PERPANJANGAN KONTRAK KERJA KARYAWAN PADA
PT MITRA SUKSES ONE
Diajukan untuk memenuhi salah satu syarat memperoleh gelar Sarjana Teknik Informatika
Disusun oleh:
Nama : Heru Sigit Pramono NIM : 311510088
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK
UNIVERSITAS PELITA BANGSA
KABUPATEN BEKASI
ii
HALAMAN PERSETUJUAN
Nama : Heru Sigit Pramono
NIM : 311510088
Program Studi : Teknik Informatika-S1
Judul Tugas Akhir : Analisa Algoritma C4.5 Untuk Proses Seleksi Perpanjangan Kontrak Kerja Karyawan Pada PT Mitra Sukses One
Tugas Akhir ini telah diperiksa dan disetujui, Kabupaten Bekasi, 27 Oktober 2019
Menyetujui:
Dosen Pembimbing I Dosen Pembimbing II
Ir. U. Darmanto Soer, M.Kom NIDN. 0429106003
Yoga Religia, S.Kom., M.Kom NIDN. 0419089301
Mengetahui:
Ka. Prodi Teknik Informatika Dekan Fakultas Teknik
Aswan S. Sunge, SE., M.Kom NIDN. 0426018003
Putri Anggun Sari, S.Pt., M.Si NIDN. 0424088403
iii
NIM : 311510088
Program Studi : Teknik Informatika-S1
Judul Tugas Akhir : Analisa Algoritma C4.5 Untuk Proses Seleksi Perpanjangan Kontrak Kerja Karyawan Pada PT Mitra Sukses One
Tugas Akhir ini telah diujikan dan dipertahankan dihadapan dewan penguji pada sidang tugas akhir tanggal 7 Desember 2019. Menurut pandangan kami, tugas akhir
ini memadai dari segi kualitas maupun kuantitas untuk tujuan penganugrahan gelar Sarjana Komputer (S. Kom)
Kabupaten Bekasi, 7 Desember 2019 Dewan Penguji:
Dosen Penguji I Dosen Penguji II
Suherman, S.Kom., M.Kom NIDN. 030808680
Edora, S.Pd., M.Pd NIDN. 0401099001 Ka. Prodi Teknik Informatika
Aswan S. Sunge, SE., M.Kom NIDN. 0426018003
iv Nama : Heru Sigit Pramono
NIM : 311510088
Menyatakan bahwa karya ilmiah saya yang berjudul:
“Analisa Algoritma C4.5 Untuk Proses Seleksi Perpanjangan Kontrak Kerja Karyawan Pada PT Mitra Sukses One”
Merupakan karya asli saya (kecuali cuplikan dan ringkasan yang masing-masing telah saya jelaskan sumbernya dan perangkat pendukung seperti laptop dll). Apabila dikemudian hari, karya saya disinyalir bukan karya asli saya, yang disertai dengan bukti-bukti yang cukup, maka saya bersedia untuk dibatalkan gelar saya beserta hak dan kewajiban yang melekat pada gelar tersebut. Demikian Surat pernyataan ini saya buat dengan sebenarnya.
Dibuat di: Kabupaten Bekasi Tanggal: 27 Oktober 2019 Yang menyatakan
v Nama : Heru Sigit Pramono
NIM : 311510088
Demi mengembangkan ilmu pengetahuan, menyetujui untuk memberikan kepada Universitas Pelita Bangsa Hak Bebas Royalti Non-Eksklusif (Non-Exclusive
Royalty-Free Right) atas karya ilmiah saya yang berjudul:
“Analisa Algoritma C4.5 Untuk Proses Seleksi Perpanjangan Kontrak Kerja Karyawan Pada PT Mitra Sukses One”
Beserta perangkat yang diperlukan (bila ada). Dengan Hak Bebas Royalti Non-Eksklusif ini, Universitas Pelita Bangsa berhak untuk menyimpan data, mengcopy ulang, mempergunakan dan mengelola dalam bentuk database, serta mendistribusikan dan menampilkan/mempublikasikan karya ilmiah ini di internet atau media lain untuk kepentingan akademis tanpa ijin dari saya selama tetap mencantumkan saya sebagai penulis dan pemilik hak cipta. Segala bentuk tuntutan hukum yang timbul atas pelanggaran Hak Cipta karya ilmiah ini menjadi tanggungjawab saya pribadi.
Dibuat di: Kabupaten Bekasi Tanggal: 27 Oktober 2019 Yang menyatakan
vi
UCAPAN TERIMAKASIH
Segala puji dan syukur penulis panjatkan kepada Allah SWT yang telah memberikan rahmat dan anugrahkan-Nya kepada penulis, sehingga penulis dapat menyelesaikan Laporan Tugas Akhir ini. Penulisan Laporan Tugas Akhir dengan judul “Analisa Algoritma C4.5 Untuk Proses Seleksi Perpanjangan Kontrak Kerja Karyawan Pada PT Mitra Sukses One” dimaksudkan untuk mencapai gelar Sarjana Komputer Strata Satu pada Program Studi Teknik Informatika, Universitas Pelita Bangsa.
Penulis menyadari bahwa dalam penyusunan Laporan Tugas Akhir ini bukanlah dari jerih payah sendiri, melainkan dari bimbingan berbagai pihak. Oleh sebab itu penulis mengucapkan banyak terimakasih kepada semua pihak yang turut membantu dalam proses penulisan Laporan Tugas Akhir ini, yaitu kepada:
1. Hamzah M. Mardi Putra, S.K.M., M.M, selaku Rektor Universitas Pelita Bangsa 2. Putri Anggun Sari, S.Pt., M.Si, selaku Dekan Fakultas Teknik Universitas Pelita
Bangsa
3. Aswan S. Sunge, SE., M.Kom, selaku ketua Program Studi Teknik Informatika 4. Ir. U. Darmanto Soer, M.Kom, selaku Dosen Pembimbing I dan Yoga Religia,
S.Kom, M.Kom, selaku Dosen Pembimbing II yang telah memberikan bimbingan dan masukan kepada penulis
5. Seluruh Dosen pengajar Strata satu (S1) Teknik Informatika Universitas Pelita Bangsa, yang telah mendidik dan memberikan pengetahuan kepada penulis selama mengikuti perkuliahan.
6. Seluruh staff dan management PT Mitra Sukses One yang telah memberikan kesempatan kepada penulis untuk melakukan penelitian.
ii
Penulis menyadari bahwa mungkin masih terdapat kekurangan dalam Laporan Tugas Akhir ini. Oleh karena itu, kritik dan saran dari pembaca sangat bermanfaat bagi penulis. Semoga laporan ini dapat bermanfaat bagi semua pihak yang membacanya.
Kabupaten Bekasi, 24 Oktober 2019
viii
ABSTRAK
Banyaknya parameter dalam menentukan diperpanjang atau tidaknya kontrak kerja karyawan menyebabkan ketepatan dan kecepatan dalam penilaian kerja kurang terpenuhi. PT Mitra Sukses One memiliki karyawan kontrak lebih dari 500 karyawan, masalah yang dihadapi adalah perusahaan kesulitan dalam melakukan proses seleksi perpanjangan kontrak kerja karyawan, karena waktu proses yang lama serta kerumitan pada proses pengambilan keputusan sehingga subjektifitas bisa terjadi dalam penentuan keputusan. Tujuan dari penelitian ini adalah menganalisis data penilaian kinerja karyawan untuk hasil yang lebih akurat dan efisien. Teknik data mining dengan metode algoritma C4.5 digunakan dalam penelitian ini untuk melakukan klasifikasi sehingga menghasilkan pohon keputusan serta aturan-aturan yang berguna sebagai masukan dalam menentukan proses pengambilan keputusan. Dari 633 dataset penilaian kinerja karyawan dilakukan pengujian sebanyak lima kali, pembagian pengujian dengan data training dan data testing yang berbeda. Berdasarkan hasil yang diperoleh menunjukan bahwa algoritma C4.5 dalam melakukan klasifikasi data penilaian kinerja karyawan dengan menggunakan tools WEKA yang memiliki nilai accuracy, precision dan recall tertinggi yaitu pengujian pada proporsi 90% (570 data) dari data training dan 10% (63 data) dari data testing dengan accuracy 95.24%, precision 95.60% dan
recall 95.20%. Hal ini menunjukkan bahwa algoritma C4.5 memiliki performa yang
sangat baik dalam melakukan klasifikasi sehingga dapat di implemetasikan untuk proses pengambilan keputusan bagi perusahaan.
ix
ABSTRACT
The many parameters in determining whether or not an employee's work contract is extended causes the accuracy and speed in the work assessment to be less fulfilled. PT Mitra Sukses One has more than 500 contract employees, the problem faced is that the company has difficulty in selecting the employee contract extension process, because of the long processing time and complexity of the decision making process so that subjectivity can occur in decision making. The purpose of this study is to analyze employee performance appraisal data for more accurate and efficient results. Data mining techniques with the C4.5 algorithm method are used in this study to classify them so that they produce decision trees and rules that are useful as input in determining the decision making process. Of the 633 employee performance assessment datasets, five times were tested, the division of testing with different training data and testing data. Based on the results obtained show that the C4.5 algorithm in classifying employee performance appraisal data using WEKA tools which has the highest accuracy, precision and recall values is testing at a proportion of 90% (570 data) of training data and 10% (63 data) from testing data with an accuracy of 95.24%, precision 95.60% and recall 95.20%. This shows that the C4.5 algorithm has a very good performance in doing the classification so that it can be implemented for the decision making process for the company.
