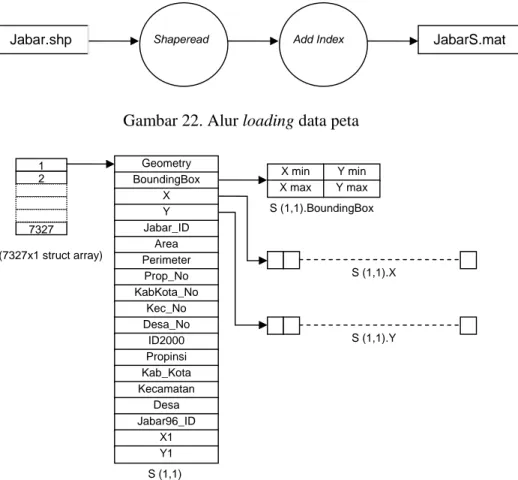
Peta digital desa di Jawa Barat dan Banten tahun 2000 didapat dalam format Mapinfo per masing-masing provinsi. Peta kedua peta kemudian dikonversi ke dalam format Shapefile dan digabung menjadi satu. Selanjutnya peta shapefile dimuat (loading) ke dalam lingkungan Matlab menggunakan fungsi shaperead yang tersedia di Matlab Mapping Toolbox. Dalam Matlab, peta desa disimpan sebagai variabel S (JabarS.mat) dengan tipe struct. Nomor indeks pada variabel S merepresentasikan urutan obyek bersangkutan dalam shapefile. Alur loading data peta disajikan pada Gambar 22, sedangkan ilustrasi struktur variabel S digambarkan sebagai berikut (Gambar 23).
Gambar 22. Alur loading data peta
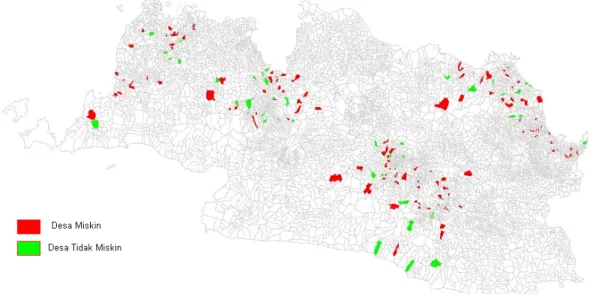
Gambar 23. Struktur Variabel S
Shaperead Add Index JabarS.mat Jabar.shp 1 7327 2 S (7327x1 struct array) Geometry BoundingBox X Y Jabar_ID Area Perimeter Prop_No KabKota_No Kec_No Desa_No ID2000 Propinsi Kab_Kota Kecamatan Desa Jabar96_ID X1 Y1 S (1,1) X min X max Y min Y max S (1,1).BoundingBox S (1,1).X S (1,1).Y
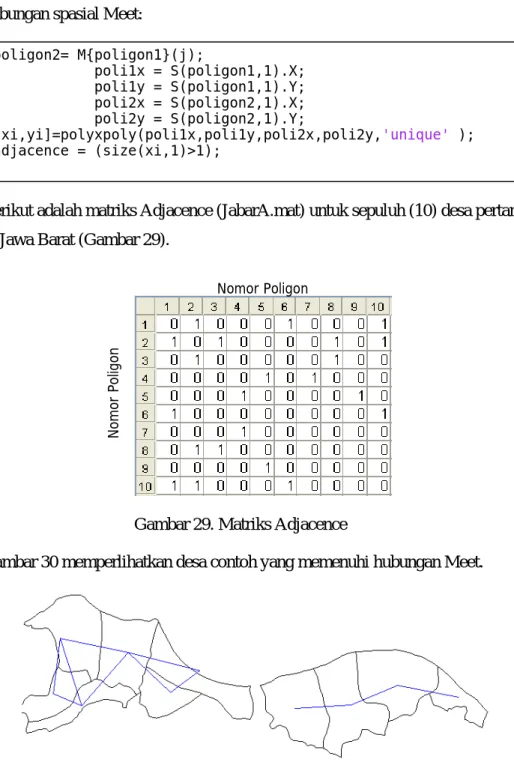
Gambar 24 memperlihatkan batas desa di Jawa Barat beserta lokasi ke-167 desa miskin/tidak miskin berdasarkan Santoso A(2000). Sumber data Santoso 2000 Jawa Barat meliputi 7 kabupaten yaitu : Pandeglang, Serang, Bogor, Bandung, Cirebon, Indramayu dan Garut. Pemilihan kabupaten tersebut didasarkan atas pertimbangan bahwa kabupaten yang dipilih merupakan kabupaten dengan persentase desa miskin (menurut kriteria BPS tahun 1995) dari desa yang terkena Susenas cukup besar yaitu sekitar 50 persen. Sehingga diperoleh jumlah desa miskin yang cukup mewakili untuk desa-desa di Jawa Barat.
