Indonesian Medical Question Classification
with Pattern Matching
Wiwin Suwarningsih
a,b, Iping Supriana
a, Ayu Purwarianti
a aSchool of Electrical Engineering and Informatics, Institut Teknologi Bandung, Jl. Ganesa 10 Bandung, Indonesia
b
Research Center for Informatics, Indonesian Institute of Science, Jl. Cisitu 21 Bandung, Indones
Abstract— Indonesian medical question-answering system
requires the extraction of named entity recognition process. This research aims to propose and evaluate a systematic approach to classify Problem, Intervention, Comparison and Outcome (PICO) from the Indonesian medical sentences. We here declare that the extraction using the PICO frames for Indonesian medical sentences is the first. PICO frame advantage is to accelerate the classification process based on the criteria of Problem, Intervention, Comparison, and Outcome. Our strategy here was to build a combining question term with multiple classifiers and repetition. The training and test data were generated automatically from Indonesia medical literature with 200 sentences by the exact pattern match of head words of P-I-C-O categories. This approach achieved F-measure values of 0.90 for Problem and Intervention; 0.89 for Problem, Intervention, and Comparison; 0.91 for Problem, Comparison and Outcome. It then can be concluded that by the pattern in matching criteria of the training set and the classification of PICO elements is reproducible with minimal expert intervention.
Keywords—pattern matching, PICO frame, question answering, semantic feature
I. INTRODUCTION
Indonesian medical question answering system is a new generation search engine for medical domain with Indonesian sentences. It is the collection of natural language processing technology and classification information technology. The efficient identification of Indonesian natural language requires an extraction name entity recognition process to support any clinical care decisions with the best available scientific evidence [1]. Evidence based medicine contributed to medical decision making, identification component in medical article (i.e. patient, intervention, comparison, and outcome = PICO) [2] and question answering system.
Schardt et al. in [3] concluded that asking a good question positions the base for search success, and PICO helps to enhance citation retrieval. This approach was more useful to be applied in formulating the number of treatments or preventive action questions compared to other types of medical questions. The difficulty in quickly locating the PICO components poses a barrier against evidence based medicine (EBM) applications [4].
Demner-Fushman et al. [4], meanwhile, surveyed the clinical question answering by using manually crafted pattern matching rules (knowledge-based approach) or combination base classifiers (statistical approach) to detect PICO elements.
Chung [6] studied the detection of “P”, “I” and “O” key sentences in a method section in randomized controlled test abstracts. At this point, several rhetorical roles using a sequential framework of Conditional Random Fields (CRFs) to label PICO at the sentence level were brought. Huang et al.
[5], evaluated the adequacy and suitability of PICO frames as a knowledge representation by analyzing 59 real-world primary-care clinical questions. They discovered that only two questions in our corpus contain all four PICO elements, and that 37% of questions contained both intervention and outcome.
From these studies, we obtained a number of things that can be further explored and improved to classification Indonesian medical question with PICO frames. On the other hand some previous studies used the manually selected features and a limited number of features contributed to performance [7]. The model described an Indonesian medical problem using the dimensions of Problem (P), Intervention (I), Comparison (C) and Outcome (O). Another point was related to our intention to pattern detection by combining several multiple classifiers based on “P”, “I”, “C” or “O”. The reason for determining the use of PICO frames was to enhance the specificity and conceptual clarity of medical problems, leading to more complex search strategies, and yielding more precise search results
The rest of the paper is organized as follows. Section 2 describes some related works, followed by Section 3 presenting the details of proposed method and material. Section 4 is to describe and discuss our experimental result using 200 Indonesian sentences. Finally, research conclusion and subsequent research plan are presented in Section 5.
II. RELATED WORK
One common approach to understand the nature of medical information needs is by collecting and classifying some real clinical questions from physicians [10]. Such analyses have yielded a number of question taxonomies at various levels of details [11][12]. We, at this point highlighted their differences as follows.
