KOMPARASI ALGORITMA UNTUK ANALISA SENTIMEN REVIEW
PRODUK PADA TWITTER
Esther Irawati Setiawan
Teknik Informatika Sekolah Tinggi Teknik Surabaya e-mail: [email protected]
ABSTRAK
Opini masyarakat akan suatu produk dapat diketahui dari berbagai web jejaring sosial seperti Facebook dan Twitter. Opini yang dijumpai pada jejaring sosial lebih detail dalam bahasa sehari-hari, tidak seperti opini pada web produk itu sendiri. Penelitian ini melakukan komparasi tiga algoritma sentiment analysis pada review berbagai produk dalam jejaring social Twitter. Penelitian ini juga mengembangkan sebuah website analisa sentimen yang menyediakan beberapa ulasan produk pada Twitter yang dikelompokkan berdasarkan sentimen positif dan sentimen negatif. Penelitian utama yang dilakukan adalah pengelompokan tweets tentang suatu produk berdasarkan sentimennya. Klasifikasi sentimen terdiri dari dua tahap. Tahap pertama adalah ekstraksi data tweets yang didapatkan dari Twitter Search API. Hasil ekstraksi pada tahap ini akan dilakukan parsing untuk melakukan proses penentuan subjek dan objek pada kalimat tersebut dan kemudian dilakukan proses feature reduction. Proses feature reduction ini digunakan untuk mengurangi feature space. Tahap kedua adalah memproses data tweets tersebut dengan algoritma Baseline, Naïve Bayes, dan Maximum Entropy. Hasil perhitungan dengan algoritma-algoritma tersebut akan ditampilkan berupa pengelompokan sentimen beserta dengan laporan grafiknya. Website yang dikembangkan juga akan memberikan saran produk yang biasanya dilihat juga oleh pengguna yang lain sesuai produk yang dicari dengan algoritma Apriori.
Kata kunci: klasifikasi, sentiment analysis, naive bayes
ABSTRACT
Public opinion on the product can be known from va rious social networks like Facebook and Twitter. Opinions on social network usually are detailed in everyday languages. A research about sentiment analysis is conducted to find out reviews of a specific product. This research develops a sentiment analysis website that provides various product reviews from Twitter, grouped by positive sentiment and negative sentiment. The main feature in this research is to group tweets about a product by its sentiment. Sentiment classification consists of two main stages. The first stage is the extraction of tweets obtained from Twitter Search API. The result extracted at this stage will be parsed to make process of checking the subject and object of the sentence and then process feature reduction. The process of reduction feature is used to reduce the feature space. The second phase is the tweets data processing with Baseline, Naive Bayes and Maximum Entropy algorithms. The results of the process with these algorithms will be displayed in the form of grouping sentiment along with graph report. The website developed also provides product suggestions that other users usually also search in corresponding to the product that the user sought.
Keywords: classification, sentiment analysis, naïve bayes
PENDAHULUAN
Banyaknya produk-produk yang beredar di pasaran saat ini menyebabkan pelanggan bingung mana produk yang terbaik. Untuk mencari informasi dan testimonial tentang produk mana yang terbaik, biasanya pelanggan bertanya pada teman terdekat atau keluarganya. Hal ini menyebabkan
komentar-komentar tentang produk yang dimiliki. Untuk melihat komentar-komentar tentang suatu barang di Twitter, pengguna harus mencari dan membacanya satu demi satu. Oleh karena itu, untuk mempermudah dalam pembacaan komentar-komentar tentang suatu produk dari Twitter, diperlukan pengelompokan tweets tentang komentar yang baik dan yang buruk. Penelitian ini bertujuan untuk menampilkan info tentang review positif atau negatif suatu produk dari Twitter dan mengelompokkannya berdasarkan klasifikasi sentiment.
