SKRIPSI
KLASIFIKASI PENGGUNAAN PROTOKOL
KOMUNIKASI PADA TRAFIK JARINGAN
MENGGUNAKAN ALGORITMA
NAÏVE BAYES
I MADE BAYU DIBAWAN
JURUSAN TEKNIK ELEKTRO
FAKULTAS TEKNIK UNIVERSITAS UDAYANA
JIMBARAN-BALI
▸ Baca selengkapnya: berikut ini merupakan protokol penunjang jaringan voip, kecuali.
(2)i
SKRIPSI
KLASIFIKASI PENGGUNAAN PROTOKOL
KOMUNIKASI PADA TRAFIK JARINGAN
MENGGUNAKAN ALGORITMA
NAÏVE BAYES
I MADE BAYU DIBAWAN
(1104405023)
JURUSAN TEKNIK ELEKTRO
FAKULTAS TEKNIK UNIVERSITAS UDAYANA
JIMBARAN-BALI
ii
KLASIFIKASI PENGGUNAAN PROTOKOL KOMUNIKASI PADA
TRAFIK JARINGAN MENGGUNAKAN ALGORITMANAÏVE BAYES
Skripsi Ini Diajukan Sebagai Persyaratan Memperoleh Gelar Sarjana S1 (Starata1) Pada Jurusan Teknik Elektro Fakultas Teknik Universitas Udayana
I MADE BAYU DIBAWAN
NIM 1104405023
JURUSAN TEKNIK ELEKTRO DAN KOMPUTER
FAKULTAS TEKNIK UNIVERSITAS UDAYANA
BUKIT JIMBARAN
i
LEMBAR PERNYATAAN ORISINALITAS
Tugas Akhir / Skripsi ini adalah hasil karya saya sendiri, dan semua sumber baik yang dikutip maupun dirujuk telah saya nyatakan dengan benar.
Nama : I Made Bayu Dibawan NIM : 1104405023
TandaTangan :
i
KATA PENGANTAR
Om Swastyastu puji syukur kehadapan Ida SangHyang Widhi Wasa/Tuhan Yang Maha Esa, karena atas segala limpahan berkat dan Rahmat-Nya, sehingga proposal yang berjudul ʻʻKLASIFIKASI PENGGUNAAN PROTOKOL
KOMUNIKASI PADA TRAFIK JARINGAN MENGGUNAKAN
ALGORITMA NAÏVE BAYES” ini dapat diselesaikan dengan tepat waktu. Tugas akhir ini disusun untuk memenuhi salah satu syarat dalam menyelesaikan pendidikan sarjana strata satu (S1) pada Jurusan Teknik Elektro Fakultas Teknik Universitas Udayana.
Terwujudnya tugas akhir ini tidak lepas dari bantuan berbagai pihak yang telah mendorong dan membimbing penulis, baik tenaga, ide-ide, maupun pemikiran. Oleh karena itu dalam kesempatan ini penulis ingin mengucapkan terimakasih yang sebesar-besarnya kepada :.
1. Bapak Prof. Ir. Ngakan Putu Gede Suardana, MT.,.Ph.selaku Dekan Fakultas Teknik Universitas Udayana.
2. Bapak Wayan Gede Ariastina, ST.M.Engsc.Ph.D selaku Ketua Jurusan Teknik Elektro Fakultas Teknik Universitas Udayana.
3. BapakDr. I Made Oka Widyantara, ST., MT.selaku dosen pembimbing I yang telah banyak memberikan arahan, waktu, semangat serta saran-saran selama penyusunan tugas akhir.
4. Ibu Ir.Linawati. MEngSc.PhD. selaku dosen pembingbing II yang telah banyak memberikan arahan, waktu, semangat, serta saran-saran selama penyusunan tugas akhir.
5. Bapak Ir. I Made Mataram, M.Erg.,MT selaku pembimbing akademik yang telah membimbing dari semester 1, memberikan semangat dan dukungan dalam menjalani perkuliahan.
ii
7. Bapak dan Ibu beserta keluarga besar atas motivasi, dukungan, serta saran-saran yang selalu diberikan.
8. Rekan - rekan mahasiswa angkatan 2011 Fakultas Teknik Elektro Universitas Udayana.
Penulis menyadari bahwa tugas akhir ini masih jauh dari kesempurnaan, oleh karena itu kritik saran yang membangun dari berbagai pihak sangat penulis harapkan demi perbaikan-perbaikan ke depan.
Akhir kata, Saya mohon maaf yang sebesar-besarnya apabila dalam penyusunan tugas akhir ini terdapat banyak kesalahan. Semoga tugas akhir ini dapat bermanfaat khususnya bagi penulis tugas akhir ini dan pada umumnya bagi para pembaca.
i ABSTRAK
Penggunaan model komunikasi berbasiskan teknologi jaringan komputer merupakan teknologi yang sudah banyak digunakan. Model komunikasi pada jaringan komputer, menggunakan aturan komunikasi yang sesuai dengan standar tipe komunikasi yang sering dikenal dengan nama network protocol. Penggunaan
network protocol dalam komunikasi di jaringan komputer, terkadang menuntut adanya prioritas komunikasi yang sering dikenal denganQoS(Quality of Service). Dasar pemberian prioritas (QoS) adalah dengan penganalisaan terhadap Trafik Jaringan.. Pada penelitian ini melakukan klasifikasi terhadap data capture Trafik Jaringan yang di olah menggunakan Algoritma Naïve Bayes. Tools yang digunakan untuk capture Trafik Jaringan yaitu aplikasi wireshark. Dari hasil observasi terhadap dataset jaringan melalui proses perhitungan menggunakan
Algoritma Naïve Bayes memiliki tingkat keakuratan yang sangat tinggi. Hal ini dibuktikan dengan hasil perhitungan yang mencapai nilai 92,34 %. Hasil proses klasifikasi akan dijadikan sebagai acuan dalam penentuan pemberian Prioritas terhadapNetwork protocolyang sering digunakan dalam komunikasi jaringan.
i
ABSTRACT
Usage-based communication model of computer network technology is a technology that is already widely used. Model communications on a computer network, using the rules of communication in accordance with the standard type of communication that is often known as the network protocol. Use of network communication protocol in computer networks, sometimes requires the priority communication commonly known as QoS (Quality of Service). Basic prioritization (QoS) is by analyzing the network traffic. In this study the classification of the data capture network traffic that though the use of Naïve Bayes algorithm. Tools used to capture network traffic that wireshark application. From the observation of the network dataset through the calculation process using Naïve Bayes algorithm has a very high level of accuracy. This is evidenced by the results of calculations which reached 92.34%. The results of the classification process will be used as a reference in determining giving priority to the Network protocol that is often used in network communications.