x
DAFTAR ISI
HALAMAN PERSETUJUAN ... ii
HALAMAN PENGESAHAN ... iii
PERNYATAAN KEASLIAN SKRIPSI ... iv
PERNYATAAN PERSETUJUAN PUBLIKASI ... v
UCAPAN TERIMAKASIH... vi
ABSTRAK ... viii
ABSTRACT ... ix
DAFTAR ISI ... x
DAFTAR TABEL ... xiii
DAFTAR GAMBAR ... xiv
DAFTAR LAMPIRAN ... xv
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Identifikasi Masalah ... 3 1.3 Rumusan Masalah ... 3 1.4 Batasan Masalah ... 3 1.5 Tujuan Penelitian ... 4 1.6 Manfaat Penelitian ... 4 1.6.1 Bagi Penulis ... 4
1.6.2 Bagi Institusi (Universitas Pelita Bangsa) ... 4
1.6.3 Bagi Objek Penelitian (PT. Mitra Sukses One) ... 4
BAB II LANDASAN TEORI ... 5
2.1 Data Mining ... 5
2.1.1 Pengertian Data Mining ... 5
ii 2.2 Algoritma C4.5 ... 14 2.2.1 Algoritma ... 14 2.2.2 Pohon Keputusan ... 15 2.3 Kebutuan Software ... 31 2.3.1 Microsoft Excel ... 31
2.3.2 Waikato Environment for Knowledge Analysis (WEKA) ... 31
2.4 Tinjauan Pustaka ... 35
2.4.1 Kajian Jurnal Pertama ... 35
2.4.2 Kajian Jurnal Kedua... 35
2.4.3 Kajian Jurnal Ketiga ... 36
2.4.4 Kajian Jurnal Keempat... 36
2.4.5 Kajian Jurnal Kelima ... 37
BAB III METODE PENELITIAN ... 40
3.1 Objek Penelitian ... 40
3.1.1 Sekilas Tentang Perusahaan... 40
3.1.2 Visi dan Misi Perusahaan ... 40
3.1.3 Struktur Organisasi ... 41
3.2 Metode Pengumpulan Data ... 42
3.3 Jenis Data ... 42
3.4 Data yang Digunakan ... 43
3.5 Metode yang Digunakan... 43
3.6 Perangkat Lunak ... 53
3.7 Kerangka Berfikir ... 54
BAB IV HASIL PENGUJIAN DAN PEMBAHASAN ... 56
ii 4.1.1 Langkah Perhitungan ... 57 4.1.2 Langkah Pengujian ... 75 4.2 Hasil Pengujian ... 81 4.2.1 Pengujian Pertama ... 81 4.2.2 Pengujian Kedua ... 83 4.2.3 Pengujian Ketiga ... 85 4.2.4 Pengujian Keempat ... 87 4.2.5 Pengujian Kelima ... 89
4.3 Analisis Hasil Pengujian ... 91
4.4 Evaluasi ... 96
BAB V PENUTUP ... 99
5.1 Kesimpulan ... 99
5.2 Saran ... 99
xiii
DAFTAR TABEL
Tabel 2. 1 Keputusan Bermain Tenis ... 17
Tabel 2. 2 Node 1 Jumlah Kasus Keptusan YA dan TIDAK ... 19
Tabel 2. 3 Node 1 Hasil Perhitungan Entorpy Bermain Tenis ... 23
Tabel 2. 4 Node 1 Hasil Perhitungan Gain Bermain Tenis ... 24
Tabel 2. 5 Dataset Bermain Tenis Yang Memiliki KELEMBABAN = TINGGI ... 26
Tabel 2. 6 Node 1.1 Hasil Perhitungan Bermain Tenis ... 27
Tabel 2. 7 Node 1.2 Hasil Perhitungan Bermain Tenis ... 29
Tabel 2. 7 Penelitian Terdahulu... 37
Tabel 3. 1 Atribut Data Penelitian ... 46
Tabel 3. 2 Atribut Yang Digunakan ... 47
Tabel 3. 3 Penilaian Kinerja Karyawan ... 49
Tabel 3. 4 Pembangian Data ... 51
Tabel 3. 5 Confusion Matrix ... 52
Tabel 4. 1 Sample Data Training Penilaian Kinerja Karyawan ... 56
Tabel 4. 2 Jumlah Kasus Keputusan Diperpanjang dan Diberhentikan ... 57
Tabel 4. 3 Hasil Perhitungan Entropy Node 1 Data Training ... 66
Tabel 4. 4 Hasil Perhitungan Gain Node 1 Data Training ... 70
Tabel 4. 5 Hasil Perhitungan Node 1.1 Data Training ... 72
Tabel 4. 6 Perbandingan Hasil Klasifikasi Data Training ... 92
xiv
DAFTAR GAMBAR
Gambar 2. 1 Bidang Ilmu Data Mining ... 6
Gambar 2. 2 Tahapan Data Mining ... 7
Gambar 2. 3 Data Mining Menurut CRISP-DM ... 9
Gambar 2. 4 Model Pohon Keputusan ... 16
Gambar 2. 5 Pohon Keputusan Hasil Perhitungan Bermain Tenis Node 1 ... 26
Gambar 2. 6 Pohon Keputusan Hasil Perhitungan Node 1.1 Bermain Tenis ... 28
Gambar 2. 7 Pohon Keputusan Hasil Perhitungan Node 1.1.2 Bermain Tenis ... 30
Gambar 2. 8 Tampilan Utama WEKA ... 32
Gambar 3. 1 Struktur Organisasi ... 41
Gambar 3. 2 Sample Formulir Status Penilaian Kinerja Karyawan ... 45
Gambar 3. 3 Model Penelitian yang Diusulkan ... 51
Gambar 3. 4 Antarmuka Explorer WEKA ... 54
Gambar 3. 5 Kerangka Pemikiran ... 55
Gambar 4. 1 Pohon Keputusan Node 1 ... 72
Gambar 4. 2 Pohon Keputusan Node 1.1 ... 74
Gambar 4. 3 Tampilan Setelah Data Training Terhubung ... 76
Gambar 4. 4 Tampilan Pemilihan Algoritma C4.5 ... 77
Gambar 4. 5 Tampilan Hasil Klasifikasi Algoritma C4.5 Data Training ... 78
Gambar 4. 6 Informasi Classifier Model Pohon Keputusan ... 79
Gambar 4. 7 Hasil Pohon Keputusan Algoritma C4.5 Menggunakan WEKA... 80
Gambar 4. 8 Tampilan Hasil Pengujian Algoritma C4.5 Data Testing ... 81
Gambar 4. 9 Pengujian Data Training 50% ... 82
Gambar 4. 10 Pengujian Data Testing 50% ... 83
Gambar 4. 11 Pengujian Data Training 60% ... 84
Gambar 4. 12 Pengujian Data Testing 40% ... 85
Gambar 4. 13 Pengujian Data Training 70% ... 86
Gambar 4. 14 Pengujian Data Testing 30% ... 87
Gambar 4. 15 Pengujian Data Training 80% ... 88
Gambar 4. 16 Pengujian Data Testing 20% ... 89
Gambar 4. 17 Pengujian Data Training 90% ... 90
Gambar 4. 18 Pengujian Data Testing 10% ... 91
Gambar 4. 19 Grafik Precision... 93
Gambar 4. 20 Grafik Recall ... 93
Gambar 4. 21 Grafik Accuracy ... 94
Gambar 4. 22 Pohon Keputusan Data Training 90% (570 data) ... 95
Gambar 4. 23 Confuision Matrix Hasil Pengujian Data Testing 10% (63 data) ... 97
xv
DAFTAR LAMPIRAN
Lampiran 1 Lembar Kendali Bimbingan Skripsi ... 104 Lampiran 2 Formulir Penilaian Kinerja Karyawan ... 106
1 1.1 Latar Belakang Masalah
Kemajuan teknologi adalah sesuatu yang tidak bisa dihindari dalam kehidupan ini, karena kemajuan teknologi akan berjalan sesuai dengan kemajuan ilmu pengetahuan. Dengan adanya teknologi yang berkembang pesat pada saat ini tentunya akan mempengaruhi dalam dunia pekerjaan. Karyawan adalah Sumber Daya Manusia (SDM) yang merupakan aset perusahaan yang sangat berharga dan harus dikelola dengan baik agar dapat memberikan kontribusi yang optimal dalam kemajuan perusahaan atau instansi. Keberadaan karyawan adalah salah satu alasan perusahaan dalam menentukan keberlangsungan aktivitas usaha. Status kontrak kerja karyawan di perusahaan merupakan hal yang penting dan perlu diperhatikan demi tercapainya tujuan perusahaan. Dalam hal untuk menentukan apakah seorang karyawan itu layak untuk diperpanjang kontrak kerjanya atau diputus kontraknya sering terjadi kesulitan dalam menentukan hal tersebut, disamping banyaknya kriteria penilaian yang diperlukan untuk memutuskan, faktor lain seperti sikap kerja dan attitude karyawan tersebut juga perlu diperhatikan (Priyono & Indrajit, 2017).
Pada perusahaan kegiatan penilaian kinerja karyawan sulit dilaksakan karena frekuensi tatap muka antara Human Resources Departement (HRD) dan karyawan sangat minim (Windy, Rika, & Kautsar, 2014). Keputusan seorang HRD adalah hal yang sangat vital pada perusahaan kususnya dalam mengelola karyawan untuk dampak selanjutnya. Karena itulah dalam penilaian kinerja karyawan harus dilakukan secara obyektif dan efisien agar proses seleksi dapat berjalan sesuai dengan yang diharapkan perusahaan. PT. Mitra Sukses One yang bergerak di bidang outsourcing memiliki karyawan kontrak lebih dari 500 karyawan sehingga perusahaan kesulitan melakukan proses seleksi karyawan atau penyaringan karyawan yang masih layak dan memenuhi syarat untuk dilakukan proses perpanjangan kontrak kerja. Diperpanjang atau tidaknya
kontrak kerja karyawan, sangat ditentukan oleh fungsi seleksi ini. Jika fungsi ini tidak dilaksanakan dengan baik maka dengan sendirinya akan berakibat fatal terhadap pencapaian tujuan-tujuan perusahaan.
Data mining mempunyai fungsi yang penting untuk membantu mendapatkan informasi yang berguna bagi perusahaan. Banyaknya parameter dalam menentukan diperpanjang atau tidaknya kontrak kerja karyawan menyebabkan ketepatan dan kecepatan dalam penilaian kerja kurang terpenuhi. Metode klasifikasi data mining merupakan sebuah teknik yang dilakukan untuk memprediksi class atau properti dari data itu sendiri. Adapun metode klasifikasi data mining memiliki beberapa algoritma salah satunya yaitu algoritma C4.5. Penyeleksian ini dilakukan sesuai kriteria-kriteria klasifikasi utama dengan menggunakan algoritma C4.5 yang dapat mengelola nilai inputan yang sesuai dengan kriteria-kriteria pada penilaian kinerja karyawan yang mempunyai nilai prioritas tertentu. Algoritma C4.5 digunakan untuk membentuk pohon keputusan yang membagi kumpulan data yang besar menjadi himpunan-himpunan record yang lebih kecil dengan menerapkan serangkaian aturan keputusan untuk mengklasifikasikan data.
