dengan cepat serta penelusuran yang lebih singkat. Sebaliknya jika nilai yang digunakan dalam praktisnya maka hasil yang didapatkan umumnya memperlambat proses penelusuran nilai
error yang paling kecil. Dalam penggunaan metode
ini para peniliti biasanya menggunakan cara memperbesar nilai dari Variabel Learning Rate saat hasil yang dicapai jauh dari target, dan sebaliknya saat hasil yang dicapai dekat dengan nilai target.
Conjugate Gradient Backpropagation (CGP) Conjugate Gradient Backpropagation memiliki
perbedaan dibandingkan dengan metode GD yaitu pada saat melakukan proses update, dimana untuk metode GD proses tersebut dilakukan setiap penggunaan rumus sedangkan pada proses CGX,
update dilakukan setiap iterasi dilakukan. Quasi-Newton Backpropagation (BPGS)
Metode Newton ini merupakan improvisasi dari metode CGX, dimana pencapaian nilai konfigurasi dapat dilakukan lebih cepat.
Algoritme backpropagation dijalankan dengan melakukan generalisasi hukum pembelajaran Widrow-Hoff yang dikenal sebagai delta rule atau metode Least Mean Square (LMS). LMS melibatkan teknik gradient descent, teknik dimana parameter setiap bobot bergerak dalam arah yang berlawanan dengan error gradient. Setiap langkah menuruni gradient menghasilkan error yang lebih kecil sampai suatu error minimum tercapai. Fungsi aktivasi yang dipergunakan pada JST dengan memakai algoritme backpropagation Umumnya fungsi aktivasi yang dipergunakan adalah fungsi Sigmoid. Model backpropagation neural network dapat dilihat pada Gambar 4.
Gambar 4 Model backpropagation neural network. Prosedur pembelajaran multilayer perceptron terdiri atas dua fase: forward pass dan backward
pass.
Forward Pass, Dalam fase ini dilakukan
perhitungan dari input layer ke arah output layer. Sebuah input data dimasukkan ke multilayer
perceptron untuk kemudian secara bertahap
menghitung output dari masing-masing layer. Saat perhitungan telah sampai di output layer, akan diperoleh nilai error yang merupakan selisih output
layer terakhir dengan teaching signal. Output
neuron Ii pada input layer adalah Ii = xi (1)
Output neuron Hj pada hidden layer adalah
, (2)
dengan,
(3)
Setelah output neuron Hj diperoleh, selanjutnya perhitungan diteruskan untuk menghitung Ok pada
output layer.
, (4)
dengan,
(5)
Error, yaitu selisih antara nilai output dengan
target yang harus dicapai dalam hal ini didefinisikan sebagai Mean Square Error (MSE), yang dihitung
. (6)
Backward Pass, dalam fase ini dilakukan
perhitungan dengan arah terbalik, yaitu dari output
layer ke arah input layer. Error yang dihitung di
atas dipakai untuk update weight tiap layer secara bertahap, dari output layer ke arah input layer. Dengan demikian pertama, apabila model tersebut terdiri atas 3 layer (input, hidden dan output layer), yang diupdate pertama kali adalah weight antara
hidden layer dengan output layer.
