1
PENGELOMPOKAN KABUPATEN/KOTA DI JAWA TIMUR
BERDASARKAN KESAMAAN NILAI FAKTOR-FAKTOR YANG
MEMPENGARUHI TINGKAT PENGANGGURAN TERBUKA
DENGAN METODE HIRARKI DAN NONHIRARKI
Nama : Arinda Rochmi Lailiya
Pembimbing : Ir.Dwiatmono Agus W.,M.Kom Co. Pembimbing : Adatul Mukarromah, M.Si Fakultas/Jurusan : FMIPA/Statistika
Abstrak
Jawa T imur m erupakan pr ovinsi de ngan j umlah penduduk t erbanyak kedua dan j umlah pe nganggur terbanyak ketiga di Indonesia pada tahun 2010. Banyaknya jumlah penduduk tersebut berpotensi dalam mempengaruhi ketenagakerjaan di Jawa Timur, terutama pada Tingkat Pengangguran Terbuka (TPT) . Penanganan terhadap faktor-faktor yang berpengaruh terhadap TPT dilakukan guna menurunkan TPT di J awa T imur. Namun hal t ersebut be lum c ukup k arena m asih di temui pe ningkatan T PT pada beberapa k abupaten/kota. H al i ni di mungkinkan adany a k etidaksesuaian pe nanganan de ngan permasalahan pada kabupaten/kota tersebut. Sehingga pada pe nelitian ini dilakukan pengelompokan untuk m engetahui pe rmasalahan m endasar pa da s etiap k abupaten/kota, s ehingga t indakan atau kebijakan dal am m enurunkan pun dapat di lakukan de ngan t epat. D i sisi l ain, pe nelitian i ni j uga bertujuan unt uk m embandingkan m etode y ang t erbaik dar i be berapa m etode dalam pengelompokan hirarki dan nonhi rarki. P erbandingan m etode dinilai be rdasarkan ni lai s ebaran t erkecil, di mana dengan 6 kelompok FCM mampu memberikan hasil pengelompokan terbaik.
Kata kunci : TPT, hirarki, nonhirarki, FCM 1. Pendahuluan
Tingkat P engangguran Terbuka (TPT) m erupakan salah satu i ndikasi d alam m engukur kesejahteraan m asyarakat di I ndonesia. Provinsi J awa Timur t ercatat m emiliki j umlah pe nduduk terbanyak kedua d i Indonesia se telah J awa B arat, y aitu sebanyak 3 7,476 j uta j iwa (BPS, 201 0). Banyaknya j umlah p enduduk t ersebut tentunya akan berpotensi dalam mempengaruhi ko mpleksitas ketenagakerjaan di Indonesia. Kementerian Tenaga Kerja dan Transmigrasi Republik Indonesia (2010) menyebutkan ba hwa Jawa T imur m erupakan p rovinsi ya ng m emiliki jumlah penganggur t erbanyak ketiga d i Indonesia, y aitu s ebesar 8 28.943 j iwa. B erita R esmi S tatistik d alam B PS ( 2010) menyebutkan bahwa TPT di Jawa Timur mencapai 4,91 persen dan meningkat pada bulan Mei 2010 hingga 5,6 persen. Secara rata-rata, TPT di Jawa Timur pada tahun 2010 turun sebesar 0,83 persen jika dibandingkan tahun 2009. Walaupun tampak adanya kemajuan dalam penurunan TPT di Jawa Timur, namun pada beberapa kabupaten/kota masih ditemui adanya peningkatan TPT. Hal ini dimungkinkan kurangnya kesesuaian p enanganan t erhadap m asalah p ada m asing-masing ka bupaten/kota, k arena masalah k etenagakerjaan untuk s etiap k abupaten/kota t idak selalu s ama. O leh karena i tulah, upaya pengelompokan diharapkan m ampu m enggabungkan ka bupaten/kota ya ng m emiliki kesamaan p ada beberapa faktor-faktor yang berpengaruh terhadap masalah ketenagakerjaan, dalam hal ini adalah TPT. Dengan d emikian, solusi p enurunan secara m erata akan l ebih t erarah k arena p enanganan akan disesuaikan dengan permasalahan atau karakter masalah pada setiap kabupaten/kota.
Sejauh ini terdapat beberapa macam metode pengelompokan yang diteliti tingkat kebaikannya dan d iterapkan p ada b eberapa kasus. Mingoti & Lima (2006) membuktikan bahwa diantara metode pengelompokan hirarki tradisional (single linkage, complete linkage, dan sebagainya), k-means , fuzzy c-means dan SOM neural network, metode fuzzy c-means yang memiliki hasil paling baik pada kasus outlier maupun overlapping. Junjie L i, Michael, & Y iu-Ming (2008) juga m enunjukkan b ahwa pengelompokan dengan a lgoritma fuzzy c -means memberikan k euntungan d iantaranya d apat meningkatkan a lgoritma k-means dan ha silnya cenderung ko nsisten. Penelitian lainnya j uga menunjukkan ba hwa diantara a lgoritma pengelompokan, fuzzy c -means yang pa ling di percaya da n sering digunakan (Velmurugan & Santhanam, 2010).
Penelitian i ni bertujuan untuk m embandingkan ke baikan hasil p engelompokan b erdasarkan faktor-faktor ya ng m empengaruhi TPT y ang d ilakukan d engan m etode hi rarki d an nonhirarki. Hasil pengelompokan terbaik d inilai b erdasarkan k riteria s ebaran i nternal t erkecil a tau internal c luster
2
dispersion ra te (icdrate) ( Mingoti & Lima, 200 6). Setelah itu, akan di peroleh k elompok kabupaten/kota yang memiliki kesamaan pada faktor-faktor yang mempengaruhi TPT di Jawa Timur. Adanya p enelitian i ni d iharapkan m ampu m enggambarkan kesamaan permasalahan ketenagakerjaan pada beberapa kelompok kabupaten/kota di Jawa Timur.
2. Analisis Faktor
Analisis faktor merupakan suatu teknik analisis yang bertujuan untuk mendefinisikan struktur yang m endasar p ada a ntar v ariabel ( Hair, Black, Babin, & A nderson, 2007). Johnson da n W ichern (2002) m enyebutkan bahwa a nalisis f aktor d apat m enggambarkan v ariabel-variabel ya ng s aling berkorelasi dengan kuantitas random yang disebut sebagai faktor. Secara garis besar, dengan analisis faktor akan didapatkan beberapa f aktor yang mampu menerangkan semaksimal mungkin keragaman dari va riabel-variabel a sli t anpa k ehilangan banyak i nformasi d an a ntar f aktor p un b ersifat sa ling bebas.