i DAFTAR ISI
Halaman
JUDUL. ... i
LEMBAR PERSYARATAN GELAR... ii
LEMBAR PERNYATAAN ORISINALITAS ... iii
LEMBAR PENGESAHAN ... iv 1.1 Latar Belakang ... 1
1.2 Rumusan Masalah ... 4
1.3 Tujuan Penulisan ... 4
1.4 Manfaat Penulisan ... 4
1.5 Ruang Lingkup Dan Batasasn Masalah ... 5
1.6 Sistematika Penulisan ... 5
BAB II TINJAUAN PUSTAKA 2.1 Tinjauan Mutakhir... ... 7
2.2 Tinjauan Pustaka ... 10
2.2.1 Data Mining ... 10
2.2.2 Cross Industry Standard Process for Data Mining... 14
2.2.3 Klasifikasi... 17
2.2.4 Protokol Jaringan………... 17
2.2.5 AlgoritmaNaïve Bayes ... 21
2.2.6 Pengukuran Kinerja Klasifikasi ... 24
ii
2.2.8 Wireshark ... 26
2.2.9 Pentaho Data Integration (PDI) ... 27
BAB III METODE PENELITIAN 3.1 Lokasi dan Waktu Penelitian ... 29
3.2 Sumber dan Jenis Data Penelitian... 29
3.2.1 Sumber Data... 29
3.2.2 Metode Pengumpulan Data... 30
3.2.3 Jenis Data Penelitian ... 30
3.3 Alat Penelitian... 30
3.4 Tahapan Penelitian... 31
3.4.1 Pengembangan Metode Data Mining... 31
3.4.1.1 Pemahaman Bisnis ... 32
3.4.1.2 Pemahaman Data ... 33
3.4.1.3 Pengolahan Data ... 35
3.4.1.4 Pemodelan... 36
3.4.1.5 Implementasi denganMATLAB ... 37
3.4.1.6 Implementasi Model Algoritma padaMATLAB ... 41
3.5 Metode Analisis ... 42
BAB IV HASIL DAN PEMBAHASAN 4.1 Pengolahan Data Mentah ... 44
4.1.1 Transformasi Data ... 45
4.2 Perhitungan Data Mining ... 47
4.2.1 Perhitungan Akurasi... 49
4.3 Evaluasi... 50
4.3.1 Hasil Pengukuran Akurasi ... 50
4.3.2 Data Hasil Klasifikasi ... 52
BAB V KESIMPULAN DAN SARAN 5.1 Simpulan ... 55
i
DAFTAR TABEL
Halaman
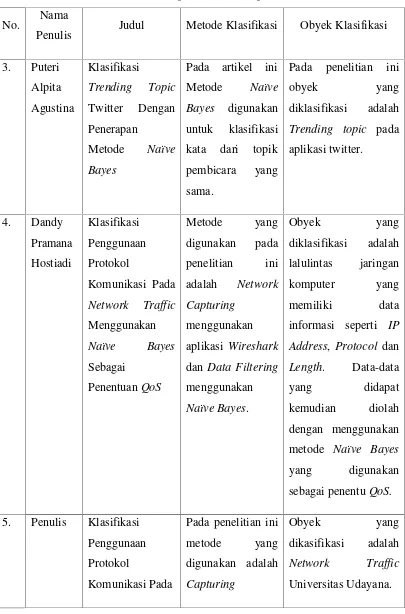
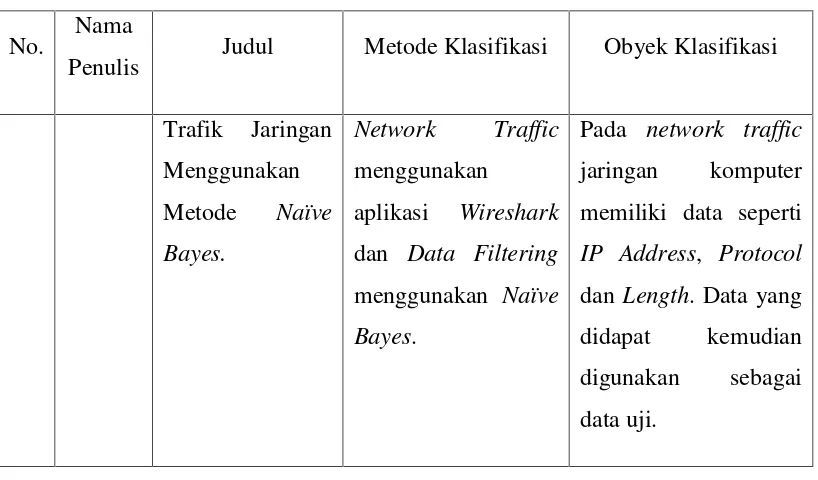
Tabel 2.1Tinjauan mutakhir (state of the art)... 5
Tabel 2.2Tinjauan mutakhir (state of the art)Lanjutan... 9
Tabel 2.3Tinjauan mutakhir (state of the art)Lanjutan ... 10
Tabel 2.4Perbedaan data mining dengan yang bukan data mining. ... 8
Tabel 2.5Confusion Matriks... 24
Tabel 3.1Tabel Contoh Kelas Label (dandy, 2013) ... 27
Tabel 3.1Parameter Akurasi ... 40
Tabel 3.2Model label kelas ... 43
Tabel 4.1Model label kelas ... 46
Tabel 4.2Data latih yang telah dilakukan inisialisasi ... 47
Tabel 4.3Perhitungan manual... 48
Tabel 4.4Confusion matrik ... 49
i
DAFTAR GAMBAR
Halaman
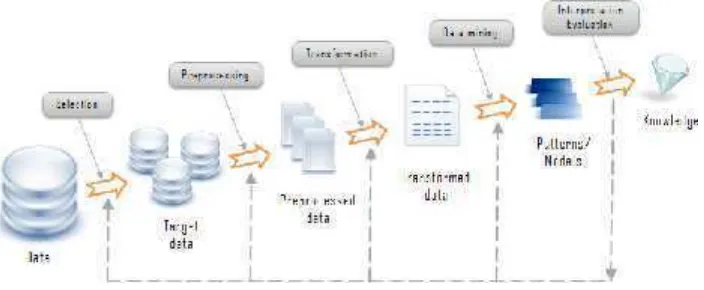
Gambar 2.1Gambar Tahapan Data Mining ... 9
Gambar 2.2CRISP–DM... 15
Gambar 2.3Topologi jaringan Universitas Udayana ... 26
Gambar 2.4Gambar aplikasi wireshark... 18
Gambar 2.5Pengolahan data pada aplikasi PENTAHO ... 28
Gambar 3.1CRISP–DM... 32
Gambar 3.2Penempatan capturing data ... 33
Gambar 3.3Proses export .csv ... 34
Gambar 3.4Atribut capture wireshark... 34
Gambar 3.5Pemilihan Atribut ... 35
Gambar 3.6FlowchartSistemNaïve Bayes... 37
Gambar 4.1Preprocessing data ... 44
Gambar 4.2Execution Result ... 45
Gambar 4.3Hasil akurasi Klasifikasi Trafik Jaringan Universitas Udayana menggunakan AlgoritmaNaïve Bayes... 51
Gambar 4.4Banyakprotokolberdasarkan prioritas... 53
Gambar 4.5Banyaklength rangeberdasarkan prioritas ... 53
i
DAFTAR SINGKATAN
K-NN = K-Nearest Neighbor SVM = Support Vector Machine JST = Jaring Saraf Tiruan WWW = World Wide Web
HTTP = Hypertext Transfer Protocol DNS = Domain Name System UDP = User Datagram Protokol MAD = Mean Absolute Difference TCP = Transmission Control Protocol IMAP = Internet Message Access Protocol SSH = Secure Shell Hosting
FTP = File Transfer Protocol SSL = Secure Socket Layer Qos = Quality Of Service
GUI =Graphical User Interface
TCP = Transmission Control Protocol
1
BAB I
PENDAHULUAN
1.1 Latar Belakang
Pengembangan pengetahuan mengenai teknologi informasi dan komunikasi berkembang cukup pesat. Salah satu perkembangan teknologi informasi dan komunikasi yang sangat terlihat saat ini adalah adanya penggunaan teknologi komputer. Penggunaan model komunikasi berbasiskan teknologi jaringan komputer merupakan teknologi yang sudah banyak digunakan. Model komunikasi pada jaringan komputer, menggunakan aturan komunikasi yang sesuai dengan standar tipe komunikasi yang sering dikenal dengan namanetwork protocol. Jumlah dari port yang mengidentifikasikan network protocol menurut IANA adalah sejumlah 65.536 port.
