UNTUK PENGOLAHAN GUDANG DATA WISATAWAN DI OBYEK WISATA DIY DALAM MEMANTAU KUNJUNGAN WISATAWAN
YANG DIIMPLEMENTASIKAN MENGGUNAKAN TEKNIK ON LINE ANALYTICAL PROCESSING (OLAP)
(Studi Kasus : Dinas Pariwisata Provinsi Daerah Istimewa Yogyakarta)
Skripsi
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Oleh :
Markus Herjuno Dwianto 07 5314 056
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
2012
i
DATA WAREHOUSE TOURIST PROCESSING IN THE TOUR OBJECT OF DIY FOR MONITORING TOURIST VISIT WHICH IS
IMPLEMENTED USING ON LINE ANALYTICAL PROCESSING (OLAP) TECHNIQUE
(Case Study : Dinas Pariwisata Provinsi Daerah Istimewa Yogyakarta)
A Thesis
Presented as Partial Fullfillment of the Requirements
To Obtain the Sarjana Komputer Degree
By :
Markus Herjuno Dwianto 07 53140 56
INFORMATICS ENGINEERING STUDY PROGRAM FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
2012
ii
iii
iv
v
vi
vii
“Kita bisa berani bertindak jika mempunyai,
N Y A L I dan U S A H A …”
Skripsi ini saya persembahkan untuk :
KATA PENGANTAR
Segala puji syukur penulis panjatkan kepada Allah Bapa, Tuhan Yesus
Kristus, Bunda Maria di Surga, karena berkat bimbingan-Nya dan kehendak-Nya
penulis dapat menyelesaikan penyusunan tugas akhir yang berjudul
“Membandingkan Aplikasi MySQL, LucidDB, dan Oracle XE untuk Pengolahan Gudang Data Wisatawan di Obyek Wisata DIY dalam Memantau Kunjungan
Wisatawan yang Diimplementasikan Menggunakan Teknik On Line Analytical Processing (OLAP)”.
Tugas akhir ini disusun sebagai salah satu syarat untuk memperoleh gelar
sarjana strata satu pada Program Studi Teknik Informatika Fakultas Sains dan
Teknologi Universitas Sanata Dharma Yogyakarta.
Pada saat pengerjaan tugas akhir ini penulis banyak mendapatkan bantuan
dari berbagai pihak, oleh karena itu penulis ingin mengucapkan terima kasih
kepada :
1. Ibu PH. Prima Rosa, S.Si., M.Sc., selaku Dekan Fakultas Sains dan
Teknologi.
2. Ibu Ridowati Gunawan, S.Kom., M.T., Ketua Prodi Teknik Informatika
sekaligus dosen pembimbing yang telah memberikan bimbingan, arahan,
saran, meluangkan waktu, dan kebaikannya sehingga penulis dapat
menyelesaikan tugas akhir ini.
3. Bapak Puspaningtyas Sanjoyo Adi, S.T., M.T., dan Bapak JB. Budi
Darmawan, S.T., M.Sc, selaku dosen penguji yang telah memberikan
penilaian, kritik dan saran.
4. Dinas Pariwisata Provinsi DIY yang telah membantu memberikan informasi
data yang dibutuhkan penulis dalam menyusun tugas akhir ini.
viii
ix
5. Kedua orang tuaku yang baik hati, Ibu Theresia Sri Haryati dan Bapak YB.
Widiyanto yang selalu memberikan doa, dukungan, perhatian, dan pengertian
kepada penulis sehingga penulis dapat menyelesaikan tugas akhir ini.
6. Mbak Prima, Mas Doni, dan seluruh keluarga besar Hardjolaksono dan
Dirdjosoemarto yang memberikan perhatian, arahan dan dukungan kepada
penulis dalam tugas akhir ini. Dan juga untuk dik Geni yang selalu menghibur
penulis dengan tingkahnya.
7. Ni Made Kristianingsih Kuatra S.Kom., yang selalu sabar, tersenyum dan
mendukung, dan juga memberikan doa, perhatian, ketelitian, hiburan,
semangat, dan waktu untuk berbagi cerita sehingga penulis semakin nyaman
dalam menyelesaikan tugas akhir ini.
8. Sahabat seperjuangan, Taufik S.Kom., Riko, Franky, Miko, Obi, Yudha,
Leonardus S.Kom., Albertus Dio S.Kom, Bowo, dan juga teman-teman TI’07
Arum, Dita, Ana, Sinta, Tiwi, dan semuanya yang membantu dan mendukung
penulis agar secepatnya menyelesaikan tugas akhir ini.
9. Semua pihak yang secara langsung maupun tidak langsung membantu dan
mendukung penulis dalam menyelesaikan tugas akhir ini.
Penulis merasa masih banyak kekurangan dalam penyusunan tugas akhir ini.
Untuk itu penulis mengharapkan kritik dan saran yang membangun dari pembaca
agar berguna bagi penulis ke depannya. Semoga tugas akhir ini bermanfaat bagi
semua pihak, khususnya pada bidang Teknik Informatika.
Yogyakarta, 8 Mei 2012
DAFTAR ISI
HALAMAN JUDUL ... i
HALAMAN JUDUL INGGRIS ... ii
HALAMAN PERSETUJUAN ... iii
HALAMAN PENGESAHAN ... iv
LEMBAR PERNYATAAN PERSETUJUAN ... v
HALAMAN KEASLIAN KARYA ... vi
MOTTO ... vii
KATA PENGANTAR ... viii
DAFTAR ISI ... x
DAFTAR TABEL ... xiv
DAFTAR GAMBAR ... xvi
ABSTRAK ... xx
1.3 Tujuan Penelitian ... 4
1.4 Manfaat Penelitian ... 4
1.5 Batasan Masalah ... 4
1.6 Metodologi Penelitian ... 5
1.7 Sistematika Penulisan ... 5
BAB II ... 7
LANDASAN TEORI ... 7
2.1 Dinas Pariwisata Propinsi Daerah Istimewa Yogyakarta ... 7
x
2.1.1 Visi dan Misi Dinas Pariwisata Propinsi Daerah Istimewa Yogyakarta .. 7
2.2 Data Warehouse atau Gudang Data ... 8
2.2.1 Pengertian Data warehouse atau Gudang Data ... 8
2.2.2 Komponen – Komponen Gudang Data ... 9
2.2.3 Karakteristik Gudang Data ... 10
2.2.4 Manfaat Dari Gudang Data ... 13
2.2.5 Arsitektur Gudang Data ... 14
2.2.6 Pembuatan Gudang Data ... 16
2.2.7 Extract, Transform, Load (ETL) ... 17
2.3 Pentaho Data Integration (Kettle) ... 17
2.3.1 Pentaho Data Integration ... 17
2.3.2 Komponen Aplikasi Kettle ... 18
2.3.3 Job/Transformation ... 19
2.3.3.1 Koneksi Database... 19
2.3.3.2 Hop dan Job ... 20
2.3.3.3 Transformation ... 21
2.4 Multi Dimensional Modelling ... 21
2.4.1 Tabel Fakta dan Dimensi ... 22
2.4.2 Surrogate Key ... 24
2.5 Pengertian OLAP (Online Analitycal Processing) ... 24
2.6 Oracle XE ... 24
2.6.1 Struktur Database Oracle XE ... 25
2.6.2 Keuntungan Menggunakan Oracle XE ... 25
2.7 LucidDB ... 26
2.7.1 Arsitektur LucidDB ... 26
2.7.2 OLAP Integration ... 27
2.7.3 Menjalankan Server LucidDB ... 27
2.7.4 Schema dan Tables ... 29
xi
2.8 MySQL ... 31
2.9 Head-to-Head MySQL, LucidDB, dan Oracle XE ... 32
2.9.1 Data Size Limits ... 32
2.9.2 Indexes Information ... 33
2.9.2.1 MySQL Indexes Information ... 33
2.9.2.2 LucidDB Indexes Information ... 33
2.9.2.3 Oracle XE Indexes Information ... 34
2.9.2.4 Perbandingan Indexes Information ... 35
BAB III ... 37
ANALISIS DAN PERANCANGAN SISTEM ... 37
3.1 Identifikasi dan Analisis Kebutuhan ... 37
3.2 Mengumpulkan dan Menganalisa Sumber Data ... 38
3.3 Langkah Mendesain Gudang Data ... 39
3.3.1 Membaca Data Legacy ... 39
3.3.2 Menggabungkan Data Dari Sumber Terpisah ... 41
3.3.3 Memindahkan Data Dari Sumber ke Server Gudang Data ... 41
3.3.4 Memecah Gudang Data ke Dalam Tabel Fakta dan Dimensi ... 46
3.3.5 Membandingkan Performansi Database ... 49
BAB IV ... 50
IMPLEMENTASI SISTEM ... 50
4.1 Arsitektur Sistem ... 50
4.2 Langkah Pembuatan Gudang Data ... 51
4.2.1 Membaca Data Legacy ... 51
4.2.2 Memindahkan Data ke Server Gudang Data ... 53
4.2.3 Memecah Gudang Data Dalam Tabel Dimensi Dan Tabel Fakta ... 57
4.3 Pembentukan OLAP ... 61
4.3.1 Skema Bintang Pariwisata ... 61
4.4 Implementasi Use Case ... 64
xii
xiii
4.4.1 Use Case Memantau Kunjungan Wisatawan ... 64
BAB V ... 68
ANALISIS HASIL ... 68
5.1 Penyelesaian Rumusan Masalah ... 68
