LAPORAN TUGAS DATA MINING
PENERAPAN K-MEANS ALGORITM CLUSTERING
PADA DATA PRODUKSI GARAM SETIAP PROVINSI DI INDONESIA
Disusun Oleh :
Yogi Anggara [1500018073]
Rynto E. S. [1500018074]
Ridho Febrian [1500018083]
Mayang Notri.S [1500018102]
Vita Silvia [1500018114]
Indriyanto A. P [1500018118]
Prodi Teknik Informatika
Fakultas Teknologi Industri
Universitas Ahmad Dahlan
Yogyakarta
Latar Belakang
garam adalah salah satu bahan poko dalam masakkan. Indonesia salah satu produksen garam yang masih terbatas
produksinya di karenakkan asih menggunakkan cara tradisional dalam produksinya, yaitu dengan cara penyinaran
sinar matahari. Produksi garam di Indonesia ini hanya mampu memenuhi kebutuhan garam dalam negeri, in juga
salah satu dampak dari masih tradisionalnya cara produksi garam. Bahkan pada waktu-waktu sebelumnya di
Indonesia di katakkan sedang krisis garam, sehingga pemerintah meimpor garam dari Australia untuk memenuhi
kebutuhan garam di Indonesia. Dengan adanya keputusan tersebut berdampak pada harga garam local yang bisa
merugikan petani garam di Indonesia.
Dengan adanya data set ini kami bisa menghitung dan memperkirakkan dengan luas lahan, tingkat produktifitas
dapat mengetahui seberapa banyak garam yang bisa di produksi. Sehingga data set ini bisa jadi acuhan
pemerintahan untuk mengembangkan system pembuatan garam dan impor garam luar negeri yang bisa membebani
ptani garam.
Tujuan
Dengan menghitungan data set “Data Produksi Garam Setiap Provinsi Di Indonesia Menggunakkan K-Means Algoritm Clustering” :
1. Untuk mengetahui tingkat produktivitas pembuatan garam di setiap daerah
2. Untuk mengetahui tingkat produksi garam di setiap daerah
3. Untuk medapatkkan data yang telah dikelompokkan sehingga dapat menghasilkan informasi
Dasar teori
K-Means
K-Means adalah suatu metode penganalisaan data atau metode Data Mining yang melakukan proses pemodelan
tanpa supervisi (unsupervised) dan merupakan salah satu metode yang melakukan pengelompokan data dengan
sistem partisi. Metode k-means berusaha mengelompokkan data yang ada ke dalam beberapa kelompok, dimana
data dalam satu kelompok mempunyai karakteristik yang sama satu sama lainnya dan mempunyai karakteristik
yang berbeda dengan data yang ada di dalam kelompok yang lain. Dengan kata lain, metode ini berusaha untuk
meminimalkan variasi antar data yang ada di dalam suatu cluster dan memaksimalkan variasi dengan data yang ada
di cluster lainnya.
CLustering
Clustering atau klasterisasi adalah metode pengelompokan data. Menurut Tan, 2006 clusteringadalah sebuah
proses untuk mengelompokan data ke dalam beberapa cluster atau kelompok sehingga data dalam
satu cluster memiliki tingkat kemiripan yang maksimum dan data antarcluster memiliki kemiripan yang minimum.