Update weight pada Hidden Layer - Output Layer. Weight wkj yang menghubungkan neuron j pada Hidden layer dan neuron k pada Output layer diupdate berdasarkan formula berikut:
, (7)
Dengan,
5 η adalah learning rate yang mengontrol kecepatan
perubahan posisi weight pada algoritme gradient
descent, Hj adalah output neuron ke-j pada hidden
layer, sedangkan δk didefnisikan sebagai berikut
. (9)
Update weight pada Input Layer - Hidden Layer selanjutnya, weight wji yang menghubungkan neuron i pada input layer dan neuron j pada Hidden
Layer di update berdasarkan formula berikut:
, (10)
Dengan,
. (11)
Apakah stopping criteria telah dicapai. Apabila telah dicapai, maka proses training berhenti. Jika belum dicapai, kembali ke langkah awal. Stopping
criteria ini biasanya ditetapkan berdasarkan
minimum Mean Square Error (MSE) yang harus dicapai, atau maksimum iterasi yang dilakukan. Contoh proses training dihentikan apabila MSE telah mencapai nilai 0.001 atau iterasi telah mencapai 104 epochs.(Nugroho A.S 2010)
Setelah model NN mendapatkan weight yang optimal (yang mendekati output target yaitu nilai aktual crop variable) maka model NN dapat melakukan prediksi dengan satu kali iterasi
forward pass dan mendapatkan nilai prediksi. Supervised Learning
Tujuan pada pembelajaran supervised learning adalah untuk menentukan nilai bobot-bobot koneksi di dalam jaringan sehingga jaringan dapat melakukan pemetaan (mapping) dari input ke
output sesuai dengan yang diinginkan. Pemetaan
ini ditentukan melalui satu set pola contoh atau data pelatihan (training data set). Setiap pasangan pola
p terdiri atas vektor input xp dan vektor target tp.
Setelah selesai pelatihan, jika diberikan masukan xp seharusnya jaringan menghasilkan nilai
output tp. Besarnya perbedaan antara nilai vektor
target dengan output aktual diukur dengan nilai
error yang disebut juga dengan cost function:
E =
∑
P∑ t
s
di mana n adalah banyaknya unit pada output
layer. Tujuan dari training ini yaitu mencari suatu
nilai minimum global dari E.
Root Mean Square Error (RMSE)
Pada sebuah model, memeriksa galat dapat dilakukan dengan menghitung Root Mean Square
Error (RMSE) dengan persamaan sebagai berikut:
∑
dimana n adalah jumlah data, adalah nilai aktual data ke-i, dan adalah nilai prediksi data ke-i.
Koefisien Determinasi (R2)
Koefisien determinasi disimbolkan dengan R2
, sedangkan persamaannya sebagai berikut:
∑∑
dimana adalah nilai y hasil prediksi dan adalah rata-rata dari y aktual (Sembiring 1995).
Sembiring (1995) menyatakan bahwa semakin dekat dengan 1 makin baik kecocokan data dengan model, sedangkan semakin dekat dengan 0 maka semakin buruk kecocokan data dengan model. Range nilai yaitu dari 0 sampai dengan 1.
Cross Validation
Teknik membagi data dilakukan dengan cara membagi data menjadi data training dan data
testing, setelah itu dilakukan uji coba ke beberapa fold. Contoh cross validation 5 fold, maka 4/5 dari
data akan dijadikan data training dan 1/5 menjadi data testing.
Menurut Fu (1994), K-fold cross validation mengulang k-kali untuk membagi sebuah himpunan contoh secara acak menjadi k subset yang saling bebas, setiap ulangan disisakan satu subset untuk pengujian dan subset lainnya untuk pelatihan.
Supplied Test Set
Teknik pengujian dimana model data training diuji ke data tes yang baru, yang masih belum dikenali polanya.
METODE PENELITIAN
Tahapan yang dilakukan pada penelitian ini dapat dilihat pada Gambar 5.
Studi Pustaka
Studi pustaka dilakukan untuk memperoleh informasi yang dibutuhkan selama penelitian serta memahami tahapan yang harus dilakukan dalam metode penelitian. Informasi yang harus diketahui dalam penelitian ini yaitu mengenai hyperspectral dan backpropagation neural network.
6 Gambar 5 Tahap metode penelitian.
Pengenalan Data
Pada penelitian ini digunakan data
hyperspectral tanaman padi yang berisi informasi
nilai-nilai reflectance tiga fase pertumbuhan tanaman padi yaitu vegetatif, reproduktif, dan
ripening. Panjang gelombang yang digunakan
untuk nilai-nilai reflectance yaitu 350 sampai dengan 2500 nanometer dengan interval 1 nanometer untuk ketinggian 10 cm (Field_Spect 10) dan 50 cm (Field_Spect 50), sedangkan untuk ketinggian 2000 m (Hymap) digunakan panjang gelombang 459 sampai dengan 2490 nanometer. Jumlah band pada data awal Hymap yaitu 126
band. Alat untuk mengukur data spektral
Field_Spect 10 dan Field_Spect 50 yaitu
spectrometer tipe USB4000 sedangkan untuk data
Hymap menggunakan sensor Hymap (Hyperspectral Mapper).
