PENERAPAN KNOWLEDGE DISCOVERY IN
DATABASES UNTUK MENGANALISIS
HUBUNGAN PARA PELAKU USAHA DENGAN
KELAYAKAN MENGIKUTI LOMBA PADA
EVENT WANITA WIRAUSAHA PT. GAYA
FAVORIT PRESS
Muhammad Zuhdi C.I.
1, Fathan Qoriba
2, Nellia Anggun P.S.
3,
Eka Miranda
41,2,3,4 School of Information Systems
Jln. K.H Syahdan 9, Kemanggisan, Palmerah, Jakarta Barat
[email protected], [email protected], [email protected] , [email protected]
ABSTRAK
TUJUAN DARI PENELITIAN INI ADALAH untuk menerapkan Knowledge Discovery in Databases
(KDD) untuk menemukan hubungan antara Pelaku Usaha dengan kelayakan mengikuti lomba. Mengklasifikasikan Pelaku Usaha ke dalam kelas yang telah dibentuk dengan menggunakan teknik Classification yaitu Bayesian classifier. METODOLOGI YANG DIGUNAKAN PADA PENELITIAN INI
DI MULAI dengan Analisis kebutuhan dengan teknik Observasi, Studi Pustaka dan Wawancara. Adapun
metodologi proses penerapan yang dipakai adalah Knowledge Discovery in Databases (KDD) (Han dan Kamber (2006)). HASIL PENELITIAN INI ADALAH pengetahuan baru (Knowledge) yang dapat digunakan untuk mendukung proses bisnis yang sedang berjalan dan disertai visualisasi informasi dalam bentuk laporan, grafik ataupun chart pada Event Wanita Wirausaha. KESIMPULAN DARI PENELITIAN
INI ADALAH penerapan KDD ini digunakan oleh staff dari event Wanita Wirausaha untuk kepentingan
eksekutif agar proses analisis terhadap Pelaku Usaha menjadi lebih mudah dan Memberikan tampilan dalam bentuk visual terhadap hasil analisis untuk memudahkan eksekutif dalam memahaminya.
Kata Kunci :
Profil Pelaku Usaha, Klasifikasi, Knowledge Discovery In Databases(KDD)
ABSTRACT
PURPOSE OF THIS RESEARCH IS to implement Knowledge Discovery in Databases (KDD) to find
relationship between Entrepreneur and advisability to follow the race. Classify Entrepreneur into a class that has been established by using the Bayesian classifier Classification techniques. METHODOLOGY USED IN
THIS RESEARCH START with requirement analysis with observation techniques, Library Studies and
Interviews. The methodology used in the application is Knowledge Discovery in Databases (KDD) (Han and Kamber (2006)). THESE RESULTS ARE new knowledge (Knowledge) which can be used to support ongoing business processes and information along with visualization in the form of reports, graphs or charts on Event Wanita Wirausaha. CONCLUSION OF THIS RESEARCH IS KDD implementation is used by the staff of the event Wanita Wirausaha for the benefit of the executive process analysis requirement of business actors become easier and provide a visual display in the form of the results of the analysis to enable executives to understand.
PENDAHULUAN
Dewasa ini setiap perusahaan-perusahaan besar di Indonesia ataupun di dunia telah menggunakan teknologi informasi, komputer serta telekomunikasi untuk mendukung bisnis perusahaannya. Dengan begitu pesatnya perkembangan pasar serta banyaknya data yang ada di dalam perusahaan, mereka harus bisa mengolah data tersebut menjadi suatu informasi yang bermanfaat atau data tersebut hanya akan menjadi sesuatu yang tidak berguna.
Hal ini mendorong kebutuhan perusahaan untuk dapat menganalisis data kemudian mengekstrak pengetahuan dan wawasan melalui analisis data dalam jumlah besar, serta dapat menyajikannya dalam bentuk
visual yang berguna bagi pengguna dan pada akhirnya membantu pengambilan keputusan yang tepat agar
perusahaan dapat bersaing dengan pesaing mereka.
PT. Gaya Favorit merupakan perusahaan yang khususnya bergerak dalam bidang media cetak, PT. Gaya Favorit pertama kali terbentuk pada tahun 1972 sebagai majalah perempuan pertama di Indonesia. Perusahaan ini juga bergerak di bidang-bidang lain selain media cetak seperti Internet, Brand activation and
The Communities serta memiliki divisi-divisi yang terdiri atas divisi Creative boutique, Event Organizer, Radio station, Publisihng House dan Online publication. PT Gaya Favorit saat ini telah menaungi 14 (empat
belas) majalah, yaitu Gadis, Dewi, Ayah Bunda, Parenting, Cita Cinta, Fit, Cleo, Men’s Health, Femina,
Reader’s Digest, Primarasa, Estetica, Best Life, dan Pesona.
Penelitian ini hanya akan membahas salah satu event yang dimiliki oleh PT.Gaya Favorit yaitu Wanita Wirausaha, di mana event ini adalah salah satu event yang bergerak di bidang jasa. Mereka mendapatkan keuntungan dari pengadaan seminar-seminar dan workshop dengan tujuan memberikan arahan dalam membangun dan mengembangkan usaha, serta mengadakan lomba mengenai wirausaha dimana pelaku usaha yang sudah mendaftar lomba akan dipantau dan dibantu dalam mengembangkan usahanya.
Penelitian ini akan melakukan analisis terhadap data untuk menemukan sebuah pengetahuan baru (Knowledge) dengan menggunakan tahapan Knowledge Discovery in Databases (KDD) dan teknik data
mining yaitu Classfication. Teknik Classification bekerja dengan mengelompokkan data berdasarkan data training dan nilai atribut klasifikasi. Aturan pengelompokan tersebut akan digunakan untuk klasifikasi data
baru ke dalam kelompok yang ada. (Mewati Ayub, 2007)
Classification memprediksi kelas dari sebuah hal dari sekumpulan atribut yang mendeskripsikan hal
tersebut, dimana proses prediksi itu dilakukan berdasarkan dengan database yang telah memiliki label kelas terlebih dahulu. Classifier learining adalah sebuah proses seleksi yang memiliki tingkat akurasi yang tinggi. Tehnik Naive Bayes adalah salah satu dari tehnik Classification yang sederhana namun dapat memberikan tingkat akurasi yang sangat baik. (Langseth dan Nielsen, 2006)
Sebagai contoh, jika mereka ingin menganalisis data Pelaku Usaha apakah Pelaku Usaha tersebut masuk kedalam kategori Layak dalam artian berpotensi layak untuk mengikuti lomba (sesuai dengan kriteria lomba), Dipertimbangkan (bisa sesuai, bisa tidak) atau Tidak Layak (tidak sesuai dengan kriteria lomba).
Penelitian ini akan mengklasifikasikan Pelaku Usaha menjadi tiga kelas, yaitu kelas Layak, Dipertimbangkan dan Tidak Layak berdasarkan atribut-atribut tertentu yaitu Range_Usia, Pendidikan_terakhir, Pekerjaan, Jenis_Usaha1, Lama_usaha, Jenis_Usaha2, Skala_Usaha, Jumlah_Tenaga_Kerja dan Pemasaran_online. Hasil pengklasifikasian ini dapat digunakan untuk mendukung dan membantu proses bisnis yang sedang berjalan di dalam event Wanita Wirausaha.
METODOLOGI PENELITIAN
Metodologi penelitian yang digunakan dalam skripsi ini terdiri atas : 1. Analisis kebutuhan
Pada tahap awal akan dilakukan analisis terhadap kebutuhan, permasalahan yang muncul dalam perusahaan, serta kebutuhan perusahaan, dilakukan dengan teknik :
a. Observasi
Mengadakan observasi terhadap sumber data event Wanita Wirausaha. Hal ini dilakukan agar penelitian ini sesuai dengan keadaan sebenarnya yang sedang terjadi di perusahaan. Hasil observasi kemudian akan digunakan sebagai awal dalam menerapkan tahapan
Knowledge Discovery.
b. Studi Pustaka
Mencari dan mengumpulkan materi-materi dan literatur-literatur yang berkaitan dengan penyusunan skripsi, seperti informasi dari buku-buku, dan penelitian yang terkait dengan topik skripsi ini. Materi-materi tersebut digunakan sebagai bahan pembelajaran dan referensi untuk menerapkan tahapan Knowledge Discovery.
c. Wawancara
Berdiskusi langsung dengan pihak terkait dalam perusahaan untuk mendapatkan informasi yang akan dicari.
2. Penerapan Proses Knowledge Discovery in Databases
Penerapan proses Knowledge Discovery in databases (KDD) ini menggunakan langkah-langkah menurut Han dan Kamber (2006, p7), yaitu meliputi:
a. Data cleaning b. Data integration c. Data selection d. Data transformation e. Data mining f. Pattern evaluation g. Knowledge presentation 3. Evaluasi
Pada tahap ini akan dilakukan evaluasi terhadap salah satu dari tahapan knowledge discovery yaitu
data mining dengan menggunakan metode Classifier Accuracy Measures untuk mengetahui tingkat
akurasi dari klasifikasi yang dilakukan.
HASIL DAN PEMBAHASAN
Identifikasi Kebutuhan Informasi
Berdasarkan hasil interview, studi lapangan yang telah kami lakukan maka telah diidentifikasikan kebutuhan yang dibutuhkan untuk menerapkan knowledge discovery ini yaitu terdiri atas:
Data Yang Digunakan
Data yang digunakan pada penelitian ini berasal dari satu sumber yaitu Pelaku Usaha. Dimana data Pelaku Usaha adalah data yang didata pertama kali saat ingin mengikuti lomba setelah mengikuti seminar yang diselenggarakan oleh Wanita Wirausaha (WanWir). Data yang dicatat adalah data pribadi.
Gambar 1. Training Data
Gambar 1 diatas merupakan contoh training data yang digunakan dalam penerapan KDD pada tahap Data Mining. Berikut penjelasan atas atribut yang akan dianalisis:
Identifikasi atribut yang akan di analisis
Adapun atribut dan keterkaitan antar atribut yang akan dianalisis pada proses mining meliputi: 1. Hubungan kelayakan mengikuti lomba dengan Usia
2. Hubungan kelayakan mengikuti lomba dengan pendidikan 3. Hubungan kelayakan mengikuti lomba dengan pekerjaan 4. Hubungan kelayakan peserta lomba dengan jenis_usaha1 5. Hubungan kelayakan peserta lomba dengan jenis_usaha2 6. Hubungan kelayakan peserta lomba dengan lama_usaha 7. Hubungan kelayakan peserta lomba dengan skala_usaha
8. Hubungan kelayakan peserta lomba dengan jumlah_tenaga_kerja
9.
Hubungan kelayakan peserta lomba dengan pemasaran_onlinePenerapan Proses Knowledge Discovery In Databases
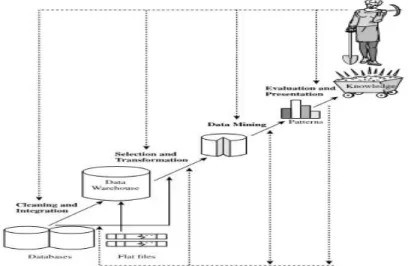
Penerapan Proses Knowledge Discovery ini melalui tahap – tahap Knowledge Discovery in
Databases (KDD), yaitu:
Gambar 2 diatas merupakan tahapan dari KDD, dimana tahapan tersebut digunakan dalam penerapan Knowledge Discovery atas perusahaan. Tahapan – tahapan tersebut adalah Data Cleaning, Data
Integration, Data Selection, Data Transformation, Data Mining, Pattern Evaluation, Knowledge Presentation.
Data Cleaning & Integration
Langkah awal dalam tahapan Knowledge Discovery in Databases (KDD) yaitu melalui tahap data
cleaning. Proses yang dilakukan adalah dengan melakukan Penghapusan dari data noise dan “null”,
Membuang data duplikasi dan Memperbaiki kesalahan pada data seperti kesalahan penulisan. Tahap
integration sudah dilakukan pada sumber data yang telah diperoleh, tetapi tools ini juga dapat
mengintegrasikan data yang baru dimasukkan dengan data yang sudah ada sebelumnya.
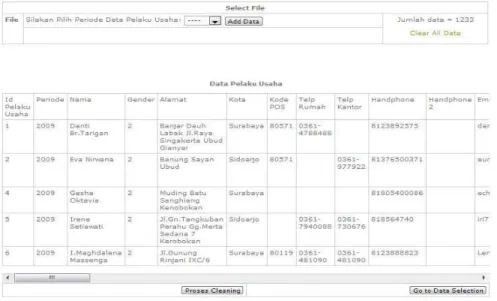
Tujuan dari data cleaning adalah agar data yang akan di proses dalam data mining merupakan data yang bersih dan berkualitas.Pada penulisan ini data yang akan di gunakan dalam proses cleaning bersumber dari Tabel Pelaku Usaha. Data tersebut masih belum bersih sehingga di lakukan proses data cleaning..
Gambar 3. Data Cleaning
Pada gambar 3 diatas dapat dilihat bahwa setelah tombol Proses cleaning ditekan maka jika ada salah satu nilai dari sembilan atribut (Range_Usia, Pendidikan, Pekerjaan, Jenis_usaha1, Lama_Usaha, Jenis_Usaha2, Skala usaha, Jumlah_tenaga_kerja serta Pemasaran_online) pada satu record berisi “null” maka record tersebut akan langsung dihapus karena mengandung data yang dianggap dapat menganggu proses mining. Selanjutnya setelah tahap cleaning selesai user dapat menekan tombol “Go to Data Selection” dimana tombol tersebut untuk melanjutkan ketahapan selanjutnya yaitu Data Selection.
Data Selection
Berdasarkan penjelasan yang telah diterangkan pada sub atribut yang akan dianalisis dan setelah melakukan tahap Cleaning & Integration, maka pada tahap ini atribut yang akan di gunakan dalam proses data mining meliputi :
1. Atribut Id Pelaku Usaha sebagai primary key.
2. Atribut Kota digunakan untuk pemilihan data proses mining berdasarkan Kota asal Pelaku Usaha tersebut.
3. Atribut Usia digunakan untuk proses mining guna mengetahui hubungan antara kelayakan untuk mengikuti lomba dengan umur pelaku usaha yang bersangkutan.
4. Atribut Pendidikan_Terakhir digunakan untuk proses mining guna mengetahui hubungan antara kelayakan untuk mengikuti lomba dengan pendidikan terakhir yang telah dijalani oleh pelaku usaha yang bersangkutan
5. Atribut Pekerjaan digunakan untuk proses mining guna mengetahui hubungan antara kelayakan untuk mengikuti lomba dengan pekerjaan utama yang sedang di jalani oleh pelaku usaha yang bersangkutan.
6. Atribut Jenis_Usaha1 digunakan untuk proses mining guna mengetahui hubungan antara kelayakan untuk mengikuti lomba dengan jenis usaha yang sedang dijalani oleh pelaku usaha yang bersangkutan, apakah usaha tersebut adalah usaha utama, sampingan ataupun musiman. 7. Atribut Lama_Usaha digunakan untuk proses mining guna mengetahui hubungan antara
kelayakan untuk mengikuti lomba dengan Lama Usaha yang telah dijalani oleh pelaku usaha yang bersangkutan.
8. Atribut Jenis_Usaha2 digunakan untuk proses mining guna mengetahui hubungan antara kelayakan untuk mengikuti lomba dengan bidang usaha yang sedang dijalani oleh pelaku usaha yang bersangkutan, apakah usaha tersebut termasuk dalam bidang Jasa, Perdagangan, Produsen ataupun Supplier.
9. Atribut Skala_Usaha digunakan untuk proses mining guna mengetahui hubungan antara kelayakan untuk mengikuti lomba dengan Skala Usaha dari bisnis yang telah dijalani oleh pelaku usaha yang bersangkutan.
10. Atribut Jumlah_Tenaga_Kerja digunakan untuk proses mining guna mengetahui hubungan antara kelayakan untuk mengikuti lomba dengan jumlah tenaga kerja yang dimiliki oleh pelaku usaha yang bersangkutan.
11. Atribut Pemasaran_Online digunakan untuk proses mining guna mengetahui hubungan antara kelayakan untuk mengikuti lomba dengan apakah pelaku usaha telah melakukan pemasaran online ataupun tidak.
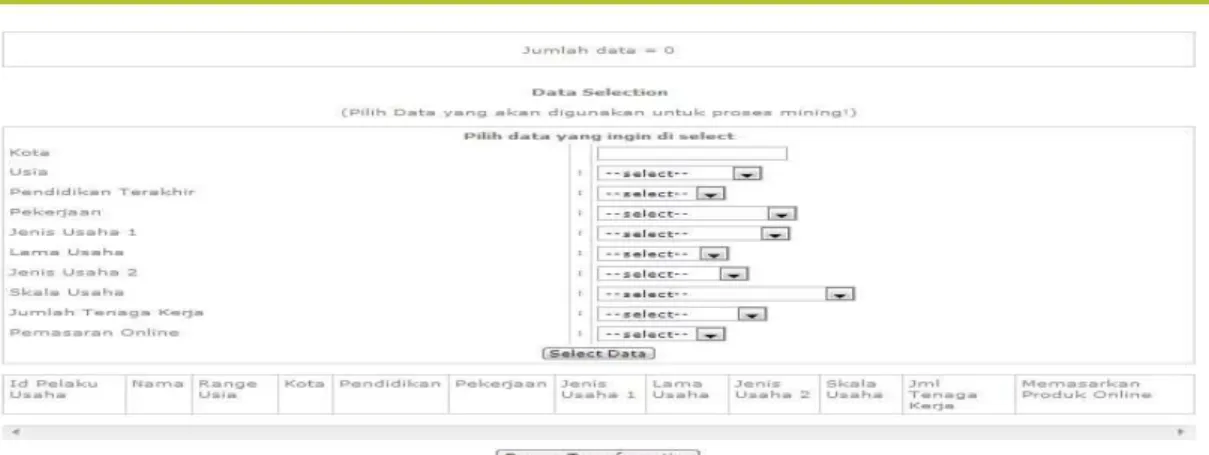
Berikut ini adalah proses pemilihan data yang dilakukan dapat dilihat pada gambar:
Gambar 4 diatas menjelaskan proses selanjutnya setelah user menekan tombol “Select Data” maka akan tampil keseluruhan data berdasarkan atribut yang telah mereka pilih, kemudian user bisa melanjutkan ke tahap berikutnya yaitu data transformation dengan menekan tombol “Proses Transformation”. Mereka juga dapat mengulang tahapan data selection dengan menekan tombol “Restart Selection” untuk memilih kembali atribut apa saja yang mereka ingin gunakan pada proses mining.
Data Transformation
Transformasi data merupakan proses mentransformasi data ke dalam bentuk yang dibutuhkan untuk proses data mining selanjutnya. Jadi pada tahap ini dilakukan beberapa perubahan pada atribut – atribut yang bentuknya masih belum sesuai untuk melakukan penggalian.
Pada awalnya sumber data masih berbentuk numerik yaitu berupa “1,2,3,4,5” kemudian akan dirubah sesuai dengan bentuk berdasarkan nilai atribut dan tipe data yang sesuai untuk proses mining.
Gambar 5. Data Transformation
Gambar 5 diatas menjelaskan data yang telah dipilih pada data selection tetapi nilai dari setiap atribut nya masih berupa numerik, dan akan di transformasi ke dalam bentuk kategorikal. Hasil dari proses transformasi dapat dilihat pada gambar 6.
Data Mining
Tahap data mining merupakan tahap dimana proses mencari pola atau informasi menarik.Teknik yang digunakan adalah Naïve Bayesian Classification dengan menghitung probabilitas keanggotaan kelas.
Gambar diatas merupakan tampilan dari proses Data Mining, dimana telah digambarkan formula yang akan digunakan dalam proses mining.
Dapat disimpulkan proses dari Data Mining Bayesian Classifier yaitu:
1. Mempersiapkan nilai estimasi dari setiap kelas (Layak, Dipertimbangkan dan Tidak Layak) yang dibentuk dengan nilai sembilan atribut penentunya.
2. Menghitung nilai yang diperoleh setiap masing – masing atribut yang telah dipilih dan kelas – kelasnya dari proses estimasi yang telah dilakukan dengan menggunakan formula bayes.
3. Membandingkan nilai hasil perhitungan dari setiap kelasnya, baik Layak, Dipertimbangkan dan Tidak Layak. Kelas yang memiliki hasil perhitungan yang paling tinggi maka akan ditentukan menjadi Kelas dari setiap Record nya.
Pattern Evaluation
Setelah melakukan proses data mining, tahap selanjutnya yaitu pattern evaluation. Pada proses ini dilakukan evaluasi terhadap hasil proses mining yang telah dilakukan.
Pada tools yang dipakai, sumber data diambil dari entitas Pelaku usaha. Pengambilan data tersebut bertujuan untuk mengetahui profil calon peserta lomba dan kelas apa yang cocok bagi mereka. Atribut yang digunakan dalam seleksi berdasarkan keterkaitan dengan analisa yang dilakukan. Atribut yang di gunakan adalah Range_usia, jenis_usaha1, lama_usaha, skala_usaha, pendidikan, pekerjaan, jenis_usaha2, jumlah_tenaga_kerja, pemasaran_online. Proses data mining ini menggunakan teknik naïve bayes classsifikation. Dimana hasil output dari proses tersebut adalah tiga kelas yaitu ‘Layak’, ‘Dipertimbangkan’, ‘Tidak layak’.
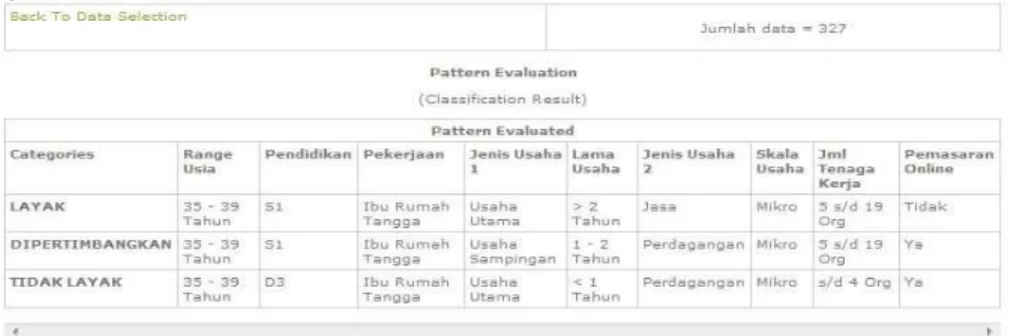
Berikut ini adalah hasil evaluasi dari proses data mining berupa pola-pola khas dari para calon peserta lomba yaitu berupa profil dimana hal ini terkait dengan analisis atribut yang dilakukan berdasarkan kelas yang telah terbentuk.
Gambar 7. Pattern Evaluation
Gambar 7 diatas adalah contoh pola yang telah ditemukan dari tahap pattern evaluation.
Knowledge Presentation
Setelah semua tahap proses mining di lakukan,tahap terakhir dalam KDD adalah tahap Knowledge presentation. Tahap ini bertujuan untuk mempresentasikan tujuan dan memvisualisasikan hasil yang telah di hasilkan dalam proses mining. Knowledge presentation ini akan di gunakan untuk menyajikan informasi – informasi yang telah di hasilkan pada proses mining sebelum akan di gunakan oleh user. Knowledge presentation ini akan di sajikan dalam bentuk chart. Berikut adalah contoh chart yang merepresentasikan hubungan kelayakan mengikuti lomba dengan atribut yang dianalisis yaitu atribut pendidikan terakhir berdasarkan pola yang telah ditemukan terdapat pada gambar berikut:
Gambar 8. Knowledge Presentation
Gambar 8 menjelaskan pola ataupun hasil akhir dari tahapan KDD yang disajikan melalui tampilan visual berupa chart batang.
Evaluasi Performasi Metode Klasifikasi
Evaluasi yang dilakukan adalah mengukur tingkat akurasi tools dalam melakukan prediksi. Evaluasi akan menggunakan metode Classifier Accuracy Measurables.
Perhitungan Classifier Accuracy Measurables
Jumlah Sumber data sebelum Cleaning: 1.570 Record Jumlah sumber data sesudah Cleaning: 1.233 Record
Dimana sumber data tersebut akan dibagi dengan ketentuan 2/3 dari sumber data menjadi training data, dan 1/3 dari sumber data akan menjadi testing data.
Training Data: 1.233 x (2/3) = 822 Record Testing Data: 1.233 x (1/3) = 411 Record
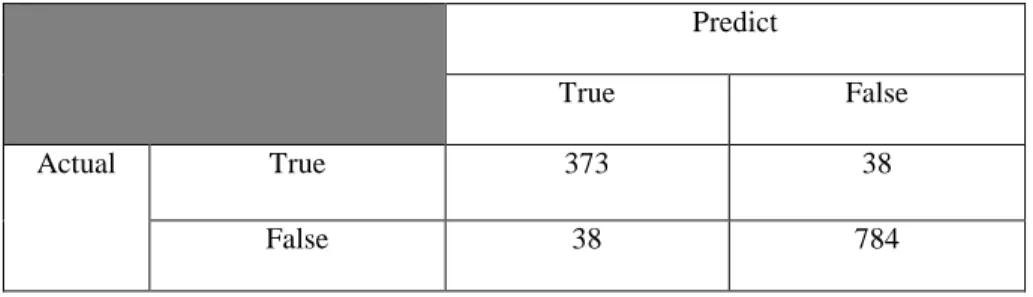
Confusion Matrix
Tabel 1. Confusion Matrix
Predict True False Actual True 373 38 False 38 784 T_pos = 373 Record F_pos = 38 Record T_neg = 784 Record F_neg = 38 Record Sensivity (Total) = = =0.90 Specificity (Total) = = = 0.95 Precision (Total) = = = 0.90
Accuracy (Total) = sensitivity + specifity = 0.90 + 0.95 = 0.94 x = 94 %
Kesimpulan Evaluasi Classifier Accuracy Measurables
Berdasarkan evaluasi perhitungan Classifier Accuracy Measureables diperoleh bahwa keakuratan dari prediksi yang telah dilakukan dengan melalui tahapan Knowledge Discovery in Databases (KDD) yaitu sebesar 94%.
Adapun faktor – faktor yang menentukan kualitas dari prediksinya adalah nilai True_positive (T_pos): 373, False_positive (F_pos): 38, True_negative (T_neg): 784, dan False_negative (F_neg): 38, dengan ketentuan semakin besar nilai T_pos dan T_neg, serta semakin kecil nilai F_pos dan F_neg, maka semakin besar nilai akurasi yang dihasilkan.
