1
CLASTERING DATA AKADEMIK MAHASISWA FAKULTAS
TEKNIK USNI DENGAN ALGORITMA K-MEANS
LAPORAN AKHIR PENELITIAN
Disusun Oleh
Bosar Panjaitan, S.Kom, M.Kom (KETUA)
Turkhamun Adi Kurniawan, ST, M.Kom (Anggota)
Teknik Informatika
Fakultas Teknik
Universitas Satya Negara Indonesia
JAKARTA
ii
DAFTAR ISI
Halaman
DAFTAR ISI ... ii
BAB I PENDAHULUAN ... 1
1.1 Latar Belakang Masalah ... 1
1.2 Rumusan Masalah ... 1
1.3 Batasan Masalah ... 2
1.4 Tujuan Penelitian ... 2
1.5 Manfaat Penelitian ... 2
BAB II TINJAUAN PUSTAKA... 3
2.2 Penelitian Relepan ... 3
2.2 Data Mining ... 3
2.3 Clustering ... 4
2.4 K-Means ... 4
2.5 Algoritma K-Means: ... 5
BAB III METODE PENELITIAN ... 6
3.1 Objek Penelitian ... 6
3.2 Jadwal Penelitian ... 7
BAB IV ... 8
HASIL DAN PEMBAHASAN ... 8
Tabel 4.1. Data Inisial ... 8
Tabel 4.2 Data Hasil seleksi ... 9
Tabel 4.5 Tabel Keanggotaan ... 10
Tabel 4.9 Deskipsi Data Per Cluster ... 25
BAB V ... 27
5.1 Kesimpulan ... 27
1
BAB I PENDAHULUAN
BAB I PENDAHULUAN
1.1 Latar Belakang Masalah
Seiring dengan perkembangan teknologi, perguruan tinggi perguruan tinggi di Jakarta semakin megalami persaingan yang ketat dalam memperoleh calon mahasiswa. Teknologi bukan lah segalanya dalam menentukan strategi penerimaan mahasiswa baru tetapi harus diikuti dengan analisis data.
Fakultas Teknik Universitas Satya Negara Indonesia (USNI) sebagai institusi pendidikan telah memiliki data akademik dan administrasi dalam jumlah yang sangat besar, tetapi belum dimanfaatkan secara maksimal. Data akademik mahasiswa merupakan data yang dihimpun dari hasil kegiatan penerimaan mahasiswa baru, dan proses belajar lulus dari suatu perguruan tinggi. Data pribadi mahasiswa, data rencana studi, dan data hasil studi (nilai dan indeks prestasi) merupakan contoh data akademik suatu perguruan tinggi. Di samping itu, bagian admisi pada setiap awal tahun akademik melakukan rekrutmen calon mahasiswa baru. Data mahasiswa baru yang dihimpun pada saat pendaftaran dan/atau registrasi berupa nilai ujian nasional (UN) rata-rata dan/atau nilai hasil tes masuk perguruan tinggi. Jumlah data yang terakumulasi dari tahun ke tahun perlu dilakukan analisis untuk dapat membuka peluang dihasilkannya informasi yang berguna dalam pembuatan alternatif keputusan bagi manajemen perguruan tinggi.
Untuk memperoleh calon mahasiswa yang lebih banyak, diperlukan strategi promosi yang tepat dengan dasar pengolan data terhadap data-data mahasiswa baru yang sudah ada antara lain: asal sekolah, prestasi akademik, lokasi tempat tinggal, tren keminatan calon mahasiswa, kemampuan calon mahasiswa (akademik dan/atau finansial), proses pembelajaran, serta prospek lulusan kedepannya
1.2 Rumusan Masalah
Adapun rumusan masalah dalam penelitian ini adalah Bagaimana mengklaster data akademik mahasiswa Fakultas Teknik USNI dengan algoritma K-Means?
2
1.3 Batasan Masalah
Agar tidak terjadi melebarnya pokok permasalahan
a. Data yang digunakan dalam penelitian ini adalah data akademik tahun 2014/2015 b. Variabel pengukuran hanya menggunakan Nilai UN dan IPK mahasiswa baru
1.4 Tujuan Penelitian
Adapun tujuan dari penelitian ini adalah mengklaster data akademik mahasiswa fakultas teknik Universitas Satya Negara Indonesia
1.5 Manfaat Penelitian
Membantu pihak manajemen Fakultas Teknik dalam menyusun strategi penerimaan mahasiswa baru.
