1
Klasifikasi Buah Jeruk Menggunakan Metode Naive Bayes Berdasarkan Analisis Tekstur dan Normalisasi Warna
Wildan Agustian1, Dra. Sri Setyaningsih, M.Si1Arie Qur’ania, M.Kom1 1. Program Studi Ilmu Komputer FMIPA UNPAK – BOGOR, Jl. Pakuan, Bogor
16143, Indonesia Email :[email protected]
Program Studi Ilmu Komputer FMIPA – Universitas Pakuan Abstrak
Klasifikasi adalah proses yang penting untuk mengenali dan membedakan sesuatu hal dengan hal lainnya, hal ini dapat berupa hewan, tumbuhan, maupun manusia. Identifikasi ini dilakukan dengan mengenali ciri khas yang dimiliki sesuatu hal tersebut. Salah satu cara untuk mengklasifikasikan buah jeruk bisa dilakukan menggunakan metode naive bayes dengan cara berbasis citra. Buah jeruk bisa dikenali berdasarkan tekstur dan warnanya. Umumnya buah jeruk memiliki warna yang identik yaitu hijau dan kuning. Contohnya jeruk orange dan mandarin. Hal ini menyebabkan sulit untuk mengklasifikasi jenis jeruk tersebut. Dua teknik ekstraksi fitur digunakan dalam penelitian ini adalah Normalisasi Warna dan analisis tekstur. Normalisasi warna menghasilkan tiga nilai yaitu red, green, blue. Sedangkan analisis tekstur memiliki empat nilai yang terdiri dari fitur entropi, kontras, energi, homogenitas.
Kata kunci : buah jeruk, naive bayes, analisis tekstur, normalisasi warna Pendahuluan
Sebagai negara yang berada pada garis katulistiwa, Indonesia merupakan salah satu negara terkaya di dunia dengan berbagai macam produk sayur-sayuran dan jenis buah-buahan. Sebagian varietas sayur-sayuran dan buah-buahan dunia tumbuh indonesia. Varietas yang paling beragam adalah varietas buah-buahan.
Indonesia merupakan negara yang beriklim tropis. Hal ini mengakibatkan berbagai varietas tanaman serta buah-buahan di Indonesia beragam. Buah-buahan di Indonesia sangat beragam. Mulai dari varietas buah-buahan yang khas iklim tropis yaitu pisang, sampai apel dan jeruk. Salah satu varietas buah yang sangat beragam adalah buah jeruk.
Negara indonesia memiliki
beragam varietas jeruk. Di seluruh dunia di perkirakan terdapat kurang lebih 600 varietas jeruk, yang sebagiannya itu berada di Indonesia. Varietas jeruk di Indonesia yaitu jeruk yang paling khas seperti jeruk medan, jeruk bali, jeruk
santang hingga jeruk mandarin, jeruk nipis, jeruk lemon dan jeruk orange.
Namun varietas yang banyak ini
mengakibatkan susahnya membedakan varietas jeruk satu dan lainnya. Hal ini di karenakan sebagian varietas jeruk di indonesia memiliki warna dominan yaitu jingga dan kuning. Sebagai contoh kita sangat sulit membedakan antara jenis jeruk mandarin dengan jenis jeruk orange karena keduanya sedikit identik warnanya
serta ukurannya. Kondisi ini
mengakibatkan perlunya suatu metode yang bisa mengklasifikasikan varietas jeruk dengan akurat. Salah satu metode
pengklasifikasian adalah metode
klasifikasi naive bayes.
Naive Bayes merupakan salah satu
metode pada probabilistic reasoning.
Naive Bayes merupakan algoritma klasifikasi yang sangat efektif dan efisien. Metode Naive Bayes bertujuan untuk melakukan klasifikasi data pada klas tertentu. Untuk kerja pengklasifikasi
2 diukur dengan nilai predictive accuracy (Zhang, 2007).
Sebelumnya telah dilakukan
penelitian tentang klasifikasi jeruk.