Clustering merupakan proses partisi satu set objek data ke dalam himpunan bagian yang disebut
dengan cluster. Objek yang di dalam cluster memiliki kemiripan karakteristik antar satu sama lainnya dan berbeda
dengan cluster yang lain. Partisi tidak dilakukan secara manual melainkan dengan suatu algoritma clustering. Oleh
karena itu, clustering sangat berguna dan bisa menemukan group atau kelompokyang tidak dikenal dalam
data. Clustering banyak digunakan dalam berbagai aplikasi seperti misalnya pada business inteligence, pengenalan
pola citra, web search, bidang ilmu biologi, dan untuk keamanan (security). Di dalam business
inteligence, clusteringbisa mengatur banyak customer ke dalam banyaknya kelompok. Contohnya
mengelompokan customer ke dalam beberapa cluster dengan kesamaan karakteristik yang kuat. Clustering juga
dikenal sebagai data segmentasi karena clustering mempartisi banyak data set ke dalam banyak group berdasarkan
Data Produksi Garam
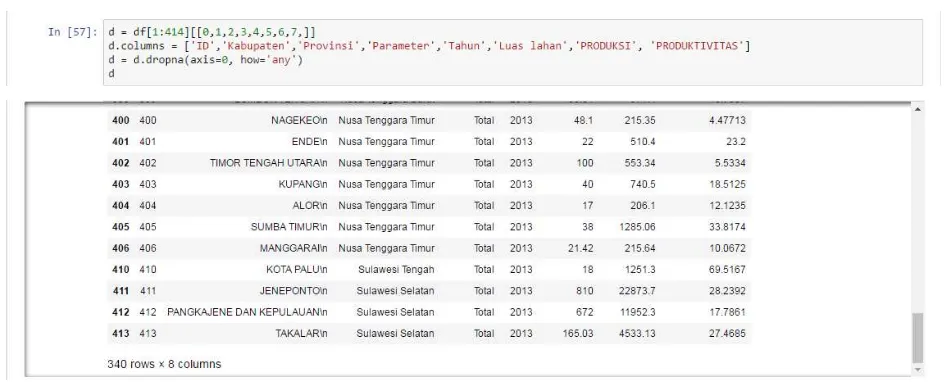
Terdapat 415 data dengan 8 atribut :
1. Id : varchar 5 auto increatmen
2. Kabupaten : varchar 25
3. Nama provinsi : varchar 25
4. Param garam : varchar 15
5. Tahun : date
6. Luas lahan : int 15
7. Produksi : int 15
Data produksi garam setelah di filter
Data yang telah di clastering, yang awal 415 menjadi 351 data yang telah di filter, dengan 8 atribut :
1. Id : varchar 5 auto increatmen
2. Kabupaten : varchar 25
3. Nama provinsi : varchar 25
4. Param garam : varchar 15
5. Tahun : date
6. Luas lahan : int 15
7. Produksi : int 15
Penerapan dalam aplikasi anaconda
A.
Melakukan Import Library yang akan digunakan untuk clustering
B.
Melakukan Import data excel alumni kedalam python
Gambar 1 : hasil dari import data produksi garam, dengan jumlah data 415
C.
Seleksi kolom dari data frame yang akan dilakukan clustering keseluruhan
Gambar 2 : setting untuk mengatur berapa banyak kolom dan baris yang di gunakkan,
D.
Check kembali hasil formating data table apakah sudah sesuai
Gambar 3: pada gambar tersebut dapat di ketahu bahwa type data produksi dan produktivitas harus di
ubah ke float.
E.
Merubah type data obyek ke float pada data produksi dan produktivitas
Gambar 4 : hasil dari perubahan
F.
Cek kembali type data
Gambar 5 : data telah berubah dari objek ke float
G.
Ubah index dataframe agar lebih memudahkan dalam melakukan clustering.
H.
Ambil data PRODUKSI dan PRODUKTIVITAS untuk dilakukan cluster.
Gambar 7 : .as_matrix() merupakan konversi dataframe ke format matrix. Terbentuk matrik-matrik
I.
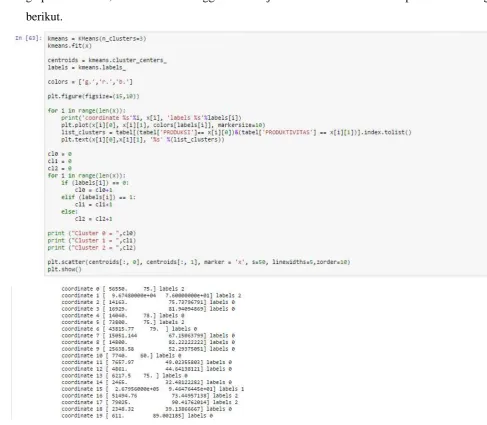
Proses clustering, clustering akan dilakukan pada data alumni dengan 2 jumlah feature
diantaranya IPK dan MASA STUDI. Jumlah cluster yang ditentukan adalah 3. Dengan ploting
graph 2 dimensi, dikarenakan menggunakan 2 jumlah feature. Perintah dapat dilihat sebagai
berikut.