Berdasarkan uraian di atas maka penulis tertarik untuk menganalisis proses seleksi perpanjangan kontrak kerja karyawan pada PT. Mitra Sukses One. Penelitian ini membentuk model klasifikasi pohon keputusan menggunakan metode algoritma C4.5 guna membantu mengatasi beberapa permasalahan yang terjadi pada proses seleksi perpanjangan kontrak kerja karyawan di PT. Mitra Sukses One. Maka dalam penyusunan laporan tugas akhir ini penulis mengambil judul “ANALISA ALGORITMA C4.5 UNTUK PROSES SELEKSI PERPANJANGAN KONTRAK KERJA KARYAWAN PADA PT MITRA SUKSES ONE”.
1.2 Identifikasi Masalah
Berdasarkan uraian latar belakang di atas, penulis mencoba mengidentifikasi masalah yang merupakan dasar bagi pembahasan. Adapun masalah yang dapat diidentifikasikan adalah:
1. Proses penentuan status perpanjangan kontrak karyawan yang membutuhkan waktu yang lama dan kurang efektif.
2. Subjektifitas bisa terjadi untuk mengurangi kerumitan proses pengambilan keputusan akibat banyaknya alternatif.
1.3 Rumusan Masalah
Berdasarkan latar belakang dan identifikasi masalah yang telah dipaparkan, maka rumusan masalah yang dikemukakan adalah bagaimana mengaplikasikan data mining dengan metode algoritma C4.5 untuk menilai kinerja karyawan terbaik dengan akurasi yang tinggi, sehingga dapat membantu proses seleksi perpanjangan kontrak kerja sesuai kebutuhan perusahaan?
1.4 Batasan Masalah
Karena keterbatasan waktu dan mengingat banyaknya permasalahan yang dihadapi oleh perusahaan maka penulis melakukan pembatasan masalah. Adapun batasan masalah ini adalah:
1. Penulis hanya membahas penggunaan data mining untuk menentukan karyawan yang layak dikontrak ulang di PT. Mitra Sukses One dengan menggunakan metode algoritma C4.5.
2. Pengembangan aplikasi menggunakan tools WEKA sebagai perangkat lunak bantuan untuk menentukan karyawan yang layak dikontrak ulang di PT. Mitra Sukses One.
1.5 Tujuan Penelitian
Tujuan dari penelitian ini adalah menganalisis data untuk hasil yang lebih akurat dan efisien sehingga dapat membantu pihak perusahaan dalam proses seleksi perpanjangan kontrak kerja karyawan.
1.6 Manfaat Penelitian 1.6.1 Bagi Penulis
Menambah wawasan atau pengetahuan tentang penerapan data mining menggunakan metode algoritma C4.5 sebagai bentuk implementasi nyata menganalisis data.
1.6.2 Bagi Institusi (Universitas Pelita Bangsa)
Hasil dari penelitian ini dapat digunakan sebagai refrensi bagi peneliti lain yang berkaitan dengan data mining menggunakan metode algortima C4.5 dan dapat dikembangkan untuk penelitian selanjutnya.
1.6.3 Bagi Objek Penelitian (PT. Mitra Sukses One)
Adapun manfaat dari penelitian ini adalah membantu mempermudah HRD dalam melakukan analisis data dengan tepat sehingga dalam proses seleksi perpanjangan kontrak kerja karyawan bisa lebih akurat dan efisien
5 2.1 Data Mining
2.1.1 Pengertian Data Mining
Data Mining adalah suatu teknik menggali informasi berharga yang terpendam atau tersembunyi pada suatu koleksi data (database) yang sangat besar sehingga ditemukan suatu pola yang menarik yang sebelumnya tidak diketahui (Siregar dan Puspabhuana, 2018: 8).
Menurut Muflikhah, dkk (2018: 4) menyimpulkan bahwa berbagai ragam tentang pendefinisian data mining, meliputi:
1. Penguraian (yang tidak sederhana) dari sekumpulan data menjadi informasi yang memiliki potensi secara implisit (tidak nyata/jelas) yang sebelumnya tidak diketahui.
2. Penggalian dan analisis, dengan menggunakan peranti otomatis atau semi otomatis, dari sejumlah besar data yang bertujuan untuk menemukan pola yang memiliki arti.
3. Data mining juga merupakan bagian dari knowledge discovery dalam database (KDD).
Menurut Siregar dan Puspabhuana (2018: 8) karakteristik data mining sebagai berikut:
a. Data mining berhubungan dengan penemuan sesuatu yang tersembunyi dan pola data tertentu yang tidak diketahui sebelumnya.
b. Data mining biasa menggunakan data yang sangat besar. Biasanya data yang besar digunakan untuk membuat hasil lebih dapat dipercaya.
Berdasarkan definisi-definisi yang telah disampaikan, hal penting yang terkait dengan data mining adalah (Kusrini dan Luthfi 2009: 4):
1. Data mining merupakan suatu proses otomatis terhadap data yang sudah ada. 2. Data yang akan diproses berupa data yang sangat besar.
3. Tujuan data mining adalah mendapatkan hubungan atau pola yang mungkin memberikan indikasi yang bermanfaat.
Sumber : Kusrini dan Luthfi, 2019
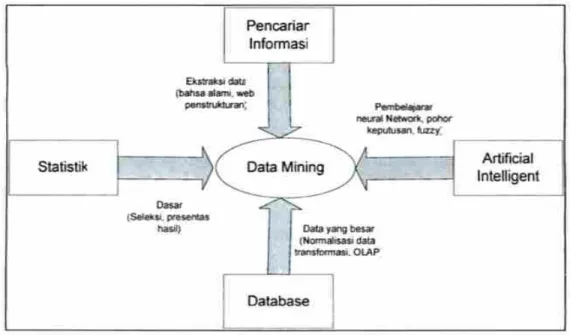
Gambar 2. 1 Bidang Ilmu Data Mining
Data mining bukanlah suatu bidang yang sama sekali baru. Salah satu kesulitan untuk mendefinisikan data mining adalah kenyataan bahwa data mining mewarisi banyak aspek dan teknik dari bidang-bidang ilmu yang sudah mapan terlebih dahulu. Gambar 2.1 menunjukkan bahwa data mining memiliki akar yang panjang dari bidang ilmu seperti kecerdasan buatan (artificial intelligent), machine learning, statistik,
database, dan juga information retrieval Pramudiono, 2005 dalam (Kusrini dan Luthfi
Istilah data mining dan Knowledge Discovery in Database (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lain. Dan salah satu tahapan dalam keseluruhan proses KDD adalah data mining Fayyad, 1996 dalam (Kusrini dan Luthfi 2009: 6).
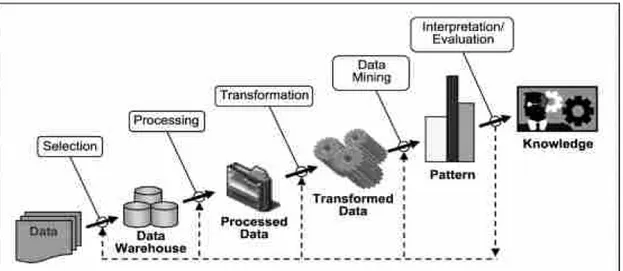
Sumber : https://www.kajianpustaka.com/2017/09/data-mining.html Gambar 2. 2 Tahapan Data Mining
Menurut Fayyad, 1996 dalam (Kusrini dan Luthfi 2009: 6) proses KDD secara garis besar dapat dijelaskan sebagai berikut:
1. Data Selection
Pemilihan (seleksi) data dari sekumpulan data operasional perlu dilakukan sebelum tahap penggalian informasi dalam KDD dimulai. Data hasil seleksi yang akan digunakan untuk proses data mining, disimpan dalam suatu berkas, terpisah dari basis data operasional.
2. Pre-processing/Cleaning
Sebelum proses data mining dapat dilaksanakan, perlu dilakukan proses
lain membuang duplikasi data, memeriksa data yang inkonsisten, dan memperbaiki kesalahan pada data, seperti kesalahan cetak (tipografi). Juga dilakukan proses enrichment, yaitu proses “memperkaya” data yang sudah ada dengan data atau informasi lain yang relevan dan diperlukan untuk KDD, seperti data atau informasi eksternal.
3. Transformation
Coding adalah proses transformasi pada data yang telah dipilih, sehingga data
tersebut sesuai untuk proses data mining. Proses coding dalam KDD merupakan proses kreatif dan sangat tergantung pada jenis atau pola informasi yang akan dicari dalam basis data.
4. Data Mining
Data mining adalah proses mencari pola atau informasi menarik dalam data terpilih dengan menggunakan teknik atau metode tertentu. Teknik, metode, atau algoritma dalam data mining sangat bervariasi. Pemilihan metode dan algoritma yang tepat sangat bergantung pada tujuan dan proses KDD secara keseluruhan.
5. Interpretation/Evalution
Pola informasi yang dihasilkan dari proses data mining perlu ditampilkan dalam bentuk yang mudah dimengerti oleh pihak yang berkepentingan. Tahap ini merupakan bagian dari proses KDD yang disebut interpretation. Tahap ini mencakup pemeriksaan apakah pola atau informasi yang ditemukan bertentangan dengan fakta atau hipotesis yang ada sebelumnya.
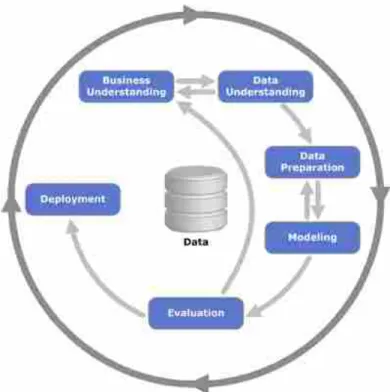
Cross-Industry Standard Process for Data Mining (CRISP-DM) yang
dikembangkan tahun 1996 oleh analis dari beberapa industri menyediakan standar proses data mining sebagai strategi pemecahan masalah secara umum dari bisnis atau unit penelitian. Dalam CRISP-DM, sebuah proyek data mining memiliki siklus hidup yang terbagi dalam 6 (enam) fase. Keseluruhan fase berurutan yang ada tersebut
bersifat adaptif dan fase berikutnya dalam urutan bergantung kepada keluaran dari fase sebelumnya. Hubungan penting antar fase digambarkan dengan panah. Sebagai contoh, jika proses berada pada fase modeling. Berdasar pada perilaku dan karakteristik model, proses mungkin harus kembali kepada fase data preparation untuk perbaikan lebih lanjut terhadap data atau berpindah maju kepada fase evaluation. Proses data mining menurut CRISP-DM dapat dilihat pada Gambar 2.3.
