Fakultas Ilmu Komputer
5518
Implementasi Metode
Text Mining
dan
K-Means Clustering
untuk
Pengelompokan Dokumen Skripsi (Studi Kasus: Universitas Brawijaya)
Muhammad Sholeh hudin1, M Ali Fauzi2, Sigit Adinugroho3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Penelitian atau tugas akhir7 merupakan syarat kelulusan7 mahasiswa. Setiap tahun 7penelitian menjadi bertambah7 dan memungkinkan mahasiswa 7mengambil topik yang sama7 atau hampir serupa. Melalui penelitian ini dikembangkan sebuah aplikasi untuk mengelompokkan laporan skripsi mahasiswa. Hasil dari pengelompokan laporan skripsi ini akan memperlihatkan bagaimana pola kemiripan dan keterkaitan antar penelitian dari waktu ke waktu. Hasil dari pengelompokan ini juga menunjukkan kapan tema penelitian mahasiswa menjadi bervariasi dan kapan tema penelitian menjadi kurang bervariasi. Laporan penelitian mahasiswa atau biasa disebut dengan laporan skripsi dapat dikelompokkan berdasarkan tema, objek maupun metode dari penelitian tersebut. Proses ekstraksi dokumen skripsi ini dilakukan dengan memanfaatkan teknologi dari text mining. Lalu untuk proses pengelompokan dokumen skripsi ini dilakukan dengan menggunakan metode k-means clustering pada sekumpulan dokumen skripsi dengan mengambil abstrak, kata kunci dan daftar isi sebagai informasi penting yang dapat mewakili isi dari dokumen. Lalu dokumen akan dilakukan preprocessing terlebih dahulu dengan menggunakan metode textmining. Untuk tahap preprocessing dibagi menjadi beberapa bagian, yakni tokenisasi, filtering, stemming dan term weighting. Setelah dokumen melewati tahap
preprocessing, maka dokumen dapat dikelompokkan dengan menggunakan metode dari k-means clustering. Pada penelitian ini uji coba dilakukan dengan memasukkan jumlah cluster yang bervariasi. Dari hasil analisis dengan memasukkan nilai cluster yang berbeda telah didapatkan nilai optimal dengan memasukkan jumlah 𝑘 = 4 dengan nilai silhouette yang dihasilkan 0,483695522.
Kata kunci: k-means clustering, silhouette coefficient, clustering dokumen, text mining
Abstract
Research or final assignment is a requirement of graduation students. Every year the research becomes increasing and allows the students to take the same or similar topics. Through this research developed an application to classify student thesis reports. The results of this grouping also indicate that the themes are varied and when the themes becomes non-varied. Student research reports or commonly called a thesis report can be grouped by theme, object or method of the research. The process of extracting this thesis is done by using text mining technology. Then the process of grouping thesis document can be done by using k-means clustering method on a set of thesis documents by taking abstract, keywords and table of contents as an important information that represents the content of the document. Then the document will be done preprocessing first by using text mining method. To process the preprocessing is divided into several parts, namely tokenisasi, filtering, stemming and term weighting. After the document passes through the preprocessing process, then the document can be grouped by using the method of k-means clustering. In this experiment, trials are conducted by entering the number of clusters that vary. From the results of the analysis by entering the different cluster values have obtained the optimal value by entering the number of 𝑘 = 4 with the resulting silhouette value 0,483695522.
Keywords:k-means clustering, silhouette coefficient, clustering document, text mining
1. PENDAHULUAN
Perkembangan teknologi saat ini sudah
dalam sebuah repository perpustakaan Universitas. Berbagai karya ilmiah dari sivitas akademika mulai dari skripsi, laporan penelitian, laporan kerja praktik dan lain sebagainya telah tersedia dalam versi digital.
Setiap tahun Universitas Brawijaya telah meluluskan banyak mahasiswa dengan penelitian yang beragam. Dan setiap tahunnya jumlah laporan skripsi selalu bertambah. Semakin bertambahnya penelitian skripsi ini menumbuhkan peluang semakin banyaknya mahasiswa yang mengambil penelitian dengan tema, objek dan metode penelitian yang mirip atau hampir sama.
