UJI ALGORITMA
PROBABILISTIC MODEL, VECTOR SPACE
MODEL,
DAN
EXTENDED BOOLEAN MODEL
PADA
SISTEM REKOMENDASI DIFFERENTIAL DIAGNOSE
PENYAKIT PARU – PARU
(Studi Kasus: Puskesmas Jebed, Pemalang)
SKRIPSI
Diajukan Untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh:
Vincentius Ardha Dian Rigitama
095314051
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
2013
PROBABILISTIC MODEL, VECTOR SPACE MODEL, AND
EXTENDED BOOLEAN MODEL ALGORITHMS TEST IN
LUNG DISEASE DIFFERENTIAL DIAGNOSE
RECOMMENDATION SYSTEMS
(Case Study: Puskesmas Jebed, Pemalang)
A Thesis
Presented As A Partial Fulfillment of The Requrements
To Obtain The Bachelor Degree
Informatics Engineering Study Program
By:
Vincentius Ardha Dian Rigitama
095314051
INFORMATIC ENGINEERING STUDY PROGRAM
FACULTY OF SCIENCE AND TECHNOLOGY
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
HALAMAN PERSETUJUAN
SKRIPSI
UJI ALGORITMA PROBABILISTIC MODEL, VECTOR SPACE MODEL, DAN EXTENDED BOOLEAN MODEL PADA SISTEM REKOMENDASI
DIFFERENTIAL DIAGNOSE PENYAKIT PARU - PARU
Oleh:
Vincentius Ardha Dian Rigitama NIM: 095314051
Telah disetujui oleh:
Dosen Pembimbing Tugas Akhir
Puspaningtyas Sanjoyo Adi, S.T., M.T. Tanggal: ………
HALAMAN PENGESAHAN
SKRIPSI
UJI ALGORITMA PROBABILISTIC MODEL, VECTOR SPACE MODEL, DAN EXTENDED BOOLEAN MODEL PADA SISTEM REKOMENDASI
DIFFERENTIAL DIAGNOSE PENYAKIT PARU - PARU
Dipersiapkan dan ditulis oleh Vincentius Ardha Dian Rigitama
NIM: 095314051
Telah dipertahankan di depan Panitia Penguji Pada tanggal 18 Juli 2013
Dan dinyatakan memenuhi syarat
Susunan Panitia Penguji
Nama lengkap Tanda Tangan
Ketua Sri Hartati Wijono, S.Si., M.Kom. ………. Sekretaris JB. Budi Darmawan, S. T., M. Sc. ………. Anggota Puspaningtyas Sanjoyo Adi, S.T., M.T. ……….
Yogyakarta, …….. Faklutas Sains dan Teknologi
Universitas Sanata Dharma Dekan,
(Paulina Heruningsih Prima Rosa, S.Si., M.Sc.)
PERNYATAAN KEASLIAN KARYA
Saya menyatakan dengan sesungguhnya bahwa skripsi yang saya tulis ini
tidak memuat karya atau bagian karya orang lain, kecuali yang telah disebutkan
dalam kutipan dan daftar pustaka sebagaimana layaknya karya ilmiah.
Yogyakarta, 18 Juli 2013
Penulis,
Vincentius Ardha Dian Rigitama
HALAMAN MOTO
“Jalan yang berlubang itu bukan sebuah hambatan, tetapi
jalan yang harus dilalui. Tidak ada sesuatu yang tidak
mungkin, everything is possible.”
HALAMAN PERSEMBAHAN
Kupersembahkan skripsi ini kepada:
Tuhan Yesus Kristus dan Bunda Maria atas lindungan dan kasih – Nya.
Keluarga saya, Bapak Iwan, Ibu Yudhia, kakak Andreas dan Mita, dan adik Tika yang selalu mendoakan dan memberi dukungan saya.
Orang – orang spesial yang selalu membantu, memberikan semangat, kritik, dan saran:
Bp. Puspaningtyas, Ibu Tatik, & Pak Wawan selaku trio tim penguji pendadaran yang hebat, “usted hace todo el mundo tiene miedo”.
Yosefina Agustin, Agustinus Wikrama, & Benediktus Eki yang selalu menjadi senasib seperjuangan.
J.S Wulandari, Aden, Henfry, Unggul, Jenny, Audris, & Ageng yang selalu mendukung, memotivasi, dan membantu dalam pengerjaan, gracias!!
TIM DEJ yang sangat memotivasi dan menginspirasi.
Teman – teman TI 2009, Ustedes son lo máximo!
muchas gracias por todo,
@vincentiusardha
ABSTRAKSI
Differential diagnose adalah penentuan dua atau lebih penyakit atau
kondisi yang diderita pasien dengan membandingkan dan mengontraskan secara
sistematis hasil – hasil tindakan diagnostik. Petugas pelayanan kesehatan, dengan
berdasarkan pada pengamatan gejala pasien, akan menemukan sejumlah penyakit
yang mungkin terjadi. Hal ini tidak menutup kemungkinan adanya kesalahan
differential diagnose penyakit pasien. Masalah tersebut kemudian akan
diselesaikan menggunakan sebuah solusi dengan membuat sebuah aplikasi yang
mampu memberi urutan penyakit yang mungkin menjadi differential diagnose.
Dengan berdasar pada gejala – gejala umum yang ada dalam pedoman
yang telah dijadikan menjadi dokumen pendek, differential diagnose dihitung
menggunakan 3 (tiga) algoritma information retrieval, yakni extended boolean
model, vector space model, dan probabilistic model. Sistem akan diuji oleh 4
orang dokter, dengan mengisi kuesioner yang berisi gejala umum pasien dan
membandingkannya dengan hasil sistem. Hasil dari sistem kemudian dihitung
menggunakan algoritma recall – precision.
EBM mempunyai unjuk kerja paling tinggi diantara ketiga model dengan
rerata penurunan terhadap titik optimal sebesar 0,32473871. Rerata penurunan
terhadap titik optimal VSM adalah 0,3031798. PM mempunyai rerata penurunan
terhadap titik optimal sebesar 0,3676046. Algoritma EBM merupakan algoritma
terbaik yang dapat diterpakan pada sistem yang mampu memberikan akurasi
sebesar 81%.
ABSTRACT
Differential diagnose is the determination of two or more diseases or
conditions suffered by patients, with comparing and contrasting the results of
diagnostic measures in systematic way. A doctor, based on the observations of the
patient's symptoms, will make a differential diagnosis. There is a possibility of a
wrong differential diagnosis. Based on that problem, will be solved by creating an
application that is able to provide feedback to the user the sequence of diseases
that may be included in the differential diagnosis.
Based on general symptoms that written in the guidelines, thats will be
present as a short document. Few of short documents, will be use as a collections.
Differential diagnosis will be calculated using three (3) information retrieval
algorithms, the extended Boolean models, the vector space models, and the
probabilistic models. We can define a short document is a document with number
of maximal term is 30. The system will be tested by 4 doctors. Testing method is
by filling out a questionnaire and then compared with the results of the system.
After that, the results will be calculated using recall – precision algorithm.
EBM has the highest performance among the three models, with a mean
decrease from the optimal point is a 0,2473871. The mean decrease from the
optimal point of VSM is a 0,3031798. PM has the lowest performance, with a
mean decrease from the optimal point is a 0,3676046. Extended Boolean Models
is the best algorithm that will be used in system and able to provide an accuracy at
81%.
LEMBAR PERNYATAAN PERSETUJUAN
PUBLIKASI KARYA ILMIAH UNTUK KEPERLUAN AKADEMIS
Yang bertanda tangan di bawah ini, saya mahasiswa Universitas Sanata Dharma:
Nama : Vincentius Ardha Dian Rigitama
Nomor Mahasiswa : 095314051
Demi mengembangkan ilmu pengetahuan, saya memberikan kepada perpustakaan
Universitas Sanata Dharma karya ilmiah saya yang berjudul:
UJI ALGORITMA PROBABILISTIC MODEL, VECTOR SPACE MODEL,
DANEXTENDED BOOLEAN MODEL PADA SISTEM REKOMENDASI
DIFFERENTIAL DIAGNOSE PENYAKIT PARU – PARU
Beserta perangkat yang diperlukan. Dengan demikian saya memberikan kepada
Perpustakaan Universitas Sanata Dharma hak untuk menyimpan, mengalihkan
dalam bentuk media lain, mengelolanya dalam bentuk pangkalan data,
mendistribusikan secara terbatas, dan mempublikasikannya di Internet atau media
lain untuk kepentingan akademis tanpa perlu meminta izin dari saya maupun
memberikan royalti kepada saya selama tetap mencantumkan nama saya sebagai
penulis.
Demikian pernyataan ini saya buat dengan sebenarnya.
Dibuat di Yogyakarta,
Pada tanggal: 18 Juli 2013
Yang menyatakan,
Vincentius Ardha Dian Rigitama
KATA PENGANTAR
Puji dan syukur kepada Tuhan karena atas segala berkat dan
bimbingan-Nya, penulis dapat menyelesaikan tugas akhir ini dengan baik. Tugas akhir ini
ditulis untuk memenuhi salah satu syarat untuk memperoleh gelar Sarjana
Komputer dari Program Studi Teknik Informatika Universitas Sanata Dharma.
Penulis menyadari bahwa selesainya tugas akhir ini tak lepas dari bantuan orang –
orang di sekitar penulis. Oleh sebab itu, penulis mengucapkan terima kasih
kepada:
1. Tuhan Yesus Kristus yang selalu membimbing dan menuntun
penulis dalam menyelesaikan tugas akhir ini dan juga karena telah
mengabulkan doa penulis sehingga tugas akhir ini dapat selesai
dengan baik.