SENTIMENT CLASSIFICATION
Sentiment Classification adalah analisa sentimen dari suatu teks, apakah teks itu termasuk positif atau negatif. Analisis sentimen merupakan bagian dari opinion mining [3]. Analisis sentimen merupakan proses memahami, mengekstrak dan mengolah data tekstual secara otomatis untuk mendapatkan informasi [4]. Analisa sentimen dilakukan untuk melihat pendapat terhadap sebuah masalah, atau dapat juga digunakan untuk mengidentifikasi tren di masyarakat [6]. Komentar diklasifikasikan ke dalam dua kelas, yaitu kelas sentimen positif dan kelas sentimen negatif. Besarnya pengaruh dan manfaat dari analisa sentimen, menyebabkan penelitian ataupun aplikasi mengenai analisa sentiment berkembang pesat, bahkan di Amerika kurang lebih 20-30 perusahaan memfokuskan pada layanan analisa sentimen. Pada dasarnya analisa sentiment merupakan klasifikasi, tetapi kenyataanya tidak semudah proses klasifikasi biasa karena terkait penggunaan bahasa. Permasalahan yang muncul adalah adanya ambiguitas dalam penggunaan kata, tidak adanya intonasi dalam sebuah teks, dan perkembangan variasi bahasa itu sendiri.
SISTEM ANALISA SENTIMEN
Pada penelitian ini input yang diperlukan adalah sebuah teks atau kata, berupa nama suatu produk atau merek. Dari kata yang diinputkan tersebut, sistem akan mencari tweets dari Twitter atau ke dalam database tweets yang pernah tersimpan jika koneksi internet tidak memungkinkan. Selain itu input kata tersebut digunakan untuk menentukan produk atau merek yang biasa dicari oleh pengguna lain.
Output utama yang akan dihasilkan dari system ini adalah penilaian dari tweets yang telah diproses. Tweets tersebut akan dikelompokkan berdasarkan
kelompok positif dan negatif. Jumlah total tweets, jumlah tweets positif, dan jumlah tweets negatif akan ditampilkan. Selain itu data yang dihasilkan akan ditampilkan juga dalam bentuk grafik untuk memudahkan pengguna dalam melakukan perbandingan. Output lainnya berupa saran produk atau merek lain yang biasanya dicari oleh pengguna lainnya ketika mencari suatu produk atau merek tertentu. Pengguna juga dapat melihat berapa banyak pengguna yang menjadi member yang menyukai produk ini. Sistem yang akan dibuat berupa website yang mengukur popularitas suatu produk berdasarkan tweets yang ditulis dari pengguna Twitter.
Tahapan feature reduction terdiri dari empat bagian. Bagian pertama yaitu Username, bagian kedua adalah URL, bagian ketiga adalah tagar, bagian yang terakhir adalah repeated letters atau huruf yang berulang.
Setelah data-data tweets diproses dalam tahapan feature reduction, data-data tersebut diproses menggunakan algoritma Baseline, Naive Bayes, dan Maximum Entropy. Selain itu, terdapat juga fitur rekomendasi yang menggunakan Algoritma Apriori untuk menentukan saran produk.
Dalam penelitian ini, terdapat beberapa batasan antara lain: pengelompokan komentar dalam bahasa Inggris. Kemudian dalam data training, komentar yang mengandung baik dan buruk dalam sebuah tweets akan dimasukan sebagai komentar normal. Selanjutnya, dalam data training, retweet tidak akan diproses karena retweet hanya memposting ulang postingan sebelumnya. Sistem hanya bisa menganalisa tweets sebatas huruf normal dan list emoticons yang sudah tersedia. Dan penanganan komentar yang terpisah dalam beberapa tweets tidak bisa karena komentar didapatkan dari twitter tanpa memperhatikan hubungan antar tweets.