Sumber : https://www.stellarconsulting.co.nz/data/crisp-dm-still-a-leader/
Gambar 2. 3 Data Mining Menurut CRISP-DM
Menurut Larose, 2005 dalam (Kusrini dan Luthfi 2009: 9) Dalam CRISP-DM, siklus hidup data mining yang terbagi dalam 6 (enam) fase yaitu:
1. Fase pemahaman bisnis (Business Understanding Phase)
a. Penentuan tujuan proyek dan kebutuhan secara detail dalam hidup bisnis atau unit penelitian.
b. Menerjemahkan tujuan dan batasan menjadi formula dari permasalahan data mining.
c. Menyiapkan strategi awal untuk mencapai tujuan. 2. Fase pemahaman data (Data Understanding Phase)
a. Mengumpulkan data.
b. Menggunakan analisis penyelidikan data untuk mengenali lebih lanjut data dan pencarian pengetahuan awal.
c. Mengevaluasi kualitas data.
d. Jika diinginkan, pilih sebagian kecil grup data yang mungkin mengandung pola dari permasalahan.
3. Fase pengolahan data (Data Preparation Phase)
a. Siapkan data awal, kumpulkan data yang akan digunakan untuk keseluruhan fase berikutnya. Fase ini merupakan pekerjaan berat yang perlu dilaksanakan secara intensif.
b. Pilih kasus dan variabel yang ingin dianalisis dan yang sesuai analisis yang akan dilakukan.
c. Lakukan perubahan pada beberapa variabel jika dibutuhkan. d. Siapkan data awal sehingga siap untuk perangkat pemodelan. 4. Fase pemodelan (Modeling Phase)
a. Pilh dan aplikasikan teknik pemodelan yang sesuai.
b. Perlu diperhatikan bahwa beberapa teknik mungkin untuk digunakan pada permasalahan data mining yang sama.
c. Jika diperlukan, proses dapat kembali ke fase pengolahan data untuk menjadikan data ke dalam bentuk yang sesuai dengan spesifikasi kebutuhan teknik data mining tertentu.
5. Fase evaluasi (Evaluation Phase)
a. Pengevaluasi satu atau lebih model yang digunakan dalam fase pemodelan untuk mendapatkan kualitas dan efektivitas sebelum disebarkan untuk digunakan.
b. Menetapkan apakah terdapat model yang memenuhi tujuan pada fase awal. c. Menentukan apakah terdapat permasalah penting dari bisnis atau penelitian
yang tidak tertangani dengan baik.
d. Mengambil keputusan yang berkaitan dengan penggunaan hasil dari data
mining.
6. Fase penyebaran (Deployment Phase)
a. Menggunakan model yang dihasilkan. Terbentuknya model tidak menandakan telah terselesaikannya proyek.
b. Contoh sederhana penyebaran: pembuatan laporan.
c. Contoh kompleks penyebaran: penerapan proses data mining secara paralel pada departemen lain.
2.1.2 Pengelompokan Data Mining
Menurut Larose, 2005 dalam (Kusrini dan Luthfi 2009: 10) data mining dibagi menjadi beberapa kelompok berdasarkan tugas yang dapat dilakukan yaitu:
1. Deskripsi
Terkadang peneliti dan analis secara sederhana ingin mencoba mencari cara untuk menggambarkan pola dan kecenderungan yang terdapat dalam data. Sebagai contoh, petugas pengumpulan suara mungkin tidak dapat menemukan keterangan atau fakta bahwa siapa yang tidak cukup profesional akan sedikit didukung dalam pemilihan presiden. Deskripsi dari pola dan kecenderungan sering memberikan kemungkinan penjelasan untuk suatu pola atau kecenderungan.
2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel target estimasi lebih ke arah numerik dari masa ke arah kategori. Model dibangun menggunakan
record lengkap yang menyediakan nilai dari variabel target sebagai nilai
prediksi. Selanjutnya, pada peninjauan berikutnya estimasi nilai dari variabel target dibuat berdasarkan nila variabel prediksi. Sebagai contoh, akan dilakukan estimasi tekanan darah sistolik pada pasien rumah sakit berdasarkan umur pasien, jenis kelamin, indeks berat badan, dan level sodium darah. Hubungan antara tekanan darah sistolik dan nilai variabel reduksi dalam proses pembelajaran akan menghasilkan model estimasi. Model estimasi yang dihasilkan dapat digunakan untuk kasus baru lainnya.
Contoh lain yaitu estimasi nilai indeks prestasi kumulatif mahasiswa program pascasarjana dengan melihat nilai indeks prestasi mahasiswa tersebut pada saat mengikuti program sarjana.
3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi, kecuali bahwa dalam prediksi nilai dari hasil akan ada dimasa mendatang.
Contoh prediksi dalam bisnis dan penelitian adalah:
a. Prediksi harga beras dalam tiga bulan yang akan datang.
b. Prediksi persentase kenaikan kecelakaan lalu lintas tahun depan jika batas bawah kecepatan dinaikan.
Beberapa metode dan teknik yang digunakan dalam klasifikasi dan estimasi dapat pula digunakan (untuk keadaan yang tepat) untuk prediksi.
4. Klasifikasi
Dalam klasifikasi, terdapat terget variabel kategori. sebagai contoh, penggolongan pendapatan dapat dipisahkan dalam tiga kategori yaitu pendapatan tinggi, pendapatan sedang, dan pendapatan rendah.
a. Menentukan apakah suatu transaksi kartu kredit merupakan transaksi yang curang atau bukan.
b. Memperkirakan apakah suatu pengajuan hipotek oleh nasabah merupakan suatu kredit yang baik atau buruk.
c. Mendiagnosis penyakit seorang pasien untuk mendapatkan termasuk kategori penyakit apa.
5. Pengklusteran
Pengklusteran merupakan pengelompokan record, pengamatan, atau memperhatikan dan membentuk kelas objek-objek yang memiliki kemiripan. Kluster adalah kumpulan record yang memiliki kemiripan satu dengan yang lainnya dan tidak memiliki kemiripan dengan record-record dalam kluster lain. Pengklusteran berbeda dengan klasifikasi yaitu tidak adanya variable target dalam pengklusteran. pengklusteran tidak mencoba untuk melakukan klasifikasi, mengestimasi, atau memprediksi nilai dari variable target. Akan tetapi, algoritma pengklusteran mencoba untuk melakukan pembagian terhadap keselurahan data menjadi kelompok-kelompok yang memiliki kemiripan (homogen), yang mana kemiripan record dalam suatu kelompok akan bernilai maksimal, sedangkan kemiripan dengan record dalam kelompok lain akan bernilai minimal.
Contoh pengklusteran dalam bisnis dan penelitian adalah:
a. Mendapatkan kelompok-kelompok konsumen untuk target pemasaran dari suatu produk sebuah perusahaan yang tidak memiliki dana pemasaran yang besar.
b. Untuk tujuan audit akuntansi, yaitu melakukan pemisahan terhadap perilaku finansial dalam baik maupun mencurigakan.
c. Melakukan pengklusteran terhadap ekspresi dari gen, untuk mendapatkan kemiripan perilaku dari gen dalam jumlah besar.
6. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan atribut yang muncul dalam satu waktu. Dalam dunia bisnis lebih umum disebut analisis keranjang pasar.
Contoh asosiasi dalam bisnis dan penelitian adalah:
a. Meneliti jumlah pelanggan dari perusahaan telekomunikasi seluler yang diharapkan untuk memberikan respon positif terhadap penawaran upgrade layanan yang diberikan.
b. Menemukan barang dalam supermarket yang dibeli secara bersamaan dan barang yang tidak pernah dibeli secara bersamaan.
2.2 Algoritma C4.5
Algoritma C4.5 merupakan algoritma yang digunakan untuk membentuk pohon keputusan (Kusrini dan Luthfi, 2009: 13).
2.2.1 Algoritma
Nofriansyah dan Nurcahyo (2019: 16) menyatakan bahwa algoritma C4.5 merupakan salah satu solusi pemecahan kasus yang sering digunakan dalam pemecahan masalah pada teknik klasifikasi. Keluaran dari algoritma C4.5 itu berupa sebuah decision tree layaknya teknik klasifikasi lain.
Menurut Santosa dalam (Nofriansyah dan Nurcahyo, 2019: 17) algoritma C4.5 merupakan pengembangan dari ID3. Jika suatu set data mempunyai beberapa pengamatan dengan missing value yaitu record dengan beberapa nilai variable tidak ada, jika jumlah pengamatan terbatas maka atribut dengan missing value dapat diganti dengan nilai rata-rata dari variable yang bersangkutan.
2.2.2 Pohon Keputusan
Menurut Kusrini dan Luthfi (2009: 13) pohon keputusan merupakan metode klasifikasi dan prediksi yang sangat kuat dan terkenal. Metode pohon keputusan mengubah fakta yang sangat besar menjadi pohon keputusan yang merepresentasikan aturan. Aturan dapat dengan mudah dipahami dengan bahasa alami. Dan mereka juga dapat diekspresikan dalam bentuk bahasa basis data seperti Structured Query
Language untuk mencari record pada kategori tertentu. Pohon keputusan juga berguna
untuk mengeksplorasi data, menemukan hubungan tersembunyi antara sejumlah calon variabel input dengan sebuah variabel target. Karena pohon keputusan memadukan antara eksplorasi data dan pemodelan, dia sangat bagus sebagai langkah awal dalam proses pemodelan bahkan ketika dijadikan sebagai model akhir dari beberapa teknik lain.
Pohon keputusan adalah pohon yang ada dalam analisa pemecahan masalah, pemetaan mengenai alternatif-alternatif pemecahan masalah yang dapat diambil dari masalah tersebut (Sulianta dan Juju, 2010: 56).
Pohon tersebut juga memperlihatkan faktor-faktor kemungkinan atau probabilitas yang akan mempengaruhi alternatif-alternatif keputusan tersebut, disertai dengan estimasi hasil akhir yang akan didapat bila kita mengambil alternatif keputusan tersebut. Pohon keputusan misalnya saja bisa digunakan manajemen dan bisnis, yaitu dalam hal perencanaan bisnis berikutnya. Perencanaan bisnis yang baik sebenarnya memuat tahap tahap yang dapat memaksimalkan peluang keberhasilan. Salah satu tahap yang penting adalah tahap pengambilan keputusan.