2. Bapak Puspaningtyas Sanjoyo Adi, S. T., M. T., selaku dosen
pembimbing yang telah meluangkan waktu, ide, serta pikiran untuk
membantu penulis dalam menyelesaikan tugas akhir ini.
3. Ibu Sri Hartati Wijono, S.Si., M.Kom., selaku ketua dosen penguji
yang telah meluangkan waktu untuk menguji tugas akhir ini.
4. Kepala Puskesmas Jebed, dr. Setiawan Raharjana, dan seluruh
keluarga besar Puskesmas Jebed, yang telah membantu saya dalam
mendapatkan data penelitian.
5. Keluarga saya, Bapak Iwan, Ibu Yudhia, kakak Andreas dan Mita,
dan adik Tika yang selalu mendoakan dan memberi dukungan
kepada penulis sehingga tugas akhir ini dapat selesai dengan baik
dan tepat pada waktunya.
6. Yosefina Agustin Nugraheni Bere, wanita spesial yang juga selalu
memberikan yang terbaik untuk memberi dukungan tak terbatas
kepada penulis agar tidak menyerah dan selalu bersemangat untuk
menyelesaikan tugas akhir ini dengan baik dan tepat waktu.
7. Tim DEJ, yang selalu menjadi inspirasi dan motivasi kepada
penulis.
8. J.S. Wulandari, Tinus, Eki, Audris, Aden, Unggul, Henfry, Surya,
mb. Anas, dan teman yang tidak bisa saya sebutkan, yang selalu
menyemangati, menghibur, memberi inspirasi, dan membantu
penulis dalam menyelesaikan tugas akhir ini.
Yogyakarta, 18 Juli 2013
Penulis
DAFTAR ISI
HALAMAN PERSETUJUAN ... ii
HALAMAN PENGESAHAN ... iii
PERNYATAAN KEASLIAN KARYA ... iv
HALAMAN MOTO ... v
HALAMAN PERSEMBAHAN ... vi
ABSTRAKSI ... vii
ABSTRACT ... viii
LEMBAR PERNYATAAN PERSETUJUAN ... ix
KATA PENGANTAR ... x
DAFTAR ISI ... xii
DAFTAR GAMBAR ... xvi
DAFTAR TABEL ... xvii
DAFTAR QUERY BASIS DATA... xx
DAFTAR LIST CODE ... xxi
DAFTAR GRAFIK ... xxii
DAFTAR LAMPIRAN ... xxiii
BAB I ... 1
PENDAHULUAN ... 1
1.1. Latar Belakang Permasalahan ... 1
1.2. Rumusan Masalah ... 3
1.3. Batasan ... 4
1.4. Tujuan Penelitian ... 5
1.5. Manfaat Penelitian ... 6
1.6. Metode Penelitian ... 7
1.7. Luaran ... 8
1.8. Sistematika Penulisan ... 9
BAB II ... 10
LANDASAN TEORI ... 10
2.1. Gambaran Umum Lokasi Penelitian ... 10
2.1.1. Gambaran Umum Kondisi Kesehatan Masyarakat ... 12
2.1.2. Penyakit Paru – Paru di Puskesmas Jebed ... 12
2.2. Penyakit Paru – Paru ... 14
2.3. Information Retrieval ... 16
2.4. Indexing ... 18
2.5. Term Frequency ... 21
2.6. Tokenizing ... 24
2.7. Stemming ... 25
2.7.1. Porter Stemmer Algorithm ... 26
2.7.2. Aturan Algoritma Porter untuk Bahasa Indonesia ... 27
2.8. Vector Space Model ... 30
2.9. Extended Boolean Model ... 32
2.10. Probabilistic Model ... 36
2.10.1. Probability Ranking Principle (PRP) ... 38
2.11. Algoritma Evaluasi: Recall – Precission ... 45
BAB III ... 46
ANALISIS DAN PERANCANGAN ... 46
3.1 Deskripsi Kasus ... 46
3.2 Cara Penyelesaian Masalah ... 48
3.2.1 Indexing ... 48
3.2.2 Pemrosesan Query ... 52
3.2.3 Permodelan ... 53
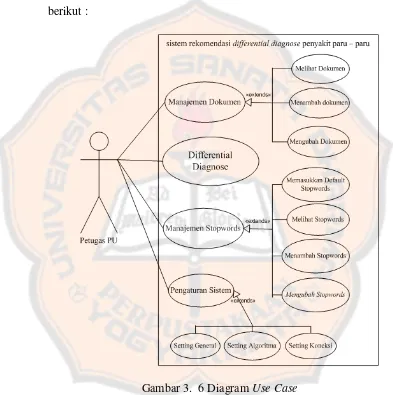
3.3 Diagram dan Skenario Use Case ... 54
3.4 Perancangan Sistem ... 65
3.4.1 Langkah penelitian ... 65
3.4.2 Perancangan Basis Data ... 67
3.4.3 Desain Antarmuka ... 71
3.4.4 Cara Pengujian dan Analisa Hasil ... 73
3.4.5 Class Diagram ... 74
3.5. Perhitungan Contoh Kasus ... 77
3.5.1 Vector Space Model ... 81
3.5.2 Extended Boolean Model ... 83
3.5.3 Probabilistic Model ... 85
BAB IV ... 87
IMPLEMENTASI ... 87
4.1. Spesifikasi Perangkat Keras dan Lunak ... 87
4.2. Implementasi Tabel Basis Data ... 88
4.3. Implementasi Kelas Indexing ... 89
4.3.1. Proses Indexing ... 90
4.3.2. Pemisahan Kata (Tokenizing) ... 90
4.3.3. Stemming ... 91
4.3.4. Pembacaan File Dokumen ... 97
4.3.5. Stopword Removal ... 99
4.3.6. Penyimpanan pada Basis Data ... 100
4.3.7. Penambahan Dokumen... 104
4.3.8. Perubahan Dokumen ... 105
4.3.9. Penambahan Stopword ... 108
4.3.10. Perubahan Stopword ... 109
4.4. Implementasi Proses Query Processing ... 112
4.5. Implementasi Proses Searching ... 113
4.5.1. Probabilistic Model (PM) ... 117
4.5.2. Vector Space Model (VSM) ... 121
4.5.3. Extended Boolean Model (EBM) ... 123
BAB V ... 125
HASIL DAN PEMBAHASAN ... 125
5.1. Hasil Pengukuran (kuesioner) ... 125
5.2. Analisa Unjuk Kerja Model ... 141
5.3. Perbandingan Lama Waktu Pencarian... 151
5.4. Perhitungan Akurasi Differential Diagnose Sistem ... 155
BAB VI ... 158
KESIMPULAN DAN SARAN ... 158
6.1. Kesimpulan ... 158
6.2. Saran ... 159
DAFTAR PUSTAKA ... 160
LAMPIRAN ... 162
DAFTAR GAMBAR
Gambar 2. 1 Kerangka dari sistem IR sederhana (P. Ingwersen, 1992) ... 17
Gambar 2. 2 Operasi teks logical view dari sebuah dokumen ... 20
Gambar 2. 3 Proses tokenizing ... 24
Gambar 2. 4 Desain dari Porter Stemmer for Bahasa Indonesia ... 26
Gambar 2. 5 Vector Space Model ... 30
Gambar 2. 6 Contoh perhitungan peringkat menggunakan persamaan 26 ... 43
Gambar 2. 7 Contoh perhitungan peringkat menggunakan persamaan 27 ... 44
Gambar 2. 8 Contoh recall dan precision hasil IR... 45
Gambar 3. 1 Gambar flowchartPorter Stemmer yang diimplementasikan ... 49
Gambar 3. 2 Rancangan flowchartstored procedureindexing database ... 50
Gambar 3. 3 Rancangan proses perhitungan binary tf ... 51
Gambar 3. 4 Rancangan pemrosesan query ... 52
Gambar 3. 5 Rancangan proses pencarian ... 53
Gambar 3. 6 Diagram Use Case ... 54
Gambar 3. 7 Diagram blok (indexing) ... 66
Gambar 3. 8 Diagram blok (searching) ... 66
Gambar 3. 9 ER Diagram... 67
Gambar 3. 10 Relasi antar tabel ... 67
Gambar 3. 11 Desain menu utama MainForm ... 71
Gambar 3. 12 Desain menu DiagnoseForm ... 72
Gambar 3. 13 Desain menu DaftarForm untuk mengelola dokumen ... 72
Gambar 3. 14 Desain menu StopwordsForm untuk mengelola kata buang ... 73
Gambar 3. 15 Diagram kelas keseluruhan ... 74
Gambar 3. 16 Diagram kelas proses indexing ... 75
Gambar 3. 17 Diagram kelas untuk proses searching... 76
Gambar 5. 1 Hasil pencarian PM query 1 ... 134
Gambar 5. 2 Hasil pencarian VSM query 1 ... 134
Gambar 5. 3 Hasil pencarian EBM query 1 ... 134
DAFTAR TABEL
Tabel 2. 1 Tabel Detail Penduduk ... 11
Tabel 2. 2 Gambaran lima besar penyakit di Puskesmas Jebed ... 13
Tabel 2. 3 10 besar penyakit paru – paru Puskesmas Jebed... 13
Tabel 2. 4 Tabel gejala umum penyakit paru - paru ... 14
Tabel 2. 5 Perbedaan sistem data retrieval dan sistem information retrieval ... 16
Tabel 2. 6 Kelompok rule pertama: inflectional particles ... 27
Tabel 2. 7 Kelompok rule kedua: inflectional possesive pronouns ... 28
Tabel 2. 8 Kelompok rule ketiga: first order of derivational prefixes ... 28
Tabel 2. 9 Kelompok rule keempat: second order of derivational prefixes ... 29
Tabel 2. 10 Kelompok rule kelima: derivationalsuffixes ... 29
Tabel 2. 11 Tabel persamaan perhitungan ukuran kesamaan dalam EBM ... 35
Tabel 2. 12 Contingency Table (Baeza-Yates dan Ribeiro-Neto, 2011)... 41
Tabel 3. 1 Contoh penggunaan binary TF ... 50
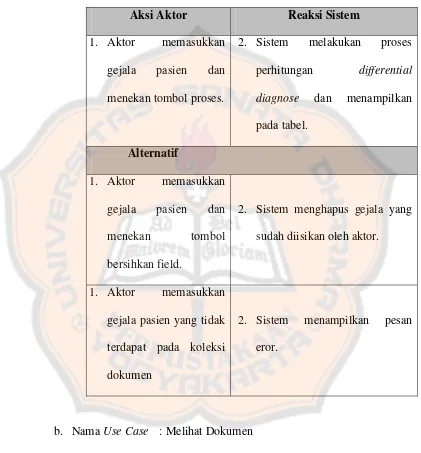
Tabel 3. 2 Tabel skenario caseDifferential Diagnose ... 55
Tabel 3. 3 Tabel skenario case Melihat Dokumen ... 56
Tabel 3. 4 Tabel skenario case Menambah Dokumen ... 56
Tabel 3. 5 Tabel skenario case Mengubah Dokumen ... 58