Misalkan t erdapat variabel r andom X dengan variabel sebanyak q , ya ng memiliki r ata-rata µ dan m atrik k ovarians
∑
, m aka m odel f aktor d ari X yang m erupakan ko mbinasi l inear beberapa variabel s aling b ebas yang t idak teramati adalah F1,F2,...,Fm disebut sebagai common factors danditambahkan dengan ε1,ε2,...,εp disebut specific factor , sehingga secara khusus dapat ditulis pada
persamaan (1). 1 1 2 12 1 11 1 1−µ =l F +l F + +lpFp+ε X ... 2 2 2 22 1 21 2 2−µ =l F +l F + +l pFp+ε X ... (1) : : : q p qp q q q q l F l F l F X −µ = 1 1+ 2 2+...+ +ε
Dengan : Fk =Common factor ke-k
lhk= Loading factor ke-k dan variabel ke-h
µ
h= rata-rata variabel hh
ε
= Spesific factor ke-hdimana i = 1, 2, … , n adalah banyaknya observasi k = 1, 2, … , p adalah banyaknya common factor
h = 1, 2, … , q adalah banyaknya variabel asli (Johnson & Wichern, 2002). Dalam notasi matriks persamaan (2) dapat ditulis sebagai :
X( )q×1 −µ( )q×1 =L(q×p) ( )Fp×1 +ε( )q×1 (2)
Beberapa h al y ang harus d ipenuhi sebelum d ilakukan a nalisis f aktor a dalah a danya k orelasi antar variabel dan adanya kecukupan sampel. Pengujian independensi dapat dilakukan dengan Barlett Test of Spericity seperti pada persamaan (3).
−
−
+
=
6
5
2
1
ln
R
n
p
Bartlett
(3)Dimana |R| = nilai determinan dari matrik korelasi n = banyaknya observasi atau pengamatan p = banyaknya variabel
Untuk kecukupan sampel dapat diukur berdasarkan nilai Kaizer-Meyer-Olkin (KMO) measure of sampling adequacy yang ditunjukkan oleh persamaan (4).
∑∑
∑∑
∑∑
≠ ≠ ≠ + = j i ij j i ij j i ij a r r KMO 2 2 2 (4) dimana 2 ijr
adalah korelasi antara variabel i dan j, sedangkan 2ij
a
adalah korelasi parsial antara variabel i dan j (Yamin & Kurniawan, 2009).Berdasarkan H air,dkk ( 2010), sampel di katakan cukup bi lamana K MO > 0, 5. A dapun klasifikasi KMO adalah sebagai berikut.
KMO ≤ 0,9 : memuaskan 0,8 < KMO ≤ 0,9 : sangat bagus
3
0,7 < KMO ≤ 0,8 : bagus0,6 < KMO ≤ 0,7 : cukup bagus 0,5 < KMO ≤ 0,6 : tidak cukup bagus KMO ≤ 0,5 : tidak layak
3. Pengelompokan Hirarki (Hierarchical Clustering)
Pengelompokan h irarki disajikan s ecara b erjenjang d ari n, (n -1) hingga 1 kelompok. F ungsi jarak yang seringkali digunakan adalah Euclidean, dimana didefinisikan sebagai jarak antara observasi ke-i dan ke-k. Rumus jarak Euclidean dirumuskan pada persamaan (5).
=
∑
− k ik hk x x h i d(, ) ( )2 (5)dimana i=1,2,…,n ; k=1,2,..,p dan i ≠ h
Beberapa macam metode hirarki dalam Johnson dan Wichern (2002) diantaranya sebagai berikut. a. Single Linkage
Single L inkage membentuk ke lompok-kelompok d ari i ndividu d engan m enggabungkan j arak terdekat atau terkecil. Pada awalnya, dipilih jarak terkecil dalam D={di,h} dan menggabungkan
objek-objek ya ng b ersesuaian u ntuk m embentuk s uatu c kelompok. S ecara m atematis d rumuskan p ada persamaan (6).
d(i,h)g = min {di,g , dh,g} (6)
b. Complete Linkage
Metode ini mengelompokkan semua individu dalam cluster yang berada paling jauh satu sama lainnya. Awalnya didefinisikan m atriks j arak D ={di,h} l alu dipilih j arak yang t erjauh d an m
engga-bungkan objek-objek yang bersesuaian. Prosedur complete linkage dirumuskan pada persamaan (7).
d(i,h)g = max {di,g , dh,g} (7)
c. Average Linkage
Metode i ni m emperlakukan j arak a ntara d ua cluster sebagai j arak r ata-rata a ntara se mua pasangan i ndividu. Prosedur average linkage dimulai d engan m endefinisikan m atrik D={di,h} unt uk
memperoleh objek-objek paling dekat. Algoritma average linkage ditunjukkan pada persamaan (8).
g ih l g lg g ih N N d d ) ( ) (
∑∑
= (8)Dimana dlg adalah jarak antara objek l pada kelompok (ih) dan objek g . N(ih) adalah banyaknya
anggota dalam kelompok (ih), sedangkan Ng adalah banyaknya anggota pada kelompok g.
d. Ward
Prosedur pengelompokan metode Ward adalah meminimumkan peningkatan kriteria error sum of square (ESS). Pada setiap step dalam analisis ini akan mempertimbangkan gabungan dari sepasang cluster yang mungkin. Dua cluster yang memiliki peningkatan ESS paling minimum kemudian akan berkelompok. Jika cluster sebanyak c maka ESS merupakan jumlahan dari ESSc.
ESS = ESS1 + ESS2 + … + ESSc
Ketika semua cluster bergabung menjadi satu kelompok dari n item, maka n ilai E SS dirumuskan oleh persamaan (9).
∑
= − − = n i i i x x x x 1 ESS ( )'( ) (9) 4. Metode NonhirarkiPengelompokan nonhirarki be rawal da ri m enentukan i nisial ba nyak kelompok dan berhenti pada i terasi m aksimum. K eanggotaan d an p usat k elompok d iperoleh b erdasarkan o ptimasi f ungsi objektif.
a. k-Means
Pengelompokan dengan m enggunakan m etode k-means didasarkan p ada n ilai f ungsi keanggotaannya, d imana f ungsi k eanggotaan t ersebut d idasarkan p ada j arak m inimum a ntara o bjek dengan pusat cluster yang disebut fungsi objektif. Misalkan X adalah data observasi, u adalah fungsi keanggotaan dan v adalah pusat kelompok (cluster). Maka fungsi keanggotaan k-means didefinisikan pada persamaan (10) dan fungsi objektif didefinisikan pada persamaan (11).
4
− = − = lainnya 0 min jika 1 2 2 , , i j i j ij v x v x u (10)∑∑
= = − = c j n i j j i v x P 1 1 2 ) ( (11)dimana i=1,2,…,n ; j=1,2,…,c dan (j) i
x adalah observasi ke-i pada kelompok ke-j b. Fuzzy c-Means
Fuzzy c -Means (FCM) m erupakan metode yang di kembangkan da ri hard k -means dengan menerapkan s ifat f uzzy d alam f ungsi ke anggotaannya. M etode i ni s ering s ekali d igunakan d alam pembentukan pol a da n robust terhadap s uatu k ejadian outlier maupun overlapping c luster. D engan melibatkan t eknik fuzzy dalam clustering, d ata akan b erkumpul dalam sebuah cluster berdasarkan derajat keanggotaan antara 0 dan 1. Fungsi objektif FCM ditunjukkan pada persamaan (12).
∑∑
= = = n i c j ij w ijD u P 1 1 (12) dimana u uij i n c j ij ≤ ≤ ∈ =∑
= 1 1 0 1 1 ], , ( ,Fungsi obj ektif pa da F CM di boboti ol eh de rajat k eanggotaan u dimana c adalah b anyaknya kelompok dan n adalah banyaknya objek yang akan dikelompokkan. Sedangkan w adalah nilai pangkat pembobot yang besarnya lebih besar dari 1, dan seringkali ditentukan sebesar 2 oleh Bezdek (Alata, Molhim, & R amini, 2008). Dalam FCM, Dij adalah p engukuran j arak a ntara p usat cluster v ke-j
dengan objek x ke-i. Dari beberapa penelitian untuk clustering, pengukuran jarak yang pada umumnya sering digunakan adalah jarak Euclidean yang dirumuskan pada persamaan (13).