5.2 Pengujian Cube Pariwisata ... 70
5.3 Perbandingan Performansi ... 75
5.3.1 Proses Pembentukan Tabel ... 75
5.3.2 Penghitungan Akses Waktu ... 87
BAB VI ... 93
KESIMPULAN DAN SARAN ... 93
6.1 Kesimpulan ... 93
6.2 Saran ... 93
DAFTAR PUSTAKA ... 94
DAFTAR TABEL
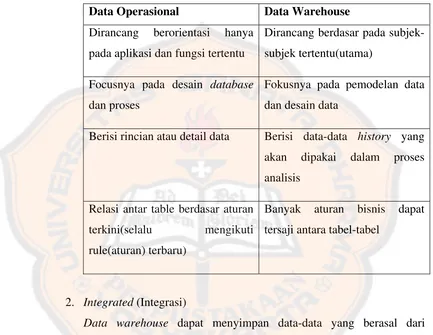
Tabel 2.1 Perbedaan Data Operasional dan Data Warehouse ... 11
Tabel 2.2 Arti warna Hop ... 20
Tabel 2.3 Arti Warna Hop Pada Job ... 20
Tabel 2.4 Perbandingan data size limits MySQL, LucidDB, dan Oracle XE ... 32
Tabel 2.5 Indexes Information antara MySQL, LucidDB, dan Oracle XE ... 35
Tabel 3.1 Data Kunjungan Wisatawan ke Obyek Wisata DIY ... 37
Tabel 3.2 Perubahan Susunan Kolom Data ... 38
Tabel 3.3 Kunjungan Wisatawan ... 40
Tabel 3.4 Contoh Data Kunjungan Wisatawan ... 40
Tabel 3.5 Konversi Tabel Data Kunjungan Wisatawan ... 41
Tabel 3.6 Proses Pemindahan ke Tabel master_kabupaten ... 42
Tabel 3.7 Struktur Data ms_kabupaten ... 42
Tabel 3.8 Proses pemindahan ke Tabel ms_nama_obyekwisata ... 42
Tabel 3.9 Struktur Data ms_obyekwisata ... 43
Tabel 3.10 Proses Pemindahan ke Tabel ms_jeniswisatawan ... 43
Tabel 3.11 Struktur Data ms_jenis wisatawan ... 43
Tabel 3.12 Proses Penggabungan Tabel ms_obyekwisata dengan ms_jeniswisatawan 44 Tabel 3.13 Struktur Data Tabel ms_obyekdanwisatawan ... 44
Tabel 3.14 Proses Penggabungan Data ke Tabel ms_pengunjung ... 45
xiv
xv
Tabel 3.15 Struktur Data Tabel ms_pengunjung... 46
Tabel 3.16 Tabel Proses Pembentukan ds_kunjungan ... 48
Tabel 3.17 Tabel Proses Pembentukan ds_wisata ... 48
Tabel 5.1 Sintak query SQL 1 ... 71
Tabel 5.2 Sintak query SQL 2 ... 73
Tabel 5.3 Sintak query SQL 3 ... 74
Tabel 5.4 Pengujian Waktu Pembentukan Tabel Tahun 2009 Pada MySQL ... 76
Tabel 5.5 Pengujian Waktu Pembentukan Tabel Tahun 2009 Pada LucidDB ... 76
Tabel 5.6 Pengujian Waktu Pembentukan Tabel Tahun 2009 Pada Oracle XE ... 77
Tabel 5.7 Tabel Jumlah Rows Pada Setiap Tabel Tahun 2009 dan 2009-2011 ... 82
Tabel 5.8 Pengujian Waktu Pembentukan Tabel Tahun 2009-2011 Pada MySQL ... 83
Tabel 5.9 Pengujian Waktu Pembentukan Tabel Tahun 2009-2011 Pada LucidDB ... 83
Tabel 5.10 Pengujian Waktu Pembentukan Tabel Tahun 2009-2011 Pada Oracle XE . 84 Tabel 5.11 Tabel Hasil Rata-Rata Pembentukan Tabel 2009 dan 2009-2011 ... 86
Tabel 5.12 Tabel Penghitungan Akses Waktu Pada Tahun 2009 ... 87
DAFTAR GAMBAR
Gambar 2.1 Arsitektur Gudang Data ... 15
Gambar 2.2 Contoh Hop ... 21
Gambar 2.3 Simbol Transformation ... 21
Gambar 2.4 Star Schema ... 23
Gambar 2.5 Snowflake Schema ... 23
Gambar 2.6 Struktur Database Oracle XE ... 25
Gambar 2.7 Skema Arsitektur LucidDB ... 26
Gambar 2.8 Letak Server LucidDB ... 27
Gambar 2.9 Proses Startup Server LucidDB ... 28
Gambar 2.10 Letak Aplikasi Client LucidDB ... 28
Gambar 2.11 Koneksi ke host “localhost” ... 29
Gambar 2.12 Melihat Daftar Seluruh Schema ... 29
Gambar 2.13 Melihat Daftar Seluruh Table ... 30
Gambar 2.14 Membuat schema PHI ... 30
Gambar 2.15 Membuat table di schema PHI ... 30
Gambar 2.16 Menambahkan row pada table... 31
Gambar 3.1 Diagram Use Case ... 38
Gambar 3.2 Ilustrasi Penggabungan Data Dari Sumber Terpisah ... 41
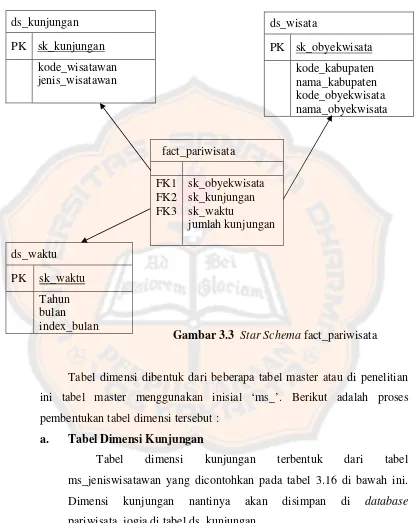
Gambar 3.3 Star Schema fact_pariwisata ... 47
xvi
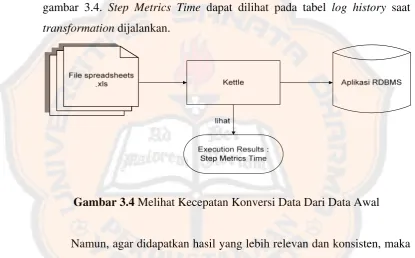
Gambar 3.4 Melihat Kecepatan Konversi Data Dari Data Awal ... 49
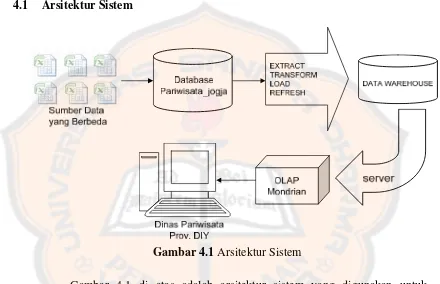
Gambar 4.1 Arsitektur Sistem ... 50
Gambar 4.2 Tabel ms_kunjunganwisatawan_sql.ktr ... 52
Gambar 4.3 Proses Konversi Data ... 52
Gambar 4.4 Tabel ms_kunjunganwisatawan ... 53
Gambar 4.5 Tabel ms_kabupaten_sql.ktr ... 53
Gambar 4.6 Tabel ms_kabupaten ... 54
Gambar 4.7 Tabel ms_obyekwisata_sql.ktr ... 54
Gambar 4.8 Tabel ms_obyekwisata ... 54
Gambar 4.9 Tabel ms_jeniswisatawan_sql.ktr ... 55
Gambar 4.10 Tabel ms_jeniswisatawan ... 55
Gambar 4.11 Tabel ms_obyekdanwisatawan_sql.ktr ... 55
Gambar 4.12 Tabel ms_obyekdanwisatawan ... 56
Gambar 4.13 Tabel ms_pengunjung_sql.ktr ... 56
Gambar 4.14 Tabel ms_pengunjung ... 57
Gambar 4.15 Tabel ds_kunjungan_sql.ktr ... 57
Gambar 4.16 Tabel ds_kunjungan ... 58
Gambar 4.17 Tabel ds_wisata_sql.ktr ... 58
Gambar 4.18 Tabel ds_wisata ... 59
Gambar 4.19 Tabel ds_waktu_sql.ktr ... 59
Gambar 4.20 Tabel ds_waktu ... 60
xvii
Gambar 4.21 Tabel fact_pariwisata_sql.ktr ... 60
Gambar 4.22 Tabel fact_pariwisata ... 61
Gambar 4.23 Skema pariwisata_jogja_sql ... 61
Gambar 4.24 Pemantauan Kunjungan Wisatawan di DIY Tahun 2009 ... 65
Gambar 4.25 Pemantauan Kunjungan Wisatawan di DIY Tahun 2009-2011 ... 66
Gambar 5.1 Hasil Pemantauan Kunjungan Wisatawan pada OLAP ... 69
Gambar 5.2 Jumlah Pengunjung Obyek wisata di Kabupaten Bantul tahun 2009.. 70
Gambar 5.3 Hasil Cube Pariwisata Pengujian 1 ... 71
Gambar 5.4 Hasil query sql 1 ... 72
Gambar 5.5 Hasil Cube Pariwisata Pengujian 2 ... 72
Gambar 5.6 Hasil query sql 2 ... 73
Gambar 5.7 Hasil Cube Pariwisata Pengujian 3 ... 74
Gambar 5.8 Hasil query sql 3 ... 75
Gambar 5.9 Waktu Pembentukan Tabel ms_kunjunganwisatawan ... 78
Gambar 5.10 Waktu Pembentukan Tabel ms_kabupaten ... 78
Gambar 5.11 Waktu Pembentukan Tabel ms_obyekwisata ... 78
Gambar 5.12 Waktu Pembentukan Tabel ms_jeniswisatawan ... 79
Gambar 5.13 Waktu Pembentukan Tabel ms_obyekdanwisatawan ... 79
Gambar 5.14 Waktu Pembentukan Tabel ms_pengunjung ... 79
Gambar 5.15 Waktu Pembentukan Tabel ds_kunjungan ... 79
Gambar 5.16 Waktu Pembentukan Tabel ds_wisata ... 80
xviii
xix
Gambar 5.17 Waktu Pembentukan Tabel ds_waktu ... 80
Gambar 5.18 Waktu Pembentukan Tabel fact_pariwisata ... 80
Gambar 5.19 Grafik Perbandingan Waktu Pembentukan Tabel Tahun 2009 ... 81
Gambar 5.20 Grafik Perbandingan Waktu Pembentukan Tabel Tahun 2009-2011 .. 85
Gambar 5.21 Contoh Penggunaan Metode Calculating Page Loading Time ... 87 Gambar 5.22 Grafik Perbandingan Akses Waktu Tahun 2009 ... 89
xx
ABSTRAK
Dalam perkembangan teknologi, muncul media berupa sistem database yang digunakan untuk mengakomodasi penyimpanan data agar lebih tersimpan secara
terstruktur. Sistem database tersebut juga didukung dengan teknik gudang data yang yang didesain untuk mendukung pengambilan keputusan. Teknik gudang data ini
digunakan untuk mengintegrasikan data kunjungan wisatawan yang terdapat di Dinas
Pariwisata Provinsi Daerah Istimewa Yogyakarta (DIY). Pembuatan gudang data
tersebut juga diintegrasikan dengan sistem database yang sesuai dengan kebutuhan Dinas Pariwisata Provinsi DIY untuk memantau kunjungan wisatawan di obyek
wisata DIY. Gudang data yang terbentuk akan digunakan untuk keperluan database online analytical processing (OLAP) yang meliputi obyek wisata yang berada di DIY berdasarkan kabupaten dan kota, jenis wisatawan yang berkunjung, dan waktu
kunjungan di tiap obyek wisata setiap bulannya.