Huang et al. [5] evaluated the adequacy and suitability of PICO frames as a knowledge representation by analyzing 59 real-world primary-care clinical questions. They found that the PICO framework was primarily centered on therapy questions, but less suitable to represent other types of clinical information needs.
2015 International Conference on Automation, Cognitive Science, Optics, Micro Electro-Mechanical System, and Information Technology (ICACOMIT), Bandung, Indonesia, October 29–30, 2015
Huang et al. [7] brought a number of rhetorical roles using a sequential framework with Conditional Random Fields (CRFs) to label PICO at the sentence level.
Ely et al. [10] clarified whether first sentences of these
components are quite good to train naive Bayes classifiers for sentence-level PICO element detection. Here, they have extracted 1.985 structured abstracts of randomized controlled trials with any P/I/O label from PubMed for naive Bayes classifiers training.
Fiol et al. [12] developed the formulation of a focused clinical question containing well-articulated PICO elements and widely believed to be the key in efficiently finding high-quality evidence and the key to evidence-based decisions. In addition, some empirical studies have revealed the improvment of the specificity and conceptual clarity of medical problems through the use of PICO frames [10].
III. PROPOSED METHOD
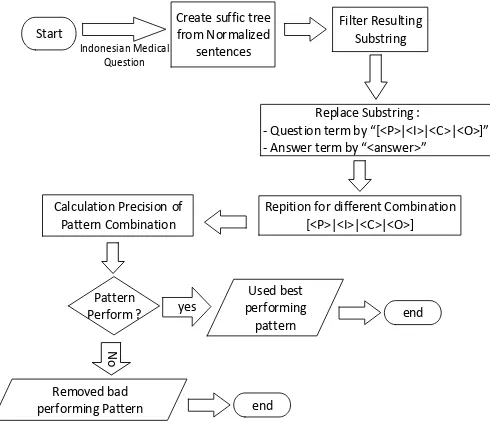
The flowchart of this study is illustrated in Fig.1. The first step was to convert text input into the suffix tree representation of meaning such as substring. In the following step the resulted substring was filtered. The third step was substring a replacement for a question term with <P>|<I>|<C>|<O> and answering term with <answer>. The fourth step was to built the combinination of the question in term with multiple classifiers and repetition.
The next step dealt with the calculation precision of pattern combination and pattern performing qualification. If the combination pattern was performed, then it used for system else removed the pattern.
Create suffic tree from Normalized
sentences
Filter Resulting Substring
Replace Substring :
- Question term by “[<P>|<I>|<C>|<O>]” - Answer term by “<answer>”
Repition for different Combination [<P>|<I>|<C>|<O>] Calculation Precision of
Pattern Combination
Pattern Perform ? yes
No
Start
Indonesian Medical Question
Used best performing
pattern
Removed bad performing Pattern
end
end
Fig 1. Flowchart of the Pattern Combination Process
IV. RESULT AND DISCUSSION
Categorizing question can be performed through multiple ways. Many works have attempted to be as specific
as possible in obtaining the type of the answer. However, since the main focus of this research in finding the answer was not a definite answer type, we, as a result, were able to look at the problem from a more general perspective. Each component is discussed in detail in the following subsections.
A. Result
This section presents the results of various tasks set at the beginning of this work. It shows in the relationship patterns detected by our methods for each of seven pattern combinations. Those matching the seventh pattern combination of PICO represented the results of our approach to capture some generalized relations involving whole clauses, a complex problem which had not been adequately addressed in the past. The performances in terms of precision, recall, and F-measures are also presented in this section. Similarly, a previous study by Huang et al. [5] proposed a reproducible approach of training sentence preparation from PubMed abstracts, and used a base classifier to evaluate pure bag-of-word features for PICO element detection.
In this research, some relevant labels for P/I/C/O components were manually selected, in this case, with a total of 200 sentences from Indonesian medical literature at least about one of the P/I/C/O labels. In detail, 198 abstracts were with P-labels, 129 with I-labels, 190 with C-labels and 178 with O-labels.