Data awal yang digunakan yaitu data spektral (Data 0.0 dan data Hymap) dan data crop variabel. Data tersebut diperoleh dari wilayah Indramayu dan Subang. Setiap daerah terdiri atas sepuluh segmen yang setiap segmen berukuran 500 x 500 meter, setiap segmen terdiri atas sepuluh petakan (quadrate) yang setiap petakan berukuran 10 x 10 meter, dan setiap petakan dibagi menjadi beberapa titik percobaan tempat pengambilan data spektral. Satu kali mengambil nilai spektral pada setiap titik
percobaan, spektrometer memperoleh lima sampai dengan lima belas kali nilai untuk setiap panjang gelombang 350 sampai dengan 2500 nanometer. Data Hymap yang diperoleh tidak untuk seluruh titik percobaan di setiap daerah, karena hal tersebut data Field_Spect 10, Field_Spect 50, dan data crop variabel yang digunakan sesuai dengan data yang ada pada data Hymap.
Data 0.0 berisi dua folder yaitu folder10 dan 50, yang berarti data Field_Spect 10 cm dan Field_Spect 50 cm. Setiap folder berisi file-file txt yang berisi nilai reflectance dari setiap titik percobaan pada setiap petakan dan juga terdapat sebuah file yang berisi daftar nama file dari file
reflectance tersebut. Data crop variabel terdiri atas
data LAI, SPAD, dan yield. Alat untuk mengukur LAI yaitu LICOR-LAI 2000, alat untuk mengukur SPAD yaitu chlorophyll meter (SPAD-502 Minolta), sedangkan nilai yield diperoleh melalui pengukuran ubinan saat masa panen.
Pada data spektral ada beberapa nilai-nilai LAI, SPAD, dan yield yang kosong, sehingga pada pengujian hanya digunakan data yang memiliki nilai LAI, SPAD, atau yield sesuai prosedur uji data.
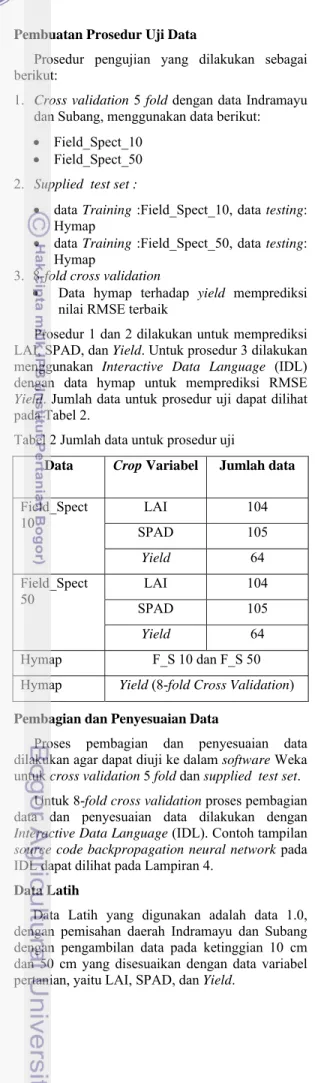
Praproses
Praproses dilakukan pada Data 0.0 dan data Hymap mengikuti diagram alur yang dapat dilihat pada Gambar 6. Praproses data dimulai dari data 0.0, kemudian data 0.1, data 0.2, dan data 1.0. Keseluruhan praproses data dikerjakan menggunakan software Interactive Data Language (IDL). Penjelasan tahap praproses dapat dilihat pada Tabel 1.
Tabel 1 Nama data dan tahap praproses data
Nama
Data Tahap Praproses
Data 0.0 Data pengukuran dalam bentuk
text file
Data 0.1
Data rerata ulangan pengukuran, Nilai spektral yang diambil pada tiap titik
percobaan dilakukan perhitungan setiap panjang gelombang.