3
BAB II TINJAUAN PUSTAKA
BAB II
TINJAUAN PUSTAKA
2.2 Penelitian Relepan
PENERAPAN METODE KLASTERING UNTUK MEMETAKAN POTENSI TANAMAN KEDELAI DI JAWA TENGAH DENGAN MENGGUNAKAN METODE FUZZY C-MEAN oleh Indra Setiawan Teknik Informatika Universitas Dian Nuswantoro Semarang
CLUSTERING KUALITAS BERAS BERDASARKAN CIRI FISIK MENGGUNAKAN METODE K-MEAN oleh Silvi Agustina1) , Dhimas Yhudo2) , Hadi Santoso3) , Nofiadi Marnasusanto4) , Arif Tirtana5) , Fakhris Khusnu6*)
Optimasi K-Means Clustering Menggunakan Particle Swarm Optimization pada Sistem Identifikasi Tumbuhan Obat Berbasis Citra K-Means Clustering Optimization Using Particle Swarm Optimization on Image Based Medicinal Plant Identification System FRANKI YUSUF BISILISIN 1 , YENI HERDIYENI 1* , BIB PARUHUM SILALAHI
2.2 Data Mining
Teknologi data mining merupakan salah satu alat bantu untuk penggalian data pada basis data berukuran besar dengan spesifikasi kerumitan tinggi dan telah banyak digunakan pada lingkungan aplikasi bisnis seperti perbankan, provider telekomunikasi, perusahaan pertambangan, perminyakan, dan lain-lain [1]. Clustering merupakan salah satu teknik data mining yang berfungsi melakukan pengelompokan sejumlah data atau objek ke dalam cluster (group) sehingga setiap cluster akan berisi data yang semirip mungkin dan berbeda dengan objek dalam cluster yang lainnya. Teknik klasifikasi merupakan pendekatan fungsi klasifikasi dalam data mining yang digunakan untuk melakukan prediksi atas informasi yang belum diketahui sebelumnya. Beberapa algoritma yang dapat digunakan antara lain adalah algoritma Decission Tree C.45, Artificial Neural Networks (ANN), K-Nearest Neighbor (KNN), algoritma Naive Bayes, Neural Network serta algoritma lainnya.
4
2.3 Clustering
Klasterisasi merupakan teknik atau metode untuk mengelompokkan sejumlah besar data menjadi suatu bagian-bagian kecil data yang mempunyai atribut kemiripan dalam sifat, letak, ciri atau filter lain yang telah ditentukan. Teknik atau metode klasterisasi dapat dikelompokkan menjadi dua kategori besar, yaitu : (1) Metode Hirarki (Hierarchical Clustering) dan (2) Metode Non-Hirarki/Partisi (Partitional Hierarchical). Referensi [1] menunjukkan bahwa Algoritma K-Modes merupakan metode pengembangan dari K-Means yang mampu mengelompokkan data kategorikal dan menghasilkan klaster yang lebih stabil dengan waktu komputasi yang lebih singkat daripada metode K-Means.
Teknik klasifikasi merupakan pendekatan untuk menjalankan fungsi klasifikasi dalam data mining yaitu untuk menggolongkan data. Teknik klasifikasi ini dapat pula digunakan untuk melakukan prediksi atas informasi yang belum diketahui sebelumnya. Beberapa algoritma yang dapat digunakan antara lain adalah algoritma Decission Tree C.45, Artificial Neural Networks (ANN), K-Nearest Neighbor (KNN), algoritma Naive Bayes, Neural Network serta algoritma lainnya.
Tujuan pekerjaan pengelompokan (clustering) data dapat dibedakan menjadi dua, yaitu pengelompokan untuk pemahaman dan pengelompokan untuk penggunaan. Jika tujuannya untuk pemahaman, kelompok dalam tujuan ini hanya sebagai proses awal untuk kemudian dilanjutkan dengan pekerjaan inti seperti peringkasan atau summarization (rata-rata, atau standar deviasi), pelabelan kelas untuk setiap kelompok untuk kemudian digunakan sebagai data latih klasifikasi, dan sebagainya. Sementara jika untuk penggunaan, tujuan utama pengelompokan biasanya adalah mencari prototipe kelompok yang paling representatif terhadap data, memberikan abstraksi dari setiap objek data dalam kelompok dimana sebuah data terletak di dalamnya.
2.4 K-Means
K-Means merupakan salah satu metode pengelompokan data nonhierarki(sekatan) yang berusaha mempartisi data yang ada ke dalam bentuk dua atau lebih kelompok. Metode ini mempartisi data ke dalam kelompok sehingga data yang berkarakteristik berbeda dikelompokkan yang lain. Adapun tujuan pengelompokan data ini adalah untuk memiminimalkan fungsi objektib yang diset dalam pengelompokan, yang pada umumnya
5
berusaha meminimalkan variasi di dalam satu kelompok dan memaksimalkan variasi antar kelompok.
2.5 Algoritma K-Means:
1) Menentukan Jumlah kelompok;
2) Menentukan koordinat titik tengah setiap cluster;
3) Menentukan jarak setiap objek terhadap koordinat titik tengah;
4) Mengelompokkan objek‐objek tersebut berdasarkan pada jarak minimumnya; 5) Tentukan pusat cluster baru ;
6) Apakah ada selisih antara cluster lama dengan cluster baru?, Jika masih ada kembali ke langkah-1, jika tidak lanjut kelangkah 6.
7) Selesai.
Pada langkah 2 lokasi sentroid(titik pusat) setiap kelompok yang diambil dari rata-rata (mean) semua nilai data pada setiap fiturnya harus dihitung kembali. Jika M menyatakan jumlah data dalam sebuah kelompok, i menyatakan fitur ke –i dalam sebuah kelompok, dan P menyatakan dimensi data, untuk menghitung sentroid fitur ke-i digunakan formula:
Ci=1
𝑀∑ 𝑥
𝑀 𝑗=1 j
Formula tersebut dilakukan sebanyak P dimensi sehingga i mulai dari 1 sampai P. Sedangkan pada langkah 4 dilakukan perhitungan jarak dengan menggunakan formula Euclidean:
D(x2,x1)=√(∑𝑝𝑗=1|𝑥2𝑗−𝑥1𝑗|).
