Pengelompokan Kabupaten Kota di Provinsi Jawa Tengah
dengan Fuzzy C-Means Clustering
(Studi Kasus : Jumlah Kasus Gizi Buruk, Faktor Sarana dan Tenaga
Kesehatan serta Faktor Kependudukan di Jawa Tengah Tahun 2014)
Trissya Anjar Risqiyani
1, Ayundyah Kesumawati., S.Si., M.Si
21
Mahasiswi Statistika (FMIPA, Universitas Islam Indonesia) 2
Dosen Statistika (FMIPA, Universitas Islam Indonesia) [email protected]
Abstrak— Gizi buruk menjadi salah satu masalah besar di Indonesia. Adanya beban nilai gizi buruk bagi Indonesia berpengaruh terhadap pembangunan manusia. Rendahnya pengetahuan masyarakat akan bahayanya gizi buruk menjadi salah satu alasan semakin tingginya angka gizi buruk di Indonesia. Beberapa indikator kesehatan yang menunjukkan masih rendahnya prioritas pembangunan kesehatan di Jawa Tengah, seperti tingginya kematian bayi dan balita, gizi buruk, kurangnya akses fasilitas kesehatan, angka kejadian penyakit menular, dan kondisi sanitasi menjadi salah satu penyebab angka gizi buruk di Jawa Tengah cukup tinggi. Salah satu cara yang dapat dilakukan pemerintah adalah dengan mengetahui kelompok Kabupaten Kota mana yang harus mendapatkan perhatian khusus dalam penanganan gizi buruk di Jawa Tengah. Tujuan dari penelitian ini adalah untuk mengetahui pengelompokan wilayah-wilayah yang memiliki kasus gizi buruk tinggi, sarana dan tenaga kesehatan yang rendah, jumlah penduduk miskin yang tinggi dan IPM yang rendah untuk melaksanakan program pemerintah tentang kesehatan nasional. Salah satu pengelompokan yang cukup terkenal atau banyak yang digunakan adalah pengelompokan dengan Fuzzy C-Means. Fuzzy C-Means merupakan metode clustering yang merupakan bagian dari metode hard K-Means. Fuzzy C-Means menggunakan model pengelompokkan fuzzy sehingga data dapat menjadi anggota dari semua kelas atau cluster terbentuk dengan derajat atau tingkat keanggotaan yang berbeda antara 0 dan 1. Tingkat keberadaan data dalam suatu kelas ditentukan oleh derajat keanggotaan. Dari hasil analisis pengelompokan dengan Fuzzy C-Means didapatkan jumlah kelompok optimum sebanyak empat kelompok dengan nilai Indeks Xie dan Beni optimum yaitu 2.186631. Kelompok pertama terdiri dari 7 kabupaten, kelompok kedua terdiri dari 13 kabupaten, kelompok ketiga terdiri dari 5 kota dan kelompok keempat terdiri dari 10 kabupaten.
Kata kunci: Gizi Buruk, Fuzzy C-Mean Cluster,Indeks Xie dan Beni I. PENDAHULUAN
Di Indonesia persoalan gizi menjadi salah satu persoalan utama dalam pembangunan manusia. Beban gizi buruk dan gizi lebih harus dilihat sebagai tantangan pembangunan. Tantangan ini tidak hanya dihadapi oleh negara rentan, namun juga negara berkembang dan bahkan maju. Menurut UNICEF Indonesia (2016) di Indonesia, kekurangan gizi yang dialami balita sangat kurus merupakan masalah kesehatan masyarakat yang sangat serius. Pada [1] tahun 2012, Indonesia masuk lima besar dalam masalah gizi buruk. Permasalahan ekonomi kerap menjadi alasan utama banyaknya kasus gizi buruk, hal ini diikuti dengan faktor lingkungan yang tidak sehat, juga kurangnyaketersediaan air bersih. Menurut Zuber Safawi [8] beberapa indikator kesehatan yang menunjukkan masih lemahnya prioritas pembangunan kesehatan di Jawa Tengah, seperti tingginya kematian bayi dan balita, gizi buruk, kurangnya akses fasilitas kesehatan, angka kejadian penyakit menular, dan kondisi sanitasi. Jawa tengah masih menghadapi masalah gizi buruk yang mendera calon generasi penerusnya. Berdasarkan survey yang sama, prevelensi gizi buruk menunjukkan 3,3 persen dan gizi kurang mencapai 12,4 persen. Artinya terdapat 157 balita kurang gizi hingga gizi buruk setiap 1.000 balita di Jawa Tengah. Indikator tersebut
kemungkinan ditopang oleh tingginya angka kemiskinan di Jawa Tengah yang mencapai 4,863 juta jiwa pada September 2012. Pada [13] kelebihan dari Fuzzy C-Means adalah dapat melakukan clustering lebih dari satu variabel secara sekaligus.