Gunawan (2013) melakukan penelitian tentang Klasifikasi Citra Jeruk Kintamani Berdasarkan Fitur Warna dan Ukuran Mengggunakan Pendekatan Euclidean. Penelitian ini mengklasifikasikan mutu jeruk berdasarkan 3 jenis jeruk yaitu kualitas 1, kualitas 2 dan kualitas 3. Arham et al (2013) melakukan penelitian Evaluasi Mutu Jeruk Nipis Dengan Pengolahan Citra dan Jaringan Syaraf Tiruan. Penelitian ini mengklasifikasikan mutu jeruk berdasarkan kematangan jeruk
yaitu awal/tua dan matang/lewat.
Kusumaet al (2013) melakukan penelitian tentang Klasifikasi Buah Jeruk Berdasarkan Warna dan Diameter dengan Teknik Linear Discriminat Analisis. Penelitian ini mengklasifikasikan jeruk berdasarkan 2 jenis jeruk yaitu lemon dan manis. Ketiga penelitian tersebut berbasis desktop yang hanya bisa di eksekusi di platform Windows.
Berdasarkan uraian diatas maka
perlu dilakukan penelitian tentang
Klasifikasi Buah Jeruk Menggunakan Metode Naive Bayes Berdasarkan Analisis Tekstur dan Normalisasi Warna yang
dapat di jalankan di semua
platform.Selanjutnya diharapkan dapat
membantu dalam mengklasifikasi varietas jeruk yang beragam.
Metodologi Penelitian
Tahapan penelitian untuk
melakukan klasifikasi buah jeruk
menggunakan metode naive bayes
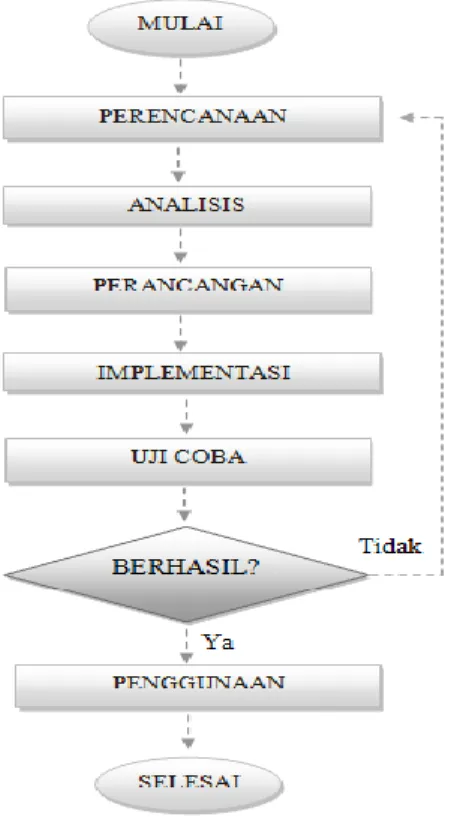
berbasis webdapat dilihat pada Gambar 1.
Gambar 1. Tahap Penelitian
Pada tahapan perencanaan terlebih dahulu dikumpulkan beberapa bahan serta data yang dapat dijadikan landasan awal
untuk melengkapi pendefinisian
permasalahan tersebut. Tahap
perencanaan/identifikasi masalah
berkaitan dengan akuisisi citra,
preprosessing serta diagnosa
permasalahan sehingga dapat ditentukan sasaran dan faktor kritis permasalahan yang ada, diantaranya :
1. Studi Kepustakaan 2. Studi Lapang a. Akuisisi Citra
Pengambilan data dilakukan
dengan menggunakan kamera digital.
Citra dihasilkan dengan melakukan
capture dari objek yang sebenarnya untuk
menghasilkan gambar digital yang
memiliki resolusi tinggi. Proses capture
menggunakan kamera digital akan
memperlihatkan secara jelas dan detail tekstur dari citra. Pada penelitian ini citra jeruk digunakan adalah 4 jenis jeruk, masing – masing terdiri dari 10 sample
3 untuk data latih dan 10 sample untuk pengujian.
b. Preprosessing
Preprosesing terhadap citra jeruk
dilakukan pada tahapan ini, citra
diseragamkan ukurannya menjadi 16x16 piksel dan melakukan perubahan bentuk
citra ke dalam format grayscale 8 bit (28 =
256 derajat keabuan).
Gray = 0,2989 x R + 0,5870 x G + 0,1140 x B ...(1) Pada tahapan analisis dilakukan suatu analisa, mengenai sistem yang akan di buat serta kemungkinan-kemungkinan
yang akan terjadi, sehingga dapat
dipersiapkan sejak awal agar tercipta
sistem yang friendly dan mudah
digunakan, serta dapat berjalan sesuai dengan yang di inginkan.