6
BAB III METODE PENELITIAN
BAB III
METODE PELATIHAN
3.1 Objek Penelitian
Objek penelitian bersumber dari data mahasiswa yang telah melakukan registrasi di Universitas Satia Negara Indonesia. Atribut data yang akan digunakan adalah nama mahasiswa, jurusan SLTA, nilai UAN, kota asal mahasiswa, program studi yang dipilih dan IPK. Hasil yang diperoleh dari penelitian ini diharapkan dapat menampilkan profil mahasiswa, keterkaitan antara nilai UN terhadap IPK mahasiswa, serta sebaran asal sekolahnya. Dari hasil analisis tersebut diharapkan dapat membantu pihak admisi perguruan tinggi dalam menyusun strategi promosi program studi yang menjadi target. Penggalian informasi pada sebuah data yang berukuran besar (mempunyai jumlah record dan jumlah atribut yang cukup banyak) tidak dapat dilakukan dengan mudah.
Prosedur pelaksanaan yang dilakukan dalam penelitian ini meliputi:
1) Menghimpun data yang bersumber dari bagian akademik dan admisi untuk mahasiswa jenjang D3 dan S1, selanjutnya diintegrasikan untuk dilakukan data cleaning.
2) Menentukan jumlah cluster yang akan diproses lebih lanjut dan menetapkan titik pusat dari masing-masing cluster.
3) Selanjutnya langkah-langkah yang dilakukan adalah menyusun data-data yang akan diolah termasuk parameter dan alternatif yang akan dirangking, merancang dan memproses perhitungan menggunakan metode K-Means untuk mendapatkan nilai pengelompokan mahasiswa berdasar-kan Nila Rata-rata UN dan IPK.
4) Hasil proses yang telah dinyatakan valid selanjutnya dilakukan analisis yang dikaitkan dengan kelompok dari asal kota sekolahnya.
7
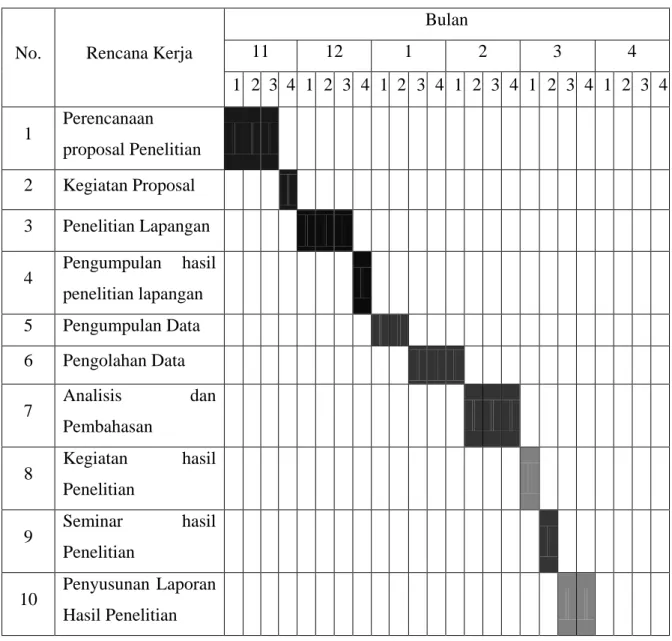
3.2Jadwal Penelitian
Tabel 3.1 Jadwal Penelitian
No. Rencana Kerja
Bulan 11 12 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 2 3 4 1 Perencanaan proposal Penelitian 2 Kegiatan Proposal 3 Penelitian Lapangan 4 Pengumpulan hasil penelitian lapangan 5 Pengumpulan Data 6 Pengolahan Data 7 Analisis dan Pembahasan 8 Kegiatan hasil Penelitian 9 Seminar hasil Penelitian 10 Penyusunan Laporan Hasil Penelitian
8
BAB IV
HASIL DAN PEMBAHASAN
4.1 Hasil
Setelah dilakukan pengumpulan data dari data-data mahasiswa dengan tahun masuk tahun akademik 2012/2013, 2013/2014, dan 2014/205 maka diperoleh data seperti dalam tabel berikut ini:
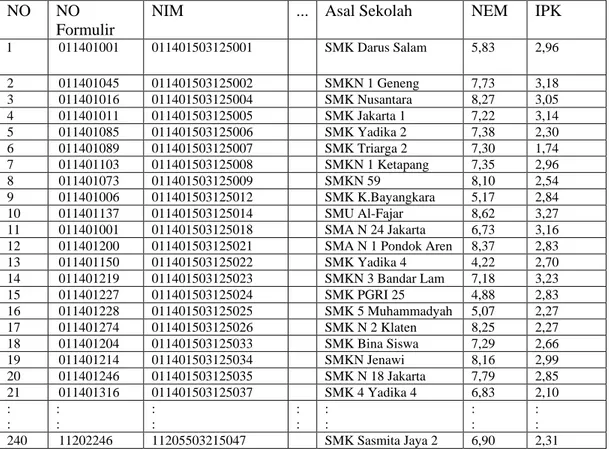
Tabel 4.1. Data Inisial
NO NO
Formulir
NIM ... Asal Sekolah NEM IPK
