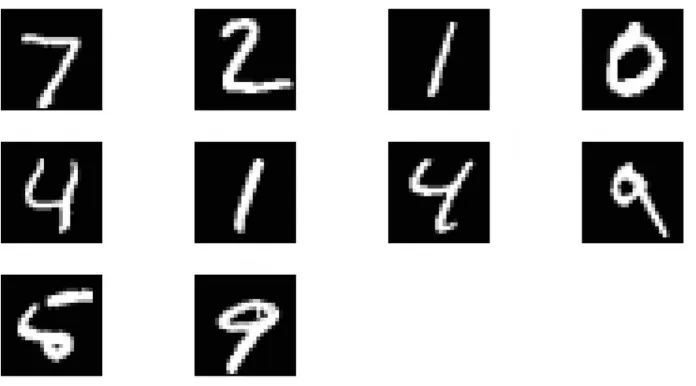Buku Saku
PENGANTAR
DEEP NEURAL NETWORK
UNTUK SISTEM CERDAS
Achmad Benny Mutiara
Rina Refianti
Desain
: M. Alhazen
Desain dan Layout
: M. Alhazen
Diterbitkan pertama kali oleh Universitas Gunadarma
Hak Cipta dilindungi Undang-Undang
Jakarta 2018
KATA PENGANTAR
P
uji syukur kami panjatkan kepada Allah SWT, yang telah memberikan rahmat dan kemu-dahan sehingga bisa menyelesaikan Buku yang berjudulPENGANTAR DEEP NEURAL NETWORKS UNTUK SISTEM CERDAS.Buku ini disusun sebagai buku ajar untuk matakuliah pengantar kecerdasan buatan lanjut. Buku ini disusun dengan mengambil materi dari paper-paper karya penulis terkenal di bidang
Deep Learning dan Deep Neural Networks dan juga digabungkan pengalaman penulis dalam menyelesaiakn riset yang terkait dengan bidangDeep Learning dan Deep Neural Networks.
Buku ini disusun dalam 6 bab, yang mencakup: tentang RBMs, tentang toolbox yang dikembangkan oleh Tanaka dan Okutomi dan MNIST basis data, pengaturan parameter DNNs, beberapa contoh sederhana DNNs, dan pemrosesan suara dengan DNNs.
Misi dari penerbitan buku ini adalah untuk digunakan mahasiswa, dosen dan pembaca yang tertarik pada peminatan kecerdasan buatan dan sistem cerdas. Mengingat saat ini buku jenis ini sangat jarang ditulis oleh penulis dari Indonesia.
Akhirnya sekali lagi kami mengucapkan terima kasih kepada PUREK II Universitas Gu-nadarma, berbagai pihak yang banyak membantu sehingga bisa diterbitkannya buku PEN-GANTAR DEEP NEURAL NETWORKS UNTUK SISTEM CERDAS.
Tiada gading yang tak retak, kami masih menyadari bahwa buku ini masih jauh dari sempurna, saran dan kritik yang sangat membangun sangat kami harapkan.
Bogor, Maret 2018
DAFTAR ISI
KATA PENGANTAR i
DAFTAR ISI iii
DAFTAR GAMBAR v
1 PENDAHULUAN 1
2 Mesin Boltzmann Terbatas (MBT) 3
2.1 Algoritma Divergensi Kontrastif . . . 5
2.2 Deep Belief Network . . . 6
3 Toolbox DNN 11 3.1 MNIST . . . 11
3.2 Running Contoh: DNN-MNIST . . . 12
3.3 Pemahaman Toolbox Dengan Contoh Basis Data MNIST . . . 13
3.4 Pengaturan Parameter . . . 18
4 Contoh-Contoh Lebih Lanjut 19 4.1 Pembelajaran Mandiri . . . 19
4.1.1 Skript . . . 19
4.1.2 Hasil-Hasil . . . 20
4.1.3 Diskusi . . . 22
4.2 Prediksi Pola-Pola . . . 22
4.2.2 Hasil-Hasil . . . 24
4.2.3 Diskusi . . . 25
4.2.4 Masalah XOR . . . 26
4.2.5 Skript . . . 27
4.2.6 Hasil-Hasil . . . 28
4.2.7 Diskusi . . . 30
5 Pengolahan Suara (Speech Processing) 31 5.1 Fitur-Fitur Ucapan . . . 31
5.2 DNN dan Pengolahan Ucapan . . . 32
6 Ringkasan 35
DAFTAR GAMBAR
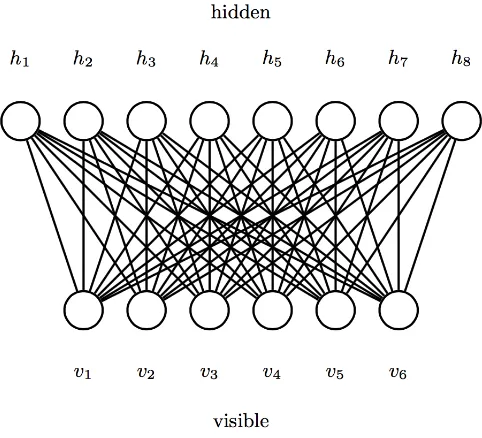
2.1 Sebuah MBT dengan sebuah layar tampak dan layar tersembunyi. . . 4
2.2 Blok pembangun sebuah MBT: sebuah neuron stokastik binera. Pada contoh ini, tampak ke tersembunyi, hj merupakan probabilitas pemroduksian sebuah spike [11]. . . 4
2.3 Algoritma Divergensi Kontrastif (DK). . . 5
2.4 Sebuah belief network tidak-terbatas. Semakin banyak MBT(Restricted Boltz-mann Machines (RBMs)), semakin dalam pembelajaran, yaituDeep Belief Net-works(DBN)[12]. . . 7
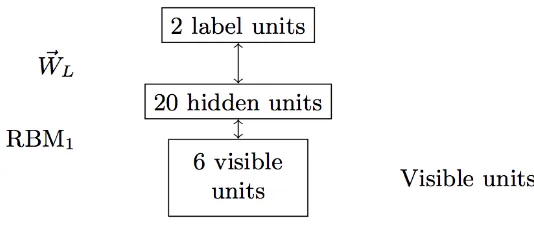
2.5 Sebuah DBN hybrid untuk pembelajaran terpandu (supervised learning). . . . 8
2.6 Sebuah DBN hybrid untuk pembelajaran terpandu [12]; Basis data MNIST. . 8
3.1 Arsitektur DNN lainya untk basis data MNIST [24]. . . 12
3.2 Skript Matlab/Octave script: analisis N = 10 citra uji dari basis data MNIST. 13 3.3 Lanjutan Gbr.3.2 . . . 14
3.4 10 contoh pengujian pertama dari basis data MNIST. Yang pertama adalah digit 7, kemudian 2; yang terakhir adalah digit 9. . . 14
3.5 Input dan output dari DNN untuk basis data MNIST. . . 15
4.1 Contoh pembelajaran mandiri dengan MBT tunggal. . . 20
4.2 Skript Matlab/Octave: contoh pembelajaran mandiri. . . 21
4.3 Lanjutan Gbr.4.2. . . 21
4.4 Arsitektur DNN untuk contoh pembelajaran terpandu: prediksi pola. . . 22
4.5 Skript Matlab/Octave: contoh prediksi pola. . . 23
4.6 Lanjutan Gbr.4.5. . . 24
4.8 Skript Matlab/Octave: Contoh XOR. . . 27 4.9 Lanjutan Gbr.4.8. . . 28
5.1 Pengolahan Ucapan . . . 32 5.2 Contoh audio. (a) Audio direpresentasikan dalam bentuk gelombang
BAB 1
PENDAHULUAN
Sistem cerdas melibatkan pendekatan kecerdasan buatan termasuk jaringan syaraf tiruan. Tutorial ini berfokus terutama pada Deep Neural Networks (DNNs).