Tabel 3. 6 Tabel skenario case Melihat Stopword ... 59
Tabel 3. 7 Tabel skenario case Mengubah Stopword ... 59
Tabel 3. 8 Tabel skenario case Mengubah Stopword ... 60
Tabel 3. 9 Tabel skenario case Memasukkan Default Stopword ... 61
Tabel 3. 10 Tabel skenario case Pengaturan Sistem: Setting General ... 62
Tabel 3. 11 Tabel skenario case Pengaturan Sistem: Setting Algoritma ... 63
Tabel 3. 12 Tabel skenario case Pengaturan Sistem: Setting Koneksi ... 64
Tabel 3. 13 Keterangan tabel dokumen pada basis data ... 68
Tabel 3. 14 Keterangan tabel kata_dasar pada basis data ... 69
Tabel 3. 15 Keterangan tabel dokumen_kata pada basis data ... 69
Tabel 3. 16 Keterangan tabel kata_stop pada basis data ... 70
Tabel 3. 17 Keterangan tabel dictionary pada basis data ... 71
Tabel 3. 18 Tabel pendataan token ... 78
Tabel 3. 19 Tabel pengurutan dan pengelompokan token ... 79
Tabel 3. 20 Tabel frekuensi kata dalam dokumen contoh ... 80
Tabel 3. 21 Perhitungan idf menggunakan persamaan log𝑁𝑁𝑁𝑁𝑁𝑁 ... 80
Tabel 3. 22 Perhitungan w dokumen dan query contoh kasus (VSM) ... 81
Tabel 3. 23 Perhitungan w dokumen dan query contoh kasus (EBM) ... 83
Tabel 3. 24 Contingency table PM ... 85
Tabel 3. 25 Perhitungan w dokumen contoh kasus (PM)... 86
Tabel 3. 26 Tabel pengurutan dokumen PM ... 86
Tabel 5. 1 Daftar query ... 126
Tabel 5. 2 Rekap kemungkinan differential diagnose query 1 ... 128
Tabel 5. 3 Rekap differential diagnose query 2 ... 128
Tabel 5. 4 Rekap differential diagnose query 3 ... 129
Tabel 5. 5 Rekap differential diagnose query 4 ... 129
Tabel 5. 6 Rekap differential diagnose query 5 ... 129
Tabel 5. 7 Rekap differential diagnose query 6 ... 130
Tabel 5. 8 Rekap differential diagnose query 7 ... 130
Tabel 5. 9 Rekap differential diagnose query 8 ... 130
Tabel 5. 10 Rekap differential diagnose query 9 ... 130
Tabel 5. 11 Rekap differential diagnose query 10 ... 131
Tabel 5. 12 Rekap differential diagnose query 11 ... 131
Tabel 5. 13 Rekap differential diagnose query 12 ... 131
Tabel 5. 14 Rekap differential diagnose query 13 ... 131
Tabel 5. 15 Rekap differential diagnose query 14 ... 132
Tabel 5. 16 Rekap differential diagnose query 15 ... 132
Tabel 5. 17 Rekap differential diagnose query 16 ... 132
Tabel 5. 18 Rekap differential diagnose query 17 ... 132
Tabel 5. 19 Rekap differential diagnose query 18 ... 133
Tabel 5. 20 Rekap differential diagnose query 19 ... 133
Tabel 5. 21 Rekap differential diagnose query 20 ... 133
Tabel 5. 22 Rekap differential diagnose query 21 ... 133
Tabel 5. 23 Precision-Recall responden R1 pada query 1 (PM)... 135
Tabel 5. 24 Maksimal precision setiap titik recall R1 pada query 1 (PM) ... 135
Tabel 5. 25 Precision-Recall responden R1 pada query 1 (VSM) ... 135
Tabel 5. 26 Maksimal precision setiap titik recall R1 pada query 1 (VSM) ... 136
Tabel 5. 27 Precision-Recall responden R1 pada query 1 (EBM) ... 136
Tabel 5. 28 Maksimal precision setiap titik recall R1 pada query 1 (EBM) ... 136
Tabel 5. 29 Perhitungan interpolasi responden R1 untuk query 1 (PM) ... 137
Tabel 5. 30 Perhitungan interpolasi responden R1 untuk query 1 (VSM) ... 138
Tabel 5. 31 Perhitungan interpolasi responden R1 untuk query 1 (EBM) ... 138
Tabel 5. 32 Perhitungan rerata interpolasi (PM) ... 142
Tabel 5. 33 Perhitungan rerata interpolasi (VSM) ... 142
Tabel 5. 34 Perhitungan rerata interpolasi (EBM) ... 143
Tabel 5. 35 Daftar penurunan nilai precision PM ... 145
Tabel 5. 36 Daftar penurunan nilai precision VSM ... 146
Tabel 5. 37 Daftar penurunan nilai precision EBM ... 148
Tabel 5. 38 Perhitungan rerata interpolasi seluruh model beserta nilai penurunan terhadap optimal ... 148
Tabel 5. 39 Tabel perbandingan nilai penurunan precision seluruh model ... 150
Tabel 5. 40 Daftar waktu pencarian (PM) ... 152
Tabel 5. 41 Daftar waktu pencarian (VSM) ... 153
Tabel 5. 42 Daftar waktu pencarian (EBM) ... 153
Tabel 5. 43 Tabel perbandingan waktu pencarian ... 154
Tabel 5. 44 Diagnose penyakit untuk setiap query ... 156
Tabel 5. 45 Perhitungan akurasi model ... 157
Tabel 6. 1 Perbandingan rerata penurunan interpolasi model mengacu pada tabel 5.39 ... 158
Tabel 6. 2 Perbandingan algoritma mengacu pada tabel 5.39, 5.43, dan 5.45 ... 159
DAFTAR QUERY BASIS DATA
Query 4. 1 Query DDL tabel dokumen ... 88
Query 4. 2 Query DDL tabel katadasar ... 88
Query 4. 3 Query DDL tabel katastop ... 88
Query 4. 4 Query DDL tabel dokumen_kata ... 89
Query 4. 5 Query DDL tabel dictionary... 89
Query 4. 6 Query SQL_CEKKATA ... 100
Query 4. 7 Stored procedure insert_dokumen_table ... 101
Query 4. 8 Stored procedure insertKata ... 103
DAFTAR LIST CODE
List Code 4. 1 List indexingDokumen ... 90
List Code 4. 2 Penggunaan metode replaceAll ... 90
List Code 4. 3 Penggunaan metode split ... 91
List Code 4. 4 Stemming ... 92
List Code 4. 10 getCountWord ... 97
List Code 4. 11 List pembacaan dokumen ... 98
List Code 4. 12 Stopword removal ... 100
List Code 4. 13 List insertDokumen ... 102
List Code 4. 14 Penambahan Dokumen ... 105
List Code 4. 15 List ubahIsiDokumen ... 107
List Code 4. 16 List penambahan stopword ... 109
List Code 4. 17 List perubahan stopword ... 111
List Code 4. 18 List pemrosesan query ... 113
List Code 4. 19 List getIndex ... 115
List Code 4. 20 List getSimilarity ... 116
List Code 4. 21 List hitungBobotPerKata ... 117
List Code 4. 22 List getDokumenRelevanByQuery ... 118
List Code 4. 23 getDFRelevan ... 119
List Code 4. 24 similarity (PM) ... 121
List Code 4. 25 similarity (VSM) ... 123
List Code 4. 26 similarity (EBM) ... 124
DAFTAR GRAFIK
Grafik 5. 1 Grafik interpolasi responden R1 untuk query 1 (PM) ... 139
Grafik 5. 2 Grafik interpolasi responden R1 untuk query 1 (VSM) ... 139
Grafik 5. 3 Grafik interpolasi responden R1 untuk query 1 (EBM) ... 140
Grafik 5. 4 Grafik unjuk kerja PM pada pencarian query ... 144
Grafik 5. 5 Grafik unjuk kerja VSM pada pencarian query ... 145
Grafik 5. 6 Grafik unjuk kerja EBM pada pencarian query ... 147
Grafik 5. 7 Grafik interpolasi seluruh model ... 149
DAFTAR LAMPIRAN
Lampiran 1 Contoh Form Kuesioner ... 163
Lampiran 2 Query Gejala ... 169
Lampiran 3 Kuesioner Responden 1 ... 171
Lampiran 4 Kuesioner Responden 2 ... 176
Lampiran 5 Kuesioner Responden 3 ... 181
Lampiran 6 Kuesioner Responden 4 ... 186
Lampiran 7 Hasil Perhitungan Precision Semua Responden (PM) ... 191
Lampiran 8 Hasil Perhitungan Precision Semua Responden (VSM) ... 199
Lampiran 9 Hasil Perhitungan Precision Semua Responden (EBM) ... 207
Lampiran 10 Tabel Interpolasi Semua Query (PM) ... 215
Lampiran 11 Tabel Interpolasi Semua Query (VSM) ... 216
Lampiran 12 Tabel Interpolasi Semua Query (EBM) ... 217
Lampiran 13 Source Code Program ... 218
BAB I
PENDAHULUAN
1.1.Latar Belakang Permasalahan
Paru – paru adalah organ tubuh manusia yang terdapat di dalam
dada. Paru – paru berfungsi sebagai tempat pertukaran oksigen dan
mengeluarkan karbondioksida dari darah dengan bantuan hemoglobin.
