BAB 2
TINJAUAN TEORITIS
2.1Statistik Non Parametrik
Test statistik non parametrik adalah test yang modelnya tidak menetapkan syarat-syaratnya yang mengenai parameter-parameter populasi yang merupakan induk sampel penelitiannya. Oleh karena itu, observasi-observasi independent dan variabel yang diteliti pada dasarnya memiliki kontinuitas. Uji metode non parametrik atau bebas sebaran adalah prosedur pengujian hipotesa yang tidak mengasumsikan pengetahuan apapun mengenai sebaran populasi yang mendasarinya kecuali selama itu kontinue.
Dalam kegiatan penelitian, biasanya lebih banyak digunakan analisis statistik parametrik daripada statistik non parametrik. Statistik parametrik digunakan jika kita telah mengetahui model matematis dari distribusi populasi suatu data yang akan dianalisis. Jika kita tidak mengetahui suatu model distribusi populasi dari suatu data dan jumlah data relatif kecil atau asumsi kenormalan tidak selalu dapat dijamin penuh, maka kita harus menggunakan statistik non parametrik (statistik bebas distribusi).
Statistik non parametrik memiliki keunggulan atau kelebihan yaitu kebanyakan prosedur non parametrik memerlukan asumsi dalam jumlah yang minimal maka kemungkinan untuk beberapa prosedur non parametrik perhitungan-perhitungan dapat dilakukan dengan cepat dan mudah, terutama bila terpaksa dilakukan secara manual. Jadi pengguna prosedur-prosedur ini menghemat waktu yang diperlukan untuk perhitungan dan ini merupakan bahan pertimbangan bila hasil penyajian harus segera tersaji atau bila mesin hitung berkemampuan tinggi tidak tersedia. Dengan statistik non parametrik juga dengan dasar matematik dan statistik yang kurang biasanya
konsep dan metode prosedur non parametrik mudah dipahami. Prosedur-prosedur non parametrik boleh menggunakan skala pengukuran.
Sedangkan kelemahan dari statistik non parametrik adalah karena perhitungan-perhitungan yang dibutuhkan untuk kebanyakan prosedur non parametrik cepat dan sederhana. Prosedur ini kadang-kadang digunakan untuk kasus-kasus yang lebih tepat ditangani prosedur-prosedur non parametrik sehingga cara seperti ini sering menyebabkan pemborosan informasi. Kendatipun prosedur non parametrik terkenal karena prinsip perhitungan yang sederhana. Pekerjaan hitung-menghitung selalu membutuhkan banyak tenaga dan menimbulkan kejenuhan.
Dalam implementasi, penggunaan prosedur yang tepat merupakan tujuan dari peneliti. Beberapa parameter yang dapat digunakan sebagai dasar dalam penggunaan statistik non parametrik adalah :
1. hipotesa yang diuji tidak melibatkan parameter populasi
2. skala yang digunakan lebih lemah dari skala prosedur parametrik 3. asumsi-asumsi parametrik tidak terpenuhi
Banyak prosedur non parametrik yang dapat digunakan dalam analisis statistik, diantaranya :
1. Uji Chi-Kuadrat 2. Uji Binomial 3. Uji Run
4. Uji Kolmogrov Smirnov Satu Sampel 5. Uji Dua Sampel Independen
6. Uji Beberapa Sampel Independen 7. Uji Dua Sampel yang Berkaitan 8. Uji Beberapa Sampel yang Berkaitan
2.2Hipotesa
Hipotesa secara etimologi dibentuk dari dua kata, yaitu : kata hypo yang berarti
masih belum sempurna. Pengertian ini kemudian diperluas dengan maksud sebagai kesimpulan yang belum sempurna, sehingga perlu disempurnakan dengan membuktikan kebenaran hipotesis tersebut. Pembuktian itu hanya dapat dilakukan dengan menguji hipotesis dengan data di lapangan.
Penaksiran parameter populasi dan uji hipotesa adalah dua pokok pembicaraan dalam statistik inferensi. Teknik inferensi pertama dikembangkan berdasarkan pada sejumlah asumsi tentang sifat populasi darimana suatu sampel diambil. Teknik inferensi seperti ini dalam statistika digolongkan dalam Statistik Parametrik, karena harga-harga populasi merupakan “parameter” yang ditaksir atau hipotesis yang diuji.
Permasalahan yang harus diselesaikan dalam teknik ini adalah menaksirkan parameter-parameter populasi yang didistribusikan sudah diasumsikan berdasarkan data sampel, atau menguji hipotesis tertentu yang berhubungan dengan parameter, misalnya uji hipotesis bahwa mean µ mempunyai nilai sama dengan 0.
