Student Clustering Based
OlllAcademic Using K .. Means Algoritms
HirOlllnm.us Leong1, Shlnta Estn Wab.yun.ingrum2
1,2 Faculty of Computer Science, Faculty of Computer Science Unika Soegijapranata [email protected]
Abstract
One goal of clustering data mining is to find a cluster of a particular data modeling. By modeling the data, it can provide more description of the data being analyzed and can be visualized in graphical form. One of the methods used in data mining to search for data modeling is to use K-Means algorithm analysis. K-K-Means algorithm is used to find groupings of data with specific points, called the centroid. By grouping the data, then large amounts of data, grouped in a simpler
visualization. The final results can be used as Decision Support System. Keyword: K·Means Algoritms, Data Mining, Clustering
1. Pendahuiuan
Sistem pembelajaran di perguruan tinggi dibangun berdasarkan perencanaan yang relevan dengan tujuan pendidikan yang ingin dicapai. Sehingga perIu diterapkan berbagai strategi dan teknik yang menunjang pengembangan mahasiswa untuk berpikir kritis, bereksplorasi, berkreasi dalam
memanfaatkan berbagai sumber
pengetahuan.
Salah satu proses dalam
pengembangan sistem pembelajaran tersebut adalah pengembangan dan pembaharuan proses dan kegiatan perkuliahan antara dosen dan mahasiswa. Keseluruhan pengembangan dan pembaharuan, tertuang dalam proses kegiatan belajar mengajar yang diatur oleh kurikulum.
Kurikulum memberlkan perangkat rencana dan pengaturan tentang isi, bahan kajian maupun bahan pelajaran sampai pada cara penyampaian dan penilaian yang digunakan sebagai pedoman dalam penyelenggaraan kegiatan belajar mengajar.
Pedoman penilaian kepada
mahasiswa menjadi tolak ukur bagi suatu program studi dalam pengembangan kurlkulum dan kualitas pendidikan yang ingin dicapai.
Penelitian tentang 'Student Clustering Based On Academic Using K-Means Algorithms' adalah penelitian yang ingin menggambarkan proses penilaian mahasiswa dalam bentuk analisis data
mining. Bahan analisis adalah nilai akademik mahasiswa secara keseluruhan.
Hasil akhir yang ingin dicapai dari penelitian 1m adalah penggambaran mahasiswa secara cluster atau secara pemodelan kelompok nHai baik indeks prestasi komulatif (IPK) mahasiswa maupun nHai mahasiswa pada mata kuliah-mata kuliah tertentu dan dapat divisualisasikan dalam bentuk tabel dan graflk.
2. Tiinjauan Pustaka 2.1 Konsep Data Mining
Pengertian data mining mengacu pada kata "menyaring" atau "menambang" pengetahuan dari sejumlah data berukuran besar. Berry dan Linoff mendeflnisikan data mining sebagai: "suatu proses eksplorasi dan analisis, dengan cara otomatis atau semi otomatis, dari sejumlah data yang besar supaya menemukan pola dan aturan yang sangat penting"
Umumnya data mining mempunyai pengertian yang sama dengan istilah "Knowledge Discovery in Databases" atau menemukan pengetahuan dalam database. Proses menemukan pengetahuan dalam database menggunakan beberapa langkah iteratif secara sekuensial yaitu sebagai berikut:
1. Data cleaning (untuk membersihkan data pencilan dan tidak konsisten)
2. Data integration (menggabungkan data dari beberapa sumber data yang berbeda)
3. Data selection (mengambil data yang relevan dari database yang akan digunakan dalam proses analisis)
4. Data transformation (data
ditransformasikan atau digabungkan dalam bentuk form untuk proses analisis) 5. Data mining (proses-proses mendasar
dengan menggunakan metode kecerdasan buatan dalam menemukan pola-pola yang khusus dari analisis data)
6. Pattern Evaluation (mengidentiftkasikan pola yang menarik berdasarkan pengukuran tertentu dari pengetahuan) 7. Knowledge presentation (teknik yang
digunakan untuk visualisasi dan representasi pengetahuan)
Berdasarkan fungsi dan tujuannya, semua proses eksplorasi dalam data mining dapat digolongkan ke dalam 2 kategori besar yaitu proses data mining yang bersifat deskriptif atau menjelaskan dan proses data mining yang bersifat prediktif atau meramalkan.
2.2 Algoritma KaMeans
Algoritma K-Means adalah metode clustering secara partisi yang membagi data ke dalam beberapa kelompok yang berbeda yang disebut sebagai cluster. Dalam proses algoritma K-Means, dilakukan proses secara iteratif dengan penentuan kelompok/cluster dilakukan secara acak. Setiap data akan dibagi berdasarkan jarak minimal rata-rata data tersebut ke cluster terdekat.
Berikut adalah langkah-langkah algoritma K-Means:
Tentukan jumlah cluster K yang akan dibentuk
1. Tentukan centroid C secara acak
2. Hitunglah jarak setiap data ke masing-masing centroid menggunakan rumus jarak antar data (euclidian distance)
n
d(x, y) =
L
(Xi - Yi)2 ..••...•••..•• (1)i=l Keterangan:
d
=
distance/jarak titik (X, y)Xi = titik X data ke-i
Yi
=
titik Y data ke-i3. kelompokkan setiap data berdasarkan jarak terdekat data tersebut dengan setiap centroid C. Tentukan posisi centroid C yang barn dengan cara menghitung nilai rata-rata dari data-data yang ada pada centroid yang sama
C. = (:.
)Ld
l ••••••••••••••• (2) Keterangan:nk adalah jumlah data dalam cluster k dan di adalah data ke-i dalam cluster k
4. Lakukan kembali langkah 3, jika posisi centroid barn tidak sama dengan centroid yang lama (proses iterasi sampai kondisi centroid ke n sama dengan centroid n-l) 3. Metodologi Peneiitiu
Metode yang digunakan dalam penelitian adalah metode CRISP-DM (CRoss Industry Standard Process for Data Mining).
Metode CRISP-DM adalah standarisasi yang berhubungan dengan proses pemodelan data mining. Standarisasi ini tidak mengacu pada teknologi tertentu, melainkan pada semua tingkatan pengguna data mining untuk menyelesaikan masalah perusahaan atau lembaga secara umum.
Gambar 3.1 Metode CRISP-DM
Business Understanding: merupakan fase inisialisasi awal pengembangan data IDlrung yaitu pemahaman tentang obyektivitas dan kebutuhan. Pemahaman tersebut diterjemahkan ke dalam defmisi
masalah yang akan diselesaikan dengan data
mining sehingga dapat dirancang
perencanaan awal untuk mencapai tujuan. Data Understanding: Fase data understanding dimulai dengan eksplorasi
data yang akan digunakan dalam
permasalahan data mining, ver~fikasi dan menemukan pengertian awal dan data yang akan digunakan dalam proses analisis. Dari proses-proses tersebut, maka dapat di?erol~h hal-hal menarik untuk penyusunan hlpotesls dari informasi yang tersembunyi.
Data Preparation: Hampir sebagian besar dari proses pemodelan data mining terfokus pada fase data preparation atau persiapan data. Pengumpulan data, penilaian terhadap data, konsolidasi dan pembersihan data, seleksi dan transformasi data dibutuhkan dalam fase ini.
Modeling: Fase modeling adalah fase pemilihan model analisis yang akan diimplementasikan dalam data mining, misalnya decision tree, neural network,
aturan asosiasi, dan lain-lain. Pemilihan
model analisis disesuaikan dengan
pennasalahan yang diselesaikan, bahkan beberapa model dapat diimplementasikan dalam penyelesaian masalah.