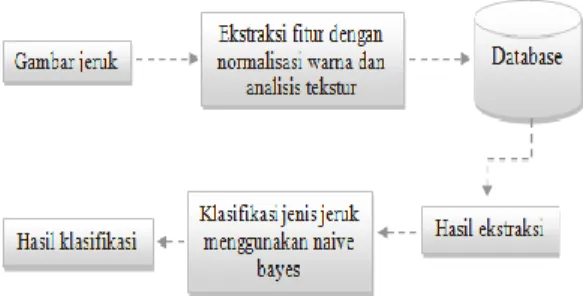
Adapun rancangan sistem secara umum dari aplikasi yang akan dikembangkan adalah seperti pada Gambar 2 berikut ini.
Gambar 2. Sistem yang Dikembangkan Adapun metode yang digunakan adalah :
a. Naive Bayes
Model statistik merupakan salah satu model yang terpercaya sangat andal
sebagai pendukung pengambilan
keputusan. Konsep probabilitas
merupakan salah satu model statistik. Salah satu metode yang menggunakan konsep probabilitas adalah metode naive bayes. Pada metode ini, semua atribut akan memberikan kontribusinya dalam
pengambilan keputusan, dengan bobot atribut yang sama penting dan setiap atribut saling bebas satu sama lain.(Zhang, 2007)
...(2)
f(x) = nilai probabilitas kemunculan π = 3.14
σ = standar deviasi parameter µ = rata-rata parameter
e = exponensial (2,71) x = nilai parameter
Alur algoritma metode naive bayes adalah sebagai berikut :
a) Memasukan data pengetahuan
berdasarkan parameter
b) Menghitung nilai rata-rata dan standar deviasi dari setiap parameter
c) Mencari probabilitas nilai
kemunculan dari setiap parameter d) Menghitung likelihood dari setiap
klasifikasi
e) Mencari probabilitas terbesar. b. Analisis tekstur
Tekstur adalah sifat – sifat atau karakteristik yang dimiliki oleh suatu daerah yang cukup besar sehingga secara alami secara alami sifat tadi dapat berulang dalam daerah tertentu.Pada lingkungan alami, permukaan objek seperti potongan kayu, rerumputan, hamparan pasir pantai, tekstil, kulit, dan sebagainya memiliki tekstur.Citra juga dapat dipandang memiliki tekstur yang terbentuk akibat variasi dan atau gradasi keabuan pada citra digital. Tekstur adalah fitur yang bergantung konteks, maksudnya, tekstur tidak dapat didefinisikan hanya dari piksel saja tetapi harus dalam kaitannya dengan piksel lain dalam suatu wilayah citra (Hauta-Kasari, 1999: 13).Kegunaan analisis tekstur di antaranya untuk mengklasifikasikan objek berdasarkan perhitungan fitur tekstur, di
4 antaranya entropi, energi, kontras, homogenitas (Haralick et al. 1973).Karena matriks I memiliki empat aras keabuan, maka jumlah nilai piksel tetangga dan nilai piksel referensi pada area kerja matriks berjumlah empat. Berikut adalah area kerja matriks.
Gambar 3. Area kerja matriks
Gambar 4. Matriks asal, matriks I Hubungan spasial untuk d=1 dan θ=0o
pada matriks diatas dapat dituliskan dalam matriks berikut.
Gambar 5. Pembentukan matriks kookurensi dari matrik I
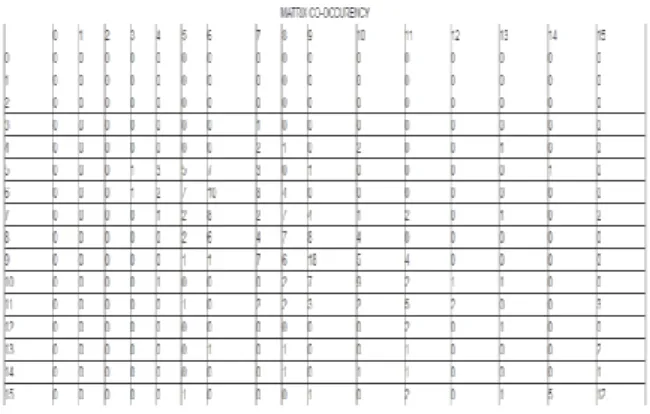
Sudut orientasi menentukan arah hubungan tetangga dari piksel-piksel referensi, orientasi θ=0o berarti acuan dalam arah horizontal atau sumbu x positif dari piksel-piksel referensi. Acuan sudut berlawanan arah jarum jam. Angka 2 pada (0,0) berarti jumlah hubungan pasangan (0,0) pada matriks asal berjumlah 2.