Dij =
(
xi −vj)
2 (13)Adapun fungsi keanggotaan uij dan pusat cluster vj dirumuskan berturut-turut sebagai berikut.
( )
1 1 1 1 1 − = −∑
= w ij c j w ij ij D D udan
∑
∑
= = = n i w ij n i i w ij j u x u v 1 1 dimana 1≤ j ≤ c5. Calinski – Harabasz Pseudo F-statistic
Salah satu metode alternatif yang digunakan untuk menentukan banyaknya kelompok optimum adalah Pseudo F-statistic yang dirumuskan oleh Calinski dan Harabasz. Penelitian oleh Milligan dan Cooper ( 1985) m enunjukkan ba hwa P seudo F -statistic yang s elanjutnya d isebut P seudo F , m em-berikan hasil terbaik diantara 30 metode dan merupakan metode yang dapat digunakan secara global. Rumus Pseudo F tertulis pada persamaan (14) (Orpin dan Kostylev, 2006).
− − − = c n R c R 2 2 1 1 F Pseudo (14) dimana
(
)
SST SSW SST R2= −;
2 1 1 1 SST∑∑∑
= = = − = c n i c j p k k k ij x x;
dan 2 1 1 1 SSW∑∑∑
= = = − = c n i c j p k k j k ij x xdimana R2 = proporsi jumlah kuadrat jarak antar pusat kelompok dengan jumlah kuadrat sampel
terhadap rata-rata keseluruhan
SST = total jumlah dari kuadrat jarak terhadap rata-rata keseluruhan
SSW = total jumlah dari kuadrat jarak sampel terhadap rata-rata kelompoknya n = banyaknya sampel
c = banyaknya kelompok
5
p = banyaknya variabelk ij
x
= sampel ke-i pada kelompok ke-j dan variabel ke-kk
x = rata-rata sampel pada variabel-k k
j
x = rata-rata sampel pada kelompok ke-j dan variabel ke-k (Hinde, Whiteway, Ruddick,
Heap., 2010)
6. Internal Cluster Dispersion Rate (icdrate)
Kriteria d alam m enilai k ebaikan pengelompokan pada i ntinya adalah untuk m enilai homogenitas d alam cluster dan h eterogenitas a ntar cluster. Merujuk p ada E viritt d alam Mingoti & Lima ( 2006), pe rbandingan m etode pengelompokan dapat di ukur de ngan m enghitung r ata-rata persebaran dalam kelompok a tau internal c luster di spersion r ate (icdrate) terhadap p artisi se cara keseluruhan. 2 R 1 SSW SSW) (SST 1 SST SSB 1− = − − = − = icdrate (16)
dimana SSB adalah total jumlah dari kuadrat jarak sampel terhadap rata-rata keseluruhan, sedangkan SSW a dalah total j umlah d ari kuadrat j arak sampel t erhadap r ata-rata ke lompoknya. S emakin ke cil nilai icdrate, maka semakin baik hasil pengelompokannya.
7. Multivariate Analysis of Varians (MANOVA)
Multivariate A nalyze of V arians (MANOVA) a dalah s uatu t eknik ya ng d igunakan u ntuk mengkaji pengaruh dari satu atau lebih suatu perlakuan terhadap respon (Johnson & Wichern, 2002). Uji MANOVA dilakukan setelah data memenuhi asumsi-asumsi sebagai berikut:
1. Matriks varians kovarians antar perlakuan identik/ homogen. 2. Setiap populasi memiliki distribusi multivariate normal. Adapun susunan tabel MANOVA ditampilkan pada Tabel 1.
Tabel 1 Tabel MANOVA
Sumber variasi Matrik Jumlah Kuadrat Derajat Bebas
Perlakuan B c-1 Residual W n-c Total Terkoreksi B+W n-1 Keterangan: T j j c j j x x x x n B=
∑
( − )( − ) =1∑∑
= = − − = nc i c j T j ij j ij x x x x W 1 1 ) )( (∑∑
= = − − = + nc i c j T ij ij x x x x W B 1 1 ) )( (Pada pengujian MANOVA diberikan hipotesis sebagai berikut. H0 : µ1=µ2 =...= µc =0
H1 : minimal ada satu pasangµj ≠0 (j = 1,2,....,c)
Statistik Uji W B W + = Λ*
H0 ditolak jika jika Λ >Fc−,n−c *
1 (α) (Johnson & Wichern, 2002).
Keterangan :
W : Matriks sum of square residuals B : Matriks sum of square treatment n : Jumlah Sampel
c : Banyaknya kelompok
6
a. Pemeriksaan Distribusi Multivariat NormalAsumsi variabel d ependen berdistribusi m ultivariat normal perlu dilakukan karena pengujian dalam MANOVA menggunakan Wilk’s Lambda yang berdistribusi chi-square. Variabel X dengan p variabel d ikatakan b erdistribusi m ultivariat n ormal dengan parameter μ dan ∑ bila m emiliki f ungsi densitas pada persamaan (17).
(
)
(
)
− − ∑ = µ − µ π x S x X X X f 1 2 p p 2 p 2 exp 21 T 1 2 1 / / | | ) ( ) ,..., , ( (17)Pemeriksaan m ultivariat normal d ilakukan d engan cara m embuat q-q pl ot dari 2
i
d dan qi .
Tahapan-tahapan dalam pembuatan q-q plot adalah sebagai berikut (Johnson & Wichern, 2002). 1. Tentukan nilai vektor rata-rata Xdan invers dari matrik varians kovarians S-1.
2. Tentukan ni lai 2
i
d yang m erupakan j arak M ahalanobis s etiap p engamatan d engan vektor r ata-ratanya.
(
X X)
S(
X X)
di2 = i− T −1 i− dimana i=1, 2, … , n (18)
3. Urutkan 2
i
d dari yang terkecil hingga terbesar, 2 2 2 2 1) ( ) ( ) ( d ... dn d < < < . 4. Tentukan nilai n i pi 2 1 − = , i=1,2,…,n
5. Tentukan nilai qi yang didekati dengan χ2p
(
(
n− j−12)
/n)
.6. Buat scatter plot dengan ordinat 2
i
d dan axis qi.
7. JIka terdapat plot lebih dari 50% nilai 2
i
d < 2 50%
, p
χ dan membentuk pola garis lurus, maka dapat dikatakan bahwa data berdistribusi multivariat normal (Johnson & Wichern, 2002).
b. Uji Homogenitas Matrik Varians Kovarians
Matrik v arians-kovarians da pat di uji de ngan m enggunakan u ji B ox’s M ( Hair, dk k., 2010) . Hipotesis dan statistik uji Box’s M dirumuskan sebagai berikut.