EvaKuatnon: Fase evaluation atau evaluasi adalah fase analisis terhadap model yang digunakan, bagaimana kinerja model terhadap analisis data yang digunakan; apakah model yang diimplementasikan sudah atau belum memenuhi fase pertama
Deployment: Fase deployment
mendefinisikan bagaimana model
dikembangkan dalam bentuk sistem, siapa yang akan menggunakannya, dan seberapa sering sistem tersebut digunakan. Terdapat 3 langkah yang ada dalam fase ini, yaitu: Perencanaan deployment, Perencanaan pengawasan dan pemeliharaan; langkah ini penting apabila hasil dari pemodelan dalam data mining digunakan secara periodik. 4. Basil Penelitian dan PembahasaJlJl
Persiapan data adalah proses awal dari
implementasi sistem. Dalam proses
persiapan data, perlu dilakukan persiapan
database mahasiswa Fakultas
llmu
KomputerNAMAMHS KD JUR ANGKAIAN NIRM TPLHR TGLHR KELAMIN MARITAL ALAMAT KOTA TELEPON AGAMA DARAH KODEPOS ALAMAT_ASAl. NIRL . berikut: THNAJAR KD_MSI.IJI FKI NIM FI';2 KDMK_PI.IS NILAI KELAS NO ARSIP OPERATOR TANGGAL KD_JUR DOSEN
Gambar 4.1 Schema Database
Tiga tabel utama menyimpan data tentang mahasiswa, mata kuliah dan hasil studi mahasiswa. Dari sejumlah kolom yang tersedia, maka diambil data yang dijadikan bahan analisis yaitu data mahasiswa (nim dan nama mahasiswa), data mata kuliah (kode matakuliah, nama mata kuliah dan besar sks) dan data hasil studi berupa nilai.
Berikut adalah contoh penerapan algoritma clustering untuk analisis data nilai mata kuliah dengan nama Relational Database Management System (RDBMS).
Tabel 4 1 Data WK dan Nilai RDBMS _.
-nim ipk jrdbms 3:.-..z..:I'.Y 09.02.0001 3.83 ~1. 0 09.02.0002 3.90 4.0 09.02.0003 3.14 3.0 09.02.0004 3.88 4.0 09.02.0005 2.95 3.5 09.02.0007 2.76 1.0 09.02.0008 3.88 4.0 09.02.0010 2.58 1.0 09.02.0011 2.68 2.5 09.02.0013 3.76 3.5 09.02.0016 3.74 3.5 09.02.0017 3.62 3.5 09.02.0021 2.97 4.0 09.02.0029 2.73 3.0 09.02.0030 3.71 4.0 09.02.0033 3.28 3.0 09.02.0051 2.95 2.5 09.02.0052 3.42 3.0 09.02.0056 2.65 2.5 09.02.0058 2.57 2.5
Langkah pertama adalah menentukan jumlah cluster yang akan dibentuk. Sebagai contoh: ditentukan dua cluster secara acak sebagai berikut:
Cl = (2.75, 3.00)
C2
=
(3.25, 3.75)Langkah kedua adalah menghitung jarak setiap titik terhadap C 1 dan C2 menggunakan rumus distance. Perhitungan jarak data pertama dengan nim 09.02.0001 adalah sebagai berikut:
d1 (x, y)
=
~(3.83-2.75)2 + (4.0-3.00)2=
1.47d2 (x, y)
=
~(3.83
- 3.25)2 + (4.0-3.75)2=
0.63Nilai minimal 0.63 sehingga data pertama masuk ke dalam pengelompokan cluster C2
Dengan cara yang sama, maka data selanjutnya dapat diperoleh perhitungan jarak dan pengelompokan clusteringdalam bentuk tabel sebagai berikut:
T b 14 2H i1H' a e
.
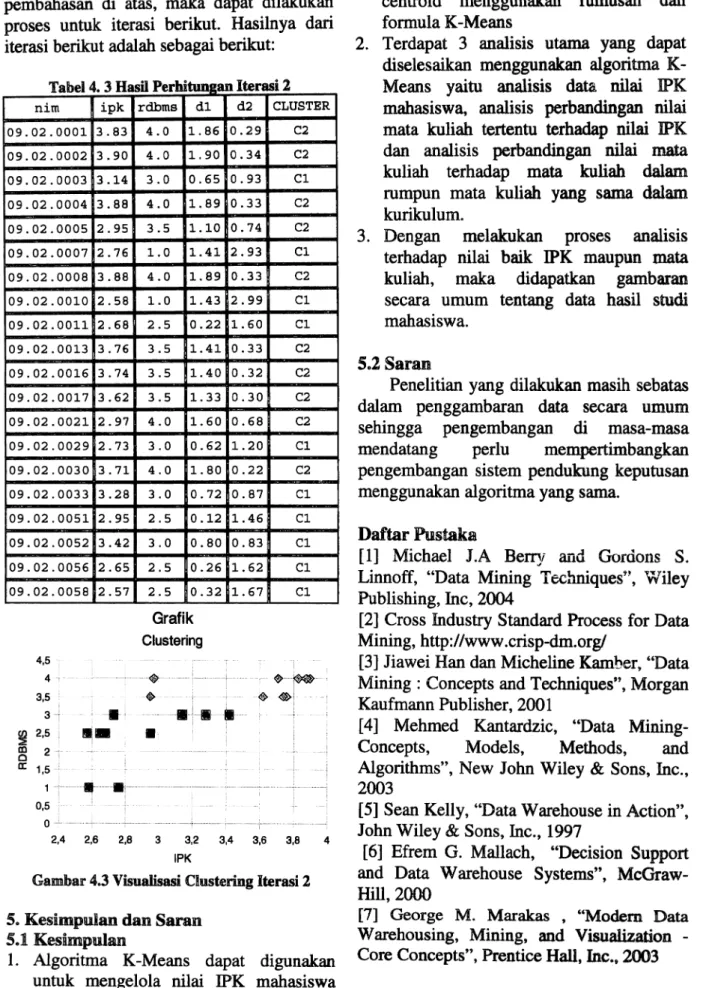
as ltungan terasl I . 1nim ipk rdbms d1 d2 CLUSTER 09.02.0001 3.83 4.0 1.47 0.63 C2 09.02.0002 3.90 4.0 1.52 0.69 C2 09.02.0003 3.14 3.0 0.39 0.76 C1 09.02.0004 3.88 4.0 1.51 0.68 C2 09.02.0005 2.95 3.5 0.54 0.39 C2 09.02.0007 2.76 1.0 2.00 2.79 C1 09.02.0008 3.88 4.0 1.51 0.68 C2 09.02.0010 2.58 1.0 2.01 2.83 C1 09.02.0011 2.68 2.5 0.50 1. 37 C1 09.02.0013 3.76 3.5 1.13 0.57 C2 09.02.0016 3.74 3.5 1.11 0.55 C2 09.02.0017 3.62 3.5 1. 00 0.45 C2 09.02.0021 2.97 4.0 1. 02 0.38 C2 09.02.0029 2.73 3.0 0.02 0.91 C1 09.02.0030 3.71 4.0 1.38 0.52 C2 09.02.0033 3.28 3.0 0.53 0.75 C1 09.02.0051 2.95 2.5 0.54 1.29 C1 09.02.0052 3.42 3.0 0.67 0.77 Cl 09.02.0056 2.65 2.5 0.51 1.39 C1 09.02.0058 2.57 2.5 0.53 1.42 C1
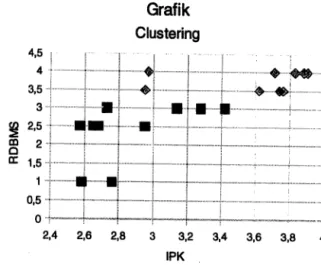
Apabila data dalam bentuk tabel di atas, digambarkan dalam bentuk grafIk clustering, maka didapatkan visualisasi sebagai berikut:
Grafik Clustering
4.:
!J..!-~J.~
3.5 . . .... '.L ... ,1 • ..; ... + ' • • ' I : 3····:-.1
···.1..+.
~ 2.51~·1
m 2 .. t ... + ... l~
1.51+1···+
·· .. ···i1: •..
0.5f
... , ... i·· i ••••• ~_ ••• M ••••••• . .... i ... 1... ... -+ ... -+ .... . ••• ••••• M •••••••••••••••••• I ~ U U 3 U U U U 4 IPKGambar 4.2 Visualisasi Clustering lterasi 1
Langkah terakhir adalah menentukan posisi titik centroid yang barn dengan perhitungan
mengambil nilai rata-rata dari data yang ada pada
centroid Cl dan centroid C2.
nim ipk 09.02.0003 3,14 09.02.0007 2,76 09.02.0010 2,58 09.02.0011 2,68 09.02.0029 2,73 09.02.0033 3,28 09.02.0051 2.95 rdbms 3 1 1 2,5 3 3 2,5 09.02.0052 3,42 3 09.02.0056 2,65 2,5 09.02.0058 2,57 2,5
Cl barn
=
AVERAGE (IPK, RDBMS)=
(2.88,2.4) nim ipk rdbms 09.02.0002 3,9 4 09.02.0004 3,88 4 09.02.0005 2,95 3,5 09.02.0008 3,88 4 09.02.0013 3,76 3,5 09.02.0016 3,74 3,5 09.02.0017 3,62 3,5 09.02.0021 2,97 4 09.02.0030 3,71 4C2 barn = AVERAGE (IPK, RDBMS) = (3.62,3.8)
Dengan cara yang sarna pada pembahasan di atas, maka dapat dilakukan proses untuk. iterasi berikut. Hasilnya dari iterasi berikut adalah sebagai berikut:
Tabel 4. 3 HasH Perbitunaan Iterasi 1
nirn 09.02.0001 09.02.0002 09.02.0003 09.02.0004 09.02.0005 09.02.0007 09.02.0008 09.02.0010 09.02.0011 09.02.0013 09.02.0016 09.02.0017 09.02.0021 09.02.0029 09.02.0030 09.02.0033 09.02.0051 09.02.0052 09.02.0056 09.02.0058 4,5 , 3,5
3:
~ 2,5 :g 2: a: 1,5 1 0,5 o ipk 3.83 3.90 3.14 3.88 2.95 2.76 3.88 2.58 2.68 3.76 3.74 3.62 2.97 2.73 3.71 3.28 2.95 3.42 2.65 2.57 rdbrns d1 4.0 1.86 4.0 1. 90 3.0 0.65 4.0 1.89 3.5 1.10 1.0 1.41 4.0 1.89 1.0 1.43 2.5 0.22 3.5 1.41 3.5 1.40 3.5 1.33 4.0 1. 60 3.0 0.62 4.0 1. 80 3.0 0.72 2.5 0.12 3.0 0.80 2.5 0.26 2.5 0.32 Grafik Clustering d2 CLUSTER 0.29 C2 0.34 C2 0.93 C1 0.33 C2 0.74 C2 2.93 C1 0.33 C2 2.99 C1 1.60 C1 0.33 C2 0.32 C2 0.30 C2 0.68 C2 1.20 C1 0.22 C2 0.87 C1 1.46 C1 0.83 C1 1.62 C1 1.67 C1 """"'~""'~ u U U 3 U U U U 4 IPKGamb8ll' 4.3 Visualisasi Cllllstering Iterasi 2
5. Kesimpulan dan Saran 5.1 Kesfimpulan
1. Algoritma K-Means dapat untuk mengelola nilai IPK menjadi pengelompokan Pengelompokan IPK dapat
digunakan mahasiswa clustering. dilakukan
dengan perhitungan jarak dan nilai centroid menggunakan rumusan dan formula K-Means
2. Terdapat 3 analisis utama yang dapat diselesaikan menggunakan algoritma K-Means yaitu analisis data nilai lIPK
mahasiswa, analisis perbandingan nilai mata kuliah tertentu terhadap nilai lPK
dan analisis perbandingan nilai mata kuliah terhadap mata kuliah dalam rumpun mata kuliah yang sarna dalam kurikulum.
3. Dengan melakukan proses analisis terhadap nilai baik IPK maupun mata kuliah, maka didapatkan garnbaran secara umum tentang data hasil stum mahasiswa.
5.2 Saran
Penelitian yang dilakukan masih sebatas dalarn penggarnbaran data secara umum sehingga pengembangan di masa-masa mendatang perlu mempertimbangkan pengembangan sistem pendukung keputusan menggunakan algoritma yang sarna.
Daftar Pustaka
[1] Michael I.A Bern) and Gordons S. Linnoff, "Data Mining Techniques", Wiley Publishing, Inc, 2004
[2] Cross fudustry Standard Process for Data Mining, http://www.crisp-dm.orgl
[3] Iiawei Han dan Micheline Kamber. "Data Mining: Concepts and Techniques", Morgan Kaufmann Publisher, 2001
[4] Mehmed Kantardzic, "Data Mining-Concepts, Models, Methods, and Algorithms", New John Wiley & Sons, Inc., 2003
[5] Sean Kelly, "Data Warehouse in Action", John Wiley & Sons, Inc., 1997
[6] Efrem G. Mallach, "Decision Support and Data Warehouse Systems", McGraw-Hill,2ooo
[7] George M. Marakas , "Modem Data Warehousing, Mining, and Visualization -Core Concepts", Prentice Hall, Inc., 2003