Sebuah citra memiliki penyebaran piksel secara acak tanpa struktur yang
tetap yang menyebabkan matriks intensitas co-occurrence tidak akan mempunyai pasangan dengan pola tertentu. Fitur yang berfungsi untuk mengukur keteracakan dari distribusi intensitas tersebut yaitu entropi.Fitur yang berfungsi untuk mengukur konsentrasi pasangan intensitas adalah energi.Fitur yang digunakan untuk mengukur kekuatan perbedaan intensitas adalah kontras. Fitur homogenitas berfungsi untuk mengukur tingkat homogeni variasi intensitas (Ahmad 2005), persamaan dari fitur tersebut disajikan pada persamaan 3 – 6 berikut :
Persamaan untuk keempat fitur tersebut adalah sebagai berikut :
1 0 , 2)
,
(
n j ij
i
P
Energi
………...….(3)
1 0 , 2 ) ( , n j i j i j Pi Kontras ………..(4)
1 0 , 1 ) , ( n j i i j j i P s Homogenita ……(5)
1 0 , )) , ( ln ( ) , ( n j i j i P j i P Entropi .(6) Dimana: i dan j adalah sifat keabuan dari resolusi 2 piksel yang berdekatan
p (i,j) adalah frekuensi relatif matriks dari resolusi 2 piksel yang berdekatan.
c. Normalisasi Warna
Untuk menghitung nilai warna dan menafsirkan hasilnya dalam model warna
RGB yaitu dengan melakukan
normalisasi.Normalisasi dilakukan karena sejumlah citra mempunyai penerangan yang berbeda. Hasil perhitungan dari
normalisasi akan menghilangkan
pengaruh penerangan, sehingga nilai untuk setiap komponen warna dapat dibandingkan satu sama lainnya walaupun
berasal dari citra dengan kondisi
5 menghitung normalisasi adalah sebagai berikut :
adalah sebagai berikut :
... (7) ... (8) ... (9)
r = nilai prosentase red g = nilai prosentase green b = nilai prosentase blue R= jumlah red
G= jumlah green B= jumlah blue
Algoritma Normalisasi warna adalah sebagai berikut :
a) Input data citra
b) Menentukan nilai RGB dari setiap pixel
c) Menjumlahkan nilai keseluruhan niali RGB
d) Menjumlahkan masing masing nilai R(red), G(green), B(blue)
e) Mencari prosentase nilai RGB.
Hasil dan Pembahasan
Halaman utama adalah halaman yang pertama di akses ketika website dibuka. Halaman ini terdiri terdiri dari 3 bagian, yaitu header, menu dan banner..Tampilan halaman utama dapat dilihat pada gambar 6.
Gambar 6. Tampilan Halaman Utama Proses Ekstraksi Analisis Tekstur
Halaman analisis tekstur. Pada halaman ini akan diketahui, citra jeuk, entropi, energi, kontras, homogenitas,
untuk analisis tekstur. Tampilan proses ekstraksi analisis tekstur dapat dilihat pada gambar 7.
Gambar 7. Tampilan Halaman Hasil Ekstraksi Analisis Tekstur Proses Normalisasi Warna
Halaman normalisasi warna. Pada halaman ini akan diketahui, citra jeuk, nilai prosentase red, green, blue, untuk normalisasi warna. Tampilan proses ekstraksi normalisasi warna dapat dilihat pada gambar 8.