Gambar 24. Desa Miskin/Tidak Miskin di Pandeglang, Serang, Bogor, Bandung, Cirebon, Indramayu dan Garut.
3.2 Membangun neighborhood graph
Setelah data peta desa termuat dalam lingkungan Matlab dilakukan pembangunan neighbourhood graph yang merepresentasikan hubungan diantara desa-desa tersebut. Gambar 25 memperlihatkan sebagian desa dengan label nomor yang merepresentasikan urutan desa bersangkutan dalam matriks S (dan juga dalam shapefile).
Gambar 25. Sebagian desa di Jawa Barat 3.2.1 Cek MBR
Neighbourhood graph disimpan dalam sebuah matriks N x N, sehingga
membutuhkan waktu yang lama jika dilakukan pemeriksaan hubungan ketetanggaan untuk sebuah desa dengan seluruh desa selainnya. Untuk mempercepat maka dilakukan refinement melalui pemeriksaaan MBR desa yang berpotongan. Gambar 26 memperlihatkan sepuluh (10) desa pertama dalam S beserta MBR-nya masing-masing. Pada Gambar 26 terlihat adanya kesalahan dalam penentuan titik acuan MBR yang menyebabkan MBR desa 1 dianggap tidak berpotongan dengan MBR desa 2. Kesalahan ini diduga karena keterbatasan Matlab Mapping Toolbox. Pemeriksaan ulang terhadap kesalahan pengecekan MBR masih dilakukan secara manual (pengamatan visual) dan baru ditemukan satu kesalahan.
Berikut adalah pernyataan untuk pemeriksaaan MBR beserta hasilnya untuk sepuluh desa pertama di atas. Matriks not_separate sebagai hasil pemeriksaan MBR disajikan dalam Gambar 27.
Gambar 27. Matriks not_separate 3.2.2 Membangun List
Berdasarkan matriks not_separate kemudian dibentuk list desa yang MBR-nya tidak terpisah (not_separate_list). Variabel not_separate_list menggunakan struktur cell seperti digambarkan pada Gambar 28.
Gambar 28. Not_Separate_List if ( (maxX1 < minX2) ||... (minX1 > maxX2) ||... (maxY1 < minY2) ||... (minY1 > maxY2)) not_separate(poligon1,poligon2) = false; not_separate(poligon2,poligon1) = false; Nomor Poligon N om or Po ligo n 1 : MBR Tidak terpisah 0 : MBR Terpisah Nom or List
3.2.3 Periksa Adjacency
Selanjutnya untuk semua desa yang MBR-nya berpotongan dilakukan pemeriksaan hubungan ketetanggaan. Dalam penelitian ini hubungan ketetanggaan didasarkan pada hubungan topologi Meet. Berikut statemen yang digunakan untuk memeriksa apakah dua buah poligon (batas desa) memenuhi hubungan spasial Meet:
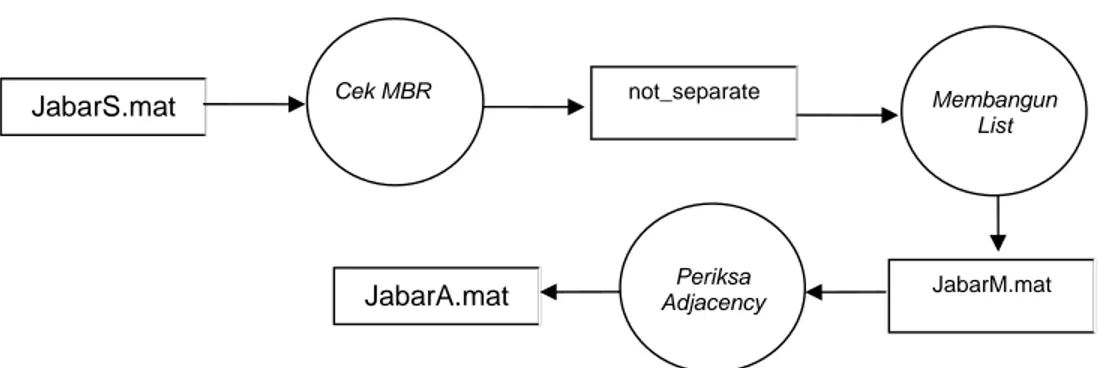
Berikut adalah matriks Adjacence (JabarA.mat) untuk sepuluh (10) desa pertama di Jawa Barat (Gambar 29).