Untuk mendapatkan suatu sampel yang mempunyai distribusi tertentu sesuai dengan asumsi distribusi populasinya sangatlah sulit. Oleh karena itu, dikembangkanlah suatu teknik inferensi yang tidak memerlukan asumsi-asumsi tertentu tentang distribusi sampelnya. Teknik inferensi seperti ini dalam statistik dikenal dengan statistik Non-Parametrik, karena tidak memerlukan penaksiran atau uji hipotesis yang berhubungan dengan parameter populasinya.
Adapun sifat-sifat yang harus dimiliki untuk menetukan hipotesa adalah :
1. Hipotesa harus muncul dan ada hubungannya dengan teori serta masalah yang diteliti
2. Setiap hipotesis adalah kemungkinan jawaban terhadap persoalan yang diteliti 3. Hipotesis harus dapat diuji atau terukur sendiri untuk menetapkan hipotesis
yang benar kemungkinannya didukung oleh data empiric.
Perlu diingat, apapun syarat suatu hipotesis, yang jelas bahwa penampilan setiap hipotesis adalah bentuk statement, yaitu pernyataan tentang sifat atau keadaan hubungan dua atau lebih variabel yang akan diteliti.
Adapun jenis hipotesis yang mudah dimengerti adalah hipotesis nol
H0 ,hipotesa aternatif
Ha , hipotesa kerja
Hk . Tetapi yang biasa adalah
H0 yang merupakan bentuk dasar atau memiliki statement yang menyatakan tidak ada hubungan antara dua variabel x dan variabel y yang akan diteliti atau variabel independent (x) tidak mempengaruhi variabel dependent (y).2.3Analisis yang Digunakan
2.3.1 Analisis Univariat
Dilakukan untuk mengetahui distribusi frekuensi dari masing-masing independent dan variabel dependent.
2.3.2 Analisis Bivariat
Hipotesis yang diuji biasanya adalah kelompok inti berbeda dalam ciri khas tertentu, dengan demikian perbedaan itu berhubungan dengan frekuensi relatif masuknya anggota-anggota kelompok kedalam beberapa kategori.
Untuk menguji hipotesa ini kita menghitung banyak kasus dari masing-masing kelompok yang termasuk dalam berbagai kategori dan membandingkan proporsi dari kasus-kasus dari suatu kelompok dalam berbagai kategori dengan proporsi kasus dari kelompok lain. Dalam hal ini digunakan hipotesa Chi-Kuadrat.
2.4Uji Chi-Kuadrat
Uji Chi-Kuadrat merupakan salah satu prosedur non parametrik yang dapat digunakan dalam analisis statistik yang sering digunakan dalam praktek. Teknik Chi-Kuadrat (Chi-Square : Chi dibaca : Kai, simbol dari huruf Yunani : 2) ditemukan oleh Helmat pada tahun 1875, tetapi baru tahun 1900 pertama kali diperkenalkan kembali oleh Karl Pearson.
Uji Chi-Kuadrat digunakan untuk menguji kebebasan antara dua sampel (variabel) yang disusun dalam tabel baris kali kolom atau menguji keselarasan dimana pengujian dilakukan untuk memeriksa ketergantungan dan homogenitas apakah data sebuah sampel yang diambil menunjang hipotesis yang menyatakan bahwa populasi asal sampel tersebut mengikuti suatu distribusi yang telah ditetapkan. Oleh karena itu, uji ini juga dapat disebut uji keselarasan (goodness of fit test), karena untuk menguji
apakah sebuah sampel selaras dengan salah satu distribusi teoritis (seperti distribusi normal, uniform, binomial dan lainnya).
Pada kedua prosedur tersebut selalu meliputi perbandingan frekuensi yang teramati dengan frekuensi yang diharapkan bila hipotesis nol yang ditetapkan benar, karena dalam penelitian yang dilakukan data yang diperoleh tidak selamanya berupa data skala internal saja, melainkan juga data skala nominal, yaitu yang berupa perhitungan frekuensi pemunculan tertentu.
Perhitungan frekuensi pemunculan juga sering dikaitkan dengan perhitungan persentase, proporsi atau yang lain sejenis. Chi-Kuadrat adalah teknik statistik yang dipergunakan untuk menguji probabilitas seperti itu, yang dilakukan dengan cara mempertentangkan antara frekuensi yang benar-benar terjadi, frekuensi yang diobservasi (observed frequencies) disingkat F0 atau O dengan frekuensi yang
diharapkan (expected frequencies) disingkat Fh atau E.
