isprsarchives XL 7 W4 175 2015
Teks penuh
Gambar
Dokumen terkait
After an introduction about historical photographic heritage and the requirements of new photogrammetric software (based on dense image matching algorythm), this paper
First, we describe the detection of potential mirror contours in a 2D panoramic representation of the point cloud based on a jump edge detection and 3D contour extraction
Based on the disabled person population database, the affairs management system and the statistical account system, the data were effectively integrated and the united
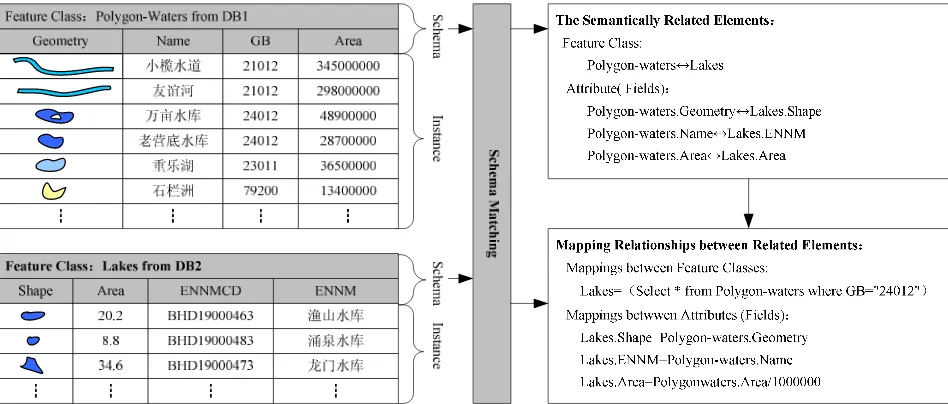
The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Volume XL-7/W4, 2015 2015 International Workshop on Image and Data Fusion, 21 –
Through the comparison of different dimensionality reduction method and different classification method for the low-dimensional data, the result illuminates the proposed method
The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, Volume XL-7/W4, 2015 2015 International Workshop on Image and Data Fusion, 21 –
This method combines the statistical texture features and texture features, considering the weight contribution and the Bhattacharyya distance, and the method of
Recently, interests in 3D indoor modeling and positioning have been growing. Data fusion by using different sensors data is one of the 3D model producing methods. For a data
