398
PERBANDINGAN TEKNIK SAMPLING DALAM
RANDOM FOREST PADA KELAS IMBALANCED
Studi Kasus Perilaku Seksual Remaja di Indonesia Hasil SDKI 2012
Yogo Aryo Jatmiko1, Septiadi Padmadisastra2, Anna Chadidjah3Prodi Magister Statistika Terapan, Universitas Padjajaran, Bandung1,2,3
email : [email protected]
ABSTRAK
Random Forest merupakan salah satu metode ensemble untuk meningkatkan ketepatan
klasifikasi suatu data. Kinerja klasifikasi suatu data umumnya dievaluasi menggunakan ukuran akurasi data. Namun, hal ini menjadi kurang tepat ketika data yang digunakan merupakan data yang imbalanced. Salah satu cara untuk mengatasi hal ini adalah dengan melakukan resample pada data asli, yaitu over-sampling pada kelas minoritas atau
under-sampling pada kelas mayoritas. Selain kedua metode diatas, terdapat metode hybrid Synthetic Minority Over-sampling Technique (SMOTE), yaitu suatu metode kombinasi
dari over-sampling pada kelas minoritas dan under-sampling pada kelas mayoritas. Perbedaan teknik sampling tentunya memberikan perbedaan dalam keakuratan dan ketepatan hasil klasifikasi prediksi. Tujuan dari penelitian ini adalah membandingkan beberapa teknik sampling dalam Machine Learning menggunakan metode Random
Forest pada data imbalanced. Aplikasi dilakukan pada kelas imbalanced perilaku seksual
remaja berdasarkan hasil SDKI 2012. Berdasarkan hasil penelitian, ketiga metode meningkatkan presisi, recall, dan sensitivity hasil klasifikasi dibandingkan dengan data asli.
Kata kunci: Random Forest, Over-sampling, Under-sampling, SMOTE, SDKI2012
1. PENDAHULUAN
Metode ensemble merupakan sebuah metode dengan gagasan melakukan berbagai macam gabungan kombinasi dari banyak pemilah tunggal (classifier) menjadi sebuah prediksi akhir berdasarkan proses voting mayoritas. Random Forests (RF) adalah salah satu metode ensemble dalam pohon keputusan yang merupakan pengembangan dari metode Bootsrap Aggregating (Bagging). Berbeda dengan Bagging, Random Forest dikembangkan dengan gagasan perlu adanya penambahan layer pada proses resampling acak pada Bagging. Oleh karena itu, bukan hanya data sampel yang diambil secara acak untuk membentuk pohon klasifikasi, tetapi juga variabel prediktor diambil sebagian secara acak dan baru dipilih sebagai pemilah terbaik saat penentuan pemilah pohon, sehingga diharapkan menghasilkan prediksi yang lebih akurat [1]. Random Forests (RF) merupakan salah satu metode ensemble untuk meningkatkan akurasi suatu klasifikasi data dari sebuah pemilah tunggal yang tidak stabil melalui kombinasi banyak pemilah dari suatu metode yang sama dengan proses voting untuk memperoleh prediksi klasifikasi akhir [2].
Ukuran kinerja ketepatan klasifikasi dari sebuah algoritma Machine Learning seperti
Random Forest biasanya dievaluasi menggunakan ukuran akurasi. Namun, hal ini
menjadi tidak tepat ketika dataset yang digunakan merupakan sebuah data yang imbalanced [3]. Data imbalanced adalah suatu kondisi dimana kategori klasifikasi tidak
399
terwakili secara seimbang [3]. Sebagai gambaran, pada 100 baris data dalam suatu dataset klasifikasi kelas biner, sebanyak 80 baris berkode kelas 1 dan 20 sisanya berkode kelas 2. Kondisi ini merupakan kondisi sebuah dataset yang imbalanced karena rasio antara kelas 1 terhadap kelas 2 adalah 80:20 atau 4:1. Imbalanced merupakan kejadian yang biasa dalam suatu dataset, namun ketika perbandingan kelas seperti 4:1 diatas, dataset imbalanced bisa menyebabkan masalah seperti Accuracy
Paradox [4]. Accuracy Paradox untuk analisis prediktif menyatakan bahwa model
prediktif dengan tingkat akurasi tertentu mungkin memiliki daya prediksi lebih besar daripada model dengan tingkat akurasi yang lebih tinggi. Dalam kondisi seperti ini lebih baik menggunakan ukuran ketepatan klasifikasi yang lain selain ukuran akurasi, seperti presisi dan recall [4].
Komunitas Machine Learning menanggapi permasalahan kelas yang imbalanced melalui dua pendekatan [3]. Pendekatan pertama adalah dengan menetapkan biaya yang berbeda untuk contoh-contoh training. Pendekatan lain adalah dengan melakukan
resample pada data asli, baik melalui over-sampling pada kelas minoritas, under-sampling pada kelas mayoritas maupun dengan memadukan under-under-sampling pada
kelas mayoritas dengan bentuk khusus dari over-sampling pada kelas minoritas, yang dikenal dengan
Synthetic Minority Over-sampling Technique (SMOTE) [3].
Sebagai bagian dari masyarakat, remaja merupakan bagian yang sedang mengalami perubahan baik perubahan fungsi organ tubuh maupun perubahan fungsi sosial. Tiga Permasalahan Kesehatan Reproduksi Remaja (TRIAD KRR) merupakan masalah yang menonjol dikalangan remaja, yaitu seputar seksualitas, HIV dan AIDS, serta Napza. Rendahnya pengetahuan remaja tentang Kesehatan Reproduksi Remaja (KRR) menimbulkan kegiatan seksual yang tidak bertanggung jawab dikalangan remaja. Setiap tahunnya 50.000 remaja meninggal dunia karena kehamilan dan komplikasi persalinan di seluruh dunia [5]. Hal ini ditunjukkan oleh hasil SDKI 2012 dimana terdapat 0,9 persen remaja wanita dan 8,3 persen remaja pria belum kawin di Indonesia yang pernah melakukan hubungan seksual [6]. Persentase remaja yang melakukan hubungan seksual di luar nikah masih jauh lebih kecil dibandingkan jumlah seluruh remaja di Indonesia. Hal ini menyebabkan dataset perilaku seksual remaja memilki kelas yang imbalanced. Berdasarkan latar belakang yang telah dipaparkan, penelitian ini bertujuan untuk membandingkan beberapa teknik sampling (over-sampling, under-sampling dan SMOTE) dalam Machine Learning menggunakan metode Random Forest pada kelas
400
2. METODE PENELITIAN
2.1 Data dan Variabel Penelitian
Analisis ini menggunakan data dengan sampel sebanyak 1500 secara Simple
Random Sampling (SRS) dari dataset hasil SDKI 2012 dengan responden remaja berumur
15-24 tahun dan status belum kawin/belum hidup bersama, baik data remaja laki-laki ataupun perempuan. Data-data dari SDKI 2012 memberikan informasi yang lengkap mengenai perilaku maupun pengetahuan tentang hubungan seksual pranikah remaja yang terjadi di Indonesia.
Variabel yang digunakan dalam analisis ini adalah sebagai berikut:
1) Variabel tak bebas (Y):
Remaja pernah atau tidak melakukan hubungan seksual di luar nikah (pernah =0 ; tidak pernah =1)
2) Variabel bebas (X) terdiri dari:
a. Klasifikasi daerah kota/desa (1 = kota ; 0 = desa) b. Umur
c. Jenis Kelamin (laki-laki = 1 ; perempuan = 0) d. Merokok ( Ya = 1 ; tidak = 0)
e. Mengonsumsi alkohol (pernah = 1 ; tidak pernah = 0) f. Mengonsumsi narkoba (pernah = 1 ; tidak pernah = 0) g. Pernah/tidak pacaran (pernah =1 ; tidak pernah = 0) h. Sekolah (masih sekolah = 1 ; tidak sekolah lagi = 0)
i. Tingkat Pendidikan (pernah sekolah SLTP ke atas = 1 ; lulus SD ke bawah = 0) j. Komunikasi kesehatan reproduksi dengan Ibu (Ya = 1 ; Tidak = 0)
k. Komunikasi kesehatan reproduksi dengan Bapak (Ya = 1 ; Tidak = 0)
l. Komunikasi kesehatan reproduksi dengan Saudara Kandung (Ya = 1 ; Tidak = 0) m. Mempunyai teman yang pernah atau tidak melakukan hubungan seksual di luar
nikah (Ya =1 ; Tidak =0)
Penelitian ini terbatas pada data-data hasil pengolahan data SDKI remaja laki-laki dan perempuan tahun 2012. Data remaja perempuan diambil dari data Wanita Usia Subur (WUS) yang berumur 15-24 tahun dan status perkawinannya belum kawin. Variabel yang dipilih merupakan hasil pengolahan data SDKI dengan mempertimbangkan validitas serta untuk observasi-observasi yang mengandung missing value tidak disertakan dalam analisis.
2.2 Random Forest
Random Forests (RF) merupakan salah satu metode ensemble untuk meningkatkan
akurasi suatu klasifikasi data dari sebuah pemilah tunggal yang tidak stabil melalui kombinasi banyak pemilah dari suatu metode yang sama dengan proses voting untuk memperoleh prediksi klasifikasi akhir [2]. Istilah Random Forests diusulkan pertama kali oleh Tin Kam Ho dari Bell Labs pada tahun 1995. Pengembangan Random Forests dilakukan oleh Leo Breiman pada tahun 2001 dari proses Bootsrap Aggregating atau yang lebih popular dengan sebutan Bagging. Dalam proses bagging digunakan
resampling bootstrap untuk membangkitkan pohon klasifikasi yaitu suatu teknik
401
mengkombinasikannya untuk memperoleh prediksi akhir. Sedangkan dalam metode
Random Forests proses pengacakan tidak hanya dilakukan pada data sampel saja
melainkan juga pada pengambilan variabel bebas sehingga pohon klasifikasi yang dibangkitkan akan memiliki ukuran dan bentuk yang berbeda-beda [1]. Berikut merupakan algoritma Random Forest menurut Liaw dan Wiener [1].
1. Mengambil n data sampel dari dataset awal dengan teknik resampling bootstrap dengan pengembalian.
2. Untuk setiap dataset hasil resampling bootstrap, buat sebuah pohon klasifikasi tanpa melalui proses pruning, dengan melakukan modifikasi berikut
a. Pada setiap node, penentuan pemilah terbaik didasarkan pada variabel-variabel prediktor yang diambil secara acak mtry.
b. Jumlah variabel yang diambil secara acak (m) dapat ditentukan melalui perhitungan
√𝑚 atau √𝑚 [8]. 2
3. Melakukan prediksi klasifikasi data sampel berdasarkan pohon klasifikasi yang terbentuk. 4. Mengulangi langkah 1 sampai dengan langkah 3 sejumlah K pohon klasifikasi yang diinginkan. 5. Melakukan prediksi klasifikasi data sampel akhir dengan mengkombinasikan hasil prediksi
sejumlah K pohon klasifikasi yang didapatkan berdasarkan aturan majority vote.
2.3 Teknik Sampling Kelas Imbalanced
Beberapa teknik sampling dalam Machine Learning yang digunakan untuk mengatasi kelas
imbalanced.
1. Under-sampling
Suatu metode sampling dimana metode yang digunakan dalam kategori ini berisi resampling eliminasi dari kelas mayoritas secara acak sampai jumlahnya sebanyak contoh dari kelas lainnya (kelas minoritas) [7].
2. Over-sampling
Suatu metode sampling dimana metode yang digunakan dalam kategori ini berisi resampling dari kelas minoritas secara acak sampai jumlahnya sebanyak contoh dari kelas lainnya (kelas mayoritas) [7].
3. Synthetic Minority Over-sampling Technique (SMOTE)
Suatu metode sampling dimana kelas minoritas dilakukan over-sampling dengan membuat sampel “sintetis” daripada dilakukan over-sampling dengan melakukan duplikasi pada data sebenarnya. Tergantung kepada jumlah over-sampling yang dibutuhkan, neighbours dari k- nearest neighbours dipilih secara acak. Berikut adalah algoritma SMOTE menurut Chawla [3]
Algorithm SMOTE(T, N, k)
Input: Jumlah sampel kelas minoritas T; Jumlah SMOTE N%; Jumlah nearest neighbors k Output: (N/100)* T sampel kelas minoritas buatan
1. (∗ Jika N kurang dari 100%, acak sampel kelas minoritas karena hanya persentase acaknya yang akan diambil SMOTE.∗)
2. if N <100
3. then Randomize the T minority class samples 4. T = (N/100) ∗ T
5. N = 100
6. endif
7. N = (int)(N/100) (∗ Jumlah SMOTE adalah kelipatan integral dari 100.∗) 8. k = Jumlah nearest neighbors
9. numattrs = Jumlah attributes
10. Sample[ ][ ]: array untuk sampel kelas minoritas yang asli
11. newindex: menyimpan hitungan jumlah sampel sintetis yang dihasilkan, diinisialisasi ke 0 12. Synthetic[ ][ ]: array untuk sampel sintetis
(∗ Menghitung k nearest neighbors untuk setiap sampel kelas minoritas.∗)
402 13. for i ←1 to T
14. Menghitung k nearest neighbors for i, Dan simpan indeks dalam nnarray 15. Populate(N, i, nnarray)
16. endfor
Populate(N, i, nnarray) (∗Fungsi untuk membangkitkan sampel sintetis. ∗)
17. while N != 0
18. Pilih angka random antara 1 dan k, sebut saja nn. (*Langkah ini memilih salah satu k nearest neighbors dari i.*)
19. for attr←1 to numattrs
20. Hitung: dif= Sample[nnarray[nn]][attr] –Sample[i][attr] 21. Hitung: gap = random number between 0 and 1 22. Synthetic[newindex][attr] = Sample[i][attr] + gap ∗dif
23. Endfor 24. newindex++ 25. N = N−1 26. Endwhile
27. return (∗ Akhir Populasi. ∗)
2.4 Ukuran Ketepatan Klasifikasi
Pengukuran ketepatan klasifikasi diukur melalui beberapa ukuran, yaitu, sensitivitas, spesifikasi, G- means, Apparent Error Rate (APER) dan total accuracy rate (1-APER) yang dihitung berdasarkan Tabel Klasifikasi [9]. Bentuk umum Tabel Klasifikasi adalah sebagai berikut:
Tabel 1. Tabel Klasifikasi
Aktual Prediksi Total
0 1
0 𝑛11 𝑛12 𝑛1.
1 𝑛21 𝑛22 𝑛2.
Total 𝑛.1 𝑛.2 𝑁
Dimana,
𝑛11= jumlah observasi dari kelas 1 yang tepat diprediksi sebagai kelas 1 𝑛22=jumlah observasi dari kelas 2 yang tepat diprediksi sebagai kelas 2 𝑛12= jumlah observasi dari kelas 1 yang salah diprediksi sebagai kelas 2 𝑛21=jumlah observasi dari kelas 2 yang salah diprediksi sebagai kelas 1 𝑛1.= jumlah observasi dari kelas 1
𝑛2.= jumlah observasi dari kelas 2 𝑁= jumlah observasi
403
Berdasarkan Tabel 1, persamaan untuk menghitung ketepatan klasifikasi berupa sensitivitas, spesifikasi, G-means, Apparent Error Rate (APER) dan total accuracy rate (1-APER) adalah sebagai berikut:
Dikarenakan dataset yang digunakan merupakan dataset yang imbalanced, sehingga kemungkinan terjadi accuracy paradox sehingga perlu digunakan ukuran lain seperti presisi dan recall.
Tabel 2. Tabel Klasifikasi Aktual Prediksi Negatif Positif Negatif 𝑇𝑁 𝐹𝑃 Positif 𝐹𝑁 𝑇𝑃 D i m a n a , 𝑇 𝑁 = T r u e N e g a t i v e = j u m l a h o b s e r v a s i Dimana,
𝑇𝑁= True Negative = jumlah observasi negatif yang tepat diprediksi 𝑇𝑃= True Positive = jumlah observasi positif yang tepat diprediksi
𝐹𝑁= False Negative = jumlah observasi negatif yang salah diprediksi sebagai positif 𝐹𝑃= False Positive = jumlah observasi positif yang salah
diprediksi sebagai negatif Berdasarkan tabel 2. Rumus presisi dan recall adalah sebagai berikut [3]:
𝑇𝑃 Presisi (dalam %) = × 100% 𝑇𝑃 + 𝐹𝑃 (6) 𝑇𝑃 𝑟𝑒𝑐𝑎𝑙𝑙 (dalam %) = × 100% 𝑇𝑃 + 𝐹𝑁 (7)
Tujuan utama pada data training dari dataset imbalanced adalah untuk meningkatkan recall tanpa mempengaruhi presisi. Namun, tujuan dari presisi dan recall sering berseberangan, karena ketika meningkatkan nilai true positive untuk kelas minoritas, jumlah dari false positive juga meningkat, ini akan menyebabkan nilai presisi berkurang. 𝑛11 Sensitivitas (dalam %) = × 100% 𝑛1. (1) 𝑛22 Spesifikasi (dalam %) = × 100% 𝑛2. (2) 𝐺 − 𝑚𝑒𝑎𝑛𝑠 = √𝑠𝑒𝑛𝑠𝑖𝑡𝑖𝑣𝑖𝑡𝑎𝑠 × 𝑠𝑝𝑒𝑠𝑖𝑓𝑖𝑘𝑎𝑠𝑖 (3) 𝑛21 + 𝑛12 𝐴𝑝𝑝𝑎𝑟𝑒𝑛𝑡 𝐸𝑟𝑟𝑜𝑟 𝑅𝑎𝑡𝑒 (APER) (dalam %) = × 100% 𝑁 (4) 𝑛11 + 𝑛22 𝑡𝑜𝑡𝑎𝑙 𝑎𝑐𝑐𝑢𝑟𝑎𝑐𝑦 𝑟𝑎𝑡𝑒 (1 − APER) (dalam %) = × 100% 𝑁 (5)
404
3. HASIL DAN PEMBAHASAN
Hasil perhitungan klasifikasi pada Tabel 3. menunjukkan bahwa 1-APER random forest pada data asli (original) bernilai 0,9109 atau dengan kata lain, data sampel yang tepat diklasifikasikan secara keseluruhan sebanyak 91,09 persen dengan metode random forest. Lebih detil, akurasi klasifikasi lainnya perlu diperhatikan juga, mengingat data yang digunakan merupakan dataset yang imbalanced. Sensitivity random forest pada data asli bernilai 0 yang artinya tidak ada data sampel remaja yang pernah melakukan hubungan seksual pranikah yang tepat diklasifikasikan pernah melakukan hubungan seksual pranikah. adapun nilai specificity random foret pada data asli bernilai 0,9976 yang artinya sebanyak 99,76 persen remaja yang tidak pernah melakukan hubungan seksual pranikah tepat diklasifikasikan tidak pernah. Keseimbangan akurasi prediksi diukur dari nilai
G-means yang biasa digunakan untuk mengukur permasalahan data imbalanced. Hal ini
diperlukan karena metode klasifikasi cenderung baik dalam memprediksi kelas dengan data sampel yang lebih banyak namun buruk dalam memprediksi kelas dengan data sampel yang sedikit. Tabel 3. Menunjukkan bahwa G-means random forest pada data asli bernilai 0, yang artinya terjadi ketidakseimbangan prediksi.
Hasil akurasi tersebut menunjukkan bahwa metode random forest bagus dalam mengklasifikasikan remaja yang tidak pernah melakukan hubungan seksual pranikah, namun tidak dapat menangkap remaja yang pernah melakukan hubungan seksual pranikah. Hal ini menandakan bahwa terjadi hasil akurasi yang bias atau biasa dikenal
accuracy paradox, dimana analisis prediktif menyatakan bahwa model prediktif dengan
tingkat akurasi tertentu mungkin memiliki daya prediksi lebih besar daripada model dengan tingkat akurasi yang lebih tinggi. Dalam kondisi seperti ini lebih baik menggunakan ukuran ketepatan klasifikasi yang lain selain ukuran akurasi, seperti presisi dan recall [4].
Tabel 3.
Ukuran Kinerja Teknik Sampling
Akurasi Original Under Over SMOTE
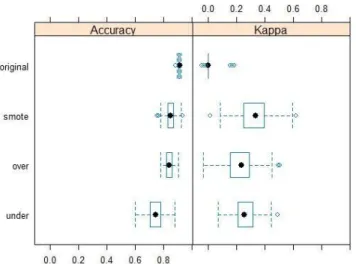
1-APER 0.9109 0.7194 0.8352 0.8374
APER 0.0891 0.2806 0.1648 0.1626
Sensitivity 0.0000 0.8462 0.3590 0.5641
Specificity 0.9976 0.7073 0.8805 0.8634
G-means 0.0000 0.7736 0.5622 0.6979
Tabel 3. menunjukkan bahwa 1-APER random forest pada ketiga teknik sampling memberikan nilai akurasi yang lebih kecil, dimana akurasi pada teknik sampling SMOTE masih lebih baik disbanding Over- sampling dan Under-sampling. Adapun nilai sensitivity random forest pada Under-sampling bernilai 0,8462 yang artinya sebesar 84,62 persen data sampel remaja yang pernah melakukan hubungan seksual pranikah yang tepat diklasifikasikan pernah melakukan hubungan seksual pranikah. Nilai ini lebih besar dibandingkan Over-sampling dan SMOTE, yaitu 0,3590 dan 0,5641.
405
Gambar 1. Nilai Akurasi Teknik Sampling
Tabel 4. Menunjukkan bahwa ketiga teknik sampling (Under-sampling,
Over-sampling, dan SMOTE) memberikan nilai presisi dan recall yang lebih
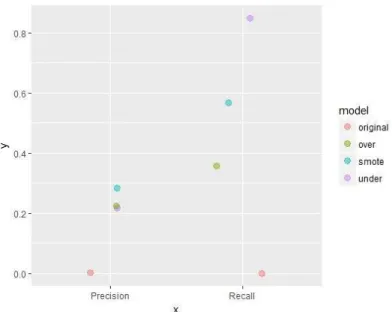
baik dibandingkan data asli. Teknik sampling SMOTE memberikan nilai presisi paling besar yaitu 0,2821 yang artinya sebesar 28,21 persen tingkat ketepatan antara remaja yang pernah melakukan hubungan seksual pranikah dengan tingkat remaja yang diklasifikasikan pernah melakukan hubungan seksual pranikah. Sedangkan Under-sampling dan Over- sampling memberikan nilai presisi sebesar 0,2157 dan 0,2222. Sementara, teknik sampling Under-sampling memberikan nilai recall paling besar yaitu 0,9797 yang artinya sebesar 97,97 persen tingkat keberhasilan sistem dalam menemukan kembali informasi remaja yang pernah melakukan hubungan seksual pranikah. Sedangkan SMOTE dan
Over-sampling memberikan nilai recall sebesar 0,9542 dan 0,9352.
Tabel 4.
Ukuran Presisi dan Recall Teknik Sampling
Akurasi Original Under Over SMOTE
Precision 0.0000 0.2157 0.2222 0.2821 Recall 0.9129 0.9797 0.9352 0.9542
406
Gambar 2. Perbandingan Presisi dan Recall Teknik Sampling
4. KESIMPULAN
Data remaja yang pernah melakukan hubungan seksual pranikah hasil SDKI 2012 menghasilkan akurasi yang bias dengan metode random forest dilihat dari nilai sensitivity yang bernilai 0. Secara umum, ketiga metode teknik sampling yang digunakan baik Under-sampling, Over-sampling dan SMOTE meningkatkan nilai sensitivity, presisi, dan recall dari data asli. Teknik
Under-sampling memberikan nilai sensitivity dan recall yang paling besar yaitu 84,62
persen dan 97,97 persen, sedangkan presisi terbaik diberikan oleh teknik sampling SMOTE dengan nilai 28,21 persen.
5. DAFTAR PUSTAKA
[1] A. Liaw and M. Wiener, “Classification and Regression by Random Forest”, R News, vol. 2, 2002. pp. 18-22
[2] M. V. Wezel and R. Potharst, “Improved Customer Choice Prediction using Ensemble Method”,
European Journal of Operational Research, vol.181, 2007. pp. 436-452
[3] N. V. Chawla, K. W. Bowyer, L. O. Hall, and W. P. Kegelmeyer, “SMOTE: Synthetic Minority Over- sampling Technique,” Journal of Artificial Intelligence Research, vol. 16, pp. 321–357, 2002. (references)
[4] Zhu, Xingquan, “Knowledge Discovery and Data Mining: Challenges and Realities”, IGI Global, 2007.pp. 118–119, ISBN 978-1-59904-252-7.
[5] Reproductive Helath: Teen Pregnancy, [Internet] 2008. [cited 2017 september 27] available from: http://www.cdc.gov
[6] Y. A. Jatmiko, dan S. Wahyuni, “Determinan Perilaku Seksual Remaja di Indonesia”, Prosiding Seminar Ilmiah Kependudukan, Bandung, 2014.
[7] N. Japkowicz, “The Class Imbalance Problem: Significance and Strategies.” In Proceedings of the 200 International Conference on Artificial Intelligence (IC-AI’2000): Special Track on Inductive Learning Las Vegas, Nevada, 2000.