EKSTRAKSI DATA
Gambar 1. Arsitektur Sistem
Formatnya berbasis teks dan terbaca manusia serta digunakan untuk merepresentasikan struktur data sederhana dan larik asosiatif (disebut objek). Format JSON sering digunakan untuk mengirimkan data terstruktur melalui suatu koneksi jaringan dalam proses yang disebut serialisasi. Sebagai contoh, ketika ingin mencari tweets dengan query “iphone”, maka sistem akan melakukan request ke Twitter Search API dengan mengakses url tertentu yaitu “http://search.twitter.com/search.json?q=iphone &rpp=3&lang=en”. Pengaksesan ke url tersebut merupakan permintaan data ke Twitter Search API dengan parameter query adalah iphone, rpp (the number of tweets to return each page) adalah 1tweet per page, dan lang (bahasa yang diinginkan) adalah en (bahasa inggris). Maka sistem akan mendapatkan sebuah file Json yang berisi tweets yang dapat dilihat pada Gambar 2. Gambar 2 menunjukkan isi dari file JSON yang akan diekstraksi atau melalui proses diserialization. Pada file JSON tersebut terdapat data-data berupa waktu proses, page, query, dan result. Data result
Gambar 2. Contoh isi file JSON
berisi tweets-tweets yang didapat. Karena permintaan atau request url hanya meminta 1 tweets, maka isi dari result hanya berisi sebuah tweets saja. Data tweets yang didapat berupa array
{
"completed_in": 0.032, "max_id": 243234064331571200, "max_id_str": "243234064331571200", "next_page":
"?page=2&max_id=243234064331571200&q=iphone&lang=e n&rpp=3",
"page": 1, "query": "iphone", "refresh_url":
"?since_id=243234064331571200&q=iphone&lang=en", "results": [
{
"created_at": "Wed, 05 Sep 2012 06:28:14 +0000",
"from_user": "bramruiter", "from_user_id": 3053101, "from_user_id_str": "3053101", "from_user_name": "Bram Ruiter", "geo": null,
"id": 243234064331571200, "id_str": "243234064331571200", "iso_language_code": "en", "metadata": {
"result_type": "recent" },
... } ],
"results_per_page": 1, "since_id": 0, "since_id_str": "0" }
Input Produk
Mengumpulkan Tweets
Database
Memparsing Tweets
Feature Reduction
Naïve Bayes Algoritm menggunaka
Output berupa saran produk Memproses saran
produk dengan Algoritma Apriori
Output Berdasarkan
Baseline Twitter Search API
Baseline Algoritm menggunak
MaxEnt Algoritm
Output Berdasarkan Naïve Bayes
Output Berdasarkan
MaxEnt Admin
Input Produk User
Mengumpulkan Tweets
Output pengelompokan
Tweets
of result. Isi dari result adalah detail-detail dari tweets tersebut. Mulai dari tanggal tweets tersebut dibuat, user yang menulis, id user tersebut, nama user, bahasa, id tweets, profile image, dan isi dari tweets. Pemrosesan ekstraksi ini berujuan mengambil data-data tweets yang ada.
PARSING
Parser merupakan salah satu komponen dalam sebuah interpreter yang berguna untuk memeriksa sintaks dan membangun struktur data dalam serbuah parse tree untuk menentukan struktur gramatikal sebuah kalimat. Parser yang dipakai dalam penelitian ini adalah parser milik Stanford. Stanford Parser ini dapat digunakan untuk bahasa yang lain selain bahasa Inggris, misalkan bahasa China, German, Arab, Italia, Bulgaria, dan Portugal. Parser ini menyediakan Stanford Dependencies untuk output struktur tree. Dalam penelitian ini, parser digunakan dalam pemeriksaan subjek dan objek suatu kalimat yang ada pada tweets. Tujuan dilakukan parsing adalah untuk mengurangi pemrosesan selanjutnya, jika kalimat pada tweets yang diproses subjek dan objeknya bukanlah sesuai yang diminta.
FEATURE REDUCTION
Setelah data-data tweets melalui proses parsing, data-data tersebut akan melalui proses feature reduction. Feature reduction ini bertujuan untuk mengurangi feature space ketika memproses tweets [1]. Feature reduction ini terdiri dari 4 bagian utama. Bagian pertama yaitu Username. Pengguna twitter sering mengikutkan username Twitter ketika mengirimkan tweets dengan tujuan mengarahkan pesan mereka ke usernam yang dituju. Standar yang baku untuk menulis username pada suatu tweets adalah dengan menyertakan simbol @ sebelum username (misalnya @alecmgo). Untuk menyamakan semua username agar mengurangi pemrosesan maka semua kata yang diawali simbol @ akan diganti dengan token USERNAME.