Uji Coba Secara Manual
Gambar: contoh data dari data produksi garam di ambil 5 sempel data untuk di hitung
Langkah pertama algoritma K-means Menanyakan kepada pemakai algoritma k-means,
catatan-catatan yang ada akan dibuat menjadi berapa kelompok. Jika diambil
pengkelompokannya dengan jumlah tiga, nilai k-nya adalah 3 atau k=3
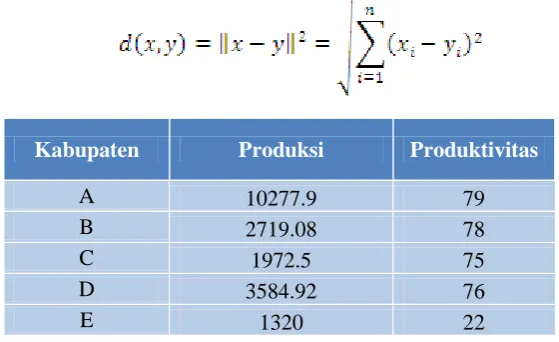
Kabupaten Produksi Produktivitas
Gambar : table yang telah di kelompokkan
Langkah Kedua algoritma K-Means
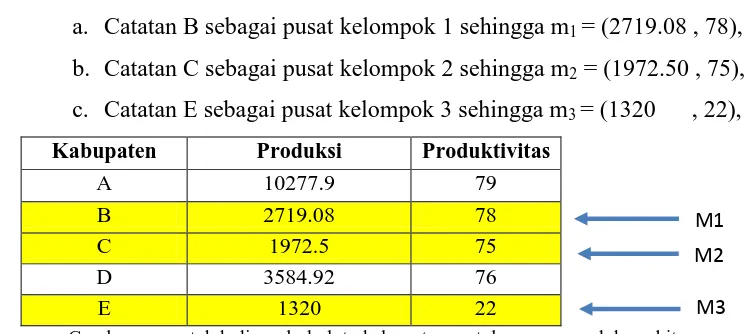
Pada langkah kedua algoritma ini, kita akan secara sembarang memilih k=3 buah titik pusat
(dari 5 data yang ada) sebagai pusat-pusat kelompok awal, misalnya:
a.
Catatan B sebagai pusat kelompok 1 sehingga m
1= (2719.08 , 78),
b.
Catatan C sebagai pusat kelompok 2 sehingga m
2= (1972.50 , 75),
c.
Catatan E sebagai pusat kelompok 3 sehingga m
3= (1320 , 22),
Gambar: yang telah di symbol data kabupaten, untuk mempermudah perhitungan
Catetan :
ID Kabupaten NamaProvinsi ParamGara
m
Perhitungan rasio ke-1
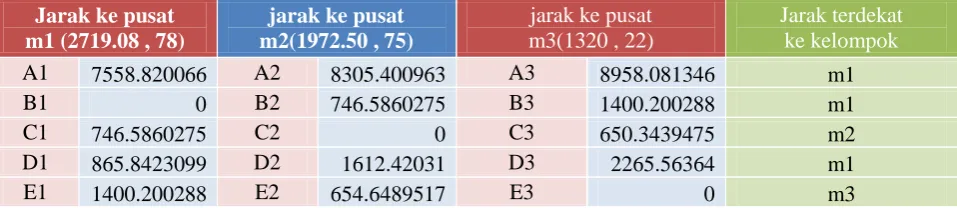
Langkah Ketiga algoritma K-Means kelompok
Pada langkah ini setiap data akan ditentukan pusat kelompok terdekatnya. Data tersebut akan ditetapkan
sebagai anggota kelompok yang terdekat pusat kelompoknya menggunakan rumus sebagai berikut:
Kabupaten Produksi Produktivitas
a. A1 didapatkan dari titik nasabah A(10277.9 , 79) dengan titik pusat m1 (2719.08 , 78)
A1 = d (x,y) =√ √ √
b. A2 didapatkan dari titik nasabah A(10277.9 , 79) dengan titik pusat m2 (1972.50 , 75)
A2 = d (x,y) =√ √ √
a. A3 didapatkan dari titik nasabah A(10277.9 , 79) dengan titik pusat m3 (1320 , 22)
A3 = d (x,y) =√ √ √
Untuk penghitungan B1 sampai E3 dilakukan langkah yang sama seperti di atas. Dan Menghasilkan seperti yang
tampak dalam table dibawah ini:
Untuk setiap data akan ditentukan pusat kelompok terdekatnya dengan cara membandingkan nilai jarak setiap data dengan pusat M, dengan mencari nilai paling terkecil. Sehingga di dapatkan table dibawah ini :
Jarak ke pusat
Dari table 2 didapatkan keanggotaan sebagai berikut:
a.
Kelompok 1 (atau m1) ={A, B, D}
b.
Kelompok 2 (atau m2) = {C}, dan
c.
Kelompok 3 (atau m3) = {E}.
Pada langkah ini dihitung pula rasio antara besaran Between Cluster Variation (BCV) dengan Within
Cluster Variation (WCV), seperti berikut:
a.
Rumus untuk menghitung Between Cluster Variation (BCV) sebagai berikut:
∑
Dimana i dan j adalah pusat kelompok. Karena pusat kelompok ada 3 dan d(m
i,m
j)
Menyatakan jarak Euclidean dari m
ike m
j, Maka penyelesaian BCV menjadi sebagai berikut:
BCV= d(m1,m2) + d(m1,m3) + d(m2,m3)
Dengan m1 (2719.08 , 78), m2(1972.50 , 75), dan m3(1320 , 22), sehingga :
d (m1, m2) = √ √ √ d (m1, m3) = √ √ √ 1400.200288 d (m2, m3) = √ √ √
Sehingga didapatkan hasil sebagai berikut :
BCV= d(m
1,m
2) + d(m
1,m
3) + d(m
2,m
3)
b.
Rumus untuk menghitung Within Cluster Variation (WCV) sebagai berikut:
Dari table di atas didapatkan
Jarak terkecil A = 7558.820066
Perhitungan Rasio Ke-2
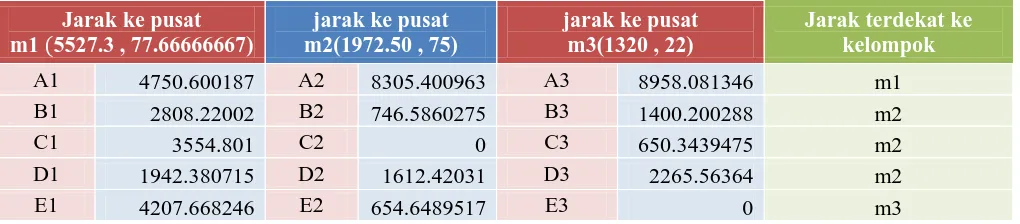
Langkah keempat Algoritma K-means (iterasi ke1)
Pada langkah ini, pembaruan pusat-pusat kelompok yang baru akan dilakukan seperti berikut:
Jarak ke pusat
Pada langkah ini, pembaruan pusat-pusat kelompok yang baru akan dilakukan seperti berikut:
a) m1 = rata-rata(mA, mB, mD) = 5527.3 , 77.66666667)
b) m2 = rata-rata(mC) = (1972.5 , 75)
c) m3 = rata-rata(mE) = (1320, 22)
selanjutnya, kita akan kembali ke langkah 3 untuk mencari pembadingan
Langkah ketiga Algoritma K-Means (iterasi-2)
A.
Pada langkah ini setiap nasabah akan ditentukan pusat kelompok terdekatnya. Nasabah tersebut
akan ditetapkan sebagai anggota kelompok yang terdekat pusat kelompok yang baru (cara
seperti langkah 3 diatas)
.
Contoh penghitungan:
a) A1 didapatkan dari titik nasabah A(10277.9 , 79) dengan titik pusat m1 5527.3 , 77.66666667)
A1 = d (x,y) =√ √ √
b) A2 didapatkan dari titik nasabah A(10277.9 , 79) dengan titik pusat m2 (1972.5 , 75)
A2 = d (x,y) =√ √ √
Dari table diatas didapatkan keanggotaan sebagai berikut:
Sehingga didapatkan hasil sebagai berikut :
BCV= d(m
1,m
2) + d(m
1,m
3) + d(m
2,m
3)
BCV = 3554.801 + 4207.668246 + 654.6489517 = 8417.118198
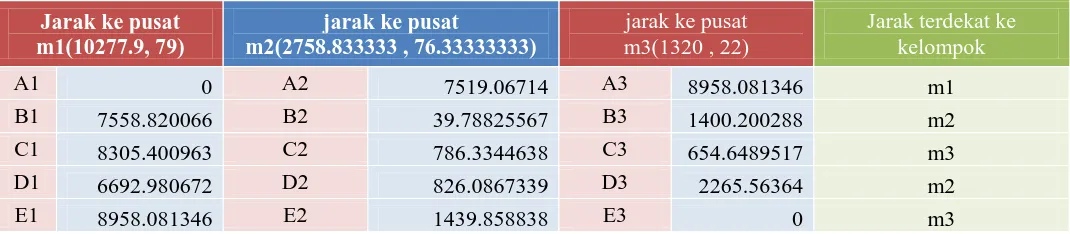
Perhitungan Rasio Ke-3
Langkah keempat Algoritma K-means (iterasi ke1)
Pada langkah ini, pembaruan pusat-pusat kelompok yang baru akan dilakukan seperti berikut:
Pada langkah ini, pembaruan pusat-pusat kelompok yang baru akan dilakukan seperti berikut:
m1 = rata-rata(mA) = (10277.9, 79)
m2 = rata-rata(, mB, mC , mD) =
m3 = rata-rata(mE) = (1320, 22)
Langkah ketiga Algoritma K-Means (iterasi-2)
Pada langkah ini setiap nasabah akan ditentukan pusat kelompok terdekatnya. Nasabah tersebut
akan ditetapkan sebagai anggota kelompok yang terdekat pusat kelompok yang baru (cara
seperti langkah 3 diatas)
.
Contoh penghitungan:
a) A1 didapatkan dari titik nasabah A(10277.9 , 79) dengan titik pusat m1 (10277.9, 79)
A1 = d (x,y)=√ √
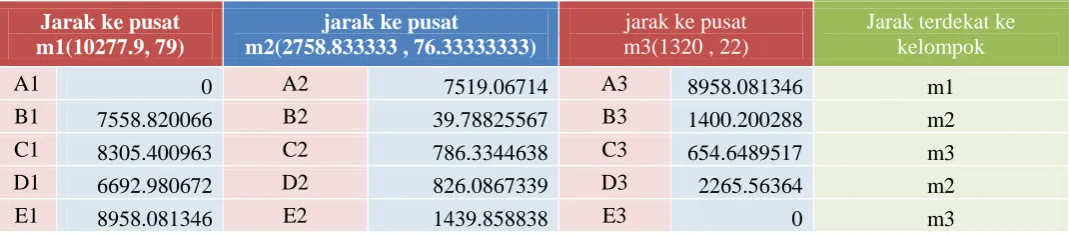
b) A2 didapatkan dari titik nasabah A(10277.9 , 79) dengan titik pusat m2 (2758.833333 , 76.33333333)
A2 = d (x,y)=√ √
Dari table diatas didapatkan keanggotaan sebagai berikut:
a)
Kelompok 1 (atau m1) ={A}
b)
Kelompok 2 (atau m2) = {B, D}, dan
c)
Kelompok 3 (atau m3) = { C, E}.
Pada langkah ini dihitung pula rasio antara besaran Between Cluster Variation (BCV) dengan within
Cluster Variation (WCV), seperti berikut:
BCV= d(m
1,m
2) + d(m
1,m
3) + d(m
2,m
3)
Dengan m1
(10277.9, 79),m2(2758.833333 ,76.33333333) dan m3(1320 , 22), sehingga :
d (m1, m2) =√
Sehingga didapatkan hasil sebagai berikut :
BCV= d(m
1,m
2) + d(m
1,m
3) + d(m
2,m
3)
BCV = 7519.06714 + 8958.081346 + 1439.858838 = 17917.00732
C.
Besar Rasio 3
WCV =
0 + 39.78825567+ 654.6489517 + 826.0867339+ 0 = 1520.523941Sehingga besarnya rasio adalah
=
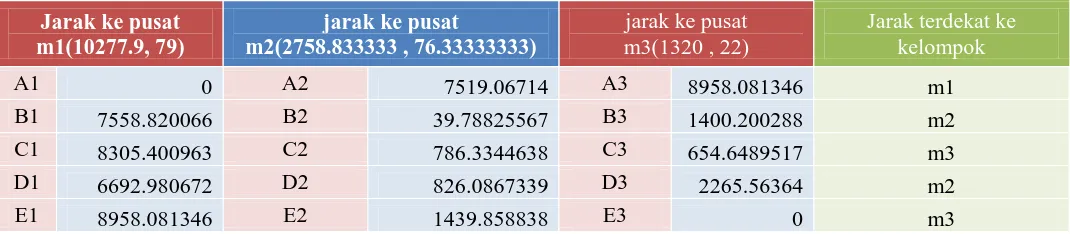
Perhitungan Rasio Ke-4
Langkah keempat Algoritma K-means (iterasi ke1)
Pada langkah ini, pembaruan pusat-pusat kelompok yang baru akan dilakukan seperti berikut:
Jarak ke pusat
Pada langkah ini, pembaruan pusat-pusat kelompok yang baru akan dilakukan seperti berikut:
m1 = rata-rata(mA) = (10277.9, 79)
m2 = rata-rata(mB , mD) =
m3 = rata-rata(mC , mE) =
Langkah ketiga Algoritma K-Means (iterasi-2)
Pada langkah ini setiap nasabah akan ditentukan pusat kelompok terdekatnya. Nasabah tersebut
akan ditetapkan sebagai anggota kelompok yang terdekat pusat kelompok yang baru (cara
seperti langkah 3 diatas)
.
Contoh penghitungan:
a) A1 didapatkan dari titik nasabah A(10277.9 , 79) dengan titik pusat m1 (10277.9, 79)
A1 = d (x,y)=√ √
b) A2 didapatkan dari titik nasabah A(10277.9 , 79) dengan titik pusat m2 (3152 , 77)
A2 = d (x,y)=√ √
c) A3 didapatkan dari titik nasabah A(10277.9 , 79) dengan titik pusat m3 (1646.25 , 48.5)
A3 = d (x,y)=√ √
m3(1646.25 , 48.5) Jarak terdekat ke kelompok
A1 0 A2 7125.900281 A3 8631.703886 m1
B1 7558.820066 B2 432.9211549 B3 1073.23551 m2
C1 8305.400963 C2 1179.501696 C3 327.3244759 m3
D1 6692.980672 D2 432.9211549 D3 1938.865034 m2
E1 8958.081346 E2 1832.825414 E3 327.3244759 m3
Dari table diatas didapatkan keanggotaan sebagai berikut:
d)
Kelompok 1 (atau m1) ={A}
e)
Kelompok 2 (atau m2) = {B, D}, dan
f)
Kelompok 3 (atau m3) = { C, E}.
Pada langkah ini dihitung pula rasio antara besaran Between Cluster Variation (BCV) dengan within
Cluster Variation (WCV), seperti berikut:
8305.400963 C2 1179.501696 C3 327.3244759 m3
D1
6692.980672 D2 432.9211549 D3 1938.865034 m2
E1
8958.081346 E2 1832.825414 E3 327.3244759 m3
Sehingga didapatkan hasil sebagai berikut :
BCV= d(m
1,m
2) + d(m
1,m
3) + d(m
2,m
3)
BCV = 7125.900281 + 8631.703886 + 1506.019692 = 17263.62386
Besar Rasio 4
WCV =
0 + 432.9211549 + 327.3244759 + 432.9211549 + 327.3244759 = 1520.491262Sehingga besarnya rasio adalah
=
Perhitungan Rasio Ke-5
Langkah keempat Algoritma K-means (iterasi ke1)
Pada langkah ini, pembaruan pusat-pusat kelompok yang baru akan dilakukan seperti berikut:
Jarak ke pusat
Pada langkah ini, pembaruan pusat-pusat kelompok yang baru akan dilakukan seperti berikut:
m1 = rata-rata(mA) = (10277.9, 79)
m2 = rata-rata(mB , mD) =
m3 = rata-rata(mC , mE) =
Langkah ketiga Algoritma K-Means (iterasi-2)
Pada langkah ini setiap nasabah akan ditentukan pusat kelompok terdekatnya. Nasabah tersebut
akan ditetapkan sebagai anggota kelompok yang terdekat pusat kelompok yang baru (cara
seperti langkah 3 diatas)
.
Contoh penghitungan:
d) A1 didapatkan dari titik nasabah A(10277.9 , 79) dengan titik pusat m1 (10277.9, 79)
A1 = d (x,y)=√ √
e) A2 didapatkan dari titik nasabah A(10277.9 , 79) dengan titik pusat m2 (3152 , 77)
A2 = d (x,y)=√ √
f) A3 didapatkan dari titik nasabah A(10277.9 , 79) dengan titik pusat m3 (1646.25 , 48.5)
A3 = d (x,y)=√ √
m3(1646.25 , 48.5) Jarak terdekat ke kelompok
A1 0 A2 7125.900281 A3 8631.703886 m1
B1 7558.820066 B2 432.9211549 B3 1073.23551 m2
C1 8305.400963 C2 1179.501696 C3 327.3244759 m3
D1 6692.980672 D2 432.9211549 D3 1938.865034 m2
E1 8958.081346 E2 1832.825414 E3 327.3244759 m3
Dari table diatas didapatkan keanggotaan sebagai berikut:
g)
Kelompok 1 (atau m1) ={A}
h)
Kelompok 2 (atau m2) = {B, D}, dan
i)
Kelompok 3 (atau m3) = { C, E}.
Pada langkah ini dihitung pula rasio antara besaran Between Cluster Variation (BCV) dengan within
Cluster Variation (WCV), seperti berikut:
8305.400963 C2 1179.501696 C3 327.3244759 m3
D1
6692.980672 D2 432.9211549 D3 1938.865034 m2
E1
8958.081346 E2 1832.825414 E3 327.3244759 m3
Sehingga didapatkan hasil sebagai berikut :
BCV= d(m
1,m
2) + d(m
1,m
3) + d(m
2,m
3)
BCV = 7125.900281 + 8631.703886 + 1506.019692 = 17263.62386
Besar Rasio 5
WCV =
0 + 432.9211549 + 327.3244759 + 432.9211549 + 327.3244759 = 1520.491262Sehingga besarnya rasio adalah
=
Perhitungan Rasio Ke-6
Langkah keempat Algoritma K-means (iterasi ke1)
Pada langkah ini, pembaruan pusat-pusat kelompok yang baru akan dilakukan seperti berikut:
Jarak ke pusat
Pada langkah ini, pembaruan pusat-pusat kelompok yang baru akan dilakukan seperti berikut:
m1 = rata-rata(mA) = (10277.9, 79)
m2 = rata-rata(mB , mD) =
m3 = rata-rata(mC , mE) =
Langkah ketiga Algoritma K-Means (iterasi-2)
Pada langkah ini setiap nasabah akan ditentukan pusat kelompok terdekatnya. Nasabah tersebut
akan ditetapkan sebagai anggota kelompok yang terdekat pusat kelompok yang baru (cara
seperti langkah 3 diatas)
.
Contoh penghitungan:
g) A1 didapatkan dari titik nasabah A(10277.9 , 79) dengan titik pusat m1 (10277.9, 79)
A1 = d (x,y)=√ √
h) A2 didapatkan dari titik nasabah A(10277.9 , 79) dengan titik pusat m2 (3152 , 77)
A2 = d (x,y)=√ √
i) A3 didapatkan dari titik nasabah A(10277.9 , 79) dengan titik pusat m3 (1646.25 , 48.5)
A3 = d (x,y)=√ √
m3(1646.25 , 48.5) Jarak terdekat ke kelompok
A1 0 A2 7125.900281 A3 8631.703886 m1
B1 7558.820066 B2 432.9211549 B3 1073.23551 m2
C1 8305.400963 C2 1179.501696 C3 327.3244759 m3
D1 6692.980672 D2 432.9211549 D3 1938.865034 m2
E1 8958.081346 E2 1832.825414 E3 327.3244759 m3
Dari table diatas didapatkan keanggotaan sebagai berikut:
j)
Kelompok 1 (atau m1) ={A}
k)
Kelompok 2 (atau m2) = {B, D}, dan
l)
Kelompok 3 (atau m3) = { C, E}.
Pada langkah ini dihitung pula rasio antara besaran Between Cluster Variation (BCV) dengan within
Cluster Variation (WCV), seperti berikut:
8305.400963 C2 1179.501696 C3 327.3244759 m3
D1
6692.980672 D2 432.9211549 D3 1938.865034 m2
E1
8958.081346 E2 1832.825414 E3 327.3244759 m3
Sehingga didapatkan hasil sebagai berikut :
BCV= d(m
1,m
2) + d(m
1,m
3) + d(m
2,m
3)
BCV = 7125.900281 + 8631.703886 + 1506.019692 = 17263.62386
Besar Rasio 6
WCV =
0 + 432.9211549 + 327.3244759 + 432.9211549 + 327.3244759 = 1520.491262Sehingga besarnya rasio adalah
=
Kesimpulan
Jarak ke pusat m1(10277.9 , 79)
jarak ke pusat m2(3152 , 77)
jarak ke pusat m3(1646.25 , 48.5)
Jarak terdekat ke kelompok
A1
0 A2 7125.900281 A3 8631.703886 m1
B1
7558.820066 B2 432.9211549 B3 1073.23551 m2
C1
8305.400963 C2 1179.501696 C3 327.3244759 m3
D1
6692.980672 D2 432.9211549 D3 1938.865034 m2
E1
8958.081346 E2 1832.825414 E3 327.3244759 m3
Pada perhitungan ke 4, 5 , 6 memiliki nilai batas yang sama dan nilai rasio yang sama maka perhitungan di
hentikan. Sebab nilai batas telah di temukan, yaitu :
m1 = rata-rata(mA) =C1 = (10277.9 , 79)
m2 = rata-rata(mB , mD) =C2 = (3152 , 77)
m3 = rata-rata(mC , mE) =C3 = (1646.25 ,48.5)
sehingga nilai batas tersebut di jadikkan sebagai acuhan data untuk menentukan pengelompokkan data setiap
claster.