PEMBENTUKAN METADATA SECARA OTOMATIS
PADA DOKUMEN WEB DENGAN ASSOCIATIVE NETWORKS
Darmawan Fatriananda, Angelina Prima Kurniati, dan Bayu Erfianto Institut Teknologi Telkom, Bandung
[email protected], [email protected], dan [email protected]
ABSTRACT
Web documents have metadata in form of structured text, which is helpful in determining relevant web documents. Although having a very important value, metadata is generally ignored and sometimes incomplete, because the process of finding, creating or maintaining metadata on a web page manually is fairly difficult. Automatic generation of metadata can assist the discovery of relevant information within the documents. In addition, for the web document authors, automatic metadata generation in a web document is more efficient and more consistent than the manual process (a people-oriented). This study discusses an automatic metadata generation system using associative networks. The methods are used to determine associative network connectivity between documents. There are two algorithms used to create an associative network, occurrence associative network, and co-occurrence associative network. Test results showed that energy filtering of the recommended metadata is good to be implemented to generate fewer but more precise metadata. It is also showed that keywords metadata recommendations result in a better solution when using co-occurrence associative network.
Keywords: Metadata Generation, Assoiative Network, Occurrence, Cooccurrence, Filter.
1.
Pendahuluan
1.1 Latar Belakang
Informasi yang didapat dari Internet biasanya berupa dokumen web yang memiliki elemen-elemen teks yang dapat diproses lebih lanjut untuk membantu penemuan dokumen yang relevan. Suatu dokumen web memiliki metadata berupa teks yang terstruktur yang dapat membantu dalam menentukan dokumen web yang relevan. Meskipun memiliki nilai yang sangat penting, metadata pada umumnya diabaikan dan kalaupun ada seringkali isinya tidak lengkap[3], karena menemukan, membuat atau memelihara metadata pada suatu halaman web secara manual ini terbilang sulit[2]. Hal ini tentu saja menghambat efektivitas pelayanan atau pemberian informasi yang relevan.
Pembentukan metadata secara otomatis dapat membantu penemuan informasi yang relevan. Selain itu bagi pembuat dokumen web, pembentukan metadata secara otomatis dalam suatu dokumen web ini menjadi lebih efisien dan lebih konsisten daripada proses manual[4]. Dokumen-dokumen web yang saling berhubungan dapat berbagi (shared) metadata. Teknik berbagi (shared) metadata ini merupakan teknik ekstraksi dengan pendekatan ekstraksi berdasar pada konten yang dapat membantu mengurai biaya komputasi[7]. Penelitian menunjukkan bahwa pembentukan metadata secara otomatis dapat menghasilkan metadata yang baik, namun tetap memerlukan pertimbangan intelektual manusia[5]. Teknik yang dilakukan dalam pembentukan metadata secara otomatis ini adalah dengan melakukan ekstraksi metadata dan isi dari dokumen. Teknik ekstraksi yang berdasarkan isi (content) ini kurang efisien untuk jenis dokumen multimedia (audio, video, dan gambar)[10]. Selain itu, proses ekstraksi yang berdasar pada isi (content) ini ternyata menghabiskan biaya komputasi yang sangat besar[6].
Penelitian ini membahas pembentukan metadata secara otomatis dengan menggunakan metode associative network. Metode associative network digunakan untuk menentukan keterhubungan antar dokumen. Terdapat dua algoritma yang digunakan untuk membuat associative network, yaitu occurrence associative network dan coocurrence associative network. Algoritma occurrence associative network melakukan pendekatan pada kutipan (biasanya berupa hyperlink) yang ada pada dokumen web, sedangkan coocurance associative network melakukan pendekatan pada nilai properti-properti pada metadata seperti author, keyword, identifier, description, publisher, format, dan tanggal publish. Setelah ditentukan dokumen yang memiliki keterhubungan, kemudian dilakukan propagasi metadata dengan algoritma particle swarm untuk proses shared (berbagi) metadata dari dokumen web yang memiliki metadata lengkap ke dokumen web yang metadatanya kurang atau tidak lengkap[8].