Bagian Kedua adalah URL. Pengguna twitter sering juga menyertakan link dalam tweets mereka, untuk menyamakan semua link maka akan diganti dengan token URL (misalanya “http://tinyurl.com/cvvg9a" diubah menjadi URL).
Bagian ketiga adalah tagar. Pengguna user sering menggunakan tagar agar pengguna lain dapat
mecari topik yang sejenis yang ditulis oleh orang lain juga. Standart baku penggunaan tagar adalah dengan menyertakan simbol # sebelum nama topik tertentu (misalnya #iphone). Untuk menyamakan semua tagar yang ada maka akan diganti dengan token HASHTAG.
Bagian yang terakhir adalah repeated letters atau huruf yang berulang. Twitter berisi bahasa yang sangat sangat kasual. Contohnya, jika dicari kata ”hungry” dengan perulangan huruf ”u” yang berjumlah bebas di tengah (misalnya huuuungry, huuuuuuungry, huuuuuuuuuungry) di Twitter, ada kemungkinan besar hasil yang ditemukan tidak ada. Oleh karena itu, setiap ada huruf yang muncul berturut-turut lebuh dari dua kali akan diganti dengan dua huruf saja. Dalam contoh diatas, kata-kata itu akan diubah menjadi ”huungry”. Selain melakukan feature reduction, pada bagian ini dilakukan juga perubahan pada nama produk yang digunakan sebagai query. Nama produk tersebut diubah menjadi QUERY_TERM dengan tujuan query itu sendiri tidak mempengaruhi hasil klasifikasi.
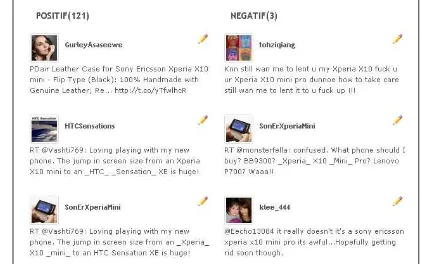
Gambar 3. Contoh Tampilan hasil ouput klasifikasi sentiment dengan Baseline
ALGORITMA BASELINE
poor. Dalam penelitian ini, digunakan
sekitar 259
kata positif dan 344 kata negatif.
L1={List of Positif words} L2={List of Negatif words} for each tweets t in database do for each words w in t do
increment count of positif words in L1 that contained in w
increment count of negatif words in L2 that contained in w
end
Segmen Program 1. Pseudocode Algoritma Baseline
NAÏVE BAYES CLASSIFIER
Naïve Bayes Classifier merupakan algoritma yang memanfaatkan metode probabilitas dan statistik yang dikemukakan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi probabilitas di masa depan berdasarkan pengalaman di masa sebelumnya. Algoritma ini merupakan algorima sederhana yang bekerja dengan baik untuk kategorisasi teks [1].
Terdapat dua tahapan utama dalam proses klasifikasi teks, yaitu tahap pelatihan dan tahap klasifikasi. Pada tahap pelatihan dilakukan proses analisis terhadap sampel dokumen berupa pemilihan vocabulary, yaitu kata yang mungkin muncul dalam koleksi dokumen sampel. Selanjutnya adalah penentuan probabilitas prior bagi tiap kategori berdasarkan sampel dokumen. Pada tahap klasifikasi ditentukan nilai kategori dari suatu dokumen berdasarkan term yang muncul dalam dokumen yang diklasifikasi.
Pada penelitian ini, data training yang digunakan sebanyak 40.000 tweets. Tweet yang digunakan untuk data training ini telah dipilih dengan ketentuan tertentu. Ada beberapa syarat yang diperlukan untuk memilih tweets yang akan digunakan untuk data training. Syarat pertama yaitu Emoticon yang terdapat dalam teks tweets akan dihilangkan. Syarat kedua adalah tweets yang termasuk dalam dua kategori sekaligus yaitu positif dan negatif akan dihilangkan. Hal ini muncul ketika terdapat dua subjek. Retweets dihilangkan karena retweets melakukan proses copy tweets orang lain dan diposting ke account lain. Repeated tweets dihapus terutama ketika Twitter API memberikan data yang sama. Semua tweets yang
terdapat pada data training ini kemudian akan digunakan sebagai data training.
