i
INDEKS DAN PENCARIAN
CHAINED HASH TABLE
PADA
PEMEROLEHAN INFORMASI MENGGUNAKAN
HASH
FUNCTION
:
KNUTH’S MULTIPLICATION METHOD
DAN
DIVISION METHOD
STUDI KASUS : PERPUSTAKAAN
UNIVERSITAS SANATA DHARMA
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Teknik Komputer (S.Kom.)
Program Studi Teknik Informatika
Oleh: Linardi NIM : 085314057
FAKULTAS SAINS DAN TEKNOLOGI UNIVERSITAS SANATA DHARMA
ii
CHAINED HASH TABLE
INDEX AND SEARCHING IN
INFORMATION RETRIEVAL WITH
HASH FUNCTION
:
KNUTH’S MULTIPLICATION METHOD
DAN
DIVISION
METHOD
CASE STUDY :
LIBRARY OF SANATA DHARMA UNIVERSITY
THESIS
Presented as Partial Fullfilment of the Requirements To Obtain the Computer Bachelor Degree
In Informatics Engineering
By: Linardi NIM : 085314057
FACULTY OF SCIENCE AND TECHNOLOGY SANATA DHARMA UNIVERSITY
iii
iv
v
vi
HALAMAN MOTO
Tetapi carilah dahulu Kerajaan Allah dan
kebenarannya, maka semuanya itu akan ditambahkan
kepadamu.
vii
HALAMAN PERSEMBAHAN
Skripsi ini saya persembahkan kepada Tuhan YME yang selalu
menjadi sandaran dan topangan saat menghadapi masalah, dan
menyertaiku dalam menyelesaikan skripsi.
Untuk Ibu , Ayah, kakak, dan keponakan saya atas dukungan
kalian semua.
Buat yang tercinta, Silvia Natalia, atas
support
, dukungan dan
viii
ABSTRAKSI
Perpustakaan Universitas Sanata Dharma ( USD ) menggunakan sebuah sistem pencarian koleksi yang mengharuskan pemustaka untuk memiliki informasi yang memadai seperti judul, pengarang, dll. Pemustaka akan mengalami kesulitan dalam menemukan koleksi apabila hanya memiliki sedikit informasi mengenai isi koleksi yang ingin ditemukan. Sistem IR (Information Retrieval) dapat menjadi salah satu solusi penyelesaiannya. Terdapat beberapa permasalahan dalam pengembangan IR, salah satunya yaitu bagaiman melakukan pencarian yang cepat dan hemat sumber daya. Hal ini berkaitan dengan bentuk dan struktur data yang digunakan sebagai indeks. Salah satu struktur data yang dapat digunakan untuk menyelesaikannya adalah struktur dataHash table.
Dari latar belakang tersebut, dikembangkan sebuah sistem untuk menguji unjuk kerjaDivision methoddanKnuth’s multiplication methodsebagaihash function
ix
ABSTRACT
Library of Sanata Dharma University (USD) uses a collection searching system that requires the user to have adequate information such as title, author, etc. Users will have difficulty in finding the collection if they just have little information about the contents of the collection. This problem can be solved by an IR (Information retrieval) system. In developing IR, there are some problem such as how to do a fast and efficient searching. This relates to the form and data structure that used for the index. Hash table data structure can be used to solve this problems.
x
xi
KATA PENGANTAR
Puji dan syukur saya panjatkan pada Tuhan YME yang telah melimpahkan berkatnya sehingga saya dapat menyelesaikan tugas akhir ini.
Pada kesempatan ini saya ingin mengucapkan terima kasih pada pihak-pihak yang telah membantu saya dalam menyelesaikan skripsi ini, baik dalam hal bimbingan, perhatian, kasih sayang, semangat, kritik dan saran yang diberikan. Ucapan terima kasih ini saya sampaikan antara lain kepada :
1. Ibu Paulina Heruningsih Prima Rosa, S.Si., M.Sc selaku Dekan Fakultas Sains dan Teknologi Universitas Sanata Dharma.
2. Ibu Ridowati Gunawan, S.Kom, M.T. selaku ketua jurusan Teknik Informatika Sanata Dharma.
3. Bapak Eko Hari Parmadi S.Si., M.Kom. selaku Dosen Pembimbing Akademik Teknik Informatika angkatan 2008.
4. Ibu Sri Hartati Wijono, S.Si., M.Kom. selaku Dosen Pembimbing TA, terima kasih atas bimbingannya selama saya mengerjakan skripsi ini.
5. Bapak JB. Budi Darmawan, S.T, M.Sc. dan AlbertusAgung Hadhiatma S.T., M.T. selaku Dosen Penguji Pendadaran skripsi saya, terima kasih atas masukkan dalam memperbaiki skripsi ini.
xiii
DAFTAR ISI
HALAMAN JUDUL INDONESIA... i
HALAMAN JUDUL INGGRIS ... ii
HALAMAN PERSETUJUAN...iii
HALAMAN PENGESAHAN... iv
PERNYATAAN KEASLIAN KARYA ... v
HALAMAN MOTO ... vi
HALAMAN PERSEMBAHAN ...vii
ABSTRAKSI ...viii
ABSTRACT... ix
LEMBAR PENYATAAN PERSETUJUAN ... x
KATA PENGANTAR ...xi
DAFTAR ISI...xiii
DAFTAR GAMBAR ...xix
DAFTAR TABEL... xxi
DAFTAR LISTING ...xxii
xiv
BAB I PENGANTAR ... 1
1.1. Latar Belakang ... 1
1.2. Rumusan Masalah ... 4
1.3. Tujuan Penelitian... 4
1.4. Batasan Permasalahan ... 4
1.5. Manfaat Penelitian... 5
1.6. Luaran... 5
1.7. Metodologi Penelitian ... 5
1.8. Sistematika Penulisan... 7
BAB II LANDASAN TEORI ... 8
2.1. Perpustakaan... 8
2.1.1. Perpustakaan Universitas Sanata Dharma... 8
2.2. Information Retrieval ( IR ) ... 9
2.3. DataPreprocessing... 10
2.3.1. Tokenizing... 10
2.3.2. Stopword Removal... 10
2.3.3. Stemming... 11
xv
2.5. IndexingandSearching... 16
2.6. Hash Table... 17
2.6.1. Chained Hash Table... 17
2.6.2. Hash Function... 19
2.6.2.1. Mixing Step ... 19
2.6.2.2. Division Method... 21
2.6.2.3. Knuth’s Multiplication Method ... 21
2.7. Metodologi FAST ... 22
BAB III ANALISIS DESAIN... 26
3.1. Analisis Sistem... 26
3.1.1. Fase Definisi Ruang Lingkup (Scope Definition Phase) ... 26
3.1.2. Fase Analisis Masalah (Problem Analysis Phase) ... 27
3.1.2.1. Gambaran Sistem Lama ... 27
3.1.2.2. Gambaran Sistem Penelitian ... 27
3.2. Perancangan Penelitian ... 28
3.2.1. Data Penelitian ... 28
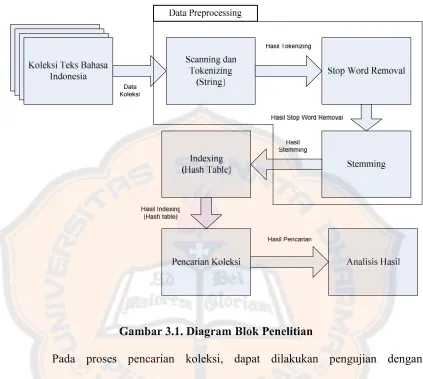
3.2.2. Diagram Blok Penelitian ... 28
xvi
3.2.4. FlowchartProses... 30
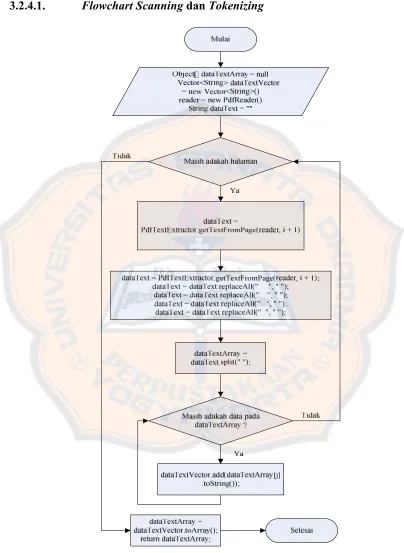
3.2.4.1. Flowchart ScanningdanTokenizing... 31
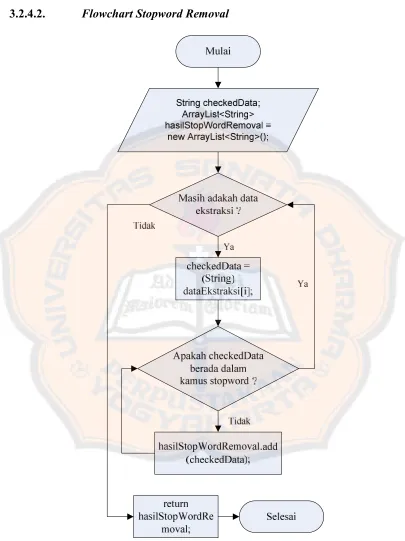
3.2.4.2. Flowchart Stopword Removal... 32
3.2.4.3. FlowchartPorterStemmer... 33
3.2.4.4. Flowchart Indexing... 34
3.2.4.5. Flowchart Searching ... 37
3.2.5. Skenario Pengujian... 38
3.2.5.1. Pengujian Waktu PemrosesanIndex... 38
3.2.5.2. Pengujian Sumberdaya Memori ... 38
3.2.5.3. Pengujian Persebaran Data dalamHash Table... 38
3.2.5.4. Pengujian Waktu Pencarian Koleksi ... 39
BAB IV IMPLEMENTASI ... 40
4.1. Implementasi Proses... 40
4.1.1. ImplementasiPreprocessing... 40
4.1.1.1. TahapScanningdanTokenizing... 41
4.1.1.2. TahapStopword Removal... 43
4.1.1.3. TahapStemming... 44
xvii
4.1.3. ImplementasiSearching... 66
BAB V HASIL PENGUJIAN DAN ANALISA... 72
5.1. Hasil Pengujian ... 72
5.1.1. Hasil Pengujian Waktu PemrosesanIndex... 73
5.1.2. Hasil Pengujian Sumber Daya Memori... 74