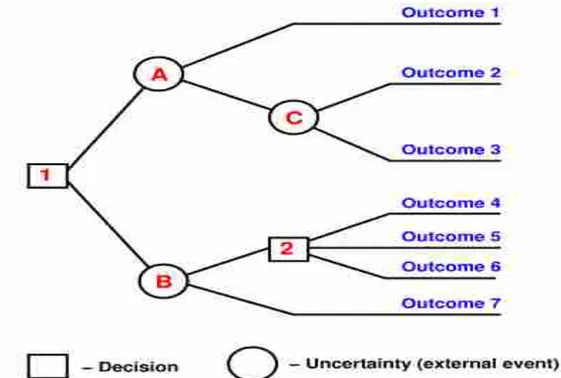
Pohon keputusan adalah model prediksi menggunakan struktur pohon atau struktur berhirarki. Berikut contoh dari pohon keputusan dapat dilihat di gambar 2.4 berikut ini:
Sumber : https://fairuzelsaid.files.wordpress.com/2009/11/decision-tree.gif Gambar 2. 4 Model Pohon Keputusan
Pohon keputusan memiliki manfaat sebagai berikut:
1. Berguna dalam mengeksplorasi data, sehingga data yang tersembunyi bisa diolah dan dikembangkan lagi.
2. Untuk mem-break down proses pengambilan keputusan yang kompleks menjadi lebih simpel sehingga pengambil keputusan akan lebih menginterpretasikan solusi dari permasalahan.
3. Bisa dijadkan sebagai tools pengambilan keputusan terakhir.
4. Mengubah keputusan yang kompleks menjadi lebih simple, spesifik dan mudah.
Selain memiliki kelebihan pohon keputusan juga memiliki kekurangan, diantaranya: 1. Kesulitan dalam mendesain pohon keputusan yang optimal.
2. Hasil kualitas keputusan yang didapatkan dari metode pohon keputusan sangat tergantung pada bagaimana pohon tersebut didesain.
3. Terjadi overlap terutama ketika kelas-kelas dan kriteria yang digunakan jumlahnya sangat banyak. Hal tersebut juga dapat menyebabkan meningkatnya waktu pengambilan keputusan dan jumlah memori yang diperlukan. Tetapi ketika kriterianya lebih simpel tentu saja pengambilan keputusan menjadi lebih cepat.
4. Pengakumulasian jumlah eror dari setiap tingkat dalam sebuah pohon keputusan yang besar.
Agar memudahkan penjelasan mengenai algoritma C4.5, berikut ini contoh kasus yang dituangkan dalam tabel 2.1.
Tabel 2. 1 Keputusan Bermain Tenis
NO CUACA SUHU KELEMBABAN BERANGIN MAIN
1 Cerah Panas Tinggi TIDAK Tidak
2 Cerah Panas Tinggi YA Tidak
3 Berawan Panas Tinggi TIDAK Ya
4 Hujan Sejuk Tinggi TIDAK Ya
5 Hujan Dingin Normal TIDAK Ya
6 Hujan Dingin Normal YA Ya
7 Berawan Dingin Normal YA Ya
8 Cerah Sejuk Tinggi TIDAK Tidak
9 Cerah Dingin Normal TIDAK Ya
10 Hujan Sejuk Normal TIDAK Ya
11 Cerah Sejuk Normal YA Ya
12 Berawan Sejuk Tinggi YA Ya
13 Berawan Panas Normal TIDAK Ya
Dalam kasus yang tertera pada tabel 2.1, akan dibuat pohon keputusan untuk menentukan main tenis atau tidak dengan melihat keadaan cuaca, temperatur, kelembaban dan keadaan angin.
Secara umum algoritma C4.5 untuk membangun pohon keputusan adalah sebagai berikut (Kusrini dan Luthfi, 2009: 15):
a. Pilih atribut sebagai akar.
b. Buat cabang untuk tiap-tiap nilai. c. Bagi kasus dalam cabang
d. Ulangi proses untuk setiap cabang sampai semua kasus pada cabang memiliki kelas yang sama.
Untuk memilih atribut akar, didasarkan pada nilai gain tertinggi dari atribut-atribut yang ada. Untuk mendapatkan nilai gain, harus ditentukan terlebih dahulu nilai entropy. Adapun rumus untuk mencari nilai entropy adalah sebagai berikut:
!"#$%&'()) = - −
/012
&3
∗log
8&3
Keterangan:
S : Himpunan kasus. A : Fitur.
n : Jumlah partisi S.
Pi : Proporsi dari Si terhadap S.
Entropy(S) merupakan jumlah bit yang diperkirakan dibutuhkan untuk dapat mengekstrak suatu kelas (+ atau -) dari sejumlah data acak pada ruang sampel S. Entropy dapat dikatakan sebagai kebutuhan bit untuk menyatakan suatu kelas. Semakin kecil nilai entropy maka akan semakin entropy digunakan dalam mengekstrak suatu kelas. Entropy digunakan untuk mengukur ketidakpastian S (Nofriansyah dan Nurcahyo, 2019: 17).
Sedangkan untuk menghitung gain digunakan rumus sebagai berikut:
9:3"(), <) = !"#$%&'()) − -
.
/ 012[ )
0]
[ ) ]
∗ !"#$%&'()
0)
Keterangan: S : Himpunan kasus A : Atributn : Jumlah partisi atribut A |Si| : Jumlah kasus pada partisi ke i |S| : Jumlah kasus dalam S
Gain (SA) merupakan perolehan informasi dari atribut A relative terhadap output data S. Perolehan informasi didapat dari output data atau variabel dependen S yang dikelompokkan berdasarkan atribut, dinotasikan dengan gain (SA) (Nofriansyah dan Nurcahyo, 2019: 17).
Berikut ini adalah penjelasan lebih rinci mengenai masing masing langkah dalam pembentukan pohon keputusan dengan menggunakan algoritma C4.5 untuk menyelesaikan permasalahan pada tabel 2.1.
a. Menghitung jumlah kasus, jumlah kasus untuk keputusan Ya, jumlah kasus untuk keputusan Tidak, dan Entropy dari semua kasus dan kasus yang dibagi berdasarkan atribut CUACA, SUHU, KELEMBABAN, dan BERANGIN.
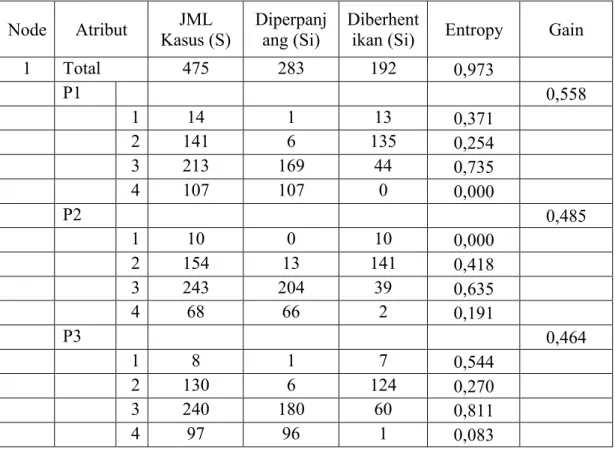
Tabel 2. 2 Node 1 Jumlah Kasus Keptusan YA dan TIDAK
NODE ATRIBUT
JML KASUS
(S)
YA
(Si) TIDAK (Si) ENTROPY GAIN
1 TOTAL 14 10 4 ?
CUACA ?
BERAWAN 4 4 0 ?
HUJAN 5 4 1 ?
NODE ATRIBUT KASUS JML (S)
YA (Si)
TIDAK
(Si) ENTROPY GAIN
SUHU ? DINGIN 4 0 4 ? PANAS 4 2 2 ? SEJUK 6 2 4 ? KELEMBABAN ? TINGGI 7 4 3 ? NORMAL 7 7 0 ? BERANGIN ? TIDAK 8 2 6 ? YA 6 4 2 ?
Adapun cara perhitungan entropy akar pada tabel 2.2 menggunakan persamaan sebagai berikut: !"#$%&'()) = - − / 012 &3∗log 8 &3
1) !"#$%&' (@%#:A) = B−2CC ∗ A%D8E2CCFG + B−2I2C∗ A%D8E2I2CFG
= E−0,286 ∗A%D8(0,286)F + E−0,714 ∗A%D8(0,714)F
= Q−0,286 ∗ (−1,807)R + Q−0,714 ∗ (−0,485)R = 0,516 + 0,347 = 0,863 2) Entropy (Cuaca) !"#$%&' (UV$:W:") = X−0 4∗ A%D8B 0 4GY + X− 4 4∗ A%D8B 4 4GY
= E−0 ∗A%D8(0)F + E−1 ∗A%D8(1)F
= Q−0 ∗ (−0)R + Q−1,000 ∗ (−0)R = 0 + 0
!"#$%&' (Z[\:") = X−1 5∗ A%D8B 1 5GY + X− 4 5∗ A%D8B 4 5GY
= E−0,200 ∗A%D8(0,200)F + E−0,800 ∗A%D8(0,800)F
= Q−0,200 ∗ (−2,322)R + Q−0,800 ∗ (−0,322)R = 0,464 + 0,258
= 0,722
!"#$%&' (]V$:ℎ)=_−35∗ A%D2B35G`+_−25∗ A%D2B25G`
= E−0,600 ∗A%D8(0,600)F + E−0,400 ∗A%D8(0,400)F
= Q−0,600 ∗ (−0,737)R + Q−0,400 ∗ (−1,322)R = 0,422 + 0,529 = 0,971 3) Entropy (Suhu) !"#$%&' (b3"D3") = X−0 4∗ A%D8B 0 4GY + X− 4 4∗ A%D8B 4 4GY
= E−0 ∗A%D8(0)F + E−1 ∗A%D8(1)F
= Q−0 ∗ (−0)R + Q−1,000 ∗ (−0)R = 0 + 0 = 0 !"#$%&' (c:":d) = X−2 4∗ A%D8B 2 4GY + X− 2 4∗ A%D8B 2 4GY
= E−0,500 ∗A%D8(0,500)F + E−0,500 ∗A%D8(0,500)F
= Q−0,500 ∗ (−1)R + Q−0,500 ∗ (−1)R = 0,500 + 0,500
!"#$%&' ()V\[e) = X−2 6∗ A%D8B 2 6GY + X− 4 6∗ A%D8B 4 6GY
= E−0,333 ∗A%D8(0,333)F + E−0,667 ∗A%D8(0,667)F
= Q−0,333 ∗ (−1,585)R + Q−0,667 ∗ (−0,585)R = 0,528 + 0,390 = 0,918 4) Entropy (Kelembaban) !"#$%&' (@3"DD3) = X−4 7∗ A%D8B 4 7GY + X− 3 7∗ A%D8B 3 7GY
= E−0,571 ∗A%D8(0,571)F + E−0,429 ∗A%D8(0,429)F
= Q−0,571 ∗ (−0,807)R + Q−0,429 ∗ (−1,222)R = 0,461 + 0,524 = 0,985 !"#$%&' (f%$g:A) = X−0 7∗ A%D8B 0 7GY + X− 7 7∗ A%D8B 7 7GY
= E−0 ∗A%D8(0)F + E−1 ∗A%D8(1)F
= Q−0 ∗ (−0)R + Q−1,000 ∗ (−0)R = 0 + 0 = 0 5) Entropy (Berangin) !"#$%&' (@3h:e) = X−2 8∗ A%D8B 2 8GY + X− 6 8∗ A%D8B 6 8GY
= E−0,250 ∗A%D8(0,250)F + E−0,750 ∗A%D8(0,750)F
= Q−0,250 ∗ (−2,00)R + Q−0,750 ∗ (−0,415)R = 0,500 + 0,311
!"#$%&' (i:) = X−4 6∗ A%D8B 4 6GY + X− 2 6∗ A%D8B 2 6GY
= E−0,667 ∗A%D8(0,667)F + E−0,333 ∗A%D8(0,333)F
= Q−0,667 ∗ (−0,585)R + Q−0,333 ∗ (−1,585)R = 0,390 + 0,528
= 0,918
Hasil perhitungan entropy ditunjukan pada tabel 2.3 berikut.