Fuzzy C-Means dapat mengenalkan pola yang lebih fleksibel dan memudahkan pemecahan perhitungan dari masalah yang dirumuskan. Dengan rumusan masalah bagaimana hasil pengelompokkan dan pemetaan wilayah kota/kabupaten di Provinsi Jawa Tengah berdasarkan analisis Fuzzy C-Means.
II. METODE PENELITIAN
A. Populasi dan Sampel Penelitian
Dalam penelitian ini yang digunakan data sekunder dengan populasi unit pengamatan 35 Kabupaten dan Kota di Provinsi Jawa Tengah denagn sampel penduduk Jawa Tengah yang masuk dalam pendataan berdasarkan kriteria variabel yang digunakan pada penelitian ini di Tahun 2014.
B. Variabel Penelitian dan Definisi Operasional Variabel
Penelitian ini akan dikelompokan wilayah-wilayah yang memiliki kesamaan berdasarkan variabel-variabel yang digunakan. Variabel yang digunakan merupakan jumlah kasus gizi buruk yang disertai dengan faktor sarana dan tenaga kesehatan serta faktor kependudukan.
C. Alat dan Metode Analisis Data
Metode yang digunakan merupakan metode clustering dengan metode analisis Fuzzy C-Means. Analisis Fuzzy C-Means bertujuan untuk mengelompokkan kabupaten dan kota di Provinsi Jawa Tengah menjadi kelompok-kelompok berdasarkan variabel-variabel yang sudah ditentukan oleh peneliti. Pertama kali adalah menentukan pusat cluster, yang akan menandai lokasi rata-rata untuk tiap cluster. Dengan cara memperbaiki pusat cluster dan derajat keanggotaan tiap-tiap titik data secara berulang, maka akan dapat dilihat bahwa pusat cluster akan bergerak menuju lokasi yang tepat. Perulanagn didasarkan pada minimasi fungsi objektif yang menggambarkan jarak dari titik data yang diberikan ke pusat cluster yang terbobot oleh derajat keanggotaan titik data tersebut. Output dari Fuzzy C-Means adalah deret pusat cluster dan beberapa derajat keanggotaan untuk tiap-tiap data. Pada penelitian ini alat bantu yang digunakan yaitu software R.i386 2.15.0 dan Microsoft Excel 2013.
III. HASIL DAN PEMBAHASAN
A. Penentuan Jumlah Klaster Terbaik
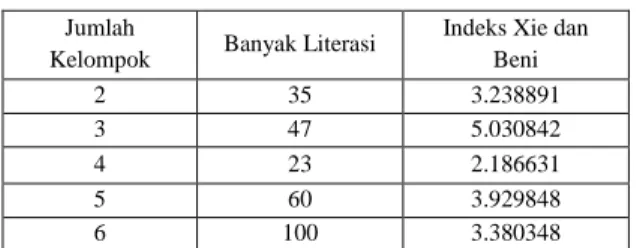
Untuk penentuan jumalh klaster terbaik dapat diketahui dengan Indeks Xie dan Beni. Semakin kecil nilai Xie dan Beni, maka akan menghasilkan hasil yang baik. Berikut ini hasil dari perhitungan nilai Xie dan Beni
Tabel 1. Nilai Indeks Xie dan Beni Jumlah
Kelompok Banyak Literasi
Indeks Xie dan Beni 2 35 3.238891 3 47 5.030842 4 23 2.186631 5 60 3.929848 6 100 3.380348
Dari tabel 5.1 didapatkan nilai indeks Xie dan Beni optimum pada jumlah kelompok 4 dengan nilai indeks Xie dan Beni yaitu 2.186631. Proses iterasi yang terakhir pada iterasi ke 23.
B. Pusat Klaster
Dari jumlah kelompok optimum didapatkan iterasi terakhir (iterasi ke-23), pusat klaster Vkj yang dihasilkan dengan k= 1,2,3,4,…,9 dan j = 1,2,3,4 adalah
Tabel 2. Pusat Cluster Cluster centers: [,1] [,2] [,3] [,4] [,5] [,6] [,7] 1 -0.22588953 1.0578556 1.0578556 -0.1013989 -0.2697814 0.009330146 -0.1942898 2 0.23575737 -0.3018458 -0.3018458 0.3451870 0.3959732 0.473914408 -0.3596262 3 -0.64066621 -0.9210700 -0.9210700 -1.7111355 -1.3269757 0.115992047 1.9782095 4 0.04852925 -0.1108037 -0.1108037 0.4316788 0.2013706 -0.520944741 -0.4296082 [,8] [,9] 1 0.3850020 0.5533614 2 -0.6301731 -0.7506881 3 1.5927895 1.3099816 4 -0.3902865 -0.2783241
Pada tabel 2 merupakan pusat cluster yang masih berupa data hasil standarisasi, maka perlu dilakukan transformasi kembali ke data awal untuk diperoleh pusat cluster dari masing-masing kelompok. Misalkan untuk pusat cluster variabel pertama akan ditransformasi ke data awal yaitu penderita gizi buruk dengan menggunakan persamaan
a. Pusat klaster pertama variabel penderita gizi buruk
b. Pusat klaster kedua variabel penderita gizi buruk
c. Pusat klaster ketiga variabel penderita gizi buruk
d. Pusat klaster keempat variabel penderita gizi buruk
Untuk variabel penderita gizi burukpada pusat klaster pertama berada pada 63.93 jiwa, untuk pusat klaster kedua 107.1 jiwa, untuk pusat klaster ketiga 25.09 jiwa dan untuk pusat klaster keempat 89.63 jiwa. untuk hasil selengkapnya mengenai pusat klaster sebagai berikut :
a. Untuk pusat klaster pertama terdiri dari kabupaten kota dengan penderita gizi buruk 63.93 jiwa, jumlah puskesmas sebanyak 23.17, jumlah dokter sebanyak 65.1, jumlah bidan desa sebanyak 242.67 , jumlah penduduk miskin 109.77 ribu orang, rata-rata anggota rumah tangga 3.73, Kepadatan penduduk 1531.12 /km2, rata-rata lama sekolah 7.7 tahun, dan IPM 71.82.
b. Untuk pusat klaster pertama terdiri dari kabupaten kota dengan penderita gizi buruk 107.16 jiwa, jumlah puskesmas sebanyak 13.99, jumlah dokter sebanyak 38.24, jumlah bidan desa sebanyak 306.61 , jumlah penduduk miskin 160.54 ribu orang, rata-rata anggota rumah tangga 3.82, Kepadatan penduduk 1131.63 /km2, rata-rata lama sekolah 6.43 tahun, dan IPM 65.8.
c. Untuk pusat klaster pertama terdiri dari kabupaten kota dengan penderita gizi buruk 25.09 jiwa, jumlah puskesmas sebanyak 9.8, jumlah dokter sebanyak 26, jumlah bidan desa sebanyak 12.26 , jumlah penduduk miskin 29.14 ribu orang, rata-rata anggota rumah tangga 3.75, Kepadatan penduduk 6780.4 /km2, rata-rata lama sekolah 9.28 tahun, dan IPM 75.33
d. Untuk pusat klaster pertama terdiri dari kabupaten kota dengan penderita gizi buruk 89.6 jiwa, jumlah puskesmas sebanyak 15.28, jumlah dokter sebanyak 42, jumlah bidan desa sebanyak
318.1 , jumlah penduduk miskin 145.7 ribu orang, rata-rata anggota rumah tangga 3.63, Kepadatan penduduk 962.53 /km2, rata-rata lama sekolah 6.74 tahun, dan IPM 67.99.