1 011401001 011401503125001 SMK Darus Salam 5,83 2,96 2 011401045 011401503125002 SMKN 1 Geneng 7,73 3,18 3 011401016 011401503125004 SMK Nusantara 8,27 3,05 4 011401011 011401503125005 SMK Jakarta 1 7,22 3,14 5 011401085 011401503125006 SMK Yadika 2 7,38 2,30 6 011401089 011401503125007 SMK Triarga 2 7,30 1,74 7 011401103 011401503125008 SMKN 1 Ketapang 7,35 2,96 8 011401073 011401503125009 SMKN 59 8,10 2,54 9 011401006 011401503125012 SMK K.Bayangkara 5,17 2,84 10 011401137 011401503125014 SMU Al-Fajar 8,62 3,27 11 011401001 011401503125018 SMA N 24 Jakarta 6,73 3,16
12 011401200 011401503125021 SMA N 1 Pondok Aren 8,37 2,83
13 011401150 011401503125022 SMK Yadika 4 4,22 2,70 14 011401219 011401503125023 SMKN 3 Bandar Lam 7,18 3,23 15 011401227 011401503125024 SMK PGRI 25 4,88 2,83 16 011401228 011401503125025 SMK 5 Muhammadyah 5,07 2,27 17 011401274 011401503125026 SMK N 2 Klaten 8,25 2,27 18 011401204 011401503125033 SMK Bina Siswa 7,29 2,66 19 011401214 011401503125034 SMKN Jenawi 8,16 2,99 20 011401246 011401503125035 SMK N 18 Jakarta 7,79 2,85 21 011401316 011401503125037 SMK 4 Yadika 4 6,83 2,10 : : : : : : : : : : : : : : 240 11202246 11205503215047 SMK Sasmita Jaya 2 6,90 2,31
Setelah mengumpulkan data maka dilanjutkan dengan pemilihan atribut yang dibutuhkan untuk proses Algoritma K-Means.
9
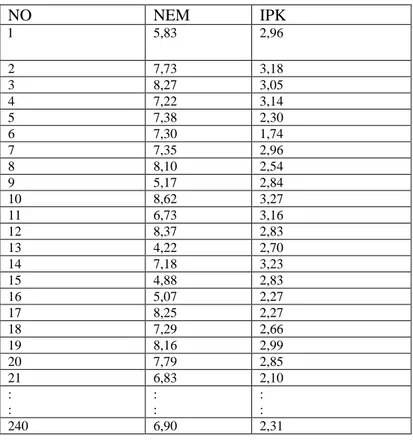
Tabel 4.2 Data Hasil seleksi
NO NEM IPK 1 5,83 2,96 2 7,73 3,18 3 8,27 3,05 4 7,22 3,14 5 7,38 2,30 6 7,30 1,74 7 7,35 2,96 8 8,10 2,54 9 5,17 2,84 10 8,62 3,27 11 6,73 3,16 12 8,37 2,83 13 4,22 2,70 14 7,18 3,23 15 4,88 2,83 16 5,07 2,27 17 8,25 2,27 18 7,29 2,66 19 8,16 2,99 20 7,79 2,85 21 6,83 2,10 : : : : : : 240 6,90 2,31
Setelah data hasil seleksi ini diperoleh, maka dilanjutkan dengan pengolahan data. Data diolah dengan menggunakan SPSS versi 21 diperoleh hasil sebagai berikut:
Tabel 4.3 Initial Cluster Centers
Cluster
1 2 3
NEM 3,37 6,22 9,23
10
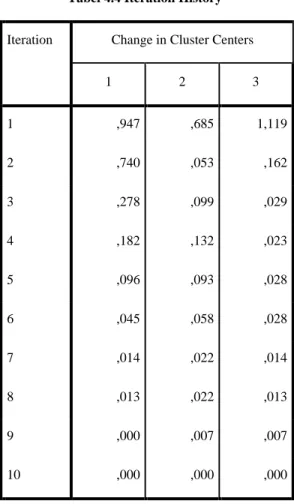
Tabel 4.4 Iteration Historya
Iteration Change in Cluster Centers
1 2 3 1 ,947 ,685 1,119 2 ,740 ,053 ,162 3 ,278 ,099 ,029 4 ,182 ,132 ,023 5 ,096 ,093 ,028 6 ,045 ,058 ,028 7 ,014 ,022 ,014 8 ,013 ,022 ,013 9 ,000 ,007 ,007 10 ,000 ,000 ,000
a. Convergence achieved due to no or small change in cluster centers. The maximum absolute
coordinate change for any center is ,000. The current iteration is 10. The minimum distance between initial centers is 3,104.