ALGORITMA MAXIMUM ENTROPY
Algoritma Maximun Entropy ini merupakan ini memanfaatkan weight vector untuk menentukan klasifikasi sentimen [1]. Pada penelitian ini, digunakan Stanford Classifier dalam pemrosesan data-data tweets. Algoritma ini memerlukan proses training terlebih dahulu. Training tersebut bertujuan untuk menghitung weight dari kata-kata pada tiap kalimat di tweets yang diproses.
Maximum Entropy menggabungkan contextual evidence untuk memperkirakan probabilitas kelas linguistik tertentu yang terjadi dengan konteks linguistik. Dalam melakukan klasifikasi, dilakukan pengamatan konteks linguistik bBdan dilakukan prediksi kelas linguistik aA dengan conditional probability distribution p, yang mana p(a|b) adalah probabilitas dari kelas dengan beberapa context b, dimana p adalah:
probabilitas distribution p, probabilitas tersebut digunakan untuk menentukan evidence. Evidence diwakilkan dengan fungsi yang diketahui sebagai contextual predicates dan feature. Jika A={a1 … tergantung ada tidaknya informasi yang berguna untuk beberapa context bB. Contextual predicates digunakan di features, yang mana fungsinya adalah fj :AxB {0,1}. Diberikan)
Fitur product suggestion ini bertujuan untuk memberikan saran kepada pengguna tentang produk lain yang bisa dicari. Produk yang disarankan berasal dari produk-produk lain yang dicari oleh pengguna lainnya ketika mencari suatu produk yang sama dengan yang dicari pengguna. Untuk menentukan saran produk ini digunakan algoritma Apriori [10]. Algoritma Apriori termasuk jenis association rule data mining. Analisa asosiasi atau association rule mining adalah teknik data mining untuk menemukan rule/aturan keterkaitan antara suku yang merupakan kombinasi item. Dalam melakukan proses penentuan saran produk menggunakan algoritma Apriori, diperlukan nama-nama produk lain yang dicari oleh pengguna lain. Setelah mendapatkan nama produk tersebut, nama-nama produk tersebut akan diproses dengan algoritma apriori.
L1= {frequent items};
For (k= 1; Lk!=∅; k++) do begin Ck+1= candidates generated from Lk;
for each transaction t in
database do
increment the count of all candidates in Ck+1
that are contained in t
Lk+1= candidates in Ck+1
with min_support end
return ∪kLk;
Segmen Program 2. Pseudocode Algoritma Apriori
USER FEEDBACK
Untuk mengembangkan sistem ini diperlukan juga bantuan dari pengguna. Pengguna dapat memberikan saran jika ada klasifikasi sentiment yang salah atau kurang cocok. Pemberian saran ini akan disimpan dalam database dan nantinya akan digunakan untuk mengembangkan hasil sistem. Ketika pengguna memberikan masukan, pengguna akan diberi pertanyaan termasuk di kelompok mana tweets tersebut menurut pengguna. Masukan tersebut akan disimpan dulu di database dan akan diperiksa dahulu kebenarannya oleh admin di halaman admin. Masukan pengguna ini bertujuan
untuk mengurangi kesalahan website ketika mengelompokan tweets selanjutnya.
