Nama : Mochamad Iqbal Saepudin NPM : 50407526
Pembimbing : Dr.Lintang Yuniar Banowosari, SKom, MSc. Implementasi Mapreduce pada Very Large Database System
ABSTRAKSI
Melihat tingginya angka jumlah penduduk Indonesia yang memasuki usia dewasa untuk membuat KTP (kartu tanda penduduk) maka akan dibutuhkan Database dalam skala VLDB (Very Large Database), data penduduk perlu dilakukan pemeriksaan kembali agar tidak terjadi duplikasi data di mana setiap penduduk hanya boleh memiliki satu Kartu Tanda Penduduk. Proses menganalisa KTP ini dapat dengan mudah dilakukan dengan konsekuensi mampu membayar harga hardware dan lisensi Software.
Tujuan penelitian ini adalah bagaimana memanfaatkan aplikasi-aplikasi opensource untuk mengolah sebuah Database sendiri yang dibangun diatas framework Mapreduce yang dapat bekerja dan memproses secara terparalel.
Dengan mengandalkan dan mengembangkan aplikasi Opensource alias gratis untuk diunduh yaitu Hadoop, Sqoop, dan Hive dapat dibentuk menjadi sebuah Framework Mapreduce yang mampu bekerja memproses dan menganalisis dengan baik karena bekerja memproses input data secara terparalel oleh lebih dari satu mesin.
ABSTRACT
See the high rate of indonesia population who enter adulthood to make KTP (identity cards) it will be required a database on scale VLDb (Very Large Database), population data need to be re-examination in order to avoid duplication data in which each people may only have one Identity Cards. The process of analyzing the card can be easily done with the consequence able to pay the cost hardware and software licenses.
The purpose of this research is how to take advantage an opensource applications to process own database that built on top MapReduce framework and the process could be work in parallel.
By relying and developing software Opensource or free applications for download like a Hadoop, Sqoop, and the Hive can be formed into a Mapreduce framework that able to process and analyze can be easily done because the input data was processed in parallel way by more than one machine to work.
PENDAHULUAN
Jumlah penduduk Indonesia tahun 2011 diperkirakan mencapai 240 juta jiwa atau atau sekitar 60 juta keluarga [4]. Dengan melihat tingginya angka jumlah penduduk Indonesia yang memasuki usia dewasa untuk membuat KTP (kartu tanda penduduk) maka akan dibutuhkan Database dalam skala VLDB (Very Large Database) karena dimana akan terdapat jutaan baris dan ratusan tabel untuk dapat menampung semua data penduduk Indonesia, data penduduk perlu dilakukan pemeriksaan kembali agar tidak terjadi duplikasi data di mana setiap penduduk hanya boleh memiliki satu Kartu Tanda Penduduk karena dilihat dari fungsi utamanya yaitu untuk menghindari kecurangan pajak, menyembunyikan identitas (misalnya teroris), memudahkan membuat paspor yang tidak dapat dibuat di seluruh kota dan menjaga terjadi kecurangan pada saat pemilihan umum atau pemilihan kepala daerah karena setiap penduduk hanya boleh memiliki satu suara yang ditandai dengan penggunaan KTP
Facebook.com merupakan situs jejaring sosial terkenal di dunia, situs ini mampu menghasilkan satu petabyte data setiap harinya untuk disimpan dan dianalisis. kekuatan terbesar situs tersebut adalah dengan mengandalkan dan mengembangkan aplikasi Opensource alias gratis untuk diunduh seperti Hadoop, Hbase, Hive, Thrift, Cassandra, HipHop, dan lain-lain [6]. Usahanya memanfaatkan sebagian besar aplikasi bersifat opensource tersebut menjadikan Facebook.com dikatakannya mampu dengan mudah mengolah data besar setiap harinya karena data diolah secara terparalel.
Melihat usahanya yang dapat dilakukan oleh para developer facebook.com maka aplikasi opensource tersebut juga dapat dibentuk menjadi sebuah Framework yang mampu bekerja untuk mengolah database meskipun memiliki kapasitas VLDB. Dengan memanfaatkan kemampuan Hadoop Mapreduce dan Hive dalam data warehousing dapat memproses dan menganalisis data berukuran VLDB sehingga mampu bersaing dengan perangkat lunak enterprise lain yang harus membayar harga untuk membeli lisensi agar dapat menggunakan semua fitur handalannya.