Inti dariDNNsadalahMesin Boltzman Terbatas(MBT) (Restricted Boltzmann Ma-chines (RBMs)) yang diusulkan oleh Smolensky [23, 10], dan diteliti secara serius oleh Hinton dkk. [13, 12, 11], dimana istilah/terminologideep berasal dari Deep Beliefs Networks (DBN) [12]. Bab selanjut mendeskripsikan hubungan antara MBT, DBN dan DNNs.
Dewasa ini, istilahDeep Learning (DL) menjadi populer dalam literaturmachine learning. [15, 3, 22]. Akan tetapi , DL terutama mengacu pada Deep Neural Networks (DNNs) dan khususnya DBN dan MBT [15]. Beberapa penelitian yang berkaitan dengan DL berfokus pada komputasi kinerja tinggi untuk mempercepat pembelajaran DNN, yaitu Unit Pengolahan Grafis (dikenal dengan GPU), Message Passing Interface (MPI) di antara teknologi paralelisasi lainnya [3].
Sebuah survei yang luas tentang kecerdasan buatan dan khususnya DL telah dipublikasikan belum lama ini, yang mencakup DNN, Convolutional Neural Networks (CNN), Recurrent Neural Networks (RNN), di antara banyak strategi pembelajaran lainnya [22].
Mesin Boltzman Terbatas (MBT) didefinisikan sebagai berikut: ”Satu lapisan unit tersem-bunyi (hidden units) yang tidak terhubung satu sama lain dan memiliki koneksi simetris yang tidak berarah ke lapisan unit tampak (visible units). Unit tampak (visible units) dan keadaan tersembunyi (hidden states) diambil dari distribusi kondisional mereka menggunakan sampel
Gibbs dengan menjalankan rantai Markov sampai mencapai distribusi stasionernya. Aturan belajar sama dengan aturan belajar maximum likelihood [divergensi kontrastif (contrastive divergence)] untuk logistic belief net tak terbatas dengan bobot yang terikat” [12].
Pembela-jaran dengan contrastive divergence dari PoE merupakan basis dari algoritma pembelajaran DBNs [10, 12].
Kami merekomendasikan paper dari Fischer dan Igel [6] sebagai pengantar sederhana yang menjelaskan pelatihan MBT dan hubungannya dengan model grafis termasukMarkov Random Fields (MRFs); dan juga menyajikan rantai Markov untuk menjelaskan bagaimana MBT menarik sampel dari distribusi probabilitas, misalkan distribusi Gibbs dari MRF.
Blok pembangun MBT adalah neuron stokastik biner [12]. Namun demikian, ada beber-apa cara untuk mendefinisikan neuron terlihat nyata, dimana MBT-Gaussian-Biner banyak digunakan [6].
Kita dapat menggunakan toolbox MATLABR
/Octave yang tersedia untuk umum untuk RBM yang dikembangkan oleh Tanaka dan Okutomi [24]. Toolbox ini menerapkan sparsitas [16], dropout [4] dan inferensi baru untuk MBT [24].
Kontribusi utama tutorial ini adalah contoh-contoh DNNs berikut kode sumber dalam Mat-lab/Octave untuk membangun sistem cerdas. Oleh karena itu, semangat tutorial ini adalah agar orang dapat dengan mudah mengeksekusi contoh dan melihat hasil seperti apa yang diperoleh. Ada contoh-contoh dengan pembelajaran mandiri (unsupervised) atau terpandu (supervised), dan contoh-contoh untuk tugas prediksi dan klasifikasi juga disediakan. Selain itu, pengaturan parameter DNNs berikut contohnya juga ditunjukkan.
BAB 2
Mesin Boltzmann Terbatas (MBT)
Sebuah MBT digambarkan seperti pada Gbr. 2.1. Lapisan tampak (visible layer) merupakan input, data tanpa label, ke jaringan syaraf tiruan. Lapisan tersembunyi (hidden layer) mem-peroleh fitur dari data masukan, dan masing-masing neuron menangkap fitur yang berbeda [12]. Secara definisi, MBT merupaka graph bipartit yang tidak berarah. Sebuah MBT memi-liki m unit tampak (visible units) V~ = (V1, V2, . . . , Vm), data input, dan n unit tersembunyi
(hidden units)H~ = (H1, H2, . . . , Hn), fitur-fitur [6]. Konfigurasi bersama, (~v, ~h) dari unit-unit
tampak dan tersembunyi memiliki sebuah energi yang dinyatakan sebagai berikut[14]
E(~v, ~h) =−
dimana vi dan hj berurutan merupakan keadaan-keadaan biner dari unit-unit tampak dan
tersembunyi; ai, bj menyatakan bias-bias, dan wij adalah sebuah bobot bernilai riil terkait
setiap tepi dalam jaringan [11], lihat Gbr. 2.1.
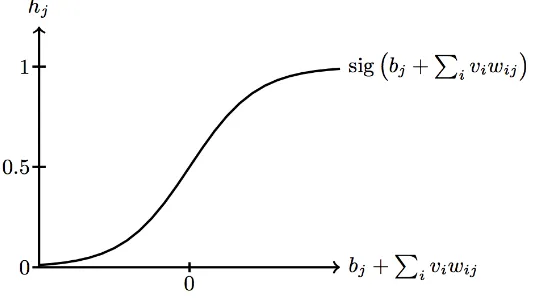
Blok pembangun MBT adalah neuron stokastik biner [12]. Gbr. 2.2 menunjukan bagaimana memperoleh keadaan suatu neuron tersembunyi dari suatu layar tampak (data).
Sebuah MBT dapat dipandang sebagai sebuah jaringan neural stokastik. Pertama, bobot-bobot wij diinisialisasi secara acak. Kemudian, data yang akan dipelajari ditetapkan pada
lapisan tampak; daata ini dapat berupa gambar, sinyal, dan sebagainya. Selanjutnya, keadaan neuron pada lapisan tersembunyi diperoleh melalui persamaan berikut:
p(hj = 1|~v) = sig bj +
Gambar 2.1. Sebuah MBT dengan sebuah layar tampak dan layar tersembunyi.
dengan fungsi aktivasi sigmoid, sig(x) = 1/(1− e−x), lihat Gbr. 2.2. Langkah ini, dari
tampak ke tersembunyi, dinyatakan sebagaihvihji
0
, pada saatt = 0 [12, 6, 24].
Mesin Boltzmann Terbatas (MBT) 5
2.1
Algoritma Divergensi Kontrastif
Gambar 2.3. Algoritma Divergensi Kontrastif (DK).
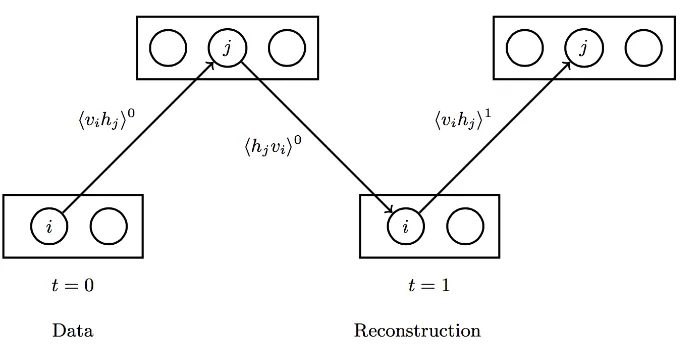
Pembelajaran dalam sebuah MBT dicapai melalu algoritma Divergensi Kontrastif (DK), lihat Gbr. 2.3 [12]. Langkah pertama dari algoritma DK adalah hvihji
0
, seperti tampak pada gambar. Langkah berikutnya adalah ”rekonstruksi” lapisan tampak dengan persamaan berikut:
yaitu, tersembunyi ke tampak. Langkah ini dinyatakan dengan hhjvii
0
. Keadaan baru dari lapisan tersembunyi diperoleh dengan menggunakan hasil rekonstruksi sebagai data masukan, dan langkah ini dinyatakan sebagai hvihji
1
; pada saat t = 1. Akhirnya, bobot-bobot dan bias-bias disesuaikan dengan cara berikut [12]:
∆wij =ε hvihji
dimana ε adalah laju pembelajaran. MBT menemukan model yang lebih baik jika ada lebih banyak langkah algoritma DK yang dilakukan; DKk digunakan untuk menunjukkan
Algorithm 1Pseudocode Algoritma Divergensi Kontrastif (DK).
1. Mengatur unit tampak (visible units) ke vektor pelatihan
2. Untuk (For) k ←1 sampai (to) maksimum iterasi lakukan (do)
(a) Untuk (For) s←1 sampai (to) ukuran data pelatihan lakukan (do)
i. Memperbarui seluruh unit tersembunyi secara paralel dengan Persamaan 2.2 ii. Memperbarui seluruh unit tampak secara paralel untuk memperoleh
rekon-struksi dengan Persamaan 2.3
iii. Memperbarui kembali seluruh unit tersembunyi secara paralel dengan Per-samaan 2.2
iv. Memperbarui bobot dan bias dengan Persamaan 2.4-2.6 v. Memilih vektor pelatihan yang lain
(b) akhir (end)
3. akhir (end)
2.2
Deep Belief Network
SebuahDeep Belief Network (DBN) [12] digambarkan seperti Gbr. 2.4. Perbandingan Gbr. 2.1 dengan Gbr. 2.4, kita dapat melihat bahwa sebuah DBN dibangun melalui penumpukan MBT. Dengan demikian, semakin banyak tingkat yang dimiliki suatu DBN, DBN semakin dalam (deeper). Neuron tersembunyi pada suatu MBT1 menangkap fitur dari neuron tampak.
Ke-mudian, fitur tersebut menjadi masukan bagi MBT2, dan seterusnya sampai MBTr tercapai;
lihat juga Gbr. 2.5. DBN mengekstraksi fitur-fitur secara suatu cara yang mandiri (unsuper-vised manner) atau pembelajaran yang mendalam (deep learning).
Sebuah DBN hybrid telah diusulkan untuk pembelajaran terpandu/terbimbing (supervised learning), lihat Gbr. 2.5. Jaringan ini menambahkan label pada lapisan teratasnya. Bobot-bobotW~Lantara lapisan teratas dan lapisan terakhir dari neuron-neuron tersembunyi, memori
asosiatif, dipelajari dengan cara terpandu/terbimbing. Proses ini disebut fine-tunning [12], dan ini dapat dicapai dengan berbagai algoritma yang berbeda termasuk backpropagation
Mesin Boltzmann Terbatas (MBT) 7
Gambar 2.5. Sebuah DBN hybrid untuk pembelajaran terpandu (supervised learning).
Mesin Boltzmann Terbatas (MBT) 9
Hinton dkk. menerapkan DNN pada database digit tulisan tangan MINST 1
[12], lihat Gbr. 2.6. Pada saat itu, DNN menghasilkan kinerja terbaik dengan tingkat kesalahan 1,25 % dibandingkan dengan metode lain termasuk Support Vector Machines (SVM) yang memiliki tingkat kesalahan 1,4
1
BAB 3
Toolbox DNN
Kita menggunakan toolbox publik dari MATLABR
yang dikembangkan oleh Tanaka dan Oku-tomi [24], dan dapat diunduh secara online1
. Toolbox ini berdasarkan paper [12]. Toolbox ini berisikan sparsitas [16], dropout [4] dan novel baru MBT yang diusulkan oleh Tanaka [24]. Jika toolbox telah diunduh dan di-unzipped, ini akan membangkitkan direktori-direktori berikut
• /DeepNeuralNetwork/
• /DeepNeuralNetwork/mnist
3.1
MNIST
Database MNIST2
dari digit tulisan tangan memiliki sekumpulan 60.000 contoh pelatihan, dan satu set tes 10.000 contoh. Begitu MNIST telah diunduh dan di-unzipped, kita akan mendapatkan file berikut
• train-images-idx3-ubyte: training set images
• train-labels-idx1-ubyte: training set labels
• t10k-images-idx3-ubyte: test set images
• t10k-labels-idx1-ubyte: test set labels
1
http://www.mathworks.com/matlabcentral/fileexchange/42853-deep-neural-network
2
Catatan bahwa jika kita meng-compress file-file *.gz files, maka kita perlu mencek nama-nama file, dan mengganti “.” dengan “-”. Kita harus meletakkan file-file di dalam direktori
/DeepNeuralNetwork/mnist/.
3.2
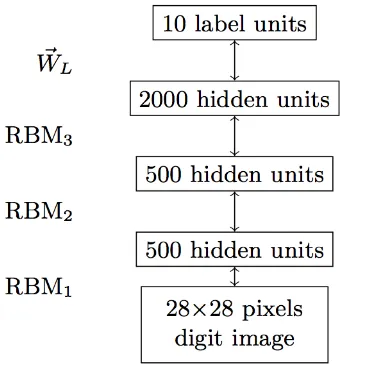
Running Contoh: DNN-MNIST
File /mnist/testMNIST.m merupakan file utama dari contoh yang disediakan oleh toolbox untuk melatih sebuah DNN bagi basis data MNIST. Contoh menggunakan sebuah jaringan hybrid dengan hanya dua layer tersembunyi dari 800 neuron setiap layernya, lihat Gbr. 3.1. Kita telah menguji toolbox pada Octave3
3.2.4 dan MATLABR
7.11.0.584 (2010b), keduannya dalam Window Operating Systems.
Gambar 3.1. Arsitektur DNN lainya untk basis data MNIST [24].
Skript testMNIST.m akan membangkitkan file mnistbbdbn.mat dengan DNN yang telah dilatih. Setiap kali testMNIST.m selesai akan muncul informasi atau hasil seperti berikut:
• For training data: rmse = 0.0155251; ErrorRate = 0.00196667 (0.196%); Tanaka et al. reported 0.158% [24].
• For test data: rmse = 0.0552593; ErrorRate = 0.0161 (1.6%); Tanaka et al. reported 1.76% [24].
3
Toolbox DNN 13
Waktu komputasi yang diperlukan untuk melatih 60,000 contoh-contoh MNIST dan 10,000 contoh-contoh untuk pengujian adalah sekitar 3 hari pada sebuah komputer dengan memori 384 GB, 4 CPUs 2.3GHz dengan 16 cores masing-masing (total 64 cores).
3.3
Pemahaman Toolbox Dengan Contoh Basis Data
MNIST
Setiap kali skript contoh (testMNIST.m) telah berhasil dieksekusi, kita menjalankan skript seperti tampak pada Gbr. 3.2.
% Skript Matlab/Octave % load data untuk pelatihan dan pengujian dari file-file
load mnistbbdbn; % load DNN terlatih
dbn = bbdbn; % set dbn sebagai jaringan terlatih
N = 10; %jumlah data uji untuk analisis
IN = TestImages(1:N,:); %load hanya N records dari data pengujian
OUT = TestLabels(1:N,:); %load hanya N dari data pengujian
for i=1:N,
imshow(reshape(IN(i,:),28,28));
name = [’print img-training-’,num2str(i),’.jpg -djpeg’] eval(name); %save the plot, file in jpeg format
end
% v2h: memperoleh output dari DNN out = v2h( dbn, IN );
% memperoleh nilai-nilai maksimum (m) dari out dan indeks-indeks (ind) [m ind] = max(out,[],2);
out = zeros(size(out)); % menginisialisasi variabel out
% selanjutnya, mengisi dengan "satu" nilai-nilai maksimum %yang berada pada (ind):
for i=1:size(out,1) out(i,ind(i)) = 1; end
% selanjutnya bandingkan out vs OUT. Katakan output dari DNN (out) vs % output yang diharapkan (OUT)
ErrorRate = abs(OUT-out); % secara analitik membandingkan OUT vs out
% sum(ErrorRate,2) melakukan penjumlahan dalam dua dimensi(sum in two % dimensions),
% pertama per baris kemudian kolom yang dihasilkan.
% Kemudian dibagi 2; jika beberapa output gagal, jumlahnya akan dihitung % dua kali.
% mean menampilakan persentase kesalahan, dikenal sebagai "error rate". ErrorRate = mean(sum(ErrorRate,2)/2) % Akhirnya Error rate diperoleh.
Gambar 3.3. Lanjutan Gbr.3.2
Toolbox DNN 15
Skript ini membangkitkan N = 10 citra via imshow, lihat Gbr. 3.4. Citra-citra adalah bagian dari 10 contoh pengujian pertama.
Setiap citra disimpan dalam sebuah vektor ukuran 784, yang bersesuaian dengan sebuah citra ukuran 28×28 piksel. Dan setiap piksel menyimpan bilangan antara 0 dan 255, dimana 0 berarti latar belakang (putih) dan 255 berarti latar depan (hitam); lihat Gbr. 3.4.
Gambar 3.5. Input dan output dari DNN untuk basis data MNIST.
Pada Gbr. 3.5, kita menampilkan input dan output dari DNN untuk basis data MNIST. VariabelIN merepresentasikan input dari sampel-sampel pelatihan atau pengujian. Variabel
OUTmerupakan output pelatihan, dan variabel out output pengujian. Kedua variabel out-put merepresentasikan label-label dari digit-digit untuk belajar/mengenali (digit dari 0 sampai 9).
Sebagai contoh, skript pada Gbr. 3.2 membangkitkan hasil sebagai berikut:
out =
Variabel out mewakili label-label. Setiap baris terkait dengan setiap digit citra4
, dan
4
setiap kolom menandakan akitivasi atau tidak digit-digit 0–9. Yaitu, kolom pertama mewakili digit 0, dan kolom terakhir digit 9. Contoh example, perhatikan kiri-atas pada Gbr. 3.4, citra yang mewakili digit 7 hanya mengaktifkan kolom 8 (yaitu 0 0 0 0 0 0 0 1 0 0) dari baris pertama variabel out. Citra di sisi kanan digit 7 sesuai dengan 2, sehingga kolom ketiga diaktifkan pada baris kedua variabelout, dan seterusnya. Pada contoh iniErrorRateadalah nol, karena sepuluh sampel pengujian pertama berhasil dikenali. Mari kita membuat skenario hipotetis di mana DNN gagal mengenali citra pertama (digit 7), yaitu bayangkan bahwa output terlihat seperti berikut ini:
Lihatlah baris pertama, sekarang baris ini menunjukkan bahwa gambar digit pertama pada Gbr. 3.4 sesuai dengan digit 6, bukan digit 7. Oleh karena itu,Errorratemengukur kesalahan ini via fungsi absdari perbedaan antara output yang diharapkan OUTdan output dari DNN, which is out. Maka tingkat kesalahan diperoleh sebagai berikut:
Toolbox DNN 17
Sekarang, kita menjumlahkan setiap baris. Ini untuk mendeteksi berapa banyak perbedaan yang ditemukan oleh sampel uji.
sum(ErrorRate,2)
Jika ada kesalahan, maka hasilnya dibagi dengan 2. Ini karena jika ada beberapa perbedaan per setiap sampel, kita akan memiliki dua nilai 1 seperti yang ditunjukkan di atas.
sum(ErrorRate,2)/2
Akhirnya, tingkat kesalahan dinyatakan sebagai nilai rata-rata:
mean(sum(ErrorRate,2)/2)
ans = 0.10000
3.4
Pengaturan Parameter
Ada beberapa parameter perlu diatur ketika bekerja dengan DNN, termasuk statistik untuk memantau algoritma divergensi kontrastif, ukuran batch, pemantauan overfitting (iterasi), laju belajarε, bobot awal, jumlah unit tersembunyi dan lapisan tersembunyi, jenis unit (misalnya biner atau Gaussian), dropout, antara lain [16, 11, 4, 6]. Dalam praktiknya, kita hanya bisa fokus pada hal-hal berikut:
• Maksimum iterasi (MaxIter), yang juga dikenal sebagai k untuk algoritma divergensi kontrastif.
• Laju belajar ǫ (StepRatio).
• Tipe unit (yaitu distribusi Bernoulli atau Gaussian).
BAB 4
Contoh-Contoh Lebih Lanjut
Di samping contoh basis data MNIST, seperti dijelaskan di atas, bab ini menyajikan contoh-contoh untuk pembelajaran mandiri (unsupervised) dan terpandu (supervised); termasuk tu-gas prediksi dan klasifikasi.
4.1
Pembelajaran Mandiri
Kami sekarang menunjukkan contoh untuk pembelajaran mandiri. Arsitektur jaringan adalah RBM tunggal dengan enam unit yang terlihat dan delapan unit tersembunyi; lihat Gbr. 4.1. Tujuannya adalah untuk mempelajari pola sederhana (Pattern) seperti yang ditunjukkan di bawah ini dalam skrip pada Gbr. 4.2. Patternini adalah contoh yang sangat sederhana dari data yang tidak berlabel.
Semua waktu komputasi yang dilaporkan di seluruh bagian ini diperoleh dan dilakukan pada komputer pribadi dengan karakteristik berikut: 2.3 GHz Intel Core i7 dan 4GB memory; Linux-Ubuntu 12.04 dan GNU Octave 3.2.4.
4.1.1
Skript
Gambar 4.1. Contoh pembelajaran mandiri dengan MBT tunggal.
4.1.2
Hasil-Hasil
Ketika skript pada Gbr. 4.2 dieksekusi, beberapa data ditampilkan. Pertama, data pelatihan (pola kita) ditampilkan:
TrainData =
1 1 0 0 0 0
0 0 1 1 0 0
0 0 0 0 1 1
kemudian output setelahpretrainDBN adalah:
out =
9.9e-01 9.9e-01 1.0e-04 1.2e-04 2.5e-05 2.6e-05
5.0e-04 4.3e-04 9.9e-01 9.9e-01 6.1e-04 6.0e-04
4.2e-06 3.6e-06 5.9e-06 5.4e-06 9.9e-01 9.9e-01
Output ini merupakan probabilitas [0,1], yang dikenal sebagai rekonstruksi, sehingga kita dapat menerapkan fungsi round, dan kemudian kita peroleh:
Contoh-Contoh Lebih Lanjut 21
Inputs = 6; % #no variables as input
TrainData = Pattern(:,1:Inputs) TestData = TrainData;
nodes = [Inputs 8]; % [#inputs #hidden]
bbdbn = randDBN( nodes, ’BBDBN’ ); % Bernoulli-Bernoulli RBMs nrbm = numel(bbdbn.rbm);
Gambar 4.2. Skript Matlab/Octave: contoh pembelajaran mandiri.