UJI COBA
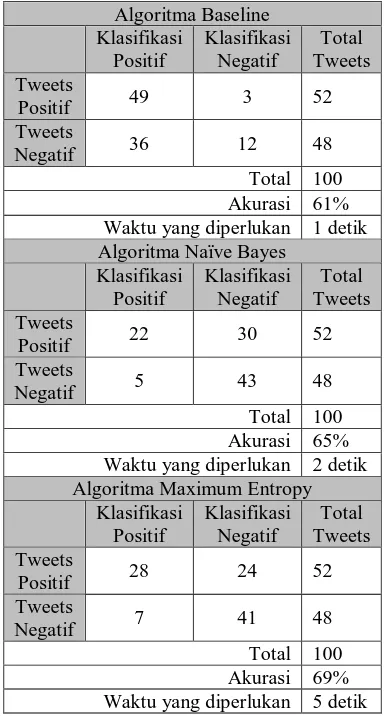
Pada bagian ini akan dijabarkan mengenai uji coba yang telah dilakukan dalam rangka menguji kemampuan serta keakurasian algoritma yang diimplementasikan pada penelitian ini dalam melakukan klasifikasi sentiment dari suatu nama produk yang diinputkan. Pada tabel 1 ditunjukkan hasil pengujian ketika dicari nama produk “iphone”. Hasil evaluasi output klasifikasi sentiment dari pencarian tersebut tampak dalam tabel berikut.
Tabel 1. Tabel Evaluasi Output Pengujian dengan
Pencarian “iphone” Waktu yang diperlukan 1 detik Algoritma Naïve Bayes Waktu yang diperlukan 2 detik Algoritma Maximum Entropy Waktu yang diperlukan 5 detik
Dengan Naïve Bayes, selama 2 detik dihasilkan 27 termasuk positif dan 73 termasuk negatif dengan akurasi 65%. Dengan Maximum Entropy, selama 5 detik dihasilkan 35 termasuk positif dan 65 termasuk negatif dengan akurasi 69%.
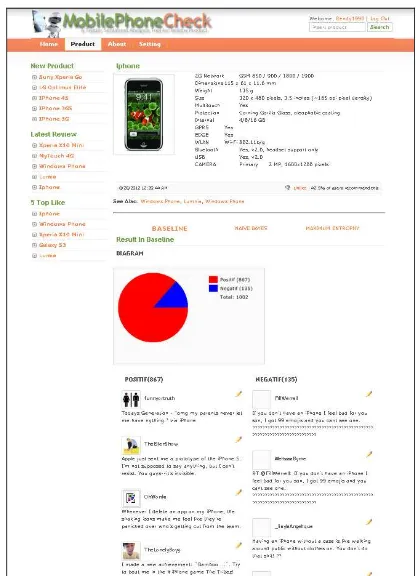
Gambar 4. Contoh Tampilan Hasil Analisa Sentimen
Setelah dilakukan ujicoba untuk lima kasus pencarian produk, dapat dilihat keefektifan kerja dari masing-masing algoritma dalam melakukan klasifikasi sentiment berbeda-beda. Pada ujicoba pertama, kedua dan kelima algoritma Maximum Entropy memiliki akurasi paling tinggi dalam melakukan klasifikasi sentiment. Dalam ujicoba ketiga dan keempat algoritma baseline yang memiliki akurasi paling tinggi. Untuk lebih jelas dapat dilihat pada table berikut.
Tabel 2. Tabel Evaluasi Ujicoba
Algoritma P1 P2 P3 P4 P5
Baseline 61% 57% 78% 70% 68%
Naïve
Bayes 65% 76% 64% 54% 69% Maximum
Entropy 69% 77% 62% 56% 75%
Dari tabel tersebut, dapat disimpulkan bahwa algoritma Maximum Entropy menunjukan hasil yang paling baik dari algoritma Baseline dan Naïve bayes. Algoritma Maximum Entropy memiliki
akurasi paling tinggi dalam melakukan klasifikasi sentiment pada ujicoba pertama, kedua, dan kelima. Dapat disimpulkan 3 dari 5 percobaan akurasi maksimum entropy yang paling tinggi.
Selain itu, dilakukan juga uji coba dengan kuesioner yang dilakukan untuk mengetahui pendapat pengguna mengenai website yang dikembangkan. Terdapat 20 orang responden yang menjawab pertanyaan yang disediakan pada kuesioner. Pada kuesioner terdapat 8 pertanyaan yang diberikan kepada pengguna untuk mengetahui apakah website yang dibuat telah mencapai sasaran untuk menjadi sebuah website sentiment analysis yang meyediakan review produk untuk membantu pengguna dalam mencari review dari produk tertentu. Pertanyaan-pertanyaan yang terdapat pada kuesioner dapat dikelompokkan menjadi dua bagian. Bagian pertama meliputi performa dari aplikasi yaitu kecepatan pemrosesan, keakuratan pengelompokan sentiment, penyajian informasi serta interface dan fitur-fitur yang ada. Bagian kedua berupa pertanyaan apakah responden mau menggunakan website ini untuk keperluan mencari review suatu produk dan apakah responden akan menggunakan website ini bila website ini dipublikasikan di internet.
Tabel 2. Pertanyaan dan Prosentase Jawaban Untuk Bagian Pertama
Pertanyaan Baik Cukup Kurang
Tampilan 90% 10% 0%
Performa 50% 35% 15%
Fitur-fitur website 50% 50% 0% Keakuratan pengelompokan
sentiment 60% 35% 5%
Saran produk lain yang
diberikan 55% 45% 0%
Dari hasil kuesioner, dapat disimpulkan bahwa website dikembangkan pada penelitian ini cukup baik dan telah memenuhi tujuan dibuatnya website maupun penelitian ini.
KESIMPULAN
Adapun beberapa kesimpulan yang didapatkan antara lain:
2. Proses analisa dari Maximum Entropy menunjukan akurasi yang lebih baik daripada Baseline dan Naïve Bayes. Untuk meningkatkan kinerja dari proses klasifikasi sentiment diperlukan training data yang lebih banyak dan perbaikan dalam penggunaan algoritma.
3. Waktu pemrosesan merupakan masalah yang harus diperhatikan. Untuk mengatasi hal ini dapat dilakukan analisa terhadap review suatu produk terlebih dahulu dan pengguna hanya melihat hasilnya tanpa perlu menunggu proses klasifikasi.
DAFTAR PUSTAKA
1. Apach Go, Alec, Richa Bhayani, Lei Huang. Twitter Sentiment Classification using Distant Supervision. 2009. Tersedia: http://cs.stanford.edu/people/alecmgo/papers/T witterDistantSupervision09.pdf
2. Dang, Yan., Zhang Yulei., Hsinchun Chen. A Lexicon Enhanced Method for Sentiment Classification: An Experiment on Online Product Reviews. 2010. Tersedia: https://www.computer.org/csdl/mags/ex/2010/0 4/mex2010040046.pdf
3. Liu, Bing. Sentiment Analysis A Multi-Faceted Problem, IEEE Intelligent Systems. 2010. Tersedia:
http://www.cs.uic.edu/~liub/FBS/IEEE-Intell-Sentiment-Analysis.pdf
4. Liu, Bing. Sentiment Analysis and Subjectivity, in Handbook of Natural Language Processing.
2010. Tersedia:
http://gnode1.mib.man.ac.uk/tutorials/NLP-handbook-sentiment-analysis.pdf
5. Pang, Bo., Lillian Lee, Shivakumar Vaithyanathan. Thumbs up? Sentiment Classification using Machine Learning
Techniques. Tersedia:
http://www.cs.cornell.edu/home/llee/papers/sent iment.pdf
6. Pang, Bo dan Lilian Lee. Opinion Mining and Sentiment Analysis, Foundations and Trends in Information Retrieval. 2008. Tersedia: http://www.cs.cornell.edu/home/llee/omsa/omsa .pdf
7. Ratnaparkhi, Adwait. A Simple Introduction to Maximum Entropy Models for Natural LanguageProcessing.1997. Tersedia: http://repository.upenn.edu/cgi/viewcontent.cgi ?article=1083&context=ircs_reports
8. Russell, Matthew A. 21 Recipes for Mining Twitter. O’Reilly. 2011
9. Russell, Matthew A. Mining the Social Web. O’Reilly. 2011
10. Wasilewska, Anita. Apriori Algoritm. Tersedia: