perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
i
ESTIMASI PARAMETER PADA MODEL DATA PANEL DINAMIK MENGGUNAKAN ARELLANO-BOND
GMM (GENERALIZED METHOD OF MOMENTS)
oleh
HAYU SUSILOWATI M0106041
SKRIPSI
ditulis dan diajukan untuk memenuhi sebagian persyaratan memperoleh gelar Sarjana Sains Matematika
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SEBELAS MARET
SURAKARTA 2011
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
iii MOTO
“ sesungguhnya bersama kesulitan ada kemudahan” (QS. Al-Insyirah: 6)
“Mawar takkan sempurna tanpa duri Mentari takkan sempurna tanpa cahaya Kebahagiaan takkan sempurna tanpa kesengsaraan
Manusiapun takkan sempurna tanpa cinta demikian juga dengan
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
iv
PERSEMBAHAN
Karya ini penulis persembahkan untuk:
Ibu dan Bapak tercinta atas doa, kasih sayang, dan pengorbanan yang telah diberikan.
Mas Whi tersayang yang selalu memberikan motivasi, kasih sayang dan perhatian. Mbak Ati, Mas Yanto, dan keponakan-keponakan tersayang atas doa dan semangat
yang telah diberikan.
Sahabatku Ella, Linda, Tya, Dyah, Astri, Ayuk, Dukut, Iwan, Wiwit, Ardi, Anank, yang telah memberikan makna indahnya sebuah persahabatan.
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
v ABSTRAK
Hayu Susilowati, 2011. ESTIMASI PARAMETER PADA MODEL DATA
PANEL DINAMIK MENGGUNAKAN ARELLANO-BOND GMM
(GENERALIZED METHOD OF MOMENTS). Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Sebelas Maret.
Banyak perilaku ekonomi mempunyai hubungan dinamik, misalnya permintaan dinamik pada gas alam, permintaan dinamik pada bensin, dan listrik rumah tangga. Analisis data panel untuk persoalan tersebut menggunakan model data panel dinamik. Salah satu estimator pada model data panel dinamik yaitu Arellano-Bond GMM (Generalized Method of Moments). Estimator Arellano-Arellano-Bond GMM
sesuai untuk ukuran data yang besar yaitu dengan periode waktu (T) kecil dan jumlah
individu (n) besar, selain itu juga dapat menghilangkan efek individu karena adanya
operasi pembedaan pertama dalam estimasinya. Tujuan dari penelitian ini adalah untuk menentukan estimasi parameter pada model data panel dinamik menggunakan Arellano-Bond GMM dan menerapkannya pada indeks harga saham dengan variabel
dependen Volume saham dan variabel independennya Open, High, Low, dan Close.
Berdasarkan hasil penelitian diperoleh kesimpulan bahwa model data panel dinamik
pada harga saham yaitu Volumei,t = – 0.1223409 Volumei,t-1 – 195593.2 Openi,t +
452977.2 Highi,t+ 86794.41 Lowi,t – 269414.9 Closei,t .
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
vi ABSTRACT
KATA PENGANTAR
Alhamdulillahi Rabbil’alamin. Puji syukur penulis panjatkan kehadirat Allah SWT yang telah memberikan nikmat, rahmat, dan hidayahNya sehingga penulis dapat menyelesaikan skripsi ini. Penulis juga tidak lupa mengucapkan terima kasih kepada beberapa pihak yang telah banyak memberikan masukan untuk perbaikan penulisan skripsi ini, khususnya kepada
1. Irwan Susanto, DEA. dan Dra. Diari Indriati, M.Si. selaku Pembimbing I dan
Pembimbing II yang telah memberikan bimbingan, nasehat, kritik dan saran selama penyusunan skripsi ini.
2. Seluruh rekan-rekan Matematika angkatan 2006 atas dukungan dan doa yang
telah diberikan.
3. Serta semua pihak yang terkait yang telah memberikan dorongan dan bantuan
sehingga dapat tersusunnya skripsi ini.
Selanjutnya, semoga skripsi ini dapat bermanfaat bagi pihak yang membutuhkan.
Surakarta, Mei 2011
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
vii DAFTAR ISI JUDUL ………. i PENGESAHAN ……….. ii MOTO ……...………... iii PERSEMBAHAN………... iv ABSTRAK……….. v ABSTRACT…….……… viKATA PENGANTAR ………. vii
DAFTAR ISI ……… viii
DAFTAR TABEL ……… x
DAFTAR NOTASI ……….. xi
BAB I PENDAHULUAN ………. 1
1.1. Latar Belakang Masalah ………. 1
1.2. Perumusan Masalah ……… 3
1.3. Batasan Masalah ………. 3
1.4.Tujuan Penelitian……….. 3
1.5. Manfaat Penelitian………... 3
BAB II LANDASAN TEORI ……… 4
2.1. Tinjauan Pustaka ………. 4
2.1.1. Matriks……….….………... 4
2.1.2. Konsep dasar metode momen………..………..… 5
2.1.3. Sifat-sifat estimator….………...………. 5
2.1.4. Regresi linear………...………... 6
2.1.5. Data panel…..………... 7
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
viii
2.1.7. Konsep instrumen………... 12
2.1.8. Uji signifikansi model………... 13
2.1.9. Uji sargan……… 13
2.2. Kerangka Pemikiran ……….. 14
BAB III METODE PENELITIAN ………. 15
BAB IV PEMBAHASAN ………..… 16
4.1 Model Data Panel Dinamik……….…………..….. 4.1.1. Konsep GMM………...……. 4.1.2. Arellano-Bond GMM………. 4.2. Contoh Penerapan……….. ………...………. 4.2.1. Deskripsi data………. 4.2.2. Hasil estimasi model……….. 4.2.3. Pemilihan model ……….... 16 16 18 19 19 21 24 BAB V PENUTUP ………. 25 5.1. Kesimpulan ………. 25 5.2. Saran ………... 25 DAFTAR PUSTAKA ……….. 26 LAMPIRAN ………. 27
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
ix DAFTAR TABEL 2.1. 2.2. 4.1. 4.2. 4.3.Kerangka Umum Data Panel Satu Variabel Independen ………
Kerangka Umum Data Panel k Variabel Independen …..……...
Deskripsi Data Panel……… Hasil Estimasi Arelano-Bond GMM Tahap Pertama Satu Lag……….. Hasil Estimasi Arelano-Bond GMM Tahap Kedua Satu Lag…………
8 9 20 22 23
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
x
DAFTAR NOTASI
)ŋ. : variabel independen pengamatan individu ke-i dan periode ke-t
ŋ. ŋ,. ǘ i t ŋ. Ω J Z V W
: variabel dependen pengamatan individu ke-i dan periode ke-t
: lag value variabel dependen pengamatan individu ke-i dan periode ke-t-1
: efek individu ke- i
: efek waktu ke- t
: komponen error pengamatan individu ke-i dan periode ke-t
: parameter yand tidak diketahui
: ruang parameter berupa himpunan dari semua kemungkinan nilai parameter yang memenuhi asumsi
: parameter dari lag value variabel dependen
: parameter dari variable independen : variabel instrument
: matriks kovarian : variansi
: statistik uji sargan : matriks instrument
i t
: indeks dari individu : indeks dari waktu
FT
: variansi error
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
1
BAB I
PENDAHULUAN
1.1
Latar Belakang Masalah
Statistika adalah alat untuk mengambil keputusan. Keputusan yang
diambil adalah untuk menjawab karakteristik populasi menggunakan sampel,
menjawab distribusi variabel random populasi menggunakan estimasi distribusi
yang sesuai berdasarkan dari sampel yang digunakan, serta menjawab parameter
populasi menggunakan statistik sampel.
Keputusan yang diambil tidak terlepas dari data. Data yang diperoleh
berdasarkan skala pengukuran, hasil pengukuran, dan kuantitatif pengukuran.
Skala pengukuran dapat dikategorikan menjadi empat skala yaitu nominal,
ordinal, interval, dan rasio. Berdasarkan hasil pengukuran dapat dibagi menjadi
data kualitatif dan data kuantitatif. Untuk jenis kuantitatif pengukuran terdiri dari
data diskrit dan data kontinu. Berdasarkan waktu pengumpulannya data dapat
dibagi menjadi tiga yaitu data time series (runtun waktu), data cross section (lintas
bagian), dan data panel. Data runtun waktu yaitu data yang dikumpulkan menurut
urutan waktu, data
cross section
yaitu data yang dikumpulkan pada waktu
tertentu untuk sejumlah variabel pada sejumlah objek tertentu, dan data panel
yaitu data yang menggabungkan data
time series dan data
cross section
(Purwanto, 2006).
Data panel biasa disebut data longitudinal atau
data runtun waktu
silang
(cross sectional time series) dimana banyak kasus (orang, perusahaan,
negara, dan lain-lain) diamati pada dua periode waktu atau lebih yang
diindikasikan dengan penggunaan data time series.
Data panel
dapat menjelaskan
dua macam informasi yaitu informasi
cross-section pada perbedaan antar subjek,
dan informasi
time series yang merefleksikan perubahan pada subjek waktu.
Ketika kedua informasi tersebut tersedia maka
analisis data panel dapat
digunakan. Data panel sering digunakan dengan tujuan untuk meningkatkan
jumlah obervasi (sampel) dan juga untuk mengetahui variasi antar unit yang
berbeda menurut ruang dan variasi yang muncul menurut waktu.
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
2
Data panel akhir-akhir ini lebih dikenal dalam menentukan estimasi
model data panel dinamik dalam ekonometrika. Kelebihan data panel dibanding
data
cross section
yaitu dapat digunakan untuk menentukan estimasi model
dinamik dari observasi pada suatu titik dalam waktu yang jarang didapat dari
suatu survei
cross section, untuk memberikan informasi yang cukup tentang
periode waktu dari hubungan dinamik yang akan diteliti. Kelebihan data panel
dibanding data time series yaitu digunakan untuk mengamati heterogenitas dalam
dinamika penyesuaian antara individu atau perusahaan yang berbeda
(Bond,
2002).
Banyak perilaku ekonomi mempunyai hubungan dinamik (dinamis),
misalnya permintaan dinamis pada gas alam pada berbagai negara, permintaan
dinamis pada bensin di berbagai wilayah, kebutuhan listrik pada beberapa rumah
tangga, dan persamaan dinamis gaji pada beberapa orang. Analisis data panel
untuk persoalan tersebut menggunakan model data panel dinamik. Data panel
dinamik dapat dibagi menjadi dua, yaitu data panel dinamik efek tetap dan data
panel dinamik efek random. Data panel dinamik efek tetap apabila lag
value
variabel dependen tidak berkorelasi dengan komponen error, sedangkan dalam
data panel dinamik efek random lag
value variabel dependen berkorelasi dengan
komponen error.
Dalam model data panel dinamik, ada banyak estimator untuk
mengestimasi parameter pada model diantaranya yaitu
Ordinary Least Squares
(OLS),
Maximum Likelihood,
dan GMM
(Generalized Method of Moments).
Dalam penelitian Muslim (2007), digunakan estimasi Maximum Likelihood untuk
mengestimasi model data panel dinamik efek tetap. Dalam tulisan ini peneliti
memfokuskan pada salah satu estimator pada model data panel dinamik yaitu
Arellano-Bond
GMM dan menerapkannya pada indeks harga saham dengan
variabel dependennya yaitu
Volume saham, sedangkan variabel independennya
yaitu Open, High, Low, dan Close.
Estimator Arellano-Bond
GMM sesuai untuk ukuran data yang besar
yaitu dengan periode waktu
T kecil dan jumlah individu n besar, selain itu juga
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
3
dapat menghilangkan efek individu karena adanya operasi pembedaan pertama
dalam estimasinya.
1.2
Rumusan Masalah
Berdasarkan uraian dalam latar belakang masalah, dapat dirumuskan
permasalahan sebagai berikut.
1.
Bagaimana menentukan estimasi parameter pada model data panel dinamik
menggunakan Arellano-Bond GMM.
2.
Bagaimana menerapkan model data panel dinamik dalam kasus ekonometrika
yaitu pada indeks harga saham menggunakan estimator Arellano-Bond GMM.
1.3
Batasan Masalah
Untuk membatasi permasalahan agar tidak meluas, penelitian ini hanya
difokuskan pada estimasi parameter model data panel dinamik dengan
menggunakan Arellano-Bond pembedaan GMM.
1.4
Tujuan Penelitian
Berdasarkan perumusan masalah, maka tujuan dari penulisan ini adalah
sebagai berikut.
1.
Mengetahui bagaimana menentukan estimasi parameter pada model data panel
dinamik menggunakan Arellano-Bond GMM.
2.
Mengetahui bagaimana penerapan model data panel dinamik dalam kasus
ekonometrika yaitu pada indeks harga saham menggunakan estimator
Arellano-Bond GMM.
1.5
Manfaat Penelitian
Manfaat yang diharapkan dari penelitian ini adalah dapat memberikan
pemahaman lebih dalam tentang model data panel khususnya model data panel
dinamik dan bagaimana menentukan estimasi parameter modelnya menggunakan
Arellano-Bond GMM.
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
4
BAB II
LANDASAN TEORI
2.1
Tinjauan Pustaka
Dalam bagian ini akan diuraikan beberapa teori yang berhubungan
dengan permasalahan yang dibicarakan. Dasar teori tersebut mencakup tentang
penjelasan definisi serta teorema yang berhubungan dengan topik yang dibahas
diantaranya yaitu definisi matriks, konsep dasar metode moment, sifat-sifat
estimator, regresi linear, data panel, model data panel dinamik, konsep instrumen,
uji signifikansi model, dan uji sargan.
2.1.1
Matriks
Definisi 2.1. Matriks (Anton, 1987: 22)
Sebuah matriks adalah susunan segi
empat siku-siku dari bilangan-bilangan. Suatu matriks A berukuran m× n adalah
susunan mn bilangan real di dalam tanda kurung siku dan disusun dalam m baris
dan n kolom sebagai berikut:
A =
o
ǘǘo
ǘ. o
ǘo
ǘo
. o
.
.
.
.
o
ǘo
. o
Definisi 2.2. Transpose Matriks (Anton, 1987: 27) Jika
A = [aij] =
o
ǘǘo
ǘ. o
ǘo
ǘo
. o
.
.
.
.
o
ǘo
. o
adalah matriks berukuran m × n maka
A’= A
T= [aij
T] =
o
ǘǘo
ǘ. o
ǘo
ǘo
. o
.
.
.
.
o
ǘo
. o
dimana aij
T= aji , 1 ≤ i ≤ m, 1 ≤ j ≤ n.
Definisi 2.3. Invers Matriks (Anton, 1987: 34) Jika terdapat matriks A yang
berukuran n × n dan matriks B yang berukuran n × n sedemikian sehingga AB =
BA = I , dimana I adalah matriks identitas maka matriks B disebut invers A.
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
5
2.1.2
Konsep dasar metode momen
Menurut Bain dan Engelhardt (1991: 291) misalkan
X
1,
X
2, …,
X
nmerupakan sampel random dari suatu populasi, prinsip dari metode momen adalah
menyamakan momen ke
j dari populasi, yaitu
ǘ, . . ,
=
9
, dengan
momen ke j dari sampel yaitu
=
∑
ŋ ǘ9
ŋdimana j= 1,2,...,k. Estimator untuk parameter
qdiperoleh dengan menyelesaikan
sistem persamaan
9 =
∑
ŋ ǘ9
ŋdimana j= 1,2,...,k dan akan dinotasikan dengan
q~.
2.1.3
Sifat-sifat estimator
Sifat-sifat estimator yang baik diantaranya yaitu,
1.
Tak Bias (Bain dan Engelhardt, 1991: 302)
Definisi 2.4. Sebuah estimator T dikatakan estimator tak bias untuk
t (q ) jika
E(T)= t (q )
untuk semua
q
Î
W. Jika tidak demikian maka T dikatakan estimator bias
untuk t (q ).
Definisi 2.5. Jika T adalah estimator untuk
t(q ), maka bias dari T
didefinisikan sebagai
b(T) = E(T)- t (q )
dan mean squared error (MSE) dari T didefinisikan sebagai
MSE(T) = E[T-t (q )]
2Teorema 2.1. Jika T adalah estimator untuk
t (q ), maka
MSE(T)=Var(T)+[b(T)]
22.
Konsisten (Bain dan Engelhardt, 1991: 311)
Definisi 2.6. Barisan estimator {T
n} untuk
t(
q) dikatakan konsisten (simpel
konsisten) jika untuk setiap
e> 0
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
6
1
)
|
)
(
(|
lim
n®¥P
T
n-
t
q
<
e
=
untuk setiap
qÎW.
Ini berarti bahwa barisan estimator {Tn} untuk
t(
q) dikatakan konsisten bila
T
nkonvergen stokastik ke
t(
q) untuk n mendekati tak hingga.
Definisi 2.7. Barisan estimator {T
n} untuk t (q ) dikatakan MSE konsisten jika0
)]
(
[
lim
n®¥E
T
n-
t
q
2=
untuk setiap q Î W.
3.
Asimtotik tak bias
Definisi 2.8. (Bain dan Engelhardt, 1991: 312) Barisan estimator {T
n} untukt(q ) dikatakan asimtotik tak bias jika
)
(
)
(
lim
n®¥E
T
n=
t
q
untuk setiap q Î W.
2.1.4
Regresi linear
Analisis regresi merupakan suatu analisis yang menggambarkan
hubungan atau model antara dua variabel atau lebih. Pada analisis regresi dikenal
dua jenis variabel yaitu variabel dependen atau variabel tak bebas yaitu variabel
yang dipengaruhi oleh variabel lainnya, dan dinotasikan dengan
Y dan variabel
independen atau variabel bebas yaitu variabel yang tidak dipengaruhi oleh
variabel lainnya, dan dinotasikan dengan
X. Berdasarkan banyaknya variabel
independen regresi linear dibagi menjadi dua macam yaitu regresi linear
sederhana dan regresi linear berganda. Regresi linear sederhana adalah model
regresi dengan satu variabel independen, sedangkan regresi linear berganda adalah
model regresi dengan variabel independen lebih dari satu.
Menurut
Montgomery dan Peck
(1992: 7), regresi linear sederhana dapat
dimodelkan
Y
i=
J
+
J
ǘX
i+
(2-1)
dimana,
Yi
: variabel dependen pada observasi ke- i
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
7
X
i: variabel independen pada observasi ke- i
: komponen error
dengan
= 0
, Var
=
, dan
~ (0, )
.
Menurut
Montgomery dan Peck
(1992: 118), regresi linear berganda
dengan k variabel independen dapat dimodelkan
Y
i=
J
+
J
ǘX
i1+
J
X
i2+ . . . .+
J
X
ik+
ŋ(2-2)
Regresi linear apabila dituliskan dalam notasi matriks menjadi,
Y= X
J
+
dimana Y=
ǘ.
.
, X =
1 9
ǘǘ. . 9
ǘ1 9
ǘ. . 9
.
.
. .
.
.
.
. .
.
1 9
ǘ. . 9
,
J
=
J
J
ǘ.
.
J
, dan
=
ǘ.
.
.
2.1.5
Data panel
Data panel adalah data yang menggabungkan data
time series
dan data
cross section. Baltagi (2005: 4) mengemukakan bahwa data panel memiliki
beberapa keuntungan dan kerugian, keuntungan dari data panel yaitu
a.
dengan mengkombinasikan data time series dan data cross section, data panel
memberikan data yang lebih informatif, lebih variatif, dan mengurangi
kolinearitas antar variabel,
b.
dengan mempelajari bentuk
cross section yang berulang-ulang, data panel
dapat digunakan untuk mempelajari dinamika perubahan,
c.
data panel dapat mengidentifikasi dan mengukur pengaruh yang tidak dapat
dideteksi dalam data time series dan data cross section,
d.
dapat disusun dan menguji model perilaku yang lebih dalam dibanding
dengan data time series dan data cross section,
e.
dapat dikumpulkan dalam unit-unit mikro, misalnya individu, perusahaan dan
rumah tangga.
Disamping memiliki keuntungan data panel juga memiliki kelemahan,
adapun kelemahan data panel yaitu
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
8
a.
masalah desain dan pengumpulan data,
b.
kesalahan pengukuran,
c.
dimensi time series yang singkat,
d.
cross section yang saling berhubungan.
Green (2003: 285) mengemukakan bahwa data panel secara umum dapat
dimodelkan
yit =
J
xit +
ŋ+
t + u(2-3)
dimana,
y
it: variabel dependen pengamatan individu ke-i dan periode ke-t
x
it: variabel independen pengamatan individu ke-i dan periode ke-t
ŋ
: efek individu
t
: efek waktu
u
: komponen error
Kerangka umum data panel untuk satu variabel independen ditunjukkan
pada Tabel 2.1. Indeks i menunjukkan individu dari data cross section dan indeks
t menunjukkan waktu dari data time series.
Tabel 2.1. Kerangka Umum Data Panel Satu Variabel Independen
I
T
yit
xit
1
.
.
1
1
.
.
T
y
11 . .y1T
x
11 . .x1T
.
.
.
.
.
.
.
.
N
.
.
N
1
.
.
T
yN1
.
.
yNT
xN1
. .xNT
Kerangka umum data panel untuk lebih dari satu variabel independen
ditunjukkan pada Tabel 2.2. Indeks
i menunjukkan individu dari data
cross
section dan indeks t menunjukkan waktu dari data time series.
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
9
Tabel 2.2. Kerangka Umum Data Panel k Variabel Independen
I
T
y
itx
1it. . .
x
kit1
.
.
1
1
.
.
T
y11
. .y
1Tx111
. .x
11T. . .
. . .
. . .
. . .
xk11
.
.
x
k1T.
.
.
.
.
.
.
.
.
.
.
.
N
.
.
N
1
.
.
T
yN1
.
.
yNT
x1N1
. .x1NT
. . .
. . .
. . .
. . .
xkN1
.
.
xkNT
Dari model (2-3), data panel dapat dikelompokkan dalam dua model
yaitu data panel efek tetap dan data panel efek random.
Data panel efek tetap merupakan data panel yang mempunyai asumsi
bahwa
ŋdan
t bersifat deterministik, model ini terdiri dari dua bagian yaitumodel efek tetap satu
arah dengan
ŋatau
t sama dengan nol danmodel efek
tetap dua
arah dengan
ŋdan
t tidak sama dengan nol.Data panel efek random merupakan data panel yang mempunyai asumsi
bahwa
ŋberdistribusi independen identik dengan mean nol dan variansi
serta
tberdistribusi independen identik dengan mean nol dan variansi
, model ini
terdiri dari dua bagian yaitu model efek random satu
arah dengan
ŋatau
tsama
dengan nol dan model efek random dua
arah dengan
ŋdan
t tidak sama dengannol
.
2.1.6
Model data panel dinamik
Menurut Hsiao (2003: 69), model data panel dinamik adalah suatu model
yang terdapat hubungan dinamik, ditandai dengan adanya lag variabel dependen
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
10
diantara variabel independennya. Menurut Behr (2003), model data panel dinamik
dinyatakan dengan persamaan (2-4)
ŋ,.
=
ŋ,. ǘ+ J)
ŋ,.+
ŋ+
ŋ,.(2-4)
dengan,
ŋ,.
: pengamatan variabel dependen unit ke-i pada periode ke-t
ŋ,. ǘ
: lag value dari variabel dependen
)′
ŋ,.: vektor baris variabel independen dengan dimensi k unit ke-i pada periode
ke-t dengan k adalah banyaknya variabel independen
ŋ
: efek individu
ŋ,.: komponen error
dimana dan
J
merupakan parameter yang tidak diketahui, i = 1, 2, 3, . . . ,
n
adalah indeks dari individu, t = 1, 2, 3, . . . , T adalah indeks dari waktu dengan
ŋ,.
~
0,
dan
| | < 1
.
Secara umum model persamaan data panel dinamik dengan efek individu
apabila diubah ke dalam bentuk matrik yaitu
y = y
-1+ x
J
+ D +
dimana
=
ǘ..
.
,
ŋ=
ŋǘ ŋ..
.
ŋ,
) =
)
ǘ)
..
.
)
,
)
ŋ=
)′
ŋǘ)′
ŋ..
.
)′
ŋ=
Ä
=
1
1
..
.
1
dengan dimensi T dan
=
ǘ
..
.
Model data panel dinamik dibagi dalam dua macam yaitu model data
panel dinamik efek tetap dan model data panel dinamik efek random.
Menurut Behr (2003), bentuk persamaan model data panel dinamik efek
tetap dengan parameter dan
J
dinyatakan dengan persamaan (2-5)
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
11
ŋ,.
=
ŋ,. ǘ+ J)
ŋ,.+
ŋ+
ŋ,.(2-5)
dimana dan
J
merupakan parameter yang tidak diketahui, i
= 1, 2, . . . . ,
n
adalah indeks dari individu, dan t = 1, 2, . . . . , T adalah indeks dari waktu dengan
ŋ,.
~
0,
dan
| | < 1.
Model data panel dinamik efek tetap memiliki
asumsi:
1.
komponen error tidak berkorelasi dengan variabel independen: E(
)
ŋ,. ŋ,.) = 0
,
2.
variabel independen berkorelasi dengan efek individu: E
()
ŋ,. ŋ) ≠
0,
3.
komponen error (i.i.d) tidak berkorelasi dengan lag variabel dependen:
E(
ŋ,. ǘ ŋ,.) = 0
.
Menurut Hsiao (2003: 75), bentuk persamaan model data panel dinamik
efek random dinyatakan dengan persamaan (2-6)
ŋ,.
=
ŋ,. ǘ+ J)
ŋ,.+
ŋ,.(2-6)
dimana
ŋ,.=
ŋ+
ŋ,., dan
J
merupakan parameter yang tidak diketahui, i =
1, 2, . . . ,
n adalah indeks dari individu dan t = 1, 2, . . . . , T adalah indeks dari
waktu dengan
ŋ,.~
0, dan | | < 1.
Model data panel dinamik efek
random memiliki asumsi:
1.
ŋ=
ƕano a = ƕ
0 t ktn o
oa
2.
(
ŋ.) = ƕano a = ƕ, k =
0 t ktn o
oa
3.
variabel independen tidak berkorelasi dengan efek individu: E
)
ŋ,. ŋ= 0
,
4.
komponen error tidak berkorelasi dengan efek individu: E
ŋ ŋ,.= 0
,
5.
komponen error berkorelasi dengan lag variabel dependen: E(
ŋ,. ǘ ŋ,.) ≠ 0
.
2.1.7
Konsep instrumen
Menurut Behr (2003), metode instrumen merupakan salah satu cara yang
mungkin untuk menghindari hasil yang bias karena adanya korelasi antara
variabel independen
X dengan komponen error ( ). Ide dasar instrumen yaitu
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
12
mencari sebuah variabel
Z yang berkorelasi tinggi dengan variabel X
tetapi tidak
berkorelasi (orthogonal) dengan komponen error ( ). Variabel
Z digunakan
sebagai variabel independen baru.
Masalah korelasi antara variabel X yang diamati dengan komponen error
( ) ditunjukkan pada persamaan (2-7).
p lim
ǘ9′ ≠ 0
(2-7)
Pada bentuk regresi linear
y
=
J
X
+ dengan Var ( ) =
, masalah bias dapat
dihindari dengan menggunakan instrumen
Z yang berkorelasi dengan variabel
X
dan orthogonal terhadap komponen error ( ) ditunjukkan pada persamaan (2-8)
dan (2-9).
p lim
ǘƦ′9 = Σ ≠ 0
(2-8)
p lim
ǘƦ′ = 0
(2-9)
Mengalikan model regresi
y
=
J
X
+ dengan
Z’
didapatkan persamaan (2-10)
dan (2-11).
Z’y =
Ʀ′
X
J
+
Ʀ′
(2-10)
var(
Ʀ′ )
= Z’ var(
)
Z =
Ʀ′Ʀ
(2-11)
Dari persamaan (2-10) diperoleh estimator Ordinary Least Squares (OLS)
J = (Ʀ 9)′Ʀ′9
ǘ(Ʀ 9)′Ʀ′
Ide
Generalized Least Squares
(GLS) yaitu estimator
Ordinary Least Squares
(OLS) dengan menambahkan pembobot V
-1ke dalam estimasinya. Menggunakan
estimator
Generalized Least Squares
(GLS) dengan
V
-1= (Z’Z)
-1diperoleh
estimator variabel instrumen (2-12) dan (2-13).
2
= (Ʀ 9)′
ǘƦ′9
ǘ(Ʀ 9)′
ǘƦ′
=
(9′Ʀ(Ʀ′Ʀ)
ǘƦ′9
ǘ9′Ʀ(Ʀ′Ʀ)
ǘƦ′
(2-12)
2
= 9′ 9
ǘ9′
dengan P = Z(Z’Z)
-1Z’
(2-13)
Menyisipkan y =
X
J
+ pada persamaan (2-13) menghasilkan persamaan (2-14).
2
= 9′ 9
ǘ9 (
X
J
+
)
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
13
2
=
(9′Ʀ(Ʀ′Ʀ)
ǘƦ′9
ǘ9′Ʀ(Ʀ′Ʀ)
ǘƦ′
X
J
+
(9′Ʀ(Ʀ′Ʀ)
ǘƦ′9
ǘ9′Ʀ(Ʀ′Ʀ)
ǘƦ′
=
J +
ǘ9 Ʀ(Ʀ Ʀ)
ǘƦ′9
ǘ ǘ9 Ʀ(Ʀ Ʀ)
ǘƦ′
(2-14)
Dari persamaan (2-14) diambil batas probabilitas yang menunjukkan estimator
yang tidak bias,
p lim
2=
J +
lim
ǘ9 Ʀ(Ʀ Ʀ)
ǘƦ′9
ǘ ǘ9 Ʀ(Ʀ Ʀ)
ǘƦ′
p lim
2=
J +
Σ Σ
ǘΣ
ǘΣ Σ
ǘΣ
=
J
Dimana
Σ = 0,
jadi jelas bahwa ide instrumen adalah tidak adanya korelasi
antara
Ʀ
dan .
2.1.8
Uji signifikansi model
Uji
Wald merupakan uji signifikansi bersama dari variabel independen
yang berdistribusi asimtotik
dimana
k
merupakan banyaknya parameter yang
akan diestimasi. Uji
Wald bertujuan untuk mengetahui ada tidaknya hubungan
dalam model (Arellano dan Bond, 1991) dengan H
0:
(J) = 0
, maka statistik
ujinya yaitu,
ǖo d=
(J)′( ′ )
− 1(J)
(2-15)dan
=
(J)
.Daerah penolakan H
0yaitu apabila nilai
Wald lebih besar
dibandingkan nilai
.
2.1.9
Uji sargan
Uji sargan digunakan untuk mengetahui validitas penggunaan variabel
instumen yang jumlahnya melebihi jumlah parameter yang diestimasi (kondisi
overidentifying restrictions). Dengan hipotesis nol kondisi
overidentifying
restrictions
dalam estimasi model valid. Menurut Arellano dan Bond (1991) uji
sargan dihitung,
= ̂ ǖ ∑ŋ ǘǖŋ ŋ̂ ŋ̂ ǖŋ ǖ ̂ ~ ( ) (2-16)
Dimana
p merupakan banyaknya kolom
W, K
yaitu banyaknya variabel
independen, dan
̂
menyatakan residual dari estimasi model.
W
merupakan
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
14
matriks yang terdiri atas variabel instrumen yang terbentuk. Statistik uji
s
berdistribusi asimtotik
dengan derajat bebas banyaknya kolom
W
dikurangi
banyaknya variabel independen. Daerah penolakan H
0yaitu apabila nilai s
lebih
besar dibandingkan nilai
( ).
2.2
Kerangka Pemikiran
Mengacu pada tinjauan pustaka dapat disusun suatu kerangka pemikiran
yang mendasari penulisan skripsi ini. Dalam kasus ekonometrika sering dijumpai
adanya model data panel. Apabila terdapat hubungan dinamik dalam model data
panel maka digunakan model data panel dinamik. Hubungan dinamik dalam data
panel ditunjukkan dengan adanya hubungan antara variabel dependen dengan lag
value-nya. Ada banyak estimator untuk mengestimasi parameter pada model data
panel dinamik, salah satunya yaitu estimator Arellano-Bond
GMM. Estimator
Arellano-Bond GMM sesuai untuk ukuran data yang besar yaitu dengan periode
waktu
T kecil dan jumlah individu
n besar, selain itu juga dapat menghilangkan
efek individu karena adanya operasi pembedaan pertama dalam estimasinya.
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
15
BAB III
METODE PENELITIAN
Pada penelitian ini, metode yang digunakan adalah studi literatur dan
penerapan kasus, dengan pengumpulan bahan melalui buku-buku referensi dan
karya ilmiah yang meliputi hasil-hasil penelitian dan jurnal. Dengan metode
tersebut, penulis dapat menjelaskan mengenai estimasi parameter pada model data
panel dinamik dengan menggunakan estimator Arellano-Bond
GMM. Adapun
langkah penelitian adalah sebagai berikut:
1.
Menentukan estimasi parameter dalam model data panel dinamik dengan
menggunakan Arellano-Bond GMM.
a.
Menentukan matriks instrumen
ǖŋyang diperoleh dengan melakukan
pembedaan pertama.
b.
Menentukan matriks kovarian V
yang digunakan dalam estimator
Arellano-Bond GMM tahap pertama.
c.
Mengestimasi matriks kovarian
yang diperoleh dari residu estimasi
Arellano-Bond GMM tahap pertama kemudian digunakan digunakan dalam
estimator Arellano-Bond GMM tahap kedua.
2.
Mengaplikasikan model data panel dinamik pada indeks harga saham di
beberapa perusahaan di Indonesia dengan menggunakan bantuan
software
STATA 10.
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
16
BAB IV
PEMBAHASAN
Pada pembahasan ini akan dibicarakan dua permasalahan pokok yaitu
estimasi parameter model data panel dinamik menggunakan Arellano-Bond GMM
dan contoh penerapannya pada indeks harga saham beberapa perusahaan di
Indonesia.
4.1
Model Data Panel Dinamik
Menurut Hsiao (2003: 69), model data panel dinamik adalah suatu model
yang terdapat hubungan dinamik, ditandai dengan adanya lag variabel dependen
diantara variabel independennya. Menurut Menurut Behr (2003), model data
panel dinamik dapat dinyatakan pada persamaan (4-1)
ŋ,.
=
ŋ,. ǘ+ J)
ŋ,.+
ŋ+
ŋ,.(4-1)
dengan
ŋ,.
: pengamatan variabel dependen unit ke-i pada periode ke-t
ŋ,. ǘ
: lag value dari variabel dependen
)′
ŋ.: vektor baris variabel independen dengan dimensi k unit ke-i pada periode
ke-t dengan k adalah banyaknya variabel independen
ŋ
: efek individu
ŋ,.: komponen error
dimana dan
J
merupakan parameter yang tidak diketahui,
i = 1, 2, . . . . ,
n
adalah indeks dari individu dan t = 1, 2, . . . . , T adalah indeks dari waktu dengan
ŋ,.
~
0,
dan
| | < 1
.
4.1.1
Konsep GMM
Selama beberapa periode terakhir, GMM menjadi lebih populer. Menurut
Behr (2003), konsep dasar GMM terkadang merupakan sebuah alternatif
sederhana yaitu ketika turunan fungsi
Maximum Likelihood
sulit ditentukan. Inti
dari estimasi GMM adalah menggunakan kondisi ortogonalitas. Secara umum
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
17
GMM sesuai untuk ukuran data yang besar, sehingga ketika digunakan untuk
observasi data yang kecil seringkali tidak lebih efisien dibanding metode lain.
Menurut Wawro (2002), untuk menentukan ide bagaimana GMM bekerja
berdasarkan regresi cross section ada pada persamaan (4-2)
ŋ
= )
ŋJ +
ŋ(4-2)
dimana
)
ŋadalah matriks variabel independen berukuran 1 x
k,
J
adalah matriks
berukuran
k
x 1 dari parameter yang akan diestimasi, dan
iadalah komponen
error dengan asumsi
E(
)
ŋ ŋ) = 0
. Dengan mensubtitusi
ŋpada persamaan (4-2)
diperoleh persamaan (4-3).
[)
ŋ(
ŋ− )
ŋJ )] = 0
(4-3)
Momen populasi diestimasi dengan momen sampel dengan menggunakan metode
momen, dari persamaan (4-3) diperoleh persamaan (4-4)
ǘ
∑
ŋ ǘ)
ŋ(
ŋ− )
ŋJ )
= 0
(4-4)
dimana
J
estimator, kemudian dengan estimasi OLS (Ordinary Least Squares),
didapat persamaan (4-5).
J = (∑
ŋ ǘ)
ŋ)
ŋ)
ǘ(∑
ŋ ǘ)
ŋ)
(4-5)
Selain itu dapat ditulis dengan persamaan (4-6).
J = (9 9)
ǘ9
(4-6)
Estimator GMM dapat dicari dengan penerapan metode momen, yaitu
dengan kondisi bahwa variabel instrumen
ŋorthogonal terhadap komponen error
yaitu
(
ŋ ŋ) = 0
, dengan mensubtitusi
ŋpada persamaan (4-2) diperoleh
[
ŋ(
ŋ− )
ŋJ )] = 0
(4-7)
Momen populasi diestimasi dengan momen sampel, dari persamaan (4-4)
diperoleh persamaan (4-8).
ǘ
∑
ŋ ǘ ŋ− )
ŋJ
= 0
(4-8)
Jika banyaknya kolom dalam
z
i(banyaknya kondisi momen) lebih besar
dari banyaknya parameter yang akan diestimasi maka persamaan (4-8) tidak ada
solusinya. Untuk mengatasinya dipilih
J
sehingga meminimumkan kuadratik
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
18
dengan W adalah matrik pembobot semidefinit positif. Solusinya dicari dengan
sedikit manipulasi diperoleh persamaan (4-9).
J = (9 ƦǖƦ′9)
ǘ9 ƦǖƦ′
(4-9)
Agar estimator GMM efisien dipilih W= V
-1, dimana
=
o Ʀ
ŋ ŋ= [Ʀ
ŋ ŋ ŋƦ
ŋ]
dengan
Ʀ
ŋ ŋ ŋƦ
ŋ=
ǘ∑ Z
ǘ ŋ ŋ′
Z
dan diperoleh persamaan (4-10).
ǖ = V
ǘ=
ǘ∑ Z
ŋ ŋ′
ǘZ
ǘ(4-10)
4.1.2
Arellano-Bond GMM
Menurut Behr (2003), model data panel dinamik pada persamaan (4-1)
apabila dilakukan pembedaan pertama dapat mengilangkan efek individu
ŋdan
diperoleh
ŋ,.
−
ŋ,. ǘ=
(
ŋ,. ǘ−
ŋ,.) + ()
ŋ,.− )
ŋ,. ǘ)J +
ŋ,.−
ŋ,. ǘ(4-11)
Dari persamaan (4-11) untuk t = 3, persamaan dapat diestimasi menjadi
ŋ,
−
ŋ,=
(
ŋ,−
ŋ,ǘ) + ()
ŋ,− )
ŋ,)J +
ŋ,−
ŋ,dimana terdapat instrumen
ŋ,ǘ,
)
ŋ,′, dan )
ŋ,ǘ′. Dari persamaan (4-11) untuk t = 4,
persamaan dapat diestimasi menjadi
ŋ,w
−
ŋ,=
(
ŋ,−
ŋ,) + ()
ŋ,w− )
ŋ,)J +
ŋ,w−
ŋ,dimana terdapat instrumen
ŋ,ǘ,
ŋ,,
)
ŋ,ǘ′, )
ŋ,′dan )
ŋ,′. Untuk t = T didapat
persamaan (4-12),
ŋ,
−
ŋ, ǘ=
(
ŋ, ǘ−
ŋ,) + ()
ŋ,− )
ŋ, ǘ)J +
ŋ,−
ŋ, ǘ(4-12)
dan terdapat instrumen
ŋ,ǘ,
ŋ,, … . . ,
ŋ,,
, )
ŋ,ǘ′, )
ŋ,′, … . . , )
ŋ,′ ǘ.
Persamaan instrumen dapat ditulis yaitu pada persamaan (4-13),
W¢Fy =W¢FXg +W¢F
e
(4-13)
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
19
9=
ŋ,−
ŋ,ǘ)
ŋ,− )
ŋ, ŋ,−
ŋ,)
ŋ,w− )
ŋ,.
.
.
.
ŋ, ǘ−
ŋ,)
ŋ,− )
ŋ, ǘF = I
NÄF
Tdan
F
T=
− 1
1
0
.
0
0
− 1 1
.
0
.
.
.
.
0
0
0
0 − 1 1
dengan dimensi (T-1)x T.
9 = (
ǘ,9
ŋ)
, g = (
, J
),
W =
(ǖ
ǘ, ǖ , . . . , ǖ )
dan
ǖa =[ a,1, )a,1′ , )a,2′ ] 0 0
0 [ a,1, a,2, )a,1′ , )
a,2 ′ , ) a,3 ′ ] 0 0 0 0 ⋮ ⋮ ⋮
0 0 [ a,1, a,2, . , a, − 2, )a,1′ , )
a,2
′
, . , )a, − 1′ ]
Prosedur estimasi terdiri dari dua tahap, estimator tahap pertama
dibuat
menggunakan matriks kovarian pada persamaan (4-14)
V=W’GW =
∑
ŋ ǘǖ
ŋǖ
ŋ(4-14)
dimana G=( IN Ä GT’ ) dan GT= FTFT’=
2
− 1
0
0
− 1
2
.
0
0
.
.
− 1
0
0
− 1
2
.
Estimator tahap pertama Arellano-Bond GMM yaitu pada persamaan (4-15).
ǘ
= (9′ǖ
ǘǖ′9)
ǘ9′ǖ
ǘǖ′
(4-15)
Tahap kedua estimasi GMM menggunakan residu pada estimasi tahap
pertama untuk mengestimasi matriks kovarian pada persamaan (4-16).
= ∑
ŋ ǘǖ
ŋ′ ′ǖ
ŋ(4-16)
Hasil estimator tahap kedua Arellano-Bond GMM yaitu pada persamaan (4-17).
= (9′ǖ
ǘǖ′9)
ǘ9′ǖ
ǘǖ′
(4-17)
4.2
Contoh Penerapan
4.2.1
Deskripsi data
Data yang digunakan untuk penerapan model data panel dinamik adalah
data saham yang terdiri dari variabel
Volume, Open, High, Low, dan Close. Data
diperoleh
dari data saham harian
BEJ (Bursa Efek Jakarta)
bulan Desember
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
20
2010. Berdasarkan penelitian Muslim (2007), variabel dependen yang digunakan
yaitu Volume (volume harga) dan variabel independennya terdiri dari Open (harga
pembukaan),
High
(harga tertinggi), Low
(harga terendah), dan
Close
(harga
penutupan). Data yang terdiri dari variabel dependen dan variabel independen
masing-masing berbentuk data
cross section terdiri dari 25 indeks harga saham
dari beberapa perusahaan di Indonesia (Lampiran 1), sedangkan banyak
pengulangannya 16 hari dengan 5 hari kerja tiap minggu. Data diawali pada
tanggal 8 Desember 2010 dan diakhiri pada tanggal 30 Desember 2010 (Lampiran
2). Ringkasan data terdiri dari nilai rata-rata, standar deviasi, nilai tertinggi dan
nilai terendah untuk masing-masing variabel dapat dilihat pada Tabel 4.1.
Dari Tabel 4.1, banyak data panel seluruhnya yaitu
= 400
, dengan
banyak data cross section
= 25
dan data time series
= 16
. Mean merupakan
rata-rata dari keseluruhan data. Standar deviasi overall menunjukkan penyebaran
data dari keseluruhan data. Standar deviasi
between
menunjukkan penyebaran
data diantara data
cross section
yaitu diantara 25 perusahaan. Standar deviasi
within menunjukkan penyebaran data didalam data cross section itu sendiri.
Tabel 4.1. Deskripsi Data Panel
Variabel
Mean
Std Dev
Observasi
Open overall
between
within
309.845
153.2707
155.484
15.01598
N = 400
n = 25
T = 16
High overall
between
within
316.505
156.6775
158.947
15.27986
N = 400
n = 25
T = 16
Low overall
between
within
303.6575 150.3494
152.6683
13.17394
N = 400
n = 25
T = 16
Close overall
between
within
310.2025 153.777
156.1789
13.13361
N = 400
n = 25
T = 16
Volume overall
between
within
1190036 5049152
1764208
4743260
N = 400
n = 25
T = 16
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
21
Dari Tabel 4.1 dapat dilihat bahwa nilai standar deviasi overall
untuk
semua variabel cukup besar, hal ini menunjukkan adanya heterogenitas dalam
keseluruhan data panel. Untuk keempat variabel independen yaitu
Open,
High,
Low, dan
Close nilai standar deviasi
between
lebih besar dibanding nilai standar
deviasi overall maupun nilai standar deviasi within. Nilai standar deviasi between
untuk keempat variabel menunjukkan adanya heterogenitas diantara data
cross
section, hal ini mengindikasikan adanya efek individu dalam model data panel.
4.2.2
Hasil estimasi model
Data panel terdiri dari variabel dependen dan variabel independen dengan
= 25
indeks harga saham dari berbagai perusahaan di Indonesia dan dimensi
waktu yaitu
= 16
hari. Variabel dependen dalam model yaitu
Volume
(volume
harga saham) sedangkan variabel independennya yaitu Open (harga pembukaan),
High (harga tertinggi), Low (harga terendah), dan Close (harga penutupan).
Berdasarkan penelitian Muslim (2007), model data panel dinamik yang
diestimasi yaitu
Volumei,t =
rVolumei,t-1 +
b
1Openi,t +
b
2Highi,t +
b
3Lowi,t +
b
4Closei,t
dengan,
Volumei,t : volume harga saham yang diamati pada perusahaan ke-i dan waktu
ke-t
Volumei,t-1
: volume harga saham yang diamati pada perusahaan ke-i dan waktu
ke-t-1
Openi,t
: harga pembukaan yang diamati pada perusahaan ke-i dan waktu ke-t
Highi,t
: harga tertinggi yang diamati pada perusahaan ke-i dan waktu ke-t
Lowi,t
: harga terendah yang diamati pada perusahaan ke-i dan waktu ke-t
Closei,t
: harga penutupan yang diamati pada perusahaan ke-i dan waktu ke-t
dimana dan
J
merupakan parameter yang diestimasi menggunakan
Arelano-Bond GMM dengan bantuan sofware Stata 10.