TINJAU PUSTAKA
Data WarehouseData warehouse adalah sebuah sistem yang mengambil dan menggabungkan data secara periodik dari sistem sumber data ke penyimpanan data bentuk dimensional atau normal. Data warehouse merupakan penyimpanan data yang berorientasi objek, terintegrasi, mempunyai variant waktu, dan menyimpan data dalam bentuk nonvolatile sebagai pendukung manejemen dalam proses pengambilan keputusan [8].
Data warehouse menyatukan dan menggabungkan data dalam bentuk multidimensi. Pembangunan data warehouse meliputi pembersihan data, penyatuan data dan transformasi data dan dapat dilihat sebagai praproses yang penting untuk digunakan dalam data mining. Selain itu data warehouse mendukung On-line Analitycal Processing (OLAP), sebuah perkakas yang digunakan untuk menganalisis secara interaktif dari bentuk multidimensi yang mempunyai data yang rinci. Sehingga dapat memfasilitasi secara efektif data generalization dan data mining.
Hadoop
Hadoop adalah Framework software berbasis Java dan Opensource yang berfungsi untuk mengolah data yang sangat besar secara terdistribusi dan berjalan di atas cluster yang terdiri dari beberapa komputer yang saling terhubung [3]. Hadoop dapat mengolah data dalam jumlah yang sangat besar hingga petabyte dan dijalankan di atas ribuan komputer. Terinspirasi dari whitepaper Google yang membahas tentang Mapreduce dan Google File
System dibuat oleh Doug Cutting dan nama Hadoop ini berasal dari boneka gajah milik anaknya. Hadoop bersifat opensource dan berada dibawah bendera Apache Software Foundation.
Mapreduce
Mapreduce pertama kali dikenalkan oleh Jeffrey Dean dan Sanjay Ghemawat dari Google, Inc. Saat ini model pemrograman Mapreduce digunakan pada sistem pengolahan data di Google dan juga di Yahoo.
Mapreduce merupakan sebuah Framework untuk pengolahan Dataset besar pada beberapa jenis masalah yang didistribusikan menggunakan sejumlah besar komputer (node) yang disebut sebagai cluster jika semua node menggunakan hardware yang sama atau sebagai grid jika node menggunakan hardware berbeda. Komputasi pengolahan dapat terjadi pada data yang disimpan secara tidak terstruktur dalam Filesystem atau secara terstruktur dalam Database.
Pemetaan (Map) Simpul yang mengambil Input Master dan memecah input menjadi bagian-bagian kecil dan mendistribusikannya ke para pekerja (nodes worker). Sebuah node worker dapat melakukannya pekerjaannya berulang kali dalam setiap giliran yang mengarah pada multi-level tree structure. Node worker memproses sub-input yang ditanganinya dan mengirim hasil proses tersebut kembali kembali pada input master.
Pengurangan (Reduce) dimulai dari sebuah node master yang akan bertugas mengambil hasil dari Node worker untuk semua sub-input dan menggabungkan mereka dalam beberapa cara untuk mendapatkan output. Output itulah yang merupakan jawaban dari permasalahan awal yang akan dipecahkan.
Gambar-1 Mapreduce
Keuntungan dari Mapreduce ini adalah proses map and reduce dijalankan secara terdistribusi. Dalam setiap proses mapping bersifat independen sehingga proses dapat dijalankan secara simultan dan paralel. Demikian pula dengan proses reducer dapat dilakukan secara paralel diwaktu yang sama, selama output dari operasi mapping mengirimkan key value yang sesuai dengan proses reducernya. Proses Mapreduce ini dapat diaplikasikan di cluster server yang jumlahnya sangat banyak sehingga dapat mengolah data dalam jumlah petabyte hanya dalam waktu beberapa jam.
Didalam Hadoop, Mapreduce engine ini terdiri dari satu Jobtracker dan satu/banyak Tasktracker. Jobtracker adalah server penerima job dari client, sekaligus akan mendistribusikan jobs tersebut ke Tasktracker yang akan mengerjakan sub job sesuai yang diperintahkan Jobtracker. Strategi ini akan mendekatkan pengolahan data dengan datanya sendiri, sehingga ini akan sangat signifikan mempercepat proses pengolahan data.