Gambar 29. Matriks Adjacence
Gambar 30 memperlihatkan desa contoh yang memenuhi hubungan Meet.
Gambar 30. Desa yang memenuhi hubungan Meet. poligon2= M{poligon1}(j); poli1x = S(poligon1,1).X; poli1y = S(poligon1,1).Y; poli2x = S(poligon2,1).X; poli2y = S(poligon2,1).Y; [xi,yi]=polyxpoly(poli1x,poli1y,poli2x,poli2y,'unique' ); adjacence = (size(xi,1)>1); Nomor Poligon Nomor Poligon
Secara singkat alur pembentukan Neighbourhood Graph digambarkan pada Gambar 31.
Gambar 31. Alur pembentukan Neighbourhood Graph 3.3 Membangun neigborhood index
Algoritme karakterisasi spasial selain melibatkan nilai atribut setiap obyek juga memperhitungkan hubungan antarobyek. Dalam penelitian ini hubungan antarobyek yang digunakan adalah jarak dan arah. Untuk menghindari perhitungan jarak dan arah yang berulang-ulang, maka jarak dan arah sebuah desa terhadap desa lainnya disimpan dalam Neighbourhood Index. Neighbourhood Index direalisasikan sebagai sebuah tabel di dalam sistem manajemen basis data SQL Server. Gambar 32 menggambarkan alur pembangunan Neighbourhood Index.
Gambar 32. Alur pembangunan Neighbourhood Index JabarS.mat Hitung Jarak Cari Arah berdasarkan MBR Cari Arah berdasarkan titik pusat Cari Exact Direction File Topologi T_1 s/d T_7327 Load ke SQL Server Neighbourhood Index
JabarS.mat Cek MBR not_separate Membangun List
JabarM.mat
Periksa Adjacency JabarA.mat
3.3.1. Hitung Jarak
Jarak antar dua desa didefinisikan sebagai jarak garis lurus antara titik pusat kedua desa (Gambar 33). Jarak antar dua desa dihitung berdasarkan jarak eucledian sebagai berikut:
distance = sqrt(((center(1,1)- center(2,1)).^2) + ((center(1,2)- center(2,2)).^2));
Gambar 33. Visualisasi jarak antardesa 3.3.2. Cari Arah
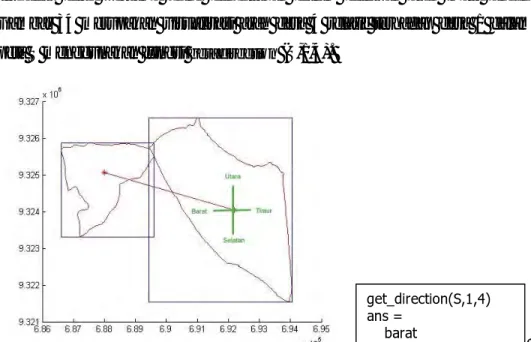
Arah antara dua desa didefinisikan sebagai posisi desa kedua secara relatif terhadap desa pertama yang dinyatakan dalam delapan arah mata angin. Gambar 34 merupakan visualisasi arah desa 4 relatif terhadap desa 1 dalam peta S menggunakan fungsi get_direction (S,1,4).