Data 0.2
Data rata-rata tiap petakan dihitung dari data 0.1 dan data yang mengandung noise dihapus.
Data 1.0
Resampling data spektral
menjadi 114 band yang disesuaikan dengan template
band pada data Hymap.
Evaluasi dan Analisis Hasil
Gambar 6 D Contoh dapat dilih Gambar 7 File-file Baris pe menunjukk reflectance gelombang terakhir b nilai-nilai s Dari se rata-rata u kemudian Data 0.1 Diagram alur p h reflectance y hat pada Gamba
Contoh file ref
e tersebut terdi ertama mer kan banyakn e. Kolom p g sedangkan aris kedua sa spektral. etiap file data untuk setiap disimpan ke d dengan nama proses data. yang terdapat p ar 7. flectance pada
iri atas 6 samp rupakan hea nya pengamb pertama adala kolom ked ampai terakhir 0.0 dilakukan panjang gelo dalam file baru a file yang sa pada Data 0.0 Data 0.0. pai 16 kolom. ader yang bilan nilai ah panjang dua sampai r merupakan perhitungan ombang dan u pada folder ama. Contoh nama IN01q1 SB01q data t sedang menunj percoba Lampir Pro rata tia yaitu m memili disimpa Contoh IN01q1 dilakuk gelomb gelomb jika nil 1300 n 1700 n data te dipergu Contoh Lampir Tah seluruh file. Ni menjad reflecta untuk p Hymap data 0 Hymap reflecta gelomb Dat panjang nanome yang d data un menjad 116 ba merupa (proses sebelum tersebu dihapu band y daerah panjang Field_S Pad untuk s Data 0 1.0 dap file Data 1p2_10, IN 1p2_10 dan s tersebut diam kan SB artin jukkan quadra aan. Contoh ref ran 1.
ses data selanj ap panjang gelo menghitung rat iki kode q an ke dalam f h untuk file 1p2_10, sampa kan perhitung bang. Hasil bang tersebut d lai rata-rata pa nanometer dan nanometer terda ersebut diangg unakan untuk h reflectance ran 2.
hap proses data h data yang ad ilai-nilai reflec di kolom dari f
ance yang disim
panjang gelom p. Nilai-nilai r 0.2 dilakukan p, sehingga u
ance dikalikan
bang dalam sat ta hymap terdir g gelombang eter dan lebar dilakukan pada ntuk panjang di 114 band. and karena t akan band t s penyerapan m jatuh ke per ut dihapus se s (band 115 yang mengandu Indramayu g gelombang Spect 10 dan F da data Hymap seluruh file men
.2 menjadi dat pat dilihat pada
0.0 yaitu 01q1p3_10, eterusnya. Sim mbil dari dae
nya dari wilay
ate, dan p me eflectance data
njutnya yaitu m ombang untuk
ta-rata dari beb yang sama
file baru pada
dengan kode ai dengan kode gan rata-rata perhitungan disimpan ke da ada range 600 n range 1500
apat nilai yang gap memiliki k analisis d data 0.2 dap a terakhir yaitu da pada data 0 ctance setiap fi file pada data
mpan ke dalam mbang yang ter
reflectance yan penyesuaian untuk data 1 n dengan 1000 tuan 1/1000 nan ri atas 126 ban 459 sampai r band berbed a data tersebut gelombang te Pemilihan 126 terdapat sepul terjadinya wa panjang gelom rmukaan bumi edangkan dua dan 116) kar ung noise. Dat dilakukan pe agar sesuai ield_Spect 50. juga dilakukan njadi sebuah fi ta 1.0. Contoh a Lampiran 3. IN01q1p1_1 SB01q1p1_1 mbol IN artiny erah Indramay yah Subang, enunjukkan tit 0.1 seperti pad menghitung rat setiap quadrat berapa file yan