Data yang digunakan diperoleh dari Dinas Pariwisata Provinsi DIY yang
selanjutnya akan dilakukan penyesuaian format data dan disimpan di server gudang data. Kemudian gudang data dipecah ke dalam tabel fakta dan tabel dimensi. Proses
penyesuaian format data hingga menjadi tabel fakta dan tabel dimensi dilakukan
dengan membandingkan performansi waktu database yang digunakan, yaitu MySQL, LucidDB, dan Oracle XE agar diperoleh database yang tepat, guna membantu pihak Dinas Pariwisata Provinsi DIY dalam membuat gudang data pariwisata untuk
memantau jumlah kunjungan wisatawan yang berkunjung ke obyek wisata di DIY.
Perbandingan performansi waktu yang telah dilakukan menghasilkan
pernyataan bahwa Oracle XE dapat memberikan waktu proses pembentukan tabel yang lebih cepat meskipun data tabel mengalami penambahan data atau jumlah rows untuk tahun 2011. Sedangkan dalam pengujian waktu akses pada tahun
2009-2011 yang mengalamai penambahan data, Oracle XE juga memberikan proses waktu
xxi
ABSTRACT
In technology development, emerging media in the form of a database system
that is used to accommodate the stored data storage to be more structured. Database
system is also supported by engineering data warehouse designed to support making
decision. Engineering data warehouse is used to integrate data of tourists visit in the
Dinas Pariwisata Provinsi Daerah Istimewa Yogyakarta (DIY). Preparation of a data
warehouse is also integrated with the database system in accordance with the Dinas
Pariwisata Provinsi DIY needs to monitor the tourist attractions in Yogyakarta.
Formed data warehouse database will be used for online analytical processing
(OLAP), which includes a tourist attraction located in the province by district and
city, the type of tourists who visit, and visits in each of the attractions of each month.
The data used were obtained from the Dinas Pariwisata Provinsi DIY would do
next adjustments to the format data and stored in a data warehouse server. Then
broken down into the data warehouse fact tables and dimension tables. The process of
adjusting the data format to be a fact table and dimension tables by comparing the
performance of the database used, namely MySQL, LucidDB, and Oracle XE
database to obtain appropriate, to assist the Dinas Pariwisata Provinsi DIY in making
tourism a data warehouse to monitor the number of visits tourists visiting the
attractions in the province.
Time performance comparison was done produced a statement that Oracle XE
can provide a time table creation process is much faster even though the data tables
have additional data or the number of rows for the years 2009-2011. While the access
time of testing in the year 2009-2011 which is experiencing the addition of data,
BAB I
PENDAHULUAN
1.1. Latar Belakang
Provinsi Daerah Istimewa Yogyakarta (DIY) terdiri dari 1 kota dan 4
kabupaten. Kota tersebut adalah Kota Yogyakarta, sedangkan 4 kabupaten
terdiri dari Kabupaten Sleman, Kabupaten Bantul, Kabupaten Gunung
Kidul, dan Kabupaten Kulon Progo. Kondisi topografi provinsi DIY juga
beraneka ragam, mulai dari berbentuk dataran yang datar, lereng
pegunungan, dan daerah pantai. Keanekaragaman tersebut membuat
wisatawan yang berkunjung ke provinsi DIY ingin menjelajahi obyek-obyek
wisata yang tersebar mulai dari pegunungan hingga ke pantai.
Banyaknya obyek wisata dan keanekaragaman dari obyek wisata
tersebut membuat DIY menjadi daya tarik tujuan wisata yang terkenal di
Indonesia dan mancanegara. Setiap tahunnya, jumlah kunjungan wisatawan
nusantara dan mancanegara ke DIY mengalami peningkatan. Jumlah
kunjungan wisatawan ke obyek wisata di DIY dikumpulkan dan direkap
oleh Dinas Pariwisata Provinsi Daerah Istimewa Yogyakarta. Jumlah
kunjungan wisatawan tersebut didapat dengan cara meninjau secara
langsung ke tiap obyek wisata yang berada di Provinsi DIY.
Data pariwisata yang terdiri dari nama obyek wisata, jenis wisatawan,
dan kunjungan per bulan dijadikan patokan oleh Dinas Pariwisata Provinsi
DIY dalam memantau kunjungan wisatawan di setiap obyek wisata di DIY.
Namun kunjungan wisatawan yang berubah-ubah dari waktu ke waktu,
diperlukan suatu penanganan agar mudah dipantau pelaksanaannya.
Eksplorasi data menjadi hal penting agar data kunjungan wisatawan dapat
dipantau dengan baik.
Terkait dengan eksplorasi data tersebut, saat ini teknologi informasi
telah berkembang dengan pesat khususnya mengenai teknik penyimpanan
data. Berawal dari penyimpanan data tersebut, seseorang maupun instansi
didukung untuk mengolah data secara efektif dan efisien. Hal ini disebabkan
oleh jumlah data yang terus bertambah dari waktu ke waktu sehingga
diperlukan pengelolaan yang baik agar dapat menghasilkan informasi yang
tepat dan berguna bagi penggunanya. Salah satu teknologi yang digunakan
untuk mengolah data dan membantu untuk pengambilan keputusan adalah
metode gudang data. Gudang data diartikan sebagai database yang saling
bereaksi yang dapat digunakan untuk query dan analisis, bersifat orientasi subyek, terintegrasi, time-variant, dan tidak berubah, yang digunakan untuk membantu para pengambil keputusan (Gustiarahman, 2006).
Dalam hal penelitian yang dilakukan penulis ini, metode gudang data
dapat menjadi solusi karena salah satu keuntungan gudang data adalah
menjadikan eksplorasi data menjadi lebih mudah. Sedangkan untuk
mendukung penggunaan implementasi metode gudang data, beberapa
aplikasi relational database management systems mengklaim bahwa pihak mereka mendukung penggunaan gudang data. Seperti MySQL dan Oracle, yang mana keduanya merupakan nama besar dalam bidang database management systems. Pihak MySQL mengklaim bahwa MySQL dirancang untuk mempermudah penanganan kasus-kasus yang berhubungan dengan
data warehouse (www.mysql.com). Sedangkan Oracle mengklaim bahwa mereka dapat memberikan performance yang maksimal untuk data warehouse (www.oracle.com). Selain kedua nama besar tersebut, muncul database management systems baru yaitu LucidDB yang diluncurkan pada 2007. Berdasarkan deskripsi produknya, LucidDB adalah RDBMS open source yang pertama dan dikembangkan sepenuhnya untuk gudang data dan business intelligence (www.luciddb.org).
di atas yaitu MySQL, LucidDB, dan Oracle XE yang mana ketiganya bersifat gratis. Gudang data yang nantinya terbentuk digunakan untuk keperluan
databaseOLAP yang mencakup obyek wisata di tiap kabupaten dan jumlah kunjungan wisatawan setiap bulannya.