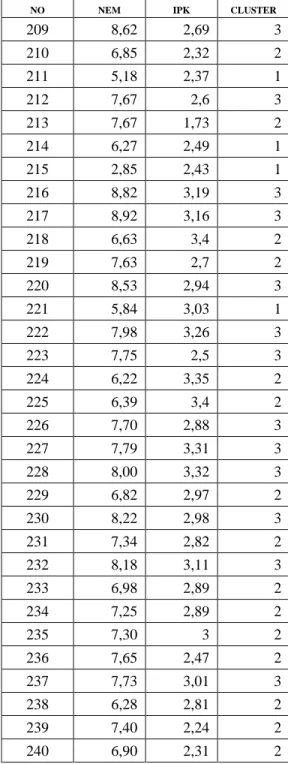
Tabel 4.5 Tabel Keanggotaan
NO NEM IPK CLUSTER
1 5,83 2,96 1 2 7,73 3,18 3 3 8,27 3,05 3 4 7,22 3,14 2 5 7,38 2,3 2 6 7,30 1,74 2 7 7,35 2,96 2 8 8,10 2,54 3
11
NO NEM IPK CLUSTER
9 5,17 2,84 1 10 8,62 3,27 3 11 6,73 3,16 2 12 8,37 2,83 3 13 4,22 2,7 1 14 7,18 3,23 2 15 4,88 2,83 1 16 5,07 2,89 1 17 8,25 2,27 3 18 7,29 2,66 2 19 8,16 2,99 3 20 7,79 2,85 3 21 6,38 2,1 2 22 8,45 3,11 3 23 7,95 2,64 3 24 8,09 2,91 3 25 8,52 2,93 3 26 8,08 2,97 3 27 7,68 2,7 3 28 7,73 2,71 3 29 6,69 3,04 2 30 8,32 2,87 3 31 8,05 2,94 3 32 9,23 2,21 3 33 6,12 2,29 1 34 7,13 3,13 2 35 7,75 2,78 3 36 7,02 3,16 2 37 5,97 2,94 1 38 7,45 2,95 2 39 7,73 3,15 3 40 6,05 3,22 1 41 9,03 2,21 3 42 5,05 2,7 1 43 7,92 2,76 3 44 4,83 3,37 1 45 7,97 2,41 3 46 7,20 2,87 2 47 7,06 1,85 2 48 8,57 2,22 3
12
NO NEM IPK CLUSTER
49 9,40 2,97 3 50 7,37 3,24 2 51 8,37 3,27 3 52 5,83 3,17 1 53 5,08 3,26 1 54 5,85 3,17 1 55 5,90 3,74 1 56 7,65 3,52 3 57 8,35 2,61 3 58 8,80 3,55 3 59 6,37 3,26 2 60 7,50 3,37 3 61 4,55 2,77 1 62 7,25 1,63 2 63 8,79 3,51 3 64 6,98 3,22 2 65 5,58 3,01 1 66 7,63 3,18 3 67 7,13 2,76 2 68 6,63 2,96 2 69 4,73 2,61 1 70 5,33 2,95 1 71 7,78 3,29 3 72 5,97 2,49 1 73 5,48 2,11 1 74 7,88 1,64 3 75 5,48 2,72 1 76 7,22 2,83 2 77 3,37 2,12 1 78 6,75 3 2 79 6,50 1,97 2 80 5,48 2,61 1 81 5,23 3,17 1 82 5,12 2,52 1 83 6,67 2,92 2 84 6,10 3,12 1 85 7,98 1,7 3 86 8,40 2,53 3 87 5,27 2,72 1 88 7,08 3,06 2
13
NO NEM IPK CLUSTER
89 5,33 2,1 1 90 7,37 2,74 2 91 8,13 2,72 3 92 7,85 1,96 3 93 6,42 3,49 2 94 7,08 2,97 2 95 6,88 3,38 2 96 8,34 3,18 3 97 7,59 3,25 3 98 8,38 3,52 3 99 6,03 1,65 1 100 5,43 2,3 1 101 8,37 2,34 3 102 7,57 3,07 2 103 5,83 2,83 1 104 5,80 2,68 1 105 7,60 2,21 2 106 5,92 3,03 1 107 6,62 2,86 2 108 5,07 2,43 1 109 7,38 3,25 2 110 5,83 1,97 1 111 7,48 2,46 2 112 8,77 2,96 3 113 6,73 2,89 2 114 7,47 2,79 2 115 8,60 3,21 3 116 8,05 2,09 3 117 7,16 2,89 2 118 5,32 2,73 1 119 7,72 2,88 3 120 7,07 2,68 2 121 7,37 2,9 2 122 8,21 3,03 3 123 7,08 2,62 2 124 8,95 3,15 3 125 5,55 2,84 1 126 6,51 3,06 2 127 8,63 3,07 3 128 7,39 2,86 2
14
NO NEM IPK CLUSTER
129 7,37 2,59 2 130 8,07 2,8 3 131 6,03 2,59 1 132 8,78 2,53 3 133 8,83 3,3 3 134 8,38 2,86 3 135 9,03 3,22 3 136 8,20 2,73 3 137 7,95 2,84 3 138 7,58 2,42 2 139 8,87 2,89 3 140 6,90 2,61 2 141 7,02 2,84 2 142 6,57 2,72 2 143 8,72 2,92 3 144 7,38 2,71 2 145 7,28 2,92 2 146 6,44 2,72 2 147 5,72 2,01 1 148 6,43 3,17 2 149 6,65 2,82 2 150 6,18 1,25 1 151 4,42 2,05 1 152 7,40 2,15 2 153 8,68 2,7 3 154 6,18 3,02 1 155 7,03 3,15 2 156 6,52 2,61 2 157 7,12 2,54 2 158 6,07 2,71 1 159 7,18 2,57 2 160 5,77 1,89 1 161 6,67 2,85 2 162 8,08 3,32 3 163 8,32 3,35 3 164 6,55 2,9 2 165 7,37 1,98 2 166 7,65 3,23 3 167 6,00 2,94 1 168 5,52 2,84 1