Manusia membutuhkan pasokan oksigen secara terus – menerus untuk
proses respirasi sel, dan membuang kelebihan karbondioksida sebagai
limbah beracun produk dari proses tersebut. Pertukaran gas antara oksigen
dengan karbondioksida dilakukan agar proses respirasi sel terus
berlangsung. Oksigen yang dibutuhkan untuk proses respirasi sel ini
berasal dari atmosfer, yang menyediakan kandungan gas oksigen sebanyak
21% dari seluruh gas yang ada. Oksigen masuk kedalam tubuh melalui
perantaraan alat pernapasan yang berada di luar. Pada manusia, alveolus
yang terdapat di paru – paru berfungsi sebagai permukaan untuk tempat
pertukaran gas.
Kekurangan pasokan oksigen selama selang waktu diluar ambang
batas kemampuan seseorang dapat menyebabkan kematian (PDPI, 2003).
Dengan demikian, mendapatkan oksigen merupakan kebutuhan primer
yang harus dipenuhi oleh seseorang. Udara bersih yang kaya akan oksigen
sangat dibutuhkan oleh sistem pernapasan manusia untuk melakukan
proses metabolisme. Akan tetapi, udara yang tercemar dapat merusak
fungsi dari paru – paru, atau bahkan merusak paru – paru secara fisik.
Dampak kesehatan dari pencemaran udara yang paling umum
dijumpai adalah INSA (infeksi saluran napas atas), termasuk di antaranya,
asma, bronkitis, dan gangguan pernapasan lainnya. Beberapa zat pencemar
dikategorikan sebagai toksik dan karsinogenik (PDPI, 2003). Sebagai
contoh dampak dari pencemaran udara di Jakarta yang berkaitan dengan
kematian prematur, perawatan rumah sakit, berkurangnya hari kerja
efektif, dan INSA pada tahun 1998 senilai dengan 1,8 trilyun rupiah dan
akan meningkat menjadi 4,3 trilyun rupiah di tahun 2015 (DEPKES
RI,2000).
Tingginya tingkat pencemaran udara di Indonesia menjadi salah
satu faktor penyebab terjangkitnya penyakit paru – paru. Penyakit paru –
paru dapat menyerang manusia di segala usia. Beberapa penyakit paru –
paru mempunyai gejala umum yang sama, seperti batuk, sesak nafas,
mengi, ataupun nyeri di dada. Hal tersebut menyebabkan kemunculan
sejumlah penyakit pada differential diagnose.
Differential diagnose merupakan tahap sebelum diagnose dan
ditentukan berdasarkan pada gejala yang ditemukan pertama kali. Pada
tahap ini, diagnose penyakit yang pasti belum dapat disimpulkan tetapi
hanya kemungkinan – kemungkinan penyakit yang muncul dari gejala
khususnya pada bagian poli umum, dengan berdasarkan pada pengamatan
gejala pasien, akan menemukan sejumlah penyakit yang mungkin terjadi
(differential diagnose). Hal ini tidak menutup kemungkinan adanya
kesalahan differential diagnose penyakit pasien. Kesalahan pada
differential diagnose akan berimbas pada kesalahan pemberian obat,
dengan demikian pasien mengkonsumsi obat yang seharusnya tidak
dikonsumsi.
Perkembangan teknologi dapat membantu dalam penentuan
differential diagnose. Komputerisasi dilakukan dengan memanfaatkan
algoritma pada ilmu information retrieval (temu kembali informasi).
Komputerisasi pada differential diagnose ini bukan merupakan hal yang
mudah. Hal ini dikarenakan gejala umum pada tiap penyakit yang akan
dijadikan model bukan merupakan dokumen panjang. Model dari tiap
penyakit biasanya hanya terdiri dari 5 – 10 gejala umum. Hal ini berbeda
dengan penerapan ilmu information retrieval pada umumnya, yaitu
menggunakan dokumen dengan jumlah kata atau kalimat dalam jumlah
yang besar (dokumen panjang).
1.2. Rumusan Masalah
Berdasarkan pada latar belakang permasalahan, maka masalah
1. Bagaimana membangun sistem rekomendasi differential
diagnose penyakit paru – paru yang dapat melakukan
differential diagnose dengan baik berbasis pada information
retrieval dengan menggunakan dokumen pendek? Dokumen
pendek adalah dokumen yang berjumlah kata maksimal 30
kata.
2. Bagaimana unjuk kerja algoritma extended boolean model,
vector space model: cosine similarity,dan probabilistic model
untuk dokumen pendek pada sistem rekomendasi differential
diagnose penyakit paru – paru secara akurat?
3. Bagaimana keakuratan algoritma information retrieval
(extended boolean model, vector space model: cosine
similarity,dan probabilistic model) untuk dokumen pendek
pada sistem rekomendasi differential diagnose penyakit paru –
paru?
1.3. Batasan
Dengan permasalahan yang terjadi dan telah diungkapkan di atas,
penulis bermaksud menyusun skripsi dengan judul “Uji Algoritma
Probabilistic Model, Vector Space Model, dan Extended Boolean Model
Pada Sistem Rekomendasi Differential Diagnose Penyakit Paru - Paru”.
1. Studi kasus hanya dilakukan di Puskesmas Jebed Pemalang.
2. Melakukan differential diagnose hanya pada penyakit paru –
paru yang termasuk sepuluh besar di Puskesmas Jebed.
3. Data yang digunakan dari tahun 2009 hingga tahun 2011.
4. Differential diagnose hanya dilakukan berdasarkan gejala
awal, penyakit yang awal diagnose dengan cek lab tidak
digunakan.
5. Differential diagnose lanjutan berdasar hasil cek lab tidak akan
dibahas.
6. Sistem rekomendasi yang dibangun tidak menangani
pemberian saran terkait (langkah lanjutan yang dilakukan).
7. Differential diagnose dilakukan secara terkomputerisasi
dengan penerapan teknologi informatika, ilmu information
retrieval.
8. Algoritma information retrieval yang digunakan adalah
extended boolean model, vector space model: cosine
similarity,dan probabilistic model.
1.4.Tujuan Penelitian
Tujuan yang akan dicapai dalam penulisan skripsi ini adalah:
1. Mengkaji algoritma extended boolean model, vector space
dokumen pendek yang akan diterapkan pada sistem
rekomendasi differential diagnose penyakit paru – paru.
2. Melakukan implementasi algoritma extended boolean model,
vector space model: cosine similarity,dan probabilistic model
dengan menggunakan dokumen pendek pada sistem
rekomendasi differential diagnose penyakit paru – paru.
3. Melakukan pengujian aplikasi yang telah dibangun
menggunakan algoritma recall – precission untuk mengetahui
algoritma information retrieval terbaik untuk menangani
differential diagnose penyakit paru – paru menggunakan
dokumen pendek.
1.5.Manfaat Penelitian
Manfaat dari pembangunan perangkat lunak sistem rekomendasi
differential diagnose penyakit paru – paru ini adalah membantu
mengkonversi gejala – gejala yang muncul dari pengamatan terhadap
pasien menjadi sebuah rekomendasi differential diagnose penyakit paru –
paru secara tepat, cepat, akurat, dan efisien dengan algoritma yang
menghasilkan nilai paling baik. Tidak hanya itu, pembangunan perangkat
lunak ini sekaligus menguji algoritma pada dokumen pendek. Dengan
demikian pengujian algoritma extended boolean model, vector space
menentukan algoritma yang paling baik pada dokumen pendek. Dengan
penerapan algoritma terbaik, sistem diharapkan dapat membantu peran
pelaku pelayanan kesehatan dalam menentukan tindak lanjut sebagai
penanganan serta dasar pengambilan diagnose akhir pada penyakit paru –
paru.
1.6.Metode Penelitian
Metode penelitian yang digunakan adalah:
1. Studi Pustaka: metode studi pustaka ini dilakukan dengan
mengambil referensi dari internet, buku, dan jurnal penelitian
yang berhubungan dengan konsep information retrieval serta
penyakit paru – paru.
2. Analisis dan Perancangan Sistem: melakukan analisis kebutuhan
dari sistem yang akan dibangun. Dilanjutkan dengan
perancangan sistem yang akan diimplementasikan menjadi
sebuah sistem yang dapat berjalan dengan baik dan sesuai
dengan yang diharapkan.
3. Implementasi Sistem: implementasi sistem menggunakan dasar
analisa desain sistem yang telah dibuat. Melakukan eksplorasi
dan penerapan algoritma extended boolean model, vector space
4. Evaluasi Algoritma Sistem: pengujian algoritma extended
boolean model, vector space model: cosine similarity, dan
probabilistic model pada perhitungan kemiripan gejala.