%Learning stage
fprintf( ’Training...\n’ ); opts.Layer = nrbm-1;
bbdbn = pretrainDBN(bbdbn, TrainData, opts); %Testing stage
fprintf( ’Testing...\n’ );
1 1 0 0 0 0
0 0 1 1 0 0
0 0 0 0 1 1
Total waktu yang digunakan adalah 0.254730 detik.
4.1.3
Diskusi
Kami menemukan bahwa DNN pada Gbr. 4.1 mampu mempelajari pola yang diberikab secara mandiri. Kita menggunakan stepRatio 2.5 karena ini memungkinkan kita untuk memiliki lebih sedikit iterasi, yaitu MaxIter = 50. Beberapa penulis merekomendasikan lajur pembe-lajaran (stepRatio) 0.01 [11, 24], tetapi dengan pengaturan ini, kita memerlukan setidaknya 1.000 iterasi untuk mempelajari pola ; lihat §4.2.4 untuk masalah pengaturan parameter.
4.2
Prediksi Pola-Pola
Contoh berikut mensimulasikan skenario prediksi time series. Kita menguji dua pola yang berbeda (Pattern1 dan Pattern2). Data pelatihan kita adalah matriks dengan delapan kolom, yang menunjukan jumlah variabel. Kita hanya menggunakan enam variabel seba-gai input, dan dua variabel kolom terakhir sebaseba-gai output. Gagasan utamanya adalah bah-wa kita memberi masukan jaringan hanya dengan enam variabel, kemudian jaringan harus “ memprediksi ” dua variabel berikutnya; lihat Gbr. 4.4. Dibandingkan dengan contoh se-belumnya, kita menggunakan pembelajaran terpandu seperti yang ditunjukkan di atas pada contoh MNIST, lihat§3. Oleh karena itu, label adalah dua kolom terakhir dari pola (output), yaitu TrainLabels.
Contoh-Contoh Lebih Lanjut 23
4.2.1
Skript
Skript untuk contoh ini ditunjukkan pada Gbr. 4.4.
% Matlab/Octave script
Pattern=Pattern1; % set the pattern to simulate
Inputs = 6; % #no variables as input
Outputs = 2; % #no. variables as ouputs
TrainData = Pattern(:,1:Inputs); % get the training data, inputs
TrainLabels = Pattern(:,Inputs+1:Inputs+Outputs); % show the labels
TestData = TrainData; % we test with the same training data
TestLabels = TrainLabels;
nodes = [Inputs 20 Outputs]; % [#inputs #hidden #outputs] bbdbn = randDBN( nodes, ’BBDBN’ ); % Bernoulli-Bernoulli RBMs nrbm = numel(bbdbn.rbm);
% meta-parameters or hyper-parameters
% meta-parameters or hyper-parameters
bbdbn = pretrainDBN(bbdbn, TrainData, opts);
bbdbn= SetLinearMapping(bbdbn, TrainData, TrainLabels); opts.Layer = 0;
bbdbn = trainDBN(bbdbn, TrainData, TrainLabels, opts); fprintf( ’Testing...\n’ );
out = v2h( bbdbn, TestData ); [TestData out]
Skript pada Gbr. 4.5 menghasilkan output berikut. Pertama, ia akan mencetak TrainData
dan TrainLabels bersama dengan instruksi [TrainData TrainLabels]:
Training...
Contoh-Contoh Lebih Lanjut 25
Testing... ans =
0.0000 0.0000 0.0000 0.0000 0.0000 1.0000 0.0031 0.9881 0.0000 0.0000 0.0000 0.0000 1.0000 0.0000 0.9911 0.0011 0.0000 0.0000 0.0000 1.0000 0.0000 1.0000 0.0044 0.0112 0.0000 0.0000 1.0000 0.0000 1.0000 0.0000 0.0092 0.0073 0.0000 1.0000 0.0000 1.0000 0.0000 0.0000 0.0065 0.0002 1.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.0003 0.0041
Seperti pada contoh sebelumnya, kita menerapkan fungsiround, sehingga kita peroleh:
[TestData round(out)]
Dalam contoh ini, kita menetapkan DNN untuk memprediksi dua variabel yang diberikan enam variabel input. Kita menemukan bahwa DNN berhasil memprediksi pola yang diberikan. Di sini, kita hanya menampilkan hasil untuk Pattern1, tetapi hasil untuk Pattern2 serupa. Kita mulai menguji DNN dengan pola yang berbeda, dan kita menemukan secara tidak sengaja dengan suatu pola yang DNN tidak dapat memprediksinya (4 input, 2 output):
ans =
0.00000 0.00000 0.00000 0.00000 0.49922 0.49922
0.00000 0.00000 0.00000 0.00000 0.49922 0.49922
0.00000 0.00000 0.00000 1.00000 0.00993 0.00993
0.00000 0.00000 1.00000 0.00000 0.01070 0.01070
0.00000 1.00000 0.00000 0.00000 0.01142 0.01142
1.00000 0.00000 0.00000 0.00000 0.01109 0.01109
Dua baris pertama dari data pelatihan memiliki nilai input yang sama, tetapi mereka memiliki output yang berbeda. Oleh karena itu, DNN “ secara cerdas ” menyarankan output 0,499 (probabilitas).
4.2.4
Masalah XOR
Masalah XOR adalah masalah non-linear yang merupakan tes tipikal bagiclassfier karena ini adalah masalah yang tidak bisa dipelajari oleh classifier linear sederhana. Dalam literatur jaringan saraf, contoh dari classifier linear adalah perceptron yang diperkenalkan oleh Frank Rosenblatt pada tahun 1957 [20]. Satu dekade kemudian, Marvin Minsky dan Seymour Paper menulis buku terkenal merekaPerceptrons, dan mereka menunjukkan bahwa perceptrons tidak dapat memecahkan masalah XOR [18]. Mungkin sebagian karena publikasi Perceptrons, ada penurunan penelitian dalam jaringan saraf sampai algoritma backpropagation muncul sekitar dua puluh tahun setelah publikasi Minsky dan Paper.
Di sini, kita menganalisis masalah XOR dengan DNN; lihat Gbr. 4.7.