SIMPULAN DAN SARAN
Setelah Menganalisis dan Menerapkan tahapan KDD (Knowledge Discovery in Databases) pada PT. Gaya Favorit event Wanita Wirausaha. Maka dapat ditarik beberapa kesimpulan, yaitu:
1) Penerapan KDD ini digunakan oleh staff dari event Wanita Wirausaha untuk kepentingan eksekutif agar proses analisis terhadap Pelaku Usaha menjadi lebih mudah karena alat bantu analisis ini dapat mengekstrak data dalam jumlah yang besar serta mengklasifikasikan ke dalam kelas yang terbentuk bagi para calon peserta lomba (Pelaku Usaha).
2) Adapun atribut yang digunakan untuk pembentukan kelas dan mengetahui profil calon Peserta Lomba pada teknik ini terdiri atas empat atribut utama yaitu Range usia, Lama usaha, Jenis usaha 1 serta Skala Usaha dan lima atribut pendukung yaitu Pendidikan Terakhir, Pekerjaan, Jenis usaha 2, Jumlah Tenaga Kerja serta Pemasaran Online.
3) Hasil Evaluasi Performansi Metode Klasifikasi dengan menggunakan metode Classifier Accuracy Measurables menunjukan bahwa keakuratan dari prediksi yang telah dilakukan sebesar 94%.
4) Alat bantu analisis ini memberikan visualisasi informasi terhadap hasil analisis dalam bentuk laporan, grafik ataupun chart dan memberikan manfaat bagi eksekutif event Wanita Wirausaha di mana output
yang dihasilkan dapat menjadi bahan pertimbangan untuk penentuan tema seminar serta workshop yang akan diadakan oleh Femina Group.
Dari penerapan KDD (Knowledge Discovery in Databases) yang telah dilakukan, ada beberapa saran yang dapat dijadikan masukan agar penerapan ini dapat diimplementasikan dan berjalan dengan baik, yaitu sebagai berikut:
1) Memperluas ruang lingkup data mining sehingga dapat menghasilkan informasi yang lebih dapat dipercaya.
2) Menambahkan fitur notification pada alat bantu analisis sehingga pengguna dapat mengetahui data mana saja yang sudah serta akan di input.
3) Memberikan hak akses yang berbeda bagi pengguna yang akan mengakses alat bantu analisis ini sehingga masing-masing bagian memiliki tugasnya sendiri dalam alat bantu analisis ini.
4) Untuk menambah tingkat akurasi alat bantu analisis ini sebaiknya jumlah data yang digunakan ditambah atau lebih banyak dari sebelumnya sehingga dapat menghasilkan tingkat akurasi yang lebih baik dari sebelumnya.
REFERENSI
Ayub, Mewati. (2007). Proses Data Mining dalam Sistem Pembelajaran Computer. Sistem Informasi. Vol. 2 (1) : 21-30.
Jiawei, Han., Micheline, Kamber.(2006). Data Mining: Concepts and Techniques. Amsterdam: Morgan Kaufmann Publishers
Langseth H, Nielsen Thomas D.(2006). Classification using Hierarchical Naive Bayes models. Mach Learn(online).Vol 63 : 135 – 159. Di akses 6 April 2013 dari http://proquest.com
RIWAYAT PENULIS
Muhammad Zuhdi Cholis Ismail, lahir di kota DKI Jakarta pada 31-Oktober-1992. Penulis menamatkan pendidikan S1 di Universitas Bina Nusantara dalam bidang Sistem Informasi pada tahun 2013.
Fathan Qoriba, lahir di kota DKI Jakarta pada 25-September-1991. Penulis menamatkan pendidikan S1 di Universitas Bina Nusantara dalam bidang Sistem Informasi pada tahun 2013.
Nellia Anggun Puspita Sari, lahir di kota DKI Jakarta pada 26-Novermber-1990. Penulis menamatkan pendidikan S1 di Universitas Bina Nusantara dalam bidang Sistem Informasi pada tahun 2013.