5. Pengujian dan Perbaikan: perangkat lunak yang telah dibangun
diuji untuk meminimalkan error dan dapat bekerja dengan baik
secara akurat.
6. Analisis Luaran Sistem: melakukan pengujian perangkat lunak
dan pengkajian berdasarkan data uji serta menghitung akurasi
menggunakan algoritma recall – precission. Ketiga algoritma
information retrieval akan dikaji berdasarkan penurunan
terhadap nilai optimal (1.0), waktu pencarian, serta akurasi
untuk menentukan algoritma terbaik yang diterapkan pada
perangkat lunak.
7. Kesimpulan dan Saran: membuat kesimpulan dan saran dari
seluruh tahapan yang dilalui.
1.7.Luaran
Luaran dari penelitian ini adalah terciptanya perangkat lunak
“Sistem Rekomendasi Differntial Diagnose Penyakit Paru - Paru”
menggunakan algoritma information retrieval (extended boolean model,
vector space model: cosine similarity,dan probabilistic model) yang
1.8. Sistematika Penulisan
Tulisan ini akan dibahas dalam enam (6) bab, yaitu sebagai
berikut:
Bab I : berisi pendahuluan yang membahas latar belakang
permasalahan, rumusan masalah yang berisi masalah yang
akan dibahas pada tulisan ini, batasan yang dibahas, tujuan
penelitian, manfaat penelitian, metodologi, luaran, dan
sistematika penulisan.
Bab II : berisi review literatur yang digunakan sebagai sebagai acuan
penulisan.
Bab III : berisi analisis dan perancangan sebagai acuan dalam
implementasi sistem rekomendasi differential diagnose
penyakit paru – paru.
Bab IV : berisi implementasi sistem.
Bab V : berisi hasil dan analisa dari penelitian yang telah dilakukan.
BAB VI : berisi kesimpulan dari analisa berdasar metode dan literatur
yang ada, serta saran yang diberikan untuk pengembangan
BAB II
LANDASAN TEORI
Differential diagnose adalah penentuan dua atau lebih penyakit
atau kondisi yang diderita pasien dengan membandingkan dan mengontraskan
secara sistematis hasil – hasil tindakan diagnostik
(www.kamuskesehatan.com, 2012). Perkembangan teknologi dapat
diupayakan untuk berperan membantu proses differential diagnose.
Pendekatan yang digunakan adalah memanfaatkan algoritma pada
information retrieval. Pendekatan ini tergolong berbeda karena dokumen /
model yang digunakan merupakan sebuah dokumen pendek. Untuk lebih
jelasnya pada bab ini akan dibahas mengenai teori-teori apa saja yang akan
digunakan untuk menunjang penulisan.
2.1.Gambaran Umum Lokasi Penelitian
Puskesmas Jebed adalah salah satu unit pelayanan kesehatan di
Kabupaten Pemalang. Terletak di Kecamatan Taman, di desa Jebed
Selatan. Wilayah kerjanya terdiri atas 11 desa dengan jumlah penduduk
sekitar 78.000 jiwa. Desa yang ditangani adalah sebagai berikut:
1. Jebed Utara
2. Jebed Selatan
3. Cibelok
4. Kaligelang
5. Penggarit
6. Kejambon
7. Sokawangi
8. Pener
9. Gondang
10.Jerakah
11.Sitemu
Sedangkan dari 11 desa yang ditangani, jumlah penduduk yang
ditangani oleh Puskesmas Jebed adalah sebagai berikut:
Tabel 2. 1 Tabel Detail Penduduk
Laki - Laki (Tahun) 0-4 5-14 15-44 45-64 >=65 JML
Jumlah 4.375 8.706 17.709 6.031 2.160 38.960
Perempuan (Tahun) 0-4 5-14 15-44 45-64 >=65 JML
Jumlah 4.123 8.377 18.168 5.740 2.537 38.945
Detail keterangan Puskesmas Jebed adalah sebagai berikut:
Nama : Pusat Kesehatan Masyarakat Jebed
Kode UPK : P3327090203
Alamat : Jl. Raya Jebed Selatan, Jebed
Kepala (Plt) : dr. Paulus Setiawan R.
Jumlah Desa : 11
Hari Pelayanan : Senin – Sabtu
Jam Pelayanan : 07.30 – 14.00 WIB
2.1.1. Gambaran Umum Kondisi Kesehatan Masyarakat
Menurut Kepala Puskesmas Jebed, kesadaran masyarakat tentang
kesehatan dapat dikatakan sangat kurang sekali. Kondisi ekonomi
masyarakat yang didominasi oleh masyarakat dengan taraf menengah ke
bawah, juga mempengaruhi pola hidup masyarakat yang jauh dari hidup
sehat. Sebagai contoh, masyarakat Desa Sokawangi menggunakan air
sungai yang kotor sebagai sarana untuk kegiatan MCK dan juga untuk
kegiatan memasak. Penularan penyakit juga dapat dikatakan mudah
terjadi, hal ini dikarenakan pengetahuan masyarakat tentang bahaya
penyakit dan penularannya sangat kurang.
2.1.2. Penyakit Paru – Paru di Puskesmas Jebed
Menurut Kepala Puskesmas Jebed, puskesmas ini menangani
Penyakit paru – paru termasuk ke dalam penyakit yang mendapatkan
perhatian khusus. Berikut adalah gambaran lima (5) besar penyakit yang
ditangani Puskesmas Jebed.
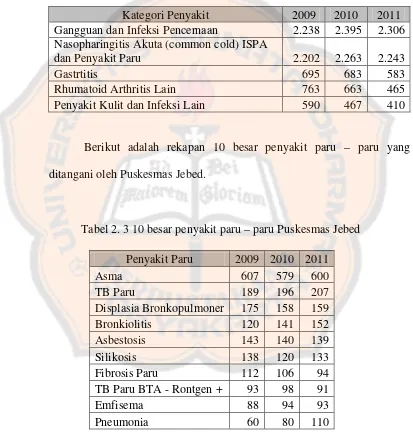
Tabel 2. 2 Gambaran lima besar penyakit di Puskesmas Jebed
Kategori Penyakit 2009 2010 2011
Gangguan dan Infeksi Pencernaan 2.238 2.395 2.306 Nasopharingitis Akuta (common cold) ISPA
dan Penyakit Paru 2.202 2.263 2.243
Gastrtitis 695 683 583
Rhumatoid Arthritis Lain 763 663 465
Penyakit Kulit dan Infeksi Lain 590 467 410
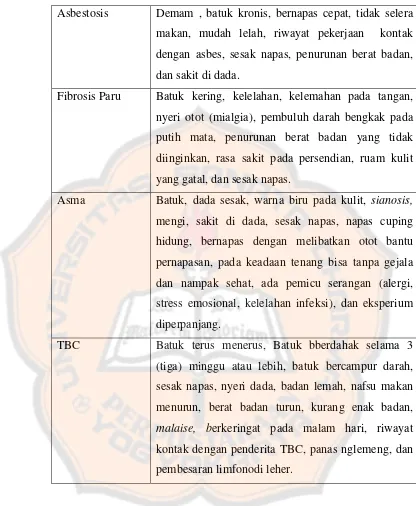
Berikut adalah rekapan 10 besar penyakit paru – paru yang
ditangani oleh Puskesmas Jebed.
Tabel 2. 3 10 besar penyakit paru – paru Puskesmas Jebed
Penyakit Paru 2009 2010 2011
Asma 607 579 600
TB Paru 189 196 207
Displasia Bronkopulmoner 175 158 159
Bronkiolitis 120 141 152
Asbestosis 143 140 139
Silikosis 138 120 133
Fibrosis Paru 112 106 94
TB Paru BTA - Rontgen + 93 98 91
Emfisema 88 94 93
Pneumonia 60 80 110
Dari tabel 2.3 dapat dilihat bahwa, penyakit asma merupakan
2.2. Penyakit Paru – Paru
Penyakit paru – paru sangat bervariasi jenisnya. Penyebab penyakit
paru – paru juga dapat dikatakan sangat bervariasi, dari udara yang
tercemar, perpindahan bakteri penyakit, hingga masuknya virus ke dalam
rongga paru – paru. Menurut pedoman penganggulangan penyakit yang
dikeluarkan oleh pemerintah Indonesia, gejala – gejala umum yang ada
pada penyakit paru – paru dapat dilihat pada tabel 2.2. Penyakit yang
diambil merupakan penyakit yang sering ditemui pada Puskesmas Jebed.
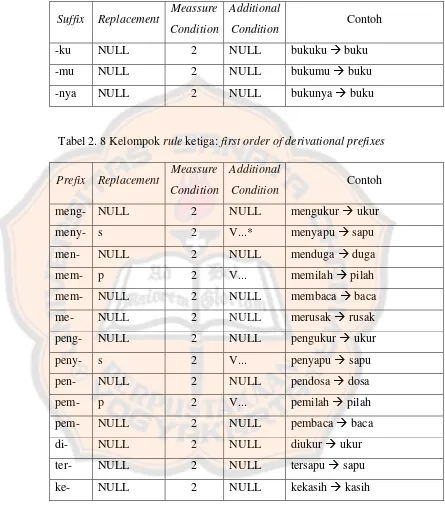
Tabel 2. 4 Tabel gejala umum penyakit paru - paru
Penyakit Gejala Umum
Bronkiolitis Batuk kering serak, batuk terus menerus, bernapas
cepat, demam, denyut jantung cepat, rinorea, hidung
tersumbat, sesak napas, mengi, muntah setelah
makan, napas cuping hidung, ada riwayat infeksi
saluran napas, retraksi dinding dada, dan riwayat
kontak dengan penderita infeksi saluran napas.