H0 : Σ1 = Σ2 = Σ3 = Σ4= Σ5= Σ6
H1 : minimal ada satu Σi dan Σj yang berbeda, dengan i ≠ j
Statistik Uji : − − − =
∑
∑
= = c j i c j i hitung c v v 1 pool 1 i 1 2 lnS 2 1 S ln 2 1 1 2( ) χ dimana∑
∑
= = = c j i c j i i pool v S v S 1 1 − + − + − =∑
∑
= = 6( 1)( 1) 1 3 2 1 1 2 1 1 1 pp kp v v c c j i c j i vi =ni - 1Keputusan gagal tolak H0 bilamana χhitung2
≤
2 1 12
1(k−)p(p+)
χ
(Rencher, 2002)
8. Pengangguran
Penduduk usia kerja t erbagi m enjadi d ua go longan, y aitu p enduduk yang t ermasuk a ngkatan kerja d an b ukan a ngkatan k erja. B erdasarkan Sensus P enduduk d alam Statistics I ndonesia (2011), angkatan ke rja d idefinisikan s ebagai p enduduk ya ng b erumur 1 5 t ahun ke atas ya ng mempunyai pekerjaan selama seminggu yang lalu, baik yang bekerja maupun yang sementara tidak bekerja karena suatu se bab se perti m enunggu p anenan a tau c uti, t idak m emiliki p ekerjaan t etapi se dang m encari pekerjaan. S edangkan p enduduk ya ng b erumur 1 5 t ahun y ang t idak b ekerja a tau t idak m encari pekerjaan karena sekolah, berumah tangga, atau secara fisik dan mental memungkinkan untuk bekerja, tergolong bukan angkatan kerja.
Pengangguran a tau t una karya a dalah istilah u ntuk o rang yang tidak b ekerja s ama sekali, sedang mencari pekerjaan, bekerja kurang dari 2 hari dalam seminggu , atau seseorang yang sedang
7
berusaha u ntuk m endapatkan p ekerjaan yang layak. B erdasarkan p engertian t ersebut, m aka pengangguran dapat dibedakan menjadi tiga macam, diantaranya:
1. Pengangguran t erselubung ( Disguissed U nemployment) a dalah t enaga k erja y ang t idak bekerja secara optimal karena suatu alasan tertentu.
2. Setengah menganggur (Under U nemployment), a dalah t enaga kerja yang tidak b ekerja secara optimal karena tidak ada pekerjaan untuk sementara waktu.
3. Pengangguran t erbuka (Open U nemployment) a dalah o rang ya ng m asuk d alam a ngkatan ke rja (berusia 15 tahun sampai 64 tahun) yang sungguh-sungguh tidak melakukan/mempunyai pekerja-an. P engangguran j enis i ni c ukup b anyak k arena m emang b elum m endapat p ekerjaan p adahal telah berusaha secara maksimal.
Dalam m engukur t ingkat pe ngangguran bi asanya di gunakan i ndikator T ingkat P engangguran Terbuka (TPT). Ukuran ini dapat digunakan untuk mengindikasikan seberapa besar penawaran kerja yang tidak terserap dalam pasar kerja di sebuah negara atau wilayah. Tingkat pengangguran terbuka dapat dihitung dengan menggunakan rumus pada persamaan (17).
100% x Kerja Angkatan Jumlah Menganggur yang Penduduk Jumlah TPT = (17)
Pada penelitian Santoso (2009) yang mengklasifikasikan TPT parah dan tidak parah, terdapat beberapa v ariabel yang m enjadi f aktor-faktor penyebab T PT. Perumusan f aktor-faktor pe nyebab tersebut merupakan hasil dari penelitian Imron dan Murtini dengan regresi berganda serta dari Dinas Tenaga Kerja, Transmigrasi da n K ependudukan Provinsi Jawa T imur. Faktor-faktor ya ng mempengaruhi TPT tersebut diantaranya sebagai berikut.
1. Prosentase Tenaga Kerja Indonesia (TKI) dari jumlah angkatan kerja. 2. Prosentase banyaknya angkatan kerja dari jumlah penduduk usia kerja. 3. Prosentase angkatan kerja yang berpendidikan di atas SMA.
4. Rasio b anyaknya p erusahaan p er 100 a ngkatan ke rja. R asio i ni m enunjukkan pe luang ke rja yang ditawarkan setiap perusahaan untuk 100 angkatan kerja.
5. Laju p ertumbuhan e konomi ya ng m enunjukkan b esarnya p eningkatan P DRB t ahun ini dibandingkan dengan tahun sebelumnya.
6. Upah Minimum Kabupaten/Kota (UMK) yang ditetapkan oleh pemerintah.
7. Prosentase pe ncapaian U pah M inimum K abupaten/ K ota ( UMK) t erhadap K ondisi H idup Layak (KHL).
8. Tingkat investasi d aerah y ang t erdiri d ari peningkatan P enanaman M odal D alam N egeri (PMDN) dan Penanaman Modal Asing (PMA).
9. Penelitian Sebelumnya
Mingoti da n Lima (2006) m elakukan pe nelitian yang m embandingkan m etode pe ngelom-pokan SOM neural network dengan fuzzy c-means (FCM), k-means, dan algoritma metode hirarki tradisional s eperti single l inkage, c omplete l inkage, c entroid l inkage, av erage l inkage, Ward. Perbandingan dilakukan dengan kriteria internal cluster dispersion rate (icdrate) dan disimulasikan pada data yang memiliki pencilan (outlier) dan overlapping. Penelitian menunjukkan bahwa FCM memberikan hasil pe ngelompokan ya ng t erbaik da n c enderung s tabil pa da da ta ya ng memiliki outlier maupun overlapping. Sebaliknya, Z OM neural n etwork justru m erupakan m etode ya ng paling buruk dalam memberikan hasil pe ngelompokan ka rena sangat s ensitif terhadap kejadian outlier maupun overlapping.
10. Metodologi Penelitian
Dalam pe nelitian ini da ta ya ng di gunakan m erupakan da ta s ekunder yang di peroleh da ri beberapa i nstansi p emerintahan, d iantaranya B adan P usat Statistik ( BPS), D inas Tenaga K erja, Transmigrasi, dan Kependudukan (Disnakertransnduk) dan Badan Penanaman Modal (BPM) Provinsi Jawa Timur. Variabel yang digunakan dalam penelitian ini mencakup 10 variabel yang tercatat pada tahun 2009 di setiap kabupaten/kota di provinsi J awa Timur. Variabel-variabel t ersebut diantaranya sebagai berikut.
1. Tingkat pe ngangguran terbuka ( rasio jumlah pe ngangguran terbuka de ngan j umlah a ngkatan kerja) yang kemudian disebut variabel TPT.
8
3. Prosentase angkatan kerja, yang kemudian disebut sebagai variabel AK(%).
4. Prosentase angkatan kerja berpendidikan SMA ke atas, yang kemudian disebut sebagai variabel AK>SMA (%).
5. Rasio banyaknya perusahaan per 100 angkatan kerja, yang kemudian disebut sebagai variabel rasio.
6. Laju pertumbuhan ekonomi daerah, yang kemudian disebut sebagai variabel LPE (%). 7. Tingkat upah minimum kabupaten/kota, yang kemudian disebut sebagai variabel UMK.
8. Persentase upah m inimum d ari K ondisi H idup L ayak ( KHL), yang k emudia disebut se bagai variabel UMK-KHL (%).
9. Tingkat Penanaman Modal Dalam Negeri yang kemudian disebut sebagai variabel PMDN (%). 10. Tingkat Penanaman Modal Asing, yang kemudian disebut sebagai variabel PMA (%)
Tahapan-tahapan analisis pada penelitian ini, diantaranya sebagai berikut.