The most informative features were used by classifiers trained with all sentences. Table I lists the comparing F-measures, precision and recall for the features with the determinant of the likelihood of a sentence being positively or negatively identified as a P/I/C/O sentence. For example, in terms of P-sentence detection, a sentence containing
‘merasakan gejala’ (In English: feeling) was more likely to be
detected as a positive P-sentence, while a sentence containing
‘tidak dapat’ (In English: cannot) was likely to be detected as
a negative one. When a sentence was composed of more high-positive features used by classifiers of Problem category, it would be more likely to be identified as a P sentence of the classifier.
TABLE I.COMPARE THE F-MEASURE, PRECISION, AND RECALL FOR EACH CATEGORIES
Categories F-Measure Precision Recall
P 0,85 0,84 0,86 I 0,78 0,77 0,79 C 0,89 0,88 0,87 O 0,88 0,89 0,87
Regarding the issue of whether the automatically assigned PICO categories in the test/training set were accurate, we assessed the accuracy of 250 randomly selected sentences containing the combination of all P/I/C/O headings from the database.
independently. For the first type of pattern template, the one composed of two different category combinations of P/I/C/O occurred together in the same clause, it was simply a matter of counting the occurrences in the data of each of the component phrase. These counts represented the distribution of the clusters in each category by multiplying these probabilities P/I/C/O to acquire the probability of the pair occurred in the same clause under the independence assumption.
TABLE II.COMPARISON OF THE F-MEASURE, PRECISION, AND RECALL
PATTERN COMBINATION BASED ON PICOCATEGORIES.
Pattern combination Based on PICO
Categories
F-Measure Precision Recall
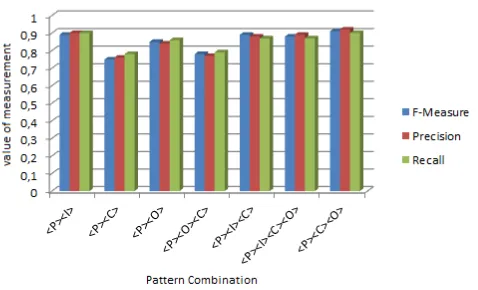
<P><I> 0,89 0,90 0,90 <P><C> 0,75 0,76 0,78 <P><O> 0,85 0,84 0,86 <P><O><C> 0,78 0,77 0,79 <P><I><C> 0,89 0,88 0,87 <P><I><C><O> 0,88 0,89 0,87 <P><C><O> 0,91 0,92 0,90
Table II lists the approach achieving the F-measure values of 0.89 for Problem and Intervention; 0.89 for Problem, Intervention, and comparison; 0.91 for Problem, Comparison and Outcome. It should be noted here that the significant calculation was also unusual for the more-specific combination. Instead of considering the probability of co-occurrence of two combinations under the independence assumption, we are now considering the probability of the co-occurrence of a word and a phrase (or in some cases, of two phrases) which was much lower, and increase the significance of an observed high count.
The performances of F-measure, precision and recall of seven pattern combinations with feature counts between 100 and 250 are charted in Fig. 2.
Fig 2. Pattern Combination Performance
In such cases, our pattern combination was over-generalized, since it assumed that any word from the cluster could emerge in that position in the pattern, when, in fact, we had the weighty observations of only a phrase word. Before proceeding to score the patterns by their statistical significance, the program went over each one to check whether the over-generalization phenomenon occurred in the
combination pattern, and if so, it would replace that combination pattern with the more combinations.
B. Discussion
The pattern matching approach and exploited a collection of manually created question templates [8], i.e. questions having some open concepts to be filled with data instances, mapped into the conceptual model of the knowledge domain.
In our question classification algorithm, we categorized the questions into four cores and 15 combinations for sub-categories. During the process of matching a template to a user question the fixed categories (fixed1,…, fixedm) was bound to the user question. A similar approach, focused on classifying the user questions with the help of pre-determined semantic patterns, was applied in a feasibility study for creating a QA prototype for the oral surgery domain [9].