Silikosis Demam, batuk kronis, bernapas cepat, tidak selera
makan, mudah lelah, riwayat pekerjaan kontak
dengan silikon, sesak napas, penurunan berat badan,
dan sakit di dada.
Displasia
Bronkopulmoner
Batuk kronis, bernapas cepat, warna biru pada kulit,
sianosis, mengi, postur leher buruk, postur bahu
buruk, postur badan buruk, sesak napas, dan perkusi
Asbestosis Demam , batuk kronis, bernapas cepat, tidak selera
makan, mudah lelah, riwayat pekerjaan kontak
dengan asbes, sesak napas, penurunan berat badan,
dan sakit di dada.
Fibrosis Paru Batuk kering, kelelahan, kelemahan pada tangan,
nyeri otot (mialgia), pembuluh darah bengkak pada
putih mata, penurunan berat badan yang tidak
diinginkan, rasa sakit pada persendian, ruam kulit
yang gatal, dan sesak napas.
Asma Batuk, dada sesak, warna biru pada kulit, sianosis,
mengi, sakit di dada, sesak napas, napas cuping
hidung, bernapas dengan melibatkan otot bantu
pernapasan, pada keadaan tenang bisa tanpa gejala
dan nampak sehat, ada pemicu serangan (alergi,
stress emosional, kelelahan infeksi), dan eksperium
diperpanjang.
TBC Batuk terus menerus, Batuk bberdahak selama 3
(tiga) minggu atau lebih, batuk bercampur darah,
sesak napas, nyeri dada, badan lemah, nafsu makan
menurun, berat badan turun, kurang enak badan,
malaise, berkeringat pada malam hari, riwayat
kontak dengan penderita TBC, panas nglemeng, dan
pembesaran limfonodi leher.
Tabel 2.4 merupakan pedoman gejala umum untuk melakukan
differential diagnose pada penyakit paru – paru di Indonesia. Tabel 2.4
merupakan kesimpulan survei yang dilakukan Ikatan Dokter Indonesia
(IDI) dan pemerintah Indonesia dari hasil pengamatan pada pasien
2.3. Information Retrieval
ISO 2382/1 mendefinisikan Information Retrieval (IR) sebagai
tindakan, metode dan prosedur untuk menemukan kembali data yang
tersimpan, kemudian menyediakan informasi mengenai subyek yang
dibutuhkan. Informasi termasuk pengetahuan terkait yang dibutuhkan
untuk mendukung penyelesaian masalah dan akuisisi pengetahuan.
Menurut Lancaster (1968), sebuah sistem information retrieval tidak
memberitahu pengguna mengenai masalah yang ditanyakannya. Sistem
tersebut hanya memberitahukan keberadaan atau ketidakberadaan dan
keterangan dokumen – dokumen yang berhubungan dengan permintaannya
(van Rijsbergen, 1979). Dengan demikian, sistem IR hanya
memberitahukan keberadaan serta keterangan dokumen berdasarkan query
dari pengguna. Sifat pencarian sistem IR berbeda dengan sistem data
retrieval (misalnya dalam sistem manajemen basis data) dalam beberapa
segi, antara lain spesifikasi query yang tidak lengkap, dan tingkat
ketanggapan kesalahan yang tidak peka (van Rijsbergen, 1979).
Tabel 2. 5 Perbedaan sistem data retrieval dan sistem information retrieval
Data Retrieval Information Retrieval
Matching Exact Match Partial (best) Match
Model Deterministik Probabilistik
Klasifikasi Monothetic Polythetic
Bahasa Query Artificial Natural
Spesifikasi Query Lengkap Tidak Lengkap
Item yang diinginkan Matching Relevan
Respon Error Sensitif Tidak Sensitif
Kerangka dari sistem IR secara sederhana terbagi menjadi dua
bagian. Untuk lebih jelasnya, gambar 2.1 merupakan kerangka sederhana
sistem IR
Gambar 2. 1 Kerangka dari sistem IR sederhana (P. Ingwersen, 1992)
Bagian pertama adalah pencari informasi atau pengguna sistem.
Pengguna dari sistem IR harus menerjemahkan informasi yang dicarinya
agar dapat diproses oleh sistem dengan cara memasukan kata kunci. Kata
oleh sistem. Bagian kedua adalah bagian dari dokumen. Pada bagian ini
dokumen – dokumen direpresentasikan dalam bentuk indeks. Query
pengguna akan diproses melalui fungsi kesamaan untuk membandingkan
query dengan indeks dari dokumen untuk mendapatkan dokumen yang
relevan. Sistem IR mungkin tidak memberikan hasil apapun jika memang
tidak ditemukan dokumen yang relevan.
2.4. Indexing
Mencari sebuah informasi yang relevan sangat tidak mungkin
dapat dilakukan oleh sebuah komputer, meskipun dilakukan oleh sebuah
komputer yang memiliki spesifikasi yang canggih. Agar komputer dapat
mengetahui sebuah dokumen itu relevan terhadap sebuah informasi,
komputer memerlukan sebuah model yang mendeskripsikan bahwa
dokumen tersebut relevan atau tidak. Salah satu caranya adalah dengan
menggunakan indeks istilah. Indeks adalah bahasa yang digunakan di
dalam sebuah buku konvensional untuk mencari informasi berdasarkan
kata atau istilah yang mengacu ke dalam suatu halaman. Dengan
menggunakan indeks pencari informasi dapat dengan mudah menemukan
informasi yang diinginkannya. Pada sistem temu-kembali informasi,
indeks ini nantinya yang digunakan untuk merepresentasikan informasi di
Elemen dari indeks adalah index term yang didapatkan dari teks
yang dipecah di dalam sebuah dokumen. Elemen lainnya adalah bobot
istilah (term weighting) sebagai penentuan peringkat dari kriteria relevan
pada sebuah dokumen yang memiliki istilah yang sama. Proses pembuatan
indeks dari sebuah dokumen teks atau dikenal dengan proses analisis teks
(automatic teks analysis) melalui beberapa tahap (Baeza-Yates dan
Ribeiro-Neto, 1999):
1. Proses penentuan digit, tanda hubung, tanda baca dan penyeragaman
dari huruf yang digunakan.
2. Penyaringan kata meliputi penghilangan kata yang memiliki arti niliai
paling rendah (stopwords) untuk proses IR.
3. Penghilangan imbuhan kata, baik awalan maupun akhiran kata.
Penghilangan imbuhan kata ini dikenal dengan stemming.
4. Pemilihan istilah untuk menentukan kata atau stem (atau kelompok
kata) yang akan digunakan sebagai elemen indeks.
5. Pembentukan kategori istilah terstruktur seperti kelompok persamaan
kata yang digunakan untuk perluasan dari query dasar yang diberikan
oleh pengguna sistem IR dengan istilah lain yang sesuai.
Pengindeksan dapat dilakukan dengan dua cara yaitu manual dan
otomatis. Idealnya, untuk mendapatkan indeks istilah yang sempurna
sebuah pengindeksan dilakukan secara manual (konvensional). Akan
tetapi, menurut Salton, sistem pencarian dan analisa teks yang sepenuhnya
dibandingkan dengan sistem konvensional yang menggunakan
pengindeksan dokumen manual dan formulasi pencarian. Untuk lebih
jelasnya mengenai proses pengindeksan dari sebuah dokumen yang
memiliki sekumpulan teks menjadi istilah dapat dilihat pada Gambar 2.2
(Baeza-Yates dan Ribeiro-Neto, 1999).
Gambar 2. 2 Operasi teks logical view dari sebuah dokumen
Inverted index adalah salah satu mekanisme untuk pengindeksan
sebuah koleksi teks yang digunakan untuk mempercepat proses pencarian.
Struktur dari inverted index terdiri dari dua elemen yaitu kosakata dan
posisinya di dalam sebuah dokumen (Baeza-Yates dan Ribeiro-Neto,
1999). Sebagai contoh, istilah t1 terdapat dalam dokumen D1, D2, dan D3
sedangkan istilah t2 terdapat dalam dokumen D1 dan D2 maka inverted
index yang dihasilkan adalah sebagai berikut:
t1→ D1, D2, D3
Penggunaan inverted index di dalam sistem IR memiliki
kelemahan yaitu lambat di dalam pengindeksan, tetapi cepat di dalam
proses pencarian informasi.
2.5. Term Frequency
Term Frequency (TF) adalah algoritma pembobotan heuristik
yang menentukan bobot dokumen berdasarkan kemunculan term (istilah).
Semakin sering sebuah istilah muncul, semakin tinggi bobot dokumen
untuk istilah tersebut, dan sebaliknya. Hasil pembobotan ini selanjutnya
akan digunakan oleh fungsi perbandingan untuk menentukan dokumen –
dokumen yang relevan. Terdapat empat buah algoritma TF yang
digunakan (Wibowo, 2011):
• Raw TF
Raw TF menentukan bobot suatu dokumen terhadap istilah
dengan menghitung frekuensi kemunculan suatu istilah tersebut pada
dokumen. Raw TF selanjutnya akan dituliskan sebagai tf.
• Logarithmic TF
Logarithmic TF mengurangi tingkat kepentingan kemunculan
kata dalam menghitung bobot dokumen terhadap suatu istilah dengan
melakukan log terhadap TF. Log TF dapat dihitung dengan
𝑙𝑙𝑙𝑙𝑁𝑁 = 1 + log(𝑙𝑙𝑁𝑁) ( 1 )
• Binary TF
Binary TF menyeragamkan bobot dokumen terhadap istilah
dengan memberi nilai 0 dan 1. Nilai 1 menyatakan suatu istilah
muncul minimal satu kali dalam suatu dokumen, sementara 0
menyatakan sebaliknya.