Pada penelitian yang dilakukan penulis untuk mendukung
pemantauan wisatawan di DIY, maka penulis akan menggunakan aplikasi
engine OLAP yaitu Mondrian yang berbasis open source, dan kemudian membandingkan penggunaan aplikasi relational database management systems antara MySQL, LucidDB, dan Oracle XE agar diperoleh beberapa statement mengenai performansi antara ketiganya. Statement yang dihasilkan dapat dilihat dari kecepatan akses antara MySQL, LucidDB, dan Oracle XE saat melakukan konversi data dari data awal, dan proses meng-load data dari database.
Hasil yang diperoleh dari perbandingan ketiga aplikasi relational database management systems tersebut dapat digunakan sebagai acuan Dinas Pariwisata Provinsi DIY untuk mengimplementasikan keperluan
databaseOLAP yang mencakup obyek wisata di tiap kabupaten dan jumlah kunjungan wisatawan setiap bulannya, sehingga dapat mendukung kinerja
para petugas Dinas Pariwisata Provinsi DIY untuk memantau kunjungan
wisatawan di DIY.
1.2. Rumusan Masalah
Berdasarkan latar belakang yang telah diuraikan, maka permasalahan
yang akan dirumuskan dalam penelitian ini adalah :
1. Bagaimana membuat gudang data untuk keperluan database Online Analytical Processing (OLAP) yang mencakup obyek wisata di tiap kabupaten dan jumlah kunjungan wisatawan setiap bulannya dengan
relational database management systems yaitu MySQL, LucidDB, dan Oracle XE?
2. Bagaimana membandingkan performansi basisdata antara MySQL, LucidDB, dan Oracle XE?
1.3. Tujuan Penelitian
Tujuan dari dilakukannya penelitian ini adalah membantu pihak Dinas
Pariwisata Provinsi DIY dalam membuat gudang data pariwisata untuk
memantau jumlah kunjungan wisatawan yang berkunjung ke obyek wisata
di DIY.
1.4. Manfaat Penelitian
Manfaat yang didapat dari peneltian ini adalah mengetahui aplikasi
relational database management systems antara MySQL, LucidDB, dan Oracle XE yang cocok digunakan untuk mendukung pemakaian gudang data, khususnya dalam pemantauan wisatawan di DIY.
1.5. Batasan Masalah
Batasan yang akan diberlakukan untuk penelitian ini adalah :
1. Data rekapitulasi pariwisata yang digunakan adalah data pariwisata
Daerah Istimewa Yogyakarta tahun 2009.
2. Implementasi dengan menggunakan Kettle (Pentaho Data Integration).
3. Sistem ini hanya digunakan untuk memantau perkembangan
wisatawan di DIY .
1.6. Metodologi Penelitian
Metodologi yang digunakan di dalam penelitian ini adalah sebagai
berikut :
1. Pengumpulan Data
Mengumpulkan dan menganalisa data yang akan digunakan.
Mengekstrak data dan menyesuaikan data ke dalam gudang data (data warehouse).
2. Perancangan Pembuatan Gudang Data
Perancangan pembuatan gudang data di penelitian ini meliputi :
a. Membaca data legacy.
b. Menggabungkan data dari sumber terpisah.
c. Memindahkan data dari sumber ke server gudang data. d. Memecah gudang data ke dalam tabel fakta dan dimensi.
3. Mengimplementasikan pembuatan gudang data berdasarkan
perancangan yang telah dibuat.
4. Membandingkan performansi aplikasi relational database management systems yaitu MySQL, LucidDB, dan Oracle XE.
5. Menganalisa performansi penggunaan antara MySQL, LucidDB, dan Oracle XE.
6. Menyusun laporan Tugas Akhir.
1.7. Sistematika Penulisan
Sistematika penulisan tugas akhir ini terdiri atas enam bab, yang
diuraikan selengkapnya sebagai berikut :
BAB I : PENDAHULUAN
Bab ini berisi latar belakang penulisan tugas akhir, rumusan
masalah, batasan masalah, metodologi penelitian, dan sistematika
BAB II : LANDASAN TEORI
Bab ini membahas sekilas tentang gudang data dan juga
teori-teori lain yang mendukung dalam penulisan tugas akhir ini.
BAB III : ANALISIS DAN PERANCANGAN SISTEM
Bab ini berisi analisa dan perancangan gudang data.
BAB IV : IMPLEMENTASI SISTEM
Bab ini berisi pembuatan gudang data.
BAB V : ANALISIS HASIL
Bab ini berisi laporan hasil pembangunan gudang data dan
analisa performansi aplikasi relational database management systems.
BAB VI : KESIMPULAN DAN SARAN
Bab ini berisi beberapa kesimpulan yang didapat dan saran-saran
7
BAB II
LANDASAN TEORI
2.1 Dinas Pariwisata Propinsi Daerah Istimewa Yogyakarta
Dinas Pariwisata Propinsi Daerah Istimewa Yogyakarta terletak di jalan
Malioboro 56 Yogyakarta.
2.1.1 Visi dan Misi Dinas Pariwisata Propinsi Daerah Istimewa Yogyakarta
Visi dari Dinas Pariwisata Propinsi Daerah Istimewa Yogyakarta adalah
terwujudnya Yogyakarta sebagai Daerah Tujuan Wisata Utama Tahun 2010
berdasarkan keunggulan potensi wisata yang berkualitas, berwawasan budaya,
berwawasan lingkungan, berkelanjutan dan menjadi salah satu pendorong
tumbuhnya ekonomi kerakyatan (http://visitingjogja.com).
Misi dari Dinas Pariwisata Propinsi Daerah Istimewa Yogyakarta adalah
sebagi berikut (http://visitingjogja.com) :
1. Mengembangkan industri pariwisata yang berbasis pemberdayaan
ekonomi kerakyatan dengan memperluas jaringan kerja dan
kesempatan berusaha dalam rangka peningkatan pendapatan
masyarakat, Pendapatan Asli Daerah dan devisa.
2. Mengkoordinasikan peningkatan Kualitas dan Kuantitas Promosi
dengan kabupaten/kota, instansi dan institusi terkait, stakeholder dan
pemerhati pariwisata berdasarkan pada pengembangan dan/atau
konservasi destinasi berlandaskan RIPPDA yang berbasis kekayaan
budaya, kekayaan alam dan ekowisata serta kebijakan pro jender.
3. Mewujudkan berbagai kebijakan serta konsep tentang penataan,
pengembangan, preservasi, konservasi, regulasi dan kerjasama antar
menyeluruh, berkelanjutan dan implementatif berdasarkan data yang
akurat.
4. Mendorong peningkatan mutu dan inovasi terhadap sumberdaya
pariwisata, produk pariwisata, sistem pelayanan, manajemen dan
pemeliharaan kualitas destinasi.
5. Menyelenggarakan sistem pemasaran dengan meningkatkan strategi
promosi yang berorientasi pada efektifitas, efisiensi, kualitas,
informatif, tepat sasaran, dan mampu mengantisipasi, mengenal serta
mendorong timbulnya permintaan berdasarkan analisa pasar yang
komprehensif, katalis dan holistik.
2.2 Data warehouse atau Gudang Data
2.2.1 Pengertian Data warehouse atau Gudang Data
Pengertian data warehouse atau gudang data dapat bermacam-macam namun mempunyai inti yang sama, seperti pendapat beberapa ahli berikut ini (Gustiarahman, 2006) :
Menurut W.H. Inmon dan Richard D.H., data warehouse adalah koleksi data yang mempunyai sifat berorientasi subjek, terintegrasi, time-variant, dan
bersifat tetap dari koleksi data dalam mendukung proses pengambilan
keputusan management.
Menurut Vidette Poe, data warehouse merupakan database yang bersifat analisis dan read only yang digunakan sebagai fondasi dari sistem penunjang keputusan.
Menurut Paul Lane, data warehouse merupakan database relasional yang didesain lebih kepada query dan analisa dari pada proses transaksi, biasanya mengandung history data dari proses transaksi dan bisa juga data dari sumber lainnya. Data warehouse memisahkan beban kerja analisis dari beban kerja transaksi dan memungkinkan organisasi menggabung/konsolidasi data dari
Jadi, data warehouse merupakan metode dalam perancangan database, yang menunjang DSS(Decission Support System) dan EIS (Executive
Information System). Secara fisik data warehouse adalah database, tapi perancangan data warehouse dan database sangat berbeda. Dalam perancangan database tradisional menggunakan normalisasi, sedangkan pada data warehouse normalisasi bukanlah cara yang terbaik.
Dari definisi-definisi yang dijelaskan tadi, dapat disimpulkan data warehouse adalah database yang saling bereaksi yang dapat digunakan untuk query dan analisisis, bersifat orientasi subjek, terintegrasi, time-variant, tidak berubah yang digunakan untuk membantu para pengambil keputusan.
2.2.2 Komponen-Komponen Gudang Data
Ada banyak komponen yang terdapat dalam gudang data, diantaranya
(Connoly & Begg, 2008) :
1. Penyimpan data
Penyimpan data operasional adalah komponen yang paling umum
dalam gudang data. Setiap hari organisasi akan melakukan
penyimpanan data operasional dimana data yang disimpan adalah
tunggal untuk suatu aplikasi tertentu. Fungsi dari penyimpanan data
operasional dalam gudang data adalah sebagai sumber aliran data
mentah. Organisasi dalam penyimpanan data ini pada umumnya
berorientasi subyek, dan berfokus pada pelanggan, produk, order,
kebijakan hal lain diseputarnya. Penyimpanan data ini sering juga
disebut sebagai gudang data secara fisik.