Contoh-Contoh Lebih Lanjut 27
4.2.5
Skript
Skript untuk masalah XOR ditunjukan pada Gbr. 4.8.
%Matlab/Octave script
TrainData = [0 0; 0 1; 1 0; 1 1];
TrainLabels = [0; 1; 1; 0]; TestData = TrainData;
TestLabels = TrainLabels;
nodes = [2 12 1]; % [#inputs #hidden #outputs]
bbdbn = randDBN( nodes, ’BBDBN’ ); % Bernoulli-Bernoulli RBMs
nrbm = numel(bbdbn.rbm);
bbdbn = pretrainDBN(bbdbn, TrainData, opts);
bbdbn= SetLinearMapping(bbdbn, TrainData, TrainLabels); opts.Layer = 0;
bbdbn = trainDBN(bbdbn, TrainData, TrainLabels, opts); %Testing stage
fprintf( ’Testing...\n’ );
TestData = [0.1 0.1; 0 0.9; 1 0.2; 0.8 1];
TestData
out = v2h( bbdbn, TestData ) %Printing results
fprintf( ’\nResults:\n\n’ );
rmse= CalcRmse(bbdbn, TestData, TestLabels);
ErrorRate= CalcErrorRate(bbdbn, TestData, TestLabels); fprintf( ’For test data:\n’ );
fprintf( ’rmse: %g\n’, rmse );
fprintf( ’ErrorRate: %g\n’, ErrorRate );
Gambar 4.9. Lanjutan Gbr.4.8.
4.2.6
Hasil-Hasil
Skript pada Gbr. 4.8 melibatkan hanya dua variabel dan satu output, sehingga TrainData
dan TrainLabels adalah sebagai berikut:
TrainData =
Sebelum menjalankan skript Gbr. 4.8, kita menguji berbagai konfigurasi untuk DNN. Kita mulai dengan pengaturan hyper-parameter berikut:
nodes = [2 3 3 1]; % [#inputs #hidden #hidden #outputs] pts.MaxIter = 10;
TrainLabels merupakan sebuah vektor kolom, dan out’merupakan sebuah vektor baris, dimanaout’merupakan transpose dariout. Dengan demikian, output yang dharapkan adalah
out’ = 0 1 1 0. Output dari DNN dengan pengaturan ini adalah:
Contoh-Contoh Lebih Lanjut 29
Pengaturan ini tidak bekerja dengan parameter-parameter di atas. Jika kita menambahkan lebih banyak iterasiopts.MaxIter = 100, ia masih tidak bekerja sebagaimana mestinya, dan kami mendapatkan hasil:
out’ = 0.47035 0.51976 0.49161 0.50654
Jika kita menambahkan lebih banyak neuron tersembunyinodes = [2 12 12 1]dengan jum-lah iterasi yang sama, maka kinerjanya meningkat. Outputnya sekarang adajum-lah:
out’ = 0.118510 0.906046 0.878771 0.096262
Performanya masih lebih baik jika kita menambahkan lebih banyak iterasi
opts.MaxIter = 1000. Outputnya sekarang adalah:
out’ = 0.014325 0.982409 0.990972 0.012630
Elapsed time: 32.607048 seconds
Percobaan sebelumnya membutuhkan waktu sekitar 33 detik. Untuk mengurangi komplek-sitas jaringan, kita mengurangi jumlah neuron yang tersembunyi. Sekarang kita memi-liki satu layer tersembunyi nodes = [2 12 1], dan dengan jumlah iterasi yang sama
opts.MaxIter = 1000. Dalam 24 detik, hasilnya adalah:
out’ = 0.043396 0.950205 0.947391 0.059305
Elapsed time: 23.640984 seconds
Sekarang, jika kita mengurangi jumlah iterasi dengan lebih sedikit neuron seperti eksper-imen sebelumnya, yaitu. opts.MaxIter = 100, hasilnya lebih cepat tetapi kinerja menurun (decay). Jadi hasilnya sekarang adalah:
out’ = 0.16363 0.80535 0.82647 0.20440
Elapsed time: 2.617439 seconds
Hiperparameter lainnya adalah opts.StepRatio, laju belajar, jadi kita menyetel param-eter ini ke opts.StepRatio = 0.01, dan jumlah iterasi adalah opts.MaxIter = 1000. Kita menemukan hasil yang serupa dengan percobaan sebelumnya, yaitu kita tidak mencapai out-put yang diinginkan.
Namun demikian, jika kita menggunakan opts.StepRatio = 2.5 dan
out’ = 0.022711 0.955236 0.955606 0.065202 Elapsed time: 0.806343
Eksperimen penting lainnya adalah menguji kinerja dengan nilai nyata. Jadi kita men-gubah data uji, dan kita mendapatkan hasil berikut:
TestData =
Akhirnya, kami melakukan beberapa eksperimen dengan menyetel hyperparameter
opts.object ke ‘Square’ atau ‘CrossEntorpy’, dan kami tidak menemukan perbedaan dalam kinerja. Flag opts.verbosehanya untuk menunjukkan atau tidaknya kinerja pelatihan.
4.2.7
Diskusi
BAB 5
Pengolahan Suara (
Speech Processing
)
Speech Processing memiliki beberapa aplikasi termasukSpeech Recognition,Language Identifi-cation, danSpeaker Recognition; lihat Gbr. 5.1. Terkadang, informasi tambahan disimpan dan dikaitkan dengan ucapan. Oleh karena itu, Speaker Recognition dapat berupa teks dependen atau teks independen. Selain itu, Speaker Recognition melibatkan berbagai tugas seperti [2]:
• Identifikasi Pengucap (speaker Identification)
• Deteksi Pengucap (Speaker Detection)
• Verifikasi Pengucap (Speaker Verification).
5.1
Fitur-Fitur Ucapan
Gambar 5.1. Pengolahan Ucapan
5.2
DNN dan Pengolahan Ucapan
Seperti yang ditunjukkan di atas, DNN memiliki fleksibilitas untuk digunakan sebagai pembe-lajaran mandiri atau terpandu. Oleh karena itu, DNN dapat digunakan untuk masalah regresi atau klasifikasi dalam pengenalan suara; lihat Gbr. 5.3.