Banyaknya penggunaan network protocol dalam suatu komunikasi terkadang menuntut adanya penggunaan prioritas komunikasi seperti kualitias troughput, delay time, realability dan kemanan komunikasi. Penggunaan service prioritas sering disebut dengan istilah QoS. Dasar pemberian prioritas (QoS)
adalah dengan penganalisaan terhadap Network traffic. Network traffic atau
Internet Traffic adalah lalu lintas komunikasi data dalam jaringan yang ditandai dengan satu set aliran statistikal dengan penerapan pola terstruktur, Pola terstruktur yang dimaksud adalah informasi dari header data informasi komunikasi. Klasifikasi yang tepat terhadap sebuah trafik internet sangat penting dilakukan terutama dalam hal desain perancangan arsitektur jaringan, manajemen jaringan dan keamanan jaringan. Klasifikasi yang dilakukan adalah berdasarkan atas banyaknya tipe aktifitas komunikasi. Aktifitas komunikasi dalam jaringan komputer diatur dalam proses komunikasi menggunakan network protocol.
2
Terkait dengan klasifikasi trafik jaringan komputer, beberapa penelitian telah dilakukan dengan fokus pada penerapan data mining. Rachili (2007) mengajukan penelitian mengenai Email Filtering Menggunakan Naïve Bayesian. Pada penelitian tersebut Naïve Bayesian filter dibangun dari sekumpulan email
yang telah diklasifikasikan ke dalam spam mail dan legitimate mail. Hasil yang didapat dari klasifikasi tersebut dibangun sebuah database filter yang digunakan untuk mengidentifikasi email sebagai spam atau legitimate mail. Naïve Bayes filter mengklasifikasikan email dengan menghitung probabilitas email
berdasarkan nilai probabilitas token pada databasefilteryang telah dibangun.
Internet Traffic Classification Using Bayesian Analysis Techniques yang dilakukan oleh Andrew W. Moore dan Denis Zuev adalah menggambarkan pengklasifikasi Internet Traffic pada Machine-Learning sebagai penentu QoS (Quality of Service)dengan tingkat akurasi yang tinggi menggunakanNaïve Bayes Estimator. Data (data latih) yang dipergunakan dalam acuan pengklasifikasian adalah data yang diolah sendiri.
Judul Penelitian Klasifikasi Trending Topic Twitter Dengan Penerapan Metode Naïve Bayes yang dilakukan oleh Puteri Alpita Agustina adalah mengklasifikasikan beragam topik pembicaraan yang popular pada aplikasi Twitter dimana beberapa topic pembicaraan dapat digolongkan sebagai topik pembicaraan yang sama atau kategori tertentu. Pada penelitaannya digunakan 5 kategori yang masing-masing memiliki 20 fitur. Metode Naïve Bayes menggunakan klasifikasi kata dari topik pembicara yang sama dengan membandingkan setiap fitur yang dimiliki oleh tiap kategori.
Dalam pengambilan sebuah trafik jaringan komputer, terdapat beberapa masalah diantaranya:
a. Standarisasi atau format dalam trafik jaringan komputer tidak selalu sama antar perangkat maupun antar penggunatool.
3
tersebut memiliki system yang secara default atau hanya memiliki kapasitas penyimpanan yang kecil.
c. Tidak sembarang orang yang dapat mengambil dan menganalisis suatu trafik jaringan untuk megetahui aktifitas dalam lalulintas jaringan.
Solusi yang dapat ditawarkan dalam permasalahan diatas terkait dengan pengambilan informasi trafik jaringan adalah dengan mengambil sebuah capture trafik dari sebuah komunikasi jaringan komputer. Tentunya dalam hal ini seorang administrator akan menggunakan tool yang memiliki kemampuan dan terakui keakuratannya. Sehingga nantinya pengambilan informasi yang didapat dari
capture trafik lebih bermanfaat. Ketika capture traffic telah dimiliki oleh admin jaringan, maka tugas seorang administrator jaringan akan lebih mudah dalam melakukan pengklasifikasian terhadap aktifitas yang rawan akan keamanan (apakah terdapat serangan keamanan / hacking) atau termasuk lalulintas yang normal. Implementasinya pada suatu system jaringan komputer. Capture trafik
yang didapat adalah dalam jumlahrecordyang besar.
Record dari hasil lalu litas jaringan merupakan catatan transaksi yang dilakukan oleh host dalam aktifitas yang dilakukannya. Salah satu aplikasi yang mampu mengenalkan bagaimana bentuk data trafik capture adalah aplikasi wireshark. Trafik capture yang dihasilkan oleh aplikasi wireshark dapat terdiri dari jumlah record yang besar hingga 200.000 record per 3 menit. Hal yang diutamakan adalah bagaimana seorang administrator mampu menganalisis dan membaca dengan tepat tentang adanya keamanan jaringan terutama yang berhubungan dengan serangan (hacking) dari hasil capture trafik yang ada. Bagi administrator yang kurang mengerti mengenai trafik jaringan akan memerlukan waktu yang lama untuk membaca dari hasilcapturetrafik.