5.1.3. Hasil Pengujian Persebaran Data dalamHash Table... 75
5.1.3.1. Grafik PersebaranDivision Method ( 383Bucket)... 75
5.1.3.2. Grafik PersebaranKnuth’s Multiplication Method( 383Bucket).... 76
5.1.3.3. Grafik PersebaranDivision Method ( 1531Bucket)... 77
5.1.3.4. Grafik PersebaranKnuth’s Multiplication Method( 1531Bucket).. 78
5.1.3.5. Grafik PersebaranDivision Method ( 6143Bucket)... 79
5.1.3.6. Grafik PersebaranKnuth’s Multiplication Method( 6143Bucket).. 80
5.1.3.7. Grafik PersebaranDivision Method ( 24571Bucket)... 81
5.1.3.8. Grafik PersebaranKnuth’s Multiplication Method( 24571Bucket) 82 5.1.4. Hasil Pengujian Waktu Pencarian ... 83
5.2. Analisa Hasil Pengujian ... 85
5.2.1. Analisa Pengujian Waktu Pemrosesan Indeks ... 85
xviii
5.2.3. Analisa Pengujian Persebaran Data dalamHash Table... 87
5.2.4. Analisa Pengujian Waktu Pencarian ... 88
BAB VI KESIMPULAN DAN SARAN ... 93
6.1. Kesimpulan... 93
6.2. Saran... 94
DAFTAR PUSTAKA ... 95
xix
DAFTAR GAMBAR
Gambar 2.1. KomponenInverted Index... 16
Gambar 2.2. Ilustrasi strukturchained hash table... 18
Gambar 2.3. Algoritma PJWHash... 20
Gambar 3.1. Diagram Blok Penelitian ... 29
Gambar 3.2. Diagram Kelas UML... 30
Gambar 3.3.Flowchart ScanningdanTokenizing... 31
Gambar 3.4.Flowchart Stopword Removal... 32
Gambar 3.5.Flowchart Porter Stemmer(Porter, 1980) ... 33
Gambar 3.6.Flowchart IndexingdenganKnuth’s multiplication method... 35
Gambar 3.7.Flowchart IndexingdenganDivision Method... 36
Gambar 3.8.Flowchart Searching... 37
Gambar 5.1. Grafik Persebaran Data untuk Division Methoddengan ukuran 383Bucket... 76
Gambar 5.2. Grafik Persebaran Data untuk Knuth’s Multiplication Method dengan ukuran 383Bucket... 77
Gambar 5.3. Grafik Persebaran Data untuk Division Methoddengan ukuran 1531Bucket... 78
xx
Gambar 5.5. Grafik Persebaran Data untuk Division Methoddengan ukuran
6143Bucket... 80 Gambar 5.6. Grafik Persebaran Data untuk Knuth’s Multiplication Method
dengan ukuran 6143Bucket... 81 Gambar 5.7. Grafik Persebaran Data untuk Division Methoddengan ukuran
24571Bucket... 82 Gambar 5.8. Grafik Persebaran Data untuk Knuth’s Multiplication Method
dengan ukuran 24571Bucket... 83 Gambar 5.9. Grafik Perbandingan Waktu Pembentukan Hash Table ... 86 Gambar 5.10. Grafik Perbandingan Penggunaan Memori ... 87 Gambar 5.15. Grafik Perbandingan Standar Deviasi Persebaran Data dalam
xxi
DAFTAR TABEL
Tabel 5.1. Hasil Pengukuran Waktu Pembentukan Indeks ... 73 Tabel 5.2. Hasil Pengukuran Jumlah Memori Pembentukan Indeks ... 74 Tabel 5.3. Hasil Pengukuran Pengujian Waktu Pencarian pada Hash
Function :Division Method... 84 Tabel 5.4. Hasil Pengukuran Pengujian Waktu Pencarian pada Hash
xxii
DAFTAR LISTING
xxiii
DAFTAR LAMPIRAN
1
BAB I
PENGANTAR
1.1. Latar Belakang
Perpustakaan Universitas Sanata Dharma (USD) yang terletak di Yogyakarta merupakan salah satu Perpustakaan Perguruan Tinggi. Perpustakaan terdiri dari 2 (dua) unit perpustakaan yaitu Perpustakaan USD yang terletak di Mrican dan Paingan yang dikelola secara sentralisasi. Koleksi yang terdapat dalam Perpustakaan USD dibagi kedalam beberapa kategori yaitu : koleksi buku, tugas akhir, majalah, artikel majalah, suara (audio), gambar (image), gambar bergerak (video), dan e-book. Terdapat lebih dari 350.000 judul koleksi yang siap digunakan pada Perpustakaan USD. Dalam melakukan pelayanannya, Perpustakaan USD mengunakan sebuah "sistem terbuka" yang memungkinkan pemustaka untuk dapat memilih dan mencari sendiri koleksi yang diinginkannya.
informasi yang memadai mengenai kata kunci yang dibutuhkan. Contohnya, seorang pemustaka ingin mencari koleksi yang mengandung informasi mengenai pertumbuhan bakteri, maka pemustaka harus mengetahui kata kunci pencarian yang dapat dikenal oleh sistem, misalnya kata “mikrobiologi” sebagai kata kunci judul buku atau kata “Gemilang” sebagai kata kunci penerbit. Jika pemustaka hanya mengetahui penggalan kalimat yang terdapat pada pustaka tanpa mengetahui kata kunci yang terdapat pada sistem, maka pemustaka akan kesulitan untuk menemukan koleksi yang dibutuhkan. Hal ini menjadi keterbatasan sistem pencarian Perpustakaan USD karena pemustaka harus mengetahui kata kunci yang tepat agar pemustaka menemukan koleksi yang diinginkan.
Salah satu pendekatan yang dapat digunakan untuk menyelesaikan permasalahan tersebut adalah dengan menggunakan Information Retrieval System
(Sistem Pemerolehan Informasi). Sebuah Sistem Pemerolehan Informasi memungkinkan untuk dilakukannya pencarian bukan hanya pada kata kunci (judul, penerbit, dan lainnya) tertentu melainkan juga pada keseluruhan isi atau teks yang terdapat dalam pustaka koleksi. Beberapa tahapan dalam pengembangan sebuah Sistem Pemerolehan Informasi yaitu : pengumpulan data, tokenizing, stemming,
indexing,searching, dan pemodelan hasil pencarian.
pengaruh besar dalam hal efisiensi Information Retrieval System adalah pada proses pembuatan index dan pencarian informasi (searching). Menurut (Loudon, 1999), struktur data yang dapat mengakomodasi kebutuhan dalam pembuatan index dan pencarian (searching) adalahHash Table.
Terdapat beberapa permasalahan yang kerap muncul dalam pengembangan sebuah Hash Table yaitu : menentukan jenis hash table, fungsi hash (hash function) yang optimal untuk bentuk data tertentu, panjang hash table yang optimal dalam penggunaan sumber daya memori dan kecepatan akses. Sebuah hash table yang baik apabila diterapkan kedalam sebuah Information Retrieval System akan mendukung efisiensi dalam pencarian informasi (Bell, Harries, McKenzie, 1990). Dalam penelitian ini, penulis akan menganalisa unjuk kerja Knuth’s multiplication method
danDivision Method sebagaihash functionpadaChained Hash Table denganmixing step PJWHash sebagai proses indexing untuk data berupa data teks koleksi Perpustakaan Universitas Sanata Dharma yang berupa teks berbahasa Indonesia. Diharapkan penelitian ini dapat memberikan dukungan positif dalam pengembangan sebuah mesin Pencarian Koleksi Perpustakaan berbasis Information Retrieval System
1.2. Rumusan Masalah
Adapun masalah-masalah yang dapat dirumuskan dalam penelitian ini antara lain :
1. Bagaimanakah unjuk kerja Knuth’s multiplication method dan Division methodsebagaihash function padaChained Hash Table denganmixing step
PJWHash pada data berupa data teks berbahasa Inggris?