15
NO NEM IPK CLUSTER
169 7,03 2,68 2 170 8,38 3,09 3 171 6,85 2,9 2 172 8,72 3,13 3 173 6,75 2,84 2 174 5,07 2,87 1 175 7,88 3,13 3 176 8,27 3,13 3 177 5,15 2,88 1 178 6,70 2,96 2 179 7,17 2,93 2 180 6,90 2,88 2 181 7,68 3,04 3 182 7,23 2,85 2 183 5,48 2,85 1 184 5,80 1,42 1 185 8,32 3,27 3 186 7,48 3,23 2 187 7,87 2,92 3 188 7,52 1,5 2 189 5,73 1,33 1 190 8,25 3,49 3 191 6,85 2,58 2 192 7,73 3,25 3 193 7,48 2,98 2 194 8,00 2,83 3 195 6,07 3,11 1 196 6,85 3,16 2 197 7,27 3 2 198 7,60 3,04 3 199 8,26 3,38 3 200 6,45 3,31 2 201 8,60 3,34 3 202 6,27 2,82 2 203 5,68 0,95 1 204 5,82 2,88 1 205 7,13 3,03 2 206 8,32 2,55 3 207 6,93 0,94 2 208 7,80 2,75 3
16
NO NEM IPK CLUSTER
209 8,62 2,69 3 210 6,85 2,32 2 211 5,18 2,37 1 212 7,67 2,6 3 213 7,67 1,73 2 214 6,27 2,49 1 215 2,85 2,43 1 216 8,82 3,19 3 217 8,92 3,16 3 218 6,63 3,4 2 219 7,63 2,7 2 220 8,53 2,94 3 221 5,84 3,03 1 222 7,98 3,26 3 223 7,75 2,5 3 224 6,22 3,35 2 225 6,39 3,4 2 226 7,70 2,88 3 227 7,79 3,31 3 228 8,00 3,32 3 229 6,82 2,97 2 230 8,22 2,98 3 231 7,34 2,82 2 232 8,18 3,11 3 233 6,98 2,89 2 234 7,25 2,89 2 235 7,30 3 2 236 7,65 2,47 2 237 7,73 3,01 3 238 6,28 2,81 2 239 7,40 2,24 2 240 6,90 2,31 2
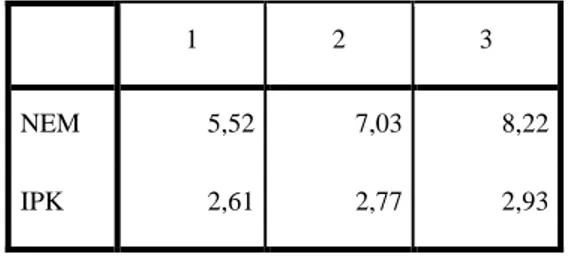
Tabel 4.6 Final Cluster Centers
17
1 2 3
NEM 5,52 7,03 8,22
IPK 2,61 2,77 2,93
Tabel 4.7 Distances between Final Cluster Centers
Cluster 1 2 3
1 1,521 2,723
2 1,521 1,202
3 2,723 1,202
Tabel 4.8 Number of Cases in each Cluster Cluster 1 58,000 2 92,000 3 90,000 Valid 240,000 Missing ,000 4.2 Pembahasan
Dari hasil eksekusi program dapat ditampilkan data per Cluster sebagai berikut: a. Seluruh Cluster 3
Tabel 4.8 Cluster 3
NO NEM IPK CLUSTER
18 2 7,40 2,15 3 3 8,68 2,7 3 4 6,18 3,02 3 5 7,03 3,15 3 6 6,52 2,61 3 7 7,12 2,54 3 8 6,07 2,71 3 9 7,18 2,57 3 10 5,77 1,89 3 11 6,67 2,85 3 12 8,08 3,32 3 13 8,32 3,35 3 14 6,55 2,9 3 15 7,37 1,98 3 16 7,65 3,23 3 17 6 2,94 3 18 5,52 2,84 3 19 7,03 2,68 3 20 8,38 3,09 3 21 6,85 2,9 3 22 8,72 3,13 3 23 6,75 2,84 3 24 5,07 2,87 3 25 7,88 3,13 3 26 8,27 3,13 3 27 5,15 2,88 3 28 6,7 2,96 3
19 29 7,17 2,93 3 30 6,9 2,88 3 31 7,68 3,04 3 32 7,23 2,85 3 33 5,48 2,85 3 34 5,8 1,42 3 35 8,32 3,27 3 36 7,48 3,23 3 37 7,87 2,92 3 38 7,52 1,5 3 39 5,73 1,33 3 40 8,25 3,49 3 41 6,85 2,58 3 42 7,73 3,25 3 43 7,48 2,98 3 44 8 2,83 3 45 6,07 3,11 3 46 6,85 3,16 3 47 7,27 3 3 48 7,6 3,04 3 49 8,26 3,38 3 50 6,45 3,31 3 51 8,6 3,34 3 52 6,27 2,82 3 53 5,68 0,95 3 54 5,82 2,88 3 55 7,13 3,03 3