1. Mendeskripsikan secara st atistik kondisi TPT dan f aktor-faktor yang berpengaruh pada tahun 2009.
2. Melakukan p enyelidikan a pakah t erdapat k asus m ultikolinearitas melalui t es B arlett. Ji ka terbukti a da, m aka d ilakukan p enyelesaiannya dengan a nalisis f aktor. Namun s ebelumnya dilakukan u ji k ecukupan s ampel d engan KMO se bagai sy arat l ayaknya a nalisis f aktor dilakukan.
3. Mendapatkan ba nyak kelompok y ang opt imum pa da s etiap m etode pengelompokan. Metode hirarki d an k-means menggunakan n ilai P seudo F , s edangkan m etode F CM m enggunakan indeks S.
4. Melakukan pengelompokan terhadap k abupaten/kota d engan i nput s ejumlah kelompok ya ng optimum.
5. Membandingkan hasil pengelompokan semua metode, baik hirarki maupun nonhirarki dengan menggunakan kriteria icdrate.
6. Mendapatkan kabupaten/kota yang berkelompok berdasarkan hasil pengelompokan terbaik. Mendeskripsikan secara statistik untuk setiap kelompok kabupaten/kota.
11. Analisis dan Pembahasan Deskripsi Statistik
Secara st atistik p ada t ahun 2 009, d eskripsi mengenai T ingkat P engangguran Terbuka ( TPT) beserta f aktor-faktor yang mempengaruhinya di provinsi J awa Timur dapat diketahui p ada T abel 1 . Tabel 1 m enunjukkan ba hwa rata-rata j umlah pe nganggur di J awa T imur pa da t ahun 2009 t ercatat sebanyak 4.626 jiwa dari 1 00.000 penduduk us ia kerja. S elain i tu, d iketahui b ahwa TPT t erkecil di Jawa Timur s ebanyak 1 .321 j iwa, s edangkan ya ng t ertinggi s ebanyak 10.188 j iwa dari100.000 penduduk usia kerja. Selain itu, pada 100.000 penduduk usia kerja di J awa Timur pada tahun 2009 terdapat 5 5.484 j iwa ya ng m erupakan a ngkatan k erja. N amun d isayangkan, r ata-rata pe ndidikan angkatan kerja di Jawa Timur dengan tamatan terakhir SMA terdapat sekitar 2.087 jiwa dari 10.000 angkatan kerja. Tabel 1 juga menunjukkan bahwa rata-rata angkatan kerja yang bekerja di luar negeri (TKI) cukup kecil yaitu sebesar 0,12%.
Tabel 1 Deskripsi Statistik TPT dan Faktor-Faktor yang Berpengaruh Pada Tahun 2009 di Jawa Timur
Variabel Rata-rata Deviasi Standar Minimum Maksimum
TPT 4,626 2,066 1,321 10,188 %TKI 0,2124 0,2267 0,0177 0,791 % AK 55,484 4,116 48,662 67,688 %AK>SMA 20,87 9,45 5,54 46,91 Rasio 0,12 0,1195 0,0171 0,6942 LPE (%) 5,057 0,994 4,07 10,02 UMK 734.552 123.899 571.25 971.624 Pencapaian UMK-KHL (%) 89,53 10,05 61,33 106,71 PMDN (%) 10,26 24,39 0 97,35 PMA (%) 12,63 25,92 0 100
9
Selain itu, tampak bahwa setiap 100 orang dari 10.000 angkatan kerja di Jawa Timur rata-rata memperebutkan 12 pe rusahaan ya ng a da. S elain i tu, di ketahui ba hwa Laju P ertumbuhan E konomi (LPE) Jawa T imur ra ta-rata sebesar 5 ,057% dari t ahun sebelumnya. R ata-rata U MK d i Jawa Timur pun dinilai cukup tinggi yaitu sebesar Rp 734.552,00 dan rata-rata pencapaiannya terhadap Kebutuhan Hidup Layak (KHL) adalah sebesar 89,52%. Namun rata-rata prosentase investasi pada tahun 2009 ini baik dalam negeri maupun asing masih dirasa rendah. Rata-rata Prosentase Penanaman Modal Dalam Negeri (PMDN) pada tahun 2009 adalah sebesar 10,26%, sedangkan Penanaman Modal Asing (PMA) sekitar 12,63%. Agar keragaman dapat dilihat secara serentak, maka perlu dilakukan standarisasi untuk semua v ariabel. H al i ni d ikarenakan sa tuan p ada s etiap v ariabel b erbeda. Standarisasi t ersebut bertujuan u ntuk m enyamakan satuan, s ehingga k eragaman m asing-masing v ariabel dapat disajikan secara bersama dalam satu diagram yaitu seperti pada Gambar 1.
PMA PMDN UM K-KHL ( %) UMK LPE ( %) Perus ahaa n AK>S MA (% ) AK (% ) TKI ( %) TPT 6 5 4 3 2 1 0 -1 -2 -3 D at a
Gambar 1 Boxplot TPT dan Faktor-Faktor yang Berpengaruh di Jawa Timur Pada Tahun 2009 yang Telah Distandarisasi
Gambar 1 m enunjukkan b ahwa TPT d an v ariabel-variabel y ang mempengaruhinya t ampak beragam pada beberapa kabupaten/kota di Jawa Timur. Keragaman yang tinggi terlihat pada variabel TPT, prosentase angkatan kerja berpendidikan di atas SMA, rasio perusahaan per 100 angkatan kerja, Laju Pertumbuhan Ekonomi (LPE), prosentase PMDN dan PMA dimana terdapat beberapa kabupaten/ kota yang memiliki nilai ekstrim (outlier).
Analisis Faktor
Dalam m elakukan p engelompokan d engan m enggunakan j arak Euclidean, k orelasi a ntar variabel harus diatasi dengan menggunakan analisis faktor. Adanya korelasi tersebut dapat diketahui dari hasil pengujian dependensi dengan tes Barlett, dimana hipotesisnya adalah sebagai berikut. H0 :
ρ
=
I
H1 :
ρ
≠
I
Keputusan tolak H0 bilamana p-value < α ( α=5%).
Hasil t es Barlett padaTabel 2 m enunjukkan bahwa t erdapat korelasi antar v ariabel. S elain pengujian dependensi, ke layakan untuk dilakukan a nalisis faktor j uga pe rlu di dahului de ngan pengujian kecukupan sampel yaitu m elalui t es KMO. Analisis faktor dikatakan layak d ilakukan b ila nilai KMO>0,5 (Hair, dkk., 2010). Dengan nilai KMO sebesar 0,55 (Tabel 2), maka dapat dikatakan bahwa kesembilan variabel perlu dilakukan analisis faktor.
Tabel 2 Uji Kelayakan Analisis Faktor
Keterangan Nilai
KMO measure of Sampling Adequacy 0,55
Barlett's Test of Sphericity Chi-Square 89,732
p-value 0,000
Ekstraksi variabel di lakukan de ngan m etode principal c omponent dengan analisis m atrik korelasi. Selain itu juga dilakukan rotasi varimax untuk memudahkan dalam interpretasi. Berdasarkan Gambar 2, nilai eigen > 1 t erjadi ketika variabel direduksi maksimal menjadi 4 f aktor dan keempat faktor t ersebut d apat m ewakili 7 8% v ariabel a sli. Meskipun pr oporsi ku mulatif y ang di berikan cenderung k ecil, n amun e mpat f aktor tersebut m ampu m enggambarkan k orelasi yang t erjadi antar
10
sembilan variabel a sli. Oleh k arenanya, empat f aktor t ersebut merupakan b anyak f aktor yang p aling optimum dalam menggambarkan korelasi dan keragaman.
Gambar 2 Diagram Eigenvalue dan Proporsi Kumulatif
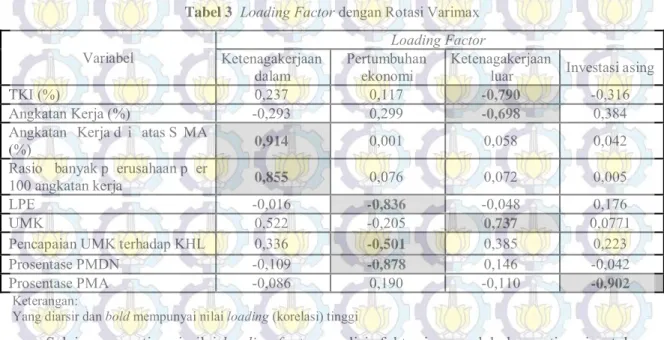
Berdasarkan nilai loading factor pada T abel 3 , da pat diketahui bahwa v ariabel prosentase angkatan kerja berpendidikan di atas SMA dan rasio banyaknya perusahaan per 100 a ngkatan dapat dinamakan s ebagai f aktor k etenagakerjaan d alam d aerah. L aju P ertumbuhan E konomi ( LPE), Pencapaian U MK t erhadap K HL d an P enanaman M odal D alam N egeri (PMDN) d apat d ikatakan sebagai f aktor p ertumbuhan ekonomi d aerah. P rosentase T KI, angkatan k erja, d an UMK l ebih mengarah pada ketenagakerjaan yang bekerja di luar kota atau luar negeri, sehingga dinamakan faktor ketengakerjaan l uar d aerah. P enanaman M odal A sing ( PMA) m erupakan v ariabel y ang t idak berkorelasi dengan variabel manapun, sehingga dinamakan faktor investasi asing.
Tabel 3 Loading Factor dengan Rotasi Varimax
Variabel Ketenagakerjaan Loading Factor
dalam Pertumbuhan ekonomi Ketenagakerjaan luar Investasi asing
TKI (%) 0,237 0,117 -0,790 -0,316
Angkatan Kerja (%) -0,293 0,299 -0,698 0,384
Angkatan Kerja d i atas S MA
(%) 0,914 0,001 0,058 0,042
Rasio banyak p erusahaan p er
100 angkatan kerja 0,855 0,076 0,072 0,005
LPE -0,016 -0,836 -0,048 0,176
UMK 0,522 -0,205 0,737 0,0771
Pencapaian UMK terhadap KHL 0,336 -0,501 0,385 0,223
Prosentase PMDN -0,109 -0,878 0,146 -0,042
Prosentase PMA -0,086 0,190 -0,110 -0,902
Keterangan:
Yang diarsir dan bold mempunyai nilai loading (korelasi) tinggi
Selain mengestimasi nilai loading factor, analisis faktor juga melakukan estimasi untuk score factor . Nilai score factor tersebut yang kemudian menjadi nilai dari keempat faktor yang terbentuk. Sehingga, pengelompokan akan dilakukan d engan menggunakan nilai score f actor yang m erupakan cerminan dari kesembilan variabel asli.
Hierarchical Clustering
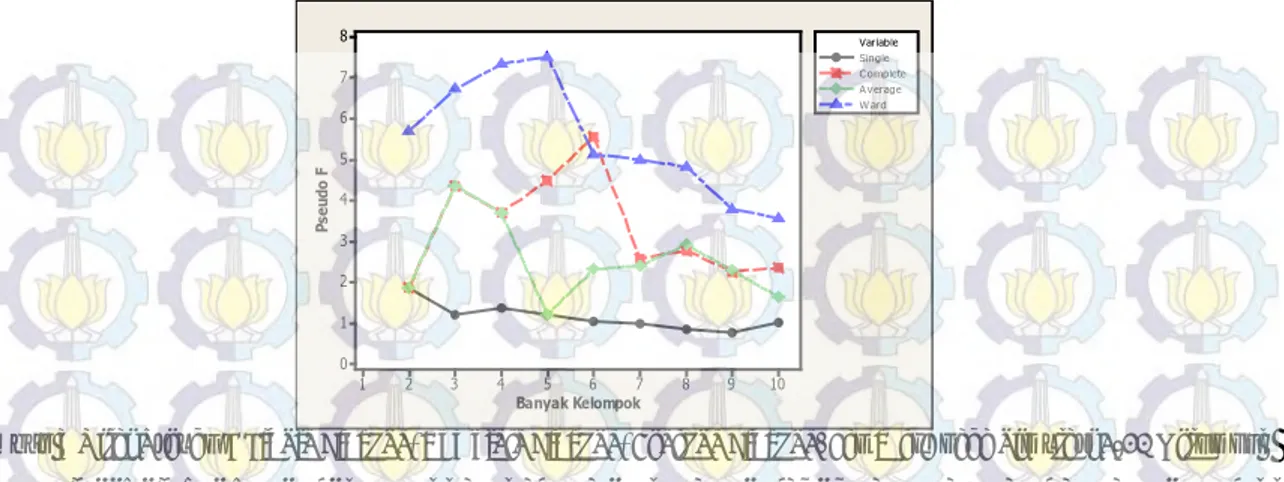
Penentuan ba nyaknya ke lompok y ang opt imal pa da m etode h irarki di dasarkan p ada ni lai statistik P seudo F yang o ptimal. B erdasarkan n ilai P seudo F t erbesar, single l inkage menunjukkan bahwa d engan 2 ke lompok a kan m emberikan h asil ya ng o ptimal, s edangkan complete l inkage sebanyak 6 kelompok, average linkage sebanyak 3 kelompok dan ward sebanyak 5 kelompok.
11
10 9 8 7 6 5 4 3 2 1 8 7 6 5 4 3 2 1 0 Banyak Kelompok Ps eu do F Single Complete Average Ward VariableGambar 3 Nilai Pseudo F Single Linkage, Complete Linkage, Average Linkage, dan Ward pada Simulasi 2-10 Kelompok
Single linkage mengelompokkan kabupaten/kota menjadi dua zona. Gambar 4a menunjukkan bahwa kabupaten/kota d i J awa T imur cenderung m emiliki p ermasalahan y ang s ama, k ecuali Bojonegoro yang tampak sangat berbeda dengan kabupaten/kota lainnya. Hasil pengelompokan yang dibentuk oleh complete linkage seperti pada Gambar 4b, menunjukkan bahwa Madiun dan Sampang memiliki kesamaan, sedangkan Bojonegoro d an Surabaya merupakan kabupaten/kota ya ng memiliki karakteristik sangat b erbeda d engan kabupaten/kota lainnya. H asil p engelompokan y ang d ilakukan average linkage (Gambar 4c) tidak jauh berbeda dengan hasil pengelompokan single linkage, dimana sebagian b esar k abupaten/kota d i J awa T imur m emiliki p ermasalahan y ang sa ma. N amun, average linkage menunjukkan ba hwa M adiun da n Sampang m emiliki pe rbedaan de ngan ka bupaten/kota lainnya. Berdasarkan G ambar 4 d, t ampak b ahwa hasil pengelompokan metode ward c ukup berbeda dengan ha sil p engelompokan p ada m etode hi rarki l ainnya. H al i ni d imungkinkan k arena w ard mempertimbangkan keragaman dalam satu kelompok.