1.3. Tujuan Penelitian
Tujuan-tujuan yang ingin dicapai penulis dalam penelitian ini adalah sebagai berikut :
1. Mengetahui unjuk kerjaKnuth’s multiplication method danDivision method
sebagai hash function pada Chained Hash Table dengan mixing step
PJWHash pada data berupa data teks berbahasa Inggris.
1.4. Batasan Permasalahan
Beberapa batasan permasalahan dalam penelitian ini adalah sebagai berikut : 1. Kategori data teks yang akan digunakan yaitu : datae-book.
2. Data teks koleksi Perpustakaan USD yang akan digunakan akan melalui melalui proses scanning, tokenizing, stemming, dan indexing (inverted index).
4. Pengujian hash table yang akan dilakukan adalah berupa pengujian persebaran data dalam hash table, penggunaan sumberdaya memori,
processing time(waktu pemrosesan), dansearching time(waktu pencarian). 5. Pengujian sistem pada penelitian dilakukan dengan bahasa pemrograman
Java.
6. Prosesstemmingdilakukan dengan menggunakan algoritmaPorter Stemmer.
1.5. Manfaat Penelitian
Penelitian ini diharapkan dapat membantu pengembangan Sistem Pencarian Koleksi Perpustakaan USD berbasis Information Retrieval System yang lebih efisien dalam melakukan prosesindexingdan pencarian koleksi.
1.6. Luaran
Luaran yang diharapkan penulis melalui penelitian ini adalah diperolehnya informasi mengenai unjuk kerja Knuth’s multiplication method dan Division method
sebagai hash function pada Chained Hash Table untuk studi kasus Perpustakaan Universitas Sanata Dharma.
1.7. Metodologi Penelitian
Metode yang digunakan penulis dalam melaksanakan penelitian ini adalah
1. Analisis Ruang Lingkup
Menganalisis ruang lingkup permasalahan baik mengenai sistem sebelumnya dan solusi yang ditawarkan.
2. Analisis Permasalahan
Melakukan analisis dari permasalahan yang muncul pada sistem sebelumnya.
3. Perancangan Penelitian
Melakukan perancangan penelitian yang akan dilakukan dan metode pengujian yang akan diterapkan pada hasil penelitian.
4. Pelaksanaan Penelitian
Melakukan penelitian yang telah dirancang sebelumnya untuk mengetahui unjuk kerja indexing dan pencarian menggunakan Knuth’s multiplication methoddanDivision methodsebagaihash functionpadachained hash table. 5. Analisis Hasil Penelitian
1.8. Sistematika Penulisan
Sistematika penulisan pada penelitian ini dibagi kedalam beberapa bagian sebagai berikut :
BAB I : Berisi latar belakang munculnya permasalahan yang akan diteliti, rumusan permasalahan, tujuan penelitian, batasan masalah, metodologi penelitian, dan sistematika penulisan. BAB II : Berisi landasan-landasan teori yang digunakan penulis dalam
penyusunan penulisan penelitian ini.
BAB III : Berisi analisis permasalahan dan perancangan penelitian yang akan dilaksanakan.
BAB IV : Berisi implementasi sistem pengujian.
BAB V : Berisi hasil dan pembahasan penelitian yang telah dilaksanakan.
8
BAB II
LANDASAN TEORI
Pada bagian ini, penulis akan membahas mengenai dasar-dasar teori yang digunakan dalam penulisan penelitian. Dasar-dasar teori tersebut dapat dipaparkan sebagai berikut :
2.1. Perpustakaan
Menurut Undang-undang Nomor 43 Tahun 2007 tentang Perpustakaan, dtuliskan bahwa Perpustakaan adalah institusi pengelola koleksi karya tulis, karya cetak, dan/atau karya rekam secara profesional dengan sistem yang baku guna memenuhi kebutuhan pendidikan, penelitian, pelestarian, informasi, dan rekreasi para pemustaka. Seperti yang diketahui, Perpustakaan dibedakan menjadi : Perpustakaan Nasional, Umum, Sekolah / Madrasah, Perguruan Tinggi, dan Khusus. Perpustakaan Sekolah dan Perguruan Tinggi harus mengikuti Standar Nasional Perpustakaan sebagai acuan penyelenggaraan, pengelolaan, dan pengembangannya (Indonesia, 2007).
2.1.1. Perpustakaan Universitas Sanata Dharma
Kampus Paingan. Kedua Perpustakaan Universitas Sanata Dharma (USD) dikelola secara sentralisasi. Perpustakaan kampus Mrican merupakan perpustakaan Pusat, sedangkan Perpustakaan Kampus Paingan merupakan perpustakaan cabang. Perpustakaan Kampus Paingan berkonsentrai pada pelayanan pengguna bagi civitas akademika Universitas Sanata Dharma (USD) yang berada di Kampus Paingan. Sebuah jaringan komputer digunakan untuk menghubungkan Perpustakaan Mrican dan Paingan agar dapat melayani penggunanya secara online.
2.2. Information Retrieval ( IR )
2.3. DataPreprocessing
Data preprocessing merupakan tahap awal dalam pengembangan sebuah Sistem Pemerolehan Informasi. Adapun tahap-tahap yang dikerjakan meliputi :
scanningdata,tokenizing,stop-word removal, dan prosesstemming.
2.3.1. Tokenizing
Teks dalam bentuk asli nya, berupa rangkaian karakter tanpa informasi eksplisit mengenai batas-batas kata dan kalimat. Sebelum proses lebih lanjut dapat diterapkan, teks perlu untuk dipotong ke dalam bentuk kata-kata. Proses pemotongan ini disebuttokenization atautokenizing. Hasil pemotongan biasa disebut sebagai tokens. Tidak hanya kata-kata yang dianggap sebagaitokens, tetapi juga angka, tanda baca, tanda kurung, tanda kutip, dan lainnya (Schmid, 2008).
Sebagai contoh terdapat sebuah kalimat : Andi bermain bola bersama Koko di lapangan. Kalimat tersebut apabila dikenakan proses tokenizing maka akan diperoleh hasil berupa potongan-potongan kata yaitu : Andi; bermain; bola; bersama; Koko; di; lapangan. Dari hasil proses tokenizing, masih diperlukan beberapa langkah sebelum data dapat di proses kedalam bentukindex. Langkah berikut setelah data teks melalui prosestokenizingini adalah prosesstopword removal.
2.3.2. Stopword Removal
(Manning, Raghavan, Schutze, 2008). Contoh-contohstopworddalam bahasa Inggris seperti : is, am, a, at, the, in, on, dan lain sebagainya.
Salah satu strategi umum yang sering digunakan dalam menentukan kata-kata stopword dalam koleksi kata (dictionary) yang didapatkan adalah dengan mengurutkan kata-kata pada koleksi berdasarkan collecction frequency yaitu frekuensi kemunculan kata bersangkutan didalam seluruh koleksi dokumen. Pada umumnya kata-kata yang termasuk kedalamstopwordadalah kata-kata yang memiliki frekuensi kemunculan tertinggi. Pembuangan stopword ini disebut sebagai proses
stopword removal. Proses stopword removal ini memberikan sedikit banyak sumbangan kedalam hal efisiensi dalam penyimpanan dan pembuatan index dari koleksi kata yang didapatkan melalui prosestokenizing(Manning, 2008).
2.3.3. Stemming
Untuk alasan ketatabahasaan dalam sebuah dokumen teks, akan digunakan berbagai bentuk berbeda dari sebuah kata seperti kata “compute” dapat diubah kedalam beberapa bentuk lain seperti : “computer”, “computing”, “computation”, dan lain sebagainya. Dalam tata bahasa Inggris, hal ini dikenal sebagai penambahan akhiran. Tugas dari proses stemming ini adalah untuk mengubah kembali kata-kata dalam koleksi yang memiliki imbuhan kedalam bentuk kata dasarnya atau kata unik yang sudah pasti menggambarkan kata dasarnya. Salah satu algoritma stemming
1. Langkah 1 : menghilangkan kejamakan kata, akhiran –ed dan –ing caresses -> caress
ponies -> poni ties -> ti caress -> caress cats -> cat feed -> feed agreed -> agree disabled -> disable matting -> mat mating -> mate meeting -> meet milling -> mill messing -> mess meetings -> meet
2. Langkah 2 : mengubah huruf “y” pada akhir kata menjadi “i” apabila terdapat huruf vokal didalam kata yangstem.
(m>0) ABLI → ABLE conformabli → conformable (m>0) ALLI → AL radicalli → radical
(m>0) ENTLI → ENT differentli → different
(m>0) ELI → E vileli vile
(m>0) OUSLI → OUS analogousli → analogous (m>0) IZATION → IZE vietnamization → vietnamize (m>0) ATION → ATE predication → predicate (m>0) ATOR → ATE operator → operate (m>0) ALISM → AL feudalism → feudal (m>0) IVENESS → IVE decisiveness → decisive (m>0) FULNESS → FUL hopefulness → hopeful (m>0) OUSNESS → OUS callousness → callous (m>0) ALITI → AL formaliti → formal (m>0) IVITI → IVE sensitiviti → sensitive (m>0) BILITI → BLE sensibiliti → sensible
3. Langkah 3 : menghilangkan akhiran ganda (double suffix) seperti kata yang berakhiran –ization (mangandung akhiran –ize dan –ation) diubah misal menjadi –ize.