C. Pengelompokkan Klaster
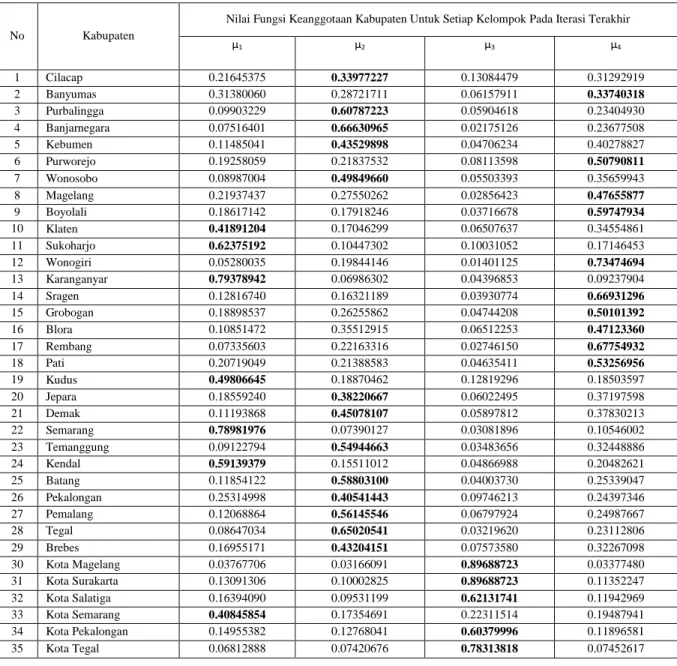
Nilai fungsi keanggotaan adalah kecenderungan suatu anggota untuk masuk kedalam kelompok tertentu. Dari iterasi terakhir (iterasi ke-23) pada kelompok optimal, dapat dilihat derajat keanggotaan tiap provinsi pada tabel 5.3 di bawah ini;
Tabel 3. Nilai Fungsi Keanggotaan Kabupaten Untuk Setiap Kelompok Pada Iterasi Terakhir
No Kabupaten
Nilai Fungsi Keanggotaan Kabupaten Untuk Setiap Kelompok Pada Iterasi Terakhir
µ1 µ2 µ3 µ4 1 Cilacap 0.21645375 0.33977227 0.13084479 0.31292919 2 Banyumas 0.31380060 0.28721711 0.06157911 0.33740318 3 Purbalingga 0.09903229 0.60787223 0.05904618 0.23404930 4 Banjarnegara 0.07516401 0.66630965 0.02175126 0.23677508 5 Kebumen 0.11485041 0.43529898 0.04706234 0.40278827 6 Purworejo 0.19258059 0.21837532 0.08113598 0.50790811 7 Wonosobo 0.08987004 0.49849660 0.05503393 0.35659943 8 Magelang 0.21937437 0.27550262 0.02856423 0.47655877 9 Boyolali 0.18617142 0.17918246 0.03716678 0.59747934 10 Klaten 0.41891204 0.17046299 0.06507637 0.34554861 11 Sukoharjo 0.62375192 0.10447302 0.10031052 0.17146453 12 Wonogiri 0.05280035 0.19844146 0.01401125 0.73474694 13 Karanganyar 0.79378942 0.06986302 0.04396853 0.09237904 14 Sragen 0.12816740 0.16321189 0.03930774 0.66931296 15 Grobogan 0.18898537 0.26255862 0.04744208 0.50101392 16 Blora 0.10851472 0.35512915 0.06512253 0.47123360 17 Rembang 0.07335603 0.22163316 0.02746150 0.67754932 18 Pati 0.20719049 0.21388583 0.04635411 0.53256956 19 Kudus 0.49806645 0.18870462 0.12819296 0.18503597 20 Jepara 0.18559240 0.38220667 0.06022495 0.37197598 21 Demak 0.11193868 0.45078107 0.05897812 0.37830213 22 Semarang 0.78981976 0.07390127 0.03081896 0.10546002 23 Temanggung 0.09122794 0.54944663 0.03483656 0.32448886 24 Kendal 0.59139379 0.15511012 0.04866988 0.20482621 25 Batang 0.11854122 0.58803100 0.04003730 0.25339047 26 Pekalongan 0.25314998 0.40541443 0.09746213 0.24397346 27 Pemalang 0.12068864 0.56145546 0.06797924 0.24987667 28 Tegal 0.08647034 0.65020541 0.03219620 0.23112806 29 Brebes 0.16955171 0.43204151 0.07573580 0.32267098 30 Kota Magelang 0.03767706 0.03166091 0.89688723 0.03377480 31 Kota Surakarta 0.13091306 0.10002825 0.89688723 0.11352247 32 Kota Salatiga 0.16394090 0.09531199 0.62131741 0.11942969 33 Kota Semarang 0.40845854 0.17354691 0.22311514 0.19487941 34 Kota Pekalongan 0.14955382 0.12768041 0.60379996 0.11896581 35 Kota Tegal 0.06812888 0.07420676 0.78313818 0.07452617
Berdasarkan tabel 3 didapat informasi bahwa anggota pada tiap cluster diperoleh dari nilai anggota yang paling besar pada setiap kabupaten kota. Dapat dilihat untuk Kabupaten Cilacap memiliki nilai fungsi keanggotaan tertinggi pada kelompok kedua, maka Kabupaten Cilacap akan masuk ke dalam kelompok dua. Berikut akan disajikan tabel hasil pengelompokkannya.