2. Data pasar (mart data)
Data pasar sering dilihat sebagai cara untuk meningkatkan masukan ke
dalam bidang dari gudang data dan membuat seluruh kesalahan
menjadi kecil. Data pasarnya biasanya digunakan untuk memperkecil
3. Metadata
Metadata merupakan salah satu contoh dari gudang data secara
logikal. Yang digunakan untuk memperoleh informasi dan mengakses
data secara aktual. Sistem legacy pada umumnya tidak menyimpan record tentang karakteristik dari data, seperti berapa item data yang ada, dimana lokasi data, dari mana data itu berasal, atau bagaimana
data dapat diakses. Metadata adalah data sederhana tentang data yaitu
lebih memperhatikan informasi yang disimpan tentang gudang dari
pada informasi yang disediakan oleh gudang.
4. Sistem pendukung keputusan dan sistem informasi eksekutif
Keduanya bukanlah bagian dari gudang data akan tetapi
aplikasi-aplikasinya digunakan untuk gudang data.
2.2.3 Karakteristik Gudang Data
Karakteristik data warehouse menurut Inmon (2002), yaitu : 1. Subject Oriented (Berorientasi subyek)
Data warehouse berorientasi subyek artinya data warehouse didesain untuk menganalisa data berdasarkan subyek-subyek tertentu dalam
organisasi, bukan pada proses atau fungsi aplikasi tertentu.
Data warehouse diorganisasikan di sekitar subjek-subjek utama dari perusahaan (customers,products dan sales) dan tidak diorganisasikan pada area-area aplikasi utama (customer invoicing, stock control dan product sales). Hal ini dikarenakan kebutuhan dari data warehouse untuk menyimpan data-data yang bersifat sebagai penunjang suatu
keputusan, dari pada aplikasi yang berorientasi terhadap data.
Jadi dengan kata lain, data yang disimpan adalah berorientasi kepada
data operasional dan data warehouse dapat dilihat pada tabel 2.1 di bawah ini :
Tabel 2.1 Tabel Perbedaan Data Operasional dan Data Warehouse
Data Operasional Data Warehouse
Dirancang berorientasi hanya
pada aplikasi dan fungsi tertentu
Dirancang berdasar pada
subjek-subjek tertentu(utama)
Focusnya pada desain database dan proses
Fokusnya pada pemodelan data
dan desain data
Berisi rincian atau detail data Berisi data-data history yang akan dipakai dalam proses
analisis
Relasi antar table berdasar aturan
terkini(selalu mengikuti
rule(aturan) terbaru)
Banyak aturan bisnis dapat
tersaji antara tabel-tabel
2. Integrated (Integrasi)
Data warehouse dapat menyimpan data-data yang berasal dari sumber-sumber yang terpisah kedalam suatu format yang konsisten
dan saling terintegrasi satu dengan lainnya. Dengan demikian data
tidak bisa dipecah-pecah karena data yang ada merupakan suatu
kesatuan yang menunjang keseluruhan konsep data warehouse itu sendiri.
Syarat integrasi sumber data dapat dipenuhi dengan berbagai cara
variabel, konsisten dalam struktur pengkodean dan konsisten dalam
atribut fisik dari data.
Contoh pada lingkungan operasional terdapat berbagai macam aplikasi
yang mungkin pula dibuat oleh developer yang berbeda. Oleh karena itu, mungkin dalam aplikasi-aplikasi tersebut ada variabel yang
memiliki maksud yang sama tetapi nama dan format nya berbeda.
Variabel tersebut harus dikonversi menjadi nama yang sama dan
format yang disepakati bersama. Dengan demikian tidak ada lagi
kerancuan karena perbedaan nama, format dan lain sebagainya.
Barulah data tersebut bisa dikategorikan sebagai data yang terintegrasi
karena kekonsistenannya.
3. Time Variant (Rentang Waktu)
Seluruh data pada data warehouse dapat dikatakan akurat atau valid pada rentang waktu tertentu. Untuk melihat interval waktu yang
digunakan dalam mengukur keakuratan suatu data warehouse, kita dapat menggunakan cara antara lain :
a. Cara yang paling sederhana adalah menyajikan data warehouse pada rentang waktu tertentu, misalnya antara 5 sampai 10 tahun ke
depan.
b. Cara yang kedua, dengan menggunakan variasi/perbedaan waktu
yang disajikan dalam data warehouse baik implicit maupun explicit secara explicit dengan unsur waktu dalam hari, minggu, bulan dsb. Secara implicit misalnya pada saat data tersebut diduplikasi pada setiap akhir bulan, atau per tiga bulan. Unsur
waktu akan tetap ada secara implicit di dalam data tersebut.
c. Cara yang ketiga, variasi waktu yang disajikan data warehouse melalui serangkaian snapshot yang panjang. Snapshot merupakan tampilan dari sebagian data tertentu sesuai keinginan pemakai dari
4. Non-volatile
Karakteristik keempat dari data warehouse adalah non-volatile, maksudnya data pada data warehouse tidak di-update secara real time tetapi di refresh dari sistem operasional secara reguler. Data yang baru selalu ditambahkan sebagai suplemen bagi database itu sendiri dari pada sebagai sebuah perubahan. Database tersebut secara kontinyu menyerap data baru ini, kemudian secara incremental disatukan dengan data sebelumnya.
Berbeda dengan database operasional yang dapat melakukan update, insert dan delete terhadap data yang mengubah isi dari database sedangkan pada data warehouse hanya ada dua kegiatan memanipulasi data yaitu loading data (mengambil data) dan akses data (mengakses data warehouse seperti melakukan query atau menampilan laporan yang dibutuhkan, tidak ada kegiatan updating data).
2.2.4 Manfaat Dari Gudang Data
Data warehouse merupakan pendekatan untuk menyimpan data dimana sumber-sumber data yang heterogen (yang biasanya tersebar pada beberapa
database OLTP) diimigrasikan untuk penyimpanan data yang homogen dan terpisah. Keuntungan yang didapatkan dengan menggunakan data warehouse tersebut dibawah ini (Gustiarahman, 2006) :
1. Data diorganisir dengan baik untuk query analisis dan sebagai bahan untuk pemrosesan transaksi.
2. Perbedaan diantara struktur data yang heterogen pada beberapa
sumber yang terpisah dapat diatasi.
3. Aturan untuk transformasi data diterapkan untuk memvalidasi dan
4. Masalah keamanan dan kinerja bisa dipecahkan tanpa perlu mengubah
sistem produksi.
Membangun data warehouse tentu saja memberikan keuntungan lebih bagi suatu perusahaan, karena data warehouse dapat memberikan keuntungan strategis pada perusahaan tersebut melebihi pesaing-pesaing mereka.
Keuntungan tersebut bagi perusahaan antara lain (Gustiarahman, 2006) :
1. Kemampuan untuk mengakses data yang besar.
2. Kemampuan untuk memiliki data yang konsisten.
3. Kemampuan kinerja analisa yang cepat.
4. Mengetahui adanya hasil yang berulang-ulang.
5. Menemukan adanya celah pada business knowledge atau business process.
6. Mengurangi biaya administrasi.
7. Memberi wewenang pada semua anggota dari perusaahan dengan
menyediakan kepada mereka informasi yang dibutuhkan agar kinerja
bisa lebih efektif.
2.2.5 Arsitektur Gudang Data
Tipe arsitektur sebuah gudang data ditunjukkan pada gambar 2.1 di
Gambar 2.1 Arsitektur Gudang Data
Dan berikut adalah 3 jenis sistem gudang data yang diketahui saat ini,
yaitu (Gustiarahman, 2006) :
1. Functional Data warehouse (Data warehouse Fungsional)
Kata operasional disini merupakan database yang diperoleh dari kegiatan sehari-hari. Data warehouse dibuat lebih dari satu dan dikelompokkan berdasar fungsi-fungsi yang ada di dalam perusahaan
seperti fungsi keuangan (financial), marketing, personalia dan lain-lain. Keuntungan dari bentuk data warehouse seperti ini adalah, sistem mudah dibangun dengan biaya relatif murah sedangkan kerugiannya
adalah resiko kehilangan konsistensi data dan terbatasnya kemampuan
dalam pengumpulan data bagi pengguna.
2. Centralized Datawarehouse (Data warehouse Terpusat)
Bentuk ini terlihat seperti bentuk data warehouse fungsional, namun terlebih dahulu sumber data dikumpulkan dalam satu tempat terpusat,
kemudian data disebar ke dalam fungsinya masing-masing, sesuai
kebutuhan persuhaan. Data warehouse terpusat ini, biasa digunakan oleh perusahaan yang belum memiliki jaringan eksternal. Keuntungan
yang tinggi sedang kerugiannya adalah biaya yang mahal serta
memerlukan waktu yang cukup lama untuk membangunnya.
3. Distributed Data warehouse (Data warehouse terdistribusi)
Pada data warehouse terdistribusi, digunakan gateway yang berfungsi sebagai jembatan penghubung antara data warehouse dengan workstation yang menggunakan sistem beraneka ragam. Dengan sistem terdistribusi seperti ini memungkinkan perusahaan dapat
mengakses sumber data yang berada diluar lokasi perusahaan
(eksternal). Keuntungannya adalah data tetap konsisten karena
sebelum data digunakan data terlebih dahulu di sesuaikan atau
mengalami proses sinkronisasi. Sedangkan kerugiannya adalah lebih
kompleks untuk diterapkan karena sistem operasi dikelola secara
terpisah juga biayanya yang paling mahal dibandingkan dengan dua
bentuk data warehouse lainnya.