Tabel 2. 3 Node 1 Hasil Perhitungan Entorpy Bermain Tenis
NODE ATRIBUT KASUS JML
(S)
YA
(Si) TIDAK (Si) ENTROPY GAIN
1 TOTAL 14 10 4 0,863 CUACA ? BERAWAN 4 4 0 0 HUJAN 5 4 1 0,722 CERAH 5 2 3 0,971 SUHU ? DINGIN 4 0 4 0 PANAS 4 2 2 1 SEJUK 6 2 4 0,918 KELEMBABAN ? TINGGI 7 4 3 0,985 NORMAL 7 7 0 0 BERANGIN ? TIDAK 8 2 6 0,811 YA 6 4 2 0,918
Setelah itu lakukan perhitungan gain untuk setiap atribut.
Adapun cara perhitungan gain akar pada tabel 2.3 menggunakan persamaan sebagai berikut: 9:3"(), <) = !"#$%&'()) − -. / 012 [ )0 ] [ ) ] ∗ !"#$%&'()0)
1) 9:3" (@%#:A, ][:j:) = 0.863 − BEC 2C∗ 0F + E k 2C∗ 0.722F + E k 2C∗ 0.971FG = 0.863 − ((0.286 ∗ 0) + (0.357 ∗ 0.722) + (0.357 ∗ 0.971)) = 0.863 − (0 + 0.347 + 0.258) = 0.863 − 0.605 = 0.258 2) 9:3" (@%#:A, )[ℎ[) = 0.863 − BEC 2C∗ 0F + E C 2C∗ 1.000F + E l 2C∗ 0.918FG = 0.863 − ((0.286 ∗ 0) + (0.286 ∗ 1.000) + (0.429 ∗ 0.918)) = 0.863 − (0 + 0.286 + 0.394) = 0.863 − 0.680 = 0.183 3) 9:3" (@%#:A, mVAVgn:n:") = 0.863 − BEo 2C∗ 0.985F + E o 2C∗ 0FG = 0.863 − ((0.500 ∗ 0.985) + (0.500 ∗ 0)) = 0.863 − (0.492 + 0) = 0.863 − 0.492 = 0.371 4) 9:3" (@%#:A, UV$:"D3") = 0.863 − BEp 2C∗ 0.811F + E l 2C∗ 0.918FG = 0.863 − ((0.571 ∗ 0.811) + (0.429 ∗ 0.918)) = 0.863 − (0.463 + 0.394) = 0.863 − 0.857 = 0.006
Hasil perhitungan gain ditunjukan pada tabel 2.4 berikut.
Tabel 2. 4 Node 1 Hasil Perhitungan Gain Bermain Tenis
NODE ATRIBUT KASUS JML
(S)
YA (Si)
TIDAK
(Si) ENTROPY GAIN
1 TOTAL 14 10 4 0,863
NODE ATRIBUT KASUS JML (S)
YA (Si)
TIDAK
(Si) ENTROPY GAIN
BERAWAN 4 4 0 0 HUJAN 5 4 1 0,722 CERAH 5 2 3 0,971 SUHU 0,184 DINGIN 4 0 4 0 PANAS 4 2 2 1 SEJUK 6 2 4 0,918 KELEMBABAN 0,371 TINGGI 7 4 3 0,985 NORMAL 7 7 0 0 BERANGIN 0,006 TIDAK 8 2 6 0,811 YA 6 4 2 0,918
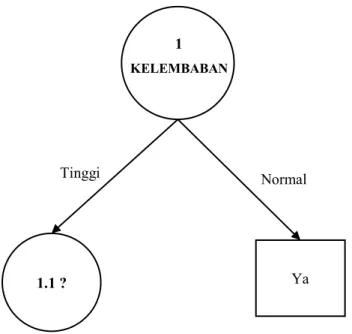
Dari hasil pada tabel 2.4, dapat diketahui bahwa atribut dengan gain tertinggi adalah KELEMBABAN yaitu sebesar 0,371. Dengan demikian KELEMBABAN dapat menjadi node akar.
Ada dua nilai atribut dari KELEMBABAN yaitu TINGGI dan NORMAL. Dari kedua nilai atribut tersebut, nilai atribut NORMAL sudah mengklasifikasikan kasus menjadi 1, yaitu keputusan-nya Ya, sehingga tidak perlu dilakukan perhitungan lebih lanjut. Tetapi untuk nilai atribut TINGGI masih perlu dilakukan perhitungan lagi.
Dari hasil tersebut dapat digambarkan pohon keputusan sementaranya tampak seperti gambar 2.5.
Sumber : Pengolahan data
Gambar 2. 5 Pohon Keputusan Hasil Perhitungan Bermain Tenis Node 1 b. Menghitung jumlah kasus, jumlah kasus untuk keputusan Ya, jumlah kasus
untuk keputusan Tidak. Entropy dari semua kasus dan kasus yang dibagi berdasarkan atribut CUACA, SUHU dan BERANGIN, yang dapat menjadi node akar dari nilai atribut TINGGI.
Untuk memudahkan membuat tabel node 1.1, dataset di filter dengan mengambil data yang memiliki KELEMBABAN = TINGGI, berikut ditunjukan pada tabel 2.5.
Tabel 2. 5 Dataset Bermain Tenis Yang Memiliki KELEMBABAN = TINGGI
CUACA SUHU KELEMBABAN BERANGIN MAIN
CERAH Panas Tinggi TIDAK Tidak
CERAH Panas Tinggi YA Tidak
BERAWAN Panas Tinggi TIDAK Ya
HUJAN Sejuk Tinggi TIDAK Ya
CERAH Sejuk Tinggi TIDAK Tidak
1.1 ? Ya
Tinggi Normal
1
CUACA SUHU KELEMBABAN BERANGIN MAIN
BERAWAN Sejuk Tinggi YA Ya
HUJAN Sejuk Tinggi YA Tdak
Setelah itu lakukan perhitungan gain untuk tiap-tiap atribut. Hasil perhitungan ditunjukan pada tabel 2.6.
Tabel 2. 6 Node 1.1 Hasil Perhitungan Bermain Tenis
NODE ATRIBUT KASUS JML
(S)
YA (Si)
TIDAK
(Si) ENTROPY GAIN
1.1 KELEMBABAN 7 3 4 0,985 CUACA 0,700 BERAWAN 2 2 0 0 HUJAN 2 1 1 1 CERAH 3 0 3 0 SUHU 0,020 DINGIN 0 0 0 0 PANAS 3 1 2 0,918 SEJUK 4 2 2 1 BERANGIN 0,020 TIDAK 4 2 2 1 YA 3 1 2 0,918
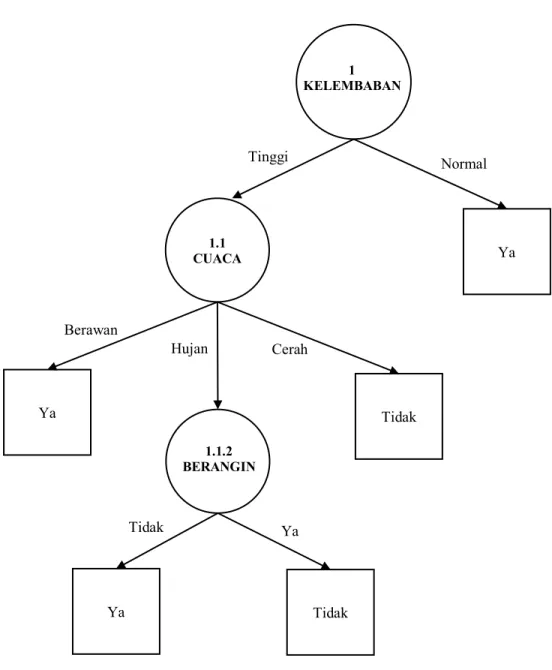
Dari hasil pada tabel 2.6 dapat diketahui bahwa atribut dengan gain tertinggi adalah CUACA yaitu sebesar 0,700. Dengan demikian CUACA dapat menjadi node cabang dari nilai atribut TINGGI. Ada tiga nilai atribut dari CUACA yaitu BERAWAN, HUJAN dan CERAH. Dari ketiga nilai atribut tersebut, nilai atribut BERAWAN sudah mengklasifikasikan kasus menjadi l. yaitu keputusannya Ya dan nilai atribut CERAH sudah mengklasifikasikan kasus menjadi satu dengan keputusan Tidak, sehingga tidak perlu dilakukan
perhitungan lebih lanjut, tetapi untuk nilai atribut HUJAN masih perlu dilakukan perhitungan lagi.
Pohon keputusan yang terbentuk sampai tahap ini ditunjukkan pada gambar 2.6 berikut:
Sumber : Pengolahan data
Gambar 2. 6 Pohon Keputusan Hasil Perhitungan Node 1.1 Bermain Tenis c. Menghitung jumlah kasus, jumlah kasus untuk keputusan Ya, jumlah kasus
untuk keputusan Tidak, dan entropy dari semua kasus dan kasus yang dibagi berdasarkan atribut SUHU dan BERANGIN, yang dapat menjadi node cabang dari nilai atribut HUJAN. Setelah itu lakukan perhitungan gain, untuk tiap-tiap atribut. Hasil perhitungan ditunjukan pada tabel 2.7.