1.2 Tujuan Penelitian Tujuan penelitian ini adalah:
1. Mengimplementasikan metode associative network dengan algoritma occurrence associative network dan cooccurrence associative network untuk teknik ektraksi. Kemudian mengimplementasikan teknik propagasi metadata dengan menerapkan algoritma particle swarm[9] pada pembentukan metadata secara otomatis.
1.3 Rumusan Masalah
Rumusan masalah dalam penelitian ini adalah bagaimana membuat, menemukan atau melengkapi metadata secara manual dengan implementasi metode associative network menggunakan algoritma occurrence dan cooccurrence pada proses pembentukan associative network, serta algoritma particle swarm pada proses propagasi metadata dalam pembentukan metadata secara otomatis. Hasil dari pembentukan metadata ini yang kemudian dianalisis.
Sedangkan batasan masalah dalam penelitian ini adalah:
1. Data yang digunakan untuk membentuk metadata bentuk fisiknya adalah halaman web.
2. Resource metadata didapat dari http://kdl.cs.umass.edu/proximity/proximity.html, kemudian di-export ke MySQL sebagai database. Untuk file fisik dokumen html dapat diunduh di http://www-2.cs.cmu.edu/~WebKB/. 3. Properti-properti metadata yang digunakan dalam penerapan algoritma cooccurence associative network adalah keyword. Keyword dipilih karena merupakan properti yang sering digunakan. Properti pada dataset yang digunakan merupakan properti yang didefinisikan oleh suatu institusi yang bernama Dublin Core.
2.
Landasan Teori
2.1 Metadata
Metadata merupakan istilah dari proses identifikasi suatu atribut dan struktur dari sebuah data atau informasi. Metadata merupakan data yang menjelaskan sebuah data itu sendiri (Data about data)[16]. Metadata adalah data ilmu pengetahuan yang dimiliki yang diinterpretasikan sebagai informasi untuk menentukan sebuah keputusan[15].
Banyak standar metadata yang sudah dipublikasikan saat ini, namun yang paling banyak dipakai adalah bentuk metadata MARC dan Dublin Core[1]. Di Indonesia MARC diadopsi menjadi INDOMARC agar memudahkan identifikasi proses katalogisasi yang sesuai dengan kaidah dan kesepakatan para pustakawan di Indonesia. Sedangkan Dublin Core merupakan salah satu metadata yang digunakan untuk web resource description and discovery. Dublin Core dihadirkan karena ada beberapa pihak yang merasa kurang sesuai untuk menggunakan bentuk MARC sehingga diadakan suatu kesepakatan menyusun sebuah metadata baru yang lebih mudah dan fleksibel. Metadata Dublin Core tersusun atas 15 elemen dasar yaitu[11]: Title, Creator, Subject, Description, Publisher, Contributor, Date, Type, Format, Identifier, Source, Language, Relation, Coverage, dan Rights.
2.2 Associative Networks
Associative Network adalah jaringan yang menghubungkan resource berdasarkan beberapa ukuran kemiripan. Sebuah associative network direpresentasikan oleh struktur data sebagai berikut:
G = (N, E, W) (1)
dimana N adalah himpunan resources, E ⊆ N × N adalah himpunan relasi antar resources, dan W adalah himpunan nilai bobot untuk semua edge sehingga | W | = | E |.
Algoritma associative network dibagi menjadi dua bagian yaitu: 1. Occurrence Associative Network
Jaringan asosiatif dapat dibangun jika suatu resource berhubungan langsung dengan resource lainnya. Dalam dunia web, suatu dokumen yang berhubungan langsung dengan dokumen lainnya dapat dilihat melalui hyperlink (tag href dalam sintax HTML).
2. Cooccurrence Associative Network
Cooccurrence associative network dibangun berdasar dari nilai properti metadata pada resource yang sama. Sebagai contoh, jika dua resource memiliki nilai keyword, penulis (author), atau citation yang sama, maka akan terdapat beberapa derajat kesamaan.