Tabel 4. Hasil Pengelompokkan Kabupaten Kota
Provinsi Kelompok
Provinsi Kelompok Kabupaten Semarang, Kabupaten Kendal dan Kota Semarang
Kabupaten Cilacap, Kabupaten Purbalingga, Kabupaten Banjarnegara, Kabupaten Kebumen, Kabupaten Wonosobo, Kabupaten Jepara, Kabupaten Demak, Kabupaten Temanggung, Kabupaten Batang, Kabupaten Pekalongan, Kabupaten Pemalang, Kabupaten Tegal, dan Kabupaten Brebes
2
Kota Magelang, Kota Surakarta, Kota Salatiga, Kota Pekalongan dan Kota Tegal 3 Kabupaten Banyumas, Kabupaten Purworejo, Kabupaten Magelang, Kabupaten Boyolali,
Kabupaten Wonogiri, Kabupaten Sragen, Kabupaten Grobogan, Kabupaten Blora, Kabupaten Rembang, Kabupaten Pati
4
D. Pembagian Wilayah
Gambar 1 Pembagian Cluster Berdasarkan Pengelompokan variabel
E. Perbandingan Hasil Clustering
Untuk melihat perbandingan hasil clustering, maka akan dilihat dari keanggotaan yang terbentuk pada setiap metode. Menurut Lobo [12] SOM merupakan metode pengelompokkan yang menyediakan penataan kelas-kelas berdasarkan topologinya. SOM dilatih secara iteratif melalui sejumlah iterasi/epoch. Sebuah epoch didefinisikan sebagai proses dari semua pola input sehingga masing-masing pola input akan diproses sebanyak jumlah epoch.
Menurut Muslem [7] kedua metode ini tergolong kedalam unsupervised learning, artinya pembelajaran yang tidak terawasi. Dalam konsep artificial neural network sebuah output tidak ditentukan target yang harus dicapai.
Tabel 5 Tabel perbandingan anggota tiap cluster dengan metode Fuzzy C-Means dan SOM.
Cluster Fuzzy C-Means SOM
1
Kabupaten Klaten, Kabupaten Sukoharjo, Kabupaten Karanganyar, Kabupaten Kudus, Kabupaten Semarang,
Kabupaten Kendal dan Kota Semarang
Kab. Banyumas, Kab. Purbalingga, Kab. Banjarnegara, Kab. Kebumen, Kab. Purworejo, Kab. Wonosobo, Kab. Magelang, Kab. Boyolali,
Kab. Klaten, Kab. Wonogiri, Kab. Sragen, Kab. Grobogan, Kab. Blora, Kab.Rembang, Kab. Pati, Kab. Jepara, Kab. Demak, Kab. Temanggung, Kab.
Batang, Kab. Pekalongan, Kab. Pemalang, Kab. Tegal, Kab. Brebes
2
Kabupaten Cilacap, Kabupaten Purbalingga, Kabupaten Banjarnegara, Kabupaten Kebumen, Kabupaten Wonosobo, Kabupaten Jepara, Kabupaten Demak,
Kabupaten Temanggung, Kabupaten Batang, Kabupaten Pekalongan, Kabupaten Pemalang,
Kabupaten Tegal, dan Kabupaten Brebes
Kab. Sukoharjo, Kab. Karanganyar, Kab. Kudus, Kab. Semarang, Kab. Kendal, Kota Semarang
3 Kota Magelang, Kota Surakarta, Kota Salatiga, Kota Pekalongan dan Kota Tegal
Kota Magelang, Kota Surakarta, Kota Salatiga, Kota Pekalongan, Kota Tegal
4
Kabupaten Banyumas, Kabupaten Purworejo, Kabupaten Magelang, Kabupaten Boyolali, Kabupaten
Wonogiri, Kabupaten Sragen, Kabupaten Grobogan, Kabupaten Blora, Kabupaten Rembang, Kabupaten Pati
Kab. Cilacap
Dari tabel 5 di atas diketahui bahwa terdapat kabupaten/kota yang berada dalam cluster yang sama pada metode Fuzzy C-means dan SOM yaitu pada cluster 3 dengan anggota cluster Kota Magelang, Kota Surakarta, Kota Salatiga, Kota Pekalongan, Kota Tegal. Sedangkan untuk Kabupaten cilacap pada
metode SOM menjadi anggota cluster 4, namun pada metode Fuzzy C-Means menjadi anggota cluster 2 dengan anggota lain yaitu Kabupaten Purbalingga, Kabupaten Banjarnegara, Kabupaten Kebumen, Kabupaten Wonosobo, Kabupaten Jepara, Kabupaten Demak, Kabupaten Temanggung, Kabupaten Batang, Kabupaten Pekalongan, Kabupaten Pemalang, Kabupaten Tegal, dan Kabupaten Brebes.
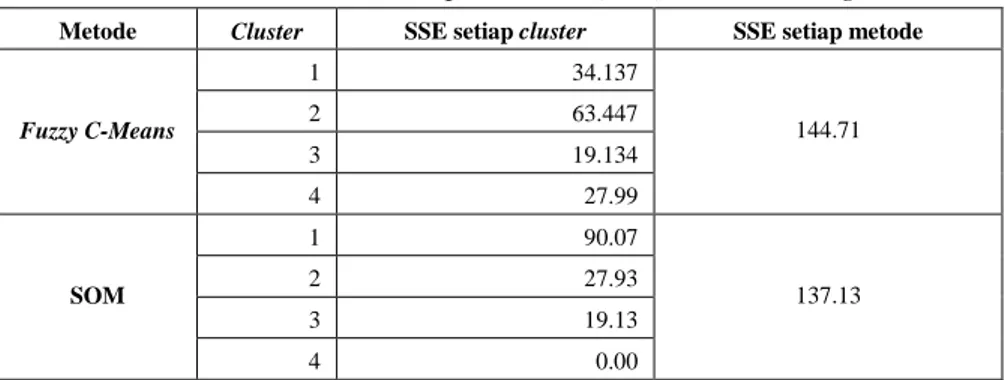
Untuk mengevaluasi hasil perbandingan kedua cluster ini peneliti menggunakan nilai jumlah kuadrat perbedaan antara observasi dengan rata-rata percluster atau Sum Square Error (SSE). Cluster yang baik yaitu cluster dengan jumlah K yang kecil dan memiliki SSE yang kecil.
Tabel 6 Hasil nilai Sum Square Error (SSE) hasil clustering.
Metode Cluster SSE setiap cluster SSE setiap metode
Fuzzy C-Means 1 34.137 144.71 2 63.447 3 19.134 4 27.99 SOM 1 90.07 137.13 2 27.93 3 19.13 4 0.00
Pada tabel diatas menjelaskan nilai SSE pada setiap cluster dengan metode Fuzzy C-Means dan SOM. Dari tabel diketahui bahwa nilai SSE cluster dengan metode SOM memiliki SSE yang lebih kecil dari metode Fuzzy C-Means. Maka pembentukan cluster dengan metode SOM memiliki kesamaan antar anggota di dalam cluster yang lebih baik dari metode Fuzzy C-Means.
Nilai SSE pada Fuzzy C-Means untuk cluster 2 memiliki nilai SSE tertinggi yaitu 63.447 dan cluster 3 memiliki nilai SSE terkecil yaitu 19.134.
Dengan metode SOM, cluster 1 juga memiliki nilai SSE tertinggi yaitu sebesar 90.07 dan cluster 4 memiliki nilai terkecil yaitu SSE sebesar 0. Hal ini menunjukan bahwa kesamaan karakteristik anggota di cluster 4 lebih baik dari kesamaan karakteristik anggota di cluster 1. Nilai 0 pada cluster 4 dengan metode SOM menunjukan bahwa keanggotaannya sama, hal ini tak heran karena di cluster 4 dengan metode SOM hanya terdiri dari satu kabupaten yaitu Kabupaten Cilacap [12].