𝑏𝑏𝑙𝑙𝑁𝑁 = � 1,𝑖𝑖𝑖𝑖𝑙𝑙𝑖𝑖𝑙𝑙𝑖𝑖ℎ𝑚𝑚𝑚𝑚𝑚𝑚𝑚𝑚𝑚𝑚𝑙𝑙𝑁𝑁𝑖𝑖𝑙𝑙𝑖𝑖𝑚𝑚𝑁𝑁𝑑𝑑𝑑𝑑𝑚𝑚𝑚𝑚𝑑𝑑𝑚𝑚
0,𝑖𝑖𝑖𝑖𝑙𝑙𝑖𝑖𝑙𝑙𝑖𝑖ℎ𝑙𝑙𝑖𝑖𝑁𝑁𝑖𝑖𝑑𝑑𝑚𝑚𝑚𝑚𝑚𝑚𝑚𝑚𝑚𝑚𝑙𝑙𝑁𝑁𝑖𝑖𝑙𝑙𝑖𝑖𝑚𝑚𝑁𝑁𝑑𝑑𝑑𝑑𝑚𝑚𝑚𝑚𝑑𝑑𝑚𝑚 ( 2 )
• Augmented TF
Augmented TF menyeragamkan bobot dokumen terhadap istilah
dengan memberikan range antara 0.5 hingga 1 sebagai bobot
dokumen. Augmented TF dapat dihitung dengan persamaan:
𝑖𝑖𝑙𝑙𝑁𝑁 = 0.5 + 0.5 × 𝑙𝑙𝑁𝑁
max𝑙𝑙𝑁𝑁𝑁𝑁𝑖𝑖𝑑𝑑𝑖𝑖 𝑖𝑖𝑑𝑑𝑙𝑙𝑚𝑚𝑑𝑑 𝑚𝑚ℎ𝑁𝑁𝑑𝑑𝑑𝑑𝑚𝑚𝑚𝑚𝑑𝑑𝑚𝑚 ( 3 ) Pembobotan lokal (tf) hanya berpedoman pada frekuensi
munculnya term dalam suatu dokumen dan tidak melihat frekuensi
kemunculan term tersebut di dalam dokumen lainnya. Pembobotan global
digunakan untuk memberikan tekanan terhadap term yang mengakibatkan
perbedaan dan berdasarkan pada penyebaran dari term tertentu di seluruh
dokumen. Banyak skema didasarkan pada pertimbangan bahwa semakin
jarang suatu term muncul di dalam total koleksi maka term tersebut
menjadi semakin berbeda. Pemanfaatan pembobotan ini dapat
menghilangkan kebutuhan stop word removal karena stop word
pembobotan global mencakup inverse document frequency (idf), squared
idf, probabilistic idf, GF-idf, entropy. Pendekatan idf merupakan
pembobotan yang paling banyak digunakan saat ini. Beberapa aplikasi
tidak melibatkan bobot global, hanya memperhatikan tf, yaitu ketika tf
sangat kecil atau saat diperlukan penekanan terhadap frekuensi term di
dalam suatu dokumen.
Faktor normalisasi digunakan untuk menormalkan vektor
dokumen sehingga proses retrieval tidak terpengaruh oleh panjang dari
dokumen. Normalisasi ini diperlukan karena dokumen panjang biasanya
mengandung perulangan term yang sama sehingga menaikkan frekuensi
term (tf). Dokumen panjang juga mengandung banyak term yang berbeda
sehingga menaikkan ukuran kemiripan antara query dengan dokumen
tersebut, meningkatkan peluang di-retrieve-nya dokumen yang lebih
panjang.
Bobot lokal suatu term i di dalam dokumen j (tfij) dapat
didefinisikan sebagai (Lee D. L., 1997):
𝑙𝑙𝑁𝑁𝑖𝑖=𝑚𝑚𝑖𝑖𝑚𝑚𝑁𝑁𝑙𝑙𝑖𝑖𝑖𝑖(𝑁𝑁
𝑖𝑖𝑖𝑖) ( 4 )
fij merupakan jumlah berapa kali termi muncul di dalam
dokumen j. Frekuensi tersebut dinormalisasi dengan frekuensi dari most
common term di dalam dokumen tersebut. Bobot global dari suatu term i
pada pendekatan inverse document frequency (idfi) dapat didefinisikan
𝑖𝑖𝑁𝑁𝑁𝑁𝑖𝑖=log (𝑁𝑁𝑁𝑁𝑚𝑚𝑖𝑖) ( 5 )
Dimana dfi adalah frekuensi dokumen dari termi dan sama dengan
jumlah dokumen yang mengandung term i. Log digunakan untuk
memperkecil pengaruhnya relatif terhadap tfij. Bobot dari termi di dalam
sistem IR (wij) dihitung menggunakan ukuran tf-idf yang didefinisikan
sebagai berikut (Lee D. L., 1997):
𝑤𝑤𝑖𝑖𝑖𝑖=𝑙𝑙𝑁𝑁𝑖𝑖𝑖𝑖 × 𝑖𝑖𝑁𝑁𝑁𝑁𝑖𝑖 ( 6 )
2.6. Tokenizing
Tokenizing adalah proses membagi deretan kalimat menjadi
kalimat, dan kalimat menjadi token – token. Token tidak hanya terdiri dari
kata – kata, tetapi juga angka – angka, tanda kutip, tanda kurung, dan tanda
baca lainnya. Proses tokenizing pada gambar 2. 4 masukan (input) berupa
sebuah kalimat “Ada riwayat infeksi saluran napas”. Proses tokenizing
memisah kalimat tersebut menjadi potongan – potongan kata
penyusunnya. Potongan kata seperti “riwayat”, “infeksi”, “saluran”, dan
“napas” akan digunakan untuk proses selanjutnya.
2.7. Stemming
Stemming merupakan suatu proses yang terdapat dalam sistem IR
yang mentransformasi kata-kata yang terdapat dalam suatu dokumen ke
kata – kata dasarnya (root word) dengan menggunakan aturan – aturan
tertentu. Sebagai contoh, kata bersama, kebersamaan, menyamai, akan di–
stem ke rootword–nya yaitu “sama”. Proses stemming pada teks berbahasa
Indonesia berbeda dengan stemming pada teks berbahasa Inggris. Pada
teks berbahasa Inggris, proses yang diperlukan hanya proses
menghilangkan sufiks. Sedangkan pada teks berbahasa Indonesia, selain
sufiks, prefiks, dan konfiks juga dihilangkan (Agusta, 2009).
Stemming khusus bahasa Inggris yang ditemukan oleh Martin
Porter. Mekanisme algoritma dalam mencari kata dasar suatu kata
berimbuhan dengan membuang imbuhan – imbuhan (atau lebih tepatnya
akhiran) pada kata–kata bahasa Inggris karena dalam bahasa Inggris tidak
mengenal awalan. Karena bahasa Inggris datang dari kelas yang berbeda,
beberapa modifikasi telah dilakukan untuk membuat Algoritma Porter
sehingga dapat digunakan sesuai dengan bahasa Indonesia. Implementasi
Porter Stemmer for Bahasa Indonesia berdasarkan English Porter
Stemmer yang dikembangkan oleh W.B. Frakes pada tahun 1992. Karena
bahasa Inggris datang dari kelas yang berbeda, beberapa modifikasi telah
dilakukan untuk membuat algoritma Porter dapat digunakan sesuai dengan
Gambar 2. 4 Desain dari Porter Stemmer for Bahasa Indonesia
2.7.1. Porter Stemmer Algorithm
Algoritma atau langkah – langkah stemming pada teknik Porter
Stemmer adalah sebagai berikut:
1. Menghapus partikel seperti: -kah, -lah, -tah
2. Mengapus kata ganti (Possesive Pronoun), seperti –ku, -mu, -nya
3. Mengapus awalan pertama. Jika tidak ditemukan, maka lanjut ke
langkah 4a, dan jika ada maka lanjut ke langkah 4b.
b. Menghapus akhiran, jika tidak ditemukan maka kata tersebut
diasumsikan sebagai kata dasar (root word). Jika ditemukan maka
lanjut ke langkah 5b.
5. a. Menghapus akhiran dan kata akhir diasumsikan sebagai kata dasar
(root word).
b. Menghapus awalan kedua dan kata akhir diasumsikan sebagai kata
dasar (root word) (Agusta, 2009).
2.7.2. Aturan Algoritma Porter untuk Bahasa Indonesia
Terdapat 5 aturan pada Algoritma Porter untuk Bahasa Indonesia.
Dasar dari aturan ini adalah membagi kata berdasarkan imbuhan yang
diberikan pada kata tersebut. Aturan tersebut dapat dilihat pada tabel
berikut (Tala, 2003):
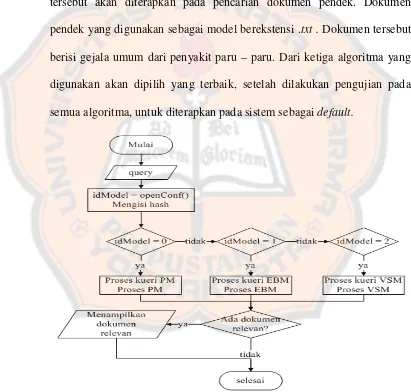
Tabel 2. 6 Kelompok rule pertama: inflectional particles
Suffix Replacement Meassure
Condition
Additional
Condition Contoh
-kah NULL 2 NULL bukukah buku
-lah NULL 2 NULL adalah ada
Tabel 2. 7 Kelompok rule kedua: inflectional possesive pronouns
Suffix Replacement Meassure
Condition
Additional
Condition Contoh
-ku NULL 2 NULL bukuku buku
-mu NULL 2 NULL bukumu buku
-nya NULL 2 NULL bukunya buku
Tabel 2. 8 Kelompok rule ketiga: first order of derivational prefixes
Prefix Replacement Meassure
Condition
Additional
Condition Contoh
meng- NULL 2 NULL mengukur ukur
meny- s 2 V...* menyapu sapu
men- NULL 2 NULL menduga duga
mem- p 2 V... memilah pilah
mem- NULL 2 NULL membaca baca
me- NULL 2 NULL merusak rusak
peng- NULL 2 NULL pengukur ukur
peny- s 2 V... penyapu sapu
pen- NULL 2 NULL pendosa dosa
pem- p 2 V... pemilah pilah
pem- NULL 2 NULL pembaca baca
di- NULL 2 NULL diukur ukur
ter- NULL 2 NULL tersapu sapu
Tabel 2. 9 Kelompok rule keempat: second order of derivational prefixes
Prefix Replacement Meassure
Condition
Tabel 2. 10 Kelompok rule kelima: derivationalsuffixes
Suffix Replacement Meassure
2.8. Vector Space Model
Vector Space Model (VSM) menganalogikan dokumen sebagai
vektor yang memiliki besaran. Gambar 2.6 menunjukkan perlakuan yang
diterapkan VSM terhadap query pencarian.