Ada beberapa hal yang perlu diperhatikan dalam menggunakan Chi-Kuadrat, yaitu sebagai berikut :
1. Chi-Kuadrat digunakan untuk menganalisa data yang berbentuk frekuensi 2. Chi-Kuadrat tidak dapat digunakan menentukan besar atau kecilnya korelasi
dan variabel-variabel
3. Chi-Kuadrat pada dasarnya belum dapat menghasilkan kesimpulan yang memuaskan
4. Chi-Kuadrat cocok digunakan untuk data kategorik, data diskrit atau data normal
Cara memberikan interpretasi terhadap Chi-Kuadrat adalah dengan menentukan df(degree of freedom) atau db(derajat bebas). Setelah itu berkonsultasi
tabel harga kritis Chi-Kuadrat. Selanjutnya membandingkan antara harga Chi-Kuadrat dari hasil perhitungan dengan harga kritis Chi-Kuadrat, akhirnya mengambil kesimpulan dengan ketentuan :
1. Bila harga test statistic untuk Chi-Kuadrat (2) sama atau lebih besar dari tabel Chi-Kuadrat maka hipotesa nol
H0 ditolak dalam hipotesa alternatif
Ha diterima.2. Bila harga Chi-Kuadrat lebih kecil dari tabel Chi-Kuadrat maka hipotesa nol
H0 diterima dan hipotesa alternatif
Ha ditolak.Ada beberapa persoalan yang dapat diselesaikan dengan mengambil manfaat dari Chi-Kuadrat, diantaranya :
1. Uji Independen antara Dua Faktor
Banyak data hasil pengamatan yang dapat digolongkan dalam beberapa faktor, karakteristik atau atribut terdiri dengan tiap faktor atau atribut terdiri dari beberapa klasifikasi, kategori, golongan atau mungkin tingkatan. Berdasarkan hasil pengamatan terhadap fenomena demikian akan diselidiki mengenai asosiasi atau hubungan atau kaitan antara faktor-faktor itu, bisa dikatakan bahwa faktor-faktor itu bersifat independent atau bebas, tepatnya bebas statistik. Selain daripada itu akan diselidiki ada atau tidaknya pengaruh mengenai beberapa taraf atau tingkatan sesuatu faktor terhadap kejadian fenomena.
Secara umum untuk menguji independent antar dua faktor dapat dijelaskan sebagai berikut : misalkan diambil sebuah sampel acak berukuran ni dengan tiap
pengamatan tunggal diduga terjadi karena adanya dua macam faktor I dan II. Faktor I terbagi atas b taraf atau tingkatan dan faktor II atas k taraf. Banyak pengamatan yang terjadi karena taraf ke-I (i = 1,2,….,b) dan taraf ke-j faktor ke-II (j = 1,2,….,k) akan dinyatakan dengan Oij. Hasilnya dapat dicatat dalam sebuah
daftar kontigensi b x k. pasangan hipotesis akan diuji berdasarkan data dengan memakai penyesuaian persyaratan data yang diuji sebagai berikut :
0
H : Kedua faktor bebas statistik
1
H : Kedua faktor tidak bebas statistik
Tabel yang disajikan akan dianalisis untuk setiap sel yang diperlukan kemudian tabel kontigensi. Data tabel tersebut di atas agar dapat dicari hubungan antara faktor-faktor dengan menggunakan statistik uji Chi-Kuadrat.
Pengujian eksak sukar digunakan, karena disini hannya akan dijelaskan pengujian yang bersifat pendekatan. Untuk itu diperlukan frekuensi teoritik atau banyak gejala yang diharapkan terjadi disini akan dinyatakan dengan Eij.
Rumusnya adalah sebagai berikut :
ij
E =
nionoj
/nDengan :
ij
E = banyak data teoritis ( banyak gejala yang diharapkan terjadi)
io
n = jumlah baris ke-i
oj
n = jumlah kolom ke-j n = total atau jumlah data
Dengan demikian misalnya didapat nilai dari teoritis masing-masing data :
n n n E n n n E11 ( 10 01)/ ; 12 ( 10 02)/ n n n E n n n E11 ( 20 01)/ ; 22 ( 20 02)/ Dan seterusnya… Jelas bahwa nn10 n20 ...nbo n01 n02 ...n0k
Sehingga nilai statistik yang digunakan untuk menguji hipotesis diatas adalah :
h j i k j Eij Eij Oij 1 2 2 ( ) Dengan :
ij
O : adalah jumlah observasi untuk kasus-kasus yang dikategorikan dalam baris ke-i dan kolom ke-j.
ij
E : adalah banyak kasus yang diharapkan untuk dikategorikan dalam baris ke-I dan kolom ke-j.