IV. SIMPULAN DAN SARAN
A. Simpulan
Berdasarkan rumusan masalah yang telah dijelaskan pada bab sebelumnya, maka diperoleh kesimpulan sebagai berikut:
1. Berdasarkan Indeks Xie dan Beni diperoleh jumlah kelompok optimum yaitu 4 kelompok. 2. Hasil pengelompokkan dengan metode Fuzzy C-Means menunjukkan 4 cluster yaitu :
a. Kelompok cluster 1 memiliki 7 anggota meliputi Kabupaten Klaten, Kabupaten Sukoharjo, Kabupaten Karanganyar, Kabupaten Kudus, Kabupaten Semarang, Kabupaten Kendal dan Kota Semarang.
b. Kelompok cluster 2 memiliki 13 anggota meliputi Kabupaten Cilacap, Kabupaten Purbalingga, Kabupaten Banjarnegara, Kabupaten Kebumen, Kabupaten Wonosobo, Kabupaten Jepara, Kabupaten Demak, Kabupaten Temanggung, Kabupaten Batang, Kabupaten Pekalongan, Kabupaten Pemalang, Kabupaten Tegal, dan Kabupaten Brebes. c. Kelompok cluster 3 memiliki 5 anggota meliputi Kota Magelang, Kota Surakarta, Kota
Salatiga, Kota Pekalongan dan Kota Tegal.
d. Kelompok cluster 4 memiliki 10 anggota meliputi Kabupaten Banyumas, Kabupaten Purworejo, Kabupaten Magelang, Kabupaten Boyolali, Kabupaten Wonogiri, Kabupaten Sragen, Kabupaten Grobogan, Kabupaten Blora, Kabupaten Rembang, Kabupaten Pati.
3. Hasil evalusi cluster menunjukan bahwa nilai Sum Square Error (SSE) dengan metode SOM memiliki nilai yang lebih kecil dari hasil clustering dengan metode Fuzzy C-Means.
B. Saran
1. Pemerintah perlu mengkaji lagi tentang penanganan kasus buruk di Indonesia khususnya di Provinsi Jawa Tengah. Dapat dilihat dari Kabupaten atau Kota yang memiliki nilai penderita kasus gizi buruk yang tinggi perlu adanya perhatian khusus agar untuk tahun-tahun berikutnya nilai tersebut tidak semakin naik.
2. Diharapkan hasil penelitian ini bisa digunakan sebagai bahan kajian pemerintah untuk mengambil kebijakan yang lebih baik untuk meningkakan sumber daya manusia di Provinsi Jawa Tengah dengan kualitas yang lebih baik.
3. Untu penelitian selanjutnya, sebaiknya dilibatkan faktor-faktor lain yang mempengaruhi gizi buruk di Provinsi Jawa Tengah dengan data yang terbaru untuk pengaplikasian pemetaan yang lebih bagus dan spesifik.
UCAPAN TERIMA KASIH
Terima kasih kepada semua pihak yang membantu dan mendukung saya untuk menyelesaikan paper ini masih belum sempurna.
DAFTAR PUSTAKA
[1] Azzahra, Fatimah. 2013. Gizi Buruk Mimpi Buruk Indonesia Yang Belum Berakhir. http://m.arrahmah.com/news/2013/03/19/gizi-buruk-mimpi-buruk-indonesia-yang-belum-berakhir.html. Diakses pada tanggal 5 Mei 2016 pukul 22:00 WIB.
[2] Bezdek, James C., dan Pal , Nikhil R. 1995. On Cluster Validity for the Fuzzy c-Means Model. IEEE Transactions On Fuzzy Systems, Vol. 3, No. 3, August 1995.
[3] Champakan, S., Srikantia, SG., and Gopalan. 1986. Kwashiorkor and Mental Development. American Journal Clinic Nutrition. 1968
[4] Kusumadewi, Sri dan Purnomo, Hari. 2004. Aplikasi Logika Fuzzy Untuk Pendukung Keputusan. Yogyakarta : Graha Ilmu. [5] Lestrina, Dini. 2009. Penanggulangan Gizi Buruk di Wilayah Kerja Puskesmas Lubuk Pakam Kabupaten Deli Serdang. Tesis.