(a) (b)
(c) (d)
Gambar 4 Peta Hasil Pengelompokan Kabupaten/Kota di Jawa Timur dengan Metode (a) Single Linkage (b) Complete
Linkage (c) Average Linkage dan (d) Ward
Nonhierarchical Clustering
Pada metode no nhirarki, indeks p enentuan b anyak kelompok ya ng o ptimum ya ng d igunakan sama h alnya d engan y ang d iterapkan pengelompokan hirarki, y aitu dengan pseudo F . Grafik pada Gambar 5 m enunjukkan b ahwa kelompok k-means akan m emberikan hasil o ptimum bila s ampel dikelompokan m enjadi 5 k elompok di mana P seudo F ya ng di hasilkannya adalah s ebesar 6, 2212.
12
Metode F CM a kan m emberikan h asil p engelompokan o ptimum b ila m elakukan p artisi s ebanyak 6 kelompok, dimana Pseudo F tertinggi ditunjukkan sebesar 11,072.
10 9 8 7 6 5 4 3 2 1 11 10 9 8 7 6 5 4 kelompok Ps eu do F K-means FCM Variable (a) (b)
Gambar 5 Grafik Penentuan Banyak Kelompok pada Metode (a) k-means dan (b) FCM
Peta k-means pada G ambar 6a da n pe ta F CM pa da G ambar 6b m enunjukkan adanya sedikit perbedaan. Sebagian b esar h asil p engelompokan d ari k edua m etode t ersebut c enderung s ama, namun FCM lebih membedakan Trenggalek dan Pacitan dengan Magetan, Ponorogo, Tulungagung dan Blitar. Berbeda d engan h asil k-means yang m engelompokkan keenam kabupaten/kota t ersebut m enjadi sa tu kelompok yang memiliki kesamaan.
(a) (b)
Gambar 6 Peta Hasil Pengelompokan Kabupaten/Kota dengan Metode (a) k-means dan (b) FCM
Pemilihan Metode Terbaik
Untuk m endapatkan hasil k elompok ka bupaten/kota y ang paling b aik, m aka k eenam metode akan dibandingkan berdasarkan tingkat kebaikan hasil pengelompokannya. Menurut Mingoti dan Lima (2006), kebaikan hasil pengelompokan dapat di tunjau berdasarkan internal cluster d ispersion ra te (icdrate). S emakin kecil n ilai icdrate, m aka semakin b aik m etode t ersebut d alam melakukan pengelompokan.
Tabel 4 Internal Cluster Dispersion Rate pada setiap Metode Pengelompokan
Metode BKO SSW SSB icdrate
Single Linkage 2 112,7272 7,2728 0,9394 Complete Linkage 6 56,7995 63,2005 0,4733 Average Linkage 3 91,494 28,506 0,7624 Ward 5 55,6448 64,3552 0,4637 K-means 5 53,4702 66,5298 0,4456 FCM 6 37,3329 82,6671 0,3111
Keterangan: Yang diarsir dan bold merupakan metode terbaik
Nilai icdrate terkecil pa da Tabel 4 di tunjukkan ol eh metode F CM yaitu sebesar 0 ,3111. Keragaman d alam kelompok yang d ihasilkannya sangat k ecil yaitu sebesar 3 7,3329dan k eragaman antar k elompok sangat t inggi yaitu se besar 8 2,6671. S ehingga da pat di simpulkan ba hwa ha sil da ri
13
metode FCM yang dipilih dalam pengelompokan kabupaten/kota di J awa Timur berdasarkan f aktor-faktor yang mempengaruhi TPT pada tahun 2009.
Evaluasi Hasil Pengelompokan
Hasil pe ngelompokkan t ersebut kemudian dilakukan pe ngujian a tau e valuasi apakah a ntar kelompok t erdapat p erbedaan y ang s ignifikan se cara s tatistik. E valuasi dilakukan d engan menggunakan MANOVA, dimana asumsi yang harus dipenuhi adalah berdistribusi multivariat normal dan matrik varians-kovarians homogen.
20 15 10 5 0 12 10 8 6 4 2 0 dd q
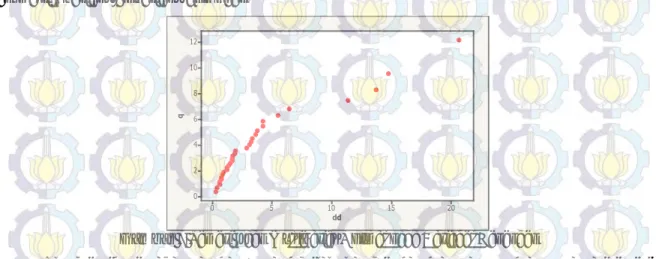
Gambar 7 Pemeriksaan Multivariat Normal pada Variabel Dependen
Plot d istribusi p ada G ambar 7 yang d ilakukan d engan b antuan p rogram s oftware M initab menunjukkan ba hwa faktor-faktor yang m empengaruhi TPT di J awa Timur pa da t ahun 2009 berdistribusi multivariat normal k arena 67, 75% data mengikuti plot d istribusi m ultivariat n ormal, sehingga asumsi distribusi terpenuhi. Dalam uji homogenitas matriks varians-kovarians, kriteria yang digunakan adalah Box’s M. Hipotesis yang diberikan dalam pengujian matrik varians-kovarians adalah sebagai berikut.
H0 : Σ1 = Σ2 = Σ3 = Σ4= Σ5= Σ6
H1 : minimal ada satu Σi dan Σj yang berbeda, dengan i ≠ j
Keputusan gagal tolak H0 terjadi bilamana p-value > α (α = 5%).
Tabel 5 Uji Homogenitas Matriks Varians-Kovarians
Keterangan Nilai
Box's M 43,264
Uji F 1,401
P-value 0,113
Nilai Box’s M sebesar 43,264 pada Tabel 5 memberikan keputusan terjadinya gagal tolak H0
karena p-value yang di tunjukkan lebih be sar da ri 0, 05. Hal t ersebut m enunjukkan b ahwa m atrik varians-kovarians bersifat homogen. Kedua asumsi sebagai prasyarat dalam melakukan uji perbedaan kelompok dengan MANOVA telah terpenuhi secara statistik, sehingga pengujian dengan MANOVA dapat di lakukan. Adapun h ipotesis ya ng di berikan da lam pe ngujian pe rbedaan ke lompok de ngan MANOVA adalah sebagai berikut.
H0 : µ1= µ2=...=µc =0
H1 : minimal ada satuµj ≠0 , dimana i, j = 1,2,..,c dan i ≠ j
Keputusan tolak H0 terjadi bilamana p-value < α ( α=5%).
Berdasarkan h asil p engujian, d iperoleh n ilai wilk’s l amda sebesar 0 ,004 d an p-value menunjukkan nilai lebih kecil dari 0,05. Hal ini dapat dikatakan bahwa t erdapat perbedaan r ata-rata antar kelompok k abupaten/kota di Jawa T imur pada t ahun 2009 . D engan d emikian, a danya pengelompokan ini p erlu u ntuk d ilakukan karena p ermasalahan yang m empengaruhi TPT d i t iap kabupaten/kota berbeda-beda, sehingga penanganannya pun juga bisa berbeda-beda.
Karakteristik Setiap Kelompok
Setiap kelompok yang terbentuk memiliki karakteristik secara statistik. Kelompok 1 dikatakan sebagai daerah TKI karena memiliki ciri prosentase TKI terbanyak daripada kelima kelompok lainnya
~
~
~
14
dengan prosentase angkatan kerja terbanyak kedua. Namun, kelompok ini memiliki jumlah perusahaan yang t ingkat p enyerapan a ngkatan kerjanya t ertinggi ke dua, na mun U MKnya m erupakan U MK terendah d an p encapaiannya t erhadap K ebutuhan H idup L ayak j uga t erendah k edua. K elompok 2 dapat d ikatakan s ebagai d aerah t umbuh d imana p ada t ahun 2009, prosentase PMDN s angat t inggi diikuti d engan LPE ya ng sangat t inggi. S elain itu, U MK d an p encapaiannya j uga sangat t inggi meskipun t ingkat pe nyerapan pe rusahaan m asih t erbilang r endah. K elompok 3 m erupakan da erah wirausaha m andiri y ang m emiliki k arakter LPE t ertinggi k edua, n amun r asio p erusahaan, T KI d an SDM angkatan kerja tidak c ukup t inggi. S elain itu, U MK d an p encapaiannya t erhadap K HL cukup tinggi. Daerah industri merupakan penamaan untuk kelompok 4 yang memiliki kualitas angkatan kerja berpendidikan d i a tas t erbanyak d an r asio p erusahaan j uga sa ngat t inggi, s erta d iperkuat d engan tingginya UMK. Kelompok 5 lebih mengarah sebagai daerah alam, yang memiliki ciri rendahnya rasio perusahaan, kualitas pendidikan angkatan kerja, LPE, UMK bahkan investasi. Ciri-ciri tersebut lebih menunjukkan bahwa angkatan kerja di daerah ini bekerja dengan bergantung pada alam. Kelompok 6 merupakan daerah investasi asing, dimana pada tahun 2009 investasi asing mulai ditanamkan di daerah ini.
12. Kesimpulan
Hasil analisis d an p embahasan y ang t elah d ilakukan d alam p enelitian i ni d apat d isimpulkan sebagai berikut.
1. Hasil pe ngelompokkan t erbaik di lakukan oleh metode FCM de ngan kelompok optimum sebanyak 6.
2. Kabupaten/kota yang berkelompok berdasarkan metode FCM adalah sebagai berikut. Daerah TKI : Ponorogo, Tulungagung, Blitar, dan Magetan.
Daerah tumbuh : Malang, Bojonegoro, dan Bangkalan.
Daerah w irausaha ( mandiri) : L umajang, J ember, B anyuwangi, J ombang, Bondowoso, Probo-linggo, Pasuruan, Tuban, Lamongan dan Pamekasan.
Daerah industri : Kediri, Sidoarjo, Mojokerto, Gresik, Surabaya dan Batu. Daerah alam : Pacitan, Trenggalek, Situbondo, Nganjuk, Ngawi, dan Sumenep. Daerah investasi asing : Madiun dan Sampang
13. Saran
Penamaan untuk s etiap kelompok sebaiknya didiskusikan dengan pihak yang berkompeten di bidangnya, m isal D inas K etenagakerjaan. Selain i tu juga b utuh p eninjauan p ada tahun-tahun sebelumnya agar hasil pe ngelompokkan l ebih t erpercaya da n da pat di pakai un tuk tahun-tahun berikutnya.
Daftar Pustaka
Badan P usat Statistik (BPS). ( 2010). B erita R esmi S tatistik N o. 29/ 05/35/Th.VIII/10 M ei 2010. <http://www. bps.go.id. Diakses 10 Oktober pukul 18.30 WIB>.
_______________________. ( 2010). H asil S ensus P enduduk 2 010 Jawa T imur D ata A gregat p er Kabupaten/Kota, (Online). <http://www.bps.go.id. Diakses 20 Oktober pukul 06.30 WIB>. Hair, J. F., Black, W. C., Babin, B. J., Anderson, R. E. (2010). Multivariate Data Analysis Seventh
Edition.
Hinde, A., Whiteway, T., Ruddick, R., & Heap, A.D. (2007). Seascape of the Australian Margin and adjacent sea floor : Keystroke Methodology. Canberra : Geoscience Australia.
Johnson, R.A. & Wichern, D.W. (2002). Applied Multivariate Statistical Analysis, 5th ed. New Jersey:
Prentice Hall International Inc.
Junjie Li, M., Michael K. Ng, Yiu-Ming Cheung, Senior Member, IEEE and Joshua Zhexue Huang. (2008). A glomerative F uzzy K -Means C lustering Algorithm w ith Selection o f N umber o f Cluster. IEEE Transactions On Knowledge And Data Engineering 20,11:1519-1533.
Kementerian T enaga K erja R epublik Indonesia. ( 2010). Pusat D ata d an Informasi K etenagakerjaan [Online].http://pusdatinaker.balitfo.depnakertrans.go.id/?sec-tion=pt&period=2010-08-01# gotoPeriod. Diakses 24 Maret 2011 pukul 09.14 WIB.
Milligan, G. W. & Cooper, M. C. (1985). An Examination of Procedures for Determining The Number of Cluster in a Data Set. Psychometrika 50, 2: 159-179.
15
Mingoti, S.A. & Lima, J.O. (2006). Comparing SOM neural Network with Fuzzy c-Means, K-means and Traditional hierarchical clustering algorithms. European journal of Operational Research 174 : 1742-1759.
Orpin, A .R. & K ostylev, V .E. ( 2006). T owards a s tatistically v alid m ethod o f te xtural s ea f loor characterization of benthic habitats. Marine Geology 225 : 209-222
Rencher, A.R., ( 2002). M ethods of M ultivariate Analysis Second Edition. J ohn Wiley & Sons, Inc. New York.
Santoso, N . ( 2009). Klasifikasi K abupaten/Kota di J awa Timur B erdasarkan Tingkat P engangguran Terbuka d engan P endekatan M ARS (Multivariate A daptive R egression Spl ine). T ugas Akhir tidak diterbitkan. Surabaya: Institut Teknologi Sepuluh Nopember Surabaya.
Statistics Indonesia. 2011 Angka P artisipasi Angkatan K erja ( APAK) [Online]. <http://www. datastatistik-indonesia.com/content/view/802/802/. Diakses 25 Pebruari 201 1 pu kul 04. 10 WIB>.
Velmurugan, T . & Santhanam, T . ( 2010). Clustering M ixed D ata P oints U sing F uzzy C -Means Clustering Algorithm for Perfomance Analysis. International Journal on ComputerScience and Engineering 02, 09:3100-3105.
Yamin, S . & K urniawan, H . ( 2009). T eknik A nalisis Statistik T erlengkap dengan S oftware S PSS. Jakarta : Salemba Infotek.