dan kemudia folder data 0. e IN01q1p1_1 e IN01q1p10_1 tiap panjan tiap panjan lam file IN01q 0 sampai denga
sampai denga g lebih dari 0.4
noise dan tida
dan pengujia pat dilihat pad
u penggabunga 0.2 menjadi sa
ile pada data 0
1.0, tetapi nil m data 1.0 hany rdapat pada da ng terdapat pad terhadap da 1.0 setiap nil 00 dan panjan nometer. nd dengan rang i dengan 249 da. Proses aw yaitu pemiliha erpilih sehingg 6 band menja luh band yan
ater absorptio mbang oleh a ). Sepuluh ban a band lainny rena merupaka ta Hymap untu embulatan nil i dengan da n penggabunga
file seperti pros reflectance da 7 0, 0, ya yu q tik da ta-te, ng an .2. 0, 10 ng ng q1, an an 48, ak an. da an atu 0.2 lai ya ata da ata lai ng ge 90 wal an ga adi ng on air nd ya an uk lai ata an es ata
8
Pembuatan Prosedur Uji Data
Prosedur pengujian yang dilakukan sebagai berikut:
1. Cross validation 5 fold dengan data Indramayu dan Subang, menggunakan data berikut: Field_Spect_10
Field_Spect_50 2. Supplied test set :
data Training :Field_Spect_10, data testing: Hymap
data Training :Field_Spect_50, data testing: Hymap
3. 8-fold cross validation
Data hymap terhadap yield memprediksi nilai RMSE terbaik
Prosedur 1 dan 2 dilakukan untuk memprediksi LAI, SPAD, dan Yield. Untuk prosedur 3 dilakukan menggunakan Interactive Data Language (IDL) dengan data hymap untuk memprediksi RMSE
Yield. Jumlah data untuk prosedur uji dapat dilihat
pada Tabel 2.
Tabel 2 Jumlah data untuk prosedur uji
Data Crop Variabel Jumlah data
Field_Spect 10 LAI 104 SPAD 105 Yield 64 Field_Spect 50 LAI 104 SPAD 105 Yield 64 Hymap F_S 10 dan F_S 50
Hymap Yield (8-fold Cross Validation)
Pembagian dan Penyesuaian Data
Proses pembagian dan penyesuaian data dilakukan agar dapat diuji ke dalam software Weka untuk cross validation 5 fold dan supplied test set.
Untuk 8-fold cross validation proses pembagian data dan penyesuaian data dilakukan dengan
Interactive Data Language (IDL). Contoh tampilan source code backpropagation neural network pada
IDL dapat dilihat pada Lampiran 4.
Data Latih
Data Latih yang digunakan adalah data 1.0, dengan pemisahan daerah Indramayu dan Subang dengan pengambilan data pada ketinggian 10 cm dan 50 cm yang disesuaikan dengan data variabel pertanian, yaitu LAI, SPAD, dan Yield.
Data Uji
Data uji yang digunakan merupakan data Hymap yang telah diproses menjadi data 1.0, yang disesuaikan dengan data variabel pertanian, yaitu LAI, SPAD, dan Yield.
Rancangan Eksperimen
Desain model backpropagation yang diterapkan pada penelitian ini dapat dilihat pada Gambar 8.
Gambar 8 Desain model backpropagation.
Inisialisasi parameter backpropagation pada Weka:
Input layer berupa masukan nilai awal hyperspectral jumlah inputan yaitu 114 band.
Bias = 1.
Learning rate = 0.1.
Fungsi sigmoid = 1/1+e-x.
Hidden neuron = 5, 10, 15, 20, 25, 30. Stopping condition = 500 epoch. Running backpropagation.
Inisialisasi parameter backpropagation pada IDL :
Input layer = matrix nilai inputan dan weight. Learning rate = 0.1.
Fungsi sigmoid = 1/1+e-x.
Hidden neuron = 10 neuron. Stopping condition = 1000 epoch. Running Backpropagation.
Lingkungan Pengembangan
Perangkat lunak yang digunakan untuk penelitian yaitu:
1. Windows 7 Proffesional sebagai sistem operasi, 2. Interactive Data Language (IDL) untuk proses
dan pengujian data,
3. Weka 3.6 sebagai pengujian data, 4. Notepad ++ ,
5. Microsoft Excel sebagai editor program.
Perangkat keras yang digunakan untuk penelitian yaitu :
1. Processor Intel Dual-Core 1.66 GHz, 2. RAM 1.5 GB,
H Hasil peng 1. Cross V Subang Penguj Indramayu SPAD, dan prediksi L dapat dilih 5 dengan G 13. Sedang data Field_ masing dap 10, Tabel 6 Gambar 14 Tabel 3 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 1 0 HASIL DAN P
gujian data men
Validation 5 F g ian cross v u dan Subang n Yield. Nilai LAI, SPAD, d hat pada Tabel
Gambar 11, da gkan nilai RM _Spect 10 dan pat dilihat pad 6 dengan Gamb 4. Prediksi nilai validation 5 fo Gambar 9 G 10 Fs 10 Indramay Fs 10 Subang PEMBAHASA nggunakan We
Fold Data Indr validation 5 g untuk peng R2 yang dipe dan Yield ma 3 dengan Gam an Tabel 7 den MSE LAI, SPAD
n Field_Spect da Tabel 4 den
bar 12, dan Tab i R2 LAI de old Grafik R2 LAI. 20 30 yu Fs 50 In Fs 50 S AN eka ramayu dan fold data gujian LAI, eroleh untuk asing-masing mbar 9, Tabel ngan Gambar D, dan Yield 50 masing-ngan Gambar abel 8 dengan engan cross 0 40 ndramayu Subang Tabel Tabel 0 0,1 0,2 0,3 0,4 0,5 0,6 0,7 0,8 0,9 4 Prediksi nil validation Gambar 10 5 Prediksi ni validation 0 10 Fs 10 Indra Fs 10 Suba lai RMSE LA 5 fold 0 Grafik RMSE ilai R2 SPAD 5 fold 20 amayu Fs 5 ang Fs 5 AI dengan cro E LAI. D dengan cro 30 40 50 Indramayu 50 Subang 9 oss oss
Tabel 6 P G 0 0,2 0,4 0,6 0,8 1 0 Fs Fs 0 1 2 3 4 5 6 7 0 Fs Fs Gambar 11 G Prediksi nilai R validation 5 fo Gambar 12 Gra 10 s 10 Indramayu s 10 Subang 10 s 10 Indramayu s 10 Subang Grafik R2 SPAD RMSE SPAD d old
fik RMSE SPA
20 30 Fs 5 Fs 5 20 30 Fs 50 Fs 50 D. dengan cross AD. 0 40 0 Indramayu 0 Subang 40 0 Indramayu 0 Subang Tabel Tabel 0 0,2 0,4 0,6 0,8 1 7 Prediksi n validation Gambar 1 8 Prediksi nil validation 0 10 Fs 10 Indra Fs 10 Suba nilai R2 Yield 5 fold 13 Grafik R2 Y ai RMSE Yiel 5 fold 20 amayu Fs 5 ang Fs 5 1 d dengan cro Yield. ld dengan cro 30 40 50 Indramayu 50 Subang 10 oss oss
G 2. Supplie Subang Supplie Field_Spec testing yai untuk Fiel mempredik 9 dan Gam pada Tabel nilai aktua pada Lamp dan untuk Tabel 9 P de In 0 0,5 1 1,5 2 2,5 3 0 Gambar 14 Gra ed Test Set g ed test set m ct 10 dan Fie tu data Hymap ld_Spect 10 d ksi data Hyma mbar 15. Untuk
l 10 dan Gamb al dan prediks
piran 5, untuk
Yield pada Lam
Prediksi nilai R engan supplie ndramayu dan S 10 Fs 10 Indramay Fs 10 Subang
afik RMSE Yie
t Data Indra menggunakan d eld_Spect 50 p. Grafik perb dan Field_Spec ap dapat dilihat k nilai RMSE bar 16. Grafik si untuk LAI d k SPAD pada mpiran 7. R2 LAI, SPAD d test set d Subang 20 30 yu Fs 50 In Fs 50 S eld. amayu dan data training dengan data bandingan R2 ct 50 dalam t pada Tabel dapat dilihat pola sebaran dapat dilihat Lampiran 6, D, dan Yield data Hymap 0 40 ndramayu Subang Gamba Tabel Gam 0 0,2 0,4 0,6 0,8 1 0 2 4 6 8 10 12 14 16 18 ar 15 Grafik ba 10 Prediksi n Yield dengan Indramayu d mbar 16 Grafik 5 10 LAI 10 LAI 50 5 10 LAI 10 LAI 50 atang perbandin nilai RMSE L n supplied test dan Subang batang perband Hymap. 15 20 SPAD 10 SPAD 50 15 20 SPAD 10 SPAD 50 1 ngan R2 Hyma AI, SPAD, da
t set data Hyma
dingan RMSE 25 30 Yield 10 Yield 50 25 30 Yield 10 Yield 50 11 ap. an ap
12 Hasil pengujian data menggunakan Interactive
Data Language (IDL)
3. 8-Fold Cross Validation
Data hymap diuji terhadap crop variabel Yield dan diprediksi nilai RMSE, setelah itu diambil nilai RMSE terkecil yang menjadi acuan hasil panen yang error. Prediksi RMSE Yield dapat dilihat pada Lampiran 8.
Evaluasi dan Analisis Hasil
Hasil pengujian dievaluasi dengan membandingkan nilai prediksi R2 dan RMSE pada prosedur pertama dan kedua pengujian data menggunakan Weka. Perubahan parameter pada jumlah neuron hidden layer memberikan tingkat akurasi R2 dan nilai error (RMSE) yang beragam. Hasil Cross Validation 5 fold :
a. Prediksi nilai R2 LAI untuk data Field_Spect 10 yaitu 0.6-0.87 mencapai nilai maksimum ketika jumlah hidden neuron 10, untuk Field_Spect 50 nilai prediksi 0.89-0.91 mencapai nilai maksimum ketika jumlah hidden neuron 5, sedangkan nilai RMSE untuk kedua data pengukuran tersebut < 0.9.
b. Prediksi nilai R2 SPAD untuk data Field_Spect 10 yaitu 0.01-0.33, untuk Field_Spect 50 nilai prediksi 0.009-0.53. Mencapai nilai maksimum bersamaan ketika jumlah hidden neuron 30, sedangkan nilai RMSE untuk kedua data pengukuran tersebut < 6.
c. Prediksi nilai R2 Yield untuk data Field_Spect 10 yaitu 0.0001-0.2, untuk Field_Spect 50 nilai prediksi 0.1-0.3. Mencapai nilai maksimum bersamaan ketika jumlah hidden neuron 15, sedangkan nilai RMSE untuk kedua data pengukuran tersebut < 3.
Hasil Supplied Test Set :
a. Prediksi nilai R2 LAI untuk data Field_Spect 10 yaitu 0.1-0.6, untuk Field_Spect 50 nilai prediksi 0.90-0.91. sedangkan nilai RMSE untuk kedua data pengukuran tersebut < 2.
b. Prediksi nilai R2 SPAD untuk data Field_Spect 10 yaitu 0.1-0.27, untuk Field_Spect 50 nilai prediksi 0.32-0.37. sedangkan nilai RMSE untuk kedua data pengukuran tersebut > 4.
c. Prediksi nilai R2 Yield untuk data Field_Spect 10 yaitu 0.0005-0.03, untuk Field_Spect 50 nilai prediksi 0.0007-0.013. sedangkan nilai RMSE untuk kedua data pengukuran tersebut < 8.
Pengujian prosedur ketiga menggunakan IDL Hasil 8-fold cross validation :
Menggunakan data hymap untuk memprediksi RMSE crop variabel Yield diperoleh hasil memuaskan, nilai RMSE terbaik yaitu 0.10153786
terjadi pada fold ke 6 dan dapat dilihat pada Lampiran 9.
KESIMPULAN DAN SARAN
Kesimpulan
Hasil penelitian menunjukkan :
1. Penggunaan parameter jumlah neuron pada
hidden layer, momentum, laju pembelajaran,
dan stopping condition menjadi faktor penting pada training dan testing data yaitu untuk menghasilkan nilai akurasi yang memuaskan baik pada pengujian Weka dan IDL.