This section concerns with, the effect of feature counts of classifier performance and the characteristics of features on classifying sentences into P/I/C/O categories.
A suffix tree was made for a set of words instead of only for a single word. It represented all suffixes from this set of words. Each word here must be terminated by a different termination label such as label “P” or “I” or “C” or “O”. A suffix tree returned a huge tree in respect of both on-depth and on-breadth. It was a challenge for execution. Filter substring refers to a work to reduce the number of nodes on-depth and sub-trees on-breadth while still retaining the concept or meaning of each node and sub-tree.
Based on filter resulting, the substring replaced the question term by a label such as <P> | <I> | <C> | <O>, and answered the term replaced by <answer>, for example
“Bagaimana caranya membantu orang pingsan agar cepat
sadar ?” (In English:How do you help people to faint in order
to be quickly concious?). Based on PICO classifying the sentence could be labelled such as the question “membantu
orang pingsan” (In English: help people to faint) term
replaced by <P> and “cepat sadar” (In English: quickly concious) term replaced by <O>. The answer term replaces by <answer>.
To categorize a problem based on its order and repetition requirements as a generalized combination, there are a couple of other characteristics assisting us to sort: (i) In generalized combinations, having all the slots filled in by only selections from one category is allowed; (ii) It is possible to have more slots than categories In this case, we altered the repletion and combination so that the repletion ≥ 2 and balance the number of combination accordingly.
dimensions of pattern combination, we then selected those terms with top term frequencies (TF) in P/I/C/O sentences.
The problem lied once again with the task of obtaining the probability of the pattern combination occurring under the assumption of independence. In this case, the two parts of the pattern combination were not a single phrase, but phrased clauses. As we might recall, there would be one position in each part of the pattern combination containing an anchor. If we ignored the anchor position for the moment, and its influence on the co-occurrence probability, we would be left with a pattern template composed of two parts, each of which was a pair of category combination of P/I/C/O.
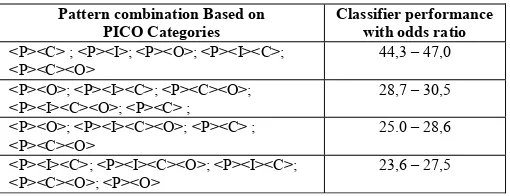
The process of selection was varied from 1% to 10% of total terms. The probability of one sentence in each P/I/C/O class was calculated precision using the selected features. We used 10-fold cross-validation to estimate the classifier performance [13]. Each dataset of the P/I/C/O combination was partitioned into ten subsets randomly. The result of calculation precision of pattern combination is presented in Table III.
TABLE III.CALCULATE PRECISION OF PATTERN COMBINATION
Pattern combination Based on PICO Categories
Classifier performance with odds ratio
<P><C> ; <P><I>; <P><O>; <P><I><C>; <P><C><O>
44,3 – 47,0 <P><O>; <P><I><C>; <P><C><O>;
<P><I><C><O>; <P><C> ;
28,7 – 30,5 <P><O>; <P><I><C><O>; <P><C> ;
<P><C><O>
25.0 – 28,6 <P><I><C>; <P><I><C><O>; <P><I><C>;
<P><C><O>; <P><O>
23,6 – 27,5
For the purpose of detecting the simple patterns comprised of a pair of PICO category, it was possible to hold in memory a two-dimensional table of counts, where the rows represented the first half of the pattern (all possible values of a certain best pattern category) and the columns represented the second half (all possible values of bad pattern category).
After obtaining this pattern performs, we could ask how many instances of each pattern were found in the data. We then compared this to the number of instances expected with an assumption that the two parts of the pattern made were available independently based on main medical task (see Table IV), and calculated the statistical significance of the pattern from these values.