20 56 8,32 2,55 3 57 6,93 0,94 3 58 7,8 2,75 3 59 8,62 2,69 3 60 6,85 2,32 3 61 5,18 2,37 3 62 7,67 2,6 3 63 7,67 1,73 3 64 6,27 2,49 3 65 2,85 2,43 3 66 8,82 3,19 3 67 8,92 3,16 3 68 6,63 3,4 3 69 7,63 2,7 3 70 8,53 2,94 3 71 5,84 3,03 3 72 7,98 3,26 3 73 7,75 2,5 3 74 6,22 3,35 3 75 6,39 3,4 3 76 7,7 2,88 3 77 7,79 3,31 3 78 8 3,32 3 79 6,82 2,97 3 80 8,22 2,98 3 81 7,34 2,82 3 82 8,18 3,11 3
21 83 6,98 2,89 3 84 7,25 2,89 3 85 7,3 3 3 86 7,65 2,47 3 87 7,73 3,01 3 88 6,28 2,81 3 89 7,4 2,24 3 90 6,9 2,31 3 b. Seluruh Cluster 2 Tabel 4.8 Cluster 2
NO NEM IPK CLUSTER
1 6,37 3,26 2 2 7,5 3,37 2 3 4,55 2,77 2 4 7,25 1,63 2 5 8,79 3,51 2 6 6,98 3,22 2 7 5,58 3,01 2 8 7,63 3,18 2 9 7,13 2,76 2 10 6,63 2,96 2 11 4,73 2,61 2 12 5,33 2,95 2 13 7,78 3,29 2 14 5,97 2,49 2 15 5,48 2,11 2 16 7,88 1,64 2 17 5,48 2,72 2
22 18 7,22 2,83 2 19 3,37 2,12 2 20 6,75 3 2 21 6,5 1,97 2 22 5,48 2,61 2 23 5,23 3,17 2 24 5,12 2,52 2 25 6,67 2,92 2 26 6,1 3,12 2 27 7,98 1,7 2 28 8,4 2,53 2 29 5,27 2,72 2 30 7,08 3,06 2 31 5,33 2,1 2 32 7,37 2,74 2 33 8,13 2,72 2 34 7,85 1,96 2 35 6,42 3,49 2 36 7,08 2,97 2 37 6,88 3,38 2 38 8,34 3,18 2 39 7,59 3,25 2 40 8,38 3,52 2 41 6,03 1,65 2 42 5,43 2,3 2 43 8,37 2,34 2 44 7,57 3,07 2 45 5,83 2,83 2 46 5,8 2,68 2 47 7,6 2,21 2
23 48 5,92 3,03 2 49 6,62 2,86 2 50 5,07 2,43 2 51 7,38 3,25 2 52 5,83 1,97 2 53 7,48 2,46 2 54 8,77 2,96 2 55 6,73 2,89 2 56 7,47 2,79 2 57 8,6 3,21 2 58 8,05 2,09 2 59 7,16 2,89 2 60 5,32 2,73 2 61 7,72 2,88 2 62 7,07 2,68 2 63 7,37 2,9 2 64 8,21 3,03 2 65 7,08 2,62 2 66 8,95 3,15 2 67 5,55 2,84 2 68 6,51 3,06 2 69 8,63 3,07 2 70 7,39 2,86 2 71 7,37 2,59 2 72 8,07 2,8 2 73 6,03 2,59 2 74 8,78 2,53 2 75 8,83 3,3 2 76 8,38 2,86 2 77 9,03 3,22 2
24 78 8,2 2,73 2 79 7,95 2,84 2 80 7,58 2,42 2 81 8,87 2,89 2 82 6,9 2,61 2 83 7,02 2,84 2 84 6,57 2,72 2 85 8,72 2,92 2 86 7,38 2,71 2 87 7,28 2,92 2 88 6,44 2,72 2 89 5,72 2,01 2 90 6,43 3,17 2 91 6,65 2,82 2 92 6,18 1,25 2 c. Seluruh Cluster 1 Tabel 4.8 Cluster 1
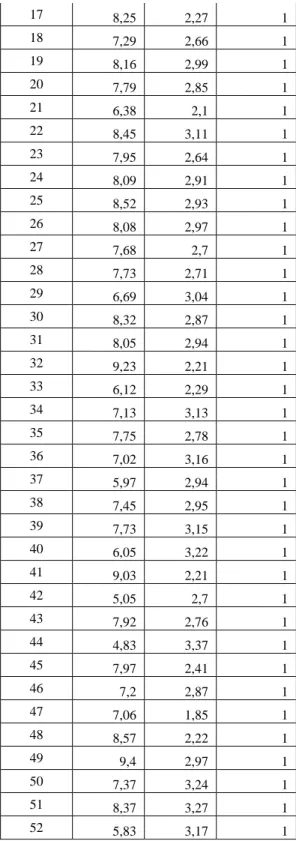
NO NEM IPK CLUSTER
1 5,83 2,96 1 2 7,73 3,18 1 3 8,27 3,05 1 4 7,22 3,14 1 5 7,38 2,3 1 6 7,3 1,74 1 7 7,35 2,96 1 8 8,1 2,54 1 9 5,17 2,84 1 10 8,62 3,27 1 11 6,73 3,16 1 12 8,37 2,83 1 13 4,22 2,7 1 14 7,18 3,23 1 15 4,88 2,83 1 16 5,07 2,89 1
25 17 8,25 2,27 1 18 7,29 2,66 1 19 8,16 2,99 1 20 7,79 2,85 1 21 6,38 2,1 1 22 8,45 3,11 1 23 7,95 2,64 1 24 8,09 2,91 1 25 8,52 2,93 1 26 8,08 2,97 1 27 7,68 2,7 1 28 7,73 2,71 1 29 6,69 3,04 1 30 8,32 2,87 1 31 8,05 2,94 1 32 9,23 2,21 1 33 6,12 2,29 1 34 7,13 3,13 1 35 7,75 2,78 1 36 7,02 3,16 1 37 5,97 2,94 1 38 7,45 2,95 1 39 7,73 3,15 1 40 6,05 3,22 1 41 9,03 2,21 1 42 5,05 2,7 1 43 7,92 2,76 1 44 4,83 3,37 1 45 7,97 2,41 1 46 7,2 2,87 1 47 7,06 1,85 1 48 8,57 2,22 1 49 9,4 2,97 1 50 7,37 3,24 1 51 8,37 3,27 1 52 5,83 3,17 1