(m>0) ICATE → IC triplicate → triplic
(m>0) ATIVE → formative → form
(m>0) ICAL → IC electrical → electric
(m>0) FUL → hopeful → hope
(m>0) NESS → goodness → good
4. Langkah 4 : menangani beberapa imbuhan seperti -ic-, -full, -ness dan sebagainya.
(m>1) AL → revival → reviv
(m>1) ANCE → allowance → allow
(m>1) ENCE → inference → infer
(m>1) ER → airliner → airlin
(m>1) IC → gyroscopic → gyroscop
(m>1) ABLE → adjustable → adjust
(m>1) IBLE → defensible → defens
(m>1) ANT → irritant → irrit
(m>1) EMENT → replacement → replac
(m>1) MENT → adjustment → adjust
(m>1) ENT → dependent → depend
(m>1 and (*S or *T)) ION → adoption → adopt
(m>1) OU → homologou → homolog
(m>1) ISM → communism → commun
(m>1) ATE → activate → activ
(m>1) ITI → angulariti → angular
(m>1) IVE → effective → effect
(m>1) IZE → bowdlerize → bowdler
5. Langkah 5 : menghilangkan akhiran seperti -ant, -ence dan sebagainya. (m>1) E → probate -> probat, rate->rate
(m=1 and not *o) E → cease → ceas
(m > 1 and *d and *L) → single letter
controll → control roll → roll
1. Langkah 6 : menghilangkan akhiran terakhir yaitu –e.
Untuk setiap langkah algoritma diatas, terdapat implementasi tertentu yang dilakukan oleh porter, seperti variabel “m” yang merupakan variabel yang menandakan jumlah pasangan vokal-konsonan ditengah kata. Contoh :
m=0 TR, EE, TREE, Y, BY.
m=1 TROUBLE, OATS, TREES, IVY.
m=2 TROUBLES, PRIVATE, OATEN, ORRERY.
2.4. Index
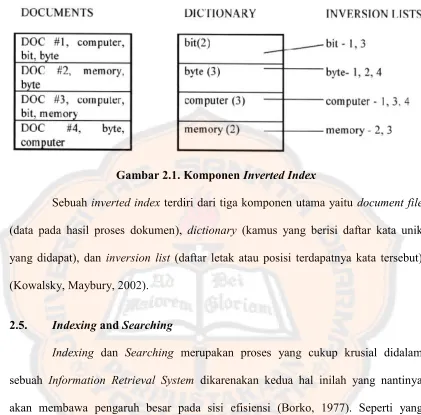
Gambar 2.1. KomponenInverted Index
Sebuah inverted indexterdiri dari tiga komponen utama yaitu document file
(data pada hasil proses dokumen), dictionary (kamus yang berisi daftar kata unik yang didapat), dan inversion list (daftar letak atau posisi terdapatnya kata tersebut) (Kowalsky, Maybury, 2002).
2.5. IndexingandSearching
2.6. Hash Table
Hash table merupakan sebuah struktur data berbentuk array yang pengaksesan isinya dilakukan melalui sebuah key value (nilai kunci). Gagasan utama dari stuktur data hash table ini adalah untuk membentuk sebuah pemetaan data dan posisi data tersebut terletak. Sebuah hash table yang baik akan memiliki persebaran data yang merata. Hash value yang digunakan untuk mengakses posisi data dalam
arraydihasilkan melalui sebuahhash function.
Sebuah hash function yang baik akan dapat memetakan data secara merata kedalam array yang tersedia. Saat sebuah hash funtion dapat menjamin bahwa tidak akan dihasilkannya sebuah hash valueyang sama, maka akan terbentuk perfect hash
(pemetaan sempurna).Perfect hashmerupakanbest case(kondisi terbaik) dari sebuah
hash table dimana dimiliki kompleksitas algoritma untuk melakukan pencarian yaitu O(1). Kompleksitas O(1) berarti bahwa pencarian dapat dilakukan dengan waktu instant (Loudon, 1999).
Unjuk kerja sebuah hash function juga sangat dipengaruhi oleh bagaimana bentuk integer data yang dimasukkan. Terutama apabila data input berupa data teks (string), maka data harus terlebih dahulu melalui process String Processing(Cormen, 1990).
2.6.1. Chained Hash Table
hash function, memetakan dua atau lebih data dengan sebuah hash value yang sama.
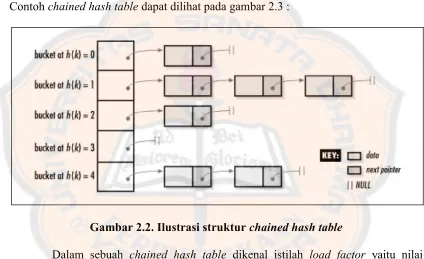
Chained Hash Table memiliki sebuah ide bahwa array statik pada hash table akan berupabucketatauarray yang didalamnya berisi struktur datalinked list. Gagasan ini dapat mengatasi collision dengan cara, data dengan hash value yang sama, akan dipetakan kedalam sebuah posisiarraynamun berada dalamlinked listyang berbeda. Contohchained hash tabledapat dilihat pada gambar 2.3 :
Gambar 2.2. Ilustrasi strukturchained hash table
Dalam sebuah chained hash table dikenal istilah load factor yaitu nilai harapan jumlah maksimal data pada sebuah posisi dalam hash table(dengan asumsi terjadi keseragaman pada persebaran data dalamhash table).
Menurut (Kruse, Rybe, 1998) salah satu keuntungan utama penggunaan
chained hash table sebagai solusi collision adalah dapat dihematnya pemakaian sumberdaya yang dibutuhkan untuk penyimpanan data. Unjuk kerja sebuah chained hash table juga tidak lepas dari hash function yang digunakan untuk menentukan
2.6.2. Hash Function
Hash Function adalah suatu fungsi atau aturan yang digunakan untuk memetakan key valuekedalam bentuk hash value sesuai dengan panjang hash table. Adapun bentuk umum rumus sebuahhash functionadalah sebagai berikut (persamaan (1)) :
Pemilihan hash function yang baik sangat signifikan dalam mempengaruhi unjuk kerja suatuhash table. Hal ini dikarenakan dengan memilih suatu hash function
yang baik, data-data dapat dipetakan kedalam hash table secara merata sehingga dapat menghindari terjadinya collision yang terlalu banyak. Contoh hash function
yang sederhana sepertiDivision method danKnuth’s multiplication method.
2.6.2.1. Mixing Step
Mixing step merupakan tahap dimana data dalam bentuk String akan diubah kedalam bentuk data Integer agar dapat diproses ketahap perhitungan hash code. PJWHash merupakanmixing functionyang dikembangkan oleh P.J. Weinberger yang didalamnya terjadi beberapa proses pergeseran bit dari kode ASCII masing-masing karakter darikey( Aho, Sethi, Ullman, 1986).
h (k) = x ... (1) keterangan : h = fungsiHash
k =key value
Proses pada PJWHash dimulai dengan membuat sebuah variabel h=0. Untuk setiap karakter dari key, dilakukan pergeseran bit kekiri sebanyak 4 bit kemudian ditambahkan dengan bit karakter bersangkutan dan disimpan kedalam variabel “h”. Jika pada 4 bit atas hasil penjumlahan tersebut terdapat bit 1, maka lakukan pergeseran 4 bit tersebut kekanan sebanyak 24 bit, hasilnya dikenakan operasi XOR terhadap variabel “h” dan hasilnya disimpan kedalam variabel “h”. Kemudian ubah 4
bitatas pada variabel “h” menjadibit0 ( Aho, Sethi, Ullman, 1986).
Algoritma tersebut dapat digambarkan dalam bahasa pemrograman C sebagai berikut :
Gambar 2.3. Algoritma PJWHash
dibutuhkan konversi tipe data kedalam tipe data Long pada bahasa pemrograman JAVA dimana hasil dari sebuah tipe data Integer akan dikenakan operasi AND terhadapbit0xffffffffL yang merupakanbit1 pada semua 32-bit bawah pada tipe data Long.
2.6.2.2. Division Method
Prinsip kerja division method adalah dengan mengambil sisa pembagian key value dengan panjanghash table sebagai hash value. Metode ini merupakan metode sederhana yang sering digunakan dalam merancang sebuah hash table. adapun penjabaran dari perhitungan pada metode division method ini adalah sebagai berikut (persamaan (2)) :
Pemilihan panjanghash table(m) padadivision methodsebaiknya dilakukan dengan memilih suatu bilangan prima yang terletak jauh dari bilangan pangkat 2 dengan tetap memperhatikanload factor hash table yang diinginkan (Loudon, 1999).