2.2.6 Pembuatan Gudang Data
Gudang data dapat diterapkan dengan mengikuti langkah-langkah pokok
seperti berikut ini (Wasito, 2010) :
1. Membaca data legacy.
Memperhatikan bagian-bagian data yang perlu untuk dibersihkan.
2. Menggabungkan data dari berbagai sumber terpisah.
Setiap jenis informasi yang diinginkan mungkin berasal dari beberapa
file yang harus digabungkan untuk digunakan pada gudang data. 3. Memindahkan data dari sumber ke server gudang data.
Membuat standarisasi format dan copy-kan data dari sumber sekaligus data dibuat bersih (clean).
4. Memecah gudang data dalam tabel fakta dan tabel dimensi.
2.2.7 Extract, Transform, Load (ETL)
Data yang akan diolah ke gudang data, pertama kali harus diekstrak
terlebih dahulu dari satu atau lebih sumber data, kemudian ditransformasi ke
bentuk yang lebih mudah untuk menganalisa dan konsisten atau bertipe sama
dengan data yang telah ada di gudang, dan akhirnya dimuat ke dalam gudang
data. Seluruh proses ini disebut sebagai ekstraksi, transformasi, dan loading (ETL) dan merupakan proses yang penting dalam setiap proyek gudang data.
Bila mengacu pada pernyataan di atas, maka gudang data memerlukan
kemampuan dalam hal sebagai berikut (www.phi-Integration.com) :
1. Membaca dari dan mengirim data ke berbagai sumber (file teks, excel, database relational, dan sebagainya).
2. Mampu meyesuaikan / transformasi data.
3. Memiliki informasi meta data pada setiap perjalanan transformasi.
4. Memiliki audit log yang baik.
5. Dapat ditingkatkan performanya dengan scale up dan scale out. 6. Mudah diimplementasikan.
2.3 Pentaho Data Integration (Kettle) 2.3.1 Pentaho Data Integration
Pentaho Data Integration (PDI) atau Kettle adalah utlities ETL open source di bawah Pentaho Corp. Amerika. Proyek ini awalnya merupakan inisiatif dari Matt Casters (http://www.ibridge.be), seorang programmer dan konsultan Business Intelligence (BI) dari Belgia yang telah menangani berbagai proyek BI untuk semua perusahaan besar. Saat ini Kettle merupakan utilitas
ETL yang sangat popular dengan beberapa fitur sebagai berikut
(www.phi-Integration.com) :
2. Dukungan untuk proses data warehouse terutama untuk Slowly Changing dan Junk Dimensions.
3. Performa dan kemampuan skalabilitas yang sudah terbuka.
4. Dapat dikembangkan dengan berbagai plugin tambahan.
2.3.2 Komponen Aplikasi Kettle
Kettle terdiri dari 4 utilitas dalam bentuk shell/batch script, yaitu (www.phi-Integration.com) :
1. Spoon
Spoon adalah utilitas grafik untuk merancang, mengeksekusi dan melakukan troubleshooting dari ETL melalui job dan transformasi. Porsi terbesar dari alokasi waktu pengembangan proyek data warehouse kettle pasti melibatkan Spoon di dalamnya.
Lingkungan kerja Spoon terdiri dari beberapa bagian sebagai berikut: a. Pulldown Menu : koleksi menu dari Spoon yang terintegrasi
dalam satu toolbar.
b. Welcome Screen : merupakan halaman pembuka kettle yang berisi informasi ke situs Pentaho. Untuk mengaktifkan welcome screen pilih menu Help | Show the Welcome Screen.
c. Toolbar: terdiri dari job/ transformasi toolbar d. Panel Execution Results, terdiri dari:
1)Execution History : Data histories eksekusi
2)Logging : Berisi detil dari eksekusi job/ transformation.
3)Job Metrics : Berisi detail dari step-step yang telah dieksekusi.
5) Performance Graphs : Tampilan grafis dari pembacaan data dari Step Metrics.
2. Pan
Pan merupakan utilitas yang digunakan untuk mengeksekusi transformasi. Umumnya dijalankan pada saat otomatisasi terjadwal
(scheduled automation). Dipaketkan dengan nama file pan.bat (batch script) dan pan.sh (BASH shell script).
3. Kithen
Kithen merupakan utilitas yang digunakan unutk mengeksekusi job. Umumnya dijalankan pada saat otomatisasi terjadwal (scheduled automation). Dipaketkan dengan nama file pan.bat (batch script) dan pan.sh (BASH shell script).
4. Carte
Merupakan utilitas cluster web server yang digunakan untuk mengeksekusi job/transformation. Terutama digunakan untuk meningkatkan performa ETL dengan pembagian load kerja pada berbagai node Carte (master dan slave).
2.3.3 Job/Transformation 2.3.3.1 Koneksi Database
2.3.3.2 Hop dan Job
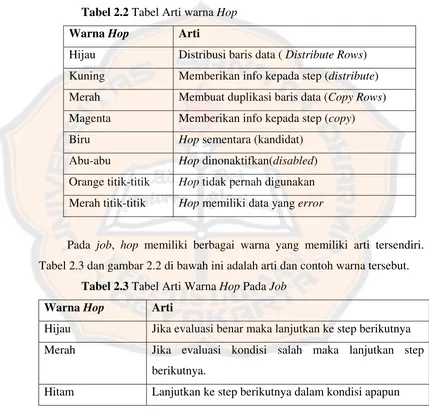
Suatu hop menggabungkan 2 step baik dengan penentu aliran / flow dari job atau penghantar data di transformation. Pada transformation, hop memiliki berbagai warna yang memiliki arti tersendiri. Tabel 2.2 di bawah ini berisi
daftar lengkap dari arti warna hop (www.phi-Integration.com).
Tabel 2.2 Tabel Arti warna Hop Warna Hop Arti
Hijau Distribusi baris data ( Distribute Rows) Kuning Memberikan info kepada step (distribute) Merah Membuat duplikasi baris data (Copy Rows) Magenta Memberikan info kepada step (copy) Biru Hop sementara (kandidat)
Abu-abu Hop dinonaktifkan(disabled) Orange titik-titik Hop tidak pernah digunakan Merah titik-titik Hop memiliki data yang error
Pada job, hop memiliki berbagai warna yang memiliki arti tersendiri. Tabel 2.3 dan gambar 2.2 di bawah ini adalah arti dan contoh warna tersebut.
Tabel 2.3 Tabel Arti Warna Hop Pada Job Warna Hop Arti
Hijau Jika evaluasi benar maka lanjutkan ke step berikutnya
Merah Jika evaluasi kondisi salah maka lanjutkan step
berikutnya.
Hitam Lanjutkan ke step berikutnya dalam kondisi apapun
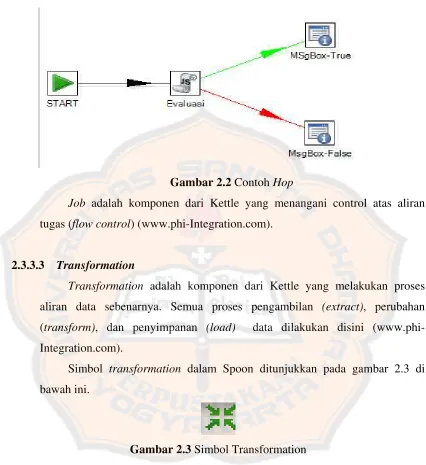
Gambar 2.2 Contoh Hop
Job adalah komponen dari Kettle yang menangani control atas aliran tugas (flow control) (www.phi-Integration.com).
2.3.3.3 Transformation
Transformation adalah komponen dari Kettle yang melakukan proses aliran data sebenarnya. Semua proses pengambilan (extract), perubahan (transform), dan penyimpanan (load) data dilakukan disini (www.phi-Integration.com).
Simbol transformation dalam Spoon ditunjukkan pada gambar 2.3 di bawah ini.
Gambar 2.3 Simbol Transformation
2.4 Multi Dimensional Modelling
Teknologi OLAP menganut multi dimensional modeling, artinya kita dapat melihat analisis pengukuran dengan pandangan berbagai dimensi. Di
dalam konsep ini kita perlu mengenal berbagai istilah yang berkaitan dengan
OLAP (www.phi-Integration.com) :
dimension dan measure dan biasanya mencakup pandangan bisnis tertentu.
2. Dimension / dimensi : adalah struktur view / sudut pandang yang menyusun cube. Dimensi dapat terdiri dari berbagai level.
3. Measure : nilai pengukuran itu sendiri.
4. Member : isi / anggota dari suatu dimension / measure tertentu.
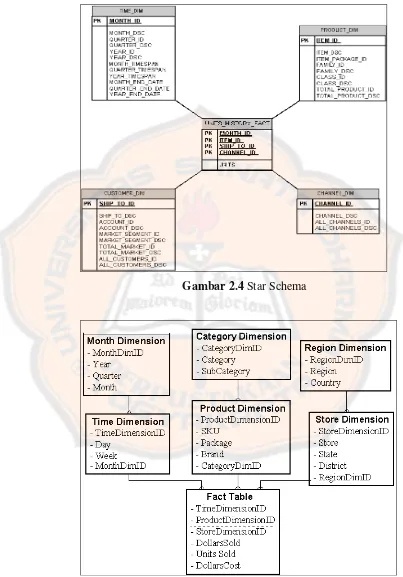
2.4.1 Tabel Fakta dan Dimensi
Di dalam model multi dimensional, database terdiri dari beberapa tabel fakta (fact table) dan tabel dimensi (dimension table) yang saling terkait. Suatu tabel fakta berisi berbagai nilai agregasi yang menjadi dasar pengukuran
(measure) serta beberapa key yang terkait ke tabel dimensi yang akan menjadi sudut pandang dari measure tersebut (www.phi-Integration.com) .