Gambar 8. Tampilan Halaman Hasil Ekstraksi Normalisasi Warna Proses Klasifikasi Naive Bayes
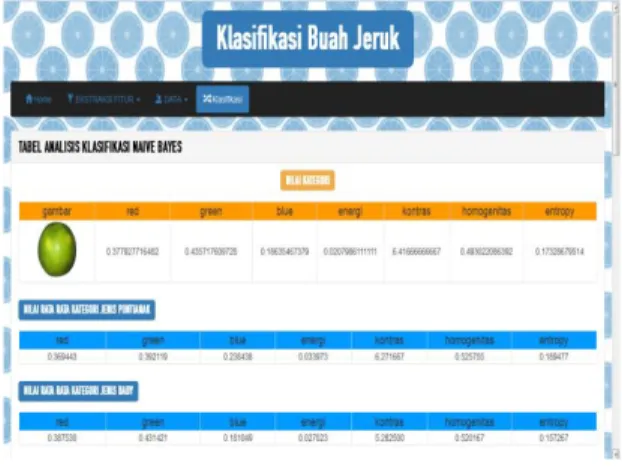
Halaman klasifikasi. Pada halaman ini akan diketahui, citra jeuk, nilai rata-rata dari parameter setiap jenis jeruk nilai standar deviasi dari parameter setiap jenis jeruk, nilai likelihood setiap jenis jeruk, serta nilai probabilitas dari setiap jeruk menggunakan metode naive bayes.
6 Tampilan proses klasifikasi dapat dilihat pada gambar 9.
Gambar 9. Tampilan Halaman Klasifikasi Perhitungan Manual Normalisasi Warna
Normalisasi warna merupakan proses Untuk menghitung nilai warna dan menafsirkan hasilnya dalam model warna
RGB yaitu dengan menghitung
prosentasenya.
Langkah untuk melakukan
normalisasi warna adalah sebagai berikut 1. Membaca nilai RGB dari setiap pixel
dan menjumlahkannya.
Gambar 10. Jumlah RGB
2. Menghitung prosentase R (merujuk persamaan 7), prosentase G (merujuk persamaan 8) dan prosentase B(merujuk persamaan 9).
Gambar 11. Hasil prosentase RGB
Perhitungan Manual Analisis Tekstur Proses yang dilakukan pertama kali pada proses analisis tekstur adalah merubah ukuran gambar menjadi 16 x 16 pixel dan merubah citra menjadi greyscale untuk kemudian di ekstraksi dengan analisis tekstur seperti ditunjukan pada gambar 12.
Gambar 12 Nilai intensitas dari citra jeruk ukuran 16 x 16 piksel
Matriks intensitas digunakan untuk menentukan matriks kookurensi. Untuk menghindari pembentukan matrik kookurensi yang terlalu besar dan dapat menyebabkan proses perhitungan menjadi lambat, biasanya ukuran matrik kookurensi dibatasi. Ukuran yang umum digunakan untuk matrik kookurensi adalah 16 X 16.Dengan demikian bila nilai intensitas maksimum lebih dari 15, harus dikonversi sehingga nilai intensitas maksimum menjadi 15 (Ahmad, 2005). Berikut adalah konversi nilainya.
Gambar 13. Penyederhanaan Intensitas 16 x 16
7 Hubungan spasial untuk d=1 dan ø=0 matriks diatas dapat dituliskan dalam matriks berikut:
Gambar 14. Matriks kookurensi Matrik kookurensi bias digunakan untuk membuat matrik normalisasi dari hasil penjumlahan antara matrik kookurensi dengan matrik transpose nya. Untuk melakukan normalisasi kita harus menghitung jumlah keseluruhan nilai yang digunakan sebagai pembagi. Nilai dari normalisasi = nilai/jumlah_total.Sehingga didapatkan hasil matriks normalisasi sebagai berikut:
Gambar 15. Matriks Normalisasi Matriks normalisasi digunakan untuk mencari nilai dari entropi, energi, kontras, dan homogenitas. Dari hasil keseluruhan penjumlahan matrik, didapat masing – masing nilai entropi, energi, kontras, dan homogenitas seperti gambar 16:
Gambar 16. Hasil Analisis Tekstur
Perhitungan manual metode naive bayes
Pada proses pengklasifikasian
menggunakan naive bayes, data citra yang telah di normalisasi RGB dan analisis tekstur masuk ke proses penginputan data pengetahuan yang nantinya di latih dan di uji. Proses pertama dalam klasifikasi naive bayes adalah mencari nilai rata rata dan standar deviasi dari data pengetahuan. Berikut adalah nilai rata-rata dan standar deviasi data pengetahuan.