2.6.2.3. Knuth’s Multiplication Method
Prinsip kerja dari Knuth’s Multiplication Method adalah dengan mengkalikan key value dengan sebuah konstanta A yang bernilai 0 < A < 1.
h(k) = k mod m ... (2) Keterangan :
h(k) =hash value
k =key value
Kemudian nilai yang didapat akan dikalikan dengan jumlah slot / bucket pada hash table. Nilai yang menjadihash valueadalah nilai hasil pembulatan kebawah dari hasil yang didapat pada perhitungan sebelumnya. Nilai A yang sering digunakan adalah 0,618 yang disebut sebagai Golden Ratio. Perhitungan golden ratio dilihat pada persamaan (3) (Loudon, 1999) :
Penjabaran rumus perhitungan hash value pada Knuth’s multiplication methoddapat dituliskan sebagai berikut (persamaan (4)) :
2.7. Metodologi FAST
Metodologi FAST (Framework for the Application of Sistem Thinking)
merupakan kerangka yang fleksibel untuk menyediakan tipe-tipe berbeda proyek dan strategi (Whitten, 2004). Adapun tahapan-tahapan yang terdapat dalam FAST adalah sebagai berikut :
ℎ( ) = ⌊ ( 1 ) ⌋... (4)
Keterangan : h(k) =hash value
m = panjanghash table
k =key value
A =golden ratio
≈
5− 12 ... (3) Keterangan :1. Scope Definition Phase
Pada tahap ini dilakukan pengumpulan informasi yang akan diteliti tingkat feasibility dan ruang lingkup proyek yaitu dengan menggunakan kerangka PIECES (Performance, Information, Economics, Control, Efficiency, Service). Hal ini dilakukan untuk menemukan inti dari masalah-masalah yang ada (problems), kesempatan untuk meningkatkan kinerja organisasi (opportunity), dan kebutuhan-kebutuhan baru yang dibebankan oleh pihak manajemen atau pemerintah (directives).
2. Problem Analysis Phase
Problem Analysis adalah studi untuk memahami sistem yang ada sekarang dan menganalisa untuk menyediakan informasi kepada tim proyek. Pada tahap ini akan diteliti masalah-masalah yang muncul pada sistem yang ada sebelumnya.
3. Requirement Analysis Phase
Tujuan dari tahapan ini adalah mengidentifikasi data, proses dan antarmuka yang diinginkan pengguna dari sistem yang baru. Alat bantu untuk memahami kebutuhan yang ada adalah dengan pemodelanuse case.
4. Logical Design Phase
menjaminusability, reliability, completeness, performance, danquality yang akan dibangun di dalam sistem.
5. Decision Analysis Phase
Pada tahap ini akan akan dipertimbangkan beberapa kandidat dari perangkat lunak dan keras yang nantinya akan dipilih dan dipakai dalam implementasi sistem sebagai solusi atas problems dan requirements yang sudah didefinisikan pada tahapan-tahapan sebelumnya.
6. Physical Design and Integration Phase
Tujuan dari tahapan ini adalah mentransformasikan kebutuhan bisnis yang direpresentasikan sebagai logical design menjadi physical design yang nantinya akan dijadikan sebagai acuan dalam membuat sistem yang akan dikembangkan. Jika di dalam logical design tergantung kepada berbagai solusi teknis, maka physical design merepresentasikan solusi teknis yang lebih spesifik.
7. Construction and Testing Phase
Mulai mengkonstruksi dan menguji komponen-komponen sistem untuk desain. Ada dua tujuan fase ini yaitu :
aMembangun dan menguji sebuah sistem yang memenuhi persyaratan bisnis dan spesifikasi desain fisik.
8. Installation and Delivery Phase
Kegiatan yang dilakukan pada fase ini adalah instalasi sistem, training user, manual sistem, mengkonversi file dandatabase yang ada ke dalamdatabase
26
BAB III
ANALISIS DESAIN
3.1. Analisis Sistem
Pada bagian ini akan dijelaskan mengenai analisa dari perancangan sistem penelitian yang akan dilakukan. Adapun perancangan sistem penelitian ini berdasarkan tahapan metodologi FAST.
3.1.1. Fase Definisi Ruang Lingkup (Scope Definition Phase)
Sistem yang ada saat ini dibangun menggunakan metodologi dan prosedur perangkat lunak secara terstruktur. Sistem pencarian koleksi adalah sebuah sistem yang digunakan untuk melakukan pencarian data koleksi berdasarkan keyword yang diinputkan oleh pengguna dan pengelolaan data oleh administrator serta staff dalam hal ini petugas di perpustakaan. Pengguna dapat melakukan pencarian (searching)
efektifitas pemerolehan informasi. Masalah yang terdapat pada sisi efisiensi adalah bagaimana membentuk index data koleksi yang efektif dan melakukan pencarian dengan cepat.
3.1.2. Fase Analisis Masalah (Problem Analysis Phase)
3.1.2.1. Gambaran Sistem Lama
Sistem pencarian yang digunakan saat ini memungkinkan pengguna untuk melakukan pencarian pada data koleksi Perpustakaan dengan memasukkan query
pada salah satu jenis kata kunci (pengarang, penerbit, judul, dan lainnya) dengan terlebih dahulu memilih kategori koleksi (buku, majalah, tugas akhir, dan lain sebagainya). Sistem dibangun menggunakan bahasa pemrograman PHP dan database SQL. Pencarian data koleksi dilakukan menggunakanquery database.
3.1.2.2. Gambaran Sistem Penelitian
Sistem yang dibangun pada penelitian ini adalah sistem yang digunakan untuk menguji salah satu solusi pembentukan index. Penelitian yang akan dilakukan ditujukan pada membandingkan unjuk kerja dua buah hash function pada chained hash table yaitu Knuth’s multiplication method dan Division method. Sistem pengujian akan dibangun dengan bahasa pemrograman JAVA. Sistem pengujian akan melakukan pengujian mengenai pemrosesan pembentukan index dan pencarian pada
memori yang digunakan, persebaran data dalam hash table, dan waktu pencarian yang dibutuhkan untuk menemukan kembali koleksi yang tersimpan.
3.2. Perancangan Penelitian
Berikut akan dipaparkan perancangan sistem pengujian yang akan dibangun pada penelitian ini.
3.2.1. Data Penelitian
Data yang digunakan penulis dalam penelitian ini berupa sejumlah data E-book yang diperoleh dari Perpustakaan Universitas Sanata Dharma (USD). Data E-bookyang digunakan berupa 71 buahE-bookberbahasa Inggris.
3.2.2. Diagram Blok Penelitian
Gambar 3.1. Diagram Blok Penelitian
Pada proses pencarian koleksi, dapat dilakukan pengujian dengan memasukkan lebih dari 1 kata pencarian. Proses pencarian yang dilakukan dengan memasukkan lebih dari 1 kata pencarian adalah proses pencarian dengan operasi AND yang akan menghasilkan koleksi yang mengandung semua kata pencarian.
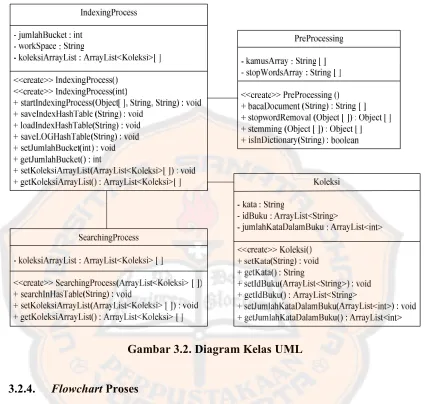
3.2.3. Diagram Kelas UML
Gambar 3.2. Diagram Kelas UML
3.2.4. FlowchartProses
3.2.4.1. Flowchart ScanningdanTokenizing
3.2.4.2. Flowchart Stopword Removal
3.2.4.3. FlowchartPorterStemmer
3.2.4.4. Flowchart Indexing
Terdapat 2 (dua) jenisindexingyang akan diujikan dalam penelitian ini yaitu
indexing menggunakan hash function Knuth’s multiplication method dan Division method. Gambar 3.11 menunjukkan flowchart proses indexing dengan Knuth’s multiplication methodsebagaihash functiondan gambar 3.12 menunjukkanflowchart
Gambar 3.6.Flowchart Indexingdengan
Gambar 3.7.Flowchart Indexingdengan
3.2.4.5. Flowchart Searching
3.2.5. Skenario Pengujian
Dibawah ini akan dijabarkan lebih lengkap mengenai parameter pengujian yang akan dilaksanakan dalam penelitian ini. Adapun parameter pengujian tersebut adalah sebagai berikut :
3.2.5.1. Pengujian Waktu PemrosesanIndex
Pengujian waktu pemrosesan merupakan pengujian yang dilakukan pada saat pembentukan index. Waktu pemrosesan yang diukur dimulai dari saat sistem mulai mengambil data pertama dari hasil stemming sampai saat sistem meletakkan data terakhir. Waktu yang didapat melalui Knuth’s multiplication method dan Division methodakan dibandingkan dan dianalisis.