Dari data-data di atas diperoleh deskripsi data sebagai berikut:
26
N.MIN IPK.MIN N.MAKS
IPK.
MAKS RATA N RATA2IPK
C1 2,85 0,95 6,27 3,74 5,46 2,61
C2 6,22 0,94 7,67 3,49 7,02 2,77
C3 7,50 1,64 9,40 3,55 8,22 2,92
Sebagai sasaran PMB terbaik tentunya adalah calon mahasiswa yang mempunyai NEM terbaik dan IPK terbaik. Hal ini terdapat di Cluster 3 dengan nilai rata NEM=8.22 dan rata-rata IPK 2,92.
Setelah dilakukan Query ternyata pada kluster 3 tidak ada asal sekolah yang mendominasi hanya beberapa siswa yang berasal dari sekolah yang sama. Dari SMK Media informatika 4 orang, SMK Budi Mulia 3 orang, SMK Triguna 2 orang, SMK Muhammadiah 9 2orang, SMK YUPPEN EK1 3 orang, SMK N 15 2 orang, SMK Pertiwi 2 2 orang, SMK KARTIKA 2 orang, selainnya 1 orang.
27
BAB V
KESIMPULAN DAN SARAN
5.1 Kesimpulan
Dari hasil dan pembahasan pada penelitian ini dapat diperoleh:
1. Dari sampel yang diambil 240 mahasiswa, ada 58 orang ada di Cluster1, 92 orang ada di Cluster2, dan 90 orang ada di Cluster3;
2. Rata-rata NEM dan IPK pada Cluster 3 adalah 8,22 dan 2,92;
3. Dari 90 data Asal sekolah hanya 4 siswa yang berasal dari SMK Meidya Informatika, 3 siswa dari SMK Budi Mulya, 3 siswa dari SMK YUPPEN EK1, dan masing-masing 2 siswa dari SMK Triguna, SMK Muhammadiah 9, SMK Pertiwi 2, SMK N 15 ,dan SMK KARTIKA; selainnya masing-masing1 siswa dari 70 sekolah;
4. Distribusi Asal sekolah sangat beragam (tidak ada dominasi);
Dari hasil tersebut dapat disimpulkan bahwa sasaran PMB fakultas teknik tidak perlu terfokus pada sekolah tertentu
5.2 Saran
Dari pengalaman sipeneliti tentang pengumpulan data mengalami hal yang cukup menyulitakan dikarenakan data base PMB kurang lengkap yaitu Nilai UAN(NEM) tidak, sehingga perlu data base PMB dilengkapi supaya untuk pengolahan data sesuai keperluan manajemen bisa lebih cepat. Diharapkan juga untuk penelitian berikut dilakukan untuk seluruh USNI.
28
DAFTAR PUSTAKA
DAFTAR PUSTAKA
[1] Eko Prasetyo, “Data Mining”,Edisi ke-1, C.V ANDI OFFSET, Yogjakarta 2012.
[2] Andi Syafrianto, “Perancangan aplikasi K-means untuk pengelompokan mahasiswa STMIK EL-ERHAMA Yogyakarta berdasarkan frekuensi kunjungan ke perpustakaan dan IPK”, Yogyakarta: STMIK EL-ERHAMA, 2005.
[3] Efraim T., Decision support systems and intelligent systems, Edisi ke-7, Andi, Yogyakarta, 2005.
[4] Jiawei Han and Micheline Kamber, Data mining concepts and techniques second edition, San Francisco: Morgan Kauffman, 2001.
[5] Oyelade, Oladipupo, Obagbuwa, “ Application of K-Menas clustering algorithm for prediction of students acaddemic performance”, International Journal of Computer Science and Information Security, Volume 7, 2010