Dalam perkembangannya, susunan fact table dan dimension table ini memiliki standar perancangan atau schema karena terbukti meningkatkan performa dan kemudahan dalam penerjemahan ke sistem OLAP
(www.phi-Integration.com).
Schema inilah yang menjadi dasar untuk melakukan data warehousing. Dua schema yang paling umum digunakan oleh berbagai OLAP engine adalah
Gambar 2.4 Star Schema
2.4.2 Surrogate Key
Surrogate key adalah key / kolom data di tabel dimensi yang menjadi primary key dari tabel tersebut. Nilai ini biasanya berupa nilai sekuensial dan tidak memiliki arti dari proses bisnis darimana sumber data berasal
(www.phi-Integration.com).
2.5 Pengertian OLAP (Online Analitycal Processing)
Dari sisi beban kerja, OLAP dirancang dan difokuskan pada kecepatan
pembacaan data terutama dari volume data yang besar. Penggunaan OLAP menggambarkan sebuah teknologi dengan menggunakan pandangan
multidimensi dari data agregat untuk menyediakan kecepatan akses informasi
untuk tujuan analisis. Namun pada umumnya database OLAP tidak mengantisipasi perubahan data yang dilakukan oleh pengguna. Tetapi
sebaliknya, isi dari database dipopulasi dengan suatu proses batch dan biasanya dilakukan dalam periode tertentu (tiap tengah malam, tiap minggu, dan
sebagainya). Proses batch ini biasanya juga melibatkan pembacaan bukan hanya satu tapi juga dari berbagai sumber data OLTP untuk diintegrasikan dan
ditransformasikan. Proses inilah yang umumnya disebut dengan data warehousing atau gudang data (www.phi-Integration.com).
2.6 Oracle XE
2.6.1 Struktur Database Oracle XE
Pada satu database Oracle XE akan memiliki lebih dari 1 tablespace. Tablespace digunakan untuk mengelompokkan data yang logic. Sehingga secara administrasi lebih mudah dikelola setiap file-nya (Handriyantini, 2009). Struktur database pada Oracle XE ditunjukkan pada gambar 2.6 berikut ini.
Gambar 2.6 Struktur Database Oracle XE
2.6.2 Keuntungan Menggunakan Oracle XE
Keuntungan yang didapat dari menggunakan Oracle XE adalah sebagai berikut :
1. Oracle XE didukung dengan pengembangan yang cepat. 2. Berbasis web.
3. Mudah untuk membuat mock-up. 4. Mudah untuk men-deploy. 5. Scalable.
6. Mempunyai server-side processing dan validasi. 7. Kuat dan mendukung komunitas pengguna.
8. Free hosting demo aplikasi.
9. Masing-masing komponen dari aplikasi dapat diolah menggunakan
2.7 LucidDB
LucidDB adalah RDBMS open source yang pertama dan dikembangkan sepenuhnya untuk gudang data dan business intelligence. Pengembangan tersebut didasarkan pada architecture seperti column-store, bitmap indexing, hash join / aggregation, dan page-level multiversioning. Setiap komponen LucidDB dirancang agar fleksibel, mempunyai integrasi data yang berkinerja
tinggi atau high performance dan pemrosesan query yang canggih.
LucidDB sangat cepat di bulk-loading atau memperbarui data dalam jumlah besar sekaligus. LucidDB dapat digunakan sebagai data warehouse, data mart, atau menyimpan data secara operasional dengan sistem transaksional lama yang digunakan sebagai sumber data (www.luciddb.org).
2.7.1 Arsitektur LucidDB
LucidDB diterapkan pada Java dan sebagiannya diimplementasikan pada
C++. Skema arsitektur LucidDB dapat dilihat pada gambar 2.7
(www.luciddb.org).
2.7.2 OLAP Integration
Karena LucidDB berbasis setengah Java, maka LucidDB dapat digunakan
ke server aplikasi J2EE. Artinya LucidDB dapat dijalankan dengan mudah
secara side-by-side dengan Mondrian yang menggunakan Java-OLAP engine, dan memungkinkan proses koneksi langsung melalui JDBC dari Mondrian ke
LucidDB tanpa koneksi yang lain. Query SQL yang digunakan oleh Mondrian untuk menerapkan implementasi MDX dari OLAP-client sesuai dengan bentuk optimasi LucidDB yang dirancang. Alur LucidDB mencakup fitur-fitur yang
dirancang untuk integrasi yang lebih kuat, seperti manajemen metadata terpadu
dan perancangan DDL untuk penciptaan cube (www.luciddb.org).
2.7.3 Menjalankan Server LucidDB
Agar LucidDB dapat berjalan dan digunakan, maka server LucidDB harus dijalankan terlebih dahulu, dan setelah itu melakukan koneksi dengan
aplikasi client. Server LucidDB yang digunakan adalah “lucidDbServer.bat” yang berada di folder “bin” instalasi LucidDb seperti gambar 2.8 di bawah ini.
Gambar 2.8 Letak Server LucidDb
listening for HTTP connections on port 8034; enter !quit to stop" seperti gambar 2.9.
Gambar 2.9 Proses Startup Server LucidDB
Setelah server sudah dijalankan, langkah selanjutnya adalah melakukan koneksi ke server dari aplikasi client yaitu "sqlline". Aplikasi client yang digunakan adalah "sqllineClient.bat" yang juga berada di folder “bin” instalasi LucidDb seperti ditunjukkan pada gambar 2.10.
Gambar 2.10 Letak Aplikasi Client LucidDB
Gambar 2.11 Koneksi ke host “localhost”
2.7.4 Schema dan Tables
Pada LucidDB tidak dikenal adanya database, karena database dikenal dengan schema. Namun untuk selebihnya seperti table dan kolom-kolom dari table masih sama seperti database relasional lainnya.
Query yang digunakan untuk mengelola schema ataupun data di dalamnya juga menggunakan bahasa SQL karena menggunakan aplikasi client yaitu “sqllineClient”. Sebagai contoh, untuk melihat hasil eksekusi daftar seluruh schema ditunjukkan seperti pada gambar 2.12 dengan mengetikkan perintah command yaitu “SELECT schema_name FROM sys_root.dba_schemas;”.
Gambar 2.12 Melihat Daftar Seluruh Schema
table_name from sys_root.dba_tables;”.
Gambar 2.13 Melihat Daftar Seluruh Table
Dari contoh schema yang ditunjukkan pada gambar 2.12, schema tersebut merupakan bawaan dari LucidDB. Namun bila ingin membuat schema yang sesuai dengan kebutuhan kita, maka sebagai contoh dapat mengetikkan
command yaitu “create schema PHI;” yang dapat dilihat pada gambar 2.14.
Gambar 2.14 Membuat schema PHI
Setelah schema PHI terbentuk, kemudian sebagai contoh selanjutnya akan dibuat table di dalam schema PHI. Table yang akan dibuat berisikan 2 fields. Contoh membuat table tersebut dengan mengetikkan command “CREATE TABLE PHI.test (nama varchar(25), nilai int);”, dan dapat dilihat pada gambar
2.15.
Selanjutnya untuk menambahkan/meng-insertkan row pada table, dapat dengan mengetik command yaitu “INSERT INTO PHI.test VALUES ('Integration', 789);” dan dapat dilihat pada gambar 2.16.
Gambar 2.16 Menambahkan row pada table
2.8 MySQL
Selain berfungsi sebagai tempat menyimpan data, MySQL juga
mempunyai fitur-fitur yang mendukung untuk metode gudang data, yaitu
(www.mysql.com) :
1. Data/Index partitioning (range, hash, key, list, composite). 2. Tidak ada practical storage limits (1 tablespace=110TB) dengan
automatic storage management. 3. Built-in Replication.
4. Strong indexing support (B-tree, fulltext, clustered, hash, GIS). 5. Multiple, configurable data/index caches.
6. Pre-loading of data into caches
7. Unique query cache (caches result set + query; not just data) 8. Parallel data load
2.9 Head-to-Head MySQL, LucidDB, dan Oracle XE 2.9.1 Data Size Limits
Ketiga RDBMS yang digunakan dalam penelitian ini mempunyai
beberapa fitur-fitur yang berbeda. Dilihat dari data size limits-nya, ketiga RDBMS ini menerapkan batasan-batasan yang berbeda pula. Namun setelah
penulis mencari referensi-referensi yang ada, hanya MySQL dan Oracle XE saja yang melansir data size limits mereka. Tabel 2.4 di bawah ini menunjukkan perbandingan data size limits ketigaRDBMS tersebut.
Tabel 2.4 Tabel perbandingan data size limits MySQL, LucidDB, dan Oracle XE (www.enotes.com).
MySQL LucidDB Oracle XE
Max DB Size Unlimited Unlimited Max NUMBER Size 64 bits 126 bits Max Row Size 64 KB (InnoDB is
limited to 8,000 bytes)
8 KB
Max Table Size MyISAM storage limits: 256TB; Innodb storage limits: 64TB
4 GB
2.9.2 Indexes Information
2.9.2.1 MySQL Indexes Information
Indexes digunakan untuk menemukan rows di column tertentu dengan cepat. Sebagian besar MySQL indexes (primary key, unique, index, dan fulltext) disimpan dalam B-tree. Pengecualian bila indexes pada jenis data spasial menggunakan R-tree, dan tabel memory yang juga mendukung hash indexes (http://dev.mysql.com).