3.2.5.2. Pengujian Sumberdaya Memori
Pengujian sumberdaya memori merupakan pengujian pada besarnya jumlah
free memory (memori bebas) yang digunakan atau dipakai pada saat pembentukan
Hash table yang bersangkutan. besarnya free memory akan diukur mulai dari saat pembacaan koleksi Perpustakaan sampai dengan saat Hash table berhasil dibentuk.
Free memoryakan ditampilkan dalam bentuk besaranbytes memory.
3.2.5.3. Pengujian Persebaran Data dalamHash Table
menampilkan nomor bucket pada hash table dan sumbu (y) akan menampilkan panjang chain (linked list) yang terbentuk didalam bucket tersebut. Pengujian yang dilakukan adalah dengan membandingkan dan menganalisis panjang chain terbesar dan terkecil, rata-rata, varians dan standar deviasi panjangchain.
3.2.5.4. Pengujian Waktu Pencarian Koleksi
Pengujian waktu pencarian merupakan pengujian yang dilakukan pada saat pengguna memasukkan query. Untuk mengukur waktu pencarian pada hash table
yang terbentuk melalui proses pengindeksan, dibutuh teknik sampling yang akan menjamin bahwa data yang digunakan pada pencarian sudah mewakili keseluruhan populasi dan lokasi bucket. Tanpa menggunakan sampling yang tepat, dapat dihasilkan data pengukuran waktu pencarian yang bias.
Untuk mengetahui lebih lanjut unjuk kerja dalam hal waktu pencarian pada kedua jenis hash function dapat dilakukan dengan mencatat beberapa informasi terkait persebaran data-data dalam hash table. Pengukuran yang dilakukan akan meliputi pencatatan persentase jumlah bucket yang tidak terisi, persentase jumlah
40
BAB IV
IMPLEMENTASI
Pada bagian ini penulis akan memaparkan proses implementasi sistem pengujian yang telah dirancang kedalam bahasa yang dapat dimengerti mesin. Spesifikasi perangkat lunak yang digunakan dalam melakukan implementasi sistem pengujian adalah sebagai berikut :
1. Sistem operasi : Windows 7 Ultimate Edition 2. Netbeans IDE 6.9.1
4.1. Implementasi Proses
Berikut akan ditampilkan proses implementasi masing-masing proses utama yang terdapat dalam sistem pengujian antara lain proses Preprocessing, proses
Indexing, dan prosesSearching.
4.1.1. ImplementasiPreprocessing
Proses Preprocessing ini merupakan proses yang akan mengolah data mentah yang berupa koleksi-koleksi perpustakaan menjadi data-data yang siap dipakai didalam tahap Indexing maupun Searching koleksi. Pada proses
Preprocessing ini, terdapat tahapan-tahapan pengolahan data yaitu : tahap Scanning
4.1.1.1. TahapScanningdanTokenizing
Pada tahap ini, data koleksi perpustakaan akan dibaca dan diekstrak data tulisan kedalam bentuk data String. Data String yang diperoleh masih berupa kesatuan sekumpulan kata-kata yang terdapat dalam fileyang dibaca. Kemudian data String ini akan dipecah kedalam bentuk Object[ ] (Object Array) dimana setiap posisi dalam Array tersebut akan diisi dengan 1 buah kata. Proses ini dilaksanakan dengan memanggilmethodbacaDocument(String).
public Object[] bacaDocument(String bookSource) { double timeStart = (double) System.nanoTime(); String inputFile = bookSource;
Object[] dataTextArray = null;
ArrayList<String> dataTextVector = new ArrayList <String>(); try {
reader = new PdfReader(inputFile);
int numberOfPages = reader.getNumberOfPages();
//dimulai pengulangan untuk ektraksi kata pada tiap halaman String dataText = "";
for (int i = 0; i < numberOfPages; i++) {
dataText = PdfTextExtractor.getTextFromPage(reader, i + 1); dataText = dataText.replaceAll("[^a-zA-Z0-9]", " ");
dataText = dataText.replaceAll(" ", " "); dataText = dataText.replaceAll(" ", " "); dataText = dataText.replaceAll(" ", " "); //tokenizing kata menjadi array
dataTextArray = dataText.split(" ");
for (int j = 0; j < dataTextArray.length; j++) {
dataTextVector.add(dataTextArray[j].toString()); }} reader.close();
} catch (IOException ex) {
Logger.getLogger(PreProcessing.class.getName()).log(Level.SEVERE, null, ex); }
//perhitungan waktu pemrosesan ektraksi kata double timeFinish = (double) System.nanoTime();
double time = ((double) (timeFinish - timeStart)) / 1000000000; System.out.println("Start time extraction : " + timeStart);
System.out.println("Finish time extraction : " + timeFinish); System.out.println("Total time use : " + time);
//menampilkan hasil panjang array keseluruhan kata dari semua halaman System.out.println("Jumlah keseluruhan array kata : " + dataTextVector.size()); //mengembalikan hasil ekstraksi
return dataTextArray; }
Listing 4.1.ScanningdanTokenizing
4.1.1.2. TahapStopword Removal
Pada tahap ini, data hasil Scanning dan Tokenizing yang berbentuk data Object Array akan dikenai proses penghapusan atau penghilangan kata-kata yang termasuk kedalam daftar kata “Stopword”. Proses ini dilaksanakan dengan memanggilmethodstopwordRemoval(Object [ ]). Kata yang dikenai prosesStopword Removal ini akan melalui dua tahap pengecekan, yaitu pengecekan terhadap kata
Stopword bahasa Indonesia dan bahasa Inggris. Keluaran method method
stopwordRemoval(Object [ ]) berupa sebuah variabel bertipe Object. Method
stopwordRemoval(Object [ ]) dapat dijabarkan sebagai berikut : public Object[] stopwordRemoval(Object[] dataEkstraksi) {
double timeStart = (double) System.nanoTime(); String checkedData;
ArrayList<String> hasilStopWordRemoval = new ArrayList<String>();
//permulaan pengecekan dan penghapusan stopwords dengan data hasil Ektraksi for (int i = 0; i < dataEkstraksi.length; i++) {
checkedData = (String) dataEkstraksi[i];
} else {
hasilStopWordRemoval.add(checkedData); } } //perhitungan waktu proses stopwordsRemoval
double timeFinish = (double) System.nanoTime();
double time = ((double) (timeFinish - timeStart)) / 1000000000; System.out.println("Start time stopword Removal : " + timeStart); System.out.println("Finish time stopword Removal : " + timeFinish); System.out.println("Total time use : " + time);
//menampilkan jumlah kata setelah stopword removal
System.out.println("Jumlah kata setelah stopword removal : " + hasilStopWordRemoval.size());
//mengembalikan hasil data array stopword removal return hasilStopWordRemoval.toArray(); }
Listing 4.2.Stopword Removal
4.1.1.3. TahapStemming
TahapStemmingmerupakan proses pencarian kata dasar dari kata-kata yang diperoleh sebelumnya (tahap Stopword Removal). Proses stemming ini akan mencari kata dasar untuk kata berbahasa Inggris akan dilakukan dengan menerapkan algoritmaPorter stemmer. Proses Stemmingdilaksanakan dengan memanggilmethod
public Object[] stemming(Object[] hasilStopwordRemoval) { double timeStart = (double) System.nanoTime();
char[] sequenceWord;
porterStemmer = new Stemmer();
ArrayList<String> hasilStemming = new ArrayList<String>(); //proses stemming dimulai
String rootWord = "";
for (int i = 0; i < hasilStopwordRemoval.length; i++) {
sequenceWord = ((String) hasilStopwordRemoval[i]).toCharArray(); porterStemmer.add(sequenceWord, sequenceWord.length);
porterStemmer.stem();
rootWord = porterStemmer.toString().toLowerCase(); hasilStemming.add(rootWord); }
Listing 4.3.Stemming
RincianlistingPorter stemmer terlampir pada dokumen ini.