2.3 Particle Swarm Algoritma Propagasi Metadata
Proses propagasi metadata dilakukan untuk merekonstruksi metadata dari resource yang metadatanya tidak lengkap, dengan menggunakan algoritma particle swarm. Algoritma particle swarm adalah teknik optimasi stokastik berdasarkan populasi yang dikembangkan oleh Dr Eberhart dan Dr Kennedy pada tahun 1995, terinspirasi oleh perilaku sosial burung atau ikan. Algoritma particle swarm ini memiliki kemiripan dengan algoritma genetik, namun tidak seperti algoritma genetik, algoritma particle swarm tidak memiliki operator evolusi seperti crossover dan mutasi. Di algoritma particle swarm, potensi solusi disebut partikel, yang melakukan pencarian melalui ruang masalah dengan mengikuti arus partikel optimal. Setiap partikel melacak dari koordinat dalam ruang masalah yang terkait dengan solusi terbaik.
(2)
sehingga
(3)
Tiap partikel pi juga memiliki nilai energi ei ∈ [0, 1]. Setiap kali sebuah edge dilintasi, partikel pi energinya akan berkurang, oleh nilai global decay ( δ ), δ ∈ [0, 1]. Nilai energi dari sebuah partikel mendefinisikan berapa banyak pengaruh rekomendasi dari nilai properti partikel metadata terhadap node yang dikunjungi dan memiliki metadata yang tidak lengkap atau tidak memiliki. Sebuah partikel metadata tidak hanya merekomendasikan nilai properti metadata namun juga menambahkan nilai energi dari nilai properti metadata.
2.4 Evaluasi Menggunakan Precision, Recall dan F-score
Hasil percobaan generate metadata dievaluasi dengan nilai F-score. Nilai F-score ini di dapat dari nilai precision dan recall dari tiap-tiap resource metadata. Precision didefinisikan sebagai jumlah dari nilai properti metadata yang diterima satu resource yang relevant terhadap jumlah nilai dari nilai properti yang te-retrieved atau yang direkomendasikan secara keseluruhan. Berikut ini adalah persamaan-persamaannya:
(4)
3.
Perancangan Sistem
3.1 Deskripsi Sistem
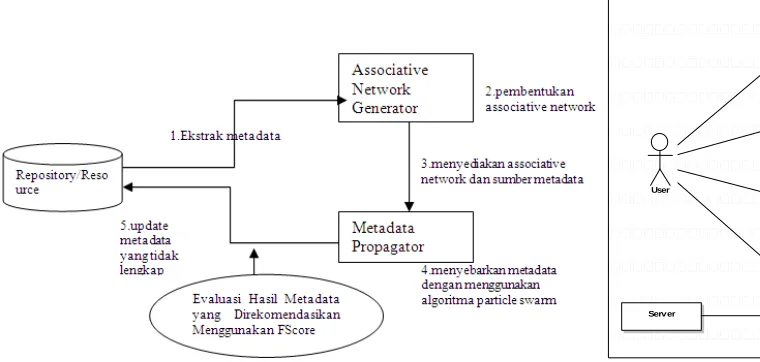
Perangkat Lunak yang dikembangkan berkemampuan untuk melakukan proses pembentukan metadata secara otomatis dengan menggunakan metoda associative network. Data input untuk perangkat lunak ini didapat dalam format file xml. File tersebut dieksplorasi menggunakan tools Proximity, dan kemudian dijadikan resource menjadi format database menggunakan MySQL. Data dari resource diekstrak kemudian dibuat associative network. Associative network ini berisi node-node yang saling berhubungan. Kemudian melalui edge-edge yang terhubung pada tiap node nya, metadata disebarkan. Metadata disebar ke node-node yang tidak memiliki metadata dan node yang metadatanya tidak lengkap.
ud Use Case Model 2
User
Server
Select Associative
Network
Select Property Metadata
Generate Metadata Browse Web Page
(a) Gambaran Umum Sistem (b) Use Case Diagram
Batasan implementasi dari perangkat lunak ini adalah:
1. Dokumen yang digunakan sebagai input adalah dokumen web dengan ekstensi file *.html atau *.jsp. Dokumen tersebut merupakan salah satu dokumen yang sudah ada di resource.
2. Properti metadata yang dapat dibuat otomatis adalah properti keyword.
3. Resource yang digunakan adalah resource yang didapat dari lingkungan Knowledge Discovery Laboratary berupa file database monetDB, yang kemudian diolah menjadi database mysql.