2.9.2.2 LucidDB Indexes Information
Indexes dibuat pada column store tables yang disebut bitmap indexes. Bitmap indexes seperti halnya btree indexes kecuali yang tidak menyimpan daftar rids yang sama dengan setiap key value di leaf pages, daftar rids digantikan dengan compressed bitmaps yang mewakili rids tersebut. Bitmap terdiri dari serangkaian byte, di mana setiap bit dalam byte yang sesuai dilepaskan. Jika bit telah ditetapkan, maka menunjukkan bahwa key value yang sama dilepaskan. Compression didapat dengan menghapus bytes yang tidak mengandung bits (http://pub.eigenbase.org).
inputan-inputan tersebut untuk disimpan dalam tahap “melepaskan”
(http://pub.eigenbase.org).
2.9.2.3 Oracle XE Indexes Information
Berdasarkan Oracle Database Data Warehousing Guide (http://docs.oracle.com), bitmap indexes disimpan dengan cara yang telah ditetapkan, terkompresi tanpa perlu campur tangan user. B-tree indexes, bagaimanapun, dapat disimpan secara khusus dengan cara dikompres untuk
memungkinkan penghematan kapasitas yang besar, menyimpan beberapa key di setiap index block, yang mana juga mengarah ke penurunan I / O dan performa yang lebih baik.
Tujuan dari kompresi adalah mengkompresi indeks B-tree, yang mengurangi penyimpanan secara overhead dari pengulangan value. Dalam kasus indeks yang non-unique, semua index columns dapat disimpan dalam format yang terkompresi, sedangkan dalam kasus indeks yang unique, setidaknya satu index column harus disimpan secara terkompresi.
Umumnya, inti dari indeks adalah grouping piece dan unique piece. Jika inti tersebut tidak didefinisikan sebagai unique piece, Oracle menyediakan form rowid yang dapat ditambahkan ke grouping piece. Kunci kompresi adalah metode yang memutus bagian grouping piece dan menyimpannya sehingga dapat digunakan bersama beberapa unique pieces. Cardinality dari kolom yang dipilih akan dikompresi untuk menentukan rasio kompresi yang dapat dicapai.
Jadi, misalnya, jika indeks yang unique yang terdiri dari lima kolom memberikan keunikan dari dua kolom terakhir, maka hal tersebut yang paling
optimal untuk memilih tiga kolom terdepan untuk disimpan secara kompresi.
Jika memilih untuk mengkompres empat kolom, pengulangan akan hilang, dan
Meskipun tujuan dari kompresi adalah mengurangi kebutuhan
penyimpanan indeks, hal tersebut juga dapat menimbulkan beberapa overhead pada penyimpanan tambahan, karena setiap entri awal memiliki overhead bernilai empat byte yang terkait dengan itu.
2.9.2.4 Perbandingan Indexes Information
Berikut adalah perbandingan mengenai indexes information yang ditunjukkan pada tabel 2.5 di bawah ini :
Tabel 2.5 Tabel Indexes Information antara MySQL, LucidDB, dan Oracle XE (www.enotes.com)
MySQL LucidDB OracleXE
R-/R+ tree MyISAM tables only No Yes Hash MEMORY, Cluster
(NDB), InnoDB,
tables only
No Cluster Tables
Expression No No Yes
Partial No No Yes
Reverse No No Yes
Bitmap No Yes Yes
GiST No No No
GIN No No No
Full-text MyISAM tables only No Yes
Penjelasan dari fitur-fitur indexes information dapat dilihat di bawah ini : 1. Hash : digunakan untuk mengindex dan mengambil suatu nilai pada
sebuah database, sehingga akan berlangsung lebih cepat jika dibanding dengan data yang asli (sebelum diindex). Atau dengan kata lain,
perubahan string dari suatu karakter ke dalam suatu nilai dengan panjang
yang tetap atau key yang merepresentasikan string aslinya.
2. Bitmap : fitur ini mendukung penggunaan data warehousing yaitu dengan cara mengurutkan data pada tabel dan didefinisikan dengan angka-angka
yang merepresentasikan nilai-nilai yang berbeda pada data. Umumnya,
indeks data lebih efisien ketika data tidak menyertakan nilai yang sama
secara berulang. Namun, bitmap lebih baik digunakan ketika nilai-nilainya berulang.
3. Full-text : pencatatan atau penyimpanan data di dalam tabel database di mana data disimpan dalam bentuk terstruktur biasanya atau struktur data
lainnya sehingga memudahkan database dalam melakukan penelusuran data. Tetapi pada MySQL hanya dapat digunakan di tabel MyISAM.
4. Spatial : spatial indexing adalah pembuatan indeks untuk objek-objek spasial. Contoh objek spasial adalah persegi, dan objek dua dimensi lain.
Objek tiga dimensi termasuk objek spasial. Secara umum, yang dimaksud
objek spasial adalah objek yang menempati ruang.
BAB III
ANALISIS DAN PERANCANGAN SISTEM
3.1. Identifikasi dan Analisis Kebutuhan
Dinas Pariwisata Provinsi DIY membutuhkan sistem gudang data
yang didukung aplikasi relational database management systems yang baik untuk memantau kunjungan wisatawan yang berkunjung di obyek-obyek
wisata provinsi DIY. Hasil dari pemantauan kunjungan wisatawan tersebut
dapat digunakan untuk menganalisa kunjungan wisatawan setiap tahunnya
di DIY. Data yang digunakan bertipe spreadsheet seperti contoh pada tabel 3.1 di bawah ini meliputi Obyek Wisata, Wisatawan, Januari, Februari,
Maret, April, Mei, Juni, Juli, Agustus, September, Oktober, November, dan
Desember akan dirancang sedemikian rupa agar menjadi sistem gudang data
yang bisa membantu Dinas Pariwisata Provinsi DIY memantau
perkembangan wisatawan di DIY.
Tabel 3.1 Data Kunjungan Wisatawan ke Obyek Wisata DIY
No Obyek Wisata Wisatawan Januari Pebruari Maret … dst
1
Kraton
Yogyakarta Wisman 5735 5452 7616 … dst
1
Kraton
3.2. Mengumpulkan dan Menganalisa Sumber Data
Data kunjungan wisatawan yang didapat dari Dinas Pariwisata DIY
berupa data Excel yang bertipe .xls. Dikarenakan Provinsi DIY terbagi atas 1 Kota dan 4 Kabupaten, maka 1 file terdiri dari 5 sheets yang setiap sheet berisikan pembagian per Kota maupun Kabupaten. Namun setelah melihat
data yang ada, penulis mencoba untuk membantu memecahkan masalah
dengan membuat gudang data untuk Dinas Pariwisata DIY beserta saran
atau anjuran mengenai aplikasi relational database management systems yang baik atau sesuai dengan kebutuhan sistem gudang data. Diagram use case dapat dilihat di gambar 3.1.
Gambar 3.1 Diagram Use Case
Berdasarkan dari data yang didapat, penulis mengubah susunan kolom
wisatawan agar mempermudah dalam proses konversi ke database, dan menambahkan kolom ‘Tahun’ agar memudahkan pemantauan kunjungan
wisatawan ke DIY. Pengubahan susunan kolom tersebut, menjadikan tabel
3.1 menjadi file bertipe .xls dengan nama susunanWisata seperti pada tabel 3.2 berikut ini.
Tabel 3.2 Perubahan Susunan Kolom Data
Obyek Wisata Wisatawan Tahun Bulan Kunjungan
Kraton Yogyakarta
Wisatawan
Kraton Yogyakarta
Wisatawan
Mancanegara 2009 Februari 5452
Kraton Yogyakarta
Wisatawan
Mancanegara 2009 Maret 7616
Kraton Yogyakarta
Wisatawan
Mancanegara 2009 April 7560
Kraton Yogyakarta
Wisatawan
Mancanegara 2009 Mei 8270
Kraton Yogyakarta
Wisatawan
Mancanegara 2009 Juni 8092
Kraton Yogyakarta
Wisatawan
Mancanegara 2009 Juli 12701
Kraton Yogyakarta
Wisatawan
Mancanegara 2009 Agustus 13996
Kraton Yogyakarta
Wisatawan
Mancanegara 2009 September 7392
Kraton Yogyakarta
Wisatawan
Mancanegara 2009 Oktober 8914
Kraton Yogyakarta
Wisatawan
Mancanegara 2009 November 5894
Kraton Yogyakarta
Wisatawan
Mancanegara 2009 Desember 5866
… dst
Gembira Loka Wisatawan Nusantara 2009 Januari 80068 Gembira Loka Wisatawan Nusantara 2009 Februari 28077 Gembira Loka Wisatawan Nusantara 2009 Maret 47901 Gembira Loka Wisatawan Nusantara 2009 April 45247 Gembira Loka Wisatawan Nusantara 2009 Mei 92199 Gembira Loka Wisatawan Nusantara 2009 Juni 150870 Gembira Loka Wisatawan Nusantara 2009 Juli 78632 Gembira Loka Wisatawan Nusantara 2009 Agustus 29053 Gembira Loka Wisatawan Nusantara 2009 September 122711 Gembira Loka Wisatawan Nusantara 2009 Oktober 48430 Gembira Loka Wisatawan Nusantara 2009 November 42637 Gembira Loka Wisatawan Nusantara 2009 Desember 84498
… dst
3.3 Langkah Mendesain Gudang Data 3.3.1 Membaca Data Legacy