Program Studi Ilmu Kesehatan Masyarakat. Universitas Sumatera Utara.
[6] Muslem., Yuniarto , Eko Mulyanto dan Purnama , I Ketut Eddy. 2014. Prosiding. Pengelompokkan Data Guru Untuk Pemilihan Calon Pengawas Satuan Pendidikan Manggunakan Metode Fuzzy C-Means dan Kohonen Self Organizing Maps. Seminar Nasional ke-9: Rekayasa Teknologi Industri dan Informasi. Sekolah Tinggi Teknologi Nasional (STTNAS) Yogyakarta.
[7] Mustapa, Yusna., Saiffudin Sirajuddin., Abdul Salam. 2013. Analisis Faktor Determinan Kejadian Masalah Gizi Pada Anak Balita di Wilayah Kerja Puskesmas Tilote Kecamatan Tilango Kabupaten Goromtalo Tahun 2013. Jurnal.
[8] Nara, Nasrullah. 2013. “Setumpuk PR Kesehatan Menunggu Gubernur Jateng”. http://regional.kompas.com/read/2013/04/17/1725044/Setumpuk.PR.Kesehatan.Menunggu.Gubernur.Jateng..html. Diakses pada tanggal 5 Mei 2016 pukul 10:00 WIB.
[9] Novrandita, Hanif. 2015. Analisis Fuzzy C-Means Pada Produksi Pertanian Kelompok Bahan Makanan. Yogyakarta : Tugas Akhir Jurusan Statistik Universitas Islam Indonesia.
[10] Revathy, S dan B. Parvathavarthini. 2013. Fuzzy Cluster Quality Index using Decision Theory. Indian Journal of Computer Science and Engineering (IJCSE) Vol. 4 No. 6 Dec 2013-Jan 2014.
[11] Sanmorino, Ahmad. 2012. Clustering Batik Images Using Fuzzy C-Means Algorithm Based on Log-Average Luminance. Jurnal. Computer Engineering and Applications Vol. 1, No. 1, June 2012.
[12] Setianingsih, Dewi. 2016. Perbandingan Hasil Analisis Karakteristik dan Segmentasi Kelompok Antara Algoritma K-Means dan Kohonen Self Organizing Maps (SOM). Skripsi. Program Studi Statistika. Universitas Islam Indonesia.
[13] Simbolon, Cary Lineker., Kusumastuti , Nilamsari dan Irawan, Beni. Clustering Lulusan Mahasiswa Matematika FMIPA UNTAN Pontianak Menggunakan Algoritma Fuzzy C-Means. Buletin Ilmiah Mat. Stat. Dan Terapannya (Bimaster). Volume 02, No.1(2013), hal. 21-26.
[14] Sugiyono. 2010. Statistika Untuk Penelitian. Bandung : Alfabeta
[15] UNICEF Indonesia. 2014. Memberantas Gizi Buruk di Indonesia. http://indonesiaunicef.blogspot.co.id/2016/04/memberantas-gizi-buruk-di-indonesia.html. Diakses pada tanggal 5 Mei 2016 pukul 20:00 WIB.
[16] Wang, Weina dan Zhang, Yunjie. 2007. On Fuzzy Cluster Validity Indices. Jurnal. Fuzzy Sets and Systems 158 (2007) 2095-2117.
[17] Wibowo, Dimas Wahyu., M. Aziz Muslim dan M. Sarosa. 2013. “Perhitungan Jumlah dan Jenis Kendaraan Menggunakan Metode Fuzzy C-Means dan Segmentasi Deteksi Tepi Canny”. Jrnal EECCIS Vol 7, No. 2 Desember 2013.
[18] Xie, X.I dan Beni, G. 1991, A validity measure for fuzzy clustering. IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 13. hal. 841-847.
![Tabel 2. Pusat Cluster Cluster centers: [,1] [,2] [,3] [,4] [,5] [,6] [,7] 1 -0.22588953 1.0578556 1.0578556 -0.1013989 -0.2697814 0.009330146 -0.19](https://thumb-ap.123doks.com/thumbv2/123dok/4427509.2964598/3.893.192.708.134.357/tabel-pusat-cluster-cluster-centers.webp)