Hasil yang diperoleh untuk estimasi parameter model menggunakan
Arelano-Bond GMM tahap pertama dengan satu lag dapat ditunjukkan pada Tabel
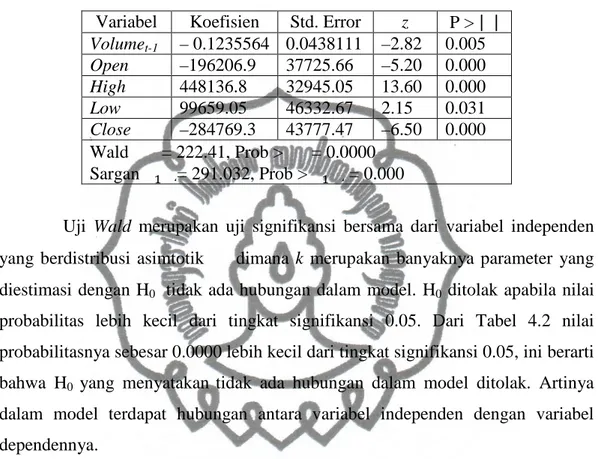
4.2. Dari Tabel 4.2 dapat diperoleh model yaitu,
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
22
Volume
i,t= –0.1235564
Volume
i,t-1– 196206.9
Open
i,t+ 448136.8
High
i,t+
99659.05
Low
i,t– 284769.3 Close
i,tTabel 4.2. Hasil Estimasi Arelano-Bond GMM Tahap Pertama Satu Lag
Variabel
Koefisien
Std. Error
z
P >
| |
Volumet-1
– 0.1235564 0.0438111 –2.82
0.005
Open
–196206.9
37725.66
–5.20
0.000
High
448136.8
32945.05
13.60
0.000
Low
99659.05
46332.67
2.15
0.031
Close
–284769.3
43777.47
–6.50
0.000
Wald
= 222.41, Prob >
= 0.0000
Sargan
ǘ w= 291.032, Prob >
ǘ w= 0.000
Uji
Wald merupakan uji signifikansi bersama dari variabel independen
yang berdistribusi asimtotik
dimana
k
merupakan banyaknya parameter yang
diestimasi dengan H
0tidak ada hubungan dalam model. H
0ditolak apabila nilai
probabilitas lebih kecil dari tingkat signifikansi 0.05. Dari Tabel 4.2 nilai
probabilitasnya sebesar 0.0000 lebih kecil dari tingkat signifikansi 0.05, ini berarti
bahwa H
0yang menyatakan
tidak ada hubungan dalam model ditolak. Artinya
dalam model terdapat hubungan antara variabel independen dengan variabel
dependennya.
Untuk masing-masing parameter, yang signifikan dalam model data
panel dinamik yaitu apabila nilai probabilitasnya lebih kecil dari tingkat
signifikansi 0.05. Dari Tabel 4.2 semua variabel dimasukkan kedalam model.
Nilai standar error untuk lag kesatu variabel
Volume
sebesar 0.0438111, untuk
variabel
Open
sebesar 37725.66, untuk variabel
High
sebesar 32945.05, untuk
variabel Low sebesar 46332.67, dan untuk variabel Close sebesar 43777.47
.
Uji sargan digunakan untuk mengetahui validitas penggunaan variabel
instrumen yang jumlahnya melebihi jumlah parameter yang diestimasi (kondisi
overidentifying restrictions). Dengan hipotesis nol kondisi
overidentifying
restrictions
dalam estimasi model valid. Dari Tabel 4.2 nilai probabilitas 0.00
lebih kecil dari tingkat signifikansi 0.05, jadi H
0ditolak. H
0ditolak berarti bahwa
kondisi overidentifying restrictions dalam estimasi model tidak valid.
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
23
Hasil yang diperoleh untuk estimasi Arelano-Bond GMM tahap kedua
dengan satu lag dapat ditunjukkan pada Tabel 4.3. Dari Tabel 4.3 dapat diperoleh
model yaitu,
Volume
i,t= – 0.1223409
Volume
i,t-1– 195593.2
Open
i,t+ 452977.2
High
i,t+
86794.41 Lowi,t – 269414.9 Closei,t
Tabel 4.3. Hasil Estimasi Arelano-Bond GMM Tahap Kedua Satu Lag
Variabel
Koefisien
Std. Error
Z
P >
| |
Volumet-1
– 0.1223409 0.0019468 – 62.84 0.000
Open
– 195593.2
4672.196
–41.86
0.000
High
452977.2
11287.81
40.13
0.000
Low
86794.41
8621.826
10.07
0.000
Close
– 269414.9
12050.66
– 22.36 0.000
Wald
= 61529.29, Prob >
= 0.0000
Sargan
ǘ w= 20.23767, Prob >
ǘ w= 1.0000
Uji
Wald merupakan uji signifikansi bersama dari variabel independen
yang berdistribusi asimtotik
dimana
k
merupakan banyaknya parameter yang
diestimasi dengan H
0tidak ada hubungan dalam model. H
0ditolak apabila nilai
probabilitas lebih kecil dari tingkat signifikansi 0.05. Dari Tabel 4.3 nilai
probabilitasnya 0.0000 lebih kecil dari tingkat signifikansi 0.05, ini berarti bahwa
H
0yang menyatakan tidak ada hubungan dalam model ditolak. Artinya dalam
model terdapat hubungan antara variabel independen dengan variabel
dependennya.
Untuk masing-masing parameter, yang signifikan dalam model data
panel dinamik yaitu apabila nilai probabilitasnya lebih kecil dari dari tingkat
signifikansi 0.05. Dari Tabel 4.3 semua variabel dimasukkan kedalam model.
Nilai standar error untuk lag kesatu variabel
Volume
sebesar 0.0019468, untuk
variabel
Open
sebesar 4672.196, untuk variabel
High
sebesar 11287.81, untuk
variabel Low sebesar 8621.826, dan untuk variabel Close sebesar 12050.66.
Uji sargan digunakan untuk mengetahui validitas penggunaan variabel
instrumen yang jumlahnya melebihi jumlah parameter yang diestimasi (kondisi
overidentifying restrictions). Dengan hipotesis nol kondisi
overidentifying
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
24
restrictions
dalam estimasi model valid. Dari Tabel 4.3 nilai probabilitas 1.0000
lebih besar dari tingkat signifikansi 0.05, jadi H
0tidak ditolak. H
0tidak ditolak
berarti bahwa kondisi
overidentifying restrictions
dalam estimasi model valid.
Oleh karena itu, validitas model tidak perlu dikhawatirkan karena uji sargan
menunjukkan hasil yang baik.
4.2.3
Pemilihan model
Berdasarkan uji sargan, model yang dapat dipakai yaitu model dengan
estimasi Arellano-Bond GMM dua tahap dengan satu lag
.
Model data panel
dinamik menggunakan estimasi Arellano-Bond GMM tahap kedua dengan satu
lag yaitu,
Volumei,t
= – 0.1223409
Volumei,t-1
– 195593.2
Openi,t + 452977.2
Highi,t
+
86794.41 Lowi,t – 269414.9 Closei,t
Error dari estimasi model data panel dinamik menggunakan
Arellano-Bond GMM tahap kedua dengan satu lag berdistribusi normal, jadi asumsi
kenormalan error dipenuhi (Lampiran 8).
Dari model data panel dinamik menggunakan estimasi Arellano-Bond
GMM tahap kedua dengan satu lag, dapat disimpulkan bahwa lag kesatu variabel
Volume
berpengaruh negatif terhadap variabel
Volume, variabel
Open dan
variabel Close berpengaruh negatif terhadap variabel Volume, sedangkan variabel
High dan variabel Low berpengaruh positif terhadap variabel Volume.
perpustakaan.uns.ac.id
digilib.uns.ac.id
commit to user
25
BAB V
PENUTUP
5.1
Kesimpulan
Berdasarkan hasil dari pembahasan dapat ditarik kesimpulan berikut.
1.
Estimator tahap pertama Arellano-Bond GMM pada model data panel
dinamik yaitu
ǘ