Gambar 2. 5 Vector Space Model
Sebagai vektor yang memiliki besaran, jarak antar dokumen dapat
dihitung menggunakan persamaan cosine similarity (Manning, et al,
2008).
𝑖𝑖𝑖𝑖𝑚𝑚 (𝐷𝐷1,𝐷𝐷2) = 𝑣𝑣
→(𝐷𝐷1). 𝑣𝑣
→(𝐷𝐷2)
�→𝑣𝑣(𝐷𝐷1)�� 𝑣𝑣
→(𝐷𝐷2)� ( 7 )
Dimana:
• 𝑖𝑖𝑖𝑖𝑚𝑚 (𝐷𝐷1,𝐷𝐷2) adalah jarak kedekatan dokumen 1 dan
dokumen 2.
• D1 adalah dokumen 1.
• D2 adalah dokumen 2.
•
𝑣𝑣
•
𝑣𝑣
→(𝐷𝐷2)adalah reperentasi vektor dokumen 2.
Salah satu cara untuk mengukur jarak antar vektor adalah dengan
menggunakan persamaan Euclidian Distance. Dengan berasumsi bahwa t
adalah komponen dari vektor, maka Euclidian Distance untuk vektor
𝑣𝑣
Dand hasil dari perkalian dot product antara 2 (dua) vektor
𝑣𝑣
→ dan
𝑚𝑚
→ dapat ditulis sebagai berikut:
∑ 𝑣𝑣
Dengan melihat persamaan 8 dan 9, persamaan 7 dapat ditulis
ulang menjadi:
Semakin besar nilai yang diperoleh, tingkat kemiripan dokumen yang
dibandingkan akan semakin tinggi. Sebaliknya, semakin kecil nilai yang
diperoleh, tingkat kemiripan dokumen yang dibandingkan semakin rendah.
Dalam membentuk model hasil pencarian, VSM membandingkan
nilai kesamaan antara query pencarian terhadap setiap dokumen yang
tersedia. Dengan melihat persamaan 7, perhitungan jarak antara query
𝑖𝑖𝑖𝑖𝑚𝑚 (𝑄𝑄,𝐷𝐷𝑖𝑖) = →𝑣𝑣(𝑄𝑄).→𝑣𝑣(𝐷𝐷𝑖𝑖)
→(𝑄𝑄)adalah reperentasi vektor query pencarian.
•
𝑣𝑣
→(𝐷𝐷𝑖𝑖)adalah reperentasi vektor dokumen i.
Dengan melihat pada persamaan 10 dan 11, dapat ditulis ulang
menjadi:
VSM akan mengurutkan dokumen berdasarkan nilai jarak
kesamaan masing – masing dokumen dengan query pencarian. Semakin
dekat jarak dokumen dengan query pencarian, posisi dokumen akan berada
semakin atas.
2.9.Extended Boolean Model
Boolean model merupakan model IR sederhana yang berdasarkan
atas teori himpunan dan aljabar. Boolean model merepresentasikan
direpresentasikan sebagai ekspresi boolean. Query dalam ekspresi boolean
merupakan kumpulan kata kunci yang saling dihubungkan melalui
operator boolean seperti AND, OR, dan NOT serta menggunakan tanda
kurung untuk menentukan scope operator. Hasil pencarian dokumen dari
model boolean adalah himpunan dokumen yang relevan (Baetza - Yates
dan Riberio – Neto, 1998). Karena sifatnya yang sederhana, boolean
model saat ini masih dipergunakan oleh sistem IR modern, antara lain oleh
www.google.com. Kekurangan model boolean diperbaiki oleh VSM dan
extended boolean model yang mampu menghasilkan dokumen – dokumen
terurut berdasarkan kesesuaian query.
Extended boolean model merupakan lanjutan dari boolean model
dengan menggabungkan karakateristik dari vector space model dengan
sifat – sifat aljabar boolean dan peringkat kesamaan antara query dan
dokumen berdasarkan p-norm model (Salton, 1989). Cara ini dikatakan
sebagai alternatif dari model klasik boolean model. Algoritma extended
boolean model (EBM) pada dasarnya merupakan model pengembangan
model vektor. Model vektor memberikan nilai kepada kata atau frasa yang
terdapat pada dokumen indeks dimana kata tersebut mempunyai asosiasi
dengan kata yang ada dalam user query (Baetza - Yates dan Riberio –
Neto, 1998). Nilai ini disebut sebagai bobot dari kata atau frasa yang
terdapat dalam dokumen. Bobot ini kemudian digunakan untuk membuat
derajat kemiripan antara tiap dokumen yang disimpan dalam text database
Dalam EBM, bobot kata dalam dokumen harus dalam interval 0
sampai 1. Oleh karena itu bobot harus dinormalisasi (Salton, 1989).
Perhitungan bobot dalam EBM dihitung menggunakan persamaan sebagai
berikut:
• tfmax i,j merupakan frekuensi maksimum kata i dalam dokumen j.
• idfi merupakan nilai idf dari kata i dalam koleksi.
• idfmax i merupakan nilai maksimum idf kata i dalam koleksi.
P-Norm model memberikan gagasan untuk memasukkan nilai p,
yaitu nilai yang menunjukkan keketatan pada operator. Nilai p berkisar
dari satu sampai tidak terhingga. Untuk P-Norm model ukuran kesamaan
antara dokumen dan query didefinisikan sebagai berikut (Savoy, 1993):
𝑖𝑖𝑖𝑖𝑚𝑚�𝐷𝐷,𝑄𝑄𝑑𝑑𝑑𝑑(𝑝𝑝)� =�𝑖𝑖1
• Persamaan 13 merupakan persamaan untuk query OR.
• Persamaan 14 merupakan persamaan untuk query AND.
• dA, dBmerupakan bobot term A dan term B pada dokumen.
• 1 ≤ p ≤ ∞.
Perhitungan ukuran kesamaan dalam EBM menggunakan
persamaan berikut (Savoy, 1993):
Tabel 2. 11 Tabel persamaan perhitungan ukuran kesamaan dalam EBM
Query Retrieval Status Value (RSV)
A OR <p> B
�𝑊𝑊𝑖𝑖𝑖𝑖𝑝𝑝 + 𝑊𝑊𝑖𝑖𝑏𝑏𝑝𝑝
𝑚𝑚
𝑝𝑝
A AND <p> B
1− �(1− 𝑊𝑊𝑖𝑖𝑖𝑖)
𝑝𝑝 + (1− 𝑊𝑊𝑖𝑖𝑏𝑏)𝑝𝑝
𝑚𝑚
𝑝𝑝
NOT A 1 – Wia
Dimana :
• p adalah nilai p-norm yang dimasukkan pada query.
• Wia adalah bobot istilah A dalam indeks pada dokumen Di.
• Wib adalah bobot istilah B dalam indeks pada dokumen Di.
• n adalah jumlah kata yang dihubungkan menggunakan operator.
Nilai P-Norm yang umum digunakan adalah 2. Pemberian
peringkat dilakukan dengan cara mengurutkan nilai yang didapat dokumen
2.10. Probabilistic Model
Probabilistic model mencoba untuk menangkap masalah pada IR
ke dalam kerangka probabilitas. Ide dasar dari model ini adalah,
berdasarkan query dari pengguna terdapat kumpulan dokumen yang berisi
sama dengan dokumen relevan dan ada yang tidak. Kumpulan dokumen
relevan tersebut merupakan kumpulan hasil yang ideal (ideal answer set).
Jika di dalam prosesnya, kumpulan jawaban ideal ini diberikan, maka tidak
akan ada kesulitan dalam melakukan proses IR (Baeza-Yates dan
Ribeiro-Neto, 1999).
Probabilistic model yang mengasumsikan beberapa hal, yaitu:
1. Klasifikasi biner, yaitu “Ada dan tidak ada”, “Relevan dan
tidak relevan”. Sebagai contoh, suatu term dapat dikatan “ada”
atau “tidak ada” dalam suatu dokumen. Dokumen juga dapat
dikatakan “relevan” atau “tidak relevan” dengan query.
2. Kerelevansian suatu dokumen adalah independen, yaitu tidak
tergantung dengen kerelevansian dokumen lain.
3. Term yang satu tidak memiliki kaitan (independent) dengan
term yang lain. Tetapi, van Rijsbergen menyatakan bahwa term
memiliki keterkaitan (dependent) dengan term yang lain.
Rijsbergen memberikan suatu mekanisme untuk menghitung
dependensi antar term yaitu dengan menggunakan pohon