2. Pemodelan prediksi dengan algoritme
backpropagation membutuhkan waktu eksekusi
yang tidak cukup singkat karena adanya
training data sebelum testing data.
3. Pengujian prosedur pertama dan kedua menggunakan Weka menunjukkan bahwa prediksi nilai R2 untuk LAI jauh lebih tinggi jika dibandingkan dengan SPAD dan Yield. Sedangkan prediksi nilai RMSE, tingkat error LAI merupakan yang terendah diikuti SPAD dan Yield.
4. Prediksi nilai R2 dan RMSE untuk LAI, SPAD, dan Yielddata Field_Spect 50 cenderung lebih baik dibandingkan data Field_Spect 10.
5. Penggunaan algoritme BPNN memberikan nilai prediksi R2 yang cukup stabil dan nilai hasil prediksi RMSE relatif tidak berbeda signifikan, ketika jumlah hidden neuron 5, 10, 15, 20, 25, dan 30 masing-masing pada data ketinggian 10 dan 50 Cm.
6. Data pengukuran daerah Indramayu memberikan nilai R2 dan RMSE relatif lebih baik dibandingkan data pengukuran daerah Subang.
7. Pengujian prosedur ketiga menggunakan 8-fold
cross validation untuk prediksi Yield
menghasilkan nilai RMSE yang memuaskan, nilai best RMSE yang diperoleh yaitu
0.10153786.
8. Error yang cukup signifikan dapat terjadi karena pengaruh dalam penggunaan alat dan cuaca yang tidak mendukung pada saat proses pengambilan data berlangsung serta human
13
Saran
Penelitian berikutnya dapat melanjutkan pengujian data dengan data lapangan baru dan memperhatikan parameter learning rate, jumlah
hidden neuron, momentum serta stoping criteria
(iterasi maksimum). Implementasi pada IDL untuk klasifikasi dan penerapan data spectral dengan distribution map untuk efisiensi prediksi hasil panen(Yield).
DAFTAR PUSTAKA
Borengasser M, Hungate WS, Watkins R.2008.
Hyperspectral Remote Sensing Principal and Applications. New York: CRC Press.
Canty M.J.2007. Image Analysis, Classification
and Change Detection in Remote Sensing. US :
CRC Press.
Evri M.2009. Hyperspectral Program “HyperSRI”. PTISDA BPPT.
Fu Limin. 1994. Neural Network in Computer
Intelligence. Singapore : McGraw-Hill.
Landgrebe, D. 2005. Multispectral Land Sensing:
Where From, Where To?. Vol 43. No 3 hal 8.
Nugroho A.S. 2010. Introduction to Artificial
Neural Network , BPPT.
Sadly M, Yasuda Y.1999. Research on a self-built
learning control mechanism in backpropagation training: convergence improvement, japan photogrammtry and remote sensing journal.
Sembiring RK. 1995. Analisis Regresi. Bandung: Penerbit ITB.
Smith R.B.2006. Introduction to Hyperspectral
Imaging.
http://www.microimages.com/getstart/pdf/hyprs pec.pdf. [ 10 Juli 2010]
Kusumadewi S, Hartati S .2006. Neuro-Fuzzy. Yogyakarta: Graha Ilmu.
15 Lampiran 1 Contoh reflectance data 0.1. Lampiran 2 Contoh reflectance data 0.2.
16 Lampiran 4 Contoh tampilan source code backpropagation neural network pada IDL
Lampiran 5 Grafik pola sebaran LAI
N i l a i a k t u a l Nilai Prediksi 0 1 2 3 4 5 6 0 1 2 3 4 5 6
17 Lampiran 6 Grafik pola sebaran SPAD
Lampiran 7 Grafik pola sebaran Yield N i l a i a k t u a l N i l a i a k t u a l Nilai Prediksi Nilai Prediksi 0 5 10 15 20 25 30 35 40 45 50 0 10 20 30 40 50 0 1 2 3 4 5 6 7 8 9 10 0 2 4 6 8 10
18 Lampiran 8 Hasil 8-fold cross validation data hymap terhadap data Yield