4.1.2. ImplementasiIndexing
dikerjakan dengan memanggil methodstartIndexingProcess(Object[ ], String, String, String, int). Berikut merupakan hasil implementasi method
startIndexingProcess(Object[ ], String, String, String, int).
public void startIndexingProcess(Object[] hasilStemmingIndonesia, String status, String idBuku, String hashMethod, int mixingStepTipe) {
double timeStart = (double) System.nanoTime(); double timeFinish;
double time;
//pengecekan status pengindeksan apakah permulaan atau sambungan if (status.equalsIgnoreCase("start")) {
wordCount = 0;
koleksiArrayList = (ArrayList<Koleksi>[])
Array.newInstance(ArrayList.class, jumlahBucket); for (int i = 0; i < jumlahBucket; i++) {
koleksiArrayList[i] = new ArrayList<Koleksi>(); } } //mulai meletakkan kedalam hash table perkata
long mixingCode; String word;
for (int i = 0; i < hasilStemmingIndonesia.length; i++) { word = ((String) hasilStemmingIndonesia[i]);
mixingCode=MS.PJWHash(word); //penghilangan angka negatif
mixingCode = Math.abs(mixingCode); int hashCode;
if (hashMethod.equalsIgnoreCase("division")) { //division method
hashCode = (int) (mixingCode % this.getJumlahBucket()); //end division method
} else {
//selesai pemotongan
hashCode = (int) (this.getJumlahBucket() * ((mixingCode * knuth) % 1)); //end multiplication method
}
boolean isIdBukuFind = false; boolean isWordFind = false; int posisiKataInHashTable = 0;
for (int j = 0; j < this.getKoleksiArrayList()[hashCode].size(); j++) { if
(this.getKoleksiArrayList()[hashCode].get(j).getKata().equalsIgnoreCase((String) hasilStemmingIndonesia[i])) {
posisiKataInHashTable = j;
for (int k = 0; k <
this.getKoleksiArrayList()[hashCode].get(j).getIdBuku().size(); k++) { if
(this.getKoleksiArrayList()[hashCode].get(j).getIdBuku().get(k).equalsIgnoreCase(id Buku)) {
isIdBukuFind = true;
this.getKoleksiArrayList()[hashCode].get(j).getJumlahKataDalamBuku().set(k, this.getKoleksiArrayList()[hashCode].get(j).getJumlahKataDalamBuku().get(k) + 1);
break; } } break; } }
if (!isWordFind) { wordCount++;
Koleksi temp = new Koleksi();
temp.setKata((String) hasilStemmingIndonesia[i]); temp.getIdBuku().add(idBuku);
temp.getJumlahKataDalamBuku().add(1);
this.getKoleksiArrayList()[hashCode].add(temp); } else if (!isIdBukuFind) {
koleksiArrayList[hashCode].get(posisiKataInHashTable).getJumlahKataDalamBuku( ).add(1); } }
//selesai meletakkan kedalam hash table perkata // memulai perhitungan waktu Hash
timeFinish = (double) System.nanoTime();
time = ((double) (timeFinish - timeStart)) / 1000000000;
System.out.println("Start time indexing HashTable : " + timeStart); System.out.println("Finish time indexing HashTable : " + timeFinish); System.out.println("Total time use : " + time);
System.out.println("Total words created in HashTable : " + wordCount); }
Listing 4.4. Pengindeksan kedalamHashTable
Berikut akan dipaparkan lebih jauh mengenai fungsi-fungsi yang dikerjakan padamethodstartIndexingProcess(Object[ ], String, String, String, int) ini. Pada awal
double timeStart = (double) System.nanoTime(); double timeFinish;
double time;
Listing 4.4.1. Variabel pencatat waktu pengindeksan
Sebelum melakukan proses pengindeksan, akan dilakukan terlebih dahulu pengecekan terhadap status pemanggilan method startIndexingProcess(Object[ ], String, String, String, int), hal ini dikarenakan terdapat dua jenis status pemanggilan yaitu “start” atau “continue”. Apabila satus pemanggilan adalah “start” maka
Hashtable yang digunakan merupakan Hashtable yang baru sedangkan bila tidak, makaHashtableyang digunakan merupakanHashtablesebelumnya (Lisitng 4.4.2). //pengecekan status pengindeksan apakah permulaan atau sambungan
if (status.equalsIgnoreCase("start")) { wordCount=0;
koleksiArrayList = (ArrayList<Koleksi>[])
Array.newInstance(ArrayList.class, jumlahBucket); for (int i = 0; i < jumlahBucket; i++) {
koleksiArrayList[i] = new ArrayList<Koleksi>(); } }
Listing 4.4.2. Pengecekan status pemanggilan method
Kemudian akan mulai dilakukan pengisian setiap kata kedalam Hashtable
yang telah disediakan. Pada awalnya akan dihitung mixing code dengan mixing step
mixingCode = 0;
mixingCode=MS.PJWHash(word);
Listing 4.6.3. Penentuanmixing step
Mixing code yang diperoleh dapat berupa nilai negatif yang tidak dapat digunakan dalam perhitungan menggunakan Hash function sehingga harus diubah kedalam bentuk positif (Listing 4.4.4).
mixingCode=Math.abs(mixingCode);
Listing 4.4.4. Pengubahan Mixing code negatif menjadi positif
Kemudian tahap selanjutnya adalah menghitung Hash code menggunakan salah satu dari kedua Hash function yang digunakan dalam penelitian sesuai parameter yang dimasukkan (Listing 4.4.5).
int hashCode;
if (hashMethod.equalsIgnoreCase("division")) { //division method
hashCode = (int) (mixingCode % this.getJumlahBucket()); //end division method
} else {
//multiplication method
hashCode = (int) (this.getJumlahBucket() * ((mixingCode * knuth) % 1)); //end multiplication method }
Setelah Hash code diperoleh, maka dilakukan pengisian kata bersangkutan kedalam Hash table yang disediakan. Kata (word) yang akan dimasukkan dibentuk kedalam sebuah objek dari kelas Koleksi. Proses ini dapat dilihat pada listing 4.4.6 dibawah ini.
boolean isIdBukuFind = false; boolean isWordFind = false; int posisiKataInHashTable = 0;
for (int j = 0; j < this.getKoleksiArrayList()[hashCode].size(); j++) { if
(this.getKoleksiArrayList()[hashCode].get(j).getKata().equalsIgnoreCase((String) hasilStemmingIndonesia[i])) {
isWordFind = true;
posisiKataInHashTable = j;
for (int k = 0; k <
this.getKoleksiArrayList()[hashCode].get(j).getIdBuku().size(); k++) { if
(this.getKoleksiArrayList()[hashCode].get(j).getIdBuku().get(k).equalsIgnoreCase(id Buku)) {
isIdBukuFind = true;
this.getKoleksiArrayList()[hashCode].get(j).getJumlahKataDalamBuku().get(k) + 1); break; } }
break; } } if (!isWordFind) {
wordCount++;
Koleksi temp = new Koleksi();
temp.setKata((String) hasilStemmingIndonesia[i]); temp.getIdBuku().add(idBuku);
temp.getJumlahKataDalamBuku().add(1);
this.getKoleksiArrayList()[hashCode].add(temp); } else if (!isIdBukuFind) {
koleksiArrayList[hashCode].get(posisiKataInHashTable).getIdBuku().add(idBuku);
koleksiArrayList[hashCode].get(posisiKataInHashTable).getJumlahKataDalamBuku( ).add(1); }
Listing 4.4.6. Pengisian objek koleksi kedalamHash table
timeFinish = (double) System.nanoTime();
time = ((double) (timeFinish - timeStart)) / 1000000000;
System.out.println("Start time indexing HashTable : " + timeStart); System.out.println("Finish time indexing HashTable : " + timeFinish); System.out.println("Total time use : " + time);
System.out.println("Total words created in HashTable : " + wordCount);
Listing 4.4.7. Pencatatan dan perhitungan total waktu pengindeksan
Selain melakukan proses pengindeksan, sistem pengujian juga memungkinkan untuk menyimpan HashTable yang telah terbentuk kedalam bentuk sebuah file .txt (file text) sebagai bentuk penyimpanan permanen. Proses penyimpanan ini dilakukan dengan memanggilmethodsaveIndexHashTable(String). public void saveIndexHashTable(String namaFile) {
double timeStart = (double) System.nanoTime(); double timeFinish;
double time;
FileWriter fw = null; try {
String lokasiSaveHashTable = workSpace + namaFile; fw = new FileWriter(lokasiSaveHashTable);
bw.newLine();
for (int i = 0; i < getJumlahBucket(); i++) {
bw.write(String.valueOf(koleksiArrayList[i].size())); bw.newLine();
for (int j = 0; j < koleksiArrayList[i].size(); j++) { bw.write(koleksiArrayList[i].get(j).getKata()); bw.newLine();
bw.write(String.valueOf(koleksiArrayList[i].get(j).getIdBuku().size())); bw.newLine();
for (int k = 0; k < koleksiArrayList[i].get(j).getIdBuku().size(); k++) { bw.write(koleksiArrayList[i].get(j).getIdBuku().get(k));
bw.newLine();
bw.write(String.valueOf(koleksiArrayList[i].get(j).getJumlahKataDalamBuku().get(k )));
bw.newLine(); } } } bw.close();
} catch (IOException ex) {
Logger.getLogger(IndexingProcess.class.getName()).log(Level.SEVERE, null, ex);
try {
fw.close();
} catch (IOException ex) {
Logger.getLogger(IndexingProcess.class.getName()).log(Level.SEVERE, null, ex); } }
timeFinish = (double) System.nanoTime();
time = ((double) (timeFinish - timeStart)) / 1000000000; System.out.println("Start time Save HashTable : " + timeStart); System.out.println("Finish time Save HashTable : " + timeFinish); System.out.println("Total time use : " + time); }
Listing 4.5. Penyimpanan hasil indeks
Sistem pengujian juga dapat mengambil dan membentuk sebuah indeks melalui sebuahfile .txt (file text). Hal ini dapat dilakukan dengan memanggilmethod
loadIndexHashTable(String).