Dengan kriteria pengujian sebagai berikut : Tolak H0 jika 2hitung 2tabel
Terima H0 jika 2hitung2tabel
Dalam taraf nyata = 0,05 dan derajat kebebasan (dk) untuk distribusi Chi-Kuadrat adalah (b-1)(k-1), dalam hal lainnya kita terima hipotesis H0.
2. Koefisien Kontigensi
Kegunaan teknik kontigensi yang diberi simbol C, adalah untuk mencari atau menghitung keeratan hubungan antara dua variabel yang mempunyai gejala ordinal ( kategori), paling tidak berjenis normal.
Cara kerja atau perhitungan koefisien kontigensi sangatlah mudah jika nilai Chi-Kuadrat sudah diketahui. Oleh karena itu biasanya para peneliti menghitung harga koefisien kontigensi setelah menemukan harga Chi-Kuadrat. Fleksibilitas rumusan ini adalah tidak terbatas pada banyaknya kategori-kategori pada sel-sel petak atau tabel Chi-Kuadrat. Test signifikansi yang digunakan tetap menggunakan tabel kritis Chi-Kuadrat, dengan derajat kebebasan (db) sama dengan jumlah kolom dikurangi satu dikalikan dengan jumlah baris dikurangi satu ((b-1)(k-1)). Rumus untuk menghitung koefisien kontigensi adalah :
n x x C hitung hitung 2 2 Dengan : C = Koefisien kontigensi
hitung
x2 = Hasil perhitungan Ci-Kuadrat
n = Banyak data
3. Metode Analisa
Dalam penelitian ini dilakukan analisa kuantitatif dengna langkah-langkah sebagai berikut :
Langkah 1 :
Pengumpulan data yang dilakukan penulis dengan mengadakan penelitian pada sekolah yang akan didata.
Langkah 2 :
Dari data yang dianalisa, lalu disusun dalam tabel distribusi frekuensi. Langkah 3 :
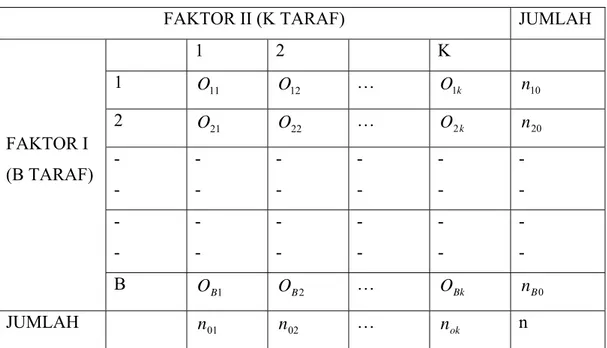
Dari data yang dianalisa maka dapat dibentuk daftar kontigensi frekuensi yang diamati seperti dibawah ini :
Tabel 2.4.1 daftar kontigensi
FAKTOR II (K TARAF) JUMLAH
FAKTOR I (B TARAF) 1 2 K 1 O11 O12 … O1k n10 2 O21 O22 … O2k n20 - - - - - - - - - - - - - - - - - - - - - - - - B OB1 OB2 … OBk nB0 JUMLAH n01 n02 … nok n Dimana :
Faktor I dan II adalah faktor-faktor yang membentuk daftar kontigensi dengan b baris dan k kolom. nij adalah frekuensi yang diamati.
b i i Eij n 1 ) ( ; i =1,2,3,…,b
b j j Eij n 1 ) ( ; j = 1,2,3,…,k Langkah 4 :Tentukan frekuensi yang diharapkan dari frekuensi yang diamati dengan rumus : n n n Eij ( io oj)/ Dengan : ij
E = frekuensi yang diharapkan n = jumlah data yang diamati
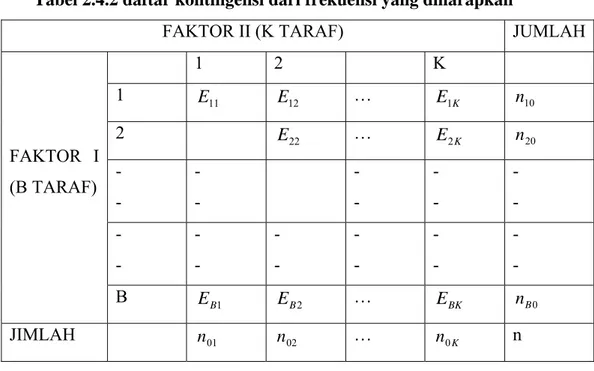
Dari rumus diatas dapat disusun tabel kontigensi dari frekuensi yang diharapkan.