4
capturetrafik data yang dihasilkan. Adapun yang digunakan sebagaitoolsaplikasi
capturetrafik data adalah aplikasiwireshark. Hasil data trafikcaptureakan diolah dengan proses data mining dengan menggunakan metode Naïve Bayes sebagai algoritma klasifikasi yang akan digunakan dalam data trafik jaringan komputer.
Dengan adanya metode Naïve Bayes, maka penganalisaan terhadap klasifikasi trafik jaringan komputer yang dilakukan dari hasil data capture trafik akan memudahkan dalam penganalisaanrecordyang besar.
1.2 Rumusan Masalah
Berdasarkan latar belakang yang telah diuraikan, maka rumusan permasalahan yang akan dibahas lebih lanjut dalam penelitian ini adalah sebagai berikut:
1. Bagaimanakah penerapan teknik Naïve Bayes untuk klasifkasi trafik jaringan Universitas Udayana ?
2. Bagaimanakah akurasi klasifikasi trafik jaringan internet Universitas Udayana didasarkan pada label kelas ?
1.3 Tujuan
Menghasilkan sistem pengklasifikasian dalam jaringan komputer dengan penggunaan datacapture traffic networkyang diolah menggunakan metodeNaïve Bayes.
1.4 Manfaat
Adapun manfaat yang dapat diambil dari penyusunan tugas akhir ini adalah sebagai berikut :
1. Bagi penulis, dapat memperkaya pengetahuan di bidang Pengklassifikasi Network Traffic menggunakan metode Naïve Bayes
5
tidak secara manual yang mengharuskan membaca dari record dalam jumlah besar.
1.5 Ruang Lingkup Dan Batasan Masalah
Dengan luasnya cakupan yang dapat terkait dengan tugas akhir ini dan untuk keseragaman pemahaman dalam penelitian, maka terdapat batasan-batasan yang perlu diberlakukan pada tugas akhir ini. Adaupun batasan permasalahan yang penulis angkat pada penelitian ini adalah :
a. Penggunaan data input yang digunakan adalah dari capture traffic network yang dalam bentuk .csv yang di dapat dari penggunaantool wireshark. b. Metode pengklasifikasian yang digunakan adalahNaïve Bayes.
c. Data set yang digunakan untuk proses klasifikasi adalah dengan membangun dataset tersendiri.
d. Waktu pengambilannetwork trafficyang dilakukan adalah selama 2 menit. e. Data uji yang digunakan dalam fase pengujian system adalah data sample
dari trafik jaringan Universitas Udayana di gedung GDLN.
1.6 Sistematika Penulisan
Sistematika penulisan dalam penyusunan tugas akhir ini terdiri dari pokok pembahasan yang saling berkaitan antara satu dengan lainnya, yaitu :
BAB I : PENDAHULUAN
6
BAB II : TINJAUAN PUSTAKA
Bab ini berisikan teori-teori dasar yang digunakan dalam pengklasifikasian penggunaan protocol komunikasi pada trafik jaringan menggunakan metodeNaïve Bayes.
BAB III : METODE PERANCANGAN SISTEM
Bab ini menjelaskan mengenai lokasi dilakukan penelitian, waktu penelitian dimulai, sumber dan jenis data yang akan diolah dalam penelitian, alat-alat penunjang dalam penelitian, dan tahapan penelitian yang dimulai dari alur analisis penelitian hingga simulasi sistem pengklasifikasian menggunakan metode
Naïve Bayes.
BAB IV HASIL DAN PEMBAHASAN
Pada bab ini akan dibahas mengenai penerapan algoritmaNaïve Bayes ke dalam sistem serta pengujiannya.
BAB V PENUTUP
7
BAB II
KAJIAN PUSTAKA
Dalam bab ini akan diuraikan mengenai teori-teori penunjang yang digunakan dalam penelitian Klasifikasi Penggunaan Protokol Komunikasi Pada Trafik Jaringan Menggunakan Metode Naïve Bayes, ringkasan dari hasil penelitian yang sudah dilakukan terkait dengan topik penelitian ini, dan perbedaan pengklasifikasian yang akan dibahas dalam penelitian ini dengan penelitian sebelumnya.
2.1 Tinjauan Mutakhir
Penelitian “Klasifikasi Penggunaan Protokol Komunikasi Pada Trafik
Jaringan Menggunakan Metode Naïve Bayes” disusun menggunakan acuan
8
Tabel 2.1Tinjauan Mutakhir (State of the art)
No. Nama
Pada penelitian ini data mining yang penelitian ini adalah jenis kelamin, usia, status, pekerjaan, penghasilan per tahun, masa pembayaran asuransi, dan cara pembayaran asuransi.
Pada penelitian ini dilakukan pengujian
mail dan 30 spam mail
9
Tabel 2.2Tinjauan Mutakhir Lanjutan
No. Nama
Penulis Judul Metode Klasifikasi Obyek Klasifikasi
3. Puteri
Pada penelitian ini obyek yang
10
Tabel 2.3Tinjauan Mutakhir Lanjutan
No. Nama
Penulis Judul Metode Klasifikasi Obyek Klasifikasi
Trafik Jaringan memiliki data seperti
IP Address, Protocol
dan Length. Data yang didapat kemudian
Concepts and Techniques” mengatakan, secara singkat data mining dapat diartikan sebagai mengektraksi atau menggali pengetahuan dari data yang berjumlah besar. Sedangkan menurut Daniel T. Laroes (2005) ada beberapa definisi dari Data Mining yang diambil dari beberapa sumber. Secara umum data miningdapat didefinisikan sebagai berikut:
a. Data mining adalah proses menemukan sesuatu yang bermakna dari suatu korelasi baru, pola dan tren yang ada dengan cara memilah-memilah data berukuran besar yang disimpan dalam repositori, menggunakan teknologi pengenalan pola serta teknik matematika dan statistik.
11
c. Data miningmerupakan bidang ilmu interdisipliner yang menyatakan teknik pembelajaran dari mesin (machine learning), pengenalan pola (pattern recognation), statistik, database, dan visualisasi untuk mengatasi masalah ekstraksi informasi dari basis data yang benar.
d. Data miningdiartikan sebagai suatu proses ekstraksi informasi berguna dan potensial dari sekumpulan data yang terdapat secara implicit dalam suatu basis data.
Pada dasarnya data mining berhubungan erat dengan analisis data dan penggunaan perangkat lunak untuk mencari pola dan kesamaan dalam sekumpulan data. Ide dasarnya adalah menggali sumber yang berharga dari suatu tempat yang sama sekali tidak diduga, seperti perangkat lunak data mining
mengekstrasi pola yang sebelumnya tidak terlihat atau tidak begitu jelas sehingga tidak seorang pun yang memperhatikan sebelumnya. Analisadata miningberjalan pada data yang cenderung terus membesar dan teknik terbaik yang digunakan kemudian berorientasi kepada data berukuran sangat besar untuk mendapatkan kesimpulan dan keputusan paling layak. Data mining memiliki beberapa sebutan atau nama lain yaitu : knowledge discovery in database (KDD), ekstraksi pengetahuan (knowledge extraction), analisa data / pola (data / pattern analysis), kecerdasan bisnis (business intelligence), data archaeology dan data dredging
(Daniel T.Larose, 2005)
Terdapat perbedaan antara pengertian data mining dengan bukan data mining yang diilustrasikan terhadap beberapa situasi sehingga dapat menggambarkan perbedaan antara data mining dengan yang bukan data mining yaitu :
Tabel 2.4Perbedaandata miningdengan yang bukandata mining
BukanData Mining Data Mining
Mencari ip address dalam log server Menemukan pola ip address yang sering
muncul dalamlog server ( pola waktu)
12
mencari ip address yang sedang download penggunaan bandwidth dengan ip address
Memberikan informasi jumlah bandwidth
yang diperlukan dari sejumlah user
Mengelompokkan kategori bandwidth
(Contoh : bandwidth SOHOenterprise,
coorporate)
Mencari email yang bersifatspam Melakukan pengklasifikasian terhadap email apakah termasuk spam atau bukan
Pada Tabel 2.4 terlihat bahwa data mining tidak hanya melakukan proses
query untuk mendapatkan suatu informasi, melainkan melakukan proses penggalian dari data yang ada untuk mendapatkan suatu informasi yang berguna dimana informasi ini sebelumnya tidak diketahui sebelumnya (tersembunyi ).
Dalam teknik data mining terdapat beberapa tahapan dalam prosesnya. Tahapan-tahapan dalam data mining tersebut dapat digambarkan sebagai berikut.
Gambar 2.1Gambar Tahapan Data Mining
13
a. Pembersihan data (selection)
Pada umumnya data yang diperoleh, baik dari database suatu perusahaan maupun hasil eksperimen, memiliki isian-isian yang tidak sempurna seperti data yang hilang, data yang tidak valid atau juga hanya sekedar salah ketik. Selain itu,ada juga atribut-atribut data yang tidak relevan dengan hipotesis data mining yang kita miliki. Data-data yang tidak relevan itu juga lebih baik dibuang karena keberadaannya bisa mengurangi mutu atau akurasi dari hasil data mining nantinya. Garbage in garbage out (hanya sampah yang akan dihasilkan bila yang dimasukkan juga sampah ) merupakan istilah yang sering dipakai untuk menggambarkan tahap ini. Pembersihan data juga akan mempengaruhi performasi dari system data mining karena data yang ditangani akan berkurang jumlah dan kompleksituasinya.
b. Pra pemrosesan (Preproccessing)
Tidak jarang data yang diperlukan untuk data mining tidak hanya berasal dari satu database tetapi juga berasal dari beberapa database atau file teks.
Preproccessing data dilakukan pada atribut-atribut yang mengidentifikasikan entinitas-entinitas yang unik seperti atribut IP address source, IP address destination, Source Port, Destination Port, Protocoldsb.
Preprocessing data perlu dilakukan secara cermat karena kesalahan pada integrasi data bisa menghasilkan hasil yang menyimpang dan bahkan menyesatkan pengambilan aksi nantinya.
c. Transformasi data (Transformation)
14
d. Aplikasi teknik data mining (Data Mining)
Aplikasi teknik data mining sendiri hanya merupakan salah satu bagian dari proses data mining. Ada beberapa teknik data mining yang sudah umum dipakai. Kita akan membahas lebih jauh mengenai teknik-teknik yang ada di seksi berikutnya. Perlu diperhatikan bahwa ada kalanya teknik-teknik data mining umum yang tersedia di pasar tidak mencukupi untuk melaksanakan data mining di bidang tertentu atau untuk data tertentu.
e. Evaluasi pola (Interpretation / Evaluation)
Dalam tahap ini hasil dari teknik data mining berupa pola-pola yang khas maupun model prediksi dievaluasi untuk menilai apakah hipotesa yang ada memang tercapai. Bila ternyata hasil yang diperoleh tidak sesuai dengan hipotesa ada beberapa alternatif yang dapat diambil seperti : menjadikannya umpan balik untuk memperbaiki proses data mining, mencoba teknik data mining lain yang lebih sesuai, atau menerima hasil ini sebagai suatu hasil yang di luar dugaan yang mungkin bermanfat.
2.2.2 Cross Industry Standard Process for Data Mining
Cross Industry Standard for Data Mining (CRIS – DM) yang dikembangkan tahun 1996 oleh analis dari beberapa industry seperti Daimbler Chrysler, SPSS, dan NCR. CRISP DM menyediakan standar proses data mining sebagai strategi pemecahan masalah secara umum dari bisnis atau unit penelitian.
15
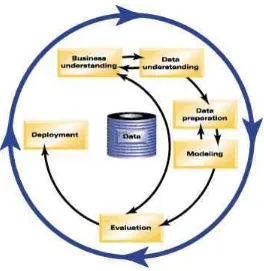
Gambar 2.2CRISP–DM
Enam fase CRISP–DM (Larose, 2005) :
1) Fase Pemahaman Bisnis (Business Understanding Phase)
a) Penentuan tujuan objek dan kebutuhan secara detail dalam lingkup bisnis atau unit penelitian secara keseluruhan.
b) Menerjemahkan tujuan dan batasan menjadi formula dari permasalahan data mining.
c) Menyiapkan strategi awal untuk mencapai tujuan. 2) Fase Pemahaman Data (Data Understanding Phase)
a) Mengumpulkan data.
b) Menggunakan analisis penyelidikan data untuk mengenali lebih lanjut data dan pencarian pengetahuan awal.
c) Mengevaluasi kualitas data.
d) Jika diinginkan, pilih sebagian kecil grup data yang mungkin mengandung pola dari permasalahan.
16
a) Siapkan dari data awal, kumpulkan data yang ingin digunakan untuk keseluruhan fase berikutnya. Fase ini merupakan pekerjaan berat yang perlu dilaksanakan secara intensif.
b) Pilih kasus dan variabel yang ingin dianalisis dan yang sesuai analisis yang akan dilakukan.
c) Lakukan perubahan pada beberapa variabel jika dibutuhkan. d) Siapkan data awal sehingga siap untuk perangkat pemodelan. 4) Fase Pemodelan (Modelling Phase)
a) Pilih dan aplikasikan teknik pemodelan yang sesuai. b) Kalibrasi aturan model untuk mengoptimalkan hasil.
c) Perlu diperhatikan bahwa beberapa teknik mungkin untuk digunakan pada permasalahan data mining yang sama.
d) Jika diperlukan, proses dapat kembal ke fase pengolahan data untuk menjadikan data ke dalam bentuk yang sesuai dengan spesifikasi kebutuhan teknik data mining tertentu.
5) Fase Evaluasi (Evaluation Phase)
a) Mengevaluasi satu atau lebih model yang digunakan dalam fase pemodelan untuk mendapatkan kualitas dan efektifitas sebelum disebarkan untuk digunakan.
b) Menetapkan apakah terdapat model yang memenuhi tujuan pada fase awal.
c) Menentukan apakah terdapat permasalahan penting dari bisnis atau penelitian yang tidak tertangani dengan baik.
d) Mengambil keputusan berkaitan dengan penggunaan hasil dari data mining.
6) Fase Penyebaran (Deployment Phase)
a) Menggunakan model yang dihasilkan. Terbentuknya model tidak menandakan telah terselesaikannya proyek.
b) Contoh sederhana penyebaran : Pembuatan laporan.
17
2.2.3 Klasifikasi
Klasifikasi merupakan proses menemukan sebuah model atau fungsi yang mendeskripsikan dan membedakan data kedalam kelas-kelas. Klasifikasi melibatkan proses pemeriksaan karakteristik dari objek dan memasukan objek kedalam salah satu kelas yang sudah didefinisikan sebelumnya (Han dank amber, 2006 ). Selain itu, klasifikasi dapat diartikan adalah fungsi pembelajaran yang memetakan (mengklasifikasi) sebuah unsur (item) data kedalam salah satu dari beberapa kelas yang sudah didefinisikan.
Menurut Han dan Kamber ( 2006 ) secara umum, klasifikasi terdiri dari dua tahap. Tahap pertama yaitu learning (proses belajar), merupakan sebuah model dibuat untuk menggambarkan himpinan kelas atau konsep data yang telah ditentukan sebelumnya. Model tersebut dibangun dengan menganalisis record-record diasumsikan ke dalam satu kelas yang telah ditentukan sebelumnya, yang dinamakan atribut kelas. Model itu sendiri bisa berupa aturan IF-THEN,decision tree, formula matematis atau neural network. Metode data mining yang umum digunakan untuk klasifikasi adalah k-nearest neighbor, decision tree (ID3,C4.5, danCart), dan jaringan saraf (neural network).
2.2.4 Protokol Jaringan Komputer
18
A. ARP (Address Resolution Protocol)
Layer IP bertugas untuk mengadakan mapping atau transformasi dari IP address ke ethernet address. Secara internal ARP melakukan resolusi address tersebut dan ARP berhubungan langsung dengan data link layer. ARP mengolah sebuah tabel yang berisi IP Address dan ethernet address dan tabel ini diisi setelah ARP melakukan broadcast ke seluruh jaringan.
B. ICMP (Internet Control Massage Protocol)
ICMP (Internet Control Message Protocol) adalah salah satu protokol inti dari keluarga protokol internet. ICMP utamanya digunakan oleh sistem operasi komputer jaringan untuk mengirim pesan kesalahan yang menyatakan, sebagai contoh, bahwa komputer tujuan tidak bisa dijangkau. ICMP berbeda tujuan dengan TCP dan UDP dalam hal ICMP tidak digunakan secara langsung oleh aplikasi jaringan milik pengguna. salah satu pengecualian adalah aplikasi ping yang mengirim pesan ICMP Echo Request (dan menerima Echo Reply) untuk menentukan apakah komputer tujuan dapat dijangkau dan berapa lama paket yang dikirimkan dibalas oleh komputer tujuan.
C. TCP/IP (Transmission Control Protocol/Internet Protocol)
TCP/IP atau sering disebut Transmission Control Protocol/Internet Protocol merupakan standar komunikasi data yang digunakan oleh komunitas internet dalam proses tukar-menukar data dari satu komputer ke komputer lain di dalam jaringan Internet.
D. UDP (User Datagram Protocol)
19
E. FTP (File Transfer Protocol)
Sebuah protokol Internet yang berjalan di dalam lapisan aplikasi yang merupakan standar untuk pentransferan berkas (file) komputer antar mesin-mesin dalam sebuah internetwork. FTP merupakan salah satu protokol Internet yang paling awal dikembangkan, dan masih digunakan hingga saat ini untuk melakukan pengunduhan (download) dan penggugahan (upload) berkas-berkas komputer antara klien FTP dan server FTP. Pada umumnya browser-browser versi terbaru sudah mendukung FTP.
F. HTTP (HyperText Transfer Protocol)
Merupakan protokol yang dipergunakan untuk mentransfer dokumen dalam World Wide Web (WWW). Protokol ini adalah protokol ringan, tidak berstatus dan generik yang dapat dipergunakan berbagai macam tipe dokumen.
G. SSH (Secure Shell Hosting)
Aplikasi pengganti remote login seperti telnet, rsh, dan rlogin, yang jauh lebih aman. Dikembangkan pertamakali oleh OpenBSD project dan kemudian versi rilis p (port) di-manage oleh team porting ke sistem operasi lainnya, termasuk sistem operasi Linux. Fungsi utama aplikasi ini adalah untuk mengakses mesin secara remote. Bentuk akses remote yang bisa diperoleh adalah akses pada mode teks maupun mode grafis/X apabila konfigurasinya mengijinkan. SCP yang merupakan anggota keluarga SSH adalah aplikasi pengganti RCP yang aman, keluarga lainnya adalah SFTP yang dapat digunakan sebagai pengganti FTP.
H. SNMP (Simple Network Management Protocol)
20
I. DNS (Domain Name System)
DNS (Domain Name System, bahasa Indonesia: Sistem Penamaan Domain) adalah sebuah sistem yang menyimpan informasi tentang nama host maupun nama domain dalam bentuk basis data tersebar (distributed database) di dalam jaringan komputer, misalkan: Internet. DNS menyediakan alamat IP untuk setiap nama host dan mendata setiap server transmisi surat (mail exchange server) yang menerima surat elektronik (email) untuk setiap domain.
J. DHCP (Dynamic Host Configuration Protocol)
DHCP (Dynamic Host Configuration Protocol) adalah protokol yang berbasis arsitektur client/server yang dipakai untuk memudahkan pengalokasian alamat IP dalam satu jaringan. Sebuah jaringan lokal yang tidak menggunakan DHCP harus memberikan alamat IP kepada semua komputer secara manual. Jika DHCP dipasang di jaringan lokal, maka semua komputer yang tersambung di jaringan akan mendapatkan alamat IP secara otomatis dari server DHCP. Selain alamat IP, banyak parameter jaringan yang dapat diberikan oleh DHCP, seperti default gateway dan DNS server.
K. Protokol Simple Service Discovery Protocol (SSDP)
Protokol Simple Service Discovery Protocol (SSDP) merupakan sebuah protokol Universal Plug and Play, yang digunakan di dalam sistem operasi Windows XP dan beberapa merek perangkat jaringan. SSDP menggunakan notifikasi pengumuman yang ditawarkan oleh protokolHypertext Transfer Protocol (HTTP) yang memberikan Universal Resource Identifier (URI) untuk tipe layanan dan juga Unique Service Name (USN). Tipe-tipe layanan diatur oleh Universal Plug and Play Steering Committee.
21
sistem-sistem pusat media digital (digital media center), di mana pertukaran media antara komputer dan media center difasilitasi dengan menggunakan SSDP.
L. Multicast DNS (MDNS)
Multicast DNS (mDNS) merupakan sebuah protokol yang menggunakan antarmuka pemrograman aplikasi yang mirip dengan sistem DNS unicast tapi diimplementasikan secara berbeda. Setiap komputer dalam jaringan menyimpan daftar catatan DNS-nya masing-masing (sebagai contoh: A record, MX record, PTR record, SRV record dan lain sebagainya) dan saat klien mDNS hendak mengetahui alamat IP dari sebuah PC dengan menggunakan namanya, PC yang memiliki catatan A yang bersangkutan akan menjawabnya dengan menggunakan alamat IP-nya sendiri. Alamat multicast yang digunakan oleh protokol mDNS ini adalah 224.0.0.251.
M. TELNET (Telecommunication network)
Telnet (Telecommunication network)Adalah sebuah protokol jaringan yang digunakan di koneksi Internet atau Local Area Network. TELNET dikembangkan pada 1969 dan distandarisasi sebagai IETF STD 8, salah satu standar Internet pertama. TELNET memiliki beberapa keterbatasan yang dianggap sebagai risiko keamanan.
N. Netbios Name Service (NBNS)
Netbios Name Service (NBNS) adalah protokol Netbios yang digunakan oleh aplikasi di OS Windows untuk digunakan pada protokol TCP/IP, sehingga ketika OS Windows tersebut melakukan koneksi internet maka akan kelihatan di Wireshark.
2.2.5 AlgoritmaNaïve Bayes
22
propabilitas dan statistik yang dikemukakan oleh ilmuwan Inggris Thomas Bayes, yaitu memprediksi peluang di masa depan berdasarkan pengalaman dimasa sebelumnya sehingga dikenal sebagai Teorema Bayes. Teorema tersebut dikombinasikan dengan Naïve dimana diasumsikan kondisi antar atribut saling bebas. KlasifikasiNaïve Bayesdiasumsikan bahwa ada atau tidak ciri tertentu dari sebuah kelas tidak ada hubungannya dengan ciri dari kelas lainnya.
Persamaan dari Teorema Bayes adalah :
... (2.1)
Dimana :
X : Data dengan class yang belum diketahui
H : Hipotesa data X merupakan suatu class spesifik P(H|X) : Probabilitas hipotesa H berdasar kondisi X (posteriori
probability)
P(H) : Probabilitas hipotesa H (prior probability)
P(X|H) : Probabilitas X berdasarkan kondisi pada hipotesa H P(X) : Probabilitas X
Untuk menjelaskan teoremaNaïve Bayes, perlu diketahui bahwa proses klasifikasi memerlukan sejumlah petunjuk untuk menentukan kelas apa yang cocok bagi sampel yang dianalisis tersebut. Karena itu, teorema bayes diatas disesuaikan sebagai berikut :
...(2.2)
Dimana variabel C mempresentasikan kelas, sementara variabel F1…Fn
23
peluang kemunculan karakteristik-karakteristik sampel pada kelas C (disebut juga
likelihood), dibagi dengan peluang kemunculan karakteristik-karakteristik sampel secara global (disebut juga evidence). Karena itu, rumus diatas dapat pula ditulis secara sederhana sebagai berikut :
...(2.3)
Nilai Evidence selalu tetap untuk setiap kelas pada satu sampel. Nilai dari
posterior tersebut nantinya akan dibandingkan dengan nilai-nilai posterior kelas lainnya untuk menentukan ke kelas apa suatu sampel akan diklasifikasikan. Penjabaran lebih lanjut rumus Bayes tersebut dilakukan dengan menjabarkan (C|F1, … , Fn) menggnakan aturan perkalian sebagai berikut :
Dapat dilihat bahwa hasil penjabaran tersebut menyebabkan semakin banyak dan semakin kompleksnya faktor-faktor syarat yang mempengaruhi nilai probabilitas, yang hampir mustahil untuk dianalisa satu persatu. Akibatnya, perhitungan tersebut menjadi sulit untuk dilakukan. Disinilah digunakan asumsi independensi yang sangat tinggi (naif), bahwa masing-masing petunjuk (F1,F2 …
Fn) saling bebas (independen) satu sama lain. Dengan asumsi tersebut, maka
berlaku suatu kesamaan sebagai berikut :
...(2.4)
24
...(2.5)
Dari persamaan diatas dapat disimpulkan bahwa asumsi independensi naif tersebut membuat syarat peluang menjadi sederhana, sehingga perhitungan menjadi mungkin untuk dilakukan. Selanjutnya, penjabaran P(C|F1,…,Fn) dapat
disederhanakan menjadi :
2.2.6 Pengukuran Kinerja Klasifikasi
Sebuah sistem yang melakukan klasifikasi diharapkan dapat melakukan klasifikasi semua set data dengan benar, tetapi tidak dapat dipungkiri bahwa kinerja suatu sistem tidak bisa 100 % benar sehingga sebuah sistem klasifikasi juga harus diukur kinerjanya. Umumnya, pengukuran kinerja klasifikasi dilakukan dengan matriks kondisi (confusion matriks).
Tabel 2.5Confusion matriks
F0 F1
F0 F00 F01
F1 F10 F11
Matriks konfusi merupakan tabel pencatat hasil kerja klasifikasi. Kuantitas matriks konfusi dapat diringkas menjadi dua nilai, yaitu akurasi dan laju error. Dengan mengetahui jumlah data yang diklasifikasi secara benar, kita dapat mengetahui akurasi hasil prediksi dan dengan mengetahui jumlah data yang diklasifikasi secara salah, kita dapat mengetahui laju error dari prediksi yang
Kelas Hasil
25
dilakukan. Dua kuantitas ini digunakan sebagai matrik kinerja klasifikasi. Untuk menghitung akurasi digunakan formula.
...(2.5)
Untuk menghitung laju error (kesalahan prediksi) digunakan formula
...(2.6)
Semua algoritma klasifikasi berusaha membentuk model yang mempunyai akurasi tinggi atau (laju error yang rendah). Umumnya, model yang dibangun memprediksi dengan benar pada semua data yang menjadi data latihnya, tetapi ketika model berhadapan dengan data uji, barulah kinerja model dari sebuah algoritma klasifikasi ditentukan.
2.2.7 Topologi Jaringan
26
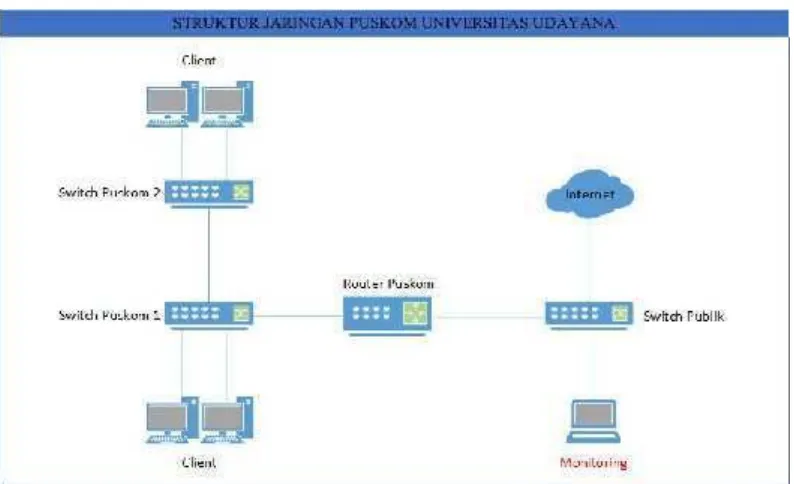
Gambar 2.3Topologi jaringan Universitas Udayana
2.2.8 Wireshark
Wireshark adalah salah satu dari sekian banyak tool Network Analyzer
yang banyak digunakan oleh Network Administrator untuk menganalisa kinerja jaringannya dan mengontrol lalu lintas data di jaringan yang di kelola.Wireshark
menggunakan interface yang menggunakan Graphical User Interface (GUI). Wireshark digunakan untuk keperluan analisis, troubleshooting, pengembangan
software dan protokol, serta digunakan untuk tujuan edukasi. Wireshark mampu menangkap paket-paket data yang ada pada jaringan. Semua jenis paket informasi dalam berbagai format protokol dapat ditangkap dan dianalisa. Manfaat dari penggunaan aplikasiwiresharkini yaitu sebagai berikut :
A. Menangkap informasi atau data paket yang dikirim dan diterima dalam jaringan komputer
27
C. Mengetahui dan menganalisa kinerja jaringan komputer yang kita miliki seperti kecepatan akses/share data koneksi jaringan ke internet
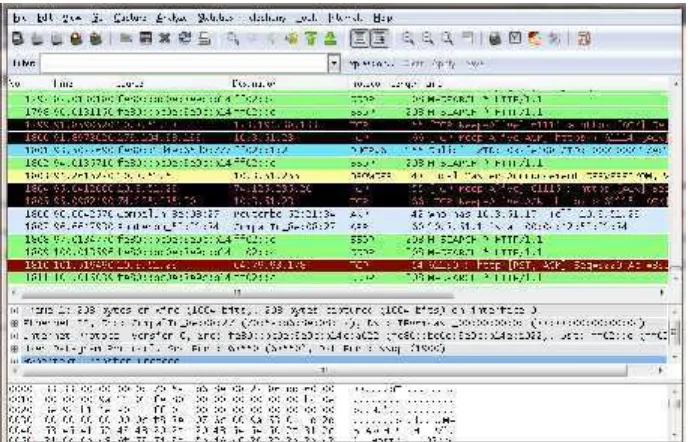
Beberapa informasi yang dapat di capture oleh tool wireshark sebagai informasi network traffic antara lain time elapse (waktu yang dicatat dalam periode tertentu), source address (berupa IP address ataupun mac address), protocol (layanan atau service yang berjalan dalam jaringan komputer), length
(ukuran data yang dikirimkan), dan info (informasi tambahan dari tiap layanan yang berjalan dalam jaringan komputer). Contoh tampilan dari aplikasi wireshark
adalah pada Gambar 2.4.
Gambar 2.4Gambar aplikasiwireshark
2.2.9 Pentaho Data Integration
28
Transformation adalah sekumpulan instruksi untuk merubah input menjadi output yang diinginkan (input-proses-output). Sedangkan Job adalah kumpulan instruksi untuk menjalankan transformasi. Ada tiga komponen dalam PDI: Spoon, Pan dan Kitchen. Spoon adalah user interface untuk membuat Job dan Transformation. Pan adalah tools yang berfungsi membaca, merubah dan menulis data. Sedangkan Kitchen adalah program yang mengeksekusi job. Berikut merupakan pengolahan data pada pentaho.
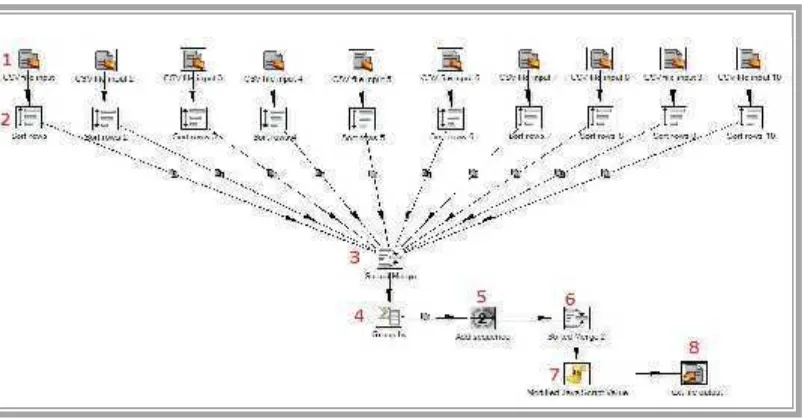
Gambar 2.5Pengolahan data pada pentaho
Berdasarkan pada Gambar 2.5, dapat dijabarkan sebagai berikut :
1. CSV file input, proses input data berupa file .csv
2. Sort rows, proses memberikan size maksimal pada tabel 3. Sorted marge, proses menyatukan keseluruhan data
4. Group by, proses pengolahan data mentah (preprocessing data) 5. Add sequence, proses pemberian nomer id
6. Sorted marge 2, proses menyatukan keseluruhan data setelah dilakukan preprocessing
7. Modified java script value, proses memberikan batas length range dan count range dengan menggunakan java script