public void loadIndexHashTable(String namaFile) { double timeStart = (double) System.nanoTime(); double timeFinish;
double time;
String lokasiLoadHashTable = workSpace + namaFile; fr = new FileReader(lokasiLoadHashTable);
BufferedReader br = new BufferedReader(fr); String jumlahBucket = "";
try {
//baca jumlahBucket
jumlahBucket = br.readLine();
this.setJumlahBucket(Integer.parseInt(jumlahBucket)); //selesai baca jumlahBucket
//buat koleksiArrayList baru dari hasil Load sesuai jumlahBucket setKoleksiArrayList((ArrayList<Koleksi>[])
Array.newInstance(ArrayList.class, this.getJumlahBucket())); for (int i = 0; i < this.getJumlahBucket(); i++) {
koleksiArrayList[i] = new ArrayList<Koleksi>(); }
//selesai buat koleksiArrayList baru dari hasil Load sesuai jumlahBucket for (int i = 0; i < this.getJumlahBucket(); i++) {
//baca jumlah Koleksi dari bucket i String jumlahKoleksi = br.readLine(); //for untuk jumlah Koleksi
wordCount++;
String kata = br.readLine(); koleksi.setKata(kata);
String jumlahKoleksiUntukKata = br.readLine();
for (int k = 0; k < Integer.parseInt(jumlahKoleksiUntukKata); k++) { String idBuku = br.readLine();
koleksi.getIdBuku().add(idBuku);
String jumlahKataDalamBuku = br.readLine();
koleksi.getJumlahKataDalamBuku().add(Integer.parseInt(jumlahKataDalamBuku)); }
koleksiArrayList[i].add(koleksi); } } } catch (IOException ex) {
Logger.getLogger(IndexingProcess.class.getName()).log(Level.SEVERE, null, ex); }
} catch (FileNotFoundException ex) {
Logger.getLogger(IndexingProcess.class.getName()).log(Level.SEVERE, null, ex);
} finally { try {
} catch (IOException ex) {
Logger.getLogger(IndexingProcess.class.getName()).log(Level.SEVERE, null, ex); } }
timeFinish = (double) System.nanoTime();
time = ((double) (timeFinish - timeStart)) / 1000000000; System.out.println("Start time Load HashTable : " + timeStart); System.out.println("Finish time Load HashTable : " + timeFinish); System.out.println("Total time use : " + time);
System.out.println("Total words loaded in HashTable : " + wordCount); }
Listing 4.6. Pembuatan indeks dari filetext
Terdapat juga method untuk melakukan proses penyimpanan LOG dari indeks HashTable yang telah terbentuk baik melalui proses indexingmaupun proses pembacaan hasil indeks dari sebuah file teks. Method ini akan menyimpan panjang
chainpada tiap bucket didalamHashTabledan menunjukkan statistik persebaran data didalam HashTable itu sendiri. Proses ini dilaksanakan dengan memanggil method
saveLOGHashTable(String).
public void saveLOGHashTable(String namaFile) { double timeStart = (double) System.nanoTime(); double timeFinish;
double time;
try {
String lokasiSaveLOG = getWorkSpace() + namaFile; fw = new FileWriter(lokasiSaveLOG);
BufferedWriter bw = new BufferedWriter(fw); int total = 0;
double average = 0;
double standardDeviation = 0; double varians = 0;
int max = Integer.MIN_VALUE; int min = Integer.MAX_VALUE;
for (int i = 0; i < this.getJumlahBucket(); i++) {
int ukuranChain = this.getKoleksiArrayList()[i].size(); //menulis kedalam LOG
bw.write(String.valueOf(ukuranChain)); bw.write("\t");
for (int j = 0; j < ukuranChain; j++) { bw.write("-"); }
bw.newLine();
max = ukuranChain; } if (ukuranChain < min) {
min = ukuranChain; } } average = total / jumlahBucket;
//perhitungan standar deviasi double totalKuadrat = 0;
for (int i = 0; i < jumlahBucket; i++) {
int ukuranChain = this.getKoleksiArrayList()[i].size();
totalKuadrat = totalKuadrat + (Math.pow((ukuranChain - average), 2)); }
varians = totalKuadrat / jumlahBucket;
standardDeviation = Math.sqrt((totalKuadrat / jumlahBucket)); //selesai perhitungan standar deviasi
bw.newLine();
bw.write("Total Hash Bucket=" + this.getKoleksiArrayList().length); bw.newLine();
bw.write("Total=" + total); bw.newLine();
bw.write("Max=" + max); bw.newLine();
bw.newLine();
bw.write("Average=" + average); bw.newLine();
bw.write("Varians=" + varians); bw.newLine();
bw.write("Standar Deviasi=" + standardDeviation); bw.newLine();
//tambahan
int counterZeroBucket=0; int
counterSector1=0,counterSector2=0,counterSector3=0,counterSector4=0,counterSect or5=0;
double sector1=0,sector2=0,sector3=0,sector4=0,sector5=0; double sizeOfEachSector=((double)max/5);
sector1=(sizeOfEachSector*1);
sector1=Double.parseDouble(String.format("%.5g%n",sector1)); sector2=(sizeOfEachSector*2);
sector2=Double.parseDouble(String.format("%.5g%n",sector2)); sector3=(sizeOfEachSector*3);
sector4=Double.parseDouble(String.format("%.5g%n",sector4)); sector5=(sizeOfEachSector*5);
sector5=Double.parseDouble(String.format("%.5g%n",sector5)); for (int i = 0; i < this.getKoleksiArrayList().length; i++) {
if (this.getKoleksiArrayList()[i].size()==0) { counterZeroBucket++;
}else if (this.getKoleksiArrayList()[i].size()<sector1) { counterSector1++;
}else if (this.getKoleksiArrayList()[i].size()<sector2) { counterSector2++;
}else if (this.getKoleksiArrayList()[i].size()<sector3) { counterSector3++;
}else if (this.getKoleksiArrayList()[i].size()<sector4) { counterSector4++;
}else if (this.getKoleksiArrayList()[i].size()<=sector5) { counterSector5++; } }
double
emptyBucket=(double)(((double)counterZeroBucket)/((double)this.getKoleksiArrayL ist().length))*100;
bw.write("Empty Bucket (%) =" + emptyBucket); bw.newLine();
bw.write("Filled Bucket (%) =" + filledBucket); bw.newLine();
bw.write("Sector 1 : 0<=x< " + sector1+" ="+counterSector1); bw.newLine();
bw.write("Sector 2 : "+(sector1-1)+"<x< " + sector2+" ="+counterSector2); bw.newLine();
bw.write("Sector 3 : "+(sector2-1)+"<x< " + sector3+" ="+counterSector3); bw.newLine();
bw.write("Sector 4 : "+(sector3-1)+"<x< " + sector4+" ="+counterSector4); bw.newLine();
bw.write("Sector 5 : "+(sector4-1)+"<x<= " + sector5+" ="+counterSector5); bw.newLine();
//tambahan bw.newLine(); //persiapan data excel
for (int i = 0; i < jumlahBucket; i++) {
bw.write(String.valueOf(this.getKoleksiArrayList()[i].size())); bw.newLine(); }
bw.close();
} catch (IOException ex) {
Logger.getLogger(IndexingProcess.class.getName()).log(Level.SEVERE, null, ex);
} finally { try {
fw.close();
} catch (IOException ex) {
Logger.getLogger(IndexingProcess.class.getName()).log(Level.SEVERE, null, ex); } }
timeFinish = (double) System.nanoTime();
time = ((double) (timeFinish - timeStart)) / 1000000000; System.out.println("Start time LOG HashTable : " + timeStart); System.out.println("Finish time LOG HashTable : " + timeFinish); System.out.println("Total time use : " + time); }
Listing 4.7. Penyimpanan LOGHashTable
Berikut akan ditunjukkan hasil implementasi dari algoritma mixxing step
PJWHash yang digunakan dalam sistem pengujian yang dibangun : public class MixingStep {
long val = 0;
for (int i = 0; i < key.length; i++) { long tmp;
val = ((val << 4) + (key[i]));
if ((tmp = (val & 0xf0000000)) != 0) { val = (val ^ (tmp >> 24));
val = (val ^ tmp); } } val=val& 0xffffffffL;
return val; }}
Listing 4.8. PJWHash
4.1.3. ImplementasiSearching
Setelah indeks terbentuk, maka dilanjutkan dengan pengujian pencarian data koleksi. Pengujian pencarian data koleksi ini dapat dilakukan dengan memanggil
method searchInHashTable(String). Pencarian data koleksi dapat dilakukan dengan memasukkan parameter berupa 1 kata atau lebih sekaligus. Dengan memasukkan kata pencarian berjumlah lebih dari 1 kata, maka akan dimunculkan juga hasil pencarian dengan operasi pencarian AND yang akan mendaftarkan idBuku yang memiliki semua kata yang digunakan dalam pencarian bersangkutan. Berikut hasil implementasi darimethodsearchInHashTable(String).