Pada penelitian ini data yang digunakan berupa dokumen teks, maka text mining adalah metode yang bisa digunakan untuk melakukan data preprocessing. Menurut Rijbergen (1979) bahwa penerapan clustering dokumen dapat meningkatkan efektifitas temu kembali informasi. Dengan mengacu pada suatu hipotesis (cluster-hypothesis) bahwa dokumen yang relevan akan cenderung berada pada
cluster yang sama jika sebuah koleksi dokumen telah dilakukan clustering. Selama ini seleksi penelitian yang dilakukan oleh dosen pembimbing skripsi masih terbilang manual. Seleksi yang dilakukan dosen pembimbing berdasarkan pengalaman dari mahasiswa yang pernah dibimbing saja. Sementara untuk peluang kemiripan dengan penelitian antar dosen pembimbing tidak diketahui. Dengan mengacu pada pengelompokan laporan skripsi ini, diharapkan dosen bisa lebih variatif dalam menyetujui proposal penelitian yang akan dilakukan oleh mahasiswa antar pembimbing.
Menurut Alfiana, Santoso dan Ali Ridho B (2012) metode K-means merupakan metode
clustering yang cukup sederhana dan umum dalam penggunaannya. K-means seringkali digunakan dalam permasalahan clustering
dikarenakan mempunyai kemampuan mengelompokkan data dalam jumlah yang cukup besar dan dengan waktu komputasi yang relatif cepat serta efisien.
Berdasarkan permasalahan diatas, solusi yang ditawarkan yaitu dengan mengelompokkan dokumen skripsi menggunakan sistem. Sehingga dapat menjadi acuan bagi tiap dosen pembimbing dalam menerima pengajuan penelitian baru. Hal ini dimaksudkan agar penelitian bisa lebih variatif setiap tahunnya. Dikarenakan penelitian ini menggunakan dokumen teks sebagai data penelitian, maka penelitian ini membutuhkan
metode text mining sebagai preprocessing nya. Begitu juga karena K-Means telah dikenal sebagai metode clustering yang sangat effisien, maka K-Means menjadi metode yang diperhitungkan dalam melakukan clustering.
2. KAJIAN PUSTAKA
2.1 Text Preprocessing
Text preprocessing merupakan salah satu komponen dalam text mining. Text preprocessing dilakukan untuk mengubah data tekstual yang tidak terstruktur ke dalam data yang terstruktur dan disimpan kedalam basis data (Langgeni, Baizal dan Firdaus, 2010). Tujuan dari preprocessing yakni menghasilkan sebuah set term index yang bisa mewakili dokumen. Komponen dari text preprocessing
dibagi menjadi beberapa bagian, yaitu:
2.1.1
TokenisasiTokenisasi adalah proses pemotongan
string input berdasarkan tiap kata penyusunnya. Pada prinsipnya proses ini adalah memisahkan setiap kata yang menyusun suatu dokumen (Asian, 2007). Pada proses ini juga dilakukan penghilangan angka, tanda baca dan karakter lain selain huruf alphabet. Hal ini dikarenakan karakter-karakter tersebut dianggap sebagai pemisah kata (delimiter) dan tidak memiliki pengaruh terhadap pemrosesan teks.
2.1.2 Filtering
Filtering adalah tahap pemilihan kata-kata penting dari hasil token, yaitu kata-kata yang
dasar. Dengan demikian dapat lebih mengoptimalkan proses text mining.
Pada penelitian ini akan digunakan algoritme stemming porter. Berikut langkah-langkah algoritme porter seperti pada penelitian yang dilakukan oleh Agusta dan Ledy (2009) adalah sebagai berikut:
1. Hapus Particle.
2. Hapus Possesive Pronoun.
3. Hapus awalan pertama. Jika tidak ada lanjutkan ke langkah 4a, jika ada maka lanjutkan ke langkah 4b.
4. a. Hapus awalan kedua. lanjutkan ke langkah 5a.
b. Hapus akhiran. jika tidak ditemukan maka kata tersebut diasumsikan sebagai root word. Jika ditemukan maka lanjutkan ke langkah 5b.
5. a. Hapus akhiran. Kemudian kata akhir diasumsikan sebagai root word
b. Hapus awalan kedua. Kemudian kata akhir diasumsikan sebagai root word.
2.1.4 Term Weighting
Term weighting adalah suatu pembobotan kata dalam suatu dokumen yang biasa digunakan dalam algoritme text mining (Asian, 2007).
Langkah untuk melakukan pembobotan dibagi menjadi beberapa bagian , yaitu
a. Term Frequency
Term Frequency (TF) adalah frekuensi dari kemunculan sebuah term (kata/frasa) dalam dokumen yang bersangkutan. Semakin besar jumlah kemunculan suatu term dalam dokumen, maka semakin besar pula bobotnya.
b. Term Weighting
Term Weighting yaitu menghitung bobot dari setiap term yang telah disimpan. Untuk mendapatkan bobot dari term dapat digunakan persamaan (1)
𝑊𝑡,𝑓= {1 + 𝑙𝑜𝑔0, 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒10 𝑡𝑓𝑡,𝑑, 𝑖𝑓 𝑡𝑓𝑡,𝑑> 0 (1)
c. Inverse Document Frequency
Inverse Document Frequency atau biasa disebut dengan IDF ini merupakan dokumen yang mengandung term atau token atau kata t. Untuk mendapatkan nilai IDF dapat digunakan persamaan (2)
𝑖𝑑𝑓𝑡= 𝑙𝑜𝑔10 𝑁/𝑑𝑓𝑡 (2)
d. TF-IDF
Weight Term Document atau biasa yang disebut TF-IDF dari suatu term atau token atau kata merupakan hasil perkalian antara tf weight
dengan idf. Rumus pada persamaan (3)
𝑊𝑡,𝑑 = 𝑊𝑡,𝑓 × 𝑖𝑑𝑓𝑡
= 𝑊𝑡,𝑓 × 𝑙𝑜𝑔10 𝑁/𝑑𝑓𝑡 (3)
2.2 K-means Clustering
Clustering merupakan proses mengelompokkan atau penggolongan objek berdasarkan informasi yang diperoleh dari data yang menjelaskan hubungan antar objek dengan prinsip untuk memaksimalkan kesamaan antar anggota satu kelas atau cluster dan meminimumkan kesamaan antar cluster
menurut Tan, Steinbach dan Kumar (2006). Sementara clustering akan membagi data ke dalam grup-grup yang mempunyai objek yang karakteristiknya sama.
Menurut Han & Kamber (2006), algoritme
k-means bekerja dengan cara membagi data ke dalam k buah cluster yang telah ditentukan. Perhitungan jarak yang digunakan dalam penelitian ini adalah cosine similarity. Tahap-tahap Algoritme dasar k-means seperti berikut: 1. Tentukan jumlah k sebagai cluster yang
ingin dibentuk.
2. Menentukan pusat cluster secara acak sebanyak k.
3. Menentukan jarak setiap data terhadap pusat cluster(centroid)
4. Mengelompokkan setiap data yang bersangkutan berdasarkan kedekatannya dengan centroid (jarak terkecil).
5. Menentukan pusat cluster baru. Memperbaharui nilai centrid dari rata-rata
cluster yang bersangkutan dengan menggunakan persamaan (4)
𝑦𝑗 (𝑡 + 1) =𝑁1𝑠𝑗∑ jϵsj 𝑥𝑗 (4)
6. Ulangi langkah 3 hingga 5 sampai anggota yang ada pada tiap cluster tidak berubah.
digunakan sebagai parameter untuk kelompok dokumen skripsi.
2.3 Cosine Similarity
Cosine Similarity merupakan fungsi yang digunakan untuk menghitung besarnya derajat kemiripan di antara dua vektor (dokumen dengan query/dokumen dengan dokumen).
Pada penelitian yang dilakukan oleh Amir Hamzah et al. (2008) menghasilkan output
bahwa perhitungan jarak terbaik dapat dilakukan dengan menggunakan cosine similarity. Untuk menghitung similarity
digunakan persamaan (5)
𝑐𝑜𝑠𝑆𝑖𝑚 (𝑑𝑗, 𝑞) = 𝑑𝑗⋅→ →𝑞 |→| ⋅|𝑑𝑗 →|𝑞 =
∑ (𝑊𝑖𝑖=1 𝑖𝑗 ⋅ 𝑊𝑖𝑞) √∑𝑡𝑖=1𝑊𝑖𝑗2 ⋅ ∑𝑡𝑖=1𝑊𝑖𝑞2
(5)
2.4 Silhouette Coefficient
Silhoutte Coefficient merupakan salah satu metode yang digunakan untuk menguji kualitas dan kekuatan dari sebuah cluster. Metode
silhouette coefficient merupakan gabungan dari metode cohesion dan metode separation.
Metode cohesion sendiri merupakan suatu metode yang digunakan untuk mengukur seberapa dekat relasi antar objek dalam satu
cluster yang sama. Sedangkan metode
separation digunakan untuk mengukur seberapa jauh sebuah cluster terpisah dengan cluster
yang lain.
Silhouette memiliki tiga tahap dalam perhitungannya, Berikut tahap perhitungan
silhouette coefficient menurut Handoyo et. al (2014):
a. Menghitung rata-rata jarak objek dengan semua dokumen yang berada dalam satu cluster dengan menggunakan persamaan (6)
𝑎(𝑖) =[𝐴]−11 ∑ 𝑗 ∈𝐴,𝑗≠𝑖 𝑑(𝑖, 𝑗) (6)
b. Kemudian menghitung jarak objek dengan semua dokumen antar cluster dengan menggunakan persamaan (7)
𝑑(𝑖, 𝐶) = 1
[𝐴]∑ 𝑗 ∈ 𝐶 𝑑(𝑖, 𝑗) (7)
c. Kemudian menghitung nilai silhouette
dengan menggunaan persamaan (8)
𝑠(𝑖) =max(𝑎(𝑖),𝑏(𝑖)𝑏(𝑖)−𝑎(𝑖) (8)
3. DATA DAN METODE
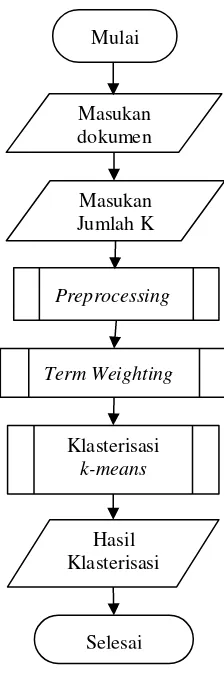
Berdasarkan Gambar (1) menjelaskan tahapan-tahapan yang dilakukan dalam pengelompokan dokumen skripsi pada penelitian ini. Dalam tahap preprocessing akan dilakukan sub proses lagi seperti yang telah dijelaskan pada bagian sebelumya. Begitupun dengan tahap term weighting juga ada sub proses yang dilakukan dalam sistem seperti yang telah dijelaskan pada bagian bab sebelumnya.
Gambar 1. Diagram Alir Sistem
Pada penelitian ini, program dibuat menggunakan Bahasa pemrograman PHP. Dan data yang nantinya diproses akan disimpan menggunakan database MySql. Pengguna dapat berinteraksi dengan program melalui antarmuka yang telah dibuat. Antarmuka yang dibuat antara lain:
1. Halaman home sistem
Mulai
Preprocessing Masukan dokumen
Masukan Jumlah K
Hasil Klasterisasi
Selesai Term Weighting
Pada halaman awal sistem ini akan langsung menampilkan dokumen yang telah tersimpan di dalam database. Dokumen ini dapat di edit, di update atau di hapus. Kemudian pada halaman ini juga tersedia tombol untuk input dokumen baru. Gambar 2 menampilkan halaman utama sistem.
2. Halaman input dokumen
Untuk memasukkan dokumen baru, pengguna harus masuk pada halaman awal terlebih dahulu. Kemudian pengguna diharuskan menekan tombol tambahkan data yang telah disediakan pada halaman tersebut.
3. Halaman stopwordlist
Halaman ini berisi kumpulan stopword
yang digunakan pada program penelitian ini.
4. Halaman clustering
Pada halaman clustering tersedia beberapa fitur. Fitur utama yaitu pengguna dapat memasukkan jumlah cluster sesuai yang diinginkan. Dibawah kolom input cluster
tersedia kolom yang akan menampilkan jumlah dokumen yang tersedia didalam database. Sehingga jumlah cluster bisa diperkirakan. Untuk fitur selanjutnya yaitu perhitungan cluster untuk dokumen yang berada pada database. Setelah cluster
dokumen didapatkan, pengguna dapat melanjutkan pada fitur pengujian cluster. Pengujian ini bertujuan untuk menguji hasil dari cluster yang didapatkan apakah sudah mendapatkan nilai yang optimal atau masih belum.
Gambar 2. Halaman awal sistem
3.1. Data yang digunakan
Pada penelitian ini menggunakan data berupa dokumen skripsi berbentuk digital yang ddidapat dari perpustakaan pusat Universitas Brawijaya. Jumlah dari dokumen skripsi yang digunakan pada penelitian ini berjumlah 30 dokumen. Dokumen tersebut terdiri dari tiga
fakultas yang antara lain: sepuluh dokumen skripsi Fakultas Ilmu Komputer, sepuluh dokumen skripsi berikutnya dari Fakultas Ekonomi dan Bisnis dan sepuluh dokumen berikutnya dari Fakultas Kedokteran Gigi.
Dokumen yang didapat sudah berbentuk word dan setiap dokumen skripsi sudah terbagi menjadi beberapa bagian, misal: bagian abstrak pada file sendiri, bagian daftar isi pada file sendiri dan bagian-bagian lain yang terpisah. Dokumen yang terpisah tersebut memudahkan penelitian ini.
3.2. Metode yang digunakan
Pada penelitian ini menggunakan metode
text mining sebagai text preprocessing nya. Kemudian TF-IDF digunakan sebagai pembobotan kata. Dan untuk pengelompokan dokumen skripsi menggunakan metode k-means clustering.
Untuk pertama kali dokumen akan dilakukan text preprocessing seperti yang telah dijelaskan pada bagian Dasar Teori. Kemudian hasil dari preprocessing akan menghasilkan kata atau term yang nantinya akan disimpan dalam database. Kemudian kata atau term ini dihitung bobotnya menggunakan metode dari
text mining yaitu TF-IDF.
Setelah dokumen memiliki bobot, langkah selanjutnya yaitu mengelompokkan dokumen tersebut berdasarkan bobot nilai yang telah dihitung sebelumnya. Pengelompokan ini dilakukan dengan menggunakan metode k-means clustering. Dan untuk perhitungan
similarity nya menggunakan metode cosine similarity.
Setelah hasil clustering dokumen didapatkan, perhitungan selanjutnya yaitu pengujian menggunakan metode silhouette coefficient. Silhouette coefficient akan membandingkan dokumen dengan dokumen lain baik yang di dalam cluster maupun diluar
cluster. Tujuan dari perbandingan ini yaitu mengetahui jarak kesamaan antar dokumen yang berada dalam satu cluster maupun luar
cluster. Sehingga diketahui hasil cluster telah optimal atau belum.
4. HASIL DAN PEMBAHASAN
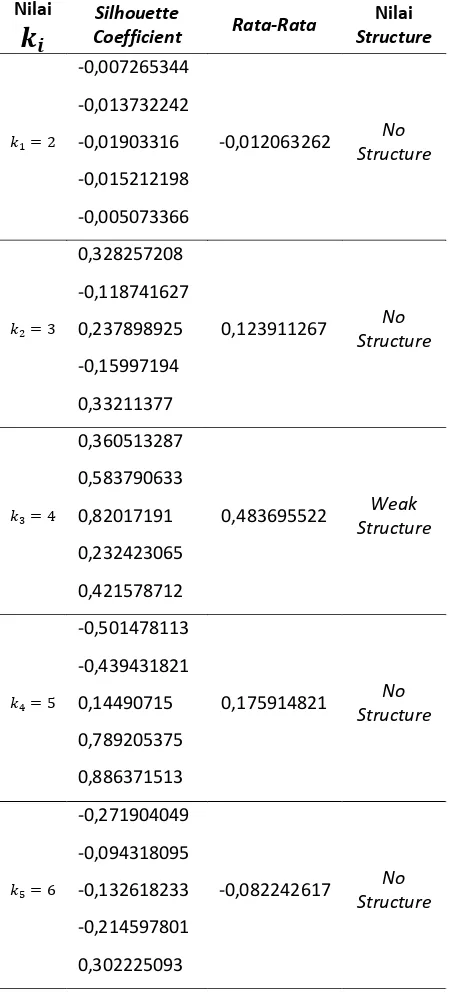
Pada pengujian ini akan dilakukan dengan memasukkan nilai k yang bervariasi sebanyak 6 kali. Untuk setiap nilai 𝑘 akan dilakukan 5 kali percobaan. Untuk hasil dari percobaan bisa dilihat pada Tabel 1.
Tabel 1. Pengujian nilai k
Nilai
Tabel 1. Pengujian nilai k (Lanjutan)
Nilai
Dari percobaan diatas dapat disimpulkan
structure dari masing-masing cluster dengan menggunakan teori dari Kaufman dan Rouseeuw (2007).
Dengan mengacu pada Tabel 1 diatas dapat disimpulkan variasi hasil dari setiap nilai 𝑘. Nilai optimal didapatkan ketika 𝑘 berjumlah 4. Nilai 𝑘 yang berada dibawah 4 tidak memiliki
structure ketika diuji menggunakan silhouette coefficient. Begitu pula ketika jumlah k diatas 4 juga tidak memiliki structure (Kauffman & Rouseeuw, 2007). Hal ini dikarenakan pada penelitian ini menggunakan dataset dokumen berjumlah 30 dokumen. Ketika nilai 𝑘 berjumlah sedikit, maka dokumen yang memiliki similaritas tinggi maupun tidak akan berada pada satu cluster yang sama. Begitu pula ketika nilai cluster yang dimasukkan semakin banyak, maka dokumen yang memiliki similaritas tinggi dan seharusnya berada pada satu cluster akan terpecah dan berada pada
cluster yang berbeda.
Dari hasil pengujian nilai 𝑘 yang ditampilkan pada Tabel 1. dapat diambil kesimpulan bahwa pada sistem ini nilai 𝑘 yang optimal terletak pada 𝑘 = 4. Hasil tersebut dapat ditampilkan dengan menggunakan grafik seperti pada Gambar 2.
Gambar 2. Grafik hasil pengujian nilai k
5. KESIMPULAN DAN SARAN
Dari uji coba yang dilakukan pada bab sebelumnya dapat diambil kesimpulan bahwa
clustering dokumen menggunakan k-means clustering dapat dilakukan pada dokumen skripsi. Sistem dapat mengelompokkan
dokumen dengan menggunakan algoritme k-means clustering dan text mining. Dokumen skripsi akan dikelompokkan dengan mengambil bagian-bagian terpenting seperti, abstrak, kata kunci dan daftar isi sebagai intisari dokumen.
Dari hasil analisis dengan memasukkan nilai cluster yang bervariasi telah didapatkan nilai optimal dengan memasukkan jumlah 𝑘 =
4dengan nilai silhouette yang dihasilkan 0,483695522. Dari hasil tersebut dapat disimpulkan bahwa nilai 𝑘 yang sedikit akan menghasilkan cluster yang kurang bagus. Begitu pula ketika memasukkan nilai 𝑘 yang terlalu besar juga akan merusak pengelompokan dokumen yang seharusnya berada pada satu
cluster menjadi terpisah antar cluster.
Dari hasil analisis, dapat disimpulkan bahwa metode text mining dengan menggunakan kata atau term sebagai fitur akan menghasilkan dimensi vektor yang cukup besar. Sehingga membuat algoritme cosine similarity
menjadi kurang optimal dalam menemukan kesamaan antar dokumen. Sehingga disarankan untuk menambahkan metode yang dapat mereduksi ukuran dimensi yang cukup besar tersebut. Secara umum ada dua tipe metode reduksi yang biasa digunakan antara lain transformasi fitur dan feature selection.
6. DAFTAR PUSTAKA
Agusta & Ledy., 2009. Perbandingan Algoritme Stemming Porter dengan Algoritme Nazief & Adriani untuk Stemming Dokumen Teks Bahasa Indonesia. Bali : Konferensi Nasional Sistem dan Informatika.
Alfina, T., Santosa, B. & Ridho, A.B., 2012.
Analisa Perbandingan Metode Hierarchical Clustering, K-means dan Gabungan Keduanya dalam Cluster Data.
Jurnal Teknik ITS. Vol. 1.
Asian, J., 2007. Effective Techniques for Indonesian Text Retrieval. PhD. Royal Melbourne Institute of Technology University.
Hamzah, A., Soesianto, F., Susanto, A. & Eko, J.E., 2008. Studi Kinerja Fungsi-Fungsi Jarak Dalam Clustering Dokumen Teks Berbahasa Indonesia. Seminar Nasional Informatika. ISSN: 1979-2328.
Yogyakarta: UPN “Veteran”.
Han, J &Kamber, M., 2006. Data Mining
Concept and Techniques Second Edition.
Burlington : Morgan Kaufman Publishers. Handoyo, R., Rumani, R.M. & Michrandi, S.N. 2014. Perbandingan Metode Clustering Menggunakan Metode Single Linkage dan K-Means pada Pengelompokan Dokumen. JSM STMIIK Mikroskil. Vol. 15, No. 2. Kaufman, L & Rousseuw, P. J., 1990. Finding
Groups in Data. New York: John Wiley & Sons.
Langgeni, Baizal & Firdaus., 2010. Clustering Artikel Berita Berbahasa Indonesia Menggunakan Unsupervised Feature Selection. Yogyakarta : Seminar Nasional Informatika.
Rijbergen, C. J., 1979. Information Retrieval. UK : Information Retrieval Group, University of Glasgow.