TABLE IV.PATTERN COMBINATION BASED ON MAIN MEDICAL TASK DIAGNOSIS, THERAPY, ETIOLOGY AND PROGNOSIS
Main medical task
Pattern combination Based on PICO Categories
DIAGNOSIS <P><C> ; <P><I>; <P><O>; <P><I><C>; <P><C><O> THERAPI <P><O>; <P><I><C>; <P><C><O>; <P><I><C><O>;
<P><C> ;
ETIOLOGI <P><O>; <P><I><C><O>; <P><C> ; <P><C><O> PROGNOSIS <P><I><C>; <P><I><C><O>; <P><I><C>;
<P><C><O>; <P><O>
V. CONCLUSION
This paper proposes the evaluation of a systematic approach to classify Problem, Intervention, Comparison and Outcome (PICO) from the Indonesian medical. An alignment method was able to detect the best performing pattern based on the difference combination of PICO that here could be used to determine an incorrect pattern in view of the calculation precision of pattern combination
For future work, for those interested in the linguistic aspects, many phenomena within the data could be of interest, for instance the amount of information each component of the clause holds about the others, and the similarity between manually grouped words and automatically pattern combination.
ACKNOWLEDGMENT
We thank anonymous reviewers for their helpful comments.
REFERENCES
[1] Jane L.Forrest, Syrene A. Miller. “Evidence-Based Decision Making in Action: Finding the Best Clinical Evidence”, Journal of Contemporary Dental Practice, 3 (3), pp: 23–35. 2012.
[2] Ke-Chun Huang, I-Jen Chiang, Furen Xiao, Chun-Chih Liao, Charles Chih-Ho Liu. “PICO element detection in medical text without metadata: Are first sentences enough?”. Journal of Biomedical Informatics, 46(5), pp. 940–946. 2013.
[3] Schardt C, Adams M, Owens T, Keitz S, Fontelo P. “Utilization of the PICO framework to improve searching PubMed for clinical questions”. BMC Med Inform Decis Making , 7(16). pp :1–16. 2007.
[4] Demner-Fushman D, Lin J. “Answering clinical questions with knowledge-based and statistical techniques”. Journal of Computer Linguistic, 33(1), pp : 63–103. 2011.
[5] Xiaoli Huang, Jimmy Lin, and Dina Demner-Fushman, “Evaluation of PICO as a Knowledge Representation for Clinical Questions”, In AMIA 2006 Symposium Proceedings. pp 359-363. 2006.
[6] G. Chung, “Sentence retrieval for abstracts of randomized controlled trials”, Journal of BMC Medical Informatics and Decision Making, 9(10), pp: 1-13, 2009.
[7] Ke-Chun Huang, Charles Chih-Ho Liu, Shung-Shiang Yang, “Classification of PICO Elements by Text Features Systematically Extracted from PubMed Abstracts”, In Proceeding of IEEE International Conference on Granular Computing, pp: 279 – 283. 2011.
[8] Andrea Andrenucci, “Automated Question-Answering Techniques and the Medical Domain, Review of the Main Approaches”. HEALTHINF, 2, pp: 07-212. 2008.
[9] Jacquemart, P. and Zweigenbaum, P. “Towards a medical Question Answering system: a feasibility study”. Studies in Health Technology and Informatics, IOS Press. 95, pp: 463-468. 2008
[10] Ely JW, Osheroff JA, Gorman PN, Ebell MH, Chambliss ML, Pifer EA, Stavri PZ. “A taxonomy of generic clinical questions: classification study”. BMJ. 321, pp: 429-432. 2000
[11] Jerome RN, Giuse NB, Gish KW, Sathe NA, Dietrich MS. “Information needs of clinical teams: analysis of questions received by the Clinical Informatics Consult Service”. Bull Med Libr Assoc. 89(2), pp:177-184, 2001
[12] Del Fiol G, Workman TE, Gorman PN, “Clinical questions raised by clinicians at the point of care: a systematic review”. JAMA Intern Med, 174(5), pp: 710-718. 2014.