HIVE
Dalam “Information Platforms and the Rise of the Data Scientist”, Jeff Hammerbacher menjelaskan informasi “Platforms sebagai locus upaya organisasi mereka untuk mencerna, mengolah, dan menghasilkan informasi” adalah bagaimana mereka melayani untuk memberikan akselarasi proses belajar dari data empiris
Satu dari resep terbesar dalam informasi platform dibangun oleh team jeff dalam facebook adalah Hive, sebuah Framework untuk data warehouse yang berjalan diatas Hadoop. Hive berkembang dari kebutuhan untuk mengelola dan belajar dari Volume data besar yang diproduksi oleh Facebook setiap harinya dari situs jaringan sosial yang berkembang. Setelah mencoba beberapa system yang berbeda, team jeff akhirnya memutuskan untuk memilih Hadoop sebagai penyimpanan serta pemrosesan karena dapat menekan biaya dan cocok dengan skalabilitas yang dibutuhkan.
Hive diciptakan untuk memungkinkan dilakukan analisis dengan kemampuan SQL yang kuat tetapi sedikit menggunakan keterampilan java programming untuk melakukan Query pada Volume data besar yang Facebook simpan dalam HDFS. Hari ini Hive adalah proyek Apache yang sukses digunakan dalam berbagai organisasi. Sebagai keperluan umumnya dalam pengolahan data terstruktur.
Tentu saja SQL tidak ideal untuk setiap masalah data besar karena tidak cocok dalam membangun algoritma pembelajaran mesin yang kompleks, tapi bagus untuk melakukan banyak analisis dan memiliki banyak keuntungan besar untuk dapat dikenal dengan baik dalam industri. SQL adalah alat bisnis intelejen sehingga Hive sangat baik untuk dapat diintegrasikan dengan produk SQL ini.
SQOOP
Kekuatan besar dari platform Hadoop adalah kemampuannya untuk dapat bekerja dengan beberapa bentuk data yang berbeda. HDFS dipercaya dapat menyimpan log dan data lain dari sejumlah sumber dan Mapreduce program dapat menguraikan beragam ad hoc data format, melakukan Extracting dengan sempurna dan menggambungkan multiple Dataset untuk menghasilkan hasil yang kuat.
Tetapi untuk berinteraksi dengan data dalam repository penyimpanan diluar HDFS, Mapreduce program perlu menggunakan external API untuk mendapatkan data diluar dari HDFS. Sqoop adalah alat Opensource yang memungkinkan user untuk extractting data dari relational Database kedalam Hadoop untuk kemudian dapat diproses lebih lanjut. Pengolahan ini dapat diselesaikan dengan program Mapreduce atau dengan alat tingkatan lebih tinggi lagi seperti Hive. Ketika hasil akhir dari analytic pipeline telah tersedia, Sqoop dapat mengekspor hasil tersebut kembali kedalam Database untuk dapat dikonsumsi oleh client yang lain.
MySQL
SQL merupakan bahasa query yang paling banyak dipilih oleh DBMS dan Development Tolls (seperti Visual Basic, Delphi, PHP, Java, dll) dalam menyediakan median bagi penggunanya untuk berinteraksi dengan basis data [2].
MySQL merupakan salah satu contoh produk DBMS yang sangat popular di lingkungan linux, tetapi juga tersedia pada windows. Banyak situs web yang menggunakan MySQL sebagai Database server (server yang melayani permintaan akses Database) [1].
Pernyataan-pernyataan SQL digunakan untuk melakukan beberapa tugas seperti update data pada Database, atau menampilkan data dari Database. Beberapa software RDBMS dan dapat menggunakan SQL, seperti Oracle, Sybase, Microsoft SQL Server, Microsoft Access dan Ingres. Setiap software Database mempunyai bahasa perintah atau sintaks yang berbeda, namun pada prinsipnya mempunyai arti dan fungsi yang sama.
ANALISIS DAN PERANCANGAN
Framework ini akan menganalisis database yang tersimpan pada MySQL dan untuk memperoleh datanya tool Sqoop dibutuhkan untuk melakukan import data menjadi text File dan me-Load data ke Hive agar user dapat menganalisis data yang diperlukan dengan memanfaatkan query Mapreduce yang telah didefinisikan pada HiveQL. Mapreduce itu sendiri terdapat pada Hadoop Distributed Filesystem yang mengatur mesin master dan slave
untuk mengerjakan fungsi Mapreduce serta menyimpan hasil eksekusinya pada Hive Metastore dengan mengandalkan tool MySQL JDBC connector.
Gambar-2 Alur Kerja Framework Analisis Masalah
Permasalahan pada penelitian ini adalah bagaimana menganalisis suatu Id unik yang dimiliki satu oleh setiap penduduk pada KTP agar tidak terjadi duplikasi KTP pada saat pembuatan, database yang disimpan berukuran Very Large Database sehingga membutuhkan sebuah Framework Mapreduce dan suatu data warehouse agar dapat menganalisis Id penduduk yang disimpan pada database.
Arsitektur Sistem
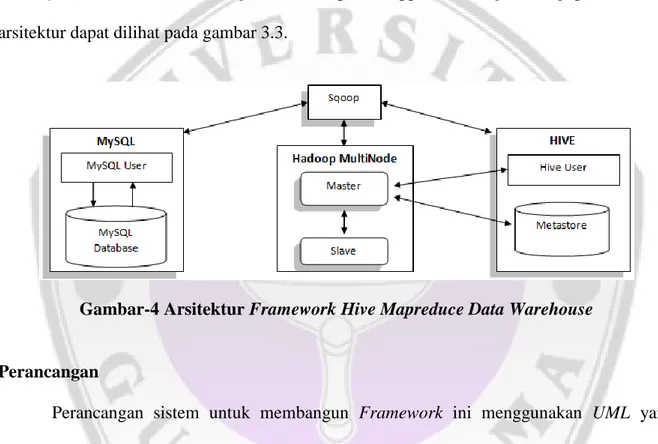
Sistem dibangun menjadi tiga sistem, yaitu sistem MySQL, sistem Apache Hive dan sistem Apache Hadoop. Sistem MySQL digunakan untuk keperluan memproduksi data dan tabel, sistem pada Hive digunakan untuk keperluan mengolah data yang telah diproduksi oleh MySQL, dan sistem Apache Hadoop merupakan mesin yang bekerja pada Hive dengan menggunakan kekuatan Mapreduce multi node. Sqoop merupakan pintu yang akan dilewati oleh MySQL untuk melakukan import data dengan menggunakan Mapreduce juga. Gambaran arsitektur dapat dilihat pada gambar 3.3.
Gambar-4 Arsitektur Framework Hive Mapreduce Data Warehouse
Perancangan
Perancangan sistem untuk membangun Framework ini menggunakan UML yang digunakan untuk merancang model sebuah sistem. Dalam memodelkan proses yang terjadi pada rancangan sistem Mapreduce akan dibuat ke dalam tiga model UML, yaitu Use case dan Activity Diagram.
Diagram Use Case
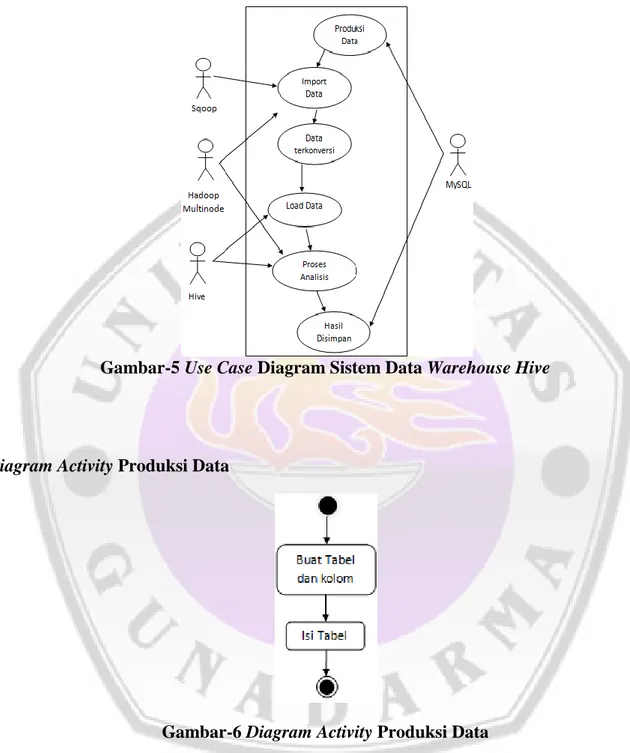
Terdapat empat peran aktor yang bekerja dalam sistem ini, MySQL mempunyai peran untuk menyimpan data dan memproduksi data, aktor Sqoop hanya melakukan proses Import tabel dalam MySQL, sedangkan Hadoop Multinode mempunyai peran banyak dalam sistem ini yaitu membantu Sqoop dalam proses import data dan melakukan analisis tabel yang
dilakukan aktor Hive. Aktor Hive mempunyai peran dalam memerintahkan fungsi Mapreduce dan menyimpan tabel dalam Metastore Hive.
Gambar-5 Use Case Diagram Sistem Data WarehouseHive
Diagram Activity Produksi Data
Gambar-6 Diagram Activity Produksi Data
Diagram Activity Produksi Data dilakukan oleh MySQL di mana hanya melakukan pembuatan tabel, field dan mengisi tabel tersebut. Semakin banyak data yang terisi maka semakin terasa keoptimalan kerja Mapreduce.
Diagram Activity Membuat Tabel dalam Hive
Gambar-7 Diagram Activity Memuat Tabel dalam Hive
Proses ini dilakukan dalam Hive, ketika data yang telah di-import harus dimasukan dalam tabel Hive maka sebelumnya tabel harus telah disiapkan untuk dapat dimasukan dalam tabel Hive. Dalam proses ini, Hive hanya perlu membuat tabel dan kolom dan type data saja.
Diagram ActivityImport Data
Gambar-8 Diagram Activity Import Data
Proses ini dilakukan oleh tool SQOOP agar dapat mengkonversi dari tabel yang berada pada MySQL ke File berbentuk text File, proses konversi dilakukan dengan menggunakan Hadoop Mapreduce. Berikut tahapan proses konversi:
1. Sqoop akan mencoba melakukan koneksi pada Driver tergantung dari koneksi Driver yang digunakan oleh Hive pada databasenya.
2. Setelah koneksi berhasil, tabel yang di-import akan dibaca kolom, record dan tipe datanya.
3. Tipe data MySQL dengan Java berbeda, tetapi memiliki kesamaan. Disini merupakan proses konversi setiap kolom dijadikan kedalam class java berikut dengan tipe datanya.
4. Setiap class java akan diproses dengan Mapreduce dan hasilnya akan berbentuk .txt yang telah dikonversi dari class-class java.
Diagram Activity Proses Analisis Data
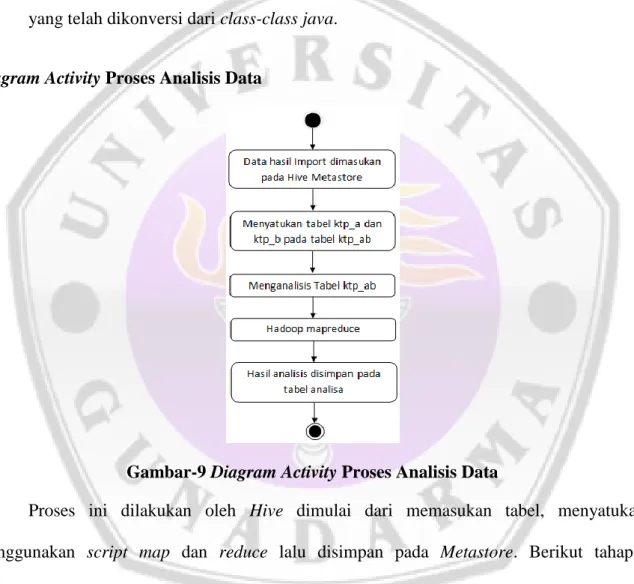
Gambar-9 Diagram Activity Proses Analisis Data
Proses ini dilakukan oleh Hive dimulai dari memasukan tabel, menyatukan, menggunakan script map dan reduce lalu disimpan pada Metastore. Berikut tahapan prosesnya:
1. Tabel yang telah dilakukan Import oleh Sqoop dimasukan pada tabel yang sebelumnya telah dibuat oleh Hive yaitu tabel ktp_a dan tabel ktp_b
2. Data yang telah dimasukan pada kedua tabel, tabel tersebut disatukan dengan mengambil kolom id dan kab dan keduanya disimpan menjadi satu pada tabel ktp_ab.
3. Dengan menggunakan Map dan Reduce script, tabel ktp_ab dilakukan perhitungan id. 4. Hasil analisis disimpan pada tabel analisa dengan kolom id dan value, kolom value
menunjukan nilai yang dimiliki ktp pada penduduk.
IMPLEMENTASI DAN PENGUJIAN Implementasi Perangkat Keras
Perangkat keras yang digunakan untuk sistem ini menggunakan spesifikasi yang sama terkecuali pada komputer master harusnya mempunyai spesifikasi yang lebih bagus dari komputer slave karena komputer master melakukan pekerjaan lebih berat tetapi pada sistem ini spesifikasi yang digunakan sama semua dan terhubung pada satu jaringan.
1. Processor dual core 2.5Ghz 2. RAM 1Gb
3. Hardisk 80Gb
4. Keyboard dan mouse 5. Switch
Implementasi Perangkat Lunak
Perangkat Lunak yang digunakan untuk membangun dan menjalankan sistem ini menggunakan Sistem Operasi Linux Ubuntu 10.10 (maverick meerkat), Apache Hadoop dan java jdk pada semua komputer, tetapi hanya pada komputer master akan dipasang server Database mysql dan apache Hive, sedangkan pada komputer slave hanya apache Hadoop saja.
1. Java Development Kit 1.6 2. Hadoop-0.20.2
3. Hive-0.7.1
4. Mysql-server dan Mysql-client 5. Sqoop
Implementasi framework Mapreduce
Untuk pembuatan sistem ini perlu dijalankan dalam Sistem Operasi Linux Ubuntu, dalam pembuatan sistem ini versi Ubuntu yang digunakan adalah ubuntu 10.10 Maverick Meerkat, lalu install semua aplikasi pendukung seperti:
1. Install sun java JDK
2. Install Hadoop secara Multinode cluster 3. Install MySQL Server dan MySQL Client 4. Install Hive secara pseudo distributed 5. Install Sqoop
framework yang telah dibuat diuji pada tabel yang telah disimpan pada Hive dan dilakukan analisis dengan script Map dan Reduce. Pengujian dilakukan pada tabel ktp_ab yang telah terisi sebanyak 20 baris. Hasil pengujian bisa dilihat pada nilai value yang keluar dan waktu yang dihasilkan oleh pekerjaan Mapreduce.
Pengujian Mapreduce
Proses kerja Mapreduce pada tabel ktp_ab dapt dilihat dalam capture screen pada gambar-10. gambar tersebut menunjukan mapreduce sedang berjalan dan berhasil memproses, 20 baris telah terisi pada tabel analisa.
Gambar-10 Mapreduce Berjalan
Tabel analisa yang telah terisi pada kolom id dan value menunjukan pengujian telah berhasil dilakukan dan sesuai dengan tujuan, hasil dapat dilihat pada gambar-11.
PENUTUP
Penulis merasa bahwa aplikasi dan tulisan ini masih jauh dari sempurna, karena itu saran yang dapat diberikan penulis untuk pengembangan selanjutnya adalah, karena Framework ini masih merupakan prototype maka masih bisa dikembangkan lebih lanjut dalam algoritma analisanya. Selain itu masih banyak implementasi aplikasi yang berjalan diatas model pemrograman pemetaan dan reduksi ini antara lain untuk aplikasi data mining, statistika, machine learning, dan search engine.
DAFTAR PUSTAKA [1] Abdul Kadir, Yogyakarta 2003.
[2] Fatansyah, Jakarta 2004.
[3] Tom White. Hadoop The Definitive Guide Second Edition, O’Reilly Media, inc., United States of America 2011.
[4] URL : http://bps.go.id 8 juli 2011.
[5] URL : http://developers.facebook.com 10 juli 2011. [6] URL : http://intelligenenterprise.com 10 juli 2011.
[7] URL : http://mahrus.wordpress.com 12 juli 2011. [8] URL : http://sbasisdata.blogsopt.com 12 juli 2011.