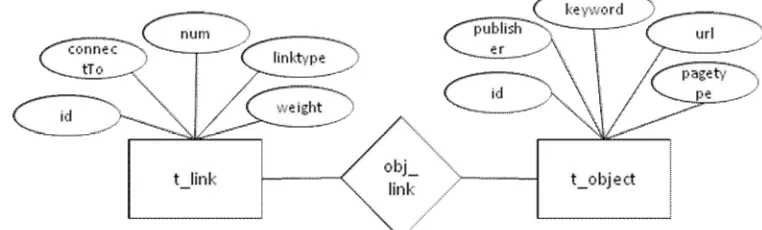
3.2 Perancangan Basis Data
Perancangan basis data dilakukan dengan ERD (entity-relationship diagram) yang ditunjukkan pada Gambar 2.
Gambar 2. Diagram Entitas-Relasi Dari Sistem
4.
Pengujian dan Analisis Hasil
4.1 Skenario Pengujian
Deskripsi mengenai skenario pengujian yang dilakukan adalah sebagai berikut:
1. Skenario 1: Menguji algoritma propagasi (particle swarm). Hal yang dianalisis adalah parameter pada algoritma propagasi yaitu nilai global-decay dan max_step (t). Dua parameter tersebut menentukan seberapa lama suatu partikel mengitari associative network untuk merekomendasikan metadata. Nilai global-decay dan max_step (t) terbaik akan digunakan pada skenario 2.
2. Skenario 2: Menguji pembentukan associative network yang berdasarkan occurrence dan cooccurrence. Hal yang dianalisis pada skenario 2 adalah pembentukan associative network yang berdasar dari dua hal yang berbeda.
4.2 Analisis Hasil Pengujian
4.2.1 Pengujian Parameter Pada Algoritma Propagasi (Particle Swarm) Pada pengujian ini digunakan 2 set data, yaitu:
1. Untuk pengujian associative network dengan occurrence, digunakan 4126 node/dokumen data training dan 1000 node data testing
2. Untuk pengujian associative network dengan cooccurrence, digunakan 2487 node/dokumen data training dan 500 node data testing
Hasil pengujian associative network dengan occurrence ditampilkan pada Tabel 1.
Tabel 1. Hasil Pengujian dengan Associative Network Berdasar Occurrence
Parameter Tanpa Filter Dengan Filter
Max step(t)
Global decay
Recall Precission Fscore Recall Precission FScore
Avg max Avg max avg Max avg max avg max avg max
10
0.1 0.57861 1 0.32459 1 0.35229 0.85714 0.38547 1 0.44896 1 0.34705 1 0.2 0.56572 0.31064 1 0.34314 0.78571 0.36206 1 0.46673 1 0.33663 0.83333 0.3 0.58629 1 0.33653 1 0.35787 0.90909 0.37738 1 0.44843 1 0.34015 0.82051 0.4 0.57266 1 0.32905 1 0.35937 0.86667 0.38048 1 0.42978 1 0.33155 0.8 0.5 0.56749 1 0.32058 1 0.34907 1 0.32658 1 0.48564 1 0.32398 0.75 0.6 0.56188 1 0.31677 1 0.34437 0.82051 0.34088 1 0.47813 1 0.33303 0.73333 0.7 0.61454 1 0.32117 1 0.36145 0.90909 0.36318 1 0.43268 1 0.31793 0.77778 0.8 0.58213 1 0.32856 1 0.3541 1 0.35263 1 0.45268 1 0.32692 0.82051 0.9 0.57562 1 0.32148 1 0.35141 1 0.33781 1 0.45303 0.31734 0.90909 0.9999 0.57501 1 0.33304 1 0.35656 1 0.34017 1 0.48727 1 0.31843 0.75 1
0.1
0.51105 1 0.399 1 0.3837 0.92857
5 0.55985 1 0.33658 1 0.35141 1 0.37953 1 0.46972 1 0.35046 0.84615 10 0.58131 1 0.34356 1 0.3633 1 0.36234 1 0.45655 1 0.33683 0.81818 20 0.57308 1 0.3311 1 0.35704 1 0.33325 1 0.44503 1 0.30871 0.88889 100 0.58147 1 0.32789 1 0.35639 0.90909 0.35488 1 0.43785 1 0.32031 1
Sedangkan pada penerapan associative network occurrence dengan filter, diperoleh nilai maksimal F-Score 1 saat global decay bernilai 1 dan max step 10 atau 100.