Saat ini, DNN telah berhasil diterapkan pada pemrosesan suara termasuk pengenalan suara [9, 26], identifikasi bahasa [7] dan generasi ucapan [17]. VOICEBOX1
merupakan sebuah toolboxSpeech Processing pada MATLABR
, yang juga tersedia untuk umum.
1
Pengolahan Suara (Speech Processing) 33
BAB 6
Ringkasan
Pendekatan jaringan saraf telah digunakan secara luas untuk membangun Sistem Cerdas. Kita memperkenalkan Deep Neural Networks (DNNs) dan Restricted Boltzmann Machines (RBMs), dan hubungannya dengan Deep Learning (DL) dan Deep Belief Nets (DBNs). Dari seluruh literatur, ada beberapa makalah pengantar untuk RBM [11, 6]. Salah satu kontribusi dari buku ini adalah contoh sederhana untuk pemahaman yang lebih baik tentang RBM dan DNN. Contohnya mencakup pembelajaran mandiri dan terpandu, oleh karena itu, kita menerapkan data yang tidak berlabel dan berlabel, untuk prediksi dan klasifikasi. Selain itu, kita memperkenalkan toolbox MATLABR
yang tersedia secara umum untuk menunjukkan kinerja DNN dan RBM [24]. Toolbox dan contoh-contoh telah diuji pada Octave, versi open source dari MATLABR
DAFTAR PUSTAKA
[1] C. M. Bishop and G. E. Hinton. Neural Networks for Pattern Recognition. Clarendon Press, 1995.
[2] J.P. Jr. Campbell. Speaker recognition: A tutorial.Proceedings of IEEE, 85(6):1437–1462, 1997.
[3] A. Coates, B. Huval, T. Wang, and A. Y. Wu, D. J.and Ng. Deep learning with COTS HPC systems. In Proceedings of the 30th International Conference on Machine Learning (ICML-2013), 2013.
[4] G. E. Dahl, T. N. Sainath, and G. E. Hinton. Improving deep neural networks for LVCSR using rectified linear units and dropout. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP-2013), pages 8609–8613, 2013.
[5] S. Davis and P. Mermelstein. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. In IEEE Transactions on Acoustics, Speech and Signal Processing, volume 28, 1980.
[6] A. Fischer and C. Igel. Training restricted Boltzmann machines: An introduction.Pattern Recognition, 14:25–39, 2014.
[7] J. Gonzalez-Dominguez, I. Lopez-Mreno, P.J. Moreno, and J. Gonzalez-Rodriguez. Frame-by-frame language identification in short utterances using deep neural networks.
Neural Networks, 64:49–58, 2015.
[8] S. Haykin. Neural Networks: A Comprehensive Foundation. Prentice Hall, 1999.
[10] G. E. Hinton. Training products of experts by minimizing contrastive divergence. Neural Computation, 14(8):1711–1800, 2002.
[11] G. E. Hinton. A practical guide to training restricted Boltzmann machines version 1. Department of Computer Science, University of Toronto, 2010.
[12] G. E. Hinton, S. Osindero, and Y. W. Teh. A fast learning algorithm for deep belief nets.
Neural Computation, 18(7):1527–1554, 2006.
[13] G. E. Hinton and R. R. Salakhutdinov. Reducing the dimensionality of data with neural networks. Science, 313(1):504–507, 2006.
[14] J. J. Hopfield. Neural networks and physical systems with emergent collective compu-tational abilities. In Proceedings of the National Academy of Sciences, volume 79, pages 2554––2558, 1982.
[15] Q. Le, M. Ranzato, R. Monga, M. Devin, K. Chen, G. Corrado, J. Dean, , and A. Ng. Building high-level features using large scale unsupervised learning. In Proceedings of International Conference on Machine Learning (ICML2012), 2012.
[16] H. Lee, C. Ekanadham, and A. Y. Ng. Sparse deep belief net model for visual area V2. In Advances in Neural Information Processing Systems (NIPS-2008), volume 20, 2008.
[17] Z.H. Ling, S.Y. Kang, H. Zen, A. Senior, M. Schuster, X.J. Qian, H. Meng, and L. Deng. Deep learning for acoustic modeling in parametric speech generation. IEEE Signal Pro-cessing Magazine, 32(3):35–52, 2015.
[18] M. L. Minsky and S. A. Papert. Perceptrons. Cambridge, MA: MIT Press, 1969.
[19] R. Rojas. Neural Networks: A Systematic Introduction. Springer-Verlag, 1996.
[20] F. Rosenblatt. The perceptron–A perceiving and recognizing automaton. Technical Re-port 85-460-1, Cornell Aeronautical Laboratory, 1957.
[21] D. E. Rumelhart, G. E. Hinton, and R.J. Williams. Learning representations by back-propagating errors. Nature, 323(1):533–536, 1986.
[22] J Schmidhuber. Deep learning in neural networks: An overview. Neural Networks, 61:85– 117, 2015.
DAFTAR PUSTAKA 39
[24] M. Tanaka and M. Okutomi. A novel inference of a restricted Boltzmann machine. In
International Conference on Pattern Recognition (ICPR2014), 2014.
[25] R. Togneri and D. Pullella. An overview of speaker identification: Accuracy and robust-ness issues. IEEE Circuits and Systems Magazine, 2(1):23–61, 2011.
![Gambar 2.4.Sebuah belief network tidak-terbatas.Boltzmann MachinesworksSemakin banyak MBT(Restricted (RBMs)), semakin dalam pembelajaran, yaitu Deep Belief Net-(DBN)[12].](https://thumb-ap.123doks.com/thumbv2/123dok/2509495.1652323/16.595.196.390.174.548/sebuah-terbatas-boltzmann-machinesworkssemakin-restricted-semakin-pembelajaran-belief.webp)
![Gambar 3.1. Arsitektur DNN lainya untk basis data MNIST [24].](https://thumb-ap.123doks.com/thumbv2/123dok/2509495.1652323/21.595.168.399.313.464/gambar-arsitektur-dnn-lainya-untk-basis-data-mnist.webp)