1.1 CUACA Ya Tinggi Normal Ya 1.1.2 ? Tidak Berawan Hujan Cerah 1 KELEMBABAN
Tabel 2. 7 Node 1.2 Hasil Perhitungan Bermain Tenis NOD E ATRIBUT JML KASUS (S) YA
(Si) TIDAK (Si) ENTROPY GAIN
1.2 KELEMBABAN TINGGI & CUACA HUJAN 2 1 1 1 SUHU 0 DINGIN 0 0 0 0 PANAS 0 0 0 0 SEJUK 2 1 1 1 BERANGIN 1 TIDAK 1 1 0 0 YA 1 0 1 0
Dari hasil pada tabel 2.7 dapat diketahui bahwa atribut dengan gain tertinggi adalah BERANGIN, yaitu sebesar 1. Dengan demikian, BERANGIN dapat menjadi node cabang dari nilai atribut HUJAN. Ada dua nilai atribut dari BERANGIN, yaitu TIDAK dan YA. Dari kedua nilai atribut tersebut, nilai atribut TIDAK sudah mengklasifikasikan kasus menjadi 1, yaitu keputusannya Ya dan nilai atribut YA sudah mengklasifikasikan kasus menjadi satu dengan keputusan Tidak, sehingga tidak perlu dilakukan perhitungan lebih lanjut untuk nilai atribut ini.
Pohon keputusan yang terbentuk sampai tahap ini ditunjukkan pada gambar 2.7 berikut:
Sumber : Pengolahan data
Gambar 2. 7 Pohon Keputusan Hasil Perhitungan Node 1.1.2 Bermain Tenis Dengan memperhatikan pohon keputusan pada gambar 2.7, diketahui bahwa semua kasus sudah masuk dalam kelas. Dengan demikian, pohon keputusan pada gambar 2.7 merupakan pohon keputusan terakhir yang terbentuk.
1.1 CUACA Ya Tinggi Normal Ya Tidak Berawan Hujan Cerah 1 KELEMBABAN 1.1.2 BERANGIN Ya Tidak Tidak Ya
2.3 Kebutuan Software 2.3.1 Microsoft Excel
Microsoft excel adalah software spreadsheet paling terkenal didunia bisnis,
perkantoran maupun pendidikan. Excel sangat membantu banyak pekerjaan disetiap bidang, dan selalu dijumpai dimanapun karena aplikasi ini sangat universal. Software
excel ini memiliki banyak fitur kalkulasi dan pembuatan grafis, serta mudah digunakan
menjadikan excel sebagai software paling banyak diminati para pengguna terutama pekerja (https://id.wikipedia.org/wiki/Microsoft_Excel).
Berikut ini adalah pengertian Microsoft excel menurut para ahli:
Menurut Shenia dan Irwan (2011:1), Microsoft Excel merupakan perangkat lunak
(software) untuk mengolah data, meliputi perhitungan dasar, penggunaan
fungsi-fungsi, pembuatan grafik, dan manajemen data. Software ini sangat membantu untuk menyelesaikan permasalahan administrative, mulai yang paling sederhana sampai dengan yang lebih kompleks.
Microsoft Excel merupakan program lembar kerja elektonik (spreadsheet) yang
dapat dipakai untuk mengelola teks, angka, rumus, database, grafik dan lain-lain dalam suatu lembar kerja elektronik (Agus J, 2006:2).
2.3.2 Waikato Environment for Knowledge Analysis (WEKA)
WEKA merupakan sebuah sistem data mining yang dikembangkan oleh Universitas Waikato di Selandia Baru yang mengimplementasikan algoritma data mining (Aksenova, 2004: 2). WEKA adalah sebuah koleksi mesin pembelajaran algoritma untuk tugas-tugas data mining. Algoritmanya dapat diterapkan secara langsung ke dataset atau dipanggil dari kode Java sendiri. WEKA berisi alat-alat untuk data pra-pengolahan (pre-processing), klasifikasi, regresi, clustering, aturan asosiasi, dan visualisasi. WEKA juga sesuai untuk mengembangkan skema pembelajaran mesin baru (www.cs.waikato.ac.nz). WEKA menyediakan inplementasi dari pembelajaran algoritma yang dapat dengan mudah untuk diterapkan pada dataset. Implementasi
tersebut juga mencakup bebagai alat untuk mengubah dataset, pre-process dataset, memberikan skema pembelajaraan, dan menganalisis klasifikasi yang dihasilkan dan kinerjanya tanpa harus menuliskan kode program (Witten, 2011: 403).
Salah satu penggunaan WEKA adalah untuk menerapkan metode pembelajaran untuk dataset dan menganalisis output untuk mempelajari data secara lebih lanjut. Penggunaan lainnya adalah digunakan sebagai model pembelajaran untuk memprediksi pada sebuah kasus baru. Penerapan lainnya dilakukan pada beberapa pembelajaran yang berbeda dan membandingkan kinerja dari mereka dan dipilih salah satu untuk digunakan dalam memprediksi. Pada tampilan utama dapat anda pilih metode pembelajaran yang diinginkan pada menu. Banyak metode yang memiliki parameter yang selaras, yang dapat diakses melalui lembar properti atau editor objek. Sebuah modul evaluasi umum digunakan untuk mengukur kinerja semua pengklasifikasian (Witten, 2011: 404). Berikut tampilan utama pada WEKA ditunjukkan pada gambar 2.8.
Sumber : WEKA Version 3.9.3
Seperti yang ditunjukkan pada gambar 2.8 WEKA GUI Chooser memiliki lima tombol utama, yaitu:
1. Explore
Explore merupakan sebuah pilihan bidang untuk menjelajahi data dengan WEKA. Explore memiliki enam jenis tab didalamnya dengan tugas sebagai berikut (Witten,
2011: 404-416):
a. Preprocess merupakan bidang pemilihan data set dan modifikasinya dengan
berbagai cara.
b. Classify merupakan pelatihan pembelajaran skema yang melaksanakan
klasifikas atau regresi dan evaluasinya.
c. Cluster merupakan pembelajaran cluster atau pengelompokan untuk dataset. d. Associate merupakan pembelajaran aturan asosiasi untuk data dan evaluasinya. e. Select attributes merupakan bidang pemilihan aspek yang paling relevan dalam
dataset.
f. Visualize merupakan bidang tampilan plot dari dua dimensi yang berbeda dari
data tersebut dan interaksinya.
2. Experimenter
Experimenter merupakan sebuah pilihan bidang untuk melakukan eksperimen dan
melakukan uji statistik antara skema pembelajaran. Experimenter memungkinkan pengguna untuk membuat percobaan dalam skala besar, mulai dari percobaan dijalankan sampai percobaan selesai hingga dilakukan analisis kinerja secara statistik terhadap apa yang telah diperoleh.
3. Knowledge Flow
Knowledge Flow merupakan sebuah pilihan bidang yang mendukung fungsi dasar
yang sama seperti explore tetapi dengan antarmuka drag dan drop. Salah satu keuntungannya adalah knowledge flow mendukung adanya pembelajaran tambahan. Pada tampilan utama knowledge flow ini pengguna dapat melihat tata letak sebuah kinerja dari proses yang dilakukannya, pengguna dihubungkan
kedalam sebuah graf berarah yang memproses dan menganalisis data. Pada bagian ini merupakan gambaran secara jelas bagaimana data berjalan dalam sistem dimana tidak disediakan dalam explore.
4. Workbench
Workbench adalah kemampuan yang menggabungkan semua antarmuka GUI
menjadi satu antarmuka. Berguna jika menemukan banyak di antara dua atau lebih antarmuka yang berbeda, seperti antara Explorer dan Eksperimen. Ini dapat terjadi jika mencoba banyak bagaimana jika di Explorer dan dengan cepat mengambil apa yang dipelajari dan memasukkannya ke dalam eksperimen terkontrol
5. Simple CLI
Simple CLI merupakan sebuah pilihan bidang yang memberikan tampilan garis
perintah sederhana yang memungkinkan adanya perintah langsung eksekusi dari WEKA untuk sistem operasi yang tidak memberikan tampilan garis perintahnya sendiri. Dibalik tampilan interaktif explore, experimenter, knowledge flow pada WEKA terdapat fungsi dasar yang dapat diakses secara langsung pada tampilan garis perintah. Garis perintah terdapat pada simple CLI, pada tampilan utama WEKA panel simple CLI terletak disebelah kanan bawah.
WEKA sebagai mesin pembelajaran yang memiliki tugas dalam penggunaan sebuah metode, WEKA memiliki beberapa metode utama dalam permasalahan data mining, yaitu regresi, klasifikasi, clustering, association rule mining, dan pemilihan atribut. Pengenalan data merupakan bagian yang tidak terpisahkan dari sebuah pekerjaan, dan banyak fasilitas visualisasi data dan alat data preprocessing yang disediakan. Semua algoritma dalam WEKA mengambil input dalam bentuk tabel relasional tunggal dalam format Attribute Relation File Format (ARFF), yang dapat dibaca dari sebuah file atau dihasilkan oleh permintaan basis data (Singhal & Jena, 2013), (Witten, 2011:407-519).
2.4 Tinjauan Pustaka
Dalam pembuatan laporan tugas akhir ini selain peneliti menggali informasi dari buku-buku, peneliti juga melakukan tinjauan pustaka pada hasil penelitian terdahulu yang berkaitan dengan judul yang digunakan sebagai studi literature dan penelusuran ilmiah, diharapkan peneliti dapat diperhatikan mengenai kekurangan dan kelebihan antara penelitian terdahulu dengan penelitian yang dilakukan. Adapun penelitian yang terkait dengan penelitian ini yaitu:
2.4.1 Kajian Jurnal Pertama
Penelitian yang dilakukan oleh Teguh Budi Santoso dan Dela Sekardiana pada tahun 2019 yang berjudul “PENERAPAN ALGORITMA C4.5 UNTUK PENENTUAN KELAYAKAN PEMBERIAN KREDIT (STUDI KASUS: KOPERIA - KOPERASI WARGA KOMPLEK GANDARIA)”. Penelitian ini membahas perihal sulitnya dalam menentukan kelayakan pemberian kredit yang sering dialami oleh pengurus koperasi, sehingga muncul masalah pada koperasi adalah macetnya pembayaran angsuran kredit nasabah pada KOPERIA. Penelitian ini bertujuan membentuk model klasifikasi pohon keputusan untuk menentukan kelayakan kredit nasabah. Hasil klasifikasi menggunakan Algoritma C4.5 pada penelitian ini menunjukan bahwa diperoleh akurasi 97,5%. Berdasarkan hasil yang diperoleh menunjukan bahwa algoritma c4.5 cocok digunakan untuk menentukan kelayakan pemberian kredit nasabah pada KOPERIA.