Gambar 34. Get_direction (S,1,4)
get_direction(S,1,4) ans =
Fungsi get_direction mengevaluasi arah berdasarkan posisi relatif MBR obyek kedua terhadap titik pusat obyek pertama yang menjadi acuan. Berikut adalah potongan programnya :
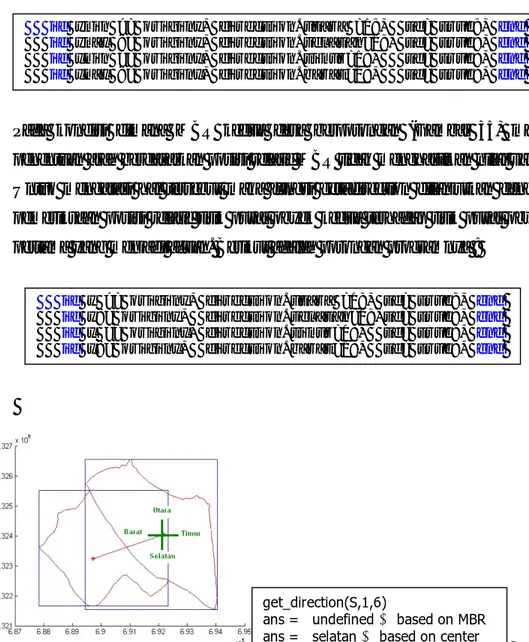
Pada kondisi dimana MBR kedua desa berpotongan (Gambar 35) maka penentuan arah berdasarkan posisi relatif MBR tidak menghasilkan nilai valid. Untuk mengatasi hal tersebut maka fungsi get_direction dilanjutkan dengan pemeriksaan posisi relatif titik pusat obyek kedua terhadap titik pusat obyek pertama yang menjadi acuan. Berikut adalah potongan programnya :
Gambar 35. Get_direction (S,1,6)
Setelah arah dalam empat mata angin utama (utara, selatan, barat, timur) ditentukan selanjutkan menentukan arah sekunder (tenggara, baratdaya, baratlaut, timurlaut). Berikut potongan programnya :
if y >= originy, direction.utara =1;, tf= true;, end if y<= originy, direction.selatan=1;,tf= true;, end if x >= originx, direction.timur=1;, tf= true;, end if x<= originx, direction.barat=1;, tf= true;, end
get_direction(S,1,6)
ans = undefined Æ based on MBR ans = selatan Æ based on center if ymin >= originy, direction.utara =1;, tf= true;, end if ymax <= originy, direction.selatan=1;, tf= true;, end if xmin >= originx, direction.timur=1;, tf= true;, end if xmax <= originx, direction.barat=1;, tf= true;, end
3.3.3. Pembentukan File Topologi
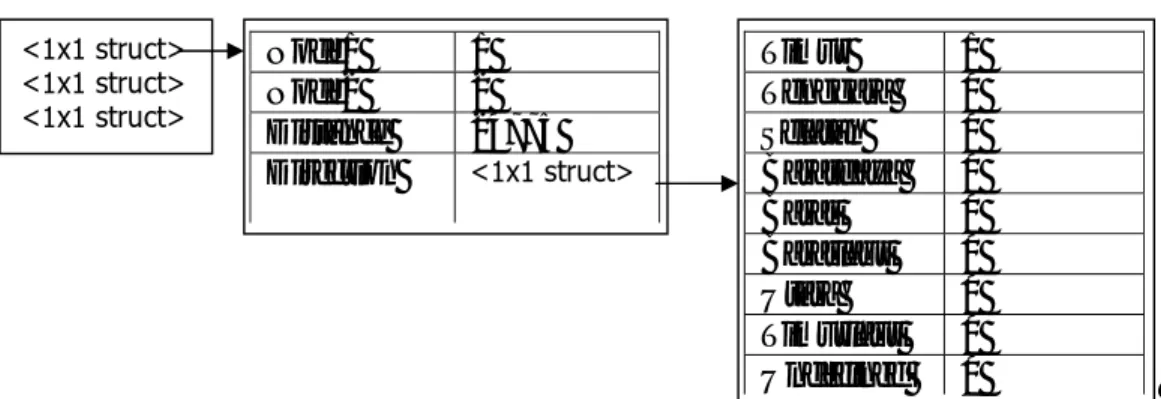
Hasil perhitungan jarak dan penentuan arah sebuah desa terhadap seluruh desa lainnya dalam peta S disimpan dalam variabel T_X (file topologi T_X.mat), dimana X menunjukkan nomor desa. Pada tahap ini terbentuk 7327 file dan masing-masing berukuran sekitar 300 KB sehingga total berukuran 975 MB. Gambar 36 memperlihatkan struktur dari file topologi :
Gambar 36. Struktur file topologi 3.3.4. Loading ke SQL Server
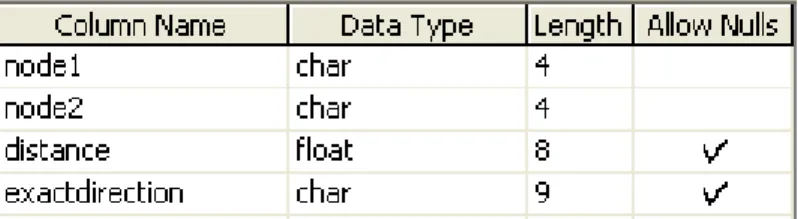
Karena setiap file topologi jika dimuat ke lingkungan Matlab akan membutuhkan ruang memori sekitar 11 MB maka tidak mungkin memuat seluruh file topologi ke memori sekaligus (membutuhkan sekitar 80 GB memori). Agar data jarak dan arah dalam file topologi dapat disimpan dan diambil dengan cepat tanpa membutuhkan memori yang sangat besar maka file topologi tersebut di-loading ke dalam basis data. Dalam SQL Server 2000, file topologi dimuat ke dalam tabel NeighbourhoodIndex pada basis data sdm dengan struktur sebagai berikut (Gambar 37):
<1x1 struct> <1x1 struct> <1x1 struct> Node1 1 Node2 2 Distance 24775 Direction <1x1 struct> Timur 1 Tenggara 0 Selatan 0 Baratdaya 0 Barat 0 Baratlaut 0 Utara 0 Timurlaut 0 Undefined 0
if (direction.timur==1 & direction.selatan==1),direction.tenggara=1;, end
if (direction.barat==1 & direction.selatan==1),direction.baratdaya=1;, end
if (direction.barat==1 & direction.utara==1),direction.baratlaut=1;, end
if (direction.timur==1 & direction.utara==1),direction.timurlaut=1;, end
Gambar 37. Struktur tabel NeighbourhoodIndex
Berikut potongan program yang digunakan untuk loading file topologi ke SQL Server :
Pada tahap ini terbentuk tabel NeighbourhoodIndex yang berisi 53.684.928 baris dan berukuran 1870 MB.
3.4 Membentuk path
Alur proses pembentukan path digambarkan pada Gambar 38 dan terdiri dari beberapa tahap yaitu :
3.4.1. Penentuan Obyek Target
Obyek target merupakan subset dari desa yang termasuk kelas miskin. Dari 177 desa di 8 kabupaten yang dijadikan sampel oleh Santoso A(2000), 122 termasuk kelas miskin. Dari desa yang termasuk kelas miskin tersebut, dipilih 3 desa dari setiap kabupaten sebagai obyek target (Tabel 5). Gambar 39 memperlihatkan sebaran ke-24 desa obyek target (kuning) diantara desa miskin (merah) dan desa tidak miskin (hijau).
conn = database(dbTarget,'',''); dbTarget harus telah terdaftar dalam ODBC connection
clear T
load(Tfile,'T') % load Tfile ke dalam variabel T
colnames = {'node1','node2','distance','exactdirection'}; for i=1:size(T,1);
% exdata = {T(i).node1, T(i).node2, T(i).distance, T(i).direction.exactdirection};
exdata{i,1} = T(i).node1; exdata{i,2} = T(i).node2; exdata{i,3} = T(i).distance;
exdata{i,4} = T(i).direction.exactdirection; end % end for i
insert(conn,tblTarget,colnames,exdata); commit(conn);
Gambar 38. Alur proses pembentukan path
Tabel 5. Desa Target
Membentuk path k=2 Obyek Target Path k=2 JabarA.mat Membentuk path k=n Neighbourhood Index Filter Predikat Path k=n
3.4.2. Membangun Path dengan k=2
Path dengan panjang dua node (path k=2) menggambarkan tetangga langsung dari desa target. Karena desa tetangga adalah desa yang berdampingan dengan desa target maka pada tahap ini filter predikat yang memeriksa arah path belum diterapkan. Berikut potongan program dari fungsi sdm_pathk2 :
function pathk2 = sdm_pathk2(A,node) counter=0; pathk2={}; for i=1:length(node) tetangga=find(A(node(i),:)); for j=1:length(tetangga) counter=counter+1; pathk2{counter,1}=[node(i) tetangga(j)]; end end
Dari 24 desa target, terbentuk 142 path k=2. Visualisasi path k=2 terdapat pada Gambar 40.
3.4.3. Membangun Filter Predikat
Filter predikat digunakan untuk menyaring arah perluasan path. Pada penelitian ini perluasan path dibatasi hingga memenuhi syarat umum sebuah node hanya muncul sekali dalam satu path. Sebuah path terdiri dari serangkaian node. Jika path terdiri dari dua node maka path tersebut hanya memiliki first_node dan
last_node. Jika jumlah node dalam path lebih dari dua node maka dalam path
tersebut terdapat sebuah node sebelum last node (before_last_node). Ketika sebuah path diperluas, maka filter predikat akan menyaring node baru mana yang akan ditambahkan ke dalam path. Ilustrasi proses perluasan path disajikan pada Gambar 41.
Gambar 41. Perluasan Path
Filter predikat yang dibangun pada penelitian ini adalah filter predikat arah (direction predicate filter) mencakup starlike dan variable_starlike filter. Filter vertical/horizontal variable starlike tidak dikembangkan karena diasumsikan bobot perluasan path memiliki kecenderungan yang sama ke seluruh arah. Dalam setiap filter predikat arah, arah path sebelum diperluas (exact_direction_previous) akan dibandingkan dengan arah path baru jika diperluas (exact_direction_new). Yang menjadi pembeda dari kedua filter predikat arah di atas adalah bagaimana menetapkan node acuan dalam mencari exact_direction_previous serta
exact_direction_new. Filter predikat arah starlike menggunakan node terakhir
(last_node dan before_last_node) sedangkan variable starlike menggunakan node pertama.
First Node Before Last Node Last Node
New Node ? ? fi lt e r Path Extended Path
Berikut potongan program filter predikat arah : switch filter case ('starlike') [jarak_new, exact_direction_new] = sdm_read_topology_db(db,lastnode,newnode); [jarak_last, exact_direction_previous] = sdm_read_topology_db(db,before_lastnode,lastnode); % absolute exact direction
if strcmp( exact_direction_new , exact_direction_previous);, tf=1; else
if strcmp(exact_direction_previous,'timur') &
(strcmp(exact_direction_new,'tenggara') | strcmp(exact_direction_new,'timurlaut')), tf=1;
elseif strcmp(exact_direction_previous,'barat') &
(strcmp(exact_direction_new,'baratdaya') | strcmp(exact_direction_new,'baratlaut')), tf=1;
elseif strcmp(exact_direction_previous,'selatan') &
(strcmp(exact_direction_new,'tenggara') | strcmp(exact_direction_new ,'baratdaya')), tf=1;
elseif strcmp(exact_direction_previous,'utara') &
(strcmp(exact_direction_new,'baratlaut') | strcmp(exact_direction_new , 'timurlaut')), tf=1; else tf=0; end % end if end %end if strcmp case ('variable_starlike') [jarak_new, exact_direction_new] = sdm_read_topology_db(db,firstnode,newnode); [jarak_last, exact_direction_previous] = sdm_read_topology_db(db,firstnode,lastnode); if strcmp( exact_direction_new , exact_direction_previous);, tf=1;
else % rel(i) is special relation of rel(1)
if strcmp(exact_direction_new , 'tenggara') &
( strcmp(exact_direction_previous,'timur')
|strcmp(exact_direction_previous,'selatan') ); tf=1;
elseif strcmp(exact_direction_new , 'baratdaya') &
( strcmp(exact_direction_previous,'barat')
|strcmp(exact_direction_previous,'selatan') ); tf=1; elseif strcmp(exact_direction_new , 'baratlaut') &
( strcmp(exact_direction_previous,'barat')
|strcmp(exact_direction_previous,'utara') ); tf=1; elseif strcmp(exact_direction_new , 'timurlaut') &
( strcmp(exact_direction_previous,'timur')
|strcmp(exact_direction_previous,'utara') ); tf=1; else tf=0;
end % end special relation end % end check direction predicate end % end switch filter
if tf==1;
extendedpath = [path newnode]; % extending path
% extendedpath =[firstnode]...[before_lastnode][lastnode][newnode] counter = counter +1;
pathkn{counter,1}= extendedpath; end %if tf
3.4.4. Membangun Path dengan k=n
Filter predikat yang terbentuk pada sub bab 3.4.3 digunakan untuk menyaring arah perluasan path. Visualisasi path dengan k=3 menggunakan filter starlike terdapat pada Gambar 42, sedangkan path dengan k=3 menggunakan filter variable starlike terdapat pada Gambar 43. Dari kedua gambar tersebut terlihat path dengan k=3 sudah banyak yang melintasi batas kecamatan.
Gambar 42. Path k =3 dengan filter starlike
Jumlah path yang terbentuk beserta jumlah desa (distinct) dapat dilihat pada Gambar 44. Dari Gambar 44 terlihat bahwa filter predikat starlike lebih kaku daripada filter predikat variable starlike sehingga menghasilkan node dan desa yang lebih sedikit.
142 105 165 211 315 228 0 50 100 150 200 250 300 350 k=2 k=3 starlike k=3 varstarlike jumlah path jumlah desa
Gambar 44. Jumlah Path dan Jumlah Desa 3.5 Menghitung frequency factor
Frequency factor, freqs(prop) menyatakan jumlah kemunculan feature prop dalam himpunan s dan card(s) menyatakan kardinalitas dari s. Dengan
menggunakan data podes 2003 maka jumlah desa yang match dengan peta adalah 86 persen. Sedangkan dari desa terlibat dalam path, yang match dengan desa podes adalah 89%. Frequency-Factor dari masing-masing variabel diperlihatkan pada Tabel 6
Tabel 6 Frequency-Factor
3.6 Membentuk aturan karakterisasi spasial
Berikut adalah aturan karakterisasi yang terbentuk dengan melihat
frequency-factor pada Tabel 6 dengan batas significance 1.0 (Nilai significance
sama dengan 1.0 berarti karakter obyek target mirip dengan karakter seluruh data):
Path k=2
Desa Miskin Æ Jalan utama angkutan lalu lintas berupa jalan aspal / beton (1.08) ^ Cara pembuangan sampah diangkut (1.27) atau dibuang ke sungai (1.00) atau cara lainnya (1.52) ^ Tempat buang air besar di jamban bersama (1.25) atau bukan jamban (1.46) ^ Ada pelanggan koran /majalah (1.03) ^ Jarak dari desa ke rumah sakit jauh (1.99)
Path k=3 filter starlike
Desa Miskin Æ Jalan utama angkutan lalu lintas berupa jalan aspal / beton (1.11) ^ Cara pembuangan sampah diangkut (1.07) atau dibuang ke sungai (1.00) atau cara lainnya (1.08) ^ Tempat buang air besar di jamban bersama (1.22) atau bukan jamban (1.34) ^ Tidak ada pelanggan koran /majalah (1.04) ^ Jarak dari desa ke rumah sakit jauh (1.55)
Jalan Utama Angkutan Lalu Lintas
Value of X2 Label K2 K3 Starlike K3 Varstarlike
1 Aspal/Beton 1.08 1.11 1.04
2 Diperkeras Batu/Kerikil 0.86 0.81 0.93
3 Jalan Tanah 0.71 0.55 0.73
4 Lainnya 0.00 0.00 0.00
Cara Pembuangan Sampah
Value of Label K2 K3 Starlike K3 Varstarlike
1 Tempat sampah kemudian diangkut 1.27 1.07 1.07
2 Dalam lubang / dibakar 0.88 0.99 0.93
3 Dibuang ke sungai 1.00 0.77 1.03
4 Lainnya 1.52 1.08 1.41
Tempat Buang Air Besar
Value of Label K2 K3 Starlike K3 Varstarlike
1 Jamban sendiri 0.77 0.85 0.83
2 Jamban bersama 1.25 1.22 0.97
3 Jamban umum 0.55 0.71 0.52
4 Bukan jamban 1.56 1.34 1.52
Keberadaan Pelanggan Koran / Majalah
Value of Label K2 K3 Starlike K3 Varstarlike
1 Ada 1.03 0.98 0.98
2 Tidak ada 0.94 1.04 1.03
Jarak dari desa ke rumah sakit
Value of Label K2 K3 Starlike K3 Varstarlike
1 Dekat 0.93 0.94 0.92
2 Sedang 0.86 1.01 0.70
Path k=3 filter variabel starlike
Desa Miskin Æ Jalan utama angkutan lalu lintas berupa jalan aspal / beton (1.04) ^ Cara pembuangan sampah diangkut (1.07) atau dibuang ke sungai (1.03) atau cara lainnya (1.41) ^ Tempat buang air besar bukan jamban (1.52) ^ Tidak ada pelanggan koran /majalah (1.03) ^ Jarak dari desa ke rumah sakit jauh (2.53)
Dalam aturan karakterisasi yang terbentuk di atas, nilai frequency-factor bagi prop/nilai Aspal/Beton pada variabel Jalan Utama Angkutan Lalu Lintas adalah sedikit di atas 1.0 untuk semua path. Hal ini menunjukkan bahwa proporsi desa yang memiliki jalan aspal/beton adalah sama baik untuk desa miskin maupun untuk keseluruhan desa.
Nilai frequency-factor untuk prop/nilai Tidak Ada pada variabel keberadaan pelanggan koran/majalah adalah 0.94 (path k=2), 1.04 (path k=3 filter starlike) dan 1.03 (path k=3 filter variabel starlike). Dengan demikian bisa disebutkan bahwa salah satu karakter desa miskin adalah tidak memiliki pelanggan koran/majalah – meskipun karakter ini tidak begitu kuat. Karakter desa miskin yang kuat adalah jarak dari desa ke rumah sakit jauh. Karakter ini ditunjukkan dengan nilai frequency-factor bagi prop/nilai Jauh yang jauh di atas 1.0 dalam semua path (1.99 , 1.55 dan 2.53). Karakter lain yang cukup kuat adalah tempat pembuangan air besar berupa jamban bersama dan bukan jamban. Nilai
frequency-factor yang menonjol bagi peubah cara pembuangan sampah terdapat
pada prop/nilai Lainnya yaitu sebesar 1.52 (pada path k=2) dan 1.41 (pada path k=3 filter variabel starlike). Untuk memperjelas kasus ini diperlukan informasi tambahan tentang cara pembuangan sampah yang termasuk dalam kategori Lainnya ini.
Secara umum diperlukan kehati-hatian dalam menerapkan aturan yang terbentuk di atas untuk menggambarkan desa miskin. Sebaiknya aturan yang dipilih adalah yang memiliki nilai frequency-factor jauh di atas 1.0 untuk semua path (misal jarak dari desa ke rumah sakit jauh). Jika nilai frequency-factor untuk semua path relatif dekat dengan 1.0 maka aturan tersebut cenderung kurang menggambarkan kondisi desa sebenarnya (misal Jalan Utama Angkutan Lalu Lintas adalah Aspal/Beton)