Tabel 2.4.2 daftar kontingensi dari frekuensi yang diharapkan
FAKTOR II (K TARAF) JUMLAH
FAKTOR I (B TARAF) 1 2 K 1 E11 E12 … E1K n10 2 E22 … E2K n20 - - - - - - - - - - - - - - - - - - - - - - B EB1 EB2 … EBK nB0 JIMLAH n01 n02 … n0K n
Dengan terbentuknya daftar frekuensi yang diamati dan daftar frekuensi yang diharapkan maka dapat ditentukan harga 2.
Langkah 5 :
Untuk menghitung harga Chi-Kuadrat, perlu diperhatikan criteria sebagai berikut :
1. Tidak boleh menggunakan data kurang dari 20.
2. frekuensi teoritis (Eij) minimum 5 setiap kotak, sebab 2 hanya berlaku apabila Eij < 5 maka 2 terhadap data tidak dapat dipertanggung jawabkan. Untuk tabel dua baris dan dua kolom dan untuk tabel lebih dari 2 x 2 sebalum menghitung 2 perlu diperhatikan dahulu
ij
E pada setiap kotakdalam tabel. Jika syarat tidak dipenuhi maka beberapa kolom atau baris perlu digabung.
3. Setiap kotak tidak boleh mempunyai frekuensi kurang dari 1.
Setiap kriteria-kriteria di atas dipenuhi maka harga 2 dapat dihitung dengan rumus :
h j i k j Eij Eij Oij 1 2 2 ( ) Untuk menguji apakah harga 2 dianggap berarti pada suatu level signifikan tertentu harus diketahui nilai kritis dari 2 dengan menggunakan daftar pencarian harga Chi-Kuadrat yang dibandingkan dengan nilai yang diperoleh dari hasil perhitungan. Dengan membaca nilai Chi-kuadrat yang tepat harus terlebih dahulu dipilih confidence coefficient yang akan dipakai dan degree of freedomnya. Untuk hal yang umum degree of freedom ini adalah sama dengan perkalian (k-1) dan (b-1) atau baris dikalikan kolom.
Degree of freedom = (k-1)(b-1)
Langkah 6 ;
Hipotesa yang diajukan adalah seperti dibawah ini : 0
H : Tidak ada hubungan antara jenis pekerjaan dan tingkat pendidikan
1
H : Ada hubungan antara jenis pekerjaan dan tingkat pendidikan orang
tua terhadap prestasi anak.
Maka kriteria penerimaan dan penolakan hipotesa ini adalah sebagai berikut : Tolak H0 jika 2hitung 2tabel
Terima H0 jika 2hitung 2tabel
Langkah 7 :
Selanjutnya akan ditentukan koefisien kontingensi ( C ) dengan menggunakan rumus sebagai berikut :
n x x C hitung hitung 2 2
Dengan : C = contingency coefficient
n = Ukuran jumlah data
hitung
2
= Harga Chi-Kuadrat
Harga C dipakai untuk nilai derajat asosiasi antara faktor-faktornya adalah dengan membandingkan harga C dengan koefisien kontingensi maksimum. Apabila harga koefisien kontingensi maksimum dihitung dengan rumus sebagai berikut :
m m
Cmaks 1
Dengan : m = harga minimum bdan k (jumlah baris dan kolom) Langkah 8 :
Dengan membandingkan C dan Cmaks maka keeratan hubungan variabel I dan
variabel II ditentukan oleh persentasenya. Hubungan antara dua variabel ini disimbolkan dengan Q dan mempunyai nilai antara -1 dan 1. Bilamana harga Q mendekati 1 maka hubungan tambah erat dan bila Q menjauhi 1 maka hubungan kedua variabel itu semakin kurang erat.
% 100
x C Q
Dengan : Q : untuk menyatakan persentase derajat hubungan antara variabel I dan variabel II
C : Koefisien Kontingensi
maks
C : Koefisien Kontingansi Maksimum
Dengan menggunakan ketentuan-ketentuan Davis (1971) sebagai berikut : 1. Sangat erat jika Q ≥ 0.70
2. Erat jika Q antara 0.50 dan 0.69 3. Cukup erat jika Q antara 0.30 dan 0.49 4. Kurang erat jika Q antara 0.10 dan 0.29 5. Dapat diabaikan jika Q antara 0.01 dan 0.09 6. Tidak ada jika Q = 0.0