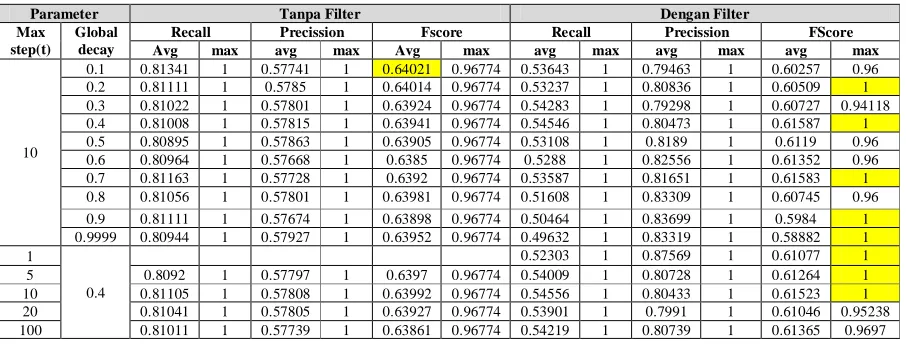
Sedangkan hasil pengujian associative network dengan cooccurrence ditampilkan dalam Tabel 2. Tabel 2. Hasil Pengujian dengan Associative Network Berdasar Cooccurrence
Parameter Tanpa Filter Dengan Filter
Max step(t)
Global decay
Recall Precission Fscore Recall Precission FScore
Avg max avg max Avg max avg max avg max avg max
Tabel 2 menunjukkan bahwa nilai F-Score maksimal dari penerapan associative network cooccurrence tanpa filter adalah 0.96774, yang diperoleh di seluruh percobaan. Sedangkan nilai rata-rata F-Score tertinggi adalah 0.64021 yang diraih saat max step = 10 dan global decay = 0.1. Sedangkan pada associative network cooccurrence dengan filter, nilai F-Score maksimal adalah 1, pada sebagian besar percobaan. Sedangkan nilai rata-rata F-F-Score tertinggi dengan filter lebih rendah daripada rata-rata F-Score tertinggi tanpa filter.
Ringkasan hasil pengujian tersebut dapat dilihat pada Tabel 3.
Tabel 3. Ringkasan Hasil Pengujian Associative Network
Jenis
Berdasarkan Tabel 3, diperoleh hasil analisis sebagai berikut:
1. Tidak semua dokumen berhasil mendapat rekomendasi metadata, baik dari pembentukan associative network berdasar occurrence ataupun coocurrence.
2. Jumlah dokumen yang berhasil di-generate ketika menerapkan associative network berdasarkan cooccurrence lebih besar daripada occurrence. Selain itu tanpa penggunaan filter atau penyaringan energi terhadap metadata yang direkomendasikan dokumen yang berhasil di-generate dengan jumlah lebih banyak dibandingkan dengan menggunakan filter. Hal ini disebabkan karena ketika dilakukan penyaringan energi, ternyata tidak semua metadata yang direkomendasikan dengan nilai energi di atas rata-rata memiliki kesamaan dengan metadata yang ada pada dokumen aslinya. Penggunaan penyaringan terhadap nilai energi yang direkomendasikan ini berpengaruh terhadap nilai recall dan precision dari dokumen yang dibentuk oleh associative network berdasarkan occurrence atau cooccurrence.
3. Nilai recall akan lebih besar dari nilai precision jika penyaringan terhadap energi tidak diterapkan, dan sebaliknya nilai precision akan menjadi lebih besar dari nilai recall jika diterapkan penyaringan energi terhadap metadata yang direkomendasikan dari associative network berdasar occurrence ataupun cooccurrence. Hal ini disebabkan karena, ketika dilakukan proses penyaringan energi metadata yang direkomendasikan menjadi berkurang sehingga hanya merekomendasikan beberapa metadata yang paling baik. Penyaringan energi baik diterapkan jika ingin menghasilkan rekomendasi metadata yang lebih sedikit tapi lebih tepat, tetapi bila ingin menghasilkan rekomendasi metadata yang banyak maka jangan menerapkan penyaringan energi.
berdasar cooccurrence tetap lebih baik. Hal ini dikarenakan properti pembentukan associative network berdasar cooccurrence-nya sama dengan properti metadata yang akan diserbarkan yaitu keyword.
5. Kedua tipe associative network yang berdasarkan occurrence dan cooccurrence dapat merekomendasikan metadata dengan tepat, dimana nilai recall dan precision nya 1.
5.
Kesimpulan
Kesimpulan yang dapat diperoleh dari penelitian ini adalah sebagai berikut:
1. Penerapan Associative Network berdasar Cooccurrence tanpa menerapkan penyaringan energi terhadap metadata yang direkomendasikan kemungkinan berhasil men-generate dokumen lebih banyak.
2. Penyaringan energi terhadap metadata yang direkomendasikan baik diterapkan jika ingin menghasilkan rekomendasi metadata yang lebih sedikit tapi lebih tepat, tetapi bila ingin menghasilkan rekomendasi metadata yang banyak maka jangan menerapkan penyaringan energi.
3. Untuk rekomendasi properti metadata keyword hasilnya akan lebih baik jika menggunakan Associative Network berdasar Cooccurrence.
Sedangkan saran pengembangan penelitian ini adalah sebagai berikut:
1. Mencoba algoritma propagasi yang proses komputasi nya lebih cepat dibanding algorima particle swarm, karena untuk performansi proses penyebaran metadata menggunakan algoritma particle swarm terhitung lama.
2. Mencoba metode penyaringan energi yang memperkecil kemungkinan dalam kegagalan merekomendasikan metadata.
Daftar Pustaka
[1] Dublin Core. Automatic Metadata Generation, http://www.ukoln.ac.uk/cgi-bin/dcdot.pl
[2] Duval, E., Hodgins, W., Sutton, S., and Weibel, S. L.(2002). Metadata principles and practices. D-Lib Mag. [3] Greenberg, J. (2004). Metadata extraction and harvesting: A comparison of two automatic meta- data generation
applications. J. Intern. Catalog.
[4] Greenberg, J.,Spurgin, K., Crystal Abe. (2005). AMeGA (Automatic Metadata Generation Application) Project. UNC School Of Information And Library Science.
[5] Han, H. C., Giles, L., Manavoglu, E., Zha, H., Zhang, Z., & Fox, E.A. (2003). Automatic document metadata extraction using support vector machines. In Proceedings of the Third ACM/IEEE-CS Joint Conference on Digital Libraries (pp. 37 – 48). New York: ACM Press.
[6] Kuwano H., Matsuo, Y., and Kawazoe, K. (2004). Reducing the cost of metadata generation by using video/ audio indexing and natural language processing techniques. NTT Technical Review.
[7] Rodriguez, M. A., Bollen, J., and Van De Sompel, H. (2009). Automatic metadata generation using associative networks. ACM Trans. Inform. Syst.
[8] Rodriguez, M A. (2007). Social decision making with multi-relational networks and grammar-based particle swarms. In Proceedings of the 40th Annual Hawaii International Conference on Systems Science (HICSS’07). [9] Xihaou, H, Particle Swarm.http://www.swarmintelligence.org/tutorials.php, diakses pada 3 januari 2010.
[10] Yang, H.-C. and Lee, C.-H. (2005).Automatic metadata generation for Web pages using a text mining approach. In Proceedings of the International Workshop on Challenges in Web Information Retrieval and Integration. IEEE. [11] Hilmann, Diane. Dublin Core Element. http://dublincore.org/documents/usageguide/elements.html. Diakses pada
14 juni 2010.
[12] Jensen, David. (2004-2007). Proximity 4.3 Tutorial. Knowledge Discovery Laboratory.
[13] P. A. Boncz and M. L. Kersten. 1995. Monet: An Impressionist Sketch of an Advanced Database System. Proceedings Basque International Workshop on Information Technology.