Gambar 17. Nilai rata rata dan standar deviasi data pengetahuan
Nilai rata-rata dan standar deviasi digunakan untuk menguji dengan data uji
dan mencari nilai probabilitas
kemunculannya dengan merujuk ke
persamaan 2. Berikut rekapitulasi
probabilitas kemunculannya.
Gambar 17. Rekapitulasi probabilitas kemunculan
Probabilitas kemunculan digunakan untuk mencari likelihood dari setiap klasifikasi dengan cara mengalikan hasil probabilitas kemunculannya dari setiap parameter jenis jeruk. Berikut hasil likelihoodnya.
8 Gambar 18. Likelihood setiap jenis
Nilai likelihood digunakan untuk menententukan probabilitasnya dengan cara membagi nilai likelihood jenis jeruk dengan jumlah likelihood keseluruhan. Berikut hasi probabilitasnya.
Gambar 18. Probabilitas setiap jenis
Dilihat dari tabel diatas
probabilitas paling besar adalah jeruk
beby. Maka citra yang dimasukan
termasuk jenis baby. Kesimpulan
Penerapan metode untuk klasifikasijeruk pada aplikasi ini menggunakan metode naive bayes berdasarkan analisis tekstur dan normalisasi warna. Perancangan system
ini menggunakan software
adobedreamweaver dengan bahasa pemrograman PHP, perancangan database menggunakan MYSQL. Tahap penelitian dimulai dengan akusisi citra sebagai pengumpulan data citra digital.
Jumlah keseluruhan data yang diambil adalah 52 data dengan 4 jenis jeruk masing – masing ada 10 citra. Dari 52 data yang ada 40 diantaranya merupakan data latih dan 12 merupakan data uji. Hasil uji coba menggunakan metode k-fold cross validation berdasarkan range data uji 1-12, mendapat presentase 91,6%. Sedangkan untuk range
data uji 41-52 mendapatkan presentase yang sama 91,6%.
Uji coba struktural yang dilakukan sesuai dengan flowchart dan uji coba fungsional sesuai dengan fungsi dari elemen-elemen aplikasi.
Berdasarkan persentase diatas bisa disimpulkan bahwa klasifikasi jeruk dengan naive bayes berdasarkan analisis tekstur dan normalisasi warna dapat mengklasifikasikan jeruk pontianak, beby, mandarin dan orange dengan baik.
Saran
Penelitian ini bisa dikembangkan dengan menggunakan metode klasifikasi lain misalnya K-Meansdan K – Nearest Neighbor.Hal ini bisa menjadi bahan perbandingan hasil akurasi dan dapat diketahui metode mana yang mendapatkan hasil terbaik untukklasifikasi citra jeruk. Selain prosesklasifikasii, penelitian bisa
dikembangkan juga dengan
menambahkan proses preprocessing yang lain seperti segmentasi, penipisan bukit, deteksi tepi, dan rotasi citra agar bisa mendapatkan hasil yang lebih baik.
Daftar Pustaka
Ahmad, U 2005. Pengolahan Citra Digital dan Tehnik Pemrogramannya. Yogyakarta : Graha Ilmu
Arham Zainul. 2004. Evaluasi Mutu Jeruk Nipis Dengan Pengolahan Citra dan Jaringan Syaraf Tiruan.
Bandung.
Betha Sidik, HI
Pohan.2007.Pemrograman
Web dengan
HTML.Informatika. Bandung. Fathansyah. 2001. Basis Data.
Informatika.Bandung.
Gunawan Deni. 2013. Klasifikasi Citra Buah Jeruk Kintamani Berdasarkan Fitur
9 Warna dan Ukuran
Menggunakan Pendekatan
Euclidean. Bandung.
Hestiningsih, Idhawati. 2004. Pengantar Pengolahan Citra. Bandung. Kusuma Indri. 2014. Klasifikasi Buah
jeruk Berdasarkan Warna dan Diameter dengan Teknik Linear Discriminat Analisis. Jakarta. Kurniawan, P.2014. Penerapan Dimensi
Fraktal dan Analisis Tekstur pada Identifikasi Tanaman obat menggunakan K Nearest Neightbor[skripsi].Bogor.
Universitas Pakuan
Zhang, H., dan Su, J. 2007.Naive Bayesian Classifers for Ranking. New Jersey.