2.4.2 Kajian Jurnal Kedua
Penelitian yang dilakukan oleh Ai Rita Rizqiah dan Agus Subekti pada tahun 2018 yang berjudul “PREDIKSI KEKAMBUHAN KANKER PAYUDARA DENGAN ALGORITMA C4.5”. Penelitian ini membahas perihal resiko terkena kanker payudara akan semakin meningkat seiring bertambahnya usia, riwayat medis keluarga, riwayat medis personal, keturunan kaukasia, menstruasi awal, menopause terlambat dan lain-lain. Tujuan dari penelitian ini yaitu untuk memperoleh knowledge
dari sekumpulan data kekambuhan pasien kanker payudara, mengidentifikasi variable/ atribut mana saja yang memiliki kontribusi besar pada data dan mengklasifikasikan data kekambuhan kanker payudara secara kasat mata/ metode manual. Penelitian ini menggunaan algoritma Naïve Bayes dan algoritma C4.5 untuk mengklasifikasikan kekambuhan pasien kanker berdasarkan atribut tertentu pada dataset kanker payudara. Hasil dari penelitian ini menunjukan bahwa algoritma C4.5 memiliki nilai akurasi 75.5% lebih baik dari pada Naïve Bayes yang hanya memilki nilai akurasi 72.7%. 2.4.3 Kajian Jurnal Ketiga
Penelitian yang dilakukan oleh Andhika Novandya dan Isni Oktria pada tahun 2017 yang berjudul “PENERAPAN ALGORITMA KLASIFIKASI DATA MINING C4.5 PADA DATASET CUACA WILAYAH BEKASI”. Penelitian ini membahas prakiraan cuaca pada umumnya sering disebut peramalan cuaca yang merupakan penggunaan ilmu dan teknologi untuk memperkirakan atmosfer bumi pada masa akan datang untuk suatu tempat tertentu. Penelitian ini bertujuan untuk mendapatkan pola klasifikasi cuaca dengan menggunakan algoritma klasifikasi data mining yaitu algoritma C4.5. Hasil pengujian algoritma C4.5 menggunakan 10-fold cross validation dan dibuktikan dengan pembuatan aplikasi web untuk pengujian sehingga menghasilkan nilai akurasi sebesar 88.89%.
2.4.4 Kajian Jurnal Keempat
Penelitian yang dilakukan oleh Beti Novianti, Tedy Rismawan dan Syamsul Bahri pada tahun 2016 yang berjudul “IMPLEMENTASI DATA MINING DENGAN ALGORITMA C4.5 UNTUK PENJURUSAN SISWA (STUDI KASUS: SMA NEGERI 1 PONTIANAK)”. Penelitian ini membahas proses penyortiran penjurusan siswa kelas X (sepuluh) SMA Negeri 1 Pontianak berdasarkan nilai rata-rata rapor SMP, nilai Ujian Nasional SMP, dan nilai tes MTK, IPA, dan IPS. Pada penelitian ini, penjurusan siswa diklasifikasi berdasarkan nilai tes akademik MTK, IPA, dan IPS, nilai rata-rata rapor SMP untuk mata pelajaran MTK, IPA, dan
IPS, nilai Ujian Nasional SMP untuk mata pelajaran MTK dan IPA, dan minat siswa. Berdasarkan hasil penelitian, didapatkan hasil klasifikasi penjurusan siswa yang sudah diuji sesuai dengan tingkat akurasi sebesar 89.74%.
2.4.5 Kajian Jurnal Kelima
Penelitian yang dilakukan oleh Izza Khaerani dan Lekso Budi Handoko pada tahun 2015 yang berjudul “IMPLEMENTASI DAN ANALISA HASIL DATA MINING UNTUK KLASIFIKASI SERANGAN PADA INTRUSION
DETECTION SYSTEM (IDS) DENGAN ALGORITMA C4.5”. Penelitian ini
membahas perihal serangan terhadap IDS yang kemungkinan terjadi dalam jaringan, baik lokal maupun yang terhubung dengan internet ketika paket data yang datang sangat banyak dan harus di analisa di kemudian hari. Tujuan dari penelitian ini adalah untuk mengklasifikasikan serangan pada data-data yang diujikan dengan menggunakan metode klasifikasi dan algoritma klasifikasi C4.5. Penelitian ini menggunakan koleksi data dari KDD’99 dan memiliki 41 atribut dimana atribut ini dilakukan fitur seleksi untuk menghapus atribut yang tidak relevan dengan menggunakan teknik evolusi. Hasil yang didapatkan dari fitur seleksi ini adalah 16 atribut dengan akurasi tinggi mencapai 98,67% dari 41 atribut yang ada. Kemudian hasilnya dilakukan pemodelan dengan menggunakan algoritma C4.5 dan menghasilkan sebuah aturan untuk digunakan dalam implementasi sistem analisa klasifikasi data.
Berikut merupakan tabel rangkuman penelitian terdahulu berupa jurnal terkait dengan penelitian yang dilakukan penulis.
Tabel 2. 8 Penelitian Terdahulu
No Peneliti, Tahun, Judul Tujuan Metode Hasil 1 Teguh Budi Santoso
dan Dela Sekardiana, 2019, Penerapan Algoritma C4.5 Untuk Penentuan Kelayakan Membentuk model klasifikasi pohon keputusan Algoritma C4.5 Berdasarkan hasil akurasi yang diperoleh yaitu 97,5%
menunjukan bahwa algoritma c4.5 cocok
No Peneliti, Tahun, Judul Tujuan Metode Hasil Pemberian Kredit
(Studi Kasus: Koperia - Koperasi Warga Komplek Gandaria) untuk menentukan kelayakan kredit nasabah digunakan untuk menentukan kelayakan pemberian kredit nasabah pada KOPERIA.
2 Ai Rita Rizqiah dan Agus Subekti, 2019, Prediksi Kekambuhan Kanker Payudara Dengan Algoritma C4.5 Untuk memperoleh knowledge dari sekumpulan data kekambuhan pasien kanker payudara, mengidentifika si variable/ atribut mana saja yang memiliki kontribusi besar pada data dan mengklasifikas ikan data kekambuhan kanker payudara secara kasat mata/ metode manual. Naïve Bayes dan Algoritma C4.5
Hasil dari penelitian ini menunjukan bahwa algoritma C4.5
memiliki nilai akurasi 75.5% lebih baik dari pada Naïve Bayes yang hanya memilki nilai akurasi 72.7%.
3 Andhika Novandya dan Isni Oktria, 2017, Penerapan Algoritma Klasifikasi Data Mining C4.5 Pada Mendapatkan pola klasifikasi cuaca dengan menggunakan algoritma Algoritma C4.5 Hasil pengujian algoritma C4.5 menggunakan 10-fold cross validation dan dibuktikan dengan pembuatan aplikasi
No Peneliti, Tahun, Judul Tujuan Metode Hasil Dataset Cuaca
Wilayah Bekasi
klasifikasi data mining
web untuk pengujian sehingga
menghasilkan nilai akurasi sebesar 88.89%. 4 Beti Novianti, Tedy
Rismawan dan Syamsul Bahri, 2016, Implementasi Data Mining Dengan Algoritma C4.5 Untuk Penjurusan Siswa (Studi Kasus: SMA Negeri 1 Pontianak) Menyortir penjurusan siswa kelas X (sepuluh) diklasifikasi berdasarkan nilai tes akademik Algoritma C4.5 Berdasarkan hasil penelitian, didapatkan hasil klasifikasi penjurusan siswa yang sudah diuji sesuai dengan tingkat akurasi sebesar 89.74%
5 Implementasi Dan Analisa Hasil Data Mining Untuk Klasifikasi Serangan Pada Intrusion Detection System (IDS) Dengan Algoritma C4.5 Mengklasifikas ikan serangan pada data-data yang diujikan dengan menggunakan metode klasifikasi dan algoritma klasifikasi C4.5 Algoritma C4.5
Hasil yang didapatkan dari fitur seleksi ini adalah 16 atribut dengan akurasi tinggi mencapai 98,67% dari 41 atribut yang ada. Kemudian hasilnya dilakukan pemodelan dengan menggunakan algoritma C4.5 dan menghasilkan sebuah aturan untuk digunakan dalam implementasi sistem analisa klasifikasi data
40 3.1 Objek Penelitian
Dalam penyusunan skripsi ini penulis melakukan penelitian di PT. Mitra Sukses One yang beralamat di Ruko Sunter Niaga Mas 3 Blok F1 Nomor 10 Cikarang Pusat – Bekasi, Jawa Barat. Penelitian ini dilakukan untuk mengumpulkan data dan keterangan yang berkaitan dengan judul penelitian.
3.1.1 Sekilas Tentang Perusahaan
PT. Mitra Sukses One adalah perusahaan outsourcing (alih daya), yang beralamat di Ruko Sunter Niaga Mas 3 Blok F1 Nomor 10 Cikarang Pusat – Bekasi, Jawa Barat. Sebagai perusahaan outsourcing PT. Mitra Sukses One menyediakan jasa recruitments dan pengelolaan tenaga kerja bagi perusahaan klien dengan manajemen pengelolaan yang disiplin hukum, comperhensif, dan mengutamakan win – win solutions dan didukung oleh tenaga yang cukup berpengalaman, terlatih, terdidik, berdedikasi, dan dengan profesionalitas yang tinggi.
Dalam menjalankan aktivitas bisnis, PT. Mitra Sukses One sangat menghargai kepercayaan klien dan mitra usaha, dengan bertekad memberikan pelayanan yang terbaik untuk klien maupun kandidat karyawan yang dikelola. PT. Mitra Sukses One senantiasa menjalankan usaha dengan memenuhi komitmen, memberikan kepastian dan menjamin kepuasan bagi klien dan mitra usaha sehingga memajukan usaha yang harmonis, dinamis, dan dapat terwujud dengan hasil yang optimal.
3.1.2 Visi dan Misi Perusahaan
Sebagai perusahaan yang baik dan ingin maju haruslah mempunyai visi dan misi kedepan guna mencapai tujuan dari perusahaan tersebut, adapun visi dan misi dari PT. Mitra Sukses One adalah sebagai berikut: